TL;DR
This paper introduces two novel approaches, Atomic and Block, for verifying the integrity of archived web content without relying solely on archive-provided fixity information, enhancing trust and efficiency.
Contribution
It proposes two new fixity verification methods that do not depend on archive-provided data, improving verification speed and reliability.
Findings
Block approach verifies fixity 4.46 times faster than Atomic.
Dissemination times vary significantly across archives, with archive.org taking longer.
The methods enable fixity verification even without an Archival Fixity server.
Abstract
The number of public and private web archives has increased, and we implicitly trust content delivered by these archives. Fixity is checked to ensure an archived resource has remained unaltered since the time it was captured. Some web archives do not allow users to access fixity information and, more importantly, even if fixity information is available, it is provided by the same archive from which the archived resources are requested. In this research, we propose two approaches, namely Atomic and Block, to establish and check fixity of archived resources. In the Atomic approach, the fixity information of each archived web page is stored in a JSON file (or a manifest), and published in a well-known web location (an Archival Fixity server) before it is disseminated to several on-demand web archives. In the Block approach, we first batch together fixity information of multiple archived…
Click any figure to enlarge with its caption.
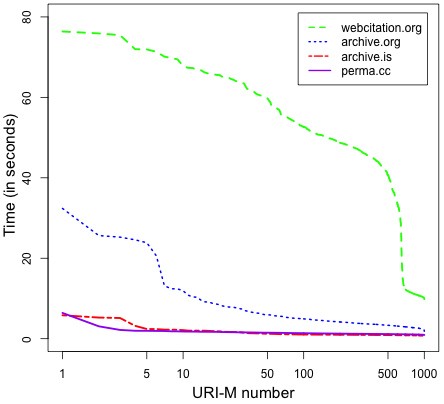 Figure 1
Figure 1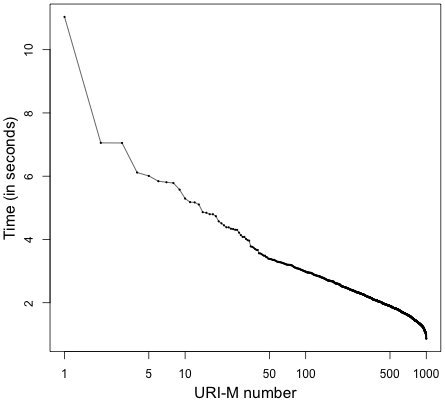 Figure 2
Figure 2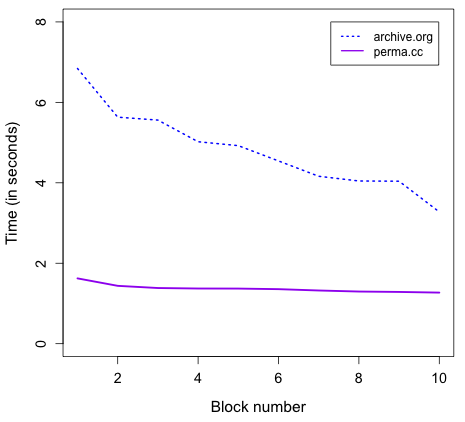 Figure 3
Figure 3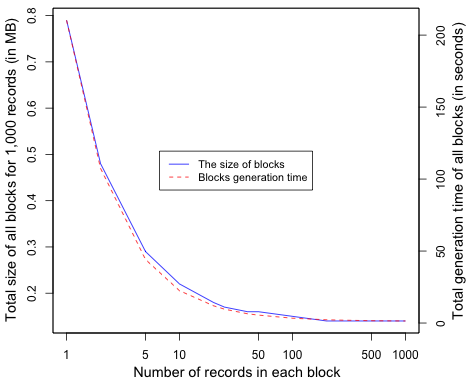 Figure 4
Figure 4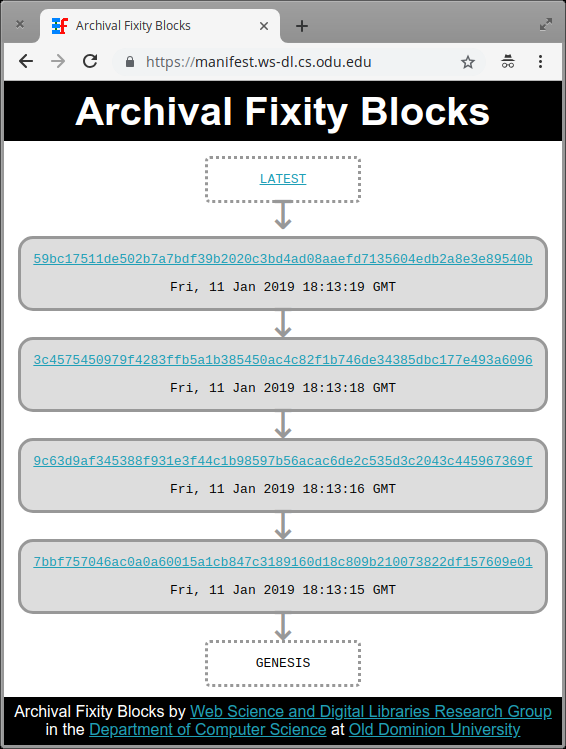 Figure 5
Figure 5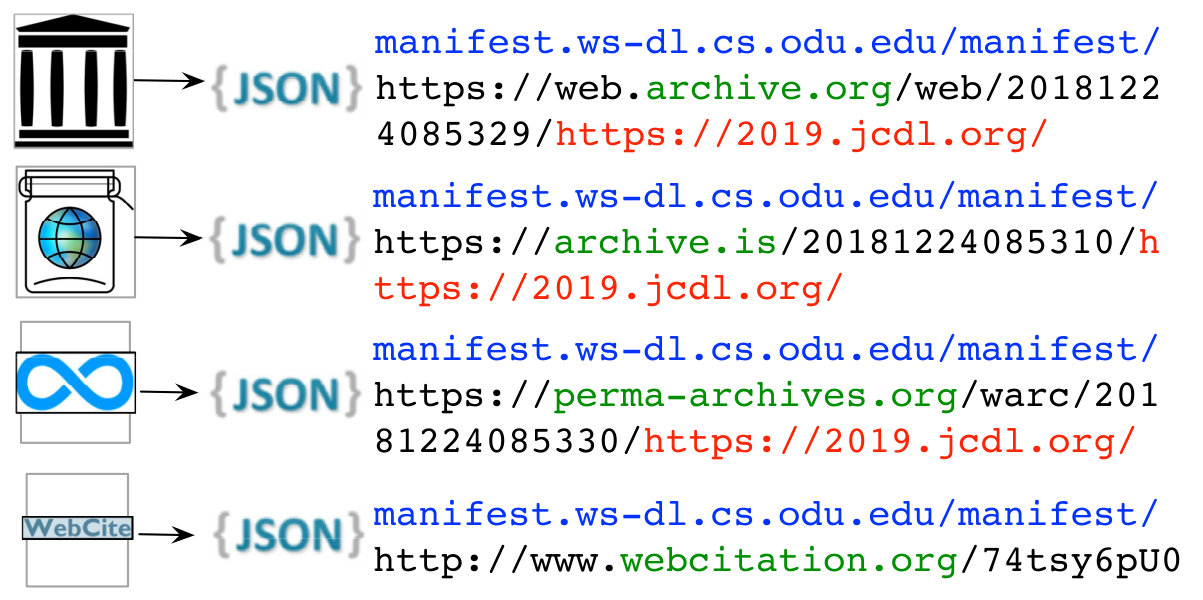 Figure 6
Figure 6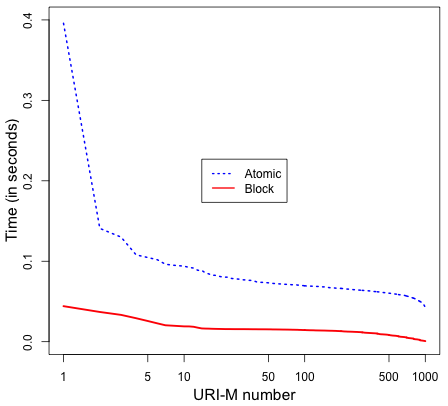 Figure 7
Figure 7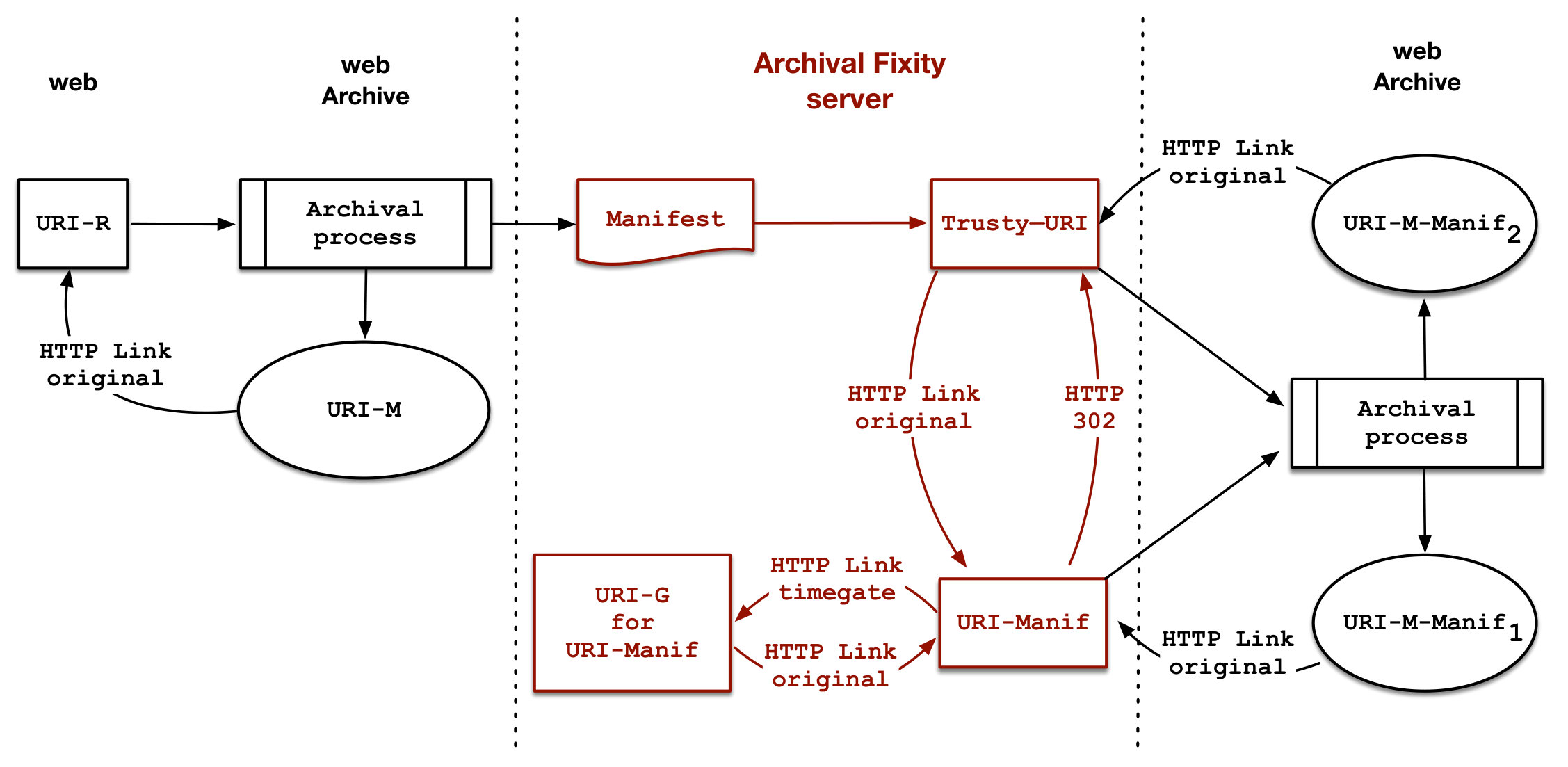 Figure 8
Figure 8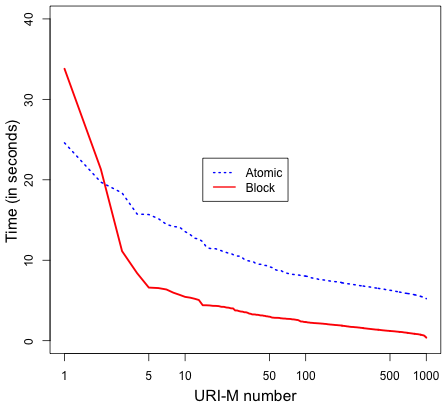 Figure 9
Figure 9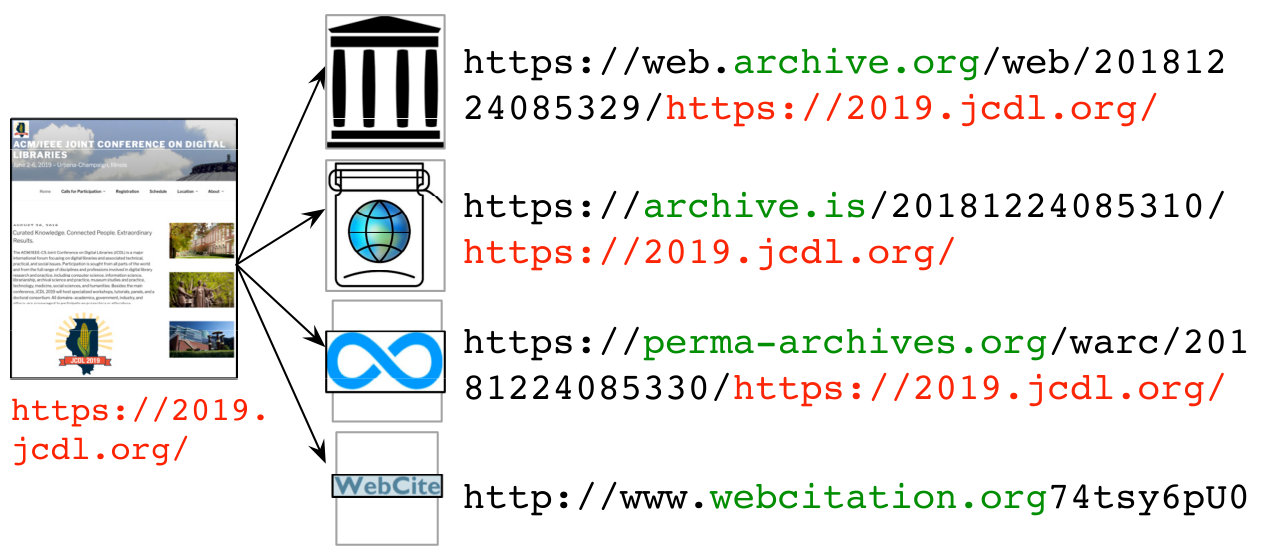 Figure 10
Figure 10 Figure 11
Figure 11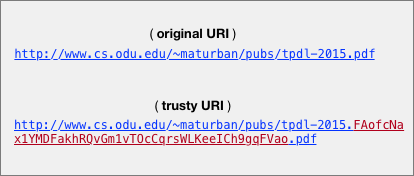 Figure 12
Figure 12| Operation | archive.is | perma.cc | IA | WebCite |
| Manifest dissemination | 0.94 | 1.18 | 3.74 | 33.82 |
| Block dissemination | - | 1.37 | 4.80 | - |
| Manifest download | 0.47 | 0.60 | 1.42 | 4.55 |
| Block download | - | 0.30 | 7.19 | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Archive Assisted Archival Fixity Verification Framework
Mohamed Aturban, Sawood Alam, Michael L. Nelson, and Michele C. Weigle
Old Dominion UniversityNorfolkVirginia23529USA
maturban,salam,mln,[email protected]
Abstract.
The number of public and private web archives has increased, and we implicitly trust content delivered by these archives. Fixity is checked to ensure an archived resource has remained unaltered since the time it was captured. Some web archives do not allow users to access fixity information and, more importantly, even if fixity information is available, it is provided by the same archive from which the archived resources are requested. In this research, we propose two approaches, namely Atomic and Block, to establish and check fixity of archived resources. In the Atomic approach, the fixity information of each archived web page is stored in a JSON file (or a manifest), and published in a well-known web location (an Archival Fixity server) before it is disseminated to several on-demand web archives. In the Block approach, we first batch together fixity information of multiple archived pages in a single binary-searchable file (or a block) before it is published and disseminated to archives. In both approaches, the fixity information is not obtained directly from archives. Instead, we compute the fixity information (e.g., hash values) based on the playback of archived resources. One advantage of the Atomic approach is the ability to verify fixity of archived pages even with the absence of the Archival Fixity server. The Block approach requires pushing fewer resources into archives, and it performs fixity verification faster than the Atomic approach. On average, it takes about 1.25X, 4X, and 36X longer to disseminate a manifest to perma.cc, archive.org, and webcitation.org, respectively, than archive.is, while it takes 3.5X longer to disseminate a block to archive.org than perma.cc. The Block approach performs 4.46X faster than the Atomic approach on verifying the fixity of archived pages.
1. Introduction
Web archives, such as the Internet Archive111http://archive.org (IA) and UK Web Archive222http://www.webarchive.org.uk/ukwa/, have made great efforts to capture and archive the web to allow access to prior states of web resources. We implicitly trust the archived content delivered by such archives, but with the current trend of extended use of other public and private web archives (Costa et al., 2017; Bailey et al., 2017), we should consider the question of validity. For instance, if a web page is archived in 1999 and replayed in 2019, how do we know that it has not been tampered with during those 20 years? One potential solution is to generate a cryptographic hash value on the HTML content of an archived web page, or memento. A memento is an archived version of an original web page (Van de Sompel et al., 2013). Figure 1 shows an example where the cURL command downloads the raw HTML code of the memento
[TABLE]
and then the hashing function sha256sum generates a SHA-256 hash on this downloaded code. By running these commands at different times we should always expect to obtain the same hash.
In the context of web archiving, fixity verifies that archived resources have remained unaltered since the time they were received (Bailey, 2014). The final report of the PREMIS Working Group (Group et al., 2005) defines information used for fixity as “information used to verify whether an object has been altered in an undocumented or unauthorized way.” Web content tampering is a common Internet-related crime in which content is altered by malicious users and activities (Kachhawa et al., 2014).
Part of the problem is the lack of standard techniques that users can apply to verify the fixity of web content (Aljawarneh et al., 2008; Gao et al., 2012). Jinfang Niu mentioned that none of the web archives declare the reliability of the archived content in their servers, and some archives, such as the Internet Archive, WAX333wax.lib.harvard.edu/collections/home.do, and Government of Canada Web Archive444www.collectionscanada.gc.ca/webarchives/index-e.html, have a disclaimer stating that they are not responsible for the reliability of the archived content they provide (Niu, 2012).
A motivating example, which shows the importance of verifying fixity of mementos, is the story of Joy-Ann Reid, an American cable television host at MSNBC. In December 2017, she apologized for writing several “insensitive” LGBT blog posts nearly a decade ago when she was a morning radio talk show host in Florida (Nelson, 2018; Sopelsa, 2017; Nelson, 2018). In April 2018, Reid, supported by her lawyers, claimed that her blog and/or the archived versions of the blog in the Internet Archive had been compromised and the content was fabricated (Ecarma, 2018). Even though the Internet Archive denied that their archived pages had been hacked (Butler, 2018), a stronger case could be made if we had an independent service verifying that those archived blog posts had not changed since they were captured by the archive. In this paper, we are introducing two approaches, Atomic and Block, to make archived web resources verifiable.
In the Atomic approach, the fixity information of each archived web page is stored in a single JSON file, or manifest, published on the web, and disseminated to several on-demand web archives. In the Block approach, we batch together fixity information, or records, of multiple archived pages to a single binary-searchable file, or block. The block then is published at a well-known web location before disseminating to archives. While we make a chain of blocks, we are not attempting to create yet another Blockchain (Narayanan and Clark, 2017). Manifests’ chain of blocks are limited in scope as we do not need to worry about consensus, eventual consistency, or proof-of-work because these blocks are generated and published by a central authority (the Block approach is described in 3.3). In both approaches, the fixity information, such as hash values, is not directly provided by archives (server-side) even though some archives’ APIs (e.g., the Internet Archive CDX server (Interent Archive, 2019)) allow accessing such information. Alternatively, we decided to calculate the fixity information based on the playback of archived resources (client-side) for two reasons. First, we are not expecting hashes generated and stored in WARC files by archives at crawl time to match those generated on the playback of mementos (Aturban et al., 2017). Second, if an archive has been compromised then it is likely the corresponding hashes have been also compromised, so we need to have the fixity information stored in independent archives (Maniatis et al., 2003).
This work introduces a basic, yet extensible, format of fixity information in the form of a structured manifest file. However, the main contribution of this paper focuses on the two suggested approaches of disseminating fixity information (or manifests) rather than strength, applicability, extension, scope, or security of the manifest. The framework describes how manifests are published, discovered, and used to verify mementos. The proposed framework does not require any change in the infrastructure of web archives. It is built based on well-known standards, such as the Memento protocol, and works with current archives’ APIs. The framework allows for the generation of manifests for selected resources instead of incurring the overhead of creating manifests for all archived resources.
We show that the size of a manifest represents about 2% of an actual memento’s content, and, on average, it takes about 1.25X, 4X, and 36X longer to disseminate a manifest to perma.cc, the Internet Archive, and WebCite (Eysenbach and Trudel, 2005), respectively, than archive.is, while it takes 3.5X longer to disseminate a block to archive.org than perma.cc. The Block approach performs 4.46X faster than the Atomic approach on verifying the fixity of archived pages. This paper is an expanded version of a conference paper (Aturban et al., 2019).
2. Background and related work
In order to automatically collect portions of the web, web archives employ web crawling software, such as the Internet Archive’s Heritrix (Sigurdsson, 2005). Having a set of seed URIs placed in a queue, Heritrix will start by fetching web pages identified by those URIs, and each time a web page is downloaded, Heritrix writes the page to a WARC file (ISO 28500:2017, 2017), extracts any URIs from the page, places those discovered URIs in the queue, and repeats the process.
The crawling process will result in a set of archived pages, or mementos. To provide access to their archived pages, many web archives that use OpenWayback (International Internet Preservation Consortium (IIPC), 2005), the open-source implementation of IA’s Wayback Machine, to allow users to query the archive by submitting a URI. OpenWayback will replay the content of any selected archived web page in the browser. One of the main tasks of OpenWayback is to ensure that when replaying a web page from an archive, all resources that are used to construct the page (e.g., images, style sheets, and JavaScript files) should be retrieved from the archive, not from the live web. Thus, at the time of replaying the page, OpenWayback will rewrite all links to those resources to point directly to the archive (Tofel, 2007). In addition to OpenWayback, PyWb (Kreymer, 2013) is another replaying tool, which is used by Perma (Zittrain et al., 2014) and Webrecorder (Kreymer, 2015).
Memento (Van de Sompel et al., 2009) is an HTTP protocol extension that uses time as a dimension to access the web by relating current web resources to their prior states. The Memento protocol is supported by most public web archives including the Internet Archive. The protocol introduces two HTTP headers for content negotiation. First, Accept-Datetime is an HTTP Request header through which a client can request a prior state of a web resource by providing the preferred datetime (e.g., Accept-Datetime: Mon, 09 Jan 2017 11:21:57 GMT). Second, the Memento-Datetime HTTP Response header is sent by a server to indicate the datetime at which the resource was captured. The Memento protocol also defines the following terminology:
URI-R - an original resource from the live Web
- -
URI-M - an archived version (memento) of the original resource at a particular point in time
- -
URI-T - a resource (TimeMap) that provides a list of mementos (URI-Ms) for a particular original resource
- -
URI-G - a resource (TimeGate) that supports content negotiation based on datetime to access prior versions of an original resource
To establish trust in repositories and web archives, different publications and standards have emphasized the importance of verifying fixity of archived resources. The report Trusted Repositories Audit & Certification (TRAC) by the Task Force on Archiving of Digital Information introduces criteria for identifying trusted digital repositories (Dale and Ambacher, 2007). In addition to the ability to reliably provide access, preserve, and migrate digital resources, digital repositories which include web archives must create preservation metadata that can be used to verify that content is not tampered with or corrupted (fixity) according to sections B2.9 and B4.4. The report recommends that preserved content is stored separately from fixity information, so it is less likely that someone is able to alter both the content and its associated fixity information (Dale and Ambacher, 2007). Thus, generating fixity information and using it to ensure that archived resources are valid will help to establish trust in web archives. Eltgrowth (Eltgrowth, 2009) outlined several judicial decisions that involve evidence (i.e., archived web pages) taken from the Internet Archive. The author mentions that there is an open question whether to consider an archived web page as a duplicate of the original web page at a particular time in the past. This concern might prevent considering archived web pages as evidence.
Different vulnerabilities were discovered in the Internet Archive’s Wayback Machine by Lerner et al. (Lerner et al., 2017) and Berlin (Berlin, 2018). They are Archive-Escapes, Same-Origin Escapes, Archive-Escapes + Same-Origin Escapes, and Anachronism-Injection. Attackers can leverage these vulnerabilities to modify a user’s view at the time when a memento is rendered in a browser. The authors suggested some defenses that could be deployed by either web archives or web publishers to prevent abusing these vulnerabilities. Cushman and Kreymer created a shared repository in May 2017 to describe potential threats in web archives, such as controlling a user’s account due to Cross-Site Request Forgery (CSRF) or Cross-Site Scripting (XSS), and archived web resources reaching out to the live web (Cushman and Kreymer, 2017). The authors provide recommendations on how to avoid such threats. Rosenthal et al. (Rosenthal et al., 2005), on the other hand, described several threats against the content of digital preservation systems (e.g., web archives). The authors indicated that designers of archives must be aware of threats, such as media failure, hardware failure, software failure, communication errors, failure of network services, media hardware obsolescence, software obsolescence, operator error, natural disaster, external attack, internal attack, economic failure, and organizational failure.
Several tools have been developed to generate trusted timestamps. For example, OriginStamp (Gipp et al., 2015) allows users to generate a trusted timestamp using blockchain-based networks on any file, plain text, or a hash value. The data is hashed in the user’s browser and the resulting hash is sent to OriginStamp’s server which then will be added to a list of all hashes submitted by other users. Once per day, OriginStamp generates a single aggregated hash of all received hashes. This aggregated hash is converted to a Bitcoin address that will be a part of a new Bitcoin transaction. The timestamp associated with the transaction is considered a trusted timestamp. A user can verify a timestamp through OriginStamp’s API or by visiting their website. Other services, such as Chainpoint (chainpoint.org) and OpenTimestamps (opentimestamps.org), are based on the same concept of using blockchain-based networks to timestamp digital documents. Even though users of these services can pass data by value, they are not allowed to submit data by reference (i.e., passing a URI of a web page). In other words, these tools are not directly timestamping web pages. The only exception is a service (Gipp et al., 2016) established by OriginStamp that accepts URIs from users, but the service is no longer available on the live web at
[TABLE]
A number of problems with blockchain-based networks are descibed by Rosenthal (Rosenthal, 2018). He indicates that having a large number of independent nodes in the network is what makes it secure, but this is not the case with many blockchain-based services, such as Ethereum (www.ethereum.org).
There are issues related to how web archives preserve and provide access to mementos that make it difficult to generate repeatable fixity information. When serving mementos, web archives often apply some transformation to appropriately replay content in the user’s browser. This includes (1) adding archive-specific code to the original content, (2) rewriting links to embedded resources (e.g., images) within an archived page so these resources are retrieved from the archive, not from the live web, and (3) serving content in different file formats like images (or screenshots), ZIP files, and WARC format (kun, 2017). Furthermore, issues, such as reconstructing archived web pages, caching, dynamic/randomly-generated content, illustrate how difficult it is to generate repeatable fixity information. Taking into account all of these archive-related issues, it becomes a challenging problem to distinguish between legitimate changes by archives and malicious changes. In our technical report (Aturban et al., 2017) we provide several recommendations of how to generate repeatable fixity information.
Kuhn et al. (Kuhn and Dumontier, 2014) define a trusty URI as a URI that contains a cryptographic hash value of the content it identifies as shown in Figure 2.
With the assumption that a trusty URI, once created, is linked from other resources or stored by a third party, it becomes possible to detect if the content that the trusty URI identifies has been tampered with or manipulated on the way (e.g., to prevent man-in-the-middle attacks (Kurian and Sekhar, 2016)). In their second paper (Kuhn and Dumontier, 2015), they introduce two different modules to allow creating trusty URIs on different kinds of content. In the module F, the hash is calculated on the byte-level file content, while in the second module R, the hash is calculated on RDF graphs. Even though trusty URIs detect altered documents, there are some limitations. First, a trusty URI is created by an owner of a resource it identifies. Second, trusty URIs can be generated on only two types of content RDF graphs and byte-level content (i.e., no modules introduced for HTML documents).
3. Methodology
The process of fixity verification of mementos can broadly be described in three phases: 1) generating manifests for mementos, 2) disseminating those manifests into different web archives, and 3) at a later date, generating manifests of the current state and comparing them with their corresponding previously archived versions. We have two approaches of manifest dissemination, namely, Atomic and Block (as described in Sections 3.2 and 3.3 respectively).
3.1. Manifest Generation
A manifest (identified by URI-Manif) consists of metadata summarizing fixity information of a memento. A manifest can be generated at or after a memento’s creation datetime. The proposed structure of a manifest file is illustrated in Figure 3, and should have the following properties:
@context: It specifies the URI where names used in the manifest file are defined.
created: The creation datetime of the manifest. It must be equal to or greater than the memento’s creation datetime.
URI-R, URI-M, and Memento-Datetime: It refers to the URI of an original resource, the URI of a memento, and the datetime when a memento was created, respectively (Van de Sompel et al., 2009).
@id: The URI that identifies a published manifest file (URI-Manif).
http-headers: Selected HTTP Response headers of the memento. As proposed by Jones et al. (Jones et al., 2016), we insert the Preference-Applied header to specify options used to retrieve the memento. For example, Original-Content refers to the raw memento—accessing unaltered archived content because archives by default return the memento after transforming its content.
hash-constructor: The commands that calculate hashes. The variable Content-Type) are replaced with the corresponding values in the http-headers The hashes are generated on both the HTML of a memento and selected response headers, and they are calculated using two different hashing algorithms, MD5 and SHA256, so even if the two functions are vulnerable to collision attacks, it becomes difficult for an attacker to make both functions collide at the same time (Rosenthal, 2017).
hash: The hash values calculated based on commands defined in hash-constructor.
3.2. Atomic Dissemination
In the Atomic approach, each memento that we are interested in verifying should have at least one corresponding manifest file containing fixity information of the memento. Once generated, the manifest should be published on the web and disseminated to different web archives. The main concept of this approach is to store the fixity information of a memento in differenent archives in addition to the archive in which the memento is preserved. This practice is recommended by the TRAC report (Dale and Ambacher, 2007) where content is maintained separately from its fixity information. Disseminating manifests can be archived through four steps:
- (1)
Push a web page into one or more archives. This will create one or more mementos, URI-M. 2. (2)
Generate a manifest by computing the fixity information of the memento. 3. (3)
Publish the manifest at a well-known location, URI-Manif. 4. (4)
Disseminate the published manifest in multiple archives. This will generate archived manifests, URI-M-Manif.
We briefly describe the steps involved in generating, publishing, and disseminating fixity information of mementos with examples. Figure 4 shows the web page https://2019.jcdl.org pushed into multiple archives, resulting in four mementos. The Python module ArchiveNow can be invoked via the command-line interface or user interface for simultaneously disseminating a web page into on-demand web archives (Aturban et al., 2018a).
Next, as shown in Figure 5, for each memento, a manifest is generated and published on the web at the Archival Fixity server,
[TABLE]
so that archives are able to access and capture those manifests. For example, the manifest of the memento
[TABLE]
is available at the URI-Manif
[TABLE]
This URI-Manif is a generic URI, which means if the Archival Fixity server creates another manifest for the same memento (marked in red), the server will publish it using the same generic URI. For this reason, the generic URI must always redirect to the most recent manifest of a memento (i.e., the manifest that is published using a trusty URI), so requesting the manifest’s generic URI
[TABLE]
will result in “302 Redirect” to the trusty URI (Figure 6)
[TABLE]
Figure 7 shows an example of retrieving all mementos (the TimeMap) from the Internet Archive of the URI-Manif:
[TABLE]
As Figure 8 shows, requesting the memento of the manifest (with generic URI) found in the TimeMap results in 302 Redirect to the archived manifest (with the trusty URI).
This 302 Redirect from the generic URI to the trusty URI has two advantages. First, as we described in Section 2, having a trusty URI will help validate the manifest content, as the hash included in the URI is the hash of the content it identifies. Second and more importantly, we can use the generic URI to discover manifests in the Archival Fixity server and archived manifests in the archives. Therefore, even in cases where the Archival Fixity server is unavailable or compromised we still can discover manifests in the archives directly (e.g., using a TimeGate or TimeMap). Figure 10 shows how the live web, the archive, and the Archival Fixity server are related in the Atomic approach.
Generally, we build trust in the content of memento from the time when fixity information is computed and published. One of the best scenarios is when a manifest is generated at ingest by the archive. In other words, the archive crawls a web page and immediately after that computes and publishes its fixity information.
The final step is to push the published manifest into multiple archives. In the example shown in Figure 9, the fixity information (or the manifest) of the memento from archive.org is disseminated to the same archive and other three archives including archive.is, perma-archives.org, and webcitation.org.
3.3. Block Dissemination
As opposed to the Atomic approach, in the Block approach we batch multiple manifests together in a single binary-searchable file along with some additional metadata (using the UKVS file format (Alam, 2019; Alam et al., 2019)), and add the reference of the previously published latest block. Then, we generate the content-addressable identity of the block, compress it, and archive it into multiple web archives by making it available at a well-known content-addressable URI (and allow people to keep local copies anywhere). While we make a chain of blocks, we are not attempting to create yet another Blockchain (Narayanan and Clark, 2017). Manifests’ chain of blocks are limited in scope as we do not need to worry about consensus, eventual consistency, or proof-of-work because these blocks are generated and published by a central authority. Linking blocks in a chain using their content-addressable hashes provides tamper-proofing, and enables discovery of previous blocks (starting from the latest or anywhere in the middle of the chain). Additionally, as long as we are depending on an archived page to be available in the archive, we can count on the archived metadata about the page to be available too. Creation and dissemination of manifest blocks is performed in the following steps:
- (1)
Identify a set of URI-Ms for their manifests to be included in the same block (a strategically chosen set may improve block compression factor and enable a more efficient lookup for verification later). 2. (2)
Generate their individual manifests in the form of a single-line JSON file (exclude @id field, needed in case of records being placed in a block, and eliminate many common fields that can go in the headers of the block). 3. (3)
Prefix each manifest JSON line with the Sort-friendly URI Reordering Transform (SURT) (Sigurðsson et al., 2006) of the corresponding URI-M. 4. (4)
Write these lines in a UKVS file along with the metadata headers as illustrated in Figure 13. 5. (5)
Add the content-addressable hash of the latest published block in the metadata as the previous block. 6. (6)
Sort the file using LC_ALL=C locale. 7. (7)
Calculate the content-addressable hash (e.g., SHA256) of this block. 8. (8)
Name the file using its content-addressable hash. 9. (9)
Compress the block file to efficiently archive it. 10. (10)
Publish the compressed block file on a URI that contains its hash. 11. (11)
Make the entrypoint (the well-known URI) redirect to the latest block’s URI (as illustrated in Figure 11). 12. (12)
Add Link response header with appropriate links to navigate through the chain of blocks, which is visually illustrated on the landing page as shown in Figure 12 (a similar approach of creating bidirectional linked list of HTTP messages was used in the HTTPMailbox (Alam, 2013)). 13. (13)
Archive the entrypoint in multiple web archives, which will implicitly archive the latest block as well due to the redirect. 14. (14)
Optionally, for further tamper-proofing post the URI of the newly published block on immutable platforms not controlled by a single authority (e.g., Twitter and GitHub’s Gist).
Although the number of public web archives is increasing (Costa et al., 2017; Bailey et al., 2017), only a few of them support an on-demand web archiving service. However, a small number (greater than one) of independent on-demand archives can suffice for of the purpose of disseminating manifests. The Block dissemination approach has a number of advantages over the Atomic approach. It requires far fewer network requests to push it to web archives and creates significantly fewer independently published manifest resources to keep track of mementos. By bundling multiple manifests in a single file, it yields a significant compression factor due to the repeated boilerplate content in each manifest file. As web archives die and new ones come to life, these blocks can be replicated and migrated externally to other places efficiently, while in the case of the Atomic approach we might lose historical manifests as old web archives die without donating their holdings to live archives. Moreover, these blocks are more tamper-proof than atomic manifests due to chaining. On the other hand, the Block approach has the disadvantage of shifting the burden of lookup of a specific record in the entire chain of blocks to the user or a service that provides verification. While individual blocks are binary searchable for fast lookup, as the number of blocks increases, one has to scan through all of them. However, this can easily be solved by scanning the entire chain once and creating a search index over the SURT field.
3.4. Verifying Fixity of Mementos
Verifying the fixity of a memento in both the Atomic and Block approaches can be achieved through three common steps:
- (a)
For the given memento, discover one or more manifests URI-Manif. In the Atomic approach, this step requires also discovering archived copies URI-M-Manif of the manifest. 2. (b)
Recompute current fixity information of the memento. 3. (c)
Compare current fixity information with discovered manifests.
In the Atomic approach, we can discover a manifest of a given memento through the Archival Fixity server. Which manifest is returned depends on the server’s API. For example, the server may respond with the closest manifest to the memento’s creation date or return the manifest that is closest to a given datetime (i.e., via a TimeGate). Once a manifest is discovered, we may use TimeGates and/or TimeMaps to retrieve its archived copies available in web archives. Again, it is possible to discover archived manifests using the generic URI even without the Archival Fixity server being involved. Next, we compute current fixity information by generating a new manifest for the given memento. Then, we compare current hash values in the new manifest with the hashes in the discovered archived manifests. In this compression step, we should only consider independent copies of the manifest. For example, if an archived manifest is delivered from the same archive where the memento is from, then this copy of the manifest should not be considered independent. In other cases, two manifests might be discovered in two cooperating archives (e.g., we know Archive-It.org is a service established by the Internet Archive).
In case of the Block approach, the fixity verification server (or any equivalent tool) needs to have access to all the blocks, either over HTTP (e.g., from a web archive) or stored locally. These blocks are then scanned for one or more matching records for the given URI-M. Corresponding single-line JSON entries (as shown in Figure 13) are extracted as historical fixity records for comparison. Remaining steps for creating current fixity information, comparing with the historical records, and generating the response summary are the same as in the case of Atomic approach.
While due to the immutable nature of blocks we can only have back references, creating a single linked list pointing from the most recent blocks to the older ones, with the help of some external metadata our archival fixity block server provides bidirectional navigational links for easy navigation along the chain back and forth (as illustrated in Figure 11 with first, last, prev, and next link relations in the link header). The content of these blocks is sorted that enables fast lookup in each block using binary search, but the chain of blocks has to be scanned linearly, which can decrease the throughput as the number of blocks increases. To deal with this issue, one can create an inverted index of existing blocks, treating URI-Ms as the keyword and blocks as the document. Additionally, the chain of blocks is in chronological order, which makes it easy to create a lightweight skip index to identify segments of the chain that were created around certain points of time in the past. Creating large blocks with a slowly growing chain will be more efficient than a rapidly growing chain of small blocks. However, an optimal block size can be decided based on how long one is willing to wait for enough records to be available for a new block creation and on the largest size of a single block that can easily be stored in web archives. Creating blocks with strategically grouped URI-Ms (e.g., mementos of nearby datetime values, URI-Rs from a set of domains, or URI-Ms from a set of archives) can also improve the efficiency of lookup (or indexing).
4. Evaluation
We conducted a study on 1,000 mementos from the Internet Archive which are a subset of a larger set of URI-Ms involved in a different research project (Aturban et al., 2018b). We did not take the size of mementos into consideration (i.e., the number of embedded resources, such as images and JavaScript/CSS files) because fixity in this paper is computed based on only the returned raw HTML content of the base file. The main reason for choosing a small set, only 1,000 URI-Ms, is because the study requires pushing at least 12 manifests for each memento in multiple archives. Sending too many archiving requests to archives might result in technical issues, such as blocking IP addresses. For example, webcitation.org responded with “WebCite has flagged your IP address for suspicious activity” after making 100 requests, but the issue was resolved after contacting the archive. Perma.cc on the other hand allows users to freely submit a maximum of 10 URIs for preserving per month. Fortunately, the archive supported us for this study by increasing this limit, so we were able to disseminate more manifests to the archive. Part of evaluation is measuring the time it takes to generate, disseminate, and verify manifests in the Atomic and Block approaches. In addition, we want to compare the size of files created in both approaches and whether all mementos are going to be verified successfully.
We wrote Python scripts (Aturban and Alam, 2019) for performing different functions:
generate_atomic(): Accepts a URI-M and returns the filename of a JSON file containing the fixity information of the memento. We generated 3,000 manifests. The main purpose of generating three manifests for each memento is because we are interested in reporting the average time for generating a manifest for each memento. Figure 14 shows an example of generating a manifest of the memento
[TABLE]
The resulting JSON file contains the fixity information including the hash calculated on the returned HTML of the memento.
publish_atomic(): Submits a given JSON to the Archival Fixity server at
[TABLE]
The server will insert @id and created metadata before publishing the new manifest on the web. Figure 15 shows an example of publishing the manifest file generated previously (in Figure 14). It returns the generic URI of the manifest URI-Manif and the trusty URI.
disseminate_atomic(): Pushes a published manifest into different archives using ArchiveNow. In our study, we used archive.org, archive.is, perma.cc, and webcitation.org resulting in creating 12,000 archived manifests (i.e., 3,000 URI-M-Manif in each archive). We used the Generic URI to push manifest into archives. Again, this URI always redirects to the trusty URI. If archives consider a “302 Redirect” as a separate resource, then the total number of archived resources created in the four archives was 24,000. Figure 16 shows an example of disseminating to four archives the manifest
[TABLE]
verify_atomic(): Accepts a URI-M, It discovers a manifest closest to the memento’s creation datetime. In addition, the function discovers archived copies of the manifest in the four archives using TimeGates and TimeMaps. Then, it computes current fixity information using generate_atomic(). Finally, it compares current fixity information with the discovered manifests and their archived copies. As a result, for each URI-M, the function returns either “Verified” or “Failed” with other information, such as hash values, URI-Manifs, and URI-M-Manifs. Figure 17 shows an example of verifying the fixity of the memento
[TABLE]
generate_block(): Accepts multiple JSON files. It generates one or more blocks depending on the selected block size. In this study, we set it to 100 manifests per block, so the total number of generated blocks was 10. The example in Figure 18 shows the output of the shell script generate_block.sh, which uses the Python function generate_block() to generate ten 100-record blocks. Figure 19 shows only four records (out of 100) of block 1. The four records have the fixity information of the following mementos:
[TABLE]
disseminate_block(): Pushes a block into two archives (archive.
org and perma.cc). Again, because we are interested in calculating the average time of disseminating block, each block is pushed three time into both archives resulting in creating 60 archived blocks (i.e., 30 per archive). We did not use archive.is and webcitation.org because .gz files were not handled correctly by those archives. Figure 20 shows an example of disseminating a block to two archives.
verify_block(): Accepts a URI-M, and discovers fixity information of the URI-M from the published blocks. Then, it computes current fixity information using generate_atomic(). Finally, it compares current and discovered fixity. The function returns either “Verified” or “Failed” with other information, such as hash values. Figure 21 shows the output of verify_block() for only 10 mementos (out of 1,000).
In addition to the Python scripts, we implemented the Archival Fixity server that is responsible for publishing and discovering manifests and blocks. For example, Figure 22 shows a request for discovering the closest manifest’s creation date to December 22, 2018 for the given memento. The server response indicates that the closest manifest was created on December 12, 2018.
The selected number of records per block affects the total size of all blocks and the time required to generate these blocks. Figure 23 illustrates that creating large blocks with a slowly growing chain is more efficient than a rapidly growing chain of small blocks. As mentioned in Section 3.4, one factor of choosing the optimal number of records in each block is the largest size of a single block that can easily be stored in web archives. For example, we tested the Internet Archive (IA) to identify the largest single file that the archive can accept for preservation. After submitting multiple files with different sizes, we found that IA can accept up to 800 MB, beyond that the archive returns “504 Gateway Time-out”.
5. Results
Figure 24 illustrates the distribution of the average time taken to generate manifests. We generated three manifests for each memento, and calculated the average time, so the the total number of generated manifests is 3,000. The manifest generation time includes: 1) downloading the raw HTML content using the Requests module in Python, 2) calculating fixity information of the downloaded content, and 3) storing the fixity information locally in JSON format. The average size of the generated manifest files is 1,157 bytes. This size represents 2.79% of the actual download HTML content, which is 41,392 bytes on average. The total size of all manifests is 1,156,657 bytes, while the total size of the blocks is 176,128 bytes. This indicates that the Block approach requires less storage space than the Atomic approach to store fixity information of the same number of mementos.
As expected, the time for disseminating manifests and blocks was the maximum time compared with other operations, such as generating and verifying manifests. Figure 25 shows that pushing manifests into webcitation.org (or WebCite) takes much longer time than other archives. On average, we wait for 33.82 seconds before WebCite finishes processing an archival request of a manifest, while the manifest disseminating average time drops down dramatically in the other three archives as Table 1 indicates. We observed that archive.org and webcitation.org add a few seconds response delay after receiving the first tens of archiving requests. In sum, it takes about 1.25X, 4X, and 36X longer to disseminate a manifest to perma.cc, archive.org, and webcitation.org, respectively, than archive.is, while it takes 3.5X longer to disseminate a block to archive.org than perma.cc. The average dissemination time of blocks in archive.org and perma.cc is shown in Figure 26.
Given a collection of mementos and web archives, the total number of resources that we are creating in the archives by the Atomic and Block approaches are and respectively, where is the selected block size. In our study, , , , and . Then a total of resources were created by the Atomic approach and only resources were created by the Block approach considering the fact that we repeated the dissemination process for three times.
Figure 27 shows the time required to discover manifests of each memento from the Archival Fixity server. Figure 28 illustates the total time for verifying the fixity of all mementos by both approaches. The verification time includes discovering manifests, computing current fixity information, downloading copies of manifests (in the Atomic approach), and comparing manifests. On average, the verification time of a memento is 6.65 seconds by the Atomic approach and 1.49 seconds by the Block approach, so the Block approach performs 4.46X faster than the Atomic approach on verifying the fixity of memento. Although we have predicted that some mementos might not be verified for reasons like an archive responds with “HTTP 500 Error”, we have not yet encountered any failed cases (i.e., all mementos are verified successfully).
6. Conclusions
Most web archives do not allow users to access fixity information. Even if fixity information is accessible, it is provided by the same archive delivering content. In this proposal, we have described two approaches, Atomic and Block, for generating and verifying fixity of archived web pages. The proposed work does not require any change in the infrastructure of web archives and is built based on well-known standards, such as the Memento protocol. While a central service is used to create manifests, this approach does not exclude additional, centralized manifest servers, possibly tailored to specific communities. The Block approach creates fewer resources in archives and reduces fixity verification time, while the Atomic approach has the ability to verify fixity of archived pages even without involving the Archival Fixity server. On average, it takes about 1.25X, 4X, and 36X longer to disseminate a manifest to perma.cc, archive.org, and webcitation.org, respectively, than archive.is, while it takes 3.5X longer to disseminate a block to archive.org than perma.cc. The Block approach performs 4.46X faster than the Atomic approach on verifying the fixity of archived pages.
We believe that the Atomic and Block approaches can be adopted to verify fixity of particular archived web pages with important content. Some future improvements can be applied to those approaches so they become scalable and can work with any number of mementos. Varying or increasing the block size in the Block approach might be one potential solution to improve its performance and reduce number of resources created in archives. Caching archived manifests in the Archival Fixity server should also improve the performance of the two approaches, so instead of discovering those manifests from the archives, we may used cached copies in the Archival Fixity server.
7. Acknowledgements
This work is supported in part by The Andrew W. Mellon Foundation (AMF) grant 11600663. This work includes contributions from Herbert Van de Sompel (DANS) and Martin Klein (LANL). We thank Ben Steinberg from the Perma.cc web archive for the generous increase in our monthly free quota to allow experimental fixity resource dissemination. We thank the WebCite archive for solving some technical issues about disseminating web resources.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2kun (2017) 2017. WARC file format. https://www.iso.org/standard/68004.html . ISO 28500:2017 (2017).
- 3Alam (2013) Sawood Alam. 2013. HTTP Mailbox - Asynchronous Restful Communication . Master’s thesis. Old Dominion University. https://doi.org/10.25777/wh 13-fd 86 · doi ↗
- 4Alam (2019) Sawood Alam. 2019. Unified Key Value Store. https://github.com/oduwsdl/ORS/blob/master/ukvs.md . (January 2019).
- 5Alam et al . (2019) Sawood Alam, Michele C. Weigle, and Michael L. Nelson. 2019. Memento Map Framework for Flexible and Adaptive Web Archive Profiling. In Proceedings of the 19th ACM/IEEE Joint Conference on Digital Libraries (JCDL) .
- 6Aljawarneh et al . (2008) Shadi Aljawarneh, Christopher Laing, and Paul Vickers. 2008. Design and experimental evaluation of Web Content Verification and Recovery (WCVR) system: A survivable security system. In Proceedings of the 3rd Conference on Advances in Computer Security and Forensics (ACSF) .
- 7Aturban and Alam (2019) Mohamed Aturban and Sawood Alam. 2019. Archival Fixity. https://github.com/oduwsdl/archival-fixity . (2019).
- 8Aturban et al . (2019) Mohamed Aturban, Sawood Alam, Michael L. Nelson, and Michele C. Weigle. 2019. Archive Assisted Archival Fixity Verification Framework. In Proceedings of the 19th ACM/IEEE Joint Conference on Digital Libraries (JCDL) .
