Thwarting finite difference adversarial attacks with output randomization
Haidar Khan, Daniel Park, Azer Khan, B\"ulent Yener

TL;DR
This paper proposes a randomized output defense mechanism against black box adversarial attacks on neural networks, effectively reducing attack success while analyzing the accuracy-robustness tradeoff.
Contribution
It introduces a novel output randomization technique that bounds error probabilities and demonstrates effectiveness against adaptive black box attacks.
Findings
Randomization confuses black box attackers effectively.
The method bounds the probability of errors in gradient estimation.
Empirical results show successful thwarting of adaptive attacks.
Abstract
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model and to the opposite "black box" setting. Black box attacks are particularly threatening as the adversary only needs access to the input and output of the model. Defending against black box adversarial example generation attacks is paramount as currently proposed defenses are not effective. Since these types of attacks rely on repeated queries to the model to estimate gradients over input dimensions, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. Randomization applied to the output of the deep neural network model has the potential to confuse potential attackers, however this introduces a tradeoff between accuracy and robustness. We show that for certain types…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1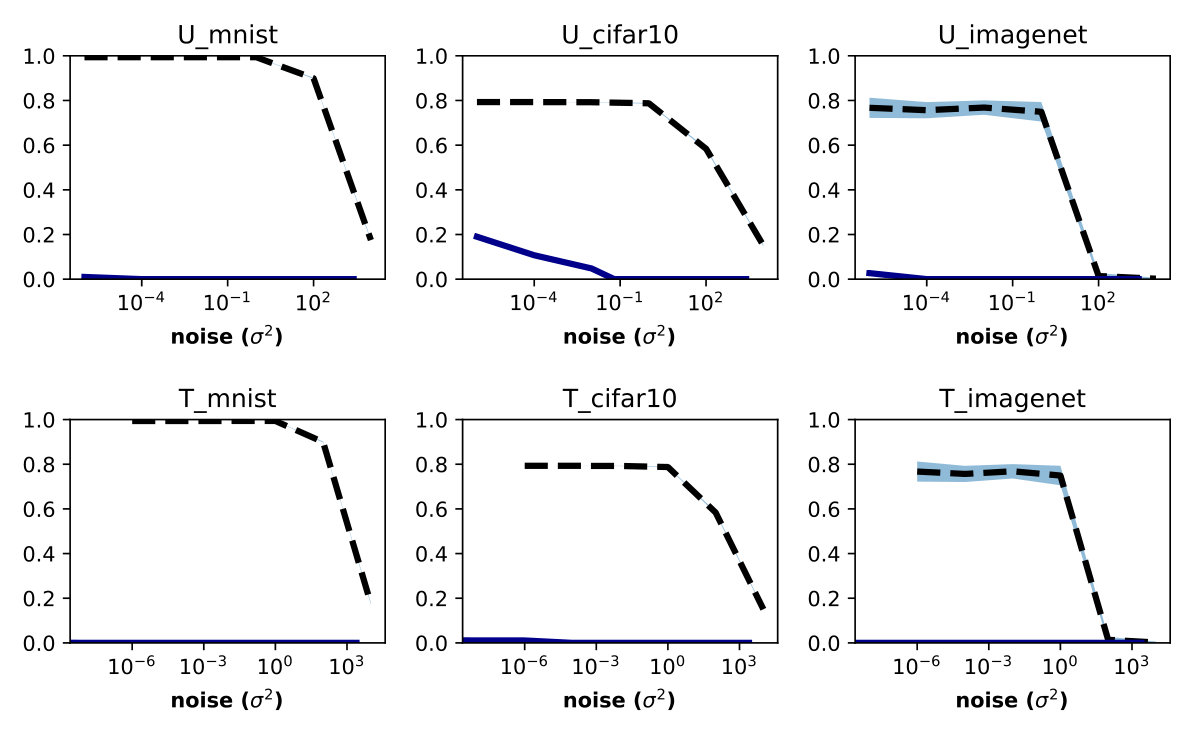 Figure 2
Figure 2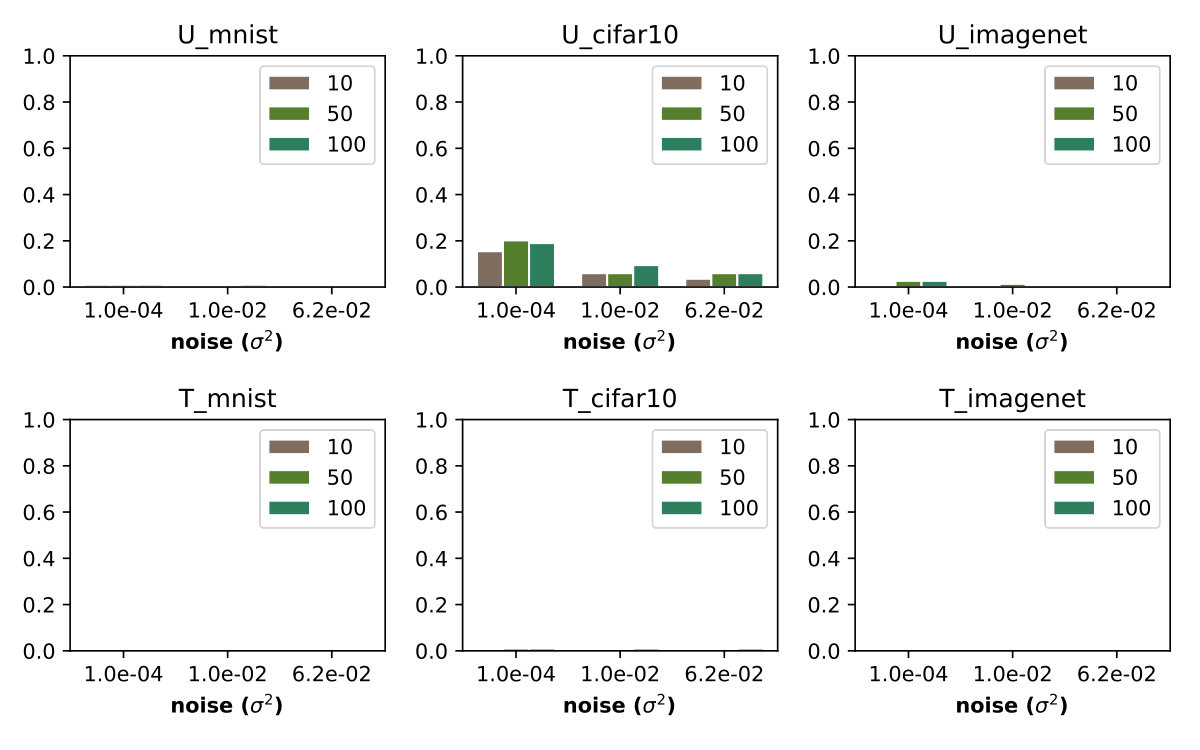 Figure 3
Figure 3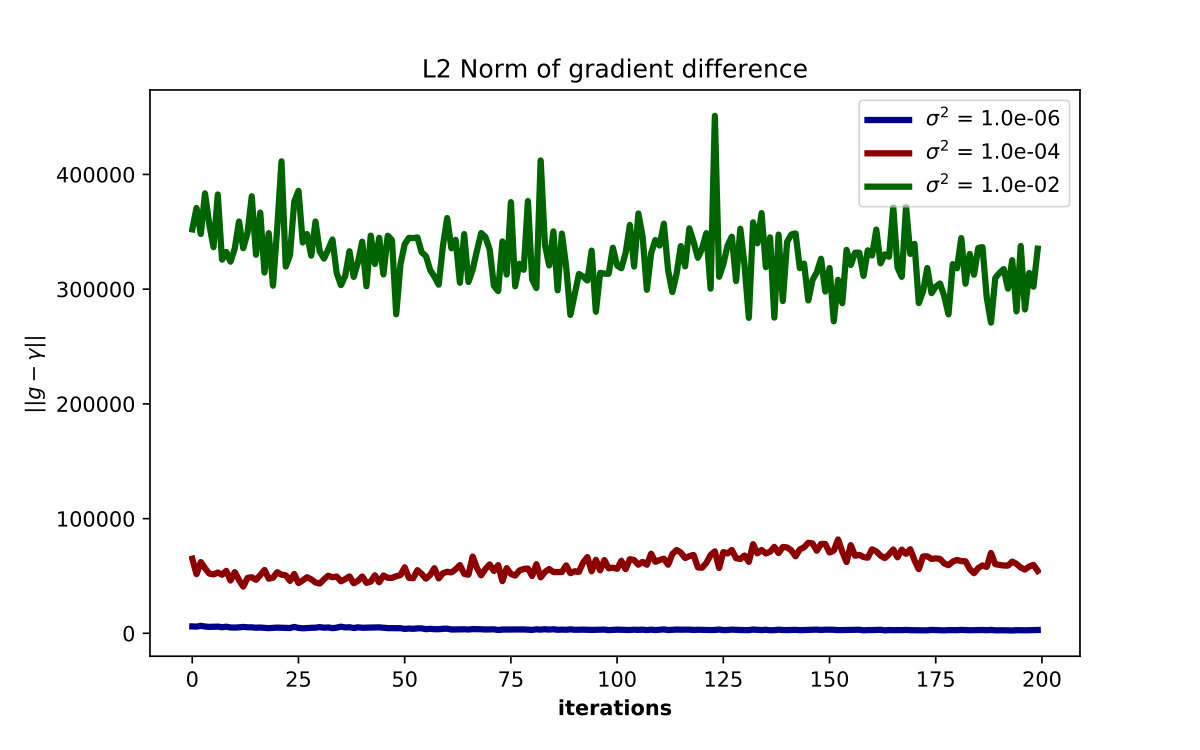 Figure 4
Figure 4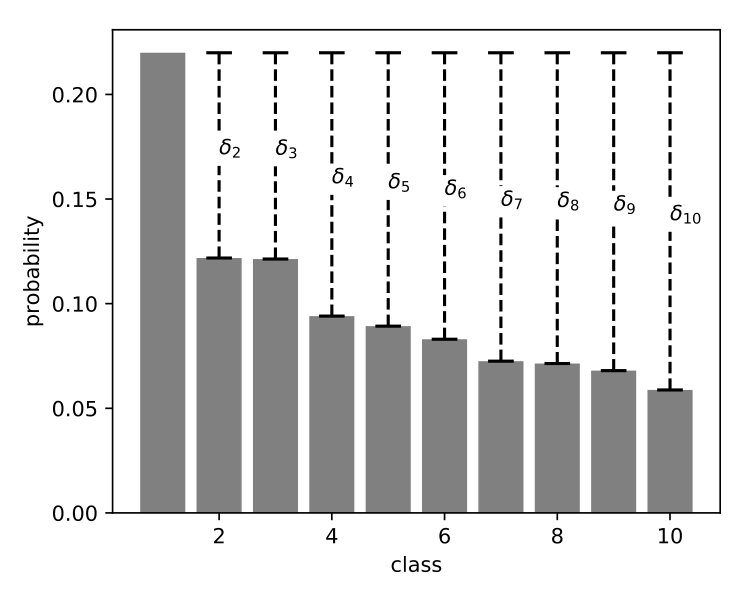 Figure 5
Figure 5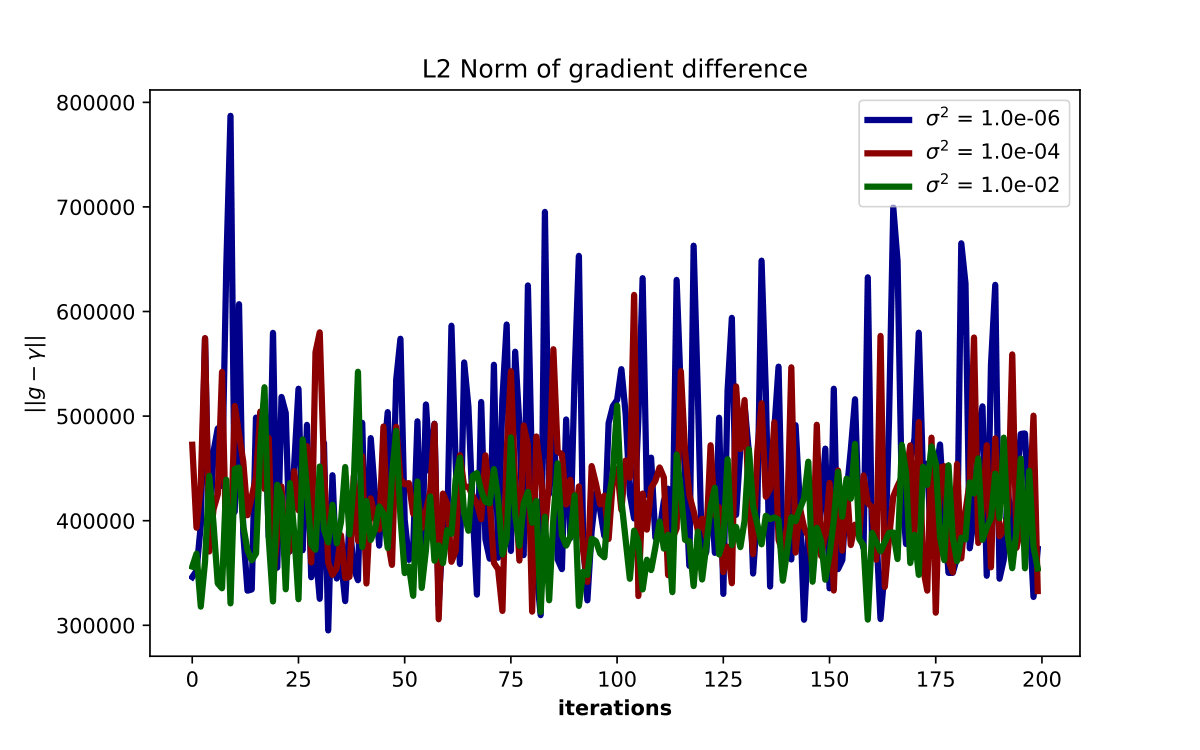 Figure 6
Figure 6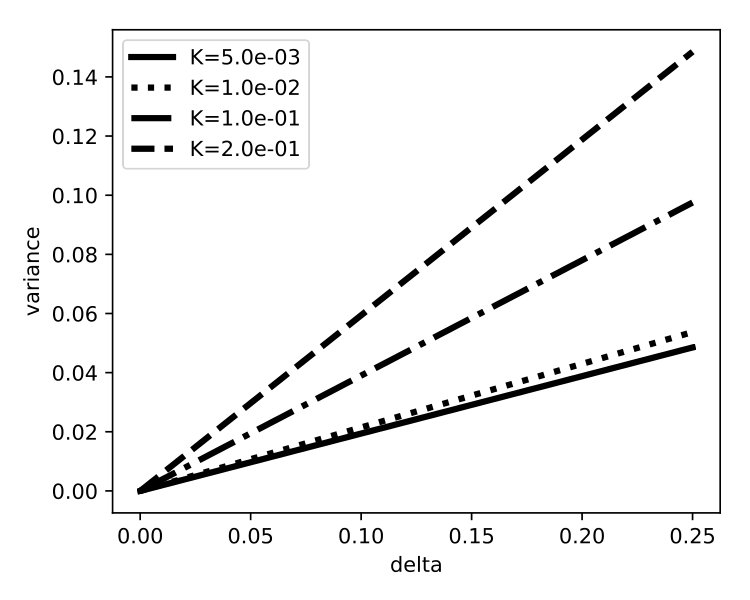 Figure 7
Figure 7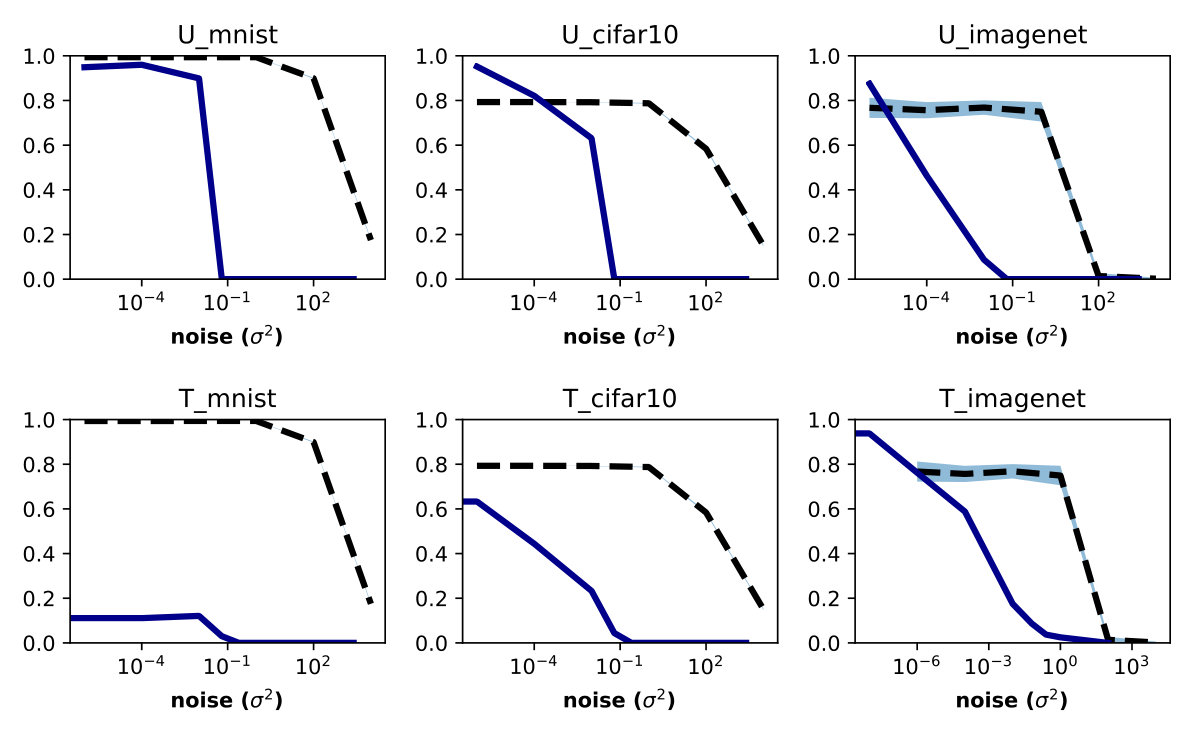 Figure 8
Figure 8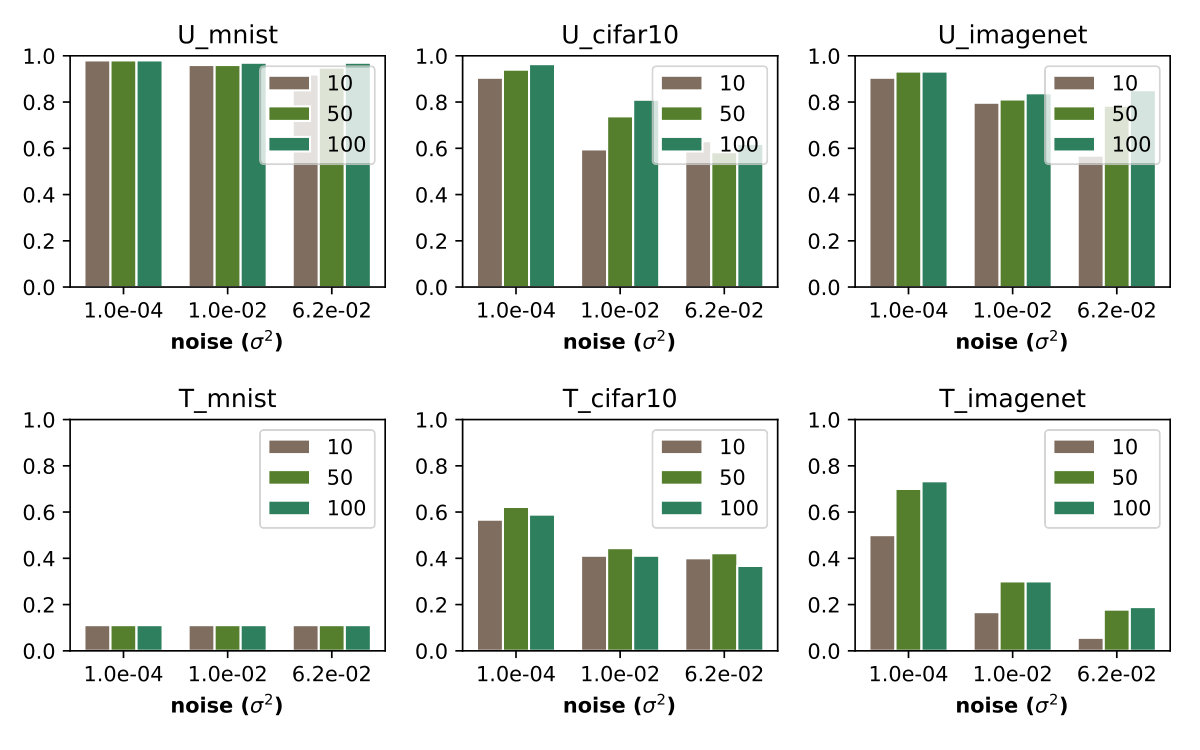 Figure 9
Figure 9| Dataset | Ex. Type | Attack Success Rate |
|---|---|---|
| MNIST | Targeted | 1.00 |
| MNIST | Untargeted | 0.99 |
| CIFAR10 | Targeted | 1.00 |
| CIFAR10 | Untargeted | 1.00 |
| Noise Variance | Attack Success Rate |
|---|---|
| 0.00e-0 | 1.00 |
| 1.00e-4 | 0.73 |
| 1.00e-2 | 0.02 |
| 5.76e-2 | 0.01 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdversarial Robustness in Machine Learning · Domain Adaptation and Few-Shot Learning · Machine Learning and Algorithms
Thwarting finite difference adversarial attacks with output randomization
Haidar Khan
Department of Computer Science
Rensselaer Polytechnic Institute
Troy, NY 12180
[email protected] &Daniel Park
Department of Computer Science
Rensselaer Polytechnic Institute
Troy, NY 12180
[email protected] &Azer Khan
Department of Computer Science
SUNY New Paltz
New Paltz, NY 12561
[email protected] &Bülent Yener
Department of Computer Science
Rensselaer Polytechnic Institute
Troy, NY 12180
Abstract
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model and to the opposite "black box" setting. Black box attacks are particularly threatening as the adversary only needs access to the input and output of the model. Defending against black box adversarial example generation attacks is paramount as currently proposed defenses are not effective. Since these types of attacks rely on repeated queries to the model to estimate gradients over input dimensions, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. Randomization applied to the output of the deep neural network model has the potential to confuse potential attackers, however this introduces a tradeoff between accuracy and robustness. We show that for certain types of randomization, we can bound the probability of introducing errors by carefully setting distributional parameters. For the particular case of finite difference black box attacks, we quantify the error introduced by the defense in the finite difference estimate of the gradient. Lastly, we show empirically that the defense can thwart two adaptive black box adversarial attack algorithms.
1 Introduction
The success of deep neural networks has led to scrutiny of the security vulnerabilities in deep neural network based models. One particular area of concern is weakness to adversarial input: carefully crafted inputs that resist detection and can cause arbitrary errors in the model Szegedy et al. [2013], Goodfellow et al. [2014]. This is especially highlighted in the domain of image classification, where an adversary creates an image that resembles a natural image to a human observer but easily fools deep neural network based image classifiers Kurakin et al. [2016].
Different types of adversarial attacks exists throughout the lifecycle of a deep neural network model. For example, adversaries can attack a model during training by injecting corrupting data into the training set or by modifying data in the training set. However, inference time attacks are more worrisome as they represent the bulk of realistic attack surfaces Grosse et al. [2016], Narodytska and Kasiviswanathan [2016], Carlini and Wagner [2018].
The input created under an inference time attack is known as an adversarial example and methods for generating such examples have recently attracted much attention. In most cases, the adversarial example is created by perturbing a (correctly classified) input such that the model commits an error. The perturbation applied to the "clean" input is typically constrained to be undetectably small Papernot et al. [2016b], Moosavi-Dezfooli et al. [2017], Carlini et al. [2017]. For images, by far the easiest domain to describe adversarial examples, an adversarial example is one that looks like an image from one class while being classified as some other class as is shown in Figure 1.
Although starting with a clean input and perturbing it to cause misclassification is a standard procedure for creating adversarial examples, other methods have also been considered. For example, starting with an example from a target class modify the example such that it appears similar to examples from another class but is still classified as belonging to the target class by the model. However this approach is not prevalent and was demonstrated only in a limited setting Ilyas et al. [2018].
Defending againsts adversarial attacks on deep neural networks is crucial and has seen relatively slow progress compared to the sophistication and progress of adversarial attacks Papernot et al. [2016c], Tramèr et al. [2017], Madry et al. [2017], Croce et al. [2018], Schott et al. [2018], Rosenberg et al. [2019]. This is because it is difficult to prove a defense can withstand the types of attacks it is designed for especially when the defense must prove capable of withstanding "adaptive" adversaries that have knowledge of the details of the defense Carlini et al. [2019].
A defense against adversarial attacks is defined by the threat model it is designed to defend against Carlini et al. [2019]. The most permissive threat model makes the weakest assumptions about the adversary. One such threat model can be assuming the adversary has complete knowledge of the model, including architecture and parameters of the underlying network. This is known as the "white-box" setting. Other threat models can also be useful, such as assuming the adversary has knowledge of the network architecture but not the parameters of the model. More restrictive threat models allow only so called “black-box” attacks, attacks that can create adversarial examples without having access to the model architecture or weights and only accessing some form of output of the model.
The rest of the paper is organized as follows. In Section 2, we discuss the threat model considered. In Section 3, we describe valid black box attacks under the threat model. Output randomization as a defense is described in Section 4. We show empirical results in Section 5, cover related approaches in Section 6, and conclude in Section 7.
2 Threat model
Adversary goals The goal of the adversary is to force the classifier to commit one of these two types of errors within a distortion limit, such that the example crafted by the adversary must be similar to the original example. The error is either targeted, where the classifier is forced to classify the given example as a certain class, or untargeted, where the classifier simply misclassifies the given adversarial example.
Adversary knowledge The adversary has access to the model only at the input and output level, not the architecture or parameters. The adversary is aware of the details of the defenses protecting the model and the type of randomness associated with any defense but not the exact random numbers generated.
Adversary capability The adversary only has access to the model by providing examples as input and observing the output probability vector generated by the model as output. The adversary can modify aspects of the input in any way as long as the input remains similar to a natural image.
3 Existing black box attacks
Black box attacks are called “gradient-free” attacks since they do not involve computing gradients of the input by backpropagation on the model under attack. Instead the gradients of the input are typically estimated by using the finite difference estimate for each input feature.
Black box attacks can be categorized by the type of output the adversary is allowed to observe:
- •
Logit layer
- •
Class probabilities/Softmax layer
- •
Top class probabilities/labels
In general, designing successful black box attacks in the label only setting is much harder than the setting where the logit layer or softmax layer is available to the attacker. We consider the easiest setting for black box attacks, where all the class probabilities are available.
3.1 ZOO black box attack
The Zeroth Order Optimization based black-box (ZOO) attack Chen et al. [2017] is a method for creating adversarial examples for deep neural networks that only requires input and output access to the model. ZOO adopts a similar iterative optimization based approach to adversarial example generation as other successful attacks, such as the Carlini & Wagner (C&W) attack Carlini and Wagner [2017]. The attack begins with a correctly classified input image , defines an adversarial loss function that scores perturbations applied to the input, and optimizes the adversarial loss function using gradient descent to find that creates a succesful adversarial example. Specifically, gradient descent is used to find such that:
[TABLE]
[TABLE]
Namely, that the perturbed input successfully fools the classifier to predict the incorrect class and that the perturbed input is similar to the original input up to some distortion limit .
The primary (and strongest) adversarial loss used by the ZOO attack for targeted attacks is given by:
[TABLE]
Where is an input image, is a target class, and is a tuning parameter. Minimizing this loss function over the input causes the classifier to predict class for the optimized input. For untargeted attacks, a similar loss function is used:
[TABLE]
where is the original label for the input . This loss function simply pushes to enter a region of misclassification for the classifier .
In order to limit distortion of the original input, the adversarial loss function is combined with a distortion penalty in the full optimization problem. This is given by:
[TABLE]
[TABLE]
In the white box setting, attackers can take advantage of the backprogation algorithm to calculate the gradient of the adversarial loss function with respect to the input coordinates () and solve the optimization problem using gradient descent. In lieu of this, ZOO uses "zeroth order stochastic coordinate descent" to optimize input on the adversarial loss directly. This is most easily understood as a finite difference estimate of the gradient of the input with the symmetric difference quotient Chen et al. [2017]:
[TABLE]
with as the basis vector for coordinate/dimension and set to a small constant. The ZOO attack uses this approximation to the gradients to create an adversarial example from the given input. Note that for an image with pixels, computing an estimate of the gradient with respect to each pixel requires queries to the model. Since this is usually prohibitive, the ZOO attack circumvents this by only estimating the gradients for a subset of coordinates at each step. ZOO also uses dimensionality reduction and a hierarchical approach to further increase the efficiency of the attack and show empirically that these methods are effective Chen et al. [2017].
3.2 Query Limited (QL) black box attack
A similar approach to ZOO is adopted by Ilyas et al. [2018] in a query limited setting. Like ZOO, the QL attack estimates the gradients of the adversarial loss using a finite difference based approach. However, the QL attack reduces the number of queries required to estimate the gradients by employing a search distribution. Natural Evolutionary Strategies (NES) Wierstra et al. [2014] is used as a black box to estimate gradients from a limited number of model evaluations. Projected Gradient Descent (PGD) Madry et al. [2017] is used to update the adversarial example using the estimated gradients. PGD uses the sign of the estimated gradients to perform an update: , with a step size and the estimated gradient . The estimated gradient for the QL attack using NES is given by:
[TABLE]
where is sampled from a standard normal distribution with the same dimension as the input , is the search variance, and is the number of samples used to estimate the gradient. The difference between this approach and ZOO is that ZOO attempts to estimate the gradient with respect to one coordinate at a time while this approach averages over perturbations to many coordinates to estimate the entire gradient directly.
In the next section, we show that applying a simple randomization function (that does not affect model accuracy) to the output of a model causes both of these attacks to fail even if the attack is adapted to the specific randomization function.
4 Thwarting black box attacks
The intuition behind output randomization is that a model may deliberately make errors in its predictions in order to thwart a potential attacker. This simple idea introduces a tradeoff between accurate predictions and the effectiveness of finite difference based black box adversarial attacks.
Output randomization for a model that produces a probability distribution over class labels replaces the output of the model by a stochastic function . The function must satisfy two conditions:
The probability of misclassifying an input due to applying is bounded by 2. 2.
The vector prevents adversaries under the given threat model from generating adversarial examples.
The first condition ensures that the applied defense minimally impacts non-adversarial users of the model, such as users of an online image classification service. The effectiveness of the defense comes from satisfying the second condition as the introduced randomness must prevent an adversary (in the appropiate setting) from producing an adversarial example.
In the following two sections, we consider a simple noise-inducing function where is a random variable.
4.1 Missclassification rate
A simple function useful for defending a model is the gaussian noise function where is a gaussian random variable with mean and variance (). In the black box setting, a user querying the model with an input receives the perturbed vector instead of the true probability vector . Note that does not necessarily represent a probability mass function like .
To verify that this function satisfies the first condition above, we wish to know the probability that the class predicted by the undefended model is the same as the class predicted by the defended model. If the output of the model for an input is , we will refer to the maximum element of as :
[TABLE]
and the rest of the elements of in decreasing order as . Suppose the model correctly classifies the input in the vector , we can express the probability that is misclassified in the vector as:
[TABLE]
We can write for as:
[TABLE]
If we define , as shown in Figure 2(a), and since is itself a gaussian with mean and variance then we can write:
[TABLE]
Using the cumulative distribution function of a standard gaussian distribution , we can write the misclassification probability as:
[TABLE]
For the special case of a gaussian noise function with mean 0 and variance we would like to fix the probability of misclassification to a value and compute the appropiate variance . We can use the inverse of the standard gaussian cdf , or the probit function, to write this easily:
[TABLE]
Note that the desired misclassification rate in any real case and so the rhs will be positive. If we consider as the confidence of the model, then the allowable variance will be larger when the model is confident and smaller otherwise. In Figure 2(b) we show the maximum allowable variance for different misclassification rates.
4.2 Finite difference gradient error
To verify the function satisfies the second condition, that it introduces error that prevents a finite difference based black box attack, we show the effect of the output randomization on the gradient accessible to the adversary.
Finite difference (FD) based approaches involve evaluating the adversarial loss at two points, and , close to (with small and unit vector ) and using the slope to estimate the gradient of the loss with respect to pixel of the input. For a loss function , the finite difference estimate of the gradient of pixel is given by:
[TABLE]
Here, we write the adversarial loss function (either the untargeted loss in Equation 2 or the targeted loss in Equation 1) in terms of the output of the model to make explicit the dependence of on the output vector of the network . and are used to distinguish between the two output vectors needed to compute the gradient estimate.When the network is defended using output randomization, the function is applied to the output vector of the network. Thus, the finite difference gradient computed by the attacker is:
[TABLE]
The error in the FD gradient introduced by the defense is given by . When is a function that adds noise to the output of the network, the expected value of the error is:
[TABLE]
This error term depends on the choice of the adversarial loss function . Since the untargeted attack is generally considered easier than the targeted attack, consider how the gradient error of the defended model behaves under the untargeted adversarial loss function. For untargeted attacks, we simplify the loss function to: where is the probability of the true class and is the maximum probability assigned to a class other than the true class of the input image.
Substituting the untargeted adversarial loss for we see:
[TABLE]
We use a second order Taylor series approximation of to approximate the expectations. If we further assume is zero-mean with variance , then and the expectation of the defended gradient is approximately:
[TABLE]
This approximation summarizes the suprising effect output randomization has on finite difference based black box attacks. Firstly, it is easy to see that the error scales with the variance of (in the zero mean case). Even when the adversary adapts to the defense by averaging over the output randomization the variance is only reduced linearly by the number of samples. Secondly, even in expectation the error is never non-zero. This is because one of two cases must be true in order for the error to be zero:
and 2. 2.
and
Case 1 cannot occur because it implies the model is predicting two different classes simultaneously. Case 2 will only occur if which means .
The reason for this behavior is mostly due to the operation in the adversarial loss function . As noted by the authors in Chen et al. [2017], the is crucial to the success of finite difference black box attacks as well trained models yield skewed distributions in the output . In our experiments, we show that this behavior holds in real world experiments on image classification datasets.
5 Empirical results
To evaluate the output randomization defense against black box attacks, we select two successful black box attacks (ZOO and QL) on benchmark image classification datasets (MNIST LeCun et al. [2010], CIFAR10 Krizhevsky et al. [2014], and ImageNet Deng et al. [2009]). Details of both the attacks and defenses can be found in our code 111Our attack code is based on https://github.com/IBM/ZOO-Attack and https://github.com/labsix/limited-blackbox-attacks for the ZOO and QL attacks respectively. and the appendix. We follow the excellent guidelines laid out in Carlini et al. [2019], most importantly we attempt to adapt the attacks to the proposed defense. In this case, this means the attacker is aware of the type of randomization applied to the output of the network. Therefore, we adapt the ZOO and QL attacks by allowing the attacker to average over the output randomization in an attempt to minimize the effect of the randomization. This type of adaptation has been shown to overcome certain types of input and model randomization defenses Athalye et al. [2018]. In our results, we refer to this as the adaptive attack.
As a sanity check, we also measure the attack success rate of a white box attacker (Carlini & Wagner L2 Carlini and Wagner [2017] attack) with randomized output. We find that the defense has some success in defending against this attack in the non-adaptive case. However the adaptive white box attacker is able to overcome the output randomization by averaging over a small number of samples. This is summarized in Figure 3.
Our main set of experiments is shown in Figure 4 and show the effects of output randomization on the non-adaptive and adaptive ZOO attacks. We show that the defense reduces the attack success rate significantly even in the adaptive attacker setting, where we average over randomness and double attack iterations. The effectiveness of the defense was not affected by targeted or untargeted attacks.
It is important to show how a defense affects the "normal" operating properties of a model and this is typically demonstrated by comparing the test set accuracy of the defended model to the undefended model. Figure 3(a) and Figure 4(a) show the effect of increasing noise levels on test set accuracy. Output randomization is an effective defense against black box attacks at noise levels as small as where model performance is identical to undefended models.
Defensive techniques without output randomization are still vulnerable to black box attacks. We evaluated defensive distillation Papernot et al. [2016c] against the ZOO attack on MNIST and CIFAR10 and found that distilled models did not reduce the attack success rate significantly, confirming the result in Carlini and Wagner [2017].
6 Related work
In this section, we discuss related gradient masking or obfuscated gradient defenses. We will focus on proactive defenses, which attempt to make a network robust, compared to reactive defenses, which attempt to detect adversarial examples. Athalye et al. [2018] defined three ways to obfuscate gradients: shattered gradients, exploding/vanishing gradients, and stochastic gradients.
Shattered gradients are a non-differentiable defense that causes a gradient to be nonexistent or incorrect. This can be done unintentionlly by introducing numeric instability. Buckman et al. [2018] and Guo et al. [2017] proposed shattered gradients defenses that introduce a non-differentiable and non-linear discretization to a model’s input. These transformation are ineffective as black box attacks are agnostic of input randomization.
Exploding gradients make a network hard to train because of an extremely deep neural network. This is generally done by using an output of a neural network as the input of another. Song et al. [2017] and Samangouei et al. [2018] both proposed defenses that utilize GANs. However, Athalye et al. [2018] shows that these defenses can be bypassed using transferability of adversarial attacks. The transferability property allows an attacker to use adversarial examples created using one model (often a surrogate model) to fool another model Papernot et al. [2016a]. Although this is a valid attack vector for even black box models, we do not consider this type of attack in this work.
Stochastic gradients randomize gradients by introducing some randomization to the network or randomly transforming the input to the network. Dhillon et al. [2018] proposed a stochastic gradients defense in which a random subset of activations are pruned. Xie et al. [2017] introduced randomness by randomly rescaling input images. Athalye et al. [2018] showed that an adaptive attacker can bypass these defenses by computing the expected value over multiple queries. We test a similar approach on output randomization and show it is not effective in the black box case (Figure 4(b)).
Although other defense methods consider introducing randomness to the input or model itself, this work is the first to our knowledge to consider randomizing the output of the model directly.
7 Conclusion
Black box attacks based on finite difference gradient estimates pose a threat to classification models without needing priveleged access to the model. In this paper, we show that this threat can averted by introducing simple types of randomization to the output of the model. Our empirical results show that even very small () perturbations to the output that do not affect model accuracy can prevent these type of attacks.
Although our work shows an encouraging result for defending against black box attacks, we show that output randomization (or other types of randomization) do not prevent white box attacks Athalye et al. [2018]. Furthermore, output randomization only prevents query based black box attacks and does not address the problem of transfer attacks Liu et al. [2016], Papernot et al. [2016a]. Transfer attacks cannot be circumvented by simply making attacks fail. Defending against them will require changing the way models are trained and designed.
Appendix
7.1 Attack details
For our evaluation, we trained models for MNIST, CIFAR10, and ImageNet that acheived 99%, 79%, and 72% test set accuracies respectively using the code provided by Chen et al. [2017]. Non-adaptive attacks were conducted using the parameters suggested by the attacks. For ZOO, these include using the ADAM Kingma and Ba [2014] solver, 9 binary search steps, and image resizing + reset ADAM for ImageNet. The adaptive attackers (both white and black) were modeled in two ways. (i) We added averaging over randomness to the attack and (ii) the number of iterations was doubled. For all of our experiments, we averaged the attack success rate over 100 images and report the mean value over 30 runs.
7.2 Extensions
Other randomization functions can be used to introduce randomness in the output instead of gaussian noise. As an extension, we considered noise sampled from a gaussian mixture model with random mixing coefficients and parameters. In theory, this type of randomization should be harder for attackers to average over and avoid. However, we saw that a white box attacker could still average over the added noise with 100 samples and circumvent the defense. Since the simple gaussian noise was effective in the blackbox case, we demonstrate our results using gaussian noise.
We also experimented with randomization of the logit layer and observed improvements over softmax layer randomization. However, we chose to present the more general softmax layer randomization for clarity.
Figure 5 shows the error between the finite difference gradients for the ZOO attack on a defended and undefended model at varying noise levels. As we expect, increased noise levels cause the overall error (measured by the norm of difference of the gradients) to increase dramatically.
Table 1 shows the results of the ZOO black box attack against defensively distilled Papernot et al. [2016c] models for MNIST and CIFAR10. Defensive distillation did not prevent the attacks in almost any case.
Table 2 shows the results of the QL black box attack against output randomization. Output randomization effectively reduces the attack success rate to 1% at small noise levels.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Athalye et al. [2018] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. 2018. URL http://arxiv.org/abs/1802.00420 .
- 2Buckman et al. [2018] Jacob Buckman, Aurko Roy, Colin Raffel, and Ian Goodfellow. Thermometer Encoding: One Hot Way To Resist Adversarial Examples. ICLR , 19(1):92–97, 2018.
- 3Carlini and Wagner [2017] Nicholas Carlini and David Wagner. Towards Evaluating the Robustness of Neural Networks. Proceedings - IEEE Symposium on Security and Privacy , pages 39–57, 2017. ISSN 10816011. doi: 10.1109/SP.2017.49 .
- 4Carlini and Wagner [2018] Nicholas Carlini and David Wagner. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings - 2018 IEEE Symposium on Security and Privacy Workshops, SPW 2018 , pages 1–7. Institute of Electrical and Electronics Engineers Inc., aug 2018. ISBN 9780769563497. doi: 10.1109/SPW.2018.00009 .
- 5Carlini et al. [2017] Nicholas Carlini, Guy Katz, Clark Barrett, and David L. Dill. Provably Minimally-Distorted Adversarial Examples. sep 2017. URL http://arxiv.org/abs/1709.10207 .
- 6Carlini et al. [2019] Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, Aleksander Madry, and Alexey Kurakin. On Evaluating Adversarial Robustness. feb 2019. URL http://arxiv.org/abs/1902.06705 .
- 7Chen et al. [2017] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. ZOO: Zeroth Order Optimization based Black-box Attacks to Deep Neural Networks without Training Substitute Models. 2017. doi: 10.1145/3128572.3140448 . URL http://arxiv.org/abs/1708.03999{%}0Ahttp://dx.doi.org/10.1145/3128572.3140448 . · doi ↗
- 8Croce et al. [2018] Francesco Croce, Maksym Andriushchenko, and Matthias Hein. Provable Robustness of Re LU networks via Maximization of Linear Regions. oct 2018. URL http://arxiv.org/abs/1810.07481 .