Optimal Passenger-Seeking Policies on E-hailing Platforms Using Markov Decision Process and Imitation Learning
Zhenyu Shou, Xuan Di, Jieping Ye, Hongtu Zhu, Hua Zhang, Robert, Hampshire

TL;DR
This paper develops an MDP-based model combined with imitation learning to optimize passenger-seeking policies for e-hailing drivers, significantly improving their efficiency and reducing unnecessary travel.
Contribution
It introduces a novel MDP framework tailored for e-hailing drivers' repositioning, incorporating new features and a dynamic adjustment strategy for better modeling competition.
Findings
Achieves 17.5% improvement over baseline hotspot strategy
Uses real Didi driver trajectories for model training
Validates model effectiveness through Monte Carlo simulation
Abstract
Vacant taxi drivers' passenger seeking process in a road network generates additional vehicle miles traveled, adding congestion and pollution into the road network and the environment. This paper aims to employ a Markov Decision Process (MDP) to model idle e-hailing drivers' optimal sequential decisions in passenger-seeking. Transportation network companies (TNC) or e-hailing (e.g., Didi, Uber) drivers exhibit different behaviors from traditional taxi drivers because e-hailing drivers do not need to actually search for passengers. Instead, they reposition themselves so that the matching platform can match a passenger. Accordingly, we incorporate e-hailing drivers' new features into our MDP model. The reward function used in the MDP model is uncovered by leveraging an inverse reinforcement learning technique. We then use 44,160 Didi drivers' 3-day trajectories to train the model. To…
Click any figure to enlarge with its caption.
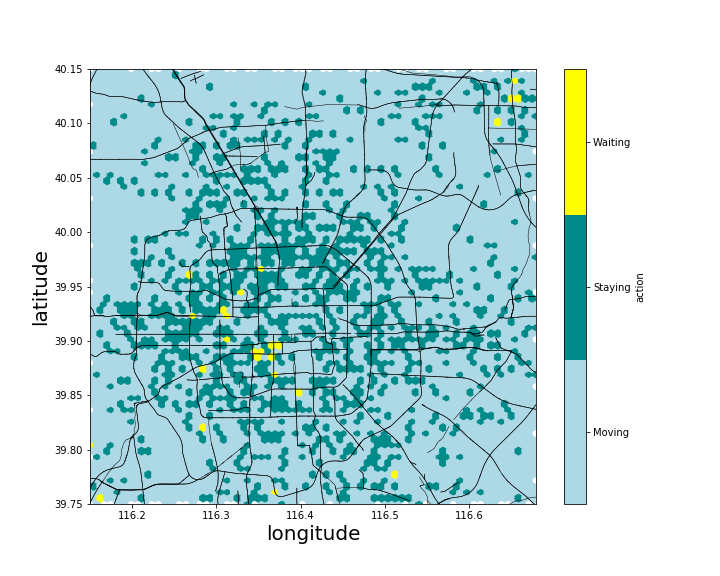 Figure 1
Figure 1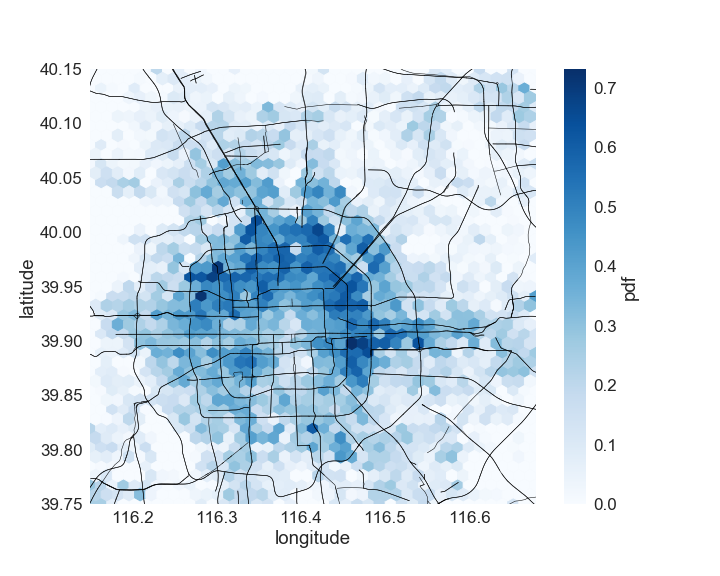 Figure 2
Figure 2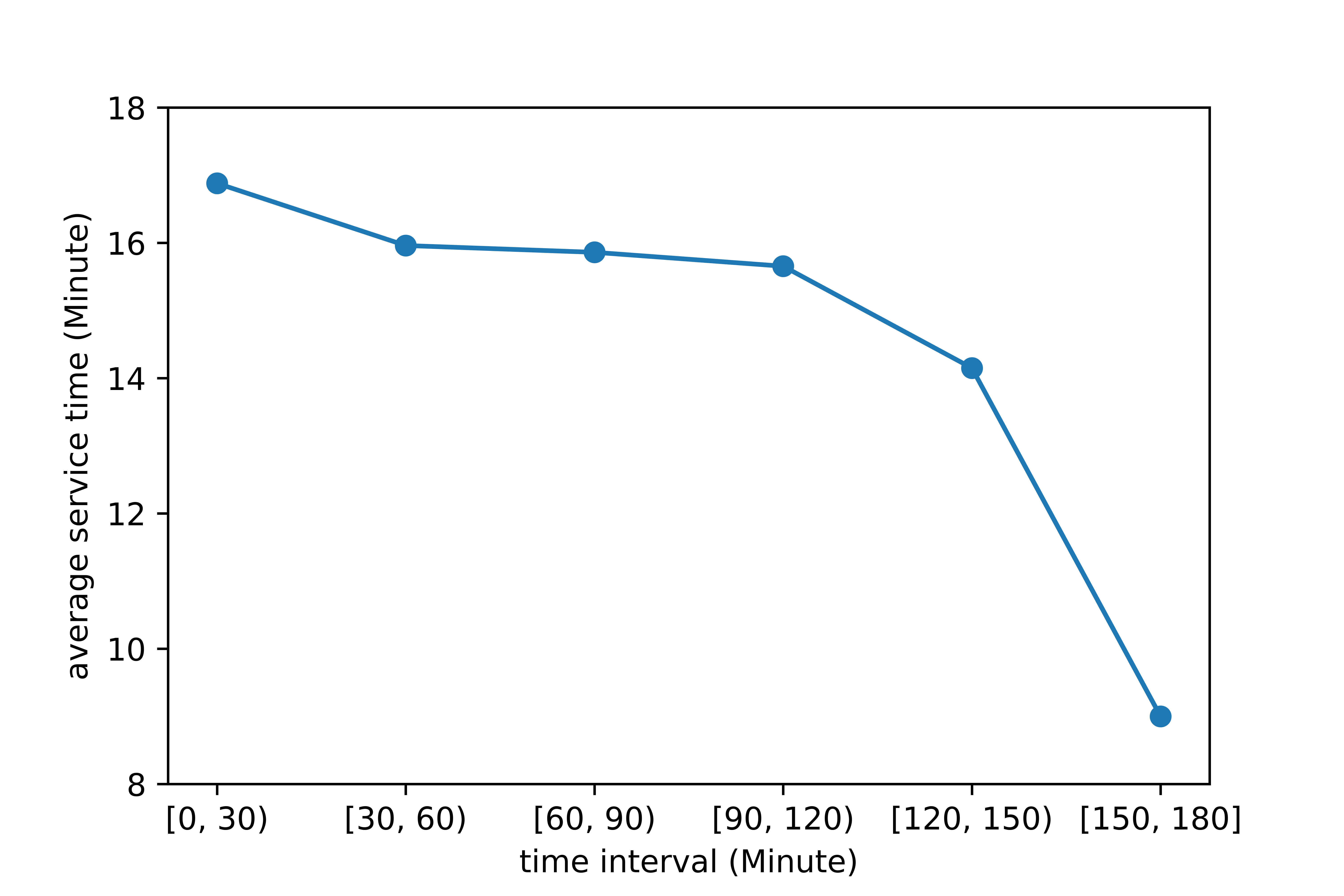 Figure 3
Figure 3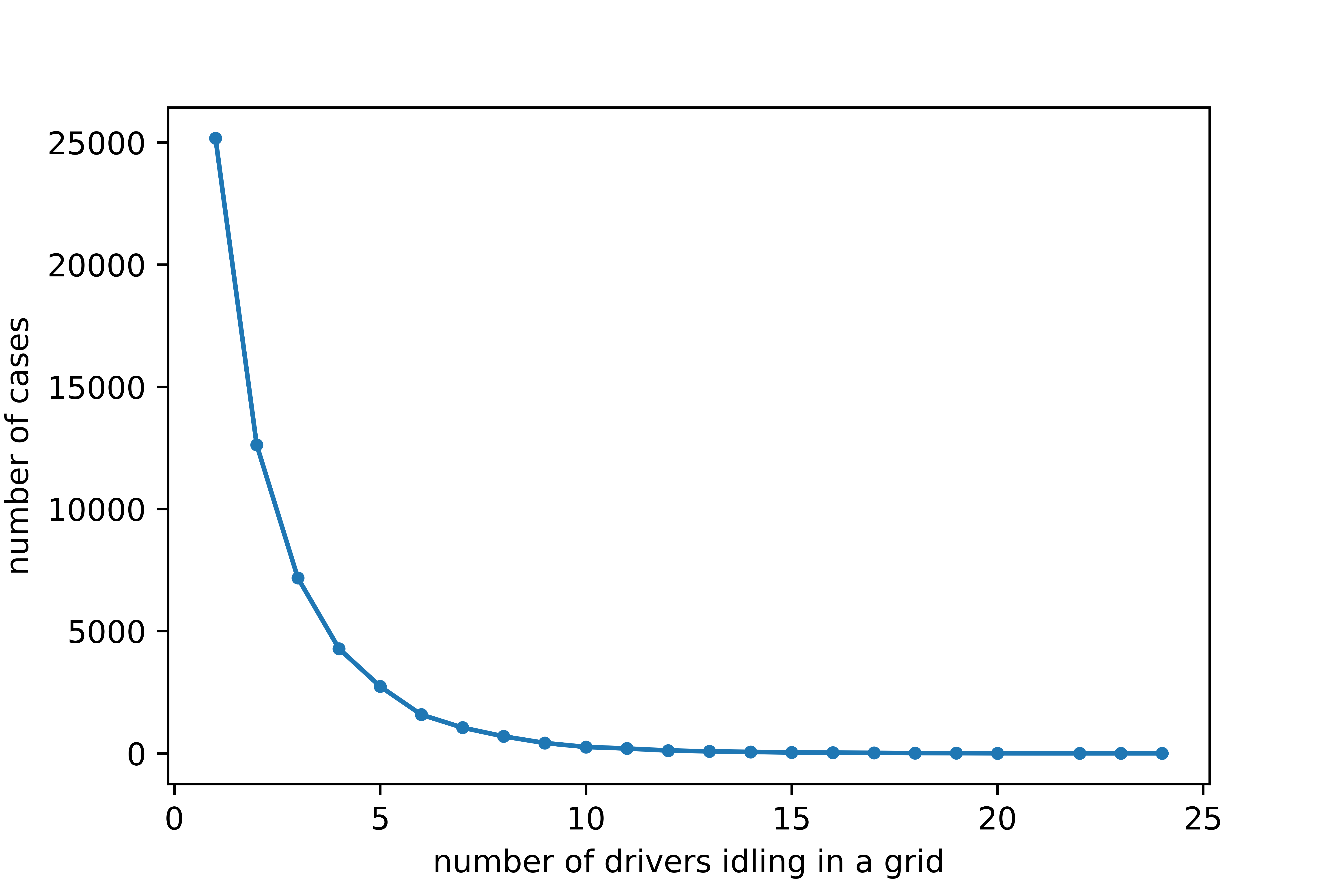 Figure 4
Figure 4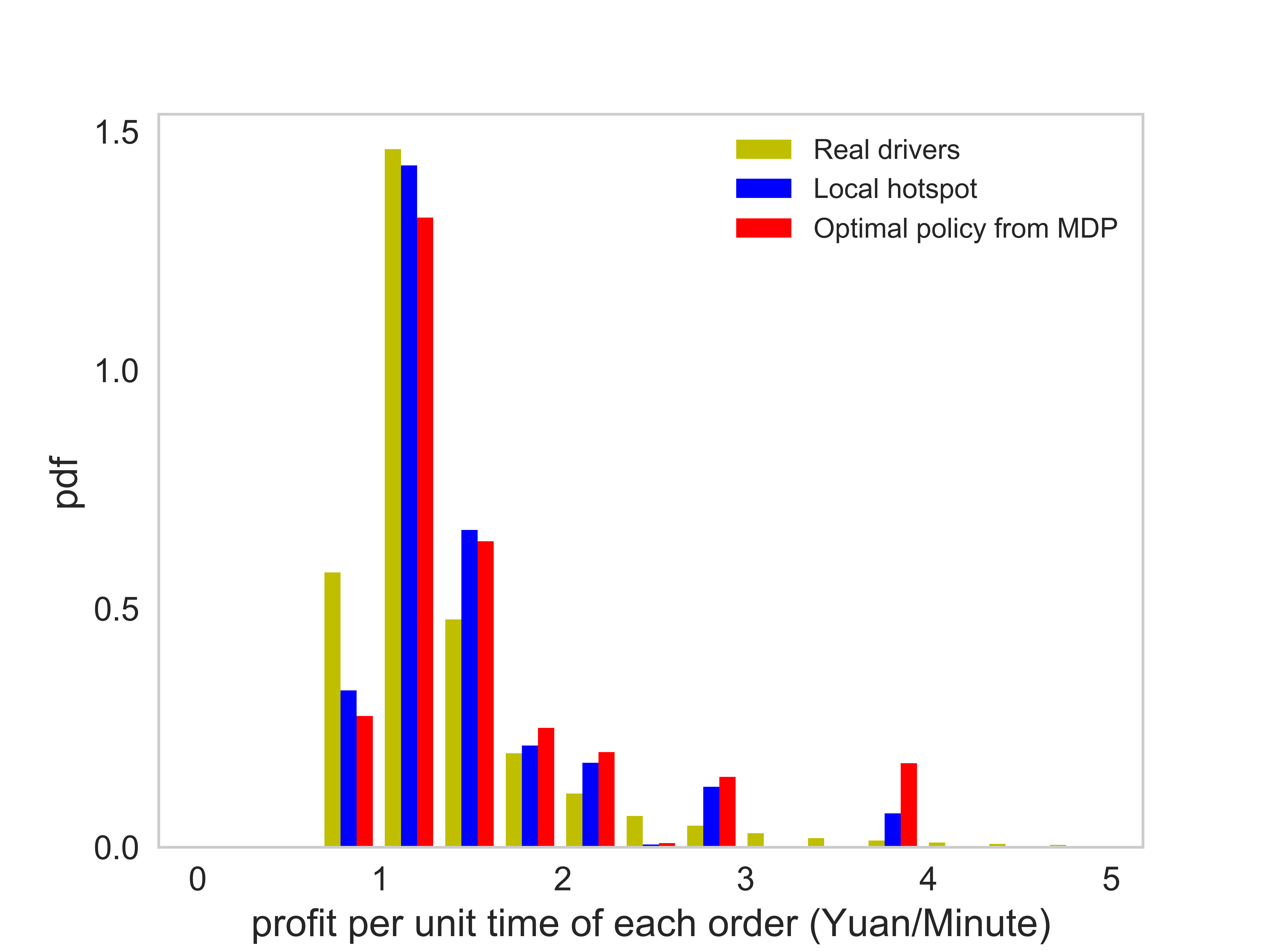 Figure 5
Figure 5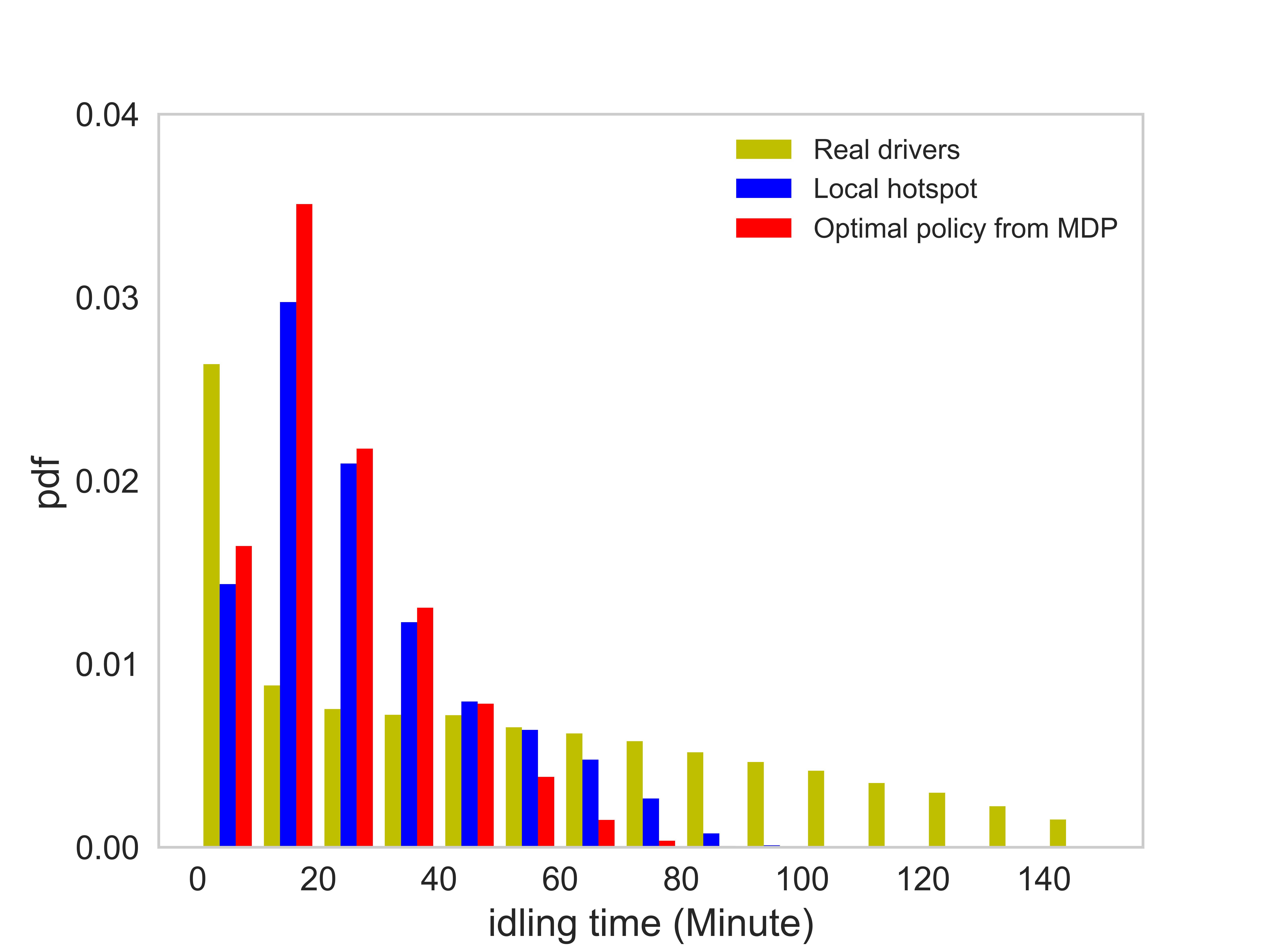 Figure 6
Figure 6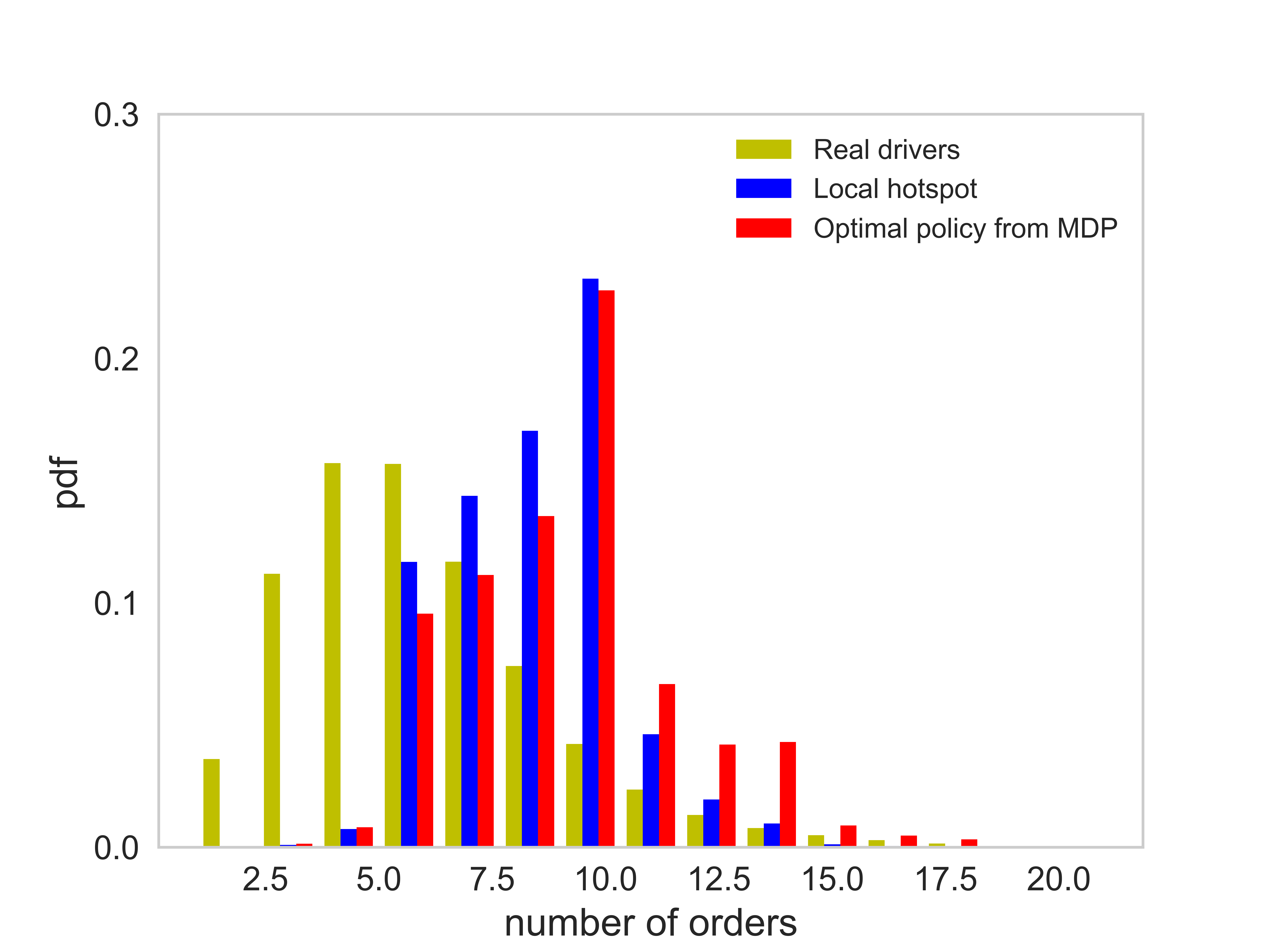 Figure 7
Figure 7 Figure 8
Figure 8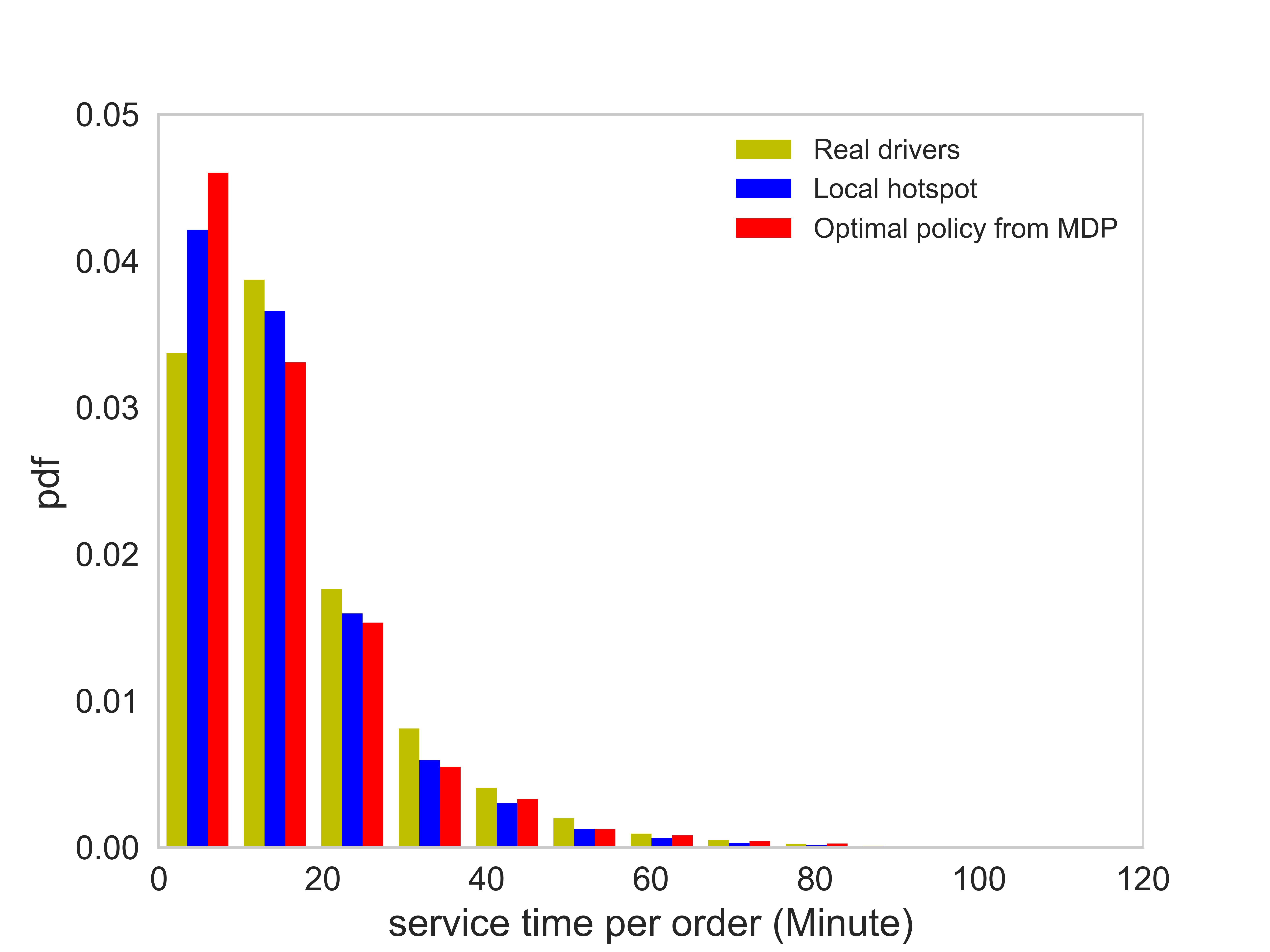 Figure 9
Figure 9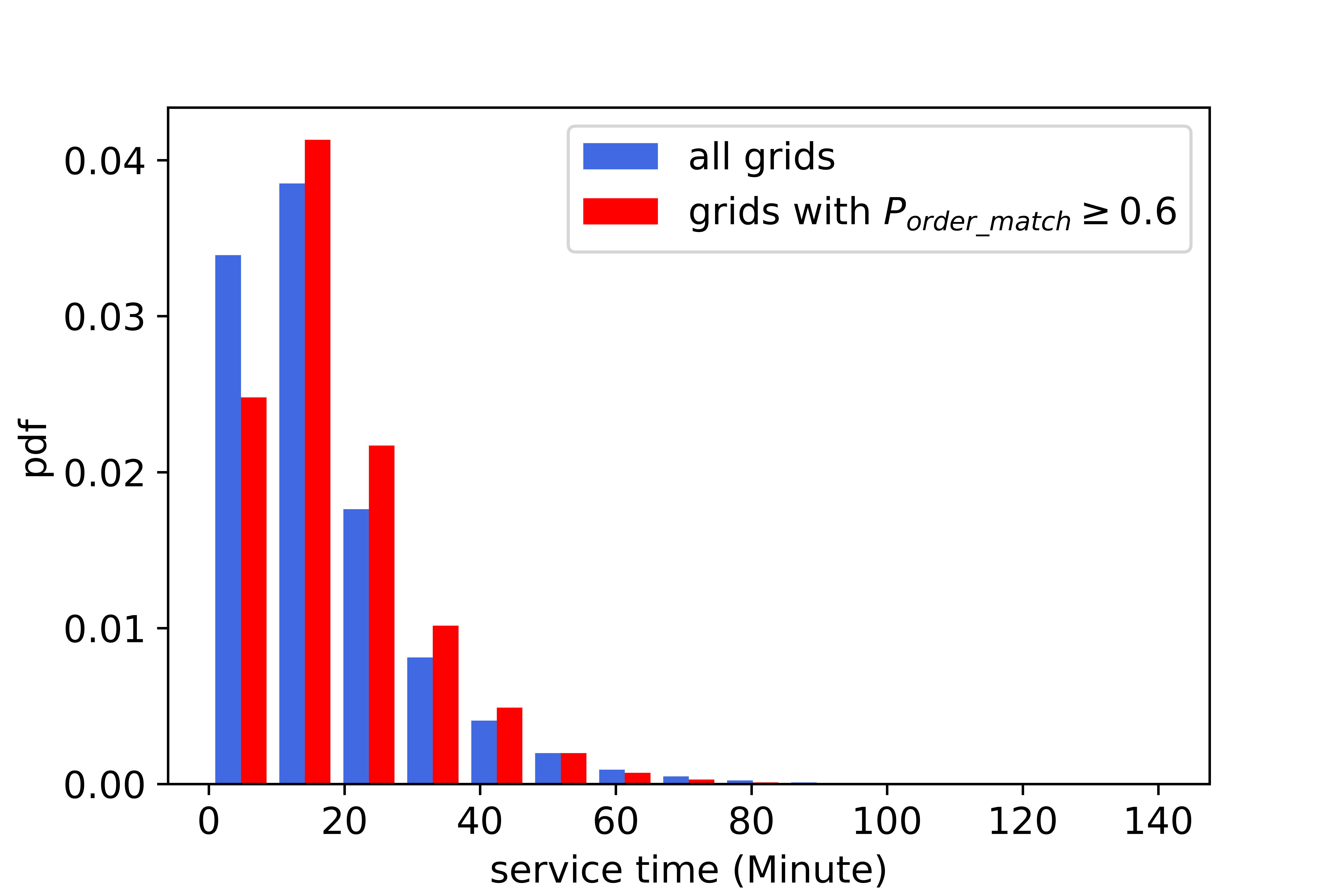 Figure 10
Figure 10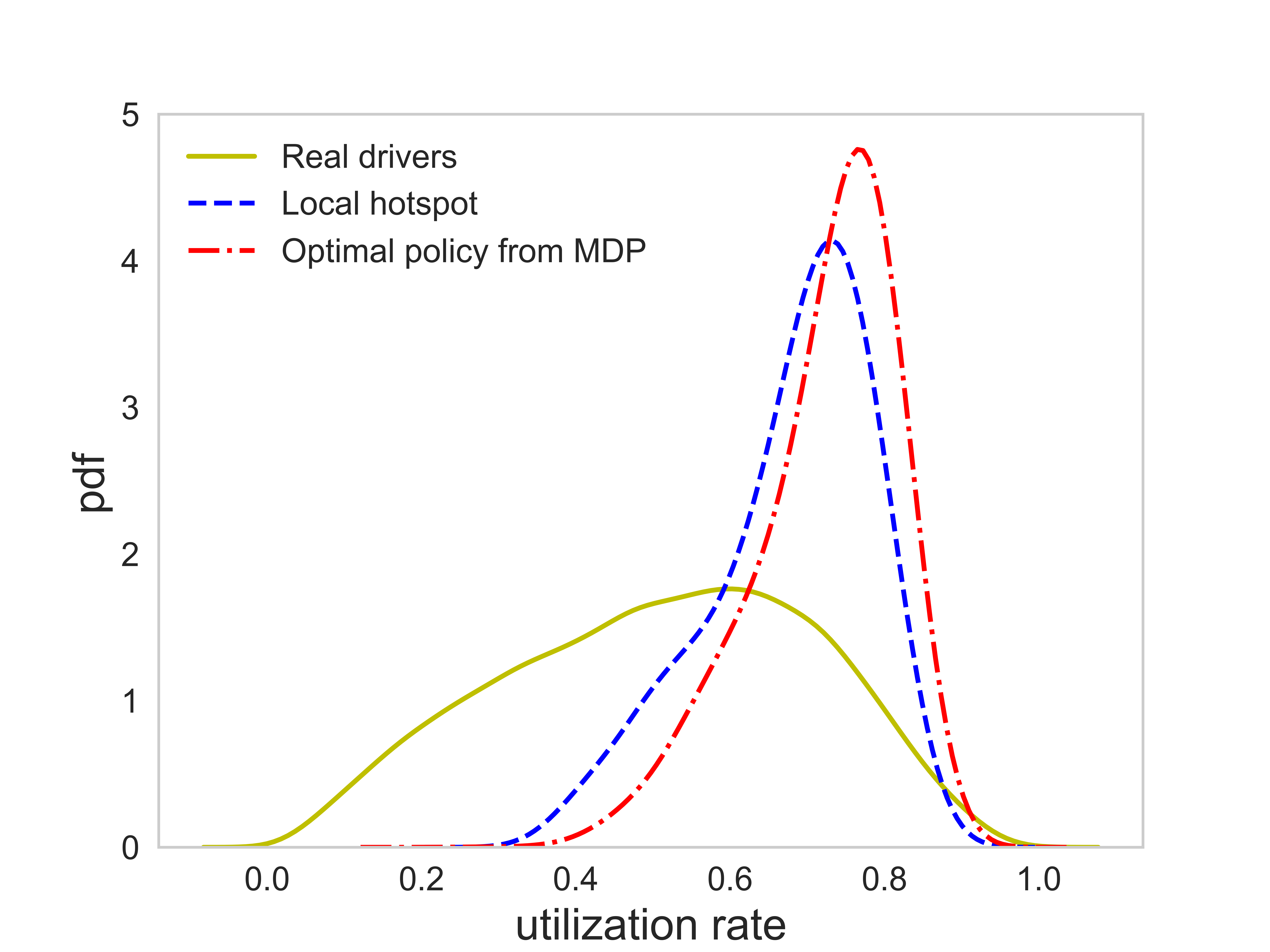 Figure 11
Figure 11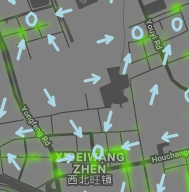 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15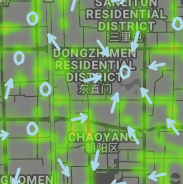 Figure 16
Figure 16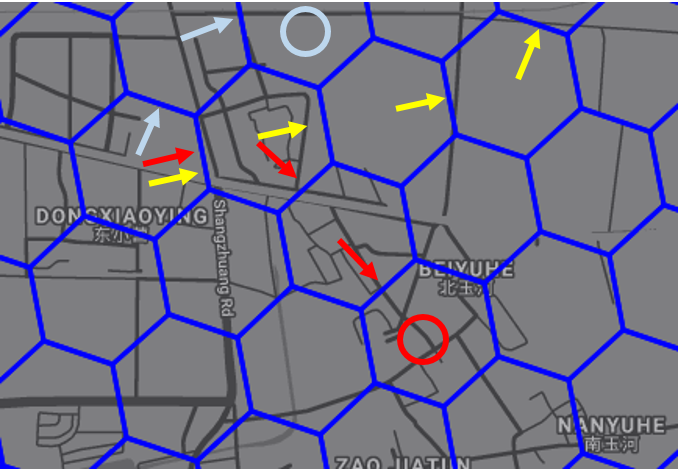 Figure 17
Figure 17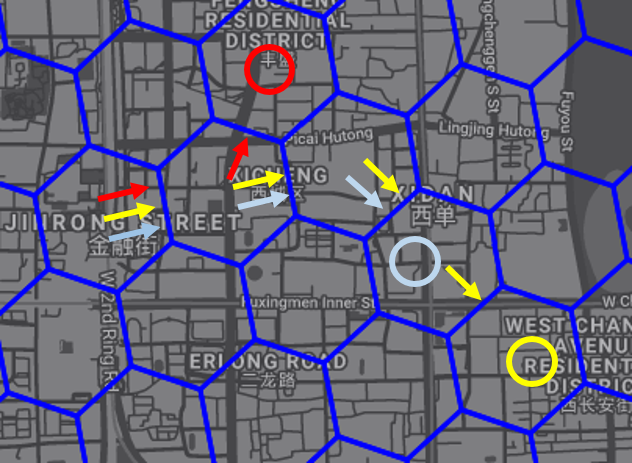 Figure 18
Figure 18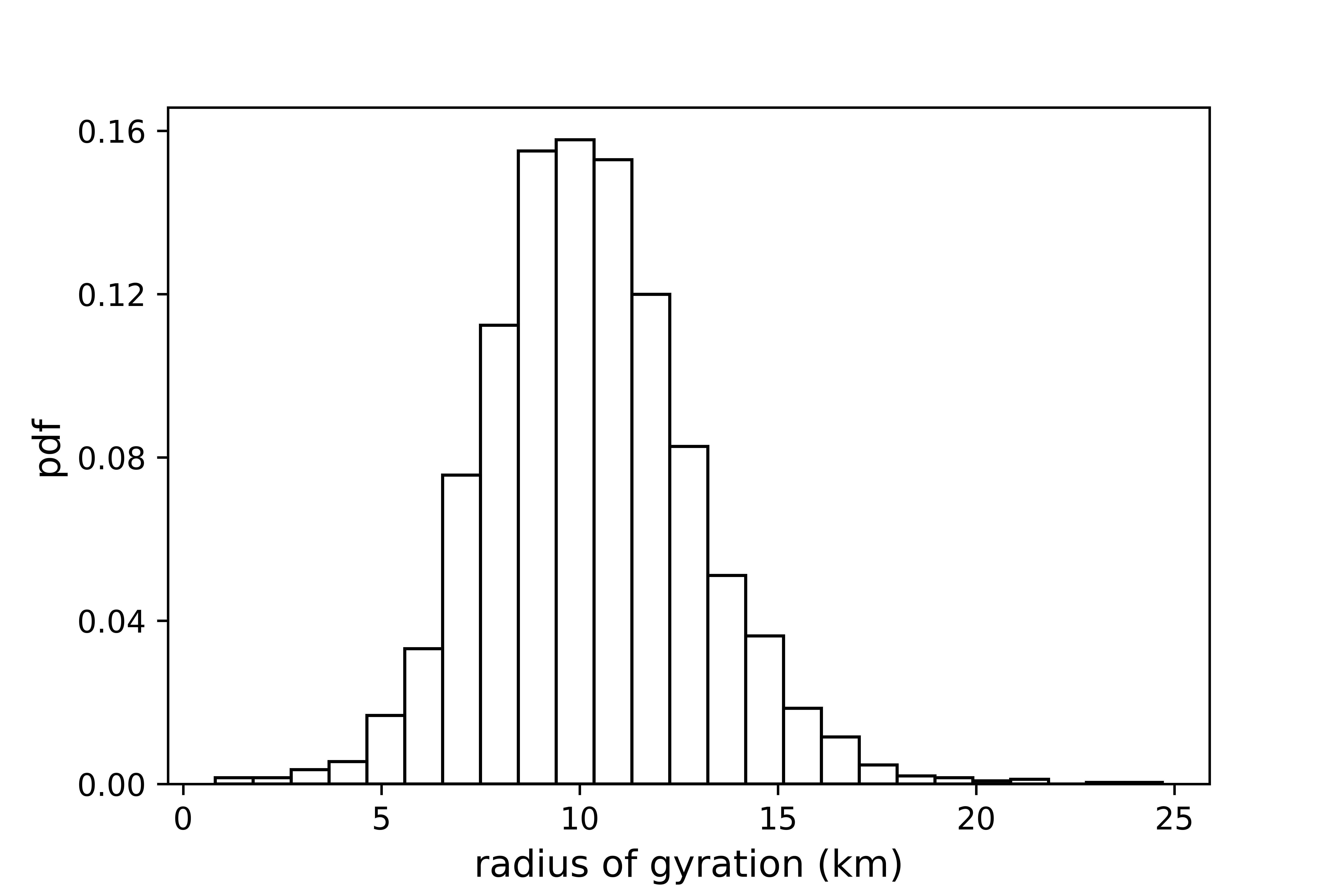 Figure 19
Figure 19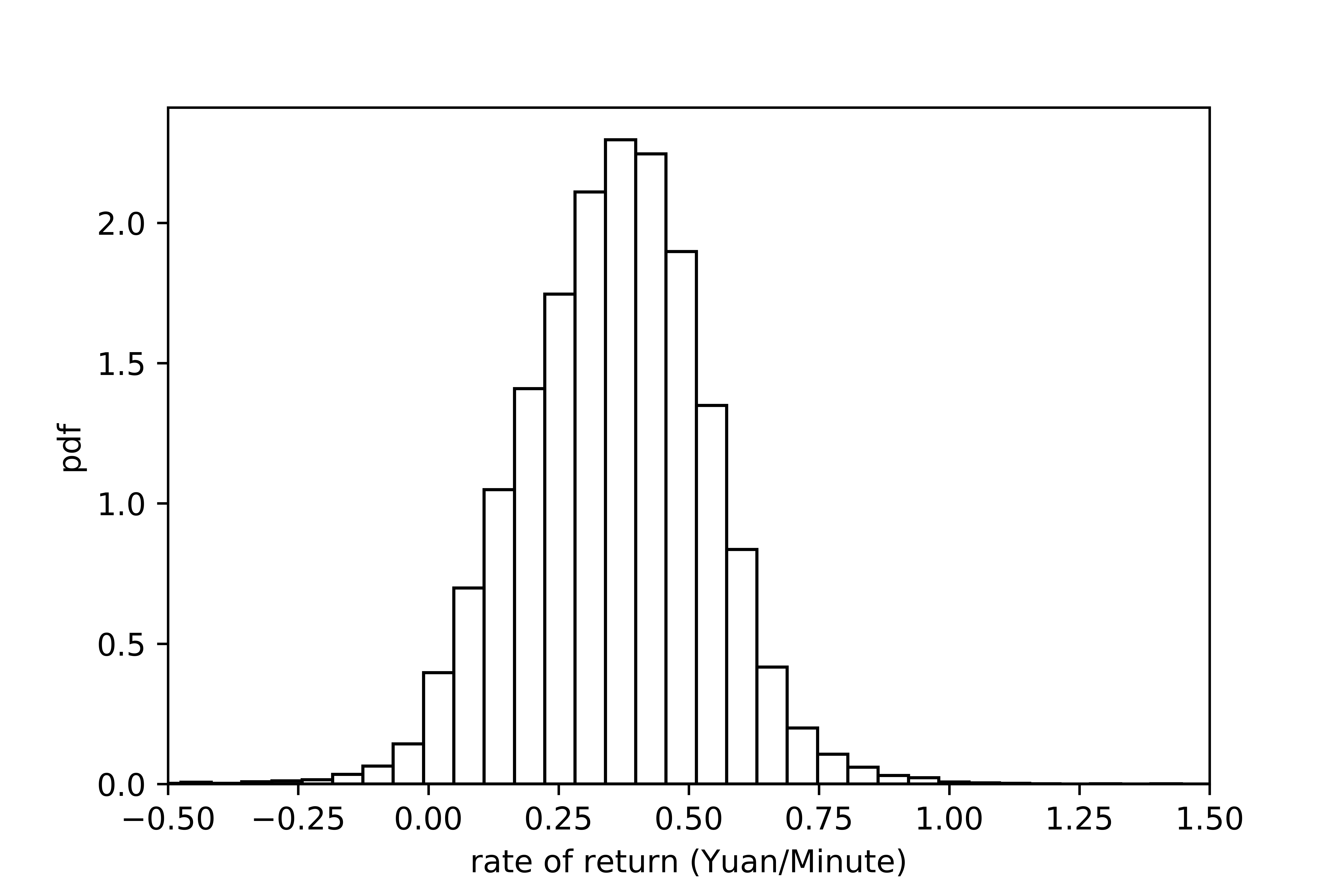 Figure 20
Figure 20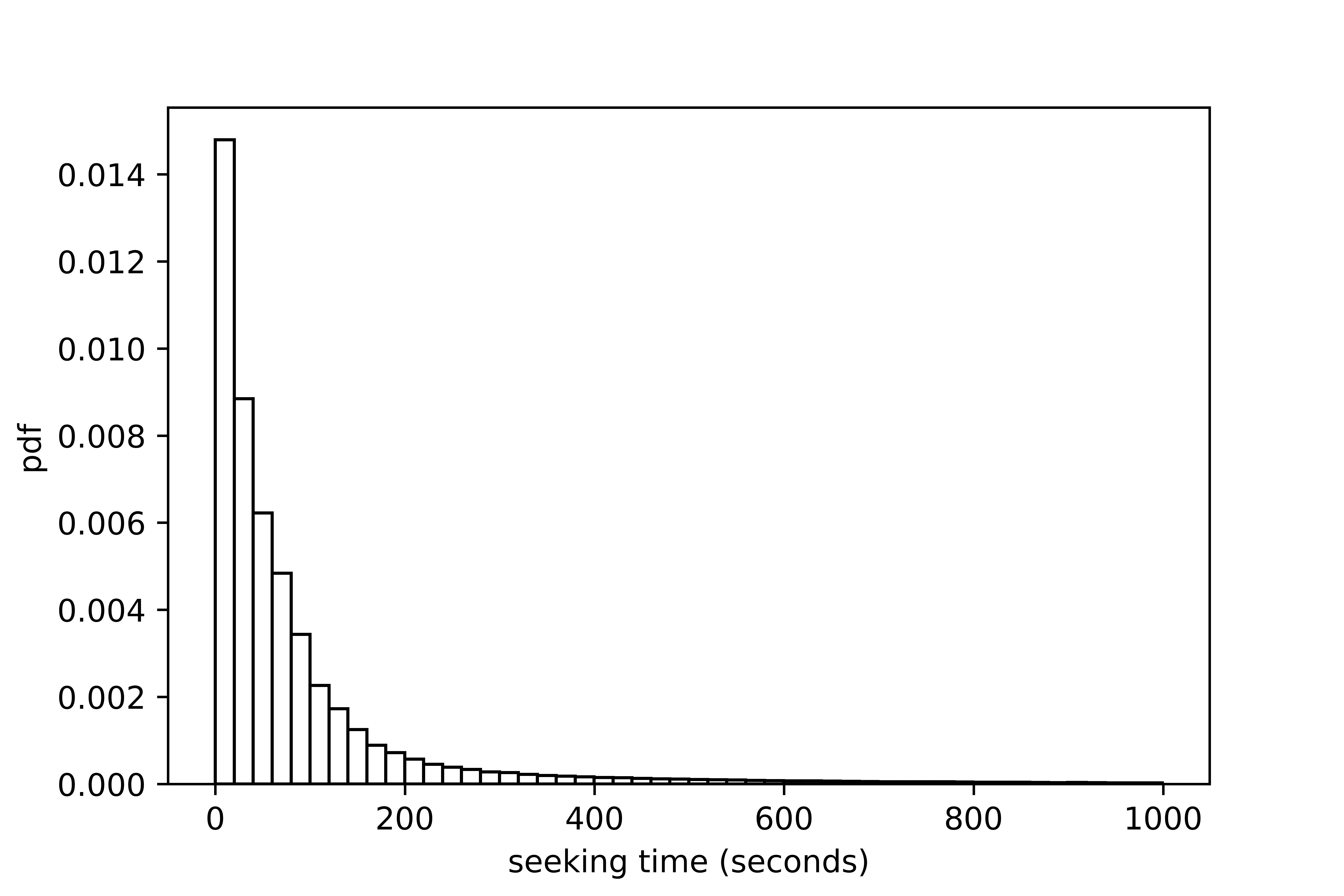 Figure 21
Figure 21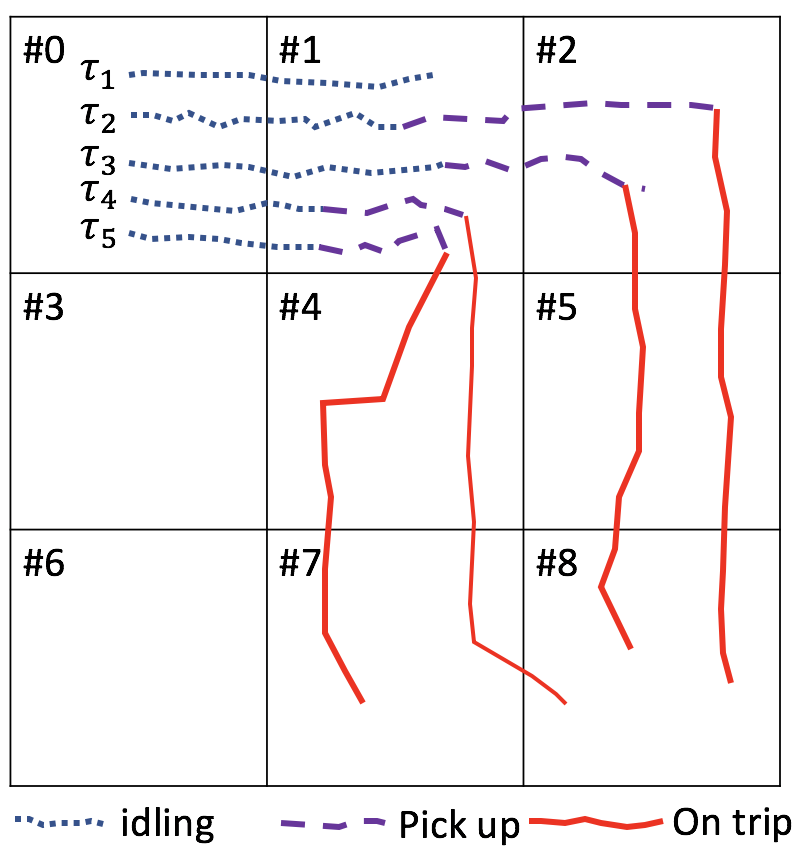 Figure 22
Figure 22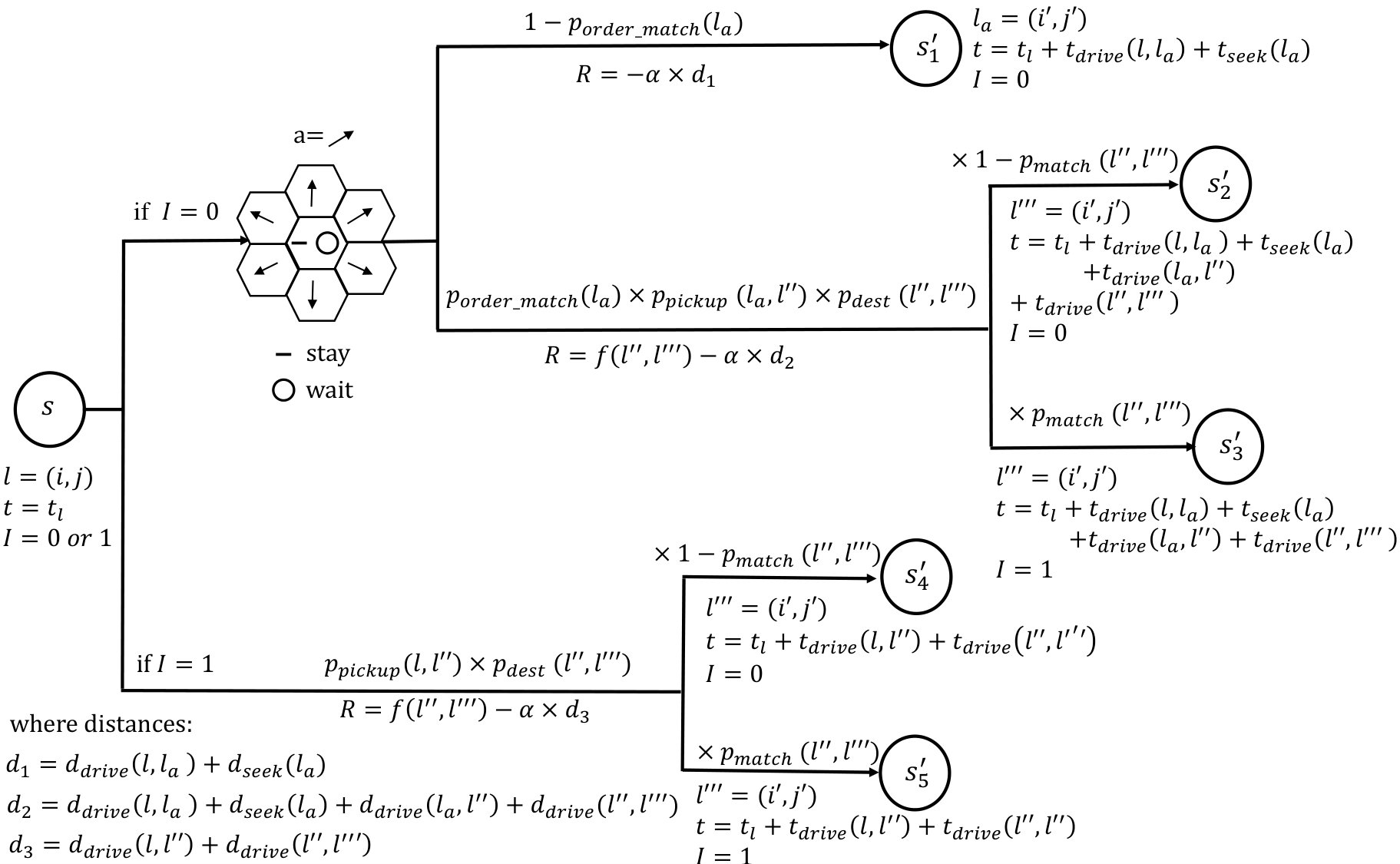 Figure 23
Figure 23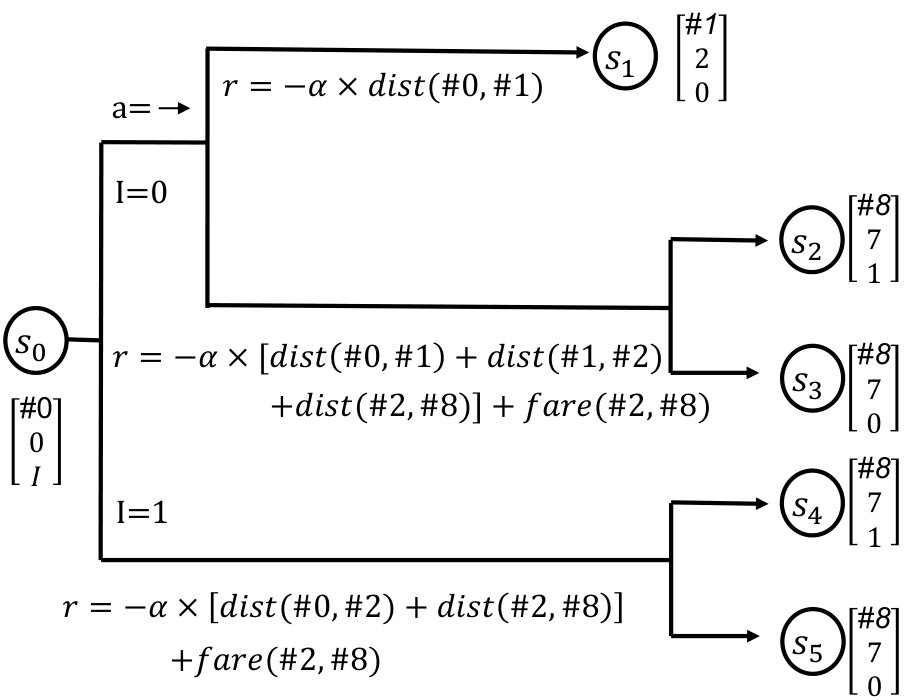 Figure 24
Figure 24 Figure 25
Figure 25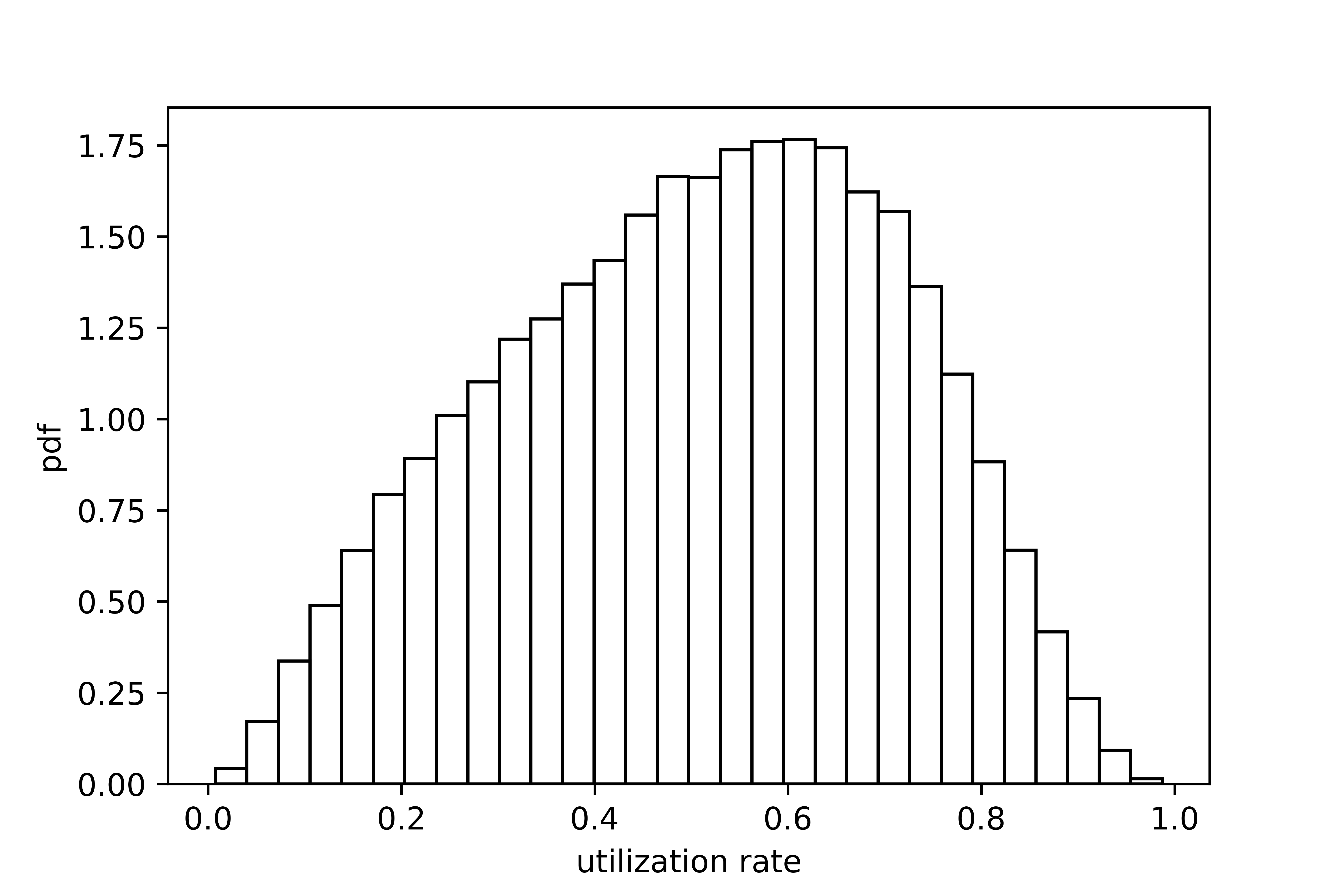 Figure 26
Figure 26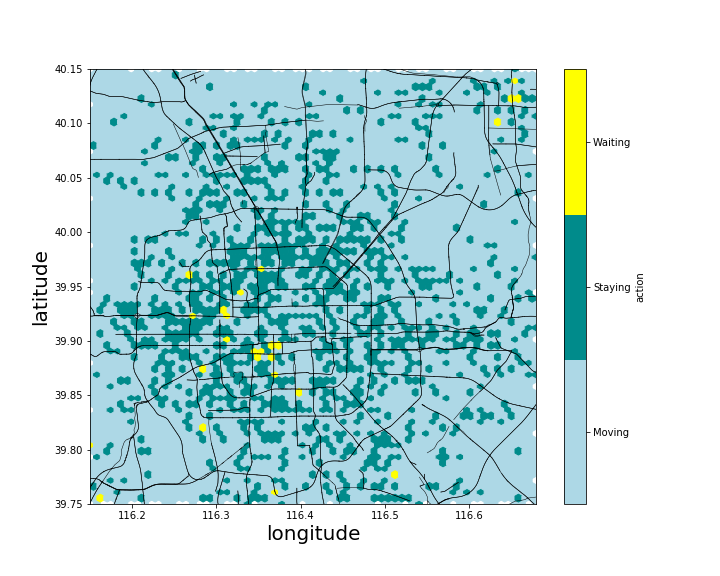 Figure 27
Figure 27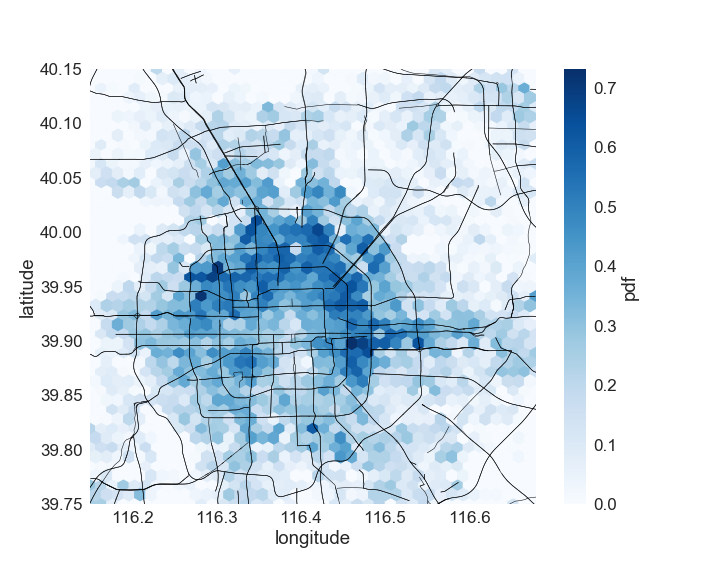 Figure 28
Figure 28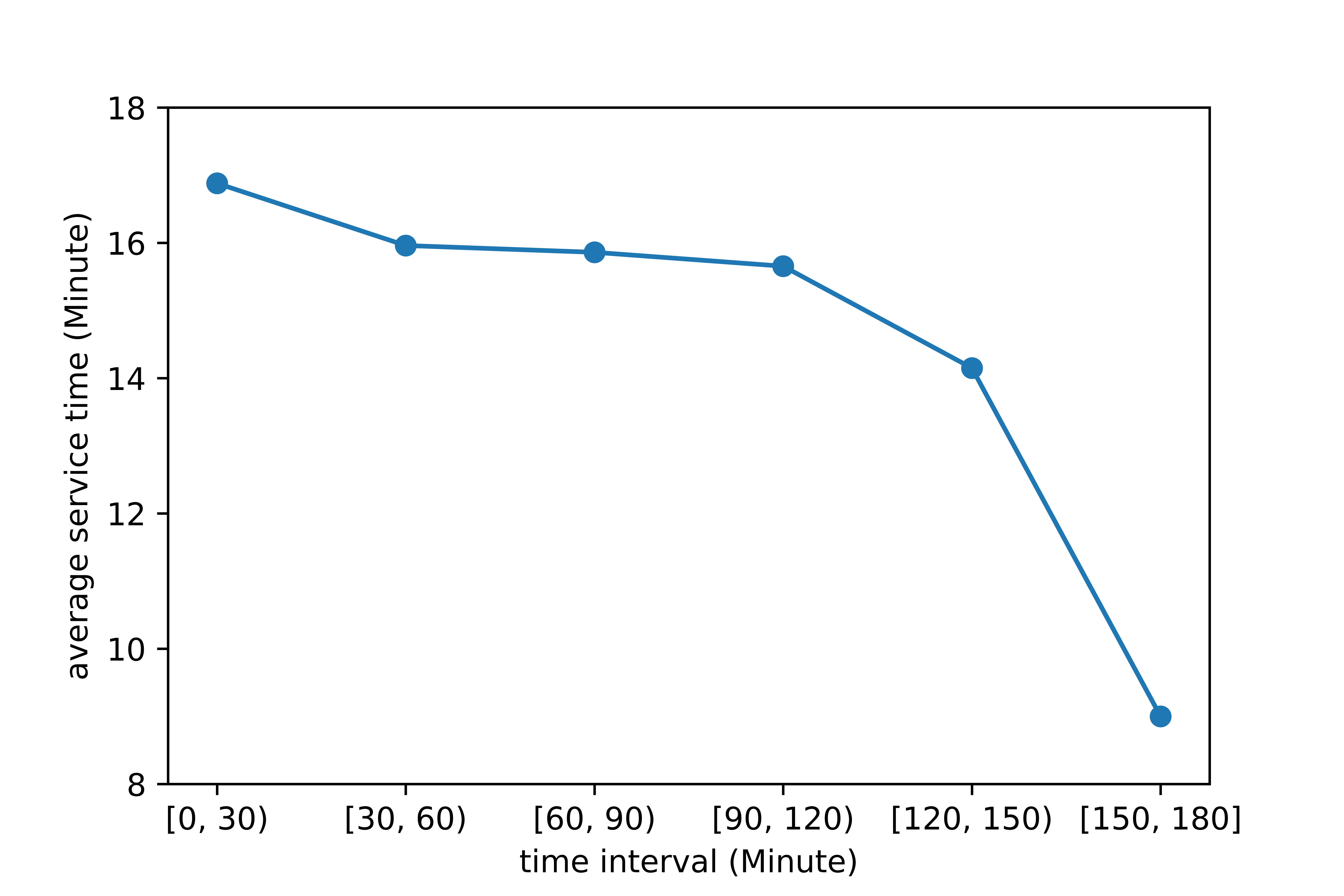 Figure 29
Figure 29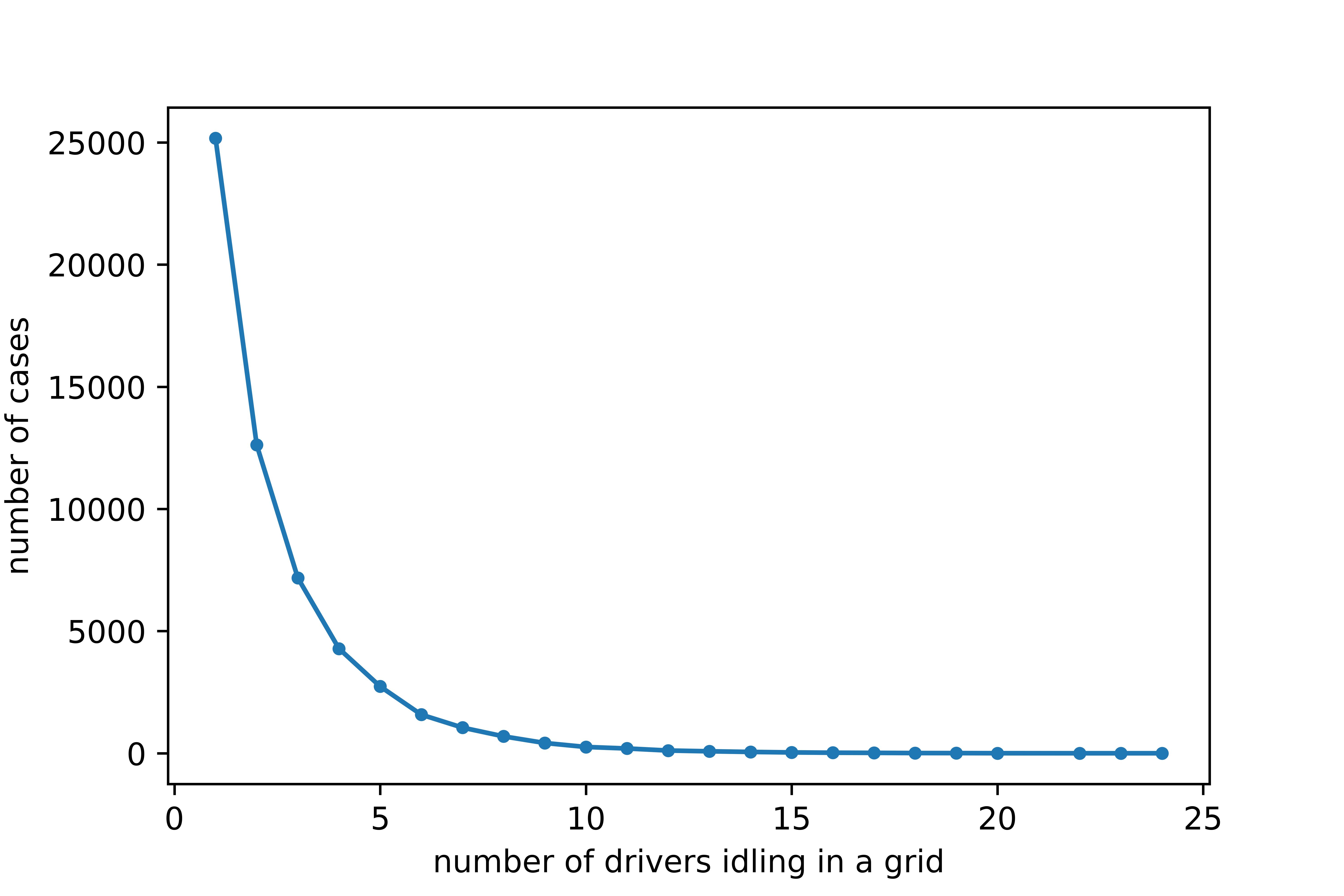 Figure 30
Figure 30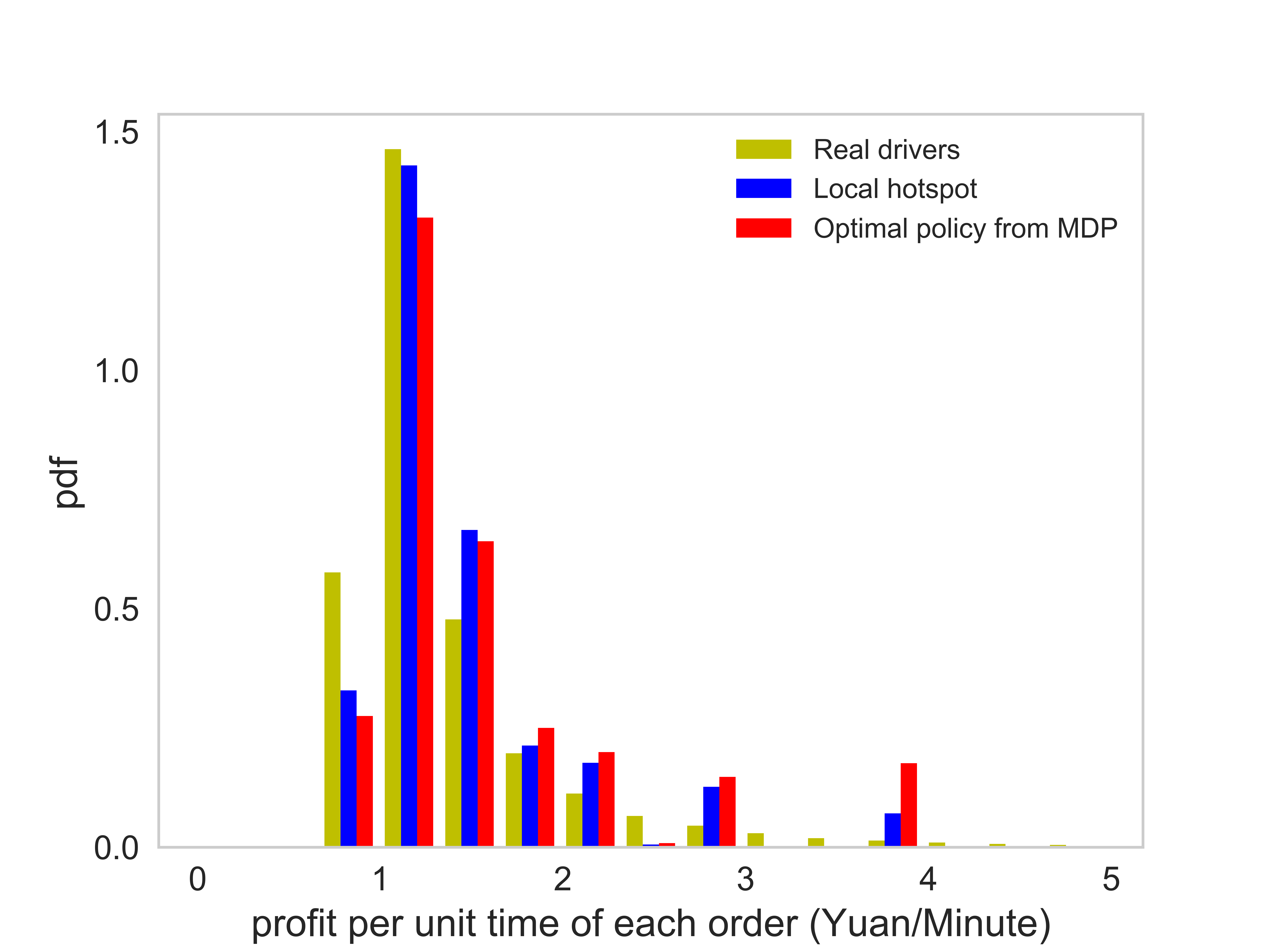 Figure 31
Figure 31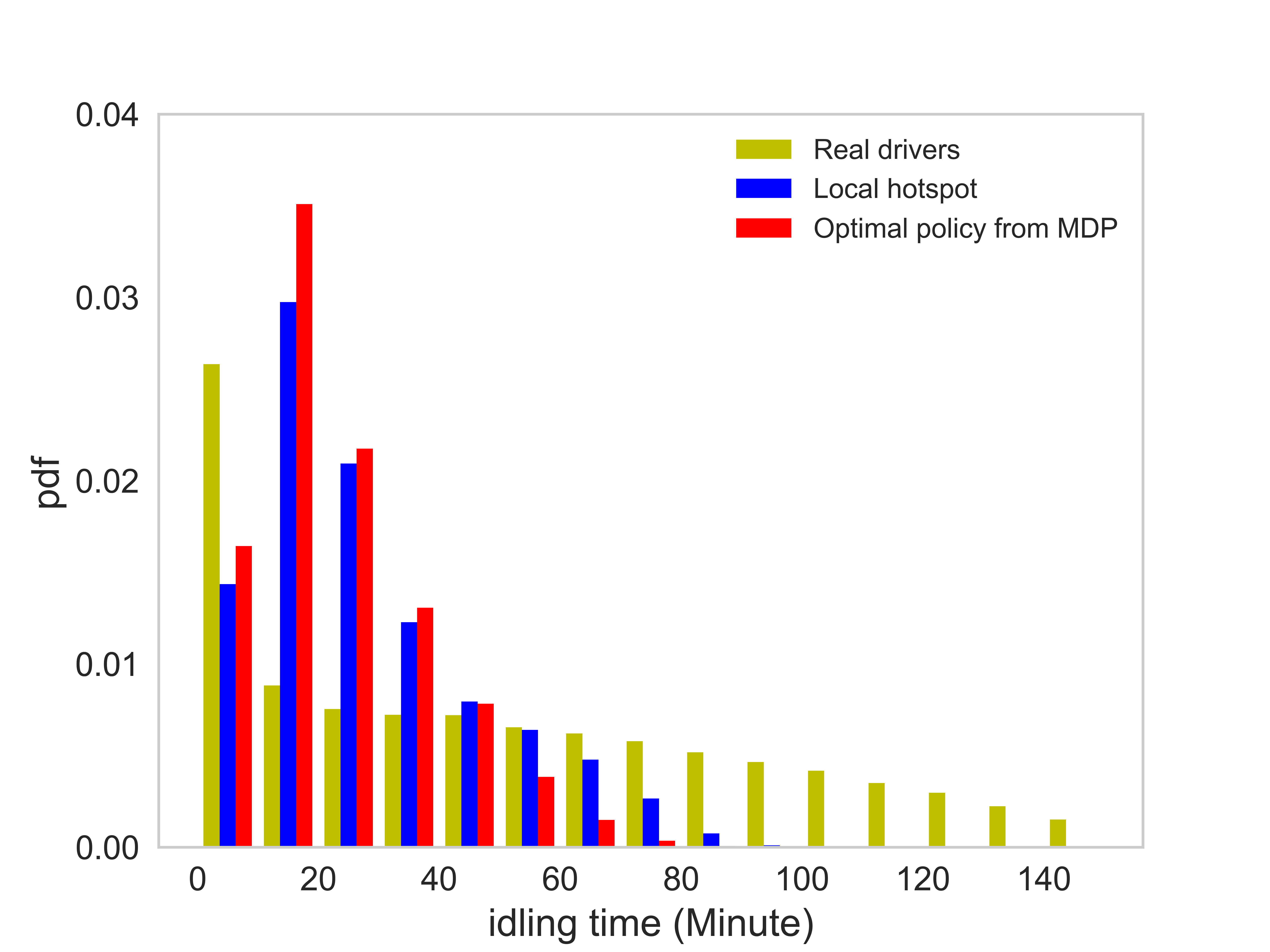 Figure 32
Figure 32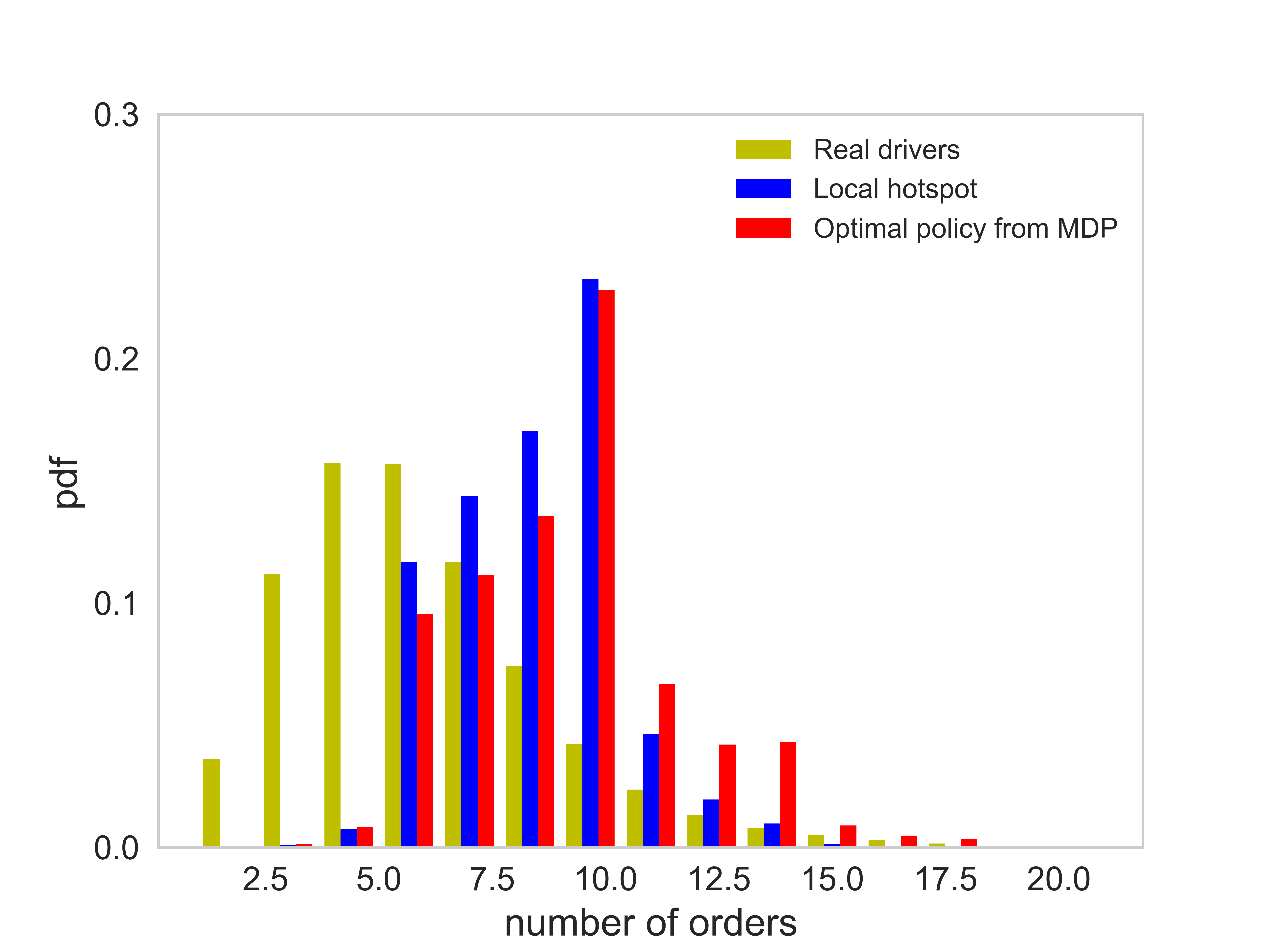 Figure 33
Figure 33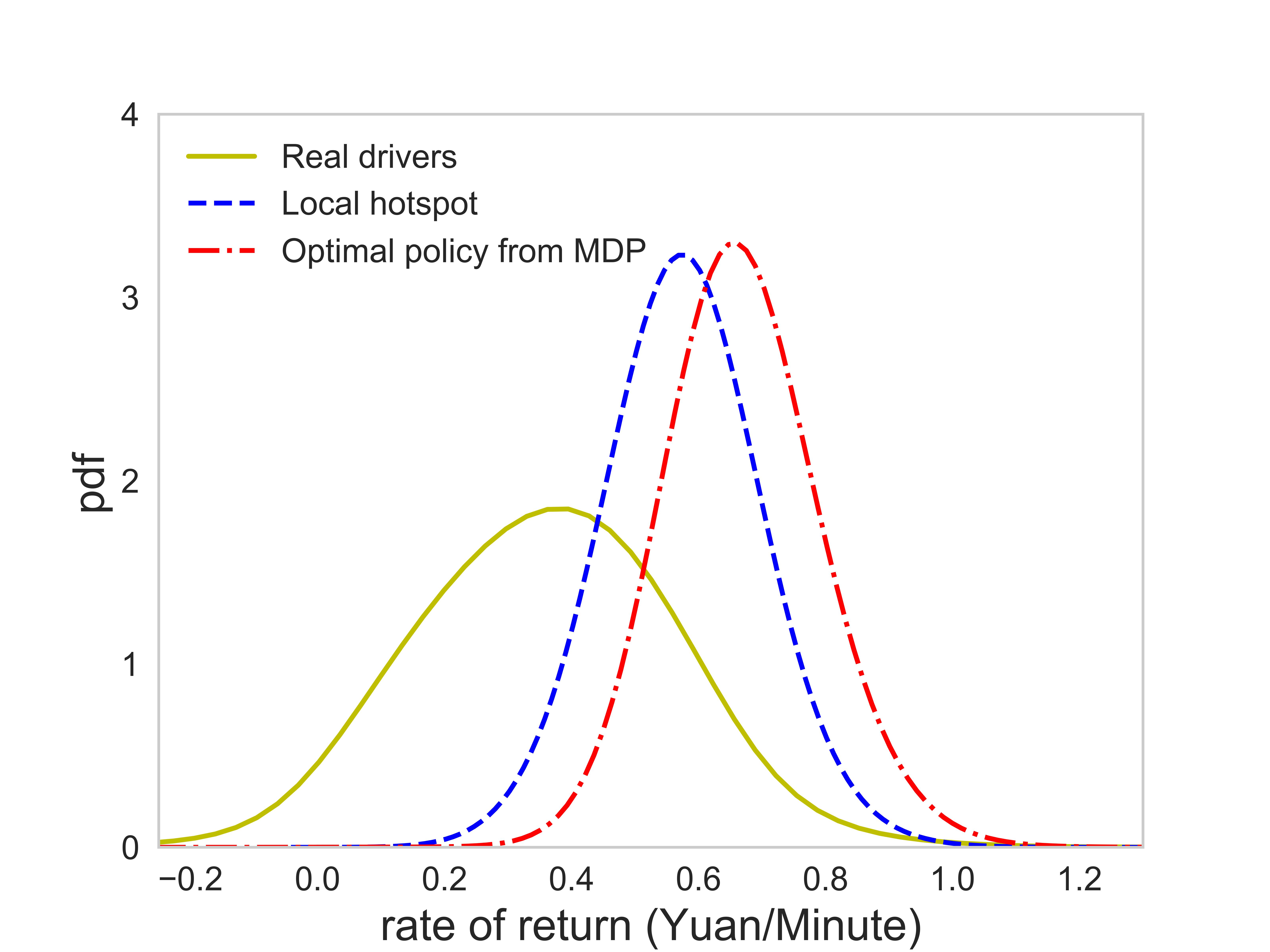 Figure 34
Figure 34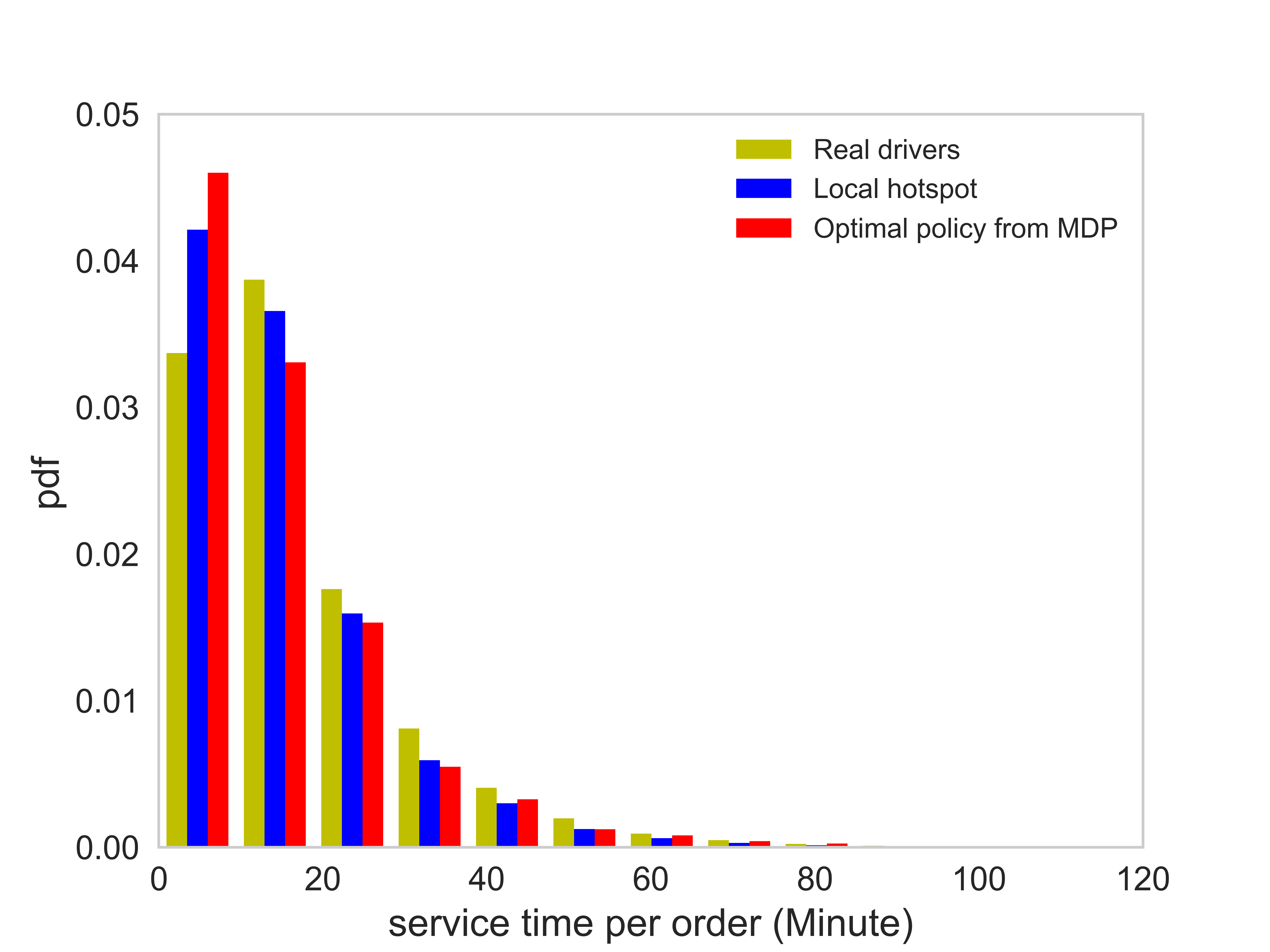 Figure 35
Figure 35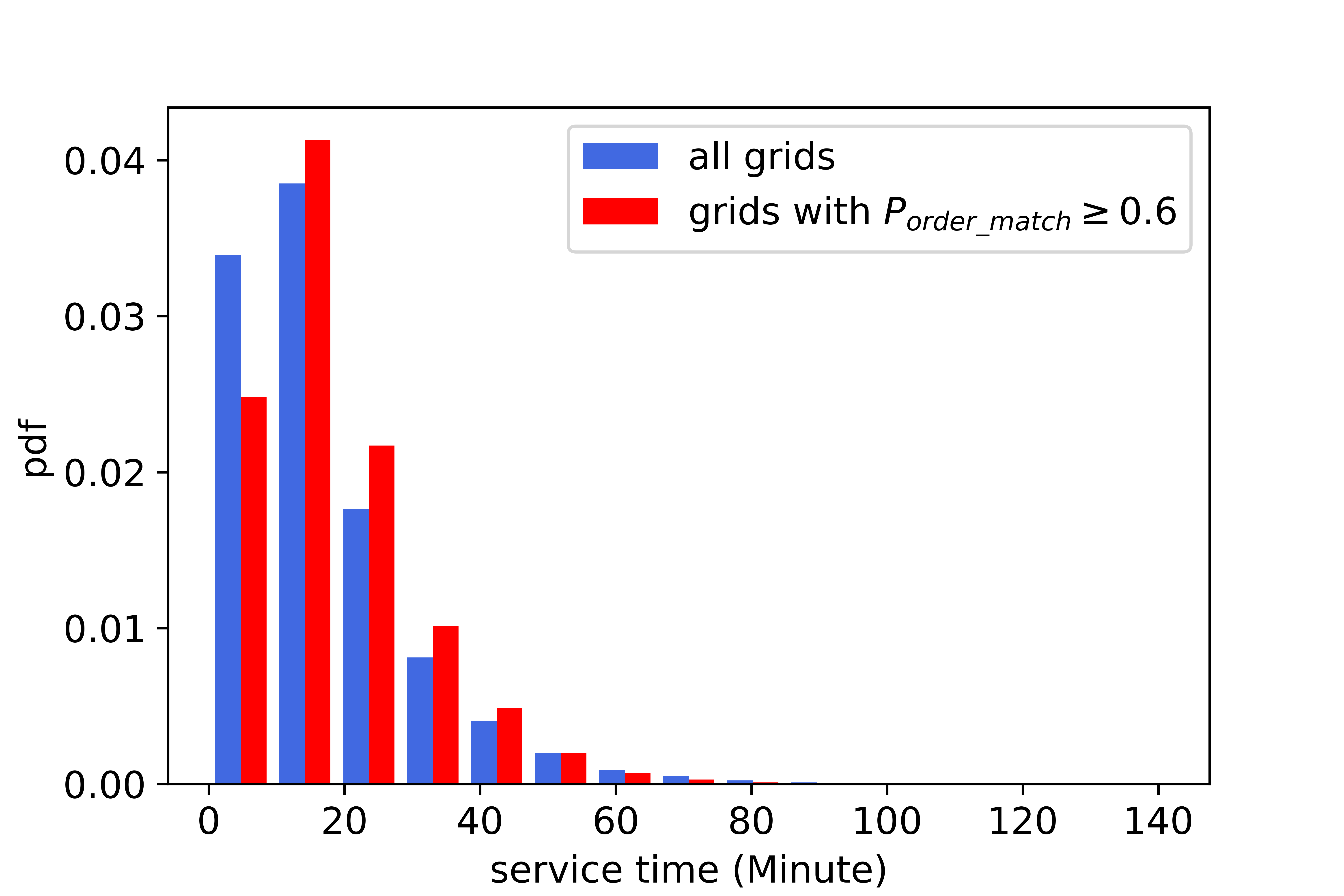 Figure 36
Figure 36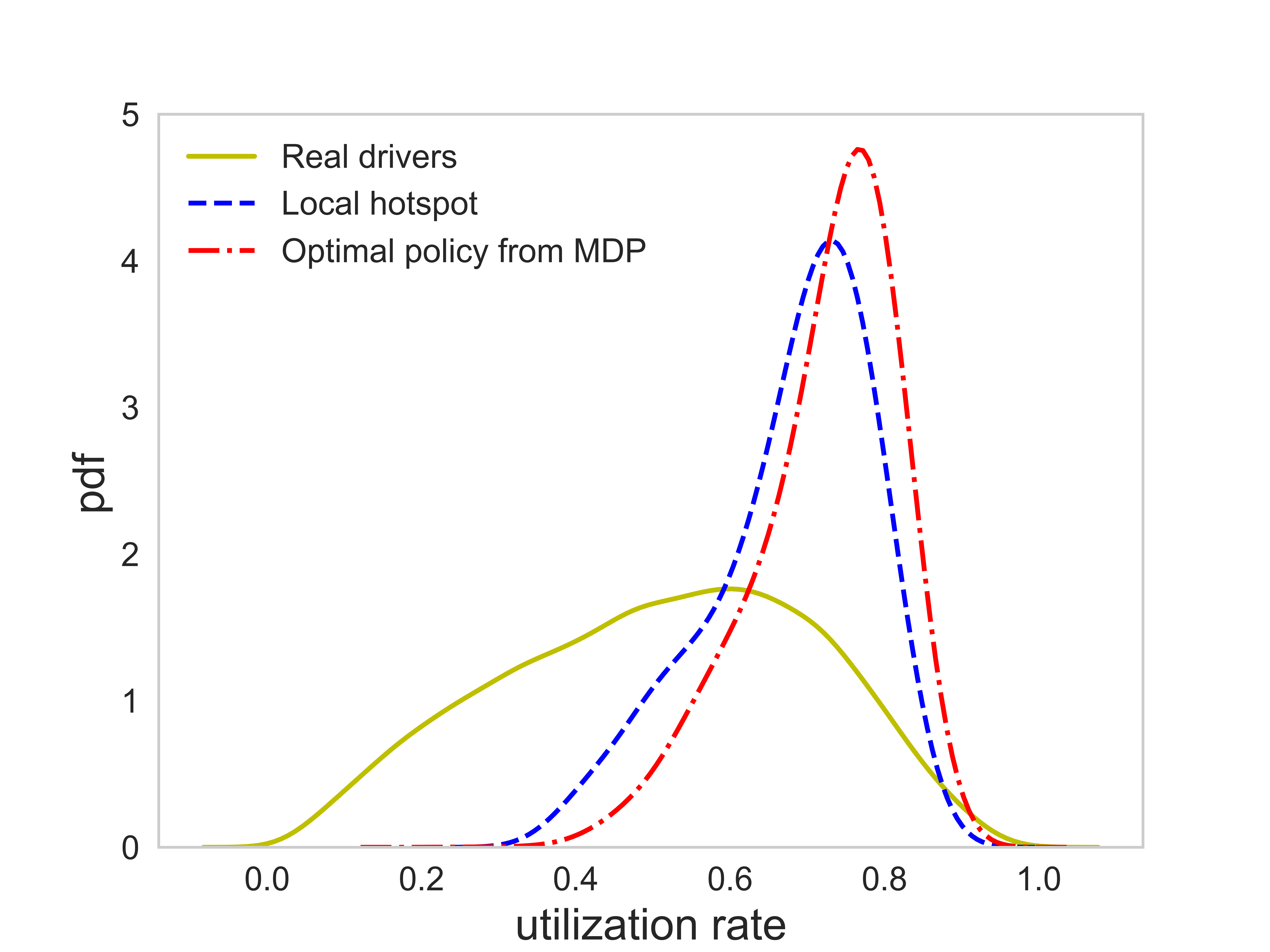 Figure 37
Figure 37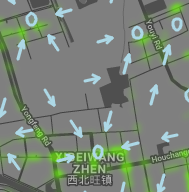 Figure 38
Figure 38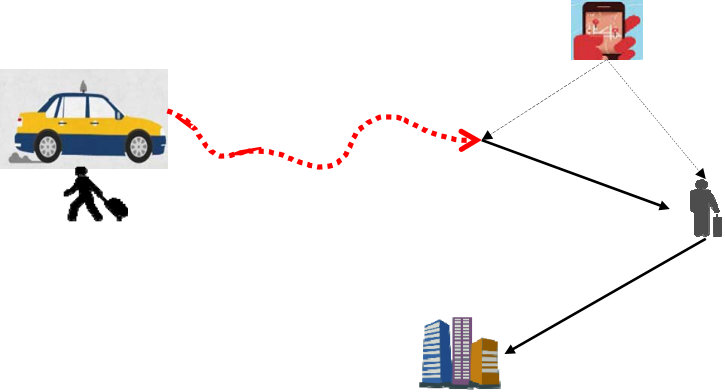 Figure 39
Figure 39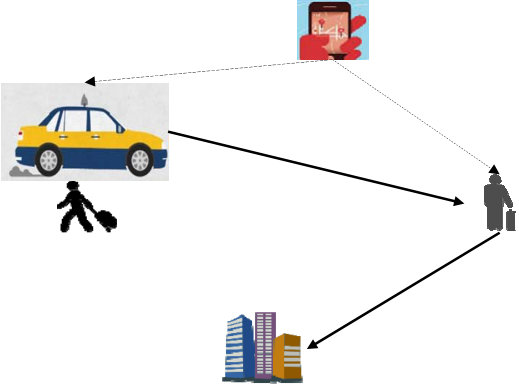 Figure 40
Figure 40| Reference | Network representation | State space | Action space | Reward | Algorithm |
| Rong et al. (2016) | Grid world | (grid id, time, incoming direction) | moving to a neighboring grid or staying in the current grid | Taxi fare | Dynamic programming |
| Verma et al. (2017) | Grid world (static and dynamic zone structure) | (day-of-week, grid id, time-interval) | moving to any chosen grid (proposed an action detection algorithm) | Taxi fare - traveling distance cost - time cost | Q-learning (Monte Carlo) |
| Gao et al. (2018) | Grid world | (grid id, operating status) | driving vacantly to neighboring grids to search, finding a passenger in the current grid, waiting static at the same spot | the ratio of the occupied taxi trip mileage to the previous empty mileage | Q-learning (Temporal Difference) |
| Yu et al. (2019) | Link node | (node id, indicator of the current pick-up drop-off cycle) | outgoing links from the current node | taxi fare - operating cost | Value iteration |
| Lin et al. (2018) | Grid world | (grid id, time interval, global state) | moving into a neighboring grid or staying in the current grid | taxi fare - operating cost | Reinforcement Learning (Deep Q learning) |
| Variable | Explanation |
|---|---|
| Index of the current grid | |
| Current time | |
| Indicator, denoting whether the driver has been matched to a request before the next drop-off | |
| State, | |
| State space, a collection of all states | |
| Action | |
| Action space | |
| Time spent on seeking for a passenger in grid | |
| Time spent on moving from grid to grid | |
| Distance traveled when seeking for a passenger in grid | |
| Distance traveled for moving from grid to grid | |
| The probability that the driver can be matched to a request during cruising in grid | |
| The probability of picking up a passenger in grid when the request from the passenger was matched to the driver in grid | |
| The probability of dropping off a passenger in grid when the passenger was picked up in grid | |
| The probability of receiving a new request before the driver finishing her current order at grid | |
| The average taxi fare from grid to grid | |
| Coefficient of fuel consumption and other operating costs per unit distance |
| real drivers | agent following the local hotspot strategy | agent following the optimal policy | |
|---|---|---|---|
| average rate of return (Yuan/Minute) | 0.36 | 0.57 | 0.67 |
| average utilization rate | 0.51 | 0.67 | 0.72 |
| average number of orders | 6.08 | 8.21 | 8.92 |
| average idling time (Minute) | 47.98 | 27.12 | 22.61 |
| average profit per unit time of each order (Yuan/Minute) | 1.35 | 1.51 | 1.68 |
| average service time per order (Minute) | 16.97 | 14.83 | 14.56 |
| The driver with a small radius of gyration | |||
| The driver with a large radius of gyration |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Optimal Passenger-Seeking Policies on E-hailing Platforms Using Markov Decision Process and Imitation Learning
Zhenyu Shou
Xuan Di
Jieping Ye
Hongtu Zhu
Hua Zhang
Robert Hampshire
Department of Civil Engineering and Engineering Mechanics, Columbia University
Data Science Institute, Columbia University
Didi Chuxing Inc., Beijing, China
National Maglev Transportation Engineering R&D Center, Tongji University, Shanghai, China
University of Michigan Transportation Research Institute, University of Michigan, Ann Arbor
Ford School of Public Policy, University of Michigan, Ann Arbor
Abstract
Vacant taxi drivers’ passenger seeking process in a road network generates additional vehicle miles traveled, adding congestion and pollution into the road network and the environment. This paper aims to employ a Markov Decision Process (MDP) to model idle e-hailing drivers’ optimal sequential decisions in passenger-seeking. Transportation network companies (TNC) or e-hailing (e.g., Didi, Uber) drivers exhibit different behaviors from traditional taxi drivers because e-hailing drivers do not need to actually search for passengers. Instead, they reposition themselves so that the matching platform can match a passenger. Accordingly, we incorporate e-hailing drivers’ new features into our MDP model. The reward function used in the MDP model is uncovered by leveraging an inverse reinforcement learning technique. We then use 44,160 Didi drivers’ 3-day trajectories to train the model. To validate the effectiveness of the model, a Monte Carlo simulation is conducted to simulate the performance of drivers under the guidance of the optimal policy, which is then compared with the performance of drivers following one baseline heuristic, namely, the local hotspot strategy. The results show that our model is able to achieve a 17.5% improvement over the local hotspot strategy in terms of the rate of return. The proposed MDP model captures the supply-demand ratio considering the fact that the number of drivers in this study is sufficiently large and thus the number of unmatched orders is assumed to be negligible. To better incorporate the competition among multiple drivers into the model, we have also devised and calibrated a dynamic adjustment strategy of the order matching probability.
keywords:
Markov Decision Process (MDP), Imitation Learning, E-hailing
Published in: Transportation Research Part C 111 (2020) 91-113.
Please cite this Paper as: Shou, Z., Di, X., Ye, J., Zhu, H., Zhang, H., Hampshire, R., 2020. Optimal passenger-seeking policies on E-hailing platforms using Markov decision process and imitation learning. Transportation Research Part C: Emerging Technologies 111, 91–113. DOI: 10.1016/j.trc.2019.12.005
1 Motivation
Taxi, complementary to massive transit systems such as bus and subway, provides flexible-route door-to-door mobility service. However, taxi drivers usually have to spend 35-60 percent of their time on cruising to find the next potential passenger (Powell et al., 2011). Such passenger-seeking process not only decreases taxi drivers’ income but also generates additional vehicle miles traveled, adding congestion and pollution into the increasingly saturated roads.
Cruising is primarily caused by an imbalance between travel demand and supply. Market regulation (Yang et al., 2002) or taxi fare structure design (Yang et al., 2010a; He et al., 2018; Battifarano and Qian, 2019) were proposed respectively to balance taxi travel demand and supply. A network equilibrium model was developed (Yang and Wong, 1998; Wong and Yang, 1998) to capture the spatial imbalance between travel demand and supply, where a logit-based probability was introduced to describe the meeting between a vacant taxi and a waiting passenger. This model, in which a taxi driver is supposed to minimize the individual search time for the next passenger, is further extended to incorporate congestion effects and customer demand elasticity (Wong et al., 2001), to include the fare structure and fleet size regulation (Yang et al., 2002), to consider multiple user classes, multiple taxi modes, and customer hierarchical modal choice (Wong et al., 2008), and to use a meeting function to describe the search frictions between vacant taxis and waiting passengers (Yang et al., 2010b; Yang and Yang, 2011; Yang et al., 2014). Recently, Di and Ban (2019) proposed a unified equilibrium framework to model the shared mobility in congested road network.
As taxis GPS trajectories become increasingly available, qualitative analysis has been performed to uncover drivers’ actual searching strategy. Liu et al. (2010) found that drivers with higher profits prefer to choose routes with higher speed in both operational and idle states. Li et al. (2011) discovered that hunting is a more efficient strategy than waiting by comparing profitable and non-profitable drivers. Several logit-based quantitative models were developed to capture idle drivers’ searching behavior (Szeto et al., 2013; Sirisoma et al., 2010; Wong et al., 2014a, b, 2015a, 2015b). The bilateral searching behavior (i.e., taxi searching for customers and customers searching for taxis) was modeled through an absorbing Markov chain approach (Wong et al., 2005). A probabilistic dynamic programming routing model was proposed to capture the taxi driver’s routing decisions at intersections (Hu et al., 2012). Furthermore, a two-layer approach, in which the first layer models the driver’s pick-up location choice and the second layer accounts for the driver’s detailed route choice behavior, was presented (Tang et al., 2016). Recently, Zhang et al. (2019a) proposed an image-based representation of taxi drivers’ passenger searching strategies and identified twenty four strategies using a dataset collected in Shenzhen, China.
Upon the understanding of drivers’ searching behavior, recommendations can be provided to idle drivers on where to find the next passenger. An accurate prediction of both taxi supply (Phithakkitnukoon et al., 2010) and demand (Moreira-Matias et al., 2012; Markou et al., 2019; Wang et al., 2019; Alemi et al., 2019) as well as travel time (Tan et al., 2018; Zhang et al., 2019b) are stepping stones to these recommendations. The objectives that recommendations aim to achieve include the minimization of waiting time at the recommended location (Hwang et al., 2015) or of the distance between the current location and the recommended location (Powell et al., 2011; Hwang et al., 2015), and the maximization of the expected fare for the next trip (Powell et al., 2011; Hwang et al., 2015), of the probability of finding a passenger (Ge et al., 2010), or of the potential profit of a driver (Qu et al., 2014; Yuan et al., 2011).
The aforementioned studies mainly focused on the recommendation of the cruising routes or next cruising locations at the immediate next step without considering the optimization of long-run payoffs. A recommended customer searching strategy may help a driver to get an order as fast as possible but may not maximize this driver’s overall profit in one day. Models which can capture drivers’ long-term optimization strategy are needed. In recent years, Markov Decision Process (MDP) becomes increasingly popular in optimizing a single agent’s sequential decision-making process given a period of time (Puterman, 1994). Several studies (Rong et al., 2016; Zhou et al., 2018; Verma et al., 2017; Gao et al., 2018; Yu et al., 2019) have employed MDPs to model idle drivers’ optimal searching strategy. In an MDP, an idle driver is an agent who makes sequential decisions of where to go to find the next passenger in a stochastic environment. The environment is characterized by a Markov process and transitions from one state to another once an action is specified by the idle driver. The driver aims to select an optimal policy which optimizes her long-term expected reward. Dynamic programming or Q-learning approaches are commonly used to solve an MDP (Sutton and Barto, 1998). Table (1) summarizes the existing studies using MDPs for passenger-seeking optimization. Note that in e-hailing, there is actually no passenger seeking because it is the e-hailing paltform that matches an idle e-hailing driver to a passenger. However, e-hailing drivers still need to reposition themselves in order to get better chance of getting matched to a passenger request. In this paper, we will use the terminologies passenger seeking and repositioning interchangably.
The existing MDP models were primarily developed for traditional taxi drivers’ sequential decision-making where a driver has to see a passenger before a match happens. In other words, an idle driver’s searching process ends only when this driver sees a passenger and the passenger accepts the ride (see Figure (1a)). E-hailing applications (such as Didi and Uber), on the other hand, offer an online platform to match a driver with a passenger even when they are not present in the same space at the same time (He and Shen, 2015; Qian and Ukkusuri, 2017). In other words, even when an idle driver sees a passenger waiting on the roadside, as long as the e-hailing platform does not match them, the driver cannot give a ride to the passenger. However, it does not mean e-hailing drivers always stay at the previous drop-off spot and wait for the platform to match. Drivers tend to reposition themselves so that the platform can find them a match sooner. As a result, the decision-making process of e-hailing drivers is quite different from the traditional taxi drivers in the following aspects:
An e-hailing driver may receive a matched order before she drops off the previous passenger, thus there is no passenger seeking (see Figure (1b)). 2. 2.
Different from traditional taxi that a driver has to see a passenger to find a match, e-hailing platforms very likely find a match even when the driver and the passenger are spatially far from each other. In other words, a driver’s search process may end before a passenger is picked up (see Figure (1c)).
Because of the inherent differences in drivers’ decision-making, this paper aims to develop an MDP to model e-hailing drivers’ sequential decision-making in searching for the next passenger. 44,160 Didi drivers’ 3-day GPS trajectories are used to calibrate and validate our model. Previously, there is research using Didi’s data for the study of large-scale fleet management (Lin et al., 2018) and large-scale order dispatch (Xu et al., 2018) in e-hailing platforms.
The major contributions of this paper are as follows: (1) In stead of following the literature where a known reward function is given based on some prior knowledge or assumptions (Rong et al., 2016; Verma et al., 2017; Lin et al., 2018; Yu et al., 2019), this work unveils the underlying reward function of the overall e-hailing driver population and crafts a novel reward function which explains the behaviors of drivers with a relatively small radius of gyration and thus paves the way for future research on discovering the underlying reward mechanism in a complex and dynamic e-hailing market. With the incomplete and noisy observed policy, this work first extracts the underlying reward function and then solves an MDP to derive the optimal policy which completes and corrects the observed policy. (2) To the best of our knowledge, this is the first study using large amounts data to devise and calibrate a dynamic adjustment strategy of the order matching probability to address the competition among multiple drivers. The strategy essentially attenuates the order matching probability in an exponential manner for subsequent drivers to be guided into a grid when some drivers have already entered the grid. The strategy is further verified to be efficient in providing different recommendations for multiple drivers.
The remainder of the paper is organized as follows. Section 2 introduces our modified MDP model and details definitions of states, actions, and state transitions and the process of extracting parameters from the data. Section 3 presents the proposed dynamic adjustment strategy of the order matching probability and details the calibration process. Section 4 introduces the data we used in this research and presents the results, including the derived optimal policy and the Monte Carlo simulation. Section 5 concludes the paper and provides some future research directions.
2 Markov Decision Process (MDP) for a single agent
2.1 Preliminaries
An MDP is specified by a tuple , where denotes the state space, stands for the allowable actions, collects rewards, defines a state transition matrix, and is the starting state. Given a state and a specified action at time , the probability of reaching state at time is determined by the probability transition matrix , which is defined as
[TABLE]
From the initial state , the process proceeds repeatedly by following the dynamics of the environment defined by the Equation (2.1) until a terminal state (i.e., either the current time exceeds the terminal time or the current state is an absorbing state) is reached. An MDP satisfies the Markov property which essentially says that the future process is independent on the past given the present, i.e.,
[TABLE]
There are two types of value functions in MDPs, namely, a state value and a state-action value . The actions that an agent will take form a policy , which is a mapping from a state and an action to the probability of taking action at state . Then the value function of a state by following the policy , denoted as , can be taken as the expectation of the future rewards, i.e.,
[TABLE]
where is a discount factor. The state-action value of taking action at state by following policy is
[TABLE]
The value function is actually a weighted average of the state-action value , i.e.,
[TABLE]
where is again the probability of taking action at state according to policy , and is the total number of actions that are allowed to be taken in state .
Several algorithms have been developed to solve the MDP, i.e., to derive the optimal policy, and the corresponding value functions, such as the dynamic programming method and the Q-learning approach (Sutton and Barto, 1998). The dynamic programming algorithm is used in this work and will be explained later in Section (2.2.4). Furthermore, these two types of value functions at optimality are related by the following mechanism
[TABLE]
The rationale underlying the relationship at optimality is simply to choose a policy which maximizes the value function expressed in Equation (2.5). For example, when an agent is at state , the optimal policy simply suggests the agent to take an action with the largest state-action value, i.e., (i.e., the probability of taking action in state is 1). Accordingly, the state-action value at optimality can be written as
[TABLE]
where is the probability of landing in state after taking action in state , and is the reward for choosing action at state and landing in state .
2.2 MDP for e-hailing drivers
In this section, we will develop an MDP model for e-hailing drivers’ stochastic passenger seeking process. Notations which will be used in the subsequent analysis are listed in Table (2).
2.2.1 States
In our MDP model, the state consists of three components, namely, a grid index , current time , and an indicator . Note that a hexagonal grid world setting with 6,421 grids is adopted in this research and will be explained later. Considering the fact that an e-hailing driver may receive a request before she drops off the previous passenger, we have therefore added an indicator into the state. The indicator denotes whether the driver has been matched to a request before she arrives at the current state. Accordingly, states with indicator [math] are decision-making states in which the driver needs to spend time on seeking the next passenger, and states with indicator are non-decision-making states. For example, is a non-decision-making state which says that the driver is in grid when and the driver has already been matched to a request so she will not spend time on seeking at the current state.
2.2.2 Actions
In decision-making states, the driver has to choose one from eight allowable actions, denoted as . In non-decision-making states, the driver will not take any action but drive to pick up the next passenger and transport the passenger to the destination. Among the allowable action space , each of the first six actions is to transit from the current grid to one of the six neighbor grids. Note that some of the six neighboring grids may be non-reachable, we thus add a large penalty, i.e., a large distance, to the transition from a grid to a non-reachable neighboring grid to prevent the agent from taking the action which leads the agent to the non-reachable neighboring grid. The seventh action is to stay and cruise around within the current grid. The last action is to wait in the current grid. We stress that the last two actions are essentially different because from the data we have observed that some drivers will just wait near the previous drop-off spot, especially when they are around downtown or transportation terminals while some drivers usually cruise within the current grid after completing a ride. In addition, the fuel cost associated with waiting can be neglected while that of staying can be substantial because the driver keeps cruising around during his/her staying in the current grid. Furthermore, drivers can take a rest and refresh their minds during waiting and hence their driving strategy can be more efficient for future trips. These arguments, however, do not necessarily suggest that the driver should always choose waiting rather than staying. Actually, drivers have to cruise around to get closer to the potential requests under certain circumstances.
2.2.3 State transition
After completing a ride, there are two possible scenarios according to two different values of the indicator. If the indicator is [math], the driver needs to specify an action, i.e. where to find the next passenger, and then moves into the grid along the direction defined by the action and spends some amount of time seeking for the next passenger in the new grid. There are two possible outcomes associated with this passenger seeking process. Either the driver confirms a request and ends up arriving at a different grid by following the passenger’s travel plan or the driver fails to find a request and stays in the current grid. The reward is usually positive for the former while negative for the latter due to the fuel consumption and other operating costs. If the indicator is , the driver drives to the pick-up spot and then transports the passenger to the destination without any passenger seeking involved.
Figure (2) illustrates the aforementioned state transition process. The driver currently stays at state .
If , the driver specifies an action , which is assumably taken as going northeast in the demonstration. Then the driver moves into the grid along the direction defined by the action and thereafter spends some amount of time on seeking the next passenger. There are two possible outcomes of this passenger seeking process.
The first possibility is that the driver fails to get any request in grid after . In this case, the state of the driver will be . The reward for this passenger seeking process is , which is negative. Let denote the probability that the driver will receive at least one request in grid . Then the probability of the occurrence of this outcome is . In other words, with probability , the driver will end up in state .
The second possibility is that the driver confirms one request during the cruising process in . The probability of the occurrence of this outcome is . We let denote the probability of confirming a request in grid and picking up the passenger in grid . Once the passenger is on board, the driver will directly move to the destination , which only depends on the passenger’s travel plan. We let denote the probability of picking up a passenger in grid and dropping off the passenger in grid . After dropping off the passenger, the driver will end up in grid at time and earn a reward of . Hence, the probability of the driver receives a request in grid , picks up the passenger in grid , and transports the passenger to grid is . Notice that for a driver, during her trip from the passenger’s origin to the passenger’s destination , there is a probability at which the driver will confirm a request before she drops off the passenger. Let denote the probability of receiving a request before the driver reaches grid . Then we can conclude that with probability , the driver will end up in state , and with probability , the driver will end up in state .
If , the driver will not need to specify any action and will directly drive to the pick-up spot of the next passenger and then transport the passenger to the destination. Again, during her trip to the passenger’s destination, there is a probability, denoted as , at which the driver will receive a request before she drops off the passenger. As illustrated in Figure (2), with probability , the driver will end up in state ; with probability , the driver will end up in state .
In both scenarios, namely, either or , the driver will thereafter start the whole process from again until the current time exceeds the time interval, i.e., a terminal state has been reached.
2.2.4 Solving MDP
The objective of the MDP model is to maximize the total expected revenue of a driver. Considering the fact that in a time interval, a driver can finish a finite number of pick-up and drop-off cycles, indicating that the MDP model is finite-horizon. When current time of the driver has reached the end of the time interval, no more actions can be taken and no more rewards can be earned. Suppose a driver is currently at state . If , meaning that the driver is at a decision-making state, the maximum expected revenue that a driver can earn by starting from and specifying an action is
[TABLE]
where , meaning that the grid in which an e-hailing driver will be cruising is dependent on the current state , actually through the grid index of , and the specified action , , , , and , , and stand for the maximum expected revenue that a driver can earn by reaching state , , and , respectively. If , meaning that the driver is at a non-decision-making state, the driver will not specify any action, and the expected revenue that the driver can earn is
[TABLE]
where , , and and stand for the maximum expected revenue that a driver can earn by reaching state and , respectively.
Then the optimal policy for a driver to follow at a decision-making state is
[TABLE]
and the maximum expected revenue that a driver can earn by reaching state is
[TABLE]
The policy in Equation (2.10) is deterministic, meaning that the driver can only take one action at the current decision-making state if she follows the policy. Actually here we slightly abuse the notation. The policy is supposed to be , i.e., the probability of taking action at state is 1. It is equivalent to say that at state , the action to take is , and thus we write the policy at state as Equation (2.10). A deterministic policy defines a one-to-one mapping from a state to an action. The deterministic policy works when there is only one driver who learns the optimal policy and follows the policy. Otherwise, there might be excess taxi supply at some areas, resulting in a localized competition among taxis. A circulating mechanism was employed to tackle this overload problem (Ge et al., 2010). A multi-agent reinforcement learning approach (Lin et al., 2018) was proposed to consider the competition among drivers. In this research, we use a dynamic adjustment strategy to update the order matching probability when multiple idling e-hailing drivers are guided into the same grid. The proposed dynamic adjustment strategy will be introduced in Section (3).
To efficiently solve the MDP, i.e., to derive an optimal policy, a dynamic programming approach is employed (Bertsekas, 2000; Sutton and Barto, 1998). The basic idea of the dynamic programming algorithm is to divide the overall problem into subproblems and hence to make use of the results of the subproblems to solve the overall problem. An important advantage of the dynamic programming algorithm is that it caches results of all subproblems and thus it is guaranteed that the same subproblem is only solved once.
Now we elucidate how we apply the dynamic programming algorithm to solve the MDP. The goal is to solve the optimal value for all states , where , , and . There are in total states, and half of them are decision-making states. We define one subproblem as solving the optimal value for one state and thus we have in total subproblems. Noticing that at the final time step, i.e., , the maximum expected reward that a driver can earn is obviously zero, we thus have for all states where . For any state with and a chosen action , the calculation of the state-action value depends on the value of some future states, i.e., , , and in Equation (2.8). In other words, the subproblem, i.e., solving the optimal value for state , depends on some subproblems, i.e., solving the optimal value of some future states, e.g., , , and . For a future state , there might be several states from which the agent will reach the future state , indicating the calculation of the optimal value of all these states requires the calculation of the optimal value of the future state , resulting in calculating the optimal value of the same state multiple times and thus wasting computation power. To avoid the repeated calculation of the optimal value for the same state, we adopt the dynamic programming algorithm. Since the optimal values for all states with are known and the optimal value of a state depends on the optimal value of some future states, we solve the optimal value of states backwards in time and simply store the solved optimal values in a hash table. Then for a state and a chosen action , we simply read the optimal values of future states , , and from the hash table and use Equation (2.8) to calculate the state-action value , based on which the optimal value of the state can be derived from Equation (2.11). The pesudo code is in Algorithm (1).
2.3 Extracting parameters from data
In the dataset we used in this research, we have GPS trajectories for both the empty and occupied trips. We now introduce how to extract the parameters we used in the state transition from the dataset.
2.3.1 Order matching probability
The order matching probability estimates the probability at which a vacant taxi can be matched to a passenger when the taxi is cruising, including staying, or waiting at grid . As we have mentioned before, the purposes for introducing waiting and staying in this work are different. In addition to six actions which allow an e-hailing driver to move into one of the six neighboring grids, the action staying gives the driver extra flexibility in choosing to stay and cruise within the current grid due to some potential benefits, such as a relatively high order matching probability in the current grid, a possibly high cost to move into neighboring grids vacantly, etc. Actually, as we have listed in Table (1), there are several studies in the literature that have already included the action staying into the action space, such as (Rong et al., 2016), (Verma et al., 2017), and (Lin et al., 2018). Thus, the way to calculate the order matching probability for staying is the same as the way to calculate the order matching probability for cruising into one of the six neighboring grids. In other words, the order matching probability for a driver just entering the grid from one of the six neighboring grids is supposed to be the same as the order matching probability for a driver who was in the grid and chose to stay in the grid.
Waiting, different from staying and other six actions which allow the driver to move into one of the six neighboring grids, is included into the action space based on the observation that sometimes a driver will choose to stop cruising and simply to wait statically for passenger requests to come in, especially when the driver is around downtown or transportation terminals. The action waiting was previously included in the action space in (Gao et al., 2018).
We thus approximate the order matching probabilities for cruising and waiting separately. We say a driver is waiting for a passenger request whenever the driver’s traveling distance is less than 200 meters for a 3-minute interval. To rule out some unrealistic waiting actions, such as a driver being stuck in traffic, we further limit the possible locations for waiting to be the places around subway stations, bus terminals, airports, and some famous tourism attractions. For cruising, the order matching probability can be approximated as the ratio of the number of times that a taxi is matched to a passenger in grid while cruising, denoted as , to the number of times that the grid is passed by an empty taxi while cruising, denoted as . For waiting, the order matching probability can be approximated as the ratio of the number of times that a taxi is matched to a passenger in grid while waiting, denoted as , to the number of times that empty taxis have waited in the grid , denoted as .
[TABLE]
2.3.2 Pick-up probability
The pick-up probability measures the likelihood of picking up a passenger at grid when the request sent from the passenger was matched to the driver at grid . This parameter can be estimated as the ratio of the the number of passenger pick-ups in grid which were matched to drivers in grid , denoted as , to , which is the summation of and .
[TABLE]
2.3.3 Destination probability
The destination probability measures the likelihood of the destination of the passenger being grid when the passenger was picked up in grid . This parameter can be estimated by dividing the number of trips ending in grid which originated from grid , denote as , by the total number of pick-ups in grid , denoted as .
[TABLE]
2.3.4 Order matching probability while on trip
As we have mentioned before, there is a probability at which the driver will receive a request when she is on the trip to transport the current passenger to the destination. We denote this order matching probability while on trip as . This probability can be estimated by dividing the number of occupied trips among which there is at least one request received by the driver before the driver reaching the destination while the origin is , denoted as , by the total number of occupied trips ending in grid and originating in grid , denoted as .
[TABLE]
2.3.5 Driving time and driving distance
The driving time and the driving distance denote the estimated driving time and driving distance from grid to grid , respectively. Here we simply take the average of all driving times from grid to grid as an approximation of the . Similarly, the driving distance is calculated by taking the average of all driving distances between grid and grid .
2.3.6 Taxi fare
The taxi fare denotes the estimated gross revenue that a driver can earn by transporting a passenger from grid to her destination grid . Here we take the average of all the fares of the occupied trips which are from grid to grid as a proxy of the real taxi fare from grid to .
2.3.7 Seeking time and seeking distance
The seeking time and the seeking distance denote the estimated seeking time and seeking distance within grid , respectively. From the field data, the distribution of the seeking time in each grid was extracted and is shown in Figure (3). The median of the distribution of the seeking time is approximately 45 seconds. Since the time step size is 1 minute in this work, thus we simply take the seeking time as 1 minute. Considering the average speed of seeking trips (around 300 meters/minute), the seeking distance is taken as 300 meters for each grid. Note that the seeking distance is zero when the driver chooses to wait.
2.3.8 The fuel consumption coefficient
estimates the fuel consumption and other operating cost per unit distance during driving. In the literature, the value of is typically assumed to be a known constant based on some common knowledge (Rong et al., 2016; Verma et al., 2017; Lin et al., 2018; Yu et al., 2019). This assumption, however, can easily result in a gap between the reward function in MDP models and the reward function of real drivers, meaning that drivers will not follow the optimal policy since the reward function used to derive the optimal policy is not the reward function of real drivers. To more appropriately determine , we opt for the inverse reinforcement learning (IRL) approach. IRL is a powerful technique to disclose the underlying reward function based on the observed behaviors, especially in the field of imitation learning where an agent’s behavior is observed by a learner who tries to imitate the agent (Ziebart et al., 2008).
A linear programming formulation of IRL in finite state spaces was first proposed in (Ng and Russell, 2000), where an extension to large state spaces was also made possible by adopting a linear function approximation. In the context of understanding the observed behaviors, Liu et al. (2013) argued that a mixed integer linear programming formulation can be more revealing. Noticing the similarity between the two approaches, we take the mixed integer linear programming formulation for simplicity. To make the paper self-explanatory, we provide a brief introduction of mixed integer linear programming formulation. Interested readers are referred to (Liu et al., 2013) for detailed explanations.
In the linear programming formulation, the underlying reward function from a state to another state is expressed as a linear combination of some simple known reward functions s, i.e.,
[TABLE]
As an example, can be either the fare a driver can collect from to or the distance a driver traveled from to . The former is considered to be positive while the latter is negative. For each simple reward function , the optimal value function can be derived by solving the MDP with as the reward function. Due to linearity, the optimal value function under the underlying reward function can be calculated as
[TABLE]
The optimal policy is also derived when solving the MDP. The objective of the mixed integer linear programming IRL is to minimize the difference between the optimal policy and the observed policy , i.e., minimize. After some mathematical manipulations, a mixed integer linear programming formulation is formed as
[TABLE]
where is a binary variable and takes value of 0 or 1 and is an arbitrarily large number. denotes the number of states where the observed policy and the optimal policy differ. The objective is thus to minimize the difference between and . Constraint (2.20) restricts the weighting parameter to be nonnegative. In the last constraint (2.20), the first term is the optimal value at state following the observed policy, and the second term is the value following other policies. Thus, we expect to hold. In reality, however, this constraint can be violated, and thus we add a large positive number to the violated constraint to keep (2.20) hold. is the probability of the transition following the policy . In this work, or has been demonstrated in Figure (2).
Remark*.*
To identify an overall reward function (i.e., determining s), we assume part of the observed policy is optimal or near optimal. Different from simply assuming a reward function based on common knowledge in the literature (Rong et al., 2016; Verma et al., 2017; Lin et al., 2018; Yu et al., 2019), we argue that the assumption used here is relaxed to some degree. Real drivers, at least part of them, are deemed to be intelligent and experienced and exhibit optimal or near optimal strategies. For a state visited by multiple drivers for multiple times, we believe the most frequently taken action carries useful information about the optimal strategy in this state and reflects the crowd wisdom. After uncovering the underlying reward function, the purpose of solving the MDP and thus deriving the optimal policy is to complete and correct the optimal policy. The incompleteness and noise in the observed policy stem from the following aspects: (1) For a real-world problem with a huge number of states (in our case study in Section 4 the number of decision-making states is ), a considerable portion of the states are not visited or at least not frequently visited; (2) Even in states with sufficient data (i.e., enough actions chosen by agents in this state), the most frequently chosen action which is taken as the observed policy in this state can still differ from the subsequent derived optimal policy, due to behavioral inconsistency; and (3) the observed policy, which is assumed to be deterministic, can be ambiguous when several actions share similar frequency in some states.
2.4 Numerical example
To illustrate the Markov Decision Process of e-hailing drivers, we use a 3 by 3 grid world numerical example, as shown in Figure (4a).
Suppose now we have the following five trajectories.
2. 2.
3. 3.
4. 4.
5. 5.
Each element in the trajectory is a tuple consisting of three items, namely, the grid index, current time, and a status indicator showing if the driver has been matched to another order during the trip. For example, basically states that the driver is at grid at time [math], and the driver has not been matched to any order before she finished the previous trip.
All five trajectories started in grid , and then the driver moved into grid during idling. After the driver searched the grid , there are two possible outcomes: either the driver finds an order match or the driver fails to find any e-hailing order. If the driver fails to get an order match after searching, the driver will move into other grids to find another order or the driver will stop working. To simplify the demonstration, we simply assume the trajectory ends in grid . For other four trajectories, the driver managed to find an e-hailing order in grid . Based on this piece information, we can calculate the probability of finding an e-hailing order in grid as .
After confirming an order match in grid , the driver drives into grid to pick up the passenger in trajectories and and stays within grid to pick up the passenger in trajectories and , respectively. Thus, the pick-up probability can be calculated as and .
When the driver picks up the passenger in grid , as illustrated in trajectories and , the passenger’s destination is grid in and grid in , respectively. Thus, the destination probability can be calculated as and .
In trajectories and , the driver drives to grid to pick up the passenger, and the passenger goes to grid . During the trip, the driver has a of receiving a new order before she arrives at the destination of the passenger. The order matching probability while on trip can thus be calculated as .
Based on the probabilities calculated above, an example of state transition is presented in Figure (4b). To make the state transition consistent with the five trajectories, we suppose the driver is initially in grid with a status indicator , i.e., the driver is in state . If , meaning that the driver needs to seek for an e-hailing order, the driver drives into grid and seeks for e-hailing orders in the grid. There are two possible outcomes associated with this case.
The driver fails to find any e-hailing order in grid . The driver will end up in state and receive a negative reward , which is actually the fuel cost. This outcome happens with probability 2. 2.
The driver successfully finds an e-hailing order in grid . For the purpose of demonstration, we assume the driver goes to grid to pick up the passenger, and the destination of the passenger is grid . The probability of this outcome is . The driver will receive a total reward of by completing this ride. During the trip, the driver may have a probability of getting a new request before she arrives at the destination of the previous passenger. Hence, there are two possible subbranches from this outcome.
- (a)
If the driver is matched to a new request before she drops off the previous passenger, then the driver will end up in state . The probability of the occurrence of this subbranch is . 2. (b)
if the driver fails to be matched to another request while on trip, the driver will then end up in . This subbranch occurs with a probability
For the sake of the completeness of the state transition, the other two subbranches associated with are also displayed in Figure (4b). These two subbranches are quite self-explanatory, and thus the detailed discussion will be omitted.
3 Sequential MDPs for multiple agents
Note that the deterministic policy derived is only applicable when there is one agent following the policy. Otherwise there can be local competition among e-hailing drivers since several drivers may be guided into the same grid. We thus need to address the competition among e-hailing drivers if there are multiple idling e-hailing drivers being present in the same region within a short time interval. Lin et al. (2018) proposed a contextual multi-agent reinforcement learning approach in which the multi-agent effect is captured by attenuating the reward through an averaging fashion. Zhou et al. (2018) employed a simple discounting factor to update the order matching probability when the taxi is being guided to a road if there are already taxis going to that road. The discounting factor proposed is effective in the sense that it makes the order matching probability smaller for subsequent taxis following the policy. However, the simple discounting factor may underestimate the order matching probability since the effect of the number of orders in each grid was neglected. In other words, except the effect of the number of drivers being guided into a grid, there is an underlying correlation between the decrease in the order matching probability and the number of orders in that grid. Here we use an example to illustrate the existence of the aforementioned correlation. We suppose an e-hailing driver is guided into grid with an order matching probability 50%. We consider two extreme scenarios: (1) there was 1 order emerging in grid and (2) there were infinite orders emerging in grid . After one driver is guided into grid , for a second driver, the order matching probability in grid is supposed to decrease substantially in the first scenario while almost keeps the same in the second scenario. The rationale underlying this argument is that compared to a grid with a smaller number of orders, a grid with a larger number of orders is capable of accepting more cruising drivers while still maintain a relatively acceptable level of order matching probability.
To incorporate this correlation, we develop a dynamic adjustment strategy. Before formally providing the form of the strategy, we list four intuitive observations: (1) The order matching probability for the first driver being guided into grid is simply ; (2) The order matching probability for the driver being guided into grid decreases with , meaning that the order matching probability is getting smaller when there are more drivers cruising vacantly in grid ; (3) For the driver, the order matching probability increases with the number of orders in grid , meaning that a grid with a larger number of orders is able to accept more cruising drivers; (4) Under the extreme scenario where there are infinitely many orders in grid , the order matching probability keeps its level at regardless of the number of drivers being guided into grid , as long as it is finite. Based on these four observations, we postulate that the order matching probability of the driver in grid takes the exponential form, i.e.,
[TABLE]
where is the number of orders in grid and is a parameter to be determined.
To calibrate the strategy for the driver, the order matching probability is required. Note that , then Equation (3.1) can be written as
[TABLE]
To utilize linear regression, we further take the logarithm and then the reciprocal of both sides of Equation (3.2), and thus Equation (3.2) can be rewritten as
[TABLE]
Denoting the left hand side of Equation (3.3) as , the purpose of the calibration is simply to verify the existence of the linear correlation between the two variables and and determine the parameter . is simply the number of historical orders in grid . The order matching probability for the driver entering grid can be calculated as follows. We use 18 10-minute intervals to split the 3-hour morning peak used in this study. For each interval, the number of orders within the interval is counted, and it is a success if the counted number is not less than . The probability of success across 18 intervals is . Calculating and for all grids, samples of and are obtained.
Ideally, the calibration can be run for any integer value of . However, due to the relatively small size of the grid and the finite number of idling drivers, cannot be taken as a very large number. To get an appropriate upper bound of in the calibration, we simply count the number of cases in which there are drivers idling in a grid within a time interval. The distribution of the number of cases versus the number of idling drivers in a grid is presented in Figure (5). For example, there are more than 25,000 cases in which there are only one idling driver in a grid within a 10-minute time interval. The trend is decreasing, indicating that the number of cases for more drivers idling in a grid within a time interval is less, which is as expected. To obtain statistically meaningful results in the calibration, we need as many samples as possible. Thus, here we choose to do the calibration for up to 4.
We obtain three lists of and three lists of for and , although the three lists for different are identical. Noticing that here we only have one parameter , we concatenate the three lists of simply into a long list and concatenate the three lists of as a long list . Then we run a linear regression through origin of the list over . Here we choose the linear regression through origin because the model is naturally linear without intercept, as shown in Equation (3.3), stemming from the requirement that the order matching probability for the first driver in a grid is . The regression result suggests the slope with p-value less than , indicating that the slope is significant. The R-square value is determined as 65%, indicating the fitted linear model is able to explain 65% of the variability and thus the adoption of a linear regression is reasonable. To visually show the goodness of the fitting, we substitute the determined value of into Equation (3.1) and plot the fitted curve together with the data for , and in Figure (6).
Based on the calibrated dynamic adjustment strategy, we can now build sequential MDPs for multiple agents and then derive one optimal policy for each agent sequentially. Recall that the dynamic adjustment strategy actually attenuates the order matching probability for the driver to be guided into grid when there are drivers idling in grid . Thus, the general MDP framework proposed in the previous section can directly be applied to the driver with a table of relatively lower order matching probabilities. In other words, there is one MDP model for each agent when multiple agents coexist, and the main distinction among these MDP models is the order matching probability (i.e., order matching probabilities of the driver are smaller than that of the driver). The optimal policy for each agent can then be obtained by solving her MDP model.
4 Case study
Nowadays, GPS-enabled devices are ubiquitously used in different types of applications. Especially for drivers, GPS devices can not only help them navigate but also record the real-time location and speed of the vehicle. Hence, a large amount of GPS trajectories, representing sequences of time-stamped geographical points, have been collected and can be a valuable asset for people to understand and tackle real-world traffic problems (Di et al., 2010, 2017; Shou and Di, 2018).
In this research we use large-scale real-world historical GPS traces collected in Beijing in the morning peak, i.e., (7 AM, 10 AM), of the first 3 weekdays in November 2017 by Didi Chuxing, China’s leading ride-hailing company. The dataset contains recorded GPS traces of 44,160 e-hailing vehicles and 158,784 e-hailing orders. Whenever an e-hailing driver is online, i.e., she has turned on the e-hailing application, one data point is sampled every 3 seconds. Each data point contains the vehicle’s location (i.e., longitude and latitude), current timestamp, the fare of the current occupied trip, if applicable, and a status indicator to record the taxi’s current operating state, which includes idle, after matching before pick-up, waiting at the pick-up location, and on trip.
Based on the characteristics of the spatial distribution of the passenger pick-up spots and passengers’ destinations, we construct a bounding box within the six ring road to cover the city area in which 90% of the e-hailing orders are preserved. The e-hailing orders which fall outside the bounding box will be disregarded. A hexagonal grid world setup is then adopted, and the city area within the bounding box is split into 6,421 hexagonal grids with the length of the diagonal of a hexagon of approximately 700 meters.
Now we use the IRL technique to uncover the general reward function for all drivers, i.e., to derive the parameter . The observed policy in each state is simply the most frequently taken action by all drivers in that state. Applying the aforementioned IRL technique with two known reward functions (i.e., fare and traveling distance ) and setting (i.e., assuming the driver will earn all the fare), we obtain . In other words, the coefficient of fuel consumption and other operating costs per unit distance is Chinese Yuan. The general reward function applicable to all drivers is .
Different from other public transportation modes, including buses and subways, which are operated according to a fixed schedule and a predefined route, e-hailing drivers are free to choose their own actions after completing a ride, resulting in a discrepancy in drivers’ income. In general, an experienced driver is familiar with the city where she operates the vehicle and is usually aware of where to go after completing a ride in order to get the next request as soon as possible. For example, an experienced driver knows where and when passenger demands will be high near some attractions, hotels, or transportation terminals. In practice, however, there is no guarantee that all drivers are experienced and have a good judgment of where to go next. In particular, the popularity of e-hailing applications has lowered the entry barrier of becoming a driver and brought a tons of rookie into the e-hailing market. To gain some basic understanding of the performance of e-hailing drivers, we adopt two metrics, namely, the rate of return and the utilization rate.
Definition 4.1**.**
(Rate of return) An e-hailing driver’s rate of return on one day is defined as the ratio of the driver’s net income (i.e., gross income minus the operating cost) to the driver’s working time.
Definition 4.2**.**
(Utilization rate) The utilization rate of an e-hailing vehicle is defined as the ratio of the time spent on carrying a passenger to the total operating time of the vehicle.
The rate of return measures a driver’s earning ability per unit time. Thus, compared with the total income, which can be largely influenced by a driver’s working time, the rate of return is a better metric to be used to measure the performance of drivers. Figure (7a) presents the probability density function (pdf) of the rate of return of all drivers across morning peaks on the first three weekdays in November 2017. The average rate of return is 0.36 (Yuan/minute). About 80% drivers have a rate of return fall within the range 0.11 to 0.60 (Yuan/minute). Top 10% drivers can reach a rate of return of 0.60 (Yuan/minute) and higher, while the bottom 10% have a rate of return below 0.11 (Yuan/minute). In terms of the utilization rate, real drivers can on average reach 0.51.
All drivers’ data was then used to train the MDP model. We will then qualitatively examine the optimal policy derived from our MDP model and conduct numerical experiments to evaluate the effectiveness of the policy.
4.1 Policy
Figure (8) presents the optimal policy at the beginning of the morning peak. Light blue color suggests the driver in the current grid to move into one of its neighboring grids to seek for the next potential e-hailing order. The color dark green in a grid stands for staying, meaning that the optimal policy is to stay and cruise within the current grid. The color yellow in a grid means waiting, indicating that the optimal policy for the driver to follow is simply to wait in the current grid. It can be seen that in many grids within the city area (i.e., around the center part of the figure), the optimal policy suggests a driver to stay after completing a ride. In suburban areas, optimal policy usually suggests drivers to move around to some grids with a high probability of receiving a request. Also, there are several places where the probability of receiving a request while waiting is quite high, and the optimal policy advices drivers to wait in these places.
Figure (9) plots the distribution of the order matching probability. It can be seen that the majority of the color dark blue, indicating a higher order matching probability, is distributed within the fourth ring road, meaning that the order matching probability is higher in the city area. Furthermore, the distribution of the order matching probability agrees well with the distribution of the optimal policy if we compare Figure (9) with Figure (8). The dark green places, indicating staying, in Figure (8) generally overlap with blue or dark blue locations in Figure (9), indicating a relatively high order matching probability. Also, when a driver is in a grid with a low order matching probability (e.g., in the nearly white area in Figure (9)), the driver needs to move around (as shown by the light blue in Figure (8)) to enter a grid with a higher order matching probability. This overlapping essentially indicates that grids with a higher order matching probability is more preferable by the agent, compared with a grid with a lower order matching probability.
4.2 Model Evaluation
To evaluate the effectiveness of the optimal policy derived from the MDP model, the performance of an agent under the guidance of the optimal policy is compared with that of an agent following one baseline heuristic, i.e., the local hotspot strategy. The local hotspot strategy essentially suggests the agent to move into grids with a higher demand sequentially and is found to perform the best among three baseline heuristics, namely, random walk, global hotspot, and local hotspot (Yu et al., 2019).
To obtain the performance of an agent according to different policies, a Monte Carlo simulation is conducted. The basic idea of the simulation is to randomly place an agent in one grid at the beginning, and let the agent move around according to the chosen policy. The environment is determined by the parameters extracted in Section (2.3). In particular, every time when the agent is in a grid , we sample a probability of finding a request from a binomial distribution with a success probability . We then sample the pick-up grid and drop-off grid from a multinomial distribution determined by the probabilities and , respectively. The driving time and driving distance can be simply obtained from and after the pickup spot and destination have been determined.
The simulation is run for millions of times to obtain robust results. We first adopt two metrics, namely, rate of return and the utilization rate of the vehicle to compare the performance of the agent under the guidance of different policies. We then examine the distribution of the number of completed orders, idling time, service time per order, and the profit per unit time of each order.
Figures (10) presents the distribution of the rate of return and the utilization rate of the agent following the optimal policy and the local hotspot strategy, respectively. It can be seen that the performance of the agent following the optimal policy is on average better than that of the agent following the local hotspot strategy. In terms of the rate of return, the average value that the agent can reach are 0.67 (Yuan/Minute) and 0.57 (Yuan/Minute) under the guidance of the optimal policy and the local hotspot strategy, respectively, meaning that the optimal policy is able to increase the average rate of return by 17.5% over the local hotspot strategy. The average rate of return of real drivers is 0.36 (Yuan/Minute). In terms of the utilization rate, the average value that the agent can reach are 0.72 and 0.67 by following the optimal policy and the local hotspot strategy, respectively, indicating a 7.5% improvement of the optimal policy over the local hotspot strategy. The average utilization rate of real drivers is around 0.51.
Figure (11) presents distributions of the number of completed orders, idling time, service time per order, and the profit per unit time of each order. The corresponding average value of each case is listed in Table (3). There are several observations worth mentioning: (1) On average the agent following the optimal policy can achieve a higher number of completed orders than the agent following the local hotspot strategy. (2) The agent following the optimal policy and the local hotspot strategy can achieve a significantly lower idling time, compared with that of real drivers. Thus, both the optimal policy and the local hotspot strategy are able to help agents find requests faster. (3) The distribution of the profit per unit time essentially says that under the optimal policy, the agent is able to find better orders. Here we say an e-hailing order is better when the profit per unit time of the order is higher. (4) The average service time of orders taken by the agent is shorter than that of real drivers.
The aforementioned observation (4), however, does not necessarily indicate that on average a shorter order is more preferable compared with a longer order. The reasons are as follows. As previously stated, for an agent, grids with relatively higher order matching probability is more preferable, compared with grids with a moderate or low order matching probability. Figure (12) presents the distribution of service time of orders starting in all grids and in grids with a relatively high order matching probability. The average service time of orders starting in all grids and in grids with a relatively high order matching probability are 17 minutes and 18.34 minutes, respectively. In other words, the passenger requests in grids with a relative higher order matching probability on average has a slightly greater service time. Hence, the average service time per order of the agent is supposed to be slightly higher than that of real drivers, which is not consistent with the observation (4).
To explain the inconsistency, we split the 3-hour time interval, i.e., the morning peak, into 6 subintervals of even length, namely, , , , , , and , and then extract the average service time of orders starting in each subinterval, which is shown in Figure (13). The average service time of orders starting in each subinterval decreases as time elapses. In the first subinterval, i.e., around the beginning of the morning peak, the agent actually takes orders with an average service time of 16.88 minutes, which is very close to 16.97 minutes, i.e., the average service time of all orders. This is as expected because the initial position of the agent is randomly chosen, meaning that the distribution of the service time of orders taken by the agent at the beginning of the time interval is supposed to be similar to that of all orders. As time elapses, the average service time of orders taken by the agent decreases because in the simulation we restrict the ending time of an order that an agent can take to be within the 3-hour time interval, and thus the agent to some degree prefers shorter orders, especially when the agent is in the last two subintervals, i.e., around the end of the 3-hour time interval. Low values of the service time of orders in the last two subintervals, i.e., 14.12 minutes and 9.01 minutes largely drag down the overall average service time of orders taken by the agent and caused the aforementioned inconsistency. Here we emphasize that in the simulation, the agent is set to complete the 3-hour time interval, and the restriction imposed by the 3-hour time interval implicitly forces the agent to take relatively shorter orders. All references listed in Table (1) except (Gao et al., 2018) used finite horizon time intervals (Rong et al., 2016; Verma et al., 2017; Lin et al., 2018) or finite pickup-dropoff cycles (Yu et al., 2019) in MDP modeling. Actually, in reality, an e-hailing driver is free to stop working at any time as long as she has achieved her preset goal, such as a nominal income, a personalized utility function, etc. Thus, an MDP with optimal stopping time modeling is a more realistic and efficient model and is left for future research.
4.3 Supply-demand ratio
Figure (14a) presents a zoom-in view of the optimal policy (shown in arrows and circles where arrows suggest the driver to move along the direction denoted by the arrow and the circle denotes staying or waiting) and the distribution of the demand (shown in heatmap) near Xibeiwang, an area outside the 5th ring road. We can see that our optimal policy suggests drivers to stay around the grid where the demand is high to take advantage of the locally high demand. Outside the 5th ring road, the overall demand is not very high and the number of idle drivers, indicating the supply, is also not large, resulting in a locally high order matching probability in high demand areas. Thus, a driver can simply take advantage of the high demand to make more profit.
Figure (14b) presents a zoom-in view of the optimal policy around Chaoyang district, which is located within the 3rd ring road. Different from the consistency between the policy and the distribution of the demand observed in Figure (14a), now it seems the derived optimal policy and the distribution of the demand is not very consistent. In other words, the optimal policy suggests drivers to move away from the areas with a high demand. The main reason is that the optimal policy is supposed to be consistent with the order matching probability, which captures the supply-demand ratio under the assumption that the number of unmatched order is negligible, instead of the real distribution of the demand. Although the order matching probability is calculated from the distribution of the demand and the number of pass-bys of idle drivers, there may exist some shift or even inconsistency between the order matching probability and the distribution of the demand. For instance, a cell with a very high demand, e.g. 100 order matches, may have a 1,000 pass-bys by idle drivers, resulting in a relatively low order matching probability in the cell, which is 0.1 in this example. Hence, it is not surprising that the derived optimal policy suggests the driver to move away from the cell with a high demand and a low order matching probability. A grid with a high demand may also have a high supply, resulting in a low order matching probability which is not preferable to the agent.
4.4 Different optimal policies for multiple agents
Now, we verify the effectiveness of the proposed dynamic adjustment strategy of the order matching probability by recommending the next several optimal actions to take for three agents who are currently in the same grid. We randomly selected two places, namely, one place around Dongxiaoying (outside the 5th ring road, thus in suburban area) and one place around Jinrongjie (inside the 2nd ring road, thus in city area).
Figure (15) presents the recommended optimal actions to take for three agents. In both cases, three agents are being recommended at the same time in the same grid. The results shows that our proposed dynamic adjustment strategy is able to provide different recommended actions for different agents. When three agents are in the same grid around Dongxiaoying, which is located outside the 5th ring road and has a relatively lower number of orders, the strategy guides the first two agents into the same grid but refers the third agent into a different grid because after guiding two agents into the same grid, the order matching probability in that grid drops quickly. The strategy also guides the first two agents into two different directions afterwards due to the competition. When three agents are in the same grid around Jinrongjie, which is located inside the 2nd ring road and has a relatively higher number of orders, the strategy guides all three agents into the same grid. Although the strategy refers the first agent into a different direction soon, the strategy guides the following two agents in almost the same direction.
As we have mentioned before, the historical number of orders in one grid is supposed to have an impact on the decrease of the order matching probability of the grid. For a grid with a higher average number of orders, like the grid located around Jinrongjie, the decrease in the order matching probability is supposed to be slower, thus it is able to accept more cruising agents while still maintains a relatively decent order matching probability. For a grid with a lower number of average number of orders, like the grid located in Dongxiaoying, the decrease in the order matching probability is supposed to be faster because with a small historical number of orders, it is not able to withstand too much competition among agents. In other words, for a grid with a small number of orders, the order matching probability is decreasing rapidly when some agents are being guided into the grid.
4.5 Heterogeneity in reward functions
Although the determined coefficient is applicable to the overall driver population at the aggregate level, it may vary from individual to individual. In other words, each driver may have a specific reward function which can be quite different from other drivers’, resulting in some discrepancies in driving patterns and strategies. To examine various driving patterns of taxis drivers, especially the change in the driving patterns from the time without e-hailing to the time when e-hailing is widely adopted, Ma et al. (2019) carried out in-depth analysis using trajectories of taxi drivers in Shanghai, China, and unveiled that on average, taxi driving patterns which were previously concentrated in some central areas are now more spread out. Inspired by this, we examine the spread of a driver’s trajectories using the radius of gyration . Radius of gyration is defined as the standard deviation of the spatial distances between a driver’s location and the centroid of the driver’s visited locations, i.e.,
[TABLE]
where is the distance between the driver’s location and the centroid of the driver’s visited places, and is the total number of the driver’s visited locations.
Figure (16) plots the distribution of the radius of gyration across the e-hailing driver population. The radius of gyration of the majority (95%) of e-hailing drivers is distributed within the range of . The e-hailing drivers on the left tail (2.5%) of the distribution has a radius of gyration below , and the drivers on the right tail has a radius of gyration above . The substantial discrepancy in the radius of gyration across the driver population indicates that drivers exhibit different driving patterns, which may stem from different intrinsic reward functions. For example, the trajectory of a driver on the left tail with a small radius of gyration is more concentrated in a small region, indicating that the driver may have some incentives (such as being close to home or being more familiar with the region) to stay within the region.
To shed some light on the distinction among driving patterns of e-hailing drivers, we simply take one driver on the left tail with a small radius of gyration () and one driver on the right tail with a large radius of gyration () and employ the IRL technique to disclose some underlying information regarding the driver’s intrinsic reward function. Here we emphasize that understanding drivers’ intrinsic reward function can be very helpful from the perspective of the platform to appropriately assign e-hailing orders. For instance, for a driver who prefers to stay within a small region, the platform is supposed to assign relatively shorter e-hailing orders to this driver. Otherwise, the driver will have a lower utility and may even be unwilling to take the assignment since the driver cares more about staying within the region over a simple higher monetary return. Thus, appropriately assigning orders can help increase the drivers’ response rate and therefore the utilization of vehicle resources, as well as the passenger satisfaction, which is beneficial for all players in the e-hailing market, including the platform, the drivers, and the passengers.
Without any knowledge of the driver’s demographic information, we devise the third simple reward function as the difference between the spatial distance between state and the centroid of the driver’s visited locations and the spatial distance between state and the centroid , i.e.,
[TABLE]
where denotes the spatial straight line distance between and . The rationale of this simple reward function can be explained as follows. For a driver with a small radius of gyration, the driver prefers to come back around the centroid after completing an order (otherwise the radius of gyration would be larger), indicating that coming back to the centroid may increase the driver’s utility/intrinsic reward. exactly does this. The driver gets a positive reward when and a negative reward when , meaning that it is beneficial for the driver to go back to the centroid. While for a driver with a large radius of gyration, the driver may not care about his/her distance to the centroid, and thus may not be important in the driver’s intrinsic reward function. We apply the IRL technique to the observed policy of these two drivers with three simple reward functions, namely, (fare), (traveling distance), and , and the derived coefficients are listed in Table (4). Again, we fix under the assumption that the driver gets all the fare.
The coefficient for is quite large () for the driver with a small radius of gyration and relatively small () for the driver with a large radius of gyration. This validates the effectiveness of the devised reward function in explaining the driver’s intrinsic reward function when the driver’s radius of gyration is small. When the driver’s radius of gyration is large, the reward function does not contribute enough to the driver’s underlying reward, meaning that the driver with a large radius of gyration does not gain more utility/reward by coming back to the centroid. We believe that there exist other types of simple reward functions which may be important in explaining a driver’s underlying reward function when the driver has a large radius of gyration and will be left in future work.
5 Conclusion
Based on a large-scale real-world historical GPS traces, this paper investigated how to improve the income and rate of return of e-hailing drivers through a modified MDP approach. We proposed an MDP model which incorporates the following distinct features of drivers with e-hailing: (1) An e-hailing driver may receive a matched order before she drops off the previous passenger, thus there is no passenger seeking; (2) Different from traditional taxi that a driver has to see a passenger to find a match, e-hailing platforms very likely find a match even when the driver and the passenger are spatially far from each other. In other words, a driver’s search process may end before a passenger is picked up.
We used 44,160 Didi drivers 3-day trajectories to train the model with a reward function uncovered by IRL. We then examined the optimal policy learned from our model and found that with e-hailing, the optimal policy suggests drivers to stay when they are in the city area, to move to some local areas with a high probability of receiving a request if they are in suburban areas, and to wait when they are at some places with a very high likelihood of receiving a request. To validate the effectiveness of the derived policy, a Monte Carlo simulation is conducted, and two metrics, namely the rate of return and utilization rate, are employed to compare the performance of the agent following the derived optimal policy with that of the agent following one baseline heuristic, namely, the local hotspot strategy. The comparison validates the effectiveness of the proposed model and shows that our model is able to achieve a 17.5% improvement and a 7.5% improvement over the local hotspot strategy in terms of the rate of return and the utilization rate, respectively. Also, the results show that under the guidance of the optimal policy, the agent is able to complete more order, decrease idling time, and find better orders. In addition, we disclose the reason why the agent not necessarily prefers a shorter order.
In the modified MDP model, the order matching probability captures the supply-demand ratio by its definition, considering the fact that the number of drivers in this study is sufficiently large and thus the number of unmatched orders is assumed to be negligible. Results show that the optimal policy does not necessarily guide an e-hailing driver to a grid with a high demand. Instead, the optimal policy suggests a driver to a grid with a low supply-demand ratio, i.e., a high order matching probability. To accurately capture the competition among drivers, we have devised and calibrated a dynamic adjustment strategy of the order matching probability when there are multiple drivers need recommendations. Also, the heterogeneity in reward functions across the driver population has been investigated. The devised simple reward function is validated to explain the driving patterns of drivers with a relatively small radius of gyration and paves the way for future research on the underlying reward function of e-hailing drivers.
There are some extensions can be done to overcome some limitations of the model:
Although a dynamic adjustment strategy for multiple agents has been devised and validated, the model does not fully incorporate the dynamic real-time multi-agent competition. In other words, since all parameters (i.e., probabilities) are predetermined, the model is not able to fully capture the competition among agents, resulting in potential overestimation issues. A multi-agent reinforcement learning approach can thus be adopted to consider the real-time competition and can yield a more realistic optimal policy for recommendation. 2. 2.
When the grid size is small, the number of states in the MDP can be large, resulting in a higher requirement in the computation power. A hierarchical MDP model which reduces a big problem into several subproblems can be an efficient tool. For example, we can first divide the whole space into big zones and then divide each zone into finer grids. 3. 3.
A more driver-specific/personalized reward function can be investigated and is expected to incorporate more factors such as safety, stress, etc. Coupled with some prior knowledge, a more powerful IRL approach, such as the maximum entropy IRL (Ziebart et al., 2008), could be an promising way to uncover more information of the underlying reward function that results in the demonstrated behavior.
Acknowledgments
This research was funded by Didichuxing under the contract No. University of Michigan/DiDi 17-PAF07456. The authors would like to thank Mr. Partrick Guan, Mr. Hanyuan Shi, and Mr. Zhaobin Mo to prepare Didi data and run codes on Didi servers for us.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alemi et al. (2019) Alemi, F., Circella, G., Mokhtarian, P., Handy, S., May 2019. What drives the use of ridehailing in California? Ordered probit models of the usage frequency of Uber and Lyft. Transportation Research Part C: Emerging Technologies 102, 233–248.
- 2Battifarano and Qian (2019) Battifarano, M., Qian, Z. S., Oct. 2019. Predicting real-time surge pricing of ride-sourcing companies. Transportation Research Part C: Emerging Technologies 107, 444–462.
- 3Bertsekas (2000) Bertsekas, D. P., 2000. Dynamic Programming and Optimal Control, 2nd Edition. Athena Scientific.
- 4Di and Ban (2019) Di, X., Ban, X. J., Nov. 2019. A unified equilibrium framework of new shared mobility systems. Transportation Research Part B: Methodological 129, 50–78.
- 5Di et al. (2010) Di, X., Liu, H. X., Davis, G. A., 2010. Hybrid extended kalman filtering approach for traffic density estimation along signalized arterials: Use of global positioning system data. Transportation Research Record 2188 (1), 165–173.
- 6Di et al. (2017) Di, X., Liu, H. X., Zhu, S., Levinson, D. M., 2017. Indifference bands for boundedly rational route switching. Transportation 44, 1169–1194.
- 7Gao et al. (2018) Gao, Y., Jiang, D., Xu, Y., Aug. 2018. Optimize taxi driving strategies based on reinforcement learning. International Journal of Geographical Information Science 32 (8), 1677–1696.
- 8Ge et al. (2010) Ge, Y., Xiong, H., Tuzhilin, A., Xiao, K., Gruteser, M., Pazzani, M., 2010. An Energy-efficient Mobile Recommender System. In: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD ’10. ACM, New York, NY, USA, pp. 899–908.