Multiwavelength cluster mass estimates and machine learning
J.D. Cohn, Nicholas Battaglia

TL;DR
This paper explores using machine learning to directly estimate galaxy cluster masses from multiwavelength data, comparing observable contributions and testing simulation-observation consistency.
Contribution
It introduces a novel approach of combining multiple observables with machine learning for cluster mass estimation, surpassing traditional scaling law methods.
Findings
Machine learning effectively combines multiwavelength data for mass estimates.
Importance Permutation quantifies each observable's contribution.
Simulation-observation correlation tests are proposed and explored.
Abstract
One emerging application of machine learning methods is the inference of galaxy cluster masses. In this note, machine learning is used to directly combine five simulated multiwavelength measurements in order to find cluster masses. This is in contrast to finding mass estimates for each observable, normally by using a scaling relation, and then combining these scaling law based mass estimates using a likelihood. We also illustrate how the contributions of each observable to the accuracy of the resulting mass measurement can be compared via model-agnostic Importance Permutation values. Thirdly, as machine learning relies upon the accuracy of the training set in capturing observables, their correlations, and the observational selection function, and as the machine learning training set originates from simulations, two tests of whether a simulation's correlations are consistent with…
Click any figure to enlarge with its caption.
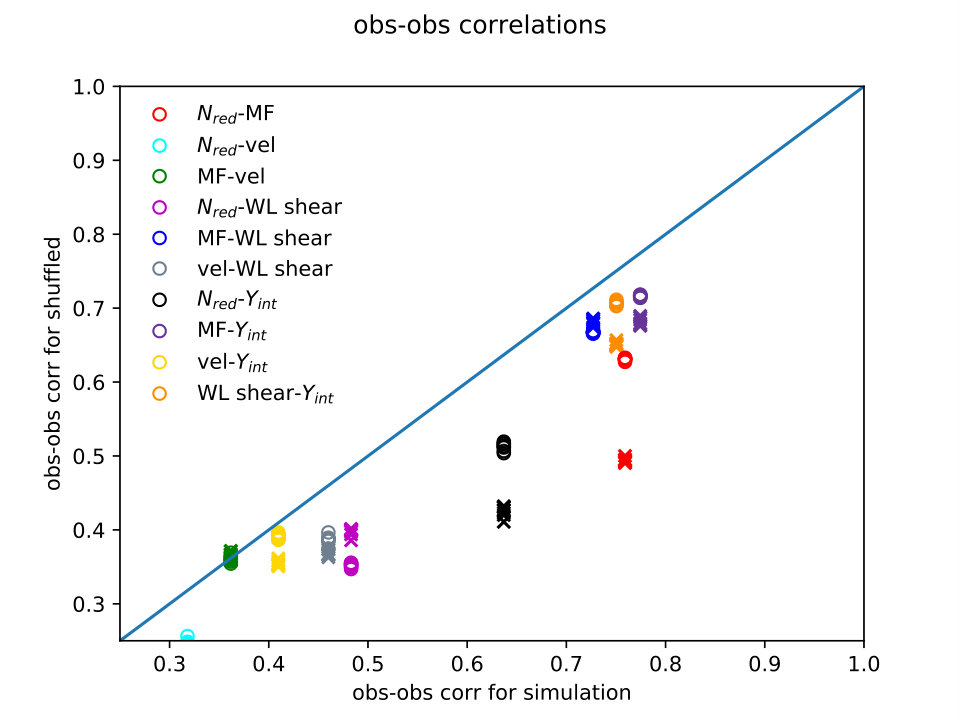 Figure 1
Figure 1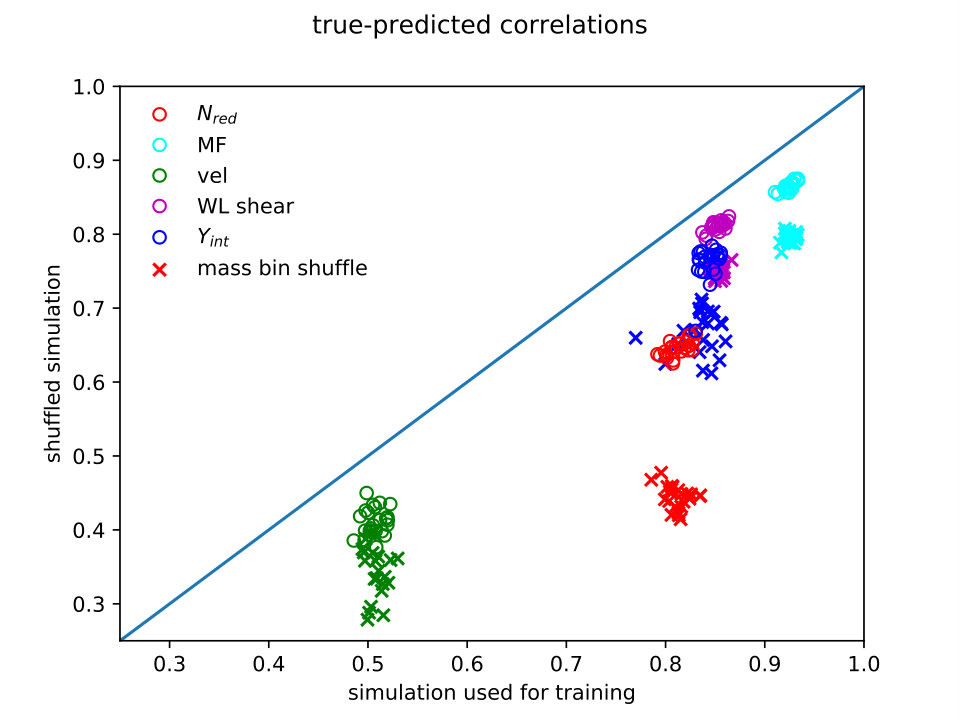 Figure 2
Figure 2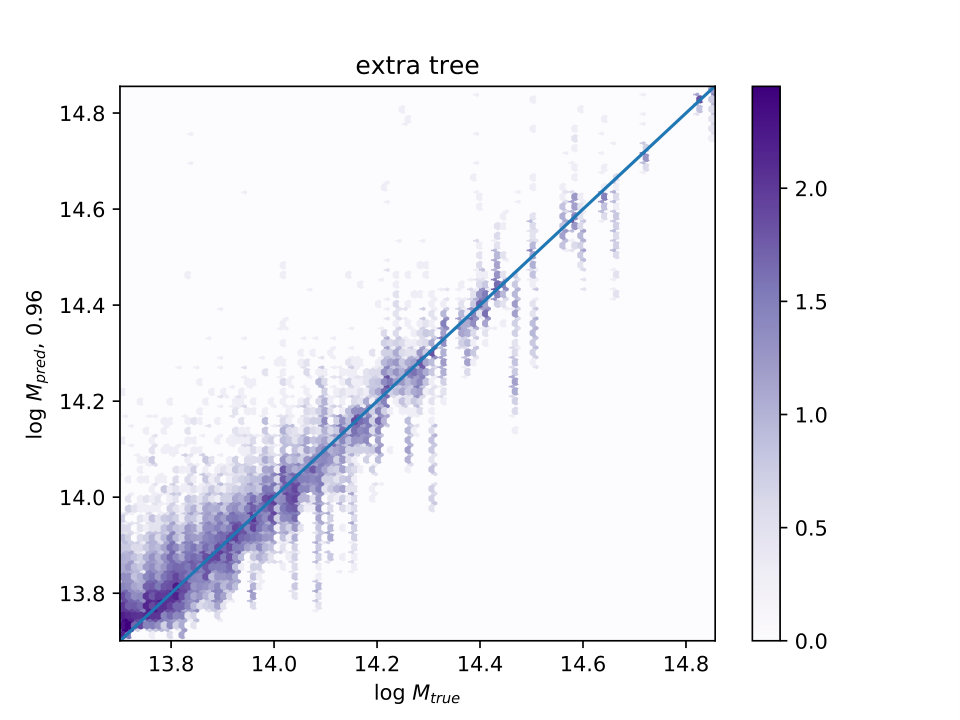 Figure 3
Figure 3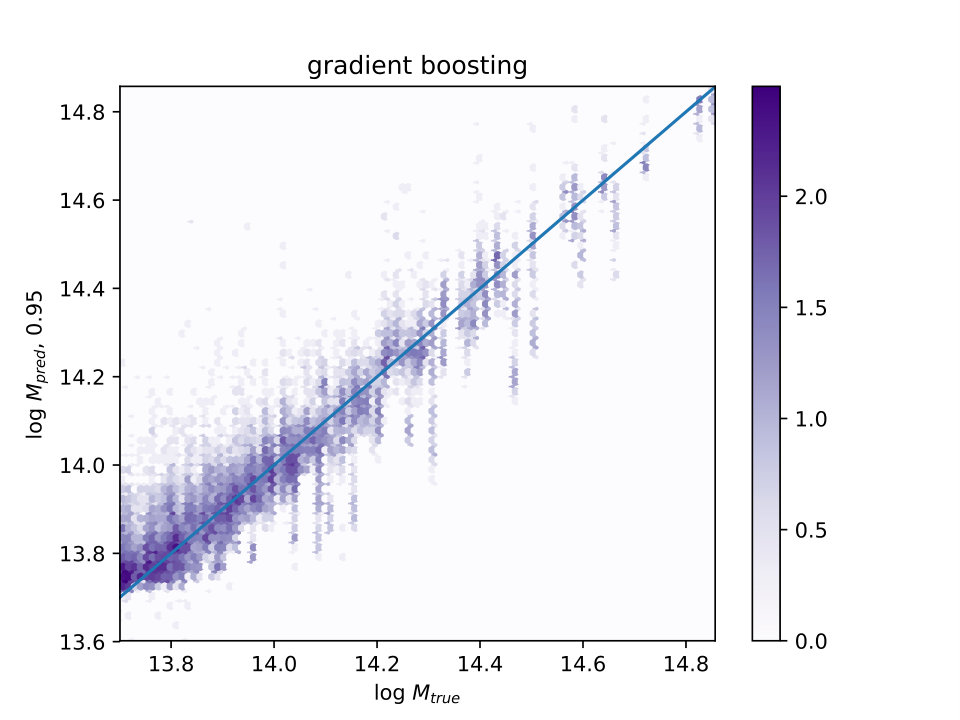 Figure 4
Figure 4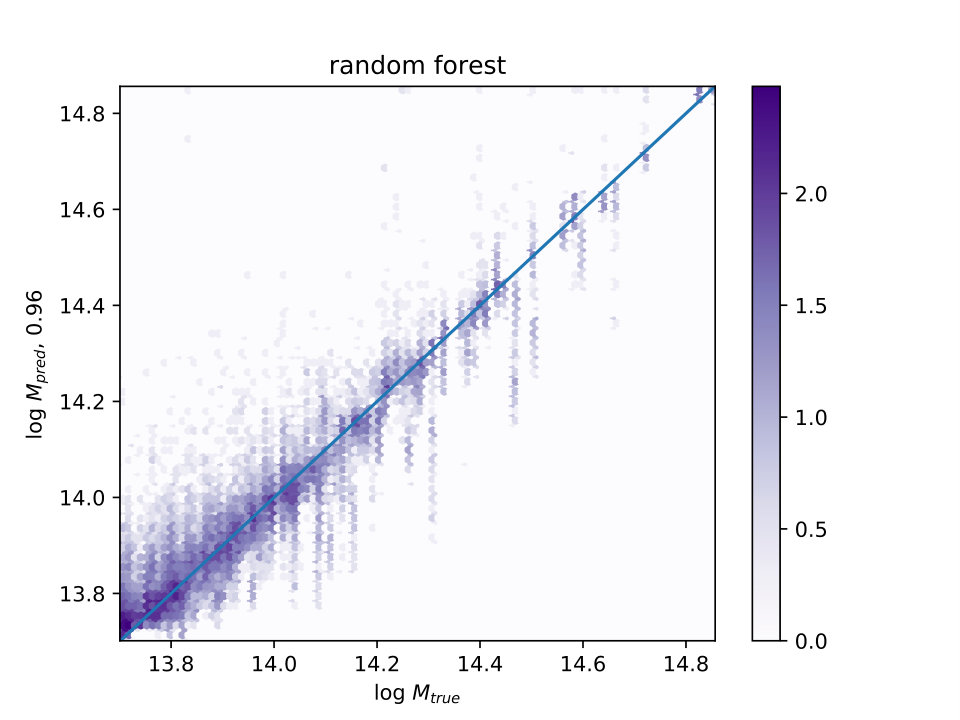 Figure 5
Figure 5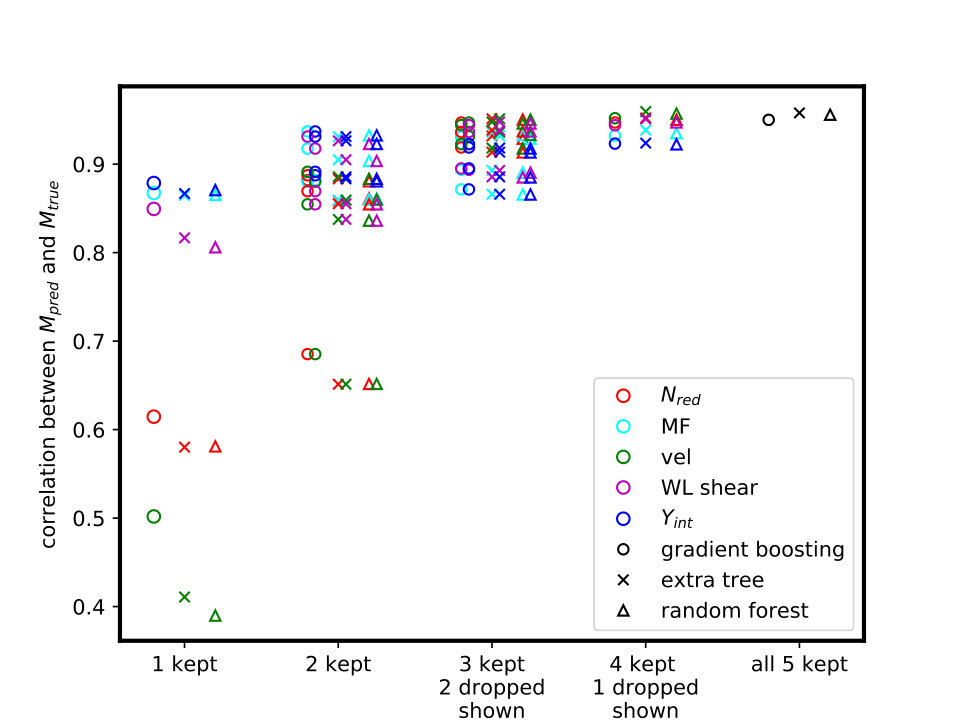 Figure 6
Figure 6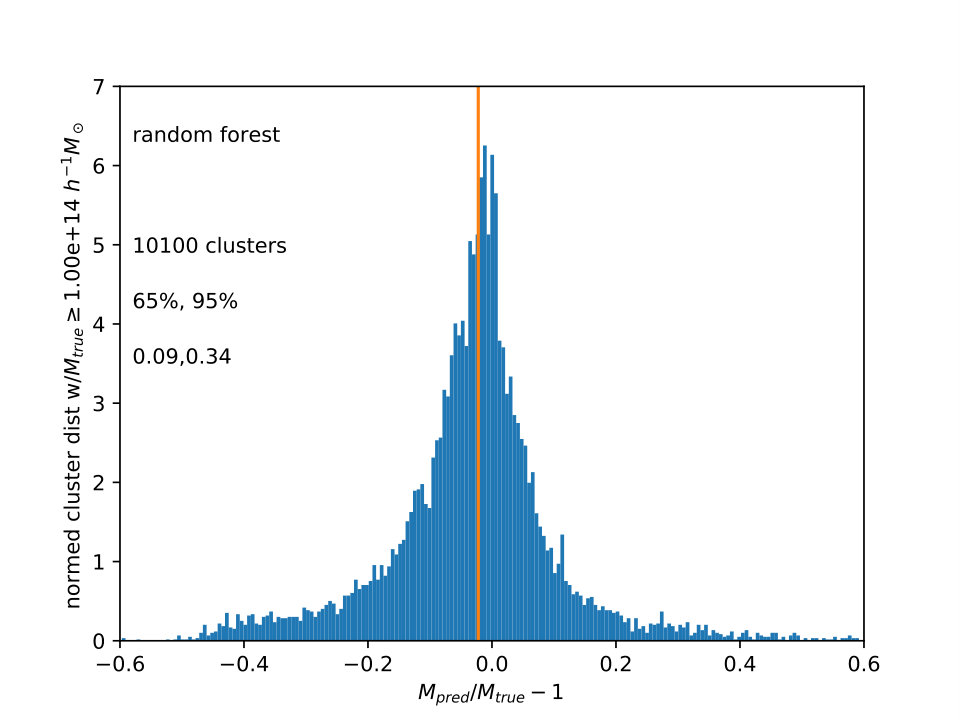 Figure 7
Figure 7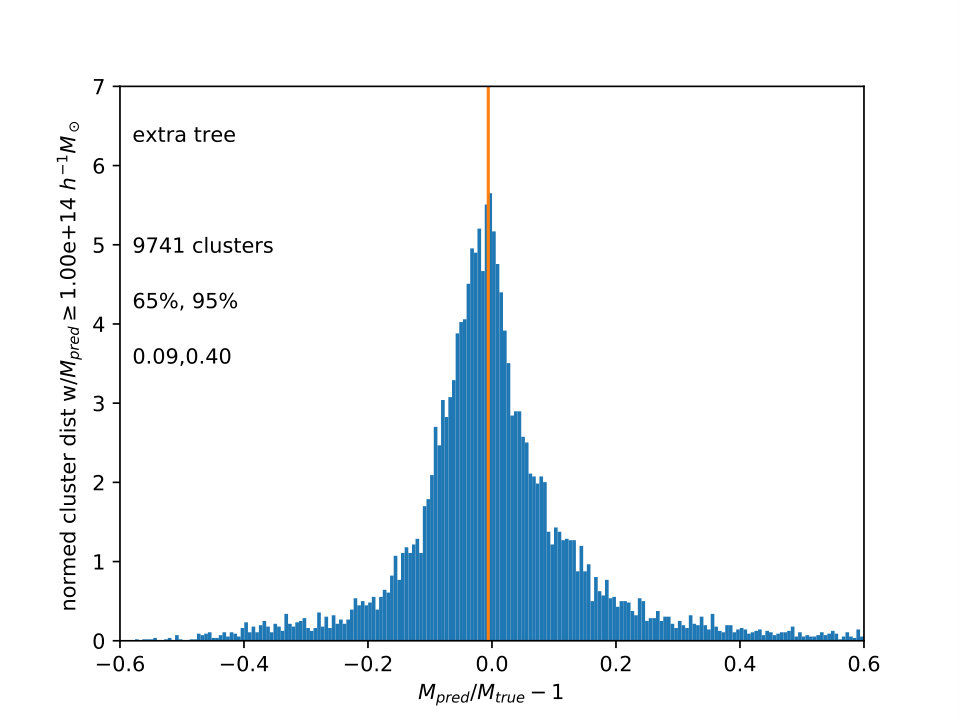 Figure 8
Figure 8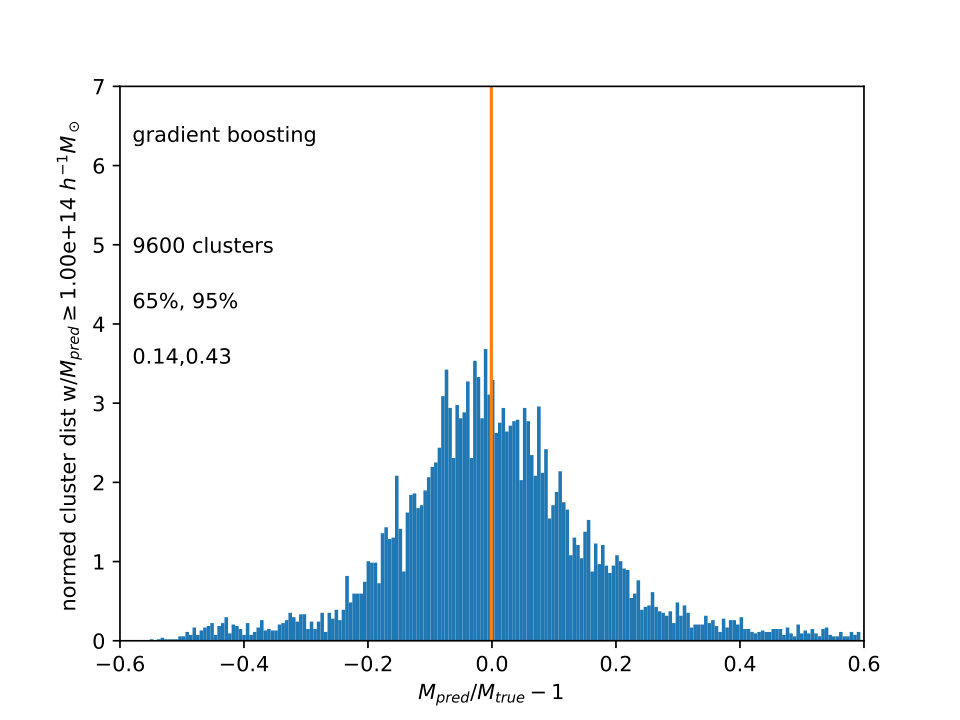 Figure 9
Figure 9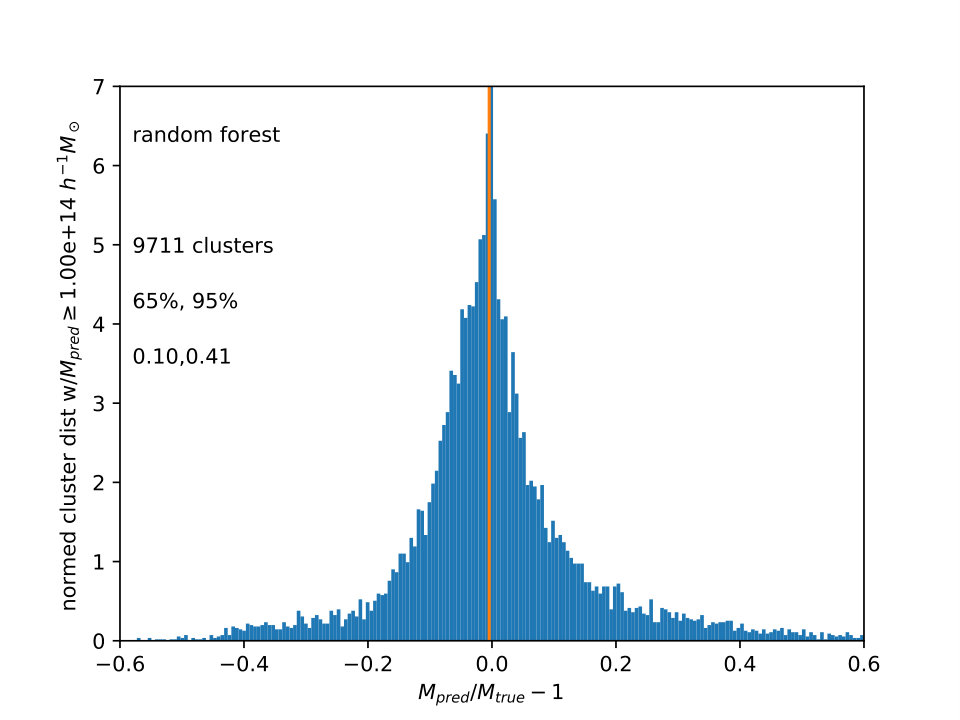 Figure 10
Figure 10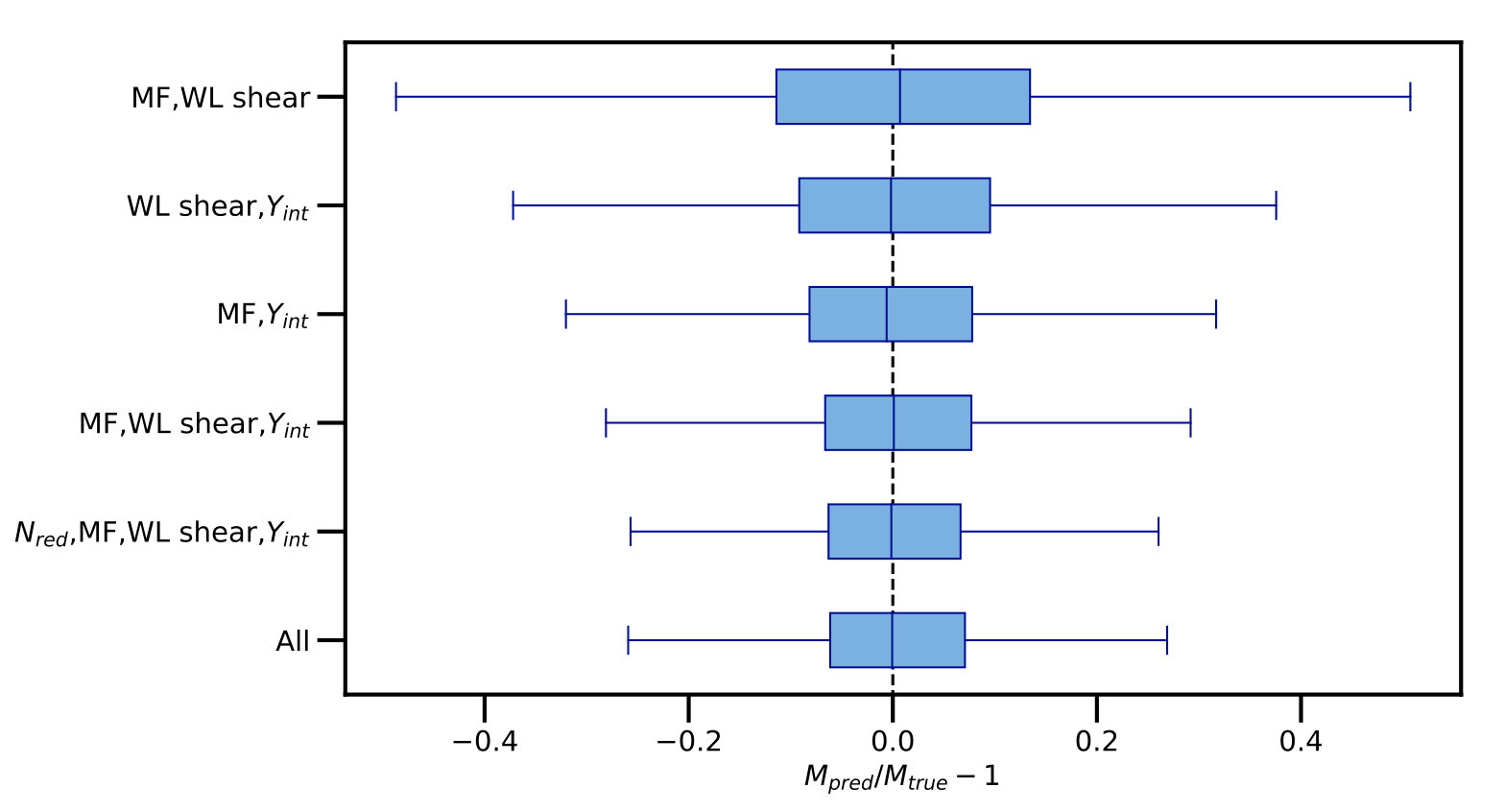 Figure 11
Figure 11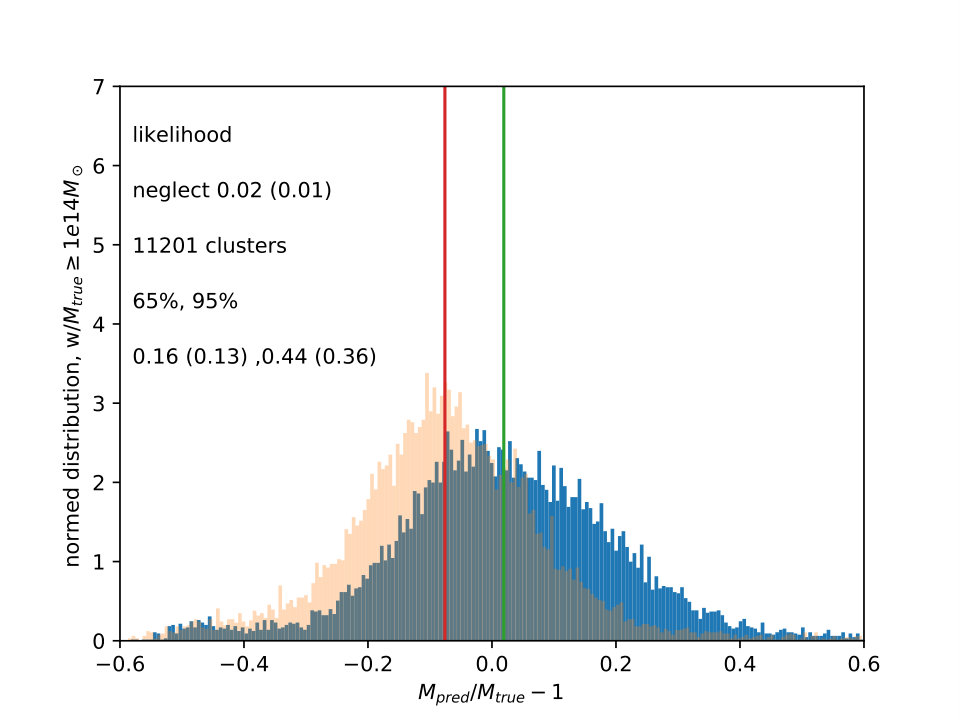 Figure 12
Figure 12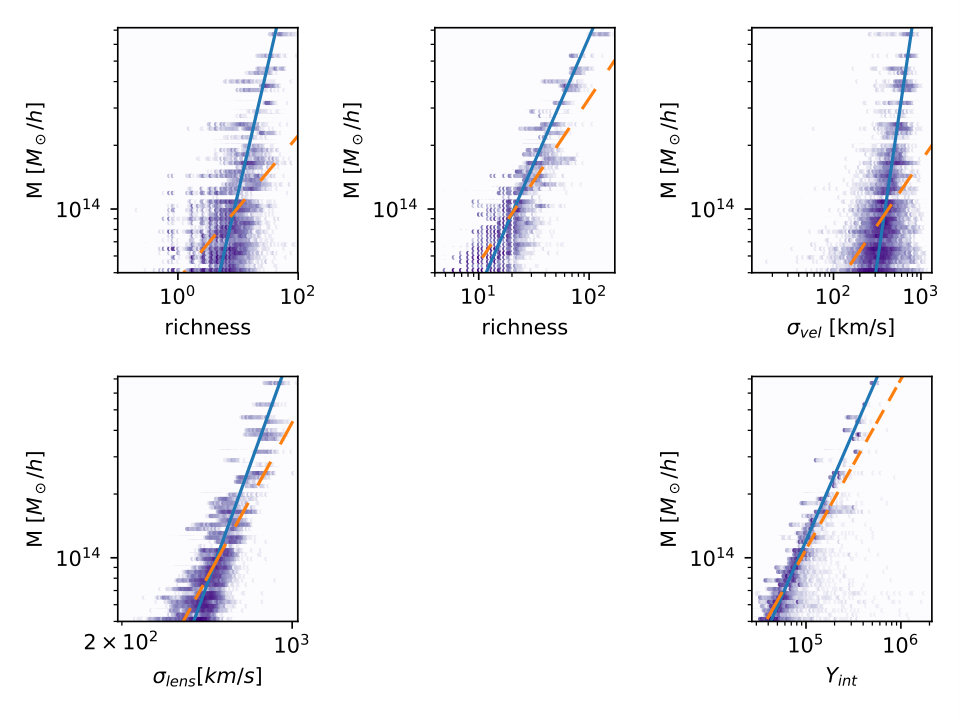 Figure 13
Figure 13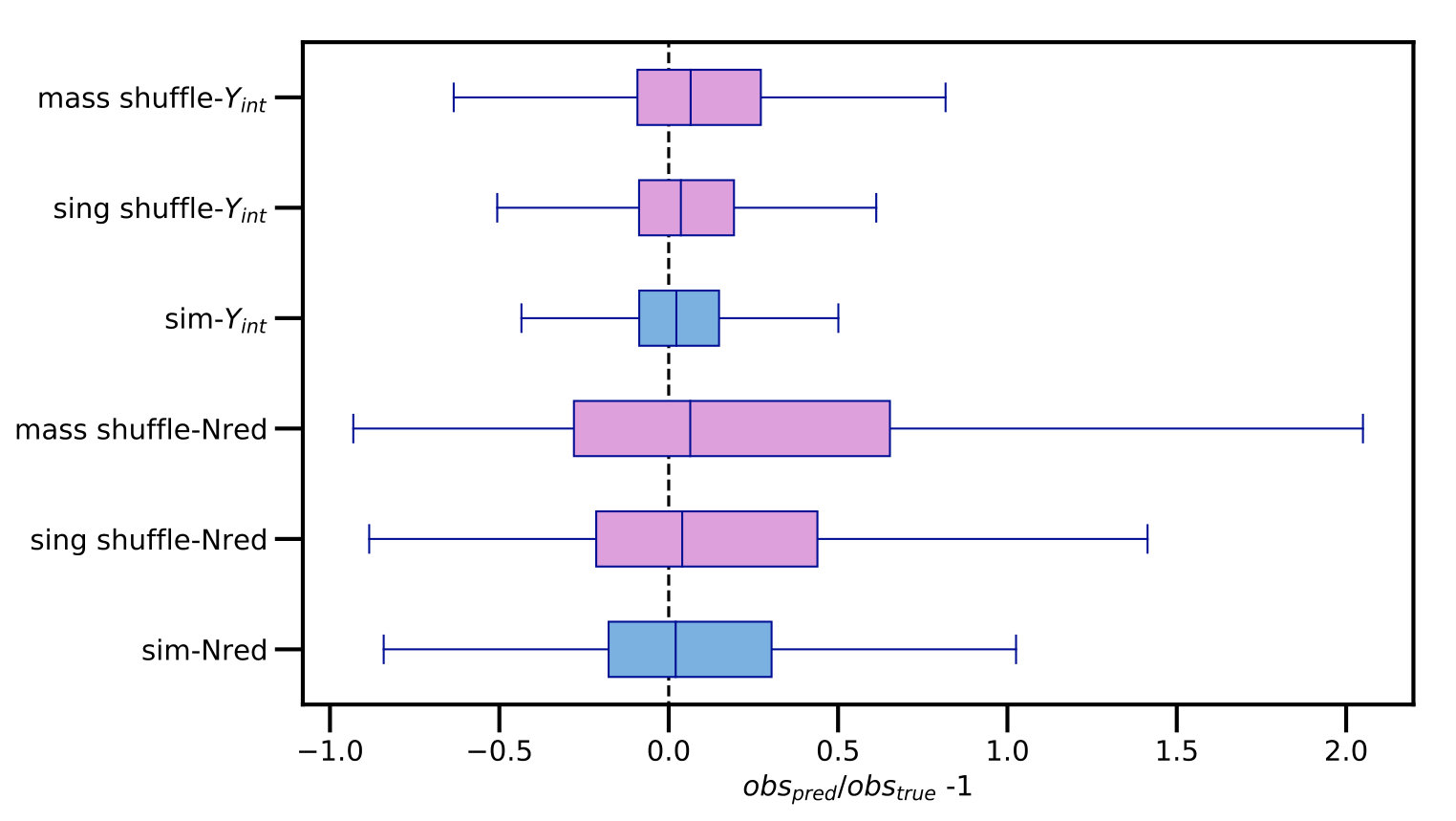 Figure 14
Figure 14Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multiwavelength cluster mass estimates and machine learning
J.D.Cohn1,2 and Nicholas Battaglia3
1Space Sciences Laboratory University of California, Berkeley, CA 94720, USA
2Theoretical Astrophysics Center, University of California, Berkeley, CA 94720, USA
3Cornell University, Ithaca, NY 14853, USA E-mail: [email protected]
Abstract
One emerging application of machine learning methods is the inference of galaxy cluster masses. In this note, machine learning is used to directly combine five simulated multiwavelength measurements in order to find cluster masses. This is in contrast to finding mass estimates for each observable, normally by using a scaling relation, and then combining these scaling law based mass estimates using a likelihood. We also illustrate how the contributions of each observable to the accuracy of the resulting mass measurement can be compared via model-agnostic Importance Permutation values. Thirdly, as machine learning relies upon the accuracy of the training set in capturing observables, their correlations, and the observational selection function, and as the machine learning training set originates from simulations, two tests of whether a simulation’s correlations are consistent with observations are suggested and explored as well.
keywords:
1 Introduction
Galaxy clusters are the most massive bound structures in the universe and are often complex. This is in part due to their tendencies to be triaxial, to lie in an anisotropic environment at intersections (nodes) of the cosmic web, and to be recently formed. A cluster’s host halo can be characterized by its mass, which characterizes many properties of the gas, galaxies and other quantities within it (for a recent review, see Wechsler & Tinker, 2018). Clustering with other halos is also most affected by a cluster’s mass (Kaiser, 1984; Cole & Kaiser, 1988; Efstathiou et al, 1988; Mo & White, 1996), although there are secondary (“assembly bias”) effects which are also under study, both for clustering and for other cluster properties, such as number of galaxies within. There also is interest in cluster masses due to the sensitivity of the cluster mass distribution to cosmological parameters (e.g., Voit, 2005; Allen, Evrard & Mantz, 2011; Borgani & Kravtsov, 2011).
A particular cluster boundary definition specifies a cluster’s halo and its mass corresponding to the particular definition. In a simulation, a definition of where a cluster halo begins and where its environment ends (given the physics included in the simulation) can be precisely applied to find the mass, especially using the available three dimensional spatial and velocity information. Observationally, it is much harder to disentangle a cluster from its surroundings and from direction dependent effects, and to account for confounding dynamical effects. For example, cluster mass can be indicated by the number of galaxies the cluster hosts (richness), but galaxies are observed in redshift space and thus can lie several Mpc from the cluster but appear to be within it. The hot cluster gas scatters CMB photons en route to us via the Sunyaev-Zel’dovich effect (Sunyaev & Zel’dovich, 1972), effectively leaving a shadow on the cosmic microwave background or CMB, but other mass along the line of sight to the cluster can also scatter these photons and thus modify the signal. Weak lensing shear captures all the mass in the cluster, but only as part of capturing all the mass between the galaxy being sheared (located behind the cluster) and us (in front of the cluster). Although X-ray measurements tend to only track the hot gas within the cluster, the dynamical state of the gas can significantly modify estimates, and even for X-ray, projection effects can contaminate the sample (e.g., Ramon-Ceja et al, 2019). There is also a suggested dynamic cluster ’edge’ definition based upon velocities and positions of galaxies in a cluster, via their splashback (for example, Adhikari, Dalal & Chamberlain, 2014; More, Diemer & Kravtsov, 2015) or backsplash (for example, Gill, Knebe & Gibson, 2005) radius; see, for example, Shin et al (2019) for a recent measurement. These dynamics are used in the caustics (Rines et al, 2003) method to find cluster masses, which has scatters due to interlopers and line of sight variations in velocity dispersions (e.g. Gifford, Miller & Kern, 2013).
Multiwavelength measurements of clusters can be combined to get a more complete picture of any given individual cluster or of a distribution of clusters. Often, the route for determining a cluster’s mass is to find a mass-observable relation for each cluster property, separately, e.g. galaxy richness or SZ flux. These fits (usually power law scaling relations) convert observables into mass estimates. For multiwavelength measurements, these power law based mass estimates plus their estimated errors are combined in a likelihood to estimate the underlying cluster mass (see Allen, Evrard & Mantz, 2011, for a detailed review and discussion). However, as the scatter between the true and estimated mass for each observable is often due to the cluster’s triaxiality, anisotropic environment and other physical cluster properties, the mass estimate errors using different observables can be correlated. These mass error correlations should be represented faithfully in the analysis, or they can impose a bias (see, for example, Allen, Evrard & Mantz, 2011; Rykoff et al, 2008; Stanek et al., 2010; White, Cohn & Smit, 2010; Angulo et al, 2012; Shirasaki, Nagai & Lau, 2016, for more details and examples of correlations). Correlations are also possible between the scatter in the observable used to select the clusters and observables used to measure the cluster masses. To summarize: observables are each converted to cluster mass via an observable specific scaling relation (usually a power law), and then combined using correlations whose form is either marginalized over or estimated from simulations.
In this note, machine learning is suggested as a method to obtain multiwavelength mass estimates of a cluster directly from the observational quantities, skipping the intermediate step of matching observations to average relations for mass (of a predetermined form, i.e., scaling relations, plus estimating their correlated mass errors) and instead going straight to the mass prediction of the combined observations. One reason one might expect this approach to be successful is that scatter around the true mass for multiwavelength observations can be analyzed using principal component analysis (Noh & Cohn, 2012), where it can be seen that the leading contribution to the scatter for each observable tends to be occur in a certain combination with that of other observables.
This suggested approach follows the philosophy of Ho et al (2019) and earlier papers (Ntampaka et al, 2015, 2016, 2017). There, galaxy cluster masses are estimated by using cluster galaxy velocities, but instead of turning all the cluster velocities into a single velocity dispersion and mapping the dispersion into a mass using a mean relation (approximate fit), the individual velocities are given to a machine learning algorithm, to encode the more detailed relations between the different galaxy velocities, their angular positions and the cluster final mass. Additionally, Armitage, Kay & Barnes (2019) combine, with no measurement errors (but fixed length cylinders to include some projection effects), several X-ray, SZ, galaxy angular position, velocity dispersion and count properties to obtain machine learning cluster masses. They consider a large range of features and include the gradient boost method as we do, below, but not the other two random forest related methods, which we found had better success. Amongst the methods they tested, they found the most success with ordinary linear regression and variants of ridge regression.
Here, using a simulation which has several different multiwavelength mock cluster observations, machine learning is used to
calculate the mass directly from the combination of the different multiwavelength observables, without going through a mass estimate for each, 2. 2.
compare subsets of multiwavelength measurements to each other to identify which combinations give the smallest scatters and biases in predicting mass (within the measurement approximations which are made in the simulation), and 3. 3.
test for whether a given simulation correctly captures correlations between different observables (again, within the context of a specific mass-observable relation given by the simulation).
Having all multiwavelength mock observations made on the same simulation guarantees a shared model for all the observables which are being compared. However, this suggested approach is also limited in its usefulness by the accuracy of the simulation (and how well this accuracy is understood); hence the interest in identifying tests for correlations such as are discussed below. This accuracy is also important for the usual scaling relations method, if a simulation is used for calibrating the scaling relation.
Again, using the various observations together in a machine learning algorithm is to be contrasted to mapping each individual observable’s measurement to mass via a predetermined scaling relation plus scatter (from a simulation) and then combining probabilities. The hope is that the simultaneous fit might include more information from the relations between the multiwavelength measurements and thus improve the accuracy. In section §2, the simulation measurements and machine learning methods are described. In section §3.1, mass estimates are made, and errors characterized. In §3.3, a few ways of testing a simulation relative to observations are suggested and explored with a simulation (relative to a simulation with shuffled observables, i.e., with artificially suppressed correlations). §4 concludes.
2 Methods and data
We use a dark matter only simulation in a periodic box of side Mpc with particles, evolved using the TREEPM (White, 2002) code, and provided by Martin White. Cluster observables are assigned as in White, Cohn & Smit (2010), hereafter WCS, which can be consulted for details beyond those found below. Although the sample used for analysis in WCS itself has a slightly larger box with higher resolution, its cluster measurements did not extend to low enough mass to reasonably expect completeness for some cuts considered here. Combining the two samples did not seem appropriate given their different resolutions and cosmologies.
The simulation background cosmological parameters are , , , and , slightly off from the best estimated current cosmology (Planck collaboration, 2016), but close enough for the concerns of interest in this note. There are outputs at 45 times equally spaced in from to [math]. Halos are found using a Friends of Friends (FoF) halo finder (Davis et al., 1985), with linking length times the mean interparticle spacing. Masses quoted below are FoF masses. As the box is fairly small, only is considered, with 117 halos with and 339 halos with . Mock observations are made of five observables. For each observation, the cluster is placed at the center of the box. To get more statistics, and to explore the effect of anisotropy, triaxiality, and their correlations, each cluster is ”observed” via all five methods below, from 96 different isotropically distributed directions on a sphere. The methods are:
- •
: red galaxy richness based on the older MaxBCG mass estimator Koester et al. (2007); colors are assigned using Skibba & Sheth (2009), with redshift evolution as detailed in appendix B2 of WCS.
- •
MF: richness from matched filter based upon Yang et al (2007). This gives each galaxy at position from the cluster center a weight made up of a projected NFW halo profile (Navarro, Frenk & White, 1997) in the plane of the sky, times a Gaussian in along the line of sight, with the galaxy kept if this weight exceeds a threshold value of 10. The details are in equations 7-11 of Yang et al (2007), with redshift replaced with real space , and replaced with . The matched filter dispersion and characteristic radius are based on the true halo mass.
- •
vel: velocity dispersions, calculated using the method descibed in detail in WCS in §5.1.
- •
: Sunyaev-Zel’dovich decrement (Sunyaev & Zel’dovich, 1972). Each particle is given the mean temperature associated with the velocity dispersion of its host halo. For each halo center, the integration of the SZ signal is done within a disk of radius perpendicular to the line of sight, through the entire box along the line of sight (apodized as in WCS Eq. 1 to avoid a sharp boundary cutoff).
- •
WL shear: fit to a dispersion using the statistic and a singular isothermal sphere profile. These are described in §3.3 of WCS. Roughly, (WCS Eq. 2) corresponds to subtracting the projected surface density in an annulus from that of a disk to decrease the contributions from material uncorrelated with the cluster. Then is converted to by multiplying factors drawn from assuming some particular cluster profile, Eq. 3 in WCS. An isothermal sphere was used; similar results were obtained as profiles and annuli parameters were varied.
See WCS and the other papers referenced above for further detail on these techniques.
The distribution of the resulting observables as a function of mass is shown in Fig. 1. Lines are fit either using a least-squares fit (dashed line) or binning in 20 log bins and finding the median observable in each and fitting to those, dropping bins with no clusters in them. These are meant to be mock observations, that is, relying primarily only on information available to an observer (rather than the three dimensional velocities and positions, exact gas content, etc., which a simulator might be able to access). However, some of the mock observations have advantages over real sky observations: using true and not including any survey dependent residuals from foreground cleaning (SZ), using real space along the redshift direction and true halo mass matched filter dependence (MF), and neglecting survey dependent photometric redshift magnitude and shape errors and galaxy shape errors (WL shear). Also, the MaxBCG richness is not in standard use anymore, however, its replacement in several new and upcoming large surveys (redmapper, Rykoff et al, 2014) does not yet have a halo model or other description which would allow its richness prediction to be reliably calculated for this sample. (There are many other richness estimators possible, see Old et al (2015) for a comparison of several of them, applied to two blinded data sets.)
For machine learning, for each mock multiwavelength observation, the input variables are the five observables (, MF, vel, ,WL shear) for each cluster, along a single line of sight. The output is the true mass for the training set, and the mass prediction for the testing set. The training set is a random selection of the set of cluster observations (1/10 of the sample), with testing done on the other 9/10. The machine learning programs used are GradientBoostingRegressor, ExtraTreesRegressor and RandomForestRegressor from sklearn in python.
The exact calls were:
- •
GradientBoostingRegressor(loss=’ls’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=’friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_split=None, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort=’auto’)
- •
ExtraTreesRegressor(n_estimators=700, min_samples_split=5, n_jobs=-1)
- •
RandomForestRegressor(n_estimators=300, n_jobs=-1, min_samples_split=5)
The GradientBoostingRegressor uses default values for the arguments, while ExtraTreesRegressor and RandomForestRegressor follow Kamdar, Turk & Brunner (2016a, b) for parameters in the function calls.
There are several detailed descriptions of these methods in the literature, in particular Breiman (2001) and Geurts, Ernst and Wehenkel (2006) for Random Forests and Extra Trees (see also the descriptions for astronomers in Kamdar, Turk & Brunner (2016a), §2.4.2 and 2.4.3). The books by Hastie, Tibshirani & Friedman (2009) and Geron (2017) have pedagogical approaches, with the latter oriented around scikit.learn in particular.
Heuristically, Random Forests and Extra Trees create regression trees based upon a training sample, splitting the sample according to one feature at a time until some condition is met. Both methods choose the feature for each subsequent split by taking a random subset of the features (in the case here, the features are the 5 observables, , MF, vel, and WL shear) and testing possible bifurcations, one for each of the features in the random feature subset. The “best” bifurcation is the one which roughly has the least final variance, where variance is calculated with respect to the mean in each branch, over all the elements in each branch, with a weighting determined by the fraction of elements in that branch. After applying this ”best” bifurcation, if the stopping condition is not met, the process repeats to create the next bifurcation of the tree. Both methods create an ensemble of trees and combine the results to reduce overfitting and improve accuracy.
The big differences between the Random Forests and Extra Trees are that the training set is used differently and the bifurcations at each step in the regression tree are chosen differently. In Random Forests, the full training set is not used for every tree in the ensemble. Instead, a bootstrap sample of the training set is used, with a different bootstrap sample for each tree that is in the combined final ensemble. Secondly, when the bifurcations are made, the “best” bifurcation is found separately for each feature (with “best” as above), and then the resulting best bifurcations of each feature are intercompared. The best of the best bifurcations is chosen to make the next tree bifurcation. For Extra Trees, instead, the whole training set is used to train each tree. Secondly, for bifurcations, a random bifurcation is chosen for each of the features being compared. These random bifurcations of each feature are compared to each other (rather than the best bifurcations of each feature in the Random Forest), but again, the “best” one amongst the features is taken. The Extra Trees method is much faster, as the “best” bifurcation is not first found for each feature separately, before comparing the separate proposed feature bifurcations to each other. It is not always evident which one will do a better job on a given problem until they are both tried.111DecisionTreeRegressor is also used in Kamdar, Turk & Brunner (2016a)). It fits to a single tree rather than an ensemble. It fails to provide reasonable scatter for the sample here, due to the small number of distinct true halo masses, especially at the high mass end.
The gradient boost method uses an ensemble of trees, as well, but instead of taking a tree ensemble with different trees having different random training samples or bifurcations, it creates a sequence of trees, where each tree fits the negative gradient of the loss function of the previous tree. The loss function chosen here is least squares.
These particular methods were chosen due to their familiarity for the authors; an exhaustive comparison of all the methods available in scikit.learn (Pedregosa et al, 2011) or elsewhere, or possibilities with custom made ML codes, was not undertaken. A more extensive comparison and exploration would be interesting to do for a machine learning study, given the initial success with these three ”out-of-the-box” methods.
3 Results
3.1 Predicting mass
The correlation between and for the three machine learning methods are shown in Fig. 2, and lie in the range 95%-96%, listed on the -axis for each panel.
To estimate the scatter in true mass for a given predicted cluster mass, the distribution in the simulation must be chosen not according to the unobservable true mass, as in Fig. 2, but according to the same selection function as was used to construct the observed sample. If the simulation can be sampled in the same way as the observations, i.e. with the same cuts on SZ flux , etc., and is accurate enough, the true mass distributions can be predicted by combining the observations and the simulation. One way to estimate the accuracy of for an observation, without a particular survey-specific selection function in hand, is to make a cut in , based on Fig. 2. This cut appears to be complete based upon Fig. 2, and so to the extent the simulation is accurate and thus to be trusted for the machine learning predictions, it can also be used to estimate the regime of applicability. For , it seems all the contributions from the lower mass clusters and above will be captured. Ideally there would be even lower mass halos measured with these observations in the simulation, and a larger sample, to confirm lower masses are not being missed with this cut, but these are not available in the current data set. This cut can be applied to both the simulation and observations without knowing the true mass distribution in the observations, and is just a stand-in for a specific but unknown selection function corresponding to a given survey.
For , is shown in Fig. 3 for the three different ML algorithms also used in Fig. 2. The distributions are not well fit by gaussian or lognormal distributions, so values of encompassing 65% and 95% of the galaxies around the median are shown. The vertical line is the median , which is slightly less than one.
Extra Trees and Random Forests have narrower scatter in than Gradient Boost, and all three histograms have tails to large , comprising the 2% of cluster lines of sight which are not shown. Again, the advantage of this approach is to calculate the mass from the measurements in combination, all at once. In principle, errors and scaling relations for the usual approach would also have to be calculated from a simulation, using distributions such as are in Fig. 1, with close attention to using the relevant selection function and its correlations with the multiwavelength measurements. Unfortunately, the effect of these errors on the mass function as a whole was difficult to estimate without adding many other assumptions, as the sample was only large because it was replicated 96 times using different lines of sight.
As pointed out by the referee, it might be expected that the tree methods (Extra Trees and Random Forest) would work better than the boosting method, as boosts work better with high bias data, and reduce bias, and trees work better with high variance data, and reduce variance. If one is using scaling relations, the mass error for each observable seems to be more dominated by variance than by bias.
For comparison with scaling relation approaches, a simple likelihood estimate can also be made. Scaling relations are found by a least squares fit to the distributions in Fig. 1. The direct least squares fit (dashed line) is terrible, with the huge scatter for the more numerous low mass clusters causing a bias for the high mass clusters. Thus, a second fit was also used, where the true masses were binned in 20 log bins, and then the median mass in each was taken to correspond to the median observable in each. The least squares fit for the nonzero bins in this case produces the solid lines shown in Fig. 1. For each observable, each cluster then has a scaling law mass prediction . The scatter covariances, are then calculated and used to give the likelihood prediction for the mass of any cluster:
[TABLE]
The ratios are shown in Fig. 4 for both this estimate, and the Random Forests estimate. For simplicity, a true mass cut, , is taken for the sample, both in the likelihood and ML estimates, to avoid the additional complications introduced by observable based mass cuts. The favorable comparison between the out of the box machine learning estimate relative to a similarly simple likelihood estimate suggest that further investigation of the ML learning methods for directly combining observables would be promising.
Comparing these two kinds of likelihood estimates against the machine learning predictions was also done for the sample used for the WCS, which has a bigger box (), higher resolution ( particles) and slightly different cosmology ( = 0.274, = 0.726, =0.7,=0.95, =0.8). This sample has more clusters above , 256 to the 117 in the smaller box, but only mock measurements for clusters with true mass down to . Thus, as mentioned earlier, was not used for the other measurements in this note. For this cluster sample, both the likelihood and ML fits were not as biased, as the median values of were usually close to zero. However, the likelihood fits for the two scaling relations shown in Fig. 1 remained broad compared to the ML fits, with half width around the median for 65% of the clusters at (0.13,0.14) and for 95% at (0.38,0.36), relative to (0.09) for 65% and (0.29) for 95% for the Random Forests fit. This is the main point of this note. In §4, several possible refinements and improvements in the machine learning approach are listed.
3.2 Subsets of multiwavelength measurements
One can also study how well mass is predicted by a given subset of the observations (within the context of the idealizations for the WL, SZ and MF measurements mentioned earlier). In Machine Learning, Importance Permutation (IP, e.g. Breiman, 2001; Strobl et al., 2008) is a model-agnostic way to determine the relative importance of each observable, i.e., to ask: ”how important is each simulated observable when inferring (in these simulations)?” The IP procedure uses the difference in the prediction accuracy before and after permuting a given predictor observable to quantify its importance. The IP is generally a reliable except for cases where the observables are highly correlated, which will result in an over-estimation of the highest ranked observables (Strobl et al., 2008). However, the lowest ranking IP will not be biased as the least correlated observables will also have the lowest IP values. Given the large correlations between observables, the IP values can be used to determine which observables provide the least information. The lowest ranking observable was vel followed by for all three machine learning programs, Gradient Boost, Extra Trees and Random Forest. The IP values for vel and ranged from 0.004 to 0.006 and 0.02 to 0.05, respectively, compared to roughly factors of two to ten larger IP values for the other observables. These are the raw IP values, which have better statistical properties than the scaled (z-score) IP values (e.g., Strobl et al., 2008). Note that these two measurements are also the two with the most complete inclusion of observational contributions to mass scatter.
Whisker plots in Fig. 5 illustrate the impact of removing observables on the distributions. Only the Extra Tree distributions are shown in Fig. 5, as results are similar for the other two methods. The baseline is the inclusion of all observables, at bottom. When the lowest IP observables, vel and , are dropped, the distributions show little to no change, consistent with their low IP values and the statement that they contain the least information for inferring . Hence, here the IP values can provide an efficient and effective way to explore the impact of removing observables on the distributions. The upper three whiskers show the distributions corresponding to pairs of the remaining three observables, MF, WL shear and . Of these three, dropping causes the most spread in . Combining the whisker plots with the IP results, one finds, for these idealized SZ, WL shear and MF multiwavelength measurements, that is the most important simulated observable for predicting cluster masses.
A brute force comparison of correlation functions between true and predicted masses gives complementary information. In Fig. 6, and correlations are shown for all combinations of observables. The circle, cross and triangle symbols denote the three different machine learning methods, and colors the observation or observations included (for using one or two observables) or the observations or observation dropped (when using three or four observables). These comparisons are based on a cut on true mass. A second step would be again to impose the selection function, but this is very survey dependent, and the simulated sample is very small; the idea here is just to give a qualitative sense of how much variation in - correlations occurs with (combinations of) different methods.
It would be interesting to apply this method to different combinations of proposed observations, for instance to explore survey strategy tradeoffs in the context of other observations. For such a study to be reliable, of course, the specific survey dependent systematic errors in all of the measurements should be included as much as possible, and the idealizations removed as much as possible.
3.3 Simulation validation
The accuracy of from machine learning as proposed here depends on the training simulations sufficiently capturing the observables as a function of true mass, the correlations between the observables, and the effects of the selection function. (As mentioned earlier, other mass estimates using scaling relations and correlations derived from simulations depend upon the accuracy of the simulations as well. In the case where the correlations are taken out by marginalization, the form of the relation is required, including the variables upon which it depends, rather than the actual numbers.)
Simulations and observations can be tested directly for agreement of some properties, such as number counts of clusters with a certain or richness or other observational quantities. The hope is to find tests which, if passed, would suggest that the simulation is also accurate for properties which are not directly measurable, such as correlations used by ML, or mass scatter correlations, used in likelihood estimates. Both of these involve the not directly observable true mass.
One test which an accurate simulation must pass is to capture correlations between observed properties, for instance requiring a simulation (with the same selection function) validate the correlations estimated in Farahi et al (2019). This is used regularly to test galaxy formation simulation models, e.g., in Agarwal, Dave & Bassett (2018).
Another angle to try to test simulated correlations between observables and the true mass is to use the machine learning encoding of joint relations between different observables, rather than only the pairwise correlation function of observables above. Specifically, one can use machine learning to predict one observable given the others, by training on all observables but one in the simulation (instead of using all observables to predict the observationally inaccessible as in §3.1). If the simulation is sufficiently accurate, the machine learning relations between observables, derived from mock simulation observations, should also hold for actual observations. Here, the true and predicted (from ML) simulation observable pairs, for instance, for , can be compared to the true vs. predicted observation observable pairs for , training and testing on the remaining four observables in the simulation, and then also testing on the observables from an observation. Crucially, predictions for both the simulation observables and the observational counterparts are based on the simulation training set.222After submission of this paper, we learned of training on one simulation and testing on another as a test being used in simulations to recover star formation histories from spectra (Lovell et al, 2019). If the simulation is close to the observations, the relation of the predictions and true values in the mock observations should be similar to the relation of the predictions and true values in the actual observations.
As the interest is in the case where the simulation matches the number counts (a first check that a reasonable training simulation will pass) but does not match all the correlations between observables, and given that there is no simulation that agrees with all observations, shuffled line of sight variants of the original simulation are taken as ”observation”. These shuffled ”observations” have the same number counts as the original simulation, but not the same correlations between observables. Two shufflings are considered:
- •
shuffling different lines of sight for each observable, separately for each individual cluster, and
- •
shuffling values of observables between lines of sight and between clusters within 0.03 dex bins in halo mass.
The latter shuffling not only mixes lines of sight but other (possibly isotropic) effects, such as local density, which might vary between clusters sharing the same mass.333We thank M. White for emphasizing this point. Each kind of shuffling is done 8 separate times, to give 16 samples for comparison with the original. To approximate a survey selection function, a minimum cut on WL shear of 530 km/s (which seems to reject most low mass halos, see Fig. 1) is made. Shuffling is done after the WL shear cut, to preserve number counts. The selection function cuts out many more clusters than the selection in §3.1, however, imposing an appropriate cut for the shuffled samples seemed to require more steps and assumptions.
Figures 7 and 8 illustrate these two kinds of comparisons between simulations and observations: direct correlations between observables, and correlations between ML predicted and true observables, each determined by the other four observables.
In the top panel of Fig. 7, correlations are shown between different simulation observables (x-axis) and their counterparts for the shuffled variants (”observations,” y-axis); if the two agreed exactly, the points would lie on the diagonal line. Of course, the observables should always be correlated to some extent as they are both taken to be proxies for true mass; however, if the scatter in observables from true mass is also correlated, when the mass-observable scatter is modified by fixing mass and shuffling observables, the correlations will change, as is seen.
The bottom panel of Fig. 7 compares correlations between machine learning predicted single observables and true observables in the simulation (-axis), and the predicted observables and true values in their shuffled counterparts (”observations,” -axis). The predicted values of each observable is obtained using the other four via machine learning, trained in both cases on 1/10 of the unshuffled simulation sample.
In both panels, crosses are mass bin shuffled variants, circles are cluster-by-cluster shuffled variants, and colors indicate which observable or observables are involved. Some pair correlations (observable-observable, top panel) or internally predicted quantities (true-pred, bottom panel) change strongly when the original simulation properties are shuffled, but not all. With an actual set of observations in hand, these shuffled simulation variants may be useful in helping to bound the expected response to changing correlations between observables (again, to the extent that the simulations are faithful).
The simulation and shuffled variants are also compared via whisker plots of machine learning predicted/true -1 values of the fifth observable, for two observables in Fig. 8. Extra Trees is shown for this example, as it gave the highest correlations between true and predicted for the original simulation. Again, the mass shuffled sample is more distinguishable from the original sample than the sample with properties shuffled only cluster by cluster, possibly due to local density variations as mentioned above.
The above examples show how correlations between observables themselves, correlations between true and machine learning predicted observables and predicted/true ratio distributions could be used to flag disagreements between simulations and observations (in practice, replacing the shuffled simulation in this example with actual sky observations, but perhaps using simulation shuffling to help bound the expected effects).
4 Summary and Discussion
In this note, three ideas were tried out on a simulation:
Using machine learning plus a simulation with mock observations to predict halo masses directly from multiwavelength observations, rather than going through scaling relation mass assignments plus correlated scatter estimates. This produced fairly tight correlations between . 2. 2.
Comparing the accuracy of machine learning mass predictions for different combinations of multiwavelength measurements, which for this simulation and mock observations gave clear answers as to which combinations have the most constraining power. These were compared via IP and brute force. The specific preferred combinations found here are not directly comparable to specific surveys. Although the and vel measurement errors are faithfully represented in this data set, the other three methods benefit from neglecting survey dependent systematics (SZ and WL), using true mass for some scalings (SZ, WL, MF, often a weak effect) and real space (MF). These systematics should be included, and the measurement approximations dropped to the appropriate extent, in order to do analyses for specific surveys. 3. 3.
Testing correlations in simulations (here used to train machine learning) by comparing relations between observables in the simulated mock observations to those in the observations. Testing is done by correlating observables within the simulated or observational data sets directly or via machine learning. In the latter case using one training sample to make predictions for both the simulations and the observations. For the example here, observations with different correlations were generated from the simulation by shuffling the different multiwavelength measurements between lines of sight, either for each cluster separately, or in mass bins. Differences were seen between the simulation and its shuffled counterparts for almost all variations of these tests.
These initial forays give encouraging results. There are several ways to go further, following up on this promising exploration. More extensive simulated data sets could allow all of these ideas to be more thoroughly tested, refined and applied and could have:
- •
larger volume and thus more clusters (there are larger simulations in the literature with with several different observables, e.g., Angulo et al, 2012).
A larger sample might also allow using fewer lines of sight per cluster, to test for and if need be get rid of possible effects introduced by related lines of sight in the small sample used here. In particular, the small number of distinct high mass halo measurements makes it difficult to estimate the effect of the machine learning mass errors on the mass function.
Also, a larger sample might allow a more refined comparison of correlations, for example, one could consider smaller bins in some observable, for instance, clusters which lie in a specific WL shear bin, more similar to Farahi et al (2019), rather than just above a minimum value as done here in §3.3.
Lastly, the small number of distinct true masses in this sample may also have some effect on ML success. DecisionTreeRegressor was also explored, for instance, but had an unreasonably high success rate, seemingly due to matching clusters directly to the exact masses found in the training set. The small number of true masses doesn’t seem to be an issue in the machine learning methods shown here, but a broader sampling of the space of possible clusters would be better.
- •
more simulated rather than “painted on” physical properties, for instance, using hydrodynamics to capture more of the baryonic effects during evolution (e.g., Shirasaki, Nagai & Lau, 2016; Henson et al, 2017), and more generally, improvements of mock observations.
- •
more cluster observables, for instance, other richness estimators could be used, such as many of the galaxy based cluster mass estimators which have been compared in Old et al (2015). The velocity information used in Ntampaka et al (2015, 2016, 2017); Ho et al (2019) could certainly be added, or X-ray, which plays an important role in many cluster studies. X-ray luminosity and X-ray temperature measurements are included in the machine learning cluster mass estimates for a 357 cluster sample by Armitage, Kay & Barnes (2019), along with mean, standard deviation, kurtosis and skewness of angular positions, stellar masses, velocities, and angular positions plus velocities of galaxies in a cylinder, number of galaxies, galaxy distribution axis ratio and SZ flux within 5 . Some of these would complement well the observables used here.
- •
more simulated observations of smaller mass halos and other possible configurations which might also pass the cluster selection cuts (depending upon the cluster finding algorithm, i.e., sample selection).
For mass predictions, improved machine learning algorithms are likely possible, as these were just ”out-of-the-box”. Extensive comparisons of algorithms could be reasonably expected to yield even better results. Ideally, such comparisons would be on data sets that are closely tuned to specific observational surveys (such as using specific cluster selection functions, or best guess estimated errors for, for instance, photometric redshifts or other measurement ingredients). In addition, it is possible that some preprocessing of the data would give more successful results, such as using observables raised to some power, thus combining some of the physics from the scaling relations with the machine learning inferences from the simulation data.
In addition, it would be good to know if there are better ways than simply sampling, as is done here, to estimate the error on as found by these machine learning approaches (such as using a“prediction interval”). For the whole sample, the distribution of predictions from a simulation is a good first estimate of these probabilities, assuming the simulation is a representative sampling, but it would be very good to have a way to analyze smaller distributions of observed clusters, down to, for example, using extensive multiwavelength measurements of a single cluster to estimate the likelihood that the cluster came from the same distribution as that of a given simulation. The scatter in in Fig. 3 seems fairly small, but in practice would have to calculated with a simulation with a better sampled population as described above, and the errors above would need to be combined with the uncertainties going into the simulation (see, for example, estimates in Shirasaki, Nagai & Lau (2016) for an enumeration of some of these).
In testing the simulations for accuracy, perhaps further information (such as “importance”) could be used to inform the simulation if it does not sufficiently match observations, and more sophisticated definitions of “match” could be used. It would also be good to incorporate the observational measurement error bars into the simulation tests, perhaps by using a distribution of observational input measurement values weighted by their likelihood. As the errors are different in observations and in the simulations, it seems that training on observations might also be possible (to predict one observable from the others), but one of the two training sets is likely preferable. In addition, the shuffling test here is similar to the analysis made setting the correlations to zero in Shirasaki, Nagai & Lau (2016); that is, the two sorts of correlations are the ones in the simulation and their decorrelated counterpart. It is not clear how a different correlation (rather than a decorrelating shuffling) would appear in these tests.
To summarize, matching each observable to a mass and then combining mass predictions relies upon calibrating each mass prediction separately, while combining the observables first, as suggested here, relies upon a joint calibration from a simulation capturing all observed properties. This machine learning based approach requires a more detailed simulation, but as some of the underlying physics is shared between observables, this approach may have the benefit of including more of the true correlations. Another possibility is to go even further with machine learning, to cosmological parameters, skipping the calculation of cluster masses along the way.444We thank G. Holder for this suggestion. Both approaches are incorporating physical assumptions about clusters and their masses, but in different ways, giving a more complete understanding when considered together.
Acknowledgements
We thank M. White for the simulations and discussions, G. Evrard for suggestions on an early draft, and the referee and editor for many helpful questions and suggestions. The simulations used in this paper were performed at the National Energy Research Scientific Computing Center and the Laboratory Research Computing project at Lawrence Berkeley National Laboratory.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adhikari, Dalal & Chamberlain (2014) Adhikari, S., Dalal, N., Chamberlain, R.T., 2014, JCAP, 11, 19
- 2Agarwal, Dave & Bassett (2018) Agarwal, S., Dave, R., Bassett, B.A., 2018, MNRAS, 478, 3410
- 3Allen, Evrard & Mantz (2011) Allen, S.W., Evrard, A.E., Mantz, A.B., 2011, ARA&A, 49, 409
- 4Angulo et al (2012) Angulo, R. E., Springel, V., White, S. D. M., Jenkins, A., Baugh, C. M., Frenk, C. S., 2012, MNRAS, 426, 2046
- 5Armitage, Kay & Barnes (2019) Armitage, Thomas J., Kay, Scott T., Barnes, David J., 2019, MNRAS, 484, 1526
- 6Breiman (2001) Breiman,L., 2001, Machine Learning, 45, 5
- 7Borgani & Kravtsov (2011) Borgani S., Kravtsov A., 2011, Adv. Sci. Lett., 4, 204
- 8Breiman (2001) Breiman L., 2001, Machine Learning, 45, 5