TL;DR
This paper introduces a graph neural network-based architecture for table recognition in document analysis, demonstrating improved performance and providing a new large-scale synthetic dataset to advance research in this area.
Contribution
It proposes a novel graph neural network architecture tailored for table recognition and releases a large synthetic dataset to facilitate further research.
Findings
Our method outperforms baseline models significantly.
Graph networks effectively model table structures.
A new large-scale synthetic dataset is introduced.
Abstract
Document structure analysis, such as zone segmentation and table recognition, is a complex problem in document processing and is an active area of research. The recent success of deep learning in solving various computer vision and machine learning problems has not been reflected in document structure analysis since conventional neural networks are not well suited to the input structure of the problem. In this paper, we propose an architecture based on graph networks as a better alternative to standard neural networks for table recognition. We argue that graph networks are a more natural choice for these problems, and explore two gradient-based graph neural networks. Our proposed architecture combines the benefits of convolutional neural networks for visual feature extraction and graph networks for dealing with the problem structure. We empirically demonstrate that our method…
Click any figure to enlarge with its caption.
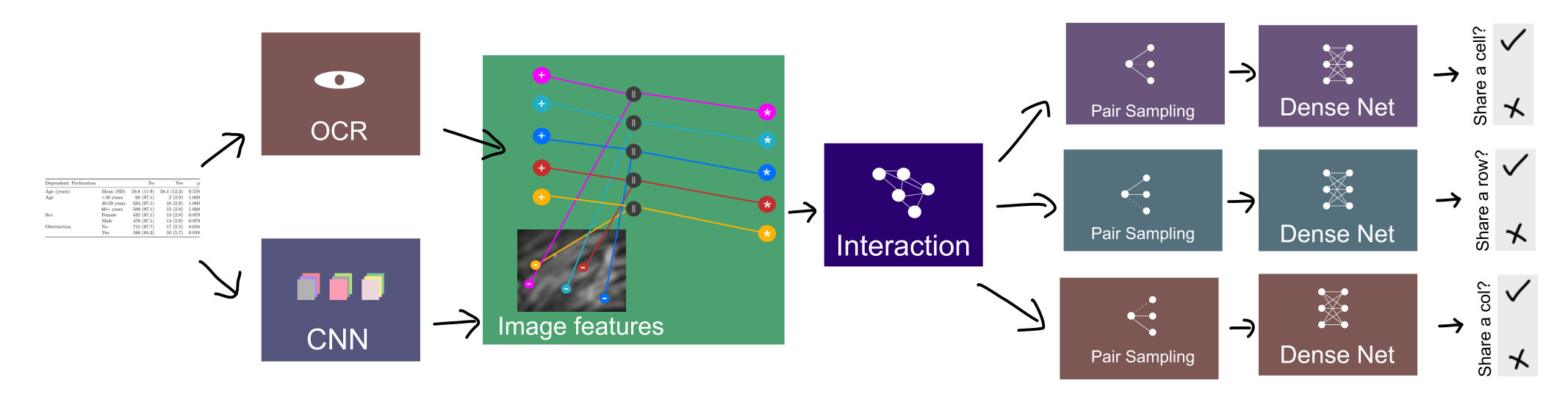 Figure 1
Figure 1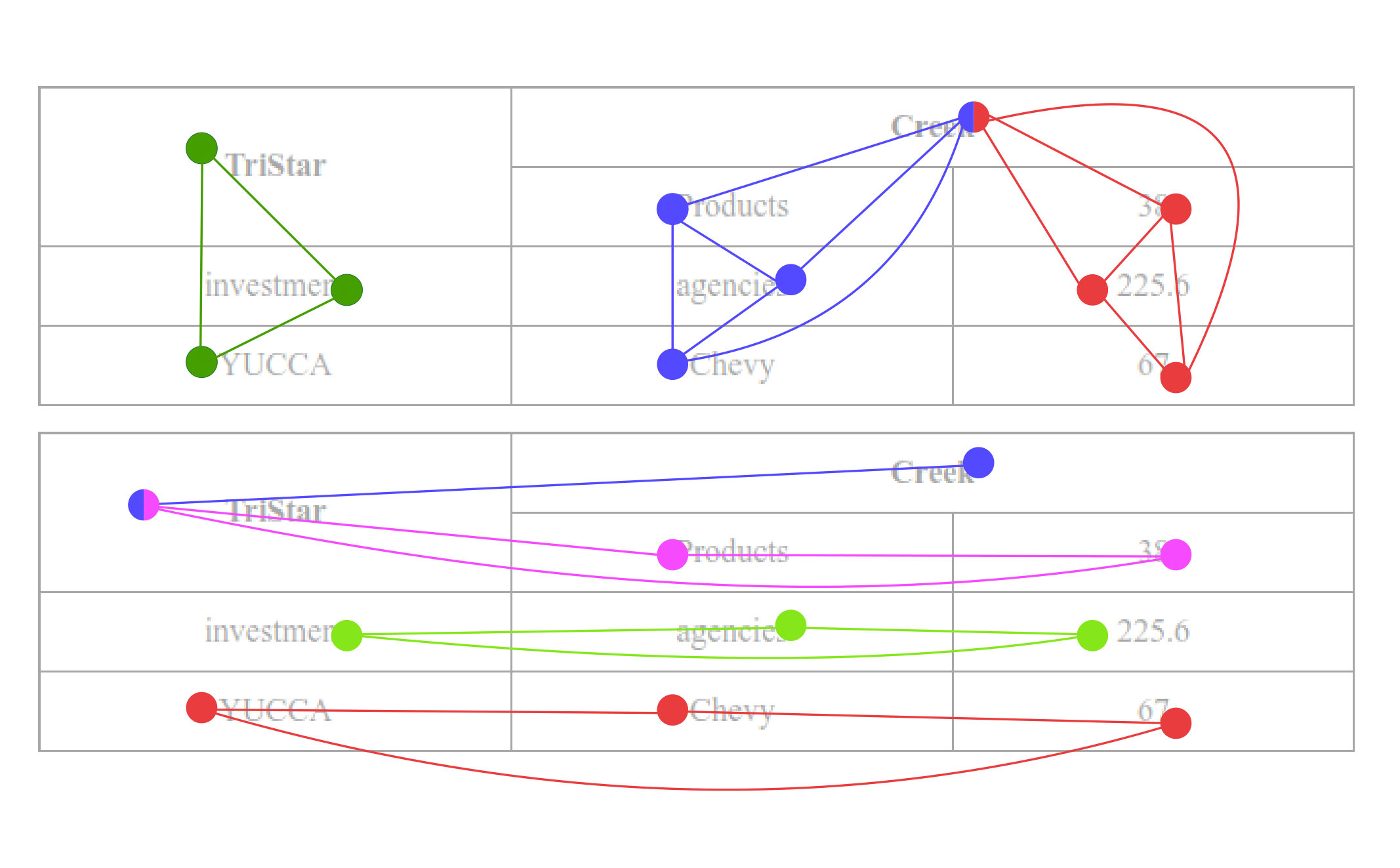 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12| Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCNN | 99.9 | 99.9 | 99.6 | 99.9 | 99.6 | 99.4 | 99.8 | 96.8 | 87.6 | 99.9 | 97.7 | 90.0 |
| GravNet* | 99.8 | 100 | 99.7 | 99.8 | 99.9 | 99.5 | 99.2 | 95.7 | 86.2 | 99.6 | 96.8 | 90.5 |
| DGCNN* | 99.8 | 99.9 | 100 | 99.9 | 99.9 | 99.8 | 99.9 | 98.1 | 94.1 | 99.8 | 99.1 | 94.3 |
| Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCNN | 0.01 | 0.5 | 16.7 | 0.06 | 3.05 | 14.1 | 0.12 | 10.4 | 32.1 | 0.04 | 6.31 | 26.4 |
| GravNet* | 0.15 | 0.18 | 6.56 | 0.17 | 0.79 | 9.01 | 0.58 | 10.2 | 33.6 | 0.28 | 7.81 | 25.28 |
| DGCNN* | 0.07 | 0.46 | 0.79 | 0.08 | 0.22 | 1.09 | 0.06 | 4.8 | 14.6 | 0.07 | 4.39 | 10.6 |
| Method | Category | Category | Category | Category |
|---|---|---|---|---|
| FCNN | 42.4 | 54.6 | 10.9 | 31.9 |
| GravNet* | 65.6 | 58.6 | 13.1 | 31.5 |
| DGCNN* | 96.9 | 94.7 | 52.9 | 68.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Rethinking Table Recognition using
Graph Neural Networks
Shah Rukh Qasim1, Hassan Mahmood1, and Faisal Shafait1,2
1School of Electrical Engineering and Computer Science (SEECS)
National University of Sciences and Technology (NUST), Islamabad, Pakistan
2Deep Learning Laboratory, National Center of Artificial Intelligence (NCAI), Islamabad, Pakistan
Email: [email protected]
Abstract
Document structure analysis, such as zone segmentation and table recognition, is a complex problem in document processing and is an active area of research. The recent success of deep learning in solving various computer vision and machine learning problems has not been reflected in document structure analysis since conventional neural networks are not well suited to the input structure of the problem. In this paper, we propose an architecture based on graph networks as a better alternative to standard neural networks for table recognition. We argue that graph networks are a more natural choice for these problems, and explore two gradient-based graph neural networks. Our proposed architecture combines the benefits of convolutional neural networks for visual feature extraction and graph networks for dealing with the problem structure. We empirically demonstrate that our method outperforms the baseline by a significant margin. In addition, we identify the lack of large scale datasets as a major hindrance for deep learning research for structure analysis and present a new large scale synthetic dataset for the problem of table recognition. Finally, we open-source our implementation of dataset generation and the training framework of our graph networks to promote reproducible research in this direction111github.com/shahrukhqasim/TIES-2.0.
Index Terms:
Table Recognition; Structure Analysis; Graph Neural Networks; Document Model; Graph Model; Dataset
I Introduction
Structural analysis is one of the most important aspects of document processing. It incorporates both physical and logical layout analysis and also includes parsing or recognition of complex structured layouts including tables, receipts, and forms. While there has been a lot of research done in physical and logical layout analysis of documents, there is still ample room for contribution towards parsing of structured layouts, such as tables, within them. Tables provide an intuitive and natural way to present data in a format which could be readily interpreted by humans. Based on its significance and difficulty level, table structure analysis has attracted a large number of researchers to make contributions in this domain.
Table detection and recognition is an old problem with research starting from the late nineties. One of the initial work is by Kieninger et al. [1]. They used a bottom-up approach on words bounding boxes using a heuristics-based algorithm. Later on, many different hand-crafted features based methods were introduced including [2], [3], [4] and [5] which relied on custom-designed algorithms. Zanibbi et al. [6] present a comprehensive survey of table detection and structure recognition algorithms at that time. An approach to recognize tables in spreadsheets was presented by [7] which classified every cell into either a header, a title, or a data cell. Significant work was done by Shafait et al. [8] where they introduced different performance metrics for the table detection problem. These approaches are not data driven and they make strong assumptions about tabular structures.
Chen et al. [9] used support vector machines and dynamic programming for table detection in handwritten documents. Kasar et al. [10] also used SVMs on ruling lines to detect tables. Hao et al. [11] used loose rules for extracting table regions and classified the regions using CNNs. They also used textual information from PDFs to improve the model results. Rashid et al. [12] used positional information in every word to classify it as either a table or a non-table using dense neural networks.
After 2016, the research trod towards using deep learning models to solve the challenge. In 2017, many papers were presented which used object detection or segmentation models for table detection and parsing. Gilani et al. [13] employed distance transform encoded information in an image and applied Faster RCNN [14] on these images. Schreiber et al. [15] also used Faster RCNN for table detection and extraction of rows and columns. For parsing, they applied object detection algorithm on vertically stretched document images. Leveraging the tables’ property to empirically contain more numeric data than textual data, Arif et al. [16] proposed to color code the document image to distinguish the numeric text and applied faster RCNN to extract table regions. Similarly, Siddique et al. [17] presented an end-to-end Faster-RCNN pipeline for table detection task and used Deformable Convolutional Neural Network [18] as feature extractor for its capability to mold its receptive field based on the input. He et al. [19] segmented the document image into three classes: text, tables, and figures. They proposed to use Conditional Random Field (CRF) to improve results from Fully Convolutional Network (FCN) conditioned on the output from the contour edge detection network. Kavasidis et al. [20] employed CRFs on saliency maps extracted by Fully Convolutional Neural Network to detect tables, and different type of charts.
Even though many researchers have shown that using object detection based approaches work well for table detection and recognition, defining the parsing problem in the form of object-detection problem is hard, especially if the documents are camera captured and contain perspective distortions. Approaches like [15] partially solve the issue but it is still not a natural approach. It also makes it harder to use further features which could be extracted independently, for instance, the language features which could possibly hint towards the existence of a table.
In this paper, we define the problem using graph theory and apply graph neural networks to it. One of the initial research in graph neural networks is done by Scarselli et al. [21] where they formulated a comprehensive graph model based on contraction maps. In recent years, they have gained a lot of traction due to the increase in compute power and with the introduction of newer methods. Many notable works include [22], [23], [24]. Battaglia et al. [25] argued that relational inductive biases are the key to achieving human like-intelligence and showed how graph neural networks are essential for it.
The use of graphs in document processing is not new. There have been many papers published which employ graph-based models for a wide range of problems. Liang et al. [26] introduced a hierarchical tree-like structure for document parsing. Work presented by Wang [27] gained a lot of popularity and was used by many researchers afterward. Hu et al. [28] introduced a comprehensive graph model involving a Directed Acyclic Graph (DAG) with detailed definitions of various elements of a table. Recently, Koci et al. [29] presented an approach where they encoded information in the form of a graph. Afterward, they used a newly-proposed rule-based remove-and-conquer algorithm. Bunke et al. [30] provides a detailed analysis of different graph-based techniques employed in the context of document analysis. These methods make strong assumptions about the underlying structure which contradicts with the philosophy of deep learning. Even though we are not the first ones to use graphs for document processing, to the best of our knowledge, we are the first ones to apply graph neural networks to our problem. We have done our experiments on the table recognition problem, however, this new problem definition applies to various other problems in document structural analysis. There are two advantages to our approach. For one, it is more generic since it doesn’t make any strong assumptions about the structure and it is close to how humans interpret tables, i.e. by matching data cells to their headers. Secondly, it allows us to exploit graph neural networks towards which there has been a lot of push lately.
In particular, we make the following contributions:
Formulate table recognition problem as a graph problem which is compatible with graph neural networks 2. 2.
Design a novel differentiable architecture which reaps the benefits of both convolutional neural networks for image feature extraction and graph neural networks for efficient interaction between the vertices 3. 3.
Introduce a novel Monte Carlo based technique to reduce memory requirements of training 4. 4.
Fill the gap of large scale dataset by introducing a synthetic dataset 5. 5.
Run tests on two state-of-the-art graph based methods and emperically show that they perform better than a baseline network
II Dataset
There are a few datasets for table detection and structure recognition published by the research community, including UW3, UNLV [31] and ICDAR 2013 table competition dataset [32]. However, the size of all of these datasets is limited. It risks overfitting in deep neural networks and hence, poor generalization. Many people have tried techniques such as transfer learning but these techniques cannot completely offset the utility of a large scale dataset.
We present a large synthetically generated dataset of 0.5 Million tables divided into four categories, which are visualized in Figure 1. To generate the dataset, we have employed Firefox and Selenium to render synthetically generated HTML. We note that synthetic dataset generation is not new and similar work [2] has been done before. Even though it will be hard to generalize algorithms from our dataset to the real world, the dataset provides a standard benchmark for studying different algorithms until a large scale real-world dataset is created. We have also published our code to generate further data, if required.
III The graph model
Considering the problem of table recognition, the ground truth is defined as three graphs wherein every word is a vertex. There are three adjacency matrices representing each of the graphs, namely cell-, row-, and column-sharing matrices. So if two vertices share a row i.e. both words belong to the same row, these vertices are taken to be adjacent to each other (likewise for cell and column sharing).
The prediction of a deep model is also done in the form of the three adjacency matrices. After getting adjacency matrices, complete cells, rows and columns can be reconstructed by solving the problem of maximal cliques [33] for rows and columns and connected components for cells. It is pictorially shown in Figure 3.
This model is valid not only for table recognition problem but can also be used for document segmentation. In that scenario, if two vertices (could be words again) share the same zone, they are adjacent. The resultant zones can also be reconstructed using the maximal clique problem.
IV Methodology
All of the tested models follow the same parent pattern, shown in Figure 2, divided into three parts: the convolutional neural network for extraction of image features, the interaction network for communication between the vertices, and the classification part to label every paired vertices as being adjacent or not adjacent (class 0 or class 1) in each of the three graphs.
The algorithm for the forward pass is also given in Algorithm 1. It takes the image ( — where , and represent height, width and number of channels in the input image respectively), positional features ( — where represents number of vertices), and other features . In addition to this, it also takes the number of samples per vertex() and three adjacency matrices (, and ) as the input during the training process. All the parametric functions are denoted by and non-parametric functions by . If all the parametric functions are differentiable, the complete architecture will be differentiable as well and hence, compatible with backpropagation.
The positional features include the coordinates of the upper left and the bottom right corner of each vertex. Other features consist only of the length of the word in our case. However, in a real-world dataset, natural language features [34] could also be appended which may provide additional information.
IV-1 Convolutional neural network
A convolutional neural network () takes an image () as its input and as the output, it generates the respective convolutional features ( — , and being the width, height and number of channels of the convolutional feature map respectively). To keep parameter count low, we have designed a shallow CNN; however, any standard architecture can be used in its place. At the output of CNN, a gather operation () is performed to collect convolutional features for each word corresponding to its spatial position in the image and form gathered features(). Since convolutional neural networks are translation equivariant, this operation works well. If the spatial dimensions of the output features are not the same as the input image (for instance, in our case, they were scaled down), the collect positions are linearly scaled down depending on the ratio between the input and output dimensions. The convolutional features are extended to the rest of the vertex features ().
IV-2 Interaction
After gathering all the vertex features, they are passed as input to the interaction model (). We have tested two graph neural networks to use as the interaction part which are the modified versions of [35] and [36] respectively. These modified networks are referred to as DGCNN* and GravNet* hereafter. In addition to these two, we have also tested with a baseline dense net (dubbed FCNN for Fully Connected Neural Network) with approximately the same number of parameters to show that the graph-based models perform better. For these three models, we have limited the total parameter count to for a fair comparison. This parameter count also includes parameters of preceding CNN and the succeeding classification dense network. As the output, we get representative features ( — being the number of representative features) of each of the vertex which are used for classification.
IV-3 Runtime pair sampling
Classifying every word pair is a memory intensive operation with memory complexity of . Since it would then scale linearly with the batch size, the memory requirements increase even further. To cater to this, we employed a Monte Carlo based sampling. The index sampling function is denoted by . this function would generate a fixed number of samples () for each of the vertex for each of the three problems (cell sharing, row sharing and column sharing).
Uniform sampling is highly biased towards class 0. Since we can’t use a large batch size due to the memory constraints, the statistics are not sufficient to differentiate between the two classes. To deal with this issue, we changed the sampling distribution () to sample, on average, an equal number of elements of class 0 and class 1 for each of the vertex. It can be easily done in a vectorized fashion as shown in Algorithm 1. Note that in the algorithm denotes an all-one matrix. Different sets of samples are collected for each of the three classes for each of the vertex (, , ). The values in these matrices represent the index of the paired samples for each of the vertex. For inference, however, we do not need to sample since we don’t need to use the mini-batch approach. Hence, we simply do it for every vertex pair. So, during training, and during inference, .
IV-4 Classification
After sampling, the elements from the output feature vector () of the interaction model and the elements from the sampling matrices are concatenated () with each other in (, , and ). These functions are parametric neural networks. As the output, we get three sets of logits , and . They can be used either to compute the loss and backpropagate through the function, or to predict the classes and form the resultant adjacency matrices.
V Results
Shahab et al [37] defined a set of metrics for detailed evaluation of the results of table parsing and detection. They defined criteria for correct and partial detection and defined a heuristic for labeling elements as under-segmented, over-segmented and missed. Among their criterion, two are the most relevant to our case, i.e. the percentage of the ground truth elements that are detected correctly (true positive rate) and the number of the predicted elements which do not have a match in the ground truth (false positive rate). In our case, as argued in Section III, the elements are cliques. So true positive rate and false positive rate is computed on all three graphs (cells, rows and columns) individually. This rate is averaged over the whole test set. These results are shown in Table I and Table II.
In addition to this, we also introduce another measure, i.e. perfect matching as shown in Table III. If all of the three predicted adjacency matrices are perfectly matched with the corresponding matrices in the ground truth, the parsed table is labeled as being end-to-end accurate. This is a strict metric but it shows how misleading can the statistics computed on the basis of individual table elements be due to the large class imbalance problem.
As expected, since there is no interaction between vertices in the FCNN, it performs worse than the graph models. Note however, that the vertices in this network are not completely segregated. They can still communicate in the convolutional neural network part. This builds the case to introduce graph neural networks further into document analysis.
Category 3 tables show relatively poor results as compared to category 4 tables. This is because category 4 images also contain those from category 1 and 2 to study the effect of perspective distortion on simpler images. We conclude that while the graph networks struggle with merged row and columns, they gracefully handle the perspective distortions.
VI Conclusion and future work
In this work, we redefined the structural analysis problem using the graph model. We demonstrated our results on the problem of table recognition and we also argued how several other document analysis problems can be defined using this model. Convolutional neural networks are the most suited at finding representative image features and graph networks are the most suited at fast message passing between vertices. We have shown how we can combine these two abilities using the gather operation. So far, we only used positional features for the vertices, but for a real-world dataset, natural language processing features like GloVe can also be used. In conclusion, graph neural networks work well for structural analysis problems and we expect to see more research in this direction in the near future.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] T. Kieninger and A. Dengel, “The t-recs table recognition and analysis system,” vol. 1655, 11 1998, pp. 255–269.
- 2[2] Y. Wangt, I. Phillipst, and R. Haralick, “Automatic table ground truth generation and a background-analysis-based table structure extraction method,” in Proceedings of Sixth International Conference on Document Analysis and Recognition . IEEE, 2001, pp. 528–532.
- 3[3] J. Hu, R. S. Kashi, D. P. Lopresti, and G. Wilfong, “Medium-independent table detection,” in Document Recognition and Retrieval VII , vol. 3967. International Society for Optics and Photonics, 1999, pp. 291–303.
- 4[4] B. Gatos, D. Danatsas, I. Pratikakis, and S. J. Perantonis, “Automatic table detection in document images,” in International Conference on Pattern Recognition and Image Analysis . Springer, 2005, pp. 609–618.
- 5[5] S. Tupaj, Z. Shi, C. H. Chang, and H. Alam, “Extracting tabular information from text files,” EECS Department, Tufts University, Medford, USA , 1996.
- 6[6] R. Zanibbi, D. Blostein, and J. R. Cordy, “A survey of table recognition,” Document Analysis and Recognition , vol. 7, no. 1, pp. 1–16, 2004.
- 7[7] I. A. Doush and E. Pontelli, “Detecting and recognizing tables in spreadsheets,” in Proceedings of the 9th IAPR International Workshop on Document Analysis Systems . ACM, 2010, pp. 471–478.
- 8[8] F. Shafait and R. Smith, “Table detection in heterogeneous documents,” in Proceedings of the 9th IAPR International Workshop on Document Analysis Systems . ACM, 2010, pp. 65–72.
