Comparison of Derivative Estimation Methods in Solving Optimal Control Problems Using Direct Collocation
Yunus M. Agamawi, Anil V. Rao

TL;DR
This paper compares four derivative estimation methods for solving large sparse nonlinear programming problems from optimal control, finding hyper-dual methods to be most efficient and easiest to implement.
Contribution
It provides a comprehensive comparison of finite-difference, bicomplex-step, hyper-dual, and automatic differentiation methods in the context of direct collocation for optimal control.
Findings
Hyper-dual method has lower total computation time.
Bicomplex-step and hyper-dual are easier to implement.
Automatic differentiation is less efficient than Taylor series-based methods.
Abstract
A study is conducted to evaluate four derivative estimation methods when solving a large sparse nonlinear programming problem that arises from the approximation of an optimal control problem using a direct collocation method. In particular, the Taylor series-based finite-difference, bicomplex-step, and hyper-dual derivative estimation methods are evaluated and compared alongside a well known automatic differentiation method. The performance of each derivative estimation method is assessed based on the number of iterations, the computation time per iteration, and the total computation time required to solve the nonlinear programming problem. The efficiency of each of the four derivative estimation methods is compared by solving three benchmark optimal control problems. It is found that while central finite-differencing is typically more efficient per iteration than either the hyper-dual…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1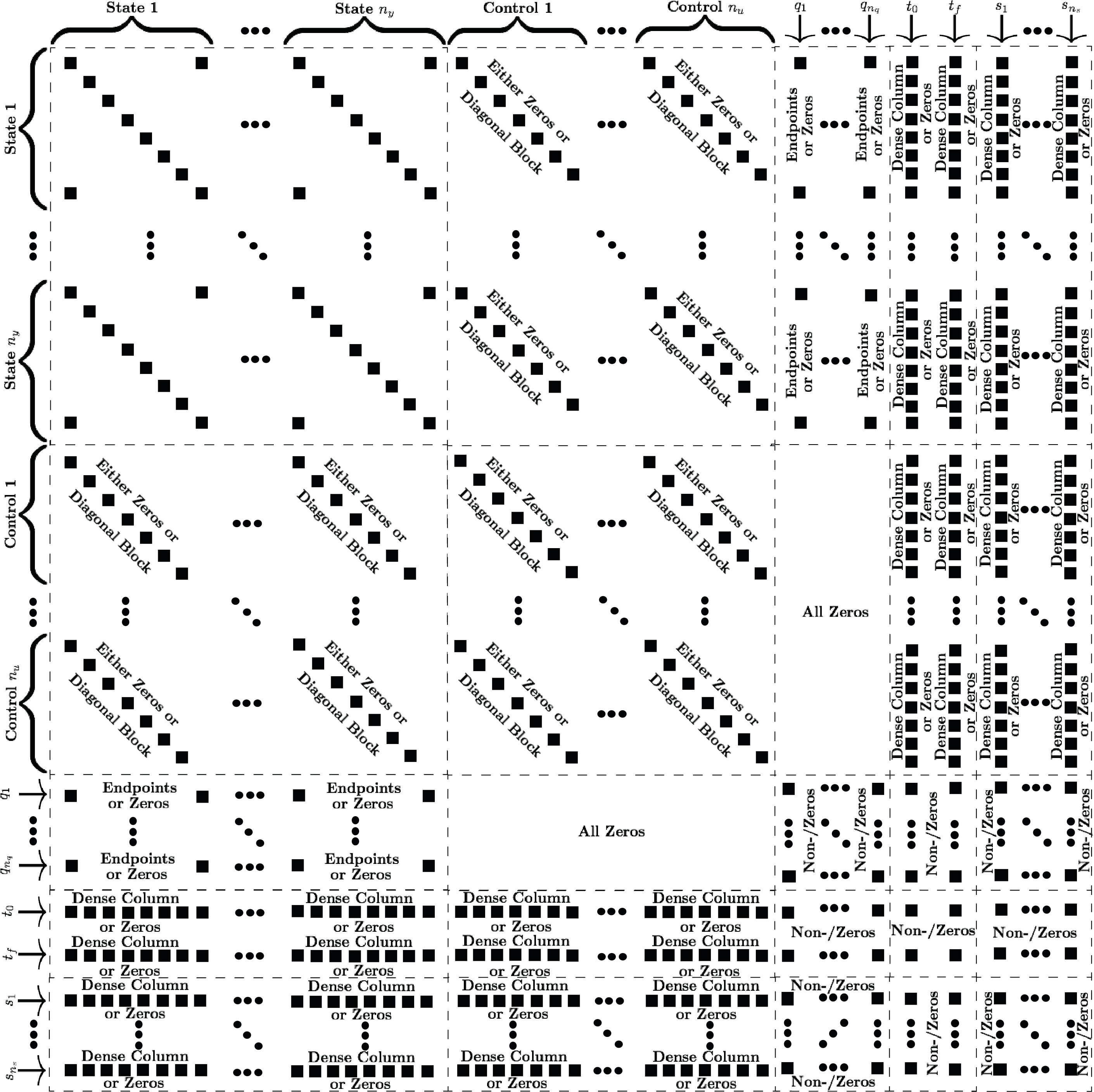 Figure 2
Figure 2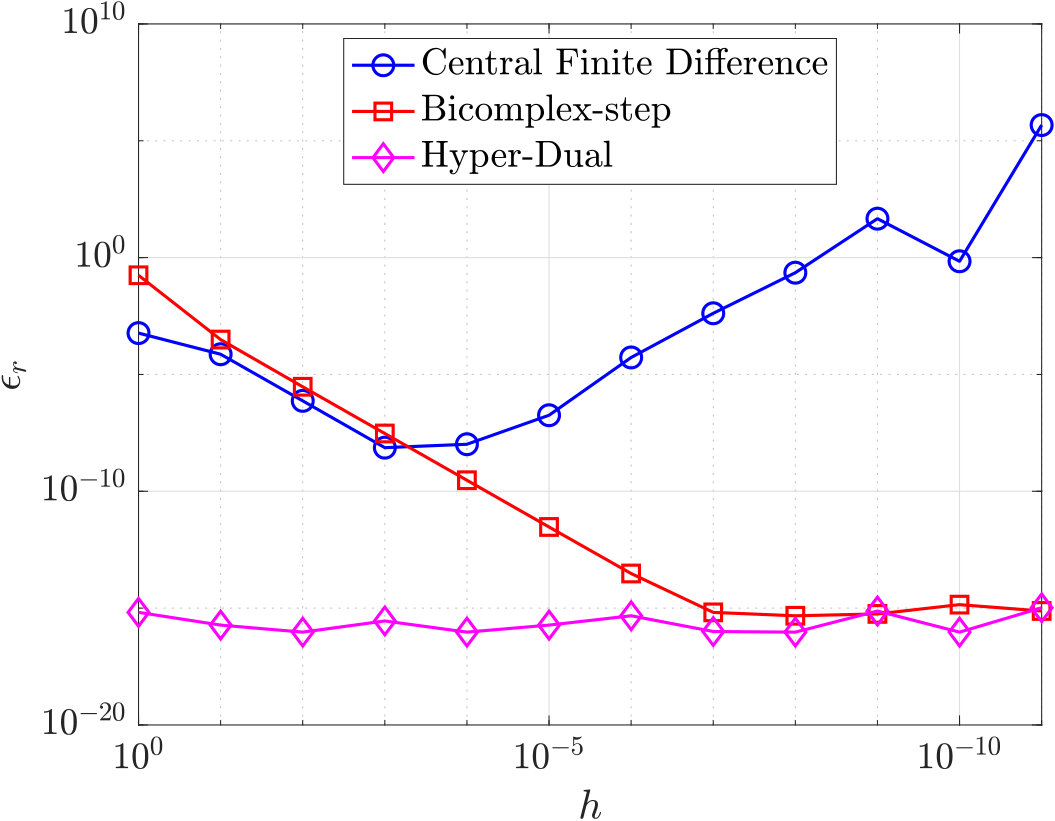 Figure 3
Figure 3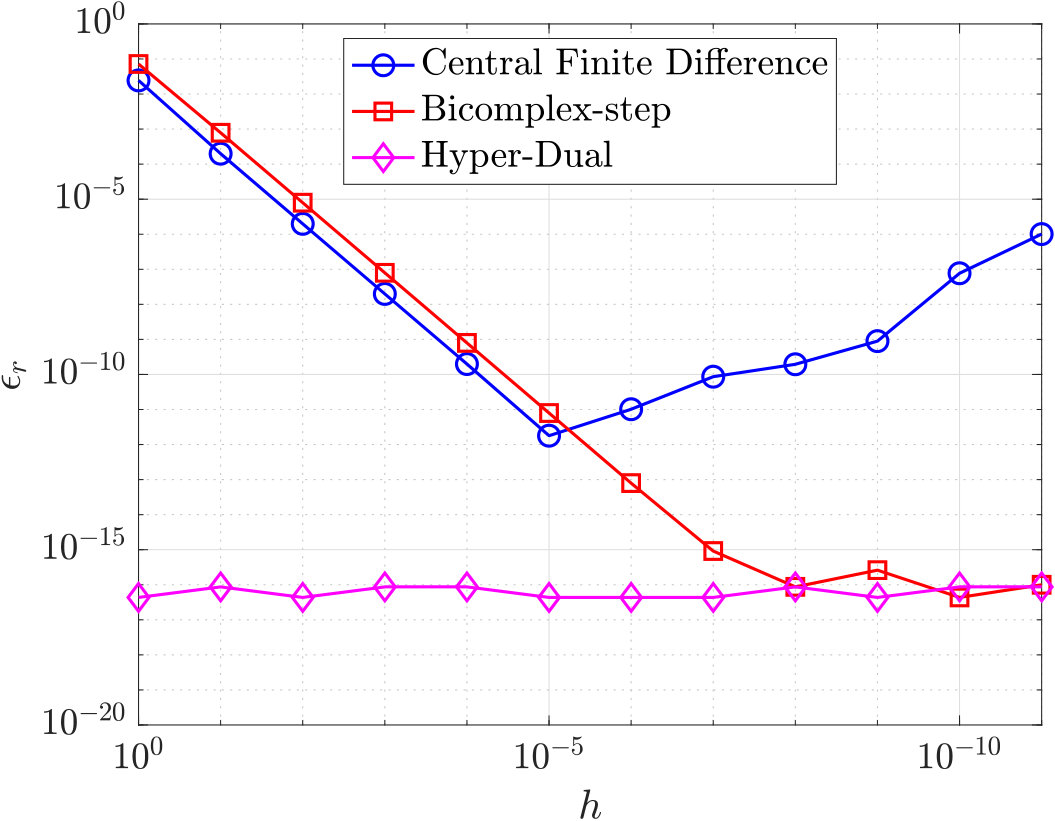 Figure 4
Figure 4 Figure 5
Figure 5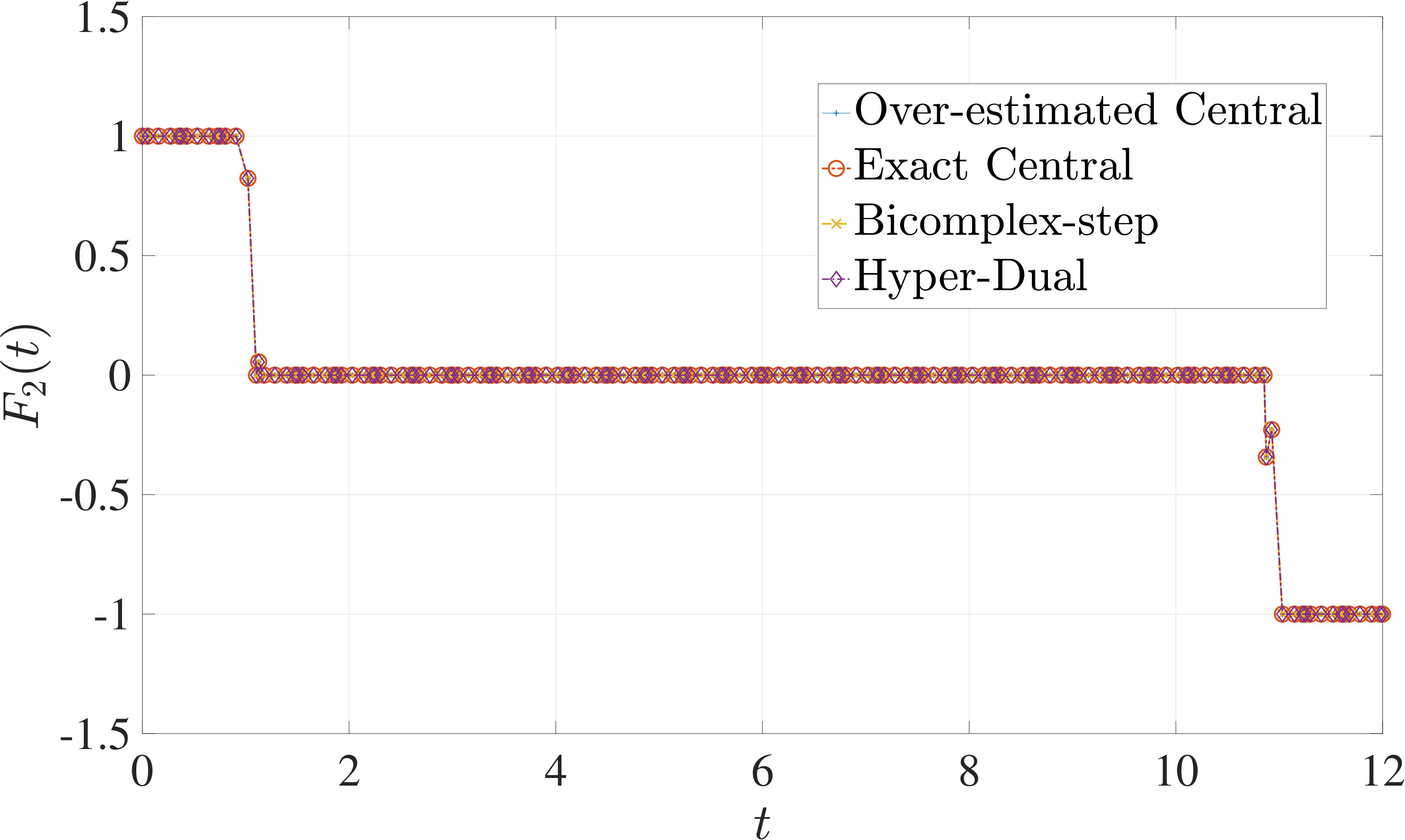 Figure 6
Figure 6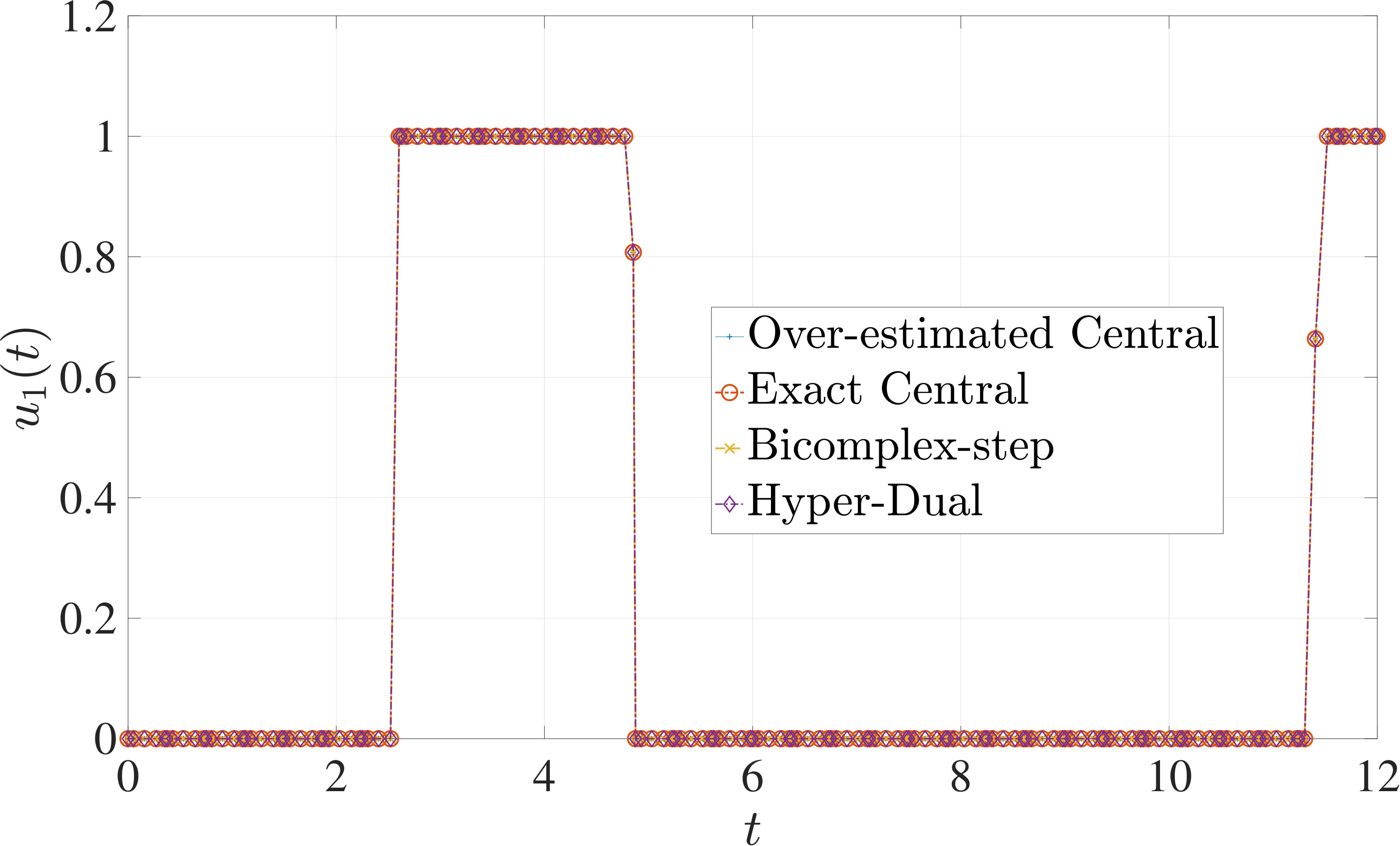 Figure 7
Figure 7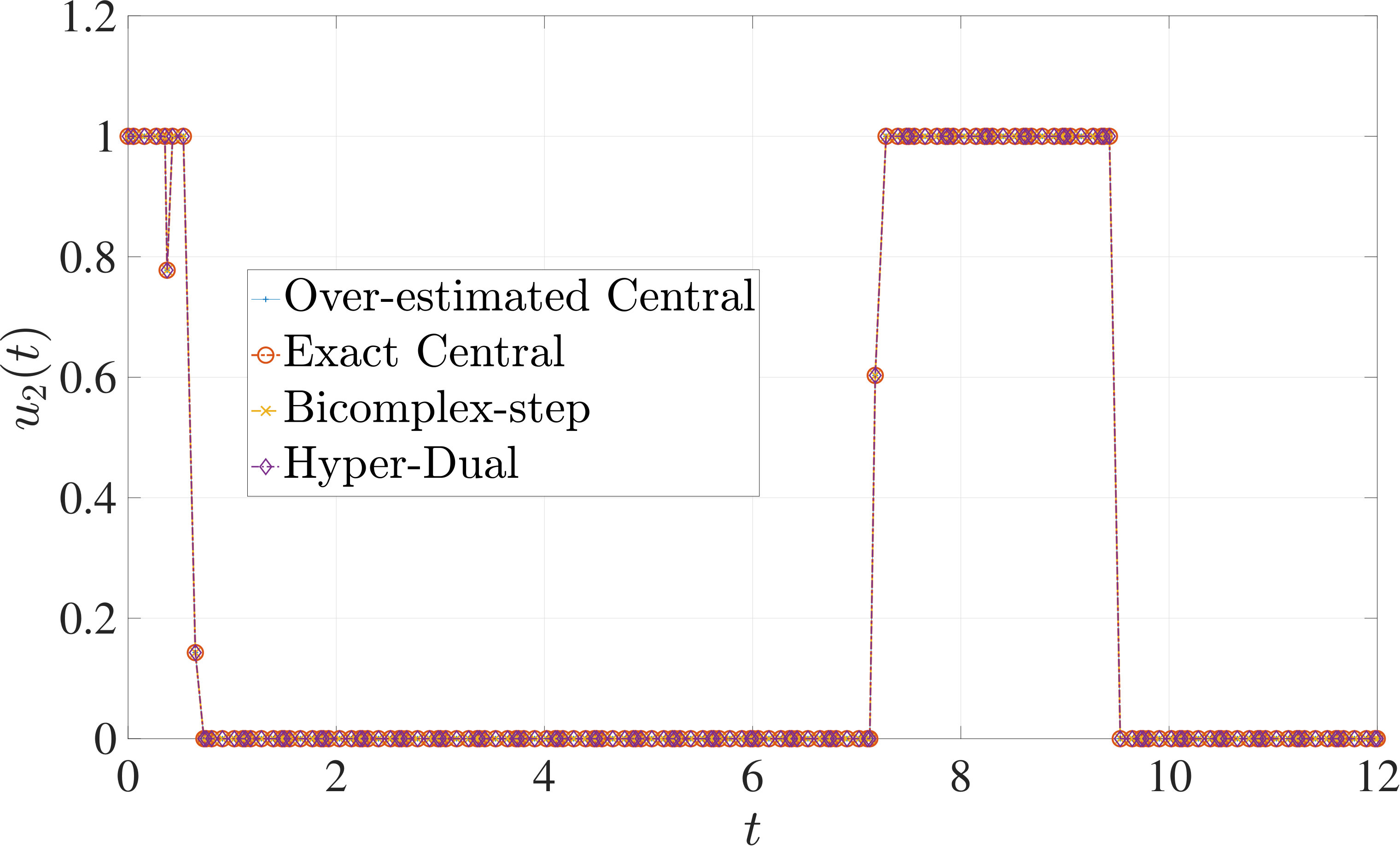 Figure 8
Figure 8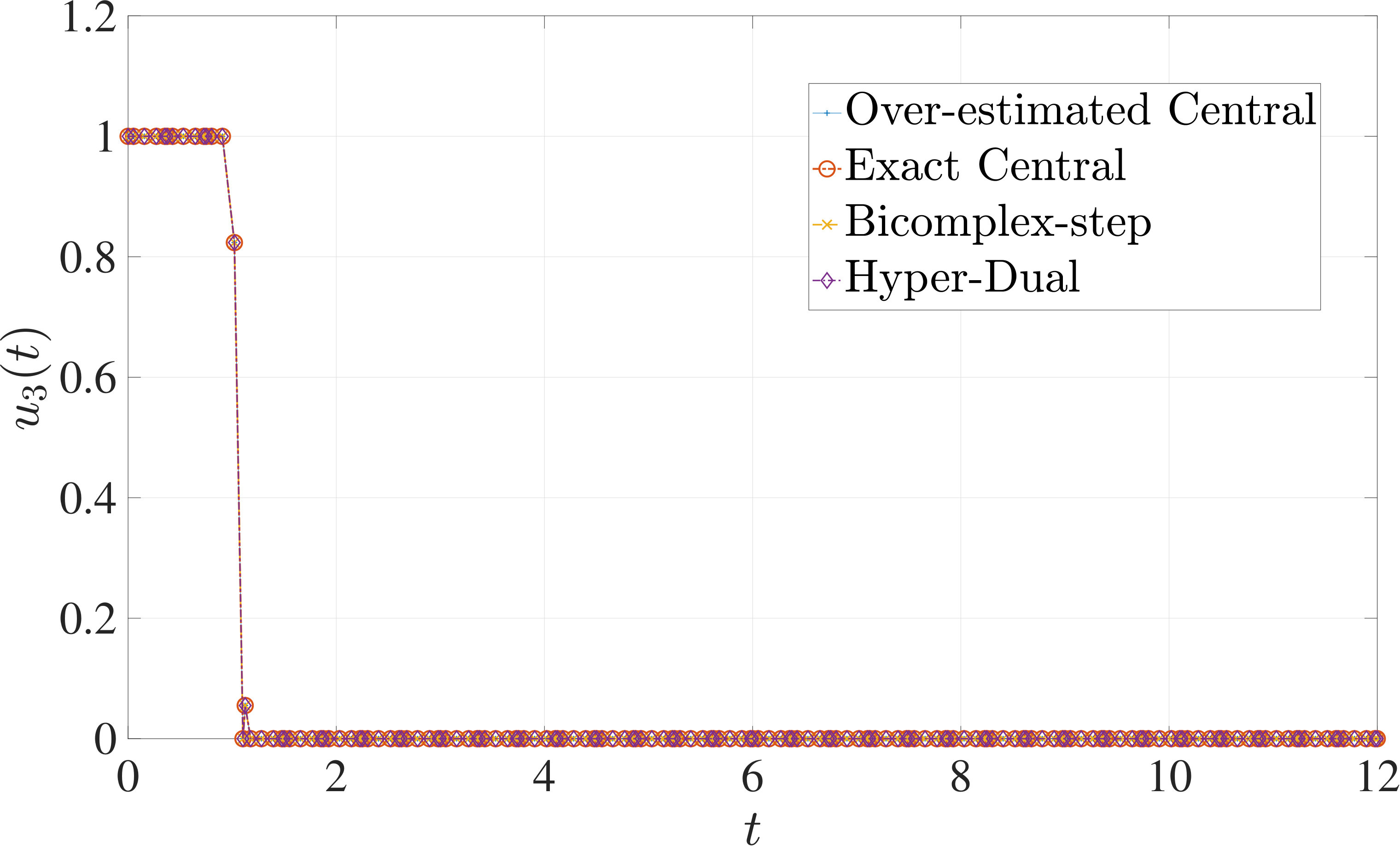 Figure 9
Figure 9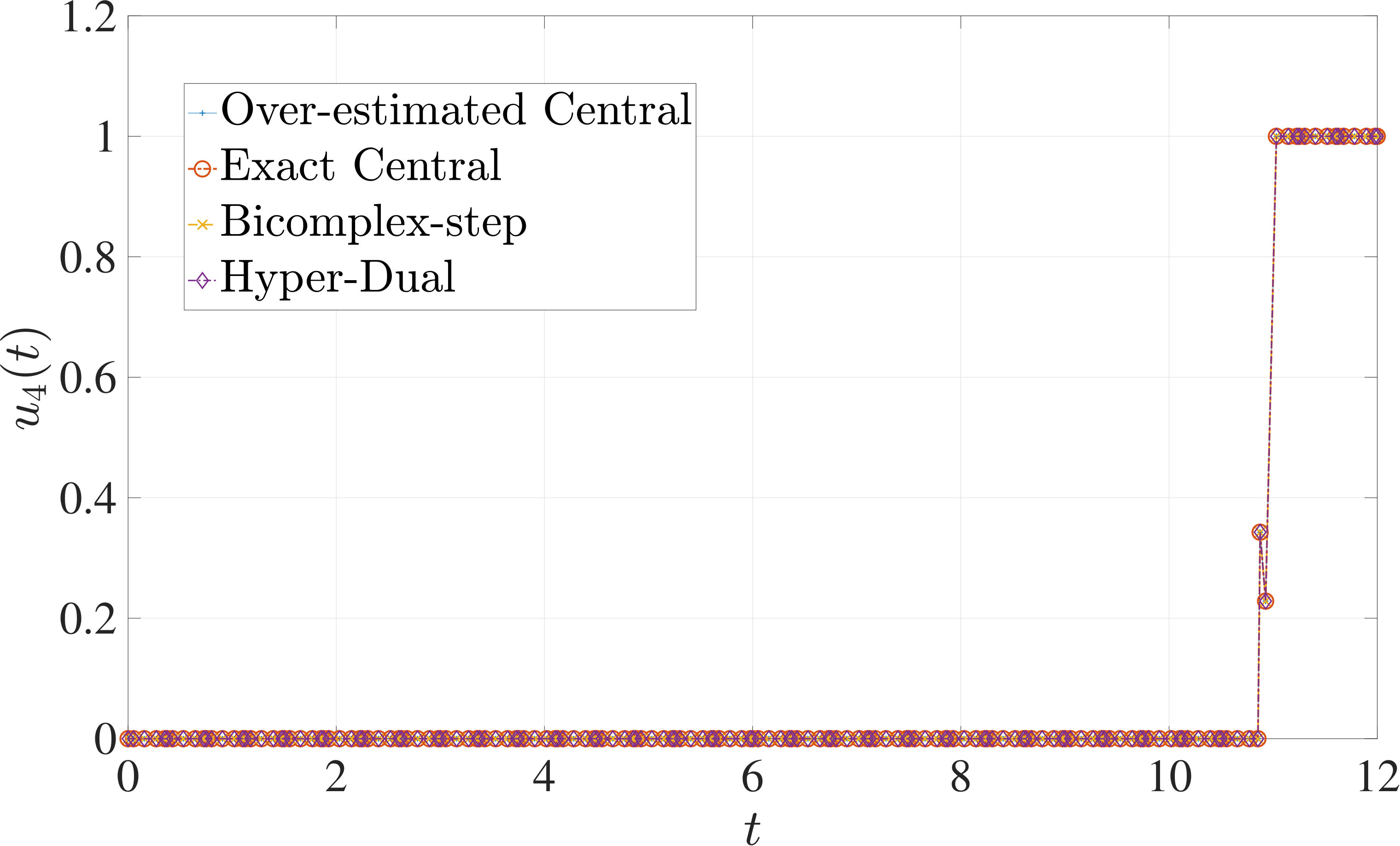 Figure 10
Figure 10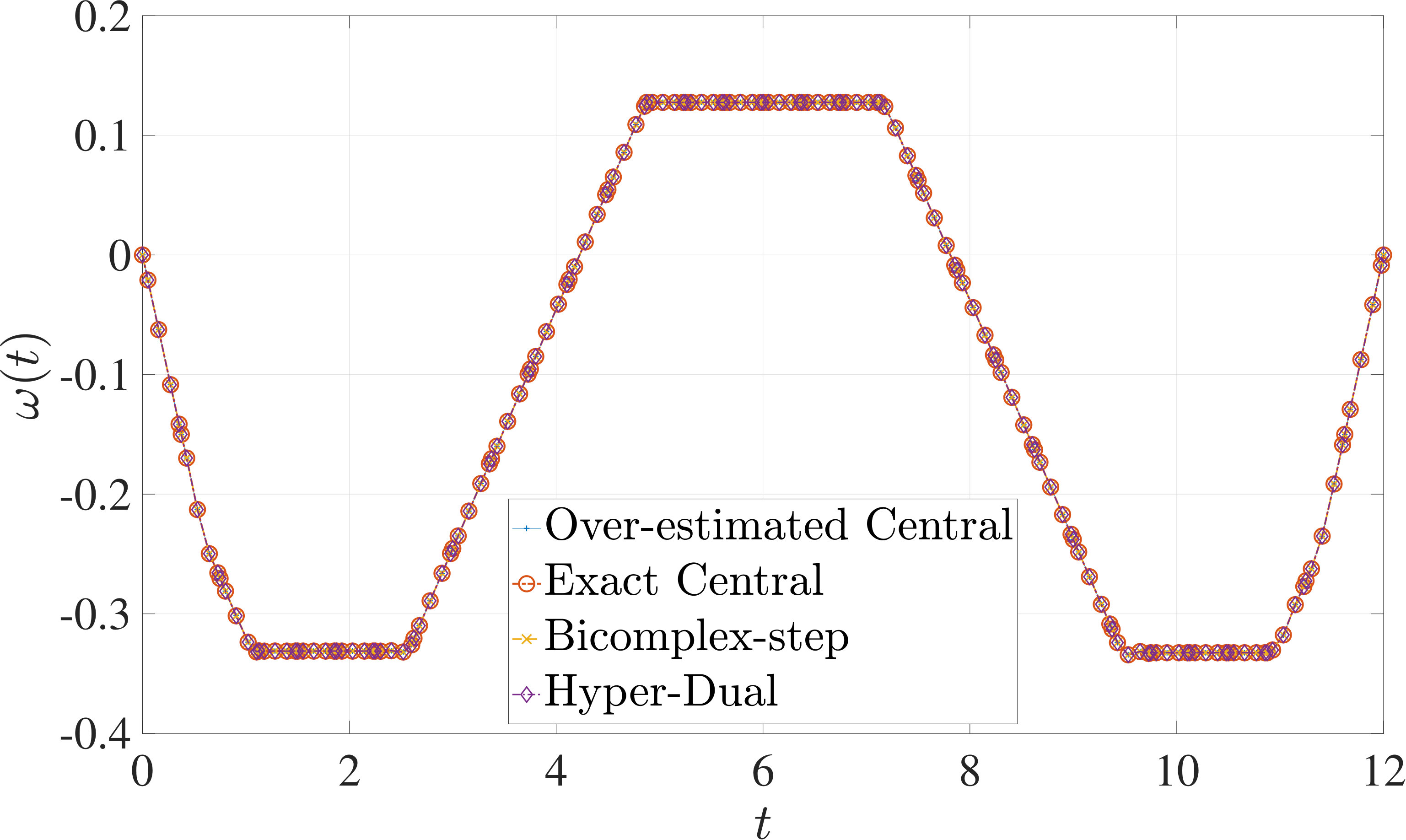 Figure 11
Figure 11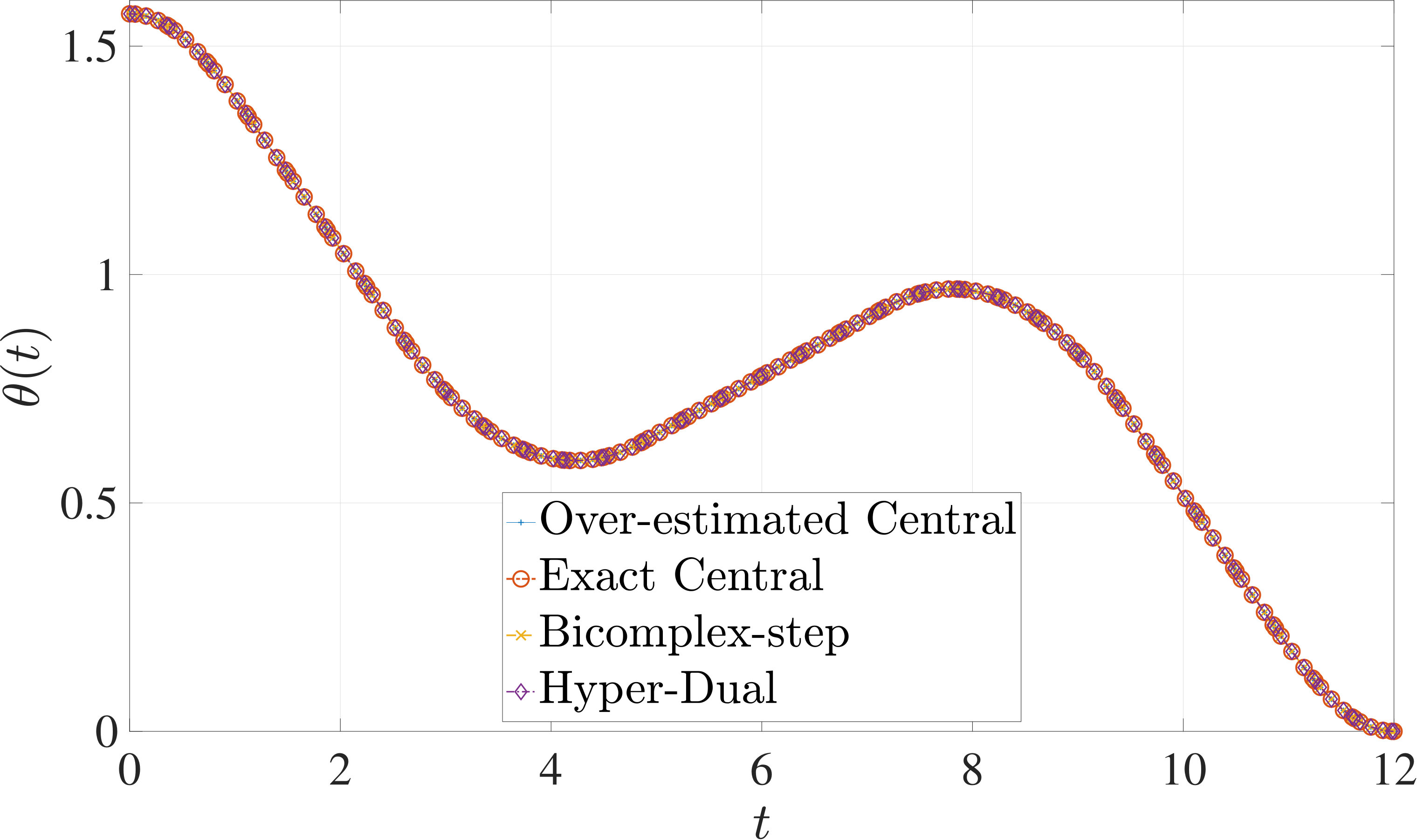 Figure 12
Figure 12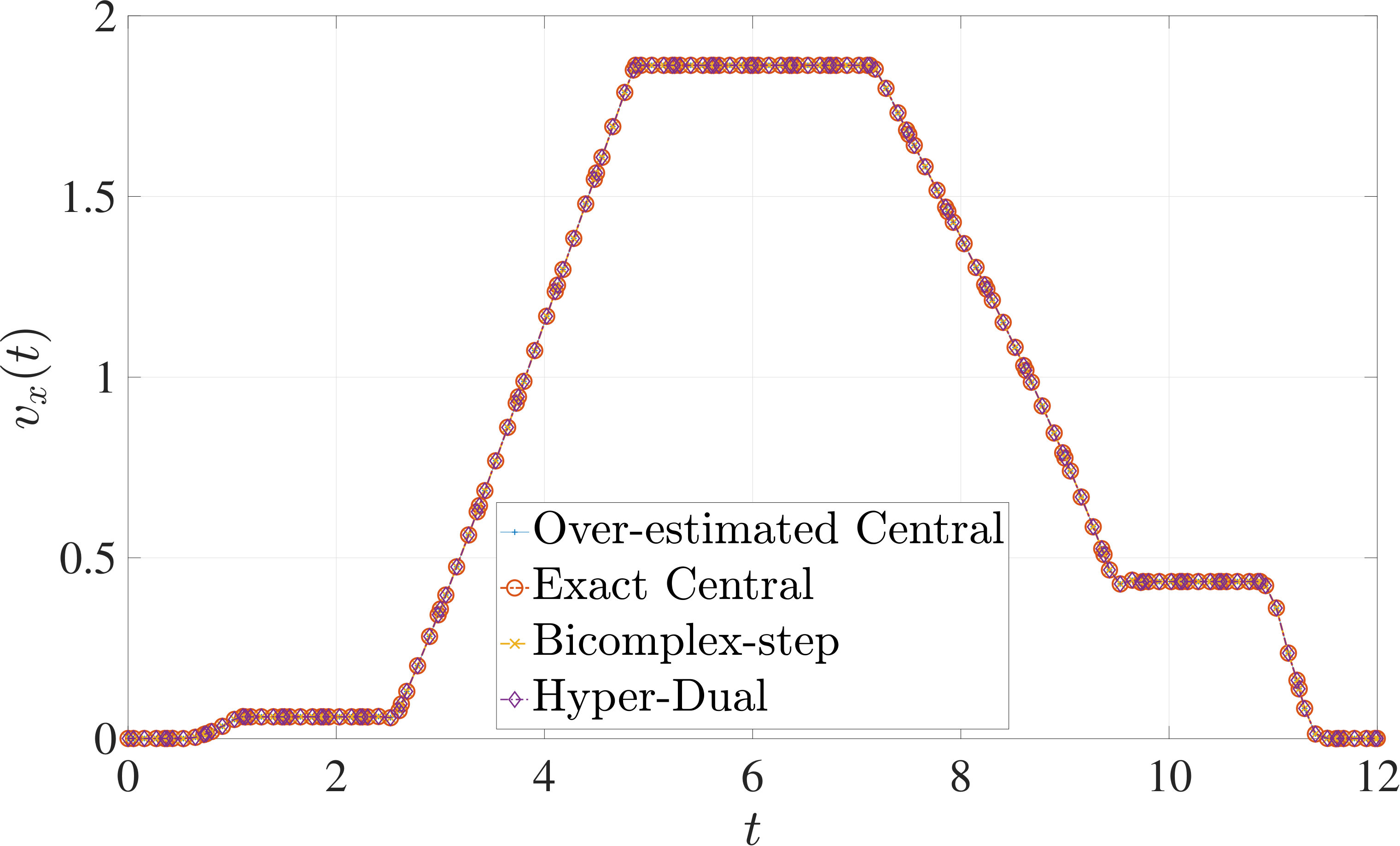 Figure 13
Figure 13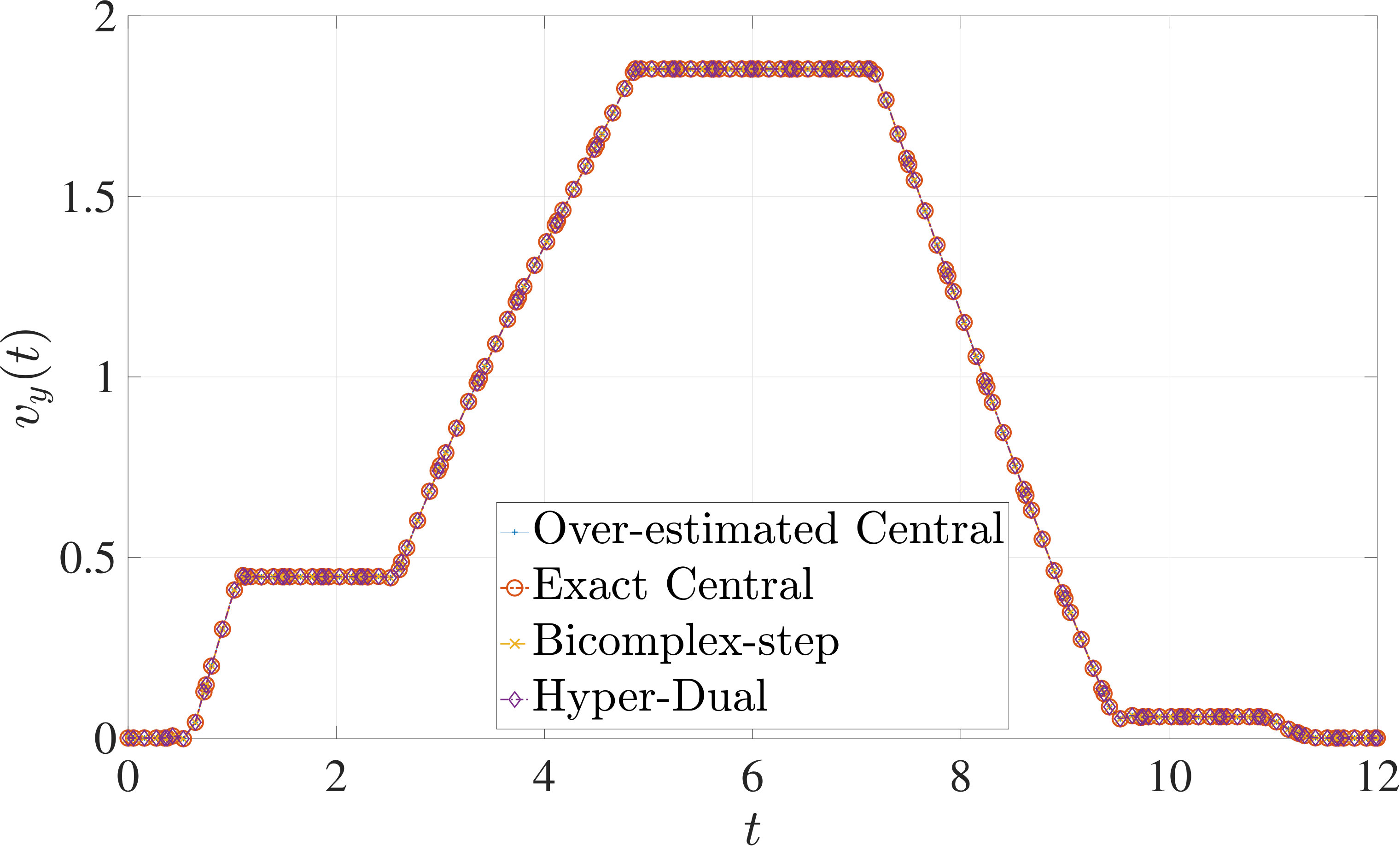 Figure 14
Figure 14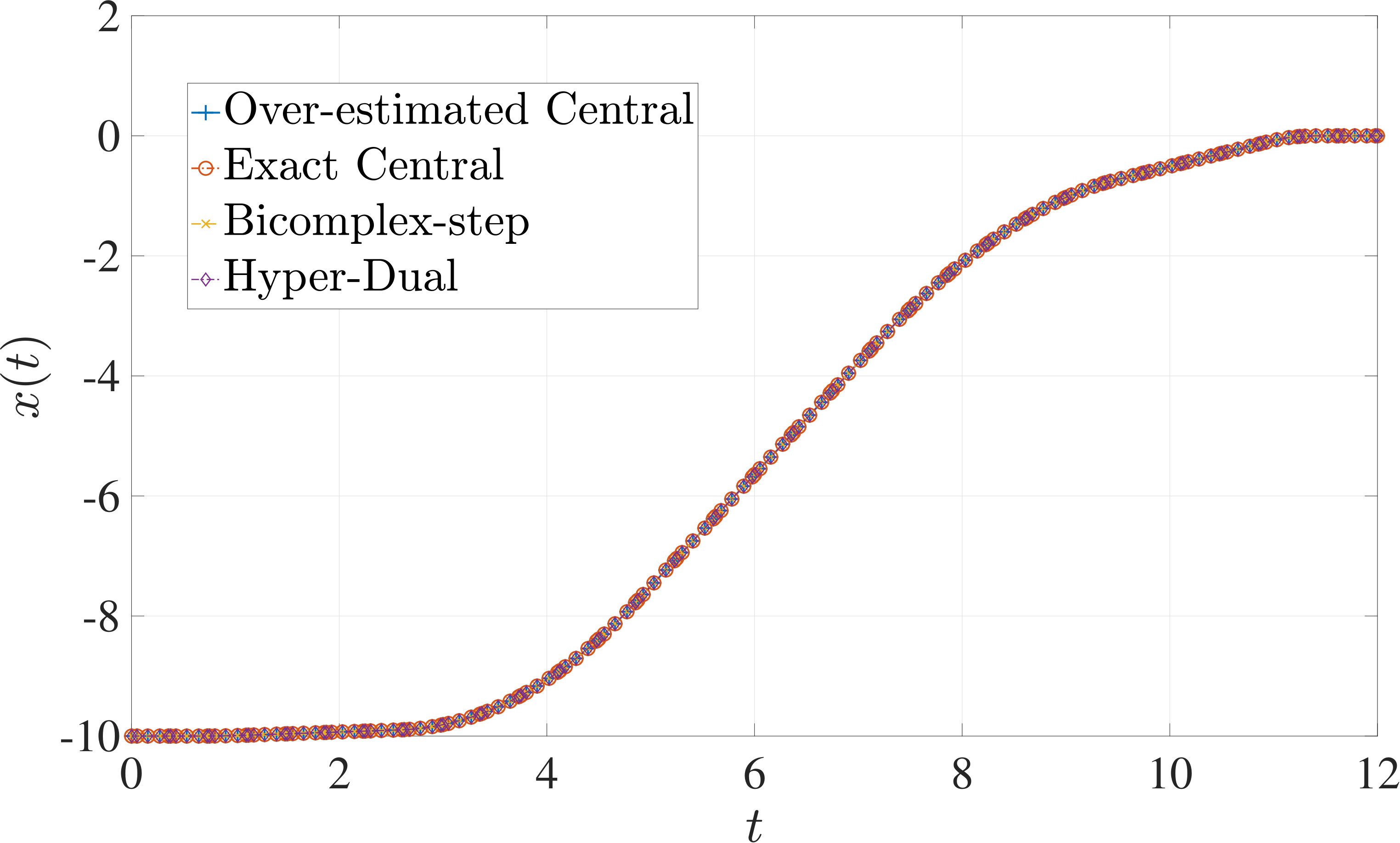 Figure 15
Figure 15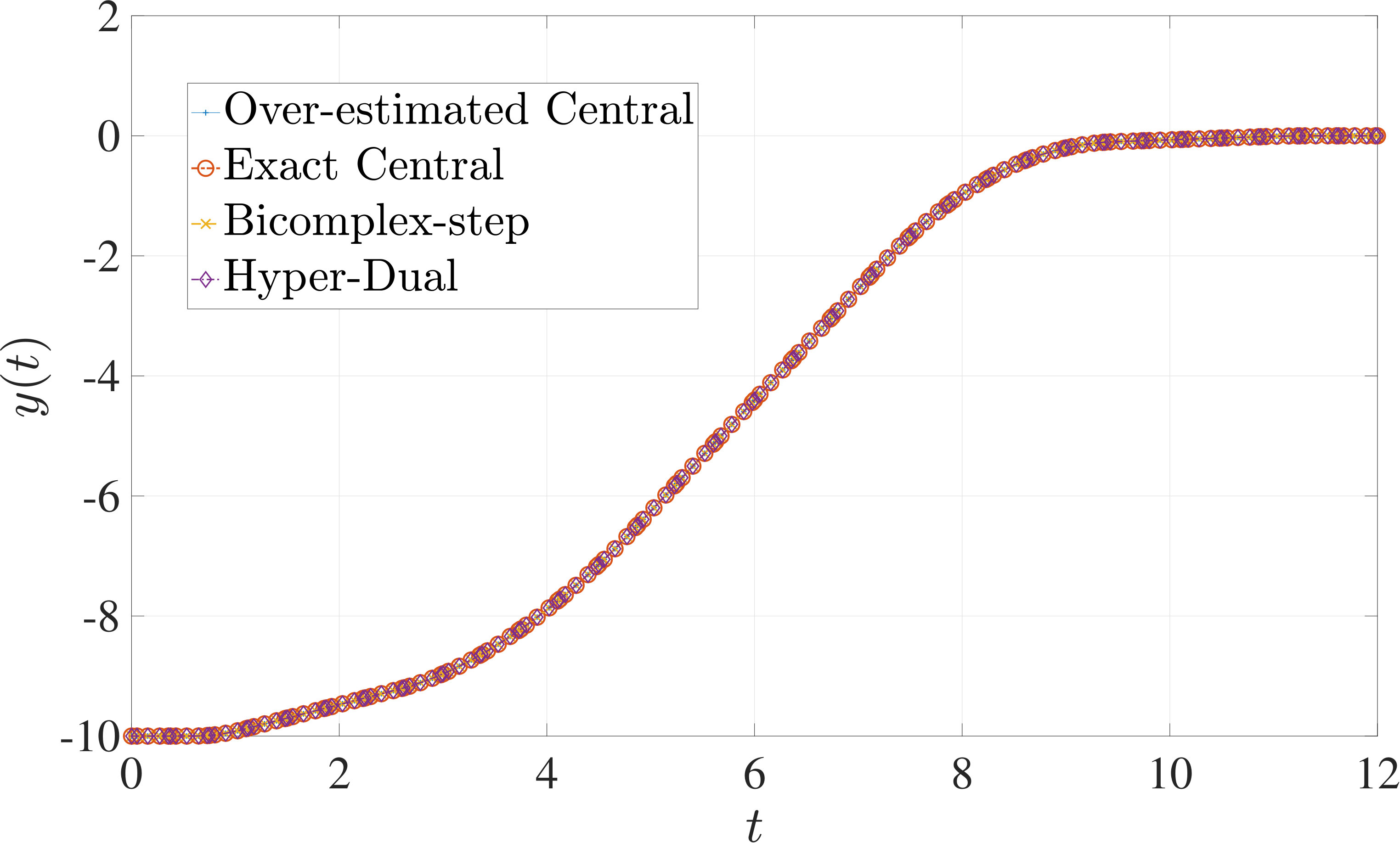 Figure 16
Figure 16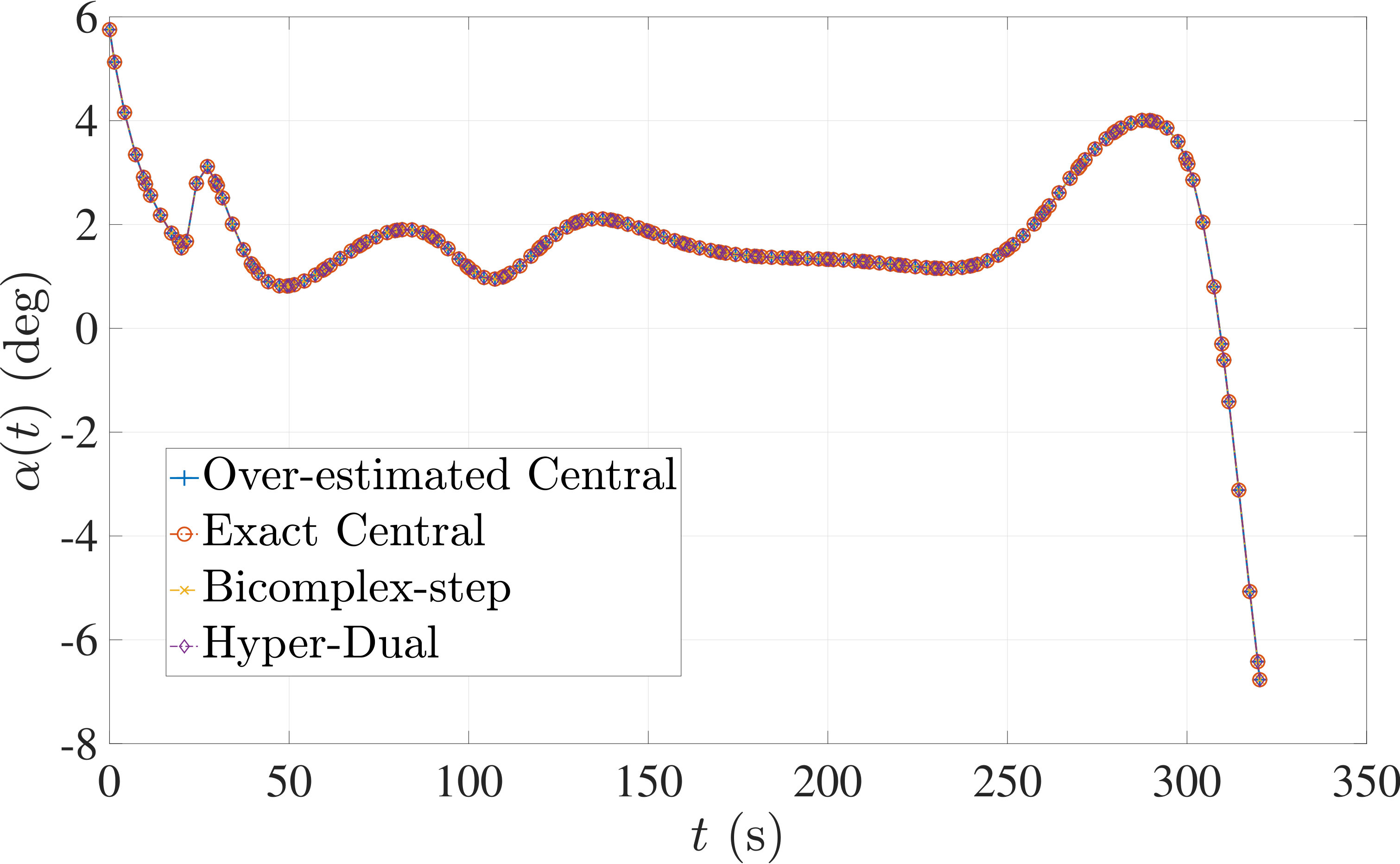 Figure 17
Figure 17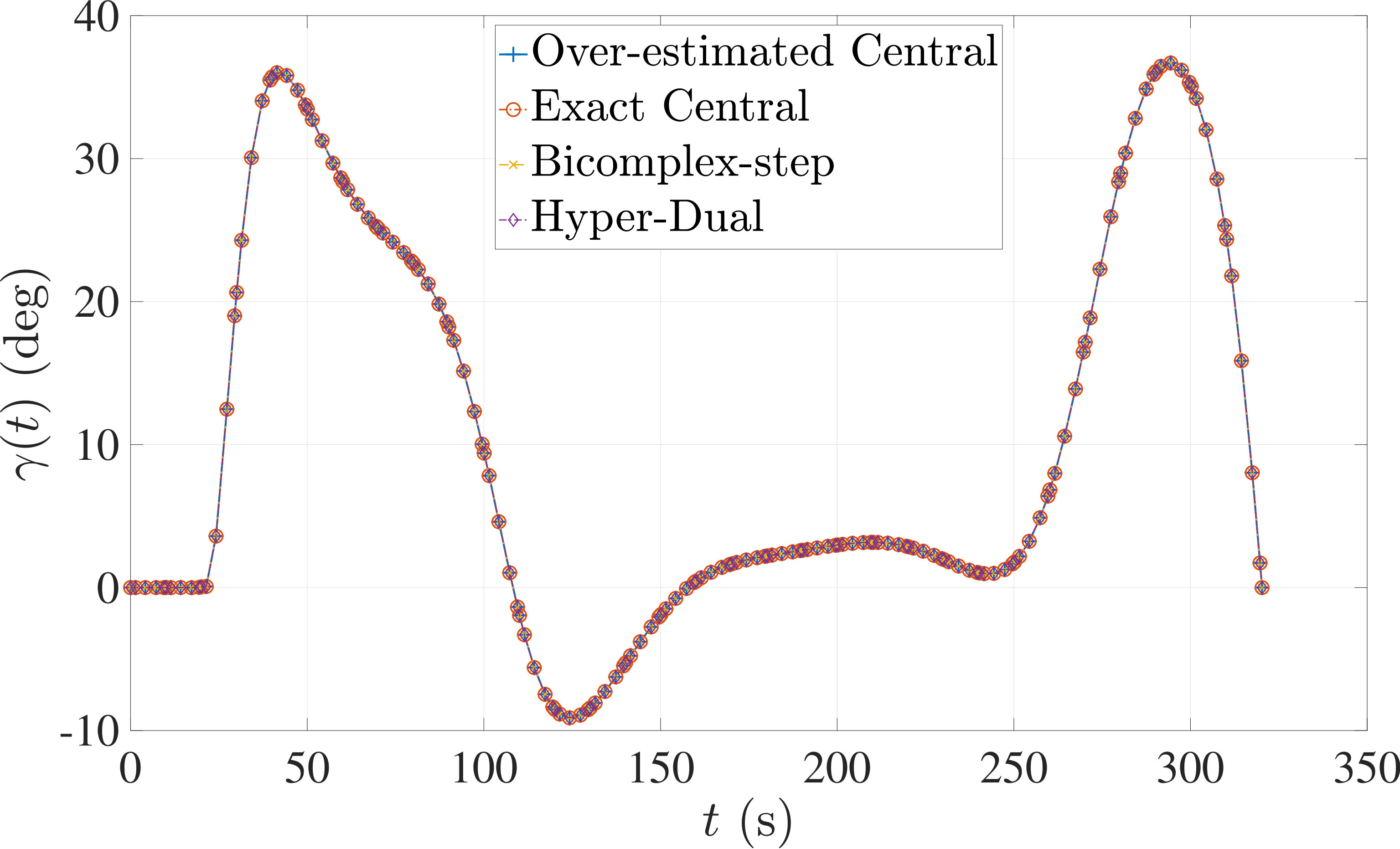 Figure 18
Figure 18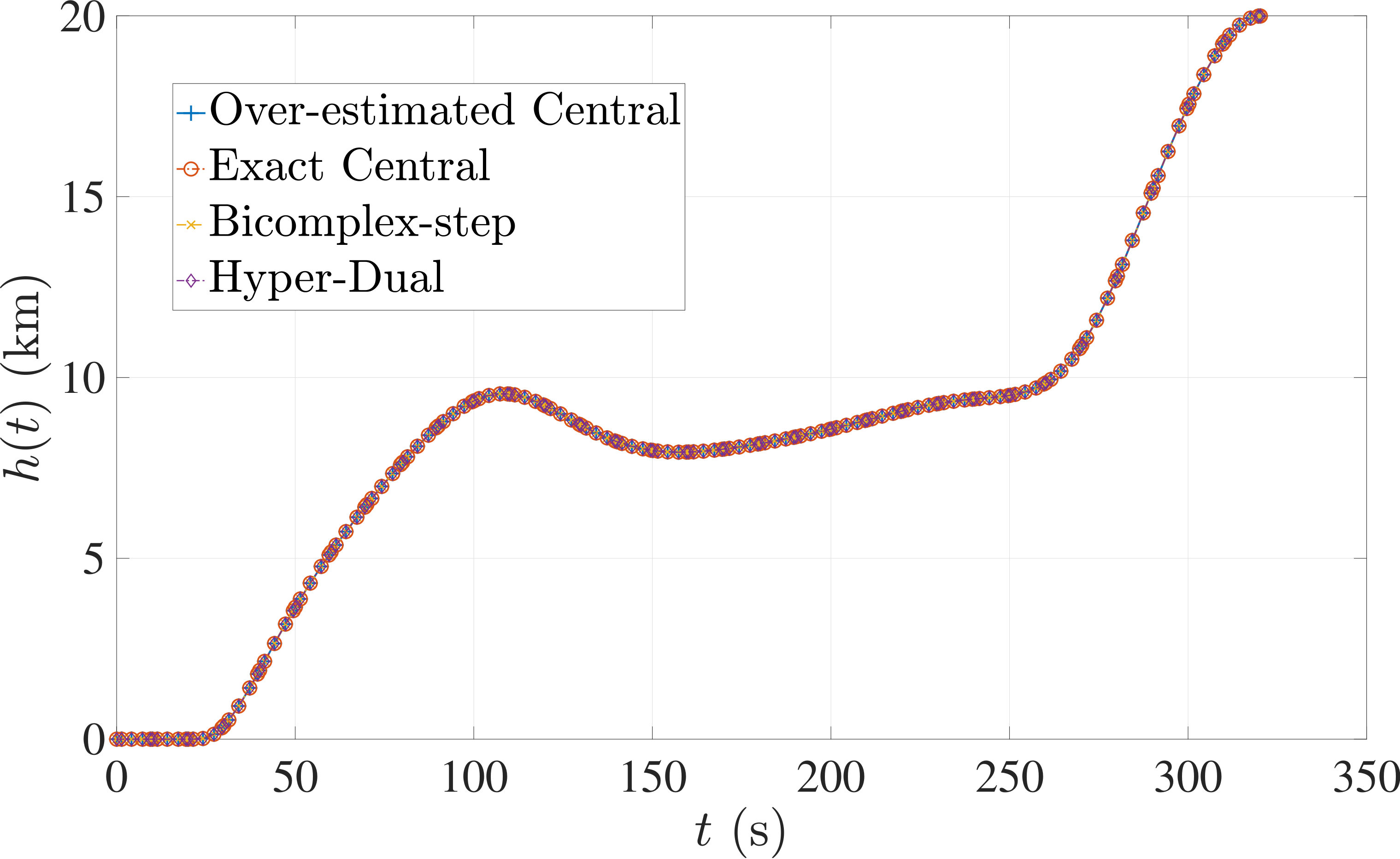 Figure 19
Figure 19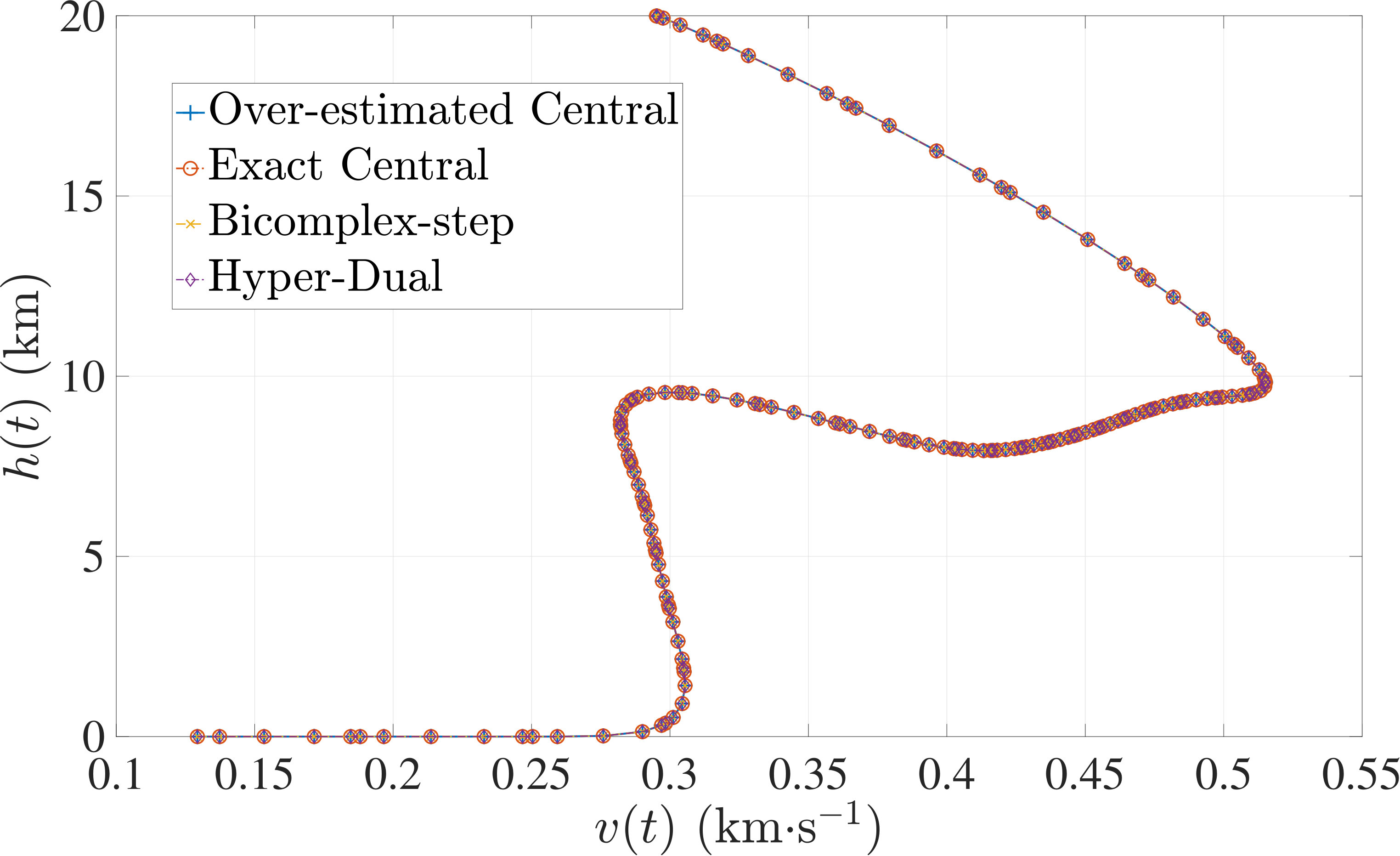 Figure 20
Figure 20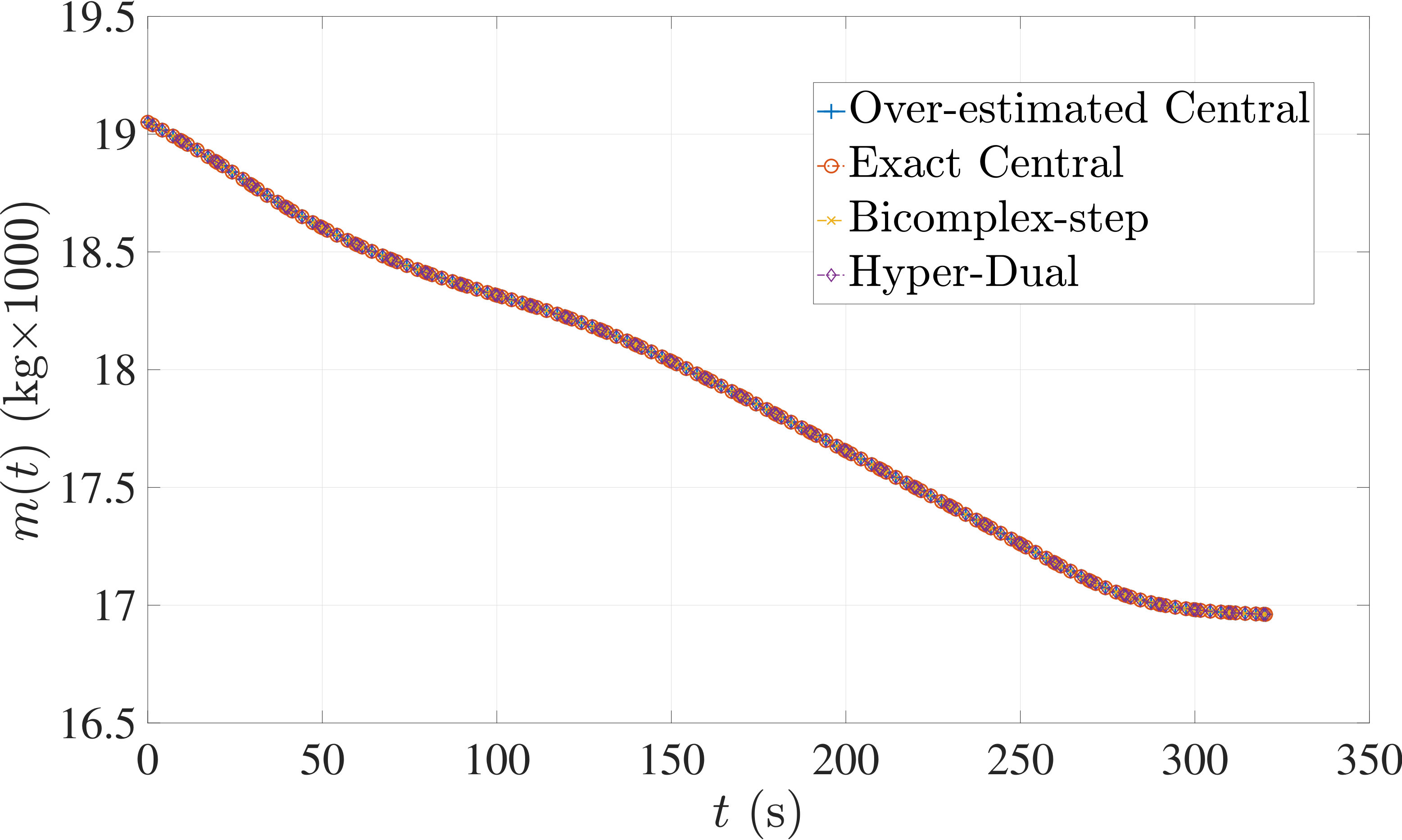 Figure 21
Figure 21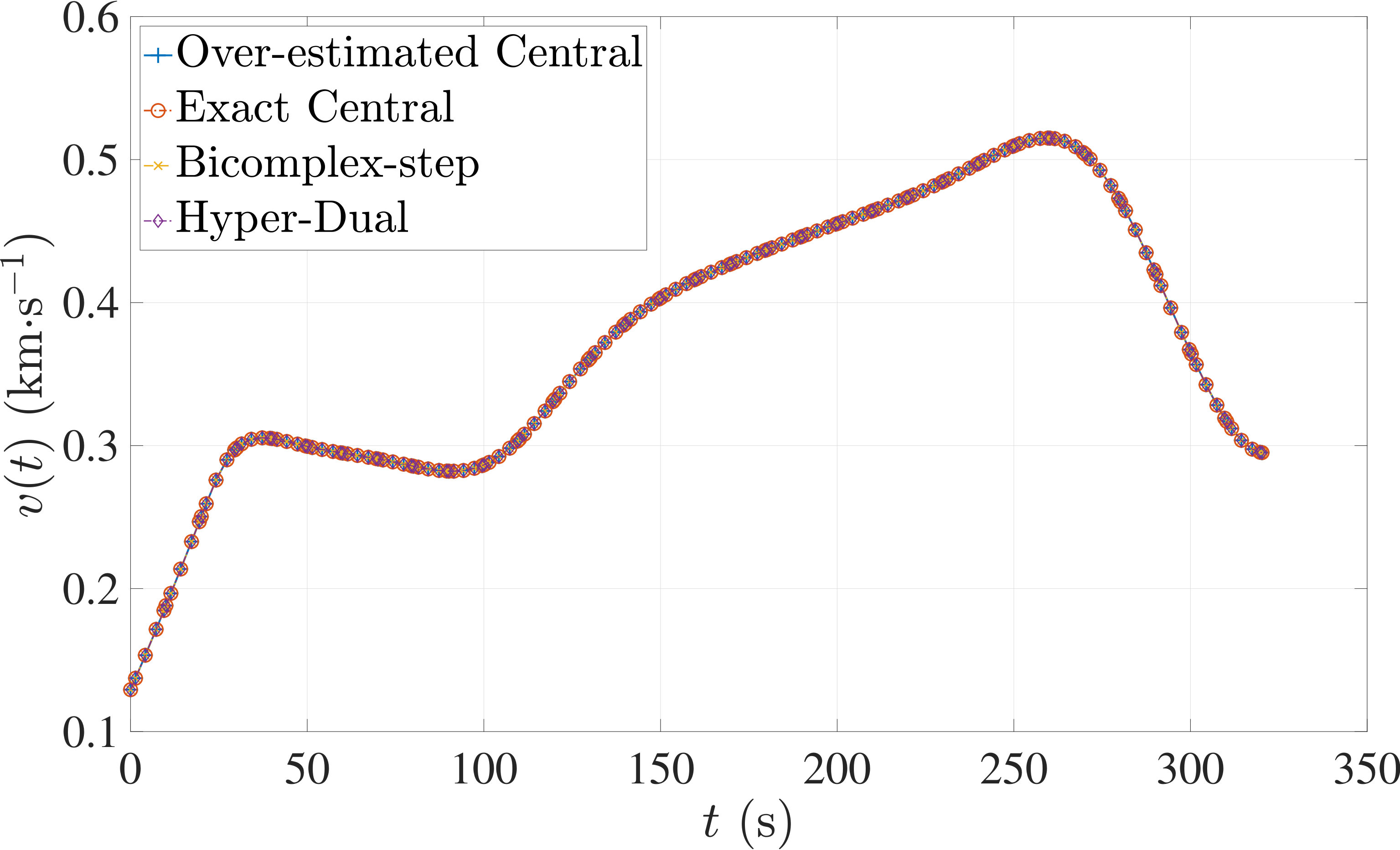 Figure 22
Figure 22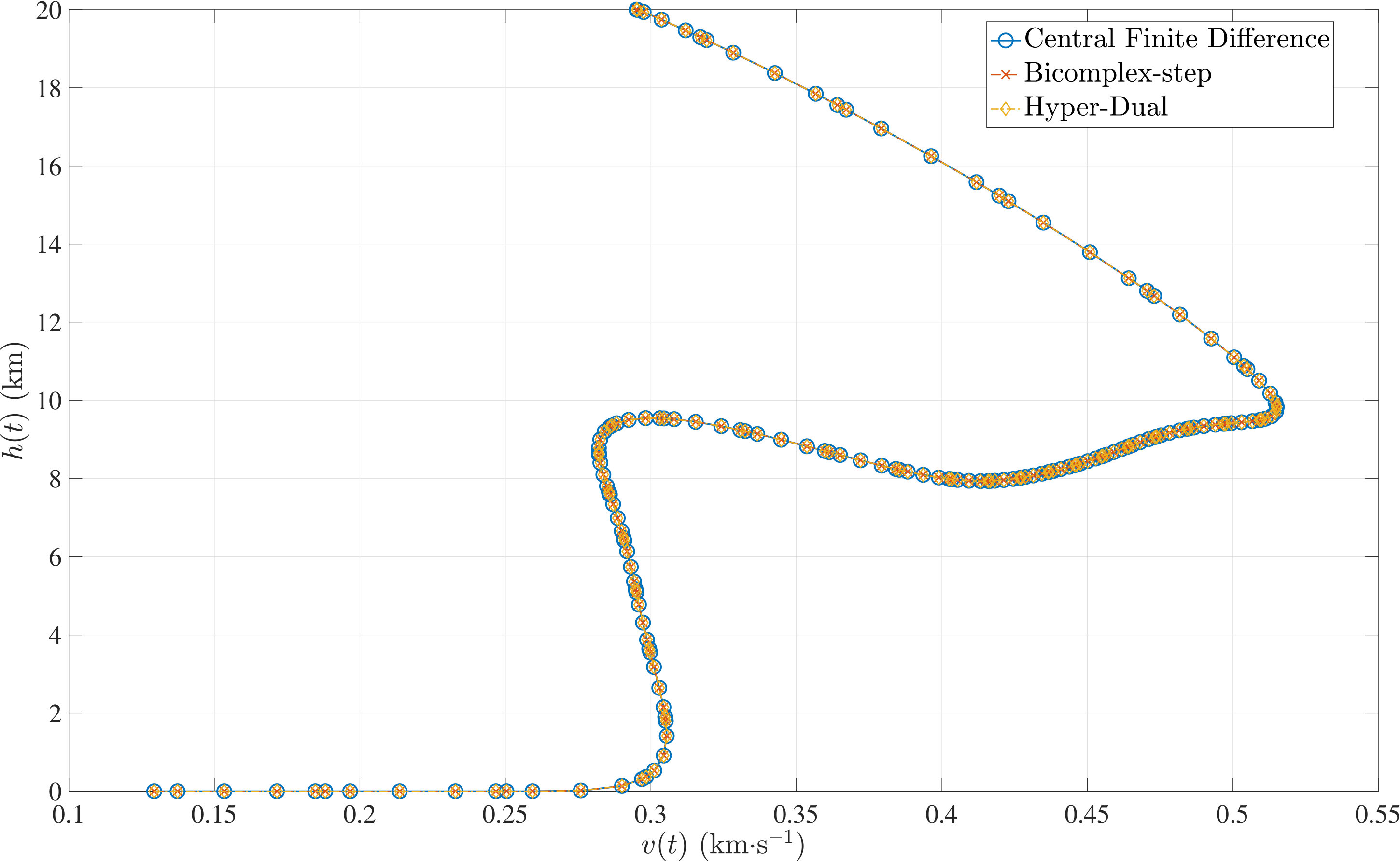 Figure 23
Figure 23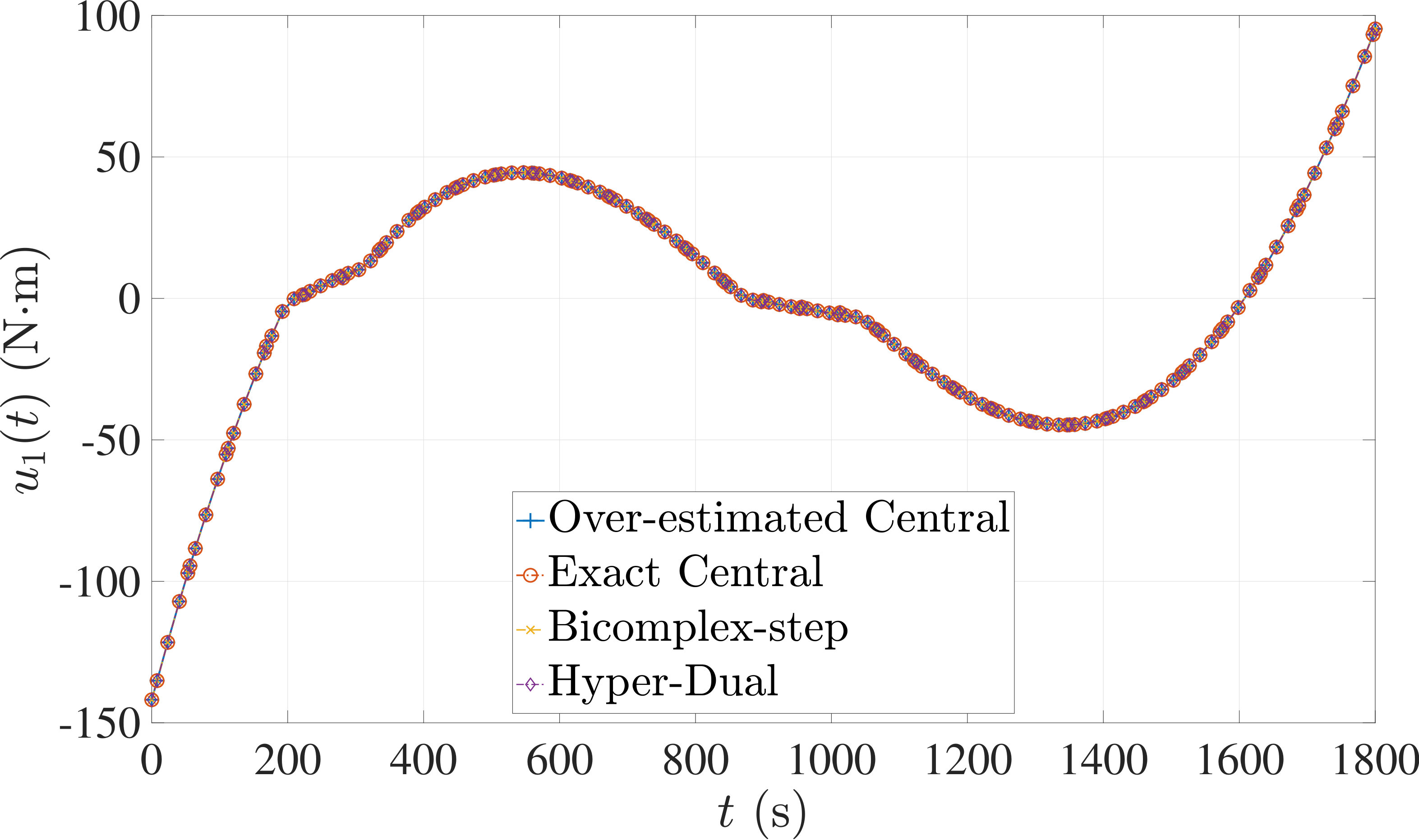 Figure 24
Figure 24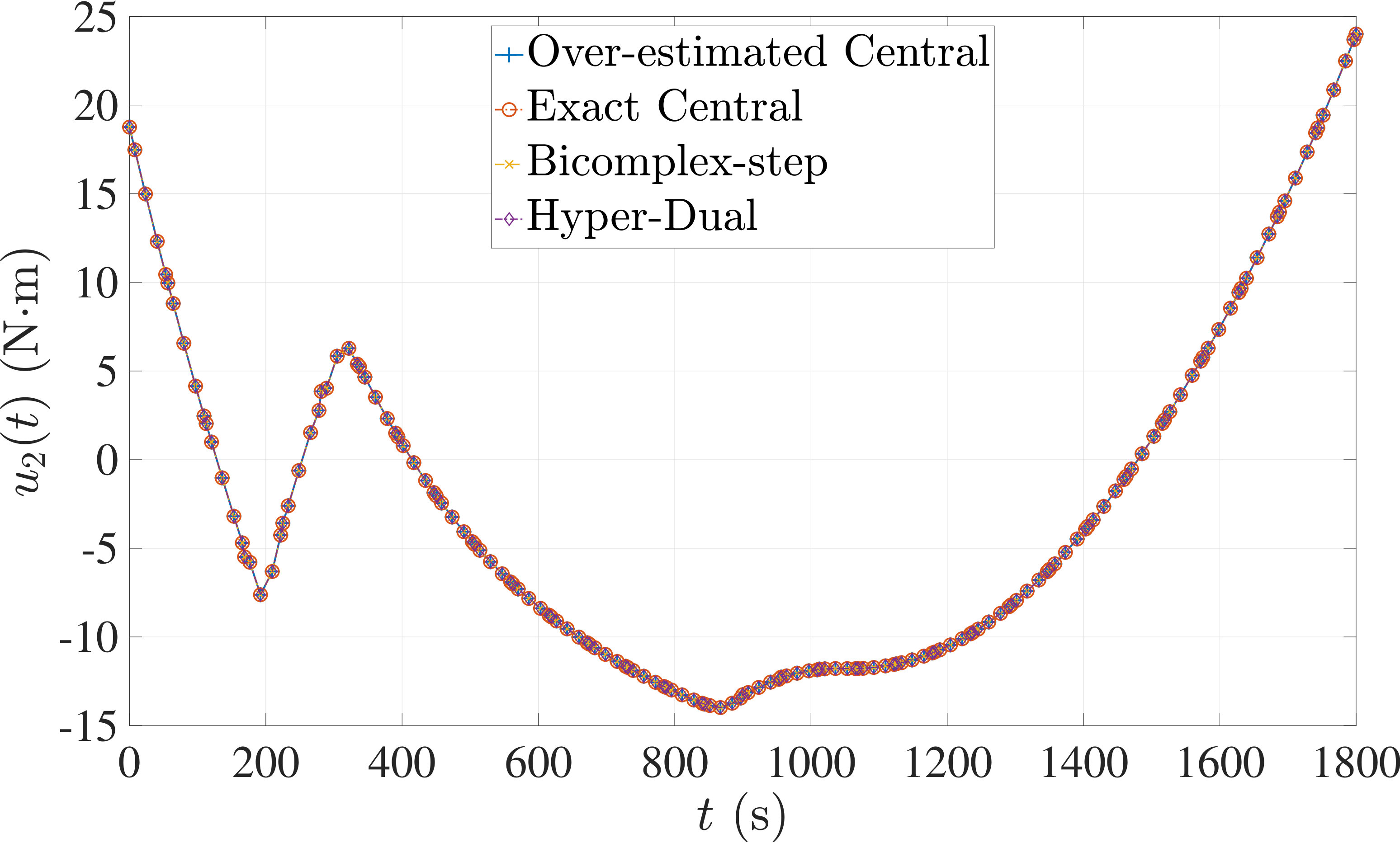 Figure 25
Figure 25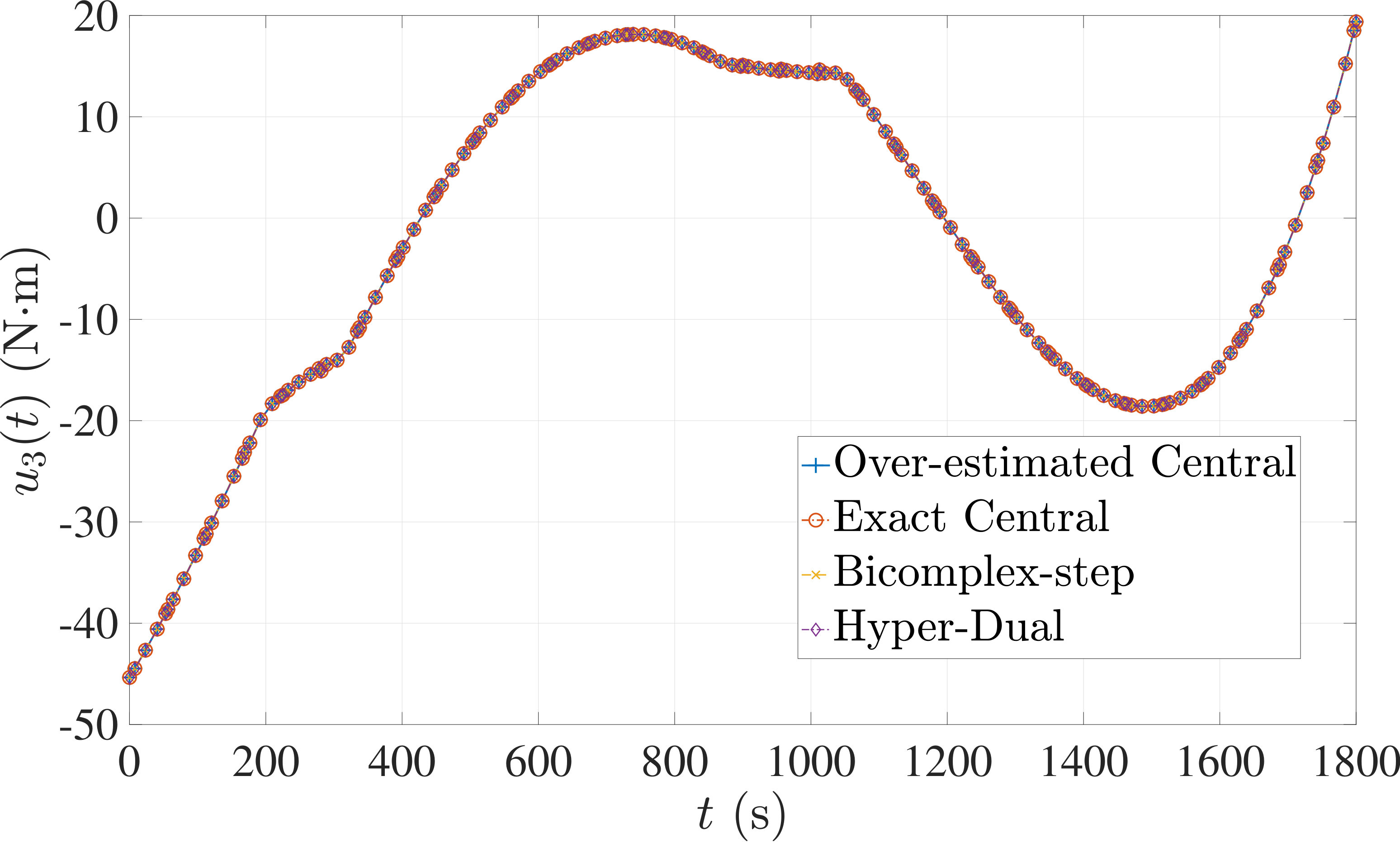 Figure 26
Figure 26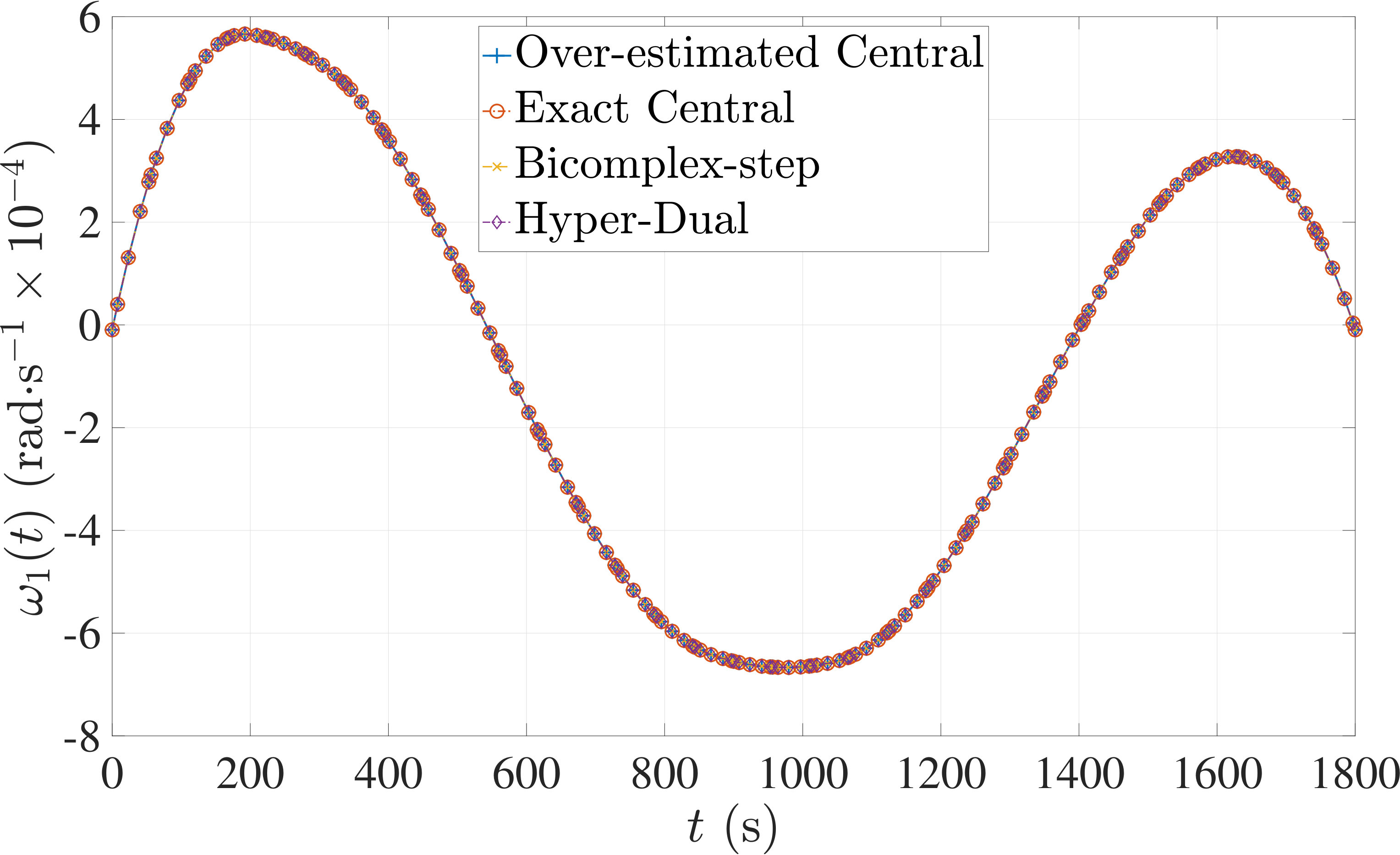 Figure 27
Figure 27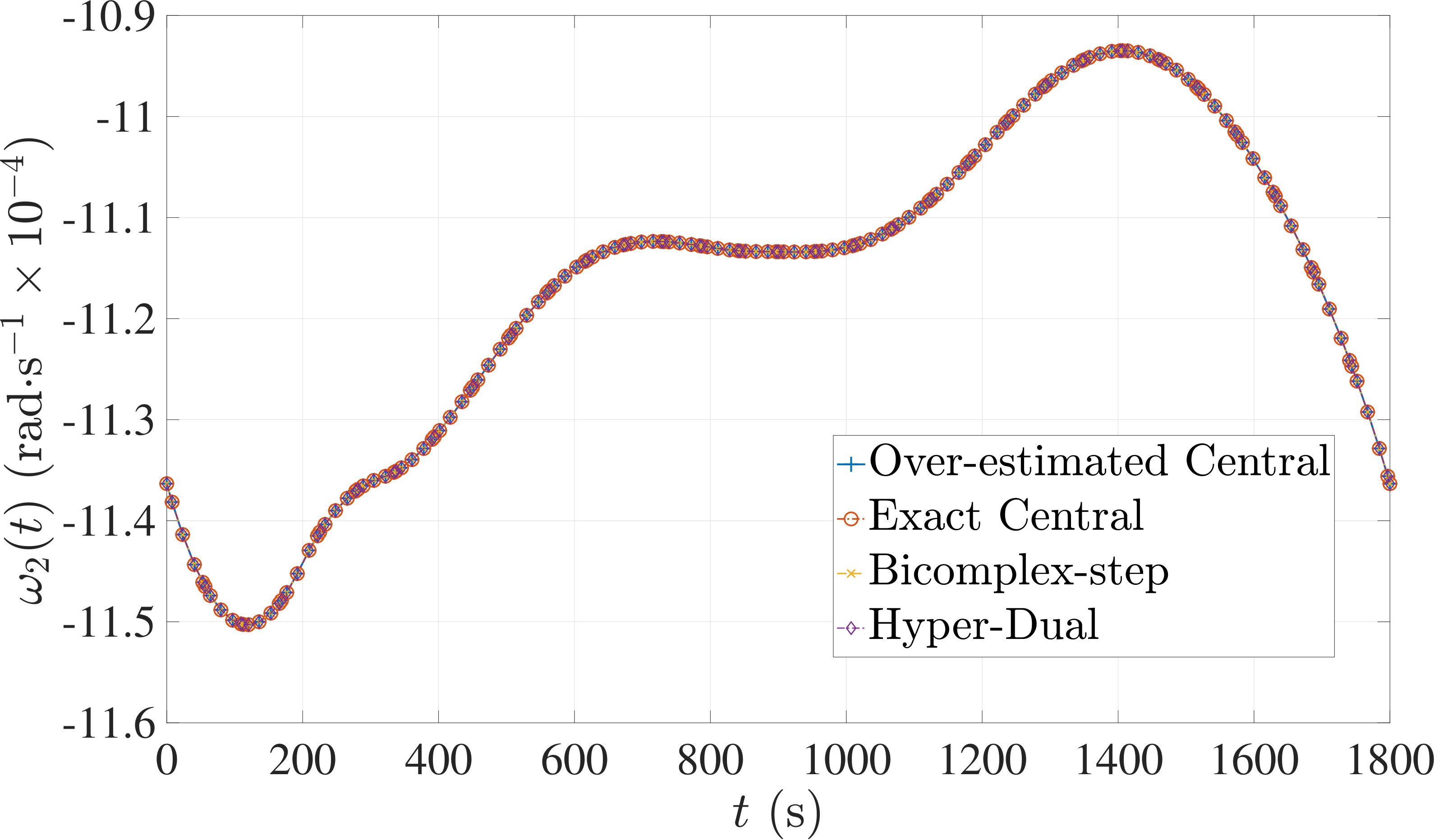 Figure 28
Figure 28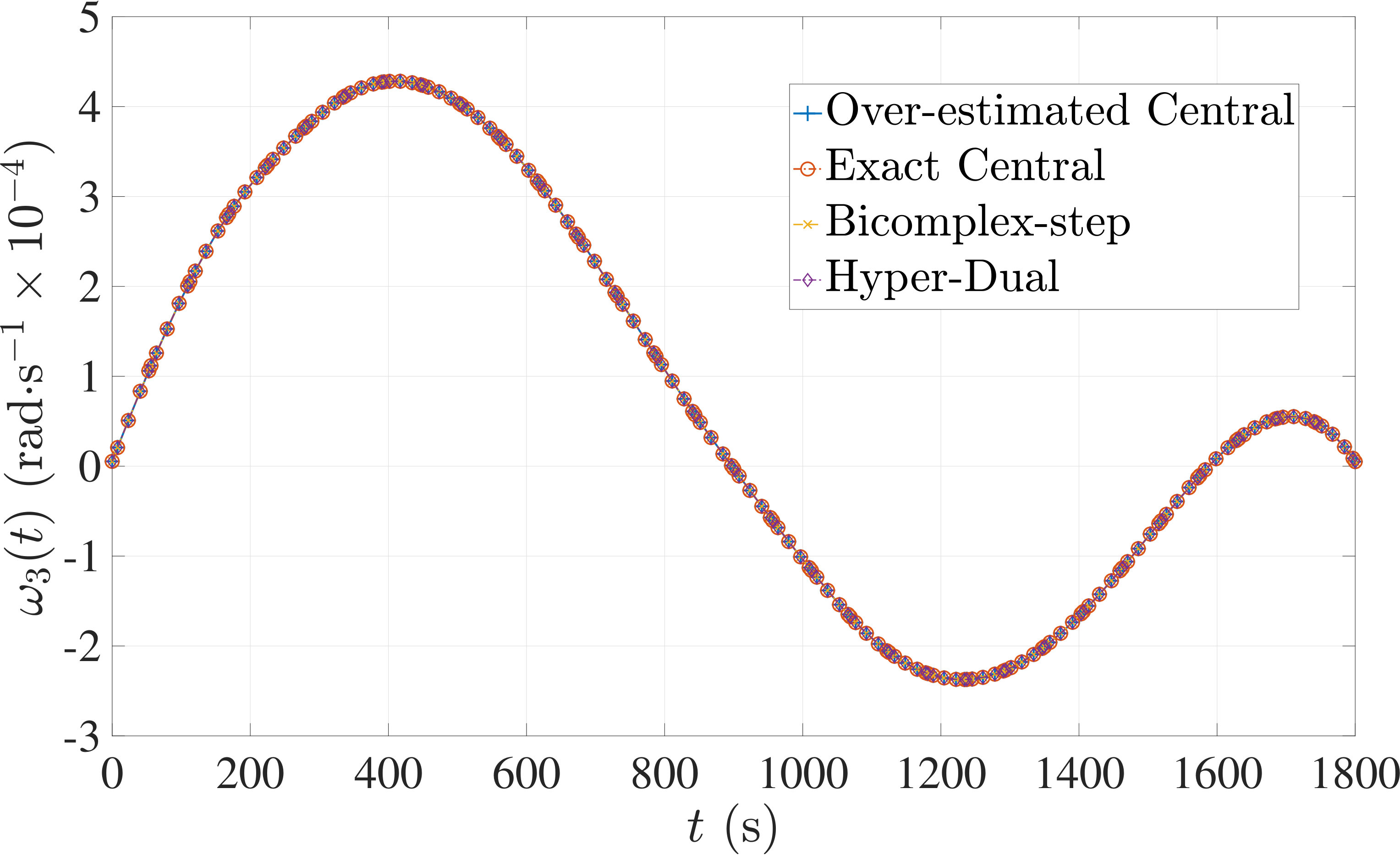 Figure 29
Figure 29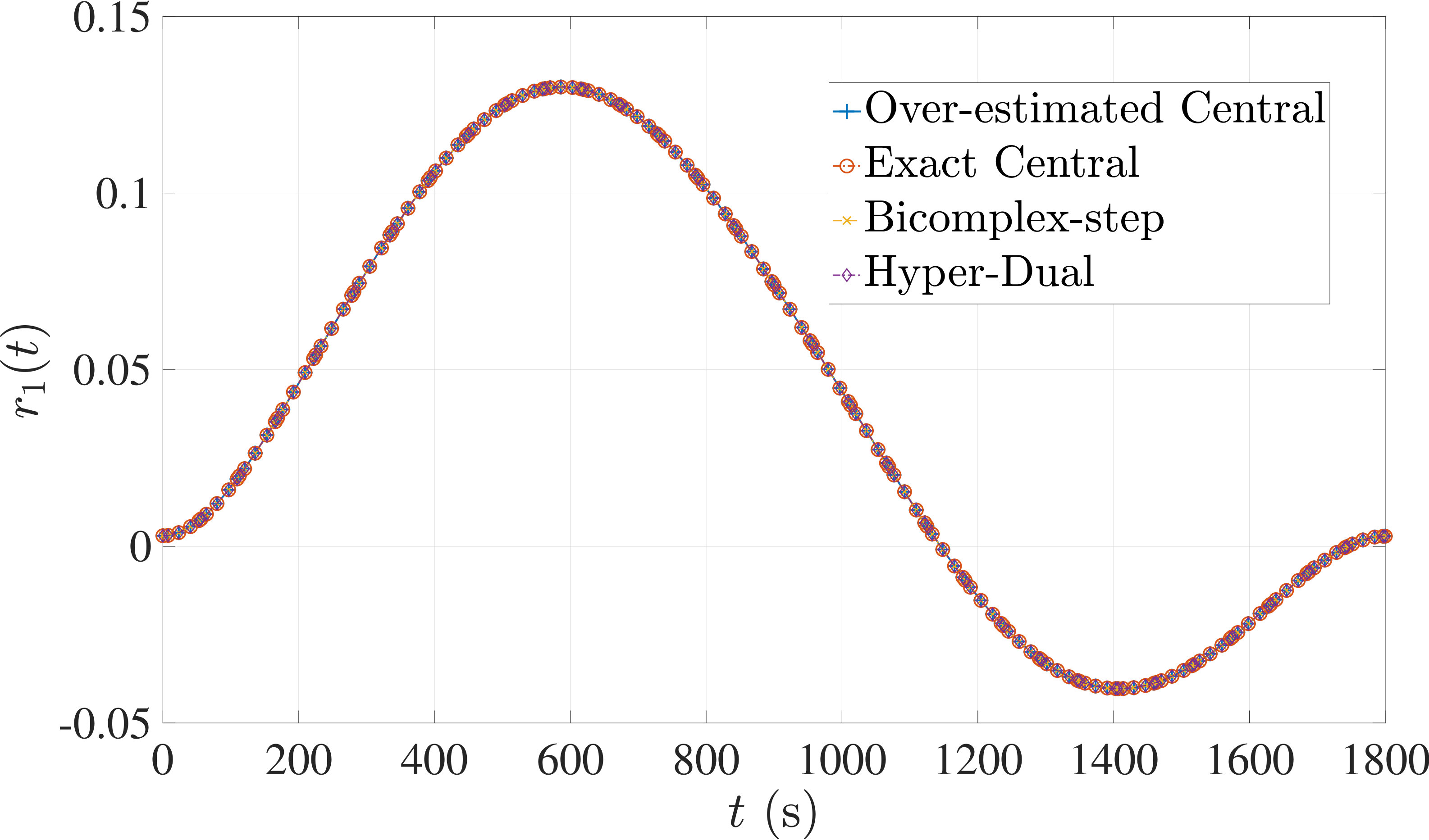 Figure 30
Figure 30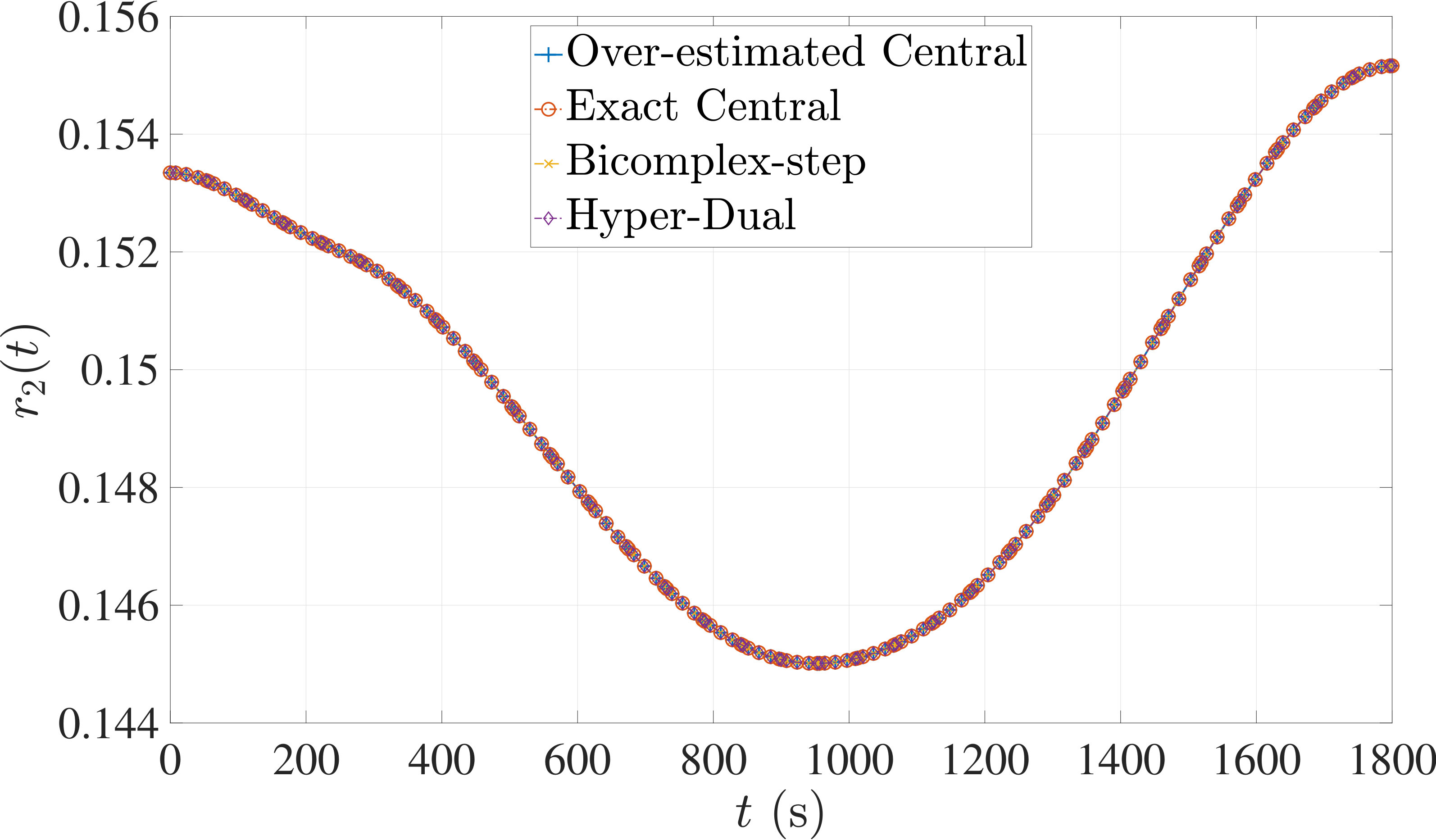 Figure 31
Figure 31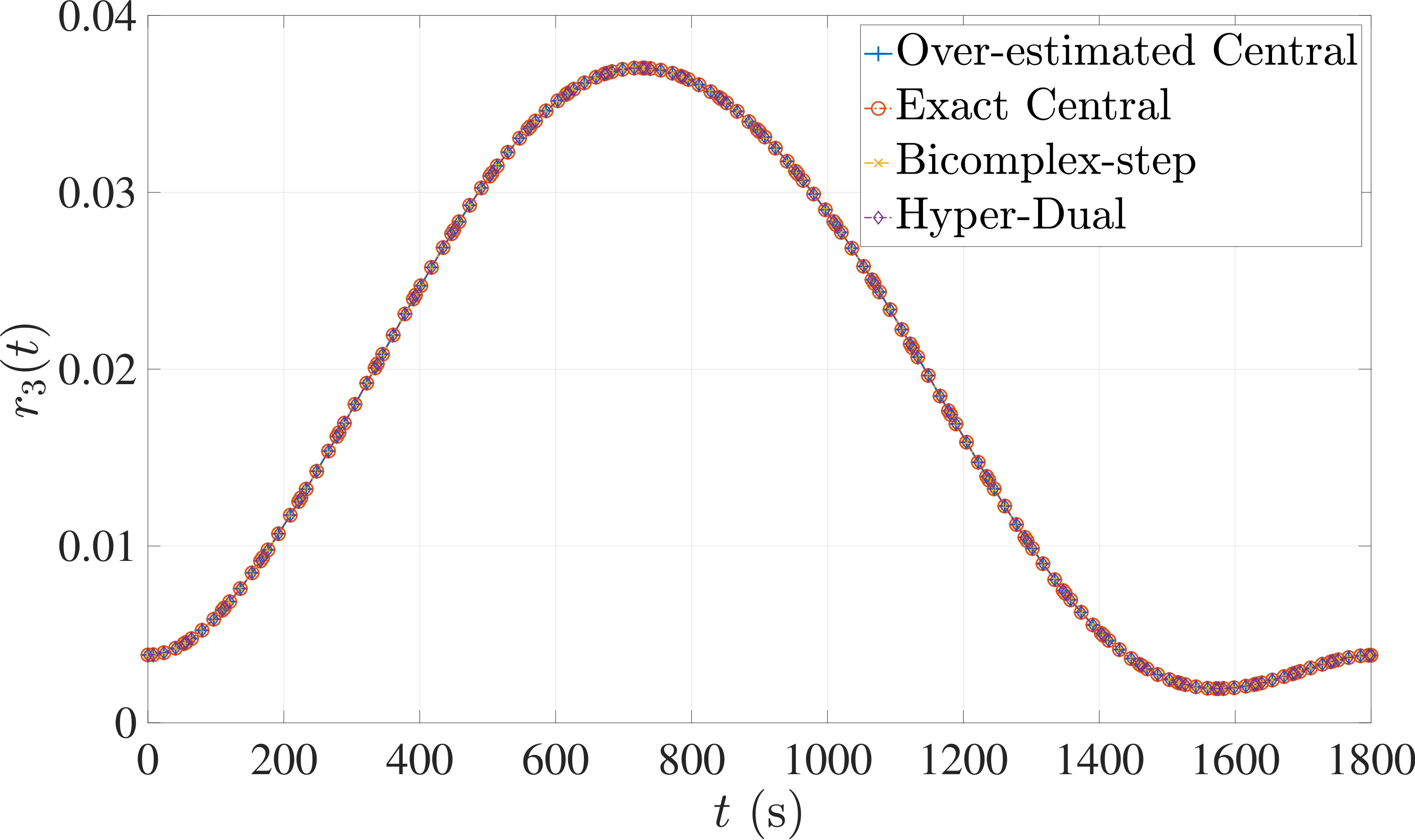 Figure 32
Figure 32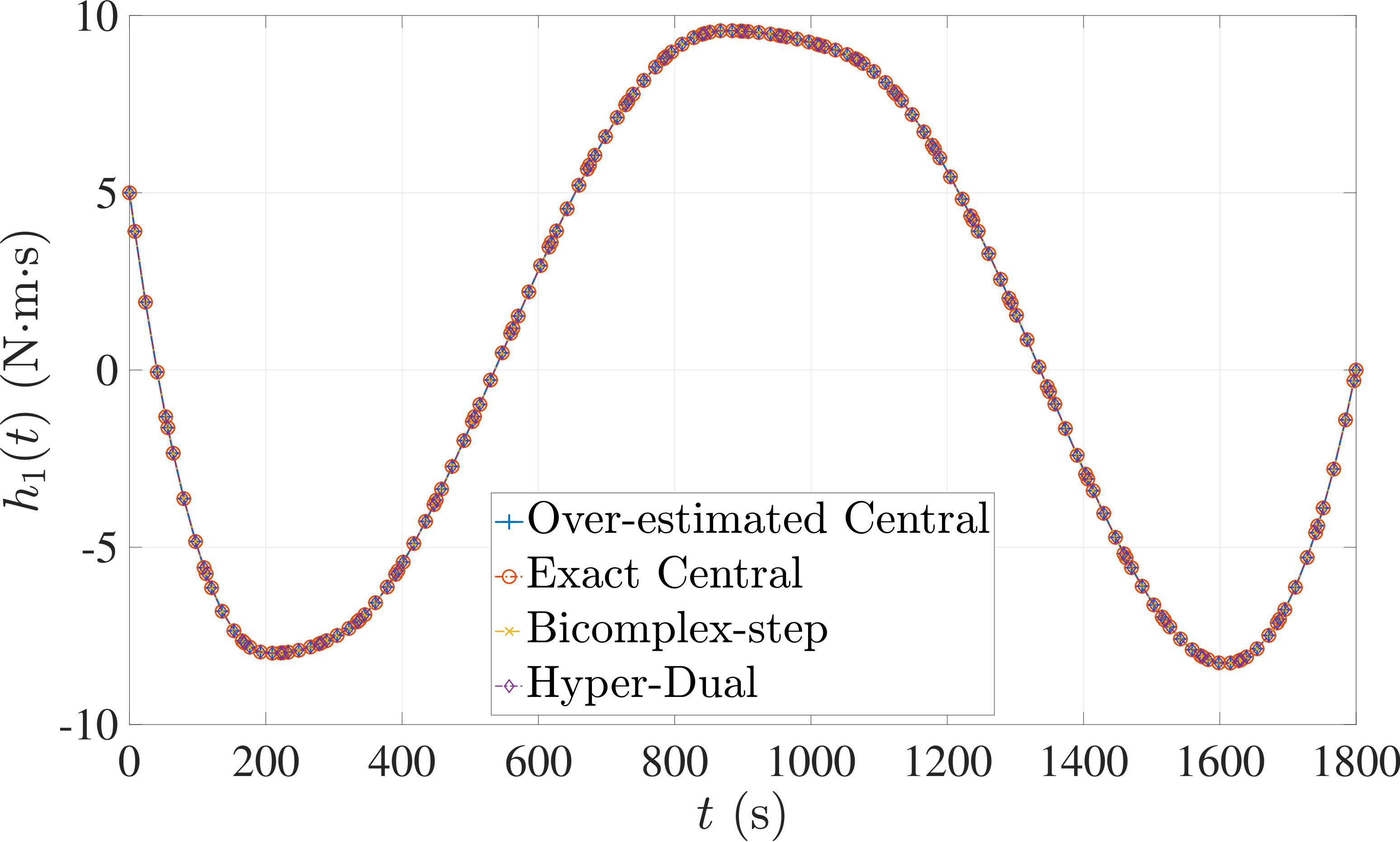 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35| = | vector field for right-hand side of dynamics | |
| = | matrix defining vector field for right-hand side of dynamics at collocation points | |
| = | automatic differentiation method | |
| = | vector field for event constraints | |
| = | bicomplex-step method | |
| = | vector field for path constraints | |
| = | matrix defining vector field for path constraints at collocation points | |
| = | Legendre-Gauss-Radau differentiation matrix | |
| = | endpoint vector | |
| = | endpoint approximation vector | |
| = | exact sparsity central finite-difference method | |
| = | vector field for integrands | |
| = | matrix defining vector field for integrands at collocation points | |
| = | perturbation step size | |
| = | base perturbation step size for finite-difference | |
| = | hyper-dual method | |
| = | number of NLP solver iterations | |
| = | objective functional | |
| = | number of mesh intervals used in phase | |
| = | Lagrange polynomial of mesh interval | |
| = | number of state components | |
| = | number of control components | |
| = | number of integral components | |
| = | number of path constraints | |
| = | number of event constraints | |
| = | number of static parameters | |
| = | number of collocation points used in mesh interval | |
| = | total number of collocation points used in phase | |
| = | over-estimated sparsity central finite-difference method | |
| = | number of phases in problem | |
| = | integral vector | |
| = | integral approximation vector | |
| = | static parameters vector | |
| = | mesh interval | |
| = | initial time | |
| = | final time | |
| = | computation time | |
| = | control | |
| = | matrix of control parameterization at collocation points | |
| = | state | |
| = | state approximation | |
| = | matrix of state approximation at discretized points | |
| = | percent change of criteria for method | |
| relative to method | ||
| = | defect constraints matrix | |
| = | integral approximation constraints vector | |
| = | support point of mesh interval | |
| = | average time per NLP iteration |
| 2 | 40 | 0 | 22.50 | 22.50 | 22.50 |
|---|---|---|---|---|---|
| 4 | 45 | 0 | 28.89 | 28.89 | 28.89 |
| 8 | 62 | 16.13 | 19.35 | 19.35 | 19.35 |
| 16 | 48 | 0 | 22.92 | 22.92 | 22.92 |
| 32 | 66 | 0 | 21.21 | 21.21 | 21.21 |
| 2 | 40 | 0 | 22.50 | 22.50 | 22.50 |
|---|---|---|---|---|---|
| 4 | 45 | 0 | 28.89 | 28.89 | 28.89 |
| 8 | 62 | 16.13 | 19.35 | 19.35 | 19.35 |
| 16 | 48 | 0 | 22.92 | 22.92 | 22.92 |
| 32 | 66 | 0 | 21.21 | 21.21 | 21.21 |
| (s) | |||||
|---|---|---|---|---|---|
| 2 | 0.0876 | 14.96 | 29.54 | 18.30 | -5982.22 |
| 4 | 0.1205 | 8.54 | 29.28 | 24.48 | -5741.15 |
| 8 | 0.2510 | 24.51 | 27.44 | 25.50 | -8390.67 |
| 16 | 0.2973 | 14.43 | 27.34 | 24.76 | -10326.47 |
| 32 | 0.7769 | 7.32 | 29.36 | 30.71 | -14885.30 |
| (ms) | |||||
|---|---|---|---|---|---|
| 2 | 0.5777 | 64.00 | 68.50 | 64.08 | -28402.91 |
| 4 | 0.6411 | 59.72 | 61.32 | 56.49 | -32794.73 |
| 8 | 0.9041 | 57.78 | 51.78 | 52.59 | -45800.42 |
| 16 | 1.5164 | 48.46 | 41.63 | 38.81 | -53367.95 |
| 32 | 2.9180 | 35.00 | 30.01 | 34.96 | -74946.84 |
| 2 | 248 | 26.61 | 79.03 | 66.94 | 71.37 |
|---|---|---|---|---|---|
| 4 | 30 | 6.67 | -43.33 | -43.33 | -43.33 |
| 8 | 52 | -1.92 | 30.77 | 30.77 | 30.77 |
| 16 | 70 | -7.14 | 32.86 | 32.86 | 32.86 |
| 32 | 53 | 0 | 26.42 | 26.42 | 26.42 |
| 2 | 248 | 26.61 | 79.03 | 66.94 | 71.37 |
|---|---|---|---|---|---|
| 4 | 30 | 6.67 | -43.33 | -43.33 | -43.33 |
| 8 | 52 | -1.92 | 30.77 | 30.77 | 30.77 |
| 16 | 70 | -7.14 | 32.86 | 32.86 | 32.86 |
| 32 | 53 | 0 | 26.42 | 26.42 | 26.42 |
| (s) | |||||
|---|---|---|---|---|---|
| 2 | 0.6529 | 31.25 | 81.39 | 69.64 | -1315.45 |
| 4 | 0.1428 | 5.09 | -14.69 | -12.51 | -7375.47 |
| 8 | 0.4029 | -1.34 | 44.02 | 41.11 | -4682.36 |
| 16 | 1.0057 | -1.12 | 49.06 | 48.54 | -4541.37 |
| 32 | 1.4072 | 0.71 | 40.26 | 42.88 | -5130.10 |
| (ms) | |||||
|---|---|---|---|---|---|
| 2 | 1.5267 | 8.21 | 37.41 | 33.18 | -8227.16 |
| 4 | 2.7067 | 5.92 | 32.05 | 36.20 | -8781.22 |
| 8 | 5.2132 | 2.38 | 36.38 | 34.10 | -9851.17 |
| 16 | 10.8110 | 7.92 | 38.30 | 38.23 | -8865.56 |
| 32 | 20.3869 | 2.69 | 32.18 | 36.26 | -8895.19 |
| 2 | 22 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|
| 4 | 33 | 0 | 0 | 0 | 0 |
| 8 | 44 | -4.55 | -4.55 | -4.55 | -4.55 |
| 16 | 50 | -6.00 | -10.00 | -6.00 | -8.00 |
| 32 | 141 | 24.11 | 39.72 | 39.72 | 36.88 |
| 2 | 22 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|
| 4 | 33 | 0 | 0 | 0 | 0 |
| 8 | 44 | -4.55 | -4.55 | -4.55 | -4.55 |
| 16 | 50 | -6.00 | -10.00 | -6.00 | -8.00 |
| 32 | 141 | 24.11 | 39.72 | 39.72 | 36.88 |
| (s) | |||||
|---|---|---|---|---|---|
| 2 | 0.2628 | 53.71 | 55.53 | 52.39 | -7420.02 |
| 4 | 0.4703 | 50.86 | 46.98 | 49.26 | -11200.24 |
| 8 | 0.8522 | 43.72 | 33.75 | 33.63 | -16350.86 |
| 16 | 1.4118 | 40.61 | 20.10 | 27.41 | -22562.69 |
| 32 | 7.7361 | 53.20 | 57.38 | 57.50 | -12922.78 |
| (ms) | |||||
|---|---|---|---|---|---|
| 2 | 8.2873 | 73.38 | 74.45 | 75.30 | -10222.58 |
| 4 | 9.2951 | 72.13 | 68.57 | 69.24 | -16673.23 |
| 8 | 11.6082 | 69.75 | 54.49 | 56.43 | -25547.80 |
| 16 | 15.8056 | 65.05 | 36.13 | 40.89 | -36645.81 |
| 32 | 26.1159 | 60.06 | 26.06 | 26.66 | -42707.56 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Comparison of Derivative Estimation Methods in Solving Optimal Control Problems Using Direct Collocation
Yunus M. Agamawi
Anil V. Rao
University of Florida
Gainesville, FL, 32611-6250 Ph.D. Student, Department of Mechanical and Aerospace Engineering. E-mail: [email protected] Professor, Department of Mechanical and Aerospace Engineering, Erich Farber Faculty Fellow and University Term Professor. E-mail: [email protected]. Associate Fellow, AIAA. Corresponding Author.
Abstract
A study is conducted to evaluate four derivative estimation methods when solving a large sparse nonlinear programming problem that arises from the approximation of an optimal control problem using a direct collocation method. In particular, the Taylor series-based finite-difference, bicomplex-step, and hyper-dual derivative estimation methods are evaluated and compared alongside a well known automatic differentiation method. The performance of each derivative estimation method is assessed based on the number of iterations, the computation time per iteration, and the total computation time required to solve the nonlinear programming problem. The efficiency of each of the four derivative estimation methods is compared by solving three benchmark optimal control problems. It is found that while central finite-differencing is typically more efficient per iteration than either the hyper-dual or bicomplex-step, the latter two methods have significantly lower overall computation times due to the fact that fewer iterations are required by the nonlinear programming problem when compared with central finite-differencing. Furthermore, while the bicomplex-step and hyper-dual methods are similar in performance, the hyper-dual method is significantly easier to implement. Moreover, the automatic differentiation method is found to be substantially less computationally efficient than any of the three Taylor series-based methods. The results of this study show that the hyper-dual method offers several benefits over the other three methods both in terms of computational efficiency and ease of implementation.
Nomenclature
1 Introduction
Optimal control problems arise in a wide variety of engineering and non-engineering disciplines. Due to the increasing complexity of modern optimal control problems and the inability to solve these problems analytically, in the past few decades the focus of research in optimal control has transitioned from theory to computation. One approach that has become important in the numerical solution of optimal control problems is the class of direct collocation methods. In a direct collocation method, the state and control of the optimal control problem are approximated using a set of basis or trial functions and the constraints are enforced at a special set of points called nodes. The continuous optimal control problem is then approximated as a large sparse nonlinear programming problem (NLP) [1] and this sparse NLP is solved using well known software [2, 3].
The sparse NLP arising from a direct collocation method is generally solved using a gradient-based method. The two categories of gradient-based methods for solving NLPs are quasi-Newton methods and Newton methods. In a quasi-Newton gradient-based method, the NLP objective function gradient and constraints Jacobian are required along with a quasi-Newton approximation to the inverse of the Hessian of the NLP Lagrangian (for example, BFGS or DFP quasi-Newton approximations). A Newton method adds to a quasi-Newton method the requirement that the Lagrangian Hessian be computed. Perhaps the most well known NLP solver that implements a quasi-Newton method is SNOPT [4], while perhaps the most well known Newton NLP solver is IPOPT [3]. In order to make it tractable to solve the NLP using a gradient-based method, it is necessary to efficiently and accurately compute the required first- and second-order derivatives of the NLP functions. In fact, the vast majority of time required for the NLP solver to obtain a solution is spent computing the required derivatives. It is also important to note that, even if the derivatives are computed efficiently, inaccuracies in the derivatives can lead to poor convergence or non-convergence of the NLP solver. Thus, the ability to supply efficient and accurate derivatives is of utmost importance when solving an NLP arising from the approximation of an optimal control problem using direct collocation.
A variety of different approaches have been developed for estimating derivatives. These approaches can be divided broadly into algorithmic methods and approximation methods. In an algorithmic method, a derivative is obtained by decomposing the function into a sequence of elementary operations and applying rules of differential calculus. Algorithmic approaches include analytic differentiation, symbolic differentiation, and automatic differentiation [5]. Analytic differentiation is the process of obtaining the derivative manually by differentiating each step in the chain rule by hand [6]. As a result, analytic differentiation is often referred to as hand differentiation. Symbolic differentiation is the process of obtaining a derivative using computer algebra such as that implemented in Maple or Mathematica. Finally, automatic differentiation is the process of decomposing a computer program into a sequence of elementary function operations and applying the calculus chain rule algorithmically through the computer [7]. It is noted that all of the aforementioned algorithmic methods can be derived from the unifying chain rule described in Ref. [5]. Finally, an approximation method evaluates the function at one or more neighboring points and estimates the derivative using this information.
Algorithmic and approximation methods for computing derivatives have relative advantages and disadvantages. The key advantage of an algorithmic method is that an exact derivative (that is, a derivative accurate to machine precision on a computer) is obtained. In addition, in some cases using an algorithmic method makes it possible to obtain a derivative in a computationally efficient manner, thus maximizing the reliability and computational efficiency of solving the nonlinear programming problem arising from a direct collocation method. It is noted, however, that algorithmic methods have several limitations. First, for a practical problem it is generally intractable to obtain an analytic derivative. Second, symbolic differentiation used in computer algebra systems suffer from expression explosion that make it intractable to compute derivatives whose forms are algebraically complex. Third, automatic differentiation can only be performed on functions where the differentiation rule has been defined via a library or database of functions. In fact, it is often intractable to define derivative rules for highly complicated functions (for example, determining the derivative rule associated with the interpolation of a multi-dimensional table).
In particular, the well-known open source automatic differentiation software ADOL-C [8, 9], which is included in this paper for comparison as the automatic differentiation method, requires a tape recording of the function evaluation for each derivative calculation. Because the record used in ADOL-C does not account for changes in flow control, problems utilizing piecewise models or interpolation of tabular data must be retaped upon each input in order to ensure the proper derivative calculation is performed. Although taping the record of the function evaluation for the derivative to be calculated can be efficient if reused, the conditional flow control nature of many optimal control problems requires retaping in order to ensure the proper flow control is computed for each input. A key advantage of an approximation method is that only the function needs to be evaluated in order to estimate the derivative which generally makes an approximation method computationally efficient. It is noted, however, that typical approximation methods (for example, finite-differencing) are not very accurate, thereby reducing the robustness with which a solution to the NLP can be obtained.
While a general NLP may not contain a great deal of structure, it has been shown in Refs. [10, 11, 12] that the derivative functions of an NLP arising from the direct collocation of an optimal control problem have a very well-defined structure. In particular, Refs. [10, 11, 12] have shown that the derivative functions of the NLP arising from a direct collocation method can be obtained with increased efficiency by computing the derivatives of the functions associated with the optimal control problem at the collocation points as opposed to computing the derivatives of the NLP functions. This exploitation of sparsity in a direct collocation NLP makes it possible to compute the derivatives of the lower-dimensional optimal control problem functions relative to the much higher-dimensional derivatives of the NLP functions. Given the increased efficiency that arises from sparsity exploitation, any derivative method employed when solving an optimal control problem using direct collocation should exploit this NLP sparsity.
The aforementioned discussion makes it relevant and useful to evaluate the effectiveness of using various approximation methods for computing derivatives required when solving an NLP arising from a direct collocation method. Typically, finite-difference approximation methods are used when solving a direct collocation NLP [1, 2, 13]. In recent years, however, much more accurate derivative approximation methods have been developed. Two such recent developments that enable the computation of higher-order (that is, beyond first-derivative) derivatives are the bicomplex-step [14], and hyper-dual [15] derivative approximations. In a bicomplex-step derivative approximation, a new class of numbers, called bicomplex numbers, is created. As its name implies, a bicomplex number is one that has one real component, two imaginary components, and one bi-imaginary component. Derivative approximations are then obtained by evaluating the functions at a particular bicomplex input argument. While more accurate than finite-difference methods, the bicomplex-step derivative approximation still has inaccuracies stemming from the bicomplex arithmetic [14]. Next, in a hyper-dual derivative approximation, a new class of numbers, called hyper-dual numbers, is created [15]. As its name implies, a hyper-dual number is one that has one real component, two imaginary components, and one bi-imaginary component. While hyper-dual numbers share some properties with those of bicomplex numbers, the mathematics associated with a hyper-dual number are fundamentally different from those of a bicomplex number. The difference in the mathematics associated with a hyper-dual number relative to other approximation methods leads to a derivative approximation that does not suffer from truncation error and is insensitive to the step size. Finally, it is noted that all three of the aforementioned derivative approximation methods fall into the category of Taylor series-based approximation methods.
The objective of this research is to evaluate the effectiveness of using the following four derivative estimation methods for use when solving an NLP arising from the direct collocation of an optimal control problem: central finite-differencing, bicomplex-step, hyper-dual, and automatic differentiation. Specifically, the objective of this paper is to provide a comprehensive comparison of the computational efficiency with which a direct collocation NLP can be solved using a Newton NLP solver with the four aforementioned derivative estimation methods. The evaluation is based on the number of iterations required to obtain a solution to the NLP, the overall computation time required to solve the NLP, and the average computation time required per iteration to compute the required derivatives. It is found that while central finite-differencing is typically more efficient per iteration than either the hyper-dual or bicomplex-step, the latter two methods have a significantly lower overall computation time due to the fact that fewer iterations are required by the nonlinear programming problem solver using these latter two methods when compared with central finite-differencing. Furthermore, it is found that although the bicomplex-step and hyper-dual are similar in performance, the hyper-dual derivative approximation is significantly easier to implement. Moreover, the three Taylor series-based derivative approximations are found to be substantially more computationally efficient methods when compared to an automatic differentiation method provided by the open source software ADOL-C [8, 9]. The results of this study show that the hyper-dual derivative approximation offers several benefits over the other two derivative approximations and the tested automatic differentiation derivative estimation method, both in terms of computational efficiency and ease of implementation.
The contributions of this research are as follows. First, this research provides a systematic evaluation of the performance of using various Taylor series-based derivative approximation methods and an automatic differentiation method when solving a nonlinear programming problem arising from a direct collocation method for optimal control. In addition, a method for determining the exact sparsity patterns of the first- and second-order NLP derivative functions is developed by estimating the continuous-time optimal control problem functions using bicomplex-step or hyper-dual derivative approximations. Furthermore, the implementation and performance behavior of the NLP solver when utilizing the three aforementioned Taylor series-based derivative approximation methods and automatic differentiation as methods are compared against one another. As mentioned, the results of this paper show that, among the methods evaluated, the hyper-dual derivative approximation is most effective and has the greatest ease of implementation for solving optimal control problems using direct collocation methods.
This paper is organized as follows. Section 2 defines the general multiple-phase optimal control problem. Section 3 describes the rationale for using Legendre-Gauss-Radau collocation points as the set of nodes to discretize the continuous optimal control problem and the Legendre-Gauss-Radau collocation method. Section 4 briefly overviews the form of the nonlinear programming problem that results from transcribing the optimal control problem. Section 5 describes the basis of the four derivative estimation methods: central finite-differencing, bicomplex-step derivative approximation, hyper-dual derivative approximation, and automatic differentiation. Section 6 briefly compares the derivative approximations obtained when using central finite-differencing versus a bicomplex-step derivative approximation, hyper-dual derivative approximation, or automatic differentiation. Section 7 provides examples that demonstrate the performance of the NLP solver when using a central finite-difference method versus a bicomplex-step method, hyper-dual method, or automatic differentiation method. Section 8 provides a discussion of both the approach and the results. Finally, Section 9 provides conclusions on this research.
2 General Multiple-Phase Optimal Control Problem
Without loss of generality, consider the following general multiple-phase optimal control problem, where each phase is defined on the interval . First, let be the phase number where is the total number of phases. Determine the state , the control , the integrals , the start times , and the terminus times in all phases , along with the static parameters that minimize the objective functional
[TABLE]
subject to the dynamic constraints
[TABLE]
the event constraints
[TABLE]
the inequality path constraints
[TABLE]
the integral constraints
[TABLE]
and the static parameter constraints
[TABLE]
where
[TABLE]
[TABLE]
and the vector components of the integral are defined as
[TABLE]
It is noted that the event constraints of Eq. (3) contain functions which can relate information at the start and/or terminus of a phase.
3 Legendre-Gauss-Radau Collocation
As stated at the outset, the objective of this research is to compare the efficiency of various derivative approximation methods for use in solving a nonlinear programming problem (NLP) arising from the direct collocation of an optimal control problem. In order to make the analysis tractable, a particular direct collocation method must be chosen. While in principle any collocation method can be used to approximate the optimal control problem given in Section 2, in this research the basis of comparison will be a recently developed adaptive Gaussian quadrature method called the Legendre-Gauss-Radau (LGR) collocation method [16, 17, 18, 19, 20, 21, 22]. It is noted that the NLP arising from the LGR collocation method has an elegant structure. In addition, the LGR collocation method has a well established convergence theory as described in Refs. [23, 24, 25].
In the context of this research, a multiple-interval form of the LGR collocation method is chosen. In the multiple-interval LGR collocation method, for each phase of the optimal control problem (where the phase number has been omitted in order to improve clarity of the description of the method), the time interval is divided into mesh intervals, such that
[TABLE]
and . For each mesh interval, the LGR points used for collocation are defined in the domain of for . The state of the continuous optimal control problem is then approximated in mesh interval , as
[TABLE]
where for is a basis of Lagrange polynomials on , are the set of Legendre-Gauss-Radau (LGR) [26] collocation points in the interval , is a non-collocated support point, and . Differentiating in Eq. (11) with respect to gives
[TABLE]
The dynamics are then approximated at the LGR points in mesh interval as
[TABLE]
where
[TABLE]
are the elements of the Legendre-Gauss-Radau differentiation matrix [16] in mesh interval , , and is the approximated control at the collocation point in mesh interval . Finally, introducing the previously omitted phase number, the phases of the problem are linked together by the event constraints
[TABLE]
where is the endpoint approximation vector in phase defined as
[TABLE]
such that is the total number of collocation points used in phase given by,
[TABLE]
and is the integral approximation vector in phase .
The aforementioned LGR approximation of the continuous optimal control problem leads to the following NLP for a -phase optimal control. Minimize the objective function
[TABLE]
subject to the defect constraints
[TABLE]
the path constraints
[TABLE]
the event constraints
[TABLE]
the integral constraints
[TABLE]
the static parameter constraints
[TABLE]
and integral approximation constraints
[TABLE]
where
[TABLE]
[TABLE]
[TABLE]
is the LGR differentiation matrix in phase , and are the LGR weights at each node in phase . It is noted that , , and correspond, respectively, to the functions that define the right-hand side of the dynamics, the path constraints, and the integrands in phase , where , , and are, respectively, the number of state components, path constraints, and integral components in phase . Finally, the state matrix, , and the control matrix, , in phase are formed as
[TABLE]
respectively, where is the number control components in phase .
4 Nonlinear Programming Problem Arising from LGR Collocation
In this section, a brief overview of the resulting nonlinear programming problem (NLP) that arises when discretizing a continuous optimal control problem using Legendre-Gauss-Radau (LGR) collocation is given. The decision vector of the NLP is comprised of the values of the state at the LGR points plus the final point in each phase, the values of the control at the LGR points in each phase, the initial time of each phase, the final time of each phase, the components of the integral vector in each phase, and any static parameters (which are independent of phase). The NLP constraints vector is comprised of the defect constraints applied at the LGR points in each phase, the path constraints at the LGR points in each phase, the integral constraints in each phase, and the event constraints (where, in general, the event constraints depend upon information at the start and/or terminus of each phase). It is noted for completeness that sparsity exploitation as derived in Refs. [11, 27, 12] requires that the first- and second-order partial derivatives of the continuous-time optimal control problem functions be computed at the collocation points [11, 27, 12]. These derivatives are then inserted into the appropriate locations in the NLP constraints Jacobian and Lagrangian Hessian. Schematics of the LGR collocation NLP derivative matrices are shown in Fig. 1 for a single phase optimal control problem. It is noted that for the NLP constraints Jacobian, all of the off-diagonal phase blocks relating constraints in phase to variables in phase for are all zeros. Similarly, for the NLP Lagrangian Hessian, all of the off-diagonal phase blocks relating variables in phase to variables in phase
for are all zeros except for the variables making up the endpoint vectors which may be related via the objective function or event constraints. The sparsity patterns shown in Fig. 1 are determined explicitly by identifying the derivative dependencies of the NLP objective and constraints functions with respect to the NLP decision vector variables. Techniques for identifying the derivative dependencies of the continuous-time optimal control problem functions in terms of the problem variables can significantly increase the sparsity of the NLP derivative matrices by enabling the removal of any elements which are simply zero. The derivation of the structure of the NLP derivative matrices and the associated sparsity exploitation has been described in detail in Refs. [11, 27, 12] and is beyond the scope of this paper.
5 Derivative Approximation Methods
As stated at the outset, the objective of this research is to provide a comparison of the use of various Taylor series-based derivative approximation methods for use in direct collocation methods for optimal control. To this end, this section provides a description of the following three Taylor series-based approximation methods: (1) finite-difference, (2) bicomplex-step, and (3) hyper-dual. In addition, a description is provided of automatic differentiation. The computational efficiency of all three Taylor series-based derivative approximation methods are compared to one another and to automatic differentiation.
5.1 Finite-Difference Methods
Consider a real function, such that is analytic, infinitely differentiable, and is defined on a domain . By truncating a Taylor series expansion of to the first-order derivative, , the central finite-difference first-order derivative approximation can be derived as
[TABLE]
where is the step size taken for the approximation and the truncation error for Eq. (28) is on the order . Similarly, the central finite-difference second-order derivative approximation can be written as
[TABLE]
where the truncation error for Eq. (29) is on the order . Extending the concepts of finite-difference methods to multivariable functions, for a real function , the second-order mixed partial derivative of at can be approximated with the central finite-difference method as
[TABLE]
where and are the step sizes taken for the independent variables and , respectively. The truncation error for Eq. (30) is on the order .
In addition to truncation error, the derivative approximations in Eqs. (28) to (30) are all subject to roundoff error due to the differences being taken to compute the approximations. Due to finite-difference methods being subject to both truncation and roundoff error, when implementing finite-differencing, an appropriate step size, , must be chosen in order to reduce the truncation error while refraining from exacerbating roundoff error. For the purposes of using finite-differencing as a method for an optimization software, the appropriate step size, , may be computed as,
[TABLE]
where is the magnitude of the independent variable at the point of interest and the base perturbation size, , is chosen to be the optimal step size for a function whose input and output are as described in Ref. [2].
5.2 Bicomplex-step Derivative Approximation
In this section, the basis of bicomplex-step derivative approximations are derived. As described in Ref. [14], an efficient and accurate way to compute derivatives required by the NLP solver is to use the bicomplex-step derivative approximation. Consider a complex number
[TABLE]
where and designates the imaginary component of the complex number in the complex plane and has the property . Extending the concept of complex numbers to second-order imaginary numbers, a bicomplex number is defined as
[TABLE]
where and designates an imaginary component distinct from that of the imaginary direction. The additional imaginary direction, , is similar to in that . For bicomplex numbers, remains (that is, is considered a bi-imaginary component distinct from either or ) and the multiplicative relationship between imaginary number components is commutative (that is ). Using the definitions of complex numbers from Eq. (32), Eq. (33) may be expanded and written in terms of its real number components as
[TABLE]
Using this definition of bicomplex numbers, consider a bicomplex function that is analytic in the domain . Because the functions of interest are real-valued, the values of can be restricted to the domain such that is isomorphic with respect to (that is, bicomplex numbers with zero imaginary components). For , a Taylor series expansion may be taken about the real component of the bicomplex number by taking purely imaginary steps and in both the imaginary component directions such that
[TABLE]
Extending the concept of a Taylor series expansion of a bicomplex function to a multivariable bicomplex function, the following partial derivative approximations can be made for a given analytic function
:
[TABLE]
where is the step size taken in a given imaginary direction and the Taylor series expansion is truncated to the second-order derivative such that the truncation error is . Thus for any given function evaluated at inputs , the first- and second-order partial derivatives may be obtained by evaluating the function with bicomplex inputs that have the same real parts and additionally the appropriate imaginary direction components so to obtain the desired partial derivatives. Such an approximation for the first- and second-order derivatives is extremely useful, as it avoids the need to explicitly (or implicitly) derive the differential equations. Additionally, bicomplex-step derivative approximations do not require taking any differences, thus avoiding roundoff error associated with finite-differencing and allowing the step sizes taken in the imaginary directions to be made arbitrarily small in order to reduce the truncation error. It is noted that although bicomplex-step derivative approximations avoid roundoff error in the method itself, the bicomplex arithmetic necessary for evaluating the functions are still subject to roundoff error in implementation, thus limiting the step size from being too small [14]. Moreover, the independent nature of the bicomplex-step derivative approximations for first-order derivatives enables two independent first-order partial derivative approximations to be computed for the same function using a single bicomplex evaluation. Furthermore, the ease of using the bicomplex-step derivative approximation to simply evaluate the function at the point of interest using bicomplex inputs with appropriate imaginary components can be taken advantage of by using operator overloading in C++. By defining a bicomplex class and using operator overloading for all elementary functions, a function written in C++ can be easily evaluated with a bicomplex input, and the resulting bicomplex output can be used to determine the desired partial derivatives. The bicomplex-step derivative approximation thus provides a fast and accurate means of determining the first- and second-order partial derivatives of a given function.
5.3 Hyper-Dual Derivative Approximation
In this section, the basis of hyper-dual derivative approximations are derived. As described in Ref. [15], an efficient and exact way to compute derivatives required by the NLP solver is to use the hyper-dual derivative approximation. Consider a dual number,
[TABLE]
where and designates the imaginary component of the dual number in the dual plane and has the property (that is, is nilpotent). Extending the concept of a dual number to second-order imaginary numbers, a hyper-dual number is defined as
[TABLE]
where and designates an imaginary component distinct from that of the imaginary direction. The additional imaginary direction, , is similar to in that . The multiplicative relationship between the imaginary directions of the hyper-dual plane is also analogous to how the bicomplex imaginary directions relate as described in Section 5.2 (that is remains and the multiplication of components is commutative).
Using this definition of hyper-dual numbers, consider a hyper-dual function that is analytic in the domain . Because the functions of interest are real-valued, values of can be restricted to the domain such that is isomorphic with respect to (that is, hyper-dual numbers with zero imaginary components). For , a Taylor series expansion may be taken about the real component of the hyper-dual number by taking purely imaginary steps and in both the imaginary component directions such that
[TABLE]
Extending the concept of a Taylor series expansion of a hyper-dual function to a multivariable hyper-dual function, the following partial derivative approximations can be made for a given analytic function :
[TABLE]
where is the step size taken in a given imaginary direction and there is no truncation error in any of the approximations due to the nilpotent property of the hyper-dual number imaginary directions. The partial derivative approximations given in Eq. (40) are known as hyper-dual derivative approximations. Thus for any given function evaluated at inputs , the first- and second-order partial derivatives may be obtained by evaluating the function with hyper-dual inputs that have the same real parts and additionally the appropriate imaginary direction components so to obtain the desired partial derivatives. Such an approximation for the first- and second-order derivatives is extremely useful, as it avoids the need to explicitly (or implicitly) derive the differential equations. Additionally, hyper-dual derivative approximations do not require taking any differences and avoid roundoff error associated with finite-differencing. Due to the properties of the hyper-dual arithmetic [15], the hyper-dual derivative approximations also avoid any susceptibility to roundoff error during function evaluation so as to maintain machine precision for all step sizes. Moreover, there is no truncation error when using the hyper-dual derivative approximations so the step size may be chosen arbitrarily. Similar to the bicomplex-step derivative approximation, the independent nature of the hyper-dual derivative approximations for first-order derivatives enables two independent first-order partial derivative approximations to be computed for the same function using a single hyper-dual evaluation, and C++ operator overloading may be employed to allow easy evaluation of functions with hyper-dual inputs. The hyper-dual derivative approximation thus provides a fast and accurate means of determining the first- and second-order partial derivatives of a given function.
5.4 Automatic Differentiation
In this section, the basis of automatic differentiation is discussed. As described in Ref. [5], automatic (algorithmic) differentiation may be derived from the unifying chain rule and supplies numerical evaluations of the derivative for a defined computer program by decomposing the program into a sequence of elementary function operations and applying the calculus chain rule algorithmically through the computer [7]. The process of automatic differentiation is described in detail in Ref. [7], and is beyond the scope of this paper. It is noted, however, that the Taylor series-based derivative methods described in Sections 5.1 through 5.3 are compared with the open source automatic differentiation software ADOL-C [8, 9].
6 Comparison of Various Derivative Approximation Methods
The purpose of this section is to highlight the important aspects and differences of implementing the derivative estimation methods described in Section 5.
6.1 Derivative Approximation Error
The estimates of the truncation error for the central finite-difference, bicomplex-step, and hyper-dual derivative approximation methods derived in Sections 5.1 – 5.3, respectively, are based on a Taylor series expansion of an analytic function. Both the central finite-difference and the bicomplex-step derivative approximations have a truncation error that is , where is the step size used for the derivative approximation. On the other hand, the hyper-dual derivative approximation has no truncation error. Moreover, finite-difference methods are inherently subject to roundoff errors due to the difference quotient used in the method. Although the bicomplex-step derivative approximation does not inherently appear to suffer from roundoff error, the evaluation of the bicomplex arithmetic for complicated functions (for example, logarithmic, power, or inverse trigonometric functions) can lead to roundoff error in the derivative approximation. On the other hand, the hyper-dual derivative approximation avoids roundoff error altogether, as the method itself requires no differences to be taken, and the values computed for the first- and second-order derivative levels are accurate to machine precision regardless of the step size used for the perturbations in the imaginary directions.
Suppose now that the relative error in a quantity is defined as
[TABLE]
where is the approximation of . Using the definition of the relative error given in Eq. (41), the accuracy of the three Taylor series-based derivative approximations is shown in Fig. 2 for the example function
[TABLE]
evaluated at . It is noted for completeness that the analytic first- and second-order derivatives of Eq. (42) are given, respectively, as
[TABLE]
It is seen from Fig. 2 that the derivative approximation error using the central finite-difference method decreases until and then starts to increase for . Next, it is seen from Fig. 2 that the bicomplex-step derivative approximation error decreases as decreases until the error reaches near machine precision (with a value ). Finally, it is seen from Fig. 2 that the hyper-dual derivative approximation error remains near machine precision regardless of the value of . It is noted that the derivative approximation error for automatic differentiation is not shown in Fig. 2 because automatic differentiation (see Section 5.4) employs the calculus chain rule and, thus, is accurate to machine precision.
6.2 Computational Efficiency Expectations
As described in Sections 5.1 – 5.3, for first- and second-order derivative approximations, central finite-differencing requires two and four real function evaluations, respectively, while both the bicomplex-step and hyper-dual derivative approximations require just one function evaluation for both first- and second-derivatives. Although the required number of function evaluations may make it appear as if the bicomplex-step and hyper-dual derivative approximations are more computationally efficient, neither of these two methods is guaranteed to be more computationally efficient than central finite-differencing. In particular, despite requiring more function evaluations, central finite-differencing only requires real arithmetic, while the bicomplex-step and hyper-dual derivative approximations require bicomplex and hyper-dual number arithmetic, respectively. Specifically, both bicomplex and hyper-dual numbers consist of four real components that lie along distinct directions. Therefore, a function evaluation using either a bicomplex or hyper-dual number requires at least four times as many operations as the function evaluation of a real number. For example, a single addition or subtraction of two bicomplex numbers requires four real number operations. Furthermore, functions such as inverse trigonometric functions and logarithmic functions require an even larger number of operations on real numbers when using either bicomplex or hyper-dual arithmetic. It is noted that hyper-dual derivative approximations require between one and times more operations than central finite-differencing [15], and bicomplex-step derivative approximations may require even more operations due to the complexity of the bicomplex arithmetic [14]. Consequently, although central finite-differencing requires multiple real function evaluations to compute the derivative approximation, it may still be the case that central finite-differencing will require fewer real arithmetic function evaluations when compared with a single hyper-dual or bicomplex function evaluation. It is noted that the computational efficiency of the bicomplex-step and hyper-dual methods can be improved significantly by taking advantage of the ability to compute simultaneous partial derivatives of the same function using a single bicomplex or hyper-dual function evaluation. In fact, whenever possible, it is important to use a single bicomplex or hyper-dual function evaluation to simultaneously estimate multiple derivatives so that the number of function evaluations is minimized. The performance of the three Taylor series-based methods relative to one another in regards to computational efficiency will thus depend on the overall complexity of the function whose partial derivatives are of interest, as well as the number of partial derivatives needed for the function.
Finally, although the automatic differentiation described in Section 5.4 utilizes real number arithmetic, the number of operations performed to compute the derivative estimation may be substantial as a result of the tracing process used to tape the record of the function evaluation that is of interest that is required when using automatic differentiation software such as ADOL-C [8, 9]. Due to the complex nature of optimal control problems, the flow control of the computer programs defining the optimal control problem functions are often conditionally-based on the function inputs (for example, as a result of piecewise models or interpolation of tabular data). Any such conditional flow control requires the tracing process of the automatic differentiation method to be invoked each time a derivative is needed, as the flow control must be properly recorded for any given input value, thus leading to a substantial amount of computation time to supply derivative estimates [9]. Consequently, even though the derivative obtained using automatic differentiation is of very high quality, the repeated retracing of the function to compute the derivative significantly decreases computational efficiency.
6.3 Identification of Derivative Dependencies
In order to maximize computational efficiency when solving an NLP arising from a direct collocation method, it is important that the fewest number of derivatives be computed. In particular, many of the functions of the original continuous optimal control problem (for example, the vector fields that define the right-hand side of the differential equations, the path constraints, and the integrands) are functions of only some of the components of the state and control. Consequently, the process of exploiting the sparse structure of the NLP leads to many zero blocks in the constraints Jacobian and Lagrangian Hessian because of the independence of these functions with respect to certain variables. Moreover, eliminating these derivatives from the constraints Jacobian and Lagrangian Hessian can significantly improve the computational efficiency with which the NLP is solved. The aforementioned discussion makes it important and useful to determine the NLP derivative dependencies based on the dependencies of the optimal control problem functions.
As it turns out, the bicomplex-step and hyper-dual derivative approximation methods described in Sections 5.2 and 5.3 have a key property that the the imaginary components for either of these methods have an independent nature that enables an accurate determination of the optimal control problem derivative dependencies which, in turn, enables computing the fewest derivatives required for use by the NLP solver. As stated, determining these derivative dependencies leads to full exploitation of the sparsity in the NLP as described in Section 4. On the other hand, central finite-differencing as described in Section 5.1 cannot easily be utilized as a tool for identifying derivative dependencies because central finite-differencing is highly susceptible to both truncation and roundoff error. In particular, because the step size used for central finite-differencing cannot be made arbitrarily small, an approximation error is always present. Thus, when trying to identify second-order derivative sparsity patterns, the evaluation of mixed partial derivatives may be nonzero even when the partial derivative itself is zero.
Because central finite-differencing cannot be employed effectively for the determination of derivative dependencies, other approaches need to be employed if central finite-differencing is chosen as the derivative estimation method when solving the NLP. One possibility for determining derivative dependencies when using central finite-differences is to use a technique that employs NaN (not a number) or Inf (infinity) propagation. Methods that employ NaN (or Inf) propagation involve evaluating a function of interest for variable dependence by setting a variable of interest equal to NaN (or Inf) and seeing if the output of the function of interest returns NaN (or Inf), which would indicate the function of interest is dependent on the variable of interest. It is noted, however, that NaN and Inf approaches are limited in that they can only identify first-order derivative dependencies. As a result, NaN and Inf propagation methods lead to an over-estimation of second-order derivative dependencies where some derivatives, which may actually be zero, are estimated to be nonzero. This over-estimation of the second-order derivative dependencies leads to a denser NLP Lagrangian Hessian which can significantly decrease computational efficiency when solving the NLP. On the other hand, using either the bicomplex-step or hyper-dual derivative approximation methods, the sparsity patterns of the NLP derivative matrices can be determined exactly which, in turn, can significantly improve computational efficiency when solving the NLP. It is noted that the automatic differentiation as discussed in Section 5.4 may also be utilized to obtain an exact first- and second-order NLP derivative matrices sparsity pattern because the obtained derivative estimates are accurate to machine precision.
7 Examples
In this section, the derivative estimation methods described in Section 5 are compared to one another in terms of their effectiveness as methods for use when solving the nonlinear programming problem (NLP) resulting from the transcription of the continuous optimal control problem using Legendre-Gauss-Radau (LGR) collocation, as developed in Sections 2 through 4. The first example is the free-flying robot optimal control problem taken from Ref. [28]. The second example is the minimum time-to-climb of a supersonic aircraft optimal control problem taken from Ref. [29]. The third example problem is the space station attitude control optimal control problem taken from Ref. [1]. All three examples demonstrate that the more accurate derivative estimates of the bicomplex-step, hyper-dual, and automatic differentiation methods as described in Section 6.1 can significantly reduce the number of NLP solver iterations required to solve the NLP as compared to when using a central finite-difference method. Note, however, that the results also show the improved computational efficiency obtained using either the bicomplex-step or hyper-dual methods relative to central finite-differencing because the NLP solver requires fewer NLP iterations to converge to a solution using the bicomplex-step and hyper-dual methods. Furthermore, even though the derivative obtained using automatic differentiation is accurate to machine precision, the lower computational efficiency of the automatically computed derivative results in a significant decrease in computational efficiency when solving the NLP. Finally, the increase in computational efficiency provided by exactly identifying the first- and second-order derivative dependencies of the continuous-time functions as discussed in Section 6.3 is highlighted by all three examples.
The following terminology is used in each example. First, denotes the number of mesh intervals used to discretize the continuous optimal control problem, where the number of collocation points used in each interval is . Furthermore, the notation , , , and is used to denote the over-estimated sparsity central finite-difference, exact sparsity central finite-difference, bicomplex-step, hyper-dual, and automatic differentiation methods, respectively. The over-estimated sparsity central finite-difference () method refers to using central finite-differencing with the NLP derivative matrices sparsity pattern obtained from identifying the derivative dependencies using NaN propagation, and the exact sparsity central finite-difference () method refers to using central finite-differencing with the NLP derivative matrices sparsity pattern obtained by using the hyper-dual derivative approximations to identify the derivative dependencies, as discussed in Section 6.3. It is noted that the bicomplex-step (), hyper-dual (), and automatic differentiation () methods utilize the same NLP derivative matrices sparsity pattern as the exact sparsity central finite-difference () method. Moreover, , , and denote the number of NLP solver iterations to converge, the total computation time required to solve the NLP, and the average computation time expended per iteration to compute the derivative approximations. Finally, the use of for , , denotes the percent reduction between the value of required using the method versus the method, as given by
[TABLE]
It is noted that the method is used as a baseline of performance comparison in order to highlight the reduced (or increased) computational expense acquired when utilizing the other methods.
All results shown in this paper were obtained using the C++ optimal control software [12] using the NLP solver IPOPT [3]. The NLP solver was set to an optimality tolerance of for all three examples. All first- and second-order derivatives for the NLP solver were obtained using the derivative estimation methods described in Section 5. All computations were performed on a 2.9 GHz Intel Core i7 MacBook Pro running MAC OS-X version 10.13.6 (High Sierra) with 16GB 2133MHz LPDDR3 of RAM. C++ files were compiled using Apple LLVM version 9.1.0 (clang-1000.10.44.2).
7.1 Example 1: Free-Flying Robot Problem
Consider the following optimal control problem taken from Ref. [1] and [28]. Minimize the cost functional
[TABLE]
subject to the dynamic constraints
[TABLE]
the control inequality constraints
[TABLE]
and the boundary conditions
[TABLE]
where
[TABLE]
The optimal control problem described by Eqs. (45) – (49) was approximated as an NLP using LGR collocation (see Section 3) using mesh intervals with in each mesh interval. The resulting set of NLPs for the different values of were then solved using an over-estimated and exact sparsity with central finite-difference, and using exact sparsity patterns with bicomplex-step, hyper-dual, and automatic differentiation. The solutions obtained in all cases are essentially identical and converge to the exact solution given in Ref. [1] as increases (see pages to of Ref. [1]). Comparisons of the computational efficiency in terms of , , and for varying values of are displayed in Table 2. It is observed from Table 2a that both the bicomplex-step, hyper-dual, and automatic differentiation methods consistently require fewer NLP solver iterations to converge than the central finite-difference method using either an over-estimated or exact sparsity pattern. Furthermore, Table 2b shows that both the hyper-dual and bicomplex-step methods require less computation time than the central finite-difference method because the NLP solver required fewer iterations to converge using either of the former two methods. Moreover, Table 2c demonstrates how identifying the exact sparsity pattern of the NLP derivative matrices can significantly improve the computational efficiency of the method, as the exact sparsity central finite-difference method takes between percent to percent less time on average per NLP solver iteration relative to the over-estimated sparsity central finite-difference method. Finally, it is observed from Tables 2b and 2c that automatic differentiation requires substantially more computation time than any of the Taylor series-based methods because automatic differentiation must repeatedly retrace the function in order to obtain the derivative.
7.2 Example 2: Minimum Time-to-Climb Supersonic Aircraft Problem
Consider the following optimal control problem taken from Ref. [29]. Minimize the cost functional
[TABLE]
subject to the dynamic constraints
[TABLE]
the control inequality constraint
[TABLE]
and the boundary conditions
[TABLE]
where
[TABLE]
The models used for the problem were created using data taken from Ref. [29].
The optimal control problem described by Eqs. (50) – (54) was approximated using LGR collocation (see Section 3) using mesh intervals with collocation points in each mesh interval. The resulting set of NLPs for the different values of were then solved using an over-estimated and exact sparsity pattern with central finite-difference, and using exact sparsity patterns with bicomplex-step, hyper-dual, and automatic differentiation. The solutions obtained in all cases are essentially identical and converge to the exact solution (see pages to of Ref. [1]). Comparisons of the computational efficiency in terms of , , and for varying values of are displayed in Table 3. It is seen in Table 3a that in nearly all cases the bicomplex-step, hyper-dual, and automatic differentiation methods require fewer NLP solver iterations to converge than the central finite-difference method using either an over-estimated or exact sparsity pattern. Furthermore, Table 3b shows that both the hyper-dual and bicomplex-step methods require less computation time than the central finite-difference method because the NLP solver requires fewer iterations to converge using either of the former two methods. Moreover, Table 3c shows that the bicomplex-step and hyper-dual methods can be more computationally efficient per NLP iteration than the central finite-difference method. In particular, for this example the central finite-difference method takes approximately percent longer on average than either of the former two methods. Finally, it may be observed from Tables 3b and 3c that the method requires substantially more computation time than any of the Taylor series-based methods because automatic differentiation must repeatedly retrace the function in order to obtain the derivative.
7.3 Example 3: Space Station Attitude Control
Consider the following optimal control problem taken from Refs. [1] and [30]. Minimize the cost functional
[TABLE]
subject to the dynamic constraints
[TABLE]
the inequality path constraint
[TABLE]
and the boundary conditions
[TABLE]
where is the state, is the control, is the identity matrix, and . In this formulation, is the angular velocity, is the Euler-Rodrigues parameter vector, is the angular momentum, and is the input moment (and is the control). Additionally,
[TABLE]
and and are the second and third column, respectively, of the matrix
[TABLE]
where . In this example the matrix is given as
[TABLE]
while the initial conditions , , and are, respectively,
[TABLE]
A more detailed description of this problem, including all of the constants , , , and , can be found in either Ref. [1] or Ref. [30].
The optimal control problem described in Eqs. (55) – (62) was approximated using LGR collocation (see Section 3) using mesh intervals with collocation points in each mesh interval. The resulting set of NLPs for the different values of were then solved using an over-estimated and exact sparsity pattern with central finite-difference, and an exact sparsity pattern using bicomplex-step, hyper-dual, and automatic differentiation. The solutions obtained in all cases are essentially identical and converge to the exact solution (see pages – of Ref. [1]). Comparisons of the computational efficiency in terms of , , and for varying values of are displayed in Table 4. It is seen in Table 4a that for mesh intervals that the number of NLP solver iterations is approximately the same for any of the five methods. On the other hand, for mesh intervals, both the bicomplex-step and hyper-dual methods require percent fewer iterations than the over-estimated central finite-difference method, while the exact sparsity central finite-difference and automatic differentiation methods require percent and percent fewer iterations, respectively. Furthermore, Table 4b shows that for all of the cases studied both the hyper-dual and bicomplex-step methods also require less computation time than the over-estimated sparsity central finite-difference method. Moreover, Table 4c shows the increase in computational efficiency per iteration when using an exact NLP sparsity pattern, as the exact sparsity central finite-difference method takes percent to percent less time on average per NLP iteration than the over-estimated sparsity central finite-difference method on all tested instances. Finally, it is observed in Tables 4b and 4c that the automatic differentiation method requires substantially more computation time than any of the Taylor series-based methods.
8 Discussion
As developed in Sections 2 through 4, transcribing a continuous optimal control problem into a large sparse nonlinear programming problem (NLP) using direct collocation introduces the necessity of an efficient method for the NLP solver employed to solve the resulting NLP. The central finite-differencing, bicomplex-step derivative approximation, and hyper-dual derivative approximation described in Sections 5.1 through 5.3 have truncation error estimates based on Taylor series expansions [2, 14, 15]. Section 6.1 demonstrated that, while the central finite-differencing and the bicomplex-step derivative approximations have truncation errors on the order of , the bicomplex-step derivative approximation has a significant advantage over central finite-differencing because of the roundoff error associated with central finite differencing. Moreover, as seen in Fig. 2, the bicomplex-step derivative approximation can be employed using an arbitrarily small step size such that the truncation error reaches near machine precision [14]. Conversely, when employing central finite-differencing, a step size must be chosen in a manner that minimizes the sum of the truncation error and the roundoff error [2]. Next, the hyper-dual derivative approximation does not suffer from either truncation error or roundoff error. As a result, an arbitrary step size may be used when implementing the hyper-dual derivative approximation, and this approximation is always accurate to machine precision. The accuracy of the hyper-dual derivative approximation is also shown in Fig. 2. Finally, the derivative estimates obtained using the automatic differentiation discussed in Section 5.4 are accurate to machine precision, because the derivative is computed algorithmically using the calculus chain rule.
The immunity of the bicomplex-step and hyper-dual derivative approximations to roundoff error enables either of these derivative approximation methods to provide extremely accurate derivative approximations for the NLP solver. In fact, the derivative estimates obtained using either of these methods are comparable in accuracy to the derivatives obtained using automatic differentiation. The accuracy of the derivative estimates supplied to the NLP solver has an enormous impact on the search direction taken by the NLP solver and the associated rate of convergence. As demonstrated by the three example problems shown in Section 7, the increased accuracy of the derivative estimates provided by the bicomplex-step, hyper-dual, and automatic differentiation methods most often enables the NLP solver to converge in fewer iterations when compared with using the derivative estimates obtained using central finite-differencing. The reason that the NLP solver does not in all cases converge in fewer iterations using bicomplex-step, hyper-dual, or automatic differentiation when compared with central finite-differencing is due to the fact that the NLP solver employs a Newton method to determine the search direction on each iteration. In particular, the Newton method is based upon a quadratic approximation which may not lead to the fastest convergence rate in the case where the NLP is highly nonlinear. Thus even though the bicomplex-step, hyper-dual, and automatic differentiation methods provide more accurate approximations of the NLP derivative matrices, the search directions chosen upon each iteration using the less accurate central finite-difference methods may, in a relatively infrequent number of cases, inadvertently cause the NLP solver to converge in fewer iterations.
For all three example problems in Section 7, the fewer number of NLP solver iterations leads to reduced computation time when using either the bicomplex-step or hyper-dual method as compared to the central finite-difference method. This lower computation time arises from the fact that the majority of computation time to solve the NLP is spent computing derivative approximations. These fewer iterations lead to fewer computations of the derivative estimates and makes the bicomplex-step and hyper-dual methods advantageous over the central finite-difference method. Interestingly, the fewer number of iterations required when using automatic differentiation is outweighed by the large computation time per iteration required when using automatic differentiation relative to the other derivative approximation methods.
Finally, for all three Taylor series-based derivative approximations presented in Sections 5.1 through 5.3, a perturbation to the inputs of the function whose derivative is of interest is required in order to compute the derivative approximation. As discussed in Section 5.1, central finite-differencing is subject to both roundoff and truncation error, thus limiting the minimum step size that can be used. The effect of the less accurate derivative approximation of central finite-differencing is demonstrated in Section 7 where the central finite-difference methods generally require more NLP solver iterations to converge when compared with either bicomplex-step, hyper-dual, or automatic differentiation. While the bicomplex-step derivative approximation described in Section 5.2 appears to be subject to only truncation error, in practice roundoff error can occur due to the evaluation of the bicomplex number arithmetic when using double precision computations. The fact that some of the derivative approximations become less accurate for step sizes below a certain magnitude when implementing the bicomplex-step derivative approximation is an artifact of using double precision arithmetic in the implementation. On the other hand, the hyper-dual derivative approximation presented in Section 5.3 is immune to both roundoff and truncation error. Thus when implementing the hyper-dual derivative approximation, the perturbation step size is arbitrary and does not affect the accuracy of the approximation. Conversely, the accuracy of central finite-differencing and bicomplex-step derivative approximations are dependent upon the step size, leading to scaling and rounding issues that make implementation more difficult and less accurate when compared with the hyper-dual approximation. Finally, although automatic differentiation provides derivative estimates that are accurate to machine precision, the computational overhead required is found to be excessively expensive, thus making implementation impractical when compared to any of the Taylor series-based derivative approximation methods.
9 Conclusions
Four derivative estimation methods, central finite-differencing, bicomplex-step, hyper-dual, and automatic differentiation, have been compared in terms of their effectiveness for use with direct collocation methods for solving optimal control problems. The process of transcribing a continuous optimal control problem into a large sparse nonlinear programming problem using a previously developed Legendre-Gauss-Radau direct collocation method is described. The form of the resultant nonlinear programming problem and the need for an efficient method to facilitate the NLP solver employed is presented. The three Taylor series-based derivative approximations, central finite-differencing, bicomplex-step, and hyper-dual, are derived. These three Taylor series-based methods are then compared to one another and compared to automatic differentiation in terms of accuracy, computational efficiency, and implementation. The performance of a nonlinear programming problem solver is then demonstrated on three benchmark optimal control problems. The performance of the NLP solver is assessed in terms of number of iterations to solve, computation time per iteration, and computation time. Despite the observation that central finite-differencing requires less computation time per iteration than either the bicomplex-step or the hyper-dual method, the latter two methods require significantly less overall computation time because the NLP solver requires significantly fewer iterations to converge to a solution. Moreover, the bicomplex-step and hyper-dual methods are found to have similar performance, although the hyper-dual method is found to be significantly easier to implement. Additionally, automatic differentiation is found to require substantially more computation time than any of the Taylor series-based methods. Finally, a preliminary comparison of the derivative estimation methods for solving optimal control problems using direct collocation is found to favor the hyper-dual method in terms of computational efficiency and ease of implementation.
Acknowledgments
The authors gratefully acknowledge support for this research from the U.S. Office of Naval Research under grant N00014-15-1-2048 and from the U.S. National Science Foundation under grants DMS-1522629, DMS-1924762, and CMMI-1563225.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Betts, J. T., Practical Methods for Optimal Control and Estimation Using Nonlinear Programming , SIAM Press, Philadelphia, 2nd ed., 2009.
- 2[2] Gill, P. E., Murray, W., and Wright, M. H., Practical Optimization , Academic Press, London, 1981.
- 3[3] Biegler, L. T. and Zavala, V. M., “Large-Scale Nonlinear Programming Using IPOPT: An Integrating Framework for Enterprise-Wide Optimization,” Computers and Chemical Engineering , Vol. 33, No. 3, March 2008, pp. 575–582.
- 4[4] Gill, P. E., Murray, W., and Saunders, M. A., “SNOPT: An SQP Algorithm for Large-Scale Constrained Optimization,” SIAM Review , Vol. 47, No. 1, January 2002, pp. 99–131. https://doi.org/10.1137/S 0036144504446096 . · doi ↗
- 5[5] Martins, J. R. and Hwang, J. T., “Review and Unification of Methods for Computing Derivatives of Multidisciplinary Computational Models,” AIAA Journal , Vol. 51, No. 11, September 2013, pp. 2582–2599. https://doi.org/10.2514/1.J 052184 . · doi ↗
- 6[6] Sobieszczanski-Sobieski, J., “Sensitivity of Complex, Internally Coupled Systems,” AIAA Journal , Vol. 28, No. 1, January 1990, pp. 153–160. https://doi.org/10.2514/3.10366 . · doi ↗
- 7[7] Griewank, A. and Walther, A., Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation , SIAM Press, Philadelphia, Pennsylvania, 2nd ed., 2008.
- 8[8] Griewank, A., Juedes, D., and Utke, J., “Algorithm 755: ADOL-C: A Package for the Automatic Differentiation of Algorithms Written in C/C++,” ACM Transactions on Mathematical Software , Vol. 22, No. 2, 1996, pp. 131–167. https://doi.org/10.1145/229473.229474 . · doi ↗