Texture retrieval using periodically extended and adaptive curvelets
Hasan Al-Marzouqi, Yuting Hu, Ghassan AlRegib

TL;DR
This paper introduces two novel curvelet-based algorithms for texture retrieval optimized for constrained-memory devices, validated on multiple datasets, with a weighted variant also effective in seismic activity classification.
Contribution
The paper proposes new curvelet-based texture retrieval algorithms and a weighted version, suitable for low-memory devices and applicable to seismic activity classification.
Findings
Algorithms perform well on CUReT, Mondial-Marmi, STex-fabric datasets.
Weighted algorithm improves seismic activity classification.
Effectiveness confirmed through experiments.
Abstract
Image retrieval is an important problem in the area of multimedia processing. This paper presents two new curvelet-based algorithms for texture retrieval which are suitable for use in constrained-memory devices. The developed algorithms are tested on three publicly available texture datasets: CUReT, Mondial-Marmi, and STex-fabric. Our experiments confirm the effectiveness of the proposed system. Furthermore, a weighted version of the proposed retrieval algorithm is proposed, which is shown to achieve promising results in the classification of seismic activities.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4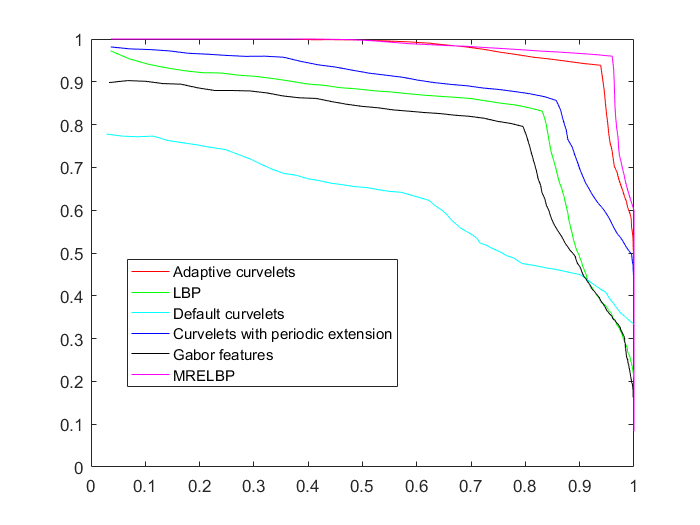 Figure 5
Figure 5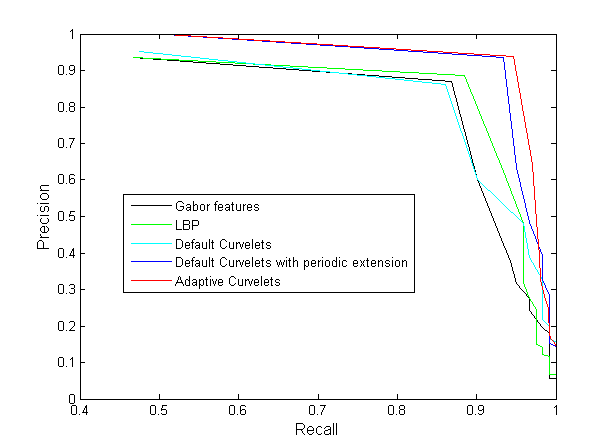 Figure 6
Figure 6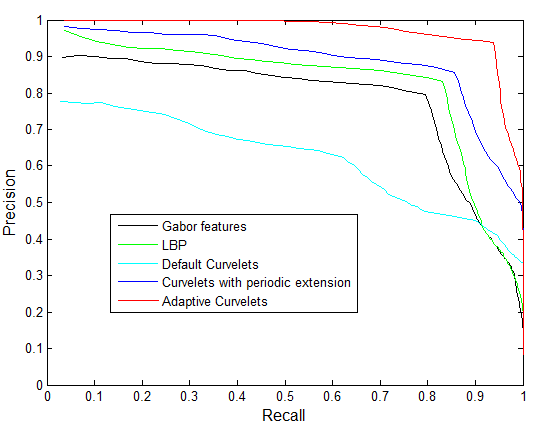 Figure 7
Figure 7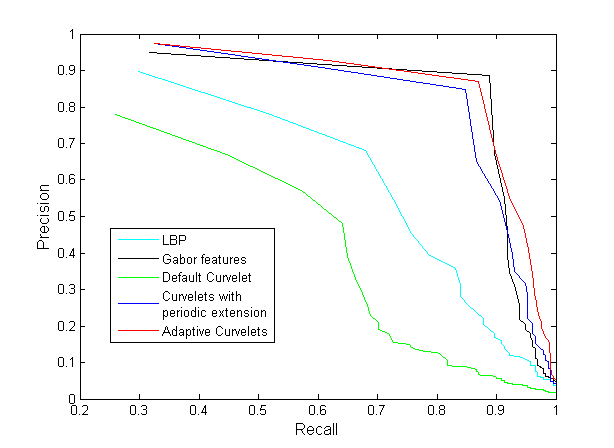 Figure 8
Figure 8 Figure 9
Figure 9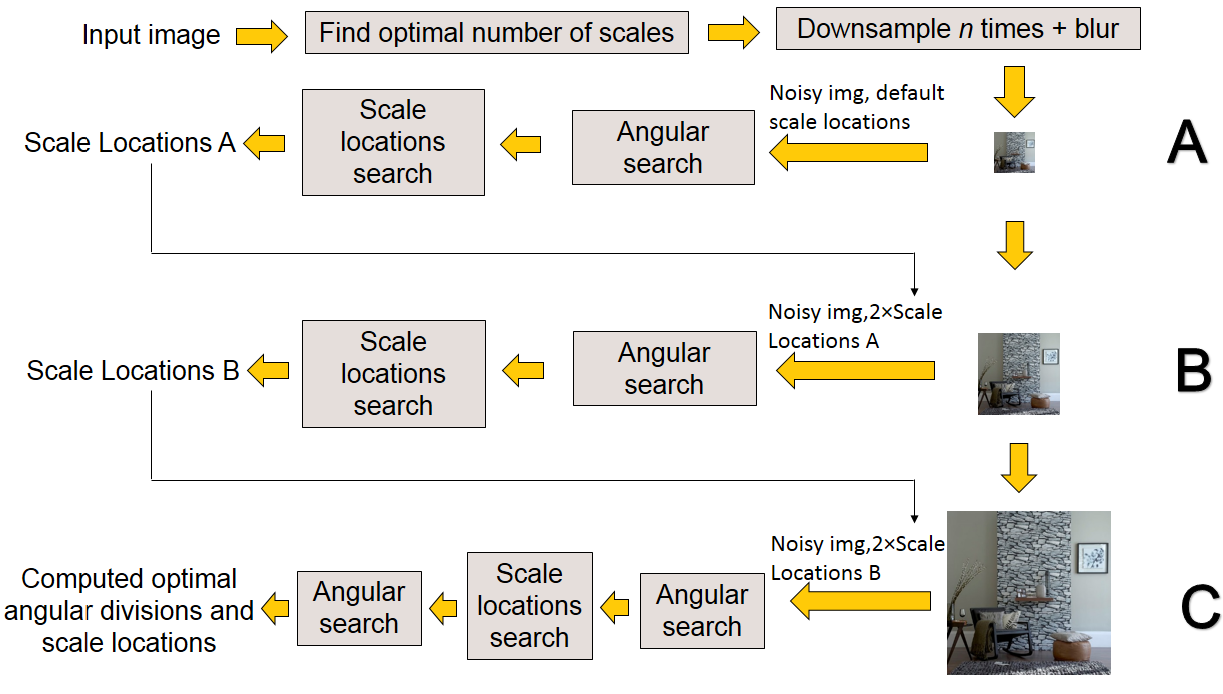 Figure 10
Figure 10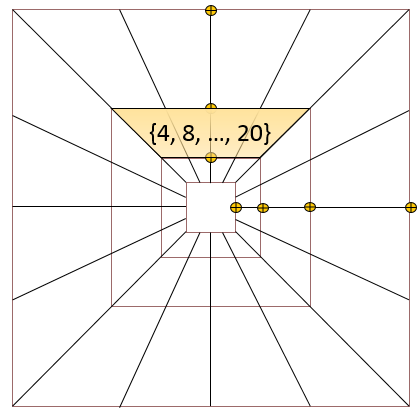 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16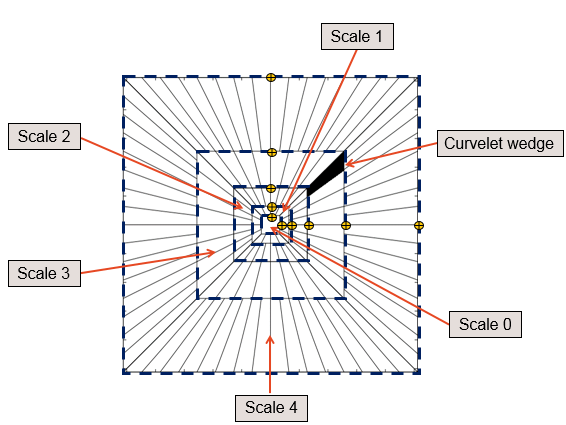 Figure 17
Figure 17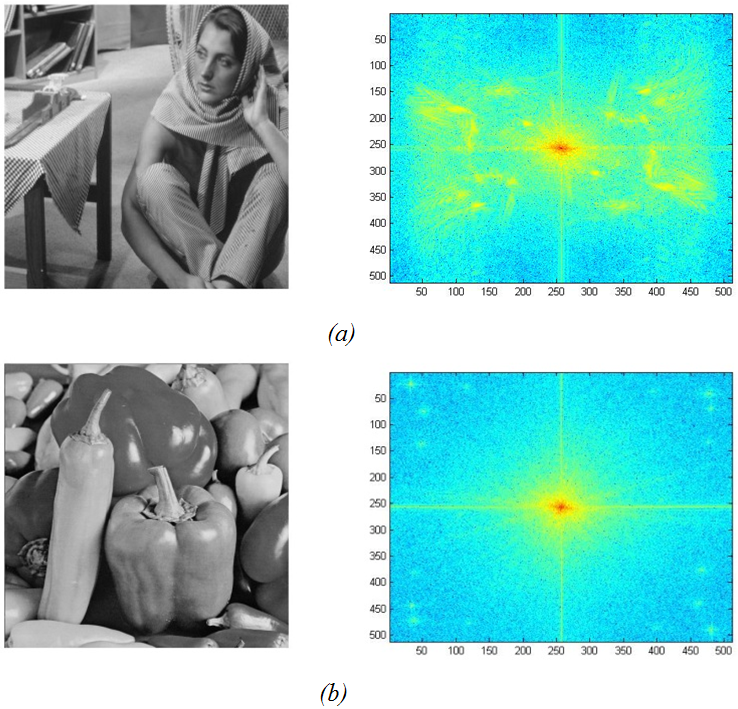 Figure 18
Figure 18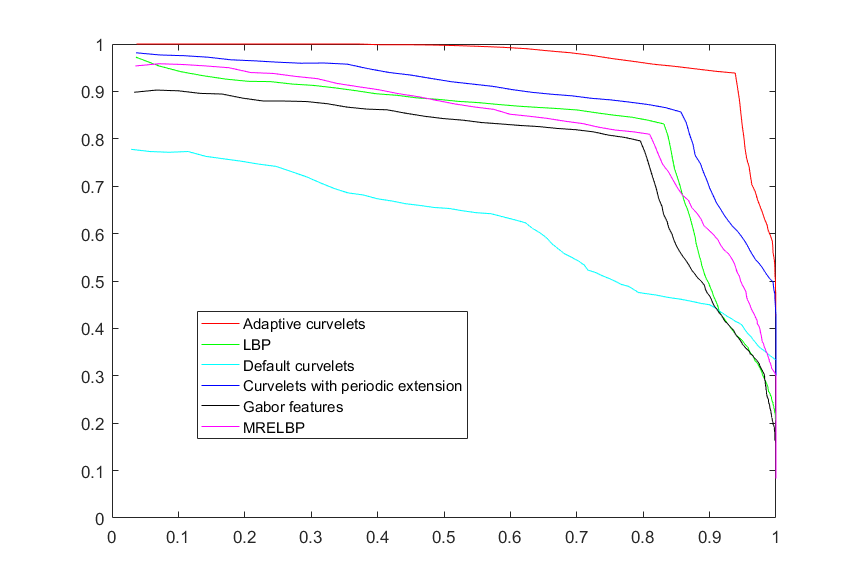 Figure 19
Figure 19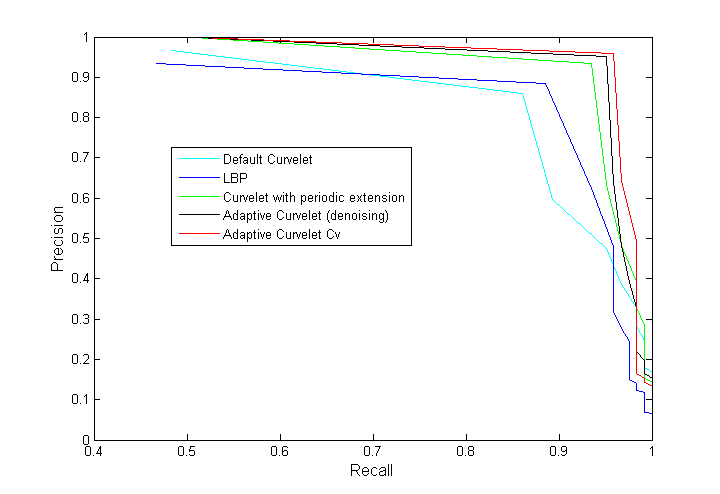 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23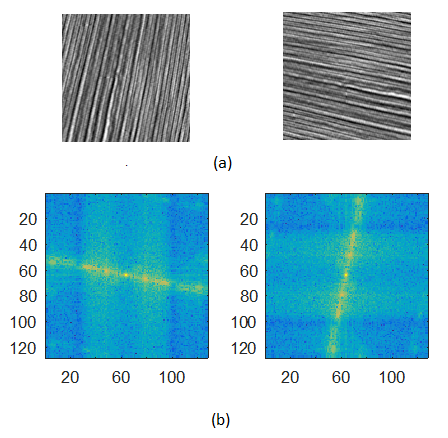 Figure 24
Figure 24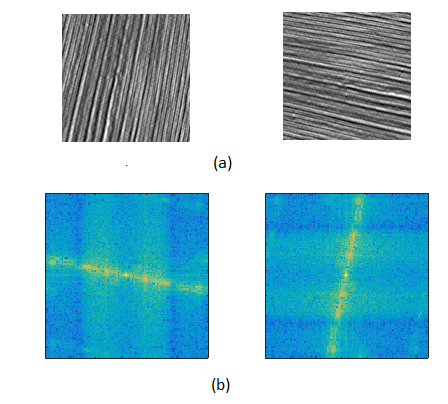 Figure 25
Figure 25 Figure 26
Figure 26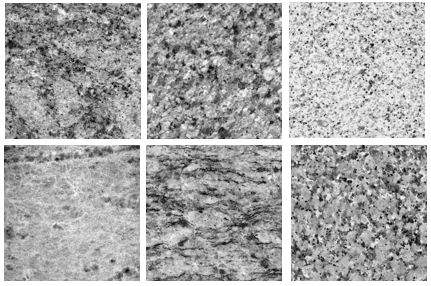 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29| P@1 | P@2 | MRR | MAP | |
| Wavelet features | 0.967 | 0.861 | 0.980 | 0.924 |
| Gabor features | 0.934 | 0.869 | 0.962 | 0.901 |
| Linear Binary Patterns (LBP) | 0.934 | 0.885 | 0.959 | 0.925 |
| Completed LBP (CLBP) | 0.984 | 0.918 | 0.986 | 0.955 |
| Median Robust Extended LBP (MRELBP) | 0.967 | 0.869 | 0.981 | 0.924 |
| Default curvelet | 0.951 | 0.861 | 0.975 | 0.916 |
| Curvelet with periodic extension | 1.000 | 0.934 | 1.000 | 0.964 |
| Adaptive curvelets | 1.000 | 0.939 | 1.000 | 0.968 |
| P@1 | P@2 | P@3 | MRR | MAP | |
| Wavelet features | 0.935 | 0.844 | 0.792 | 0.959 | 0.842 |
| Gabor features | 0.948 | 0.916 | 0.887 | 0.961 | 0.907 |
| Linear Binary Patterns (LBP) | 0.896 | 0.779 | 0.680 | 0.928 | 0.760 |
| Completed LBP (CLBP) | 0.948 | 0.851 | 0.762 | 0.965 | 0.817 |
| Median Robust Extended LBP (MRELBP) | 0.974 | 0.929 | 0.862 | 0.982 | 0.901 |
| Default curvelet | 0.779 | 0.669 | 0.571 | 0.837 | 0.636 |
| Curvelet with periodic extension | 0.974 | 0.909 | 0.849 | 0.983 | 0.896 |
| Adaptive curvelets | 0.974 | 0.927 | 0.870 | 0.984 | 0.918 |
| P@1 | P@2 | P@27 | MRR | MAP | |
| Gabor features | 0.898 | 0.903 | 0.796 | 0.937 | 0.826 |
| Linear Binary Patterns (LBP) | 0.972 | 0.954 | 0.831 | 0.973 | 0.880 |
| Completed LBP (CLBP) | 0.944 | 0.940 | 0.856 | 0.968 | 0.887 |
| Median Robust Extended LBP (MRELBP) | 0.954 | 0.958 | 0.810 | 0.966 | 0.868 |
| Default curvelets | 0.778 | 0.773 | 0.623 | 0.826 | 0.704 |
| Default curvelet with periodic extension | 0.982 | 0.977 | 0.857 | 0.989 | 0.907 |
| Adaptive curvelets | 1 | 1 | 0.939 | 1 | 0.973 |
| Time (sec.) | Length of feature vector | |
| Wavelets | 543.2 | 9 |
| Gabor features | 163 | 1152 |
| Linear Binary Patterns (LBP) | 322 | 36 |
| Completed LBP (CLBP) | 112.7 | 200 |
| Median Robust Extended LBP (MRELBP) | 929.8 | 400 |
| Default curvelets | 178.8 | 149 |
| Default curvelet with periodic extension | 267.2 | 242 |
| Adaptive curvelets | 4693.6 | 376 (average) |
| P@1 | P@2 | MRR | MAP | |
|---|---|---|---|---|
| Adaptive curvelets | 0.75 | 0.75 | 0.85 | 0.83 |
| Weighted adaptive curvelets | 0.92 | 0.83 | 0.93 | 0.91 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsImage Retrieval and Classification Techniques · Advanced Image and Video Retrieval Techniques · Medical Image Segmentation Techniques
Texture retrieval using periodically extended and adaptive curvelets
Hasan Al-Marzouqi
Yuting Hu
Ghassan AlRegib
Department of Electrical and Computer Engineering, Khalifa University of Science and Technology, AbuDhabi, United Arab Emirates
School of Electrical and Computer Engineering, Georgia Institute of Technology, Atlanta, GA, 30332, USA
Abstract
Image retrieval is an important problem in the area of multimedia processing. This paper presents two new curvelet-based algorithms for texture retrieval which are suitable for use in constrained-memory devices. The developed algorithms are tested on three publicly available texture datasets: CUReT, Mondial-Marmi, and STex-fabric. Our experiments confirm the effectiveness of the proposed system. Furthermore, a weighted version of the proposed retrieval algorithm is proposed, which is shown to achieve promising results in the classification of seismic activities.
keywords:
Texture , Curvelet , CBIR , Classification
††journal: Signal Processing: Image Communication
1 Introduction
A large amount of visual content is constantly being generated and distributed. Productive use of such visual content demands improved procedures for indexing, analyzing, and classifying such material. These procedures rely on the visual-content of image/video databases. Textures are important components in images, and many algorithms have been proposed in recent decades aimed at developing content-based texture similarity measures. These methods are used in classifying and retrieving images of textured materials. They can be extended for use as elements in the framework of general content-based image retrieval systems.
Texture images exhibit a repeated pattern of visual content, and such repetitions can be captured using frequency-domain techniques. The global holistic nature of such methods makes them appropriate for texture analysis. Frequency-domain texture-retrieval algorithms typically comprise two essential components: 1) a sparsity-inducing transform that divides the spatial content of images into sets of coefficients representing unique subbands, and 2) a similarity measure that computes a numerical distance between image representations.
Do and Vetterli [1] proposed using the Kullback-Leibler distance between generalized Gaussian density estimates of wavelet subbands. Several variants and modifications of algorithms using wavelets for texture retrieval have been proposed in the literature [2, 3, 4]. The wavelet transform offers limited directional selectivity (wavelet subbands contain either horizontal, vertical, or diagonal information). Directional transforms allow for more directional selectivity, and they have been used successfully in a variety of application areas. Steerable pyramids [5], Gabor wavelets [6], and curvelets [7] are examples of directional transforms that have been used for texture retrieval. Zujovic et al. [8] used statistical properties of a steerable pyramid representation of the texture dataset. These statistical properties included the mean, variance, horizontal and vertical autocorrelation, and cross band correlations. Gabor wavelets incorporate directional selectivity by using sets of Gaussian-shaped filters at different rotations. Manjunath et al. [9] used the mean and standard deviation of Gabor coefficients for texture retrieval. This Gabor-based algorithm is included in the multimedia content description standard MPEG-7 [10]. Gabor wavelets decomposes the input image into a set of Gabor elements. Fig. 1 shows exemplary Gabor elements representing three different orientations. Zhang et al. reported performance improvements over Gabor filters by using the default curvelet transform [11]. Curvelet elements are elongated needle-shaped elements that are generated by taking the inverse Fourier transform of anisotropic frequency bands, which we refer to as curvelet wedges. The length of each curvelet wedge is constructed to equal the square of its width. Fig. 2 illustrates a number of curvelet basis elements. Default curvelet tiling of the frequency domain is shown in Fig. 3.
Several authors [12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22] have developed texture-retrieval algorithms based on spatial domain content analysis. Ojala et al. [12] developed local binary patterns (LBP) that decompose input images into sets of coefficients representing intensity differences between a reference pixel and its neighbors. Dominant orientation templates [13, 14] use a set of dominant gradient orientations to extract features representative of the object of interest.
Guo et al. proposed completed local binary patterns (CLBP)[15] that encode both the signs and the magnitudes of local intensity differences into binary codes and combine these two complementary pieces of information using joint or hybrid feature distributions. To capture both micro- and macro-structures of images and reduce the effect of noise, Liu et al. developed median robust extended local binary patterns (MRELBP)[16] using a multi-scale sampling strategy and median intensity values. This process is more robust to illumination variations, rotation variations, and noise. A comprehensive review of LBP variants is presented in [23].
More recently, deep neural networks have been used in texture retrieval [24]. The proposed method is intensive in terms of both memory and storage demands. The neural network architecture used in [24] employs approximately 60 million parameters, making it difficult to implement on systems with limited hardware resources. Another interesting line of research integrates visual image features and click data from search engines to extract relevant images [25, 26].
In this paper, we propose new texture-retrieval algorithms based on periodically extended and adaptive curvelets. Periodic extension improves default curvelet performance by connecting boundary elements. The adaptive curvelet [27, 28] is a recently developed transform that adapts the size and location of curvelet tiles to represent a given input image more effectively. This approach adapts the direction and thickness of curvelet basis elements to better represent image features.
Some of the results shown in this paper have appeared in [29]. In this paper, we introduce a rotation-normalized variant of the published algorithm, present a weighted version of the algorithm exploiting curvelet wedge properties, and expand the experimental section with experiments covering additional texture datasets. The remainder of the paper is organized as follows. In the next two sections, we will present an overview of periodically-extended and adaptive curvelet transforms, followed by technical details of the texture-retrieval algorithm in Sections 4 and 5. Experimental results are presented in Section 6. Finally, Section 7 presents our conclusions.
2 Default curvelets with periodic extension
The curvelet transform [7] provides an efficient representation of directional features. It works by dividing the spatial content of images into different frequency bands representing unique scale and directional features.
Curvelet coefficients are generated using the 2-D fast Fourier transform (FFT). FFT is first applied to an image; then, a scale-selection algorithm is employed to compute the optimal number of scales. Scale locations, which we define as coordinates of the FFT plane that determine the outer boundary of each scale, are determined in a dyadic manner. Each curvelet scale is further divided into a number of different directional tiles, as shown in Fig. 3.
Because FFT values for real data are symmetric around the center of the FFT plane, two quadrants are sufficient for constructing the curvelet representation. To obtain real-valued coefficients for such datasets, the complex coefficients are separated into two parts, leaving the total number of tiles unchanged. Curvelet coefficients are generated by taking the inverse FFT’s of these tiles. The inverse curvelet transform restores the original image by reversing the forward transform operations. The flow of the forward and inverse curvelet algorithms is summarized in Fig. 4
The outer curvelet scale can be constructed using either a regular high-pass filter, or by employing a periodic extension window. The first option reduces computational and storage costs, while the second option reduces boundary artifacts and increases the sparsity of the transform. A performance comparison between periodically extended curvelets and default curvelets will be presented in Section 6. Curvelets constructed with outer angular divisions and a periodic extension window are used in the proposed texture-retrieval algorithms.
3 Adaptive Curvelets
Adaptive curvelets alter the number, size, and locations of curvelet tiles according to a given cost function [27]. The frequency-domain tiling that generates the best improvement in the cost function value is considered optimal. In denoising-based adaptive curvelets, the cost function is the denoising performance, as measured by the peak signal-to-noise ratio (PSNR). A synthetic noisy image is generated by adding Gaussian noise with standard deviation to the input image I. In this work, is given by
[TABLE]
where is the standard deviation of the intensities of image , and MAXI is the maximum possible intensity value. Equation (1) provides a noise level that has obvious effects on image quality, but does not overpower image details. More details regarding the relationship between values and the performance of adaptive curvelets are provided in [28]. Next, a value for the number decomposition scales is chosen, followed by search algorithms finding the optimal scale locations and number of angular divisions for each scale/quadrant pair. The algorithms converge, returning the optimal curvelet tiling for the given image. The optimization problem characterizing denoising-based adaptive curvelets can be described mathematically by
[TABLE]
where is the input image, is the artificially generated noise image, is a vector describing adaptive curvelet scale locations, is a vector that determines the number of angular decompositions used in each curvelet scale/quadrant pair, is a function that denoises the noisy image with curvelets described by and , and is a function that computes the PSNR between images and . The algorithms used to search for a solution for equation 2 are described in the next section.
3.1 The scale-selection algorithm
Scanning a large variety of widely used images, a connected region of high magnitude FFT values can be observed in the center of the FFT plane in many of these images. An example of such activity is shown in Fig. 5, which shows a plot of FFT log magnitude for two images. It is preferable to avoid dividing such connected regions into different tiles while applying the curvelet transform, to achieve a better representation of the signal of interest, We developed a heuristic algorithm to determine the number of scales guided by this observation in [30]. The algorithm works as follows:
Step 1
Define a quantity termed mid-range , as follows:
[TABLE]
If the minimum Fourier magnitude value is equal to zero, the next minimum value is chosen.
Step 2
let = 8. This is the smallest possible value for the size of the inner-most curvelet level.
Step 3
Set a square surrounding the origin of the frequency domain with a diagonal length equal to pixels.
Step 4
If any FFT magnitude value within the square is smaller than the mid-range value, exit the algorithm and return . Otherwise, go to Step 5.
Step 5
Set and return to Step 3.
The optimal number of scales is found using the value computed in Step 4 above. Using dyadic scaling, the optimal number of scales is computed as follows:
[TABLE]
where and are the vertical and horizontal image dimensions respectively. Equation 4 computes the difference between the number of scales required to reach the origin of the frequency domain from the edge of the image (i.e., total number of scales), and the number of scales necessary to reach the origin from the outer edge of the coarsest level square.
3.2 Number of angular decompositions
Optimizing the number of angular divisions is performed in a brute-force fashion in each curvelet scale/quadrant pair (Fig. 6). The tested parameters are chosen from the following sequence {4, 8, 12, 16, 20}. The number of divisions that achieve the maximum cost function value is considered optimal. The divisions are uniformly distributed in each scale/quadrant pair. Recalling FFT’s symmetry for real data, the number of parameters to optimize for real data is equal to , and is equal to for complex input data.
3.3 Scale-locations search
We propose using derivative-free optimization methods to search for adaptive curvelet scale-locations. Such methods start at an initial point x0, evaluate the cost function at a selected mesh of points in the neighborhood of x0, and define the point in the mesh with the minimum function value as the new x0. Next, the algorithm iterates until a specified convergence criterion is met. The Nelder-Mead simplex search method [31] is a popular method for generating such a mesh. It has been used extensively in a variety of application areas. In this work, it is used to find the optimal scale locations. Given a specific angular distribution, the scale location search algorithm finds optimal vectors H and V, where V1,V2VJ are the coordinates of vertical scale locations, and {H1, H2, …, HJ} are the horizontal scale locations (Fig. 3). We do not constrain curvelet scales to be of the same length and width. This makes the number of optimizing parameters equal to for real data.
3.4 Global optimization algorithm
In this section, we introduce the global optimization algorithm that combines the two previous adaptations. The algorithm uses a multi-resolution search strategy, which helps in avoiding convergence to local maxima and reduces the computational cost of the algorithm. Optimization is conducted in a hierarchical manner consisting of iterations. In each iteration, optimal scale and angular locations are found for a downsampled smoothed version of the input image. Three iterations were found to be adequate for image sizes up to 512 x 512 [28]. Increasing the number of iterations did not generate further improvements in performance. The flow of this algorithm is illustrated in Fig. 7. The algorithm terminates returning the computed optimal scale and angular decompositions. The returned tiles will be used in the next section to extract feature vectors for use in texture-retrieval applications.
4 Feature vector and distance computation
Forming a representative feature vector is essential for the success of transform-domain retrieval methods. Using the curvelet transform, the query and input images are represented by sets of coefficients identifying the spatial content relative to unique frequency bands. Curvelet elements are represented in the spatial domain by needle-shaped elongated objects, as illustrated in Fig. 2.
The similarity between two curvelet tiles representing a certain frequency band is indicative of the similarity of the spatial content in this band between the two images. Therefore, a global similarity measure between two images can be formed by including the similarities between curvelet tiles across all frequency bands. Given that edges are essential components in images, a curvelet-based similarity measure between curvelet tiles is perceptually meaningful. Furthermore, adapting curvelet coefficients to represent the query image more effectively constructs a representation from curvelet objects that is more faithful in direction and scale to the features of the image of interest.
Given two images and , where is the query image, we propose the following two algorithms for texture retrieval. The first algorithm uses default curvelets with periodic extension, while the second algorithm employs denoising-based adaptive curvelets. The periodically extended curvelet and adaptive curvelets are used to compute the curvelet coefficients representing images and . In adaptive curvelets, the optimal curvelet tiling will be learned using the query image . The learned frequency-domain tiling will be used to compute feature vectors representing images and .
The feature vectors describing images and are formed by the mean and the standard deviation of curvelet coefficients in each curvelet tile. Let the number of tiles in the optimal representation be . The feature vector representing images and is given by
[TABLE]
where is the mean of the curvelet coefficients in tile and is the standard deviation of the coefficients in the same tile.
Next, the distance between images A and B is computed by
[TABLE]
where is the norm of vector . The feature vectors can be weighted to (de-)emphasize certain scales and orientation of interest (e.g. coarse/fine or horizontal/vertical features). A general expression for a weighted feature vector is given by
[TABLE]
where is a weights vector of length equal to the number of curvelet tiles , which is determined by the adaptive curvelet search method described previously. The value of that generates the best denoising performance is used to represent query images. This parameter will vary according to the details in a given input image.
5 Coefficient sorting and approximate rotation invariance
In this section, the proposed texture-retrieval algorithm is extended to handle rotations. Rotating an image rotates its FFT magnitudes [32]. The FFT content described by certain curvelet tiles in an image, will be moved to another curvelet tile in the curvelet representation of the rotated image. By sorting curvelet tiles in each scale, one can reduce rotation artifacts in the distance computed between feature vectors representing two images. Curvelet tiles in each scale are sorted based on the sum of their coefficients magnitude. Once curvelet tiles are sorted, the distance between the images of interest can be computed. This distance will be based on feature vectors with aligned entries. This sorting mechanism was used successfully in [11].
Rotating an FFT can generate the undesired artifact of moving high magnitude FFT data to lie across the boundary between two curvelet tiles. This artifact makes the feature vector less representative of the similarity between the image and its rotated version. To reduce the effect of such cases, its preferable to use small values for the number of angular divisions. The number of angular decompositions for each curvelet scale/quadrant pair is set to four.
A texture image and its rotated variant are shown in Fig. 8. The distance between the two images using denoising-based curvelets is 388.4. Employing the rotation resilient measure, becomes 120.7.
6 Experiments
The proposed algorithm was tested in texture-image retrieval using several textured materials. The different qualitative measures that were used to assess the performance of the proposed algorithms are presented in this section, followed by retrieval results from the datasets used in this study. To ensure robustness to various noise realizations, adaptive curvelet results are obtained by using the average of five different trials.
6.1 Performance metrics
Retrieval experiments are constructed using a query image representing a class of textured material. The proposed algorithms are assigned the task of acquiring images resembling the same class of the query image from a database of testing images. The following metrics were used to evaluate the retrieval performance:
Retrieval precision: defined as the ratio of the number of correct matches retrieved, to the total number of correct matches. Precision in this context is a function of the number of retrieved images. We will focus on precision values at one, two, and at the number of relevant images. 2. 2.
Mean reciprocal rank (MRR): this is the mean reciprocal of the rank of the first relevant position. 3. 3.
Mean Average Precision (MAP): this is the mean of average precision values across all queries. The average precision (AP) is given by
[TABLE]
where and are the ranks and number of relevant images, respectively. 4. 4.
Precision-recall curves: these figures are frequently used in the analysis of retrieval performance. In such figures, precision values are plotted as a function of recall values. Recall is defined as the ratio of the number of correctly retrieved images to the number of relevant images.
6.2 Texture retrieval: Experimental setup
The algorithm is tested using three different texture databases: the Columbia-Utrecht Reflectance and Texture Database (CUReT) [33], Mondial Marmi collection of granite classes [34], and the fabric dataset included in the Salzburg Texture Image Database (STex) [35].
The CUReT database contains 61 images of real-world surfaces taken at different illumination levels and viewing directions. In our experiments, we used images taken at the first illumination setting with viewing direction 22. CUReT images are of size 640 480. They all include a textural part and a background. Three images of size 128 128 covering the textural regions were extracted from each CUReT image. One of these images was selected randomly as a query image. The remaining images were used as testing images. A sample of the images used in this study is shown in Fig. 9.
The STex dataset includes 476 images, representing different types of materials. In our experiments, we use the fabric class of images in this dataset, which includes 77 fabric samples of size 512 . Each image is divided into four non-overlapping regions. This makes the total number of images equal to 308. An image in each class is chosen as a query image, and the remaining images are used as testing images. A sample of the images used in this study is shown in Fig. 10.
The Mondial Marmi is a collection of 48 images representing 12 different granite classes. Each image is hardware-rotated using nine rotation angles: , , , , , , , , and . The images were acquired under controlled illumination conditions, and each image is of size 544 544. To save computational time, the granite images were downsampled using a downsampling factor of 1/3. Query images included an image from each class along with its rotated versions. The remaining images were used as testing images. The number of correct matches for each query image is equal to 3 9. Samples from the Mondial Marmi dataset are shown in Fig. 11.
6.3 Texture-retrieval results
The performance of the proposed methods is compared with the following algorithms:
norm of default curvelet features [11]. This algorithm uses no periodic extension or angular divisions in the outer curvelet scale 2. 2.
norm of Gabor features [6] 3. 3.
Kullback-Leibler distance on wavelet features [1] 4. 4.
Log-likelihood ratio of local binary patterns [12]. The used feature vector is composed of the concatenation of and features. In addition, we compare the performance of proposed methods with the following two variants of LBP:
- (a)
Completed LBP(CLBP) [15] (CLBP): We used the joint histogram of , , and . 2. (b)
Median robust extended LBP (MRELBP) [16]: The joint histogram of , , and was used.
Implementations of the algorithms based on Gabor, wavelet, and LBP were downloaded from the author’s websites.
The results of our experiments on the CUReT database are shown in Table 1. Precision at one results indicate that the proposed algorithms succeed in retrieving one of the correct matches as a first retrieved image. Precision at two (P@2) results show that the proposed methods are able to retrieve 93%-94% of the correct matches in our database. Precision-recall curves for methods based on Gabor features, LBP, default curvelet, curvelet with periodic extension and denoising-based adaptive curvelets are shown in Fig. 12.
Results for our experiments on the fabric database are summarized in Table 2. The proposed curvelet-based methods and MRELBP outperform other algorithms in the precision of the first retrieved result (P@1). The highest MRR and MAP values in this experiment were achieved by adaptive curvelets. Curvelets with periodic extension and adaptive curvelets successfully retrieved 75 correct matches out of 77 texture classes used in this experiment. The two classes that were misclassified are shown in Fig. 13. In contrast to other Stex-fabric images, (a sample of which was shown in Fig. 10), these two texture classes do not show uniform and repeated textural patterns. The upper part in image (a) is different from the lower part. In the center of this image, the two rows of textured material are not similar to each other in structure. Similarly, textures are not uniform in image (b). Textures in the upper right corner in image (b) are different from the rest of the image. Moreover, another unique textural area appears in the upper left corner of image (b).
Adaptive curvelet results can be further improved by training over a set of images resembling the class of interest. The training procedure as it is currently implemented uses the query image. However, training on the query image alone can overemphasize its local features.
Precision-recall curves for methods based on wavelets, Gabor features, default curvelet, curvelet with periodic extension, and denoising-based adaptive curvelets are shown in Fig. 14.
Finally, we demonstrate the capabilities of the rotation-normalized version of the algorithm. Results for our experiments on the Mondial Marmi granite database are shown in Table 3. Adaptive curvelet results are compared with results acquired using LBP, CLBP, MRELBP, and a rotation-normalized version of the Gabor retrieval method. The Gabor retrieval algorithm is normalized to rotations by using the approach detailed in Section 5. Local binary patterns are rotation invariant by construction. The number of divisions per Gabor scale/quadrant pair is kept at the default value of 3. Table 3 presents the results of our experiments, where we compare the performance of adaptive curvelets with LBP variants and the Gabor feature algorithms. It is clear that the rotation normalized adaptive curvelets algorithm outperforms the other algorithms. Adaptive curvelets achieve perfect retrieval precision up to a recall value of 0.5. Precision-recall curves are shown in Fig. 15.
6.4 Computational time and feature length
In this section, we present a comparison between the texture retrieval methods tested in this paper, in running time and feature vector length. Table 4 lists the different methods used together with the time needed to run the CUReT texture retrieval experiments. In the CUReT experiments 61 images of size 128 by 128 were matched with 122 reference images. There experiments were performed using a laptop equipped with dual 2.5GHz Intel i7 processors and 8GB of RAM. The table also lists the length of feature vectors used in each texture retrieval algorithm.
Curvelets with periodic extension take a reasonable amount of time and use a reasonable feature vector length. Adaptive curvelets achieved the best retrieval results in all of our experiments. However, learning the optimal curvelet tiling is time consuming. Feature vector length in adaptive and periodically extended curvelets is shorter than MRELBP. Retrieval results of adaptive curvelets and periodically extended curvelets are at least at the level of MRELBP.
6.5 Seismic activity characterization
Seismic data are used extensively in the oil and gas exploration industries. Efficient retrieval algorithms based on visual properties of the seismic datasets are desired. The adaptive curvelets retrieval algorithm is tested on the seismic dataset shown in Fig. 16. The figure covers the following seismic activities:
Fault:
Datasets with faults
Horizontal:
Datasets with obvious horizons
Dome:
Datasets with salt dome shapes and alike
Clear:
Datasets with none of the above activities
For efficient retrieval performance, a weighted version of the adaptive curvelet algorithm is used. The number of curvelet scale decompositions is chosen, (by the scale selection algorithm), to equal four. Fault images were retrieved using only curvelet wedges representing vertical activities . These wedges lie in the second curvelet quadrant (Fig. 17). Only the finer (outer) two curvelet scales are used for retrieval. Weights for the inner scales were set to zero. Similarly, Horizontal datasets were retrieved using curvelet wedges representing horizontal activities (first curvelet quadrant). The inner two curvelet scales (coarsest levels) were used for retrieval. Dome images were retrieved using the outer two curvelet scale and all curvelet directions. Clear images were retrieved using all curvelet scales and directions.
In a previous paper [36], we have shown that for seismic data maximizing the coefficient of variations is an effective method for learning curvelet tiles. We use this alternate cost function to improve default curvelet tiles in this experiment.
Every image in the dataset was used once as a query image, while the remaining images were used as testing images. A comparison between unweighted and weighted versions of adaptive curvelets retrieval performance is shown in Table 5. Unweighted adaptive curvelets succeed in retrieving the first correct match in 9 out of 12 images in the database. Weighted curvelets increase this ratio to 11 out of 12, where the algorithm matches image Horiz3 with Clear3 and Clear1 instead of the correct Horiz images.
7 Conclusions
New lightweight algorithms for texture-image retrieval were presented in this paper. Their performance was tested on several texture datasets. Our results strongly encourage the use of periodically extended curvelets, despite the increase in computational cost. Adaptive curvelets were shown to improve default curvelet performance by adapting curvelet tiles to represent the image of interest more efficiently. Adaptive curvelets achieved promising results in retrieving seismic data. In the future, we plan to extend these results by applying the developed texture-retrieval method to video applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Do, M. Vetterli, Wavelet-based texture retrieval using generalized gaussian density and kullback-leibler distance, Image Processing, IEEE Transactions on 11 (2) (2002) 146–158. doi:10.1109/83.982822 . · doi ↗
- 2[2] N.-E. Lasmar, Y. Berthoumieu, Gaussian copula multivariate modeling for texture image retrieval using wavelet transforms, Image Processing, IEEE Transactions on 23 (5) (2014) 2246–2261. doi:10.1109/TIP.2014.2313232 . · doi ↗
- 3[3] Y. Dong, J. Ma, Wavelet-based image texture classification using local energy histograms, Signal Processing Letters, IEEE 18 (4) (2011) 247–250. doi:10.1109/LSP.2011.2111369 . · doi ↗
- 4[4] Z.-Z. Wang, J. Yong, Texture analysis and classification with linear regression model based on wavelet transform, Image Processing, IEEE Transactions on 17 (8) (2008) 1421–1430. doi:10.1109/TIP.2008.926150 . · doi ↗
- 5[5] E. Simoncelli, W. Freeman, E. Adelson, D. Heeger, Shiftable multiscale transforms, Information Theory, IEEE Transactions on 38 (2) (1992) 587–607. doi:10.1109/18.119725 . · doi ↗
- 6[6] T. S. Lee, Image representation using 2D Gabor wavelets, Pattern Analysis and Machine Intelligence, IEEE Transactions on 18 (10) (1996) 959–971. doi:10.1109/34.541406 . · doi ↗
- 7[7] E. Candes, L. Demanet, D. Donoho, L. Ying, Fast discrete curvelet transforms, Multiscale Modeling & Simulation 5 (3) (2006) 861–899.
- 8[8] J. Zujovic, T. N. Pappas, D. L. Neuhoff, Structural texture similarity metrics for image analysis and retrieval, Image Processing, IEEE Transactions on 22 (7) (2013) 2545–2558.