Phase transition in the Kolkata Paise Restaurant problem
Antika Sinha, Bikas K. Chakrabarti

TL;DR
This paper investigates a phase transition in the Kolkata Paise Restaurant problem, analyzing how agents learn to optimize restaurant choices and how system parameters influence steady-state utilization and convergence times.
Contribution
It introduces and analyzes two crowd-avoiding strategies in the KPR problem, revealing critical behavior and scaling laws near phase transition points.
Findings
Steady state wastage fraction scales as a power law near critical points.
Convergence time diverges with a power law near phase transitions.
Critical exponents depend on the spatial dimension of the system.
Abstract
A novel phase transition behaviour is observed in the Kolkata Paise Restaurant (KPR) problem where large number () of agents or customers collectively (and iteratively) learn to choose among the restaurants where she would expect to be alone that evening and would get the only dish available there (or may get randomly picked up if more than one agent arrive there that evening). The players are expected to evolve their strategy such that the publicly available information about past crowd in different restaurants can be utilized and each of them is able to make the best minority choice. For equally ranked restaurants we follow two crowd-avoiding strategies: Strategy I, where each of the number of agents arriving at the -th restaurant on the -th evening goes back to the same restaurant on the next evening with probability , while in Strategy II,…
Click any figure to enlarge with its caption.
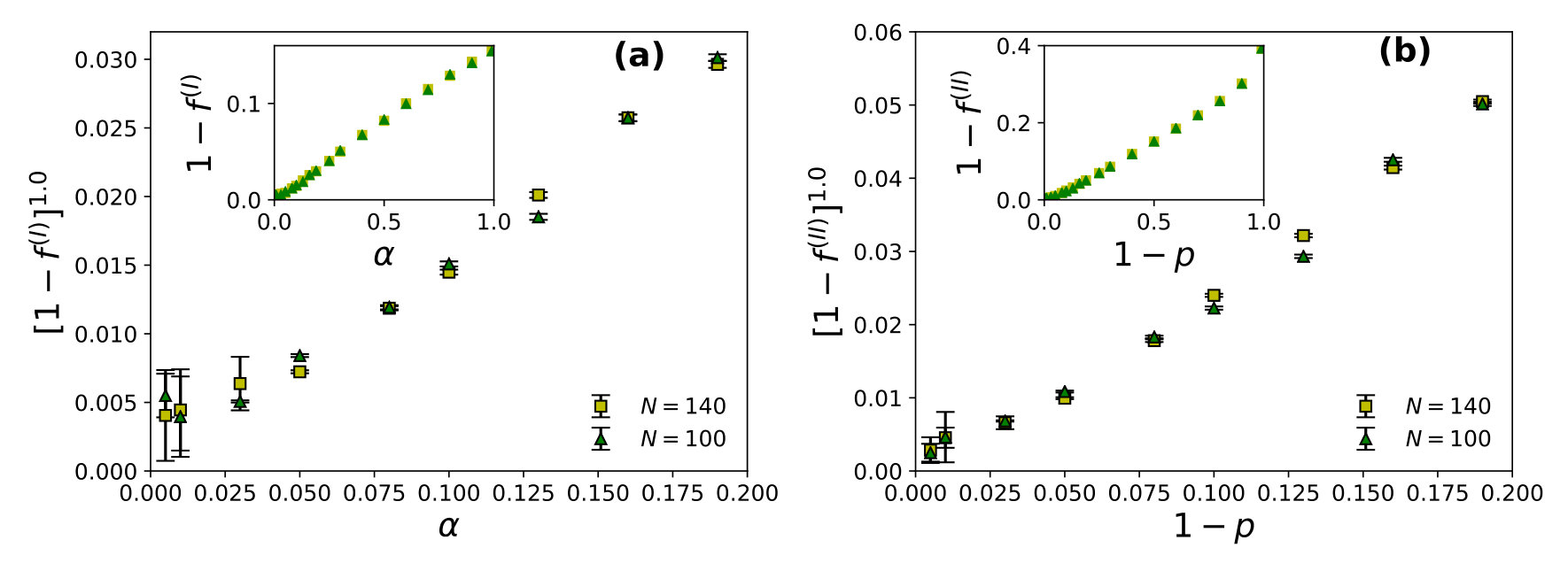 Figure 1
Figure 1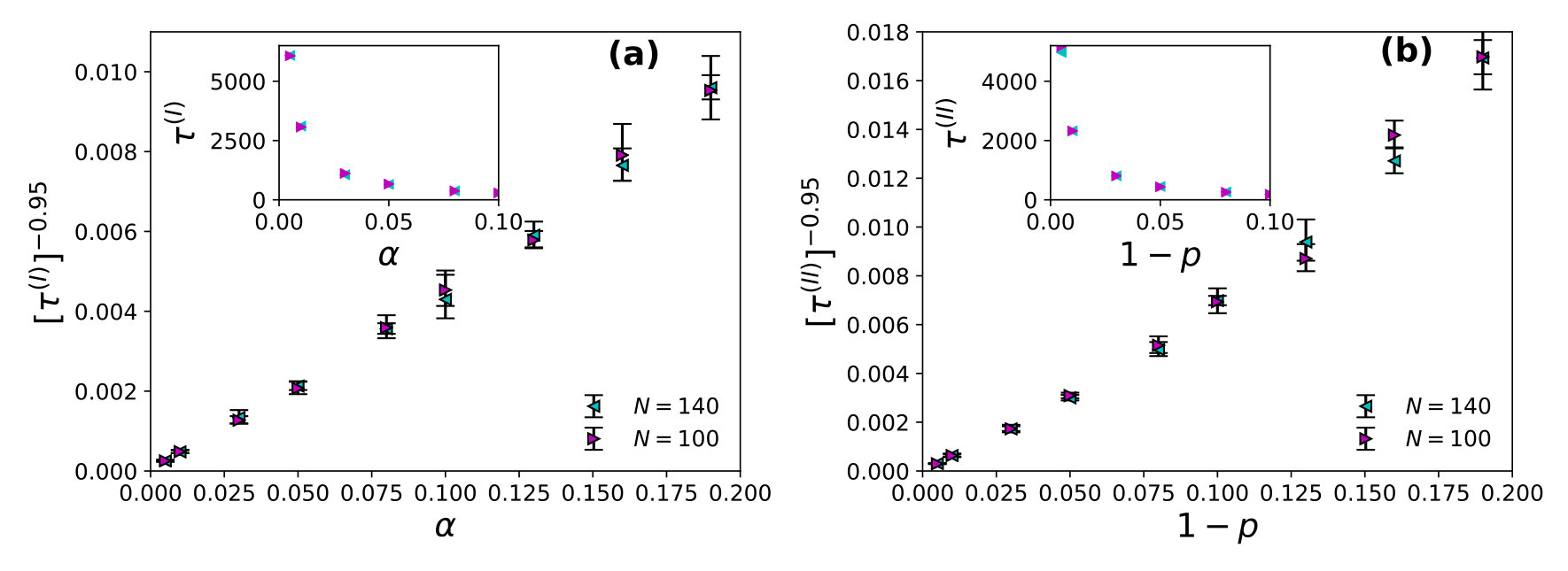 Figure 2
Figure 2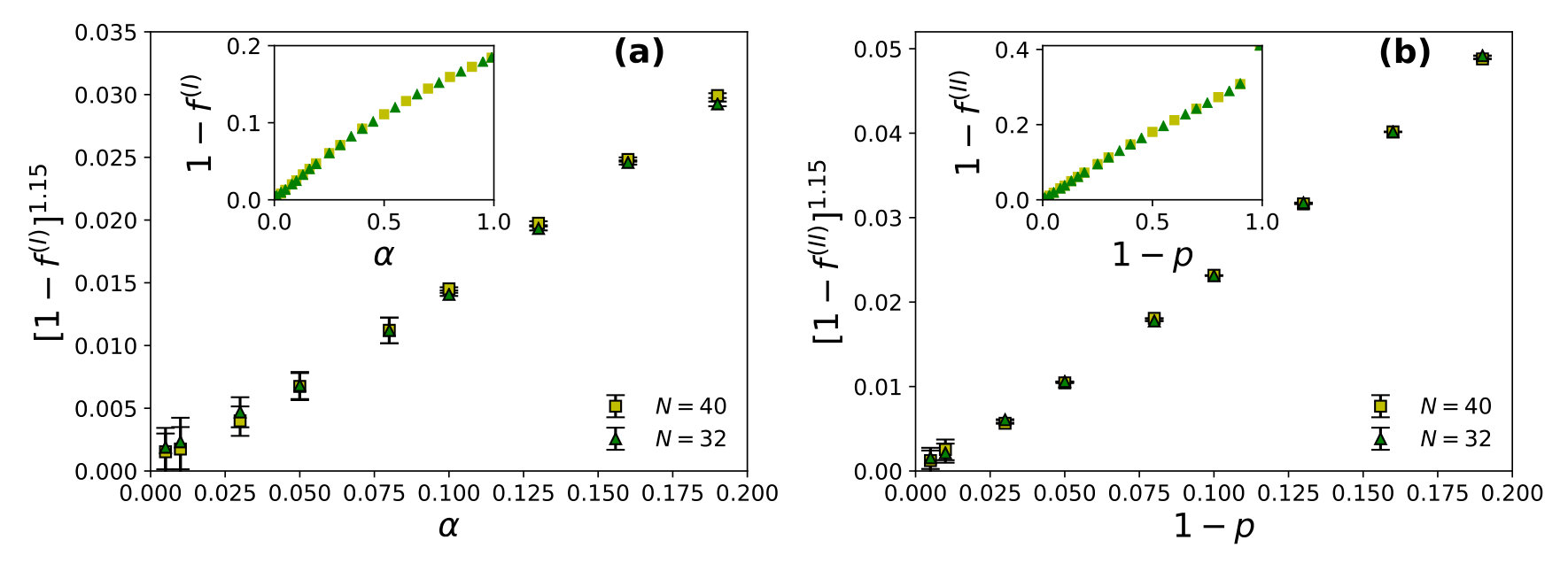 Figure 3
Figure 3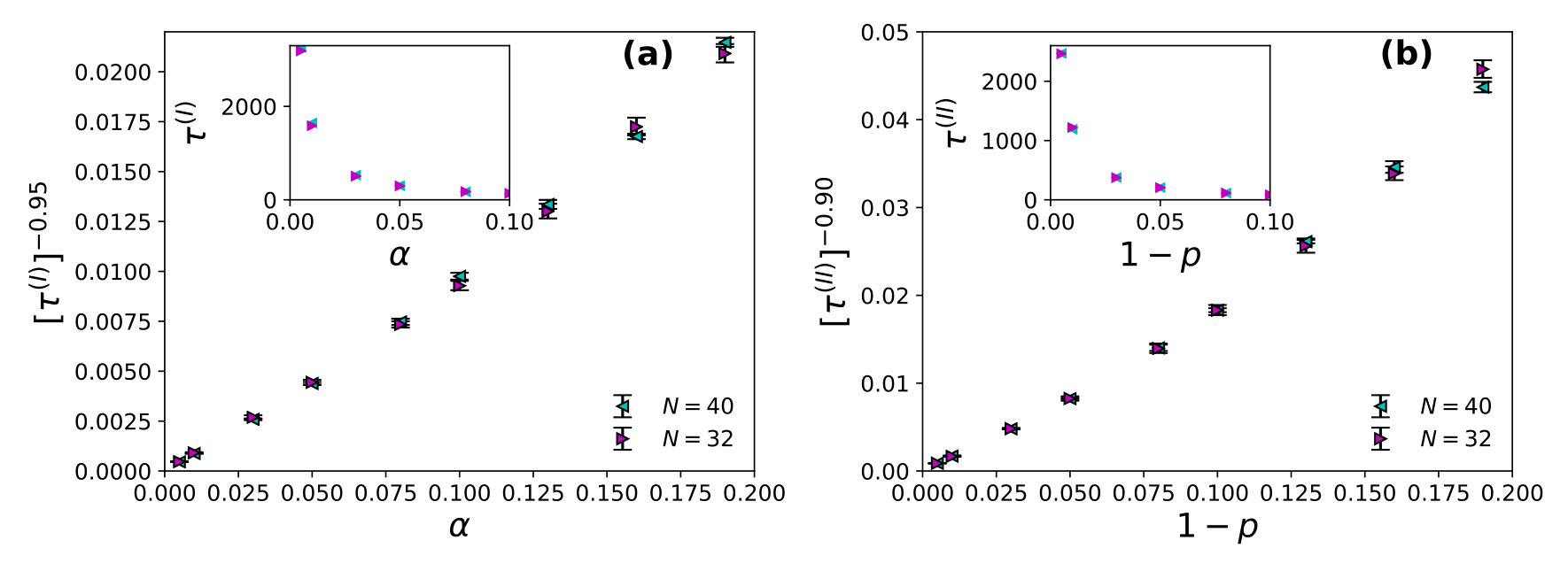 Figure 4
Figure 4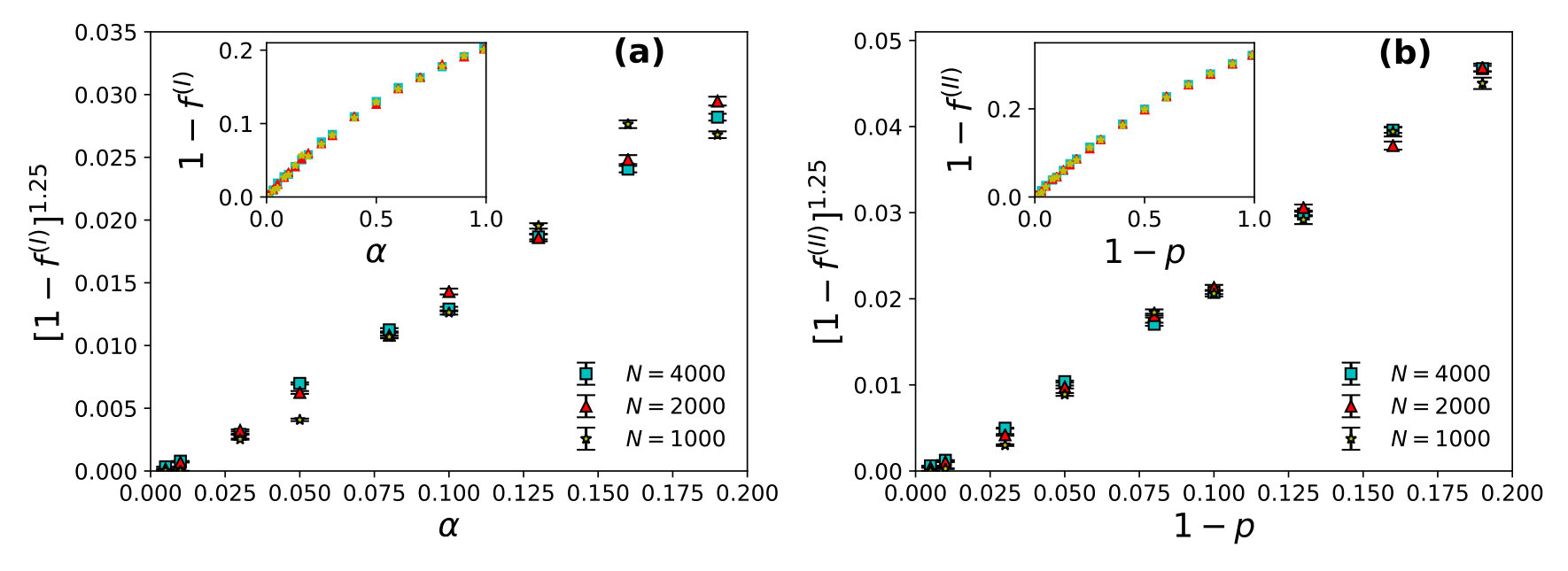 Figure 5
Figure 5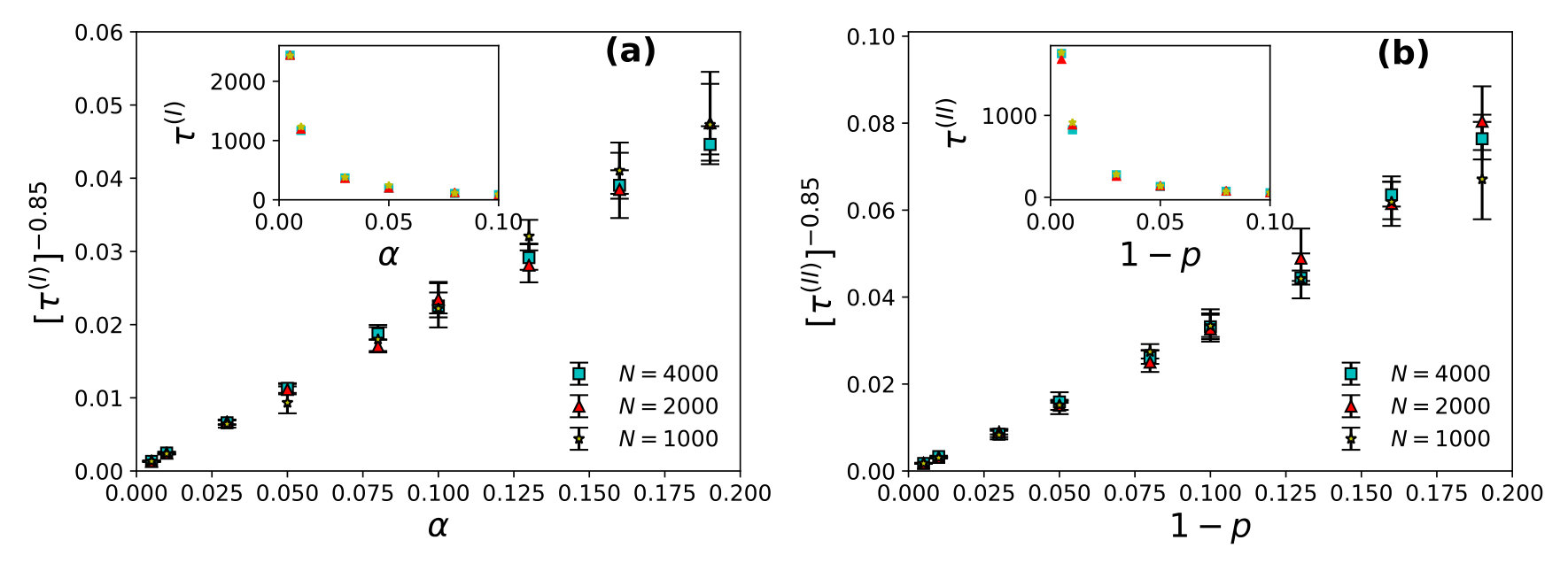 Figure 6
Figure 6| lattice dimension | ||||
|---|---|---|---|---|
| approx. | approx. | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Phase transition in the Kolkata Paise Restaurant problem
Antika Sinha
Department of Computer Science, Asutosh College, Kolkata-700026, India
Bikas K. Chakrabarti
Saha Institute of Nuclear Physics, Kolkata-700064, India
S.N.Bose National Centre for Basic Sciences, Kolkata-700106, India
Economic Research Unit, Indian Statistical Institute, Kolkata-700108, India
Abstract
A novel phase transition behaviour is observed in the Kolkata Paise Restaurant (KPR) problem where large number () of agents or customers collectively (and iteratively) learn to choose among the restaurants where she would expect to be alone that evening and would get the only dish available there (or may get randomly picked up if more than one agent arrive there that evening). The players are expected to evolve their strategy such that the publicly available information about past crowd in different restaurants can be utilized and each of them is able to make the best minority choice. For equally ranked restaurants we follow two crowd-avoiding strategies: Strategy I, where each of the number of agents arriving at the -th restaurant on the -th evening goes back to the same restaurant on the next evening with probability , while in Strategy II, with probability , when . We study the steady state (-independent) utilization fraction giving the steady state (wastage) fraction of restaurants going without any customer in any particular evening. With both the strategies we find, near (in strategy I) or (in strategy II), the steady state wastage fraction or with and the convergence time (for becoming independent of ) varies as or , with in infinite-dimension (rest of the neighboring restaurants), three-dimension ( neighbors) and two-dimension ( neighbors) respectively.
††preprint: AIP/123-QED
Social games where the players or agents try to choose for the less crowded or minority solutions (to avail of the scarce resources) are very common. In such games, a macroscopically large number of agents make decision parallelly and iteratively (in absence of any dictator), based on publicly available information (regarding past mistakes and successes), to choose where she can be alone (and avail the resource). Eventually, such collective learning makes it socially efficient. One such social minority game is the Kolkata Paise Restaurant (KPR) problem. We study the steady state statistics and the phase transition behaviour of the KPR problem Chakrabarti et al. (2009, 2017). KPR is a many-agent and many-choice repeated game, where the agents collectively learn from past mistakes, how to share best the limited resources. In this kind of games, each agent tries to anticipate and choose her own strategy, every time (learning from the publicly available past informations) in parallel mode (unguided; in absence of any instruction or non-playing agent/dictator). The restaurants are assumed to prepare every evening fixed meal plates which are equally priced (hence no budget constraint for customers). Only the crowd avoidance abilities determines the individual success in securing meal on any or successive evenings. We show that in KPR, two stochastic strategies can eventually lead to the most efficient social solution at some limiting control parameter values, corresponding to a phase transition point, thereby implying very long convergence time (critical slowing down).
I Introduction
Specifically, we consider here the case of restaurants and agents or customers or players who decide every evening (on the basis of informations about the past evenings, available to everyone), which restaurant to choose such that she will be alone there and will get the meal. Each restaurant is assumed, for simplicity, to prepare one dish every evening (generalization does not help getting any further insight at this stage). For more than one person arriving any restaurant any evening, a randomly chosen one will get the meal and rest (arriving there) will not get any that evening.
Although every evening each of the restaurants prepares one dish and in-principle everyone is entitled to a dish every evening, overcrowding due to stochasticity of choices make the probability of success for each customer less than unity in such (democratic choice) games. We measure the social efficiency by the utilization fraction on any day (evening) as
[TABLE]
with for respectively; denotes the number of agents arriving at the -th (rank) restaurant on -th evening. The fraction gives the fraction of social wastage or the fraction of restaurants going without any customer on the -th evening. The objective of social learning strategies here is to achieve = 1 preferably in finite convergence time (), i.e., for , or at least as (see e.g., Chakrabarti et al. (2017); Ghosh et al. (2010); Ghosh, Chakrabarti, and Chakrabarti (2010)).
Indeed, a dictated solution is extremely simple and very efficient: the dictator asks everyone to form a queue and visit the restaurants according to their respective positions in the queue and then asks them to shift their positions by one step (rank) in the next evening (assuming periodic boundary condition). Everyone gets the food: No wastage, i.e., the steady state (-independent) utilization fraction , and that too from the first evening (convergence time is zero). This is true even when the restaurants have ranks (agreed by all the agents or customers). However, in reality (in democracy), this dictated solution is not acceptable and each agent would like to (learn from past experience and) decide on her own every evening which restaurant to choose such that she is alone there and gets the dish. The more successful such collective learning, the more is the utilization fraction of the services. Question is, what is the maximum utilization fraction value () and convergence time () of such ‘learned’ democratic choices (due to individually learned and chosen strategies) for a large society (). Note that the dictated solution gives full utilization ( = 1) and that too in zero convergence time ( = 0) for any .
Assuming that no past history of restaurant occupancy is available, i.e., no learning, let us consider the process of randomly choosing any of the restaurant by agents (we consider = 1 in KPR game later). Then the probability of choosing any restaurant by agents on any evening is
[TABLE]
As we mentioned earlier, the agents would try to learn from the past mistakes in making their respective choices and can improve her chance to be in the minority with efficient learning strategy. We study here the dynamics of the game with two such stochastic learning strategies which allow for considerable increase in the eventual (steady state) value of the utilization fraction (). Specifically, we study here two strategies (Strategy I and Strategy II), giving the probabilities to choose going back or not to the same restaurant visited last evening or to another restaurant, depending on the last evening’s crowd-size in the chosen restaurant. We find interesting phase transition behaviour (with identical universality class) with both of these strategies. This transition behaviour is qualitatively different from the transitions observed Ghosh et al. (2012, 2014) earlier with agents’ sticking probability to any chosen restaurant and with limited resources () in KPR and similar models.
We studied here the phase transition behaviour (from steady state value of to ) and convergence or relaxation time , diverging as the critical point is approached, using both the strategies I and II in different dimensions where the choice of the agent to shift to the neighboring restaurants next evening are different (to any of the other restaurants in , to neighboring six restaurants in and to four neighboring restaurants in ).
II Strategy Description
In the following, we study numerically the dynamics of KPR game played by agents (interchangeably called players or agents) such that each evening (interchangeably called day or time) each of the agents employ some stochastic strategy, based on the past crowd information in different restaurants (available to each players), helping her to choose among restaurants, maximizing her chance of arriving at a vacant restaurant that evening and to get the dish. We study here the following strategies: I and II. We consider here all the restaurants as equally ranked (none is preferred more than the other and the choice depends only on the past crowd size).
Strategy I:
The strategy here is that any agent tries to go back to the same restaurant as chosen in the earlier evening (day) with a probability decreasing with an inverse power of the crowd size arriving there last evening and goes to any other restaurant randomly with the rest of the probability. In other words, on day , an agent goes back to her last day’s visited restaurant with probability
[TABLE]
Strategy II:
We also consider the strategy where, on the -th evening, every agent tries to go back to the same restaurant as chosen on the earlier evening with probability
[TABLE]
for choosing any of the neighbouring restaurants restaurant ().
Note that for (in Strategy I) or for (in Strategy II), every evening she will return to the first day’s chosen and visited restaurant, when of course the dynamics on successive days become trivial for both the strategies I and II. However = (for Strategy I) or (for Strategy II) case can be extremely non-trivial and, as we will see, have interesting transition and other behaviours.
III Numerical Results
Here we numerically study, with minimum = (and maximum ) and (number of restaurants = = number of agents/players), processing choice responses from each of agents to measure social utilization fraction . Steady state occurs when becomes time independent. The steady state convergence time (for , is when social utilization fraction does not change on average over the next hundred iteration, within a predefined error margin) is measured in units of time/iteration where each iteration corresponds to scanning as when each of the agents finishes one exercise of choices following Strategy I or II. Depending on the values of or in strategy I (Eqs. 3a, 3b) or II (Eqs. 4a, 4b) respectively, values of the aggregated utilization fraction and (estimated using Eq. 1) becomes unity for (in strategy I) or for (for strategy II), where or . We also study the growth of convergence time as (for strategy I) or (for strategy II) considering distinct lattices sizes. The restaurants are assumed to be situated on the lattice sites. Neighbour at each lattice site directs in , , on both side(s) of each lattice direction of the present occupied restaurant. However in , every other restaurant is a nearest neighbor. Here, in order to avoid crowd of the last evening , the agents can choose one among neighbouring restaurants following Eqs. 3a, 3b for Strategy I or Eqs. 4a, 4b for Strategy II on the next evening . Note that since plotting a diverging function (here the convergence time ) is difficult, we plot instead it’s inverse which tends to vanish at the same divergence point with an identical but negative exponent value.
III.1 Infinite dimensional lattice
Here, if number of agents had chosen the -th restaurant last evening (time ) then each of them chooses to go back to the same -th restaurant with probability on the next (-th) evening and chooses any of the remaining restaurants otherwise, for strategy I. With strategy II, the probability for each of the agents to go back to the -th restaurant on the next (-th) evening is for and to any other of the restaurants with probability . After the system stabilizes i.e., when the utilization fraction becomes independent of , we note the steady state utilization fraction with strategy I or with strategy II and note the convergence time for strategy I and for strategy II, when becomes -independent.
We find the power law fits for wastage fraction with (see Fig. 1) and with (see Fig. 2) for both of the strategies I and II. All simulations are done with up to and the steady averages up to a maximum number of runs (days/evenings) of order . For estimating values, we looked for the convergence time for or to attain the steady state value (within a small fore-assigned error margin).
III.2 Three dimensional lattice
Here the restaurants are assumed to be situated on the sites of a simple cubic lattice. number of agents had chosen the -th restaurant last evening (time ) then each of them chooses to go back to the same -th restaurant with probability next (-th) evening and chooses one among the six of its neighbouring restaurants otherwise, for strategy I. With strategy II, the probability for each of the agents to go back to the -th restaurant on the next (-th) evening is for and to any of the six neighbouring restaurants with probability . After the system stabilizes i.e., when the utilization fraction becomes independent of , we note the steady state utilization fraction with strategy I or with strategy II and note the convergence time for strategy I and for strategy II, when becomes -independent. We find the power law fits for wastage fraction with (see Fig. 3) and with (see Fig. 4) for both of the strategies I and II. All these studies are for and averaged over runs.
III.3 Two dimensional lattice
Here the restaurants are assumed to be situated on the sites of a square lattice. number of agents had chosen the -th restaurant last evening (time ) then each of them chooses to go back to the same -th restaurant with probability next (-th) evening and chooses one among the four of it’s neighbouring restaurants otherwise, for strategy I. With strategy II, the probability for each of the agents to go back to the -th restaurant on the next -th evening is for and to any of the four neighbouring restaurants with probability . After the system stabilizes i.e., when the utilization fraction becomes independent of , we note the steady state utilization fraction with strategy I or with strategy II and note the convergence time for strategy I and for strategy II, when becomes -independent. We find the power law fits for wastage fraction with (see Fig. 5) and with (see Fig. 6) for both of the strategies I and II. All these studies are for and averaged over runs.
III.4 One dimensional lattice
Here the restaurants are assumed to be situated on the sites of a linear chain. If number of agents had chosen the -th restaurant last evening (time ), then each of them chooses to go back to the same -th restaurant with probability next (-th) evening and chooses one among the two of it’s neighbouring restaurants otherwise, for strategy I. With strategy II, the probability for each of the agents to go back to the -th restaurant on the next -th evening is for and to any of the two neighbouring restaurants with probability . It is straightforward to show the phase transition disappears and for any value of or that is equal to unity and the convergence time is trivially dependent on (no critical slowing down or divergence near the critical point) as in other dimensions. This can be seen easily in the directed case, where each one chooses to hop to its right (or left) restaurants and the chain form a ring (with periodic boundary condition).
IV Summary & Discussion
The KPR problem is an iterative, many choice, many player game, where the players try to learn from their past mistakes and from the publicly available information regarding the crowd-sizes of all the restaurants in the past, to choose one where she is expected to be alone today. We consider the cases here where the number () of agents (players) equals the number of resources (restaurants). It was shown Chakrabarti et al. (2009) that no learning (random choices) leads to a societal resource utilization fraction = 1 - exp(-1) (Eqs. 2a, 2b). We study the collective learning induced phase transition in the KPR problem with (learned and mutually agreed) stochastic strategies I and II, where at the respective critical points (with diverging convergence time due to critical slowing down). These are repetitive learning stochastic strategies, which are shown to reach eventually (after the convergence time) a maximally utilized resource state which is best for most of the agents, who are not unique and every one in the game will come in turn (stochastically) to this fortunate fraction (stochastic Nash type equilibrium). As mentioned already Chakrabarti et al. (2009), random choice by agents (myopic agents can be knocked out by others choosing that restaurant next evening, as every player is equal), though still not one shot game, with utilization fraction can be analytically estimated. Here we present improvements on those results.
We have studied here the the social utilization fraction , where represents the number of customers who choose the -th restaurant for -th evening for = 0 and for numerically (Eq. 1). We considered here the case of equally ranked restaurants (and left the case where each of the restaurants have an unique rank and those ranks are agreed by all the agents for future study). The learning strategies employed by the agents here are strategies I and II respectively. Based on the observations from the previous studies Chakrabarti et al. (2017); Ghosh et al. (2010) that the probabilistic strategy to go back to the earlier chosen -th restaurant on the next evening with probability inversely proportional to the crowd size gives better success (compared to random choice), the strategies here (in both I and II) are developed such that the agents go back to the same restaurant on the next evening with probability in I and with probability if in II, and chooses any of the other restaurants with rest of the probability (Eqs. 3a, 3b and 4a, 4b). As demonstrated, both the strategies (I and II) lead to identical statistics (singularities), though the strategy II is computationally little faster; see TABLE 1.
The steady state corresponds to the case where the average utilization becomes -independent and as shown here, as in strategy I and in strategy II, though the convergence time (to reach this utilization state) diverges there. Specifically we find: and , for strategy I and and , for strategy II with and in , and respectively for both of the strategies (I and II). It may be noted that the relaxation time diverges near critical point or which indicates full social utilization fraction is not achievable in the model at any practical convergence time limit. However in any phase transition, at the transition (critical) point, the relaxation (convergence) time diverges (often called critical slowing down). The observed singularity in the divergence here for confirm the phase transition behaviour in our KPR model near or (with strategies I and II). To show the practical benefits of these strategies we also give here TABLE 1, showing the (very small) values for or . Of course the social utilization fraction values obtained here are much less than maximum possible values of unity.
We hope, further studies (and applications) of this phase transition behaviour for the practical cases as suggested and considered in refs. Park and Saad (2017); Yang, Iyer, and Frazier (2018); Martin and Karaenke ; Martin (2019) will contribute significantly in social science. It may be mentioned that in the dynamic matching of car hire problem Martin and Karaenke ; Martin (2019), extensive application of strategy I (with ) suggested considerably increased efficiency of optimization in the market, while for avoiding crowd in job slot selection for internet of things Park and Saad (2017), strategy I was modified to reward only the agents (here jobs) who come (or get thrown) alone for each restaurant (slot). However such studies also face the formidable challenges to accommodate effectively the ranking of the restaurants, heterogeneity in their learning capacities to form queues spontaneously in finite convergence time.
V Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
We are thankful to Arnab Chatterjee for helpful suggestions. AS is grateful to Saha Institute of Nuclear Physics, Kolkata for hospitality and Asutosh College, Kolkata for support. BKC is grateful to J.C. Bose Fellowship (DST, Govt. of India) Research grant for support.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Chakrabarti et al. (2009) A. S. Chakrabarti, B. K. Chakrabarti, A. Chatterjee, and M. Mitra, “The kolkata paise restaurant problem and resource utilization,” Physica A: Statistical Mechanics and its Applications 388 , 2420–2426 (2009).
- 2Chakrabarti et al. (2017) B. K. Chakrabarti, A. Chatterjee, A. Ghosh, S. Mukherjee, and B. Tamir, Econophysics of the Kolkata Restaurant Problem and Related Games: Classical and Quantum Strategies for Multi-agent, Multi-choice Repetitive Games (Springer, 2017).
- 3Ghosh et al. (2010) A. Ghosh, A. Chatterjee, M. Mitra, and B. K. Chakrabarti, “Statistics of the kolkata paise restaurant problem,” New Journal of Physics 12 , 075033 (2010).
- 4Ghosh, Chakrabarti, and Chakrabarti (2010) A. Ghosh, A. S. Chakrabarti, and B. K. Chakrabarti, “Kolkata paise restaurant problem in some uniform learning strategy limits,” in Econophysics and Economics of Games, Social Choices and Quantitative Techniques (Springer, 2010) pp. 3–9.
- 5Ghosh et al. (2012) A. Ghosh, D. De Martino, A. Chatterjee, M. Marsili, and B. K. Chakrabarti, “Phase transitions in crowd dynamics of resource allocation,” Physical Review E 85 , 021116 (2012).
- 6Ghosh et al. (2014) A. Ghosh, A. Chatterjee, A. S. Chakrabarti, and B. K. Chakrabarti, “Zipf’s law in city size from a resource utilization model,” Physical Review E 90 , 042815 (2014).
- 7Park and Saad (2017) T. Park and W. Saad, “Kolkata paise restaurant game for resource allocation in the internet of things,” in 2017 51st Asilomar Conference on Signals, Systems, and Computers; IEEE Xplore (IEEE, 2017) pp. 1774–1778.
- 8Yang, Iyer, and Frazier (2018) P. Yang, K. Iyer, and P. Frazier, “Mean field equilibria for resource competition in spatial settings,” Stochastic Systems 8 , 307–334 (2018).