Shift R-CNN: Deep Monocular 3D Object Detection with Closed-Form Geometric Constraints
Andretti Naiden, Vlad Paunescu, Gyeongmo Kim, ByeongMoon Jeon, Marius, Leordeanu

TL;DR
Shift R-CNN introduces a hybrid deep learning and geometric approach for monocular 3D object detection, achieving top results on KITTI without pre-trained depth models.
Contribution
It combines a modified Faster R-CNN with a closed-form geometric solution and a novel Volume Displacement Loss for improved monocular 3D detection.
Findings
Achieves state-of-the-art results on KITTI benchmark.
Does not rely on pre-trained depth estimation networks.
Introduces a novel geometric constraint-based refinement.
Abstract
We propose Shift R-CNN, a hybrid model for monocular 3D object detection, which combines deep learning with the power of geometry. We adapt a Faster R-CNN network for regressing initial 2D and 3D object properties and combine it with a least squares solution for the inverse 2D to 3D geometric mapping problem, using the camera projection matrix. The closed-form solution of the mathematical system, along with the initial output of the adapted Faster R-CNN are then passed through a final ShiftNet network that refines the result using our newly proposed Volume Displacement Loss. Our novel, geometrically constrained deep learning approach to monocular 3D object detection obtains top results on KITTI 3D Object Detection Benchmark, being the best among all monocular methods that do not use any pre-trained network for depth estimation.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3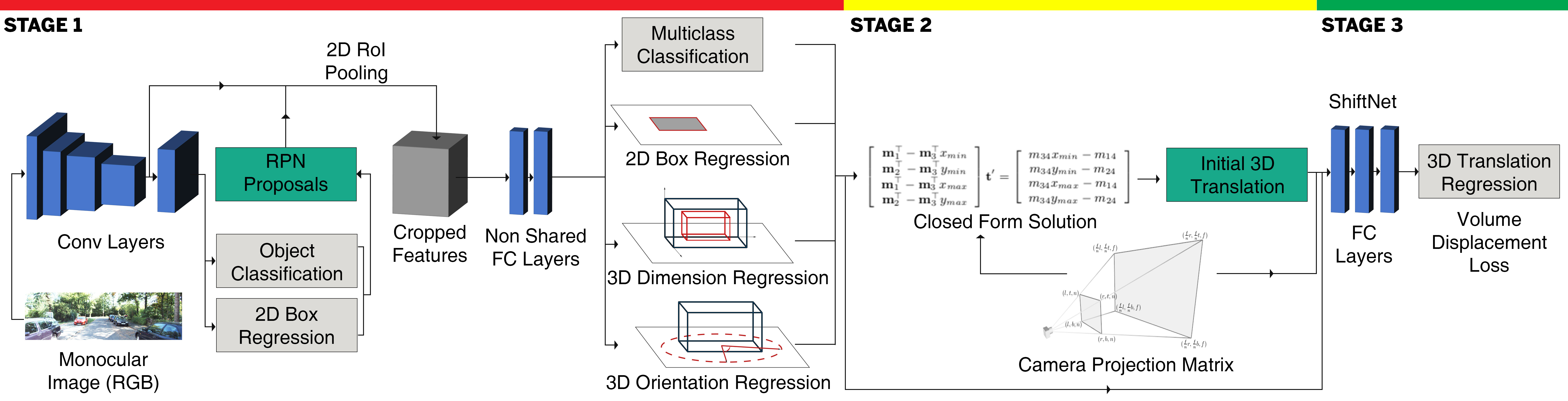 Figure 4
Figure 4| (%) | (%) | |||||||
| Method | Setup | Class | Easy | Moderate | Hard | Easy | Moderate | Hard |
| Mono3D [1] | Mono | Car (IoU0.7) | 2.53 / - | 2.31 / - | 2.31 / - | 5.22 / - | 5.19 / - | 4.13 / - |
| DeepBox3D [16] | Mono | - / 5.85 | - / 4.10 | - / 3.84 | - / 9.99 | - / 7.71 | - / 5.30 | |
| OFT-Net [20] | Mono | 4.07 / 2.50 | 3.27 / 3.28 | 3.29 / 2.27 | 11.06 / 9.50 | 8.79 / 7.99 | 8.91 / 7.51 | |
| MLF-Mono [23]* | Mono+PD | 10.53 / 7.85 | 5.69 / 5.39 | 5.39 / 4.73 | 22.03 / 19.20 | 13.63 / 12.17 | 11.60 / 10.89 | |
| ROI-10D [15]* | Mono+PD | 10.25 / 12.30 | 6.39 / 10.30 | 6.18 / 9.39 | 14.76 / 16.77 | 9.55 / 12.40 | 7.57 / 11.39 | |
| Linear System (Ours) | Mono | 7.24 / 6.80 | 5.98 / 4.14 | 5.54 / 3.50 | 14.74 / 11.75 | 12.48 / 8.34 | 11.22 / 6.80 | |
| ShiftNet (Ours) | Mono | 13.84 / 8.13* | 11.29 / 5.22 | 11.08 / 4.78* | 18.61* / 13.32 | 14.71 / 8,49 | 13.57 / 6.40 | |
| OFT-Net [20] | Mono | Ped. (IoU0.5) | - / 1.11 | - / 1.06 | - / 1.06 | - / 1.55 | - / 1.93 | - / 1.65 |
| Linear System (Ours) | Mono | 1.51 / 0.53 | 1.51 / 0.53 | 1.51 / 0.53 | 1.51 / 0.53 | 1.51 / 0.53 | 1.51 / 0.53 | |
| ShiftNet (Ours) | Mono | 7.55 / 13.36 | 6.80 / 10.59 | 6.12 / 10.59 | 8.24 / 13.81 | 7.50 / 11.44 | 6.73 / 10.76 | |
| OFT-Net [20] | Mono | Cyc. (IoU0.5) | - / 0.43 | - / 0.43 | - / 0.43 | - / 0.43 | - / 0.79 | - / 0.43 |
| Linear System (Ours) | Mono | 1.38 / 0.73 | 0.90 / 0.43 | 0.90 / 0.43 | 1.42 / 0.53 | 0.90 / 0.53 | 0.90 / 0.53 | |
| ShiftNet (Ours) | Mono | 1.85 / 3.03 | 1.08 / 3.03 | 1.10 / 3.03 | 2.30 / 3.58 | 2.00 / 3.03 | 2.11 / 3.03 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsRegion Proposal Network · Softmax · Convolution · RoIPool · Faster R-CNN
©2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Accepted to be published in 2019 IEEE International Conference on Image Processing, Sep 22-25, 2019, Taipei.
Shift R-CNN: Deep Monocular 3D Object Detection with Closed-Form Geometric Constraints
Abstract
We propose Shift R-CNN, a hybrid model for monocular 3D object detection, which combines deep learning with the power of geometry. We adapt a Faster R-CNN network for regressing initial 2D and 3D object properties and combine it with a least squares solution for the inverse 2D to 3D geometric mapping problem, using the camera projection matrix. The closed-form solution of the mathematical system, along with the initial output of the adapted Faster R-CNN are then passed through a final ShiftNet network that refines the result using our newly proposed Volume Displacement Loss. Our novel, geometrically constrained deep learning approach to monocular 3D object detection obtains top results on KITTI 3D Object Detection Benchmark [5], being the best among all monocular methods that do not use any pre-trained network for depth estimation.
Index Terms— Monocular 3D object detection, convolutional neural networks, autonomous driving, geometric constraints
1 Introduction
Autonomous driving relies on visual perception of the surrounding environment, in which the ability to perform accurate obstacle detection is a key factor. With many different types of sensors available, state of the art autonomous driving systems are based on sensor fusion [9]. When compared to LiDAR systems, which have a higher cost of production, RGB cameras are ubiquitous, much less expensive, and have a significantly higher pixel resolution. Humans drive using only visual cues, therefore high performance autonomous driving could be achieved, in principle, using vision alone.
While stereo cameras are able to recover the depth of the scene, monocular 3D perception still remains a very difficult challenge. In this paper we focus our efforts on monocular 3D object detection and propose an efficient method that combines the initial Faster R-CNN predictions with a closed-form, 2D to 3D geometric mapping solution that produces a rough estimation of an object’s 3D translation. This translation is then refined with our proposed ShiftNet network.
In summary, the main contributions of our paper are:
A 3D object detection architecture with three stages, that accurately estimates the 2D location, 3D object properties (height, width, length), its orientation and 3D translation in camera coordinates, from a single RGB image (Fig. 1). In the first stage, an adapted Faster R-CNN estimates the 2D box, dimension and orientation. In the second stage, a mathematical system of equations is solved using least squares, based on the previous estimates and the known camera projection matrix, to efficiently compute the 3D object translation by enforcing the 3D to perfectly fit the 2D. In the third stage, a fully connected network, namely ShiftNet, learns the error dependency between the first 2 stages and corrects the final translation. 2. 2.
A novel Volume Displacement Loss (VDL) used to train a network for the task of maximizing the 3D IoU by means of regression. 3. 3.
State of the art results on the KITTI 3D Object Detection Benchmark [5], compared to all other published monocular methods that do not make use of an already trained depth net.
Related Work. There is a vast literature on 2D object detection, with accurate approaches on challenging datasets. They vary from general ones, such as COCO [12], to those dedicated to autonomous driving: KITTI [5], Baidu Apollo [8], and Berkley DeepDrive [24]. 2D object detection architectures can be divided into ROI-based, two-stage models and proposal free, single-shot approaches. Single-shot detectors include YOLO [18], SSD [14] and RetinaNet [11]. Two-stage detectors include Faster R-CNN [19], Mask R-CNN [6], PANet [13].
The most powerful 3D object detection models rely on LiDAR-generated point clouds, which simplify the 3D estimation task. 3D-FCN [10] and VoxelNet [25] apply 3D convolutions to point-cloud data to generate 3D bounding boxes. AVOD [9] uses sensor fusion and jointly predicts 3D properties from LiDAR and RGB, being robust to noisy LiDAR data. PointRCNN [21] performs a point cloud foreground/background segmentation, then pools semantic point clouds for accurate canonical 3D object detection. Other approaches use stereo images for a good trade-off between quality and price. Top methods in this category use depth generated from stereo as well as RGB input. Methods include [2, 3, 17], which use stereo information to create 3D object proposals that are scored with CNNs.
Monocular 3D object detection is the most difficult task since it requires tackling the inverse geometrical problem of mapping 2D space into 3D space, in the absence of any true 3D information. Thus, top approaches rely on extra training data in order to make informed 3D estimations. Wang et al. [22] use monocular depth perception networks such as DORN [4] to generate pseudo-point clouds and then apply a state of the art LiDAR-based model [9]. ROI-10D [15] uses monocular depth estimation and lifts 2D detection into a 6D pose problem. Mono3D [1] enforces 3D candidates to lay on the ground plane, orthogonal to image plane. It also uses semantic segmentation, contextual information, object size, shape and location priors. Deep3DBox [16] uses geometric constraints by tightly fitting the 3D bounding box into the 2D box. Xu et al. [23] use multi-level fusion of Faster R-CNN and depth features for 3D object detection. Advances in stereo and monocular depth estimation could provide accurate 3D information, which could greatly improve non-LiDAR based 3D object detection systems.
2 Our 3D Object Detection Architecture
In the absence of any true depth information, estimating the 3D object translation from a single image is a harder problem than estimating its 2D bounding box, dimension and orientation. Our Shift R-CNN model (Fig. 1), combining deep learning with geometric constraints is mainly based on this observation.
2.1 Stage 1: 2D Object Detection and 3D Intrinsics Estimation
The first stage augments the Faster R-CNN model with additional learning objectives. First, we extract and score 2D region proposals by means of 2D anchors [19], using objectness classification and 2D box regression. We then employ 2D ROI pooling for feature cropping. Based on the top scoring 2D proposals, we refine the cropped features using a convolutional encoder, then split them up into 4 separate heads. For the 2D part we use standard multi-class classification and 2D box refinement. The additional 2 heads that we introduce handle local orientation and 3D dimension regression.
Angle Regression Head. Due to the periodic nature of angles, it is harder to regress them explicitly. Thus, we regress instead the estimates and of the local orientation angle w.r.t the y-axis, by also adding a constraint loss to enforce . We predict for each object different angles, one for each class, and compute the loss only on the winning one w.r.t the ground-truth local angle .
[TABLE]
[TABLE]
At inference time, .
3D Dimension Regression Head. The 3D object height, width and length (in meters) are also regressed in triplets, one per class. We do not regress the absolute dimensions, due to their low variance per class. We adopt a procedure similar to 2D bounding box regression [19], by taking into account predefined mean dimensions. Let the mean dimension for a particular class be \overline{\mathbf{d}_{c}}=\left[{\begin{array}[]{ccc}\overline{h_{c}},\overline{w_{c}},\overline{l_{c}}\\ \end{array}}\right], we denote as the object’s real predicted dimension and regress the logarithmic scale offsets w.r.t . The relation between and is seen in Eq. 4. The loss is computed only for the winner class.
[TABLE]
[TABLE]
Multi-Task Loss. We present our total Stage 1 loss in Eq. 5. The first 2 terms are the standard Faster R-CNN multiclass loss and 2D bounding box losses. For the 3D dimension regression we use a standard loss, , over the logarithmic scale offsets .
[TABLE]
2.2 Stage 2: Estimating the 3D Object Translation
Using the 2D bounding box , the 3D dimension estimates and the local orientation angle about the y-axis , the 3D bounding box reconstruction follows.
From local to global orientation. Having already predicted the local orientation angle , the global orientation angle is then determined by considering the ray from the camera origin to the center of the object :
[TABLE]
Inverse geometry problem. In order to accurately reconstruct the 3D bounding box, we need to further estimate the real 3D translation vector of the object center, in 3D camera coordinates. We formulate this estimation in a closed-form, as a least squares solution given by fitting the geometric constraints imposed by the camera projection matrix . Thus, an object described by , and , will have a depth-constrained translation in camera coordinates.
To enforce the 3D bounding box projection to fit tightly into the predicted 2D bounding box, we constrain 2 of the 4 vertical 3D edges to lay on a 2D vertical side and the upper and lower 3D corners to lay on a horizontal 2D side. Assuming that objects lay on the ground plane and that by fixing one vertical 3D edge the second vertical one must be diagonally opposed, we have configurations - from which we choose the best fit. We reconstruct the 3D bounding box at the camera center, by using the 3D dimensions , then obtain the final 3D box, in camera coordinates, by applying the rotation about the y-axis and translation :
[TABLE]
The relation between a 3D point in the world and its 2D projection in the image , using the projection matrix , is given in homogeneous coordinates:
[TABLE]
From Eq. 7 and 8, similar to [16], we obtain the following system where translation is the unknown vector:
[TABLE]
By substituting each element of , corresponding to a 2D side, and also into System 9, we propose a least squares solution for the translation, different from [16]. Here and is the element of matrix .
[TABLE]
The over-constrained System 10 can be rewritten as , with a general closed-form solution for the 3D object translation . For choosing the best fitting solution, we evaluate the 2D IoU score of the initial 2D and re-projected 3D box.
2.3 Stage 3: Refining the 3D Object Translation
Shift Network. The translation estimate from Eq. 10 alone is a good approximation of the object 3D location. However, it assumes a perfect mathematical model and, implicitly, perfect Faster R-CNN predictions. Our tests indicate that the estimate is not accurate when predictions are noisy, going from 80% accuracy with a 3D IoU of at least 0.7, to a roughly 14% if noise is present. Even a small error in the predicted values needed to solve Eq. 10, produce huge displacements of and thus low 3D IoU score.
To address this limitation, we propose an effective approach for refining the estimate . We introduce ShiftNet (SHN) in Stage 3. We model ShiftNet as a hybrid that uses the estimate from Stage 2 (Eq. 9), with the initial Stage 1 predictions and outputs an improved final translation . It learns to combine, in complementary ways, the best of the exact geometric universe with the ability of a neural net to learn in the presence of noise. The actual input fed to the network is given by , , , , and . SHN is then trained to regress . The architecture has 2 fully-connected layers with 1024 neurons, and a final layer that regresses 3 values for .
Volume Displacement Loss (VDL). Using an independent component-wise regression of does not capture correctly the final IoU detection measure. It does not take into account the object shape variations along the different dimensions. For example, an error along the Y-axis could produce a larger error in total volume than one, by the same amount, along the Z-axis. A better loss is proposed by [15], by summing the Euclidean distances between each pair of the corresponding 3D bounding box corners, but without taking in consideration the different effects errors along the different axes might have, in the final IoU.
Based on this observation, we introduce the Volume Displacement Loss (VDL) to regress as the translation that optimizes the IoU score between two 3D boxes reconstructed using the same and parameters predicted in Stage 1, but one with the the ground-truth and the other one, using the estimated . While the direct, true 3D IoU w.r.t the ground truth bounding box is not differentiable and does not define a distance in metric space, we show that our VDL loss factorizes into a sum of simple terms and can be effectively used in training.
We first express the Signed Translation Displacement Error (STDE) vector along the camera coordinates axis. We factor in the rotation and decompose the STDE relative to the object’s local coordinate axis, as it can be seen in the following Equation 11:
[TABLE]
The the VDL loss measures the displaced quantity of volume, when moving the object’s center alongside one local coordinate axis. This quantity can be expressed as a function of the 3D bounding box dimensions and elements of . The following Equation 12 defines our Volume Displacement Loss:
[TABLE]
3 Experiments
In this section, we present the experimental setup, compare to state of the art monocular approaches, and test experimentally our contributions.
3.1 Experimental Setup
Dataset. We evaluate our architecture using the KITTI 3D Object Detection dataset [5]. We use the train-val split proposed by Chen et al. [1], which splits the KITTI training set into 3712 training images and 3769 validation images and also evaluate on the online test split. Stage 1 Setup. We use a Faster R-CNN architecture with ResNet-101 backbone, and the additional angle and 3D dimension heads as described in Section 2.1. For ROI pooling we use image features from stride by atrous convolutions instead of strided ones in the final encoder part. Stage 1 network is trained end-to-end. At inference we use NMS for 2D boxes, angle, and dimension predictions.
Stage 1 Training Procedure. We train the model with SGD for 30 epochs with a batch size of 1, momentum of 0.9, initial learning rate of and 2 learning rate decays of 0.1 at 1/2 and 2/3 of the epoch count. Faster R-CNN weights are pre-trained on the COCO 2D detection [12] and for the extra heads we use He initialization [7]. Our loss weighting strategy takes into account the uncertainty of a task: 1.0, 2.0, 5.0 and 100.0 for the classification, localization, orientation and dimension regression, respectively. We train the Stage 1 model on the KITTI dataset, using Chen’s split [1] and the entire KITTI training data for the official submission. We train on the Car, Pedestrian, and Cyclist classes. We use random flip data augmentation.
Stage 3 Setup. We pre-train ShiftNet by using the corresponding ground-truth, instead of the Stage 1 generated data. This gives the network a good initialization on how to map ground truth 2D to 3D information. Then we fine-tune the network on real estimates produced by Stage 1. Compared to the Stage 2 least squares solution given by the mathematical system, ShiftNet improves on the 3D detection accuracy (0.7 3D IoU) on Car by 3% on ground truth data (71% vs. 68%) and by 6.6% on real images estimates given by the Faster R-CNN Stage 1 (13.8% vs. 7.2%). Our experiments show that a relatively simple neural net, such as ShiftNet, can infer 3D information even without directly using visual features, as can be seen in Fig. 2. We experiment with augmenting the ground-truth with additional synthetic data, obtained by randomly perturbing the ground truth 3D boxes and then projecting them with the given camera matrix, to obtain 2D boxes information. The additional pre-training on synthetic data significantly improves the accuracy (0.5 3D IoU) for the classes with fewer examples (22% vs. 20% for Pedestrian, 73% vs. 47% for Cyclist), when training on ground-truth input.
Stage 1 and 3 models (Fig. 1) are trained on a NVIDIA GTX 1080 Ti GPU and for one image, the total inference time is 259ms.
3.2 Comparison to other Methods
Our framework is evaluated on the KITTI and evaluation metrics. We use all 3 classes: Car, Pedestrian, Cyclist. Each of the classes is split into 3 difficulties: Easy, Medium, and Hard. In Table 1, we compare with monocular 3D object detection methods. We show in blue methods that use heavier monocular depth estimation networks. As we can see in Table 1, it is clear that our method outperforms all monocular 3D object detection methods that do not use depth estimation in and on both val/test splits for Car class. We outperform OFT-NET [20], which uses orthographic feature transform. We also outperform some methods that use monocular pre-trained depth prediction such as MLF-MONO [23] and ROI-10D [15] on val split, and come close to MLF-MONO on test split. On KITTI test split, these methods improve their results due to the much more training data available for depth prediction. We are also overall state of the art on the Pedestrian and Cyclist classes for monocular 3D detection. Thus, our result contradicts the assumption that these classes are too difficult to predict from monocular data.
4 Discussion and Conclusions
Compared to 2D detection (91%) and object orientation (90%), our is lower, due to noise in depth prediction, which, for an error of 1 meter, can move the 3D bounding box outside the required 0.7 3D IoU overlap. Overall, our approach proves very competitive, with top results in its category on the KITTI 3D Benchmark. Our framework builds upon the robust Faster R-CNN, augmented with 3D object dimensions and local orientation prediction. We use the output of Faster R-CNN alongside the camera projection matrix to compute an analytic solution to the 3D translation problem. Our geometric solution is then refined with ShiftNet, which learns to leverage the output of Faster R-CNN with the rigorous mathematical solution. By combining the optimal, but less robust analytic solution with the imperfect, but much more robust deep learning model, we provide a hybrid system that takes advantage of the best of both worlds. With a much lighter architecture and without a pre-trained depth network we obtain state of the art results not only on the Car class, but also on the Pedestrian and Cyclist classes, on which we outperform our competitor OFT-NET [20] on all difficulty levels.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun. Monocular 3d object detection for autonomous driving. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 2147–2156, 2016.
- 2[2] X. Chen, K. Kundu, Y. Zhu, A. Berneshawi, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals for accurate object class detection. In NIPS , 2015.
- 3[3] X. Chen, K. Kundu, Y. Zhu, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals using stereo imagery for accurate object class detection. Co RR , abs/1608.07711, 2016.
- 4[4] H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao. Deep ordinal regression network for monocular depth estimation. Co RR , abs/1806.02446, 2018.
- 5[5] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR) , 2012.
- 6[6] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Conference on , pages 2980–2988. IEEE, 2017.
- 7[7] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Co RR , abs/1502.01852, 2015.
- 8[8] X. Huang, X. Cheng, Q. Geng, B. Cao, D. Zhou, P. Wang, Y. Lin, and R. Yang. The apolloscape dataset for autonomous driving. Co RR , abs/1803.06184, 2018.