Multi-Scale Dual-Branch Fully Convolutional Network for Hand Parsing
Yang Lu, Xiaohui Liang, Frederick W. B. Li

TL;DR
This paper introduces a novel multi-scale dual-branch FCN architecture for hand parsing, addressing challenges like small size and occlusion, and proposes a new loss function to handle data imbalance, achieving state-of-the-art results.
Contribution
The paper presents a new MSDB-FCN framework with a dual-branch design, a specialized DB-Block for feature merging, and a generalized Focal Loss for improved hand parsing performance.
Findings
Achieved state-of-the-art accuracy on RHD-PARSING dataset.
Effectively handles data imbalance with Multi-Class Balanced Focal Loss.
Demonstrates superior performance in complex hand parsing scenarios.
Abstract
Recently, fully convolutional neural networks (FCNs) have shown significant performance in image parsing, including scene parsing and object parsing. Different from generic object parsing tasks, hand parsing is more challenging due to small size, complex structure, heavy self-occlusion and ambiguous texture problems. In this paper, we propose a novel parsing framework, Multi-Scale Dual-Branch Fully Convolutional Network (MSDB-FCN), for hand parsing tasks. Our network employs a Dual-Branch architecture to extract features of hand area, paying attention on the hand itself. These features are used to generate multi-scale features with pyramid pooling strategy. In order to better encode multi-scale features, we design a Deconvolution and Bilinear Interpolation Block (DB-Block) for upsampling and merging the features of different scales. To address data imbalance, which is a common problem…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5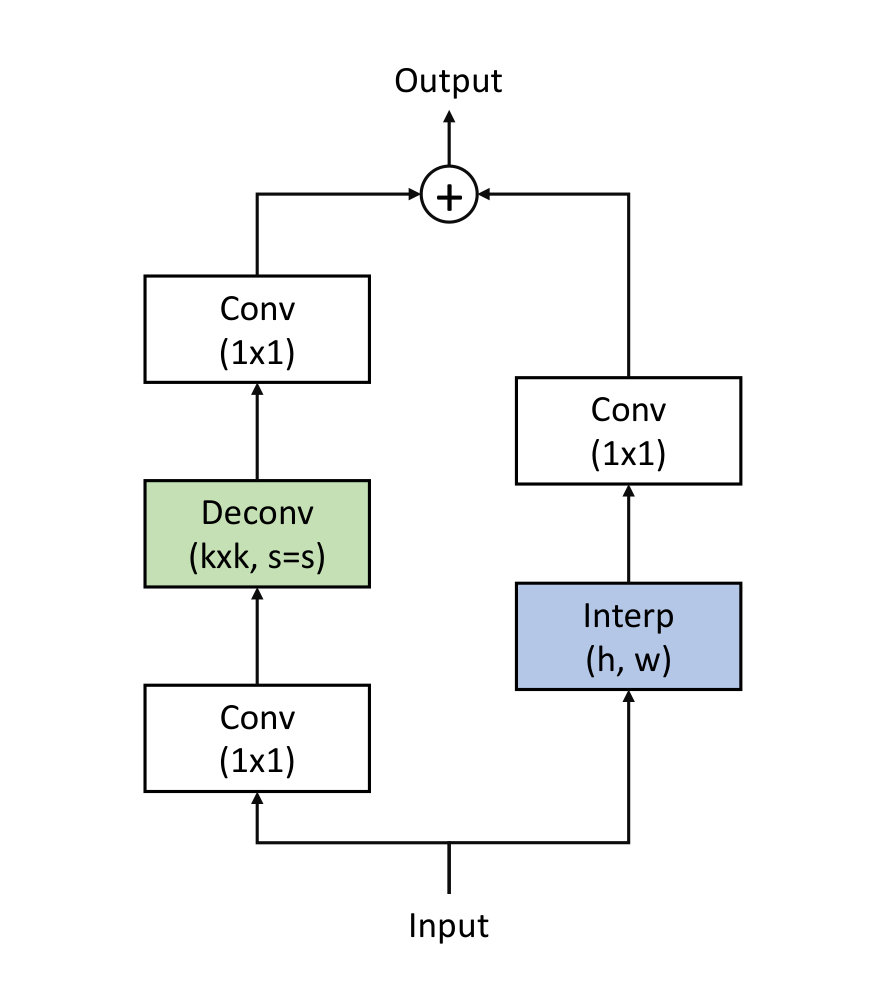 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9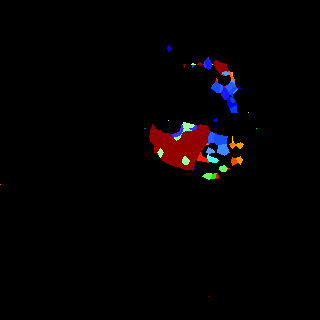 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12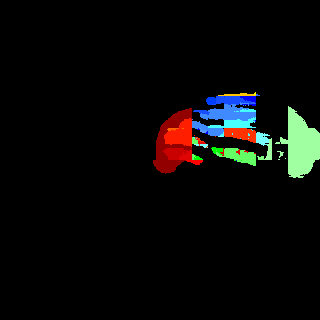 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 1
Figure 1 Figure 1
Figure 1 Figure 19
Figure 19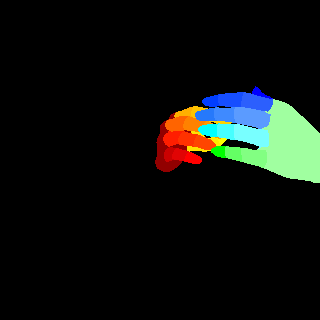 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23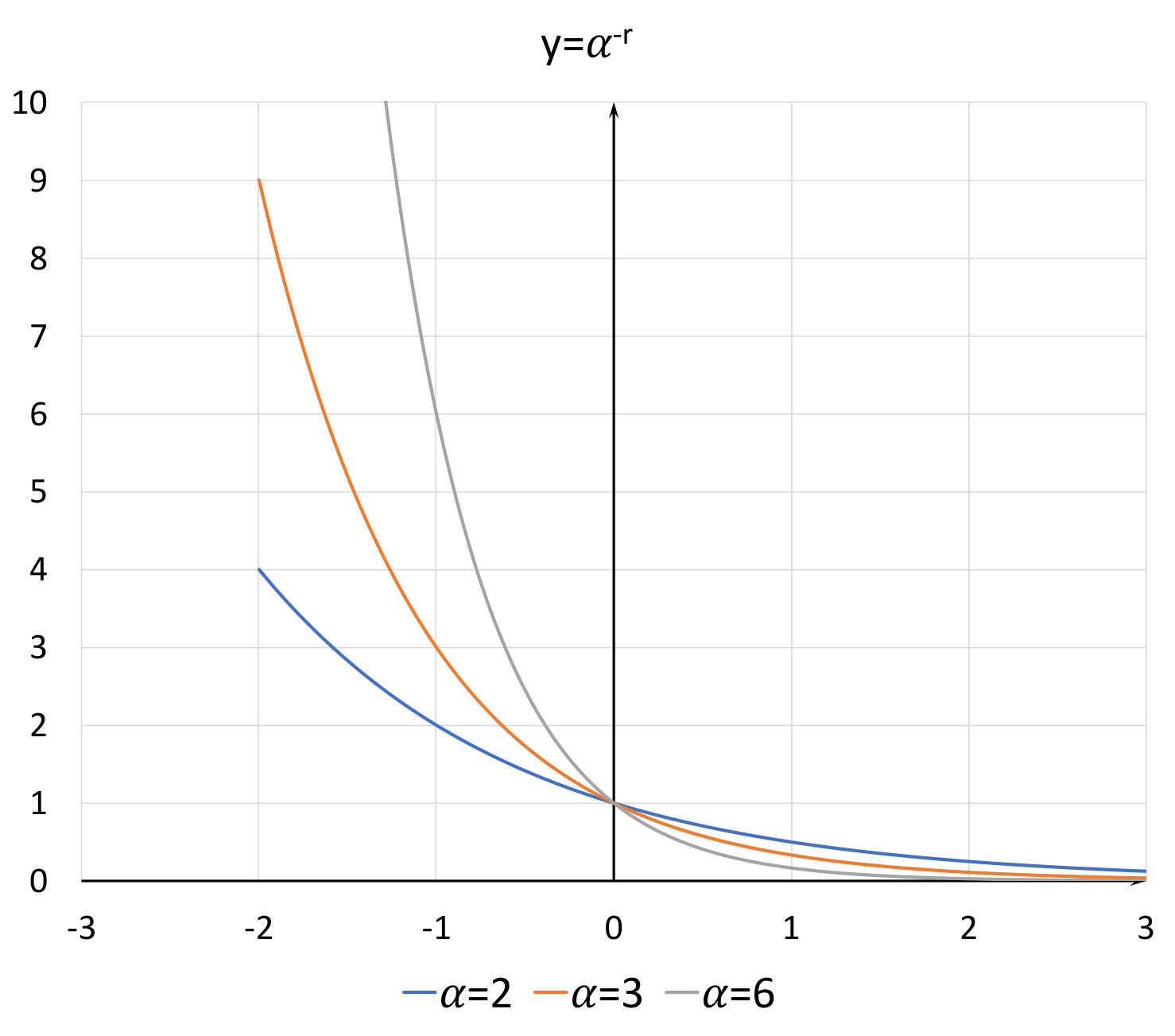 Figure 24
Figure 24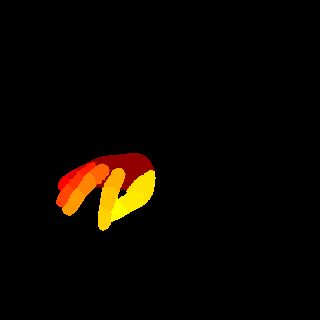 Figure 25
Figure 25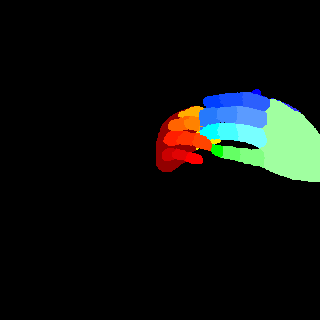 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29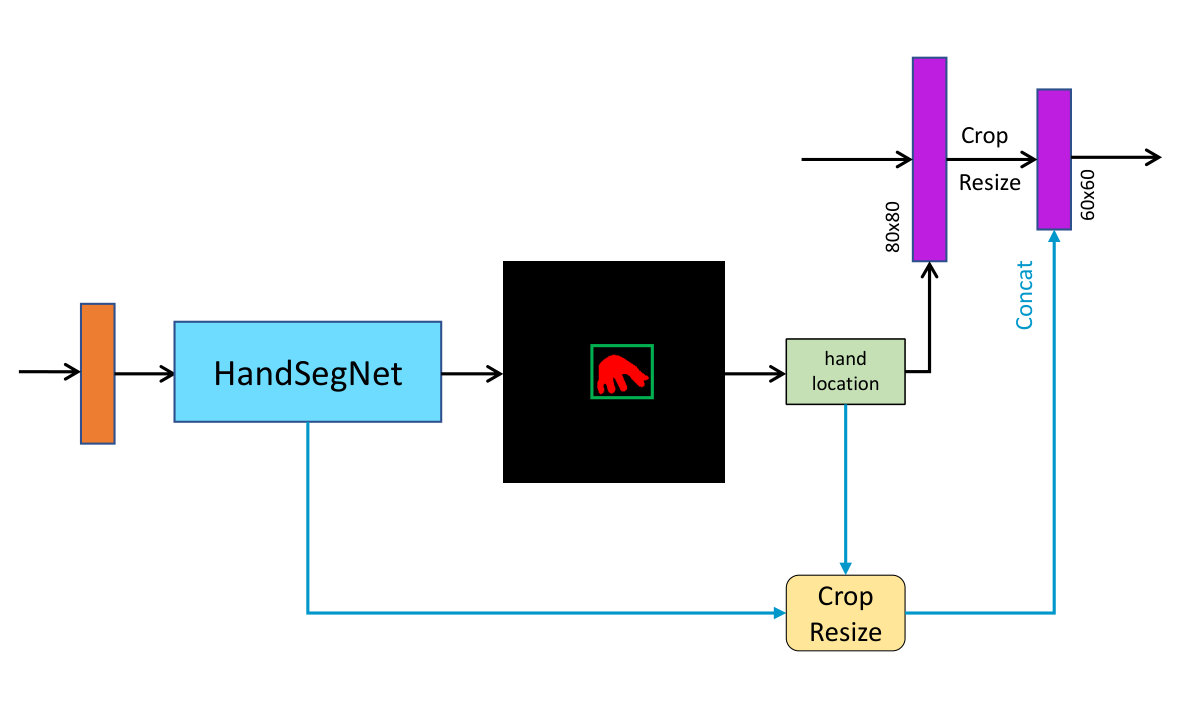 Figure 30
Figure 30 Figure 31
Figure 31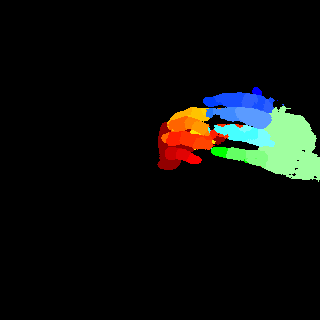 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36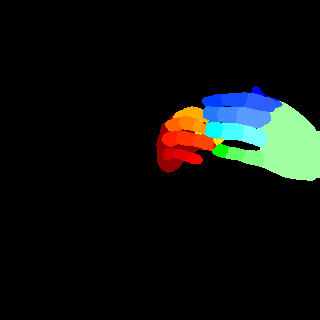 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Method | Mean IoU(%) | Mean Acc.(%) |
|---|---|---|
| ResNet50-Baseline | 51.04 | 58.98 |
| ResNet50+PB | 55.75 | 65.54 |
| ResNet50+PB+MB | 56.35 | 66.50 |
| Method | Mean IoU(%) | Mean Acc.(%) |
|---|---|---|
| MSDB-FCN+B | 55.22 | 65.32 |
| MSDB-FCN+D | 55.22 | 65.57 |
| MSDB-FCN+DB | 56.35 | 66.50 |
| Method | Mean IoU(%) | Mean Acc.(%) |
|---|---|---|
| ResNet50+CE | 51.04 | 58.98 |
| ResNet50+FL | 53.54 | 62.77 |
| ResNet50+MCB-FL | 54.87 | 67.00 |
| Method | Mean IoU(%) | Mean Acc.(%) |
|---|---|---|
| ResNet50 () | 53.54 | 62.77 |
| ResNet50 () | 55.01 | 66.10 |
| ResNet50 () | 54.87 | 67.00 |
| ResNet50 () | 53.85 | 67.63 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHand Gesture Recognition Systems · Advanced Neural Network Applications · Human Pose and Action Recognition
MethodsFocal Loss
Multi-Scale Dual-Branch Fully Convolutional Network for Hand Parsing
Yang Lu
Beihang University
Xiaohui Liang
Beihang University
Frederick W. B. Li
University of Durham
Abstract
Recently, fully convolutional neural networks (FCNs) have shown significant performance in image parsing, including scene parsing and object parsing. Different from generic object parsing tasks, hand parsing is more challenging due to small size, complex structure, heavy self-occlusion and ambiguous texture problems. In this paper, we propose a novel parsing framework, Multi-Scale Dual-Branch Fully Convolutional Network (MSDB-FCN), for hand parsing tasks. Our network employs a Dual-Branch architecture to extract features of hand area, paying attention on the hand itself. These features are used to generate multi-scale features with pyramid pooling strategy. In order to better encode multi-scale features, we design a Deconvolution and Bilinear Interpolation Block (DB-Block) for upsampling and merging the features of different scales. To address data imbalance, which is a common problem in many computer vision tasks as well as hand parsing tasks, we propose a generalization of Focal Loss, namely Multi-Class Balanced Focal Loss, to tackle data imbalance in multi-class classification. Extensive experiments on RHD-PARSING dataset demonstrate that our MSDB-FCN has achieved the state-of-the-art performance for hand parsing.
1 Introduction
Image parsing aims to segment an image into different semantic regions, providing more information to better understand the content of an image. It can be categorized into two types: scene parsing and object parsing. Scene parsing focuses on analyzing the composition of the entire scene in an image, while object parsing pays more attention on decomposing an object into different parts.
Recently, most researches on object parsing focus on human parsing [13, 6, 28, 14, 23]. Compared to human parsing, hand parsing is more challenging, because of small size, similar textures and heavy self-occlusion of hands. Successful hand parsing techniques have many potential applications, such as hand behavior analysis, sign language recognition and human-machine interaction.
State-of-the-art frameworks for image parsing are mostly based on the Fully Convolutional Networks (FCNs) [19], which have shown excellent performance on several benchmarks. One of the key success factors of these methods is involving multi-scale information [27, 2, 17] or prior knowledge [11, 10, 5]. Multi-scale features are helpful for accurate prediction of ambiguous pixels, by aggregating contextual information from different regions of an image. One way to assemble multi-scale features is using the encoder-decoder structure [17, 3, 29, 4, 16]. After generating the features, some strategies can be used to encode them together. Another approach is using multi-scale pooling strategies [7, 27, 24, 22], such as pyramid pooling. By controlling the pool size of average- or max-pooling, multi-scale features can be obtained. Similarly, embedding some semantic prior knowledge as a guide can also improve the performance of image parsing [11, 10, 5, 23]. Some studies [10, 5] have demonstrated that results can be improved by feeding a coarse-grained result to networks, providing effective contextual clues for a fine-grained parsing.
In this paper, we propose a framework for hand parsing. Different from scene parsing, it is similar to an object parsing task paying more attention to an object itself rather than the category of a scene. Because some background information may become a disturbance to accurate parsing. In contrast to human body, a hand is more complex in structure, smaller in size, comprising many similar textures and heavy in self-occlusion. These properties make hand parsing more challenging.
We therefore design a novel Multi-Scale Dual-Branch Fully Convolutional Network (MSDB-FCN) comprising a parsing branch and a mask branch to better extract multi-scale features of a hand region. The role of the mask branch is to calculate hand position and provide prior information for the parsing branch. In the parsing branch, by extracting features and merging with the prior information of the hand area, the negative impact of background is reduced, which improves the parsing accuracy. Moreover, considering the small size and complex structure of a hand, our MSDB-FCN employs more reasonable pool sizes by using multi-scale pooling to obtain multi-scale features, instead of using the original pyramid pooling strategy. For multi-scale features fusion, we design a new upsampling and context coding structure, namely Deconvolution and Bilinear Interpolation Block (DB-Block), to encode multi-context information of the hand. Compared with using either deconvolution or bilinear interpolation alone for upsampling, the model of using DB-Block gets better results.
On the other hand, the problem of data imbalance between categories significantly magnifies due to the small hand size. In response to such a situation, we propose a Multi-Class Balanced Focal Loss (MCB-FL). Despite using Focal Loss [18] may improve the accuracy of binary classification in some researches, hand parsing is alternatively a multi-class classification task. The parameter used to balance the positive and negative samples in Focal Loss becomes ineffective. Therefore, we generalize Focal Loss, proposing Multi-Class Balanced Focal Loss to balance the weights of different classes.
Our MSDB-FCN achieves the state-of-the-art performance on hand parsing benchmark RHD-PARSING. Our work can make impacts to the computer vision community since some of our techniques and structures can also be embedded in other networks. Our main contributions are:
- •
We propose a novel Multi-Scale Dual-Branch Fully Convolutional Network (MSDB-FCN) for hand parsing tasks. Since MSDB-FCN employs a Dual-Branch architecture to effectively extract the features of a hand region, our network can hence focus on hand parsing rather than processing irrelevant information.
- •
We design a new structure, namely Deconvolution and Bilinear Interpolation Block (DB-Block), for upsampling and context encoding. Compared to either applying deconvolution and bilinear interpolation alone, the network using DB-Block can better extract and merge multi-scale information.
- •
For tackling data imbalance in multi-class classification, such as image parsing and semantic segmentation, we propose Multi-Class Balanced Focal Loss to balance the weights of different classes.
2 Related Work
Our approach is closely related to the areas of (1) object extraction, (2) multi-scale features aggregation and (3) loss functions for data imbalance.
Object Extraction: Driven by the development of Convolutional Neural Networks (CNNs), researches on many computer vision tasks, such as object detection, semantic segmentation and pose estimation, have achieved remarkable success. For some specific tasks, object extraction may be required. Methods of [14, 15] combined object detection network for accurate segmentation. In [30], a network for segmentation was employed to extract the region of a hand. Yet these approaches did not make full use of the information extracted by the network, causing a large number of redundant calculations. Our MSDB-FCN employs a mask branch to calculate the position of a hand area, providing prior information to the parsing branch. The mask branch is a small subnet embedded in the network, which avoids repeated computation of feature extraction. Compared with the aforementioned methods, the structure of our model is more complete.
Multi-Scale Features Aggregation: Multi-scale features have been shown to significantly improve the performance of networks to perform many computer vision tasks. A number of researches recently focus on investigating methods to obtain and encode multi-scale features. One way is to use an encoder-decoder structure. Chen [3] used a GlobalNet to generate multi-scale features and a RefineNet to encode them. Lin [16] proposed a method of feature fusion in pairs. Lin [17] designed a multi-path RefineNet network to generate high-resolution semantic feature maps. Another way is to employ multi-scale pooling strategies, such as pyramid pooling. By controlling the pool size, we can gain features of different scales. He [7] proposed spatial pyramid pooling for visual recognition. Zhao [27] extended the approach and designed PSPNet for scene parsing task. Yang [24] adjusted the pool size and designed a bidirectional structure to aggregate multi-scale features. Our work considers the difference of hand parsing from scene parsing. We then choose suitable pooling sizes and design a novel structure for upsampling and feature coding. Our model achieves better performance than using either deconvolution or bilinear interpolation alone.
**Loss Function for Data Imbalance: ** Problems of data imbalance are often encountered in computer vision tasks. In order to balance different samples, Shrivastava [21] proposed Online Hard Example Mining (OHEM), but it only handled on easy samples. Class Balanced Loss solved class imbalance by calculating the loss of positive and negative samples separately and using weights to balanced them. Focal Loss proposed by He [18] has been shown great success in object detection, which balances the weights of different classes and samples. However, Focal Loss is only effective in binary classification. In multi-class classification, such as image parsing or semantic segmentation, the parameter used in Focal Loss to solving class imbalance becomes ineffective. In this paper, we propose a Multi-Class Balanced Focal Loss to enable multi-class classification, overcoming the limitation of Focal Loss.
3 Analysis of Hand Parsing Tasks
Comparing with generic object parsing tasks, hand parsing is more challenging due to its smaller size, complex structure, ambiguous textures and a large number of self-occlusion. In this section, we use human parsing as a comparison and further analyze the characteristics and challenges of hand parsing tasks.
We analyze the statistics of RHD-PARSING and some human parsing datasets. As in Figure 3, comparing with human body, hand generally contributes a much smaller portion of an image. Hence, it is easy to be ignored by a network. Figure 4 shows the number of segment categories required in existing human body (PASCAL-Person-Part, ATR, and LIP) and hand (RHD-PARSING) parsing datasets. In general, hand parsing requires more categories to be segmented, which means each hand part is extremely small in size. These two characteristics, namely small in part size and large in number of categories, make accurate hand parsing difficult to achieve. Figure 5 depicts the distribution of different hand parts in RHD-PARSING, indicating the proportion of some parts are imbalanced. Furthermore, as textures of the whole hand are very similar, it is typically difficult to distinguish the boundaries between different parts. Also, difficulty of parsing escalates further due to the existence of a large number of self-occlusion of hand.
A successful algorithm for hand parsing tasks must take into account some hand features. That is why generic image parsing and semantic segmentation methods cannot parse hand effectively, as they put excessive attention on the whole image instead, resulting in extracting significant amount of irrelevant information, such as the background. Our MSDB-FCN employs a novel architecture to perform well on hand parsing tasks, which will be introduced in details in Sec. 4.
4 Multi-Scale Dual-Branch Fully Convolutional Network
As depicted in Figure 2, our proposed MSDB-FCN employs a Dual-Branch structure to better extract the features of hand area. With such a novel structure, our model can therefore pay more attention on the hand itself. We also incorporate a new structure, namely Deconvolution and Bilinear Interpolation Block (DB-Block), for upsampling and feature coding, gaining excellent results. In addition, we generalize Focal Loss to a Multi-Class Balanced Focal Loss for performing multi-class classification tasks. With all of the above, our method achieves the start-of-the-art performance for hand parsing. We describe our Dual-Branch structure, DB-Block and Multi-Class Balanced Focal Loss with details in Sec. 4.1, 4.2 and 4.3, respectively.
4.1 Dual-Branch Structure
As noted previously, scene parsing pays attention to all the components of an image, while object parsing, like hand parsing, focuses more on the object itself. For object parsing, background information is not helpful and may even induce negative impact to the parsing results. For instance, some of the latest methods for image parsing do not perform well on hand parsing tasks, because a large number of background features is extracted, which confuses the results. Therefore, we design a Dual-Branch structure to locate the position of hand in feature maps and all of the subsequent operations are performed around this area. This allows our network obtaining more useful information for representing a hand.
The mask branch is a subnet for segmenting the hand, and by using the same features from a pre-trained backbone model, the parameters of the whole network will not be increased too much. The architecture of mask branch is illustrated in Figure 6. In addition, our mask branch also provides prior knowledge, such as background or hand, left or right, to the parsing branch by feature fusion. The parsing branch aggregates features from different stages of the backbone model to generate bigger and finer feature maps. With the position information from the mask branch, the features of hand area are cropped and resized to a fixed size. In order to gain more contextual information, we employ a multi-scale pooling strategy, which is same as that in [24], to get multi-scale features. We denote the features as , and they are encoded in the following structures. After getting the parsing result of hand area, the parsing branch reconstructs it into the original image size.
4.2 Deconvolution and Bilinear Interpolation Block
Figure 7 shows the structure of our Deconvolution and Bilinear Interpolation Block (DB-Block), which is used to perform upsampling and feature coding. In many existing works, deconvolution and bilinear interpolation are the mostly used upsampling methods. The advantage of deconvolution is that the parameters can be learned, restoring more image details. In contrast, with bilinear interpolation, intermediate values can be generated by the results of the permutation of surrounding values, while some lost information will not be recovered. Therefore, when processing from low to high resolution images, main information of the image can be better preserved. Inspired by [9], we design a structure to combine the advantages of deconvolution and bilinear interpolation. With a residual connection, the features from the deconvolution layer and the interpolation layer are weighted together. The feature map of the -th scale can be computed below:
[TABLE]
where denotes the feature maps generated by the DB-Block, ans represent the combination weights. and denote the resizing feature maps by deconvolution and bilinear interpolation, respectively.
The updated feature maps are then merged together to generate the final feature representation as follows:
[TABLE]
where is the weight of the -th scale. By combining Eq. 1 and Eq. 2, the above formula becomes:
[TABLE]
where and are the products of multiplying and , respectively. All weighting processes are implemented by using convolution layer, whose parameters can be learned.
4.3 Multi-Class Balanced Focal Loss
Data imbalance, such as class imbalance and sample imbalance, is a common problem in many computer vision tasks. Class imbalance refers to a large gap between the number of samples of different classes. Sample imbalance means that different samples have different classification difficulties. In hand parsing tasks, data imbalance is obvious, constituting of the imbalance between background and hand as well as the imbalance between different hand parts.
Focal Loss [18] has shown significant success in binary classification, which can be expressed as:
[TABLE]
where is used to balance positive and negative classes, where the weight of positive and negative classes are and , respectively. And the role of is to balance the samples with different difficulties. However, when dealing with multi-class classification, having only one parameter becomes insufficient, because it is incapable to give a unique weight for each different class.
To cope with data imbalance in multi-class classification, we propose a Multi-Class Balanced Focal Loss. It extends Focal Loss to cover various semantic segmentation related tasks. The definition of Multi-Class Balanced Focal Loss is as follows:
[TABLE]
where refers to the probability of the -th pixel belonging to the class , and is the probability obtained from the ground truth. represents the percentage of pixels belonging to class in the image, which can be obtained easily as follows:
[TABLE]
where is the total number of pixels of class in the image. After adding a factor , the parameter in Focal Loss becomes an exponential function , where is a positive real constant. As shown in Figure 8, classes with larger proportion have smaller weights, and in contrast, the weights of classes with smaller proportion are increased. Moreover, by changing parameter , we can get diverse weighting curves.
5 Experiments
In this section, we depict the dataset and evaluation metrics used, and describe the implementation details of our MSDB-FCN. We then report the results of our model and the comparisons with other state-of-the-art image parsing and semantic segmentation methods.
5.1 Dataset and Evaluation Metrics
**Dataset ** We evaluate our MSDB-FCN on the benchmark dataset for hand parsing: RHD-PARSING. We merge human body into the background in the ground truth of the original dataset RHD [30] and create this new dataset with 32 segmentation masks of hand together with the background for hand parsing tasks. In addition, we merge all parts of left hand and all parts of right hand to obtain segmentation labels with 3 classes. The dataset contains 41258 training images and 2728 testing images, comprising images, parsing labels and segmentation labels.
**Evaluation Metrics ** We use mean pixel accuracy and mean region Intersection over Union as our evaluation metrics.
- •
Mean Accuracy: ,
- •
Mean IoU: ,
where means the number of pixels of class which are predicted to be class , represents the number of parsing classes and is the total number of pixels of class .
5.2 Implementation
**Network Architecture ** We implement our approach on platform Keras with tensorflow as the backend. We use ResNet-50 as proposed by He [8] to be the pre-trained model. To ensure the last three stages of ResNet-50 have the same resolution, we adopt the dilated convolution strategy [26]. Our mask branch is a segmentation subnet with 5 convolution layers, 1 transposed convolution layer and 1 upsampling layer. The result of segmentation is used to calculate the location of hand, facilitating the extraction of features of hand region. For generating multi-scale features, we employ the same pool sizes of pyramid pooling as in [24] for our parsing branch. After feature fusion based on DB-Block, the multi-scale features are encoded together to generate the final result.
**Training Details ** The resolution of the input image is pixels. The whole training process of MSDB-FCN is divided into two stages. Firstly, we use the dataset with segmentation labels to train the mask branch. Subsequently, the dataset with parsing labels is employed to train the parsing branch. We choose Adam as the optimizer and the learning rate is set to . To reduce overfitting, methods for data augmentation are used, including random brightness, random channel shift and random contrast with probability of , and , respectively. All experiments are conducted on a single Nvidia Titan X Pascal GPU.
5.3 Results and Comparisons
We conduct ablation analysis to evaluate the contribution of diverse elements of our MSDB-FCN, including the Dual-Branch architecture, DB-Block and the Multi-Class Balanced Focal Loss. We also compare with state-of-the-art approaches of image parsing and semantic segmentation on RHD-PARSING dataset.
**Ablation Analysis for Dual-Branch Architecture ** The mask branch helps the network focus on the region of hand, and reduce the influence of background. The parsing branch uses multi-scale pooling strategy to generate multi-scale features and employs DB-Block to encode contextual information of different scales. In order to evaluate the effect of this Dual-Branch architecture, we compare the results of the model with different settings. As shown in Table 1, with parsing branch, the Mean IoU of our model improves and the Mean Accuracy improves compared with the baseline. And with the whole Dual-Branch architecture, our MSDB-FCN achieves improvement of Mean IoU and improvement of Mean Accuracy.
Ablation Analysis for DB-Block Architecture Our MSDB-FCN employs DB-Block for upsampling and encoding multi-scale contextual information. By a residual connection and convolution, the results of deconvolution and bilinear interpolation for upsampling are weighted and merged. As shown in Eq. 3, the features of different scales are encoded with diverse weights. In order to evaluate the effect of our DB-Block, we replace it by deconvolution and bilinear interpolation respectively. As shown in Table 2, the MSDB-FCN with DB-Block achieves better performance, which improves of Mean IoU and of Mean Accuracy on average.
**Ablation Analysis for Multi-Class Balanced Focal Loss ** In many computer vision tasks, data imbalance is a common problem. Although Focal Loss is good at binary classification, it is ineffective for multi-class classification tasks, such as image parsing and semantic segmentation, because the parameter used to balance positive and negative classes becomes irrelevant. Our Multi-Class Balanced Focal Loss generalizes Focal Loss to solve data imbalance in multi-class classification tasks. We compare the results on baseline model with diverse loss functions, including categorical cross entropy loss, Focal Loss and our Multi-Class Balanced Focal Loss, which are shown in Table 3. Compared with the model using categorical cross entropy loss, models with Focal Loss and Multi-Class Balanced Focal Loss have significantly improved the parsing performance. The model with our loss achieves improvement of Mean IoU and improvement of Mean Accuracy comparing with model using Focal Loss. To find the best weighting curve for hand parsing, we experiment with setting to different values. As shown in Table 4, in combination with Mean IoU and Mean Accuracy, we find that works the best.
**Comparisons with Other Methods **
We compare the proposed method with other leading image parsing and semantic segmentation methods on RHD-PARSING dataset. As shown in Table 5, our MSDB-FCN is more effective for hand parsing tasks and achieves the state-of-the-art performance. However, some approaches which are successful in scene parsing and semantic segmentation do not achieve satisfactory results. For further comparison, Figure 9 depicts hand parsing results from images, which comprise complex background, heavy self-occlusion and small size of hand, by running existing and our methods. Obviously, existing methods generally perform badly, producing results with incorrect hand part classification, missing hand details and mis-classification of part of the background as hand parts. This is mainly due to the excessive attention to the whole image. Object parsing, especially in small object parsing, should pays more attention to the object itself, since the large amount of background information does not contribute anything relevant. Therefore, some strategies, which extract multi-scale context of the whole image, are usually ineffective. In contrast, our method outperforms existing methods and can generate hand parsing results well matching with the ground truths.
6 Conclusion
We have proposed a novel parsing framework, called MSDB-FCN, for hand parsing tasks. Our MSDB-FCN employs a Dual-Branch architecture, including a mask branch and a parsing branch, to accurately extract the features of hand region, which makes the network pays more attention to the hand rather than other background information. To better encode the multi-scale features, we use DB-Block for upsampling and feature fusion. The DB-Block combines the advantages of Deconvolution and Bilinear Interpolation and employs a residual connection and convolution to merge the results with different weights. On the other hand, data imbalance is a common problem in many computer vision tasks as well as in hand parsing. We have extended Focal Loss to propose the Multi-Class Balanced Focal Loss for image parsing and semantic segmentation. Using such a loss in the network, our MSDB-FCN achieves the state-of-the-art performance in hand parsing tasks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. Co RR , abs/1511.00561, 2015.
- 2[2] L. Chen, G. Papandreou, F. Schroff, and H. Adam. Rethinking atrous convolution for semantic image segmentation. Co RR , abs/1706.05587, 2017.
- 3[3] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun. Cascaded pyramid network for multi-person pose estimation. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018 , pages 7103–7112, 2018.
- 4[4] H. Ding, X. Jiang, B. Shuai, A. Q. Liu, and G. Wang. Context contrasted feature and gated multi-scale aggregation for scene segmentation. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018 , pages 2393–2402, 2018.
- 5[5] H. Fang, G. Lu, X. Fang, J. Xie, Y. Tai, and C. Lu. Weakly and semi supervised human body part parsing via pose-guided knowledge transfer. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018 , pages 70–78, 2018.
- 6[6] K. Gong, X. Liang, D. Zhang, X. Shen, and L. Lin. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017 , pages 6757–6765, 2017.
- 7[7] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part III , pages 346–361, 2014.
- 8[8] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016 , pages 770–778, 2016.