Batch weight for domain adaptation with mass shift
Miko{\l}aj Bi\'nkowski, R Devon Hjelm, Aaron Courville

TL;DR
This paper introduces a batch-weighting method to address mode imbalance in unsupervised domain transfer, improving GAN performance when source and target distributions differ in class frequencies.
Contribution
It proposes a novel re-weighting technique called batch-weight to correct mass shift, along with a simplified training objective based on joint distribution discrimination and cycle-consistency.
Findings
Effective in multiple image-to-image translation tasks
Improves mode matching between source and target distributions
Simplifies training with a new objective
Abstract
Unsupervised domain transfer is the task of transferring or translating samples from a source distribution to a different target distribution. Current solutions unsupervised domain transfer often operate on data on which the modes of the distribution are well-matched, for instance have the same frequencies of classes between source and target distributions. However, these models do not perform well when the modes are not well-matched, as would be the case when samples are drawn independently from two different, but related, domains. This mode imbalance is problematic as generative adversarial networks (GANs), a successful approach in this setting, are sensitive to mode frequency, which results in a mismatch of semantics between source samples and generated samples of the target distribution. We propose a principled method of re-weighting training samples to correct for such mass shift…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2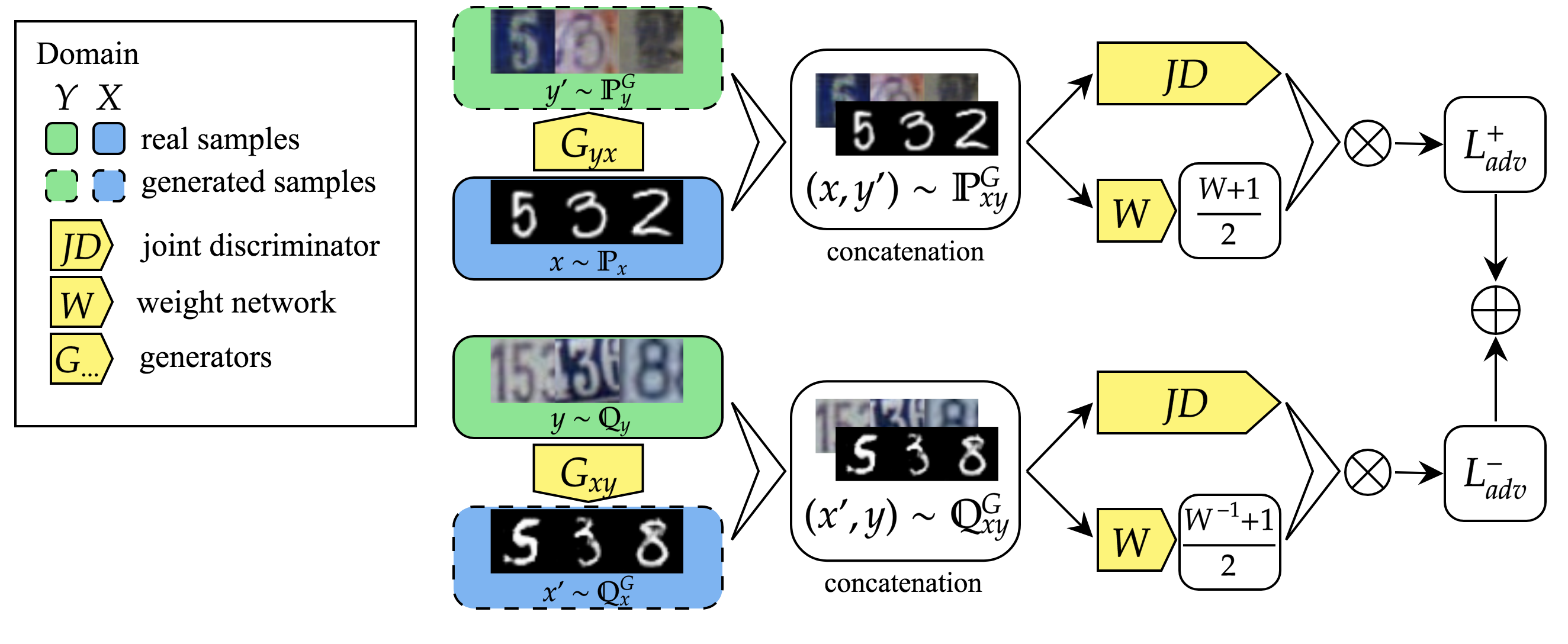 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9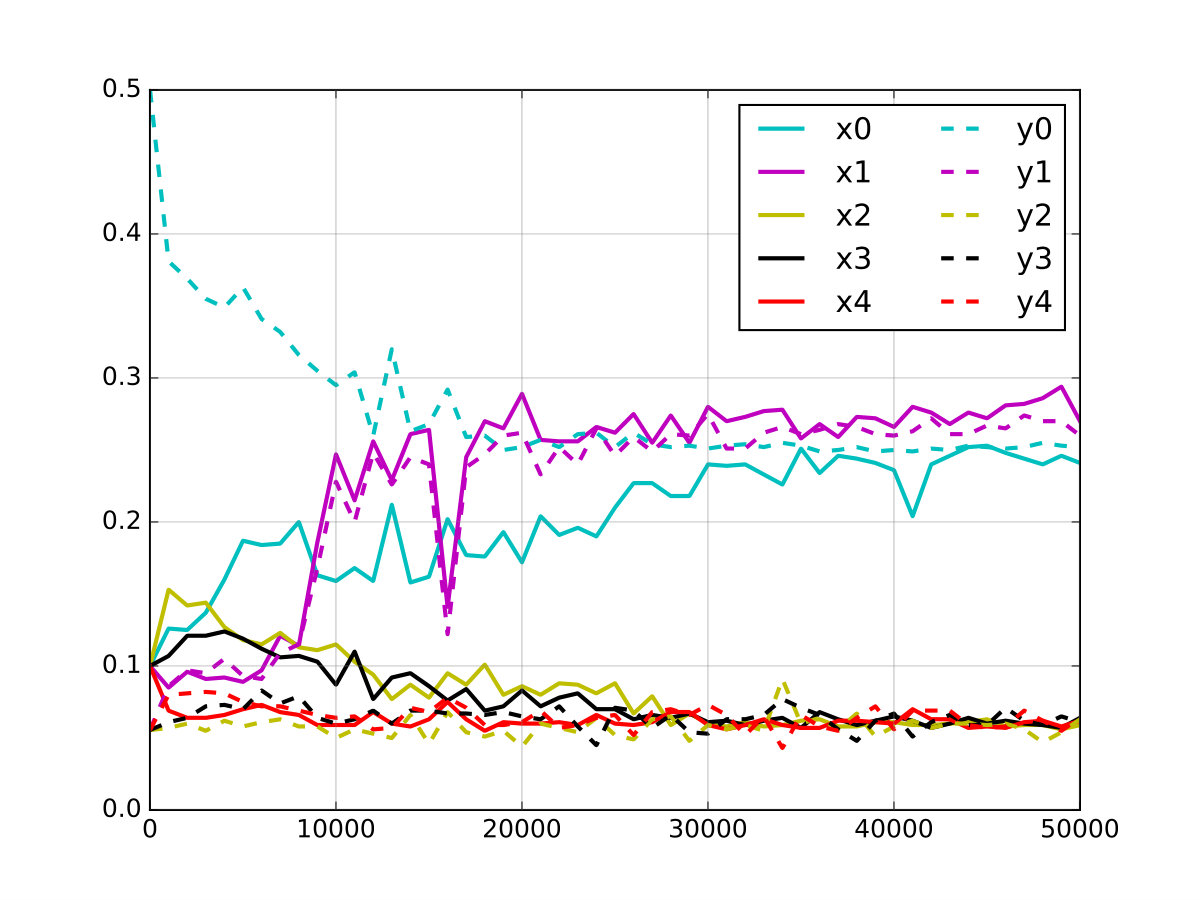 Figure 10
Figure 10 Figure 11
Figure 11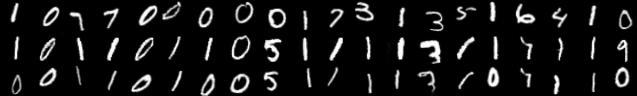 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16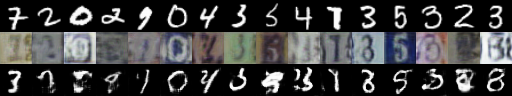 Figure 17
Figure 17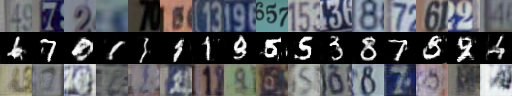 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21| image | image | |
| 4x4 conv(32) | 4x4 conv(64) | 4x4 conv(32) |
| () | () | |
| concat | ||
| 4x4 conv(64) | 4x4 conv(128) | 4x4 conv(64) |
| () | () | () |
| concat | ||
| 2 x ResBlock(128) | ||
| 4x4 conv(128) | 4x4 conv(256) | 4x4 conv(128) |
| () | () | () |
| concat | ||
| 4x4 conv(256) | ||
| fc 1024 256 | ||
| fc 256 1 |
| image | noise |
|---|---|
| KxK conv(64), stride | repeat |
| 2 x ResBlock(64) | () |
| 1x1 conv(64), stride | |
| () | |
| concat | |
| 1x1 conv(64), stride | |
| 2 x ResBlock(64) | |
| KxK transposed conv(c), stride s | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Batch weight for domain adaptation with mass shift
Mikołaj Bińkowski Corresponding author (mikbinkowski at gmail dot com). Mila, Université de Montréal
Imperial College London
R Devon Hjelm
Mila, Université de Montréal
Microsoft Research
Aaron Courville
Mila, Université de Montréal
CIFAR Fellow
Abstract
Unsupervised domain transfer is the task of transferring or translating samples from a source distribution to a different target distribution. Current solutions unsupervised domain transfer often operate on data on which the modes of the distribution are well-matched, for instance have the same frequencies of classes between source and target distributions. However, these models do not perform well when the modes are not well-matched, as would be the case when samples are drawn independently from two different, but related, domains. This mode imbalance is problematic as generative adversarial networks (GANs), a successful approach in this setting, are sensitive to mode frequency, which results in a mismatch of semantics between source samples and generated samples of the target distribution. We propose a principled method of re-weighting training samples to correct for such mass shift between the transferred distributions, which we call batch-weight. We also provide rigorous probabilistic setting for domain transfer and new simplified objective for training transfer networks, an alternative to complex, multi-component loss functions used in the current state-of-the art image-to-image translation models. The new objective stems from the discrimination of joint distributions and enforces cycle-consistency in an abstract, high-level, rather than pixel-wise, sense. Lastly, we experimentally show the effectiveness of the proposed methods in several image-to-image translation tasks.
1 Motivation
Recent developments originating from Generative Adversarial Networks [GANs, 1] allow generation of high quality images, often hardly distinguishable from the real images [2, 3]. Adversarial methods have also been successfully applied in conditional image generation, where generated samples are obtained as functions of some prior data. When the latter is also composed of images, the problem is also called image-to-image (domain) transfer or style transfer. In this scope, adversarial objectives are often combined with other loss functions to ensure desirable properties of the transfer networks. These include variants of cycle consistency loss, originally proposed in CycleGAN [4] and developed further by Huang et al. [5], Almahairi et al. [6], Lee et al. [7], leading to current state-of-the-art results in several image-to-image transfer problems.
Notwithstanding these notable results, not much attention has been paid towards understanding of unsupervised domain transfer from probabilistic point of view. Although original CycleGAN assumes deterministic transfer, later works identified the necessity of learning non-deterministic many-to-many mappings to account for features that might be present only in one of the considered domains. A common assumption made in such setting, sometimes directly [e.g., 5], but often implicitly, is the existence of latent variable that covers the shared semantics between the domains of interest. Learning the transfer function can then be decomposed to learning deterministic encoders to and stochastic decoders from such latent space.
This view, however, does not take into account the distributional differences that may exist between the domains being matched. Since probability mass is preserved trough encoders and decoders, every mode in source domain covers the same share of the distribution as its representations in latent space and the target domain do in their respective distributions. However, we do not necessarily want to match modes that consist the same shares of data.
For example, consider the task of transferring between handwritten digits [MNIST, 8], and Street View House Numbers [SVHN, 9]. These datasets are independently sampled but share semantics expressed in the digit classes, styless (e.g., seven with or without a cross), etc which we wish to correctly transfer. Since digits in MNIST are evenly distributed, we expect the correct transfer function to produce samples in which zeros cover approximately 10% of all generated ones. Yet, the distribution of the “correct” transfer function (one that maintains the digit class) would be different from the actual SVHN distribution, where ones cover around 20% of the data. Therefore such a transfer function would not be optimal in the Optimal Transport sense, i.e. it would not minimize any divergence between reference and generated distributions. Given such correct transfer-generator, a good discriminator would need to be insensitive to the disparity of mode (i.e., digit) frequencies between the source and target distributions. If not, it would provide a gradient signal to the transfer-generator that would encourage it to alter some modes to account for the missing mass of ones in its output.
We will call the described issue a mode-mass imbalance.
This issue demonstrates the view that shared semantics can be modelled through a latent variable is, in general, invalid. However, the described problem is inherent in all GAN-based approaches to domain transfer, since GAN discriminators are always trained to estimate some kind of divergence e.g., Jensen-Shannon [1]; Wasserstein distance [10, 11]; Maximum Mean Discrepancy [12, 13] between reference distribution and the generated samples. For these reasons, we propose batch weight as a solution to the issue caused by mass-preserving property of optimal transport in the context of domain transfer. Batch weight aims to re-balance samples within each batch to account for differences in the reference and generated distributions.
2 Related Work
The need to correct for mode shift between distributions of interest has been widely studied in machine learning.
2.1 Supervised learning
In supervised learning, it is often assumed that distributions and of the independent variable on the training and tests are different, but the conditionals and are equal. Such situation is known as covariate shift or sample selection bias and has been addressed in multiple works [14, 15, 16, 17, 18].
The complimentary setting when , termed label shift, has also been studied [19]. In more recent work, Lipton et al. [20] consider label shift correction for black box predictors.
2.2 Importance sampling
The problem of changing probability measure in empirical setting has has long been studied in importance sampling theory. This general technique has been used in estimating properties of distribution available indirectly through another distribution.
Importance sampling is often applied in variance reduction problems. In such, one re-weights the available sample so that the variance of the estimated quantity under new distribution is lower than with respect to the original one.
2.3 Domain transfer
The distribution shift has undergone some limited study in the context of domain transfer. Cohen et al. [21] empirically showed that the use of distribution-matching loss functions in domain transfer leads to issues when modes in target domain are under- or over-represented as compared to the source. Diesendruck et al. [22] also identifies the problem of distribution mismatch in generative modelling, however the proposed re-balancing function is provided only in case when relation between source and target distribution is available (directly or indirectly).
State-of-the-art unsupervised image-to-image translation models [5, 6, 7] assume that we are given samples and drawn from two domains and according to some distributions and , and seek (possibly random) generator functions and so that generated distributions and 111 denotes push-forward measure of through function . match with and in consistent way. Numerous techniques have been developed to ensure that the generated samples are consistent with their sources and that the transfer is invertible. Most of them are based on simple yet powerful cycle-consistency loss [4],
[TABLE]
along with the GAN objective [1]; Huang et al. [5], Lee et al. [7], Zhu et al. [23] combine as many as five different loss components to train the generator functions.
Note that in the presence of mode-mass imbalance, the assumption that generators should minimize the GAN objective violates the consistency between sources and targets. It can be shown that this assumption together with cycle consistency imply that our samples are drawn from marginals of the same distribution on , i.e. .
More complicated loss functions used in domain transfer still seek the generators that mimic the conditionals and , given marginals and . Although they do not imply the equality of the joint distributions being searched (which correspond to the correct transfer), they do imply equality of their marginals, and , which is impossible in the presence of mode-mass imbalance.
Domain transfer models often assume existence of underlying shared semantics [e.g. 5] modelled as underlying latent variable that consists common features of and . In such scenario, one aims to train encoders and decoders , and transfer between domains through . This, however, does not account for the possible mode-mass imbalance between and : even non-deterministic encoders and decoders preserve probability mass between and , and and . Therefore, the assumption that such exists is, in general, invalid. This inherent issue of domain transfer has been noted by Lavoie-Marchildon et al. [24].
3 Formulation
In this section we propose a framework to perform the unsupervised domain transfer task in the presence of mode-mass imbalance. We formulate it separately for one-sided and two-sided transfer that involve reweighting one or two domains, respectively.
3.1 One-sided batch weight
Assume that and are source and target measures on domains and , respectively. We assume that correct domain transfer from to can be represented by joint distribution such that the marginal covers the target distribution
[TABLE]
This assumption is much weaker than equality which most domain transfer models implicitly assume.
We would like to learn to transfer (possibly non-deterministically) by training a generator function that mimics the conditional . Let be a Wasserstein discriminator (we will stick to the Wasserstein framework, however similar arguments can be derived in general for any divergence).
The Wasserstein GAN optimizes the following loss function,
[TABLE]
which is equivalent to,
[TABLE]
where is a push forward measure of through .
This optimization suffers from the problem of mode-mass imbalance, as in general we do not want to match with . However we do expect to cover all the modes of , as does due to the assumption 2. If this is true, then the Radon-Nikodym derivative exists and,
[TABLE]
is an unknown function, and therefore the last expression in the above equation cannot be obtained directly. However, we may try to estimate it using e.g. neural network ,
[TABLE]
where . Such constraint can easily be enforced by a softmax layer computed over samples in the batch.
Problems 3 and 6 together motivate the following optimization criterion for Wasserstein batch-weighted domain transfer:
[TABLE]
Although optimization of the Wasserstein objective is technically equivalent to optimization of its square, in practice it is more convenient to use standard WGAN loss. Therefore the training procedure optimizes slightly different losses for weighting and generator networks. The proposed procedure for batch-weighted domain transfer is shown in Algorithm 2 in Appendix A.
3.1.1 Possible issues
Samples from modes in the source domain that are underrepresented in the target domain might be transferred poorly if too low weights are assigned to them by the weighting network. This problem essentially stems from the fact that we are weighting the generated samples, not the target ones, which biases the generator so that it values generated samples according to their frequency in target domain , even though we care about quality of , which stems from .
Alternative solution which might be more robust would involve re-weighting both samples. Thanks to the fact that if Radon-Nikodym derivatives between two distributions exist in both directions they are inverses of each other, we can formulate batch weight so that both distributions are resampled to match at their midpoint . We explore this idea in the following subsection.
3.2 Reweighting both domains
Here we assume the existence of two joint distributions on such that and that we observe samples drawn from their marginals and . and are said to represent a correct matching between these domain, i.e the transfer from to (or other way around) is considered valid if the pair can be drawn from and . Although we do not assume the same marginals, we do assume the equality of conditionals,
[TABLE]
We aim to obtain the correct transfer by learning generators that mimic the above marginals. Let and .
Let be a mixture of the two joint distributions. Thanks to the assumption of equality of the supports of and , both Radon-Nikodym derivatives and exist and satisfy,
[TABLE]
Therefore
[TABLE]
As we aim to learn the distributions and through generators and (implicitly, by learning the conditionals),
[TABLE]
We can approximate distributions on the left and right hand sides of the Equation 3.2 using available samples from marginals and , along with weighting network that approximates the derivative .
Therefore, at generation step we should optimize the following objective:
[TABLE]
where is some loss function trained adversarially.
At this point, we introduce a joint discriminator , a neural network that discriminates between distributions supported on and is a domain dependent on the GAN type. Similar idea has been applied in ALI [25]. Joint discriminator enforces cycle-consistency on the abstract- rather that pixel-level as objective 1 does.
Assuming yet again Wasserstein setting and , the full objective implied by Eq. 11 is as follows:
[TABLE]
The batch weight procedure for Wasserstein domain transfer with joint discriminator is detailed in Algorithm 1. Overview of the algorithm is also shown in Figure 1. From now on, we will call the proposed architecture a Joint Discriminator - Batch Weighted domain transfer or shortly JD-BW.
3.3 Two-domain vs. single-domain batch weight
The advantage of reweighting both domains is that it ensures that every example in each training set would receive a weight no smaller than a half of what it would get without reweighting. Therefore it may never collapse in the sense that some examples from one domain are wrongly excluded from training, i.e. assigned zero weights.
On the other hand, one-sided reweighting carries a risk of some training examples from the weighted domain getting weights very close to zero, which slows down the training (as they would have small impact on gradients). Some examples may need to be assigned very small weights, yet this can occur wrongly at early phase of training, when weighting network is imperfect. For instance, a possible failure mode would be when such low weights were assigned to the samples of lowest quality (at some point during training); in such case generator would have very little incentive to improve them.
In practice, we found reweighting both domains much more stable. Thanks to the symmetric formulation222more precisely, the invertibility of Random-Nikodym derivative., if some mode gets lower weights in one domain, the corresponding mode in the other domain is likely to receive higher weights, eventually leading to balance between reweighted domains.
3.4 Non-uniqueness and implicit bias
It is important to note that given empirical distributions and there exist many joints and satisfying equality of conditionals (Assumption 8). For instance, is a valid distribution on that has all the assumed properties, except that it leads to independent transfer between these domains.
It is worth noting the role of implicit bias of the generator network architectures used in modelling the conditional distributions and . State-of-the art image-to-image translation models [4, 5, 7] all use deep ResNets [26] or U-Nets [27] as transfer-generators. These architectures bias the generator mapping towards identity in pixel-level space, which helps obtaining satisfying transfer networks. This, however, also explains limitations of these models: the most impressive performance has so far been achieved in tasks with near pixel-to-pixel correspondence, also referred to as style transfer.
Following these approaches, we impose similar architectural constraints on to enforce the dependence structure in learned joints and .
4 Experiments
The early empirical studies confirmed the issues mentioned in Section 3.1.1: although re-weighting only generated samples (Algorithm 2) often leads to correct transfer it can be unstable. The failure modes that occur in this setting are often caused by the weighting network assigning all weight to a single example in each batch. For these reasons in this Section we focus on experiments with Algorithm 1.
4.1 Datasets
We carry out experiments on four dataset pairs.
MNIST to skewed & resized MNIST. In this experiment we alter the standard MNIST dataset by introducing bias towards zeros. In the SR-MNIST (skewed and resized MNIST) half of the samples are drawn from the class of zeros, while the other half are drawn with equal probabilities from the remaining digit classes. The images are then padded, randomly rotated by the angle and randomly cropped. The resulting digits are slightly smaller than the original ones and not necessarily centered. Although changing sampling frequency itself makes the case for batch weighting, the alterations made to the digits so that the transfer to be learnt is not trivial/deterministic. 2. 2.
MNIST to SVHN. We tackle the task of transferring between MNIST to SVHN [9] without using the labels. SVHN has an non-uniform distribution of digits and is characterized by considerably more complex features, such us font, colour, background and size. Although we use the version of SVHN with centered digits, they also often contain side-digits coming from the whole house number. To our best knowledge, this problem has not yet been solved. 3. 3.
Edges to Shoes&Bags. We combine edges2shoes and edges2handbags datasets [28] to obtain two-class datasets of edges and photos, and alter sampling of the latter so that 90% of examples are photos of shoes. In the edge-domain we leave sampling unchanged, hence 50k out of total 188k (26%) examples are contours of shoes. We carry out experiments at 128x128 resolution. 4. 4.
CelebA to Portraits. We transfer CelebA dataset of celebrity photos Liu et al. [29] to WikiArt dataset of 1714 portraits Lee et al. [7]. We randomly crop images around the faces and resize to 128x128 resolution.
4.2 Benchmarks and ablation study
We compare the performance of the proposed model with MUNIT [5], which is one of the state-of-the-art models in unsupervised image-to-image transfer. We do not compare with CycleGAN [4] and BiCycleGAN [23] as the former does not allow multimodal transfer and MUNIT is essentially its extension, while the latter requires paired training examples.
Since our model has two novel components, batch weight and joint discriminator, we also carry out two ablations on the MNIST - SR-MNIST task (Section 5.1):
- •
MUNIT with batch weight,
- •
Joint discriminator architecture without batch weight.
4.3 Network architectures
**Generators
**As stressed in Section 3.4, the architecture plays very important role in domain transfer. Following the successful architectures of Zhu et al. [4], Huang et al. [5] we use generators with several residual blocks [26] to bias the transfer towards identity.
Since we consider non-deterministic transfer, generator networks take as inputs the image and noise vector, sampled uniformly from , where for MNIST - SR-MNIST task and for other tasks. Noise vector is repeated over the spacial dimensions and concatenated to convolutional representation: halfway through the depth of the network for 32x32 models and before the first residual block for 128x128 architectures. We follow Brock et al. [3] and use spectral normalization [30] in both generator and discriminator networks. 32x32 architecture is shown in details in Table 2 in Appendix B. For 128x128 resolution we used the same generators as in MUNIT [5]333except that we used spectral normalization and did not use Adaptive Instance Norm..
**Discriminator
**For joint discriminator, we use somewhat more powerful discriminator than the DCGAN [31], as it has to discriminate between joint distributions on . The architecture at each level separately computes features of each of the images alone and of their concatenation. We use spectral normalization [30] and gradient penalty at training points444instead of interpolations between training and reference samples as originally proposed by Gulrajani et al. [32] as in [33]. Details are shown in Table 1 in Appendix B.
**Weighting network
**For weighting network, we considered several approaches. Function maps from , yet the samples it will ever see during the training are either of the form or ; there are thus multiple ways of modelling . Overall, out of the several strategies we considered for obtaining weights for the batches the following proved most stable:
[TABLE]
where the weight networks are modeled using the architecture of DCGAN discriminator [31] with four convolutional layers and features in the first layer.
We also found useful regularizing the weighting network training by clipping the values of , which lets us control (and gradually relax) the ratio between highest and lowest weights within a batch. We discuss these further in Appendix B.1.
4.4 Training details
We train all models using Adam optimizer [34] with parameters , but we used different hyperparameter settings for 32x32 and 128x128 architectures.
32x32 models. We used batch size of 128. Joint Discriminator models are trained with 5 discriminator steps per generator step, while MUNIT (benchmark) models are trained with one generator per one discriminator step, as in original implementation. For these reason, we train the latter for 3x more generator steps than the proposed architectures555This required slightly longer training for MUNIT anyway, due to simplified JD architecture.. After this number of iterations, MUNIT models seemed to converge. Overall, we train JD (MUNIT) for 50k (150k) steps in MNIST - SR-MNIST task and 250k (750k) steps in MNIST - SVHN task.
128x128 models. We used batch size of 6, 2 discriminator steps per one generator step and trained for 300k generator steps.
5 Results
5.1 MNIST to SRMNIST
We perform the unsupervised transfer task from SR-MNIST to MNIST (i.e., without using the labels in any part of our objective for any network). As zeros are over-represented in the first dataset, we anticipate this task will be difficult without properly reweighting the GAN objective. We compare to Multimodal Unsupervised Image-to-Image Translation [MUNIT, 5]
Results from this experiment are shown in Figure 2. Only Joint Discriminator architecture with Batch Weight performed well, correctly matching different digit classes. Other models often incorrectly match some kinds of SR-MNIST zeros with other MNIST digits. We monitored the batch weights assigned to each example within a batch in order to find out if weighting network(s) are capable of matching frequencies of the modes in two distributions. Figure 3 presents evolution of the weights aggregated for each of the MNIST/SR-MNIST classes (as these are the only modes we can clearly distinguish). Weighting network successfully allows the mode frequencies to gradually match between both distributions.
We also note that the proposed model achieves cycle-consistency in an abstract, high-level sense. The learned transfer is non-deterministic, yet the reconstructed SR-MNIST samples belong to the same sub-manifold as the original samples , where such sub-manifold is spanned by features non-existent in MNIST space.
5.2 MNIST to SVHN
Results from this experiment are shown in the Figure 5. Although our model does not produce as sharp images as expected and makes few mismatch errors, it provides reasonable transfer. MUNIT, on the other hand, wrongly transfers MNIST to SVHN and collapses completely in the opposite direction.
Our method also disentangles SVHN-specific features from those shared with MNIST, and models the former via noise input. Figure 4 shows samples obtained from different MNIST digits with the same noise, for 8 different noise values.
5.3 Edges to Shoes&Bags
In this experiment the main difficulty comes from difference in frequencies of bags and shoes between source and target domains. As shown in Fig. 6(a), the proposed model successfully tackled the problem, producing correctly transferred samples. MUNIT (Fig. 6(c)), on the other hand, struggled with the imbalance and often transferred bag-edges to shoes, which were over-represented in the photo domain.
5.4 CelebA to Portraits
We present results from this experiment in Fig. 6(b) and 6(d). In this experiment we were not able to quantify mass shift between different modes, as no labels/additional features are available for the Portrait dataset. However, some of such imbalances are visible, e.g. gender proportions and frequency of moustache are different in paintings than in celebrity photos.
Both models produced samples of good quality, however those coming from our model preserved much more features of the original examples. MUNIT, in fact, preserves only a pose, while all other features seem to be independent of the source image. In Appendix C we further discuss the nature of transfer learned by MUNIT in this and in the previous task.
6 Conclusion
In this work, we considered unsupervised domain transfer in the presence of mode imbalance, a situation when modes to be matched have different frequencies in source and target domains. The contributions of this paper are threefold. Firstly, we provide probabilistic formalism of unsupervised domain transfer. Secondly, we propose a novel method of batch weighting to tackle the issue of mode imbalance. Lastly, we propose a new architecture called Joint Discriminator, that not only largely simplifies the training objective, but also ensures cycle-consistency in multi-modal, high-level sense, without directly enforcing quality of reconstructions. We experimentally show effectiveness of our model and its superiority over existing benchmark in tasks where mode-mass imbalance is present.
Acknowledgements
Authors thank NVIDIA for donating a DGX-1 computer used in this work. M.B. thanks Engineering and Physical Sciences Research Council (EPSRC) for funding part of this research.
Appendix A One-sided batch weight - details
In Algorithm 2 we present the original idea of one-sided batch-weighted domain transfer.
Appendix B Architecture details
Tables 2 and 1 present generator and joint-discriminator architectures used in experiments with 32x32 images.
B.1 Weighting network
We considered three different ways of modelling weight network . Given batches of pairs of real and generated samples and we may get the weights using each of the following architectures
( concatenates two arguments)
[TABLE] 2. 2.
( takes one argument)
[TABLE] 3. 3.
(composite)
[TABLE]
The weight network(s) () were the same as DCGAN discriminator [31] with four convolutional layers and features in the first layer.
We found the last (composite) architecture to be the most stable one. The first approach, although the most natural, most probably suffers from the fact that it takes longer for joint samples to look similar to each other than it does for the marginals.
Appendix C Role of the noise term
We have observed two types of failures made by MUNIT-trained models in the presence of mode-mass imbalance, both related to what these models encode in the noise term.
In the first one, the class/mode is kept in a transferred sample depending on the noise term. This has been observed in Edges to Shoes&Bags task, see Figure 7(b) and 7(d). In multimodal domain transfer, noise term should only encode the features which are not present in the source domain. In this task, however, the MUNIT-trained model encoded the conditional mode: some noise values caused the generator ’forget’ the source image and generate one over-represented in the target domain (regardless of the source image mode/class).
The second issue is the amount of the source image features retained in the transferred one. In CelebA to Portrait transfer, MUNIT tends to keep very few features of the source image (e.g. position of eyes and and nose) and model all high-level features using noise term. As shown in Figure 8(b), samples obtained with the same source image are less similar to each other than those generated using the same noise term. With JD-BW model (Fig. 8(a)) it is the opposite: generators retain much more features of the source image, while the noise terms determines only the style of the generated portraits.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Goodfellow et al. [2014] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems , 2014, pp. 2672–2680.
- 2Karras et al. [2017] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” Co RR , vol. abs/1710.10196, 2017. [Online]. Available: http://arxiv.org/abs/1710.10196
- 3Brock et al. [2018] A. Brock, J. Donahue, and K. Simonyan, “Large scale GAN training for high fidelity natural image synthesis,” Co RR , vol. abs/1809.11096, 2018. [Online]. Available: http://arxiv.org/abs/1809.11096
- 4Zhu et al. [2017 a] J. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” Co RR , vol. abs/1703.10593, 2017. [Online]. Available: http://arxiv.org/abs/1703.10593
- 5Huang et al. [2018] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” in ECCV , 2018.
- 6Almahairi et al. [2018] A. Almahairi, S. Rajeswar, A. Sordoni, P. Bachman, and A. C. Courville, “Augmented cyclegan: Learning many-to-many mappings from unpaired data,” Co RR , vol. abs/1802.10151, 2018. [Online]. Available: http://arxiv.org/abs/1802.10151
- 7Lee et al. [2018] H.-Y. Lee, H.-Y. Tseng, J.-B. Huang, M. K. Singh, and M.-H. Yang, “Diverse image-to-image translation via disentangled representations,” in European Conference on Computer Vision , 2018.
- 8Le Cun and Cortes [2010] Y. Le Cun and C. Cortes, “MNIST handwritten digit database,” 2010. [Online]. Available: http://yann.lecun.com/exdb/mnist/