Implicit Label Augmentation on Partially Annotated Clips via Temporally-Adaptive Features Learning
Yongxi Lu, Ziyao Tang, Tara Javidi

TL;DR
This paper introduces Temporally-Adaptive Features learning, a novel method that leverages partially annotated video clips to improve single frame model accuracy by applying temporal change constraints, outperforming prior techniques.
Contribution
The paper proposes TAF, a new principled approach for implicit label augmentation using temporal constraints, enhancing single frame models from partially annotated clips.
Findings
TAF improves semantic segmentation accuracy across multiple architectures.
Empirical results show significant gains over previous methods.
TAF generalizes slow feature learning with stronger empirical support.
Abstract
Partially annotated clips contain rich temporal contexts that can complement the sparse key frame annotations in providing supervision for model training. We present a novel paradigm called Temporally-Adaptive Features (TAF) learning that can utilize such data to learn better single frame models. By imposing distinct temporal change rate constraints on different factors in the model, TAF enables learning from unlabeled frames using context to enhance model accuracy. TAF generalizes "slow feature" learning and we present much stronger empirical evidence than prior works, showing convincing gains for the challenging semantic segmentation task over a variety of architecture designs and on two popular datasets. TAF can be interpreted as an implicit label augmentation method but is a more principled formulation compared to existing explicit augmentation techniques. Our work thus connects two…
Click any figure to enlarge with its caption.
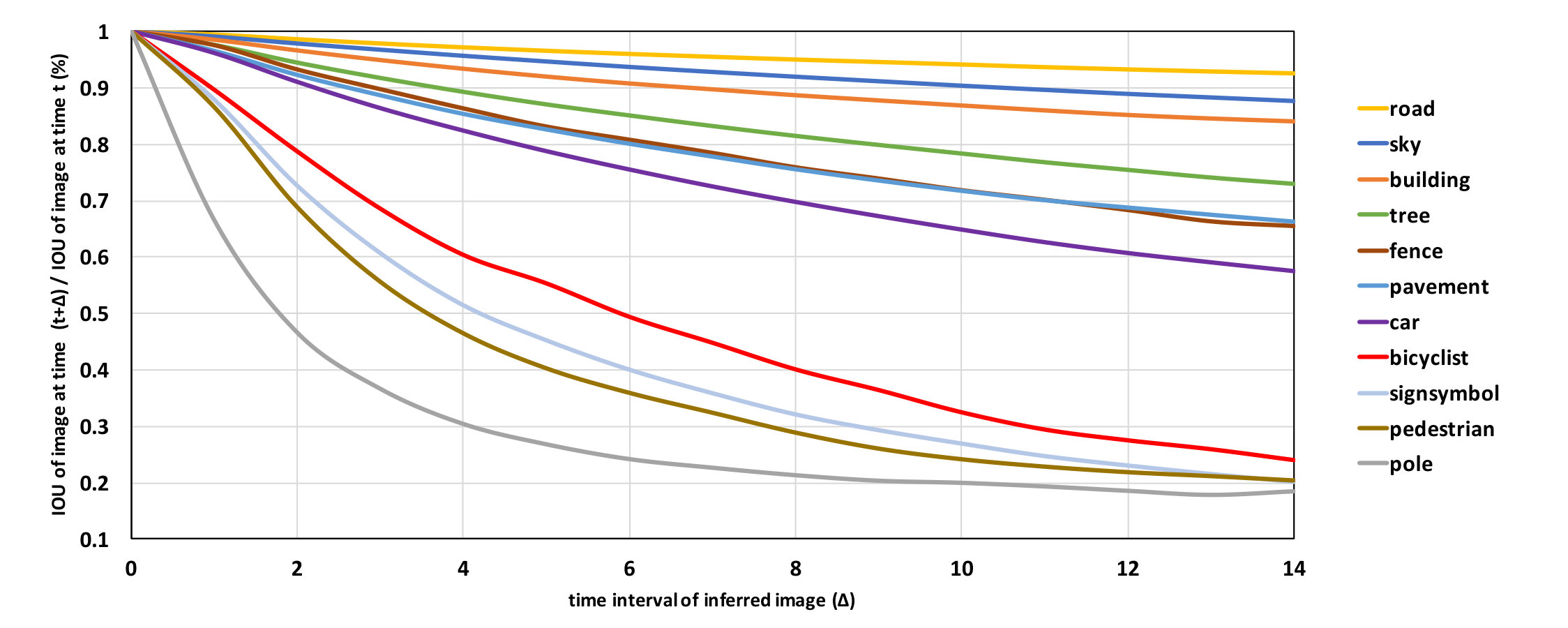 Figure 1
Figure 1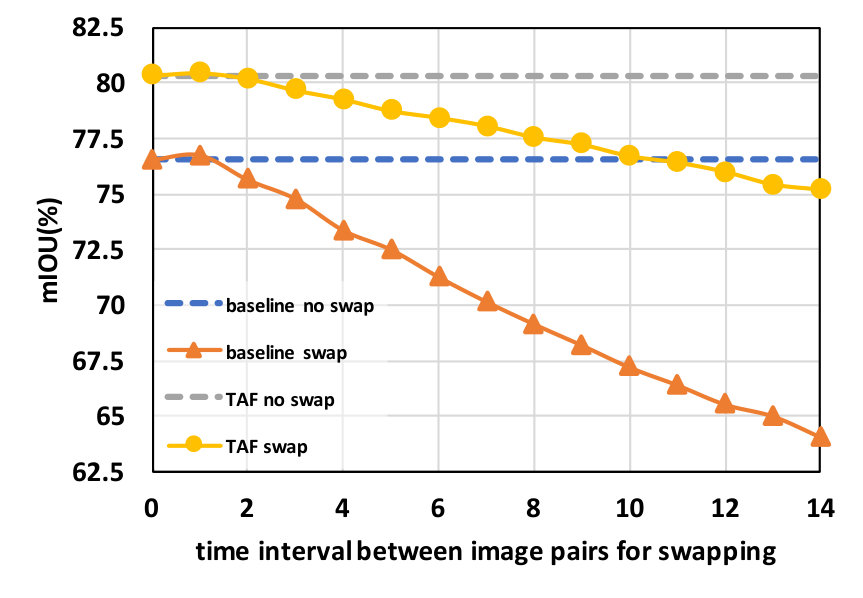 Figure 2
Figure 2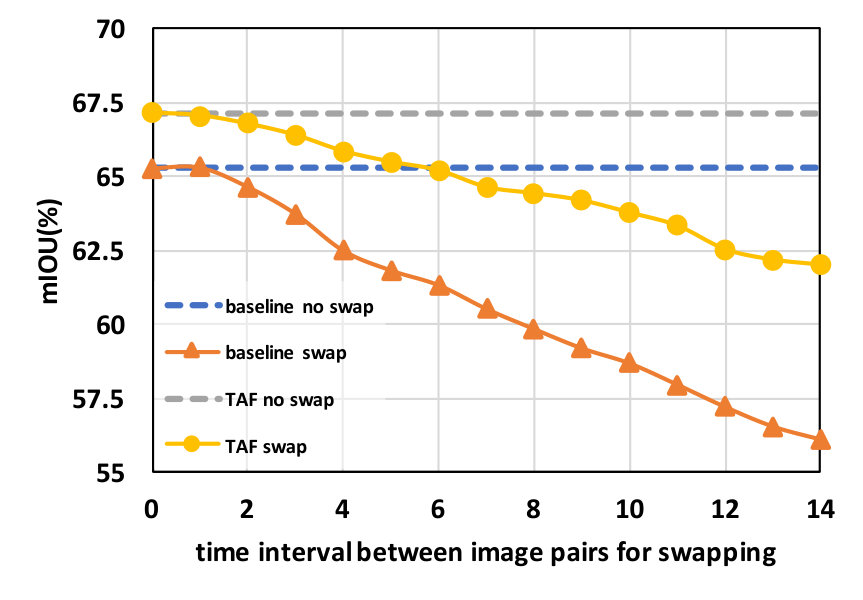 Figure 3
Figure 3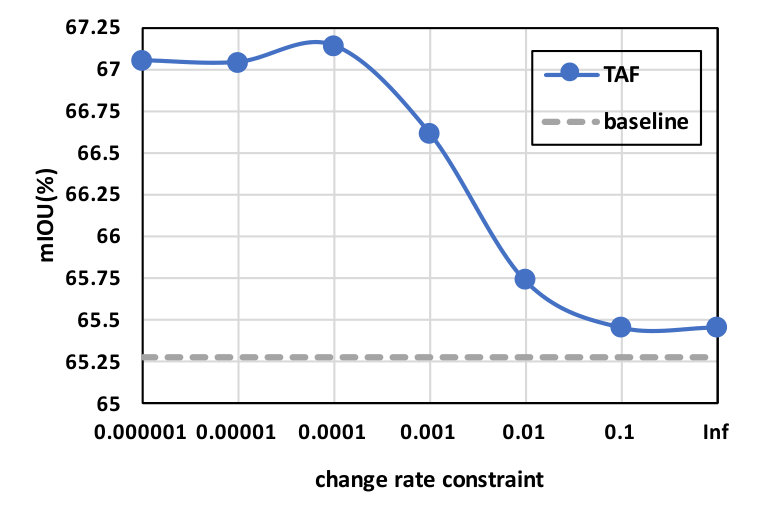 Figure 4
Figure 4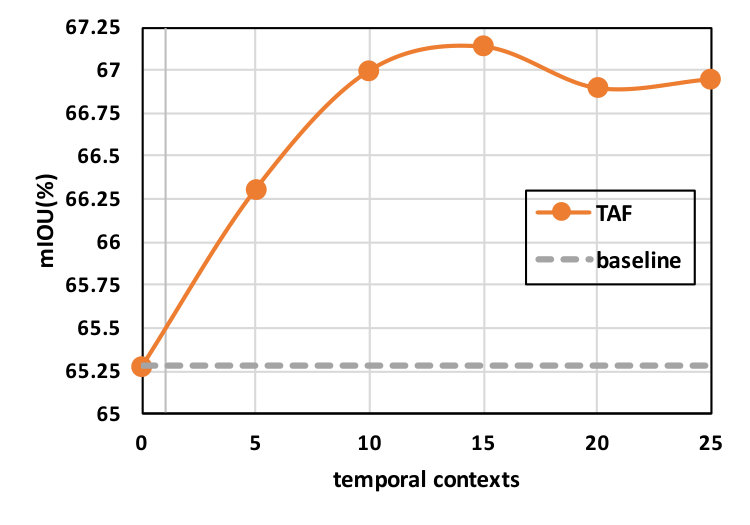 Figure 5
Figure 5 Figure 6
Figure 6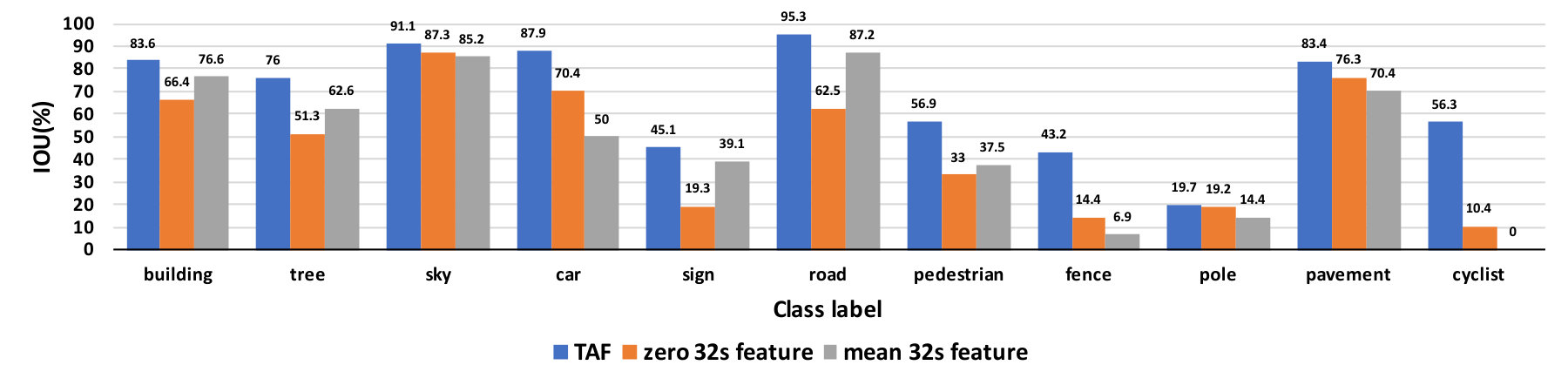 Figure 7
Figure 7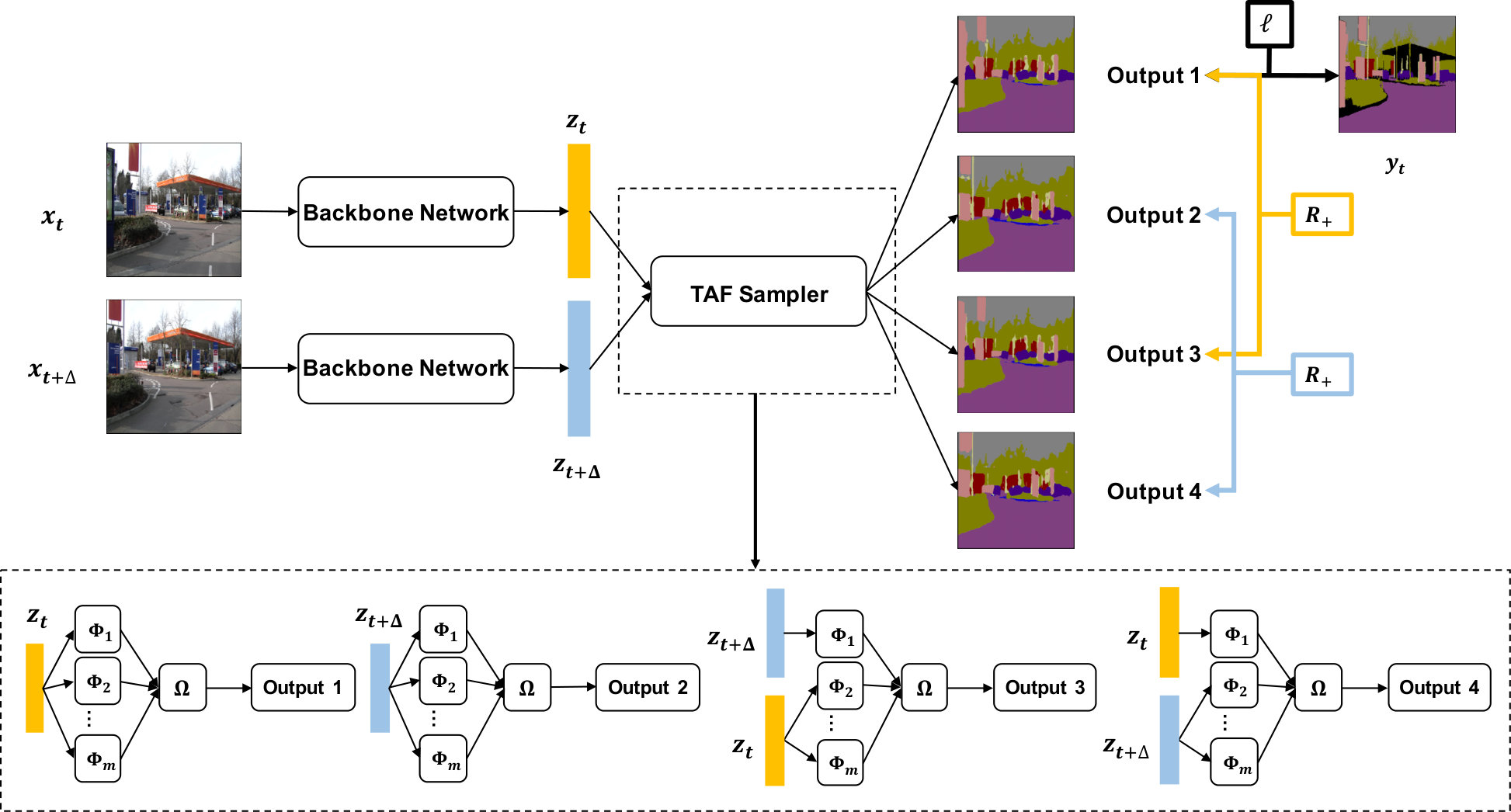 Figure 8
Figure 8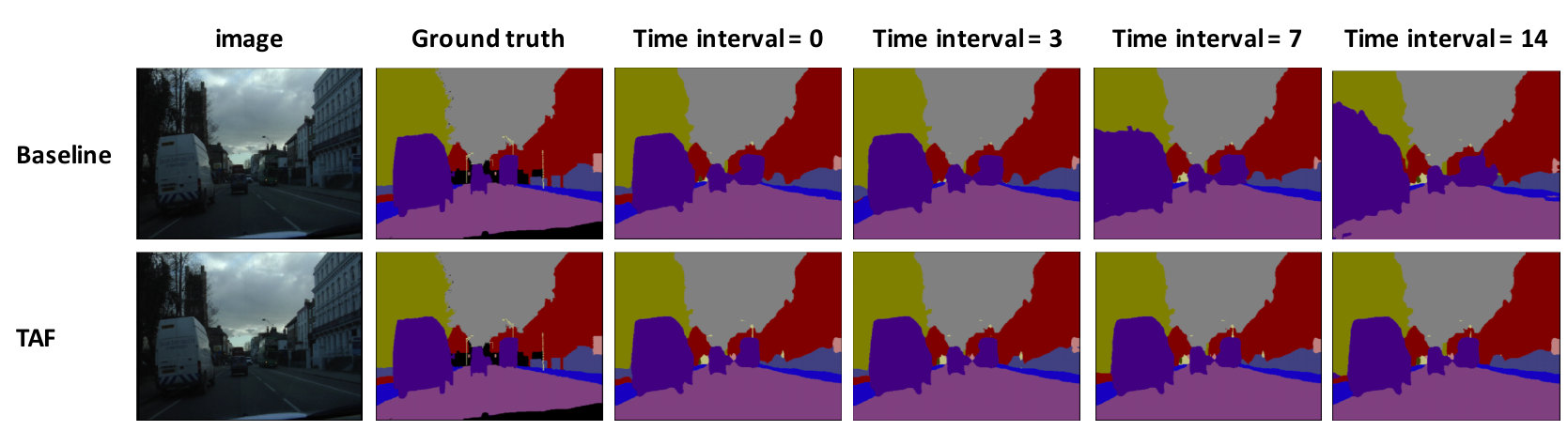 Figure 9
Figure 9| Method | Output stride | Training set | Backbone | TAF | mIOU () | Pixel acc. () |
|---|---|---|---|---|---|---|
| Camvid test set | ||||||
| FCN8s | 8,16,32 | Camvid | ResNet-50 | |||
| FCN8s | 8,16,32 | Camvid | ResNet-50 | ✓ | ||
| DeepLabV3+ | 16 | Camvid | MobileNetV2 | |||
| DeepLabV3+ | 16 | Camvid | MobileNetV2 | ✓ | ||
| DeepLabV3+ | 16 | Camvid | ResNet-50 | |||
| DeepLabV3+ | 16 | Camvid | ResNet-50 | ✓ | ||
| Cityscapes validation set | ||||||
| DeepLabV3+ | 16 | CS-0.2 | MobileNetV2 | |||
| DeepLabV3+ | 16 | CS-0.2 | MobileNetV2 | ✓ | ||
| DeepLabV3+ | 16 | CS-0.2 | ResNet50 | |||
| DeepLabV3+ | 16 | CS-0.2 | ResNet50 | ✓ | ||
| DeepLabV3+ | 16 | CS-0.5 | MobileNetV2 | |||
| DeepLabV3+ | 16 | CS-0.5 | MobileNetV2 | ✓ | ||
| DeepLabV3+ | 16 | CS-0.5 | ResNet50 | |||
| DeepLabV3+ | 16 | CS-0.5 | ResNet50 | ✓ | ||
| Method | Training set | Backbone | TAF | Init. lr | Init. Img size | Crop size | Epoch | Val size | |
| FCN8s | Camvid | ResNet-50 | 0.02 | N/A | 600 | ||||
| FCN8s | Camvid | ResNet-50 | ✓ | 0.02 | 1.0 | 600 | |||
| DeepLabV3+ | Camvid | MobileNetV2 | 0.02 | N/A | 600 | ||||
| DeepLabV3+ | Camvid | MobileNetV2 | ✓ | 0.05 | 1.0 | 600 | |||
| DeepLabV3+ | Camvid | ResNet-50 | 0.02 | N/A | 600 | ||||
| DeepLabV3+ | Camvid | ResNet-50 | ✓ | 0.05 | 0.5 | 600 | |||
| DeepLabV3+ | CS-0.2 | MobileNetV2 | 0.02 | N/A | 300 | ||||
| DeepLabV3+ | CS-0.2 | MobileNetV2 | ✓ | 0.05 | 1.0 | 300 | |||
| DeepLabV3+ | CS-0.2 | ResNet50 | 0.02 | N/A | 300 | ||||
| DeepLabV3+ | CS-0.2 | ResNet50 | ✓ | 0.05 | 1.0 | 300 | |||
| DeepLabV3+ | CS-0.5 | MobileNetV2 | 0.02 | N/A | 300 | ||||
| DeepLabV3+ | CS-0.5 | MobileNetV2 | ✓ | 0.02 | 1.0 | 300 | |||
| DeepLabV3+ | CS-0.5 | ResNet50 | 0.01 | N/A | 300 | ||||
| DeepLabV3+ | CS-0.5 | ResNet50 | ✓ | 0.01 | 1.0 | 300 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Analysis and Summarization · Music and Audio Processing · Vehicle License Plate Recognition
Implicit Label Augmentation on Partially Annotated Clips via Temporally-Adaptive Features Learning
Yongxi Lu Ziyao Tang Tara Javidi
University of California, San Diego
{yol070, zit021, tjavidi}@eng.ucsd.edu
Abstract
Partially annotated clips contain rich temporal contexts that can complement the sparse key frame annotations in providing supervision for model training. We present a novel paradigm called Temporally-Adaptive Features (TAF) learning that can utilize such data to learn better single frame models. By imposing distinct temporal change rate constraints on different factors in the model, TAF enables learning from unlabeled frames using context to enhance model accuracy. TAF generalizes “slow feature” learning and we present much stronger empirical evidence than prior works, showing convincing gains for the challenging semantic segmentation task over a variety of architecture designs and on two popular datasets. TAF can be interpreted as an implicit label augmentation method but is a more principled formulation compared to existing explicit augmentation techniques. Our work thus connects two promising methods that utilize partially annotated clips for single frame model training and can inspire future explorations in this direction.
1 Introduction
The success of modern machine learning techniques in solving challenging problems such as image recognition depends on the availability of large-scale, well-annotated datasets. Unfortunately, the most complex and useful tasks (e.g. semantic segmentation) are usually also the ones that require the most labeling efforts. This is arguably a major obstacle for large-scale applications to real-world scenarios, such as autonomous driving, where model performance is critical due to safety concerns. In this work, we focus on methods that can utilize partially annotated clip data, more precisely short video sequences with annotations only at key frames, to improve model performance. Datasets in this format are natural byproducts of typical data collection procedures. From clips, a large number of unlabeled frames is available at virtually no additional cost. But clip data can nevertheless encode rich temporal contexts useful for training more accurate models. Fully utilizing partially annotated clips in learning is an interesting problem not only for its practical relevance, but also because it provides partial answers to an interesting scientific question: Humans can naturally learn from continuous evolution of sensing signals without much “labels”, can machines do the same?
We investigate a particularly intriguing case: To train a model that benefits from temporal information during training but is used to make predictions on independent frames at inference. This is in contrast to video prediction models [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] where video clips are used at both training and inference. The main intuition of our approach is to decouple fast-changing factors and slow-changing factors in data. Fast-changing factors reflect rapid temporal dynamics and can only be learned from a labeled frame or its immediate neighbors, while slow-changing factors can be learned from data points within a larger temporal context. Our method utilizes the temporal context provided by the partially annotated clips to learn better features without diminishing the ability to learn fine-grained features with rapid temporal changes. This is achieved by allowing different parts of the model to adapt to distinct temporal change rates in data, a.k.a. Temporally Adaptive Features (TAF) learning. We propose a principled approach to formalize this intuition by introducing temporal change rate constraints in the learning problem and show that the resultant optimization problem can be efficiently approximated by a feature swapping procedure with contrastive loss. The TAF paradigm generalizes the well-motivated “slow feature” learning methods [11, 12] for self-supervised learning. In this regard, ours is the first to demonstrate significant empirical gains on a challenging real-world application via imposing temporal coherence regularization. It can also be seen as a form of implicit label augmentation and is related to explicit pseudo label generation techniques [13, 14, 15, 16] which also show promising improvements in practice. But ours is a more principled treatment that handles the important issue of label uncertainty automatically. Interestingly, our work is the first to combine these two seemingly unrelated line of research. It thus sheds new light on the theory and practice of the important problem of learning from partially annotated clips and can benefit future explorations on this topic.
The TAF framework can in theory be applied to any recognition tasks with partially annotated clip data. However, the advantage in doing so will well depend on the task. We identify semantic segmentation, the task of assigning class labels to every pixel in an image, as a good test case due to the necessity of multi-scale modeling. Natural images usually feature structures with a great variety of sizes, functions and perspectives. This results in different intrinsic spatial and temporal change rates of different structures. A useful semantic segmentation model needs to provide comprehensive understanding of all these different structures. TAF can address this challenge by allowing different parts of the model to learn features with varying temporal change rates, rather than forcing all the features to vary slowly, as is the case of slow feature learning [11, 12]. Beyond this particular task, semantic segmentation is also a good example of the broader set of “dense prediction tasks” in computer vision, such as object detection [17, 18, 19, 20, 21, 22, 23], pose estimation [24], monocular depth estimation [25, 26, 27, 28, 29, 30], instance segmentation [23, 31, 32, 33] as well as panoptic segmentation [34, 35], to name a few. Dense prediction tasks all share the key properties of laborious annotation and multi-scale features thus it is likely that our finding from semantic segmentation can directly benefit these tasks.
This paper is organized as follows. Section 2 presents our method. Section 3 compares our method to related works. Section 4 presents our empirical findings and ablation studies. Section 5 concludes the paper and discusses future directions.
2 Methods
We first introduce notations useful to our presentation. We denote the dataset as . Each input and its associated labels can be finely indexed as , where denotes the clip index and the time index within the clip, respectively. Whenever it is clear from the context, we use to denote input-label tuples at time for any particular clip.
2.1 Temporally Adaptive Feature Learning
Our method decouples the fast and slow changing factors in data by forcing the model to learn features that are adaptive to the varying temporal change rates. To be applicable to our framework, we assume the labeling function can be factorized as . We can quantify how fast the labeling function changes w.r.t. time by taking its time derivative.
[TABLE]
Note that can be seen as a function with -dimensional input where represents one of its dimensions. quantifies the variation of w.r.t. time through this dimension. The “fast” and “slow” factors are characterized by the degree at which they contribute to temporal variations in the predictive model . To instantiate this idea, our TAF frameworks solves the following empirical risk minimization problem with temporal change rates constraints.
[TABLE]
For a differentiable model, the analytical form of the constraints is available if is provided. In applications where is a high dimensional vector (such as an image), this may not be possible. Thus, we propose to use first-order finite difference to approximate the constraints via neighboring samples.
[TABLE]
The constrained optimization problem itself is difficult to solve. We can convert it into an unconstrained optimization with the following regularization term which approximate the original constraints. This permits the use of gradient-based solvers if the model is differentiable.
[TABLE]
The proposed regularization is defined on any pairs of samples separated by known interval , even if their labels are unknown. This construction thus enables learning from unlabeled data. Needless to say, TAF learning is limited to short clips as the first order approximation is valid only for small . The slack term promotes features that adapts to a distinct temporal change rate. When is small, that dimension is forced to model slow-changing factors shared within a large temporal context, which is an implicit form of data augmentation. The dimensions with large on the other hand can still model rapid motions in data important for the task. As we will discuss in ablation studies and supplementary materials, and are important hyper-parameters.
As a remark on related methods, we note that Eqns. 4 generalizes the temporal coherence regularization in [11] to multiple change rates, making it more suitable for real-world applications such as semantic segmentation where multi-scale features are essential. This regularization can also be seen as implicitly assuming constant labels across the entire clip, with the slack term acknowledging the uncertainty introduced by this approximation. In this regard, measures the growth rate of uncertainty in time of the implicit pseudo labels. Prior works suggests that properly modeling the uncertainty in pseudo labels to be important in the final task performance [13]. While TAF learning is motivated differently, it leads to a similar construction.
Finally, denotes the subset of the data with annotations, the half-length of each clip is , is the sampling period and denotes the uniform distribution defined on integers. The regularized optimization problem becomes
[TABLE]
2.2 Efficient Frame Sampling
The proposed objective function in Eqns. 5 is computationally inefficient when combined with mini-batch SGD or its variants. First of all, the computation of the sample averages requires two separate sampling streams: One for the key frames with annotations for the loss function, and the other for the regularization term using pairs of frames. In general, there is no ensured overlapping in these two streams of samples. As a result, we usually cannot use features computed from an image to update both terms. This inefficiency is exacerbated by the fact that the regularizer requires pair inputs, making the training even less efficient. Secondly, the regularization term requires separate feature exchanges for each feature dimension. When is large and the model decoupling requires re-computation of a significant portion of the model, this strategy is highly inefficient.
Our proposal is as follows: Within each mini-batch, a set of image-label tuples are first sampled from the annotated key frame subset . Each of these tuples are associated with a clip. Then, for each key frame sampled a random (unlabeled) pairing image is selected from the same clip by sampling the index difference between the key frame and the unlabeled pairing frame. In this improved procedure, all feature computations contribute to all terms in the objective function. To further make use of cached features, the regularization term is also made symmetric. To ensure tractable mini-batch updates, the summation over the dimensions are replaced by a uniform sampling of the dimension index at each training example. The efficient TAF procedure solves the following problem
[TABLE]
where we simplify the notation by assuming that the key frame is always at the center of each clip. Figure 1 illustrates how the training objective is computed between a pair of sampled images.
The number of training iterations of TAF learning is two times of the baseline as only half of the mini-batch have ground truth labels. In order to compute the pair-wise loss, the aggregation function has to be evaluated twice in each forward pass 111The first time using the original features, the second time using features after swapping.. Thus for tractable training, should be chosen to be a lightweight function. Figure 1 illustrates the proposed sampling procedure in the application of semantic segmentation, where we use a Siamese network for the backbone feature extractor and apply the TAF procedure only at the encoder layers (details in Section 2.3).
2.3 Application to Semantic Segmentation
We now provide a brief overview of two of the most popular semantic segmentation models and explain how our framework can be applied. The multi-branch structure that enable TAF learning for FCNs and DeepLab v3+ is used in a broader set of architectures for semantic segmentation [36, 20, 37, 38] and we expect similar modifications to be feasible.
FCNs
Fully convolutional networks (FCNs) [39] is one of the earliest and most popular deep-learning based architecture for semantic segmentation. It follows a straightforward multi-scale design: Feature maps at the output of three different stages of a backbone convolutional network are extracted. Due to the downsampling operators between stages, feature maps have a decreasing spatial resolution (in the case of FCN8s that we consider the output stride equals to 8, 16 and 32, respectively). The features maps are converted into class logits maps via a single layer of convolutions. The three predictions are aggregated via a cascade of upsampling and addition operations. In our modification of FCNs we assign and to represent three feature maps, where represents the stride-32, stride-16 and stride-8 feature maps respectively. The aggregation function is the single convolution layer and the following cascaded addition operations. In practice, we find swapping is sufficient for improved accuracies over the baselines.
DeepLab v3+
DeepLab v3+ [40] is a recent semantic segmentation algorithm that has achieved state-of-the-art accuracy in challenging datasets such as Pascal VOC and Cityscapes. It follows an encoder-decoder structure, where the encoder is an ASPP module [41] that consists of five branches with different receptive fields (modeling structures at different scales): Four branches with varying dilation rates and an additional image pooling branch. Similar in spirit to the FCNs case, we assign to the image pooling branch, and to the remaining branches starting from the one with largest dilation rate. The decoder is the aggregation function in our formulation.
3 Related Works
Regularization and Data Augmentation in Deep Neural Networks
There is a rich literature of generic regularization and data augmentation techniques sharing our goal of improving generalization, e.g. norm regularization [42, 43], reduction of co-adaptation [44, 45, 46] and pooling [47, 48, 49, 49]. For semantic segmentation, data augmentations techniques based on simple image transformations 222such as horizontal flipping, random cropping, random jittering, random scaling and rotation are standard practices. Recently, [50, 51, 52, 53] learn optimal transformations. These techniques are limited by not using video information but are complementary to our approach. We follow the default choice of regularization and random transformations when comparing TAF learning with corresponding baselines. Another effective solution is to use generative models for data and label synthesis [54, 55, 56, 57]. Similar to ours, these methods can improve model accuracy using unlabeled data. However, it could be intrinsically difficult to generate realistic and diverse data for complicated applications, while our method can directly utilize the large amount of real video clips.
Single Image and Video Semantic Segmentation
We use semantic segmentation [40, 41, 39, 36, 37, 58, 38] as an example to verify our method as discussed in Section 3. Importantly, our method is quite different from the related literature of video semantic segmentation [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], where video clips are utilized at both training and inference. Our work learns models using video clips at training, but the model can be used on independent frames at inference. In semantic segmentation, unlabeled frames can be used via future frame predictions [7, 8, 9, 10, 59] and label propagation [13, 14]. The former is only shown to improve video prediction results but not on single image predictions (as expected as future frame prediction is difficult from a single frame due to the lack of temporal context at test time). A few preliminary works suggest the latter can bring promising improvements to single frame predictions by generating pseudo labels [13, 14, 15, 16]. But video propagation notably relies on manual screening and careful hyper-parameter tuning to reject low quality labels [13], otherwise it could surprisingly lead to performance degradation after including pseudo-labels in some cases [14]. Our method has the advantage of not requiring manual intervention. More importantly, our work suggests that regularizing the temporal behavior of features is an implicit form of video augmentation without explicit modeling of temporal dynamics, which compared to video propagation is a simpler pipeline and could be more transferable to other tasks.
Self-Supervised Learning
Self-supervised learning utilizes the large amount of unlabeled data via carefully designed “pretext” tasks or constraints that aim at capturing meaningful real-world invariance structures in the data. The goal is to learn more robust features. Future frame prediction [9, 10, 59, 8, 7], patch consistency via tracking [6], transitive invariance [60], temporal order verification [61] and motion consistency [62, 63, 64] have been proposed as useful pretext tasks. Recently, consistency across tasks are also explored [65, 66], although these methods do not consider videos. However, as pretext tasks usually differ from the target task, a separate transfer learning step is required. Ours in contrast can be used directly on the target task. Via imposing geometric constraints, several recent works use self-supervised learning to directly address real-world tasks, most notably in depth and motion predictions [29, 25, 67, 67, 68, 28, 69, 26]. However, these methods cannot transfer easily outside of their intended geometry application. Among them, SIGNet [68] points to a unified framework for self-supervised learning of both semantic and geometric tasks which would broaden the applications of this line of works, but the existing work can only improve on geometric tasks. In contrast, TAF is not restricted to any particular task by design. Our TAF framework generalizes the temporal coherence regularization in [11, 12] to multiple change rates and is the first to validate the utility of this form of regularization on challenging real-world applications. In contrast, the prior works focus on theoretical insights and are not rigorously validated.
4 Experiments
4.1 Datasets and Evaluation Metrics
We test our approach on two widely-used datasets for semantic segmentation: Camvid [70] and Cityscapes [71]. The images of both datasets are frames captured from videos. Detailed annotations are provided on key frames. The meta-data of the datasets include the source frame ids of the annotated frames which makes unlabeled frames within the same clips available. The availability of unlabeled frames in the said clip format makes these two datasets ideal for testing our TAF framework. In particular, Camvid consists of 367 clips for training and 101/233 images for val/test. Key frames from training and test set are captured at 1Hz and annotated with 11 object classes. We capture extra frames around the key frames at 30Hz using the provided raw video. Cityscapes consists of 2975 training key frames and 500 validation images. The key frames are the 20-th frames in the provided 30-frame clips (30Hz) annotated with 19 object classes. In the interest of fast experimentation and to test our methods on small datasets, we sample 20% and 50% of the clips from Cityscapes training set, creating customary datasets with 595 and 1488 training clips respectively. We follow standard evaluation protocols and report mIOU and pixel accuracy on the held-out set.
4.2 Comparison to Baselines
To understand the advantage of the proposed method, we train FCNs and DeepLab v3+ models using the TAF learning paradigm on partially labelled clips and compare against fully supervised training using only key frames, on both Camvid and Cityscapes dataset. We use mean-average-error (L1 norm) for the contrastive loss as it is a common choice of image applications 333This choice is also discussed in the supplementary material. We find it important to first normalize the per-pixel prediction via softmax function to avoid learning degenerate features. Our training hyper-parameters are detailed in the supplementary material. We ensure to use a comparable set of hyper-parameters for both the baseline and our method whenever is applicable. For FCN8s, we show results for performing feature swapping only on the stride-32 branch as this leads to better accuracy, while for DeepLab v3+ all branches are swapped with equal probabilities. Our main results are summarized in Table 1. The main finding is that our method improves over the respective baseline methods using both segmentation algorithms and on both datasets. We note that TAF learning only affects the training time procedures. At inference time models from TAF has exactly the same complexity as the baselines, ensuring that the improvements from TAF is not resultant from increased complexity.
4.3 Ablation Studies
To further understand the proposed method, we perform ablation studies on Camvid dataset using FCN8s models trained with TAF. Feature swapping is only performed on the stride-32 branch for simplicity. We choose to perform ablation studies on this model as its simple design can lead to clearer insights. We use and the half size of each data clip (a.k.a. length of temporal context) to unless specified otherwise in particular studies.
Study on Change Rates Constraint
In our formulation controls change rates of a particular feature dimension. It is interesting to observe the model performance as a function of as this directly informs us on whether the change rate constraint is effective or not. When is [math], the feature dimension in question will be forced to stay constant across frames. This should force it to learn features that are not informative to the final prediction, effectively reducing the model capacity and consequently, the prediction accuracy. On the other hand, as goes to infinity the regularization term is effectively ignored, leading to sub-optimal results if the proposed regularization is indeed effective. Our finding as summarized in Figure 3 is as expected, verifying that the temporal change rate constraints are not trivially imposed.
Study on Temporal Context
Temporal context refers to how far apart in time a pair of training examples can be. Note that in our derivation, we assume that the pair of frames used in the constraints are sufficiently close. This is important as when the two data points are too far apart, the first order approximation become ineffective. On the other extreme, when setting the temporal context to near zero, the regularization effect is diminished. Results from varying the temporal context are summarized in Figure 3. The mIOU reaches maximum when the temporal context is roughly 15 examples (the same setting used in our main results). Interestingly, while a larger temporal context leads to sub-optimal results, the degradation remains relatively mild, suggesting that precise approximation is not critical.
Study on Feature Swapping
It is particularly interesting to see how the swapping of features between image pairs affects the prediction results. There are two trivial cases that deserve careful consideration: a) If the performance of the model (especially the baseline model) does not show a decrease in accuracy even with feature swapping, then our proposed constraints are not useful as this would suggest a natural tendency for part of the model to learn features that are insensitive to temporal changes. b) If the performance of the model does decrease after feature swapping, but both the baseline model and the TAF models demonstrate similar rate of degradation, then it would cast questions on whether the proposed constraint can actually be successfully imposed in the optimization. Furthermore, whether these constraints imposed on the training set can generalize to a test set. In Figure 4 we show that TAF learning does not result in the aforementioned trivial cases and can indeed generalize to held-out sets. Figure 5 further illustrates the effects of feature swapping.
Study on Feature Attenuation
Constraining the temporal change rate in features could lead to trivial solutions that are not discriminative [11]. In Figure 6 we show the effect of replacing the stride-32 branch either with its sample mean or zeros. The large resultant reduction in per-class accuracy suggests that TAF learning is not producing constant, trivial features as feared. However, this issue can be a function of model architectures and should be investigated further in future works.
5 Conclusion and Future Works
In this work, we propose to learn temporally-adaptive features to utilize partially annotated clips. Our proposed framework has demonstrated convincing gains on the challenging task of semantic segmentation. The ablation studies verify that our approach is learning non-trivial features that reflect the proposed temporal rate change constraints, validating our design choices. Our finding suggests the potential of such constraints in enabling self-supervised learning from clip data. It would be interesting to further validate the utility of this approach in related applications. Dense prediction tasks are natural starting points. Another interesting direction is to explore data-driven metrics, such as perceptual loss [72, 73, 74] and adversarial training [75], in constructing the contrastive loss, replacing the current heuristic choice of L1 norm. It is also interesting to further explore existing ideas from slow feature learning and video propagation (explicit label augmentation) to better model problem structures, which may in return lead to stronger results.
Supplmentary Materials for Implicit Label Augmentation on Partially Annotated Clips via Temporally-Adaptive Features Learning
5.1 Temporal Change Rates of Semantic Classes
We expect different semantic classes to demonstrate different temporal change rates. This as we discussed is a motivation for testing our method on semantic segmentation. To verify it empirically, we compare the predicted segmentation labels at against the ground truth label at . Accuracy are reported using IOU normalized by the prediction accuracy at , as shown in Figure 7. This normalization is necessary as different semantic classes have different intrinsic difficulties. Since labels are not available beyond the key frames, we use the model prediction instead in our study. Interestingly, there is a clear differentiation in the temporal change rates among different classes, as demonstrated by the large differences in change rates of the normalized IOU. Notably, the accuracies of larger or static objects such as road, sky, tree, fence, pavement tend to decrease slowly with time, suggesting low temporal change rates for those structures. On the other hand, smaller or moving objects like car, bicyclist, sign-symbol, pedestrian, pole tend change much faster with time.
5.2 Details of Training Procedures
We use mini-batch SGD optimizer with Nesterov momentum. We set momentum to and weight decay to . The batch size is 16 except for training models with ResNet50 backbone on Cityscapes, in which case due to GPU memory constraints we use batch size of 8. The training are performed on 4 Nvidia GTX 1080Ti GPUs. Synchronized batch normalization 444Implementation: https://github.com/vacancy/Synchronized-BatchNorm-PyTorch is used since the number of images per GPU is small in our setting. The ResNet-50 555Downloaded from https://download.pytorch.org/models/resnet50-19c8e357.pth [76] and MobileNet v2 666Downloaded from http://jeff95.me/models/mobilenet_v2-6a65762b.pth [77] models are pre-trained on ImageNet [78]. We adopt a learning schedule with polynomial decay with power set to , following standard practice in semantic segmentation. This schedule multiplies the initial learning rate by the factor . During training, we apply random horizontal flip, random scales between and and random cropping. For both baselines and the TAF models, we report the best results among the initial learning rate from and additionally for ATF learning from . Additional details are summarized in Table 2.
5.3 Choice of Temporal Change Rates
For FCN8s, our preliminary studies suggest that assigning and to leads to best performance. We note that this design effectively disables TAF learning on the stride-16 and stride-8 branches. This design is necessary to allow the two high resolution features to model structures with fast temporal change rates sufficiently. For DeepLab v3+, we assign . There is no advantage in disabling TAF learning on any branch. In fact, our study suggests that it leads to worse accuracy. We think that can be attributable to the decoder ( function) design of the DeepLab v3+, which provides a skip connection with output stride of from low level features and can model fast features sufficiently by itself.
5.4 Measure Temporal Change Rates Relative to Input
In our formulation the temporal change rates are directly measured by the variations in the predictive model . However, different clips can have intrinsically different rates of motions, thus it might be wise to impose the temporal change rate constraints relative to the change rates in input images. This, as we also discuss in Section 2, is not trivial since is not available. In our preliminary studies, we empirically test using norm as a measure of the change rate, using the first order approximation as we do for . Then, we set the constraints as the proportion between the change rates in and those in . We find that this does not lead to improvement over the design we presented and the training is usually less stable. We conjecture that this is attributable to our heuristic method in measuring differences between images, a point worth revisiting in future works.
5.5 Choice of Loss Functions
The loss function consists of two parts: The semantic loss function and the contrastive loss. The former compares the prediction of the model against the ground truth annotations at the key frames, while the latter compares the prediction from the model before and after feature swapping (our regularization term). For the semantic loss function, we use cross-entropy loss for both the baseline and TAF learning, per standard practice. For the contrastive loss, in our preliminary studies we experiment with a few different metrics, including mean-squared-error (MSE), mean-average-error (MAE, or L1 loss) as well as symmetric cross entropy. Among them, L1 loss leads to more stable training and best results. We note that it is important to first normalize the prediction at every pixel via a softmax function, as applying L1 norm regularization directly on the logits (before normalization) leads to degenerate solutions. We note that L1 norm is by no means the optimal choice of the metric to compare images, as it does not reflect the rich semantic structures encoded in natural images. We believe that perceptual loss or even adversarial loss (via a learnable model) could lead to better performance and are interesting future directions to explore.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Varun Jampani, Raghudeep Gadde, and Peter V. Gehler. Video propagation networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 3154–3164, 2017.
- 2[2] Mennatullah Siam, Sepehr Valipour, Martin Jagersand, and Nilanjan Ray. Convolutional gated recurrent networks for video segmentation. In 2017 IEEE International Conference on Image Processing (ICIP) , pages 3090–3094, Sep. 2017.
- 3[3] Mohsen Fayyaz, Mohammad Hajizadeh Saffar, Mohammad Sabokrou, Mahmood Fathy, Fay Huang, and Reinhard Klette. Stfcn: Spatio-temporal fully convolutional neural network for semantic segmentation of street scenes. In Chu-Song Chen, Jiwen Lu, and Kai-Kuang Ma, editors, Computer Vision – ACCV 2016 Workshops , pages 493–509, Cham, 2017. Springer International Publishing.
- 4[4] David Nilsson and Cristian Sminchisescu. Semantic video segmentation by gated recurrent flow propagation. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 6819–6828, 2018.
- 5[5] Raghudeep Gadde, Varun Jampani, and Peter V. Gehler. Semantic video cnns through representation warping. 2017 IEEE International Conference on Computer Vision (ICCV) , pages 4463–4472, 2017.
- 6[6] Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos. In The IEEE International Conference on Computer Vision (ICCV) , December 2015.
- 7[7] Nitish Srivastava, Elman Mansimov, and Ruslan Salakhutdinov. Unsupervised learning of video representations using lstms. In Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37 , ICML’15, pages 843–852. JMLR.org, 2015.
- 8[8] Xiaojie Jin, Xin Li, Huaxin Xiao, Xiaohui Shen, Zhe Lin, Jimei Yang, Yunpeng Chen, Jian Dong, Luoqi Liu, Zequn Jie, Jiashi Feng, and Shuicheng Yan. Video scene parsing with predictive feature learning. In 2017 IEEE International Conference on Computer Vision (ICCV) , pages 5581–5589, Oct 2017.