TL;DR
This paper introduces a deep neural network approach for ordinal classification using cumulative link models, integrating probabilistic link functions and a distance-aware loss function, demonstrating improved performance over existing methods.
Contribution
It presents a novel deep ordinal regression model based on cumulative link functions combined with a weighted Kappa loss, enhancing classification accuracy for ordinal data.
Findings
Models outperform nominal classifiers on ordinal tasks
Incorporating distance-based loss improves results
Statistical tests confirm model superiority
Abstract
This paper proposes a deep convolutional neural network model for ordinal regression by considering a family of probabilistic ordinal link functions in the output layer. The link functions are those used for cumulative link models, which are traditional statistical linear models based on projecting each pattern into a 1-dimensional space. A set of ordered thresholds splits this space into the different classes of the problem. In our case, the projections are estimated by a non-linear deep neural network. To further improve the results, we combine these ordinal models with a loss function that takes into account the distance between the categories, based on the weighted Kappa index. Three different link functions are studied in the experimental study, and the results are contrasted with statistical analysis. The experiments run over two different ordinal classification problems and the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11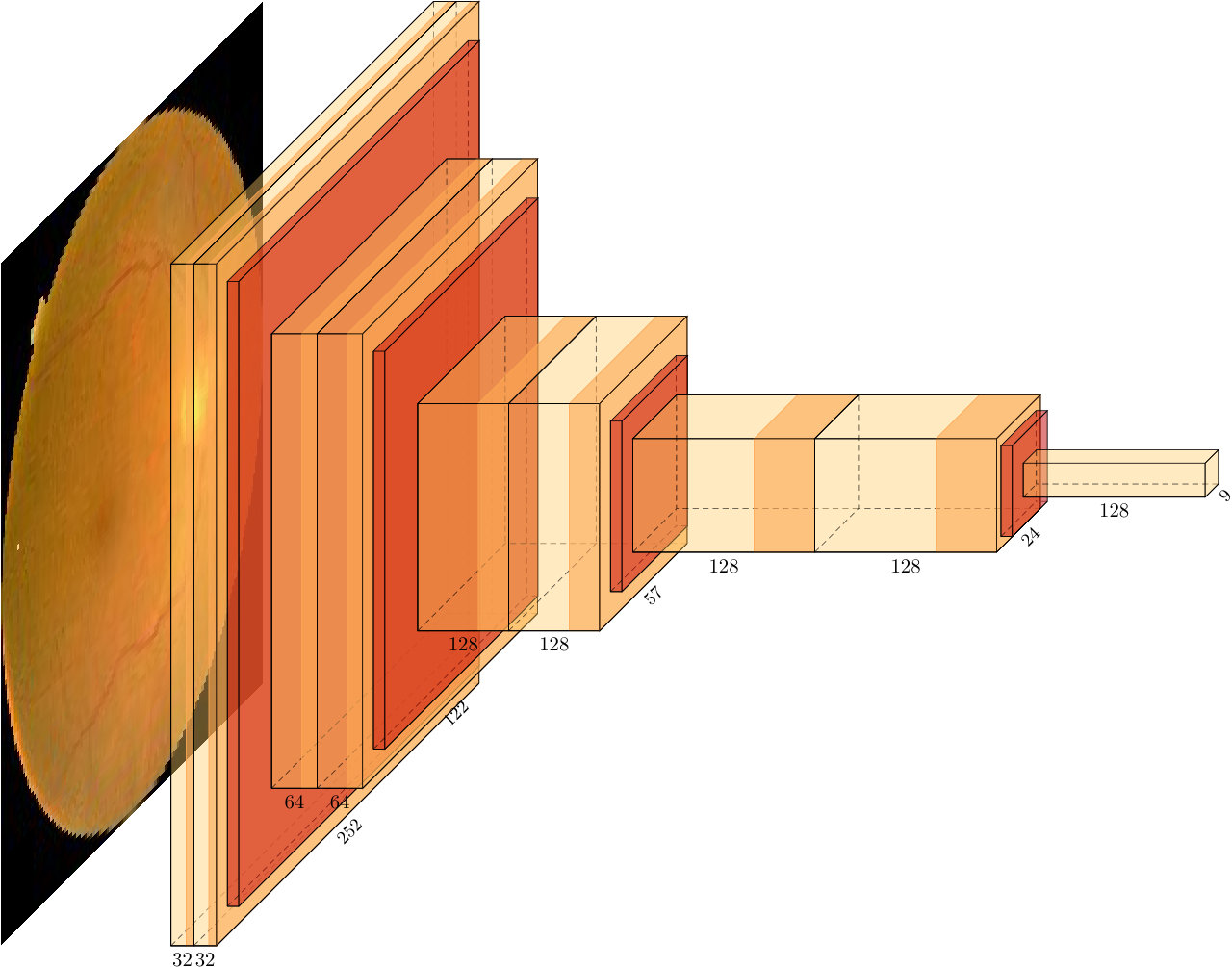 Figure 12
Figure 12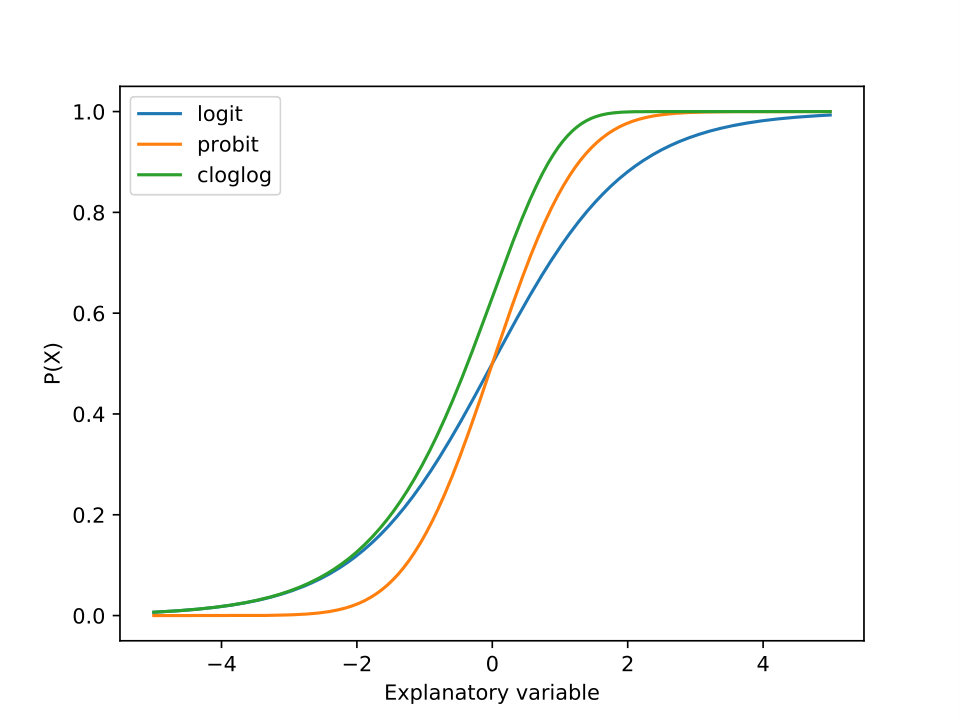 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15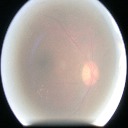 Figure 16
Figure 16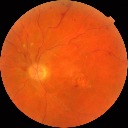 Figure 17
Figure 17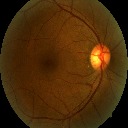 Figure 18
Figure 18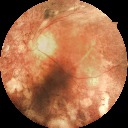 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21| Diabetic Retinopathy | Adience | ||
|---|---|---|---|
| Layer | Output | Layer | Output |
| 2 Conv3x3@32s1 | 124x124x32 | Conv7x7@32s2 | 112x112x32 |
| MaxPool2x2s2 | 62x62x32 | MaxPool3x3s2 | 55x55x32 |
| 2 Conv3x3@64s1 | 58x58x64 | 2 ResBlock3x3@64s1 | 55x55x32 |
| MaxPool2x2s2 | 29x29x64 | ResBlock3x3@128s2 | 28x28x64 |
| 2 Conv3x3@128s1 | 25x25x128 | 2 ResBlock3x3@128s1 | 28x28x64 |
| MaxPool2x2s2 | 12x12x128 | 1 ResBlock3x3@256s2 | 14x14x128 |
| 2 Conv3x3@128s1 | 8x8x128 | 2 ResBlock3x3@256s1 | 14x14x128 |
| MaxPool2x2s2 | 4x4x128 | 1 ResBlock3x3@512s2 | 7x7x256 |
| Conv4x4@128s1 | 1x1x128 | 2 ResBlock3x3@512s1 | 7x7x256 |
| AveragePool7x7s2 | 1x1x256 | ||
| BS | LF | LR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 5 | clog-log | ||||||||
| 5 | clog-log | ||||||||
| 5 | clog-log | ||||||||
| 5 | logit | ||||||||
| 5 | logit | ||||||||
| 5 | logit | ||||||||
| 5 | probit | ||||||||
| 5 | probit | ||||||||
| 5 | probit | ||||||||
| 10 | clog-log | ||||||||
| 10 | clog-log | ||||||||
| 10 | clog-log | ||||||||
| 10 | logit | ||||||||
| 10 | logit | ||||||||
| 10 | logit | ||||||||
| 10 | probit | ||||||||
| 10 | probit | ||||||||
| 10 | probit | ||||||||
| 15 | clog-log | ||||||||
| 15 | clog-log | ||||||||
| 15 | clog-log | ||||||||
| 15 | logit | ||||||||
| 15 | logit | ||||||||
| 15 | logit | ||||||||
| 15 | probit | ||||||||
| 15 | probit | ||||||||
| 15 | probit |
| BS | LF | LR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 64 | clog-log | ||||||||
| 64 | clog-log | ||||||||
| 64 | clog-log | ||||||||
| 64 | logit | ||||||||
| 64 | logit | ||||||||
| 64 | logit | ||||||||
| 64 | probit | ||||||||
| 64 | probit | ||||||||
| 64 | probit | ||||||||
| 128 | clog-log | ||||||||
| 128 | clog-log | ||||||||
| 128 | clog-log | ||||||||
| 128 | logit | ||||||||
| 128 | logit | ||||||||
| 128 | logit | ||||||||
| 128 | probit | ||||||||
| 128 | probit | ||||||||
| 128 | probit | ||||||||
| 256 | clog-log | ||||||||
| 256 | clog-log | ||||||||
| 256 | clog-log | ||||||||
| 256 | logit | ||||||||
| 256 | logit | ||||||||
| 256 | logit | ||||||||
| 256 | probit | ||||||||
| 256 | probit | ||||||||
| 256 | probit |
| DR | Adience | ||||
| LF | LF | Mean diff. | P-val | Mean diff. | P-val |
| logit | probit | ||||
| clog-log | |||||
| probit | logit | ||||
| clog-log | |||||
| clog-log | logit | ||||
| probit | |||||
| LR | LR | Mean diff. | P-val | Mean diff. | P-val |
| BS | BS | Mean diff. | P-val | Mean diff. | P-val |
| 64 | 128 | - | - | ||
| 256 | - | - | |||
| 128 | 64 | - | - | ||
| 256 | - | - | |||
| 256 | 64 | - | - | ||
| 128 | - | - | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Cumulative link models for deep ordinal classification
Víctor Manuel Vargas
Pedro Antonio Gutiérrez
César Hervás-Martínez
Department of Computer Science and Numerical Analysis, University of Córdoba, Córdoba, Spain
Abstract
This paper proposes a deep convolutional neural network model for ordinal regression by considering a family of probabilistic ordinal link functions in the output layer. The link functions are those used for cumulative link models, which are traditional statistical linear models based on projecting each pattern into a 1-dimensional space. A set of ordered thresholds splits this space into the different classes of the problem. In our case, the projections are estimated by a non-linear deep neural network. To further improve the results, we combine these ordinal models with a loss function that takes into account the distance between the categories, based on the weighted Kappa index. Three different link functions are studied in the experimental study, and the results are contrasted with statistical analysis. The experiments run over two different ordinal classification problems and the statistical tests confirm that these models improve the results of a nominal model and outperform other robust proposals considered in the literature.
keywords:
Deep learning, ordinal regression, cumulative link models, Kappa index.
††journal: Neurocomputing
1 Introduction
Deep learning, introduced by Lecun et al. [1], combines multiple machine learning techniques and allows computational models that are composed of numerous processing layers to learn representations of data with various levels of abstraction. These methods have dramatically improved the state-of-the-art in many domains, such as image classification [2, 3, 4], speech recognition [5, 6], control problems [7], object detection [8, 9, 10], privacy and security protection [11, 12], recovery of human pose [13], semantic segmentation [14] and image retrieval [15, 16, 17]. Convolutional Neural Networks (CNN) are one of the types of deep networks that are designed to process data that come in the form of multiple arrays. CNNs are appropriate for images, video, speech and audio processing, and they have been used extensively in the last years for automatic classification tasks [18, 19]. For images, each colour channel is represented by a 2D array, and convolutional layers extract the main features from the pixels, and, after that, a fully connected layer classify every sample based on its extracted features. At the output of the CNN, a softmax function provides the probabilities of the set of classes predefined in the model for classification tasks. However, the softmax may not be the best option depending on the classification problem considered.
Ordinal classification problems are those classification tasks where labels are ordered, and there are different inter-classes importances for each pair of categories. This kind of problem can be treated as nominal classification, but this discards the ordinal information. A better approach is to use specific methods that take the ordinality into account to improve the performance of the classification model. The Proportional Odds Model (POM) [20] is an ordinal alternative to the binary logistic regression. It belongs to a wider family of models called Cumulative Link Models (CLMs) [21]. CLMs are inspired in the concept of a latent variable that is projected into a 1-dimensional space and a set of thresholds that divides the projection into the different ordinal levels. A link function needs to be specified, which can be of different types, although the most common option is the logit, which is used in POM. In this paper, we explore different existing alternatives, as explained in depth in Section 3.1.
In this paper, we propose the use of CLMs for deriving deep learning ordinal classifiers111The source code is available at https://github.com/ayrna/deep-ordinal-clm.. In the case of CNNs, the model projection used by the threshold model can be obtained from the last layer of the network. Given that we work with a 1-dimensional space, the last layer would have only one neuron (projection of the pattern), and its value could be used to classify the sample into the corresponding class according to the thresholds. Some previous works have used the logit in shallow neural networks [22], but this strategy has not been considered for deep learning, and alternative link functions have not been evaluated. To further improve the results, we train these models by minimising an ordinal loss function based on the Weighted Kappa index [23], instead of using the standard cross-entropy.
An experimental study evaluating the three most common link functions is performed. Also, other parameters that can affect the training process and the model performance are studied, such as the learning rate of the optimization algorithm, the batch size, and their interaction. The nominal version of this model is used as a baseline for comparison. We contrast the results obtained with a statistical analysis to provide more robust conclusions. An ANOVA III test [24], followed by a posthoc Tukey’s test [25], is performed over runs of the experiments, because of the demands of computational time required to run a higher number of executions. The experiments are run using two different ordinal datasets: Diabetic Retinopathy [23], which contains high-resolution fundus images related with diabetes disease, and Adience [26], which includes human faces images associated with an age range.
The main contribution of this work is to introduce CLM for CNNs combined with the QWK loss function to achieve high classification performance and better stability than previous works in terms of standard deviation and stagnation problems.
The paper is organized as follows: in Section 2, we analyse previous related works. Section 3 presents a formal description of the proposal in this paper, which combines a CLM with an ordinal loss function. In Section 4, we describe the experiments and the datasets used, while, in Section 5, we present the results obtained and the statistical analysis. Finally, Section 6 exposes the conclusions of this work.
2 Related works
There are many works related to the application and development of CNN models [27], but few works focus on ordinal classification problems. The existing deep ordinal approaches are mainly based on simply using an ordinal evaluation metric, on solving the ordinal problem as multiple binary sub-problems, on using an ordinal loss functions or on constraining the probability distribution of the output layer. These works are described in the following subsections.
2.1 Simply using an ordinal evaluation metric.
Alali et al. [28] proposed a complex CNN architecture for solving Twitter Sentiment Classification as an ordinal problem. They checked that using average pooling preserves significant features that provide more expressiveness to ordinal scale. They didn’t propose any method to include the ordinal information into the classifier, but they tried to find the best CNN model architecture based on an ordinal metric.
2.2 Solving the ordinal problem as multiple binary sub-problems
Niu et al. [29] proposed a learning approach to address ordinal regression problems using CNNs. They divided the problem into a series of binary classification sub-problems and proposed a multiple output CNN optimization algorithm to collectively solve these classification sub-problems, taking into account the correlation between them.
Li et al. [30] applied deep learning techniques for solving the ordinal problem of Alzheimer’s diagnosis and detecting the different levels of the disease as multiple binary sub-problems.
Liu et al. [27] proposed a new approach which transforms the ordinal regression problem to binary classification sub-problems and use triplets with instances from different categories to train deep neural networks. In this way, high-level features describing the ordinal relationships are extracted automatically. Given that triplets must be generated, this approach is only recommended for small datasets.
Chen et al. [31] proposed a deep learning method termed Ranking-CNN. This method combines multiple binary CNNs that are trained with ordinal age labels. The binary outputs are aggregated for the final age prediction. They achieved a tighter error bound for ranking-based age estimation.
In general, all these approaches increment the number of parameters to adjust, as several binary classifiers are simultaneously learnt.
2.3 Using an ordinal loss function
De la Torre et al. [23] proposed the use of a continuous version of the quadratic weighted kappa (QWK) metric as loss function for the optimization algorithm. They compared this cost function against the traditional log-loss function using three different datasets, including the Diabetic Retinopathy database as the most complex one. They proved that their function could improve the results as it reduces overfitting and training time. Also, they checked the importance of hyper-parameter tuning. Later, in 2019, another work related to the Diabetic Retinopathy dataset was published [32] where the authors combined the QWK loss function with the use of images of a higher resolution and new dataset partitions with many more samples on the training split. Although they achieved a proper classification score, the test set only contained a small portion of the test patterns used in the Kaggle competition (around of the samples for testing against on the initial dataset splits).
Rios et al. [33] presented a CNN model designed to handle ordinal regression tasks on psychiatric notes. They combined an ordinal loss function, a CNN model and conventional feature extraction. Also, the authors applied a technique called Locally Interpretable Model-agnostic Explanation (LIME) to make the non-linear model more interpretable.
Fu et al. [34] applied deep learning techniques to Monocular Depth Estimation. They introduced a spacing-increasing discretization strategy to treat the problem as an ordinal regression problem. They improved the performance when training the network with an ordinal regression loss. Also, they used a multi-scale network structure that avoids unnecessary spatial pooling.
Pal et al. [35] defined a loss function for CNN that is based on the Earth Mover’s Distance and takes into account the ordinal class relationships.
Liu et al. [36] proposed a constrained optimization formulation for the ordinal regression problem which minimizes the negative loglikelihood for a multi-class problem constrained by the order relationship between instances.
Although the use of these losses introduces the ordinality in model learning, the nature of the models remain nominal.
2.4 Unimodal probability distributions
Beckham and Pal [26] proposed a straightforward technique to constrain discrete ordinal probability distributions to be unimodal, via the use of the Poisson and binomial probability distributions. The parameters of these distributions were learnt by using a deep neural network. They evaluated this approach on two large ordinal image datasets, including the Adience dataset used in this paper, obtaining promising results. They also included a simple squared-error reformulation [37] that was sensitive to class ordering.
This approach is the one most related to the CLMs considered in this paper. However, CLMs indirectly model a latent space together with the set of threshold separating the ordered classes, which provides a more flexible and interpretable approach to deep ordinal classification.
3 Model proposal
Based on the previous analysis of the state-of-the-art, our proposal is to combine a flexible threshold model in the output layer (different forms of a CLM) with an ordinal loss function, in order to better introduce ordinal constraints during learning.
3.1 Cumulative Link Model (CLM)
An ordinal classification problem consists in predicting the label of an input vector , where and , i.e. is in a -dimensional input space, and is in a label space of different labels. The objective in an ordinal problem is to find a function to predict the labels or categories of new patterns, given a training set of samples, . Labels have a natural ordering in ordinal problems: . The order between labels gives us the possibility to compare two different elements of by using the relation . This is not possible under the nominal classification setting. In regression (where ), real values in can be ordered by the standard operator, but labels in ordinal regression () do not carry metric information, i.e. the category serves as a qualitative indication of the pattern rather than a quantitative one.
The Proportional Odds Model (POM) arises from a statistical background and is one of the first models designed explicitly for ordinal regression [20]. It dated back to 1980 and is a member of a wider family of models lately recognised as Cumulative Link Models (CLMs) [21]. CLMs predict probabilities of groups of contiguous categories, taking the ordinal scale into account. In this way, cumulative probabilities are estimated, which can be directly related to standard probabilities:
[TABLE]
with , and considering that and .
The model is inspired by the notion of a latent variable, where represents a one-dimensional mapping. The decision rule is not fitted directly, but stochastic ordering of space is satisfied by the following general model form [38]:
[TABLE]
where is a monotonic function often termed as the inverse link function, and is the threshold defined for class . Consider the latent variable , where is the random component of the error. The most common choice for the probability distribution of is the logistic function (which is the default function for POM). Label is predicted if and only if , where the function and are to be determined from the data. It is assumed that and , so the real line defined by , is divided into consecutive intervals. Each interval corresponds to a category. The constraints ensure that increases with [20].
In this work, we consider different link functions previously proposed in CLMs for the probability distribution of , including logit, probit and complementary log-log (clog-log). These three types of links are explained below and represented in Figure 1. They all follow the same form .
The logit link function is the function used for the POM and is defined as:
[TABLE]
or the equivalent expression:
[TABLE]
- 2.
The probit link function is the inverse of the standard normal cumulative distribution function (cdf) . Its expression is:
[TABLE]
which can also be expressed as:
[TABLE]
- 3.
The clog-log takes a response that is restricted to the interval and converts it into a value in the interval (like logit and probit transformations). The clog-log expression is:
[TABLE]
with that is:
[TABLE]
logit and probit links are symmetric:
[TABLE]
which means that the response curve for is symmetric around the point , i.e. has the same rate when approaching 0 than when approaching 1. This symmetry property can be demonstrated as follows:
Let . For the logit function, we have:
[TABLE]
while:
[TABLE] 2. 2.
For the probit:
[TABLE]
which leads to:
[TABLE]
where:
[TABLE]
[TABLE]
Unlike logit and probit, the clog-log link is asymmetrical. In this way, when the distribution of the given data is not symmetric in the interval and increase slowly at small to moderate value but increases sharply near 1, the logit and probit models are inappropriate, while clog-log can lead to better results.
In this paper, the probabilistic structure of CLMs is proposed as a link function for deep convolutional neural networks. This can be achieved by defining a new type of output layer alternative to the standard softmax layer. In this way, the proposed output layer will transform the one-dimensional projection, previously denoted as , into a set of probabilities. is estimated from a nonlinear transformation of the set of features learnt by the previous layers, , where is the pattern being evaluated and is a latent representation of the pattern given by the output of a single neuron. In order to apply unconstrained optimizers while ensuring , we can redefine the thresholds. All of them can be derived from the first one in the following form:
[TABLE]
where is a learning parameter corresponding to the first threshold, is a learnable vector of parameters used to obtain the rest of the thresholds, and is the number of classes.
3.2 Continuous Quadratic Weighted Kappa (QWK) loss function
In order to increase the performance of the deep ordinal model, the CLM structure in the output layer is combined with the continuous version of the QWK loss [23] function. The Kappa index is a well-known metric that measures the agreement between two different raters. The Weighted Kappa (WK) [39] is based on the Kappa index and adds different weights to the different types of disagreements based on a weight matrix. It is useful to evaluate the performance in ordinal problems, as it gives a higher weight to the errors that are further from the correct class. This metric is defined as follows:
[TABLE]
where is the number of samples rated, is the penalization matrix (in this case, quadratic weights are considered, , ), is the confusion matrix, , is the sum of the row and is the sum of the column.
The WK defined above cannot be used as a loss function for the optimization algorithm as it is not continuous. However, it has been previously redefined [23] in terms of probabilities of the predictions:
[TABLE]
where , and are the input data and the real class of the -th sample, is the number of classes, is the number of samples, is the number of samples of the -th class, is the probability that the -th sample belongs to class (estimated using the CLM structure), and are the elements of the penalization matrix (). This loss function can be minimized using a gradient descent based algorithm.
4 Experiments
4.1 Data
In order to evaluate the different models, we make use of two ordinal datasets:
4.1.1 Diabetic Retinopathy (DR)
DR222https://www.kaggle.com/c/diabetic-retinopathy-detection/data is a dataset consisting of extremely high-resolution fundus image data. The training set consists of pairs of images (where a pair includes a left and right eye image corresponding to a patient). In this dataset, we try to predict the correct category from five levels of diabetic retinopathy: no DR ( images), mild DR ( images), moderate DR ( images), severe DR ( images), or proliferative DR ( images). The test set contains pairs of images. These images are taken in variable conditions: by different cameras, conditions of illumination and resolutions. They come from the EyePACS dataset that was used in the DR detection competition hosted on the Kaggle platform. Also, this dataset has been used in different works [23, 40], where the cost function was considered in [23] to achieve better performance. A validation set is set aside, consisting of of the patients in the training set. The images are resized to 128 by 128 pixels and rescaled to range. Data augmentation techniques, described in Section 4.3, are applied to achieve a higher number of samples. A few test images of this dataset are shown in Figure 2.
4.1.2 Adience
Adience333http://www.openu.ac.il/home/hassner/Adience/data.html dataset consists of faces belonging to subjects. We use the form of the dataset where faces have been pre-cropped and aligned. The dataset was preprocessed, using the methods described in a previous work [26], so that the images are 256 pixels in width and height, and pixels values follow a normal distribution. The original dataset was split into five cross-validation folds. The training set consists of merging the first four folds which comprise a total of images. From this, of the images are held out as part of a validation set. The last fold is used as test set. Some images of this dataset are shown in Figure 3. Adience dataset has been used in other works for human age estimation but most of them solved the problem as a multi-class problem instead of using the ordinal relation between classes. Eidinger et al. [41] presented an approach using support vector machines and neural networks. Chen et al. [42] proposed a coarse-to-fine strategy for deep CNNs. Levi and Hassner [43] presented another convolutional network model for age estimation. As previously discussed, Beckham and Pal [26] proposed a straightforward method to constrain discrete probability distributions to be unimodal. M. Duan et al. [44] proposed a hybrid approach that combines CNN with Extreme Learning Machine (ELM).
4.2 Model
CNNs have been used for both datasets. The different architectures of CNNs used in these experiments are presented in Table 1. The architecture for DR is the same that was used in [23] and the network for Adience is a small Residual Network (ResNet) [45] that was used in [26]. The most important parameters for convolutional layers are the number of filters that are used to make the convolution operation, the size of these filters and the stride, which is the number of pixels that the filter is moved in every operation. Pooling layers have similar parameters: pool size (number of pixels that will be involved in the operation) and stride. For convolutional layers, ConvWxH@FsS stands for filters of size WxH and stride S. For pooling layers, PoolWxHsS corresponds to a pool size of WxH and stride S.
The Exponential Linear Unit (ELU) [46] has been used as the activation function for all the convolutional and dense layers, instead of the ReLU [47] function, as it mitigates the effects of the vanishing gradient problem [48, 49] via the identity for positive values. Also, ELUs lead to faster training and better generalization performance than ReLU and Leaky ReLU (LReLU) [50] functions on networks with more than five layers.
After every ELU activation function of the convolutional layers, Batch Normalization [51] is applied. This method reduces the internal covariate shift by normalizing layer outputs. As the authors stated [51], it allows us to use higher learning rates and be less careful about weight initialization. In some cases, it also eliminates the need for using regularization techniques like Dropout.
At the output of the network, the CLM is used (see Section 3.1). Also, a learnable parameter rescales the projections used by the CLM to make it more stable and guarantee the convergence in most cases. The following expression describes the transformation applied to these projections:
[TABLE]
where is optimized as a free parameter along with the parameters of the model.
4.3 Experimental design
Weights are adjusted using a batch based first-order optimization algorithm called Adam [52]. We study different initial learning rates () in order to find the optimal one for each problem. We apply an exponential decay [53] across training epochs to the initial learning rate () following the expression below:
[TABLE]
Both datasets are artificially balanced using data augmentation techniques [54]. However, different transformations are applied to each one. DR dataset augmentation is based on image cropping and zooming, horizontal and vertical flipping, brightness adjustment and random rotations. Horizontal flipping is the only transformation applied to the Adience dataset. These transformations are applied every time a new batch is loaded, and the parameters of each one are randomly chosen from a defined range ( for zooming, for brightness and degrees for rotation), providing a new set of transformed images for each batch. This technique reduces the overfitting risk and provides an important performance boost as we always work with different but similar images [55].
The epoch size is equal to the number of images in the training set. It could be a higher number as we are using data augmentation, but instead of increasing the epoch size, we rather run the training for more epochs. In this case, we set the maximum number of epochs to . However, we always save the best model, that is evaluated when the training finishes.
The models are mainly evaluated using the QWK metric defined in Eq. (1). Also, other evaluation metrics are used to ease the comparison with alternative works:
Minimum Sensitivity (MS) [56] is the lowest percentage of samples correctly predicted to belong to a class with respect to the number of samples of that class.
[TABLE]
where is the confusion matrix and is the number of classes.
- 2.
Mean Absolute Error (MAE) [56] is the average absolute deviation of the predicted category from the real one.
[TABLE]
where is the number of samples, is the number of classes and O is the confusion matrix.
- 3.
Accuracy-based metrics. Correct Classification Rate (CCR) or standard accuracy is the most common metric for classification tasks and shows the percentage of correctly classified samples. We also include Top-2 CCR and Top-3 CCR [26], which are similar to CCR, but they take a prediction as correct when the real class is between the two or three classes, respectively, with the highest probability.
- 4.
1-off accuracy [41, 42, 43] marks the prediction as correct when the correct class is at one category of distance (in the ordinal scale) from the predicted one.
QWK, MAE and 1-off accuracy are ordinal evaluation metrics, while MS, CCR, Top-2 CCR and Top-3 CCR do not take the order of categories into consideration.
In order to ease reproducibility, the source code is available in a public repository444https://github.com/ayrna/deep-ordinal-clm.
4.4 Factors
In our study, three different factors are considered:
Learning rate (LR, ). LR is one of the most critical hyper-parameters to tune for training deep neural networks. Optimal learning rate can vary depending on the dataset and the CNN architecture. Previous works have presented some techniques that adjust this parameter in order to achieve better performance [57, 58]. In this work, we consider three different values for the initial value of this parameter: , and .
- 2.
Batch size (BS). Batch size is also an important parameter as it controls the number of weight updates that are made on every epoch. It can affect the training time and the model performance. In this paper, we try three different batch sizes for each dataset. For the DR dataset, we use , and , while, for Adience, , and images are used. We took the batch sizes that were used in [23] and [26] as a reference, and we expand the range on both sides.
- 3.
Link function (LF). Different link functions are used for the CLM at the last layer output: logit, probit and complementary log-log (see Section 3.1).
5 Results
In this Section, we present the results of the experiments. First, in Sections 5.1, 5.2, and 5.3, we perform the study for adjusting the value of the different parameters. Then, Section 5.4 compares the results against the state of the art.
For each dataset, we show a table with the detailed results of the experiments performed for training the model with each combination of parameters. Every parameter combination was run five times. These tables show the mean value and the standard deviation (SD) of each metric across these five executions for the test set.
5.1 Diabetic Retinopathy
Detailed test results for the DR dataset are presented in Table 2. The best result for each metric is marked in bold and the second best is in italic font.
The best mean QWK value was obtained with the clog-log link function using a BS of 10 and a LR of . However, the best CCR value was obtained with a BS of 15, the logit link and a LR of . The optimal configuration depends on the metric we are analysing. In this case, as we are working with an ordinal problem, the most reliable metric is the QWK. However, the rest of the metrics are also included to allow further comparisons with future works.
5.2 Adience
Test results for the experiments made with the Adience dataset are shown in Table 3. The best result for each metric is marked in bold and the second best is in italic font.
The best mean QWK value was obtained with the logit link function using a BS of 64 and a LR of . Also, this configuration obtained the best score for Top-2, Top-3 and 1-off accuracy, and the second best for MS, MAE and CCR. In this case, this configuration can be selected as the optimal for this problem.
5.3 Statistical analysis
In this subsection, a statistical analysis will be performed in order to obtain conclusions from the results. The significance and relative importance of the parameters concerning the results obtained, as well as the most suitable values, were obtained using an ANalysis Of the VAriance (ANOVA).
The ANOVA test [24] is one of the most widely used statistical techniques. ANOVA is essentially a method of analysing the variance to which a response is subject into its various components, corresponding to the sources of variation which can be identified. ANOVA, in this case, examines the effects of three quantitative variables (termed factors) on one quantitative response. Considered factors are the LF, the LR for the Adam optimization algorithm, and the BS. We assume that five executions are enough to do the statistical tests because of the computational time limitations.
The ANOVA test results show that there are significant differences in average QWK depending on the LF and also depending on the LR for (). Moreover, an interaction between the LF and the LR can be recognised ().
Given that there exist significant differences between the means, we analyse now these differences. A post-hoc multiple comparison test has been performed on the mean QWK obtained. An HSD Tukey’s test [25] has been selected under the null hypothesis that the variance of the error of the dependent variable is the same between the groups. The results of this test over the test set are shown in Table 4. They show that the best LF is the clog-log but the probit link performance is close to it. Also, the best value for the LR parameter is . The BS is not relevant for this dataset with the values considered.
The results of the ANOVA III test for the Adience dataset, first, demonstrate that there exist significant differences in average QWK concerning the three factors (). Secondly, we found interactions between all the pairs of factors and between all the three factors together (p-values , , and , respectively).
As we did for the DR dataset, a post-hoc multiple comparison test has been performed on the average QWK obtained for Adience. Under the null hypothesis that the variance of the error of the dependent variable is the same between the groups, the HSD Tukey’s test has been applied. The results of this test over the test set are shown in Table 4.
The results over the test set show that the best LF is the logit, the best LR is and the best BS is 128. However, the interactions between these factors made the configuration that uses a logit link, and BS of 64, the best configuration. It obtained a mean QWK value of for validation and for test. The same parameters, but using the probit link, achieves the second best result (). The standard deviation is very low for both cases.
To sum up, the results showed that the best parameter configuration depends on the problem that is being solved. The clog-log function offers the best results in DR dataset while the logit link is the best option for the Adience dataset. However, the best LR for both datasets were . It is recommended to use this value for future datasets. The best BS for DR was 10, while the best value for Adience was 128 (intermediate values considered). Finally, there are more interactions between the three factors for the Adience dataset than for DR. These results highlight the importance of adjusting the hyper-parameters for each problem instead of trying to find an optimal configuration for all the datasets.
5.4 Comparison with nominal method and previous works
Once the factor parameters have been studied and selected, experiments are run with the standard cross-entropy loss and the softmax function too in order to prove the performance improvement of considering the ordinality of the problem (QWK loss and the CLM). The evaluation metrics remains the same in order to be able to compare. When considering the nominal version, for the DR dataset, the best mean value of QWK was and was obtained when using a BS of 10 and a LR of . In the case of Adience dataset, the highest QWK was and was achieved with a BS of 64 and a LR of . There are some parameter configurations where the training process gets stagnated and a very low QWK is obtained. As we saw in Sections 5.1 and 5.2, this problem is not found when using the ordinal method.
These results are included in Table 5, together with the comparison against previous works of the state-of-the-art. All the results are given for the test set, except those from [23] (DR dataset), because the authors only provided validation results for images (however, validation results are usually better than test results). The results for [26] were obtained by reproducing their experiments because they did not provide the results for test set. As can be checked, the proposed ordinal model with the best configuration found in the previous step outperforms all the other alternatives in terms of QWK.
The performance gain of CLM over the nominal version reaches for DR and for Adience dataset. The DR dataset obtains a higher performance gain from the ordinal method than the Adience dataset. It seems that the method proposed in this work offers a more significant improvement as the given problem complexity increases. Moreover, when compared against alternative ordinal methods (many of them with a deep structure), CLMs are very competitive, possibly because of the flexibility provided by the threshold model structure (where the threshold of each class is independently adjusted). Our proposed model shows a high score and a very low standard deviation, which proves very high robustness compared to other alternatives.
6 Conclusions
This paper introduces a new deep ordinal network based on combining CLM models with a continuous QWK loss function. The proposed model is able to improve the performance of the deep network compared to the equivalent nominal version and other models proposed in previous works. Also, it is able to reduce the chance that the model gets stuck when training with some parameter configurations. We conclude that the optimal values for the different parameters considered are problem-dependant. The results highlight the importance of making an experimental design where all of these parameters are adjusted for each problem. In summary, the most significant contributions of the model proposal are the performance increase, the reduction of the number of parameters configurations that should be tried to find the best one and the prevention from over-fitting and stagnation, which grants our method high stability compared to other alternatives.
As future research, it seems that the design of new generalised link functions could be promising, which could be dynamically adapted to any problem based on a learnable parameter.
Acknowledgment
This work has been partially subsidised by the TIN2017-85887-C2-1-P and TIN2017-90567-REDT projects of the Spanish Ministry of Economy and Competitiveness (MINECO), and FEDER funds of the European Union. Víctor Manuel Vargas’s research has been subsidized by the FPU Predoctoral Program of the Spanish Ministry of Science, Innovation and Universities (MCIU), grant reference FPU18/00358.
References
- [1]
Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature 521 (7553) (2015) 436–444.
- [2]
S. Yu, S. Jia, C. Xu, Convolutional neural networks for hyperspectral image classification, Neurocomputing 219 (2017) 88–98.
doi:10.1016/j.neucom.2016.09.010.
- [3]
L. Fang, H. Zhang, J. Zhou, X. Wang, Image classification with an rgb-channel nonsubsampled contourlet transform and a convolutional neural network, Neurocomputing (2019) 1–12.
doi:10.1016/j.neucom.2018.10.094.
- [4]
F. Zhu, Z. Ma, X. Li, G. Chen, J.-T. Chien, J.-H. Xue, J. Guo, Image-text dual neural network with decision strategy for small-sample image classification, Neurocomputing 328 (2019) 182–188.
doi:10.1016/j.neucom.2018.02.099.
- [5]
G. Song, Z. Wang, F. Han, S. Ding, M. A. Iqbal, Music auto-tagging using deep recurrent neural networks, Neurocomputing 292 (2018) 104–110.
doi:10.1016/j.neucom.2018.02.076.
- [6]
Z.-T. Liu, M. Wu, W.-H. Cao, J.-W. Mao, J.-P. Xu, G.-Z. Tan, Speech emotion recognition based on feature selection and extreme learning machine decision tree, Neurocomputing 273 (2018) 271–280.
doi:10.1016/j.neucom.2017.07.050.
- [7]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529–533.
- [8]
X. Sun, P. Wu, S. C. Hoi, Face detection using deep learning: An improved faster rcnn approach, Neurocomputing 299 (2018) 42–50.
doi:10.1016/j.neucom.2018.03.030.
- [9]
W. Chu, D. Cai, Deep feature based contextual model for object detection, Neurocomputing 275 (2018) 1035–1042.
doi:10.1016/j.neucom.2017.09.048.
- [10]
R. Olmos, S. Tabik, F. Herrera, Automatic handgun detection alarm in videos using deep learning, Neurocomputing 275 (2018) 66–72.
doi:10.1016/j.neucom.2017.05.012.
- [11]
F. Tan, X. Hou, J. Zhang, Z. Wei, Z. Yan, A deep learning approach to competing risks representation in peer-to-peer lending, IEEE Transactions on Neural Networks and Learning Systems 30 (5) (2019) 1565–1574.
doi:10.1109/TNNLS.2018.2870573.
- [12]
X. Yuan, P. He, Q. Zhu, X. Li, Adversarial examples: Attacks and defenses for deep learning, IEEE Transactions on Neural Networks and Learning Systems 30 (9) (2019) 2805–2824.
doi:10.1109/TNNLS.2018.2886017.
- [13]
C. Hong, J. Yu, J. Wan, D. Tao, M. Wang, Multimodal deep autoencoder for human pose recovery, IEEE Transactions on Image Processing 24 (12) (2015) 5659–5670.
- [14]
L. Li, X. Zhao, W. Lu, S. Tan, Deep learning for variational multimodality tumor segmentation in pet/ct, Neurocomputing (2019) 1–19.
doi:10.1016/j.neucom.2018.10.099.
- [15]
M. Tzelepi, A. Tefas, Deep convolutional learning for content based image retrieval, Neurocomputing 275 (2018) 2467–2478.
doi:10.1016/j.neucom.2017.11.022.
- [16]
A. Qayyum, S. M. Anwar, M. Awais, M. Majid, Medical image retrieval using deep convolutional neural network, Neurocomputing 266 (2017) 8–20.
doi:10.1016/j.neucom.2017.05.025.
- [17]
C. Bai, L. Huang, X. Pan, J. Zheng, S. Chen, Optimization of deep convolutional neural network for large scale image retrieval, Neurocomputing 303 (2018) 60–67.
doi:10.1016/j.neucom.2018.04.034.
- [18]
C. Dong, C. C. Loy, K. He, X. Tang, Learning a deep convolutional network for image super-resolution, in: Proceedings of the European Conference on Computer Vision, Springer, 2014, pp. 184–199.
doi:10.1007/978-3-319-10593-2_13.
- [19]
O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: Proceedings of the International Conference on Medical Image Computing and Computer-assisted Intervention, Springer, 2015, pp. 234–241.
doi:10.1007/978-3-319-24574-4_28.
- [20]
P. McCullagh, Regression models for ordinal data, Journal of the royal statistical society. Series B (Methodological) (1980) 109–142.
doi:10.1111/j.2517-6161.1980.tb01109.x.
- [21]
A. Agresti, Analysis of ordinal categorical data, Vol. 656, J. Wiley & Sons, 2010.
- [22]
P. A. Gutierrez, M. Perez-Ortiz, J. Sanchez-Monedero, F. Fernandez-Navarro, C. Hervas-Martinez, Ordinal regression methods: survey and experimental study, IEEE Transactions on Knowledge and Data Engineering 28 (1) (2016) 127–146.
doi:10.1109/TKDE.2015.2457911.
- [23]
J. de la Torre, D. Puig, A. Valls, Weighted kappa loss function for multi-class classification of ordinal data in deep learning, Pattern Recognition Letters 105 (2018) 144–154.
doi:10.1016/j.patrec.2017.05.018.
- [24]
R. G. Miller Jr, Beyond ANOVA: basics of applied statistics, Chapman and Hall/CRC, 1997.
- [25]
J. W. Tukey, Comparing individual means in the analysis of variance, Biometrics 5 (2) (1949) 99–114.
- [26]
C. Beckham, C. Pal, Unimodal probability distributions for deep ordinal classification, in: Proceedings of the 34th International Conference on Machine Learning, Vol. 70, 2017, pp. 411–419.
- [27]
Y. Liu, A. W.-K. Kong, C. K. Goh, Deep ordinal regression based on data relationship for small datasets, in: Proceedings of the 26th International Joint Conferences on Artificial Intelligence, 2017, pp. 2372–2378.
- [28]
M. Alali, N. M. Sharef, H. Hamdan, M. A. A. Murad, N. A. Husin, Multi-layers convolutional neural network for twitter sentiment ordinal scale classification, in: Proceedings of the International Conference on Soft Computing and Data Mining, Springer, 2018, pp. 446–454.
doi:10.1007/978-3-319-72550-5_43.
- [29]
Z. Niu, M. Zhou, L. Wang, X. Gao, G. Hua, Ordinal regression with multiple output cnn for age estimation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4920–4928.
- [30]
H. Li, M. Habes, Y. Fan, Deep ordinal ranking for multi-category diagnosis of alzheimer’s disease using hippocampal mri data, arXiv:1709.01599 (2017) 1–28.
- [31]
S. Chen, C. Zhang, M. Dong, J. Le, M. Rao, Using ranking-cnn for age estimation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5183–5192.
- [32]
J. de La Torre, A. Valls, D. Puig, A deep learning interpretable classifier for diabetic retinopathy disease grading, Neurocomputing (2019) 1–12.
doi:10.1016/j.neucom.2018.07.102.
- [33]
A. Rios, R. Kavuluru, Ordinal convolutional neural networks for predicting rdoc positive valence psychiatric symptom severity scores, Journal of biomedical informatics 75 (2017) S85–S93.
doi:10.1016/j.jbi.2017.05.008.
- [34]
H. Fu, M. Gong, C. Wang, K. Batmanghelich, D. Tao, Deep ordinal regression network for monocular depth estimation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 2002–2011.
- [35]
A. Pal, A. Chaturvedi, U. Garain, A. Chandra, R. Chatterjee, S. Senapati, Severity assessment of psoriatic plaques using deep cnn based ordinal classification, in: OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis, Springer, 2018, pp. 252–259.
doi:10.1007/978-3-030-01201-4_27.
- [36]
Y. Liu, A. Wai Kin Kong, C. Keong Goh, A constrained deep neural network for ordinal regression, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 831–839.
- [37]
C. Beckham, C. Pal, A simple squared-error reformulation for ordinal classification, arXiv:1612.00775 (2016) 1–8.
- [38]
R. Herbrich, Large margin rank boundaries for ordinal regression, Advances in Large Margin Classifiers (2000) 115–132.
- [39]
A. Ben-David, Comparison of classification accuracy using cohen’s weighted kappa, Expert Systems with Applications 34 (2) (2008) 825–832.
doi:10.1016/j.eswa.2006.10.022.
- [40]
À. Nebot, et al., Diabetic retinopathy detection through image analysis using deep convolutional neural networks, in: A.I. Research and Development: Proceedings of the 19th Int. Conf. of the Catalan Association for A.I., Vol. 288, IOS press, 2016, pp. 58–63.
doi:10.3233/978-1-61499-696-5-58.
- [41]
E. Eidinger, R. Enbar, T. Hassner, Age and gender estimation of unfiltered faces, IEEE Transactions on Information Forensics and Security 9 (12) (2014) 2170–2179.
doi:10.1109/TIFS.2014.2359646.
- [42]
J.-C. Chen, A. Kumar, R. Ranjan, V. M. Patel, A. Alavi, R. Chellappa, A cascaded convolutional neural network for age estimation of unconstrained faces, in: Proceedings of 8th IEEE Conference on Biometrics Theory, Applications and Systems (BTAS), IEEE, 2016, pp. 1–8.
doi:10.1109/BTAS.2016.7791154.
- [43]
G. Levi, T. Hassner, Age and gender classification using convolutional neural networks, in: Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition, 2015, pp. 34–42.
- [44]
M. Duan, K. Li, C. Yang, K. Li, A hybrid deep learning cnn–elm for age and gender classification, Neurocomputing 275 (2018) 448–461.
doi:10.1016/j.neucom.2017.08.062.
- [45]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE Conference of Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [46]
D.-A. Clevert, T. Unterthiner, S. Hochreiter, Fast and accurate deep network learning by exponential linear units (elus), arXiv:1511.07289 (2015) 1–14.
- [47]
V. Nair, G. E. Hinton, Rectified linear units improve restricted boltzmann machines, in: Proceedings of the 27th International Conference on Machine Learning, 2010, pp. 807–814.
- [48]
Y. Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult, IEEE Transactions on Neural Networks 5 (2) (1994) 157–166.
- [49]
R. Pascanu, T. Mikolov, Y. Bengio, On the difficulty of training recurrent neural networks, in: Proceedings of the 30th International Conference on Machine Learning, 2013, pp. 1310–1318.
- [50]
A. L. Maas, A. Y. Hannun, A. Y. Ng, Rectifier nonlinearities improve neural network acoustic models, in: Proceedings of the 30th International Conference on Machine Learning, Vol. 28, 2013, pp. 1–6.
- [51]
S. Ioffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in: Proceedings of the 32nd International Conference on Machine Learning, Vol. 37, 2015, pp. 448–456.
- [52]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: Proceedings of the International Conference on Learning Representations, 2015, pp. 1–15.
- [53]
W.-S. Chin, Y. Zhuang, Y.-C. Juan, C.-J. Lin, A learning-rate schedule for stochastic gradient methods to matrix factorization, in: Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer, 2015, pp. 442–455.
- [54]
D. A. Van Dyk, X.-L. Meng, The art of data augmentation, Journal of Computational and Graphical Statistics 10 (1) (2001) 1–50.
doi:10.1198/10618600152418584.
- [55]
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [56]
M. Cruz-Ramírez, C. Hervás-Martínez, J. Sánchez-Monedero, P. A. Gutiérrez, Metrics to guide a multi-objective evolutionary algorithm for ordinal classification, Neurocomputing 135 (2014) 21–31.
doi:10.1016/j.neucom.2013.05.058.
- [57]
L. N. Smith, Cyclical learning rates for training neural networks, in: Proceedings of the IEEE Winter Conference on Applications of Computer Vision, 2017, pp. 464–472.
- [58]
A. Senior, G. Heigold, K. Yang, et al., An empirical study of learning rates in deep neural networks for speech recognition, in: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2013, pp. 6724–6728.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Le Cun, Y. Bengio, G. Hinton, Deep learning, Nature 521 (7553) (2015) 436–444. doi:10.1038/nature 14539 . · doi ↗
- 2[2] S. Yu, S. Jia, C. Xu, Convolutional neural networks for hyperspectral image classification, Neurocomputing 219 (2017) 88–98. doi:10.1016/j.neucom.2016.09.010 . · doi ↗
- 3[3] L. Fang, H. Zhang, J. Zhou, X. Wang, Image classification with an rgb-channel nonsubsampled contourlet transform and a convolutional neural network, Neurocomputing (2019) 1–12. doi:10.1016/j.neucom.2018.10.094 . · doi ↗
- 4[4] F. Zhu, Z. Ma, X. Li, G. Chen, J.-T. Chien, J.-H. Xue, J. Guo, Image-text dual neural network with decision strategy for small-sample image classification, Neurocomputing 328 (2019) 182–188. doi:10.1016/j.neucom.2018.02.099 . · doi ↗
- 5[5] G. Song, Z. Wang, F. Han, S. Ding, M. A. Iqbal, Music auto-tagging using deep recurrent neural networks, Neurocomputing 292 (2018) 104–110. doi:10.1016/j.neucom.2018.02.076 . · doi ↗
- 6[6] Z.-T. Liu, M. Wu, W.-H. Cao, J.-W. Mao, J.-P. Xu, G.-Z. Tan, Speech emotion recognition based on feature selection and extreme learning machine decision tree, Neurocomputing 273 (2018) 271–280. doi:10.1016/j.neucom.2017.07.050 . · doi ↗
- 7[7] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529–533. doi:10.1038/nature 14236 . · doi ↗
- 8[8] X. Sun, P. Wu, S. C. Hoi, Face detection using deep learning: An improved faster rcnn approach, Neurocomputing 299 (2018) 42–50. doi:10.1016/j.neucom.2018.03.030 . · doi ↗
