RSS-Based Q-Learning for Indoor UAV Navigation
Md Moin Uddin Chowdhury, Fatih Erden, and Ismail Guvenc

TL;DR
This paper introduces an RSS-based Q-learning approach for indoor UAV navigation in search and rescue missions, enabling UAVs to locate signal sources without GPS or prior environment knowledge.
Contribution
It proposes a novel RSS-based state and reward definition for Q-learning, eliminating the need for GPS and environment maps in indoor UAV navigation.
Findings
RSS-based Q-learning achieves comparable performance to location-based methods.
The approach works effectively in simulated indoor environments.
It enables GPS-denied indoor UAV navigation for SAR missions.
Abstract
In this paper, we focus on the potential use of unmanned aerial vehicles (UAVs) for search and rescue (SAR) missions in GPS-denied indoor environments. We consider the problem of navigating a UAV to a wireless signal source, e.g., a smartphone or watch owned by a victim. We assume that the source periodically transmits RF signals to nearby wireless access points. Received signal strength (RSS) at the UAV, which is a function of the UAV and source positions, is fed to a Q-learning algorithm and the UAV is navigated to the vicinity of the source. Unlike the traditional location-based Q-learning approach that uses the GPS coordinates of the agent, our method uses the RSS to define the states and rewards of the algorithm. It does not require any a priori information about the environment. These, in turn, make it possible to use the UAVs in indoor SAR operations. Two indoor scenarios with…
Click any figure to enlarge with its caption.
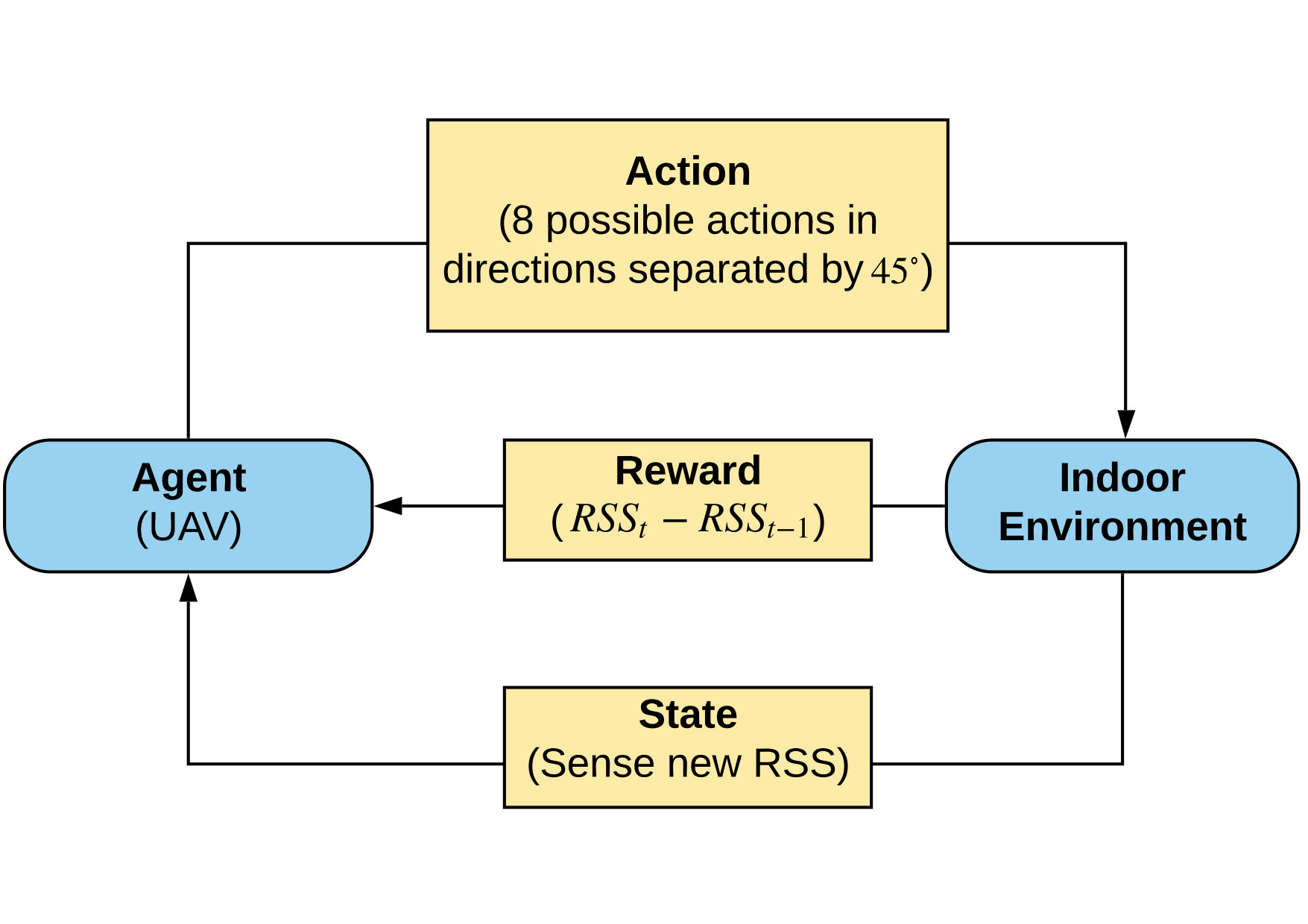 Figure 1
Figure 1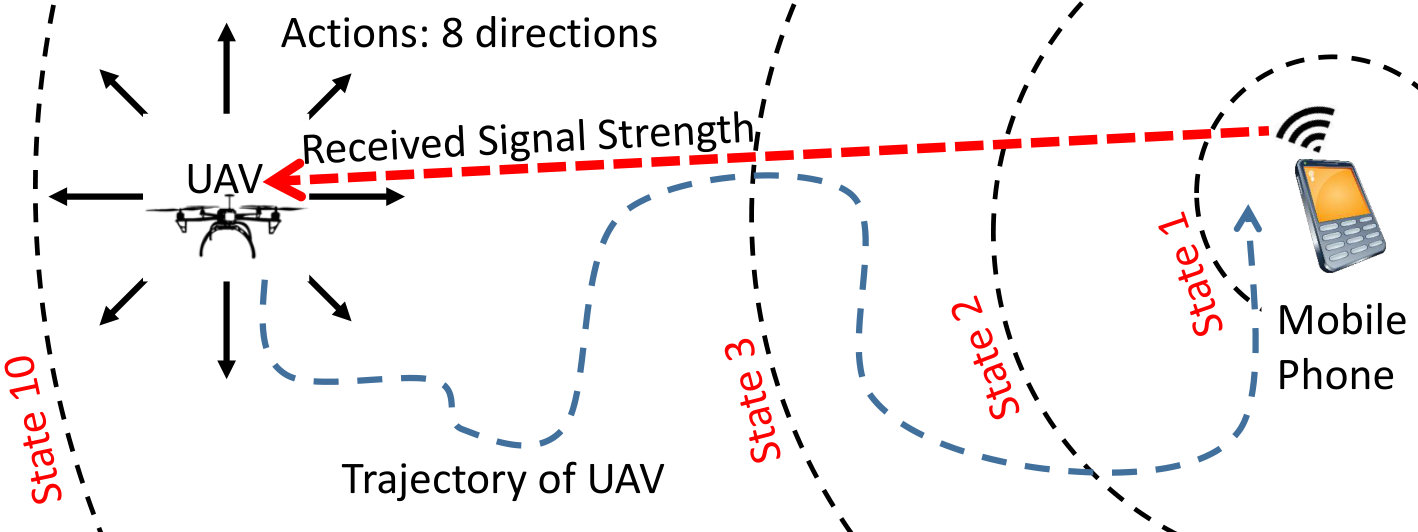 Figure 2
Figure 2 Figure 3
Figure 3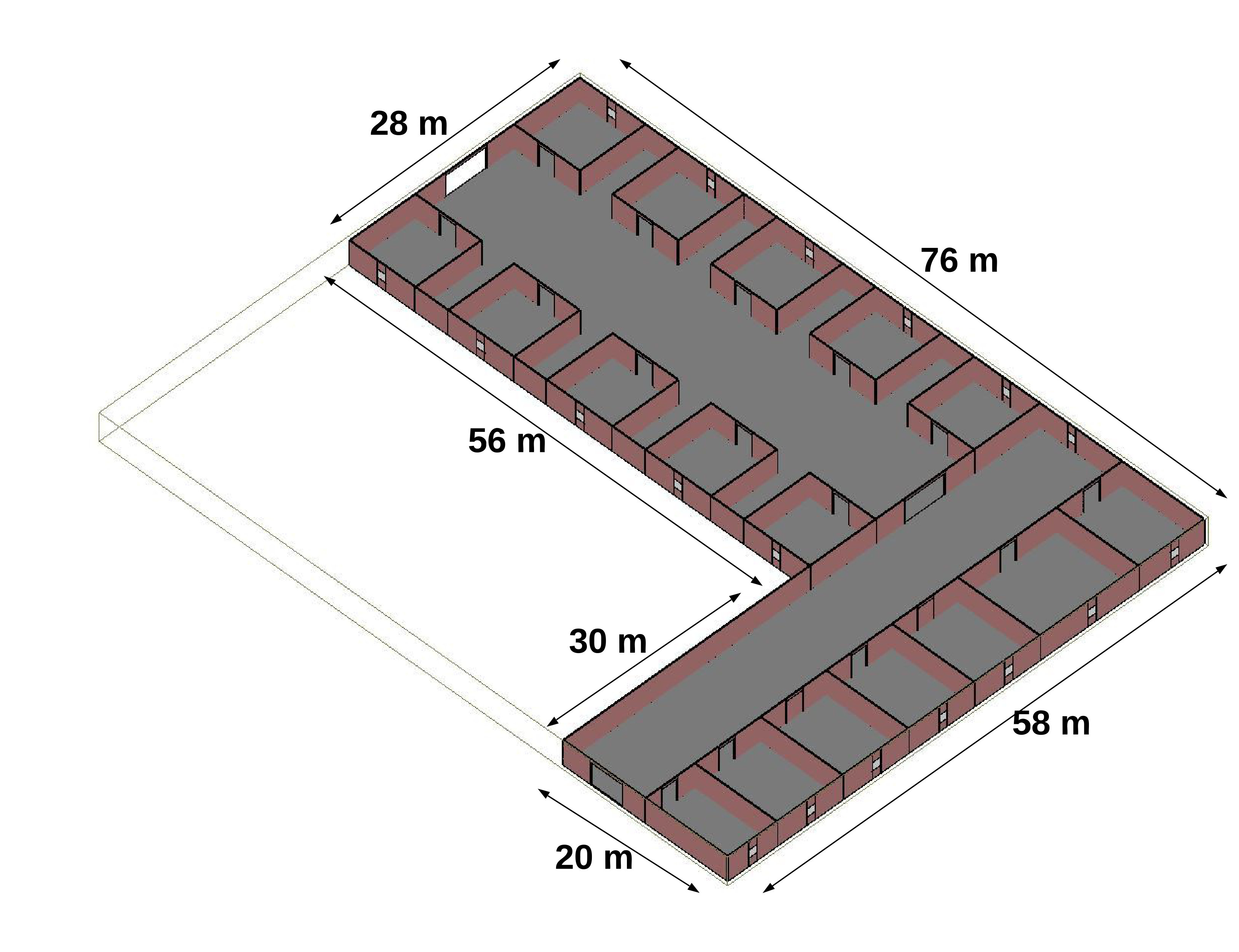 Figure 4
Figure 4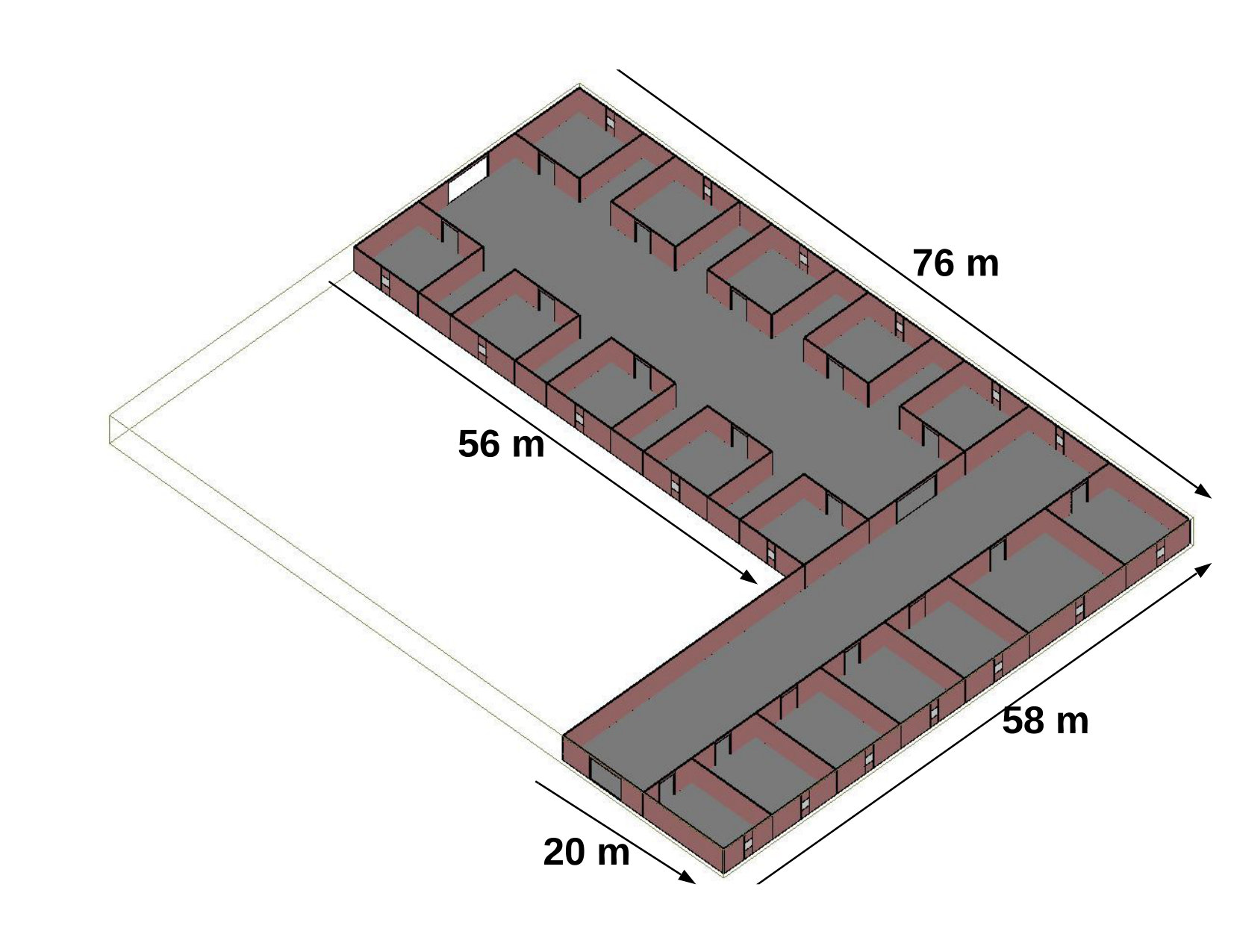 Figure 5
Figure 5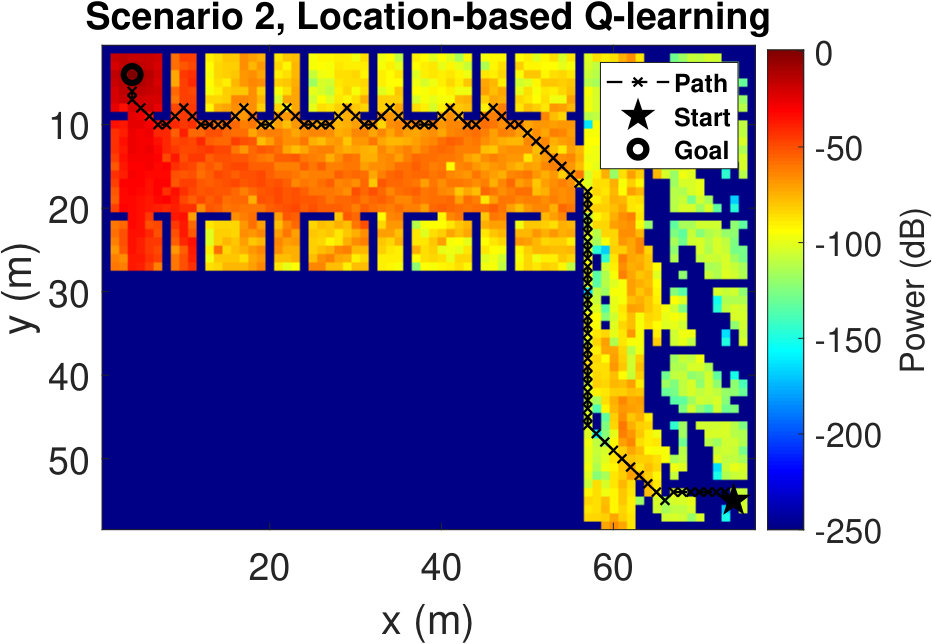 Figure 6
Figure 6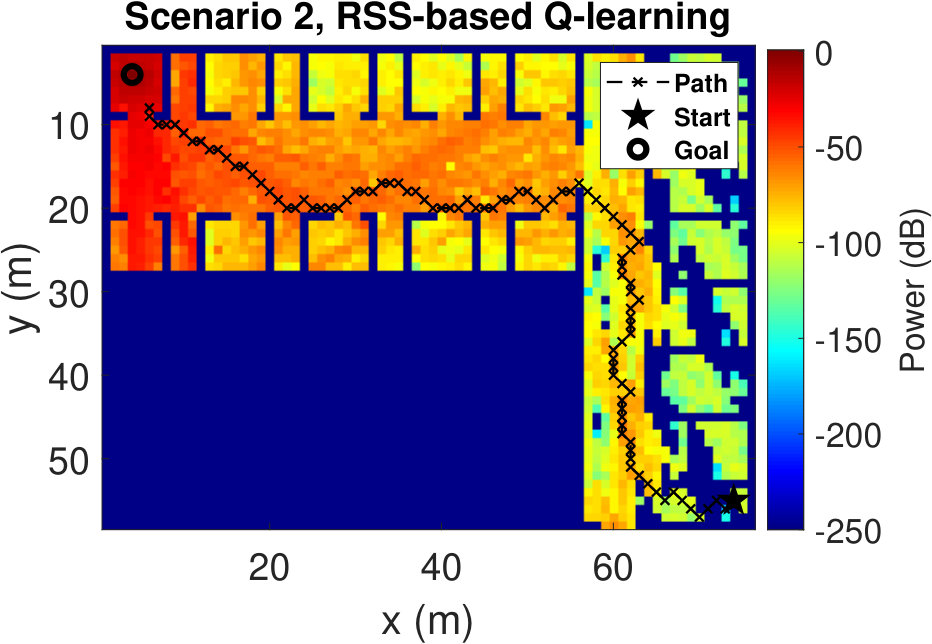 Figure 7
Figure 7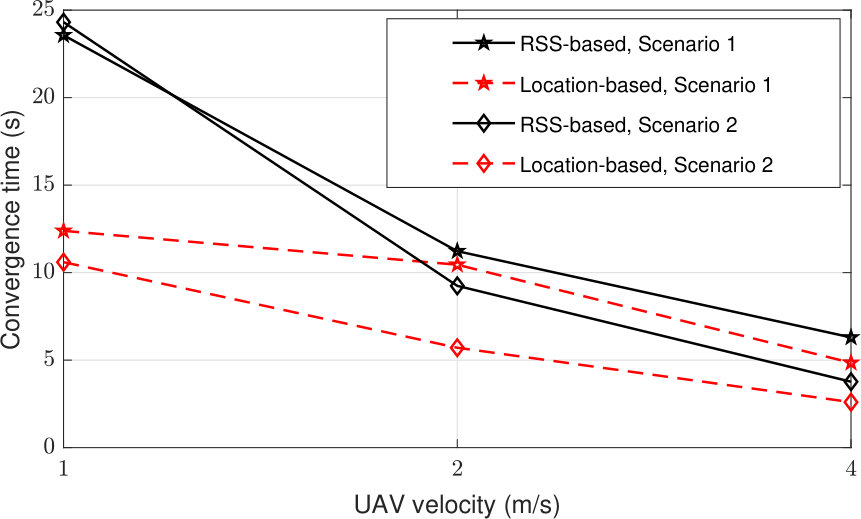 Figure 8
Figure 8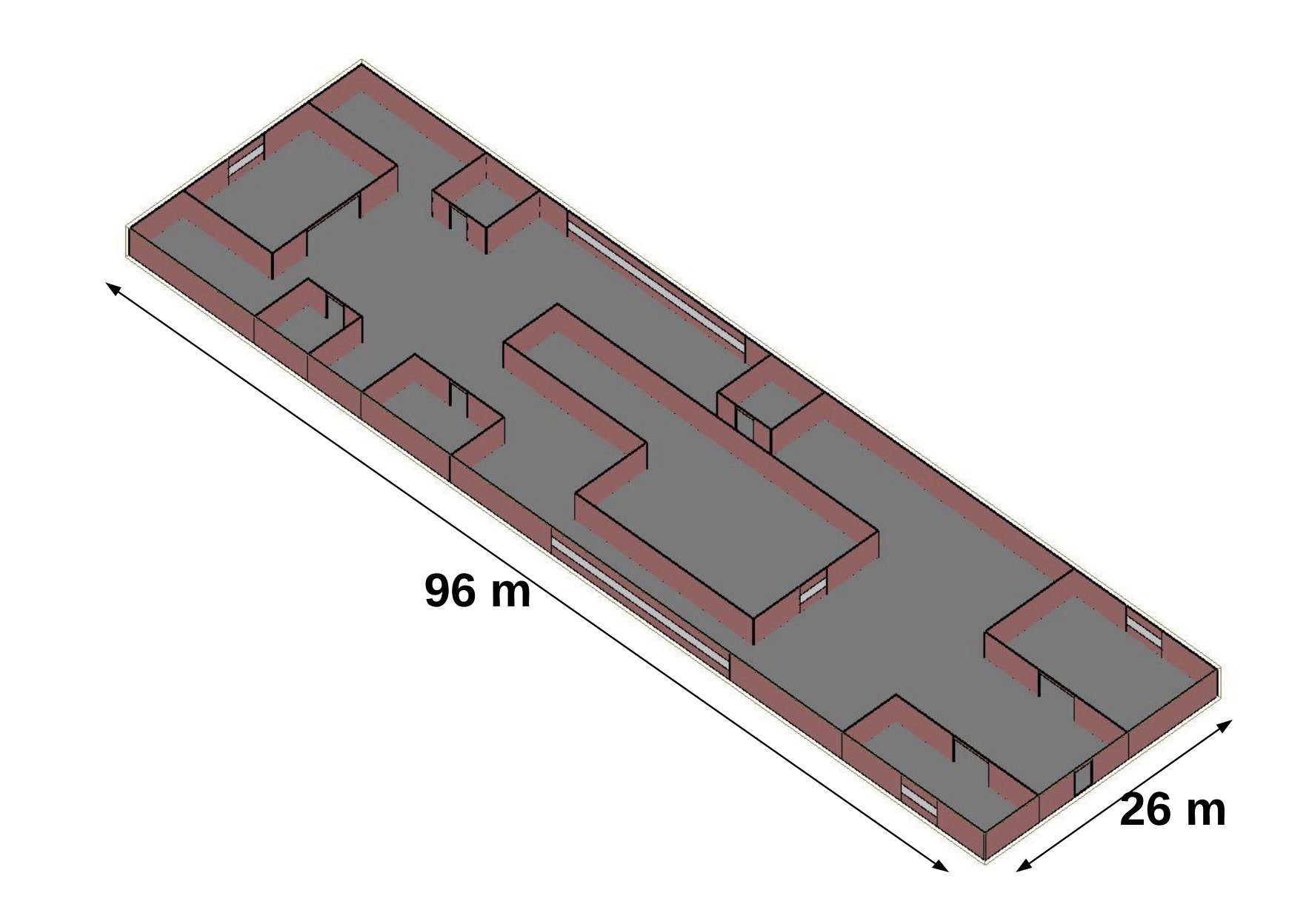 Figure 9
Figure 9 Figure 10
Figure 10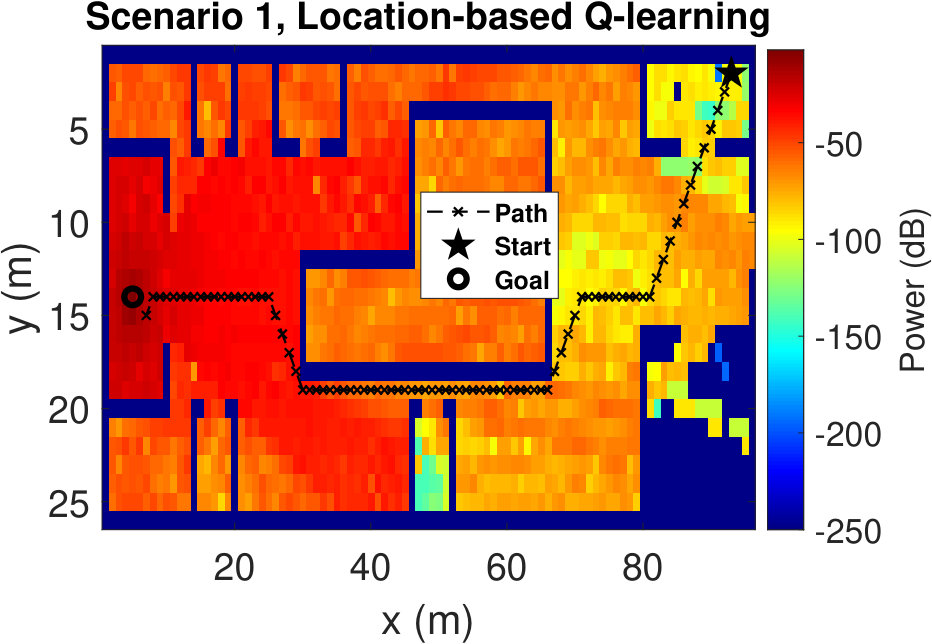 Figure 11
Figure 11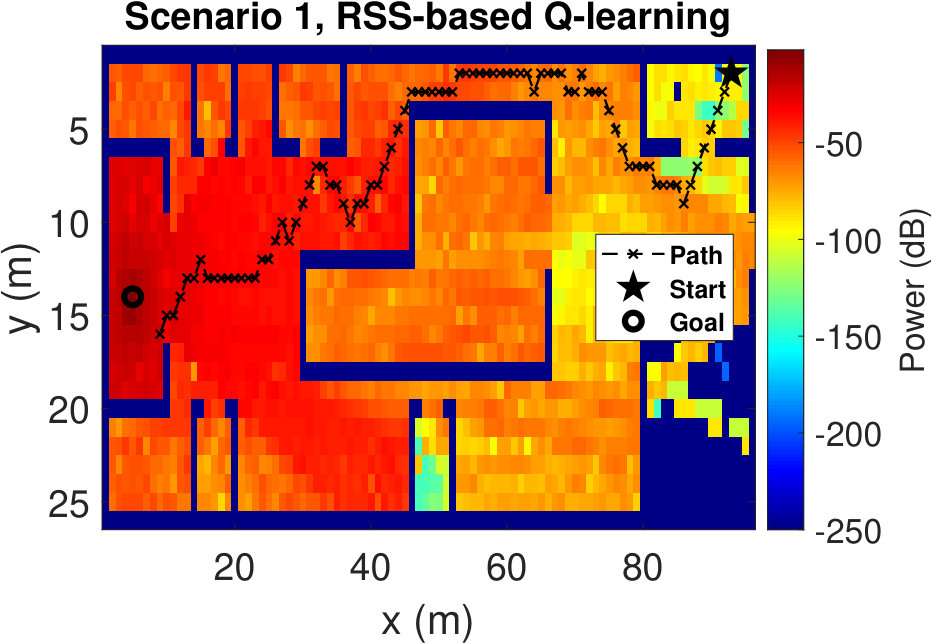 Figure 12
Figure 12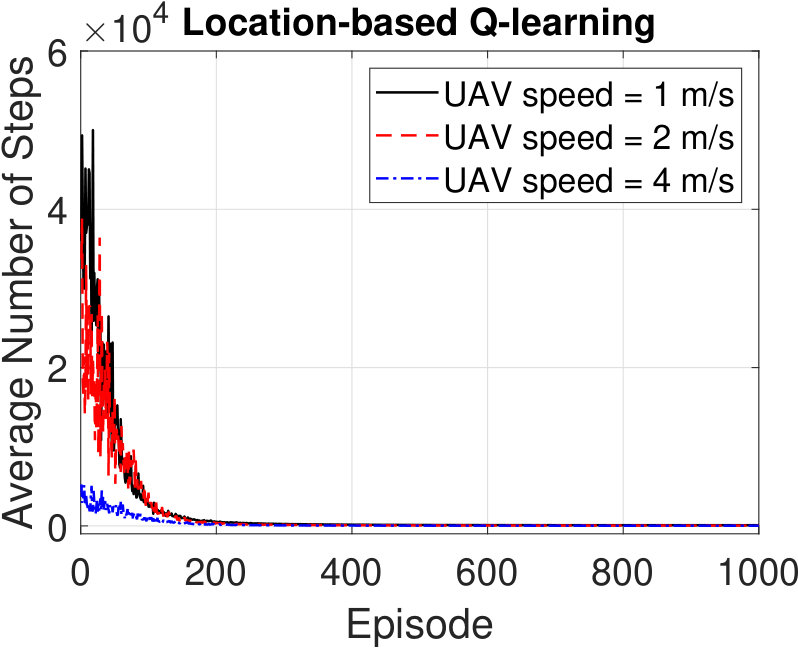 Figure 13
Figure 13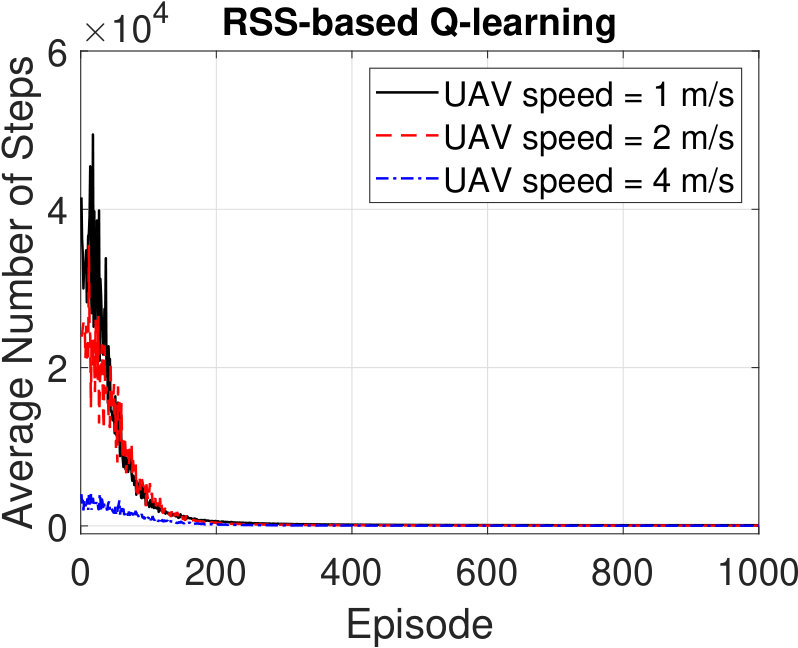 Figure 14
Figure 14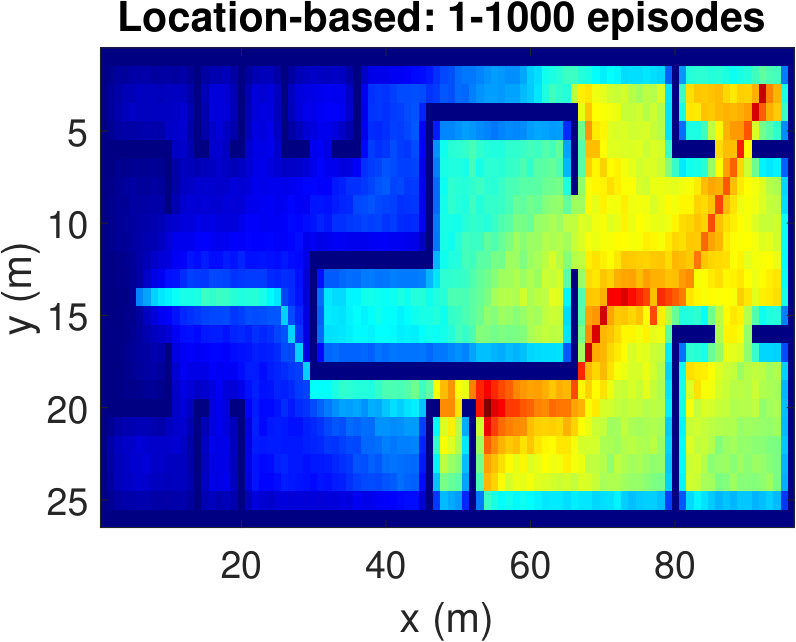 Figure 15
Figure 15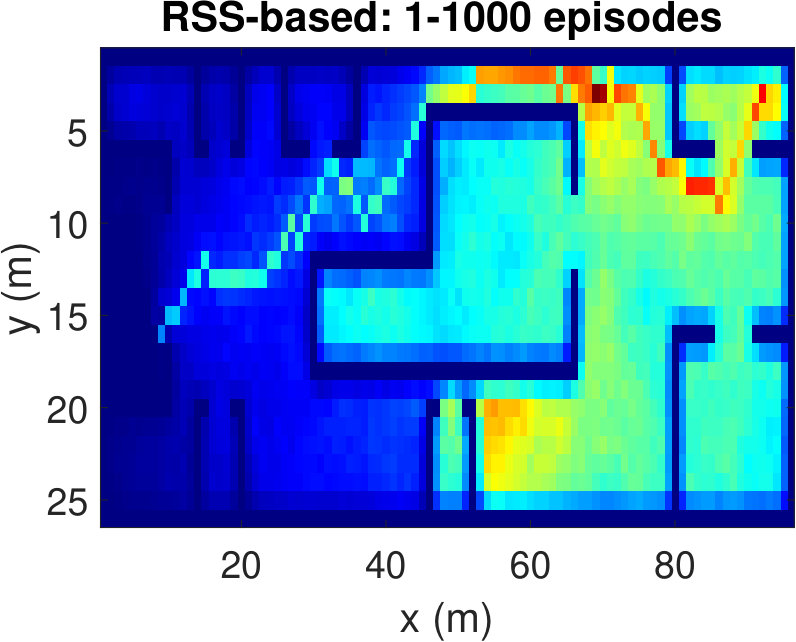 Figure 16
Figure 16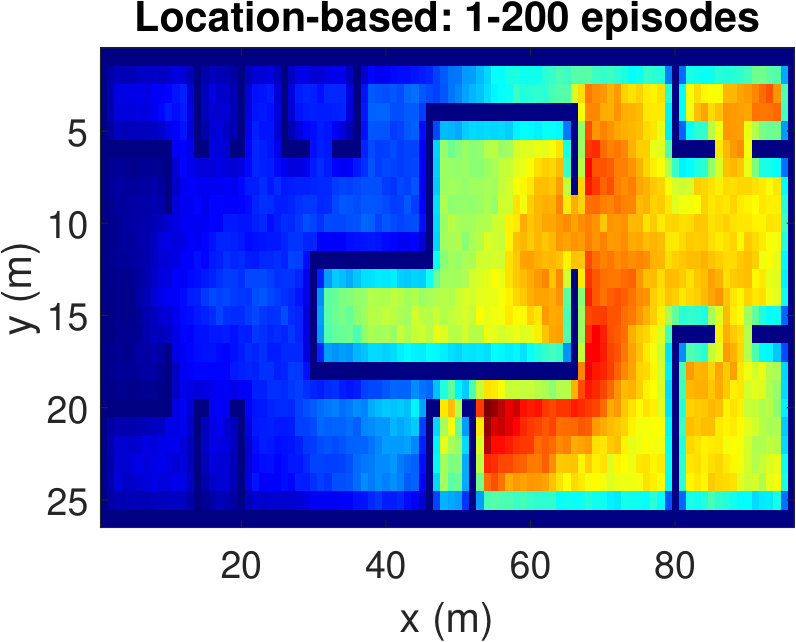 Figure 17
Figure 17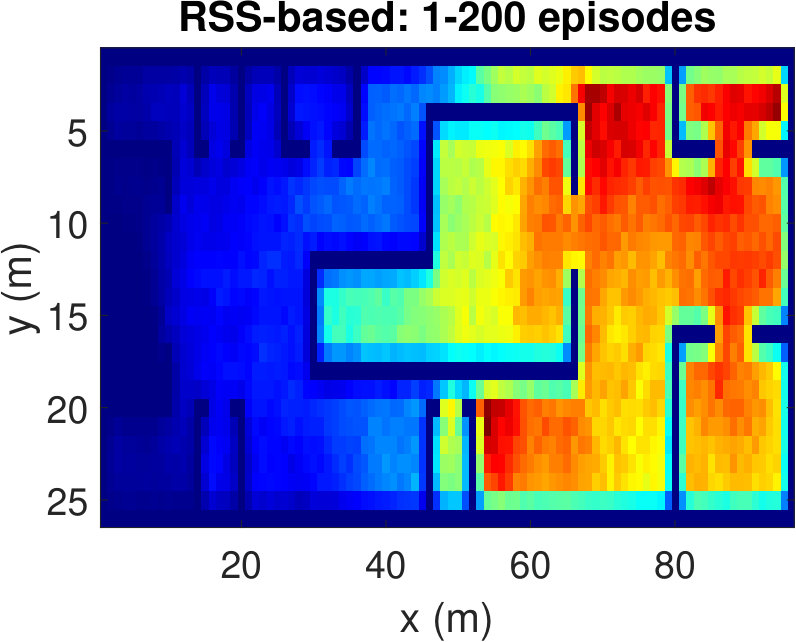 Figure 18
Figure 18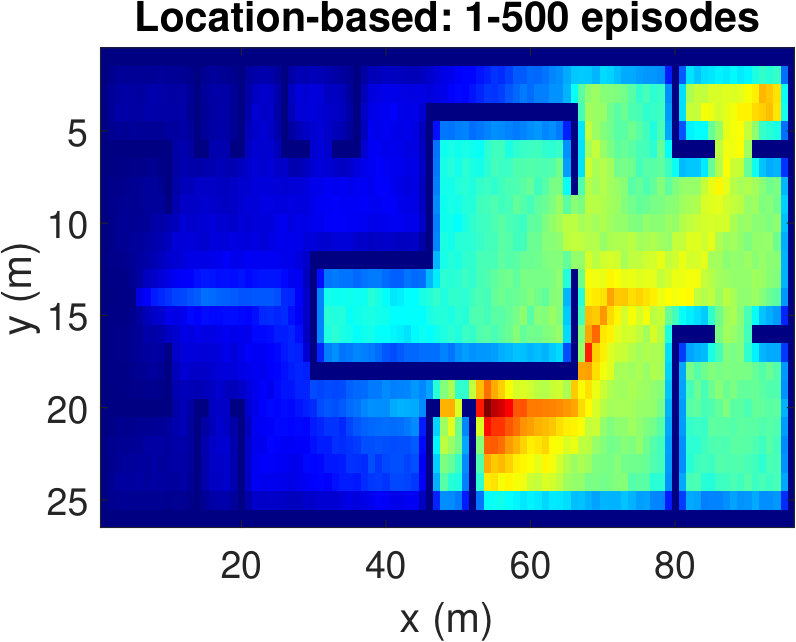 Figure 19
Figure 19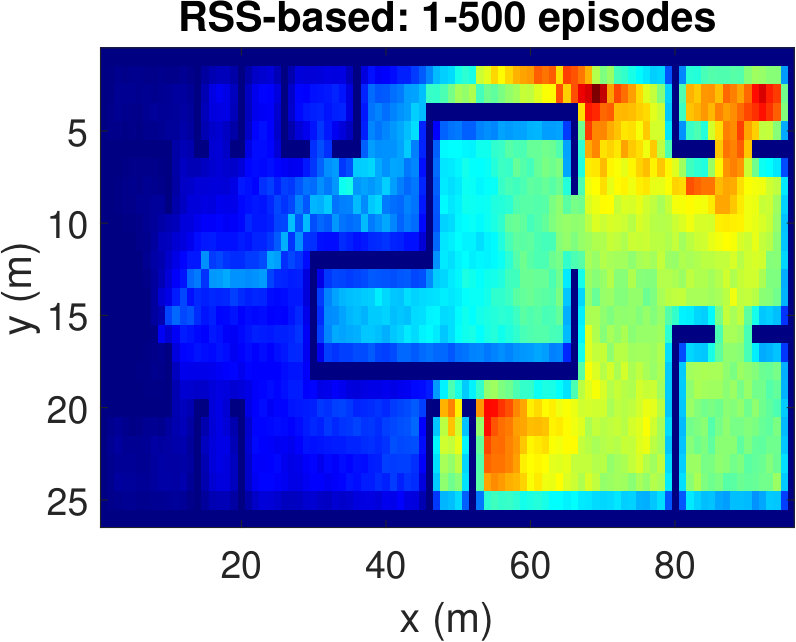 Figure 20
Figure 20| Ref. | Input | Method | Use | Target | Goal |
|---|---|---|---|---|---|
| [2] | RF signal & GPS | Random Forest | Outdoor | ✓ | Location estimation |
| [7] | RF signal & GPS | Deep RL | Outdoor | ✓ | Rescue lost victims |
| [5] | GPS & Sensors | RL | Indoor/ Outdoor | ✓ | Autonomous navigation in an unknown environment |
| [6] | GPS & Sensors | RL | Outdoor | ✓ | Localize immobile victim |
| [15] | RF signal & GPS | Predefined searching path | Outdoor | ✓ | Rescue victim |
| [13] | GPS & Sensors | Deep RL | Outdoor | ✗ | UAV navigation |
| [8] | GPS & Sensors | Deep RL | Outdoor | ✗ | Autonomous landing on a moving platform |
| [9] | Camera image | ConvNet | Indoor | ✓ | Indoor UAV navigation |
| [11] | 3D CAD models | Image processing & deep learning | Indoor | ✗ | Collision-free indoor UAV navigation |
| [10] | Camera image | Image processing & deep learning | Indoor | ✗ | Collision-free indoor UAV navigation |
| [4] | GPS | RL | Outdoor | ✓ | Maximize sum-rate |
| [16] | Infrared sensor | RL | Outdoor | ✓ | Detect targets |
| Our method | RF signal | RL | Indoor/ Outdoor | ✓ | Localize fixed victim |
| Parameter | Value |
|---|---|
| , | 1, 0.01 |
| , | 0.5, 0.05 |
| UE Transmit power | 25 dBm |
| 0.98 |
| Technique |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| RSS-based | dBm | ||||||||
| Location-based | (x,y) coordinate | m |
| Total path length (m) | ||||
|---|---|---|---|---|
| UAV speed | Scenario 1 | Scenario 2 | ||
| (m/s) | RSS-based | Location-based | RSS-based | Location-based |
| 1 | 105.88 | 94.70 | 122.61 | 119.71 |
| 2 | 104.22 | 101.25 | 121.65 | 121.05 |
| 4 | 102.91 | 98.63 | 126.22 | 114.63 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
RSS-Based Q-Learning for Indoor UAV Navigation
Md Moin Uddin Chowdhury, Fatih Erden, and Ismail Guvenc Dept. Electrical and Computer Engineering, NC State University, Raleigh, NC, 27606
Email: {mchowdh, ferden, iguvenc}@ncsu.edu
Abstract
In this paper, we focus on the potential use of unmanned aerial vehicles (UAVs) for search and rescue (SAR) missions in GPS-denied indoor environments. We consider the problem of navigating a UAV to a wireless signal source, e.g., a smartphone or watch owned by a victim. We assume that the source periodically transmits RF signals to nearby wireless access points. Received signal strength (RSS) at the UAV, which is a function of the UAV and source positions, is fed to a Q-learning algorithm and the UAV is navigated to the vicinity of the source. Unlike the traditional location-based Q-learning approach that uses the GPS coordinates of the agent, our method uses the RSS to define the states and rewards of the algorithm. It does not require any a priori information about the environment. These, in turn, make it possible to use the UAVs in indoor SAR operations. Two indoor scenarios with different dimensions are created using a ray tracing software. Then, the corresponding heat maps that show the RSS at each possible UAV location are extracted for more realistic analysis. Performance of the RSS-based Q-learning algorithm is compared with the baseline (location-based) Q-learning algorithm in terms of convergence speed, average number of steps per episode, and the total length of the final trajectory. Our results show that the RSS-based Q-learning provides competitive performance with the location-based Q-learning.
Index Terms:
Drone, Q-learning, ray tracing, RSS, unmanned aerial vehicles (UAVs), UAV navigation.
I Introduction
††This work is supported by NSF under the award CNS-1453678. The authors would like to thank Bekir S. Ciftler and Adem Tuncer for their initial inputs.
Thanks to the extensive studies and massive cost reduction in manufacturing, the interest in the use of unmanned aerial vehicles (UAVs) is expected to increase significantly in the upcoming years. Besides their widespread recreational and military use, UAVs have already started to show up in civilian applications including but not limited to precision agriculture, infrastructure health monitoring, packet delivery, restoring service after natural disasters, patrolling missions, and search and rescue (SAR) operations [1, 2].
Deployment of UAVs can make a big difference in SAR missions by providing information and data about the environment or an injured or lost person, improving network access, delivering first aid equipment, among others. UAVs can be utilized by emergency services or rescue teams in the aftermath of a disaster (e.g., a hurricane or earthquake) and can help the first responders make better decisions and save time. However, due to the unavailability of a suitable data link or precise maneuver requirements that are sometimes outside human capabilities, human control over the UAVs may not be possible [3]. Thus, it is critical to develop effective technologies and algorithms to enable the UAVs to perform complicated tasks autonomously. One issue with the autonomous use of UAVs in SAR missions is that, most of the time, the prior knowledge regarding the environment is limited, if not completely unavailable. Moreover, the environment may change with time or the models defining the target and its location may not be accurate or descriptive enough. Therefore, a UAV is required to interact with the environment, learn and make decisions by itself. Reinforcement learning (RL), which is a class of machine learning (ML) algorithms, may help to overcome these issues.
In RL, an agent learns in an interactive environment by using feedback from its actions and experiences. Usually, the environment is modeled as a Markov decision process (MDP) to leverage the dynamic programming technique that is used by the RL algorithms. The studies that do not make use of the ML either use exact models of the environment or assume the accurate information of the environment is predictable[4]. On the contrary, a branch of RL, known as Q-learning, requires a little or no prior/explicit knowledge of the environment. Q-learning is an off-policy RL algorithm which aims to find the best action to take given the current state. It learns from actions that are not known to the current policy by taking random actions and seeks to learn a policy that maximizes the total reward.
RL algorithms have already been widely studied in UAV-related researches as in many other fields of robotics. In [5], a model-based RL algorithm, TEXPLORE, is used for the autonomous navigation of UAVs. The value function is updated from a model of the environment, while also taking battery life into consideration. It is shown that their method learns faster than the traditional table-based Q-learning due to its parallel architecture. Pham et al. [6] use Q-learning to navigate the UAVs by defining states based on the UAV location. It is assumed that the UAV can observe its state at any position. In [7], GPS signal and sensory information of the local environment are used in deep RL for UAV navigation tasks in outdoor environments. In [8], deep Q-learning is used for the autonomous landing of UAVs on a moving platform. In [2], RF signals from devices are used to estimate users location using random-forest based ML technique.
There are recent promising attempts of navigating UAVs in GPS-denied indoor environments using image processing based techniques. In [9], images from a single camera are input to a convolutional neural network (ConvNet) to learn a control strategy to find a specific target. In [10], monocular images are used in a deep neural network to navigate a UAV while avoiding crashes. Negative flying data created from real collisions are used during training along with the positive data, and all training is done offline. In [11], RGB images are fed to a deep ConvNet based learning method to enable UAVs to have collision-free indoor flights, again with offline training.
Motivated by the above discussion, in this paper, we propose a new method for autonomous navigation of UAVs indoors using Q-learning. Smart devices (e.g., a smartphone) can be used to locate a victim in a SAR scenario through the propagated RF signals [12]. Presently, smart devices can continuously transmit RF signals to discover nearby APs. Furthermore, a smart device can be forced to transmit wireless signals in case of emergency [13, 14]. Based on this fact, unlike the location-based Q-learning, our approach uses RSS values instead of UAV location information while deciding future actions to navigate the UAV towards the target. It does not require any prior knowledge of the environment. There is also no need for an exact mathematical representation of the target or mapping of the environment to locate the target.
A high-level view of the system architecture is shown in Fig. 1. The receiver mounted on a UAV continuously senses the environment and picks up the RF signals from a remote wireless transmitter referred to as the source. A unique state label is assigned to the RSS value at the current position. Rewards in the Q-learning algorithm are also defined as a function of successive RSS values sensed in the current and previous positions, and Q-table is updated accordingly. Finally, the UAV takes one of the possible eight actions in different directions separated by . The proposed RSS-based Q-learning is tested in two different indoor environments. The environments and corresponding heat maps showing the RSS values for each possible UAV location are generated in a ray tracing software for a more realistic evaluation. The proposed method is compared with the baseline (i.e., location-based) Q-learning algorithm for different UAV speeds in terms of convergence speed, the number of steps taken to reach the victim in the final route, and averaged number of steps per episode.
The remainder of this paper is organized as follows. Section II briefly describes the Q-learning algorithm. Simulation setup is introduced in Section III. The RSS-based Q-learning algorithm for indoor navigation of UAVs is elaborated in Section IV. Experimental results are presented in Section V. Finally, Section VI concludes this paper.
II Background on Q-Learning
As mentioned in Section I, RL is a branch of ML that addresses problems where there is no explicit training data available. Q-learning, proposed by Watkins [17], can be used to learn optimal policies in finite MDPs [18]. This traditional table-based Q-learning maximizes the expected value of the total reward over any and all successive steps by taking action in the current state and follows an optimal policy afterwards. It learns by interacting with the environment and approximates a value function of each state-action pair through a number of iterations. The goal is to select the action which has the maximum -value using the following update rule at each iteration:
[TABLE]
where is the state reached from state after taking action , is the learning rate, is the reward attained for the current state , and is the discount factor which determines the importance of future rewards. The Q-learning loop is illustrated in Fig. 2. Note that a high sets priority towards distant future rewards whereas a lower one will force the agent to consider only immediate rewards. After updating the Q-table, the best policy can be obtained by acting greedily in every state by
[TABLE]
III Simulation Environment Setup
In this section, we describe the simulation environment for testing the proposed method. We use Wireless InSite ray tracing tool, which can provide a deterministic way of characterizing the RSS in indoor scenarios. First, we generate two arbitrary floor plans with different complexities and of size m2 and m2 (hereinafter referred to as the Scenario 1 and 2, respectively) using the floorplan feature of the software. The two floor plans are shown in Fig. 3. The height is considered to be 3 m for all the walls. We set the UE at an elevation of 1.5 m from the ground.
After generating the floor plans, we run the ray tracing simulations to obtain the RSS at each RX grid with the source being at a specified position. The UE
is assumed to transmit RF signals using 25 dBm transmit power at 2.4 GHz. The RX grids are set m apart from each other using XY grid option in the software. Half-wave dipole antennas with vertical orientation are used at each RX grid. The maximum antenna gains are considered as 0 dB for both the RXs and UE TX. The height of the grids is considered as 2 m to avoid crashing into obstacles such as tables, cubicles, chairs, etc. The height of the doors is considered to be 2.70 m. Other settings considered in the simulations are as follows. Diffuse scattering mode is disabled. A maximum of six reflections and one diffraction were allowed.
We also create the same floor plans in MATLAB. Then, we transfer the resulting RSS maps from the ray tracing to MATLAB for use in the navigation simulations. For simplicity, we assume that the UAV flies at a constant altitude. Thus, all the allowable actions that are separated by lie in the plane. We consider three different UAV speeds, namely, 1 m/s, 2 m/s and 4 m/s. Most commercial drones available in the market come with a maximum speed limit of 40 mph or 18 m/s [19]. So, our assumptions about the UAV speeds are reasonable. Note that, for simulation purposes, floor areas are partitioned into the grids and hence the UAV is forced to move from the center of one grid to that of the other. That is, if the UAV speed is set to m/s and the UAV makes a diagonal movement, e.g., moves from the grid index (1,1) to (2,2), its speed will be m/s. For simplicity, while presenting the results in Section V, we will refer to the UAV speed as m/s independent of the movement direction. We also assume that the UAV senses the RSS intermittently with a 1-second interval. In other words, the UAV will detect the RSS only when it reaches a new location. Such a sensing method will help the UAV save battery power.
IV UAV Navigation Using RSS-Based Q-Learning
In this section, we introduce the RSS-based Q-learning method for the navigation of a UAV to a wireless source. In the location-based Q-learning algorithm, states and rewards are defined based on the location of the agent, i.e., GPS coordinates. This method is not suitable for use indoors where the GPS signal is not available. It also requires the exact coordinates (or an accurate mathematical representation of the position) of the target which is also not available in most of the SAR scenarios. On the other hand, in our proposed approach, states are defined based on the RSS values at each particular grid or UAV location. RSS values are also used in the definition of rewards allowing the navigation of the UAV towards the target by providing a reasonable representation of the target location.
IV-A State and Reward Definitions
The UAV starts from an initial position and detects the RSS at that position. A state label is assigned to this particular RSS value. Based on the fact that no two grids (separated by 1 m in this case) will have the same RSS value, each location is represented uniquely by a state. Then, the UAV takes an action depending on the strategy of the algorithm in use and moves to a new location. The reward is defined as the difference between the RSS values associated with the latest and the previous position, i.e., , so that higher rewards are obtained when there is an increase in the RSS. Next, a state label is assigned to the new location based on the new RSS value, and the Q-table is updated using the update equation in (1).
It is worth noting that there may be small deviations from the previous RSS values at the next visits to the same grid. These deviations may be due to the imprecise steps taken by the UAV or some small changes in the environment or the source position. Since the states are defined based on the RSS values, this situation may lead to representing a single grid by multiple states, which, in turn, delays the convergence of the algorithm. As a solution to this problem, states can be defined as the neighborhood of the detected RSS values. If the RSS value of a new location does not lie in an already defined interval, then a new state is defined; otherwise, the same state (as one of the previous states) is attained. That is, if a state is labeled as for the RSS value detected at time , then the same state will be attained whenever a new RSS value is detected within the range . The threshold should be defined in such a way that the state will remain unchanged provided that the UAV hovers inside the boundaries of a grid.
Alternatively, states can be defined based on a set of RSS intervals determined before running the algorithm. A sufficiently wide range of RSS values can be divided into a number of discrete segments, and the states are assigned based on which segment the RSS at a particular location falls into. This technique may result in a small number of states, but it creates another interesting problem. For instance, two or more different locations in the indoor environments can be of the same state due to having close RSS values. Hence, a good action at one location can be a bad action at another one leading the UAV to crash. Consequently, instability may be observed in the Q-table update process. For simplicity, we assume a static environment and use the special case of the above-mentioned solution with , i.e., each RSS value detected at a location is given a single state label.
Each episode ends when the UAV is close enough to the target. We assume an episode ends when the distance between the UAV and the victim is less than 2 m. Using free-space path loss model [20], we calculate this RSS threshold to be -21 dBm. Note that, if the distance between the UAV and victim is less than 2 m and there is a wall between them, the RSS value pertinent to that position will be far less than -21 dBm due to the presence of the wall.
Collisions are major problems for autonomous UAV navigation, and can be avoided using a range sensor or video camera-based systems as suggested in [9, 10]. We do not address this problem in this study. However, to simulate the possible solutions, each time before the agent takes a new action, we check if that action leads to a crash. If so, the action is dropped from the list of possible actions, and another action is picked. The overall Q-learning process is summarized in Algorithm 1.
IV-B -greedy Method
To overcome the exploration-exploitation dilemma in Q-learning, we deploy -greedy method. The main idea of -greedy method is to choose a random number from [0,1] and check whether it is greater than . If it is lower than , the agent takes random action; otherwise, it goes with the “greedy” action that has the highest -value. It is shown in [18], that
starting with a high and then decreasing it with episodes can provide better convergence performance. Hence, we also start with and decrease it exponentially with a decay factor with iteration number. To increase the importance of the future rewards, we set discount factor to be 0.98. The learning model parameters used in this study are specified in Table II. In each iteration, the agent or UAV in our case, starts from an initial location and traverses through the indoor scenario. If the UAV detects the UE, it will get a reward of 1000. Once the UAV finds the target, the current episode finishes and the new one starts. Since the UAV becomes more experienced as it moves through the indoor environments, we also decay exponentially with .
Proposition 1**.**
RSS-based Q-learning algorithm is an MDP.
Proof.
According to [18] and [21], an MDP has five components: 1) finite states, 2) a finite set of actions, 3) a transition probability, 4) an immediate reward function, and 5) a decision epoch set that can be either finite or infinite. In our proposed algorithm, if the indoor scenario is of finite area, the total number of unique states will also be finite. The total number of allowable actions is eight and the UAV can choose an action by -greedy method. The reward function is defined as the difference between the RSS value of the current state and previous state and finally, the UAV takes decisions until it finds the victim, which leads to a finite decision epoch. Thus, we can conclude that the proposed indoor navigation framework is an MDP.∎
Corollary 1**.**
The Q-learning algorithm in the proposed RSS-based indoor navigation system will converge to an optimal action-value function with probability one.
Proof.
In our proposed method, the states and actions are finite and we consider to be less than one. The reward function is finite and . All the -values are updated and stored in tables. Q-tables of both RSS-based and location-based algorithms get an infinite number of updates. Thus we fulfill all the conditions mentioned in [17] for convergence. ∎
IV-C Limitations
There are a few limitations in our simulation setup which we plan to address in our future research. We assume a stationary indoor environment where the victim is stagnant, which might not always be the case. In fact, in case of emergencies, the victims might switch their locations abruptly and randomly for safety purposes. In addition, frequent sharp turns while traversing will cost the UAV with more battery power. We overlook this non-trivial issue intentionally for the sake of simplicity. We will consider battery constraints and a dynamic environment for the navigation of UAVs in our future research.
V Experiments and Results
We first investigate the trajectories followed by the UAV in both scenarios using the RSS-based algorithm. We consider a location-based Q-learning algorithm as the baseline, where we assume that the UAV can track its indoor location and the location of the target is known beforehand. Apart from these, the reward is defined as in the location-based algorithm, where is the Euclidean distance between the UAV and the victim after taking an action at time . In this way, the UAV will try to minimize its distance from the victim through the iterations. Note that, for UAV speeds greater than 1 m/s, the UAV may not land on the exact location of the victim for different starting points. Hence, we consider that an episode ends when is less than 2 m as in the case of the RSS-based Q-learning. The main differences between the two methods are summarized in Table III.
The resulting UAV trajectories for the RSS-based algorithm are shown in Fig. 4(a) and Fig.4(b). The UAV speed is considered to be 1 m/s. The UAV starts from the initial location (93 m, 2 m) in Scenario 1, and from the location (74 m, 55 m) in Scenario 2. The victim is considered to be situated at (5 m, 14 m) in Scenario 1, and at the location (4 m, 4 m) in Scenario 2. In both scenarios, we observe that the trajectories tend to avoid the regions with low RSS values. Since the reward is defined as the difference between the RSS values at successive states, the UAV shows an inclination to have higher RSS values at the next steps rather than finding the victim with the smallest path. We see the same trend for other simulations with different starting positions. Sensing the paths with higher RSS values eventually leads the UAV towards the victim. Although the UAV does not know the victim’s location, it can successfully reach the destination.
The trajectories associated with the location-based Q-learning are shown in Figs. 4(c) and 4(d) for Scenario 1 and 2. The UAV starting points and target locations are kept the same as those of the RSS-based Q-learning experiments. We observe that the UAV tries to find the shortest path towards the victim in both scenarios as expected. Note that, in Fig. 4(d), the UAV tends to enter some of the compartments. This is due to the fact that the points inside the compartments are nearer to the victim from any other point in the hallway area. For higher speeds, UAV avoids those points since the overall distance covered by the UAV will be increased otherwise.
To have a better understanding of the learning processes, we investigate the relative frequency of the state visits through the episodes. Heat maps (averaged over 100 runs) in Fig. 5 show the results for three different episode intervals. Comparing Fig. 5(a) and Fig. 5(b), we observe that the location-based Q-learning visits nearby locations to the starting point more frequently in the first 200 episodes than its RSS-based counterpart. This is because the RSS-based method tries to find the locations that provide higher signal strength and RSS values at different locations are unique. As a consequence, RSS-based method learns better policies faster. On the other hand, location-based Q-learning focuses on finding the shortest route and two or more locations might have same distances from the target. Hence, location-based method needs more explorations. From Fig. 5(c) and Fig.5(d), which show the frequency of the state visits in the first 500 episodes, we can also conclude that the RSS-based method finds the optimal policy earlier than the location-based method. Lastly, as it is clear from Figs. 5(e) and 5(f), both methods learn optimal policies during the the first 1000 episodes.
Fig. 6 shows the average number of steps taken per episode by the UAV to reach its goal for different speeds in Scenario 1. The number of steps required in each episode is averaged over 100 realizations. As expected, the number of steps decreases with the episode index. The UAV learns the representation of the indoor environment better as it becomes more experienced and hence, it requires fewer steps to reach the goal. The UAV can move to fewer states as its speed increases, and thus, the Q-learning algorithms tend to converge quicker with higher UAV speeds. Moreover, we observe that the RSS-based navigation converges within about the same number of episodes as the location-based method. Similar to the observations in Fig. 5, since the RSS-based technique only focuses on getting higher RSS values as rewards, it quickly learns to skip the states that provide lower RSS values. Meanwhile, the location-based Q-learning treats every possible state equally and hence ends up with getting higher average steps during the early episodes.
Next, we explore the convergence time of the algorithms for different UAV speeds. We record the trajectory followed by the UAV to reach its goal for each episode. If the UAV follows the same path for three consecutive episodes, we conclude that the Q-table is converged. The time elapsed until the convergence of the Q-tables is averaged over 100 executions. The results are shown in Fig. 7. Similarly to the above results, since the number of allowable actions decreases with the UAV speed, convergence time decreases for both algorithms. We observe that the RSS-based algorithm shows competitive performance in terms of convergence time with the location-based algorithm, especially for higher UAV speeds.
Finally, we provide the total length of the final trajectories in Table IV. Since Scenario 2 consists of longer hallways and include compartments, the UAV needs to take more steps to reach the goal when compared to Scenario 1. Overall, our proposed technique provides very close results to the location-based algorithm in terms of the number of steps in the final trajectory. However, having even the same number of steps does not always imply having the same computational time or path length. This is due to the fact that diagonal movements take more time than the movements in left-right and up-down paths. Since the location-based algorithm results in more straight trajectories as shown in Fig. 4, the total final path length and flight time will be smaller than those of the RSS-based algorithm.
VI Conclusion
In this paper, we studied the problem of detecting or rescuing a victim in a GPS-denied indoor environment using the RSS of the RF signals sent by the victim’s smart devices. We envisioned a rescue system by deploying a UAV, which will navigate through the indoor environments using Q-learning techniques. We presented simulation results for two indoor scenarios with different complexities. We also compared our proposed technique with the location-based Q-learning and find that RSS-based Q-learning provides competitive performance without requiring the UAV and target location information. Our results show that the RSS-based Q-learning shows less fluctuations during training than the location-based method. The convergence time decreases with the increasing UAV speed for both methods, and the RSS-based technique learns the environment earlier than its location-based counterpart.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Ezuma, F. Erden, C. K. Anjinappa, O. Ozdemir, and I. Guvenc, “Micro-UAV detection and classification from RF fingerprints using machine learning techniques,” in Proc. IEEE Aerospace Conf. , Mar. 2019.
- 2[2] V. Acuna, A. Kumbhar, E. Vattapparamban, F. Rajabli, and I. Guvenc, “Localization of Wi Fi devices using probe requests captured at unmanned aerial vehicles,” in Proc. IEEE Wireless Commun. Netw. Conf. (WCNC) , San Francisco, CA, Mar. 2017, pp. 1–6.
- 3[3] V. M. Becerra, “Autonomous control of unmanned aerial vehicles,” Electronics , vol. 8, no. 4, 2019.
- 4[4] H. Bayerlein, P. D. Kerret, and D. Gesbert, “Trajectory optimization for autonomous flying base station via reinforcement learning,” in Proc. IEEE Int. Workshop Signal Process. Advances in Wireless Commun. (SPAWC) , June 2018, pp. 1–5.
- 5[5] N. Imanberdiyev, C. Fu, E. Kayacan, and I. Chen, “Autonomous navigation of UAV by using real-time model-based reinforcement learning,” in Proc. Int. Conf. Control Autom. Robot and Vision (ICARCV) , Nov. 2016, pp. 1–6.
- 6[6] H. X. Pham, H. M. La, D. Feil-Seifer, and L. Van Nguyen, “Reinforcement learning for autonomous UAV navigation using function approximation,” in Proc. IEEE Int. Symp. Safety, Security, Rescue Robot. (SSRR) , Aug. 2018, pp. 1–6.
- 7[7] C. Wang, J. Wang, X. Zhang, and X. Zhang, “Autonomous navigation of UAV in large-scale unknown complex environment with deep reinforcement learning,” in Proc. IEEE Global Conf. Signal Inf. Process. (Global SIP) , Nov. 2017, pp. 858–862.
- 8[8] A. Rodriguez-Ramos, C. Sampedro, H. Bavle, P. De La Puente, and P. Campoy, “A deep reinforcement learning strategy for UAV autonomous landing on a moving platform,” J. Intell. & Robot. Syst. , vol. 93, no. 1-2, pp. 351–366, 2019.