Efficient Multiway Hash Join on Reconfigurable Hardware
Kunle Olukotun, Raghu Prabhakar, Rekha Singhal, Jeffrey D.Ullman, and, Yaqi Zhang

TL;DR
This paper introduces algorithms for multiway hash joins on a new reconfigurable hardware accelerator called Plasticine, achieving significant speedups over CPUs and improving multiway join efficiency.
Contribution
It presents novel algorithms for multiway joins on Plasticine hardware, demonstrating substantial performance improvements over traditional CPU implementations.
Findings
200X speedup over CPU for binary hash joins
3-way joins more efficient than cascaded binary joins by up to 45X on Plasticine
Plasticine's high compute and communication bandwidth enable these gains
Abstract
We propose the algorithms for performing multiway joins using a new type of coarse grain reconfigurable hardware accelerator~-- ``Plasticine''~-- that, compared with other accelerators, emphasizes high compute capability and high on-chip communication bandwidth. Joining three or more relations in a single step, i.e. multiway join, is efficient when the join of any two relations yields too large an intermediate relation. We show at least 200X speedup for a sequence of binary hash joins execution on Plasticine over CPU. We further show that in some realistic cases, a Plasticine-like accelerator can make 3-way joins more efficient than a cascade of binary hash joins on the same hardware, by a factor of up to 45X.
Click any figure to enlarge with its caption.
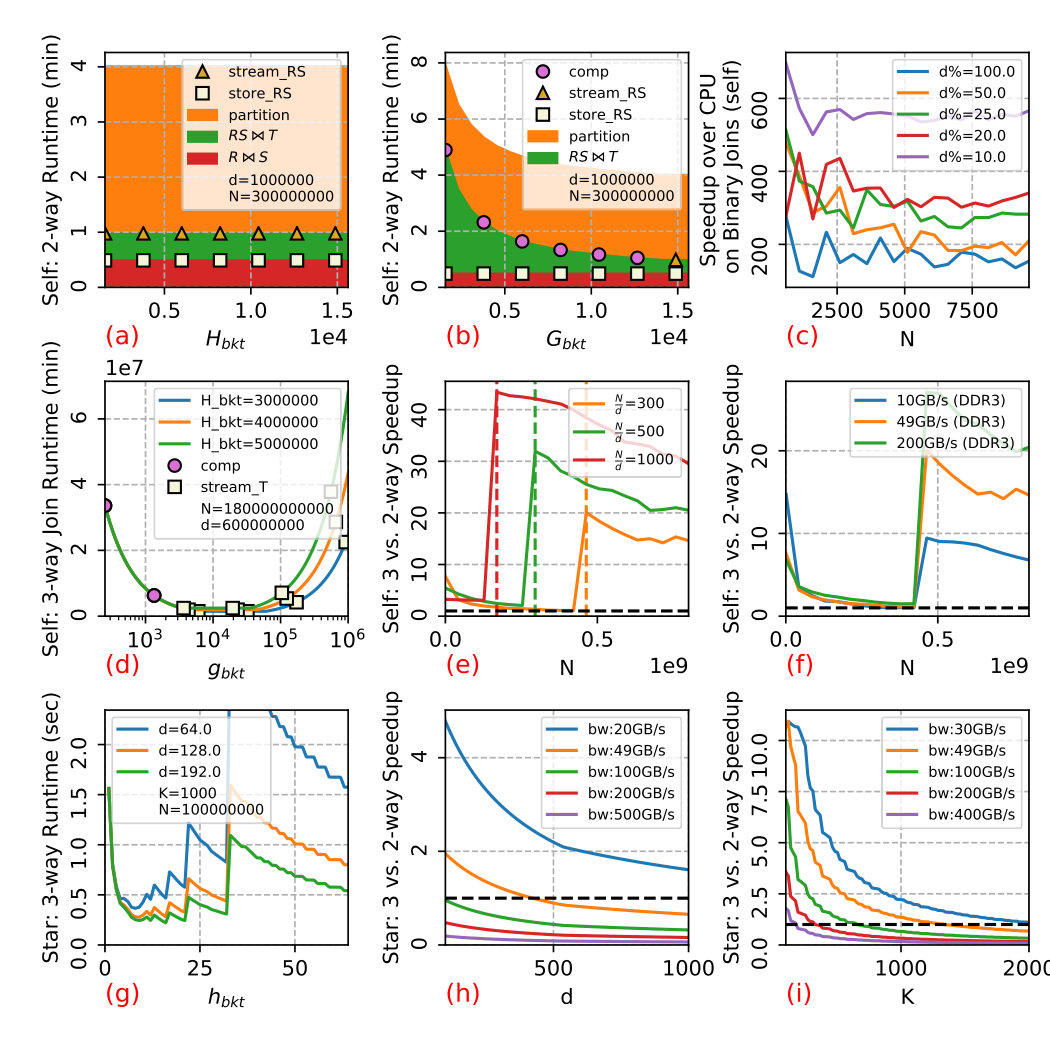 Figure 1
Figure 1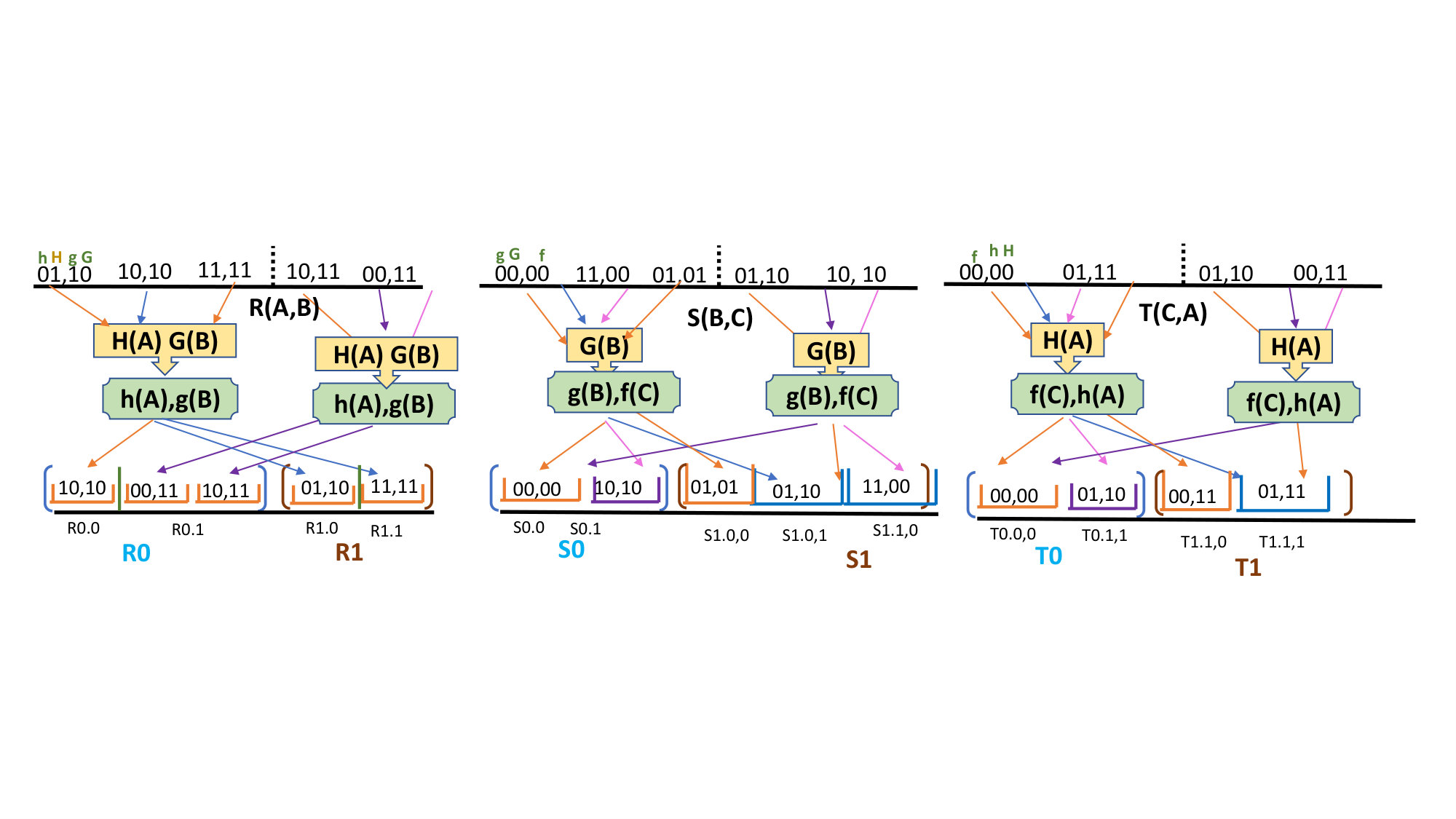 Figure 2
Figure 2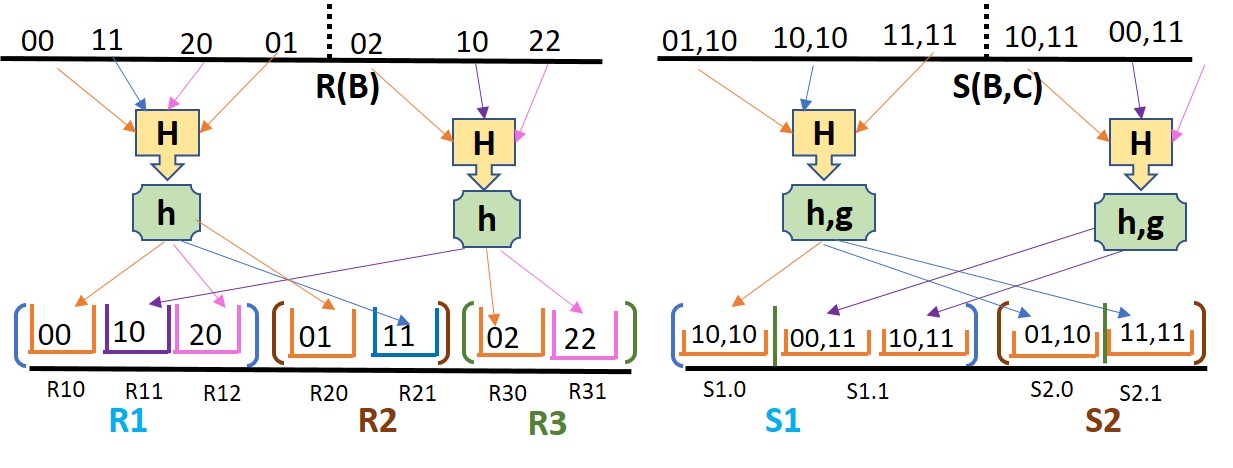 Figure 3
Figure 3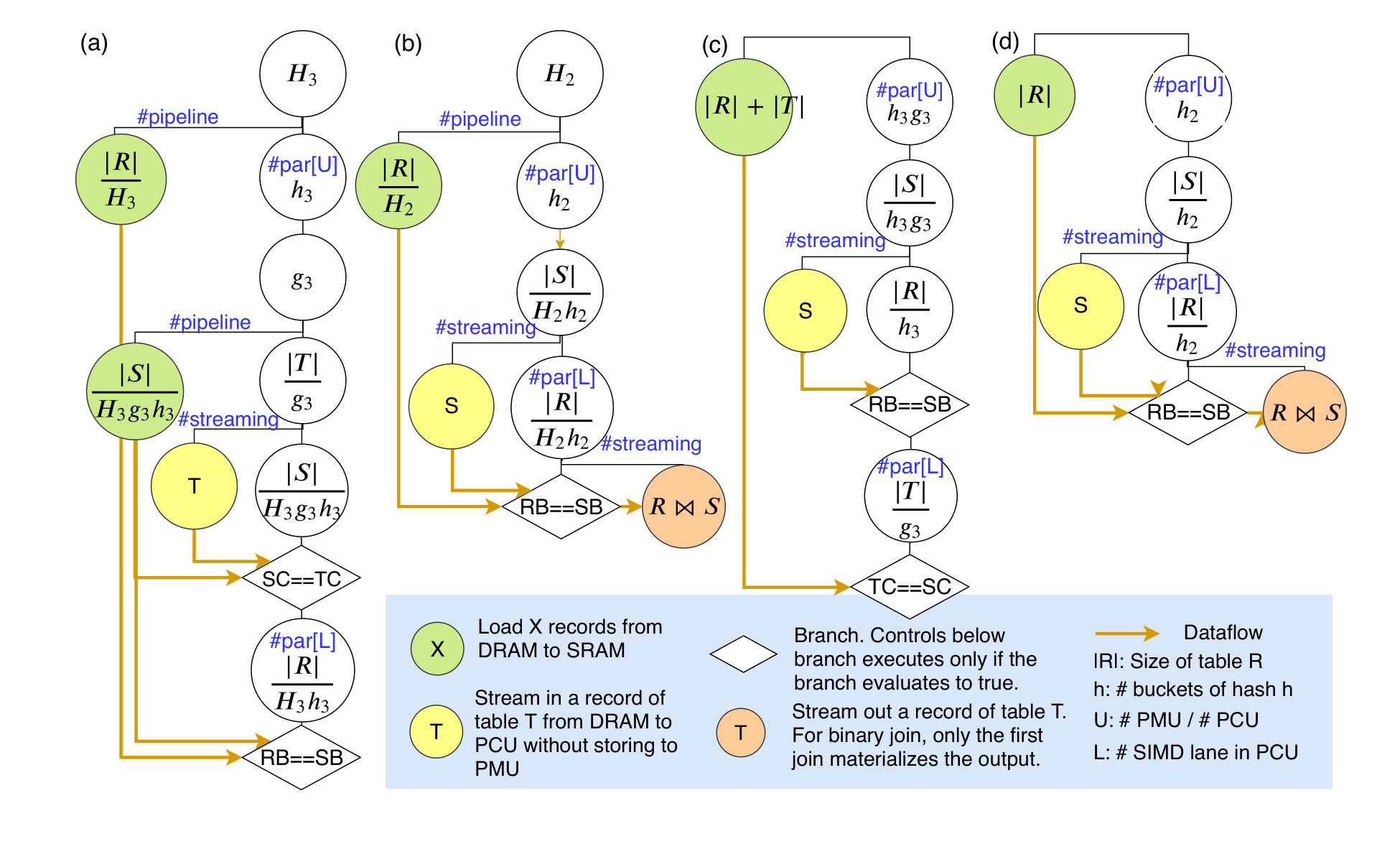 Figure 4
Figure 4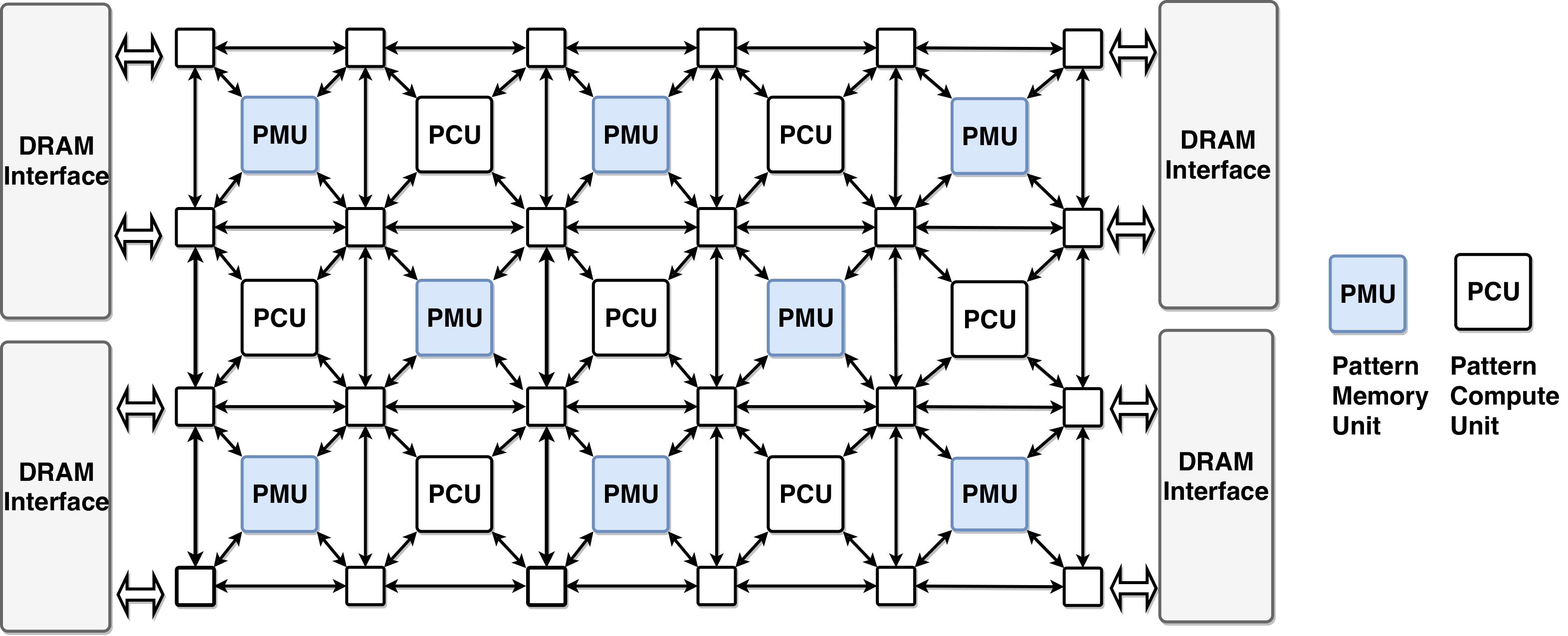 Figure 5
Figure 5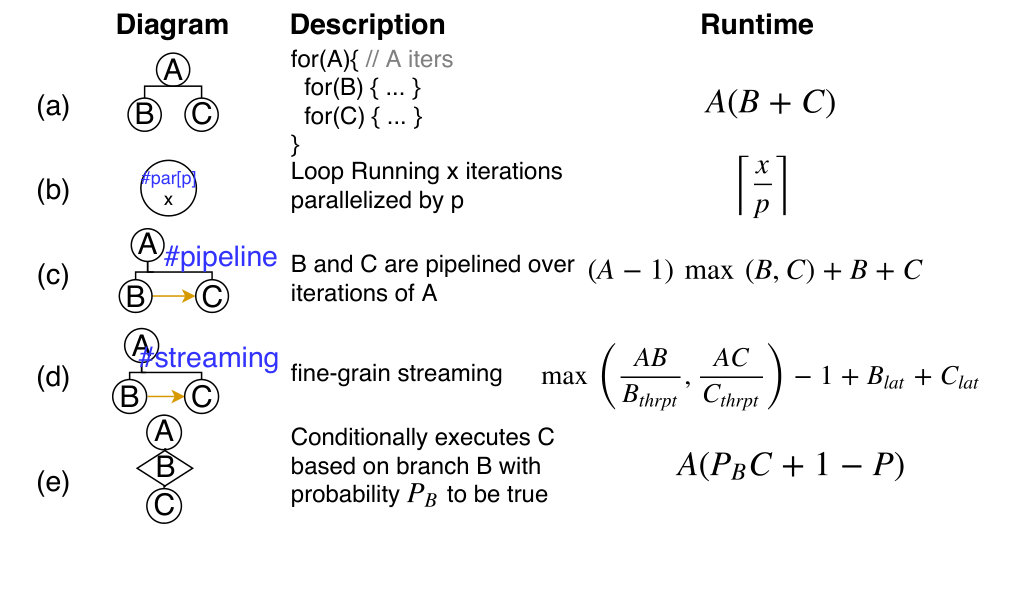 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAlgorithms and Data Compression · Interconnection Networks and Systems · Parallel Computing and Optimization Techniques
11institutetext: CS, Stanford University, CA, USA
22institutetext: Tata Consultancy Services Research, India
22email: {kunle,raghup17,rekhas2,ullman,yaqiz}@stanford.com
Efficient Multiway Hash Join on Reconfigurable Hardware
Kunle Olukotun 11
Raghu Prabhakar 11
Rekha Singhal 1122
Jeffrey D.Ullman 11
Yaqi Zhang 11
Abstract
We propose the algorithms for performing multiway joins using a new type of coarse grain reconfigurable hardware accelerator – “Plasticine” – that, compared with other accelerators, emphasizes high compute capability and high on-chip communication bandwidth. Joining three or more relations in a single step, i.e. multiway join, is efficient when the join of any two relations yields too large an intermediate relation. We show at least 200X speedup for a sequence of binary hash joins execution on Plasticine over CPU. We further show that in some realistic cases, a Plasticine-like accelerator can make 3-way joins more efficient than a cascade of binary hash joins on the same hardware, by a factor of up to 45X.
1 Motivation
Database joins involving more than two relations are at the core of many modern analytics applications. Examples 1 and 2 demonstrate two scenarios that require different types of joins involving three relations.
Example 1
(Linear 3-way join) Consider queries involving the Facebook “friends” relation . One possible query asks for a count of the “friends of friends of friends” for each of the Facebook subscribers, perhaps to find people with a lot of influence over others. There are approximately two billion Facebook users, each with an average of 300 friends, so has approximately tuples. Joining with itself will result in a relation with approximately tuples.111Technically, there will be duplicates, because if is a friend of a friend of , then there will usually be more than one friend that is common to and . But eliminating duplicates is itself an expensive operation. We assume duplicates are not eliminated. However, the output relation only involves 2 billion tuples, or 1/90000th as much data.222There is a technical difficulty with answering this query using parallel processing: we must take the union of large, overlapping sets, each produced at one processor. We cannot avoid this union if we are to get an exact count of the number of friends of friends of friends. However, we can get an asymptotically correct approximation to the size of the union using a very small amount of data to represent each set. One method to do so is the algorithm of Flajolet-Martin [7] [16]. Thus, a three-way join of three copies of might be more efficient, if we can limit the cost of the input data replication as we execute the three-way join.
Example 2
(Cyclic 3-way join) Consider the problem of finding triangles in relation . That is, we are looking for triples of people who are mutual friends. The density of triangles in a community might be used to estimate its maturity or its cohesiveness. There will be many fewer triangles than there are tuples in the join of with itself, so the output relation will be much smaller than the intermediate binary joins.
Afrati and Ullman [3] showed that in some cases, a multiway join can be more efficient than a cascade of binary joins, when implemented using MapReduce. But multiway joins are superior only when the intermediate products (joins of any two relations) are large compared to the required replication of the input data at parallel workers, and the output is relatively small; that is the case in each of the Examples 1 and 2. The limitation on the efficiency of any parallel algorithm for multiway joins is the degree to which data must be replicated at different processors and the available computing capacity. The performance benefits of multiway joins over cascaded binary joins could be perceived on hardware architectures facilitating cheap data replication.
Spatially reconfigurable architectures [24], such as Coarse-grained reconfigurable architecture (CGRA), have gained traction in recent years as high-throughput, low-latency, and energy-efficient accelerators. With static configuration and explicitly managed scratchpads, reconfigurable accelerators dramatically reduce energy and performance overhead introduced by dynamic instruction scheduling and cache hierarchy in CPUs and GPUs. In contrast to field-programmable gate arrays (FPGAs), CGRAs are reconfigurable at word or higher-level as opposed to bit-level. The decrease in flexibility in CGRA reduces routing overhead and improves clock frequency, compute density, and energy-efficiency compared to FPGAs.
Plasticine [20] is a recently proposed tile-based CGRA accelerator. As shown in Fig 1, Plasticine has a checkerboard layout of compute and memory units connected with high bandwidth on-chip network. Plasticine-like architectures offer several advantages to enable efficient multiway join acceleration. First, it has peak 12.3 FLOPS throughput designed for compute-intensive applications, like multiway join. Second, the high-bandwidth static network can efficiently broadcast data to multiple destinations, which makes replication very efficient.
1.1 Contributions
In this paper, we study algorithms to efficiently perform multiway joins on Plasticine-like accelerator. We show an advantage of such accelerators over CPU-based implementation on a sequence of binary hash joins, and additional performance improvement with 3-way joins over cascaded binary joins. Although we describe the algorithms with Plasticine as a potential target, the algorithms can also be mapped onto other reconfigurable hardware like FPGAs by overlaying Plasticine structure on top of the substrate architecture. The contributions of the paper are summarized below.
- •
Algorithms and efficient implementations for both linear and cyclic 3-way join operations for Plasticine-like accelerators. These algorithms are significantly different from the algorithms of [3] for the MapReduce implementation of the same joins.
- •
Analysis of the cost of running these algorithms in terms of the number of tuples that are read onto an accelerator chip.
- •
Performance comparison of a sequence of binary hash-join implementation on a Plasticine-like accelerator to state-of-the-art CPU hash-join on Postgres [21].
- •
Evaluation of the 3-way join algorithms compared to the cascaded binary hash-join implementation on the same accelerator.
1.2 Simplifying Assumptions
In our analyses, we shall assume a uniform distribution of join-key values. This assumption is unrealistic because there is typically skew, where some values appear more frequently than others. Small amounts of skew can be handled by leaving some components of the accelerator chip to handle “overflow” of other components. However, large amounts of skew require a modification to the algorithms along the lines of [19], which we do not cover in detail due to space limitation.
The rest of this paper is organized as follows: Section 2 presents some background and related work. Sections 3 discuss the challenges for multiway join algorithm implementation on Plasticine-like accelerator. Sections 4 and 5 present our algorithms for linear and cyclic multiway joins respectively. Section 6 compare the performance results of a sequence of binary hash joins on Plasticine-like accelerator and CPU. Further, we also compare the performance of the accelerated multiway join algorithms to an accelerated sequence of binary join approach on Plasticine-like accelerator. Finally the paper concludes with the future work in Section 7.
2 Background And Related Work
This section provides a brief background and reviews relevant related work on multiway join algorithms, hash-join acceleration, and spatially reconfigurable architectures.
2.1 Multiway joins
Efficient join algorithms are usually based on hashing [4]. Parallelism can be exploited by the parallel processing of a tree of several binary joins [17], an approach that is unsuitable for joins generating large intermediate relations, as is the case for our two introductory examples. The focus of such approaches has been to find optimal plans for parallel execution of binary joins. Henderson et al. [12] presented a performance comparison of different types of multiway-join structures to two-way (binary) join algorithm.
A leapfrog approach [23] has been used to join multiple relations simultaneously by parallel scanning of the relations that are sorted on the join key. Aberger et al. [2] have accelerated the performance of leapfrog triejoin using SIMD set intersections on CPU-based systems. The algorithm is sequential on the number of join keys and requires the relations to be preprocessed into trie data structures.
2.2 Hash-Join Acceleration
A hash-join algorithm on large relations involves three key operations - partitioning of relations, hashing of the smaller relation into a memory (build phase) followed by the probing of the second relation in the memory. Kara et al. [14] present an efficient algorithm for partitioning relations using FPGA-based accelerator. Onur et al. [15] use on-chip accelerator for hash index lookup (probing) to process multiple keys in parallel on a set of programmable ’walker’ units for hashing. Robert et al. [11, 10] use FPGA for parallelizing hashing and collision resolution in the building phase. Huang et al. [13] have explored the use of open coherent accelerator processor interface (OpenCAPI)-attached FPGA to accelerate 3-way multiway joins where the intermediate join of two relations is pipelined with a partition phase and join with the third relation.
2.3 Spatially Reconfigurable Architectures
Spatially reconfigurable architectures are composed of reconfigurable compute and memory blocks that are connected to each other using a programmable interconnect. Such architectures are a promising compute substrate to perform hardware acceleration, as they avoid the overheads in conventional processor pipelines, while retaining the flexibility. Recent work has shown that some spatially reconfigurable architectures achieve superior performance and energy efficiency benefits over fine-grained alternatives such as FPGAs and conventional CPUs [20].
Several spatially reconfigurable architectures have been proposed in the past for various domains. Architectures such as Dyser [9] and Garp [5] are tightly coupled with a general purpose CPU. Others such as Piperench [8], Tartan [18], and Plasticine [20] are more hierarchical with coarser-grained building blocks. Plasticine-like accelerator is not limited to databases alone but can efficiently accelerate multiway joins. Q100 [26] and Linqits [6] are accelerators specific to databases.
3 Accelerating Multiway Joins
We present algorithms for accelerating both linear () and cyclic () multiway joins on a Plasticine-like accelerator using hashing. There may be other attributes of relations , , and . These may be assumed to be carried along as we join tuples, but do not affect the algorithms. Also, , , , and can each represent several columns of the relations and by symmetry, assume that .
A naive approach to map the Afrati et al. [3] algorithm on Plasticine-like architecture will be bottlenecked by DRAM bandwidth and limited by the size of on-chip memory. The proposed multiway hash-join algorithms exploit the pipeline and parallelism benefits in a Plasticine-like architecture to improve the performance while eliminating the limitations mentioned above.
We partition one or more relations using hash functions, one for each of the columns used for joining, such that the size of potentially matching partitions of the three relations is less than or equal to the size of on-chip memory. The loading of a partition of a relation from DRAM to on-chip memory is pipelined with the processing of the previously loaded partition(s) on the accelerator. Further, to squeeze more processing within the given on-chip memory budget, at least one of the relations is streamed, unlike batch processing in Afrati et al.[3].
3.1 Notations
In what follows, we use to represent the number of records of a relation R. A relation ’s tuple is represented as and the column ’s values is accessed as . We use the name of hash functions–, , , , and (or , , , , and ) in certain equations to stand for the number of buckets produced by those functions. is the number of distributed memory and compute units, and we assume there is an equal number of each. is the total on-chip memory capacity.
4 Linear 3-Way Join
For the linear, three-way join , we partition the relations at two levels in a particular way, using hash functions as shown in Fig 2. The relations are partitioned using robust hash functions [25] on the columns involved in the join, which, given our no-skew assumption, assures uniform sizes for all partitions. We can first configure the accelerator to perform the needed partitioning. Since all hash-join algorithms require a similar partitioning, we shall not go into details regarding the implementation of this step.
The relations and are similar, each having one join column, while relation has two columns to join with relations and . The relative sizes of the three relations affect our choice of algorithm. The largest relation should be streamed to the accelerator to optimize the on-chip memory budget. When is largest, relations and must either be small enough to fit on the on-chip memory (discussed in detail as a “star” 3-way join in Section 6) or they should be partitioned, based on the values of attributes or , respectively, each of them having sub-partitions. Then each pair of sub-partitions is loaded on to the accelerator iteratively and matched with the corresponding one of the partition of the streamed relation . In the case of larger and relations, one of them is streamed and the other one is partitioned as discussed in detail below.
4.1 Joining Relations on Plasticine-like Accelerator
Consider the case where is no larger than or . For the first level partitioning of the relations and on attribute , we choose a number of partitions for the hash function so that a single partition of (that is, the set of tuples of whose -value hashes to that partition) will fit comfortably in one pattern memory unit (PMU) of the Plasticine. The second level of partitioning serves two purposes and involves two hash functions. First, we use hash function to divide a single partition of and into buckets each, one bucket per PMU. We use hash function to divide into a very large number of buckets. Each partition of is further partitioned into sub-partitions that correspond to a single value of . Each bucket of ’s partition may be organized by increasing values of as shown in Fig 2. Likewise, the entire relation is divided into buckets based on the value of .
We shall describe what happens when we join a single partition of , that is, the set of tuples of whose -values have a fixed value , with the corresponding partition of (the set of tuples of whose -values also have . Call these partitions and , respectively.
Bring the entire partition of onto the chip, storing each tuple in the PMU for . 2. 2.
For each bucket of , bring each tuple from that bucket from onto the chip and store it in the PMU for . 3. 3.
Once the bucket from has been read onto the chip, read the corresponding bucket of – with the same hash value – onto the chip. Since tuple can join with tuple and having any value of , we must route each tuple to every PMU. 4. 4.
Once the buckets with a given value have arrived, PCUs joins the three tiny relations at each PMU using optimized cascaded binary joins. Recall we assume the result of this join is small because some aggregation of the result is done, as discussed in Example 1. Thus, the amount of memory needed to compute the join at a single memory is small.333For just one example, if , , and are each the friends relation , and we are using the Flajolet-Martin algorithm to estimate the number of friends of friends of friends for each individual in the relation , then the amount of data that needs to be maintained in memory would be on the order of 100 bytes for each tuple in the partition , and thus would not be more than proportional to the size of the data that was read into the memory from outside. In fact, although we do not want to get into the details of the Flajolet-Martin algorithm [16], if we are willing to assume that everyone has at least some small number of friends of friends of friends, e.g., at least 256, then we can reduce the needed space per tuple to almost nothing.
The formal representation of the algorithm is presented in Algorithm 1.
4.2 Analysis of the Linear 3-way Join
Each tuple of and is read onto an accelerator chip exactly once. However, tuples of are read many times – once for each partition of . The number of partitions produced by the hash function is such that one partition of fits onto the entire on-chip memory with capacity . Thus, the number of partitions into which is partitioned is . Therefore, the number of reads for tuples of is . This function is symmetric in and , so it seems not to matter whether is the smaller or larger of the two relations. However, we also have to read once, so we would prefer that be the smaller of and . That is, the total number of tuples read is .
Thus, the number of tuples read onto the chip is greater than the sizes of the three relations being joined. However, using a cascade of two-way joins may also involve an intermediate relation whose size is much bigger than the sizes of the input relations. Thus, while we cannot be certain that the three-way join is more efficient than the conventional pair of two-way joins, it is at least possible that the algorithm proposed will be more efficient.
Example 3
Consider again the problem of getting an approximate count of the friends of friends of friends of each Facebook user, as was introduced in Example 1. We estimated the number of tuples in the friends relation as . This value is thus the sizes of each of , , and . If we take the three-way join, then the number of tuples read onto an accelerator chip is . In comparison, if we use two two-way joins, then we need to output first the join of with itself, which involves producing about tuples, and then reading these tuples back in again when we join their relation with the third relation. The three-way join will involve reading fewer tuples if . That relationship will hold if . That number is far more than can be expected on a single chip with today’s technologies, even assuming that a tuple is only eight bytes (two 4-byte integers representing a pair of user ID’s). However, for somewhat smaller databases, e.g., the 300 million Twitter users and their followers, the on-chip memory requirements are feasible, in that case, the chip needs to hold approximately 150 million tuples.444In fact, as a general rule, we can observe that the minimum memory size needed for any social-network graph is very close to half the number of nodes in the graph, regardless of the average degree of the graph (number of friends per user) and size of the relation.
5 Cyclic 3-Way Join
Consider the cyclic three-way join . The cyclic join is symmetric in all three relations. We shall therefore assume that is the smallest of the three, for reasons we shall see shortly. Similar to the linear three-way join, we shall partition such that it’s one partition fits conveniently into on-chip memory. However, in this case, since both and are shared by other relations, we will partition using hash functions and into , and buckets, respectively. The correct values of and are to be determined by considering the relative sizes of the three relations. However, we do know that .
In addition to partitioning into pieces, each of size , we use to partition into pieces, each of size , and we use to partition into pieces, each of size . The partitioning scheme is depicted in Fig 3.
As before, we are assuming that there is no significant skew in the distribution of values in any column, and we also are assuming a sufficient number of different values that hashing will divide the relations approximately evenly. In what follows, we shall only describe the join of a single partition from each of , , and . These three partitions are determined by buckets of and . That is, for a fixed value of and a fixed value of , we join those tuples of such that and with the tuples of such that and the tuples of such that . In what follows, we shall refer to these partitions as , , and , respectively. Each set of three partitions is handled the same way, either sequentially on one accelerator chip or in parallel on more than one such chip.
5.1 Joining Relations on Plasticine-like Accelerator
Now, let us focus on joining , , and . Assuming the chip has memories arranged in a square on a side, we shall use lower-level hash functions , , and . Hash functions and each map to buckets, while maps to a very large number of buckets – a sufficient number of buckets so that and can be partitioned on the basis of their -values into pieces that are sufficiently small that we can neglect the memory space needed to store one piece from one of these two relations.
Begin the join by bringing onto the chip all the tuples of . Each of these tuples is routed to only one of the PMUs – the PMU in row and column . Then we bring onto the chip each of the tuples of that have . These tuples are each stored in every PMU in the column . Thus, this tuple will meet at one of these memories, all the tuples of that share the same hash value . Finally, we pipe in the tuples of that have . Each of these tuples is read into each of the memories in row , where it is joined with the possibly matching tuples and . Any matches are sent to the output of the chip.
5.2 Analysis of Cyclic Three-Way Join
Notice first that every top-level partition of is read onto the chip only once. However, a top-level partition of is read onto chip times, once for each bucket of . Also, every top-level partition of is read times, once for each bucket of . The total number of tuples read onto an accelerator chip is thus . Recall also that , so previous function can be expressed as . To minimize this function, set its derivative with respect to to 0, which gives us . For this value of , the cost function becomes . Notice that the second term is independent of the relative sizes of the three relations, but the first term, , tells us that the total number of tuples read is minimized when we pick to be the smallest of the three relations.
Example 4
Suppose each of the three relations is the Facebook friends relation ; that is, . Then the total number of tuples read onto the chip is . If we assume as in Example 3 that the binary join of with itself has about tuples, we can conclude that the total number of tuples read by the three-way join of with itself is less than the number of tuples produced in the intermediate product of two copies of a cascade of two-way joins as long as . This condition is satisfied for as small as seven million tuples.
6 Performance Evaluation
In this section, we evaluate the algorithms proposed in the Sections 4, on Plasticine-like accelerator using a performance model. First, we show the advantage of accelerating a sequence of binary join operators by comparing its execution time on Postgres database on CPU to our simulation on the accelerator. Next, we show additional performance improvement of 3-way join (an instance of multiway join) over a cascade of two binary hash joins on the acccelerator.
We consider two categories of multiway joins in this evaluation: self-join555Self 3-way join is joining of a relation with two instances of itself e.g. Friends of friends. of a big relation of size , where N does not fit on-chip; and star-join666Star 3-way join is joining of a large fact relation with two small dimension relations e.g. TPCH [1] benchmark having join of lineitem fact relation with order and supplier dimension relations. of two small relations ( and ) each of size with a large relation, , of size , where and . The self join algorithm described in Section 4 is a generic algorithm for any linear join, whereas the algorithm used for star join is a variant of the generic algorithm that specialize for better locality when the dimension relations fit on the on-chip memory.
For a given set of relations, we observe that the proposed algorithms execution time on the accelerator is sensitive to the number of buckets and DRAM bandwidth. We first evaluate the selection of hyperparameters of the algorithms, i.e. bucket size for the cascaded binary and 3-way joins. With best bucket sizes, we compare the performance advantage of 3-way join over a cascade of binary joins for different selectivity of join columns and DRAM-bandwidths. For all experiments, we do not materialize the final output of the join in memory (refer Example 1). Instead, we assume the final results will be aggregated on the fly. Therefore, in our study, we only materialize the intermediate result of the first binary join, and the final output is immediately aggregated (e.g. perform count operation on the number of friends of friends relation).
6.1 Target Systems
The CPU system, used for performance evaluation of cascaded binary join, is Intel Xeon Processor E5-2697 v2 server with 30M shared cache and 251GB DDR3 RAM. Although the platform is multi-processor, the Postgres implementation is single threaded. Nonetheless, we do make sure no other application is contending for DRAM bandwidth. For performance evalutaion on hardware accelerator, we use performance model for the Plasticine-like architecture. It has DDR3 DRAM technology with 49GB/s read and write bandwidth , Number of PMUs(PCUs), and a peak of 12.3 TFLOPS compute throughput with 16MB on-chip scratchpad.
6.2 Accelerator’s Performance Model
The performance model is built by simulating the logic of the proposed algorithm on the hardware specification of the accelerator given in Section 6.1. We observed that the performance advantage of the proposed 3-way join over cascaded binary join depends on the number of records in the joining relations and the selectivity of the join column - lower selectivity (i.e. higher duplicates) favors multiway join. The performance model needs two inputs for simulation - the number of records of , and and the maximum distinct values over all joining columns (represented as ).
The performance model accounts for how an application is spatially parallelized and data is streamed across compute and memory units of the accelerator. The model does considers DRAM-contention while loading multiple data streams concurrently on the chip. For higher DRAM bandwidth utilization and to hide the DRAM latency, we overlap execution of the algorithm with prefetching of the data. This requires to split the on-chip memory into two buffers (double buffering) to store both the current and prefetched data. The performance model uses only half of the on-chip memory to include this optimization.
For cascaded binary join, once the intermediate result does not fit in DRAM, the performance model simulates the flushing of the intermediate data to the underlying persistent storage with much lower bandwidth (around 700MB/s from the latest SSD technology). Appendix 0.A explains the performance model in detail.
6.3 Performance Analysis of Cascaded Binary Join
A cascaded binary-join is a sequence of two binary joins- the first join is which outputs intermediate relation and second join is . For uniform distribution, the intermediate size for a cascaded binary join is [22].
Both the joins are executed on the accelerator similar to the 3-way join discussed in Section 4. The first join involves loading and matching of partitions of and using on the chip. The intermediate relation is copied from on-chip to the DRAM. The second join is identical except the output results are no longer materialized in DRAM. For the second join, we also load partitions of relation on-chip while streaming previous join intermediate result, since . The bucket sizes of the second level hash functions for both the joins are fixed to the number of PMUs, i.e. .
Fig 4 (a) shows the breakup of the execution time of a cascaded binary self join of three relations with a varying number of buckets i.e. . The orange region shows time spent in partitioning the relations for both the joins, which is dominated by the second join due to large size of the intermediate relation. Clearly, the first join is bounded by DRAM-bandwidth, varying has no impact on the performance. Fig 4 (b) shows variation of the execution time of the second join varying . The second join is compute-bound at small , as the total amount of data loaded is , whereas the total comparison is .
6.3.1 Performance comparison of Cascaded Binary Join
We compare the performance of cascaded binary join on CPU to that on the accelerator using configuration given in Section 6.1. For CPU-based implementation, we follow a COUNT aggregation immediately after the cascaded binary joins, which prevents the final output to be materialized in memory. We configure the accelerator with the same DRAM capacity as our baseline CPU.
Fig 4 (c) shows the speedup of binary self join on the accelerator over CPU with varying sizes of the relations and distinct values in joining columns (). Since the cascaded join is not parallelized on the PCU, the second join of the cascaded join is compute-bound on CPU. On the accelerator, the total amount of parallelism is the product of the number of PCUs with SIMD computation (a vector of size 16) within each PCU, which is . This shifts the performance bottleneck to DRAM for streaming in the intermediate relation. Fig 4 (c) shows that smaller percentage of unique values, are associated with increasing speedup (up to 600x) due to the large sized intermediate relation in the cacaded binary join.
6.4 Performance Analysis of Linear Self Join
We consider , where R,S,T are copies of the friend-friend relations with records and distinct users (column values).
6.4.1 Hyper-parameter Selection
We shall discuss the evaluation of hyperparameter selection of algorithm described in Section 4. Fig 4 (d) plots the execution time of 3-way join varying with and ( = number of PMUs). It shows that the algorithm achieve higher speedup for larger size partition of partition (i.e. small ) while exploiting DRAM prefetching. For small , the algorithm is compute-bound for joining buckets from three relations within PMUs (3-level nested loop). As increases, the compute complexity reduces with smaller of size buckets and the performance bottleneck shifts to DRAM bandwidth for streaming in records. For large values of , the bucket within each PMU becomes very small (i.e. ), resulting in very poor DRAM performance for loading . Although some PCU might have empty bucket, the algorithm has to wait for completion from other PCUs with non-empty buckets because all PCUs shares the streamed records. This synchronization and poor DRAM performance on bucket eventually increases execution time dramatically when becomes too large.
6.4.2 3-way Join vs. Cascaded Binary Joins
Fig 4 (e) and (f) shows the speedup of 3-way join over cascaded binary joins with varying average friends per person (), and DRAM bandwidth on the accelerator. When relation size (N) is small, 3-way join achieves up to 15x performance advantage over binary-join because the latter is heavily IO-bound compared to compute-bound 3-way join, and the accelerator favors compute bound operations. However, the speedup decreases with increase in relation size, . Because the compute complexity of 3-way join increases quadratically with , whereas, size of intermediate relation of the cascaded binary joins increases quadratically with . When the intermediate relation fails to fits in DRAM, the off-chip bandwidth drops from 49GB/s to 700MB/s, which is shown as a step increase in the speedup of 3-way over the binary join in 4 (e) and (f). With more friends per person, the performance cliff happens at smaller relation size. (f) shows that the advantage of 3-way join is more significant when intermediate result fit as binary-join will be more DRAM-bandwidth bounded for smaller DRAM; and less significant when the intermediate result does not fit, at which point, binary-join will be SSD bandwidth-bounded, whereas 3-way join can still benefit from higher DRAM bandwidth.
6.5 Performance Analysis of Linear Star 3-way Join
Now we consider a special case of linear join where and relations are small enough to fit on-chip777With plasticine, this means the dimensions relations are on the order of millions of records.. Now we only need one level of hash functions on both columns and , naming and . The only difference between cascaded binary joins and 3-way join is that binary join only performs one hash function at a time, which allow . For 3-way join, we map a hash value pair to each PMU, which restricts number of buckets to . For both 3-way and cascaded binary joins, we first load and on-chip, compute hash functions on the fly, and distribute the records to PMUs with corresponding assigned hash values (in binary join) or hash value pairs (in 3-way join). Next, we stream , compute hash values and distribute to the corresponding PMUs, where the inner join is performed.
Fig 4 (g) shows the execution time of the 3-way join with varying (Note, must be dividable by to achieve the maximum ). Fig 4 (h) and (i) shows the speedup of 3-way join over a cascade of binary star join. We can see that with increasing DRAM-bandwidth, the advantage of 3-way join eventually disappears since storing and loading intermediate results in binary join becomes free, when they fit on the chip. 3-way join can also be slower than binary join for larger number of buckets (ie. less computation), where number of buckets is for binary and for 3-way join join888Total amount of comparison in cascaded binary join roughly equals to ).
7 Conclusions
Multiway join involves joining of multiple relations simultaneously instead of traditional cascaded binary joins of relations. In this paper, we have presented algorithms for efficient implementation of linear and cyclic multiway joins using coarse grain configurable accelerator such as Plasticine, which is designed for compute-intensive applications and high on-chip network communication. The algorithms have been discussed with their cost analysis in the context of three relations (i.e. 3-way join).
The performance of linear 3-way joins algorithms are compared to the cascaded binary joins using performance model of the Plasticine-like accelerator. We have shown 200X to 600X improvements for traditional cascaded binary joins on the accelerator over CPU systems. We have concluded that 3-way join can provide higher speedup over cascaded binary joins in a DRAM bandwidth-limited system or with relations having low distinct column values () (which results in large size intermediate relation). In fact, the effective off-chip bandwidth will dramatically reduce when the intermediate size does not fit in DRAM, in which case binary join will provide a substantial improvement over 3-way join. We have shown that a Self 3-way join (e.g, friends of friend query) is 45X better than a traditional two cascaded binary joins for as large as 200 million records with 700 thousand distinct users. A data-warehouse Star 3-way join query is shown to have 11X better than that of cascaded binary joins.
In future work, we would like to explore additional levels of hashing beyond two levels, and exploring new algorithms, such as set value join [2], within on-chip join to speedup multi-way join. We plan to extend the algorithms for skewed data distribution in relations and analyze the improvements in the performance and power of the algorithms on Plasticine accelerator.
Appendix 0.A Performance Model of Plasticine
In this section, we provide more details on the analytical performance model used for algorithm performance estimation on Plasticine-like accelerator. The performance model analyzes the loop structures of each algorithm, takes into account how applications are spatially parallelized and pipelined on hardware resource, and provides a cycle-level runtime estimation given data characteristics and architectural parameters as inputs. Fig. 6 shows the loop structures of 3-way and cascaded binary self and star join algorithms on the accelerator. To avoid confusion, we use and for hash functions of binary and 3-way joins- they do not need to be the same.
In Fig. 6 (a), the circles indicate one-level of loop nest, and the hierarchy indicates the nest levels between loops. #par[P] in 6 (b) suggests a loop parallelized by P. #pipeline in Fig 6 (c) indicates overlapping execution of the inner loops across iterations of the outer loop, e.g. B can work on the second iteration of A while C is working on the first iteration of A. The pipeline construct is commonly used when a tile of data is reused multiple times on-chip, in which we can overlap prefetching of future tiles with execution of the current tile. In contrary, #streaming in 6 (d) indicates fine-grain pipelining between producer and consumer loops, where the consumer loop only scans the data once without any reuse. In such case, C can execute as soon as B produces the first chunk of data, without waiting for B to finish on one entire iteration of A.
On Plasticine-like acelerator, an example of the streaming construct is streaming data from DRAM directly to PCUs without storing to PMUs. To compute execution time (or run time) , we need the throughput (thrpt) and latency (lat) of which B and C produces/consumes data chunks. For DRAM, throughput and latency can be derived from DRAM bandwidth and response time, respectively. For loops executed on Plasticine, throughput is the amount of allocated parallelism between () and within PCUs (). We used PCUs and SIMD vector width in our evaluation. The latency is the sum of network latency (we used the worst diagonal latency on a chip, which is 24 cycles) and pipeline latency of the PCU (6 cycles). The overall runtime of the outer loop is bounded by the stage with minimum throughput.
Finally, for data-dependent execution in 6 (d), we compute runtime by associating a probability to each branch. For example, in Fig. 6 (a), the branch on indicates comparisons on S records with streamed T records. Only matches records will be compared with R records. The probability of this branch is the expected size of , which is , over the total number of comparisons performed between S and T records. The number of comparison is the product of loop iterations enclosing the branch, which is . This gives the probability of on the branch hit.
Using a similar approach, we can derive probabilities of all data-dependent branches. The runtime of each algorithm in Fig. 6 is recursively evaluated at each loop level using equations shown in Fig. 6. The exact model is open-source and can be found at https://github.com/yaqiz01/multijoin_plasticine.git.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Tpc-h: a decision support benchmark, http://http://www.tpc.org/tpch/
- 2[2] Aberger, C.R., Tu, S., Olukotun, K., Ré, C.: Emptyheaded: A relational engine for graph processing. In: Proceedings of the 2016 International Conference on Management of Data. pp. 431–446. SIGMOD ’16, ACM, New York, NY, USA (2016). https://doi.org/10.1145/2882903.2915213, http://doi.acm.org/10.1145/2882903.2915213
- 3[3] Afrati, F.N., Ullman, J.D.: Optimizing multiway joins in a map-reduce environment. IEEE Transactions on Knowledge and Data Engineering 23 , 1282–1298 (2011)
- 4[4] Balkesen, C., Alonso, G., Teubner, J., Özsu, M.T.: Multi-core, main-memory joins: Sort vs. hash revisited. Proc. VLDB Endow. 7 (1), 85–96 (Sep 2013). https://doi.org/10.14778/2732219.2732227, http://dx.doi.org/10.14778/2732219.2732227
- 5[5] Callahan, T.J., Hauser, J.R., Wawrzynek, J.: The garp architecture and c compiler. Computer 33 (4), 62–69 (Apr 2000). https://doi.org/10.1109/2.839323
- 6[6] Chung, E.S., Davis, J.D., Lee, J.: Linqits: Big data on little clients. In: Proceedings of the 40th Annual International Symposium on Computer Architecture. pp. 261–272. ISCA ’13, ACM, New York, NY, USA (2013). https://doi.org/10.1145/2485922.2485945, http://doi.acm.org/10.1145/2485922.2485945
- 7[7] Flajolet, P., Martin, G.N., Martin, G.N.: Probabilistic counting algorithms for data base applications (1985)
- 8[8] Goldstein, S.C., Schmit, H., Moe, M., Budiu, M., Cadambi, S., Taylor, R.R., Laufer, R.: Piperench: A co/processor for streaming multimedia acceleration. In: Proceedings of the 26th Annual International Symposium on Computer Architecture. pp. 28–39. ISCA ’99, IEEE Computer Society, Washington, DC, USA (1999). https://doi.org/10.1145/300979.300982, http://dx.doi.org/10.1145/300979.300982