Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
Daniel Michelsanti, Zheng-Hua Tan, Sigurdur Sigurdsson, Jesper Jensen

TL;DR
This paper investigates how training deep-learning-based audio-visual speech enhancement systems with Lombard speech improves speech quality and intelligibility in noisy environments, highlighting gender differences and the importance of visual cues.
Contribution
It provides the first comprehensive analysis of Lombard effect impact on deep-learning-based audio-visual speech enhancement, demonstrating benefits of Lombard-trained models in challenging noise conditions.
Findings
Lombard-trained models improve speech quality and intelligibility at low SNRs.
Visual modality significantly aids in acoustically challenging scenarios.
Gender differences influence Lombard speech characteristics and model performance.
Abstract
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field. We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by 54 different talkers. The results show that training…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1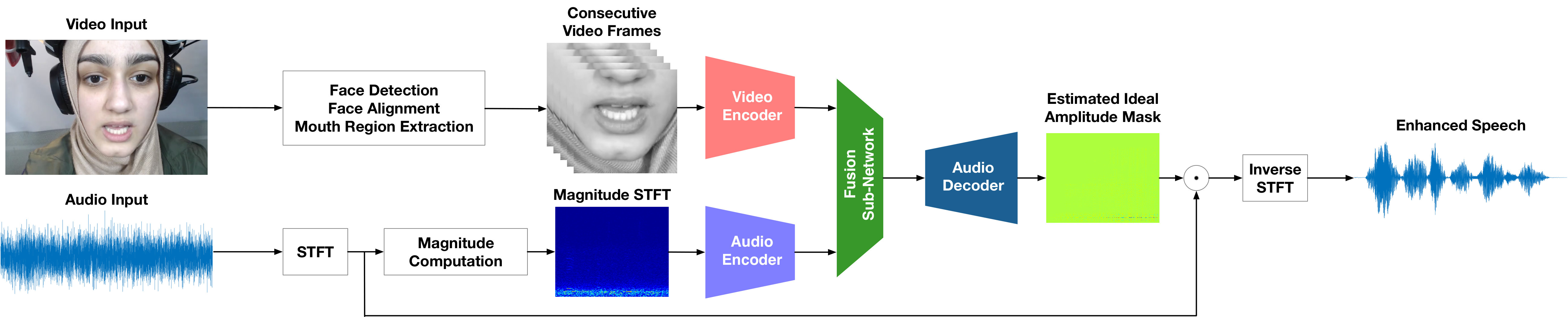 Figure 2
Figure 2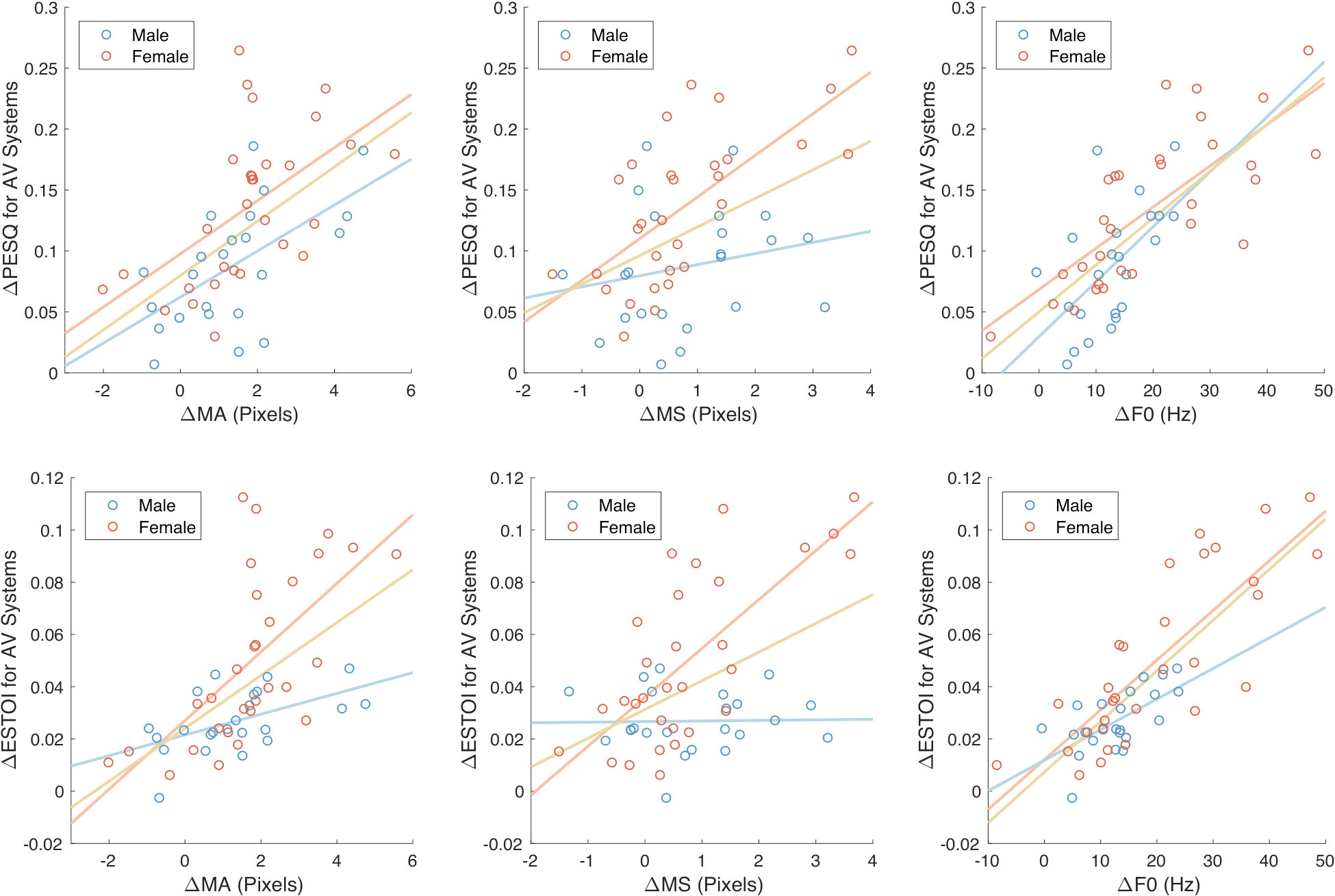 Figure 3
Figure 3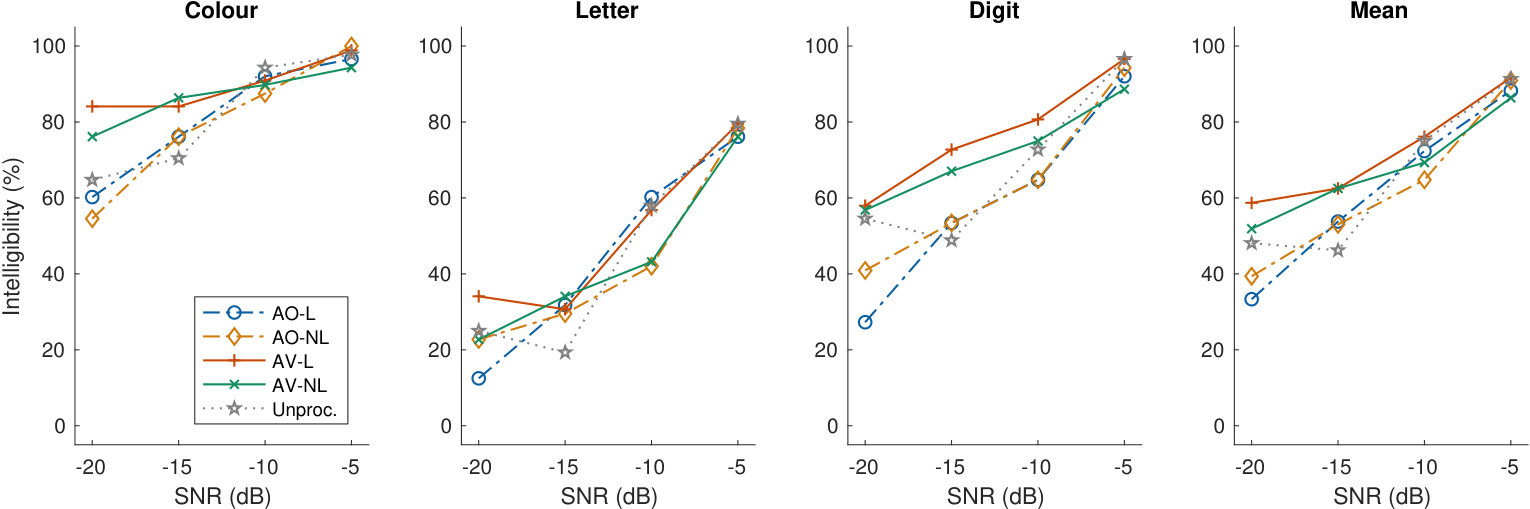 Figure 4
Figure 4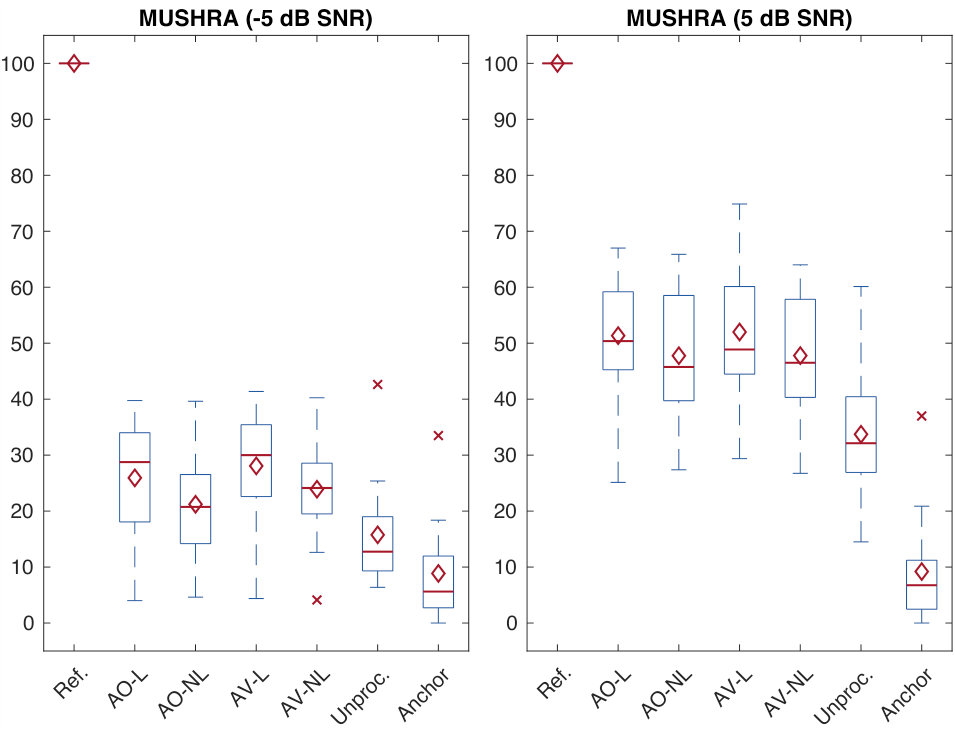 Figure 5
Figure 5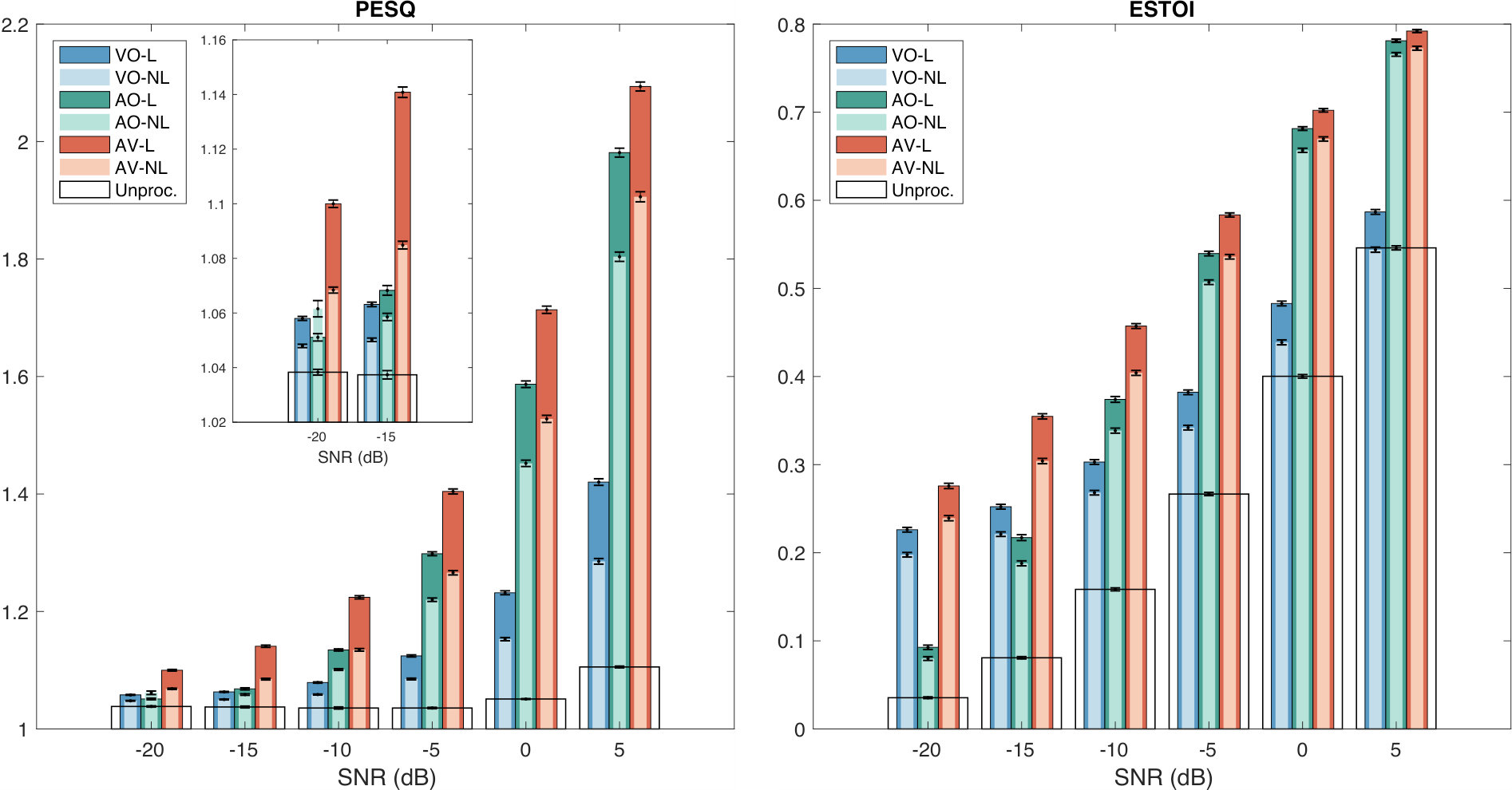 Figure 6
Figure 6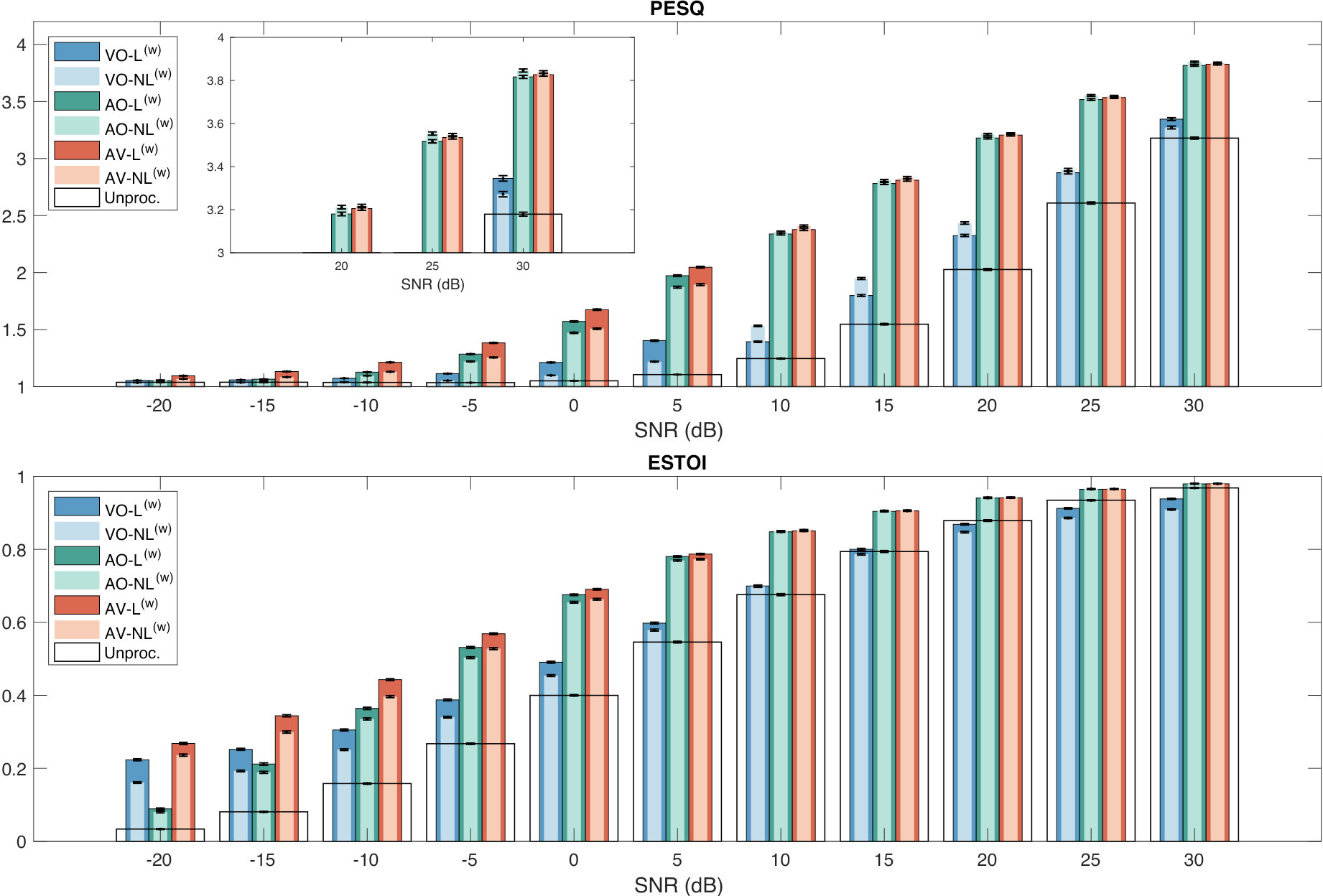 Figure 7
Figure 7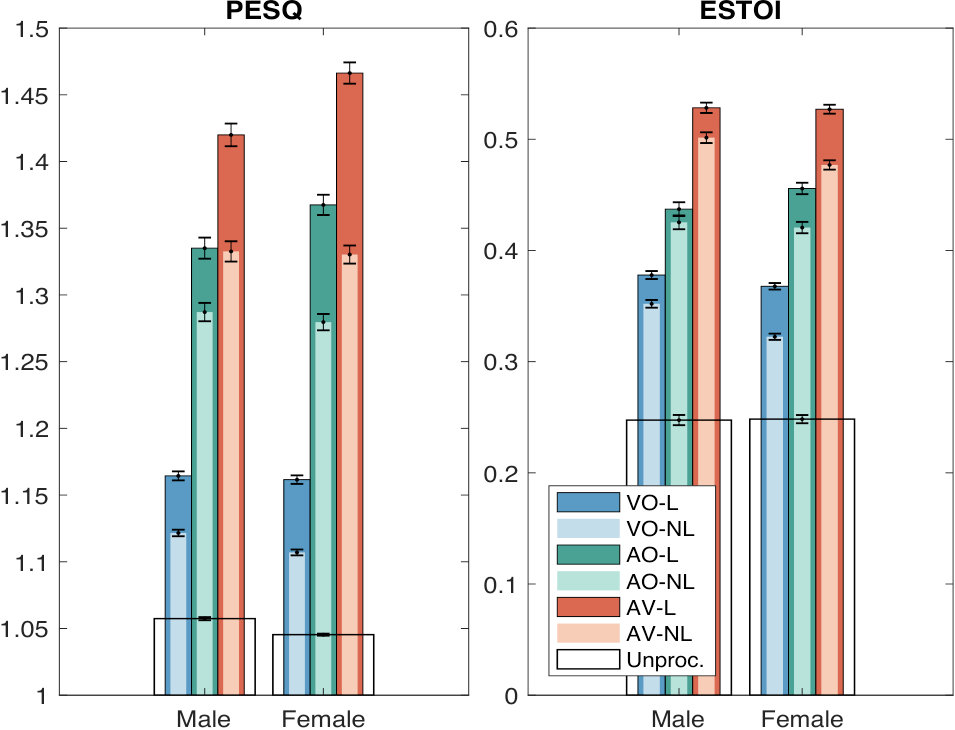 Figure 8
Figure 8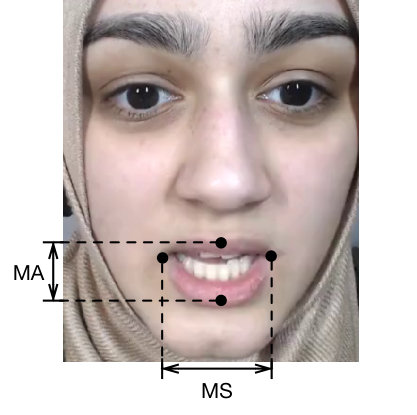 Figure 9
Figure 9| Command | Colour* | Preposition | Letter* | Digit* | Adverb |
| bin | blue | at | 0–9 | again | |
| lay | green | by | A–Z | now | |
| place | red | in | (no W) | please | |
| set | white | with | soon |
|
||||||||||||||
|
|
|||||||||||||
|
|
|
|
|
||||||||||
| Vision | VO-NL | VO-NL(w) | VO-L | VO-L(w) | ||||||||||
| Audio | AO-NL | AO-NL(w) | AO-L | AO-L(w) | ||||||||||
| Audio-Visual | AV-NL | AV-NL(w) | AV-L | AV-L(w) | ||||||||||
| PESQ | VO-L | VO-NL | AO-L | AO-NL | AV-L | AV-NL |
| - dB | 1.163 | 1.113 | 1.353 | 1.283 | 1.446 | 1.331 |
| ESTOI | VO-L | VO-NL | AO-L | AO-NL | AV-L | AV-NL |
| - dB | 0.372 | 0.335 | 0.448 | 0.423 | 0.528 | 0.488 |
| all | m | f | all | m | f | |
| PESQ (VO) - MA | ||||||
| PESQ (AO) - MA | ||||||
| PESQ (AV) - MA | ||||||
| ESTOI (VO) - MA | ||||||
| ESTOI (AO) - MA | ||||||
| ESTOI (AV) - MA | ||||||
| PESQ (VO) - MS | ||||||
| PESQ (AO) - MS | ||||||
| PESQ (AV) - MS | ||||||
| ESTOI (VO) - MS | ||||||
| ESTOI (AO) - MS | ||||||
| ESTOI (AV) - MS | ||||||
| PESQ (VO) - F0 | ||||||
| PESQ (AO) - F0 | ||||||
| PESQ (AV) - F0 | ||||||
| ESTOI (VO) - F0 | ||||||
| ESTOI (AO) - F0 | ||||||
| ESTOI (AV) - F0 |
| PESQ | VO-L(w) | VO-NL(w) | AO-L(w) | AO-NL(w) | AV-L(w) | AV-NL(w) |
| - dB | 1.153 | 1.080 | 1.346 | 1.295 | 1.424 | 1.323 |
| - dB | 2.348 | 2.418 | 3.127 | 3.155 | 3.151 | 3.169 |
| ESTOI | VO-L(w) | VO-NL(w) | AO-L(w) | AO-NL(w) | AV-L(w) | AV-NL(w) |
| - dB | 0.376 | 0.330 | 0.442 | 0.422 | 0.517 | 0.483 |
| - dB | 0.844 | 0.825 | 0.927 | 0.929 | 0.928 | 0.930 |
| Small Effect Size | Medium Effect Size | Large Effect Size |
| dB SNR | dB SNR | |||
| Comparison | ||||
| AO-L - AO-NL | ||||
| AV-L - AV-NL | ||||
| AO-L - AV-L | ||||
| AO-NL - AV-NL | ||||
| AO-L - Unproc. | ||||
| AV-L - Unproc. | ||||
| SNR | ||||
| Comparison | -20 dB | -15 dB | -10 dB | -5 dB |
| AO-L - AO-NL | ||||
| AV-L - AV-NL | ||||
| AO-L - AV-L | ||||
| AO-NL - AV-NL | ||||
| AO-L - Unproc. | ||||
| AV-L - Unproc. | ||||
| SNR | ||||
| Comparison | -20 dB | -15 dB | -10 dB | -5 dB |
| AO-L - AO-NL | ||||
| AV-L - AV-NL | ||||
| AO-L - AV-L | ||||
| AO-NL - AV-NL | ||||
| AO-L - Unproc. | ||||
| AV-L - Unproc. | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\xspaceaddexceptions
]
[orcid=0000-0002-3575-1600] \cormark[1]
[]
[]
\cortext
[cor1]Corresponding author
Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
Daniel Michelsanti [email protected] Department of Electronic Systems, Aalborg University, Denmark
Zheng-Hua Tan [email protected]
Sigurdur Sigurdsson [email protected] Oticon A/S, Denmark
Jesper Jensen [email protected], [email protected]
Abstract
[S U M M A R Y]
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field.
We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by different talkers. The results show that training deep-learning-based models with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility at low signal to noise ratios, where the visual modality can play an important role in acoustically challenging situations. We also find that a performance difference between genders exists due to the distinct Lombard speech exhibited by males and females, and we analyse it in relation with acoustic and visual features. Furthermore, listening tests conducted with audio-visual stimuli show that the speech quality of the signals processed with systems trained using Lombard speech is statistically significantly better than the one obtained using systems trained with non-Lombard speech at a signal to noise ratio of dB. Regarding speech intelligibility, we find a general tendency of the benefit in training the systems with Lombard speech.
keywords:
Lombard effect \sepaudio-visual speech enhancement \sepdeep learning \sepspeech quality \sepspeech intelligibility
1 Introduction
Speech is perhaps the most common way that people use to communicate with each other. Often, this kind of communication is harmed by several sources of disturbance that may have different nature, such as the presence of competing speakers, the loud music during a party, and the noise inside a car cabin. We refer to the sounds other than the speech of interest as background noise.
Background noise is known to affect two attributes of speech: intelligibility and quality (Loizou, 2007). Both of these aspects are important in a conversation, since poor intelligibility makes it hard to comprehend what a speaker is saying and poor quality may affect speech naturalness and listening effort (Loizou, 2007). Humans tend to tackle the negative effects of background noise by instinctively changing the way of speaking, their speaking style, in a process known as Lombard effect (Lombard, 1911; Zollinger and Brumm, 2011). The changes that can be observed vary widely across individuals (Junqua, 1993; Marxer et al., 2018) and affect multiple dimensions: acoustically, the average fundamental frequency (F0) and the sound energy increase, the spectral tilt flattens due to an energy increment at high frequencies and the centre frequency of the first and second formant (F1 and F2) shifts (Junqua, 1993; Lu and Cooke, 2008); visually, head and face motion are more pronounced and the movements of the lips and jaw are amplified (Vatikiotis-Bateson et al., 2007; Garnier et al., 2010, 2012); temporally, the speech rate changes due to an increase of the vowel duration (Junqua, 1993; Cooke et al., 2014).
Although Lombard effect improves the intelligibility of speech in noise (Summers et al., 1988; Pittman and Wiley, 2001), effective communication might still be challenged by some particular conditions, e.g. the hearing impairment of the listener. In these situations, speech enhancement (SE) algorithms may be applied to the noisy signal aiming at improving speech quality and speech intelligibility. In the literature, several SE techniques have been proposed. Some approaches consider SE as a statistical estimation problem (Loizou, 2007), and include some well-known methods, like the Wiener filtering (Lim and Oppenheim, 1979) and the minimum mean square error estimator of the short-time magnitude spectrum (Ephraim and Malah, 1984). Many improved methods have been proposed, which primarily distinguish themselves by refined statistical speech models (Martin, 2005; Erkelens et al., 2007; Gerkmann and Martin, 2009) or noise models (Martin and Breithaupt, 2003; Loizou, 2007). These techniques, which make statistical assumptions on the distributions of the signals, have been reported to be largely unable to provide speech intelligibility improvements (Hu and Loizou, 2007; Jensen and Hendriks, 2012). As an alternative, data-driven techniques, especially deep learning, do not make any assumptions on the distribution of the speech, of the noise or on the way they are mixed: a learning algorithm is used to find a function that best maps features from degraded speech to features from clean speech. Over the years, the speech processing community has put a considerable effort into designing training targets and objective functions (Wang et al., 2014; Erdogan et al., 2015; Williamson et al., 2016; Michelsanti et al., 2019b) for different neural network models, including deep neural networks (Xu et al., 2014; Kolbæk et al., 2017), denoising autoencoders (Lu et al., 2013), recurrent neural networks (Weninger et al., 2014), fully convolutional neural networks (Park and Lee, 2017), and generative adversarial networks (Michelsanti and Tan, 2017). These methods represent the current state of the art in the field (Wang and Chen, 2018), and since they use only audio signals, we refer to them as audio-only SE (AO-SE) systems.
Previous studies show that observing the speaker’s facial and lip movements contributes to speech perception (Sumby and Pollack, 1954; Erber, 1975; McGurk and MacDonald, 1976). This finding suggests that a SE system could tolerate higher levels of background noise, if visual cues could be used in the enhancement process. This intuition is confirmed by a pioneering study on audio-visual SE (AV-SE) by Girin et al. (2001), where simple geometric features extracted from the video of the speaker’s mouth are used. Later, more complex frameworks based on classical statistical approaches have been proposed (Almajai and Milner, 2011; Abel and Hussain, 2014; Abel et al., 2014), and very recently deep learning methods have been used for AV-SE (Hou et al., 2018; Gabbay et al., 2018; Ephrat et al., 2018; Afouras et al., 2018; Owens and Efros, 2018; Morrone et al., 2019).
It is reasonable to think that visual features are mostly helpful for SE when the speech is so degraded that AO-SE systems achieve poor performance, i.e. when background noise heavily dominates over the speech of interest. Since in such acoustical environment spoken communication is particularly hard, we can assume that the speakers are under the influence of Lombard effect. In other words, the input to SE systems in this situation is Lombard speech. Despite this consideration, state-of-the-art SE systems do not take Lombard effect into account, because collecting Lombard speech is usually expensive. The training and the evaluation of the systems are usually performed with speech recorded in quiet and afterwards degraded with additive noise. Previous work shows that speaker (Hansen and Varadarajan, 2009) and speech recognition (Junqua, 1993) systems that ignore Lombard effect achieve sub-optimal performance, also in visual (Heracleous et al., 2013; Marxer et al., 2018) and audio-visual settings (Heracleous et al., 2013). It is therefore of interest to conduct a similar study also in a SE context.
With the objective of providing a more extensive analysis of the impact of Lombard effect on deep-learning-based SE systems, the present work extends a preliminary study (Michelsanti et al., 2019a), providing the following novel contributions. First, new experiments are conducted, where deep-learning-based SE systems trained with Lombard or non-Lombard speech are evaluated on Lombard speech using a cross-validation setting to avoid that a potential intra-speaker variability of the adopted dataset leads to biased conclusions. Then, an investigation of the effect that the inter-speaker variability has on the systems is carried out, both in relation to acoustic as well as visual features. Next, as an example application, a system trained with both Lombard and non-Lombard data using a wide signal-to-noise-ratio (SNR) range is compared with a system trained only on non-Lombard speech, as it is currently done for the state-of-the-art models. Finally, especially since existing objective measures are limited to predict speech quality and intelligibility from the audio signals in isolation, listening tests using audio-visual stimuli have been performed. This test setup, which is generally not employed to evaluate SE systems, is closer to a real-world scenario, where a listener is usually able to look at the face of the talker.
2 Materials: Audio-Visual Speech Corpus and Noise Data
The speech material used in this study is the Lombard GRID corpus (Alghamdi et al., 2018), which is an extension of the popular audio-visual GRID dataset (Cooke et al., 2006). It consists of 55 native speakers of British English ( males and females) that are between and years old. The sentences pronounced by the talkers adhere to the syntax from the GRID corpus, six-word sentences with the following structure: <command> <color*> <preposition> <letter*> <digit*> <adverb> (Table 1). The words marked with a * are keywords, whereas the others are fillers (Cooke et al., 2006).
Each speaker was recorded while reading a unique set of sentences in non-Lombard (NL) and Lombard (L) conditions (in total, utterances per speaker). In both cases, the audio signals were recorded with a microphone placed in front of the speakers, while the video recordings were collected with two cameras mounted on a helmet to have a frontal and a profile views of the talkers.
In order to induce the Lombard effect, speech shaped noise (SSN) at dB sound pressure level (SPL) was presented to the speakers, while they were reading the sentences to a listener. The presence of a listener, who assured a natural communication environment by asking the participants to repeat the utterances from time to time, was needed, because talkers usually adjust their speech to communicate better with the people they are talking to (Lane and Tranel, 1971; Lu and Cooke, 2008), a process known as external or public loop (Lane and Tranel, 1971). Since talkers tend to regulate their speaking style also based on the level of their own speech, in what is generally called internal or private loop (Lane and Tranel, 1971), the speech signal was mixed with the SSN at a carefully adjusted level, providing a self-monitoring feedback to the speakers.
In our study, the audio and the video signals from the frontal camera were arranged as explained in Section 4 to build training, validation, and test sets. The audio signals have a sampling rate of kHz. The resolution of the frontal video stream is pixels with a variable frame rate of around frames per second (FPS). Audio and video signals are temporally aligned.
To generate speech in noise, SSN was added to the audio signals of the Lombard GRID database. SSN was chosen to match the kind of noise used in the database, since, as reported by Hansen and Varadarajan (2009), Lombard effect occurs differently across noise types, although other studies (Lu and Cooke, 2009; Garnier and Henrich, 2014) failed to find such an evidence. The SSN we used was generated as in (Kolbæk et al., 2016), by filtering white noise with a low-order linear predictor, whose coefficients were found using 100 random sentences from the Akustiske Databaser for Dansk (ADFD)111https://www.nb.no/sbfil/dok/nst_taledat_dk.pdf speech database.
3 Methodology
In this study, we train and evaluate systems that perform spectral SE using deep learning, as illustrated in Figure 1. The processing pipeline is inspired by Gabbay et al. (2018) and the same as the one used in (Michelsanti et al., 2019a). To have a self-contained exposition, we report the main details of it in this section.
3.1 Audio-Visual Speech Enhancement
We assume to have access to two streams of information: the video of the talker’s face, and an audio signal, , where is the clean signal of interest, is an additive noise signal, and indicates the discrete-time index. The additive noise model presented in time domain, can also be expressed in the time-frequency (TF) domain as , where , , and are the short-time Fourier transform (STFT) coefficients at frequency bin and at time frame of , , and , respectively. Our models adopt a mask approximation approach (Michelsanti et al., 2019b), producing an estimate of the ideal amplitude mask, defined as , with the following objective function:
[TABLE]
with , , and being the dimension of the training target. Recent preliminary experiments have shown that using this objective function leads to better performance for AV-SE than competing methods (Michelsanti et al., 2019b).
3.2 Preprocessing
In this work, each audio signal was peak-normalised. We used a sample rate of kHz and a -point STFT, with a Hamming window of samples ( ms) and a hop size of samples ( ms). Only the 321 bins that cover the positive frequencies were used, because of the conjugate symmetry of the STFT.
Each video signal was resampled at a frame rate of FPS using motion interpolation as implemented in FFMPEG222http://ffmpeg.org. The face of the speaker was detected in every frame using the frontal face detector implemented in the dlib toolkit (King, 2009), consisting of histogram of oriented gradients (HOG) filters and a linear support vector machine (SVM). The bounding box of the single-frame detections was tracked using a Kalman filter. The face was aligned based on landmarks using a model that estimated the position of the corners of the eyes and of the bottom of the nose (King, 2009) and was scaled to pixels. The mouth was extracted by cropping the central lower face region of size pixels.
Each segment of consecutive grayscale video frames spanning a total of ms was paired with the respective consecutive audio frames.
3.3 Neural Network Architecture and Training
The preprocessed audio and video signals, standardised using the mean and the variance from the training set, were used as input to a video and an audio encoders, respectively. Both encoders consisted of convolutional layers, each of them followed by leaky-ReLU activation functions (Maas et al., 2013) and batch normalisation (Ioffe and Szegedy, 2015). For the video encoder, also max-pooling and 0.25 dropout (Hinton et al., 2012) were adopted. The fusion of the two modalities was accomplished using a sub-network consisting of 3 fully connected layers, followed by leaky-ReLU activations, on the outputs of the 2 encoders. The estimated mask was obtained with an audio decoder having 6 transposed convolutional layers followed by leaky-ReLU activations and a ReLU activation as output layer. Skip connections between the layers , , and of the audio encoder and the corresponding decoder layers were used to avoid that the bottleneck hindered the information flow (Isola et al., 2017). The values of the training target, , were limited in the interval (Wang et al., 2014).
The weights of the network were initialised with the Xavier approach (Glorot and Bengio, 2010). The training was performed using the Adam optimiser (Kingma and Ba, 2015) with the objective function in Equation (1) and a batch size of . The learning rate, initially set to , was scaled by a factor of when the loss increased on the validation set. An early stopping technique was used, by selecting the network that performed the best on the validation set across the epochs used for training.
3.4 Postprocessing
The estimated ideal amplitude mask of an utterance was obtained by concatenating the outputs of the network, obtained by processing non-overlapping consecutive audio-visual paired segments. The estimated mask was point-wise multiplied with the complex-valued STFT spectrogram of the noisy signal and the result inverted using an overlap-add procedure to get the time-domain signal (Allen, 1977; Griffin and Lim, 1984).
3.5 Mono-Modal Speech Enhancement
Until now, we only presented AV-SE systems. In order to understand the relative contribution of the audio and the visual modalities, we also trained networks to perform mono-modal SE, by removing one of the two encoders from the neural network architecture, without changing the other explained settings and procedures. Both AO-SE and video-only SE (VO-SE) systems estimate a mask and apply it to the noisy speech, but they differ in the signals used as input.
4 Experiments
The experiments conducted in this study compare the performance of AO-SE, VO-SE, and AV-SE systems in terms of two widely adopted objective measures: perceptual evaluation of speech quality (PESQ) (Rix et al., 2001), specifically the wideband extension (ITU, 2005) as implemented by Loizou (2007), and extended short-time objective intelligibility (ESTOI) (Jensen and Taal, 2016). PESQ scores, used to estimate speech quality, lie between and , where high values correspond to high speech quality. However, the wideband extension that we use maps these scores to mean opinion score (MOS) values, on a scale from approximately 1 to 4.64. ESTOI scores, which estimate speech intelligibility, practically range from 0 to 1, where high values correspond to high speech intelligibility.
As mentioned before (Section 2), clean speech signals were mixed with SSN to match the noise type used in the Lombard GRID corpus. Current state-of-the-art SE systems are trained with signals at several SNRs to make them robust to various noise levels. We followed a similar methodology and trained our models with two different SNR ranges, narrow (between dB and dB) and wide (between dB and dB). We used these two ranges because on the one hand we would like to assess the performance of SE systems when Lombard speech occurs, and on the other hand we would like to have SNR-independent systems, i.e. systems that also work well at higher SNRs. Such a setup allows us to better understand whether Lombard speech, which is usually not available because it is hard to collect, should be used to train SE systems and which are the advantages and the disadvantages of various training configurations. The models used in this work are shown in Table 2.
Similarly to the work by Marxer et al. (2018), the experiments were conducted adopting a multi-speaker setup, in which all the speakers in the database were used for both training and evaluating the systems. This choice was made for a practical reason. People may exhibit speech characteristics that differ considerably from each other when they speak in presence of noise (Junqua, 1993; Marxer et al., 2018). It is possible to model these differences by training speaker-dependent systems, but this requires a large set of Lombard speech for every speaker. Unfortunately, the audio-visual speech corpus that we use, despite being one of the largest existing audio-visual databases for Lombard speech, only contains utterances per speaker, which are not enough to train a deep-learning-based model.
The experiments were performed according to a stratified five-fold cross-validation procedure (Liu and Özsu, 2009). Specifically, the data was divided into five folds of approximately the same size, four of them used for training and validation, and one for testing. This process was repeated five times for different test sets in order to evaluate the systems on the whole dataset. Before the split, the signals were rearranged to have about the same amount of data for each speaker across the training ( utterances), the validation ( utterances), and the test ( utterances) sets. This ensured that each fold was a good representative of the inter-speaker variations of the whole dataset. For some speakers, some data was missing or corrupted, so we used fewer utterances. Among the speakers, the recordings from speaker s were discarded by the database collectors due to technical issues, and the data from speaker s was used only in the training set, because only 40 of the utterances could be used. Effectively, speakers were used to evaluate our systems.
4.1 Systems Trained on a Narrow SNR Range
Since we would like to assess the performance of SE systems when Lombard speech occurs, SSN is added to the speech signals from the Lombard GRID corpus at 6 different SNRs, in uniform steps between dB and dB. This choice was driven by the following considerations (Michelsanti et al., 2019a). Since Lombard and non-Lombard utterances from the Lombard GRID corpus have an energy difference between and dB (Marxer et al., 2018), the actual SNR can be computed assuming that the conversational speech level is between and dB sound pressure level (SPL) (Raphael et al., 2007; Moore et al., 2012) and the noise level at dB SPL, like in the recording conditions of the database. The SNR range obtained in this way is between and dB. In the experiments, we used a slightly wider range because of the possible speech level variations caused by the distance between the listener and the speaker.
For all the systems, Lombard speech was used to build the test set, while for training and validation we used Lombard speech for VO-L, AO-L, and AV-L, and non-Lombard speech for VO-NL, AO-NL, and AV-NL (Table 2).
4.1.1 Results and Discussion
Figure 2 shows the cross-validation results in terms of PESQ and ESTOI for all the different systems. On average, every model improves the estimated speech quality and the estimated speech intelligibility of the unprocessed signals, with the exception of VO-NL at 5 dB SNR, which shows an ESTOI score comparable with the one of noisy speech. Another general trend that can be observed is that AV systems outperform the respective AO and VO systems, an expected result since the information that can be exploited using two modalities is no less than the information of the single modalities taken separately.
It is worth noting that VO systems’ performance changes across SNR, although they do not use the audio signal to estimate the ideal amplitude mask. This is because the estimated mask is applied to the noisy input signal, so the performance depends on the noise level of the input audio signal.
PESQ scores show that the performance that can be obtained with AO systems is comparable with VO systems performance at very low SNRs. Only for dB, AO models start to perform substantially better than VO models. The difference increases with higher SNRs. Also for ESTOI, this pattern can be observed when dB, but for dB VO systems perform better than the respective AO systems, especially at dB SNR where the performance gap is very large. This can be explained by the fact that the noise level is so high that recovering the clean speech only using the noisy audio input is very challenging, and that the visual modality provides a richer information source at this noise level.
For all the modalities, L systems tend to be better than the respective NL systems. The only exception is AO-NL, which have a higher PESQ score than AO-L at dB SNR, but this difference is very modest (). AV-L always outperforms AV-NL in terms of PESQ by a large margin, with more than dB SNR gain, if we consider the performance between dB and dB SNR. On average (Table 3), the performance gap in terms of PESQ between L and NL systems, is greater for the audio-visual case () than for the audio-only () and the video-only () cases, meaning that the speaking style mismatch is more detrimental when both the modalities are used. Regarding ESTOI, the gap between AV-L and AV-NL () is still the largest, but the one between VO-L and VO-NL () is greater than the gap between AO-L and AO-NL (): this suggests that the impact of visual differences between Lombard and non-Lombard speech on estimated speech intelligibility is higher than the impact of acoustic differences.
These results suggest that training systems with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility. This is in line with and extends our preliminary study (Michelsanti et al., 2019a), where only a subset of the whole database was used to evaluate the models.
4.1.2 Effects of Inter-Speaker Variability
Previous work found a large inter-speaker variability for Lombard speech, especially between male and female speakers (Junqua, 1993). Here, we investigate whether this variability affects the performance of SE systems.
Figure 3 shows the average PESQ and ESTOI scores by gender. Since the scores are computed on different speech material, it may be hard to make a direct comparison between males and females by looking at the absolute performance. Instead, we focus on the gap between L and NL systems averaged across SNRs for same gender. At a first glance, the trends of the different conditions are as expected: L systems are better than the respective NL ones, and AV systems outperform AO systems trained with speech of the same speaking style, in terms of both estimated speech quality and estimated speech intelligibility. We also notice that the scores of VO systems are worse than the AO ones, also for ESTOI. This is because we average across all the SNRs and VO is better than AO only at very low SNRs, but considerably worse for dB (Figure 2).
The difference between L and NL systems is larger for females than it is for males. This can be observed for all the modalities and it is more noticeable for AV systems, most likely because they account for both audio and visual differences. In order to better understand this behaviour, we provide a more in-depth analysis, investigating the impact that some acoustic and geometric articulatory features have on estimated speech quality and estimated speech intelligibility.
We consider three different features that have already been used to study Lombard speech in previous work (Garnier et al., 2006, 2012; Tang et al., 2015; Alghamdi, 2017): F0, mouth aperture (MA) and mouth spreading (MS). The average F0 for each speaker was estimated with Praat (Boersma and Weenink, 2001), using the default settings for pitch estimation. The average MA and MS per speaker were computed from facial landmarks (Figure 4) obtained with the pose estimation algorithm (Kazemi and Sullivan, 2014), trained on the iBUG 300-W database (Sagonas et al., 2016), implemented in the dlib toolkit (King, 2009).
Let F0, MA, and MS denote the average difference in audio and visual features, respectively, between Lombard and non-Lombard speech. Similarly, let PESQ and ESTOI denote the increment in PESQ and ESTOI, respectively, of AV-L with respect to AV-NL. Figure 5 illustrates the relationship between F0, MA, and MS and PESQ, and ESTOI. We notice that on average for each speaker and are both positive, with only one exception represented by a male speaker, whose is slightly less than [math]. This indicates that no matter how different the speaking style of a person is in presence of noise, there is a benefit in training a system with Lombard speech. Focusing on the range of the features’ variations, most of the speakers have positive MA, MS, and F0. This is in accordance with previous research, which suggests that in Lombard condition there is a tendency to amplify lips’ movements and rise the pitch (Garnier et al., 2010, 2012; Junqua, 1993). MA and MS values lie between and pixels, and between and pixels, respectively, for both male and female speakers. Regarding the F0 range, it is wider for females, up to Hz, against the Hz reached by males.
Among the three features considered, F0 is the one that seems to be related the most with PESQ and ESTOI. This can be seen by comparing the distributions of the circles with the least-squares lines in the plots of Figure 5 or by analysing the correlation between PESQ/ESTOI increments and audio/visual feature increments, using Pearson’s and Spearman’s correlation coefficients.
Given pairs of observations, with , from two variables and , whose sample means are denoted as and , respectively, we refer to the Pearson’s correlation coefficient as . We have that , where [math] denotes the absence of a linear relationship between the two variables, and and a perfect positive linear relationship and a perfect negative linear relationship, respectively. To complement the Pearson’s correlation coefficient, we also consider the Spearman’s correlation coefficient, , defined as (Sharma, 2005):
[TABLE]
where and indicate rank variables. The advantage of using ranks is that allows to assess whether the relationship between and is monotonic (not limited to linear).
As shown in Table 4, for AV systems, F0 has a higher correlation with PESQ (, ) and ESTOI (, ) than MA and MS. We observe that for female speakers, the correlation between the features’ increments and the performance measures’ increments is usually higher, especially when considering MS, suggesting that some inter-gender difference should be present not only for F0 (whose range is way wider for females as previously stated), but also for visual features.
In Table 4 we also report the correlation coefficients for the single modalities. The correlation of visual features’ increments with PESQ or ESTOI is sometimes higher for AO systems than it is for VO systems. This might seem counter-intuitive, because AO systems do not use visual information. However, correlation does not imply causation (Field, 2013): since visual and acoustic features are correlated (Almajai et al., 2006), it is possible that other acoustic features, which are not considered in this study even though they might be correlated with MA and MS, play a role in the enhancement. Similar considerations can be done for F0, which has a correlation with ESTOI for VO systems (, ) higher than the one for AO systems (, ). By looking at the inter-gender differences, we find that, in general, the correlation coefficients computed for female speakers are higher than the ones computed for male speakers, especially when considering MS.
In general, a performance difference between genders exists when L systems are compared with NL ones, with a gap that is larger for females. This is unlikely to be caused by the small gender imbalance in the training set (23 males and 30 females). Instead, it is reasonable to assume that this result is due to the characteristics of the Lombard speech of female speakers, which shows a large increment of F0, the feature that correlates the most with the estimated speech quality and the estimated speech intelligibility increases, among the ones considered.
4.2 Systems Trained on a Wide SNR Range
The models presented in Section 4.1 have been trained to enhance signals when Lombard effect occurs, i.e. at SNRs between and dB. However, from a practical perspective, SNR-independent systems, capable of enhancing both Lombard and non-Lombard speech, are preferred. There are several ways to achieve this goal. For example, it is possible to train a system (with Lombard speech) that works at low SNRs, and another one (with non-Lombard speech) that works at high SNRs. This approach requires switching between the two systems, which can be problematic, because it involves an online estimation of the SNR. An alternative approach is to train general systems with Lombard speech at low SNRs and non-Lombard speech at high SNRs. We followed this alternative approach, building such systems and studying their strengths and limitations. We also compared them with systems trained only with non-Lombard speech for the whole SNR range, because this is what current state-of-the-art systems do.
The test set was built by mixing additive SSN with Lombard speech at SNRs between and dB, and with non-Lombard speech at SNRs between and dB. For VO-NL(w), AO-NL(w), and AV-NL(w), only non-Lombard speech was used during training, while for VO-L(w), AO-L(w), and AV-L(w), Lombard speech was used with dB and non-Lombard speech with dB, to match the speaking style of the test set (Table 2). The results in terms of PESQ and ESTOI are shown in Figure 6.
The relative performance of the systems at dB is similar to the one observed for the systems trained on a narrow SNR range (Section 4.1): L(w) systems outperform the respective NL(w) systems, AV performance is higher than AO and VO performance, and VO is considerably better than AO only in terms of ESTOI at very low SNRs.
When dB, NL(w) systems perform better than L(w) systems in terms of PESQ. The difference is on average (Table 5) larger for VO () than it is for AO () and AV (). This can be explained by the fact that it is harder for VO-L(w) to recognise when non-Lombard speech occurs using only the video of the speaker. However, these performance gaps are smaller than the ones between L(w) and NL(w) systems at dB ( for VO, for AO, and for AV).
Regarding ESTOI at dB, the difference between AO and AV becomes negligible, with VO systems that perform considerably worse. This is because audio features are more informative than visual ones at high SNRs, making AO-SE systems already good to recover speech intelligibility. In addition, the average gaps between NL(w) and L(w) are quite small: for AO and AV, while for VO it is actually .
In general, at dB, the systems that use both Lombard and non-Lombard speech for training perform better than the ones that only use non-Lombard speech. At higher SNRs, their PESQ and ESTOI scores are slightly worse than the ones of the systems trained only with non-Lombard speech. However, this performance gap is small, and seems to be larger for the estimated speech quality than for the estimated speech intelligibility. The way we combined non-Lombard and Lombard speech for training seems to be the best solution for an SNR-independent system, although a small performance loss may occur at high SNRs.
5 Listening Tests
Although it has been shown that visual cues have an impact on speech perception (Sumby and Pollack, 1954; McGurk and MacDonald, 1976), the currently available objective measures used to estimate speech quality and speech intelligibility, e.g. PESQ and ESTOI, only take into account the audio signals. Even when listening tests are performed to evaluate the performance of a SE system, visual stimuli are usually ignored and not presented to the participants (Hussain et al., 2017), despite the fact that visual inputs are typically available during practical deployment of SE systems.
For these reasons, and in an attempt to evaluate the proposed AV enhancement systems in a setting as realistic as possible, we performed two listening tests, one to assess the speech quality and the other to assess the speech intelligibility, where the processed audio signals from the Lombard GRID corpus were accompanied by their corresponding visual stimuli. Both tests were conducted in a silent room, where a MacBookPro11,4 equipped with an external monitor, a sound card (Focusrite Scarlett 2i2) and a set of closed headphones (Beyerdynamic DT770) was used for audio and video playback. The multimedia player (VLC media player 3.0.4) was controlled by the subjects with a graphical user interface (GUI) modified from MUSHRAM (Vincent, 2005). The processed signals used in this test were from the systems trained on the narrow SNR range previously described (Section 4.1). All the audio stimuli were normalised according to the two-pass EBU R128 loudness normalisation procedure (EBU, 2014), as implemented in ffmpeg-normalize333https://github.com/slhck/ffmpeg-normalize, to guarantee that signals of different conditions were perceived as having the same volume. The subjects were allowed to adjust the general loudness to a comfortable level during the training session of each test.
5.1 Speech Quality Test
The quality test was carried out by experienced listeners, who volunteered to be part of the study. The participants were between 26 and 44 years old, and had self-reported normal hearing and normal (or corrected to normal) vision. On average, each participant spent approximately minutes to complete the test.
5.1.1 Procedure
The test used the MUlti Stimulus test with Hidden Reference and Anchor (MUSHRA) (ITU, 2003) paradigm to assess the speech quality on a scale from [math] to , divided into equal intervals labelled as bad, poor, fair, good, and excellent. No definition of speech quality was provided to the participants. Each subject was presented with sequences of trials each, to evaluate the systems at dB SNR, and to evaluate the systems at dB SNR. Lower SNRs were not considered to ensure that the perceptual quality assessment was not influenced too much by the decrease in intelligibility. One trial consisted of one reference (clean speech signal) and seven other signals to be rated with respect to the reference: hidden reference, systems under test (AO-L, AO-NL, AV-L, AV-NL), unprocessed signal, and hidden anchor (unprocessed signal at dB SNR). The participants were allowed to switch at will between any of the signals inside the same trial. The order of presentation of both the trials and the conditions was randomised, and signals from different randomly chosen speakers were used for each sequence of trials.
Before the actual test, the participants were trained in a special separate session, with the purpose of exposing them to the nature of the impairments and making them familiar with the equipment and the grading system.
5.1.2 Results and Discussion
The average scores assigned by the subjects for each condition are shown in Figure 7 in the form of box plots.
Non-parametric approaches are used to analyse the data (Mendonça and Delikaris-Manias, 2018; Winter et al., 2018), since the assumption of normal distribution of the data is invalid, given the number of participants and their different interpretation of the MUSHRA scale. Specifically, the paired two-sided Wilcoxon signed-rank test (Wilcoxon, 1945) is adopted to determine whether there exists a median difference between the MUSHRA scores obtained for two different conditions. Differences in median are considered significant for (, ), where the significance level is corrected with the Bonferroni method to compensate for multiple hypotheses tests (Field, 2013). The use of -values as the only analysis strategy has been heavily criticized (Hentschke and Stüttgen, 2011) because statistical significance can be obtained with a big sample size (Sullivan and Feinn, 2012; Moore et al., 2012) even if the magnitude of the effect is negligible (Hentschke and Stüttgen, 2011). For this reason, we complement -values with a non-parametric measure of the effect size, the Cliff’s delta (Cliff, 1993):
[TABLE]
where and are the observations of the samples of sizes and to be compared and indicates the Iverson bracket, which is if is true and [math] otherwise. As reported in Table 6, we consider the effect size to be small if , medium if , and large if , according to the indication by Vargha and Delaney (2000). The -values and the effect sizes for the comparisons considered in this study are shown in Table 7.
At dB, a significant () medium () difference exists between Lombard and non-Lombard systems for both the audio-only and the audio-visual cases. The increment in quality when using vision with respect to audio-only systems is perceived by the subjects (), but it has only a relatively small effect (). This was expected, since visual cues affect more the intelligibility at low SNRs than quality, as also shown by objective measures (Figure 2). More specifically, for non-Lombard systems, this difference is significant and greater than the one found for Lombard systems, meaning that vision contributes more when the enhancement of Lombard speech is performed with systems that were not trained with it. We can notice that there is a large () difference between the unprocessed signals and the version enhanced with Lombard systems. However, this difference is not significant, probably due to the heterogeneous interpretation of the MUSHRA scale by the subjects and their preference of the different natures of the impairment (presence of noise or artefacts caused by the enhancement).
At an SNR of 5 dB a small difference between Lombard and non-Lombard systems is observed, despite being not significant in the audio-only case (). At this noise level, audio-visual systems appear to be indistinguishable () from the respective audio-only systems. This confirms the intuition that vision does not help in improving the speech quality at high SNRs. Finally, the difference between the unprocessed signals and the respective enhanced versions using Lombard systems is both large () and significant (), which makes it clear that both AO-L and AV-L improve the speech quality.
5.2 Speech Intelligibility Test
The intelligibility test was carried out by listeners, who volunteered to be part of the study. The participants were between 24 and 65 years old, and had self-reported normal hearing and normal (or corrected to normal) vision. On average, each participant spent approximately minutes to complete the test.
5.2.1 Procedure
Each subject was presented with sequences of audio-visual stimuli from the Lombard GRID corpus: speakers SNRs (, , , and dB) processing conditions (unprocessed, AO-L, AO-NL, AV-L, AV-NL). The participants were asked to listen to each stimulus only once and, based on what they heard, they had to select the colour and the digit from a list of options and to write the letter (Table 1). The order of presentation of the stimuli was randomised.
Before the actual test, the participants were trained in a special separate session consisting of a sequence of audio-visual stimuli.
5.2.2 Results and Discussion
The mean percentage of correctly identified keywords as a function of the SNR is shown in Figure 8. We can see that among the three fields, the colour is the easiest word to be identified by the participants. In general, the following trends can be observed. At low SNRs the intelligibility of the signals enhanced with AV systems is higher than the intelligibility obtained with AO systems. This difference substantially diminishes when the SNR increases. There is no big performance difference between L and NL systems, but in general AV-L tends to have higher percentage scores than the other systems. AV-L is also the only system that does not decrease the mean intelligibility scores for all the fields if compared to the unprocessed signals.
Table 8 shows Cliff’s deltas and -values, computed with the paired two-sided Wilcoxon signed-rank test, as in the MUSHRA experiments.
The effect sizes support the observations made from Figure 8. Medium and large differences () exist between AO and AV systems, especially at low SNRs. While AO-L and AO-NL are indistinguishable () for SNR dB, there is a medium () difference between AV-L and AV-NL, except for dB SNR (). Moreover, the intelligibility increase of AV-L over the unprocessed signals is perceived by the subjects at SNR dB ().
Regarding the -values, if we focus on each SNR separately, the difference between two approaches can be considered significant for (cf. Section 5.1.2). This condition is met only when we compare AO-L with AV-L at dB SNR and AV-L with the noisy speech at dB SNR.
There are three main sources of variability that most likely prevent the differences to be significant. First, the variation in lipreading ability among individuals is large and does not directly reflect the variation found in auditory speech perception skills (Summerfield, 1992). Secondly, individuals have very different fusion responses to discrepancy in the auditory and visual syllables (Mallick et al., 2015), which in our case might occur due to the artefacts produced in the enhancement process. Finally, the participants were not exposed to the same utterances processed with the different approaches like in MUSHRA. Since the vocabulary set of the Lombard GRID corpus is small and some words are easier to understand because they contain unambiguous visemes, the intelligibility scores are affected not only by the various processing conditions, but also by the different sentences used.
6 Conclusion
In this paper, we presented an extensive analysis of the impact of Lombard effect on audio, visual and audio-visual speech enhancement systems based on deep learning. We conducted several experiments using a database consisting of speakers and showed the general benefit of training a system with Lombard speech.
In more detail, we first trained systems with Lombard or non-Lombard speech and evaluated them on Lombard speech adopting a cross-validation setup. The results showed that systems trained with Lombard speech outperform the respective systems trained with non-Lombard speech in terms of both estimated speech quality and estimated speech intelligibility. We also observed a performance difference across speakers, with an evident gap between genders: the performance difference between the systems trained with Lombard speech and the ones trained with non-Lombard speech is larger for females than it is for males. The analysis that we performed suggests that this difference might be primarily due to the large increment in the fundamental frequency that female speakers exhibit from non-Lombard to Lombard conditions.
With the objective of building more general systems able to deal with a wider SNR range, we then trained systems using Lombard and non-Lombard speech and compared them with systems trained only on non-Lombard speech. As in the narrow SNR case, systems that include Lombard speech perform considerably better than the others at low SNRs. At high SNRs, the estimated speech quality and the estimated speech intelligibility obtained with systems trained only with non-Lombard speech are higher, even though the performance gap is very small for the audio and the audio-visual cases. Combining non-Lombard and Lombard speech for training in the way we did guarantees a good compromise for the enhancement performance across all the SNRs.
We also performed subjective listening tests with audio-visual stimuli, in order to evaluate the systems in a situation closer to the real-world scenario, where the listener can see the face of the talker. For the speech quality test, we found significant differences between Lombard and non-Lombard systems at all the used SNRs for the audio-visual case and only at dB SNR for the audio-only case. Regarding the speech intelligibility test, we observed that on average the scores obtained with the audio-visual system trained with Lombard speech are higher than the other processing conditions. However, we were unable to find significant differences in most of the cases, suggesting that in future works more effort should be put into designing new paradigms for speech intelligibility tests to control the several sources of variability caused by the combination of auditory and visual stimuli.
7 Acknowledgements
This work was supported, in part, by the Oticon Foundation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abel and Hussain (2014) Abel, A., Hussain, A., 2014. Novel two-stage audiovisual speech filtering in noisy environments. Cognitive Computation 6 (2), 200–217.
- 2Abel et al. (2014) Abel, A., Hussain, A., Luo, B., 2014. Cognitively inspired speech processing for multimodal hearing technology. In: Proceedings of CICARE. IEEE, pp. 56–63.
- 3Afouras et al. (2018) Afouras, T., Chung, J. S., Zisserman, A., 2018. The conversation: Deep audio-visual speech enhancement. In: Proceedings of Interspeech. pp. 3244–3248.
- 4Alghamdi (2017) Alghamdi, N., 2017. Visual speech enhancement and its application in speech perception training. Ph.D. thesis, University of Sheffield.
- 5Alghamdi et al. (2018) Alghamdi, N., Maddock, S., Marxer, R., Barker, J., Brown, G. J., 2018. A corpus of audio-visual Lombard speech with frontal and profile views. The Journal of the Acoustical Society of America 143 (6), EL 523–EL 529.
- 6Allen (1977) Allen, J., 1977. Short term spectral analysis, synthesis, and modification by discrete Fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing 25 (3), 235–238.
- 7Almajai and Milner (2011) Almajai, I., Milner, B., 2011. Visually derived Wiener filters for speech enhancement. IEEE Transactions on Audio, Speech, and Language Processing 19 (6), 1642–1651.
- 8Almajai et al. (2006) Almajai, I., Milner, B., Darch, J., 2006. Analysis of correlation between audio and visual speech features for clean audio feature prediction in noise. In: Proceedings of Interspeech/ICSLP. p. 1634.