Reconfigurable Atomic Transaction Commit (Extended Version)
Manuel Bravo, Alexey Gotsman

TL;DR
This paper introduces new atomic commit protocols for distributed data stores that require fewer replicas, reconfigure upon failures, and are proven correct in both asynchronous and RDMA models, improving scalability and fault tolerance.
Contribution
It presents novel atomic commit protocols that reduce replica requirements to f+1, incorporate reconfiguration, and are rigorously proven correct in multiple models.
Findings
Protocols require only f+1 replicas, reducing overhead.
Protocols are proven correct under the TCS specification.
Work highlights trade-offs of using RDMA in distributed commit protocols.
Abstract
Modern data stores achieve scalability by partitioning data into shards and fault-tolerance by replicating each shard across several servers. A key component of such systems is a Transaction Certification Service (TCS), which atomically commits a transaction spanning multiple shards. Existing TCS protocols require 2f+1 crash-stop replicas per shard to tolerate f failures. In this paper we present atomic commit protocols that require only f+1 replicas and reconfigure the system upon failures using an external reconfiguration service. We furthermore rigorously prove that these protocols correctly implement a recently proposed TCS specification. We present protocols in two different models--the standard asynchronous message-passing model and a model with Remote Direct Memory Access (RDMA), which allows a machine to access the memory of another machine over the network without involving the…
Click any figure to enlarge with its caption.
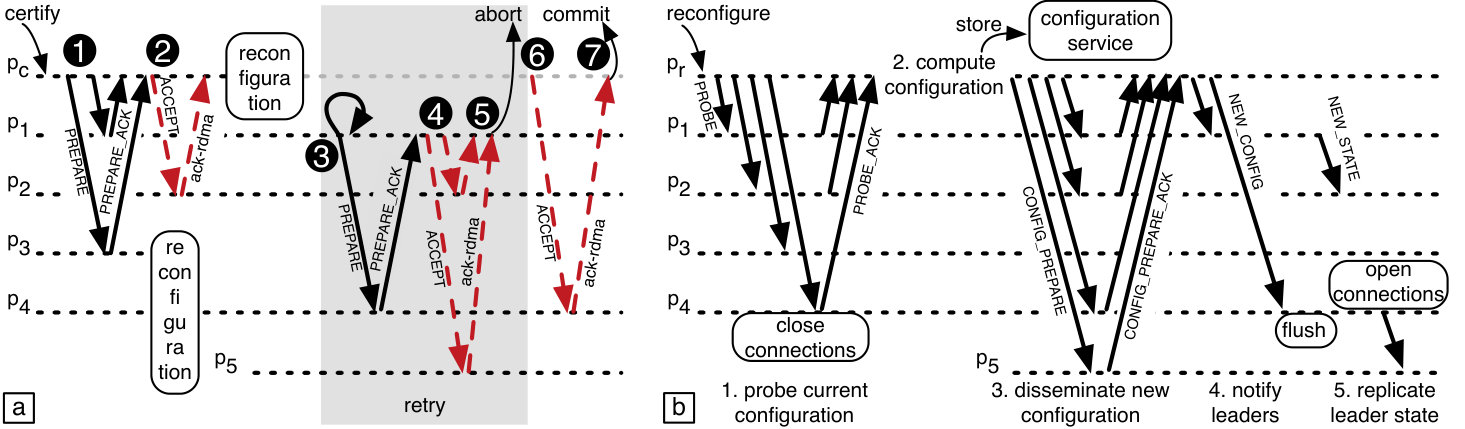 Figure 1
Figure 1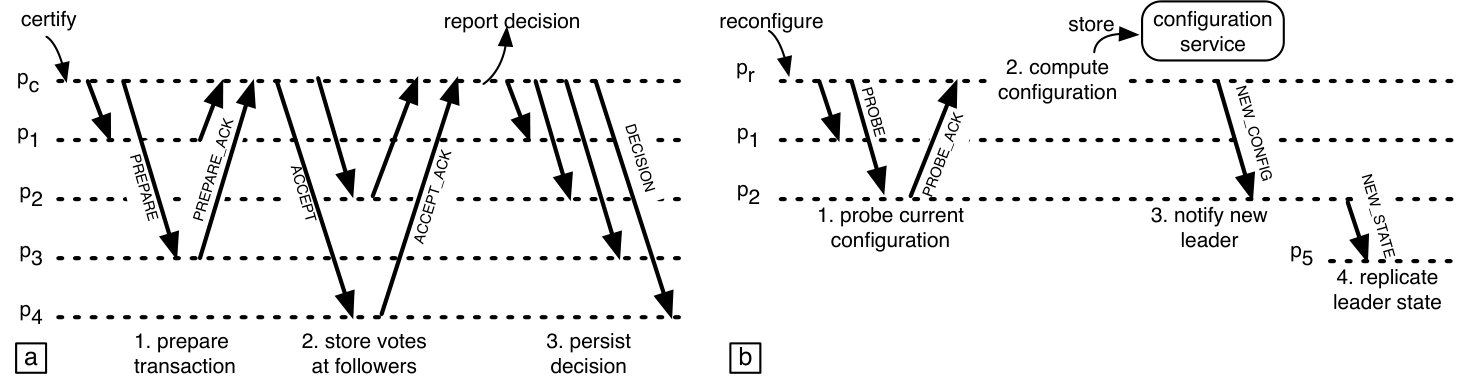 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\xspaceaddexceptions
(,$
Reconfigurable Atomic Transaction Commit (Extended Version)
Manuel Bravo
IMDEA Software Institute
and
Alexey Gotsman
IMDEA Software Institute
(2019)
Abstract.
Modern data stores achieve scalability by partitioning data into shards and fault-tolerance by replicating each shard across several servers. A key component of such systems is a Transaction Certification Service (TCS), which atomically commits a transaction spanning multiple shards. Existing TCS protocols require crash-stop replicas per shard to tolerate failures. In this paper we present atomic commit protocols that require only replicas and reconfigure the system upon failures using an external reconfiguration service. We furthermore rigorously prove that these protocols correctly implement a recently proposed TCS specification. We present protocols in two different models—the standard asynchronous message-passing model and a model with Remote Direct Memory Access (RDMA), which allows a machine to access the memory of another machine over the network without involving the latter’s CPU. Our protocols are inspired by a recent FARM system for RDMA-based transaction processing. Our work codifies the core ideas of FARM as distributed TCS protocols, rigorously proves them correct and highlights the trade-offs required by the use of RDMA.
Atomic commit, vertical Paxos, RDMA.
††journalyear: 2019††copyright: acmlicensed††conference: 2019 ACM Symposium on Principles of Distributed Computing; July 29-August 2, 2019; Toronto, ON, Canada††booktitle: 2019 ACM Symposium on Principles of Distributed Computing (PODC ’19), July 29-August 2, 2019, Toronto, ON, Canada††price: 15.00††doi: 10.1145/3293611.3331590††isbn: 978-1-4503-6217-7/19/07††ccs: Theory of computation Distributed algorithms††ccs: Theory of computation Distributed computing models
1. Introduction
Modern data stores are often required to manage massive amounts of data while providing stringent transactional guarantees to their users. They achieve scalability by partitioning data into independently managed shards (aka partitions) and fault-tolerance by replicating each shard across a set of servers (spanner, ; scatter, ; gdur, ). Such data stores often use optimistic concurrency control (wv, ), where a transaction is first executed speculatively, and the results (e.g., read and write sets) are then certified to determine whether the transaction can commit or must abort because of a conflict with concurrent transactions. The certification is implemented by a Transaction Certification Service (TCS), which accepts a stream of transactions and outputs decisions based on a given certification function, defining the concurrency-control check for the desired isolation level. TCS is the most challenging part of transaction processing in systems with the above architecture, since it requires solving a distributed agreement problem among the replicated shards participating in the transaction. This agreement problem has been recently formalized as the multi-shot commit problem (discpaper, ), generalizing the classical atomic commit problem (dwork-skeen, ) to more faithfully reflect the requirements of modern transaction processing systems (we review the new problem statement in §2).
Most existing solutions to the TCS problem require replicating each shard among replicas to tolerate crash-stop failures within each shard (spanner, ; scatter, ; uw-inconsistent, ; mdcc, ), which allows using a replication protocol such as Paxos (paxos, ). This is expensive: if transaction data are written to all replicas of the shard, only replicas are needed for the data to survive failures. Since, in this case even a single replica failure will block transaction processing, to recover we need to reconfigure the system, i.e., change its membership to replace failed replicas with fresh ones. Unfortunately, processes concurrently deciding to reconfigure the system need to be able to agree on the next configuration; this reduces to solving consensus, which again requires replicas (lower-bound, ). The way out of this conundrum is to use a separate configuration service with replicas to perform consensus on the configuration. In this way, we use replicas only to store the small amount of information about the configuration and replicas to store the actual data. This vertical approach (vertical-paxos, ), which layers replication on top of a configuration service, has been used by a number of practical systems (corfu, ; bigtable, ; farm, ). It is particularly suitable for deployment in local-area networks, where the configuration service can be reached quickly.
In this paper we propose the first rigorously proven protocols for implementing a TCS in a vertical system, with replicas per shard and an external configuration service. We present protocols in two different models—the standard asynchronous message-passing model (§3) and a model with Remote Direct Memory Access (RDMA), which allows a machine to access the memory of another machine over the network without involving the latter’s CPU (§5). Our protocols are parametric in the isolation level provided, and we prove that they correctly implement the TCS specification from the multi-shot commit problem (discpaper, ) (§4).
Our work complements and takes its inspiration from a recent FARM system (farm, ; farm2, )—a transaction processing system that achieves impressive scalability and availability by exploiting RDMA and the vertical approach. FARM currently forms the core of a graph database used to serve some of search queries in Microsoft Bing. It is a complex system that includes a number of optimizations, both specific to RDMA and not. FARM’s design was presented without a rigorous proof of correctness, and it did not highlight which features are motivated by the use of RDMA and which are inherent to the vertical approach. Our work provides a theoretical complement to FARM: we codify its core ideas as distributed transaction commit protocols and rigorously prove them correct with respect to the TCS specification. By basing our protocols on a principled footing, we are also able to provide better fault-tolerance guarantees than FARM. Finally, by presenting two related protocols using message passing and RDMA, we determine the trade-offs required by the use of RDMA.
In more detail, a straightforward way to implement TCS is using the classical two-phase commit (2PC) protocol (2pc, ). Since 2PC is not fault-tolerant, we can make each shard simulate a reliable process in 2PC using a replication protocol such as Paxos (spanner, ; scatter, ). This vanilla approach requires every 2PC action to be replicated using Paxos, which results in a high latency (7 message delays to learn a decision on a transaction (replicated-commit, )) and a high load on Paxos leaders. To improve on this, our protocol combines 2PC and Vertical Paxos (vertical-paxos, ) into one coherent protocol, thereby minimizing the latency and load on Paxos leaders. Upon a failure inside a shard, we use the reconfiguration service to replace the failed replicas, as in Vertical Paxos. This reconfiguration interacts nontrivially with the 2PC part of the protocol: e.g., reconfiguration may lead to losing undecided transactions that affected 2PC computations of decisions on other transactions—a behavior that we nevertheless show to be correct. Finally, we show that the price of exploiting RDMA to efficiently write transaction data to replicas is that reconfiguration has to be performed globally, instead of per-shard: when reconfiguring a shard, we have to ensure that the whole system is aware of the configuration before activating it.
2. Transaction Certification Service
Service interface and certification functions.
A Transaction Certification Service (TCS) is meant to be used in the context of transactional processing systems with optimistic concurrency control (wv, ), where transactions are first executed speculatively, and the results are submitted for certification to the TCS. We start by reviewing its specification proposed in (discpaper, ). Clients invoke the TCS using requests of the form , where is a unique transaction identifier and is the transaction payload, which carries the results of the optimistic execution of the transaction (e.g., read and write sets). Responses of the service are of the form , where . A TCS is specified using a certification function , which encapsulates the concurrency-control policy for the desired isolation level. The result is the decision for the transaction with payload given the set of payloads of the previously committed transactions. We require to be distributive in the following sense:
[TABLE]
where is such that and for any . This requirement is justified by the fact that common definitions of check for conflicts against each transaction in separately.
As an example, consider a transactional system managing objects from with values from , where transactions can execute reads and writes on the objects. The objects are associated with a totally ordered set of versions. Then the payload of a transaction is a triple . Here the read set is the set of objects with their versions that read, which contains one version per object. The write set is the set of objects with their values that wrote, which contains one value per object. We require that any object written has also been read: . Finally, the commit version is the version to be assigned to the writes of . We require this version to be higher than any of the versions read: . Given this domain of transactions, the following certification function encapsulates the classical concurrency-control policy for serializability (wv, ): iff none of the versions in have been overwritten by a transaction in , i.e.,
[TABLE]
TCS specification.
We represent TCS executions using histories—sequences of and actions such that every transaction appears at most once in , and each is a response to exactly one preceding . For a history we let be the set of actions in . For actions , we write when occurs before in . A history is complete if every action in it has a matching action. A complete history is sequential if it consists of pairs of and matching actions. A transaction commits in a history if contains . We denote by the projection of to actions corresponding to the transactions that are committed in . For a complete history , a linearization of (linearizability, ) is a sequential history such that and contain the same actions and
[TABLE]
A complete sequential history is legal with respect to a certification function , if its decisions are computed according to :
[TABLE]
A history is correct with respect to if has a legal linearization. A TCS implementation is correct with respect to if so are all its histories.
A TCS implementation satisfying the above specification can be readily used in a transaction processing system. For example, consider the domain of transactions defined earlier. A typical system based on optimistic concurrency control will ensure that transactions submitted for certification only read versions written by previously committed transactions. A history produced by such a system that is correct with respect to certification function (2) is also serializable (discpaper, ). Hence, a TCS correct with respect to this certification function can indeed be used to implement serializability.
Shard-local certification functions.
We are interested in TCS implementations in systems where the data are partitioned into shards from a set . In such systems TCS is usually implemented using a variant of the classical two-phase commit protocol (2PC) (2pc, ). In this protocol each shard receiving a transaction for certification first prepares it, i.e., performs a local concurrency-control check and accordingly votes to commit or abort the transaction. The votes on the transaction by different shards are aggregated, and the final decision is then distributed to all shards: the transaction can commit only if all votes are commit. When a shard votes on a transaction, it does not have information about all transactions in the system, but only those that concern it. Hence, the votes are computed using not the global certification function , but shard-local certification functions (discpaper, ), which check for conflicts only on objects managed by the shard and correspondingly take as parameters only the parts of the transaction payloads relevant to the shard: for a payload we denote this by . For example, let be the set of objects managed by a shard . For a payload of the form given above, we let , where and . There are two shard-local functions, and . As its first argument takes the set of shard-relevant payloads of transactions that previously committed at the shard, and the set of such payloads for transactions that have been prepared to commit. As their second argument, the functions take the part of the payload of the transaction being certified relevant to the shard. We require that these functions are distributive, similarly to (1).
For example, the shard-local certification functions for serializability are defined as follows: iff
[TABLE]
and iff
[TABLE]
The function certifies a transaction against previously committed transactions similarly to the certification function (2) for serializability, but taking into account only the objects managed by the shard . The function certifies against transactions prepared to commit, and its check is stricter than that of . In our example, the function aborts a transaction if: (i) it read an object written by a transaction prepared to commit; or (ii) it writes to an object read by a transaction prepared to commit. This reflects the behaviour of typical implementations, which upon preparing a transaction acquire read locks on its read set and write locks on its write set, and abort the transaction if the locks cannot be acquired.
For a sharded TCS implementation to be correct, shard-local functions have to match the global certification function, i.e., perform similar conflict checks. We formalize the required conditions as follows. Assume a function that determines the shards that need to certify a transaction with a given identifier, which are usually the shards storing the data the transaction accesses. We also assume a distinguished empty payload such that . For example, for a payload of the form given above, is such that and . We require that for a transaction with payload , for each shard , we have . We further lift the operator to sets of payloads: for any we let . Then we require that global and local certification functions match as follows:
[TABLE]
Finally, for each shard , the two functions and are required to be related to each other as follows (discpaper, ):
[TABLE]
Property (4) requires the conflict check performed by to be no weaker than the one performed by . Property (5) requires a form of commutativity: if a transaction with payload is allowed to commit after a still-pending transaction with payload , then the latter would be allowed to commit after the former.
3. Atomic Commit Protocol
System model.
We consider an asynchronous message-passing system consisting of a set of processes which may fail by crashing, i.e., permanently stopping execution. We assume that processes are connected by reliable FIFO channels: messages are delivered in FIFO order, and messages between non-faulty processes are guaranteed to be eventually delivered. A function determines the client process that issued a given transaction.
Each shard is managed by a group of replica processes, whose membership can change over time. For simplicity, we assume that the groups of replica processes managing different shards are disjoint. Each shard moves through a sequence of configurations, determining its membership. Reconfiguration is the process of changing the configuration of a shard. In our protocols reconfiguration is initiated by a replica when it suspects another replica of failing: for simplicity we do not expose it in the TCS interface. Every member of a shard in a given configuration is either the leader of the shard or a follower. A configuration of a shard is then a tuple where is the epoch identifying the configuration, is the set of processes that manage at , and is the leader of at .
Configurations are stored in an external configuration service (CS), which for simplicity we assume to be a reliable process. In practice, this service may be implemented using Paxos-like replication over processes out of which at most can fail (as done in systems such as Zookeeper (zookeeper, )). The configuration service stores the configurations of all shards and provides three operations. An operation compare_and_swap succeeds if the epoch of the last stored configuration of is ; in this case it stores the provided configuration with a higher epoch . Operations get_last and get respectively return the last configuration of and the configuration of associated with a given epoch .
Protocol preliminaries.
We give the pseudocode of our protocol in Figure 1, illustrate its message flow in Figure 2 and summarize the key invariants used in its proof of correctness in Figure 3. The protocol weaves together the two-phase commit protocol across shards (2pc, ) and a Vertical Paxos-based reconfiguration protocol within each shard (vertical-paxos, ). At any given time, a process participates in a single configuration of the shard it belongs to. The process stores the information about this configuration as well as those of other shards in several arrays: configuration epochs are stored in an array , the current members in , and the current leader in . The entries for the shard the process belongs to give the configuration the process is in; the other entries maintain information about the configurations of the other shards. A variable at a process records whether it is a leader, a follower or is in a special reconfiguring state used during reconfiguration. Each process keeps track of the status of transactions in an array , whose entries initially store start. The transaction status changes to prepared when the shard determines its vote and to decided when a final decision on the transaction is reached.
Failure-free case.
A client submits a transaction for certification by calling the certify function at any replica process, which will serve as the coordinator of the transaction (line 1). The function takes as arguments the transaction’s identifier and its payload. The transaction coordinator first sends a message to the leaders of the relevant shards, which includes the payload part for each shard (line 1). The leader of a shard arranges all transactions it receives into a total certification order, which the leader stores in an array ; a variable points to the last filled slot in the array. When the leader receives a message for a transaction for the first time (line 1), it appends the transaction to the certification order, stores the transaction’s payload in an array , and sets the transaction’s phase to prepared. It then computes a vote on the transaction and stores it in an array (line 1). The vote is computed using the shard-local certification functions and to check for conflicts against transactions that have been previously committed or prepared to commit; the results are combined using the operator, so that the transaction can commit only if both functions say so. We defer the description of the cases when the leader has previously received the transaction in the message (line 1) and when the payload in the message is an undefined value (line 1).
Our protocol next replicates the leader’s decision and the transaction payload at the followers. Instead of having the leader to do this directly, the protocol delegates this task to the coordinator of the transaction. This design is used by practical systems, such as Corfu (corfu, ) and FARM (farm, ), since it minimizes the load on the leaders, which are the main potential performance bottleneck. Instead, the network-intensive task of persisting transactions at multiple followers is spread among a number of different transaction coordinators. As we explain in the following, this optimization interacts in a nontrivial way with transaction certification. In more detail, after preparing a transaction the leader sends a message to the coordinator of the transaction, which carries the leader’s epoch, the transaction identifier, its position in the certification order, the payload, and the vote (line 1). Upon receiving the message (line 1), the coordinator forwards the data from the message to the followers in an message.
A process handles an message only if it participates in the corresponding epoch (line 1). The process stores the transaction identifier, its payload and vote, and advances the transaction’s phase to prepared. It then sends an message to the coordinator of the transaction, confirming that the process has accepted the transaction and the vote. The certification order at a follower is always a prefix with zero or more holes of the certification order at the leader of the epoch the follower is in, as formalized by Invariant 1 (Figure 3). The holes in the prefix arise from the lack of FIFO ordering in the communication between the leader of a given epoch and its followers, as the message for a given transaction is sent to the followers by the coordinator of the transaction and not directly by the leader.
The coordinator of a transaction acts once it receives messages for from every follower of its shards (line 1); it determines this using the configuration information it stores for every shard. The coordinator computes the final decision on using the operator on the votes of each involved shard: the transaction can commit if all votes are commit. The coordinator then sends the final decision in messages to the client and to each of the relevant shards. When a process receives a decision for a transaction (line 1), it stores the decision and advances the transaction’s phase to decided. In a realistic implementation, at this point the process would also upcall into the transaction processing system running at its server, to inform it about the decision and allow it to apply the transaction’s writes to the database if the decision is to commit.
In the absence of failures, our protocol allows the client to learn a decision on a transaction in 5 message delays, instead of 7 required by vanilla protocols that use Paxos as a black-box (spanner, ; scatter, ). We can further reduce this to 4 by co-locating the client with the transaction coordinator. The protocol also minimizes the load on Paxos leaders, which are the main potential bottleneck: each involved leader only has to receive one and one message, and send one message.
Reconfiguration.
When a failure is suspected in a shard , any process can initiate a reconfiguration of the shard to replace failed replicas. Reconfiguration is done only in the affected shard, without disrupting others. It aims to preserve Invariant 2, which is key in proving the correctness of the protocol. This assumes that all followers in at an epoch have received and responded to it with ; in this case we say that the transaction has been accepted at shard . The invariant guarantees that the accepted transaction will persist in epochs higher than ; this is used to prove that the protocol computes a unique decision on each transaction. The invariant also guarantees that the entries preceding in the certification order in epochs higher than may only contain the votes that the leader of at epoch took into account when computing the vote on (some of these votes may be missing due to the lack of FIFO order in the communication between the leader and its followers). This property is necessary to guarantee that the protocol computes decisions according to a single global certification order, as required by the TCS specification.
To ensure Invariant 2, a process performing reconfiguration first probes previous configurations to determine which processes are still alive and to find a process whose state contains all transactions previously accepted at the shard, which will serve the new leader. The new leader then transfers its state to the members of the new configuration, thereby initializing them. A variable at a process records whether it has ever been initialized. Our protocol guarantees that a shard can become operational, i.e., start accepting transactions, only after all its members have been initialized.
The probing phase is complicated by the fact that there may be a series of failed reconfiguration attempts, where the new leader fails before initializing all its followers. Hence, probing requires traversing epochs from the current one down, skipping epochs that are not operational. Probing selects as the new leader the first initialized process it encounters during this traversal; we can show that this process is guaranteed to know about all transactions accepted at the shard, and thus making it the new leader will preserve Invariant 2 (§4).
In more detail, a process initiates a reconfiguration of a shard by calling (line 1). The process picks an epoch number higher than the epoch of stored in the configuration service and then starts the probing phase, as marked by the flag . The process keeps track of the shard being reconfigured in , the epoch being probed in and the membership of this epoch in . The process initializes these variables when it first reads the current configuration from the configuration service (line 1). It then sends a message to the members of the current configuration, asking them to join the new epoch . Upon receiving a message (line 1), a process first checks that the proposed epoch is equal or higher than the highest epoch it has ever been asked to join, which the process stores in (we always have at a process in ). In this case, the process sets to and changes its status to reconfiguring, which causes it to stop transaction processing. It then replies to with a message, which indicates whether it has been previously initialized or not. If finds a process that has previously been initialized, and hence can serve as the new leader, ends probing (line 1). If does not find such a process in the epoch and receives at least one reply from a process that has not been initialized (line 1), can conclude that the epoch is not operational and will never become such, because it has convinced at least one of its members to join the new epoch; this is formalized by Invariant 3. In this case starts probing the preceding epoch. Since no transactions could have been accepted at the epoch , picking a new leader from an earlier epoch will not lose any accepted transactions and thus will not violate Invariant 2.
Once the probing finds a new leader for the shard (line 1), the process computes the membership of the new configuration using a function compute_membership (line 1). We do not prescribe a particular implementation of this function, except that the new membership must contain the new leader and may only contain the processes that replied to probing or fresh processes. The latter can be added to reach the desired level of fault tolerance. Once the new configuration is computed, attempts to store it in the configuration service using a compare-and-swap operation. This succeeds only if the current epoch is still the epoch from which started probing, which means that no concurrent reconfiguration occurred while was probing. In this case, sends a message with the new configuration to the new leader of .
When the new leader of receives the message (line 1), it sets to the length of its sequence of transactions, to the new epoch and to leader, which allows it to start processing new transactions. It then sends a message to its followers, containing its state. Upon receiving this message (line 1), a process overwrites its state with the one provided, changes its status to follower, and sets to true. As part of the state update, the process also updates its epoch to the new one. Hence, the process will not accept transactions from the new leader until it receives the message.
When a new configuration of a shard is persisted in the configuration service, the service sends it in a message to the members of shards other than . A process updates the locally stored configuration upon receiving this message (line 1).
Coordinator recovery.
If a process that accepted a transaction does not receive the final decision on it, this may be because the coordinator of has failed. In this case the process may decide to become a new coordinator by executing a retry function (line 1). For this, the process just sends a message to the leaders of the shards of , carrying a special undefined value as the payload. If a leader receiving has already certified , it re-sends the corresponding message to the new coordinator, including the transaction payload and vote (line 1). Otherwise, if the leader does not have the payload of , it prepares the transaction as aborted and with an empty payload (line 1). In either case, the new coordinator will finish processing the transaction as usual. The above case when the transaction is aborted because the leader of a shard does not know its payload may arise when the old coordinator crashed in between sending messages to different shards. Note that if the old coordinator was suspected spuriously and will try later to submit the transaction to a shard where it was aborted, it will just get a message with an abort vote.
Our protocol allows any number of processes to become coordinators of a transaction at the same time. Nevertheless, the protocol ensures that they will all reach the same decision, even in case of reconfigurations. We formalize this by Invariant 4: part (a) ensures an agreement on the decision on the -th transaction in the certification order at a given shard; part (b) ensures a system-wide agreement on the decision on a given transaction . The latter part establishes that the protocol computes a unique decision on each transaction. Invariant 4 is proved as a corollary of Invariant 2.
Losing undecided transactions.
Recall that our protocol uses the optimization that delegates persisting transactions at followers to coordinators (corfu, ; farm, ). We now highlight how this optimization interacts with transaction certification. Because of the optimization, transactions prepared by a leader of a shard can be persisted at followers out of order. For example, may follow in the certification order at the leader, but may be persisted at followers first. If now the leader of and the coordinator of crashes before is persisted at followers, will be lost forever, something that is allowed by Invariant 2 (due to the use of ). In this case we lose a transaction on the basis of which the vote on the transaction was computed (e.g., the payload of was in when the vote on was computed at line 1). This does not violate correctness, since the vote on makes sense also in the context excluding : due to distributivity of certification functions (§2), if was allowed to commit in the presence of (), it can also commit in its absence (). Note that in this case a decision on could not have been exposed to the client: otherwise could not get lost due to Invariant 2. Also note that, since we assume the transaction execution component produces payloads with read-sets containing only values written by committed transactions (§2), in the above case could not have read a value written by .
4. Correctness
The next theorem states the safety of our protocol, showing that it implements the TCS specification.
Theorem 4.1.
A transaction certification service implemented using the protocol in Figure 1 is correct with respect to a certification function matching the shard-local certification functions and .
We defer the proof to §A and only sketch the proof of the key Invariant 2. This relies on auxiliary Invariant 5, which we prove first.
Proof sketch for Invariant 5.
We prove the invariant by induction on . Assume that the invariant holds for all . We now show it for . The members of at are computed at line 1 by a reconfiguring process using the compute_membership function, which returns either fresh processes or processes that responded to ’s probing. Since was a member of at , it is not fresh; then by assumptions on compute_membership must have received from and replied with . The process starts probing at epoch and ends it upon receiving a message. By the induction hypothesis, is not a member of at any epoch from down to . Hence, if the probing stops before reaching , then will not be a member of at , as required. Assume now that the probing reaches . By Invariant 3, each follower in at must have sent before receiving . Then any member of at receiving will have . Hence, if any member of at replies with , we have that . Since the process will not move to the preceding epoch until at least one process replies with , this means that the probing can never go beyond . Since the process is not a member of , it cannot be included as a member of in , as required.∎
Proof sketch for Invariant 2.
We prove the invariant by induction on . Assume that the invariant holds for all . We now show it for by induction on the length of the protocol execution. We only consider the most interesting transition in line 1, when a process becomes a leader of at an epoch . We show that after this transition at we have , and .
Since was chosen as the leader of at , this process replied with to a . Therefore, was a member of at an epoch that was being probed. Probing ends when at least one process sends a . From Invariant 3 and the assumption that all followers in replied with to , we can conclude that probing could no have gone further than . Hence, .
Let be the value of at right before the transition at line 1. We have , as otherwise would not be a member of at and by Invariant 5 could not be picked as the leader of at . It is also easy to show that . Hence, .
If , then by the induction hypothesis, we have , and right after the transition in line 1, as required. Assume now that . If was the leader of at , then we trivially have , and right after the transition in line 1, as required. Otherwise, by Invariant 3, must have received and responded to it with before the transition in line 1. Then the required follows from Invariant 1.∎
We next state liveness properties of our protocol (we again defer proofs to §A). The reconfiguration procedure in the protocol will get stuck if it cannot find an initialized process, which may happen if enough processes crash, so that all shard data is lost. We now state conditions under which this cannot happen. We associate two events with each configuration of a shard : introduction and activation. Introduction indicates that the configuration comes into existence and is triggered when the configuration is successfully persisted in the configuration service (line 1). Activation indicates that the configuration becomes operational and is triggered when all the followers of the configuration have processed the messages sent by its leader (line 1).
Once a configuration has been activated, we say that it is active. We define its lifetime as the time interval between its introduction and when a succeeding configuration becomes active. Note that not every introduced configuration necessarily becomes active, since its leader may never complete the data transfer to the followers. To ensure our protocol is live we make the following assumption, similar to the ones made by other protocols with changing membership (ken-book, ; spiegelman2017dynamic, ).
Assumption 1.
At least one member in each configuration is non-faulty throughout the lifetime of a configuration.
The following two theorems show that, under this assumption, a single reconfiguration makes progress.
Theorem 4.2.
If a process attempts to reconfigure a shard and no other process attempts to reconfigure simultaneously, then if is non-faulty for long enough, it will eventually introduce a new configuration.
Theorem 4.3.
If a configuration of a shard is introduced by a process , then it will eventually be activated, provided no process attempts to reconfigure simultaneously, and and all the members of the configuration are non-faulty for long enough.
Finally, the following theorem shows that in the absence of failures or reconfigurations, transaction certification makes progress.
Theorem 4.4.
Assume that the current configuration of each shard is active, all processes are aware of the current configuration of each shard, and no reconfiguration is in progress. If a transaction is submitted for certification, then it will eventually be decided, provided no reconfiguration is attempted and all the processes belonging to the current configuration of each shard are non-faulty for long enough.
5. Exploiting RDMA
We now present a variant of our protocol that uses Remote Direct Memory Access (RDMA), which follows the design of the FARM system (farm, ; farm2, ). By comparing this protocol with that of §3 we highlight the trade-offs required by the use of RDMA. Due to space constraints, we defer the pseudocode of our protocol to §C and describe the required changes in the protocol of §3 only informally.
We assume the same system model as in §2, except that processes can communicate using RDMA. This allows a machine to access the memory of another machine over the network without involving the latter’s CPU, thus lowering latency. Like FARM, our protocol uses RDMA to implement a primitive for point-to-point communication between processes with the following interface. The primitive allows a sender process to reliably send a message to a receiver process (send-rdma ()) by remotely writing into a specific memory region of . The sender then gets an acknowledgement when the message reaches the receiver’s memory (ack-rdma ()), sent by the receiver’s network interface card (NIC) without interrupting its CPU. The receiver is notified at a later point that a new message is available (deliver-rdma ()). Hence, the guarantee provided by ack-rdma () is that the receiver will eventually deliver the message , even if the sender crashes, since the message is already in the receiver’s memory. The operation open () grants access to a region of the caller’s memory, and close () revokes it. Once the latter operation completes, cannot send any message to the caller using send-rdma. Finally, we assume that the communication primitive includes another operation: flush. This operation blocks the caller until it has delivered all messages addressed to it that have been acknowledged by its NIC through an ack-rdma.
To implement the above primitive, the receiver usually keeps a circular buffer in memory for each process that may send it a message (farm-first, ; rdma-mpi, ). The operation send-rdma () issued by a process appends a message to the corresponding buffer at the receiver using RDMA writes. Receivers periodically pull messages from the buffers and deliver them to the application via deliver-rdma. If a buffer at a process gets full, the associated sender process will not be able to send a message to until the latter pulls some messages.
Following FARM, we use the above RDMA-based communication primitive in our protocol to persists votes and decisions (steps 2 and 3 of Figure 2a). This requires the following changes to the protocol in Figure 1. First, and messages are sent using send-rdma instead of send ** (lines 1 and 1). Second, the followers do not send explicit messages to transaction coordinators (line 1); instead, the latter act once they receive an RDMA acknowledgement ack-rdma. This makes the checks at lines 1 and 1 redundant, as followers cannot reject or messages under any circumstance. The practical rationale for these changes is that persisting a transaction at followers using RDMA minimizes the time during which the transaction is prepared at leaders, which requires them to vote abort on all transactions conflicting with (via the certification function , §2); this results in lower abort rates (farm, ; binnig, ). Transaction processing at followers (e.g., adding them to the local copy of the certification order, line 1) is done off the critical path of certification.
Unfortunately, the above changes to the failure-free path of the protocol do not
preserve correctness without changes to reconfiguration, as illustrated by an
example execution in Figure 4a. In this execution, two shards
and are involved in the certification of a transaction ,
coordinated by a process from a third shard. The transaction is prepared
to commit at the leaders and of both shards (step
1
), and
the commit vote from the leader of () is persisted at the
follower using RDMA (step
2
). Before the coordinator
persists the vote from the leader of at the follower , the
leader is suspected of failure and a reconfiguration is triggered at shard
. This promotes the follower to a new leader and brings online a
fresh follower . Next, the leader of suspects the coordinator
of failure and triggers a reconfiguration to remove it. Once is
removed from its shard, retries the processing of (step
3
,
line 1 in Figure 1). The new leader of
does not know about , so this results in the transaction being aborted,
because its payload at shard is thought to be lost (steps
4
and
5
). But now the coordinator , who did not actually fail and still
believes is in the old configuration, finishes its processing by
persisting the commit vote of the old leader of at the old
follower , which is now the new leader of (step
6
). Since
this is done via RDMA, cannot reject the vote and, thus, commits the
transaction (step
7
). This violates safety, as two contradictory
results have been externalized. The protocol in §3 is not subject
to this problem, because in that protocol the new leader of the shard
would reject the message due to the failure of the check at
line 1.
To make the RDMA-based protocol correct, we need to change the reconfiguration protocol so that the whole system participates in reconfiguration instead of just the affected shard. Figure 4b illustrates the message flow of the redesigned reconfiguration protocol. Processes now maintain a single epoch variable instead of a vector. The data structures maintained by the external configuration service and its interface are adjusted accordingly. Like in our previous commit protocol, the process performing reconfiguration first probes previous configurations by sending messages. However, now probes all shards. A process receiving handles it as before (line 1), but additionally closes all incoming RDMA connections using close, which guarantees that the process accepts no more transactions at its previous epoch. This is needed because, due to communication via RDMA, the protocol cannot longer leverage the safety check at line 1. The logic of the reconfiguring process is also changed: after this process computes the new configuration and stores it in the configuration service (line 1), the process sends a new message to all processes in the configuration. Upon receiving , a process updates its locally stored configuration and replies with a message. This ensures that the whole system is aware of the new configuration before it is activated. Only after this does the reconfiguring process send a message to the leaders of the new configuration. Upon receiving (line 1), a leader first calls flush. This guarantees that all the messages that have been acknowledged as having reached ’s memory will be replicated to followers in messages; this is necessary since transaction coordinators may have already externalized decisions taken based on these acknowledgements. Finally, processes open RDMA connections to all other processes in the configuration using open: a leader after sending to its followers, and followers upon receiving (line 1).
The new protocol guarantees that: () if a process receives an message for a transaction while at epoch , then the leader that prepared was at epoch when it prepared this transaction. This property is key in proving the correctness of the protocol, as it provides the same guarantees as the removed guard in line 1, which we could not leverage due to the use of RDMA. The property () holds because: (i) at any time, a process only maintain RDMA connections to the members of its current epoch; and (ii) before persisting a vote at a follower, the coordinator of a transaction checks that the transaction was prepared in its current epoch (line 1).
We now show how the revised reconfiguration protocol prevents the bug in
Figure 4a. In this protocol, when attempts to persist the
commit vote at (step
6
), the latter will be already aware
that has been removed from the system and will close the RDMA
connection to it. Thus, will be unable to persist the vote at (this would
violate the property (*)) and will never gather enough acknowledgements to
decide the transaction. Hence, no contradictory results will be externalized. We
state and prove the correctness of the RDMA-based protocol
in §C.
6. Related Work and Discussion
Our protocols are inspired by the recent FARM system for transaction processing, which also uses replicas per shard and deals with failures using reconfiguration (farm, ; farm2, ). FARM was presented as a complete database system with a number of optimizations, including the use of RDMA. In contrast, our work distills the core ideas of FARM into protocols solving the well-defined transaction certification problem, parametric in the isolation level provided and rigorously proven correct. This allows us to simplify some aspects of the FARM design. In particular, FARM has a more complex way of determining the state of the new leader upon a reconfiguration, which merges the states from all surviving replicas of the previous configuration. In contrast, our protocols take the state of any single initialized replica. Our reconfiguration protocols also provide better fault-tolerance guarantees on a par with those of existing ones (ken-book, ; spiegelman2017dynamic, ). This is because, like Vertical Paxos I (vertical-paxos, ), our protocols look through a sequence of configurations to find the new leader, whereas FARM only considers the previous configuration. Hence, FARM reconfiguration can get stuck even when there exists a non-faulty replica with the necessary data. Finally, by presenting two related protocols using message passing and RDMA, we are able to identify the price of exploiting RDMA—having to reconfigure the whole system instead of a single shard.
There have been a number of protocols for solving the atomic commit problem, which requires reaching a decision on a single transaction (2pc, ; Hadzilacos1990, ; nbac, ; dwork-skeen, ). In contrast to these works, our protocol solves the more general problem of implementing a Transaction Certification Service, which requires reaching decisions on a stream of transactions. This problem more faithfully reflects the requirements of modern transaction processing systems (discpaper, ).
Our protocol weaves together two-phase commit (2PC) (2pc, ) and Vertical Paxos (vertical-paxos, ), instead of using Paxos replication as a black box. This is similar to several existing sharded systems for transaction processing, which integrate protocols for distribution and replication (uw-inconsistent, ; mdcc, ; replicated-commit, ; discpaper, ). However, these systems considered a static set of processes per shard, whereas we assume processes and allow the system to be reconfigured. Achieving this correctly is nontrivial and requires a subtle interplay between the reconfigurable replication mechanism and cross-shard coordination. For example, as we explained in §3, on failures our protocol may lose information about transactions that influenced votes on other transactions, but this does not violate correctness. As is well-known (cheappaxos, ), using instead of replicas results in somewhat weaker availability guarantees: upon a single failure, our protocols have to stop processing transactions while the system is reconfigured.
Acknowledgments.
We thank Dushyanth Narayanan for discussions about FARM. This research was supported by an ERC grant RACCOON.
Appendix A Correctness of the Protocol
Figure 5 summarizes additional invariants that, together with the invariants listed in Figure 3, are used to prove the correctness of the protocol. We first prove the nontrivial Invariants 1, 3, 11, 12 and 4 that were not proved in §4. We then prove Theorem 4.1.
A.1. Proof of Invariants
Proof of Invariant 1.
Assume that a process in at receives and replies with . We prove that, after the transition and while , has , and , where , and are the values of the arrays , and at the leader of at when it sent the corresponding message .
If processes , then has . Thus, has processed before. After processing this message, has , and where , and are the values of the arrays , and at the leader of at when it sent the message. Let . By lines 1, 1 and 1 we have that , and . Therefore, has , and while . Furthermore, after processing , has , and . By Invariant 9, has , and while .
We now prove that after processing and while , has , and for any such that . We prove it by induction on the length of the protocol execution from the moment in which has processed . The validity of the property can be affected by only the transition at line 1. Let be the message that triggers the transition. Assume that , as otherwise the transition does not affect the validity of the property. By the induction hypothesis, has , and for any such that after processing . Also, after processing , has , and . By lines 1, 1 and 1, , and . Then, after processing , has , and . This proves that, after processing and while , has , and for any such that . We have already proved that (i) has , and after processing and while ; and that (ii) has , and after processing and while . Hence, has , and after processing and while , as required. ∎
Proof of Invariant 3.
When processed , it set . This prevents from processing any message until it processes a or a . When processed , it also sets . By the checks in lines 1 and 1 and by the fact that can never decrease, this guarantees that only handles any of these messages if . Hence, by the time is able to process messages again it will have . By the check in line 1 and the fact that the protocol trivially guarantees that never decreases, will never send after sending a , as required. ∎
Proof of Invariant 11.
(a) Assume that all followers in at have received and replied with . Assume that all followers in at have received and replied with . Assume without loss of generality that . If , then by Invariant 6 we must have , and . Assume now that . By Invariant 2, when the leader of at sent the message it has , and . But then due to the check at line 1, we again must have , and .
(b) Assume that all followers in at have received and replied with . Assume that all followers in at have received and replied with . Assume without loss of generality that . We first show that . If , then we must have by Invariant 9. Assume now that . By Invariant 2, when the leader of at sent the message it has . But then due to the check at line 1 and Invariant 10, we again must have . Hence, . But then by Invariant 11a we must also have and . ∎
Proof of Invariant 12.
(a) Assume that a process in shard has , and . We show that then a message has been sent to , where . We prove the invariant by induction on the length of the protocol execution. The validity of the property can be affected by only the transitions at lines 1 and 1. First, consider the transition at line 1. By the induction hypothesis, satisfies the property before handling the message that causes the transition. Given that the message is only handled if , lines 1 and 1 trivially preserve the invariant. Finally, consider the transition at line 1. The transition is triggered when receives a . By the induction hypothesis, the leader of at satisfies the required before the transition. The process simply substitutes its and arrays by the arrays and . Therefore, will also satisfy the required after the transition.
(b) Follows from item (a) and Invariant 2.∎
Proof of Invariant 4.
Follows from Invariant 11, since, if a coordinator has computed the final decision on a transaction, then all followers in each relevant shard at a given epoch have accepted a corresponding vote.∎
A.2. Proof of Theorem 4.1
To facilitate the proof of Theorem 4.1, we first introduce a low-level specification TCS-LL, and prove that it is correctly implemented by the atomic commit protocol (Lemma A.1). We then show that every history satisfying TCS-LL is correct with respect to (Lemma A.3). The low-level specification TCS-LL is defined as follows.
Consider a history . Let denote the set of transactions such that is an event in , and denote the decision value of if is an event in . The history satisfies TCS-LL if for some of transactions and shards there exist , , and such that all the constraints in Figure 6 are satisfied. A protocol is a correct implementation of TCS-LL if each of its finite histories satisfies TCS-LL.
Lemma A.1.
The atomic commit protocol in Figures 1 is a correct implementation of TCS-LL.
Proof
Fix a finite execution of the atomic commit protocol with a history . Let be the set of transactions such that occurs in . For some of transactions , , and shards , we define the certification order position , and a vote computed by the protocol as follows:
Consider and . Assume that all followers in at received and responded to it with . Then, we let , and .
According to Invariants 2 and 10, this defines , and uniquely and (7) in Figure 6 holds. Furthermore, by the structure of the handler at line 1, for each such that occurs in , is defined for all and (6) holds. By Invariant 7, (8) holds.
We now prove (12). Consider such that
[TABLE]
Let be the message sent to the shard when the action was generated. Let be some epoch at which is defined according to the above definition. Assume first that . Then by Invariant 2 when the leader of starts operating, it has . But then must have occurred before the . Hence, . By Invariant 2 when the leader of at receives , it has . But then , which proves (12).
We prove (9)-(11) using the following proposition.
Proposition A.2.
The following always holds at any process in a shard :
[TABLE]
where the function determines the payload that a process has stored for a given transaction, i.e., for any transaction , and arrays and , . We lift the function to sets of transactions: for any set of transactions and arrays and , we have .
Proof.
We prove this by induction on the length of the protocol execution. The validity of the above property can be nontrivially affected only by the transitions at lines 1, 1, 1, and 1.
First consider the transition at line 1, which computes as follows:
[TABLE]
Then for some , we have
[TABLE]
From the last two conjuncts and Invariant 12 we get
[TABLE]
which implies the required.
We next consider the transition at line 1 by a process . The induction hypothesis implies that, before the transition at line 1, we have (14) at . After processing the , modifies its , , and arrays by assigning the position. Fix a . We distinguish three cases:
- (1)
. The required trivially follows from the induction hypothesis. 2. (2)
. By Invariant 1, after processing the message, has , and , where , and are the values of the arrays , and at the leader of at when it sent the . By the induction hypothesis, the leader of at satisfies the required before sending the message. Hence, by the fact that and are distributive, the required is guaranteed at for after the transition. 3. (3)
. We have that before processing the message, has processed . After processing , has , and where , and are the arrays , and at the leader of at when it sent the message. Let at after processing .
Consider first the case when . Then , after processing the message and before processing may have only processed such that . Lines 1 and 1 trivially guarantee that after processing , still has , and . By the induction hypothesis, the leader of at satisfies the required before sending the . Hence, the required is guaranteed at after the transition when .
Consider now the case when . Therefore, must have received an message and responded to it with before processing . By Invariant 1, after processing and while , has , and , where , and are the values of the arrays , and at the leader of at when it sent the . Thus, after processing , still has , and . By the induction hypothesis, the leader of at satisfies the required before sending . Hence by the fact that and are distributive, the required is guaranteed at after the transition.
Finally, the transitions at lines 1 and 1 are handled easily.∎
We now prove (9)-(11). Take the earliest point in the execution where can be determined as per the definition given earlier. Let be the epoch used in this definition. Then by Proposition A.2 at this point, at the leader of at for some we have
[TABLE]
For the fixed above, and Invariant 2 we get
[TABLE]
which establishes (10) and (11).
By Invariant 7, (8) and by the fact that and are distributive, we get
[TABLE]
which establishes (9) for the fixed above.
Finally, we prove (13). To this end, we show that if or , then a message was sent in the execution, and this had happened before any message was sent. The case of is trivial and therefore we only consider the case of . Take the earliest point in the execution where we can define , and hence, and (by (15)). Then a message could not have been sent by this point. Assume first that . Then by (15) a message has been sent earlier. Now assume that
[TABLE]
Then at this point and , so that by (15) a message has been sent earlier. We have thus proved (13).∎
Lemma A.3.
*If shard-local certification functions and satisfy (3)-(5), then every history satisfying TCS-LL is correct with respect to . *
Proof.
This follows the proof of Theorem 1 in [5]111Appendix A of https://arxiv.org/pdf/1808.00688. with minimal adjustments.∎
Proof of Theorem 4.1.
Follows from Lemmas A.1 and A.3.∎
Appendix B Proof of Liveness
We prove the nontrivial Theorem 4.2:
If a process attempts to reconfigure a shard and no other process attempts to reconfigure simultaneously, then if is non-faulty for long enough, it will eventually introduce a new configuration.
Proof.
Assume that a process attempts to reconfigure a shard . Take the earliest point in the execution where calls the reconfigure function. Let be the epoch of the last active configuration of at that point in time. The process first queries the configuration service to find the latest introduced configuration of to start the probing. Let be the epoch of this configuration.
Assume that the probing eventually ends. After this happens, computes the membership of the new configuration (lines 1). Then attempts to write into the configuration service. Since there is not other process attempting to reconfigure simultaneously, will succeed. This last step introduces , as required.
We now prove that the probing eventually ends, provided that no other process attempts reconfiguring simultaneously and is non-faulty for long enough. The probing procedure proceeds by iterations in epoch descending order, starting by probing the members of at . The process only moves to the next iteration after receiving at least one reply from a member of at the epoch being currently probed while no process replies with . Consider an arbitrary epoch such that . If is probing the members of at , then has received a from at least one member of at each epoch such that . Furthermore, because of line 1 and the check in line 1, none of these configurations will ever become active. Then by Assumption 1 and the fact that there is no concurrent reconfiguration, is guaranteed to receive at least one reply from a member of at . Hence, for each epoch that probes, either the whole probing terminates, or will eventually move to probe the previous epoch. Assume that reaches epoch . By line 1 and the check in line 1, the configurations of with epoch , such that , will never become active. Then by Assumption 1 and the fact that there is no concurrent reconfiguration, is guaranteed to receive at least one reply from a member of at . That the configuration of with epoch became active implies that every member of at has when being probed. Hence, the probing procedure is guaranteed to finish.∎
Appendix C RDMA-based Atomic Commit Protocol
We give the pseudocode of the RDMA-based protocol in Figures 7 and 8. The redesigned reconfiguration protocol uses a slightly different set of variables. Instead of the variable , the protocol uses the variable to record whether a process is ready to start reconfiguring the system, probing the system or disseminating a new configuration. A variable records the set of processes to which a process currently maintains an open RDMA connection. Also, the variables and are now arrays: and . This change is required because now reconfiguration involves all shards, instead of a single one. Finally, the data structures maintained by the external configuration service and its interface are adjusted as well. Instead of keeping a separate data structure with each shard’s sequence of configurations, the configuration service keeps a single data structure with the system’s sequence of configurations parameterized by shard. Moreover, none of the three operations of the configuration service’s interface take a shard identifier as argument anymore.
To prove the correctness of the protocol, apart from the set of invariants (Figures 3 and 5) used to prove the correctness of the atomic commit protocol in Figure 1, we require the following invariant, formalizing property (*) from §5:
Assume that the coordinator of a transaction receives a message and sends an message to a process . If receives the message, then it has right before this.
This invariant trivially holds in the atomic commit protocol in Figure 1 but is nontrivial in the RDMA-based protocol.
We first prove Invariant 13. Then we prove Invariants 3 and 1, whose proofs rely on Invariant 13. We skip the proofs for the rest of the invariants, as these are similar to the proofs of the invariants in Figures 3 and 5 of the protocol in Figure 1, with small adjustments due to differences in the protocols’ pseudocodes. Finally, we prove the following theorem.
Theorem C.1.
A transaction certification service implemented using the protocol in Figures 7 and 8 is correct with respect to a certification function matching the shard-local certification functions and .
Proof of Invariant 13.
Assume that the coordinator of a transaction receives a message and sends an message to a process . Assume further that receives the message and let at right before this transition. We prove that .
The leader of at must have received and replied with , and when it received the message, it had . Thus, must have received earlier. Also, by the check in line 7, must be a member of . Then had processed before sent the message to . When processed , it had no open connections, either because it was probed (line 8) or because it is a new process. The process only opens them, allowing it to receive , when it receives either a or a message, so that . By the fact that gets updated when processing and by the checks in lines 8 and 8, we have that . Then .
Assume now that . When processes it has . Then has received or before. When processing any of these messages, has no open connections. Therefore, must have sent after processed or . Furthermore, by the checks in lines 8 and 8, only establishes connections to the members of . Thus, must be a member of to successfully send to . Then must have received and replied with before processed or and therefore before sending . When processing , has no open connections. Thus, can only send after receiving or , where . This implies that received after setting . By the check in line 7, then would never send to at this point. Hence, we must have , which together with implies .∎
Proof of Invariant 1.
Assume that a process in at processes . We prove that, after the transition and while , has , and , where , and are the values of the arrays , and at the leader of at when it sent the corresponding message .
By Invariant 13, if processes , then has . Thus, has processed before. After processing this message, has , and where , and are the values of the arrays , and at the leader of at when it sent the message. Let . By lines 7, 7 and 8 we have that , and . By Invariant 13, has , and while . Furthermore, after processing , has , and . By Invariants 9 and 13, has , and while .
We now prove that after processing and while , has , and for any such that . We prove it by induction on the length of the protocol execution from the moment in which has processed . The validity of the property can be affected by only the transition at line 7. Let be the message that triggers the transition. Assume that , as otherwise the transition does not affect the validity of the property. By the induction hypothesis, has , and for any such that after processing . Also, after processing , has , and . By Invariant 13, must have been prepared by the leader of at . Then, by lines 7, 7 and 8, , and . Then, after processing , has , and . We have already proved that (i) has , and after processing and while ; and that (ii) has , and after processing and while . Hence, has , and after processing and while , as required. ∎
Proof of Invariant 3.
When processed , it closed all connections. This prevents from acknowledging any message until it processes a or a . When processed , it also sets . By the checks in lines 8 and 8 and by the fact that can never decrease, this guarantees that only handles any of these messages if . Hence, by the time is able to process messages again it will have . Since never decreases at a process, from this point on, by Invariant 13, will not process any message prepared in an epoch preceding , as required.∎
Lemma C.2.
The atomic commit protocol in Figures 7 and 8 is a correct implementation of TCS-LL.
Proof
This follows the proof of Lemma A.1 with minimal adjustments.∎
Proof of Theorem C.1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Balakrishnan, D. Malkhi, V. Prabhakaran, T. Wobber, M. Wei, and J. D. Davis. Corfu: A shared log design for flash clusters. In Conference on Networked Systems Design and Implementation (NSDI) , 2012.
- 2[2] C. Binnig, A. Crotty, A. Galakatos, T. Kraska, and E. Zamanian. The end of slow networks: It’s time for a redesign. PVLDB , 9(7), 2016.
- 3[3] K. Birman, D. Malkhi, and R. V. Renesse. Virtually synchronous methodology for building dynamic reliable services. In K. Birman, editor, Guide to Reliable Distributed Systems - Building High-Assurance Applications and Cloud-Hosted Services , Texts in Computer Science, chapter 22. Springer, 2012.
- 4[4] F. Chang et al. Bigtable: A distributed storage system for structured data. In Symposium on Operating Systems Design and Implementation (OSDI) , 2006.
- 5[5] G. Chockler and A. Gotsman. Multi-shot distributed transaction commit. In Symposium on Distributed Computing (DISC) , 2018.
- 6[6] J. C. Corbett et al. Spanner: Google’s globally-distributed database. In Symposium on Operating Systems Design and Implementation (OSDI) , 2012.
- 7[7] A. Dragojević, D. Narayanan, O. Hodson, and M. Castro. Fa RM: Fast remote memory. In Conference on Networked Systems Design and Implementation (NSDI) , 2014.
- 8[8] A. Dragojević, D. Narayanan, E. B. Nightingale, M. Renzelmann, A. Shamis, A. Badam, and M. Castro. No compromises: Distributed transactions with consistency, availability, and performance. In Symposium on Operating Systems Principles (SOSP) , 2015.