TL;DR
This paper provides a concise introduction to persistent homology, a key concept in topological data analysis, explaining its construction, invariance, and stability for analyzing datasets across scales.
Contribution
It offers a self-contained overview of persistent homology, emphasizing its foundational ideas and stability properties in data analysis.
Findings
Persistent homology captures scale-dependent topological features.
It is stable under data perturbations.
Provides a foundational understanding for TDA applications.
Abstract
TDA (topological data analysis) is a relatively new area of research related to importing classical ideas from topology into the realm of data analysis. Under the umbrella term TDA, there falls, in particular, the notion of persistent homology, which can be described in a nutshell, as the study of scale dependent homological invariants of datasets. In these notes, we provide a terse self contained description of the main ideas behind the construction of persistent homology as an invariant feature of datasets, and its stability to perturbations.
Click any figure to enlarge with its caption.
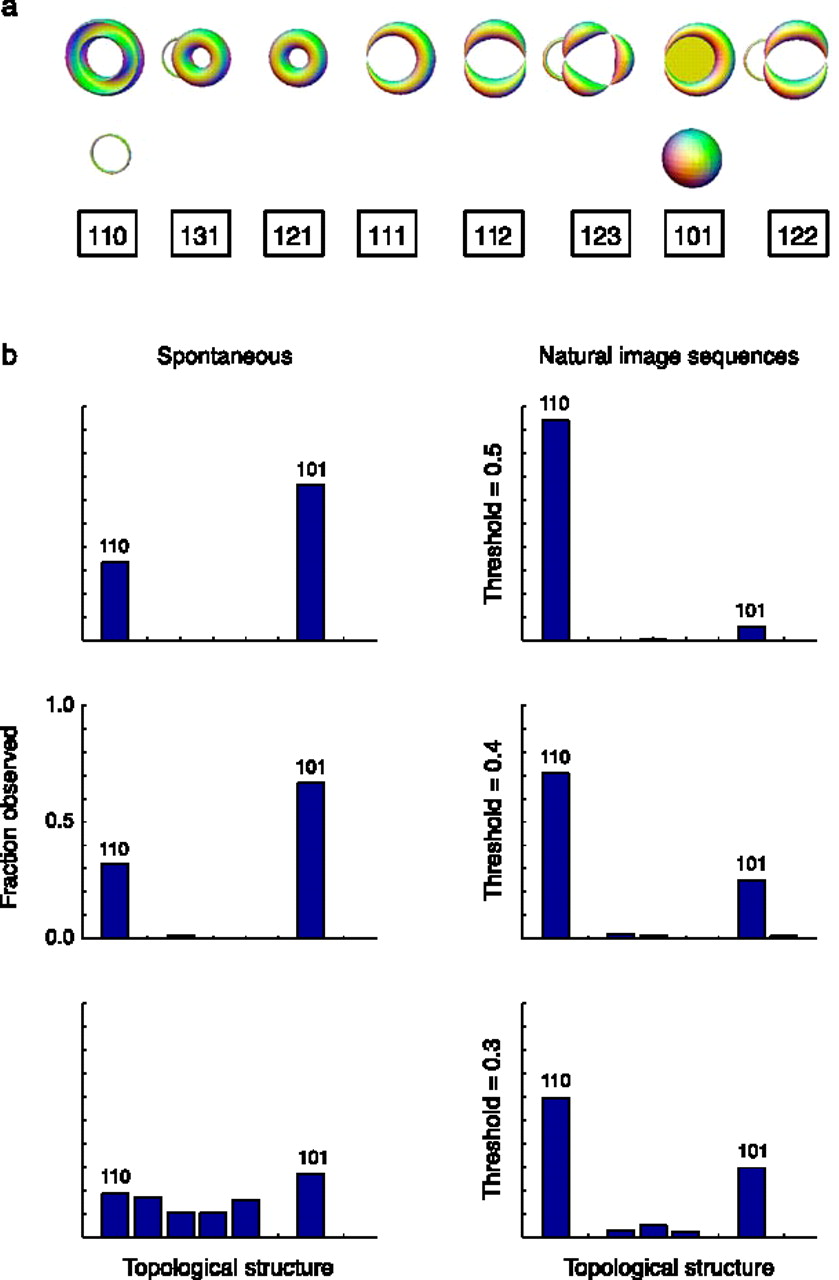 Figure 1
Figure 1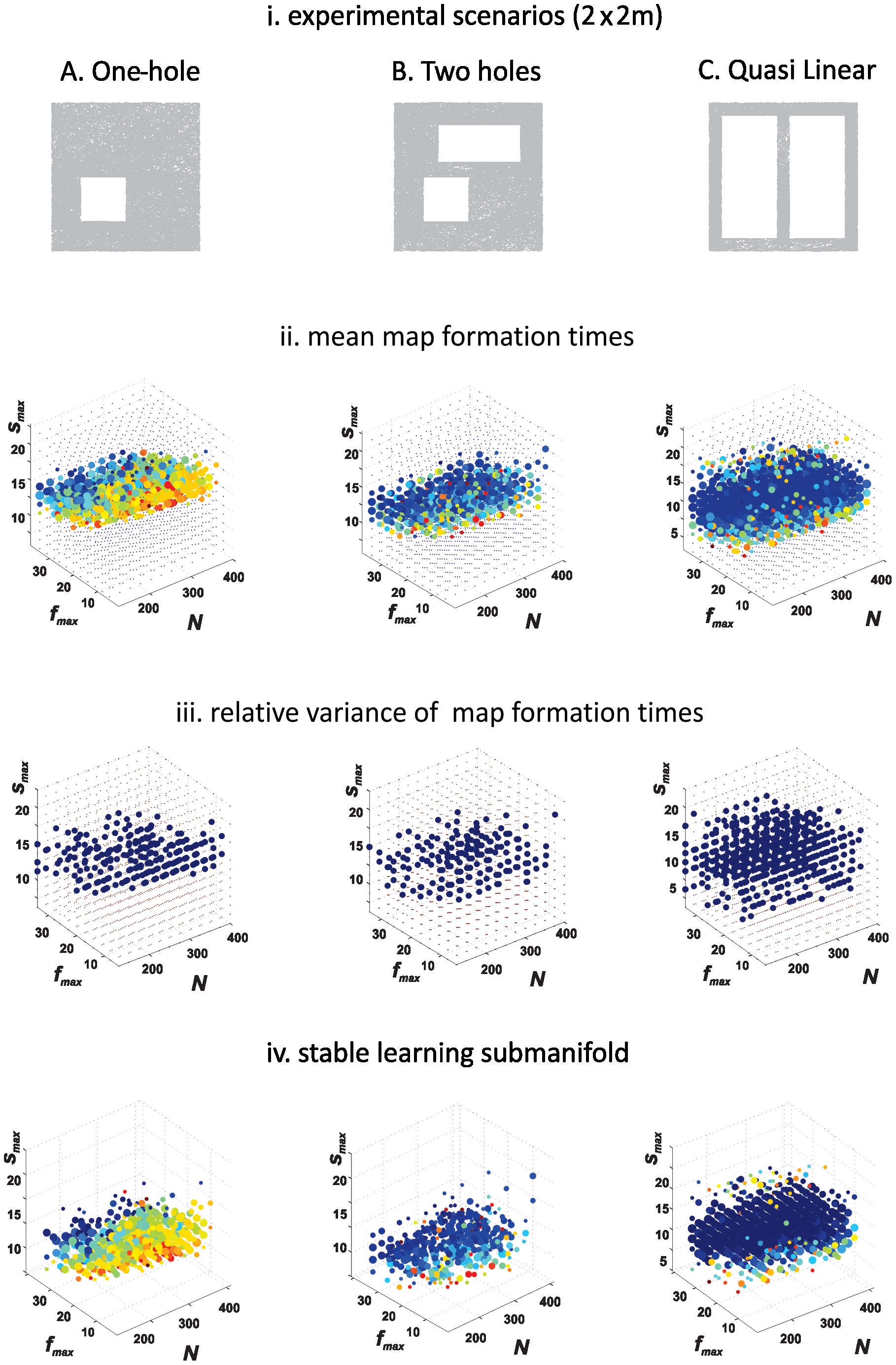 Figure 2
Figure 2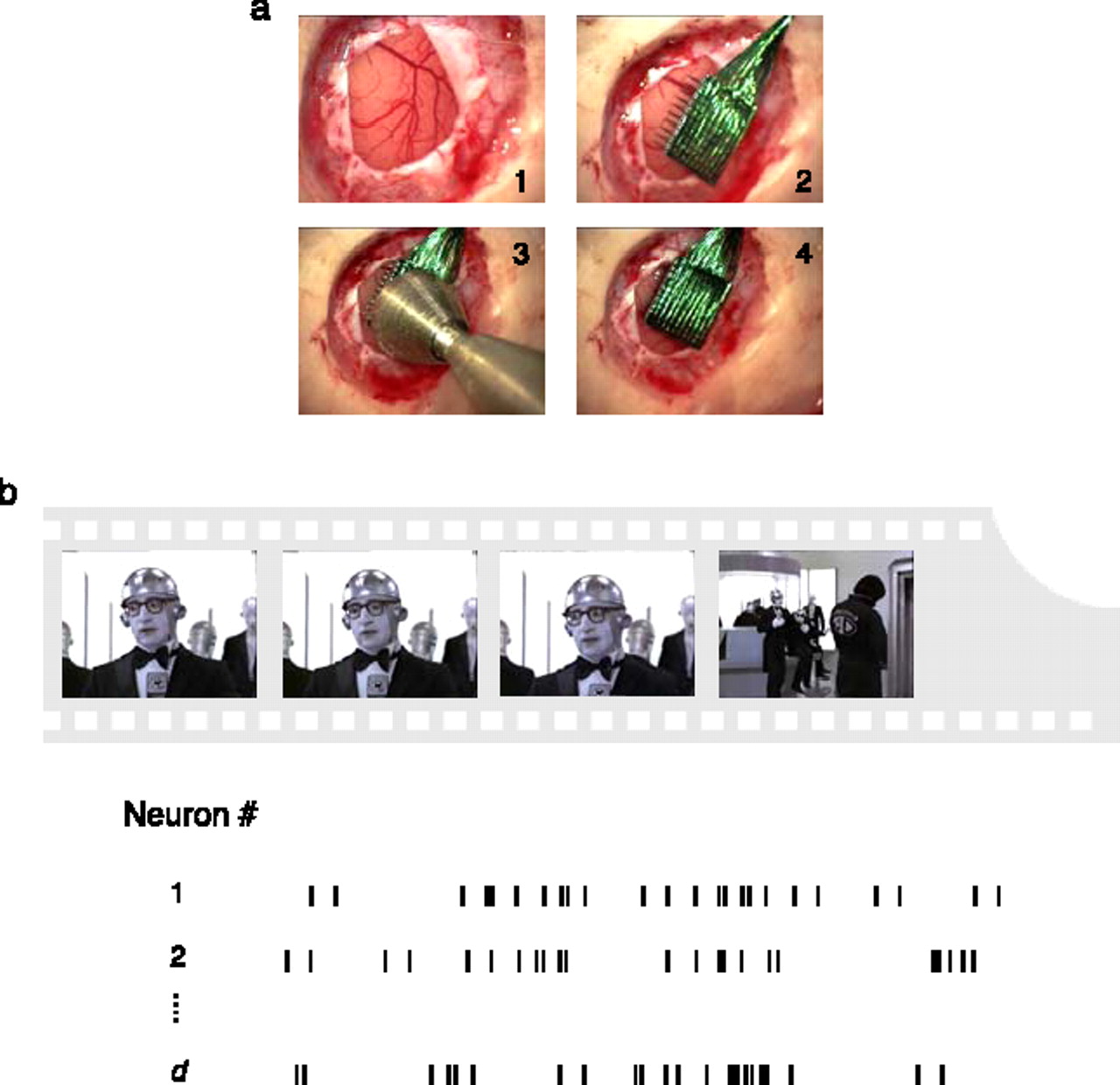 Figure 3
Figure 3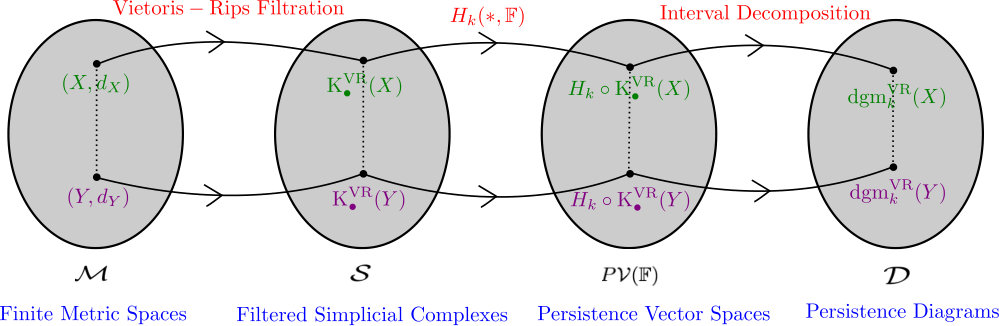 Figure 4
Figure 4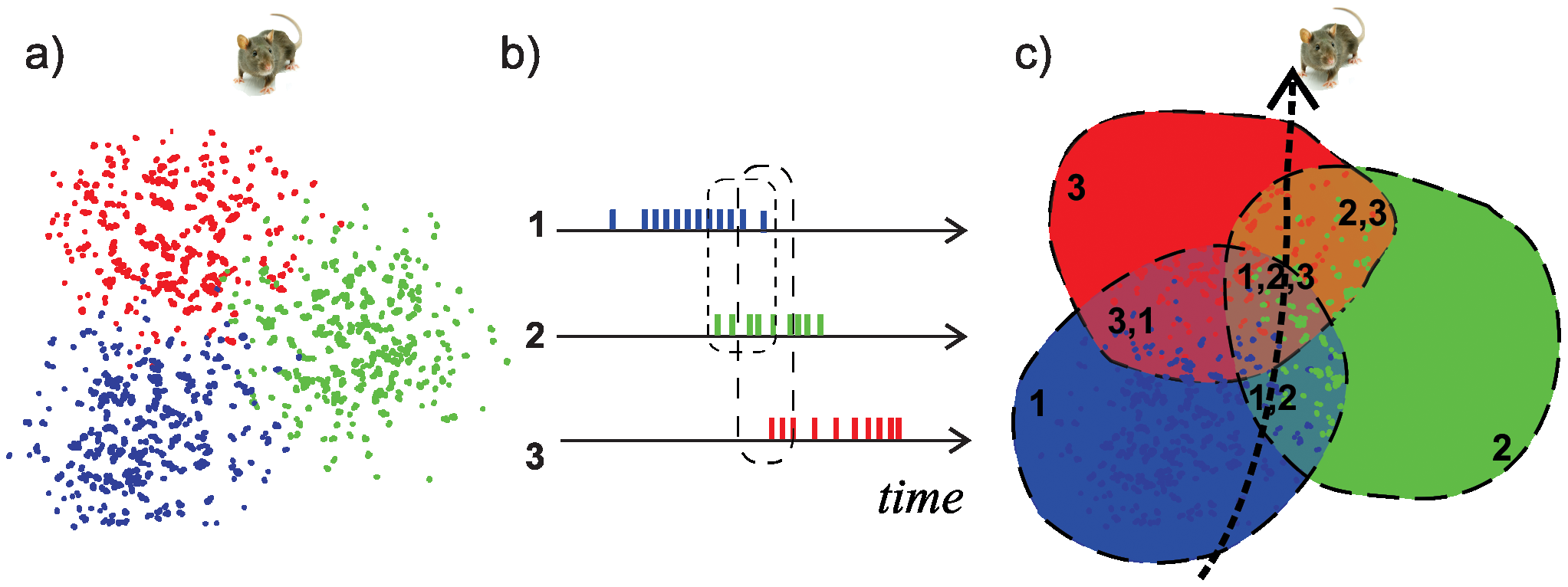 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Primer on Persistent Homology of Finite Metric Spaces
Facundo Mémoli
Department of Mathematics and Department of Computer Science and Engineering, The Ohio State University.††thanks: [email protected]
Kritika Singhal
Department of Mathematics, The Ohio State University.††thanks: [email protected]
1 Introduction
TDA (topological data analysis) is a relatively new area of research related to importing classical ideas from topology into the realm of data analysis. Under the umbrella term TDA, there falls, in particular, the notion of persistent homology PH, which can be described in a nutshell, as the study of scale dependent homological invariants of datasets.
The so called “persistent homology pipeline” is depicted in Figure 1: datasets are modeled as finite metric spaces. A given finite metric space induces a filtered simplicial complex (via the Vietoris-Rips construction), which in turn, via the homology functor induces a persistence vector space. Finally, these persistence vector spaces are decomposed into certain building blocks which give rise to a persistence diagram. The figure suggests that if two different datasets (modeled as finite metric spaces) and are given, the dissimilarity between them controls how dissimilar their persistence diagrams will be. In other words, the assignment of persistence diagram to a dataset is continuous (actually Lipschitz) in a suitable sense.
In these notes, we provide a terse self contained description of the main ideas behind the construction of persistent homology as an invariant feature of datasets, and also discuss details about its stability to perturbations. These notes also include a brief discussion about applications to biological data and an overview of software packages that implement the PH pipeline.
Other useful resources for a more in depth study of the different ideas contained in these notes are [EH10, Car09, Ghr14].
Organization.
In Section 2 we provide a mathematical formulation of clustering (in both its flat and hierarchical forms) of finite metric spaces as a precursor for the notion of persistent homology.
In Section 3 we cover the basics of simplicial homology – a necessary ingredient for later discussing the theoretical elements pertaining to persistent homology.
In Section 4 we describe the persistent homology pipeline in detail, and in particular we review the construction of Vietoris-Rips persistence barcodes. In Section 4.1 we provide an analysis of the Vietoris-Rips barcodes corresponding to zero-dimensional persistent homology.
In Section 5 we review the main theoretical elements underpinning the stability of Vietoris-Rips persistent homology of finite metric spaces.
In Section 6 we overview a number of applications of persistent homology to biological data and beyond.
Finally, Section 7 provides a list of software packages implement different parts of the persistent homology pipeline.
Acknowledgements.
These notes are meant to supplement the lectures given by the first author during the TGDA@OSU TRIPODS Summer School held at MBI during May 2018. Videos of the lectures are available at [mbi18]. We acknowledge NSF support through project CCF #1740761.
Contents
-
4.1 Interpretation of Clustering via 0-Dimensional Persistence Diagram
-
6.1 A Topological Paradigm for Hippocampal Spatial Map Formation using Persistent Homology
-
6.2 Topological Analysis of Population Activity in Visual Cortex
2 Clustering
One of the methods for extracting information from a data set is clustering the data set according to some rule. In this paper, datasets are represented as finite metric spaces. A finite metric space is a pair , where is a finite set and is a distance function. We denote by the collection of all finite metric spaces.
We start by providing a definition of a clustering method with some examples. For any , we denote the set by . Given , we denote by , the collection of all partitions of . Precisely, every is a family of sets , , such that for all , for all with , and . We refer to each , as a block of . We denote by , the collection of all pairs , where and . Formally,
[TABLE]
Definition 2.1** (Clustering Method).**
A clustering method is a map such that for every , , where .
Example 2.2
An example of a clustering method is the discrete clustering that partitions every metric space into singletons. Precisely, we have with , where is the partition of into singletons.
Example 2.3
Another example of a clustering method is the full clustering that partitions every metric space into a single block. Precisely, we have with .
There are various other examples of clustering methods such as partitioning into clusters whose diameter is bounded above by a constant, or partitioning into clusters whose diameter is bounded below by a constant, and so on [JS72]. Since we are working with finite metric spaces, the metric structure is the only information we have for determining a partition. Thus, it seems natural that for and a structure preserving map , a partition of induced by a clustering method can be determined, at least partially, using the map and a partition of induced by the same clustering method . Precisely, we want a clustering method to be a functor, see [CM13].
In order to view a clustering method as a functor, we need to view and as categories. We refer the readers to [Jac12, Spi14] for an account on category theory. We define the categorical structure on and as follows:
Definition 2.4** (Category of Finite Metric Spaces).**
Let , by abuse of notation, denote the category of finite metric spaces. The objects of are finite metric spaces , and the morphisms are defined as follows: for , we say that a set map belongs to if for all ,
[TABLE]
In other words, is -Lipschitz.
We observe that for all , the set , since the map that sends every point in to a single point in belongs to . We now define the category of partitions of finite sets.
Definition 2.5** (Category of Partitions of Finite Sets ).**
Let , by abuse of notation, denote the category of partitions of finite sets. The objects of are , where is a finite set and . Here, recall that is the family of all partitions of .
Given , and a set map , the pullback of along is defined as . Clearly, . The morphisms in are then defined as follows: for , we say that a set map belongs to if is finer than . This means that for every set , there exists a set such that .
We observe that for all , the set , since the map that sends every point of to a single point of satisfies . Thus, any is finer than , and we obtain .
We now define a clustering method to be a functor. This means that for all and ,
[TABLE]
Furthermore, satisfies and for all with ,
[TABLE]
We recall the clustering method and show that is a functor. For all , , where is the partition into singletons. For any , let be a set map such that . Then, clearly, since is the partition of into singletons, and thus is finer than any other partition of , in particular, is finer than . It is trivial to check that satisfies other properties of being a functor.
Similarly, it can be checked that the clustering method is a functor. We now provide another example of a clustering method that is also a functor, and is defined for every real number . It is called the Vietoris-Rips clustering functor.
Example 2.6** **(Vietoris-Rips clustering functor)
The Vietoris-Rips clustering functor at a fixed scale parameter , is denoted by , and is defined as follows: given and , define as , where if and only if there exists a sequence in with and , such that for all , . Then, . The clustering is referred to as the single linkage clustering of at scale .
Consider a metric space where and . Then, for all , , and for , .
The functoriality of can be seen as follows: given , let . Then, by definition, for all , . Now, let be fixed. If are such that , then there exists a sequence in such that for all , . By definition of , this implies that for all , , and therefore . Thus, we obtain that is finer than . We can similarly check that satisfies other properties of being a functor.
Given , let denote the metric space consisting of points at distance . The next theorem states the uniqueness of the Vietoris-Rips clustering functor with respect to a particular property.
Theorem 2.7** ([CM13, Theorem 6.4]).**
Let be a clustering functor for which there exists with the property that:
* is in two pieces for all , and* 2. 2.
* is in one piece for all .*
Then, is the Vietoris-Rips clustering functor with parameter .
As we discussed, we have that and the Vietoris-Rips clustering functor are examples of functorial clustering methods. It is worth pointing out that the well known average linkage and complete linkage clustering methods fail to be functorial, see [CM10].
We observe that the Vietoris-Rips clustering functor varies with . Thus, a natural question one may ask is how the clustering at scale is related to the clustering at scale . This leads to the concept of hierarchical clustering.
2.1 Hierarchical Clustering
We start by looking at an example. Consider a metric space where and . Then, we have that for all , , for , and for , . We observe that for , the clusters are singletons, and for large enough, all points fall into one cluster. In addition, for , the clusters at are obtained by merging clusters at . Such a clustering can be pictorially represented using a dendrogram.
Definition 2.8** (Dendrogram).**
Let be a finite set. A dendrogram over is a function , such that the following hold:
For all , is finer than . 2. 2.
* is the partition into singletons.* 3. 3.
There exists such that . 4. 4.
For all , there exists such that .
The parameter is referred to as the scale of partition.
A dendrogram depicting the Vietoris-Rips clustering (called the single linkage dendrogram) of the -point metric space described above is as follows:
Here, we have that , and . Precisely, we have that for every , the .
Let denote the collection of all dendrograms over a finite set and let . Then, can be viewed as a category. The objects of are as specified in the definition, and for all , a set map belongs to if for all , is finer than . We again have that for all , , since the map that takes all points of to a single point of belongs to . We are now ready to define hierarchical clustering formally.
Definition 2.9** (Hierarchical Clustering).**
A hierarchical clustering method is any functor , i.e. for any , , where .
The Vietoris-Rips clustering functor, as described in Example 2.6, is a an example of a hierarchical clustering, since for any , the function , as defined in Example 2.6, is a dendrogram over . The Vietoris-Rips clustering functor applied on induces a metric on in the following manner: given , we can find the smallest , such that and belong to same block of the partition . This provides us with a measure of dissimilarity between points of . This dissimilarity induces a metric on , referred to as an ultra-metric.
Definition 2.10** (Ultra-metric).**
Given a set , a function is called an ultra-metric if the following hold:
For all , and if and only if . 2. 2.
For all , . The second condition is referred to as the strong triangle inequality.
We now define the ultra-metric induced by the Vietoris-Rips clustering functor.
Definition 2.11** (Ultra-metric induced by ).**
Let . For every , let denote the collection of all sequences in satisfying for all with . Then, the ultra-metric induced by , denoted by , is defined as
[TABLE]
It is straightforward to check that satisfies the properties of symmetry, positivity and strong triangle inequality. We observe that for any , is the smallest at which the block containing merges with the block containing in the single linkage dendrogram of . Thus, we obtain that the Vietoris-Rips clustering functor applied to induces an ultra-metric on . It has been shown in [CM10, Theorem 18] that the Vietoris-Rips clustering functor is the unique hierarchical clustering method with this property.
We remark that the ultrametric defined above is the maximal subdominant ultrametric on X, which means that for every ultrametric on satisfying , we have .
In subsequent sections, we describe the machinery of persistent homology — a generalization of hierarchical clustering — which can be used to obtain information about a metric space. The rest of the paper is focused on developing the theory of persistent homology.
3 Simplicial Homology
In this section, we define the pre-requisites needed to develop the theory of persistent homology. We will be defining and working only with abstract simplicial complexes in this paper. For the rest of the paper, any simplicial complex is an abstract simplicial complex. We refer the reader to [Mun96] for the definitions in this section.
Definition 3.1** (Simplicial Complex).**
A simplicial complex is a collection of finite non-empty sets such that if is an element of , then so is every non-empty subset of .
For example, the collection
[TABLE]
forms a simplicial complex, but the collection does not.
Definition 3.2** (Subcomplex).**
Given a simplicial complex , a subcollection of is a subcomplex of if is a simplicial complex in itself.
The collection is a subcomplex of the simplicial complex defined above.
Definition 3.3** (Simplex of a complex).**
Every element of a simplicial complex is a simplex of .
Some of the simplices of are , , and . For every simplicial complex , if , , is a simplex of , we assume that is oriented by the ordering . We write to denote the equivalence class of the even permutations of this ordering, and to denote the equivalence class of the odd permutations of this ordering.
Definition 3.4** (Face of a simplex).**
The faces of a simplex of a simplicial complex are the non-empty subsets of .
The faces of the simplex of the simplicial complex defined above are
[TABLE]
Definition 3.5** (Dimension of a complex).**
The dimension of a simplicial complex is the largest dimension of a simplex of , where the dimension of a simplex of is . If there is no such largest dimension, then dimension of is infinite.
The dimension of the simplicial complex is .
Definition 3.6** (Vertices of a complex).**
The vertex set of a simplicial complex , denoted by , is the union of the one-point elements of .
The vertex set of the simplicial complex is .
Definition 3.7** (-skeleton of a complex).**
Given , an -skeleton of a simplicial complex , denoted by , is the collection of all simplices of of dimension at most .
We observe that the [math]-skeleton of a simplicial complex consists of all singletons of . For the simplicial complex , we have
[TABLE]
Definition 3.8** (Connected component).**
Two simplices and of a simplicial complex belong to the same connected component of if there exists a non-empty sequence of simplices of , such that for all , .
The connected components of the simplicial complex are
[TABLE]
Definition 3.9** (Simplicial map).**
Given simplicial complexes and , a map is called a simplicial map, if for every simplex of , is a simplex of .
The collection of all simplicial complexes along with simplicial maps between them forms a category. For any pair of simplicial complexes and , a map that sends every vertex of to the same vertex of is a simplicial map. Thus, the set of simplicial maps between and is non-empty. We denote the category of simplicial complexes by .
We need the following two definitions in order to define the homology groups.
Definition 3.10** (Quotient vector space).**
Let and be vector spaces over a field such that . We define an equivalence relation on as follows: for , if . For every , the equivalence class of is denoted by , and is defined as . The quotient vector space is then defined as
[TABLE]
Definition 3.11** (Isomorphic vector spaces).**
Two vector spaces and over a field are called isomorphic if there exists a bijective linear transformation .
Definition 3.12** (Chain Complex).**
Let be a simplicial complex and be a field. Let denote the collection of all simplices of of dimension . For every , we define
[TABLE]
Precisely, is the free vector space over with basis . The boundary map is defined as follows: for , and , we denote the element by . Then, we set
[TABLE]
Since is a free vector space over , it suffices to define the boundary maps on elements of . The chain complex associated to , denoted by , is defined to be the sequence of vector spaces , along with the boundary maps . Precisely, we have
[TABLE]
Lemma 3.13**.**
Let be a simplicial complex, and be the chain complex as defined above. Then, for all , we have .
Proof.
The lemma holds for any field , and the proof follows from the definition of boundary map. ∎
Since for all , we obtain that for every , the image of is contained in the kernel of .
Definition 3.14** (-Cycle and -Boundary).**
Given a simplicial complex and its associated chain complex , the kernel of the map is the set of -cycles and is denoted by . The image of the map is the set of -boundaries, and is denoted by .
By Lemma 3.13, we have that for all , .
Definition 3.15** (Simplicial Homology).**
Given , the -th homology group of a simplicial complex , is denoted by , and is defined as
[TABLE]
That is, is a quotient vector space and the elements of are equivalence classes of -cycles of .
Definition 3.16** (Betti numbers).**
Given , the -th Betti number of a simplicial complex is denoted by , and is defined as .
Lemma 3.17**.**
For every simplicial complex , is equal to the number of connected components of .
Proof.
For any simplicial complex , we have , where and . The -simplex consists of all elements of of cardinality , while the [math]-simplex consists of singletons of . We use the symbol to denote an isomorphism of the concerned spaces, and to denote the free vector space over with basis elements of . We have , and . The map satisfies . The image under of an element is . The elements belong to the same connected component, and span a subspace of dimension in with basis . In general, if a connected component in contains vertices, then the image under of the elements of belonging to is a vector space of dimension . Thus, if has connected components , then we have that . Thus, we obtain . Now, we know that consists of all singletons and therefore is equal to the number of vertices of . Every vertex of belongs to a unique connected component, therefore we have that . This implies that , and we obtain that is equal to the number of connected components of . ∎
Given simplicial complexes and , and a simplicial map , a natural question to ask is whether induces a map between chain complexes and , as well as between homology vector spaces and , for . The following proposition answers this question.
Proposition 3.18**.**
Given simplicial complexes and , a simplicial map induces a map , as well as maps , for every .
Proof.
Let and be simplicial complexes and be a simplicial map. Let and . For every , and are free vector spaces over the collection of -simplices of and respectively. Therefore, the map defined by linearly extending is a well-defined map. Precisely, we have that for , , an indexing set, , and , . Since is a simplicial map, we obtain . Thus, we obtain the following diagram:
[TABLE]
We now show that the squares in the above diagram commute. Let . Then . We have
[TABLE]
Thus, we have shown that for every . This implies that for every , the map sends the kernel of to the kernel of , and the image of to the image of . Thus, for every , sends to and to . This provides us with the map defined as . It is straightforward to check that for any simplicial complex , , and for simplicial maps , , . ∎
A direct corollary of the above theorem is the following.
Corollary 3.19**.**
Let denote the category of finite dimensional vector spaces over the field with linear transformations. Then, for every , is a functor.
We now introduce the concept of contiguous simplicial maps which will be used crucially later.
Definition 3.20** (Contiguous Simplicial Maps).**
Given simplicial complexes and , simplicial maps are said to be contiguous if for every simplex , is a simplex in .
The following lemma states that contiguous maps agree at the level of homology groups.
Lemma 3.21** ([Mun96]).**
For all , and simplicial complexes , if maps are contiguous, then .
In the next section, we describe how to use the machinery developed in this section for studying data sets.
4 Persistent Homology
Persistent homology is a tool that is widely used for studying data sets. The persistent homology pipeline consists of four steps which are outlined below. We remark that some of the terminologies used below have not been defined yet. We will define these later in the section. The pipeline is introduced before so as to provide motivation for this section.
We start with a finite metric space . We recall that every finite dataset can be viewed as a metric space by defining a measure of dissimilarity between its data points. 2. 2.
We assign a filtered simplicial complex to the metric space . There are many methods for constructing filtered simplicial complexes from finite metric spaces. We will describe some of these methods in this section. 3. 3.
For every , we apply the homology functor to the filtered simplicial complex obtained in the last step. This produces persistence vector spaces. 4. 4.
For every persistence vector space obtained in the last step, we determine the persistence diagram associated with it.
We will see that the persistence diagrams obtained in the end encode features of the input data set. We now provide missing details from the above pipeline.
Definition 4.1** (Filtered simplicial complex).**
A filtered simplicial complex is a sequence of simplicial complexes such that for all , .
We now see some examples of filtered simplicial complexes that can be constructed from a finite metric space .
Definition 4.2** (Vietoris-Rips Complex).**
Given and , define
[TABLE]
It is straightforward to see that a Vietoris-Rips complex is a legitimate simplicial complex. In addition, we have that for , . This is because, for every , , and therefore, . Thus, for every finite metric space , is a filtered simplicial complex. Here, is the inclusion map. The next proposition follows from the definitions.
Proposition 4.3**.**
Let be fixed. Then, is a functor.
Another example of a filtered simplicial complex is the Čech complex.
Definition 4.4** (Čech Complex).**
Given and , define
[TABLE]
It is an easy exercise to check that for every , is a filtered simplicial complex.
We have now explained the second step of the persistent homology pipeline. The third step is applying the homology map on a filtered simplicial complex to obtain a persistence vector space.
Definition 4.5** (Persistence Vector Space[Car14]).**
A persistence vector space over a field is a collection of vector spaces over and -linear maps with the following properties:
For all , the map is the identity map on . 2. 2.
For all , the following diagram commutes:
[TABLE]
Precisely, we have .
We use to denote the collection of all persistence vector spaces over the field .
Given a finite metric space , a filtered simplicial complex and a sequence , for every the sequence
[TABLE]
forms a persistence vector space (where the maps are induced by the simplicial inclusions), since is a functor.
Definition 4.6** (Morphisms of Persistence Vector Spaces[Car14]).**
Given , a morphism is a collection of linear maps , , such that the following diagram commutes for every :
[TABLE]
We say that is an isomorphism if each is an isomorphism of vector spaces. In this case, we write .
It will be useful to consider persistence vector spaces of finite length (indexed by natural numbers). A persistence vector space of length is any sequence of vector spaces over and -linear maps. In analogy with Definition 4.5, here we assume that the map for all and for all For , let denote the collection of all persistence vector spaces over the field of length .
Definition 4.7** (Sampling map).**
Let be any persistence vector space. Given a finite set with , we write and consider the -sampling map
[TABLE]
defined by
[TABLE]
where for each , , and
We now concentrate on persistence vector spaces of length and describe a full invariant for those. An invariant of persistent modules is any map into some set such that implies . An invariant is a full invariant if implies that .
The full invariants of persistence vector spaces are called Persistence Diagrams and will help us associate an algebraic signature to finite metric spaces.
Persistence diagrams of persistence vector spaces of length .
We now assume that for every and for every , . Thus, is the collection of all pointwise finite dimensional (pfd) persistence vector spaces of length , . The reason behind this assumption is that such persistence vector spaces have a simple representation in terms of interval persistence vector spaces.
In the same way that finite dimensional vector spaces can be classified up to isomorphism by their dimension, finite length persistence vector spaces admit a classification based on certain finite multisets of points in the plane. In particular, it is not true that persistence vector spaces can be classified by the sequence of dimensions.
Example 4.8
Assume that . Consider the vector
[TABLE]
We claim that there exists a natural number and such that but . This can be seen from the following example: let , where , and . Let , where , and . We have . Suppose and are isomorphic. Then, for , there exist isomorphisms such that all squares in the following diagram commute:
[TABLE]
Let , and , where . Here, because both and are isomorphisms. Now, we have , and similarly . Then, we obtain
[TABLE]
This contradicts the commutativity of all squares. Thus, we conclude that and are not isomorphic.
The above example shows that for , is not a full invariant of . The construction of a full invariant of a persistence vector space requires a more subtle approach which depends on the notion of persistence diagrams of persistence vector spaces (see Corollary 4.13 below).
Definition 4.9** (Interval persistence vector space).**
Given and , an interval persistence vector space is defined as follows: for all and , and for all . The map between the [math]-vector spaces, as well as maps and are specified to be the [math]-maps. The maps are specified to be identity maps. Such a persistence vector space is denoted by . Thus, we have
[TABLE]
An example of an interval persistence vector space is . We now have the following theorem.
Theorem 4.10** ([CB12]).**
For every , there exist intervals , an indexing set such that for every , , and .
Furthermore, we have the following theorem.
Theorem 4.11** (Krull-Remak-Schmidt-Azumaya [Azu50]).**
Let and be two decompositions of into interval persistence vector spaces. Then, and there exists a permutation , such that for all , there exists satisfying .
A consequence of the above theorems is that for every , if , then the multiset is a full invariant of . This multiset is called the persistence diagram of , and this brings us to the fourth step of the persistent homology pipeline.
Definition 4.12** (Persistence Diagram).**
Let and be a persistence vector space. Let . Then, the persistence diagram of , denoted by is defined as the multiset of intervals .
Corollary 4.13**.**
For any it holds that if and only if
Let denote the collection of all multisets , where are non-negative real numbers, and for , let denote the collection of all multisets , where and .
We note that for any , is a collection of points in . For , the ’s are referred to as the birth times and are represented on the x-axis, while ’s are referred to as the death times and are represented on the y-axis. Since for all , the points of lie on or above the line in . For example, consider . Then, the persistence diagram of is depicted in the following figure:
1$$2$$3$$4$$5$$6$$7$$1$$2$$3$$4$$5$$6$$b(birth)$$d(death)
Another way of depicting is through barcodes. The following diagram depicts the barcode of .
1$$2$$3$$4$$5$$6$$7
Vietoris-Rips persistence diagrams of finite metric spaces.
Now, given , we define the spectrum of as
[TABLE]
Let and write . Given an integer we consider the persistence vector space of length defined as
[TABLE]
Here, is the sampling map as given in definition 4.7. Now we need a process that is in some sense dual to sampling. Given a finite set with , we define a map
[TABLE]
to be the function satisfying
(Additivity) For all , . 2. 2.
(Definition on atomic elements) We define
- (a)
. 2. (b)
For all , . 3. (c)
For all with and , .
Note that these properties uniquely determine the map . We illustrate how the map works via the following example.
Example 4.14
Let , and . Let . Then, we have that
[TABLE]
We now have the following definition.
Definition 4.15** (-th Vietoris-Rips Persistence Diagram).**
Given and , the -th Vietoris-Rips persistence diagram of is defined as the
[TABLE]
Example 4.16
We now provide an example to illustrate the definitions. Let with . The filtered Vietoris-Rips simplicial complex of is as follows:
[TABLE]
Let and . The set of [math]-simplices of is and for , the set of -simplices of is . The set of [math]-simplices of is , the set of -simplices of is , and, for all , the set of -simplices of is . Thus, we have that and for all . Similarly, and for all . This implies that
[TABLE]
with the transition occurring at , and the notation meaning that all vector spaces hidden in the dots are . Furthermore, we have that for all . Thus, we have that for all . We now calculate , using the maps and defined above.
We have that , and therefore is a persistence vector space of length given by
[TABLE]
with the map being defined as .
Clearly, we have
[TABLE]
Thus, we obtain . We now apply the map to in order to obtain . By definition, we have
[TABLE]
Thus, we obtain .
Example 4.17
We now consider another example of a metric space with points, depicted in Figure 3. This metric space is defined as follows:
[TABLE]
Thus, consists of the corners of a square of side length , with -distance. The filtered Vietoris-Rips simplicial complex of is as follows:
[TABLE]
[TABLE]
[TABLE]
Let , , and . For and , let denote set of -simplices of . Then, we have that and for , . This implies that
[TABLE]
and for all .
For , we have , and for , . The chain complex of looks as . We have that . Clearly, , and thus we obtain that
[TABLE]
We also obtain that , and thus
[TABLE]
Clearly, for all .
For , we have , , , , and for all . The chain complex of looks as
[TABLE]
We have \mathcal{B}_{0}(\mathrm{K}^{3},\mathbb{F})=\mathrm{image}(\partial_{1})=\mathrm{span}\big{(}[2]-[1],[3]-[2],[4]-[3],[4]-[1],[3]-[1],[4]-[2]\big{)}. We observe that , and therefore
[TABLE]
We have \mathcal{Z}_{1}(\mathrm{K}^{3},\mathbb{F})=\mathrm{ker}(\partial_{1})=\mathrm{span}\big{(}[1,2]+[2,3]-[1,3],[2,3]+[3,4]-[2,4],[1,3]+[3,4]-[1,4],[1,2]+[2,4]-[1,4],[1,2]+[2,3]+[3,4]-[1,4]\big{)}. It is an easy exercise to check that . We have \mathcal{B}_{1}(\mathrm{K}^{3},\mathbb{F})=\mathrm{image}(\partial_{2})=\mathrm{span}\big{(}[2,3]-[1,3]+[1,2],[2,4]-[1,4]+[1,2],[3,4]-[1,4]+[1,3],[3,4]-[2,4]+[2,3]\big{)}. It is easy to see that , and therefore, we obtain
[TABLE]
We have \mathcal{Z}_{2}(\mathrm{K}^{3},\mathbb{F})=\mathrm{ker}(\partial_{2})=\mathrm{span}\big{(}[1,2,3]+[1,3,4]-[1,2,4]-[2,3,4]\big{)}, and therefore . We have \mathcal{B}_{2}(\mathrm{K}^{3},\mathbb{F})=\mathrm{image}(\partial_{3})=\mathrm{span}\big{(}[2,3,4]-[1,3,4]+[1,2,4]-[1,2,3]\big{)}=\mathcal{Z}_{2}(\mathrm{K}^{3},\mathbb{F}). This implies that
[TABLE]
Clearly, for , .
Therefore, the homology groups of are as follows:
[TABLE]
with the transition occurring at ,
[TABLE]
with the transition occurring at and the transition occurring at ; and for all . We now calculate and using maps and .
We have that , and therefore for , are persistence vector spaces of length given by
[TABLE]
Here, we have that for all permutations , , and . The maps of are the trivial maps. Clearly, we have
[TABLE]
Thus, we obtain that and . We now apply the map to both and to obtain
[TABLE]
[TABLE]
4.1 Interpretation of Clustering via 0-Dimensional Persistence Diagram
Let . We now make some observations about . We first observe that the number of intervals in is equal to . This is because by definition, consists of only singletons, and we know from Lemma 3.17 that , where is the number of connected components of . Thus,
[TABLE]
This implies that there are intervals in the decomposition of into interval persistence vector spaces. We simultaneously obtain that if , then for all . In the next proposition, we explicitly determine the intervals in and provide a method of associating an interval with every point of .
We now recall the single linkage dendrogram of , denoted by . We have that for every , is a partition of , and for , is finer than . Let denote the functor defined as . Here, denotes a partition of some finite metric space. It is straightforward to check that is a functor. We observe that forms a pointwise finite dimensional persistence vector space, and thus admits an interval decomposition. Then, we have the following proposition.
Proposition 4.18**.**
For all ,
[TABLE]
The proof of the above proposition is an easy exercise, and uses the observation that in the persistence vector space , every time consecutive vector spaces in the sequence are different, there is a merging of bars in the dendrogram . Thus, we observe that is equivalent to single linkage clustering of , and therefore persistent homology generalizes clustering. In the next proposition, we explicitly determine the interval decomposition of , and provide a map that associates to every element of , an interval of this decomposition.
Proposition 4.19**.**
Let be a finite metric space, with . Let , and let be the maximal sub-dominant ultrametric (Definition 2.11) on . Then,
[TABLE]
Proof.
We refer the reader to chapter of [EH10] for ideas used in this proof. In chapter of [EH10], the authors provide an algorithm for determining the intervals in for all . A proof of correctness of this algorithm also appears in [EH10, Chapter 7.1]. Here, we briefly describe their algorithm for .
We define an arbitrary ordering of elements of . Let denote the collection of subsets of of cardinality at most . By definition, is a simplicial complex. We fix the following notation here: we have only for . We define a function as and , for all . We now define an ordering on elements of as follows: we first fix . In order to determine the ordering of subsets of cardinality , we compare their values on the function . We set if . If subsets are such that , then if and only if or . Thus, we use lexicographic ordering on elements of with same value on the function . We have that every element of of cardinality is a -dimensional face of itself, and every element of cardinality is a [math]-dimensional face of any set of cardinality containing it. The ordering satisfies that if , then , and the faces of satisfy . Thus, we have a compatible ordering of the faces of .
We now write the boundary matrix using this ordering of faces. The boundary matrix is a binary square matrix of size . The size of is equal to , and the rows and columns of correspond to elements of ordered according to relation . By abuse of notation, we name the rows and columns of on their corresponding elements in . The columns of corresponding to the singleton sets of are set to be zero, while for all , the column has in the rows and , and zero everywhere else. For every column of , we denote by , the row of in which the lowest of the column appears.
We perform some column additions in the matrix such that in the new matrix, no two columns have their lowest in the same row. This is done as follows: for simplicity, we number the columns from to , with the leftmost column being numbered and the rightmost column being numbered . We scan the boundary matrix from left to right and suppose that is the first column for which there is a column , , satisfying . In this case, we add column to column . Now, , but there might be some column , such that . We then add column to column . We keep performing such column additions till there is no column to the left of column with value equal to . We then proceed to column and repeat. In the end, we obtain a matrix in which no two columns have their lowest in the same row. This matrix is called the reduced matrix and is denoted by . Now, for every non-zero column in having lowest in the row , the interval belongs to . In addition, the interval belongs to . This concludes the algorithm used to determine intervals in .
We now provide an example in order to illustrate the above algorithm. Let , with and . We have
[TABLE]
The function is defined as follows: . Thus, we have . The boundary matrix is the following:
[TABLE]
The reduced matrix obtained after performing the required column operations is the following:
[TABLE]
The algorithm now implies that . We now use the following claim to determine for any .
Claim 4.20**.**
For every , the unique column in the reduced matrix with lowest in the row is the leftmost column in the boundary matrix with lowest in the row .
Proof of Claim.
Consider the row in the matrix , and the column in which appears for the first time in this row. If this is the lowest element of its column, then the column is for some , and the interval is added to . We observe that . Now, suppose that the first of row is not the lowest element of its column. Thus, such a column is for . In the column additions performed to obtain the reduced matrix, this particular becomes the lowest of some other column in two ways. First, if some column , on the left of column is added to the column , and second if column is added to some column on its right. We first consider the case where there is a column to the left of column . In this case, we have . Now, . Since , we have that . This contradicts the assumption that the first in the row appears in the column . Therefore, there is no column with to the left of .
We now consider the second case i.e. there is a column to the right of . Here, we have . Since
[TABLE]
we have that . Thus, we have a column whose lowest is in the row , and this column appears before the column . Thus, if column is added to column , the lowest of is in row , but this does not affect the column . This implies that the column has no affect on the leftmost column of the boundary matrix with lowest in the row . Thus, we obtain that the interval corresponding to the row comes from the first column whose lowest is in row . This proves the claim. ∎
Note that this proof also suggests a method of associating an interval to every element of . In particular, the interval associated with is the interval associated with row and the first column of the boundary matrix with lowest in row . By definition, the value of such a column under function is . Thus, we have that the element is associated with the interval . We associate the interval with . ∎
Now, suppose that given finite metric spaces and , we construct the Vietoris-Rips simplicial complexes and . Then, for a fixed , we compute the persistence vector spaces and , as well as their respective persistence diagrams. Suppose that we have a method of comparing two metric spaces as well as two persistence diagrams. Then, a natural question to ask is, if and are “almost identical”, then how do the persistence diagrams associated to and compare. The next section focuses towards formalizing this question and then answering it.
5 Stability of Invariants
In this section, we formalize the following question: if are almost identical, then how do their respective -persistence diagrams, and compare. This is done by defining a notion of dissimilarity between metric spaces, as well as between persistence diagrams. Therefore, we now define a notion of distance between metric spaces, and a notion of distance between persistence vector spaces as well as between persistence diagrams.
5.1 Gromov-Hausdorff Distance
In thie section, we define a notion of distance between two finite metric spaces. Let . We say that and are identical if they are isometric.
Definition 5.1** (Isometry).**
An isometry between is a map such that is surjective, and for all , .
Note that the condition ensures that is injective. Thus, if are isometric, then there exists a bijective and distance preserving map . Since is a bijection between finite metric spaces, it has an inverse, say , with and . We now define the distortion and co-distortion of maps and .
Definition 5.2** (Distortion).**
Given , the distortion of a map is defined as
[TABLE]
Definition 5.3** (Co-distortion).**
Given , and maps , , the co-distortion of and is defined as
[TABLE]
We observe that if are isometric, then there exist maps and such that and . We now want to relax the notion of isometry between metric spaces to the notion of -isometry, for some .
Definition 5.4** (-isometry).**
Given and , maps and constitute an -isometry between and if , and .
We observe that if and constitute an -isometry between and , then is an “approximate identity” on and is an “approximate identity” on . This means the following: for every , we have
[TABLE]
Similarly, for every , we have . Now, we are ready to define a notion of distance between metric spaces.
Definition 5.5** (Gromov-Hausdorff distance).**
The Gromov-Hausdorff distance between is defined as
[TABLE]
Theorem 5.6** ([BBI01, Theorem 7.3.30]).**
The function is non-negative, symmetric and satisfies the triangle inequality; moreover if and only if and are isometric.
Thus, we now have a notion of distance between finite metric spaces. The next step is to define a notion of distance between persistence vector spaces.
5.2 Interleaving Distance
We recall that denotes the category of all persistence vector spaces over field . For , and , we recall that an isomorphism consists of maps for all , such that the following diagram commutes for all ,
[TABLE]
and is an isomorphism of vector spaces for all . We now relax this notion of isomorphism between persistence vector spaces.
Definition 5.7** (-interleaving).**
Let be fixed. Given a field , an -interleaving between , and consists of maps
[TABLE]
such that the following diagrams commute for all :
[TABLE]
The above conditions are referred to as the triangle conditions. We also want the following diagrams to commute for all . These conditions are referred to as the parallelogram conditions.
[TABLE]
We set and , and say that is an -interleaving between and .
We observe that an -interleaving is indeed a generalization of isomorphism between persistence vector spaces. In fact, if is a [math]-interleaving between and , then it is straightforward to see that for every , and . Thus, and become isomorphisms of vector spaces for all . We are now ready to define the interleaving distance between persistence vector spaces.
Definition 5.8** (Interleaving distance).**
Given a field , the interleaving distance between is defined as
[TABLE]
Proposition 5.9** ([COGDS16]).**
The function is non-negative, symmetric and satisfies the triangle inequality. However, may take value and might be zero even if and are not isomorphic.
We are now ready to prove the following stability theorem. For , we recall that is the Vietoris-Rips filtered simplicial complex associated with .
Theorem 5.10** (Stability of Vietoris-Rips persistent homology).**
For all and ,
[TABLE]
Proof.
Let be fixed. We show that if and are -isometric, then and are -interleaved. Suppose that and are -isometric. Then, there exist maps and such that , and . For some , let . This implies that for all , . Since , we obtain that for all . Thus, . Thus, for every , induces a map
[TABLE]
Similarly, for every , we obtain maps
[TABLE]
Thus, we obtain the following diagrams:
[TABLE]
[TABLE]
If the above four diagrams were to commute, then, since is a functor for every , the following diagrams will also commute: fix , and let , , and .
[TABLE]
[TABLE]
We recall that given simplicial complexes and , simplicial maps are called contiguous if for every simplex , is a simplex in . We have from Lemma 3.21 that for such maps, for all . Therefore, it suffices to show that the following maps in the four diagrams on and are contiguous [Mun96]:
2. 2.
3. 3.
4. 4.
We first consider the pair of maps . Let be a simplex. In order to show that is a simplex in , we need to show that . Let . If both , then . If both , then there exist such that and . Then,
[TABLE]
Here, the first and second inequalities hold because , while the third inequality hold because . Now, suppose that and . This implies that , and there exists such that . We have
[TABLE]
Here, the first inequality holds because , the second inequality holds because and the third inequality holds because . Thus, we have shown that This implies that the maps are contiguous. Thus, we have that for every ,
[TABLE]
The last equality holds because is a functor for every .
We can similarly show that the remaining three pairs of maps are also contiguous. Thus, we obtain that the four diagrams on and also commute. Thus, we have shown that the persistence vector spaces and are -interleaved.
Now, let . This implies that there exists a -isometry between and . By the above arguments, we obtain that and are -interleaved for all . Thus, . This implies that , and proves the theorem. ∎
We recall that for and , the Čech complex is defined as
[TABLE]
Let . Then, we have the following theorem.
Theorem 5.11** (Stability of Čech complex).**
For all , and , if and are -isometric, then the persistence vector spaces and are -interleaved.
The proof of the above theorem is similar to that of Theorem 5.10. The next step is to define a notion of distance between persistence diagrams called the bottleneck distance.
5.3 Bottleneck Distance
We recall that given and a field , denotes the category of pfd persistence vector spaces of length , and denotes the collection of all persistence diagrams , . In the last section, we showed that for every , there exists a multiset of intervals such that . A trivial fact is the following.
Fact 5.12**.**
Given a multiset of intervals , we can construct a persistence vector space such that .
We now define the bottleneck distance on . We recall that every element of is a collection of finite multisets of points , where .
Definition 5.13** (Bottleneck distance).**
Let and be elements of . A partial matching is a bijection between a subset of and a subset of , which are then the domain and co-domain of respectively. Let denote the set of all partial matchings between and . Given , the cost of is defined as follows:
[TABLE]
The bottleneck distance between and is then defined as
[TABLE]
The definition implies that the bottleneck distance is symmetric, non-negative and vanishes if . The next theorem shows that the bottleneck distance satisfies the triangle inequality.
Theorem 5.14** ([COGDS16]).**
For any , we have
[TABLE]
We now have the following theorem.
Theorem 5.15** (Isometry Theorem[Les15]).**
Given and , we have
[TABLE]
A direct corollary of the above theorem is the following.
Corollary 5.16**.**
For all and ,
[TABLE]
It is known that while computing is NP-hard, there is a polynomial time algorithm [EH10] for computing for all .
Furthermore, the inequality is tight. This is depicted by the following examples: for , let be the metric space with . Clearly, . We also observe that . Thus, , and we obtain that . Therefore, we have
[TABLE]
Now consider the metric spaces and , where is the one point metric space and is as defined above. Then, . We have and . Thus, we have . Therefore, we obtain
[TABLE]
6 Applications of Persistent Homology
In this section, we first describe two problems in neuroscience that have been studied using persistent homology. We state their problem definitions, the experimental procedures that generate a finite data set, the method used to construct an abstract simplicial complex from the data set, and finally the results obtained using persistent homology. In the third and fourth subsections, we describe further applications of persistent homology to biology as well as to other areas.
6.1 A Topological Paradigm for Hippocampal Spatial Map Formation using Persistent Homology
This subsection describes article [DMFC12] of the same title. The problem is that of identifying the topological features of an environment using the hippocampal activity of a rat moving in that environment. In every animal, the hippocampus is the region of the brain responsible for creating a mental map of the animal’s environment. This mental map is made possible by activity of the neurons in the hippocampus called place cells. As an animal explores a given environment, different place cells fire a series of action potentials in different, discrete regions of the environment. Each region, referred to as that cell’s place field, is defined by the pattern of neuronal firing, most intense at the center and attenuated towards the edges of the field. The cell remains silent when the animal is outside of the cell’s place field. Experiments on rats suggest that the information contained in place cell firing patterns encodes spatial navigation routes and somehow represents the spatial environment [BFT*+*98, MBO83, ZGMS98]. Now, suppose that spatial location is the primary determinant of each place cell’s firing. Then, co-firing of several place cells indicates that the corresponding place fields overlap, See Figure 4. Thus, the mental map formed by co-firing will be based on the properties of connectivity, adjacency and containment of place fields, and therefore will be a topological map of the environment.
A basic theorem of algebraic topology is the so called Nerve Theorem [Hat00] which we paraphrase here as: if a space is covered with a sufficient number of regions, then it is possible to reconstruct the topology of using the intersection information of the regions. This theorem and the assumption that the place fields cover the environment leads to the hypothesis that the overlaps between the place fields, as represented by temporal overlap of spike trains (an ordered list of times at which a place cell fires) provide a connectivity map that retains the topological features of the environment. Thus, the authors of [DMFC12] investigate whether a topological connectivity map can be effectively and reliably derived from neuronal spiking patterns using computational tools in the field of algebraic topology.
We now briefly describe the details of the experiments performed in [DMFC12]. The authors simulated map formation times (minimal time required to produce the correct topological signature of an environment) using different place cell parameters and three separate planar meter areas with or holes. The place cell parameters are the firing rates, the place field sizes and the number of place cells. The firing rates and the place field sizes are described by -normal distributions, with and being the respective peak values, and and being the respective standard deviations. The question was for which parameters the place cell spiking signals would be able to produce a temporal simplicial complex with the correct number of topological loops, or Betti numbers, in every dimension. The authors probed ten distributions of firing rates, with ranging from to Hz, and ten distributions of place field sizes, with ranging from to cm. The number of place cells varied independently from to . In each case, the centers of the place fields were scattered randomly and uniformly over the environment. For each combination of the parameters, and , the computation was repeated times, through which the authors computed the average time required for the emergence of correct topological features for each specific choice of ensemble parameters and . The authors fix the simulated trajectory, but choose a new set of place field centers for each set of for each repetition.
We now describe the mechanism of generating a filtered simplicial complex from the experimental data. Let , be a set of place fields with specified shapes and locations. A simplicial complex with vertex set , one for each place field, can be constructed as follows: given , a simplex if . We recall that this coincides with the Čech complex, also known as the nerve complex. The Nerve Theorem [Hat00] states that if there is a space such that and each finite intersection of the place fields is contractible, then under fairly general conditions, the nerve complex has the same homotopy type as the underlying space , and so the topological invariants computed from will agree with those corresponding to . We saw that the experimental data does not consist of the place fields, but of the spike trains of the place cells. Thus, an overlap of the place fields is identified by co-firing of the corresponding place cells. Let denote the place cells corresponding to the place fields respectively, and let denote the corresponding spike trains. We recall that for , a spike train is an ordered list of times at which the place cell fires. We fix an and an . We define a filtered simplicial complex as follows: given a simplex , we define a function on as
[TABLE]
By definition, we have if . Thus, we start with an empty simplicial complex, and then add simplices to this complex, according to the values of the simplices on the function . The homology functor is applied to this filtered simplicial complex, for . For each , this produces a persistence vector space, and thus a barcode. Barcodes are used to determine the first two Betti numbers, and . We recall that tells the number of connected components, and tells the number of -dimensional holes. The software used to analyze the data is jPLEX [SVJ08], a collection of MATLAB functions for computational topology that implements the concepts described above.
The results obtained in [DMFC12] and their interpretation are depicted in Figure 5. The authors observed that the place cell parameters of firing rate and place field size for which a reliable topological map of the environment is produced correspond well with experimentally observed place cell firing rates and place field sizes. Thus, the fact that these parameters fall into the biological range lends support to this topological paradigm.
6.2 Topological Analysis of Population Activity in Visual Cortex
This subsection describes article [SMI*+*08] of the same title. This work studies some basic aspects of the patterns of activity in the primary visual cortex (V1) evoked by natural images and during spontaneous activity. The authors focus on a topological characterization of population activity in visual cortex. The reason behind this approach is the following: it has been observed that spontaneous cortical states tend to reproduce the patterns evoked by oriented stimuli [KBT*+*03]. Now, if cortical activity is restricted to patterns evoked by an oriented stimulus, then considering that orientation is a circular variable, this leads to the hypothesis that the activity patterns of the cortical cells must have a topological structure equivalent to that of a circle. This implies that the basic question about the structure of the cortical activity data is topological in nature. This work offers the first estimate of the underlying topological structure of V1 activity.
We now describe the experimental procedures adopted in [SMI*+*08]. The authors first validate their method on simulated data by recovering the topological structure of data sets where the “ground truth” is known. The validation is done for a circle as well as torus. We refer the readers to the original paper [SMI*+*08] for details of the validation methods. The experimental studies were performed on three old-world monkeys (Macaca fascicularis), See Figure 6. The database considered in this study was obtained using micro-machined electrode arrays consisting of a square grid of electrodes mm long. The distance between neighboring electrodes was m. Spike sorting was performed online using principal component analysis on the waveform shapes. In the spontaneous condition, the eyes were covered. The stimuli in the evoked condition were image sequences generated by digitally sampling commercially available videotapes in VHS format. The selected movies included both man-made and natural landscape scenes, and segments of seconds duration were shown.
We now describe how the data points were generated from the experiment described above. The preparation of the data points for both the spontaneous and driven activity during natural image simulation was identical. After spike-sorting signals from each electrode, the authors sub-selected a group of neurons that showed the highest firing rates. Then, a point cloud was generated by binning spikes in ms windows. The spontaneous and evoked activity segments were collected in lengths of 10 s each. Thus, each of these segments contain points living in , each neuron corresponding to a dimension. The statistical package PLEX was used with a weak witness complex construction which will be explained in the next paragraph. PLEX is a MATLAB collection of functions for computational topology. The authors recorded the maximal length of persistence intervals in the -dimensional and -dimensional barcodes.
We now describe the weak witness complex construction [SMI*+*08]. Given a finite metric space , a set of points called the landmark set, and , a point is called an -witness for a -tuple of points in if , where denotes the smallest value of as varies over all of . Now, a simplicial complex is associated to and by fixing the vertex set of to be , and declaring that a collection spans a -simplex in if and only if there is an -witness in for the collection and for all its faces. Clearly, if there is an -witness for the simplex , then there is an -witness for , . Thus, we obtain that for , and this results in a filtered simplicial complex. In [SMI*+*08], out of the data points in , a landmark set of points is chosen by the max-min procedure as follows: first a random point, say from is picked. Then, the point is chosen such that is maximized. The point is chosen such that is maximized, and so on. The weak witness construction was used because, unlike the Vietoris-Rips simplicial complexes, the construction of weak witness simplicial complexes for large data sets is much more computationally tractable.
We now describe the results obtained in [SMI*+*08]. In Figure 7, different topological signatures observed in s segments of the data labeled by the first three Betti numbers are illustrated. Each row of Figure 7 represents a different “threshold” for the length of the interval of the signature (in the barcode) as a fraction of the covering radius of the data. The covering radius is defined as , where is the data set and is the set of landmarks. Larger thresholds represent instances where the signature was long-lived and likely to represent a salient feature of the data.
6.3 Further Applications to Biology
This paragraph describes some more applications of persistent homology to neuroscience. In [BSH0], the authors propose a method based on persistent homology to automatically classify neuronal network dynamics using topological features of spaces built from spike-train distances. The dynamics of a neuronal network are believed to be indicative of the computations it can perform, and thus, understanding the neuronal network dynamics enables understanding of how neuronal networks perform computations and process information. The paper [CDM18] is an extension to [DMFC12], wherein the authors use the concept of zig-zag persistent homology [CdS10, CdSM09] to account for the possibility of forgetting information in the model for memory. The results obtained in [CDM18] show that in order to achieve the best possible results in “learning” an arena, the rodent needs a balance between remembering and forgetting information. These results are in accordance with recent findings in neuroscience, where it has been proposed that forgetting is an important step in the learning process. The work by Giusti et. al. in [GGB16] explores the method of persistent homology over the traditional graph-theoretic methods, for understanding neural data.
In [XW14], persistent homology is used for the first time for protein characterization, identification and classification. The authors extracted molecular topological fingerprints based on the persistence of molecular topological invariants. In [ESR16], persistent homology is used to characterize the complex structure of chromatin inside cell nucleus. The authors apply persistent homology to human cell line data and show how this method captures complex multiscale folding methods.
In [CCR13], persistent homology is used to study evolutionary events. The authors consider a set of genomes and calculate the genetic distance between each pair of sequences. Using these distances, they calculate the homology groups across all genetic distances in different dimensions. They observe that the zero-dimensional homology provides information about vertical evolution, i.e. at a particular , the Betti number represents the number of different strains or subclades. The one-dimensional homology provides information about horizontal evolution since reticulate events (merging of different clades to form a new hybrid lineage) are represented by loops in phylogenetic networks. Some examples of reticulate events include recombination and reassortment of genomes. The genomic datasets used are those of influenza strains, HIV, rabies, dengue, flaviviruses, West Nile virus and Newcastle virus. In a follow-up paper [CLR16], persistent homology is used to study the specific evolutionary event of recombination. In [CCR13], the relation between persistent homology and explicit evolutionary histories incorporating recombination events was not studied. Therefore, in [CLR16], persistent homology is applied on appropriate genomic sets in order to characterize the genomic regions where recombination takes place and identify the gametes involved in particular recombination events. The persistent homology barcodes derived from each of these sets are structured as a “barcode ensemble” where each bar captures a recombination event. A software called TARGet is developed that generates a graph in polynomial time, capturing ensembles of minimal recombination histories. The evolutionary event of recombination has been further studied in [LRR18] where the authors introduce “novelty profiles” of evolutionary histories. The novelty profile of an evolutionary history is a list of monotonically decreasing numbers, where is the number of recombination events in the history and each number roughly measures the contribution every recombination makes to the genetic diversity in the population. Persistent homology of sampled data is used to obtain information about a novelty profile. The authors of [LRR18] provide mathematical foundation for several works that have used persistent homology to study recombination. Some other articles showing the use of persistent homology for studying recombination events are [ER14, CRE*+*16, ER16].
In a different direction, another topological method for studying finite metric spaces is Mapper [SMC07]. It is a computational method for extracting simple descriptions of high dimensional data sets in the form of simplicial complexes. This method has been widely used for analysis of biological data sets as seen in [NLC11, YSH*+*09, LWS*+*17, dNG*+*15, TOTT*+*16, OHC*+*18, SSGC*+*18, FPT*+*18, RFH*+*14, BYCH*+*12, PPIM*+*18, KPC*+*15, STGM*+*14, Cám17, PIP17, SNM17].
6.4 Applications to Other Domains
Persistent homology has also been used for shape classification. The authors of [CCSG*+*09] use persistent homology to identify signatures of finite metric spaces that are stable under the Gromov-Hausdorff distance. The signatures are nothing but metric invariants obtained using persistent homology along with attributes of the metric spaces like diameter and eccentricity. These signatures are computed and then used to measure the degree of dissimilarity of a pair of metric spaces. The authors adapt this method to compare shapes, by first uniformly sampling points from each shape to generate a finite metric space and then comparing the finite metric spaces using the identified signatures.
In this paragraph, we provide two examples where persistent homology has been used for studying chemical compounds. In [XFTW15], persistent homology is used for studying fullerenes, which are special molecules consisting of only carbon atoms. Here, the point cloud is given by the atoms of the fullerenes, and a Vietoris-Rips filtration is constructed by the usual process of assigning radii to the point cloud. The authors thus study the stability of the fullerene molecules by observing that the total curvature energies of the fullerene isomers can be well represented with the lengths of their long-lived Betti -bars. In [LBD*+*18], persistent homology is used to build a descriptor for identifying and comparing zeolites, according to their pore shapes. Zeolites are nanoporous materials made of silica. The authors performed high-throughput screening of zeolites based on this descriptor and identified best zeolites for methane storage and carbon capture applications. The results obtained in [LBD*+*18] match the existing results on top-performing zeolites for these applications.
7 Software Packages for Persistent Homology
There are various open source softwares available for computing persistent homology. These are available in R, Python, C, Java as well as in MATLAB. The softwares are Perseus [Nan], PHAT [BKR12], DIPHA [Ren], CTL [Lew14], Ripser [Bau15], TDA [FKL*+*], javaPlex [TVJA14], Dionysus [Mor], Gudhi [gud14], TDAstats [WDWS18], Scikit-TDA [NS19] and the Topology Toolkit [TFL*+*17].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Azu 50] G. Azumaya. Corrections and supplementaries to my paper concerning krull-remak-schmidt’s theorem. Nagoya Mathematical Journal , 1:117–124, 1950.
- 2[Bau 15] U. Bauer. Ripser. https://github.com/Ripser/ripser , 2015.
- 3[BBI 01] D. Burago, Y. Burago, and S. Ivanov. A Course in Metric Geometry , volume 33 of AMS Graduate Studies in Math. American Mathematical Society, 2001.
- 4[BFT + 98] E. N. Brown, L. M. Frank, D. Tang, M. C. Quirk, and M. A. Wilson. A statistical paradigm for neural spike train decoding applied to position prediction from ensemble firing patterns of rat hippocampal place cells. Journal of Neuroscience , 18(18):7411–7425, 1998.
- 5[BKR 12] U. Bauer, M. Kerber, and J. Reininghaus. PHAT (Persistent Homology Algorithm Toolbox). https://bitbucket.org/phat-code/phat , 2012.
- 6[BSH 0] J. Bardin, G. Spreemann, and K. Hess. Topological exploration of artificial neuronal network dynamics. Network Neuroscience , 0(0):1–19, 0.
- 7[BYCH + 12] C. W. Bartlett, S. Yeon Cheong, L. Hou, J. Paquette, P. Yee Lum, G. Jäger, F. Battke, C. Vehlow, J. Heinrich, K. Nieselt, R. Sakai, J. Aerts, and W. C. Ray. An eqtl biological data visualization challenge and approaches from the visualization community. BMC Bioinformatics , 13(8):S 8, May 2012.
- 8[Cám 17] P. G. Cámara. Topological methods for genomics: Present and future directions. Current Opinion in Systems Biology , 1:95 – 101, 2017. Future of Systems Biology • Genomics and epigenomics.
