Clustering without Over-Representation
Sara Ahmadian, Alessandro Epasto, Ravi Kumar, Mohammad Mahdian

TL;DR
This paper introduces algorithms for clustering data points with color labels, ensuring no over-representation of any color in clusters, with proven guarantees and effective real-world performance.
Contribution
It presents new algorithms with provable guarantees for constrained clustering that prevents color over-representation, including a linear programming approach and a simpler combinatorial method.
Findings
Algorithms effectively prevent color over-representation in clusters.
Proven performance guarantees for both general and special cases.
Successful experiments on real-world data demonstrate practical effectiveness.
Abstract
In this paper we consider clustering problems in which each point is endowed with a color. The goal is to cluster the points to minimize the classical clustering cost but with the additional constraint that no color is over-represented in any cluster. This problem is motivated by practical clustering settings, e.g., in clustering news articles where the color of an article is its source, it is preferable that no single news source dominates any cluster. For the most general version of this problem, we obtain an algorithm that has provable guarantees of performance; our algorithm is based on finding a fractional solution using a linear program and rounding the solution subsequently. For the special case of the problem where no color has an absolute majority in any cluster, we obtain a simpler combinatorial algorithm also with provable guarantees. Experiments on real-world data shows…
Click any figure to enlarge with its caption.
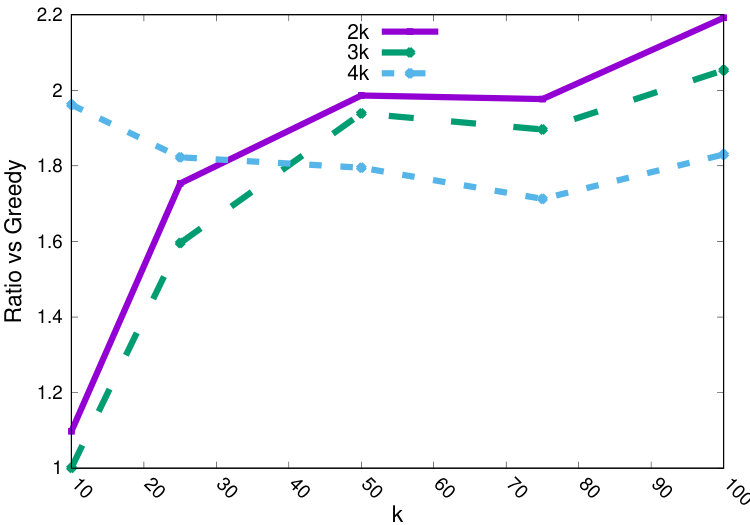 Figure 1
Figure 1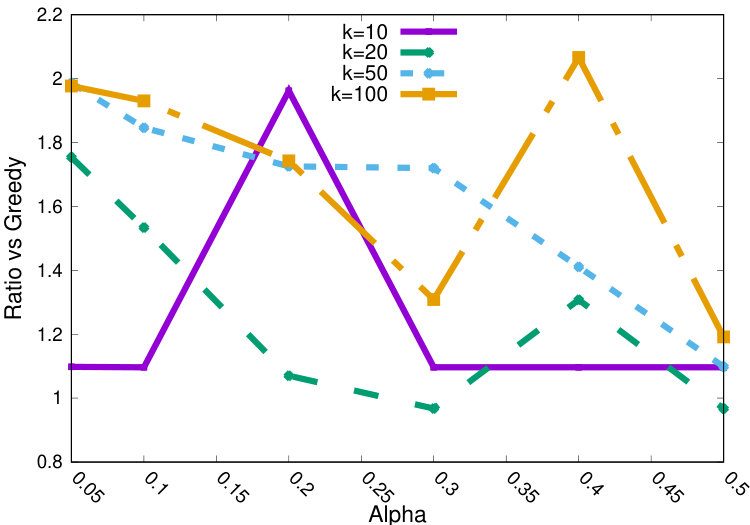 Figure 2
Figure 2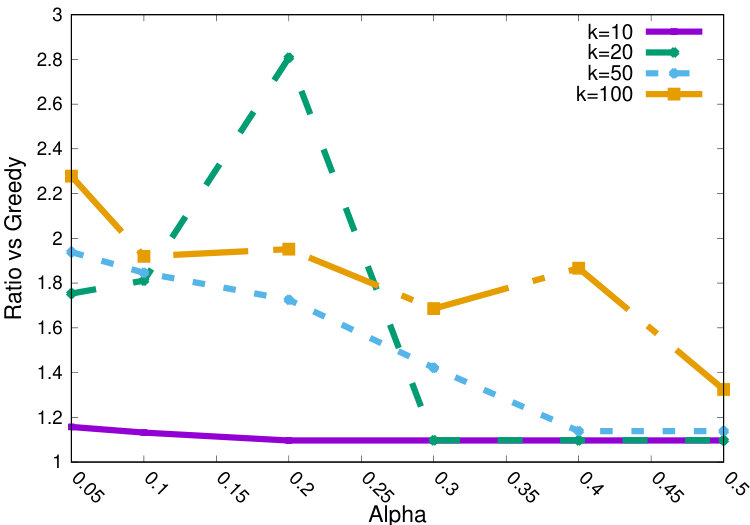 Figure 3
Figure 3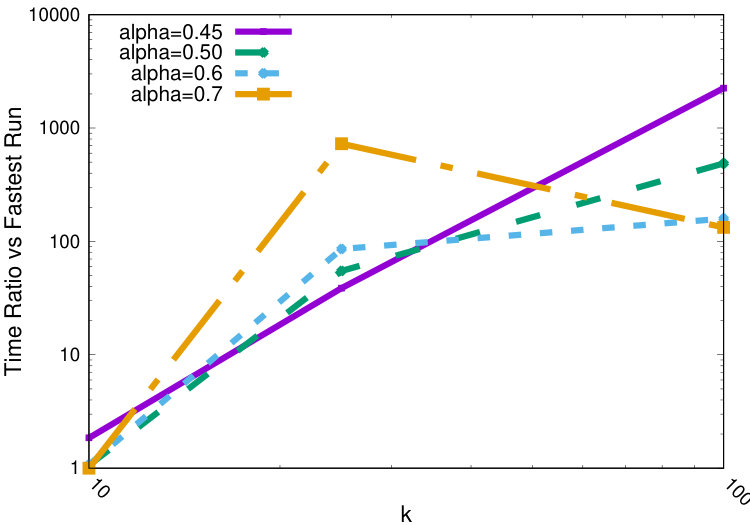 Figure 4
Figure 4| Dataset | # Points | # Dim. | # Colors | Max ratio |
| 4area | 8 | 4 | 40.2 | |
| query | 20 | |||
| reuters | 2500 | 10 | 50 | |
| victorian | 4500 | 10 | 45 |
| Dataset | Cost vs Greedy | Cost vs Random | ||||
| 4area | 0.45 | +62% | +50% | 1 | 32 | 660 |
| 0.50 | +67% | +55% | 1 | 19 | 552 | |
| 0.60 | +62% | +50% | 1 | 6 | 338 | |
| 0.70 | +64% | +52% | 0 | 2 | 124 | |
| 0.80 | +64% | +52% | 0 | 0 | 0 | |
| query | 0.07 | +6% | +7% | 1 | 132 | 66 |
| 0.08 | +6% | +7% | 1 | 9 | 46 | |
| 0.09 | +6% | +7% | 0 | 7 | 26 | |
| 0.10 | +6% | +7% | 0 | 4 | 6 | |
| reuters | 0.02 | +80% | +44% | 1 | 35 | 38 |
| 0.05 | +75% | +40% | 1 | 29 | 35 | |
| 0.10 | +53% | +22% | 1 | 24 | 29 | |
| 0.20 | +7% | -15% | 1 | 17 | 18 | |
| 0.30 | -3% | -23% | 1 | 15 | 10 | |
| 0.40 | +31% | +4% | 0 | 12 | 8 | |
| 0.50 | -3% | -23% | 0 | 9 | 6 | |
| victorian | 0.05 | +109% | +26% | 1 | 62 | 57 |
| 0.10 | +45% | -13% | 1 | 56 | 38 | |
| 0.20 | +39% | -17% | 1 | 43 | 9 | |
| 0.30 | +63% | -2% | 1 | 30 | 0 | |
| 0.40 | +45% | -13% | 1 | 17 | 0 | |
| 0.50 | +45% | -13% | 0 | 10 | 0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Clustering without Over-Representation
Sara Ahmadian
Google ResearchNew YorkNYUS
,
Alessandro Epasto
Google ResearchNew YorkNYUS
,
Ravi Kumar
Google ResearchMountain ViewCAUS
and
Mohammad Mahdian
Google ResearchNew YorkNYUS
(2019)
Abstract.
In this paper we consider clustering problems in which each point is endowed with a color. The goal is to cluster the points to minimize the classical clustering cost but with the additional constraint that no color is over-represented in any cluster. This problem is motivated by practical clustering settings, e.g., in clustering news articles where the color of an article is its source, it is preferable that no single news source dominates any cluster.
For the most general version of this problem, we obtain an algorithm that has provable guarantees of performance; our algorithm is based on finding a fractional solution using a linear program and rounding the solution subsequently. For the special case of the problem where no color has an absolute majority in any cluster, we obtain a simpler combinatorial algorithm also with provable guarantees. Experiments on real-world data shows that our algorithms are effective in finding good clustering without over-representation.
††journalyear: 2019††copyright: rightsretained††conference: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining; August 4–8, 2019; Anchorage, AK, USA††doi: 10.1145/3292500.3330987††isbn: 978-1-4503-6201-6/19/08††ccs: Information systems Clustering††ccs: Information systems Data mining††ccs: Theory of computation Facility location and clustering††ccs: Theory of computation Unsupervised learning and clustering
1. Introduction
Clustering is a fundamental problem in data mining and unsupervised machine learning. Many variants of this problem have been studied in the literature. In a number of applications, clustering needs to be performed in the presence of additional constraints, such as those associated with fairness or diversity. Chierichetti et al. (Chierichetti et al., 2017) study one such clustering problem, where the constraint is that the distribution of a particular feature (say, gender) in each cluster is identical to that of the general population. This is a highly constraining requirement, particularly in cases where the protected feature can take many values, and in many cases such a clustering does not exist. Furthermore, in many applications, such as the ones explained below, proportional representation is not really required: a clustering that ensures no particular feature value is highly over-represented in any cluster suffices.
A motivating application for our work is the following: every day, online advertising systems sell billions of advertising opportunities, specified by keywords the advertisers provide, through auctions. This is a highly heterogeneous set of auctions, and to optimize any of the auction parameters, one needs to cluster this set into smaller, more homogeneous, clusters. However, to ensure that no advertiser can manipulate this process, it is crucial that no advertiser has a large market share in any cluster (see (Epasto et al., 2018) for a theoretical justification of this statement). Hence, keywords must be clustered such that no advertiser is over-represented in any cluster.
In addition to the above, there are other settings where an upper bound on the representation of each group in each cluster can capture real-world requirements. For example, in clustering news articles, requiring that no cluster is dominated by a certain view point or a certain news source is a good way to ensure balance and diversity in each cluster. Another example is clustering a number of agents into committees, where it is desirable that no committee is dominated by agents of a certain background. See Celis et al. (2018a) for an example where a similar constraint is applied to the problem of selecting a single committee maximizing a certain scoring function.
Our contributions. In this paper we formulate the problem of clustering without over-representation and study its algorithmic properties. For the clustering part, we focus on the -center formulation. While there are many different well-studied models for clustering (such as -median, -means, -center, or correlation clustering), we have picked the -center model because of its theoretical simplicity (which allows us to prove good theoretical bounds) as well as the strong guarantees that are useful in many applications (that every point in a cluster is close to the center of that cluster).
Our formulation of the problem is in terms of a parameter that specifies the maximum fraction of nodes in a cluster that have a specific value for the protected feature. Our main results are the following. First, for the case of , we obtain a combinatorial approximation algorithm. Note that is a canonical case as it corresponds to ensuring that no cluster is dominated by a group with an absolute majority. Second, for the case of general , we give an approximation algorithm based on linear programming (LP) that achieves a bicriteria approximation guarantee. We also prove that the problem is NP-hard to approximate. Finally, we evaluate our LP-based algorithm on a number of real data sets, showing that its performance is even better than the theoretical guarantees.
Related work. Clustering is a classical problem in unsupervised learning and finds application in a variety of settings (see, e.g., Jain (2010)); examples include information retrieval, image segmentation, and targeted marketing. The most popular clustering formulation studies the problem under an optimization objective that minimizes the norm for corresponding to -median, -means, and -center, respectively. In this work, our focus is on the -center case, which admits a -approximation (Gonzalez, 1985; Hochbaum and Shmoys, 1985) and is NP-hard to approximate within a factor better than (Hsu and Nemhauser, 1979).
Fairness in machine learning is relatively new but has received a significant amount of attention. This includes research on defining notions of fairness (Calders and Verwer, 2010; Dwork et al., 2012; Feldman et al., 2015; Kamishima et al., 2012) and on designing algorithms that respect fairness (Celis et al., 2018a, b; Chierichetti et al., 2017; Joseph et al., 2016; Kamishima et al., 2012; Yang and Stoyanovich, 2017; Backurs et al., 2019). A recent line of work considers batch classification algorithms that achieve group fairness or equality of outcomes and avoid disparate impact (Calders and Verwer, 2010; Feldman et al., 2015; Kamishima et al., 2011; Fish et al., 2016).
Chierichetti et al. (2017) extended the notion of disparate impact to clustering problems and studied the fair -center problem in the case there are only two groups (also called colors). This was later generalized by Rösner and Schmidt (2018) to multiple groups, achieving a -approximation algorithm in the general case. Even with two colors, the problem is challenging, and the optimum solution can violate common conventions, e.g., a point may not necessarily be assigned to the closest open center. The main difference between our work and that of (Chierichetti et al., 2017; Rösner and Schmidt, 2018) is that the latter focuses on the problem of finding a clustering where the distribution of colors is in each cluster is exactly the same as the distribution of colors over all given data points, whereas we only require that in each cluster, the fraction of nodes of each color is at most a given threshold. Note that requiring exact proportional representation in each cluster is often prohibitively restrictive. For example, if the number of times different colors appear in the graph are relatively prime, there is no non-trivial feasible clustering in the setting of Chierichetti et al. (2017), whereas our formulation often admits non-trivial solutions.
Concurrently and independently, Bera et al. (Bera et al., 2019) and Bercea et al. (Bercea et al., 2018) obtained algorithms to convert an arbitrary clustering solution to a fair one, sacrificing both approximation and fairness. They provide bicriteria approximations for a more general problem (with upper and lower bound on the representation of a color). Our algorithm, however, is simpler and we prove (at most) an additive 2 violation for the fairness constraint (improved to 1 for a special case) in contrast to Bera et al. (Bera et al., 2019) who prove an additive 4 violation and Bercea et al. (Bercea et al., 2018) who do not bound the additive violation.
There has been some work on clustering with diversity (Li et al., 2010), where the objective is to ensure each cluster has at least a certain number of colors; our objective is clearly different from this. The large body of work on clustering with constraints (Basu et al., 2008), to the best of our knowledge, does not address the over-representation constraint.
Outline of the paper. In Section 2 we formalize the problem of finding an -capped -center clustering. In Section 3 we present our main theoretical result, an LP-based algorithm for the general case. Later, in Section 4 we provide a purely combinatorial algorithm for the case. Then in Section 5 we report the results of our empirical studies. In Section 6 we show that obtaining a decomposition in -capped clusters of minimum cost is hard for irrespective of the constraint on the number of clusters. Finally, in Section 7 we discuss future avenues of research.
2. Model and Preliminaries
In the -clustering problem, we are given a set of points in a metric space with the distance function and an integer bound , and the goal is to cluster the points into at most clusters . Various clustering problems have been studied and in this paper, we focus on -center clustering. We define the problem in terms of facility location terminology where points are referred to as clients and clusters are defined by the assignment of clients to centers (also called facilities). An instance of -center consists of a client set , a facility set , a metric space , and a positive integer bound . A feasible -center solution is a pair , where is a set of at most facilities and is a mapping that assigns each client to a facility . The goal is to find a feasible solution that minimizes the maximum radius or clustering cost defined as . Of course, in the classic -center problem, once the set is determined, assigning each client to the closest facility in yields the assignment with minimum objective. With additional constraints, however, the closest assignment might be infeasible.
Even though the standard -center problem is computationally hard, it admits an elegant 2-approximation algorithm (Hochbaum and Shmoys, 1985): first select an arbitrary point as center, then, iteratively pick the next center to be the point that is farthest from all currently chosen centers, until centers are chosen. For completeness, we present it below (Algorithm 1).
In this paper, we consider the -capped -center problem where points have colors and we have a constraint on the representation of each color in each cluster. More precisely, in an -capped -center instance , in addition to the input of classical -center, we are given a fractional bound and a color for each point . We use to denote the set of clients of color . A feasible solution is a feasible -center solution that satisfies the representation constraint, which states that for each color and each facility , the total number of clients of color assigned to should be no more than fraction of all clients assigned to . This constraint can be written as
The goal in -capped -center problem is to find a feasible solution that minimizes
Let be the optimal clustering, and let be the optimal clustering cost. A -approximation algorithm, for , outputs a clustering such that .
3. A general algorithm
We present a general algorithm to solve the -capped -center clustering problem. The main idea is to first solve a linear program (LP) relaxation of the problem to obtain a fractional solution and then modify the fractional solution—sacrificing a little both in the approximation factor and in the representation constraint—to get an integral solution. In the course of doing this, we will get what is called a bicriteria algorithm, i.e., while we get a constant-factor approximation to -capped -center, our solution will violate the upper bound mildly. In fact, we can show that for each color and each facility, there are at most two extra clients in addition to the allowed number of clients, so the cap is violated additively by at most two additional nodes—a negligible quantity for a large cluster.
3.1. An LP formulation
For a given distance , consider the problem of finding a feasible assignment of clients to facilities in such a way that the clustering cost of the solution is at most . This problem can be formulated using the following integer program (IP).
[TABLE]
Here, the indicator variable denotes if facility is open or not and the indicator variable denotes if client is assigned to facility . Note that by constraint (6), can take non-zero value only if facility is at distance at most from client . Constraint (2) captures that a facility must be open if it has a client assigned to it, (3) captures the representation constraint, and (4) captures that the total number of open facilities is at most .
Before relaxing the integrality constraint of the above IP, we strengthen it by adding the following constraint: if a facility is open, it has to serve at least clients to satisfy the representation constraint. Therefore, every integral solution of the above program must satisfy the inequality .
We consider the following LP obtained by adding this constraint and relaxing the integrality constraint (5). We use to denote the polytope defined by this LP.
[TABLE]
As mentioned above, we present a bicriteria algorithm that finds a solution that might violate the representation constraint, i.e., constraint (3.1). We use the notation , for , to denote the set of points that satisfy all the constraint for except constraint (3.1) and only violate that constraint with an additive error of , i.e., . Note that .
3.2. Outline
Recall that is the value of the optimal solution to the problem. The main idea in our algorithm is that, since the polytope is non-empty, by binary search, we can first find the smallest value such that is non-empty (since the set of distances between pairs of points is finite). Note that the non-emptiness check via solving the LP also yields a point , which is a fractional solution to the LP. The plan then is to use to construct a feasible integral solution in a slightly larger polytope, namely, , where are integral and hence will correspond to a valid solution to the -center problem.
Theorem 3.1.
Given an instance of -capped -center clustering, there is a polynomial time algorithm that finds a solution of cost at most such that
[TABLE]
In the case of , we can actually improve the additive term to and in term of multiplicative bound we get .
To prove Theorem 3.1, the integral solution is constructed from in two steps. In the first step, we construct a solution using , where is integral. This step can be thought of as determining which facilities to open based on the fractional solution. In the second step, we construct an integral solution . This step uses the open facilities to define a suitable maximum flow problem to obtain an assignment of clients to facilities. We describe these two steps.
3.3. Finding facilities to open
The goal in this step is to find where is integral. Let be a maximal subset of facilities such that any two facilities are at least distance from each other, i.e., . We open all facilities in , i.e., set for and for . Note that if is a correct guess of the optimum, none pair of clients at locations in can be served by the same center and so the size of is smaller than or equal to . Next, we show how to define . We essentially transfer the fractional assignment of clients from to . First we define a mapping as
- •
If , then .
- •
If , then where with . (Such an exists by the maximality of .)
Now for each client , we can define
[TABLE]
We now show that has the desired properties.
Lemma 3.2.
* and is integral.*
Proof.
Let us first show that can only take non-zero value if facility is at distance from it. If is non-zero, then there exists a facility where and . Since , we get that and since , , so by the triangle inequality, we have . Since is just rerouting the assignment of clients from facilities in to , for all facilities in , and has at most facilities, satisfy Constraints (1), (2), and (4). Constraint (3) is satisfied since for each ,
[TABLE]
where the inequality follows from the definition of . ∎
3.4. Assigning clients to facilities
The goal in this step is to construct a solution such that , are integral. In fact, only if . We let be the solution to the following maximum flow problem and use the fact that a network with integral bound on edges and integral demands, if feasible, always has an integral solution.
Construct a flow network as follows:
- •
.
- •
where with capacity , with capacity , with lower bound and capacity , and with lower bound and capacity .
Note that is a feasible flow of value , so there is an integral flow of value such that a client sends a flow to a facility if . Thus only if client is at distance from facility . This concludes the steps of our algorithm (Algorithm 2).
It remains to bound the violation of the representation constraint.
Lemma 3.3.
For any color and any facility , where the additive term can be improved to for .
Proof.
Let , , , and . Since is a feasible solution of , we have . Using the lower bounds and upper bounds on the edge , we know that and . Since , we can bound in terms of as follows:
[TABLE]
Now suppose for some and suppose for . Then, . If , then the largest integer smaller than is . If , then , now since , it follows that . ∎
We can bound the cost of the solution, in terms of violating the representation constraint multiplicatively as follows.
Corollary 3.4.0.
For any color and facility , for .
Proof.
Since , the term in the last line of the proof of Lemma 3.3, can be bounded by . ∎
4. An Algorithm for
In this section, we present a simple, combinatorial approximation algorithm for the important special case of . This case corresponds to finding a clustering of the points such that no color is the absolute majority in any cluster, i.e., every color in a cluster occurs at most half of the times as the cluster size. To proceed, we need two notions, namely, caplets and threshold graphs.
Caplets. Let be any graph whose set of nodes is . A caplet in is a subset with distinct colors, i.e., for . Since caplets can have either size two or three, we call the former case an edge caplet and the latter a triangle caplet. For two caplets and , let be defined as the minimum distance between pair of points of the two caplets, i.e., . Note that the distance function defined on caplets is not necessarily a metric but will be useful to bound the distance between points belonging to different caplets. The diameter of a caplet is . The diameter of a set of caplets is .
A caplet decomposition of a connected graph , if it exists, is a set of edge caplets and at most one triangle caplet such that each node in is present in exactly one caplet. Note that the only time when a caplet decomposition uses a triangle caplet is when the number of nodes in is odd. The caplet decomposition can be found in polynomial time by guessing the triangle if the size of graph is odd, and then finding the perfect matching on the remaining vertices.
Threshold graph. Given , a threshold , we define a threshold graph to be an undirected graph on the points in , where iff they have different colors and they are at distance at most from each other, i.e., and .
4.1. Algorithm
First of all, we assume that we know the optimal value . This is without loss of generality since by definition of -center, . Hence an algorithm can enumerate over the set of all possible values for ; at worst, this enumeration only costs an additional factor in the running time.111One can also get an approximation of the optimum in logarithmic many tries with standard techniques. Assuming we know , the idea is to create the threshold graph with as the threshold, and then to decompose it into caplets. Finally, the caplets can be clustered using the greedy algorithm for -center. The steps are presented in Algorithm 3.
Note that our approach is similar in spirit to the fairlet decomposition approach proposed in (Chierichetti et al., 2017). However, since our representation constraint is less stringent than the fair clustering constraint, as we will see, the reasoning becomes more delicate and involved.
To show that Algorithm 3 obtains a provably good approximation, we show a key characterization: there is a caplet decomposition of each connected component of with small diameter.
Lemma 4.1.
For each connected component of , there is a caplet decomposition such that .
Before proving the lemma, we use it to show that Algorithm 3 gives a good approximation.
Theorem 4.2.
Algorithm 3 finds a -capped -clustering solution of cost at most .
Proof.
Using Lemma 4.1, we know that the if statement (line 3 in Algorithm 3) fails for . Furthermore, since the optimal capped clustering yields a feasible solution for the -center instance and there is a 2-approximation algorithm for -center, a feasible solution can be found for (line 7). Therefore the loop terminates successfully (line 8) for some .
We next show we get a valid -capped clustering. For each color , note that the number of points of color assigned to facility is at most the number of caplets assigned to . However, by definition, each caplet is of size at least two and has distinct colors. Therefore, no color can be the absolute majority for each ; this proves the -capped property. The cost of clustering is a -approximation since each point in a caplet assigned to a facility is at most at distance from and since by Lemma 4.1. The proof is complete as . ∎
4.2. Analysis
We now prove Lemma 4.1. Let be a connected component of . There are two steps in the proof. In the first step, we find a set of caplets with respect to each facility such that . In the second step, we collect the caplets for each from the first step and appropriately modify them to obtain a caplet decomposition of such that . (If we naively take the union of the caplets for we may not get a valid caplet decomposition of since we might have more than one triangle caplet, violating the definition.)
The first step is relatively straightforward. Indeed, consider the optimal solution with open facilities and an assignment . Since for each open facility , the number of points with the same color is less than half of the points assigned to , if has even size, we can define a matching between points of different colors in . If is odd, then there are at least three colors present in . Define the triangle to include three points of different colors and the rest of points in can be matched to points of different colors. This yields with the property that it has at most one triangle caplet. Furthermore that since all the points in are at distance at most from , by the triangle inequality, any two points in are at distance at most from each other. Therefore, these points will belong to the same connected component of . Let .
Next, we consider the second step. For this, it is helpful to work with the graph such that for , we have if . Notice that is connected since it is constructed from .
The goal is to transform the caplets obtained in the first step into a valid caplet decomposition of . This is done by finding a path between two triangle caplets and “shifting” points to get a new set of edge caplets, sacrificing some in the distance between caplets. Fix henceforth.
From , we construct a set of disjoint paths with the following properties: each path in is of the form where (i) and are triangle caplets and are edge caplets, (ii) , and (iii) . Let be a minimal rooted tree spanning the nodes corresponding to triangle caplets in . Note that all the leaves in correspond to triangle caplets and the internal nodes in may be edge or triangle caplets. We perform a bottom-up procedure on , removing paths from and adding them in an iterative manner; the procedure ends when has at most one triangle caplet. Let denote the rooted subtree of rooted at a node . In the bottom-up procedure, we maintain the property that for each scanned node there is at most one triangle caplet in . Note this property is already satisfied at the leaves. Let be the deepest node in the current tree that does not satisfy this property. If has more than one child, let and be two paths starting at and ending at triangle caplets and . Note that the degree of internal nodes on and is exactly two by the choice of . We add the path to and remove the edges of from . Since and are at distance from and points inside are at distance at most from each other, and are at distance at most from each other. We continue this procedure until has at most one child. If is a leaf, then we remove if it is an edge caplet and leave it in if otherwise. Else, let be the sole child of . If is an edge caplet, we remove from . If both and are triangle caplets, we add them to and remove both of them from . We continue the procedure until we reach the root and at the end of this, there exists at most one triangle caplet that is not covered by a path in . It is also easy to see that each path in satisfies the desired properties. (See Figure 1.)
Now consider each . Recall from property (i) above that and are triangle caplets and the rest are edge caplets. We define a new set of edge caplets as follows. We pick an arbitrary point from and shift it to the next caplet and then shift some point from to the next caplet, and so on. More precisely, let be an arbitrary point in , define and let where is point in with different color than . We continue the process iteratively, where at each step , we define the edge caplet to contain point in not covered by for (), and point in with different color than . In the last step, a point is shifted and matched to a point and we define . Note this process is possible since each caplet contains at least two points of different colors, there always exists a point that has a different color than the shifted point. (See Figure 2.) By properties (ii) and (iii) above, the diameter of each caplet is at most and two consecutive caplets are at distance at most from each other. Applying the triangle inequality, we get that the diameter of the caplets in is at most .
5. Empirical evaluation
In this section we empirically evaluate our algorithms on several publicly-available datasets from the UCI Repository222http://archive.ics.uci.edu/mland DBLP333http://dblp.uni-trier.de/xml/, as well as on a proprietary dataset related to online auctions. In our empirical analysis we focus on the LP-based algorithm (Section 3). We describe the datasets used, the baselines we consider, the quality measures we compute, and finally the results.
5.1. Datasets
The datasets reported in Table 1 come from different domains and represent Euclidean spaces with dimensions ranging from to as well as a wide range of colors (between 4 and ). The datasets report different levels of balance of color distribution, from complete balance (each color is equally represented in the whole dataset) to high imbalance ( of points of one color).
We now describe more in detail the datasets used. We obtained two datasets (reuters, victorian) from text embeddings of multi-author datasets, one from a co-authorship graph embedding (4area), and one from online auctions (query). All datasets represent points in the Euclidean space and we always use the distance.
(i) reuters 444Available at archive.ics.uci.edu/ml/datasets/Reuter_50_50. It contains 50 English language texts from each of authors (for a total of texts). We transformed each text into a 10-dimensional vector using Gensim’s Doc2Vec with standard parameter settings. Here, the colors represent the author of the text. We observe that clustering doc2vec embeddings has been used extensively in language analysis (see, e.g., (Cha et al., 2017)).
(ii) victorian 555Available at archive.ics.uci.edu/ml/datasets/Victorian+Era+Authorship+Attribution. It consists of texts from 45 English language authors from the Victorian era. Each text consists of -word sequences obtained from a book of the author (we use the training dataset). The data has been extracted and processed in (Gungor, 2018). From each document, we extract a 10-dimensional vector using again Gensim’s doc2vec with standard parameter settings and we use the author as color. We use 100 texts from each author.
(iii) 4area 33footnotemark: 3. It contains points in dimensions representing each a researcher in one of four areas of CS: data mining, machine learning, databases, and information retrieval. The color is the main area of research of the author. The points are obtained by using the graph embedding method DeepWalk (Perozzi et al., 2014) on the undirected co-authorship graph of 4area, using default settings.
(iv) query. It is a representative subset of an anonymized proprietary dataset. Each point in this dataset represents a bag of queries in an online auction environment. The points have dimensions and are obtained with a proprietary embedding method that encodes semantic similarity. The color of the point is the anonymous id of the main advertiser of the submarket represented by the bag.
5.2. Experimental setup
5.2.1. Baselines
We use the following two baselines.
(i) Greedy. Because the -center problem is NP-hard, even without the additional constraint of being -capped, we use the well-known -center greedy method, which ignores the representation constraint, as a gold standard. Notice that this algorithm returns a -approximation of the cost of the optimum (without representation constraint) which is always lower than the optimum cost of our problem. To further strengthen the baseline, we post-process the output apply a round of the standard Lloyd iterative algorithm, with -center cost. This step can only improve the results. We use this method as a gold standard baseline to evaluate the increased cost incurred by our algorithm to enforce the representation constraint and we measure how much our algorithm improves the representation constraint bound of the clusters.
(ii) Random. We also compare against the baseline of sampling random points as centers and assigning all points to the nearest center selected. Because this method depends on randomness (while all other algorithms are deterministic), we rerun the algorithm ten times and report the average results. Notice that this algorithm as well does not (necessarily) respect the capped constraints.
5.2.2. Measures of quality
We evaluate the following measures of quality for a clustering.
Cost. We measure the maximum distance of a point to the nearest center in the solution. In particular, we compare the cost of the solution output by our -capped -clustering algorithm, (for a certain ), and the solution of the baselines for the same .
Additive violation of representation constraint. Recall that our algorithm in Section 3 can output a solution mildly violating the representation constraint. We wish to study how big is this violation in practice. To this end, let be a cluster in the solution output of an -capped clustering instance. The maximum allowed number of points of a certain color in the cluster is . We let be the maximum additive violation of the -capped constraint, over any cluster and any color . Our algorithm, provably, has an additive violation of at most point. We also evaluate the additive violation of the output of the greedy algorithm and random.
5.2.3. Implementation details and parameters of the algorithm
We now describe the main parameters of the algorithm in Section 3. The algorithm takes in input , , representing the number of centers allowed and parameter of the -capped constraint. To find a small for which the polytope gives a feasible solution, instead of binary search, we use following method. We obtain a lower bound on the cost the clustering by running the greedy -center algorithm and using as a lower bound, where is the cost of the solution found (this is provably a lower bound of the cost for our problem). We also bound the maximum distance of two points by (e.g., by using times the maximum distance of a fixed point to any other point) and iterate over a grid that is exponentially increasing by a multiplicative factor between these two extremes,
[TABLE]
to find the smallest feasible . Notice that a solution is found unless the problem is infeasible (i.e., is lower than the maximum fraction of points of a color). This allows us to check the LP feasibility with lower ’s first, which is better since checking feasibility becomes computationally more expensive as increases.
Finally, to speed-up the computation, we restrict the variables , that we create to be non-zero only for where is a core-set of the dataset, obtained by running the greedy algorithm to select facilities. Notice that using results, provably, in a constant factor approximation algorithm. We evaluate the effect of , and experiment with .
All our computations are run, independently, each on a single machine, from a proprietary Cloud, using Google’s Linear Optimization Package (GLOP) as our LP solver, and a maximum flow solver in C++. Both packages are available in Google’s OR tools.666https://developers.google.com/optimization/
5.3. Experimental results
Comparison with the baselines.
In Table 2, we report, for various factors, a comparison of the quality of the output of our algorithm with that of the baselines. In this table, we fix the parameters: , , and show results for all datasets and representative ’s that are close to the maximum color ratio of a color in each dataset (there is no feasible solution for ’s lower than this ratio).
First, we evaluate the ratio of the cost (i.e., the maximum distance of a point to its center) of the solution obtained by our algorithm to that of the greedy algorithm. Notice that in all datasets our algorithm reports a cost that is relatively close to the unconstrained greedy algorithm and is usually between worse and up to x worse. Interestingly, despite the fact that the unconstrained problem can have a much better optimum cost, we can sometimes obtain costs that are at most – larger than of the unconstrained solution (which in turn is lower than the actual optimum value for our problem). This result is better than that predicted by the worst-case theoretical analysis (where we show a x factor). This improvement occurs even for very close to the strongest possible representation constraint for which there is a solution.
In Table 2, we also evaluate the maximum additive violation of the color cap constraint for our algorithms as well as the baselines. As proved formally, the maximum additive violation for our algorithm () is at most for general ’s (and for the case of integer ). We observe interestingly that it is always in our experiments. Note instead that the baselines, which do not take into account the constraint, can incur very large additive violations of up to hundreds of points. This result confirms the importance of using algorithms specifically designed for this problem.
Effect of the parameters
We now study more in detail the effect of the main parameters on the quality of the clustering.
Figures 3(a) and 3(b) show the ratio of the cost of the solution over the cost of the greedy baseline, for various ranges, and distinct ’s, in the reuters dataset. Here, we compare the setting (Figure 3(a)) and (Figure 3(b)). Notice how the approximation ratio (over greedy) is always for the case and for case. As is expected, notice that larger ’s are associated with lower cost ratios (it is easier to find a low cost solution with higher ). Finally, despite the pattern being less strong, we observe generally larger ratios for larger ’s.
In Figure 4(a) we evaluate the effect of the factor used in the core-set to reduce the number of ’s variables to . Notice how generally larger ’s are associated with lower cost (ratio), but the algorithm obtains good results even with , allowing to use small LP instances in our algorithm.
Time
In Figure 4(b) we show how the running time is affected by and . As expected, larger ’s correspond to increased running times. Similarly, larger ’s mostly correspond to lower running time because it is easier to find a solution with larger and hence fewer need to be evaluated to find a non-empty .
6. Hardness
In this section, we complement our algorithmic results by proving a factor- approximation hardness for minimizing the -center cost of a -capped clustering, of arbitrary number of cluster, for . This shows the hardness of -capped clustering, with -center objective, even allowing arbitrary many clusters.
As in (Chierichetti et al., 2017), we use a reduction from the t-Star-Decomposition problem defined as follows. Given an undirected -vertex graph , and a positive integer , can be partitioned into pairwise disjoint subsets so that and contains a star of size , i.e., a center and leaves? Two well-known special cases of t-Star-Decompositionare the case (finding a perfect matching) and the case also known as -decomposition (finding a partition into connected triplets). Since a perfect matching can be found in polynomial time, t-Star-Decompositionis tractable for . Kirkpatrick and Hell (Kirkpatrick and Hell, 1983) showed that t-Star-Decompositionis NP-hard for . t-Star-Decompositionremains NP-hard (Dyer and Frieze, 1985) even if the graph is planar and bipartite, for any . In our proofs we will use that the problem is NP-hard.
Our reduction starts from input of a t-Star-Decomposition instance, and defines a set of points in a metric space with distance function and a color assignment for each point . More precisely, we construct a graph and define the metric space to be the shortest path metric where edges have unit length. Before proceeding to the main hardness result, we explain how graph is constructed in polynomial time from the bipartite graph input of t-Star-Decomposition. In the following we use the word point and vertex interchangeably.
Construction of the graph
The construction of depends on the solution to the following system of linear equations:
[TABLE]
Since this is a system of two equations in two variables, and the determinant of the system is non-zero, there exists a unique solution . If the unique solution has at least a variable that is not a non-negative integer, we construct as a trivial instance with no fair coverage (say one red node). For the rest of the construction we assume we are in the case that , are both non-negative integers.
First we define the construction for the , case then we show how to extend this to the case for any integer . In the case, the construction proceeds as follows. The graph has four layers of nodes , where each layer consists of two disjoint sets of respectively of color red and blue. The layer has a 1-to-1 correspondence with nodes in . More precisely, consists of and , corresponding to the two sides of the graphs and two nodes in are connected in iff their equivalent nodes are connected in . Then, consists of such that . In , there is a matching between each node in (resp. ), and a node in (resp. ). Now let and . Notice that from the Equations (8) are non-negative integers. Layer has components of size , and contains a complete bipartite graphs between sides , and another complete bipartite graph between sides . Finally layer consists of such that and and each node in is connected with exactly two nodes in (resp. each node in is connected with exactly two nodes in ). This completes the construction for the case, for the general we add to each layer and , disjoint sets () such that all nodes in have color (distinct from red and blue). For each , and is further subdivided in two disjoint parts , such that , , and for a complete bipartite graph (reps. form a complete bipartite graph). Finally for each , and each node in is connected with exactly 2 nodes in .
The following states our main hardness result for .
Theorem 6.1.
It is NP-hard to approximate the -capped clustering with -center objective with within a factor better than .
The theorem follows from the following two lemmas, whose proofs are deferred to the extended version of the paper.
Lemma 6.2.
Fix integer. Suppose the bipartite graph admits a t-Star-Decomposition, then has a -capped clustering of -center cost .
Lemma 6.3.
Fix integer. If there exists a solution of -center cost at most to -capped clustering of , then the bipartite graph admits a t-Star-Decomposition.
7. Conclusions
Clustering with color constraints is an algorithmic take on ensuring balance and fairness in applications. In this paper we addressed capped clustering, which is the problem of finding the best clustering where no cluster has an over-represented color. We obtained provably good algorithms for this problem; our experiments show that the algorithms are effective on different real-world datasets. While our general algorithm is based on solving an LP, it can be challenging for large number of points. It is an interesting question to develop a combinatorial algorithm for the general case that can scale to large datasets. It is also interesting to improve the bounds guaranteed by our algorithms and extend them to other clustering objectives such as -means and -median.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Backurs et al . (2019) Arturs Backurs, Piotr Indyk, Krzysztof Onak, Baruch Schieber, Ali Vakilian, and Tal Wagner. 2019. Scalable Fair Clustering. In ICML .
- 3Basu et al . (2008) Sugato Basu, Ian Davidson, and Kiri Wagstaff. 2008. Constrained Clustering: Algorithms, Applications and Theory . CRC Press.
- 4Bera et al . (2019) Suman K Bera, Deeparnab Chakrabarty, and Maryam Negahbani. 2019. Fair Algorithms for Clustering . Technical Report 1901.02393. ar Xiv.
- 5Bercea et al . (2018) Ioana O. Bercea, Martin Gross, Samir Khuller, Aounon Kumar, Clemens Rösner, Daniel R. Schmidt, and Melanie Schmidt. 2018. On the cost of essentially fair clusterings . Technical Report 1811.10319. ar Xiv.
- 6Calders and Verwer (2010) Toon Calders and Sicco Verwer. 2010. Three naive Bayes approaches for discrimination-free classification. DMKD 21, 2 (2010), 277–292.
- 7Celis et al . (2018 a) L Elisa Celis, Lingxiao Huang, and Nisheeth K Vishnoi. 2018 a. Multiwinner Voting with Fairness Constraints.. In IJCAI . 144–151.
- 8Celis et al . (2018 b) L. Elisa Celis, Damian Straszak, and Nisheeth K. Vishnoi. 2018 b. Ranking with Fairness Constraints. In ICALP . 28:1–28:15.