String-to-String Interpretations with Polynomial-Size Output
Miko{\l}aj Boja\'nczyk, Sandra Kiefer, Nathan Lhote

TL;DR
This paper characterizes string-to-string MSO interpretations as exactly the polyregular functions, showing they are closed under composition and have polynomial output size, connecting logical and automata-theoretic perspectives.
Contribution
It establishes that string-to-string MSO interpretations are equivalent to polyregular functions and are closed under composition, bridging logic and automata theory.
Findings
String-to-string MSO interpretations are exactly polyregular functions.
Polyregular functions are recognized by pebble transducers.
MSO interpretations are closed under composition.
Abstract
String-to-string MSO interpretations are like Courcelle's MSO transductions, except that a single output position can be represented using a tuple of input positions instead of just a single input position. In particular, the output length is polynomial in the input length, as opposed to MSO transductions, which have output of linear length. We show that string-to-string MSO interpretations are exactly the polyregular functions. The latter class has various characterizations, one of which is that it consists of the string-to-string functions recognized by pebble transducers. Our main result implies the surprising fact that string-to-string MSO interpretations are closed under composition.
Click any figure to enlarge with its caption.
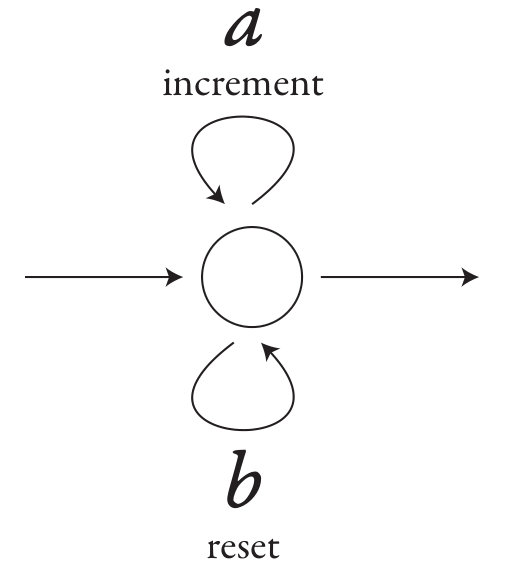 Figure 1
Figure 1 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Institute of Informatics,
University of Warsaw, [email protected] Department of Computer Science,
RWTH Aachen University, [email protected] Institute of Informatics,
University of Warsaw, [email protected]
\CopyrightMikołaj Bojańczyk and Sandra Kiefer and Nathan Lhote \ccsdesc[500]Theory of computation Transducers
Acknowledgements.
The authors would like to thank Benedikt Brütsch for helpful discussions on the topic.\hideLIPIcs\EventEditorsChristel Baier, Ioannis Chatzigiannakis, Paola Flocchini, and Stefano Leonardi \EventNoEds4 \EventLongTitle46th International Colloquium on Automata, Languages, and Programming (ICALP 2019) \EventShortTitleICALP 2019 \EventAcronymICALP \EventYear2019 \EventDateJuly 9–12, 2019 \EventLocationPatras, Greece \EventLogoeatcs \SeriesVolume132 \ArticleNo102
String-to-String Interpretations with Polynomial-Size Output
Mikołaj Bojańczyk
Sandra Kiefer
Nathan Lhote
Abstract
String-to-string mso interpretations are like Courcelle’s mso transductions, except that a single output position can be represented using a tuple of input positions instead of just a single input position. In particular, the output length is polynomial in the input length, as opposed to mso transductions, which have output of linear length. We show that string-to-string mso interpretations are exactly the polyregular functions. The latter class has various characterizations, one of which is that it consists of the string-to-string functions recognized by pebble transducers.
Our main result implies the surprising fact that string-to-string mso interpretations are closed under composition.
keywords:
MSO, interpretations, pebble transducers, polyregular functions
1 Introduction
A string-to-string function is called regular if it is computed by a deterministic two-way automaton with output. There are many equivalent models for the same class of functions: string-to-string mso transductions [10], streaming string transducers [1], and various kinds of combinator-based formalisms [2, 8, 5].
A deterministic two-way automaton can visit each input position at most once in each state, otherwise it would loop forever. This means that the length of the run – and also the size of the output word – is linear in the input string. One way to go beyond linear-sized outputs was proposed by Milo, Suciu, and Vianu [17], following earlier work by Globerman and Harel [12]: equip the automaton with pebbles which can be used to mark positions in the input word. To avoid making the model Turing-powerful, the pebbles are required to observe a so-called stack discipline: the pebbles are organised in a stack, and only the top-most pebble can be moved. In [3], it is shown that pebble transducers are equivalent to multiple other models: a higher-order functional programming language [3, Section 4], an imperative programming language with for-loops [3, Section 3], combinators [3, end of Section 4], and compositions of certain simple atomic functions [3, Section 1]. Because of the multitude of models and their polynomial size outputs, the class of functions recognised by these models is called polyregular functions.
The list of models for polyregular functions described in [3] does not include any logical model. In this paper, we fix that omission. As mentioned above, for the regular functions, which have linear size output, the logical model consists in string-to-string mso transductions. In an mso transduction, each position of the output string is interpreted as a single position of the input string. A natural idea to capture polyregular functions is to consider what we call string-to-string mso interpretations, where a position of the output string is represented by a -tuple of positions in the input string. At first glance, this idea looks suspicious: if string-to-string mso interpretations were equivalent to polyregular functions, then they would be closed under composition, because the class of polyregular functions is. However, composing two string-to-string mso interpretations
[TABLE]
raises the following issue. Suppose that positions of the intermediate word in are represented by -tuples of positions in the input word from . If an mso formula defining quantifies over a set of positions in the intermediate word to define a property of the output word in , then this corresponds to quantifying over a set of -tuples of positions in the input word. If we assume dimension , then the problem dissolves, and this is why mso transductions have dimension , whereas dimension is never used in the context of mso (as opposed to first-order logic, where the standard notion of transformation, i.e. first-order interpretation, uses higher dimension).
As our main result, we show that the problems discussed above only invalidate the natural construction for composing mso interpretations, which uses substitution of formulas. Still, and surprisingly, for structures that represent strings there exists a (less natural) construction. This follows from our main result which states that polyregular functions are exactly the string-to-string mso interpretations. Indeed, corollaries of the main result are that (a) string-to-string mso interpretations are closed under composition; and (b) for every regular string language, its inverse image under a string-to-string mso interpretation is also regular. This is because (a) and (b) are true for polyregular functions. Proving (a) and (b) directly for string-to-string mso interpretations seems hard; in fact an understandable (but wrong) first reaction to the claims (a) and (b) would be that they are false, for the reasons discussed in the previous paragraph.
It is easy to see that every polyregular function is a special case of a string-to-string mso interpretation. One argument is that a -pebble automaton can be simulated using a string-to-string mso interpretation, where configurations of the pebble automaton are represented using -tuples of positions in the input word. The difficulty lies in proving the opposite direction and it comes from the stack discipline required in a pebble automaton. A -tuple of positions used by an mso interpretation can of course be viewed as a configuration of a pebble automaton, but there does not seem to be any reason why the resulting pebble automaton should observe stack discipline. It turns out – and this is the main technical insight of this paper – that any mso formula which defines a linear ordering on -tuples of positions in strings must necessarily observe an implicit stack discipline, which makes it possible to translate a string-to-string mso interpretation into a pebble automaton.
Outline.
After describing string-to-string mso interpretations in Section 2, we revise polyregular functions via the formalism of for-programs in Section 3. In Section 4, we show that the models are equivalent.
2 Interpretations
In this section, we revise first-order and mso interpretations, which are transformations of relational structures using formulas.
2.1 Logic and interpretations
Relational vocabularies and logic.
A (relational) vocabulary is a set of relation names, each one associated with a natural number called its arity. For short, we refer to relational vocabularies simply as vocabularies. A structure over a vocabulary consists of a set called the universe and for each relation name of a corresponding relation of the same arity over the universe. To define properties of relational structures, we use monadic second-order logic and its first-order fragment with the usual syntax and semantics [20]. We use the convention that lower-case variables range over elements and upper-case variables range over sets of elements.
Interpretations.
Intuitively speaking, an interpretation is a function from relational structures to relational structures where each element of the universe of the output structure is a tuple of elements of the input structure, and the relations of the output structure are defined using formulas evaluated over the input structure.
Definition 2.1** (Interpretations over general structures).**
For , the syntax of a -dimensional first-order interpretation consists of:
two vocabularies, called the input vocabulary and the output vocabulary 2. 2.
an fo formula over the input vocabulary with free variables, called the universe formula. 3. 3.
for each and each -ary relation name of the output vocabulary, an associated fo formula over the input vocabulary, with free variables.
mso interpretations* are defined analogously, except that formulas of mso are used, but the free variables still range over elements and not over sets.*
The semantics of an interpretation is a function from structures over the input vocabulary to structures over the output vocabulary, defined as follows.
- •
The universe of the output structure is the set of -tuples of elements in the universe of the input structure which satisfy the universe formula from item 2 in Definition 2.1.
- •
An -ary relation name of the output vocabulary is interpreted as the set of -tuples of -tuples from the input structure, for which (a) each -tuple is in the output universe, and (b) the entire -tuple satisfies the formula in item 3 in Definition 2.1.
Composition.
First-order interpretations are closed under composition [14, p. 218]. Let us recall the proof. Suppose that we want to compose interpretations
[TABLE]
of dimensions and , respectively. The -dimensional composition is obtained from as follows: (a) quantification over elements of is replaced by a quantification over -tuples of elements; and (b) relation names from that appear in the input of are replaced by the corresponding formulas from . This idea does not work for mso in general, since set quantification in would need to be replaced by quantification over sets of -tuples. It does work when . This essentially corresponds to Courcelle’s transductions, for which closure under composition follows naturally [7, Theorem 7.14]. To recover closure under composition for , one can use (not necessarily monadic) second-order logic, which by Fagin’s Theorem [16, Corollary 9.9] corresponds to the polynomial hierarchy of computational complexity and is outside the scope of this paper.
2.2 String-to-string interpretations
We are interested in interpretations that transform structures which represent strings. While there are two natural ways to model strings as relational structures, namely with an order relation or with a successor relation, only the order relation is useful in our context.
Definition 2.2** (String-to-string interpretations).**
For a string , its ordered model is defined to be the following relational structure, denoted by :
- •
the universe consists of the positions in the string, i.e., natural numbers;
- •
there is a binary relation for the natural order on positions;
- •
for each there is a unary relation which is satisfied by every position with label .
A function is called a first-order string-to-string interpretation if the corresponding transformation on ordered models is a first-order interpretation for strings with length at least two111A typical operation we want to model is string duplication. When the input length is at least two, one can represent additional copies of the input string using a higher dimension. For input length , the output length will be regardless of the dimension . Another solution to this issue would be to have duplication built into the definition of interpretations. . Likewise we define mso string-to-string interpretations.
Example 2.3**.**
Consider the function which maps a word to the concatenation of all of its reversed prefixes, as in the following example (with prefixes grouped for better readability):
[TABLE]
This transformation is the running example in [3]. We show that can be seen as a string-to-string first-order interpretation. The dimension is , i.e. positions in the output word represent pairs of positions in the input word. A pair of positions in the input word is used in the output word if it satisfies the universe formula . The idea is that represents the length of the prefix, while is the position in that prefix. The label of a position is inherited from the second coordinate, as expressed by the formulas corresponding to labels on the output structure:
[TABLE]
The order on the positions of the output word is defined by the formula
[TABLE]
Note that the above formula defines the lexicographic ordering on pairs of positions, with the first coordinate being used in increasing order, and the second coordinate being used in decreasing order. This, as it will turn out, is not a coincidence, since our main technical result says that it is impossible to define a linear order on tuples of positions without implicitly using some kind of lexicographic ordering.
Successor instead of order.
When modelling a string as a relational structure, we use the order on positions. An alternative solution would be to use just the successor relation. The difference between the two solutions is that it is harder to define an order on -tuples of positions than it is to define a successor relation. It turns out that the difference is crucial, and functions that output strings with successor can be ill-behaved. Note that whether or not the input string is equipped with an order or a successor relation makes no difference, since the order on the position of the input string can be recovered in mso, which can compute the transitive closure of binary relations on positions.
Define the successor model of a string in the same way as the ordered model from Definition 2.2, except that a binary relation for successor is used instead of the order. Define a successor-mso string-to-string interpretation to be a string-to-string function which is computed by an mso interpretation, assuming that strings are represented by their successor models. Likewise, we define successor-first-order string-to-string interpretations. Successor-first-order string-to-string interpretations are closed under composition, because first-order interpretations are closed under composition. On the other hand, successor-mso string-to-string interpretations are not closed under composition and lead to undecidability, as summarised in the following theorem. The proof can be found in Appendix A.
Theorem 2.4**.**
The class of successor-mso string-to-string interpretations is not closed under composition, and strictly contains the class of (order-)mso string-to-string interpretations. 2. 2.
The following is undecidable: given a successor-first-order string-to-string interpretation and a regular language over the output alphabet, decide if is nonempty.
3 Polyregular functions
Here we describe the class of polyregular functions. It has several equivalent characterisations, see [3, Theorem 4.4], one of which consists in the aforementioned pebble transducers. For the purposes of this paper, it will be most convenient to use a slightly more abstract characterisation in terms of for-programs, a machine model for string-to-string functions. We just explain the formalism on short examples, for a more detailed description see [3].
Most of the syntactic constructions that can be used in a for-program are illustrated in Figure 1(a): (1) variables ranging over positions in the input word; (2) for-loops in which a variable iterates over all positions in the input word in increasing or decreasing order; (3) if-statements which depend on the order/labels of variables; (4) instructions which output letters. Position variables cannot be declared or written to, they are implicitly declared by for-loops and their only updates are the iterations performed by the for-loops.
The only feature of for-programs that is not used in Figure 1(a) is (5) Boolean variables. Figure 1(b) shows a program that outputs only those letters in the input word which have even distance to the last position. In the program, the Boolean variable P is declared in the scope of a for-loop. On each iteration of the loop, the variable is reinitialised to false.
A for-program is called first-order definable if Boolean variables can only be updated from false, which is their initial value upon declaration, to true. In other words, the only allowed update for Boolean variables is P := true. For the first-order restriction, it is important that Boolean variables can be declared inside for-loops, and that they are reinitialised to false at each iteration of the loop that they are declared in. The reason for the name “first-order definable” is that one can define in first-order logic the reachability relation on program states of the for-program, see [3, Lemma 5.3].
Definition 3.1**.**
A string-to-string function is called polyregular if it is computed by a for-program. It is called first-order polyregular if it is computed by a first-order definable for-program.
The class of polyregular functions has other characterisations, including the string-to-string pebble transducers introduced by Milo, Suciu and Vianu [17], as well as a higher-order functional programming language [3, Section 4]. The main result of this paper, Theorem 4.1 in the next section, adds a logical characterisation, namely string-to-string mso interpretations.
Evaluating first-order formulas.
The for-programs described above take as input strings and also output strings. One can also consider for-programs which input a string with distinguished positions and which output a Boolean value, as in Figure 1(c). The distinguished positions are represented by free variables (here x1 and x2) while the output value is taken from some distinguished Boolean variable, here P.
Lemma 3.2**.**
Let be an fo formula over strings. There is a first-order for-program which computes the following.
- •
Input.* A word and positions in ;*
- •
Output.* Yes or No, depending on whether satisfies .*
Proof 3.3**.**
The for-program implements the semantics of an fo formula. For each quantifier, it loops over all possible values for the quantified position, and a Boolean variable is used to remember if some value has already been found which renders the formula true.
A similar result is true for mso formulas, but the proof for that statement uses automata.
4 Equivalence
We show that the models defined in Sections 2 and 3 are equivalent.
Theorem 4.1**.**
String-to-string mso interpretations are exactly the polyregular functions. 2. 2.
First-order string-to-string interpretations are exactly the first-order polyregular functions.
Since the class of polyregular functions is closed under composition222Closure under composition was proved for pebble transducers in [9, Theorem 11] and for the class of for-programs in [3, Section 8.1] as a step in proving equivalence with the other models of polyregular functions., we obtain:
Corollary 4.2**.**
String-to-string mso interpretations are closed under composition.
By using Theorem 4.1, the proof of the corollary passes through for-programs. We are not aware of any direct proof that does not exploit the equivalence to polyregular functions.
The rest of this paper is dedicated to the proof of Theorem 4.1. We begin with a reduction of the first to the second item. This reduction illustrates a general phenomenon, namely that results about first-order polyregular functions often imply results about general polyregular functions, despite the latter class being larger. The reason behind this phenomenon is the following lemma, which says that for every polyregular function, all of the behaviour that is not first-order definable can be pushed into a simple preprocessing step. Define a rational function, see [4, Section 13.2], to be a string-to-string function which is recognised by a nondeterministic automaton, where every transition is labelled by a pair consisting of a letter from the input alphabet and a string over the output alphabet, and which is unambiguous in the sense that every input string admits exactly one accepting run.
Lemma 4.3**.**
A function is polyregular if and only if it is a composition consisting of:
- (a)
a (letter-to-letter) rational function; followed by 2. (b)
a first-order polyregular function. 2. 2.
A function is an mso string-to-string interpretation if and only if it is a composition consisting of:
- (a)
a (letter-to-letter) rational function; followed by 2. (b)
a first-order string-to-string interpretation.
The proof of Lemma 4.3 is based on ideas from [6, 15, 3] and uses factorisation forests.
Proof 4.4**.**
The right-to-left implications in items 1 and 2 are proved the same way: both polyregular functions and mso string-to-string interpretations are closed under pre-composition with rational functions. For the class of polyregular functions, this holds because it is closed under composition and contains all rational functions [3, Theorem 1.6]. For mso string-to-string interpretations, one observes that rational functions are a special case of mso string-to-string interpretations of dimension 1 (see [11, Figure 7], where mso interpretations of dimension 1 are the same as the so-called regular functions), and mso interpretations are closed under pre-composition with such functions (see the remarks at the end of Section 2.1).
To prove the left-to-right implications in items 1 and 2, namely the decomposition into rational pre-processing and first-order post-processing, we use the following claim.
A letter-to-letter rational function is a rational function where every transition in the underlying automaton is labelled with exactly one output letter, in which case the input and output strings have the same set of positions.
Claim 1**.**
Let be an mso formula which selects -tuples of positions in strings over an alphabet . There are a letter-to-letter rational function and a first-order formula which selects -tuples of positions in strings over the alphabet such that
[TABLE]
The claim is the special case of [6, Theorem 2] for finite strings instead of infinite trees, and its proof uses factorisation forests (see [19]). Another proof of the above claim is in [15, Theorem 3.2]. Using the claim, we immediately get the left-to-right implications in item 2. For item 1, we also use Lemma 4.3 to obtain a first-order for-program realizing the function. The main idea is that if the reachability relation is first-order definable, then one can define a first-order query which accepts consecutive produced tuples.
With the lemma, we show that item 2 in Theorem 4.1 implies item 1, i.e. if first-order string-to-string interpretations are exactly the first-order polyregular functions, then mso interpretations are exactly the polyregular functions:
[TABLE]
It remains to prove item 2 in Theorem 4.1, i.e. that first-order string-to-string interpretations are exactly the first-order polyregular functions. The right-to-left inclusion follows immediately from [3, Lemma 5.3], which says that a formula in first-order logic can define the reachability relation on program states in first-order for-programs. We are left with the left-to-right-inclusion:
[TABLE]
The rest of the paper is devoted to showing the above inclusion. When simulating a first-order interpretation by a for-program, we will mainly be concerned with the universe of the output string (which is a set of -tuples of positions in the input string) and its ordering. The labelling of the -tuples can then be recovered using the for-program from Lemma 3.2. The main result is that every first-order definable linear ordering on tuples of positions can be implemented by a for-program. To be able to speak about this result, we introduce some notation for devices that produce lists of tuples of positions.
Enumerators.
Let . A -enumerator over an alphabet is a function of the following form:
- •
Input. A string ;
- •
Output. A list of -tuples of positions in , which is nonrepeating333Every tuple appears at most once, but positions can appear in multiple tuples. We need this for the existence of the formulas stated in the following definitions..
We compare the following two ways of implementing -enumerators:
A -enumerator is called definable if there are two fo formulas: one with variables, which says when a tuple is part of the output list, and one with variables, which defines a total order on the tuples selected by the first formula. 2. 2.
A -enumerator is called programmable if its output can be computed by a first-order for-program which instead of outputting letters uses instructions of the form output (x1,...,xk) where x1xk are position variables.
For definable -enumerators, the order on tuples in the output list is given explicitly by the formula , while in programmable ones, the order is implicit from the order in which the output instructions are executed during the computation.
Example 4.5**.**
We present an enumerator based on Example 2.3. Consider the -enumerator which outputs all pairs of positions with , listed in lexicographic order, where is ordered in increasing order and is ordered in decreasing order. Here is an example:
[TABLE]
This enumerator is definable, as witnessed by the formula in Example 2.3. The formula is quantifier-free, but in general, quantifiers are allowed. Here is a for-program which computes the same function:
The following lemma is the main technical result of this paper.
Lemma 4.6**.**
Every definable -enumerator is also programmable.
Our proof of Lemma 4.6 uses two fundamental ingredients. The first is by now standard: this is Simon’s factorisation forest theorem [19], which roughly says that every string can be cut into pieces that are similar to each other. The second ingredient is new: the Domination Lemma, presented in Section 4.1, roughly says that if a string is cut into pieces that are similar to each other, then any first-order definable linear order on tuples of positions must observe an implicit stack discipline. These two results are combined in Section 4.2 to prove Lemma 4.6. Before we proceed with the proof of Lemma 4.6, we use it to complete the proof of Theorem 4.1.
Proof 4.7** (Proof of Theorem 4.1, second part).**
The only part of Theorem 4.1 that has not been proved yet is that every first-order string-to-string interpretation is polyregular. Suppose that is a -dimensional first-order string-to-string interpretation. Consider the -enumerator which inputs a string and outputs the list of -tuples of positions in that are used to represent output positions of , in the appropriate order. Apply Lemma 4.6 to obtain a first-order for-program which computes the same list. To compute the original function , we use a for-program which behaves as , except that instead of outputting a -tuple of positions like , it uses the program described in Lemma 3.2 as a subroutine to check what is the output letter that should be produced for this tuple, and outputs that letter.
4.1 The Domination Lemma
In this section we present the Domination Lemma, which says that if is a first-order definable linear order on -tuples of positions in a string, then there is an implicit stack discipline in the following sense. For every type (see below) of tuples of positions there is a coordinate such that for the subset of -tuples of positions consisting in all of type , the order is uniquely determined by the order of the -th coordinates in the string.
We begin by explaining the notions of types. For , the rank type of a structure with distinguished positions is defined to be the set of first-order formulas of quantifier rank at most and free variables that are true in . The number is the arity of the type. For arity 0, we talk about the rank type of the structure . If the structure is implicit from the context, then we talk about the rank type of the tuple . For every finite vocabulary, there are finitely many types of given arity and rank. We write for the equivalence relation on structures with distinguished elements of having the same rank type. For a binary relation , its inverse is the set . For , define to be either or its inverse, depending on the value of .
Lemma 4.8** (Domination Lemma).**
For all , there is an with the following property. Let , let be strings over some alphabet and let be the ordered structure of the concatenation extended with the block order defined by
[TABLE]
Let be a linear order on -tuples in defined by a first-order formula of quantifier rank , and let be a -ary rank type over the vocabulary of . If
[TABLE]
then there is a , called the dominating coordinate, and a , called the polarity, such that
[TABLE]
The Domination Lemma is the technical heart of this paper. The full proof is presented in Appendix C. To explain more intuitively some of the ideas that we use, we treat a special case in detail. In the Domination Lemma, the structure consists of blocks organised in a linear way. A very simple linear order – although infinite – is the natural one on the rational numbers; one reason for its simplicity is that quantifiers can be eliminated (see [13, Section 5.6.2]). Because of this, it is quite easy to prove a version of the Domination Lemma for the rational numbers and still its proof bears some similarity to the proof of the general case.
Lemma 4.9** (Rational Domination Lemma).**
Let be a linear ordering on -tuples of rational numbers defined by a quantifier-free (equivalently, first-order) formula using only the usual ordering on rational numbers. Then there is a coordinate and a polarity such that
[TABLE]
for all tuples of rational numbers satisfying and .
Proof 4.10**.**
We first prove the statement for and and then we deduce the general case.
When , then the formula defining must be either or . 2. 2.
For , we do a case analysis. Note that whether or holds depends only on the order relationship of the positions in and in the rational numbers and not on the precise values in and .
The following picture shows the two possible relationships for two pairs and when they are “consecutive” and the two possible relationships when they are “nested”:
Suppose we are given a pair and without loss of generality, assume the “consecutive growing” case for a second pair . We only show the proof for the case that there is a pair such that and are “nested growing” (“nested decreasing” works analogously). We prove that is dominating for with polarity . Consider all three remaining configurations of pairs and with . In all cases, is proved by finding an intermediate pair (drawn in yellow), whose order with respect to and follows from the assumptions “consecutive/nested growing” (in the pictures below, we assume that lower lines represent bigger tuples in the ordering ): 3. 3.
Consider the case . Fix a “growing” tuple of rational numbers, i.e. a tuple such that for it holds that . Define to be the restriction of to tuples that agree with on coordinates from . Using the reasoning from the previous item, the ordering must admit some dominating coordinate and one of the cases “growing” or “decreasing”. This must hold for every choice of and . Furthermore, the dominating coordinate depends only on and and not on , likewise for the choice of “growing” or “decreasing”. Let us write if dominates, otherwise we write . The reasoning in the following picture shows that is transitive, i.e. and implies :
Therefore, is in fact a total order on . Let be the maximum with respect to this order. The following picture explains why is the dominating coordinate from the statement of Lemma 4.8.
Suppose without loss of generality that we are in the “growing” case for each pair of coordinates. Then we can first move all coordinates apart from to positions smaller than or bigger than and then use the dominations to move them, one by one, to their final positions (always increasing the -th coordinate slightly to a value in the open interval ).
4.2 Proof of Lemma 4.6
We now return to Lemma 4.6, i.e., we prove that every definable -enumerator is also programmable. In the proof, we use the following version of the Factorisation Forest Theorem. We use the term interval for a connected set of positions in a string.
Theorem 4.11** (Factorisation Forest Theorem, aperiodic variant).**
Let be a semigroup homomorphism, where is finite and aperiodic. Then there exists a function which assigns to each string in a partition of the positions into intervals (so-called blocks) such that:
All blocks are nonempty, and for each string in of length at least 2, there are at least two blocks. 2. 2.
If a string has at least three blocks, then all of the blocks have the same value under . 3. 3.
There exists such that all strings have height at most , where the height of a string is defined as follows: letters have height 1, for other strings the height is the maximum of the heights of its blocks + 1. 4. 4.
There is a first-order formula such that for every string , the positions satisfying are exactly the first positions of the blocks of .
Apart from the Factorisation Forest Theorem and the Domination Lemma, our proof uses the following straightforward result on combining outputs of two for-programs. As a convention, if is a first-order formula with free variables and is a -enumerator, then denotes the -enumerator where the output list of is filtered so that it contains only tuples satisfying .
Lemma 4.12** (Merging Lemma).**
Let be a definable -enumerator. Let be a finite set of fo formulas , each one with free variables, such that every -tuple of positions satisfies at least one formula from . Then is programmable if and only if every is programmable.
Proof 4.13**.**
For the left-to-right implication, we observe that the filtering can be implemented by a for-program thanks to Lemma 3.2. We are left with the right-to-left implication. It suffices to examine the case . The general case follows by a straightforward induction.
Suppose that and are implemented by programs . First check whether the first tuple in the output satisfies or using the result from Lemma 3.2 and an if-statement, and then run a different program for each of the two outcomes. By symmetry, it suffices to consider inputs where the first tuple in the output of satisfies . Take the code of , and after each instruction which outputs a tuple of positions , run a copy of the code for , with its output restricted to tuples which satisfy:
- •
* is after according to ; and*
- •
there are no other tuples from the output of between and .
The first item can be checked by a for-program using the assumption that is definable and Lemma 3.2, while the second item can be checked by running a nested copy of .
We are now ready to prove Lemma 4.6. Let be a definable -enumerator. We need to describe a for-program which outputs the same list of tuples as . Let be the maximal quantifier rank of the first-order formulas used in the definition of . Apply the Domination Lemma to , , and , yielding a constant . Define to be the function which maps a string to the rank type of the corresponding ordered model of . Compositionality of first-order logic (see [16, Section 3.4]) on strings says that the image of , the set of rank types of strings, is a finite aperiodic semigroup and is a semigroup homomorphism. Apply the Factorisation Forest Theorem to , yielding a function which partitions each string into blocks and an upper bound on heights of strings. By abuse of notation, we lift notions about strings to intervals inside strings: the height of an interval in a string is defined to be the height (in the sense of item 3 in Theorem 4.11) of the infix of induced by . Likewise, we define the blocks of as the blocks of the infix induced by , viewed as intervals contained in .
To show that is also programmable, we use an induction over heights in factorisation forests. More precisely, we prove that for every there is a for-program which computes the following:
- •
Input. A string with distinguished nonempty intervals that are pairwise equal or disjoint, and such that the sum of their heights (in the sense of Theorem 4.11) is at most . Each interval is represented by its first and its last position.
- •
Output. The list restricted to tuples in .
By item 3 in Theorem 4.11, the for-program with parameter will work for every choice of pairwise equal or disjoint intervals, in particular when all of the intervals are the entire string. The induction base (where every interval has the height ) is straightforward: each interval is a singleton, and the for-program simply checks if the unique tuple in belongs to the output of by using the subroutines from Lemma 3.2. The rest of the proof is devoted to the induction step, more specifically, to producing the correct order of the tuples: whether a tuple belongs to the output or not can again be checked using the subroutines from Lemma 3.2.
Let be intervals in an input string that are pairwise disjoint or equal. Define to be the coarsest partition of the positions in the input string into intervals that satisfies . This partition uses at most intervals. Consider a factorisation
[TABLE]
where each is a block of one of the elements of . Define as in the Domination Lemma, i.e. as the ordered structure of extended with an extra order that describes the partition into factors . By item 4 of the Factorisation Forest Theorem, the order can be defined by a first-order formula which uses the input string and the endpoints of the intervals . It follows that for every -ary rank type over the vocabulary of , there is a corresponding first-order formula which selects the -tuples of positions in that have type in . Since there are finitely many choices of , it follows from the Merging Lemma that it is enough to show that for every , there is a for-program which outputs the tuples of type .
Let be a -ary rank type over the vocabulary of . We show a for-program which outputs all tuples in
[TABLE]
according to their order given by , call this order .
If an interval from has more than two blocks, then, by item 2 of the Factorisation Forest Theorem, all of these blocks have the same image under , i.e., the same rank type. Since there are at most intervals, it follows that with at most exceptions, consecutive strings and have the same rank type. Hence, for the order defined by , the Domination Lemma yields and such that
[TABLE]
This means that the tuples in are -ordered as , where is the number of blocks in and consists of the tuples from where the coordinate is in the -th block of . Our for-program can simply loop over all the blocks of – in increasing or decreasing order depending on the choice of – because the endpoints of each block can be identified in first-order logic due to item 4 of the Factorisation Forest Theorem. In each iteration of the loop, the for-program outputs the tuples in the corresponding using the following claim, thus completing the proof of the lemma.
Claim 2**.**
There is a for-program which inputs the -th block of , given by its endpoints, and outputs the tuples from ordered according to .
Proof 4.14** (Proof of the claim).**
The general idea is to replace with its -th block (call this block ) and use the induction assumption. However, if there is an such that , then replacing with would violate the assumption that the intervals are pairwise disjoint or equal (since ). To overcome this issue, we use the following simple case disjunction. For each of the possible values of
[TABLE]
construct a for-program that outputs all tuples from , where is the intersection of with the -th entry of . Since each is a union of blocks of , it is empty or its height is at most the height of . Furthermore, if is nonempty, then it is , which is a block of , and therefore its height is strictly smaller than the height of . It follows that the induction assumption can be applied to produce all tuples in , for any given choice of . These choices can be combined using the Merging Lemma.
Appendix A Successor instead of order
In this appendix, we prove Theorem 2.4, which says that:
The class of successor-mso string-to-string interpretations is not closed under composition, and strictly contains the class of (order-)mso string-to-string interpretations. 2. 2.
The following is undecidable: given a successor-first-order string-to-string interpretation and a regular language over the output alphabet, is is empty?
Proof A.1** (Proof of Theorem 2.4).**
We first show item 1. Fix an input alphabet , and consider the function which inputs a string, and outputs all pairs of positions (with the corresponding pairs of labels) in the order depicted by the following picture:
It is not hard to see that the function is a succesor-mso string-to-string interpretation (in fact even first-order logic would be enough if the input string was equipped with a labelling indicating the parity of positions). Suppose that the alphabet contains two endmarkers , and consider an input word of the form where are letters that are not endmarkers and the length is even. In this case, the output contains the letter exactly once, it contains the letter also exactly once, and the word between these two letters is exactly:
[TABLE]
If and only if the word is a palindrome, then the above word contains only letters from the diagonal . Summing up, there is a regular (and therefore also mso-definable) language such that
[TABLE]
Define to be the characteristic function of , i.e., the function from to which outputs or [math] depending on whether the input belongs to or not. We can view the characteristic function as a string-to-string function, where the output is in and which happens to only produce outputs with one letter. The following claim is not hard to see.
Claim 3**.**
A language is regular if and only if its characteristic function is a successor-mso string-to-string function.
From the claim, it follows that the characteristic function of the language in (2) is in the successor-mso class. If the class were closed under composition, then also , the characteristic function of the palindrome language in (2), would be in successor-mso, and thus by Claim 3 the palindrome language would be regular, a contradiction. 2. 2.
We now show item 2 of Theorem 2.4, i.e., that for a successor-first-order string-to-string interpretation and a regular language over the output alphabet, the emptiness of is undecidable. The proof is a standard reduction from the halting problem for Turing machines.
Let be a Turing machine. Consider the string-to-string function defined as in the previous item, except that the order on positions is as follows:
The key observation is that the output contains, for every odd , an infix of the form
[TABLE]
In the picture, the blue colouring indicates this infix for .
The above observation shows that the output of can be used to compare infixes of with other infixes; this can be used to check if an input word represents an accepting computation of the fixed Turing machine.
*The input will be required to be of the following shape: , where the *s are words that represent the consecutive configurations of an accepting computation of the Turing machine.
*We mainly need to enforce two additional properties to obtain the reduction: first, that all the *s have the same size and second, that each is the successor configuration of (and also that is initial and is final, which are simple regular properties). To enforce these two properties we only need to check properties of the infix where is the position of the second separator symbol of the input word. We can easily enforce that this position is odd by asking that all configurations are of even length.
The proof of item 2 could be improved so that the function is a successor-first-order string-to-string interpretation, which shows that emptiness of is undecidable already when is successor-first-order and is regular. This shows that the class of successor-first-order string-to-string interpretations is not contained in the class of (ordered) first-order string-to-string interpretations considered in this paper, since by our main theorem, the latter class is contained in the class of polyregular functions, and emptiness of is decidable if is regular and is polyregular [3, Theorem 1.7].
Appendix B Proof of the Factorisation Forest Theorem
We provide a proof for the aperiodic variant of the Factorisation Forest Theorem (Theorem 4.11) here. Consider a surjective homomorphism
[TABLE]
We can assume without loss of generality that is a subset of . The proof is by induction on (a) the size of ; (b) the size of . The two parameters are ordered lexicographically, with (a) being more important.
When has one element, then the blocks of a string are simply its letters; this covers the induction base. The partition of a string into letters is clearly first-order definable.
For the induction step, suppose that has more than one element. Take some and consider the functions
[TABLE]
If one of these functions is surjective, then it is a permutation, and therefore it has to be the identity by aperiodicity of the semigroup. If both functions are surjective, then must be the identity element of the semigroup (which might not exist in some semigroups. Since has at least two elements, and there is at most one identity, there must be an such that one of the functions in (7) is not surjective. Without loss of generality, assume that is not surjective, and therefore is a proper subset of the semigroup .
Consider the following two semigroup homomorphisms: the first one is the product operation
[TABLE]
in the semigroup , and the second one is
[TABLE]
obtained by restricting to the smaller alphabet. Both homomorphisms are smaller in our induction order: uses a smaller semigroup, and has a smaller alphabet. Therefore, the induction assumption can be applied to obtain both partitions into blocks and bounds and on the heights of the corresponding strings.
For a string , we define its partition into blocks with respect to the homomorphism as follows by case analysis.
Suppose that ends with and does not begin with . Decompose as follows:
[TABLE]
- (a)
If , then the blocks are and . The former word has height at most by induction assumption and the latter word has height at most 2 because it uses only the letter . It follows that has height at most . 2. (b)
Otherwise . For define to be . Note that . Consider the partition into blocks of the word with respect to the homomorphism . The blocks of are the same as the blocks of , except that in each block, the letter is replaced with the corresponding infix . Since the height of is at most from the induction assumption, and each has height at most from item (1a), we obtain a height of at most for the word . 2. 2.
We are left with the case when either begins with or does not end with . In these cases, we simply decompose the word by shaving off the beginning and the end to reduce the decomposition to case (1).
- (a)
If such that and do not begin with , and then we split into two blocks, and . According to case (1), has height at most and by induction assumption, has height at most , thus overall, has height at most . 2. (b)
Finally, let with , not beginning with , and . In that case we split into two parts again: and , has height at most 2, and from the previous case, we have a final height of at most .
It is not hard to see the partition into blocks described above is first-order definable. This completes the proof of the Factorisation Forest Theorem.
Appendix C Proof of the Domination Lemma
This section is devoted to proving the Domination Lemma. The statement of the Domination Lemma in Section 4 was chosen so that it would be most easily applied to strings and their infixes. We begin by stating a more abstract version of the lemma, called the Product Domination Lemma, which is adapted to allow for a modular proof and implies the Domination Lemma in the shape in which we use it. Before stating the Product Domination Lemma, we introduce notation for the three kinds of product operations that are relevant to us.
Elements of the direct product of structures , …, are tuples with for every . For every relation in some , there is a corresponding relation of the same arity in the direct product, which says whether or not holds after projecting to the -th coordinate. 2. 2.
The -th power of a structure is similar to the -fold direct product of , except that different coordinates can be compared, i.e., for every two tuples in the -th power of and all , we can compare and . One way of modelling such comparisons is to say that the -th power is obtained from the -fold direct product by adding for all a function which swaps coordinates and . 3. 3.
The ordered product is obtained by taking the disjoint union of the structures and adding an extra binary predicate , called the block order, such that holds if comes from an and comes from an with .
The Product Domination Lemma uses all three kinds of products: it considers a direct product of powers of ordered products.
Recall that we write for the equivalence relation on structures with distinguished elements of having the same rank type.
Lemma C.1** (Product Domination Lemma).**
Let . Then there exists an such that the following holds. Let be an initial segment of the natural numbers and let
[TABLE]
where each is an ordered product
[TABLE]
Let be a linear order on defined by a first-order formula of rank , and let be a unary rank type over . Then there exist , , and such that
[TABLE]
Proof overview.
We begin by showing, in Section C.1, that the Product Domination Lemma implies the Domination Lemma in its original form from Section 4. The rest of Section C is then devoted to proving the Product Domination Lemma. This is done in four steps. In Section C.2, we show that if we can prove the Product Domination Lemma for some nonzero polarity other than , then we can reduce the polarity down to at the cost of increasing the threshold . Next, we prove the Product Domination Lemma in four steps, which deal with special cases of increasing generality, as described below.
- •
In Section C.3 we prove domination for direct products of linear orders, i.e. structures
[TABLE]
This can be viewed as the special case of the Product Domination Lemma when all are , and furthermore all structures (called blocks in the proof) have size one.
- •
In Section C.4 we prove domination for powers of linear orders, i.e. structures
[TABLE]
This can be viewed as the special case of the Product Domination Lemma when has size one, and all blocks have size one.
- •
In Section C.5 we prove the joint generalisation of the results from the two previous sections, i.e. we consider direct products of powers of linear orders:
[TABLE]
This can be viewed as the special case of the Product Domination Lemma when all blocks have size one.
- •
In Section C.6 we complete the proof of the Product Domination Lemma.
Compositionality.
Before continuing with the proof, we state two compositionality properties of first-order logic with respect to products that will be heavily used in the proofs.
Theorem C.2** ([18]).**
The following holds for all .
Consider structures over the same vocabulary. The rank type of the ordered product
[TABLE]
is determined by the rank types of the two ordered products
[TABLE] 2. 2.
Let be a direct product of structures . For every -ary rank type in and every there is an -ary rank type in the structure such that for all
[TABLE]
Continuous functions.
Let and let and be relational structures over possibly different vocabularies. Let be a function from (the universe of) to (the universe of) and for all , denote by the function mapping -tuples of to -tuples of by component-wise application of . Then is called -continuous if for every and every subset of defined by a formula in first-order logic with quantifier rank , its inverse image under can be defined in first-order logic via a formula with quantifier rank . A function is called continuous if it is [math]-continuous.
An alternative, equivalent characterisation, which we also use in this paper, is that a function is continuous if and only if it is type-preserving, i.e., it maps tuples of the same type to tuples of the same type.
C.1 Proof of the Domination Lemma
We begin by using the Product Domination Lemma to obtain the Domination Lemma in its statement from Section 4. Let . Apply the Product Domination Lemma to and yielding some threshold value . Define
[TABLE]
We prove that satisfies the requirements of the Domination Lemma. Let and be as in the assumptions of the Domination Lemma. This means that is the ordered product of the (ordered structures associated with) the strings extended with the block order . Furthermore, the strings satisfy with at most exceptions. (The order on the blocks is , while the orders corresponding to the ordered structures are ). Let be a linear order on defined by a first-order formula of quantifier rank and let be a -ary rank type over the vocabulary of . We intend to find a dominating coordinate and a polarity that satisfy
[TABLE]
Define to be the coarsest equivalence relation on such that holds whenever . Equivalence classes of are intervals. Let be the set consisting of these equivalence classes. Since , we know from the assumptions of the Domination Lemma that has at most elements. For an equivalence class , define to be the substructure obtained by restricting to elements that come from with . We can view as an ordered product which only uses the words with . By definition, in , all blocks (i.e., all ) have the same rank type. For every , there is a first-order formula which selects the elements from inside the structure : the formula counts the number of blocks to the left which satisfy , and therefore it has quantifier rank at most . For of rank type and , define
[TABLE]
This set does not depend on once has been fixed, because, as we have argued above, one can express the containment in using a first-order formula with quantifier rank at most . Define
[TABLE]
to be the injection that is defined in the following way (where an element in the universe of is seen as an element in the universe of ):
[TABLE]
The image of this injection contains all tuples in that have -ary rank type . Since the injection sends tuple of the same type to tuples of the same type, it is continuous.
Claim 4**.**
All elements in the inverse image of under have the same rank type.
Proof C.3**.**
Note that the continuity of is not useful for this result, because it only tells us that the inverse image of is a union of rank types. The image can be defined by a first-order formula of quantifier rank at most . Therefore, if elements of have different rank types, then their images under have different rank types. This proves the claim.
By the above claim, all elements in the inverse image under of type have the same rank type over , call it . Define to be the linear order on which is the inverse image of under , i.e.
[TABLE]
Since is continuous, it follows that is defined using a first-order formula of quantifier rank . By the Product Domination Lemma, there exist , and such that
[TABLE]
By pulling this result forward across the injection , we get the corresponding conclusion for and in of type .
This finishes the proof of the Domination Lemma, assuming the Product Domination Lemma holds. The rest of this section is devoted to proving the Product Domination Lemma.
C.2 Polarity reduction
In the Product Domination Lemma, we use powers for polarities . This notation also makes sense for other nonzero integers , for example means that holds for some , . (We extend this notation to other binary relations as well.) It would be easier to prove the Product Domination Lemma for polarities with larger absolute values, since for and for , the implication
[TABLE]
has a stronger assumption than and is therefore weaker than
[TABLE]
The following lemma shows that such weaker versions are indeed enough.
Lemma C.4** (Polarity Reduction Lemma).**
Let be a relational structure, and let and be binary relations on that are defined by first-order formulas of quantifier rank at most . If is transitive and antisymmetric, then for every
[TABLE]
Proof C.5**.**
Let and be as in the assumptions and let . Suppose the two conditions in the stated implication hold. Let be such that and hold. We need to show . Let be the binary rank type that describes the pair . Since is defined using quantifier rank at most and contains , it follows that all pairs of type are contained in . Because is defined by a formula of quantifier rank , our assumptions imply that the set of pairs of type is contained in either or . To prove the lemma, we need to show that it is contained in . Define a chain to be a sequence of elements
[TABLE]
i.e. a walk in the directed graph on the universe of where is the edge relation. Note that every chain is either growing or decreasing with respect to . We need to rule out the “decreasing” case. The property “there is a chain of length that begins in ” can be defined by a first-order formula of quantifier rank . It follows inductively from and that there is a chain which begins in and has length at least . Indeed, if the maximal length of a chain beginning in was some value , there would be a chain of length beginning in since has type . This would violate that .
As discussed at the beginning of this section, a corollary of the Polarity Reduction Lemma is that it is enough to prove a weaker version of the Product Domination Lemma, where the polarity from the conclusion is in instead of . To see why, suppose that we have proved the version of the Product Domination Lemma with polarity , and we want to prove the version with polarity . Let be a unary rank type. By the weaker version of the Product Domination Lemma, there is some such that
[TABLE]
Apply the Polarity Reduction Lemma for , the structure being , and the relation defined by
[TABLE]
We obtain the conclusion of the Product Domination Lemma in its original form.
Thanks to the above reasoning, in the remaining sections it suffices to show variants of the Product Domination Lemma where the polarity in the conclusion is some nonzero number with a fixed upper bound, not necessarily 1, on its absolute value.
C.3 Direct products of linear orders
In this section, we show the special case of the Product Domination Lemma for direct products of linear orders. A corollary is going to be that every first-order definable ordering in a product of linear orders coincides with a lexicographic product of the underlying orders, at least when restricted to elements of the direct product that have the same type. The corollary is stated later in this section, but we begin with the underlying result about dominating coordinates.
Lemma C.6**.**
Let and let be a linear ordering on a direct product
[TABLE]
such that is defined by a first-order formula of quantifier rank . Then for every unary rank type in , there is a dominating coordinate and such that
[TABLE]
Note that in the above lemma, the polarity can have a value not contained in . As explained in Section C.2, at the cost of increasing the quantifier rank of the type , the polarity can be reduced to values in .
To prove Lemma C.6, we use the following observation, which expresses that first-order logic formulas with quantifier rank can only measure distances up to in a linear order. Its proof is the same as for [16, Theorem 3.6].
Lemma C.7** (Threshold Lemma).**
Let and consider two -tuples and in a linearly ordered set
[TABLE]
Then and have the same rank type if and only if they have the same quantifier-free type in the structure extended with relations for and unary relations and .
Proof C.8** (Proof of Lemma C.6).**
The proof proceeds by induction on the size of the set , i.e. on the dimension of the product. Let be a unary rank type over the vocabulary of . Consider its projections for as in Theorem C.2. By the Threshold Lemma, if an -tuple has type , then determines the distance of from the first and last positions in , measured up to threshold . If the distance from either the first or last position is , then the value of is fixed by the type . For such types, we can eliminate one coordinate, and obtain the result by using the induction assumption. We are left with the case when expresses that all coordinates are at least positions away from both the first and last positions.
Choose a tuple such that for every , coordinate is at least positions away from the first and last positions in , which can be achieved by the assumption that for all . We say that is small if for every , the absolute value of is between and . By the choice of , we know that if is small, then has the same type as . Define the sign vector of to be the subset of which contains the coordinates on which is positive, and define
[TABLE]
It is not hard to see that the family is closed under set union, and the same is true for its complement.
Claim 5**.**
Consider a partition of the powerset into two families of sets, both of which are closed under union. Then there is a such that one of the families is .
Proof C.9**.**
Since both families are closed under union, it follows from De Morgan’s law that both families are closed under intersection. One of the families does not contain the empty set, call this family . Since is closed under intersection, it follows that the intersection of all sets in is nonempty. The interesction cannot have more than one element, because otherwise it could be decomposed as a union of two sets outside , and therefore it would be outside . Hence, the intersection of all sets in is a singleton for some . This means that all sets in contain . It follows that for every , the singleton must belong to the complement of . Since this complement is closed under taking unions, every set that does not contain belongs to the complement of .
An application of the claim yields a coordinate such that either or its complement consists in exactly the sets that contain . By symmetry, we may assume the first case. By unfolding the definition of , it follows that incrementing by at least and at most and modifying all other coordinates by any number with absolute value between and yields a bigger tuple. Performing this procedure twice allows us to modify the coordinates other than by any value in , and therefore the result follows using the Threshold Lemma.
We end this section with an interesting consequence of Lemma C.6. Define a lexicographic ordering on
[TABLE]
to be an ordering that is the lexicographic product, under some ordering of , of orderings in the coordinates that are either or . If has elements, then there are lexicographic orderings, since the coordinates can be ordered in ways and for each ordering one can use or for each of the coordinates. By iteratively applying Lemma C.6 and then using the Polarity Reduction Lemma, we can infer the following result.
Corollary C.10**.**
For every , there is a threshold with the following property. Let be a linear ordering on the product
[TABLE]
such that is defined by a first-order formula of quantifier rank . For every unary rank type in , the order restricted to tuples of type coincides with one of the lexicographic orderings on .
C.4 Powers of linear orders
In this section, we prove a version of the Domination Lemma that considers powers of finite linear orders. The difference to the scenario treated in Section C.3 is that here we can compare different coordinates.
Lemma C.11** (Linear Domination Lemma).**
For all , there exists a threshold such that the following holds. If is a linear ordering on with
[TABLE]
such that is defined by a first-order formula of rank , then for every -ary rank type , there are and such that
[TABLE]
In the proof, we do a detailed case analysis of the expressive power of first-order logic on linear orderings, which relies on the Threshold Lemma.
For , a tuple is called -separated if for all in it holds that or , with the convention that and . We can extend the notion of being separated to types. A rank type is called -separated if every tuple of type is -separated, and separated if every tuple of type is -separated.
Claim 6** (Linear Domination Lemma - Separated Case).**
For all , there exists a threshold such that the following holds. If is a linear order on , where
[TABLE]
such that is defined by a first-order formula of rank , then for every separated rank type , there are and such that
[TABLE]
We first show that the separated version of the lemma implies the general version.
Proof C.12** (Proof of the Linear Domination Lemma).**
The proof proceeds by induction on the dimension . For , the statement holds by the Threshold Lemma. Let and and assume that the Linear Domination Lemma holds for dimension . Let be the value obtained using Claim 6 for dimension and quantifier rank . Let be the value obtained using the induction hypothesis for arity and quantifier rank . Let .
Let for an and consider a rank type of arity . Let be the rank type associated with . Note that all tuples of type have type but the converse does not necessarily hold. By the Threshold Lemma, the type is entirely given by quantifier-free formulas using for . If is separated, by Claim 6, the result holds for tuples of type , and thus in particular for tuples of type . Otherwise, if there is a such that and are exactly apart, then all coordinates are pairwise at most apart and thus, (and therefore also ) fixes all coordinates, such that the conclusion from the lemma trivially holds. Thus, assume that there are , and such that and are exactly apart. Without loss of generality, we assume , and .
Let be the projection to the first coordinates. Define a linear ordering over the tuples of which are images of tuples of type with respect to , and such that for all and of type . This order can be defined using a formula of quantifier rank , simply by existentially quantifying over the missing coordinates.
Moreover, by continuity of , all tuples of -type are mapped to tuples of -type . By the induction hypothesis, we know that there are and such that:
[TABLE]
Thus, we have in particular:
[TABLE]
which concludes the proof.
The proof of Claim 6 has three stages, depending on whether the arity is , or bigger. The case is actually trivial, and the most interesting case is arity .
Arity two
We first prove Claim 6 for . We need to show that there are , and such that for every separated type of arity two (we use the name binary from now on) and rank , we have:
[TABLE]
For two pairs , we say that they are -distant if for , it holds that or . We first show the following claim.
Claim 7**.**
If the statement from Claim 6 holds in the case of -distant tuples, then it holds for all tuples.
Proof C.13**.**
This is shown in exactly the same way as the Polarity Reduction Lemma. If we have two tuples of the same type of sufficiently high rank, then we can ensure that there is a sufficiently long sequence , such that the -type of is the same as the one of , for . If the sequence is long enough, then are -distant.
Let . Consider tuples (first row) and (second row) where the first coordinate of is at least larger than the second coordinate of , as in the following picture.
By the Threshold Lemma, the order relationship does not depend on the choice of and (subject to the requirements in the picture above). There are two cases, namely
[TABLE]
The cases are symmetric, we assume A1 without loss of generality.
Consider the case as above with , but the distance between and is . We use a simplified version of the Polarity Reduction Lemma in the case of a linear order. Let , hence the -type of is equal to the one of . Then and are in situation A1, which means by the transitivity of that .
Consider the case with . By the Threshold Lemma, we can assume that the distance between and is at most . Let , hence the -type of is equal to the one of . By transitivity of , we have . Now we have that since . Using the Threshold Lemma, we can assume that , which means, according to the previous paragraph, that .
Since we only compare distant separated tuples, the only remaining case is the one illustrated below. Consider now two tuples and that are related as follows:
Again there are two cases, namely
[TABLE]
Case B1 implies that the dominating coordinate is the first one and Case B2 the second.
General arity
In this section we complete the proof of the Separated Linear Domination Lemma. The main idea is that it suffices to compare tuples which differ in at most two coordinates.
Let be a linear order on -tuples in that is defined by a first-order formula of quantifier rank . Let be a separated -ary rank type and let . We prove that there is a dominating coordinate and a such that
[TABLE]
Choose distinct coordinates and let be a tuple of type . Define
[TABLE]
By the case of arity two, we have the following result:
Claim 8**.**
For every and distinct coordinates there is a dominating coordinate and a polarity such that
[TABLE]
Proof C.14**.**
Without loss of generality, we assume . Let . Since , we can assume without loss of generality that . We make a case analysis depending on whether holds or not. Assume , and let . We define the partial function from tuples of type of to pairs of elements in the universe of by keeping only the coordinates and . We also consider the function , which just fills in the missing coordinates by the coordinates of . Note that the function is continuous, hence can be defined by a formula of quantifier rank . Moreover, is also continuous, thus the tuples in the image of have the same -type . Therefore, applying the Linear Domination Lemma to the case of dimension 2, we obtain that there are , , and such that:
[TABLE]
Thus, we have in particular:
[TABLE]
Similarly, if , we define the structure . Using the same arguments and Lemma C.6, we obtain the result.
It is not hard to see that there is exactly one possibility for and – once , and have been fixed – since otherwise we would get a cycle for the order . By the Threshold Lemma, the dominating coordinate depends only on and not on the choice of , and therefore we can write for the dominating coordinate that is appropriate to coordinates . Also the polarity depends only on and . Let us write if, whenever the values at coordinates are distinct, then is the dominating coordinate for and the associated polarity is .
Claim 9**.**
If are distinct, then implies .
Proof C.15**.**
Choose arbitrarily. Consider a tuple which is -separated. This tuple has type , and shifting any coordinate by offset in still leads to a tuple that has type , because the quantifier rank of is . Define to be the tuple obtained from by adding to coordinate and adding to coordinate , and define to be the tuple obtained from by adding to coordinate and adding to coordinate . Here is a picture where and .
From the assumption of the claim it follows that , and this holds regardless of the choice of . It follows that .
From the above lemma it follows that the relation defined by
[TABLE]
is a linear order on the coordinates . Let be the maximal element according to this total order. Let be the second-to-maximal element in the total order, and let be such that holds. From Claim 9 it follows that holds for all . We show that coordinate dominates when comparing tuples where the values of coordinate are sufficiently far apart.
To finish the proof of the Linear Domination Lemma, we prove below (9) for polarity , i.e., we show
[TABLE]
Assume without loss of generality that the coordinates in some (equivalently, every) tuple of type are ordered so that they are strictly increasing. Let and be tuples as in the assumptions of the claim.
Let and be such that . We need to show . By the Threshold Lemma, we can assume that all coordinates in the tuples and avoid the first and last positions. To prove , we will find a chain of tuples that begins in , ends in , and is growing with respect to . We do the proof in the case where and , but the general case works the same. Define
[TABLE]
In general, {\color[rgb]{1,0,0}z_{i}} is defined as when and otherwise it is defined as . The choice of coordinates {\color[rgb]{1,0,0}z_{i}} is made so that they are far apart, and furthermore {\color[rgb]{1,0,0}z_{i}} is to the left/right of the tuples , depending on whether or . The chain that witnesses is given below:
[TABLE]
All tuples in the above chain have type , by the assumption that coordinates {\color[rgb]{1,0,0}z_{i}} are far apart and to the left/right of the tuples . Since the dominating coordinate is incremented as the chain progresses, and at most two coordinates change in each step, we can use the assumption that coordinate dominates when only two coordinates change to conclude that each consecutive step yields a tuple that is bigger with respect to . By transitivity, it follows that .
C.5 Direct products of powers of linear orders
In this section we prove the most general version of the Product Domination Lemma for linear orderings, namely the case of direct products of powers of linear orderings.
Lemma C.16**.**
For all , there exists a threshold such that the following holds. If is a linear order on
[TABLE]
such that is defined by a first-order formula of rank , then for every unary rank type over , there are , and such that
[TABLE]
Let be a threshold that is large enough – we will specify the required bounds during the proof. Fix for the rest of this proof a unary rank type in . Our goal is to find a dominating coordinate and a polarity as in the statement of Lemma C.16.
The general strategy is as follows. We begin in Section C.5 by looking, for every , at the projection
[TABLE]
We show that there exists which is a section of in the sense that is the identity on . By applying the results from Section C.4 about powers of linear orders, we show that there is a dominating coordinate which works for elements in the image of the section. Next, in Section C.5, we consider the projection
[TABLE]
which is defined in terms of the dominating coordinates that were found in Section C.5. Again, we find a section . By applying the results from Section C.3 about direct products of linear orders, we find a dominating coordinate which works for elements in the image of the section. Finally, in Section C.5, we combine the results about the sections and to prove the conclusion of Lemma C.16 for where .
Sections of
For each , apply Lemma C.11 about domination for powers of linear orders to and , leading to some threshold . Define
[TABLE]
Our first condition on the threshold is that
[TABLE]
Let be the information of rank that is stored in the rank type , i.e. is the unique rank type contained in type .
Let . The general idea in this part of the proof is to study the order when comparing elements of that agree on all coordinates other than . Consider the projection
[TABLE]
For of type define
[TABLE]
to be the function which fills in the missing coordinates by the values used in . This function is a section of in the sense that is the identity on . Consider the preimage of under this section, i.e. the relation defined by
[TABLE]
By Theorem C.2, is continuous, and therefore is defined by a first-order formula of same quantifier rank as , namely . Therefore, since the type has rank at least as obtained from Lemma C.11, it follows that there are a polarity and a dominating coordinate such that
[TABLE]
By Theorem C.2, if and have the same type of rank then and are the same order. Therefore, since the quantifier rank of is at least , it follows that the dominating coordinate and polarity do not depend on , as long as it has type . Because is a section of and it preserves the appropriate orderings, it follows that
[TABLE]
By applying the above to , we see that coordinate dominates whenever agree on coordinates other than :
[TABLE]
Section of
As announced in the proof strategy, we now consider the projection which uses only the dominating coordinates that were found in Section C.5:
[TABLE]
We will find a suitable section of and prove that there is a dominating coordinate for the image of that section.
Recall the type discussed in Section C.5, which is obtained by keeping only the rank information from the type . Define
[TABLE]
to be the section of that is defined by
[TABLE]
We argue why the section is -continuous. Consider a subset of the universe of structure defined by a unary formula of some quantifier rank . We want to show that the set of elements of that are sent to satisfy some formula of rank . This amounts to showing that, for a unary rank type of , there is a unary formula over which selects elements whose image with respect to has type . Using Theorem C.2, the formula can be defined by quantifying over the missing coordinates and then checking that the whole tuple satisfies , if possible, and that it is the minimal one to do so. Thus we obtain a formula of quantifier rank (the comes from the fact that we need to check minimality).
Define as the inverse image of with respect to . From continuity, it follows that is defined by a first-order formula of quantifier rank at most . Apply Lemma C.6 to this quantifier rank, yielding some threshold . We assume that
[TABLE]
Since the projection is continuous, it follows that all elements of type in are mapped by to elements of the same rank type, call it . By Lemma C.6 and the assumption (14), there are a dominating coordinate and a polarity such that
[TABLE]
Define to be for . Because is a section and it preserves the appropriate orderings, it follows that
[TABLE]
Proof of Lemma C.16
We now complete the proof of Lemma C.16. Define . Let have type and assume that
[TABLE]
To prove , as required in the conclusion of Lemma C.16, we will find an -ascending chain which begins in , ends in , and such that each step in the ascending chain is proved using the results from Sections C.5 and C.5.
Claim 10**.**
There is an of type in the image of such that and
[TABLE]
Proof C.17**.**
We say that is canonical on coordinate if for some in the image of . By Theorem C.2, if is canonical on all coordinates , then it is in the image of . Therefore, we can prove the claim by induction on the number of coordinates on which is canonical, and in the induction step we can make a single coordinate canonical, at the cost of shifting by positions, thanks to (13).
Apply Claim 10 to , yielding some of type with . Apply a symmetric result to , yielding some of type with and
[TABLE]
By definition of and the assumption (16), we see that
[TABLE]
and therefore (15) can be applied to conclude , and thus also .
C.6 Proof of the Product Domination Lemma
In this section, we complete the proof of the Product Domination Lemma, and therefore also of the Domination Lemma.
Let be a threshold that is high enough, we will specify the lower bounds on throughout the proof. Let be a unary rank type in . Consider the projection
[TABLE]
which maps each element of to the appropriate tuple of block numbers. This function is continuous. Let be the threshold obtained by applying Lemma C.16 to quantifier rank and the product . We assume that
[TABLE]
Let be the type of rank which stores the quantifier rank information of type .
We say that overlap if there is a block which intersects both and . More formally,
[TABLE]
Note that overlapping is defined purely in terms of the image under . The first step in the proof is the following claim, which shows that there is a dominating coordinate when only comparing non-overlapping elements.
Claim 11**.**
There exist , and such that
[TABLE]
Proof C.18**.**
One can show that there is a continuous section of such that preserves the type , i.e., it maps to a subset of itself. To define the section, one only needs to choose for each coordinate and each block of an appropriate representative such that tuples of type are mapped to tuples of type . Using compositionality, we thus have that maps tuples of the same type to tuples of the same type.
Define to be the pre-image of under this section. Since is continuous, the order is definable using quantifier rank . By Lemma C.16 and the definition of , there exist dominating coordinates , and a polarity such that
[TABLE]
We now extend the above result to non-overlapping elements of type , as required in the statement of the claim. Using compositionality, one can show that if and are non-overlapping, then the binary rank type of the pair in is uniquely determined by the unary rank types of and as well as the binary rank type of . Since does not change the value under , it follows that and overlap if and only if their images with respect to overlap. As we have argued at the beginning of this proof, maps the set of tuples of type to a subset of itself, and therefore if and have type , then also their images under have type . It follows that
[TABLE]
By combining this observation with (18), we obtain the conclusion of the claim.
The general idea in the rest of the proof is to show that if of type are possibly overlapping, then one can find a which overlaps neither with nor with and where can be shown using Claim 11. To find this , we will shift (or ) by several blocks to the left or right, as explained below.
For and a possibly negative integer , define to be the result of adding to all coordinates of . Note that might fall out of , e.g. because some coordinate might become negative. For , define to be the set of integers such that
[TABLE]
The key observation is the following claim, which says that either is big for all of type , or one can trivially find a dominating coordinate, because there is a choice of coordinates the values at which always lie in the same block.
Claim 12**.**
One of the following holds:
There are and such that
[TABLE] 2. 2.
For every of type , the set contains .
Proof C.19**.**
For define to be rank information stored in type , i.e. this is the unique rank type contained in . By continuity of , the image of under is a rank type in the structure , call it . By the Threshold Lemma, every rank type in amounts to measuring distances between coordinates and minimal and maximal elements, up to threshold . We say that is anchored if it fixes the distance of some coordinate to either the minimal or maximal element, i.e. some (equivalently, every) in of type is such that has distance from either or for some and . If is anchored, then item 1 in the claim holds. Suppose that is not anchored. It follows from the Threshold Lemma that for every of type and every , the shifted value has type . In particular, if and is not anchored, then has size at least for every of type . Thus, with the assumption that
[TABLE]
the result follows.
Apply Claim 12. If the first case holds, then and are dominating coordinates by vacuous truth. We are left with the other case. We will show that and , as in Claim 11, are dominating coordinates. Assume that have type and assume . We will show . By the assumption on , we know that for every integer with , there is a of type such that
[TABLE]
For every and , there are at most two choices of such that
[TABLE]
By a counting argument and thanks to the definition of , it follows that there is some with
[TABLE]
such that overlaps neither with nor with . Therefore, we can use Claim 11 to get .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Rajeev Alur and Pavol Cerný. Streaming transducers for algorithmic verification of single-pass list-processing programs. In Proceedings of the 38th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL 2011, Austin, TX, USA, January 26-28, 2011 , pages 599–610, 2011.
- 2[2] Rajeev Alur, Adam Freilich, and Mukund Raghothaman. Regular combinators for string transformations. In Proceedings of the Joint Meeting of the Twenty-Third EACSL Annual Conference on Computer Science Logic (CSL) and the Twenty-Ninth Annual ACM/IEEE Symposium on Logic in Computer Science (LICS) , page 9. ACM, 2014.
- 3[3] Mikołaj Bojańczyk. Polyregular functions, 2018. ar Xiv:1810.08760 .
- 4[4] Mikołaj Bojańczyk and Wojciech Czerwiński. Automata toolbox. URL: https://www.mimuw.edu.pl/~bojan/upload/reduced-may-25.pdf .
- 5[5] Mikołaj Bojańczyk, Laure Daviaud, and Shankara Narayanan Krishna. Regular and first-order list functions. In Proceedings of the 33rd Annual ACM/IEEE Symposium on Logic in Computer Science, LICS 2018, Oxford, UK, July 09-12, 2018 , pages 125–134, 2018.
- 6[6] Thomas Colcombet. A combinatorial theorem for trees. In International Colloquium on Automata, Languages, and Programming , pages 901–912. Springer, 2007.
- 7[7] Bruno Courcelle and Joost Engelfriet. Graph Structure and Monadic Second-Order Logic . A Language-Theoretic Approach. Cambridge University Press, June 2012.
- 8[8] Vrunda Dave, Paul Gastin, and Shankara Narayanan Krishna. Regular transducer expressions for regular transformations. In Proceedings of the 33rd Annual ACM/IEEE Symposium on Logic in Computer Science, LICS 2018, Oxford, UK, July 09-12, 2018 , pages 315–324, 2018. URL: https://doi.org/10.1145/3209108.3209182 . · doi ↗