Application of Different Simulated Spectral Data and Machine Learning to Estimate the Chlorophyll a Concentration of Several Inland Waters
Philipp M. Maier, Sina Keller

TL;DR
This study evaluates how different simulated satellite spectral data and machine learning models can accurately estimate chlorophyll a levels in inland waters, highlighting Sentinel 2's suitability for small water bodies.
Contribution
It compares the effectiveness of various simulated satellite data resolutions in estimating chlorophyll a using machine learning, emphasizing Sentinel 2's advantages.
Findings
Machine learning models perform nearly as well with Sentinel data as with hyperspectral data.
Sentinel 2 is optimal for small inland waters due to its high spatial and temporal resolution.
Simulated data can effectively replace real satellite data for water quality estimation.
Abstract
Water quality is of great importance for humans and for the environment and has to be monitored continuously. It is determinable through proxies such as the chlorophyll a concentration, which can be monitored by remote sensing techniques. This study focuses on the trade-off between the spatial and the spectral resolution of six simulated satellite-based data sets when estimating the chlorophyll a concentration with supervised machine learning models. The initial dataset for the spectral simulation of the satellite missions contains spectrometer data and measured chlorophyll a concentration of 13 different inland waters. Focusing on the regression performance, it appears that the machine learning models achieve almost as good results with the simulated Sentinel data as with the simulated hyperspectral data. Regarding the applicability, the Sentinel 2 mission is the best choice for small…
Click any figure to enlarge with its caption.
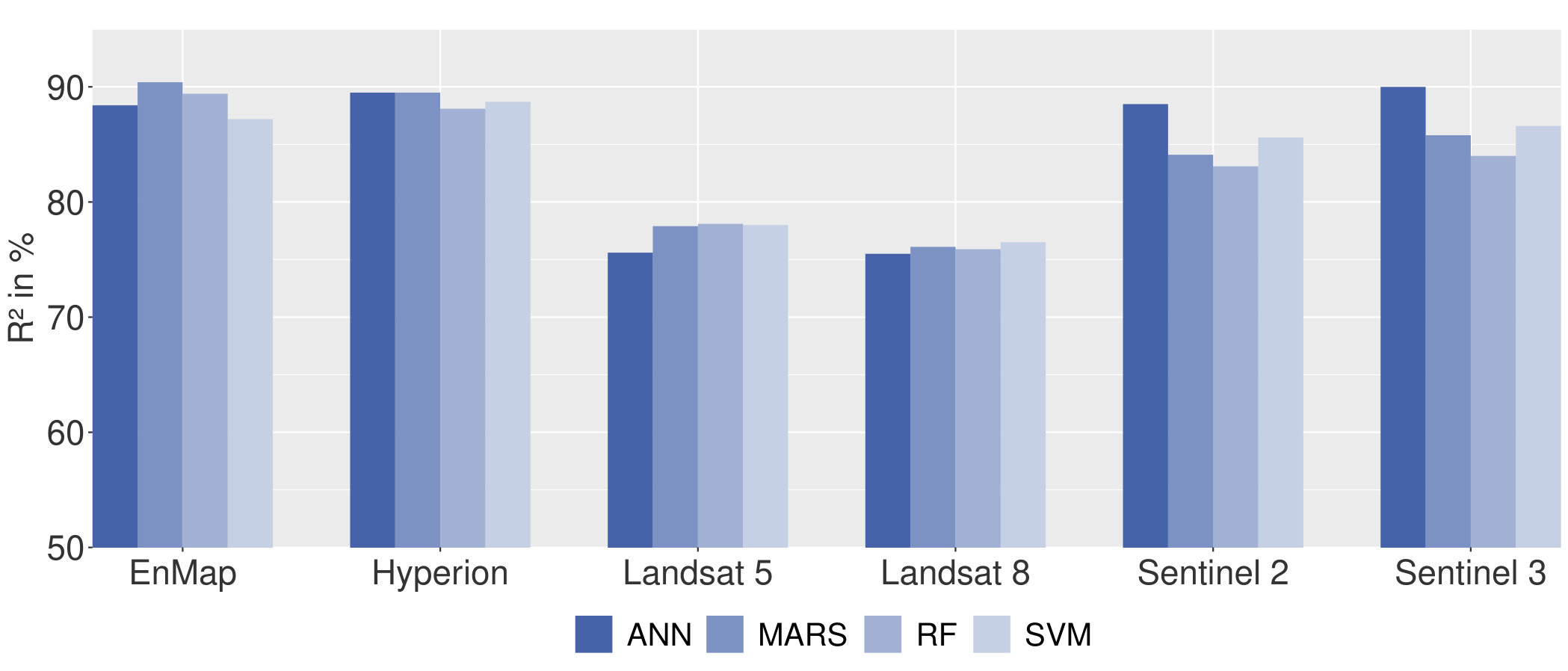 Figure 1
Figure 1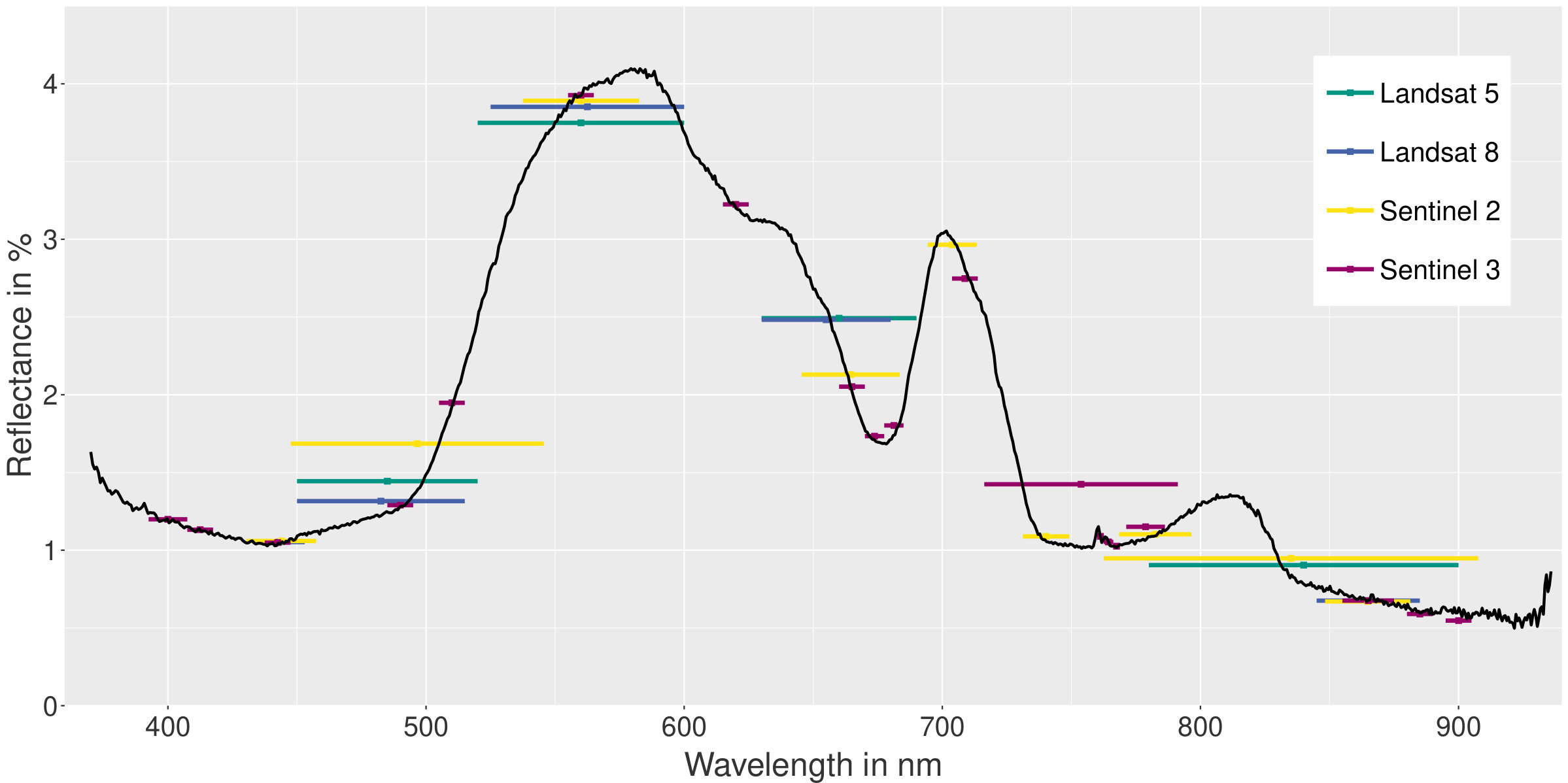 Figure 2
Figure 2| Satellite | Number | Bandwidth | Spectral range | Spatial resolution | Approach for | Data |
|---|---|---|---|---|---|---|
| mission | of bands | in nm | in nm | in m | the simulation | source |
| Sentinel 2 | Response function | [17] | ||||
| Sentinel 3 | Gaussian function | [18] | ||||
| Landsat 8 | Response function | [17] | ||||
| Landsat 5 | Response function | [17] | ||||
| Hyperion∗ | Gaussian function | [17] | ||||
| EnMAP∗ | Gaussian function | [17] |
| Simulated satellite data | RF | SVM | ANN | MARS |
|---|---|---|---|---|
| EnMAP | 10.9 | 12.6 | 11.7 | 10.1 |
| Hyperion | 11.3 | 12.2 | 11.3 | 10.5 |
| Landsat 5 | 17.8 | 18.5 | 19.6 | 19.0 |
| Landsat 8 | 18.8 | 18.8 | 20.0 | 20.5 |
| Sentinel 2 | 14.8 | 13.2 | 11.5 | 14.2 |
| Sentinel 3 | 14.3 | 14.1 | 10.9 | 13.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Application of different simulated spectral data and Machine learning to estimate the Chlorophyll a Concentration of several inland waters
Abstract
Water quality is of great importance for humans and for the environment and hence has to be monitored continuously. One possibility are proxies such as the chlorophyll a concentration, which can be monitored by remote sensing techniques. This study focuses on the trade-off between the spatial and the spectral resolution of six simulated satellite-based data sets when estimating the chlorophyll a concentration with supervised machine learning models. The initial dataset for the spectral simulation of the satellite missions contains spectrometer data and measured chlorophyll a concentration of different inland waters. The analysis of the regression performance indicates, that the machine learning models achieve almost as good results with the simulated Sentinel data as with the simulated hyperspectral data. Regrading the applicability, the Sentinel 2 mission is the best choice for small inland waters due to its high spatial and temporal resolution in combination with a suitable spectral resolution.
© 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
**Index Terms— ** Machine learning, supervised regression, chlorophyll a, hyperspectral data, spectral resolution
1 Introduction
According to the sixth sustainable development goals set by the United Nations in 2018, clean water is a key resource for humans and the environment [1]. However, the water quality is threatened extensively by human influences such as emission of wastewater or overfertilization caused by agriculture. Hence there is a great demand for a continuous and efficient system to monitor water quality (cf. [2, 3, 4]).
In addition to commonly applied in-situ probes, remote sensing as a technique is often considered when monitoring large water surfaces. Remote sensing offers some advantages over point sample measurement. In particular, satellite image data is frequently available and it is cost-efficient in the long run. Furthermore, information about water quality parameters derived by satellite images are more representative than in-situ measured point values in terms of area-wide coverage.
One important water quality parameter is chlorophyll a (chl a). It serves as a proxy for the nutrition supply of a water body. Chl a is a pigment which appears in phytoplankton, and provides the basis for photosynthesis. The occurrence of phytoplankton depends on the natural nutrition supply of a water body as well as human sources.
Chl a is detectable by passive remote sensing sensors in the visible spectrum. An absorption feature in the spectral band region around indicates chl a [5]. Several studies have already demonstrated the applicability of remote sensing data with respect to the estimation of chl a concentrations in inland waters [2, 6]. To estimate the chl a concentration with spectral data, two complementary approaches are applied. First, engineering approaches consider spectral features or band ratios [7, 8]. Second, machine learning (ML) approaches have been emerged in the last decade [9, 10, 11, 12, 6]. These approaches estimate the chl a concentration primarily in a supervised way without prior-knowledge of the underlying physical processes.
In general, the estimation of chl a concentrations in water bodies from remote sensing data is a challenging task. Inland waters are optically complex since they contain suspended and particular materials. These materials are characteristic for every inland water [3].
Another limiting factor when monitoring inland waters is the spatial resolution of the satellite images. Unfortunately, high spectral resolution is often accompanied by a lower spatial resolution. In case of the oceans, this is not an issue. With respect to inland waters however, the spatial resolution is crucial and hence an exclusion criteria of some satellite sensors. For example, the SeaWiFS (Sea-viewing Wide Field-of-view Sensor) as an ocean water observation satellite mission has a spatial resolution of more than [13]. Therefore, most of the smaller inland water bodies are represented by only one, mixed pixel which hinders the use of satellite data for the estimation of the chl a concentration of small water bodies.
Some studies investigate the trade-off between spectral and spatial resolution of satellite data recorded by the common missions [14, 15]. A thorough analysis of the estimation performance of feature engineering approaches on chl a concentrations for several simulated satellite sensors is presented in [15]. Previous work [16] addresses the effect of different hyperspectral resolutions of the input data and machine learning models when estimating chl a concentrations.
In this study, we simulate satellite data with respect to several multi- and hyperspectral satellite missions such as Landsat 5, Landsat 8, Sentinel 2, Sentinel 3, EnMAP and Hyperion. The basis of the simulated data is a spectrometer dataset of different inland waters which was conducted in the surrounding region of Karlsruhe (Germany) during the summer 2018. In total, the dataset contains datapoints. Each datapoint consists of the spectral information and the associated chl a concentration. The simulated spectral data serves as input data for selected ML models to estimate the chl a concentration of the different inland waters.
The objectives of this contribution are:
- •
the simulation of satellite data based on the measured spectrometer data by applying the spectral response function or a Gaussian function (Section 2);
- •
the estimation of the chl a concentration by applying different supervised ML models such as random forest (RF), support vector machine (SVM), multivariate adaptive regression spline (MARS) and an artificial neural network (ANN) on the respective simulated data (Section 4);
- •
the comparison of the regression performance in terms of simulated data and applied ML model (Section 4);
- •
the discussion of the regression performance with the focus on the spectral and the spatial resolution of the input data (Section 4).
2 Dataset and data simulation
The data used in this contribution is from a measurement campaign [16] in the surroundings of Karlsruhe, a city located in the Southwest of Germany. During the summer of 2018, different inland water bodies were measured with a spectrometer and water samples were evaluated with a photometer. A detailed description of the measurement campaign including the measurement setup is given in [16].
The spectrometer records hyperspectral data in a spectral range of to with a sampling interval of . Its measurement principle is based on the ratio between the incoming and the up-welling radiance in the perpendicular direction. The spectrometer was mounted on a tripod, which was placed as far as possible in the water in case of a natural water body. When measuring an artificial water body, the spectrometer was set outside the water.
The water samples for the chl a concentration analysis, which we use as reference data, were collected close to the spectrometer. The measured chl a concentrations and the respective spectra of the continuous spectrometer measurements were matched by their respective timestamps. In total, we obtain a dataset with datapoints. Each datapoint consists of the spectral data and a chl a concentration value.
For our satellite-based simulation of the spectral data, we used spectrometer data in the wavelengths range of is used. The simulation of the spectra in accordance with the satellite missions was conducted with the hsdar-package in R [17]. Three different approaches exist to calculate the satellite bands out of spectral data with different weighting functions: a Gaussian function, an equal-weighted function and the actual spectral response function. To calculate the spectra according to the Sentinel 2, Landsat 5 and Landsat-8 missions, we relied on the real spectral response function. When simulating Sentinel 3, the EnMAP and Hyperion satellite missions, we applied the Gaussian function. In the case of Sentinel 3, which is not implemented in the hsdar-package, we used the parameters central wavelength and full width at half maximum according to [18] and a Gaussian function to simulate the bands. Table 1 gives an overview of the spectral and spatial characteristics of the satellite missions which have been used for the data simulation. Furthermore, Figure 1 illustrates the bandwidth of each satellite mission in the spectral range of .
3 Methodology
For the estimation of the chl a concentration based on the different simulated satellite data, we selected four ML models: support vector machine [19], random forest [20], multivariate adaptive regression spline [21] and an artificial neural network [22]. The applied ML models are inspired by the selection in [12] due to their satisfactorily performance.
To apply these models, the dataset consisting of the chl a values and the simulated satellite data was prepared. It was split into five equally sized parts with respect to distribution of the target variable, the chl a concentration. Then, each of those parts was split randomly into two subsets: a training subset and a test subset. All five training subsets were aggregated to the final training subset. The test subset was generated similarly. As a result, the distribution of the chl a concentration in the training as well as the test subset were representative compared to the reference measurements.
The training subset was used for the training of the ML models, while the test subset remained unused until the test phase. Before starting with the training, we applied a grid search to adjust the hyperparameters of the models. For example, hyperparameters of the SVM model are the penalty function cost and the kernel parameter gamma.
During the test phase, the models were validated on the yet unknown test dataset. The performance of the regression was expressed by the coefficient of determination () and the mean absolute error (MAE). Following the regression performance on the same database in [16], we also calculated the first derivative of the spectra for the simulated hyperspectral data of the Hyperion and EnMAP mission and applied those derivatives as input data for the RF and MARS model. In addition, we pre-processed the simulated satellite data with a scaling to ensure good regression results for the the MARS, SVM and ANN models.
4 Results and Discussion
Figure 2 and Table 2 present the regression performance of estimating the chl a concentration with respect to the applied ML models as well as the different simulated satellite data. Regarding Figure 2, the regression performance of the four ML models are in the same range.
When considering the simulated satellite input data for estimating the chl a concentration, the regression results expressed as are distinguishable. For the simulated hyperspectral satellite data (EnMAP and Hyperion), the coefficient of determination () is quite similar. In case of the simulated Landsat data, the regression results are closely related. In detail, the ANN model performs worse than the other three models on these two simulated datasets. However, for the simulated Sentinel data, the ANN model provides the best regression results.
Considering the different simulated satellite data, the regression with the simulated hyperspectral data based on the EnMAP and Hyperion mission achieves the best results. The corresponding MAE values range between . The MAE values of the models with simulated multispectral data according to the Sentinel missions is in the range between . The estimation of the chl a concentration of all regression models with simulated Landsat data performs the worst compared to the other simulated satellite data. The MAE ranges between .
Analyzing bandwidth, number of bands, spectral range and resolution of the simulated satellite data, Figure 1 shows that Landsat 5 (green) and Landsat 8 (blue) have similar bands with a similar band positioning. The three bands between are nearly the same. In the spectral range of Landsat 8 provides a narrower band than Landsat 5 and it has an additional fifth narrow band near . With respect to the estimation of the chlorophyll a concentration, this additional band has no further impact on the regression task.
Similar to the simulated Landsat data, the simulated multispectral Sentinel 3 data provides a better spectral resolution and accounts for more bands with narrower bandwidths than Sentinel 2. However, the regression performance of the ML models on simulated Sentinel 3 data is not clearly better than the regression performance of the models with simulated Sentinel 2 data. When comparing the estimation performance with either simulated Sentinel data or simulated Landsat data, the outperformance of the models using the simulated Sentinel data can be well explained. First, the simulated Sentinel data is characterized by more bands. And second, these bands are well positioned within the spectral range of . For example, the simulated Sentinel data includes the extremes in the range of which are related to chl a. The mentioned spectral range is not included in the two Landsat missions and explains the poor chl a estimation of all models [14].
The simulated hyperspectral data (EnMAP and Hyperion) with a nearly constant spectral resolution of and are not shown in Figure 1 due to reason of transparency. Comparing the regression results with the simulated hyperspectral and the simulated Sentinel data, the models relying on the hyperspectral datasets perform only slightly better. This finding indicates that the band positioning of the Sentinel missions is good for the estimation of chl a concentrations.
Regarding the applicability of the simulated satellite data for a general monitoring approach in the context of inland waters, the Sentinel 2 data serves its purpose. It provides data with appealing spectral resolution, a sufficient spatial resolution and is characterized by a high temporal frequency. Hyperspectral data with a better spectral resolution leads to a satisfying chl a estimation by applying the same ML models. However, their temporal resolution stays behind the temporal resolution of the Sentinel missions referring to two satellite systems. Differentiating between the two Sentinel missions, the application of the Sentinel 3 satellites is limited to large inland water surface due to their poor spatial resolution of . In addition, the Landsat satellite missions provide an attractive spatial and temporal resolution as well. However, the regression results of the models are the worst with this data since the Landsat missions are characterized by the lowest spectral resolution of all simulated satellite missions.
5 Conclusion
In this paper, we address the estimation of chl a concentration with different simulated spectral data and supervised ML models. We rely on a spectrometer dataset measured at several inland water bodies. For the simulation of the satellite-base data, we chose six different satellite missions as examples. In addition, we apply four different supervised ML models for the estimation of the chl a concentration.
When comparing the simulated satellite data, the regression performance of all models with the simulated hyperspectral data achieves the best results due to their spectral and spatial resolution. Referring to the estimation results, the ML models combined with the simulated Sentinel data are slightly worse than the estimation based on the simulated hyperspectral data. Regarding the applicability for a generic monitoring approach of inland waters, the Sentinel 2 mission provides the best option for smaller water bodies. The Sentinel 3 mission poses an alternative for large water bodies.
When focusing on the different ML models, the choice of a specific ML model has a minor impact on the regression performance. Solely, the ANN models outperforms the other models when using the simulated Sentinel data.
In this study, we have focused on the estimation of the the chl a concentration as a selected water quality parameter. For the estimation of further quality parameters such as different algae types, the (simulated) hyperspectral data could provide an excellent basis due to its high spectral resolution. The choice of ML models and the (simulated) satellite data has to be adapted according to the respective water quality parameter which will be estimated. This investigation could be addressed in future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] United Nations Department of Economic and Social Affairs, The Sustainable Development Goals Report 2018 , 2018.
- 2[2] Koponen, S., Pulliainen, J., Kallio, K. and Hallikainen, M., “Lake water quality classification with airborne hyperspectral spectrometer and simulated MERIS data,” Remote Sensing of Environment , vol. 79, pp. 51–59, 2002.
- 3[3] Palmer, S., Kutser, T. and Hunter, P. D., “Remote sensing of inland waters: Challenges, progress and future directions,” Remote Sensing of Environment , vol. 157, pp. 1–8, 2015.
- 4[4] Maier, P. M., Hinz, S. and Keller, S., “Estimation of Chlorophyll a, Diatoms and Green Algae Based on Hyperspectral Data with Machine Learning Approaches,” 38. Wissenschaftlich-Technische Jahrestagung der DGPF und PFGK 18 Tagung in München , vol. 27, pp. 49–57, 2018.
- 5[5] Morel, A and Prieur, L., “Analysis of variations in ocean color 1,” Limnology and Oceanography , vol. 22, no. 4, pp. 709–722, 1977.
- 6[6] Keller, S., Maier, P., Riese, F., Norra, S., Holbach, A., Börsig, N. Wilhelms, A., Moldaenke, C., Zaake, A. and Hinz, S., “Hyperspectral Data and Machine Learning for Estimating CDOM, Chlorophyll a, Diatoms, Green Algae and Turbidity,” International journal of environmental research and public health , vol. 15, no. 9, 2018.
- 7[7] Gitelson, A., “The peak near 700 nm on radiance spectra of algae and water: Relationships of its magnitude and position with chlorophyll concentration,” International Journal of Remote Sensing , vol. 13, no. 17, pp. 3367–3373, 1992.
- 8[8] Gons, H. J., “Optical Teledetection of Chlorophyll a in Turbid Inland Waters,” Environmental Science & Technology , vol. 33, no. 7, pp. 1127–1132, 1999.