Multi-Precision Quantized Neural Networks via Encoding Decomposition of -1 and +1
Qigong Sun, Fanhua Shang, Kang Yang, Xiufang Li, Yan Ren, and Licheng Jiao

TL;DR
This paper introduces a novel encoding scheme for quantized neural networks using {-1,+1} to create multi-branch binary networks, enabling efficient implementation on hardware like FPGA and ASIC, with minimal performance loss.
Contribution
The paper proposes a new encoding decomposition method for QNNs into multi-branch binary networks, facilitating flexible precision and hardware-efficient deployment.
Findings
Achieves model compression and acceleration via bitwise operations.
Maintains near full-precision accuracy on ImageNet and object detection tasks.
Supports arbitrary precision encoding tailored to hardware constraints.
Abstract
The training of deep neural networks (DNNs) requires intensive resources both for computation and for storage performance. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which seriously limits their applicability in industry applications. To address this issue, we propose a novel encoding scheme of using {-1,+1} to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. Based on our method, users can easily achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is very suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate…
Click any figure to enlarge with its caption.
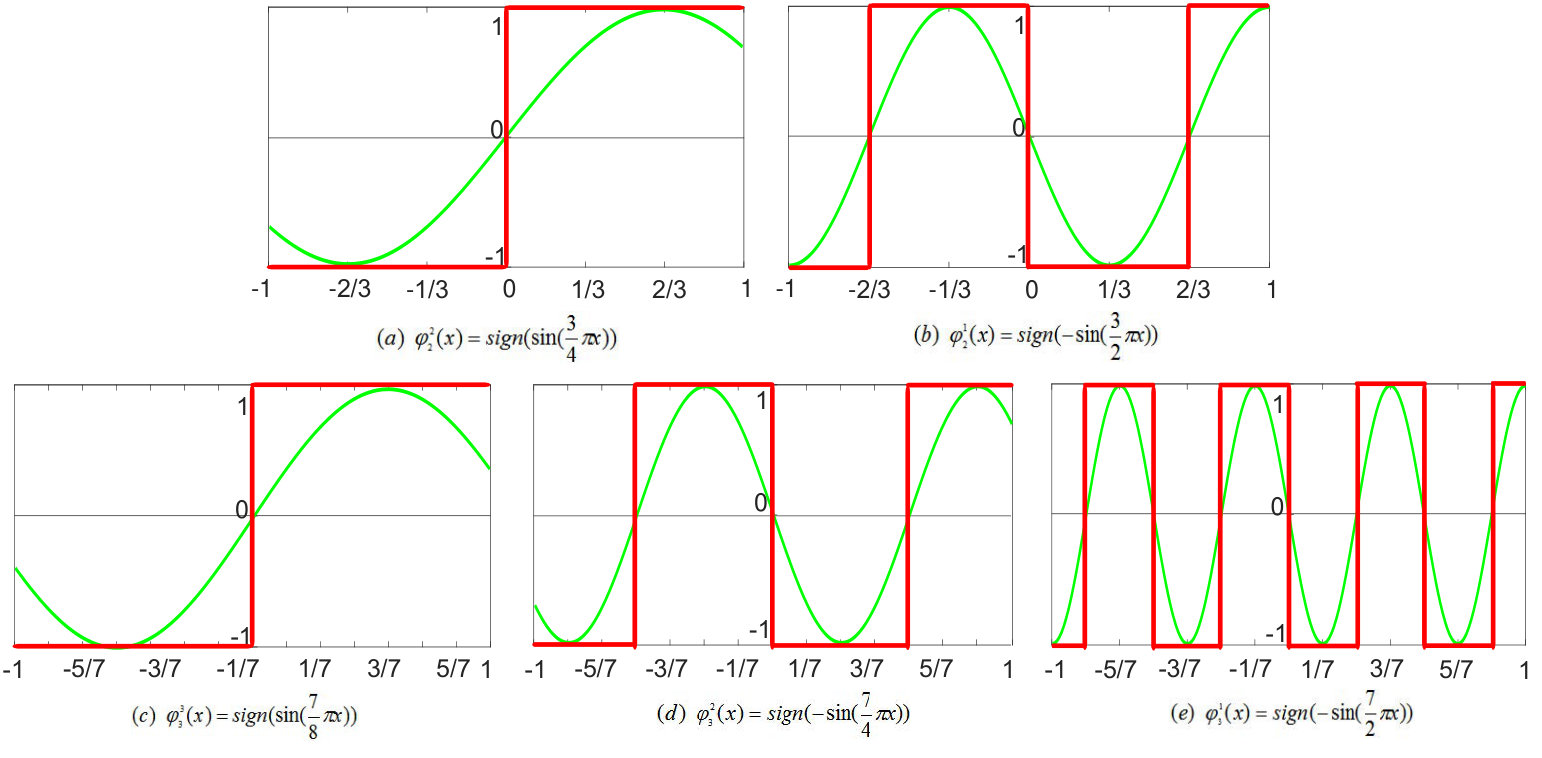 Figure 1
Figure 1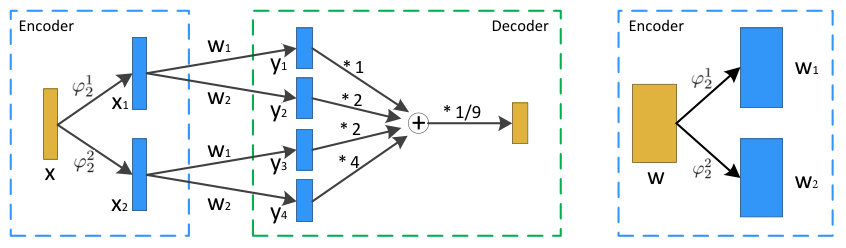 Figure 2
Figure 2| | |
|---|---|
| |
| Quantized numbers | -1 | -1/3 | 1/3 | 1 |
|---|---|---|---|---|
| Encoded states | {-1,-1} | {-1,1} | {1,-1} | {1,1} |
| Method | CIFAR-10 | ImageNet(Top-1) | ImageNet(Top-5) |
| BWN (?) | 90.10% | 60.80% | 83.00% |
| BNN (?) | 88.60% | 42.20% | 67.10% |
| XNOR-Net (?) | - | 51.20% | 73.20% |
| TWN (?) | 92.56% | 61.80% | 84.20% |
| ABC-Net[5-bit] (?) | - | 65.00% | 85.90% |
| Full-Precision | 91.40% | 68.60% | 88.70% |
| Encoded activations and weights | |||
| MBN[M=K=1] | 90.39% | 47.10% | 71.70% |
| MBN[M=K=2] | 91.06% | 56.30% | 79.48% |
| MBN[M=K=3] | 91.27% | 58.69% | 81.84% |
| MBN[M=K=4] | 91.15% | 59.57% | 82.35% |
| MBN[M=K=5] | 90.92% | 65.09% | 86.42% |
| MBN[M=K=6] | 91.01% | 67.04% | 87.69% |
| MBN[M=K=7] | 90.20% | 68.37% | 88.47% |
| MBN[M=K=8] | 90.43% | 68.63% | 88.70% |
| Method | Full-Precision | MBN[M=K=8] | MBN[M=K=6] | MBN[M=K=5] |
| mAP | 0.6392 | 0.6351 | 0.6131 | 0.5423 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Advanced Image and Video Retrieval Techniques · Image Processing Techniques and Applications
Multi-Precision Quantized Neural Networks via Encoding
Decomposition of
Qigong Sun, Fanhua Shang, Kang Yang, Xiufang Li, Yan Ren, Licheng Jiao
Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education,
International Research Center for Intelligent Perception and Computation,
Joint International Research Laboratory of Intelligent Perception and Computation,
School of Artificial Intelligence, Xidian University, Xi’an, Shaanxi Province, 710071, China
Abstract
The training of deep neural networks (DNNs) requires intensive resources both for computation and for storage performance. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which seriously limits their applicability in industry applications. To address this issue, we propose a novel encoding scheme of using to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. Based on our method, users can easily achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is very suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on both large-scale image classification tasks (e.g., ImageNet) and object detection tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its full-precision counterparts.
Introduction
Deep Neural Networks (DNNs) have been successfully applied in many fields, especially in image classification, object detection and natural language processing. Because of numerous parameters and complex model architectures, huge storage space and considerable power consumption are needed. Furthermore, with the rapid development of chip technology, especially GPU and TPU, the computing power has been greatly improved. In the rapid developing era of deep learning, researchers use multiple GPUs or computer clusters to contribute to the exploration of complex problems. Nevertheless, the energy consumption and limitation of computing resources are still significant factors in industrial applications, which are generally ignored in scientific research. In other words, breathtaking results of many DNNs algorithms under the condition of applying GPUs lag behind the demand of industry. DNNs can hardly be applied in mobile phones and embedded devices (as typical industrial applications) directly due to their limited memory and calculation resources. Therefore, the compression and acceleration of networks are especially important in future development and commercial applications.
In recent years, many solutions have been proposed to improve the energy efficiency of hardware, achieve model compression or computational acceleration, such as network sparse and pruning (?; ?; ?), low-rank approximation (?; ?; ?), architecture design (?; ?; ?), model quantization (?; ?; ?), and so on. Network sparse and pruning can dramatically reduce the redundant connections, and thus reduce the computational load in the inference process without large accuracy drop. ? (?) used low-rank tensor decomposition to remove the redundancy in the kernels which can be as a generic tool for speeding up. Since there is some redundant information in the networks, the most direct approach of cutting down those information is to optimize the structure and yield small networks (?; ?). For example, ? (?) proposed to use bitwise separable convolutions to build light networks for mobile applications. Most of those networks still utilize floating-point number representations (i.e., full-precision values). However, ? (?) discussed that the representation of the full-precision weights and activations in networks is not necessary during the training of DNNs, and a nearly identical or slightly better accuracy rate may be obtained under lower-precision representation and calculation.
Since non-differentiable discrete functions are applied in QNNs generally, there obviously exists the gradient mismatch problem in training process. Therefore, the backpropagation algorithm cannot be directly used to train QNNs. Many scholars (?; ?; ?; ?) are devoted themselves to improving the performance (e.g., accuracy and compression ratio) of QNNs, but few researchers have studied their acceleration, which is an important reason for hindering industrial promotion. To the best of our knowledge, the accelerated method used in binarized neural networks (BNNs) (?) is the most efficient strategy at present. This strategy uses bitwise operations (xnor and bitcount) to replace full-precision matrix multiplication, and results 58 faster and 32 memory saving in CPU (?). As discussed in (?), it has a higher acceleration ratio on FPGA, which can speed up to about 705 in the peak condition compared with CPU and is 70 faster than GPU. In particular, they quantized activation values and weights to bits and used bitwise logic operations to achieve extreme acceleration ratio in inference process, but they could suffer significant performance degradation. However, most models were proposed for a fixed precision, and cannot extend to other precision models. They may easily fall into local optimal solutions and suffer from slow convergence speed in training process.
The representation capability of binary parameters is insufficient for many practical applications, especially for large-scale image classification (e.g., ImageNet) and regression tasks. In order to address various complex problems and take full advantage of bitwise operations, ? (?) used the linear combination of multiple binary parameters {-1, +1} to approximate full-precision weights and activations. Therefore, the complex full-precision matrix multiplication can be decomposed into some simpler operations. This is the first time to use binary networks for image classification on ImageNet. ? (?) and ? (?) used the same technique to accelerate the training of CNNs and RNNs. In addition, those methods not only increase the number of parameters many times, but also introduce a scale factor to transform the original problem into an NP-hard problem, which naturally makes the solution difficult and high complexity.
In order to bridge the gap between low-bit and full-precision and apply to many cases, we propose a novel encoding scheme of using to easily decompose trained QNNs into multi-branch binary networks. Therefore, the inference process can be efficiently implemented by bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. Thus, our encoding mechanism can improve the utilization of hardware resources, and achieve parameter compression and computation acceleration. In our experiments, we not only validate the performance of our method for image classification on CIFAR-10 and large-scale datasets, e.g., ImageNet, but also implement object detection tasks. The advantages of our method are shown as follows:
- •
We can directly use the high-bit model parameters to initialize a low-bit model for faster training. Hence, our networks can be trained in a short time, and only dozens of times fine-tuning are needed to achieve the accuracies in our experiments. Of course, we can get better performance if we continue training the network. Thus, our multi-precision quantized networks can be easily popularized and applied to engineering practices.
- •
We propose a range of functions (called MBitEncoder) to decompose activations (for example, we can use functions to get the state of encoded bits), which are used for inference computation. Therefore, those decomposed bits can be directly used in network computation without other judgments and mapping calculations.
- •
After the process of decomposition, instead of storing all encoding bits in data types, e.g., char, int, float or double, the parameters can be individually stored by bit vectors. Thus, the smallest unit of data in electronic equipments can be reduced to 1-bit from 8-bit, 16-bit, 32-bit or 64-bit, which raised the utilization rate of resources and compression ratio of the model. Then the data can be encoded, calculated and stored in various encoding precisions.
Related Work
QNNs can effectively implement model compression, even to 32 memory saving. Many researchers are focusing on the following three classes of methods: quantification methods, the methods of optimization in training process and acceleration computation in inference process.
Quantification methods play a significant role in QNNs, and determine the state and distribution of weights and activation values. ? (?) used the notation of integer and fractional to denote a 16-bit fixed-point representation, and proposed a stochastic rounding method to quantify values. ? (?) used 8-bit quantization to convert weights into signed char and activation values into unsigned char, and all the values are integer. For multi-state quantification (8-bit to 2-bit), linear quantization is usually used in (?; ?; ?). Besides, ? (?) proposed logarithmic quantization to represent data and used bitshift operation in log-domain to compute dot products. For ternary weight networks (?), the weights are quantized to , where . In (?), the positive and negative states are trained together with other parameters. When the states are constrained to 1-bit, ? (?) applied the sign function to binarize weights and activation values {-1, +1}. In (?), the authors also used to represent the binary states, where .
It is obvious that discrete functions, which are non-differentiable or have zero derivatives everywhere, need to quantize weights or activation values. The traditional gradient descent method is unsuitable for the training of deep networks. Recently, there are many researchers devoting themselves to addressing this issue. ? (?) divided optimization methods into two categories: quantizing pre-trained models with or without retraining (?; ?; ?; ?) and directly training quantized networks (?; ?; ?; ?). (?; ?) used the straight-through estimator (STE) in (?) to train networks. STE uses the nonzero gradient to approximate the function gradient, which is not-differentiable or whose derivative is zero, and then applies the stochastic gradient descent (SGD) to update the parameters. ?; ? (?; ?) applied knowledge distillation techniques, which use high-precision teacher network to guide low-precision student network to improve network performance. In addition, some networks as in (?; ?) use the linear combination of binary values to approximate the full-precision weights and activation values. They not only increase the number of parameters many times, but also introduce the scale factor to transform the original problem into an NP-hard problem, which naturally makes the solution difficult and high complexity. ? (?) used the two valued search tree to optimize the scale factor and achieved better performance in the language model by using the quantized recurrent neural networks.
After quantizing, weights or activation values are represented in a low-bit form, which has the potential of acceleration computation and memory saving. Because the hardware implementation has a certain threshold, many scholars have avoided considering their engineering acceleration. This is also an important reason for hindering industrial promotion. The most direct quantization is to convert floating-point parameters into their fixed-point (e.g., 16-bit, 8-bit), which can achieve hardware acceleration for fixed-point based computation (?; ?). When the weight is extremely quantized to the binary weight {-1, +1} as in (?) or ternary weight {-1, 0, +1} as in (?), the matrix multiplication can be transformed into full-precision matrix addition and subtraction to accelerate computation. Especially when the weight and activation values are binarized, matrix multiplication operations can be transformed into highly efficient logical and bitcounting operations (?; ?). ?; ? (?; ?) used a series of linear combinations of {-1, +1} to approach the parameters of full-precision convolution model, and then converted floating point operations into multiple binary weight operations to achieve model compression and computation acceleration.
Multi-Precision Quantized Neural Networks
In this section, we use the multiplication of two vectors to introduce the novel encoding scheme of using to decompose QNNs into multi-branch binary networks. In each branch binary network, we use -1 and +1 as the basic elements to efficiently achieve model compression and forward inference acceleration for QNNs. Different from fixed-precision neural networks (e.g., binary, ternary), our method can yield multi-precision networks and make full use of the advantage of bitwise operations to accelerate QNNs.
Model Decomposition
As the basic computation in most neural network layers, matrix multiplication costs lots of resources and also is the most time consuming operation. Modern computers store and process data in binary format, thus non-negative integers can be directly encoded by {0, 1}. We propose a novel decomposition method to accelerate matrix multiplication as follows: Let and be two vectors of non-negative integers, where for . The dot product of those two vectors can be represented as follows:
[TABLE]
All of the above operations consist of multiplications and additions. Based on the above {0, 1} encoding scheme, the vector can be encoded to binary form using bits, i.e.,
[TABLE]
Then the right-hand side of (3) can be converted into the following form:
[TABLE]
where
[TABLE]
In such an encoding scheme, the number of represented states is not greater than . In addition, we encode another vector with -bit numbers in the same way. Therefore, the dot product of the two vectors can be computed as follows:
[TABLE]
From the above formulas, the dot product is decomposed into sub-operations, in which every element is 0 or 1. Because of the restriction of encoding and without using the sign bit, the above representation can only be used to encode non-negative integers. However, it s impossible to limit the weights and the values of the activation functions to non-negative integers.
In order to extend encoding space to negative integer and reduce the computational complexity, we propose a new encoding scheme, which uses {-1, +1} as the basic elements of our encoder rather than {0, 1}. Except for the difference of basic elements, the encoding scheme is similar to the rules shown in the formula (5), and is formulated as follows:
[TABLE]
where denotes the number of encode bit, that can represent states. At this time, we can use multiple bitwise operations (xnor and bitcount) to effectively achieve the above vector multiplications. This operation mechanism is suitable for all vector/matrix multiplications.
In neural networks, matrix multiplication is the basic computation in both the fully connected and convolution layers. Based on the above decomposition mechanism of vector multiplication, we propose the following model decomposition method for quantized networks. We first use 2-bit encoding for fully connected layer as an example to introduce the mechanism of our model decomposition, the details are shown in Figure 1. is the input data and is the weight matrix. Here, we suppose the bias does not exist. We define an ”Encoder” that can be used in the 2BitEncoder function ( and ), which will be described in the next section, to encode input data. For example, can be encoded by and , where represents high bit data and represents low bit data. These variables meet the following formula: . In the same way, the weight can be converted into and . After cross multiplications, we get four intermediate variables {}. Each multiplication can be considered as a binarized fully connected layer, whose elements are -1 or +1. This decomposition can result multi-branch layers, thus we call it as Multi-Branch Binary Networks (MBNs). For instance, we decompose the 2-bit fully connection operation into four branches binary operations, which can be accelerated by bitwise operations, and then sum over those four results by fixing scale factors to achieve the final output. This operation mechanism can be suitable for all vector/matrix multiplications. In addition to fully connected layers, convolution and deconvolution layers are also suit for neural networks.
M-bit Encoding Functions
As an important part in neural networks, activation functions can enhance the nonlinear characterization of networks. In our proposed model decomposition method, encoding function plays a critical role and can encode input data to multi-bits (-1 or +1). Those numbers represent the encoding of input data. For some other QNNs, several quantization functions have been given. However, it is not clear that what’s the affine mapping between quantized numbers and encode bits. In this part, a list of -bit encoding functions are proposed to produce the element of each bit that follows the rules for encoding data.
Before encoding, the data should be limited to a fixed numerical range. Table 1 lists four activation functions. brings the range of input data to [-1, +1], and it consists with sign function to achieve binary encoding of weights and activations (?; ?). Since the convergence of SGD obtained by using is faster than other activation functions, we propose a new activation function that retains the linear characteristics in the specific range and limits the range of input data to [0, 1]. Different from general activation functions mentioned above, the output of our -bit encoding function defined below should be numbers, which is -1 or +1. Those numbers represent the encoding of input data. Therefore, the dot product can be computed by the formula (9). In addition, at the above described experimental condition, when we use 2-bit to encode the data x and constrain to [-1, 1], there are 4 encoded states, as shown in Table 2. The affine mapping between quantized real numbers and their encoded states is given in the following table.
From the above results, we can see that there is a linear factor between quantized real numbers and encoded states (e.g., =3 for Table 2). When we use formula (9) to compute the multiplication of two encoded vectors, the value will be expanded times. Therefore, the result can multiply its scale factor to get the final result, shown as in Figure 1. Figure 2 shows the illustration of 2-bit and 3-bit encoding functions, we can see that those encoding functions are required periodic, and each function has different periods. Naturally, we apply trigonometric functions as the basic encoder functions, which are signed as red lines. After all, we use sign function to hard divide to -1 or +1. The mathematical expression can be formulated as follows:
[TABLE]
where denotes the encoding function of the first bit () of 2BitEncoder, and represents the encoder function of the second bit () of 2BitEncoder. The periodicity is obviously different from others because it needs to denote more states.
Networks Training
QNNs face the problem that the derivative is not defined, thus traditional gradient optimization methods are not applicable. ? (?) presented the HTanh function to binary quantize both weights and activations, and also defined the derivative to support back-propagation (BP) training process. They used the loss computed by binarized parameters to update full precision parameters. Similarly, ? (?) also proposed to update the weights with the help of the second parameters. ? (?) discussed that using STE to train network models containing discrete variables can obtain faster training speed and better performance.
Multi-Branch Binary Networks Training
Generated by the decomposition of QNNs, MBNs need to use -bit encoding functions to get the elements of each bit, which can be used by more efficient bitwise operations to replace arithmetic operations. We take the 2-bit encoding as an example to describe the optimization method of MBNs. The sign function of the encoder makes it difficult to implement the BP process. Thus, we approximate the derivation of the encoder function with respect to as follows:
[TABLE]
[TABLE]
Besides activations, all weights of networks also need to be quantized to binary values. We retain the real-valued weight and binarized weight in the training process, and apply to compute loss and gradient, which is used to update . is constrained between -1 to +1 to avoid excessive growth. Different from weights, the binary function for is not needed for the encoding function and directly defined as follows:
[TABLE]
For this function, we have defined the gradient function of each component to constrain the search space. That is, the input of sign function can be constrained to [-1,+1] by , and it can also speed up the convergence. The parameters of the whole network are updated by Adam (?) in the condition for differentiability.
Quantized Networks Training
The above training scheme is proposed to optimize binary networks, which can be converted into multi-state networks. However, this converter can produce many times more parameters than the original network. If we optimize the binarized network, it may easily fall into local optimal solutions and face slow convergence speed. Based on the affine mapping between quantized numbers and fixed-point integers, we can directly optimize the quantized network and then use multi-branch binary operations in inference process. There are two quantization schemes usually applied in QNNs (?; ?; ?), named linear quantization and logarithmic quantization. Due to the requirement of our encoding mechanism, linear quantization is used to quantize networks, and is defined as follows:
[TABLE]
where denotes the rounding operation, which can quantize a real number to a certainty state. We call it a hard ladder function, which can segment input codomain to multi-states. Table 2 lists the four states that quantized by formula (15). However, the derivative of this function is almost zero everywhere, it cannot be used in training process. Inspired by STE, we use the same technique to speed up computing process and yield better performance. We use the loss computed by quantized parameters to update full precision parameters. Note that for our encoding scheme with low-precision quantization (e.g., binary), we use Adam to train our model, otherwise stochastic gradient descent is used.
Experiments
Many scholars are devoted to improving the performance (e.g., accuracy and compression ratio) of QNNs, while very few researchers have studied their engineering acceleration, which is an important reason for hindering industrial promotion. Therefore, we mainly focus on an acceleration method, which is especially suitable for engineering applications. In this section, we compare the performance of our method with BWN (?), BNN (?), XNOR-Net (?), TWN (?), and ABC-Net (?) for image classification tasks on CIFAR-10 and ImageNet, and object detection tasks on Pascal VOC2007/2012 datasets.
Image Classification
CIFAR-10: CIFAR-10 is an image classification benchmark dataset, which has 50000 training images and 10000 testing images. All the images are 32 32 color images representing airplanes, automobiles, birds, cats, deer, dogs, frogs, horses, ships and trucks.
We validated our method by different bit encoding schemes, in which activations and weights are equally treated, that is, both of them use the same bit-encoding. Table 3 lists the results of our method and several state-of-the-art models mentioned above. Here we use the same network architecture as in (?; ?) except for the encoding functions. We use as the activation function and employ Adam to optimize all parameters of the network. From all the results, we can see that the representation capabilities of 1-bit and 2-bit are completely enough for small-scale datasets, e.g., CIFAR-10. Our method with low-precision encoding achieves nearly the same classification accuracy as high precision and full-precision models, while we can attain memory saving compared with its full-precision counterpart. When activations and weights are constrained to 1-bit, our network structure is similar to BNN (?), and our method yields even better accuracy mainly because of our proposed encoding functions.
ImageNet: We further examined the performance of our method with different bit encoders on the ImageNet ILSVRC-2012 dataset (?). This dataset consists of 1K categories images, and has over 1.2M images in the training set and 50K images in the validation set. We use Top-1 and Top-5 accuracies to report the classification performance. For large-scale training sets (e.g., ImageNet), it usually costs plenty of time and requires sufficient computing resources for classical full-precision models. It will be more hard to train quantized networks, thus the initialization of parameter values is particularly important. In this paper, we present as the activation function to constraint activations. In particular, the full-precision model parameters activated by can be directly used as initialization parameters for our 8-bit quantized network. After a little number of fine-tuning, 8-bit quantized networks can be well-trained. Similarly, we use the 8-bit model parameters as the initialization parameters to train 7-bit quantized networks, and so on. There has a special case, if we use and 1BitEncoder function to encode activations, all the activations will be constrained to +1. Here, we use as the activation function for 1-bit encoding. Note that we use SGD to optimize parameters when encoding bit is not less than 3, and the learning rate is set to 0.1. When the encode bit is 1 or 2, the convergent speed of Adam is faster than SGD, as discussed in (?; ?).
Table 3 lists the performance (e.g., accuracy, speedup ratio, memory saving ratio) of our method and several typical models mentioned above. Those results show that our method with 1-bit encoding performs much better than BNN (?). Similarly, our method with 5-bit encoding significantly outperforms ABC-Net[5-bit] (?). Moreover, our networks can be trained in such a short time, and to achieve the accuracies in our experiments only needs dozens of times fine-tuning. Of course, if we continue training the network, we can get better performance. Different from BWN and TWN, whose weights are only quantized rather than activation values, our method quantifies both weights and activation values simultaneously. Although BWN and TWN can obtain little higher accuracies than our method with 1-bit quantization model, our method obtains more speedup, and the speedup ratio of existing methods such as BWN and TWN is limited to . Due to limited and fixed expression ability, existing methods (such as BWN, TWN, BNN, XNOR-Net) can not satisfy higher precision requirements. In particular, our method can provide 64 available encoding choices, and hence our encoded networks with different encoding precisions have different speedup ratios, memory requirements and experimental precisions.
Object Detection
We also use the trained ResNet-18 with the Single Shot MultiBox Detector (SSD) framework (?) to validate object detection, in which the coordinate regression task coexists with classification tasks. The normally regression task has higher requirement on value precision, therefore the application of object detection presents a new challenge for QNNs.
In this experiment, our model is trained on the VOC2007 and VOC2012 train/val set, and tested on the VOC2007 test set. ResNet-18 with the SSD framework (?) is used as the basic network. Here we use the trained model parameters in ImageNet classification to initialize SSD network parameters, after dozens of times fine-tuning the results are listed in Table 4. We use Mean Average Precision (mAP) as the criterion to evaluate the performance of our model. It is clear that our method with 8-bit encoding scheme can yield very similar performance as its full-precision counterpart. When we use 6-bit to encode parameters, the evaluation index dropped by 0.0261. If the number of encode bits is constrained to 5, the performance of this task has visibly deteriorated, while our method can achieve memory saving.
As the attempt in object detection tasks, our method yields good performance on the SSD framework. Similarly, it can be applied to other frameworks, e.g., R-CNN (?), Fast R-CNN (?), SPP-Net (?) and YOLO (?).
Discussion and Conclusion
{0, 1} Encoding and {-1, +1} Encoding
As described in (?), there exists an affine mapping between quantized numbers and fixed-point integers. The quantized numbers are usually restricted to the closed interval [-1, +1]. For example, the mapping is formulated as follows:
[TABLE]
where denotes a quantized number and denotes the fixed-point integer encoded by 0 and 1. We use a -bit fixed-point integer to represent a quantized number . The product can be formulated as follows:
[TABLE]
The right-hand side of ({0, 1} Encoding and {-1, +1} Encoding) is a polynomial, which has four terms. And each term has its own scaling factor. The computation of can be accelerated by bitwise operations, however, the polynomial and scaling factor will increase the computational complexity.
For our proposed quantized binary encoding scheme (i.e., ), the product of two numbers is defined as
[TABLE]
where and denote the fixed-point integers encoded by -1 and 1. Obviously, compared with the above encoding of , the product can be more efficiently calculated by using our proposed encoding scheme.
Linear Approximation and Quantization
As described in (?; ?; ?), the weight can be approximated by the linear combination of binary subitems {} and , which can replace arithmetic operations with more efficient bitwise operations. In order to obtain the combination, we need to solve the following problem
[TABLE]
When this approximation is used in neural networks, can be considered as model weights. However, the scale factor is introduced in this approximation, and such a scheme also expands the parameters times. Therefore, this approximation can convert the original model to a complicated binary network, which is hard to train (?) and easily falls into local optimal solutions.
For our method, we use the quantized parameters to approximate as follows:
[TABLE]
where is a positive or negative odd number, and its absolute value is not larger than . Different from the above linear approximation, our method can achieve the quantized weights, and directly get the corresponding encoding elements. Thus, our networks can be more efficiently trained via our quantization scheme than the linear approximation.
Conclusions
In this paper, we proposed a novel encoding scheme of using {-1, +1} to decompose QNNs into multi-branch binary networks, in which we used bitwise operations (xnor and bitcount) to achieve model compression, computational acceleration and resource saving. In particular, we can use the high-bit model parameters to initialize a low-bit model and achieve good results in various applications. Thus, users can easily achieve different encoding precisions arbitrarily according to their requirements (e.g., accuracy and speed) and hardware resources (e.g., memory). This special data storage and calculation mechanism can yield great performance in FPGA and ASIC, and thus our mechanism is a feasible idea for smart chips. Future works will focus on improving the hardware implementation and chip technology, and exploring some ways to automatically select proper bits for various network architectures (e.g., VGG and ResNet).
Acknowledgments
This work was partially supported by the State Key Program of National Natural Science of China (No. 61836009), Project supported the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (No. 61621005), the National Natural Science Foundation of China (Nos. U1701267, 61871310, 61573267, 61502369, 61876220, 61876221, 61473215, and 61571342), the Fund for Foreign Scholars in University Research and Teaching Programs (the 111 Project) (No. B07048), the Major Research Plan of the National Natural Science Foundation of China (Nos. 91438201 and 91438103), the Program for Cheung Kong Scholars and Innovative Research Team in University (No. IRT_15R53), and the Science Foundation of Xidian University (No. 10251180018). Fanhua Shang is the corresponding author.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Bengio, Léonard, and Courville 2013] Bengio, Y.; Léonard, N.; and Courville, A. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. ar Xiv preprint ar Xiv:1308.3432 .
- 2[Courbariaux, Bengio, and David 2015] Courbariaux, M.; Bengio, Y.; and David, J.-P. 2015. Binaryconnect: Training deep neural networks with binary weights during propagations. In NIPS , 3123–3131.
- 3[Denton et al . 2014] Denton, E. L.; Zaremba, W.; Bruna, J.; Le Cun, Y.; and Fergus, R. 2014. Exploiting linear structure within convolutional networks for efficient evaluation. In NIPS , 1269–1277.
- 4[Girshick et al . 2014] Girshick, R.; Donahue, J.; Darrell, T.; and Malik, J. 2014. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR , 580–587.
- 5[Guo et al . 2017] Guo, Y.; Yao, A.; Zhao, H.; and Chen, Y. 2017. Network sketching: Exploiting binary structure in deep CN Ns. In CVPR , 4040–4048.
- 6[Gupta et al . 2015] Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; and Narayanan, P. 2015. Deep learning with limited numerical precision. In ICML , 1737–1746.
- 7[Han et al . 2015] Han, S.; Pool, J.; Tran, J.; and Dally, W. J. 2015. Learning both weights and connections for efficient neural networks. In NIPS , 1135–1143.
- 8[Hassibi and Stork 1993] Hassibi, B., and Stork, D. G. 1993. Second order derivatives for network pruning: Optimal brain surgeon. In NIPS , 164–171.