Comparison of Observed Galaxy Properties with Semianalytic Model Predictions using Machine Learning
Melanie Simet, Nima Chartab, Yu Lu, Bahram Mobasher

TL;DR
This study demonstrates that neural networks can predict galaxy properties like stellar mass and star formation rates from photometric data with accuracy comparable to traditional SED-fitting methods, using simulated and real galaxy datasets.
Contribution
The paper introduces a neural network approach trained on semianalytic galaxy models to estimate galaxy properties from photometry, showing competitive accuracy with existing methods.
Findings
Neural networks achieved biases of 0.01 dex for stellar mass and 0.09 dex for star formation rate on simulated data.
Predictions on real CANDELS galaxies are consistent with traditional SED-fitting results within known biases.
The method's accuracy is limited by noise differences and intrinsic neural network limitations.
Abstract
With current and upcoming experiments such as WFIRST, Euclid and LSST, we can observe up to billions of galaxies. While such surveys cannot obtain spectra for all observed galaxies, they produce galaxy magnitudes in color filters. This data set behaves like a high-dimensional nonlinear surface, an excellent target for machine learning. In this work, we use a lightcone of semianalytic galaxies tuned to match CANDELS observations from Lu et al. (2014) to train a set of neural networks on a set of galaxy physical properties. We add realistic photometric noise and use trained neural networks to predict stellar masses and average star formation rates on real CANDELS galaxies, comparing our predictions to SED fitting results. On semianalytic galaxies, we are nearly competitive with template-fitting methods, with biases of dex for stellar mass, dex for star formation rate, and…
Click any figure to enlarge with its caption.
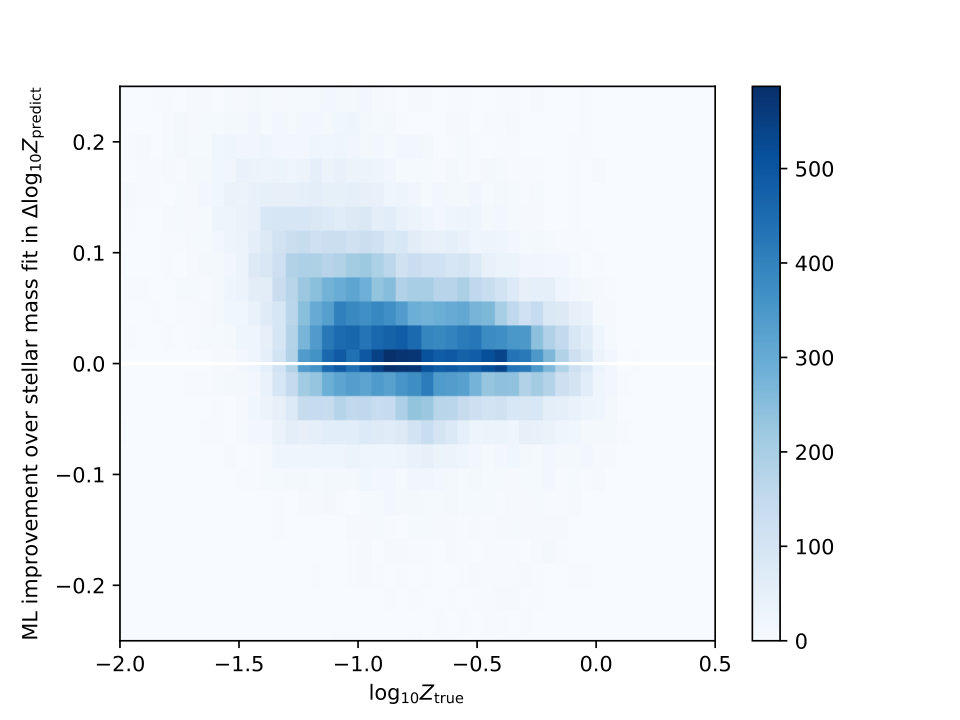 Figure 1
Figure 1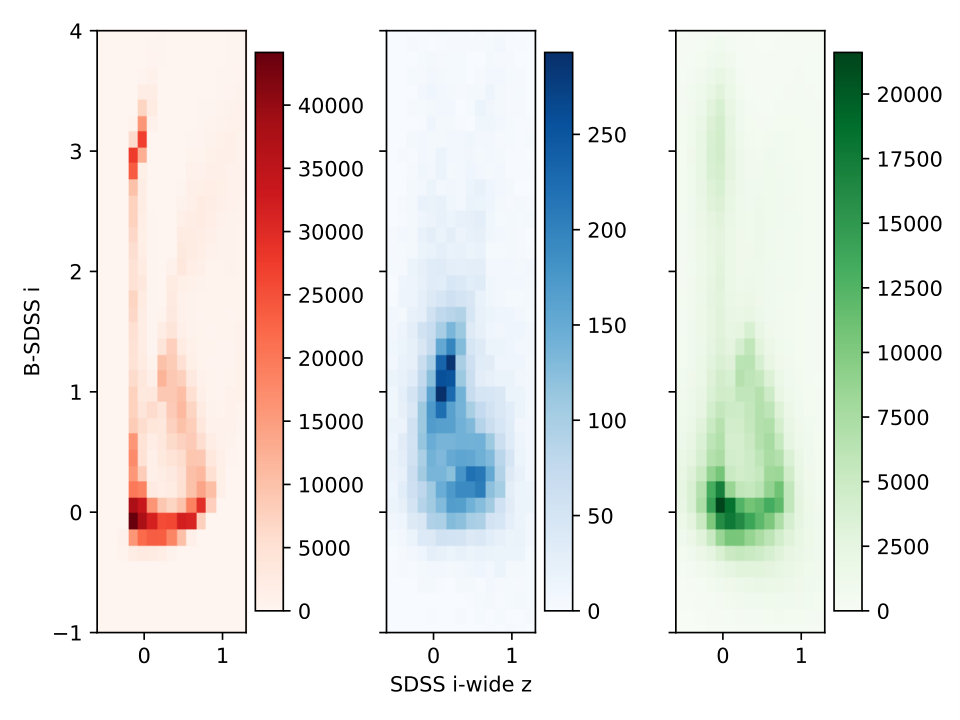 Figure 2
Figure 2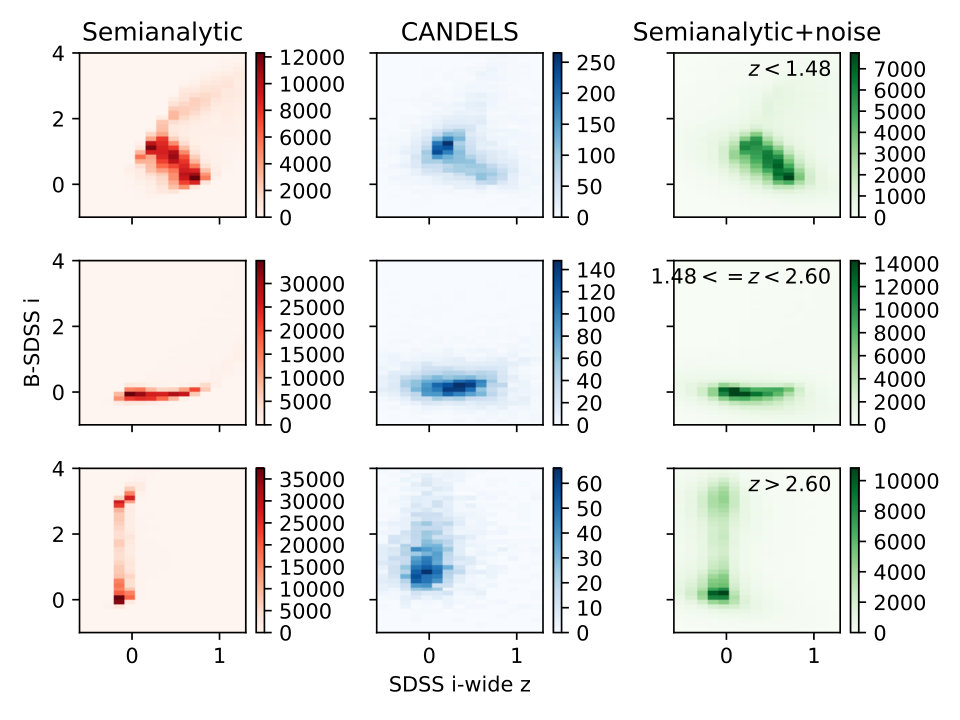 Figure 3
Figure 3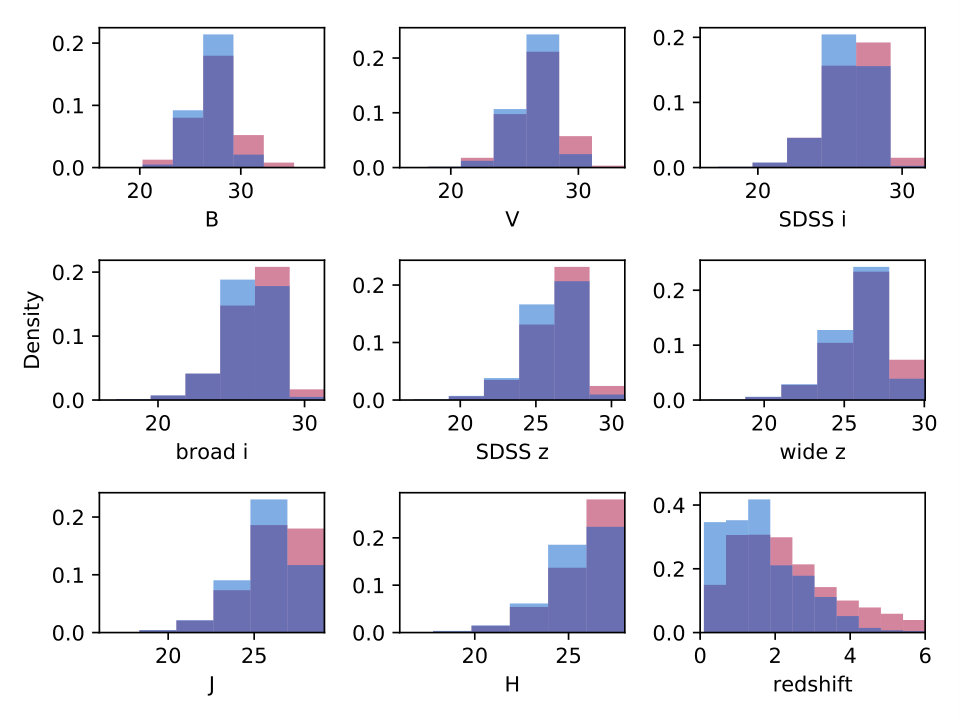 Figure 4
Figure 4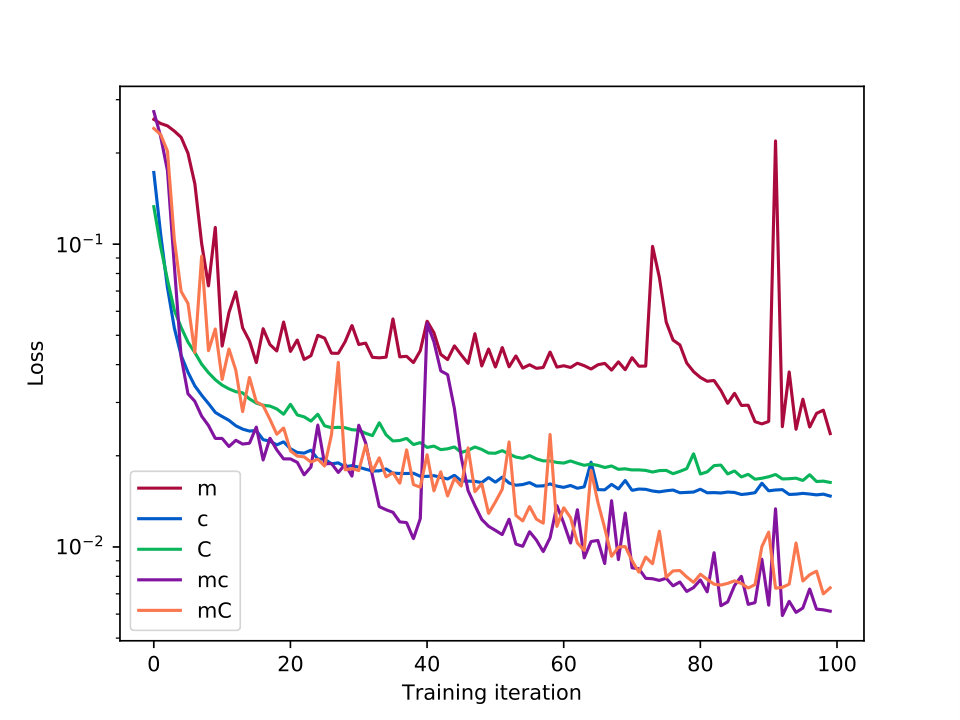 Figure 5
Figure 5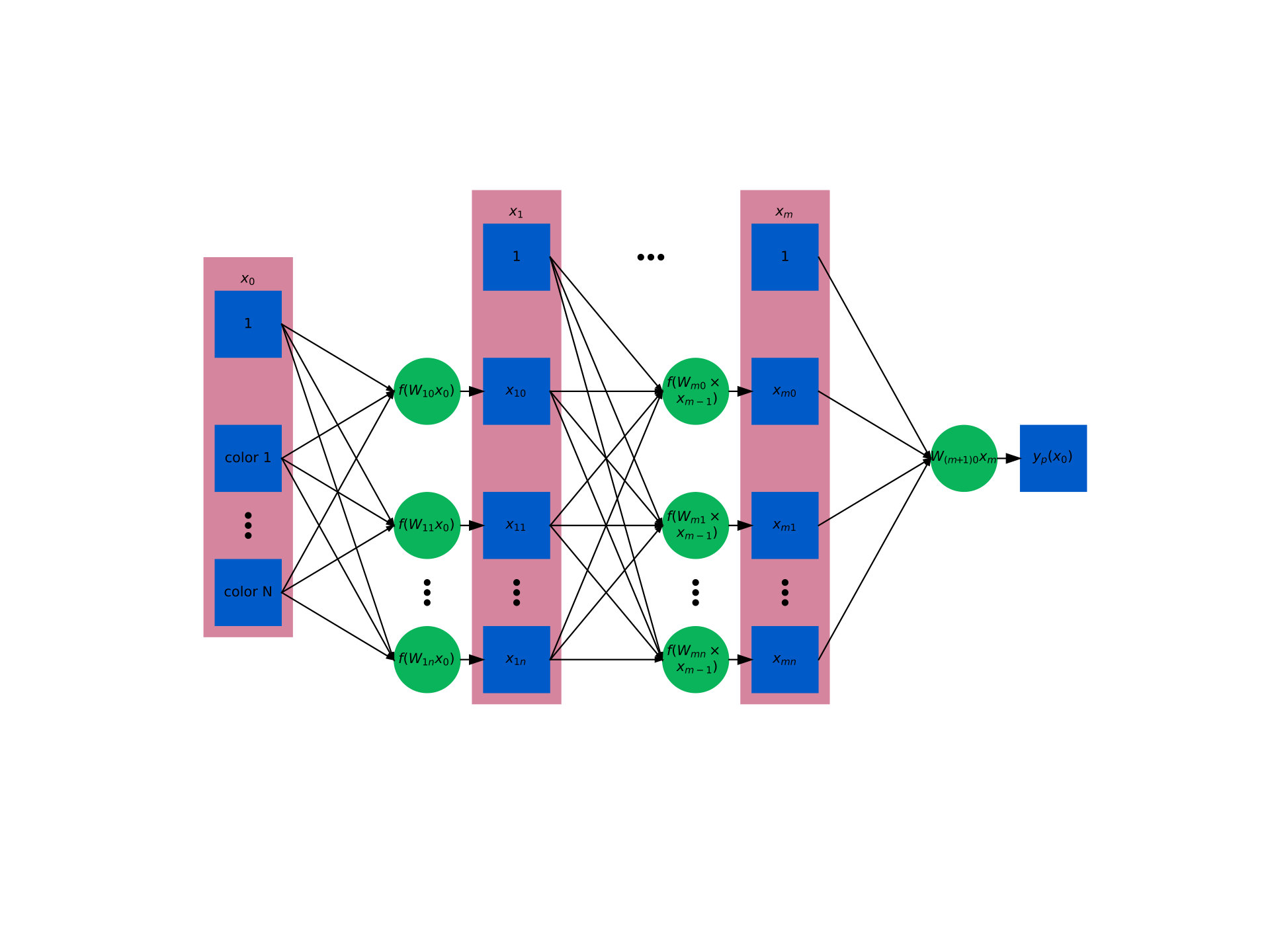 Figure 6
Figure 6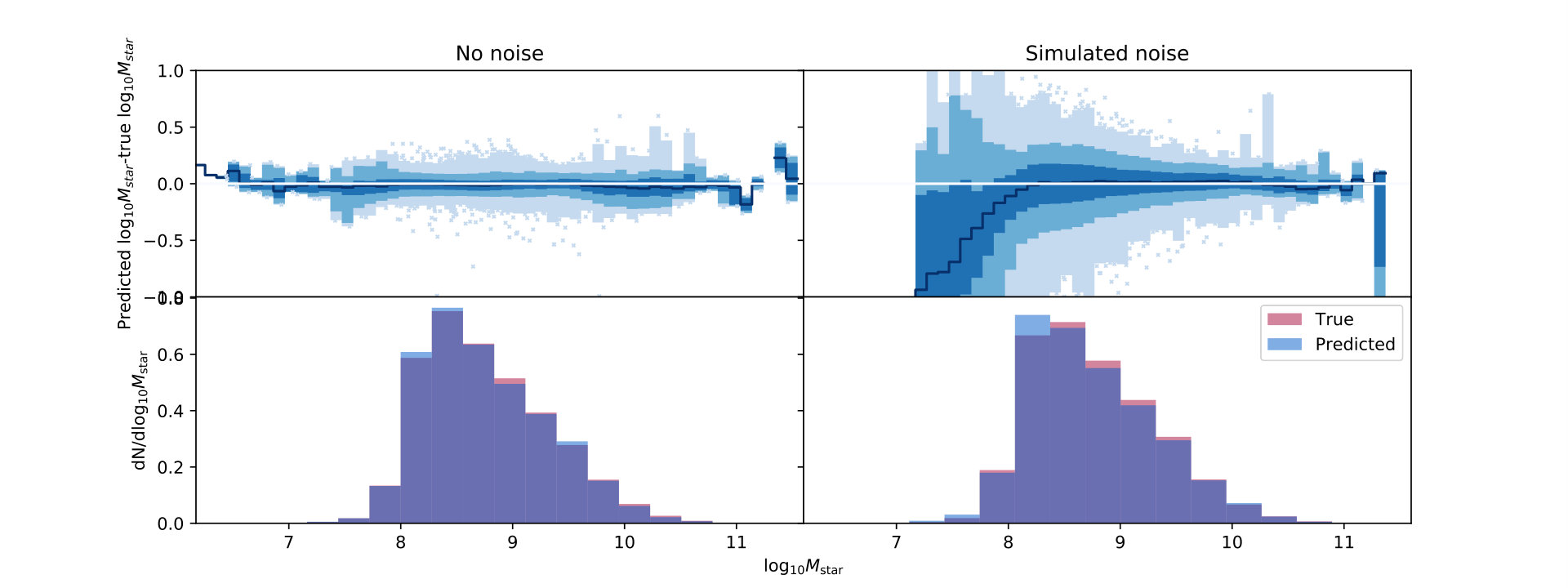 Figure 7
Figure 7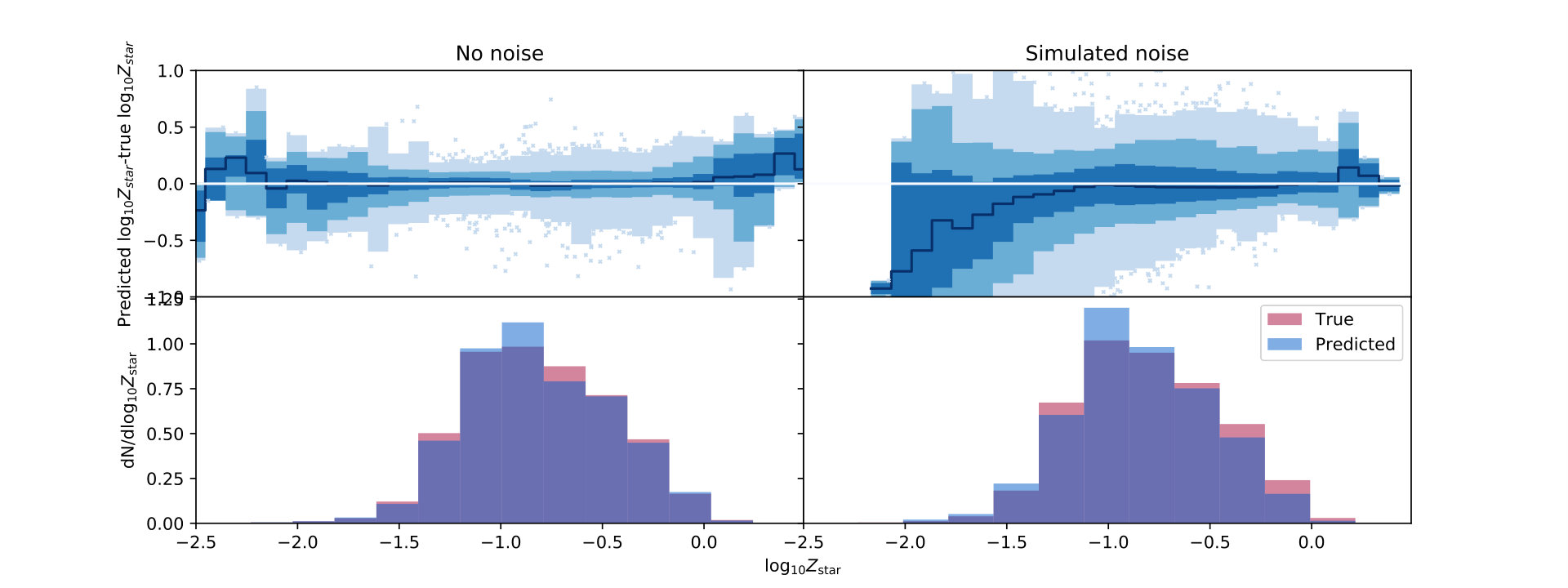 Figure 8
Figure 8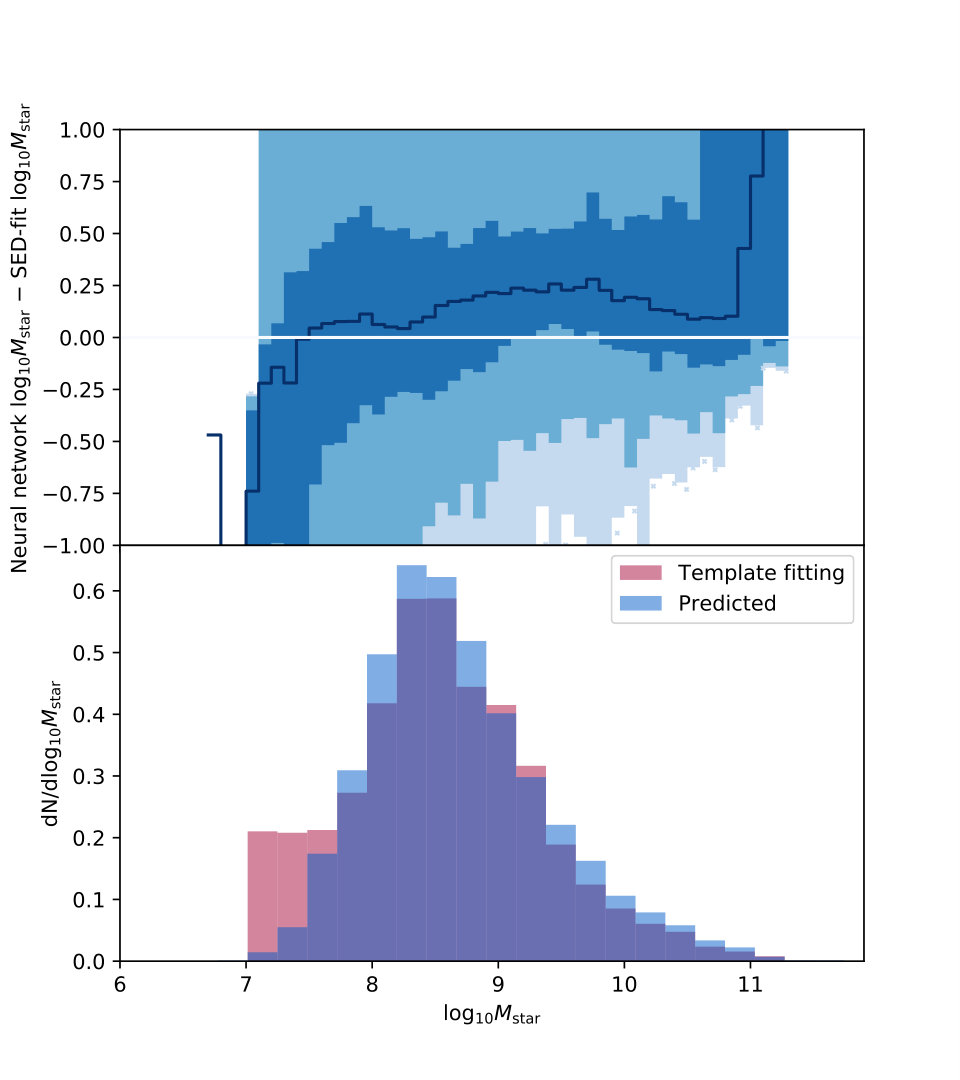 Figure 9
Figure 9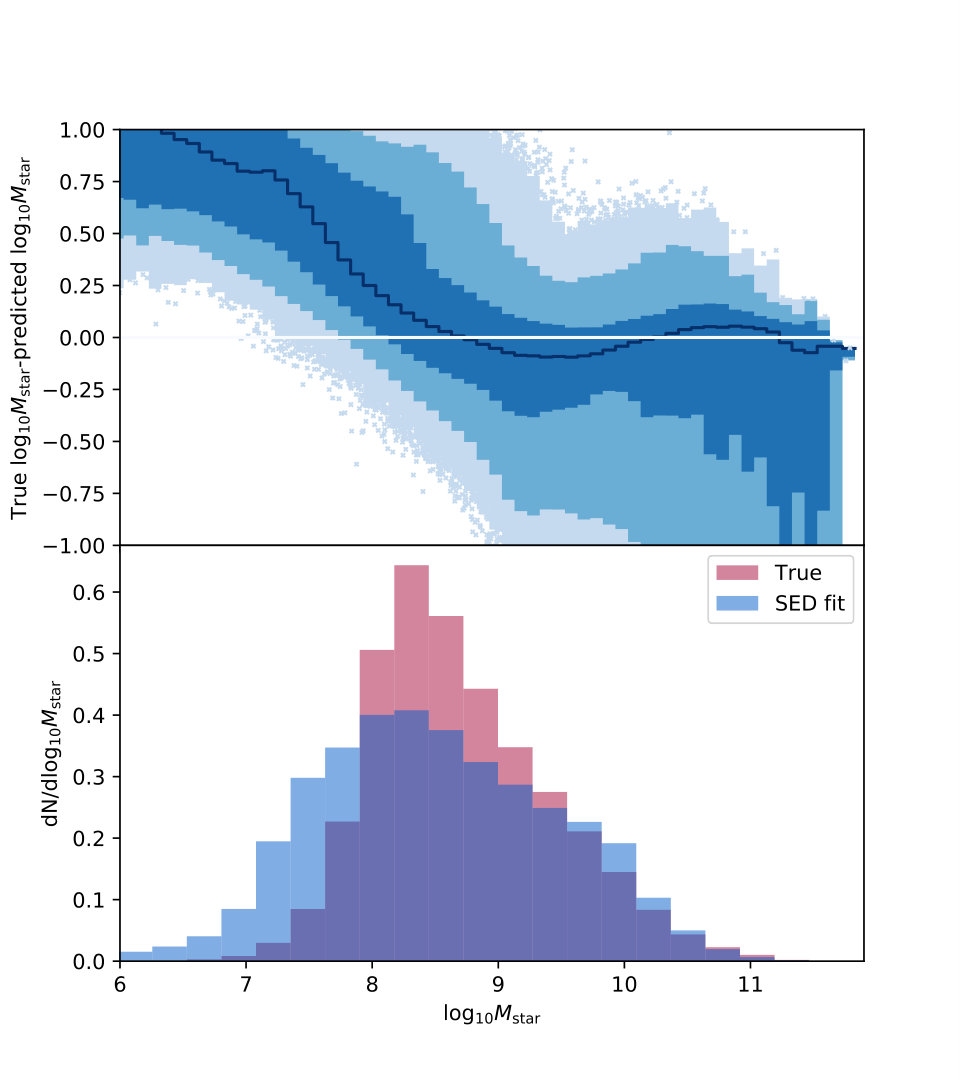 Figure 10
Figure 10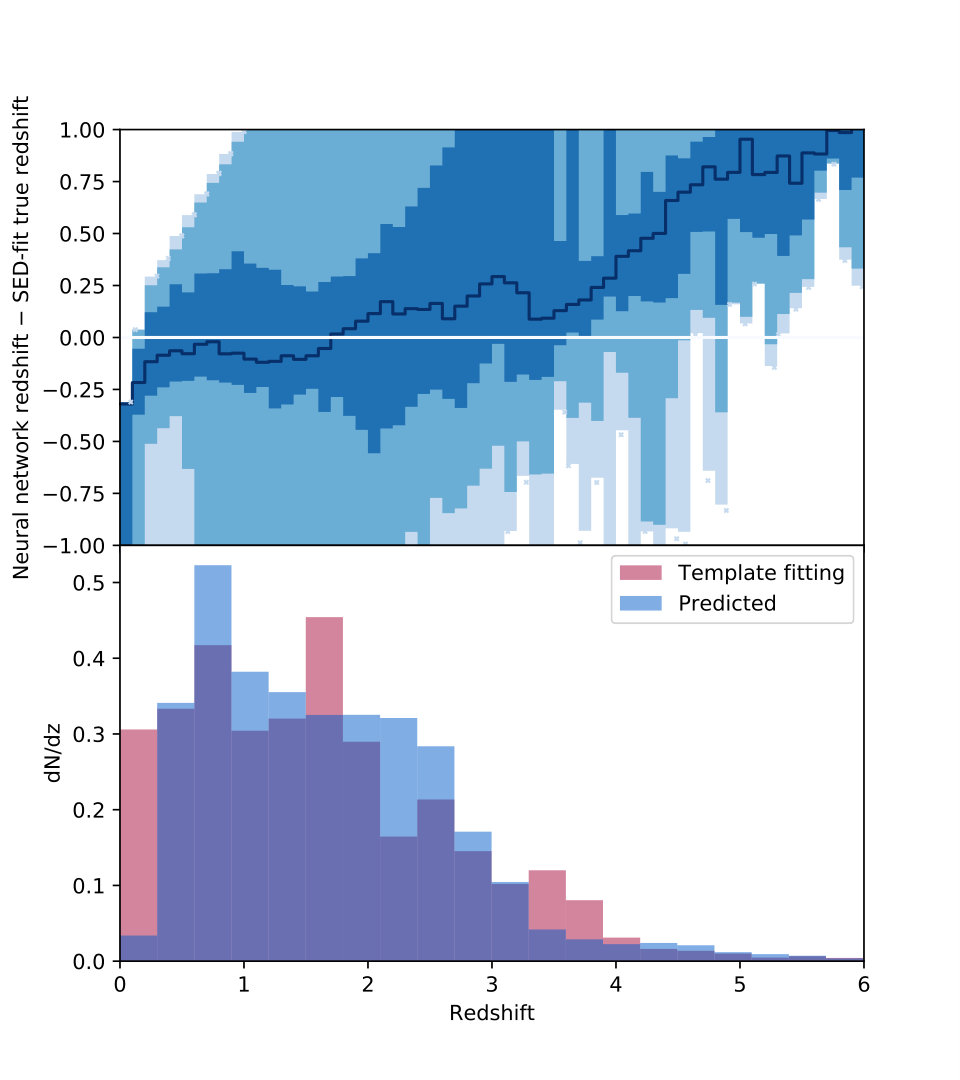 Figure 11
Figure 11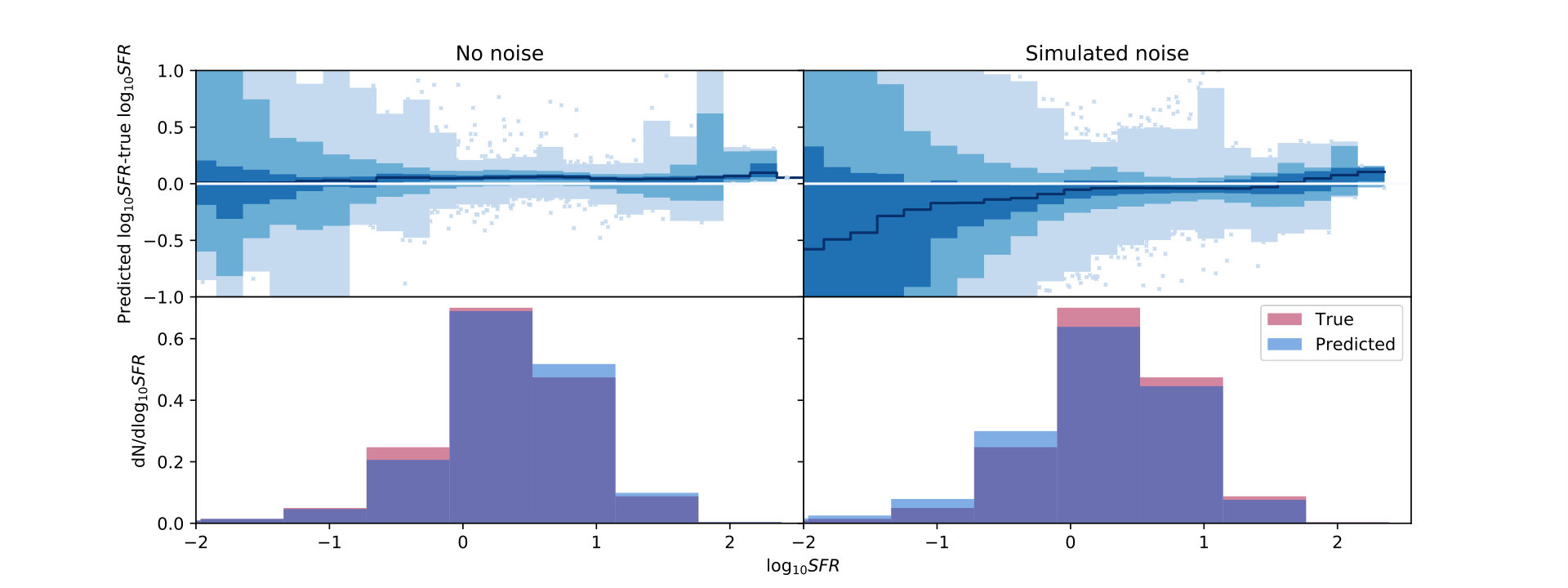 Figure 12
Figure 12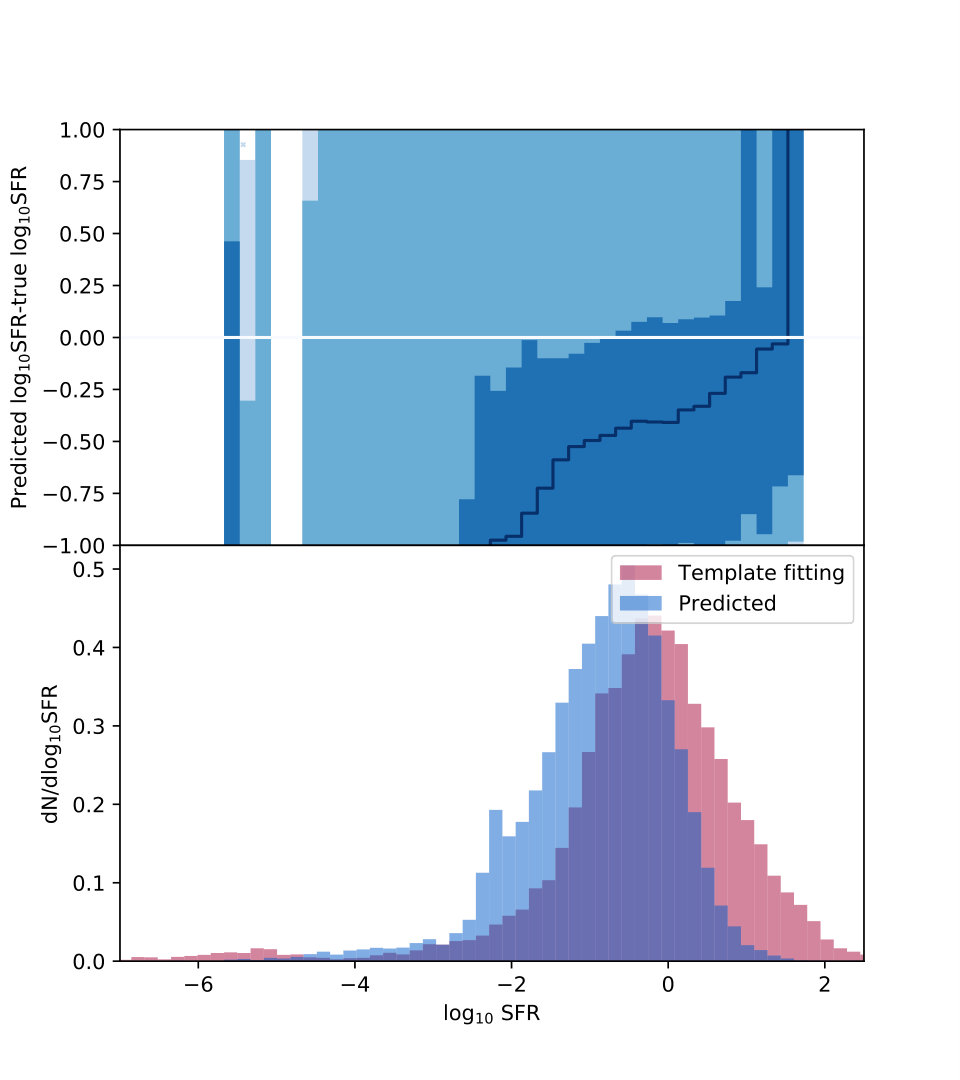 Figure 13
Figure 13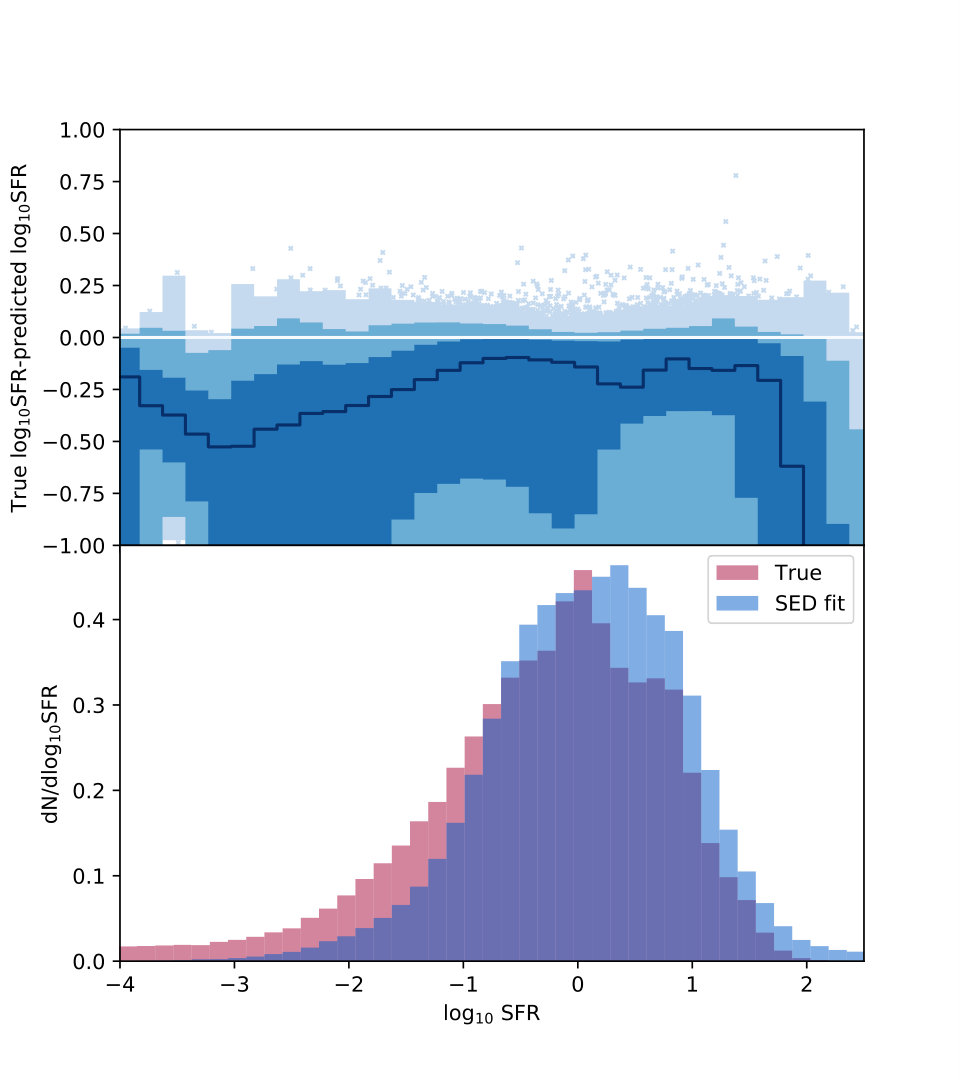 Figure 14
Figure 14| Noise | Input | Number | Average | 3 outlier | ||
| level | columns | of steps | Loss1/2 | bias | Uncertainty | rate |
| None | m | 100000 | 0.157 | 0.147 | 0.013 | |
| None | c | 100000 | 0.115 | 0.003 | 0.115 | 0.016 |
| None | C | 100000 | 0.120 | 0.119 | 0.018 | |
| None | mc | 100000 | 0.071 | 0.066 | 0.0147 | |
| None | mC | |||||
| 5 | mC | 10000 | 0.124 | 0.007 | 0.124 | 0.012 |
| Full noise | mC | 10000 | 0.204 | -0.019 | 0.203 | 0.018 |
| Noise | Input | Number | Average | 3 outlier | ||
|---|---|---|---|---|---|---|
| level | columns | of steps | Loss1/2 | bias | Uncertainty | rate |
| None | m | 100000 | 0.092 | 0.002 | 0.092 | 0.013 |
| None | c | 100000 | 0.075 | 0.010 | 0.074 | 0.015 |
| None | C | |||||
| None | mc | 100000 | 0.070 | 0.007 | 0.069 | 0.014 |
| None | mC | 100000 | 0.065 | 0.017 | 0.062 | 0.0137 |
| 5 | C | 10000 | 0.149 | -0.008 | 0.149 | 0.011 |
| Full noise | C | 10000 | 0.204 | -0.035 | 0.201 | 0.015 |
| Noise | Input | Number | Average | 3 outlier | ||
| level | columns | of steps | Loss1/2 | bias | Uncertainty | rate |
| None | m | 100000 | 0.297 | 0.291 | 0.016 | |
| None | c | 100000 | 0.178 | 0.178 | 0.015 | |
| None | C | 100000 | 0.179 | 0.179 | 0.016 | |
| None | mc | 100000 | 0.142 | 0.019 | 0.141 | 0.014 |
| None | mC | |||||
| 5 | mC | 100000 | 0.213 | 0.227 | 0.018 | |
| Full noise | mC | 100000 | 0.296 | 0.304 | 0.023 |
| Input | Number | Average | |||||
| Property | columns | of steps | Loss1/2 | bias | Uncertainty | bias | uncertainty |
| mCz | 100000 | 0.046 | -0.010 | 0.045 | 0.001 | 0.011 | |
| Cz | 100000 | 0.078 | 0.009 | 0.077 | |||
| mCz | 100000 | 0.136 | 0.136 |
| Average | 3 outlier | ||
|---|---|---|---|
| Property | bias | Uncertainty | rate |
| -0.193 | 0.424 | 0.004 | |
| 0.490 | 1.06 | 0.031 |
| Input | Number | Noise | Average | 3 outlier | ||
|---|---|---|---|---|---|---|
| Property | columns | of steps | property | bias | Uncertainty | rate |
| mC | 10000 | No noise | 0.270 | 0.950 | 0.014 | |
| mC | 10000 | 5 cut | 0.208 | 0.581 | 0.029 | |
| mC | 10000 | Full noise | 0.149 | 0.559 | 0.023 | |
| mC | 10000 | No noise | 2.14 | 0.019 | ||
| mC | 10000 | 5 cut | 1.43 | 0.029 | ||
| mC | 10000 | Full noise | 1.37 | 0.031 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Comparison of Observed Galaxy Properties with Semianalytic Model Predictions using Machine Learning
Melanie Simet
University of California Riverside, 900 University Ave, Riverside, CA 92521, USA
Jet Propulsion Laboratory, California Institute of Technology, Pasadena, CA 91109, USA
University of California Riverside, 900 University Ave, Riverside, CA 92521, USA
The Observatories, The Carnegie Institution for Science, 813 Santa Barbara Street, Pasadena, CA 91101, USA
Bahram Mobasher
University of California Riverside, 900 University Ave, Riverside, CA 92521, USA Melanie Simet [email protected]
Abstract
With current and upcoming experiments such as WFIRST, Euclid and LSST, we can observe up to billions of galaxies. While such surveys cannot obtain spectra for all observed galaxies, they produce galaxy magnitudes in color filters. This data set behaves like a high-dimensional nonlinear surface, an excellent target for machine learning. In this work, we use a lightcone of semianalytic galaxies tuned to match CANDELS observations from Lu et al. (2014) to train a set of neural networks on a set of galaxy physical properties. We add realistic photometric noise and use trained neural networks to predict stellar masses and average star formation rates on real CANDELS galaxies, comparing our predictions to SED fitting results. On semianalytic galaxies, we are nearly competitive with template-fitting methods, with biases of dex for stellar mass, dex for star formation rate, and dex for metallicity. For the observed CANDELS data, our results are consistent with template fits on the same data at dex bias in and dex bias in star formation rate. Some of the bias is driven by SED-fitting limitations, rather than limitations on the training set, and some is intrinsic to the neural network method. Further errors are likely caused by differences in noise properties between the semianalytic catalogs and data. Our results show that galaxy physical properties can in principle be measured with neural networks at a competitive degree of accuracy and precision to template-fitting methods.
galaxies: statistics, galaxies: fundamental parameters, methods: numerical
1 Introduction
Over the last decade, a number of wide-area spectroscopic surveys have been performed, including WiggleZ (Drinkwater et al., 2010), BOSS (Dawson et al., 2013), GAMA (Driver et al., 2012) and zCOSMOS (Lilly et al., 2007). These were used to measure spectral line diagnostics of physical conditions in galaxies to study the evolution of galaxies with look-back time. The results from these studies were often limited by Poisson noise due to the small number of galaxies when divided in terms of their redshifts or in physical parameter bins. In recent years the scale of such surveys have increased by many orders of magnitude in terms of both depth and area coverage. The on-going Dark Energy Survey (DES; Drlica-Wagner et al., 2018) and future Large Synoptic Survey Telescope (LSST; LSST Science Collaboration et al., 2009) will generate billions of galaxies with multi-waveband photometric data. These will soon join by space-based surveys like Euclid (Laureijs et al., 2011) and WFIRST (Spergel et al., 2015). Given their size, it is impossible to perform spectroscopic observations of individual galaxies. Therefore, techniques should be developed to measure the physical parameters associated with galaxies in these surveys, needed to study the programs they have been designed for.
The physical parameters for galaxies (redshift, stellar mass, star formation rate, extinction) are conventionally estimated by fitting their observed Spectral Energy Distributions (SEDs) to template SEDs that correspond to the type and class of galaxies in the observed sample. By shifting the model SEDs in redshift space, they are fitted to the observed SED. The physical parameters are then assigned based on the fits, for example by choosing the best-fit template or taking statistics of a probability distribution function of parameters (Bolzonella et al., 2000; Brammer et al., 2008; Ilbert et al., 2006, e.g.). A limitation in using template-fitting methods is that the results depend on a complex array of factors including the type of the galaxies used in template models, the tested parameter ranges, and the filters used in fitting. Also, the estimated physical parameters of galaxies depend on the choice of these initial parameters and the range they cover. For example, if the library of galaxy spectra does not adequately sample the the range of spectra that galaxies can take, there will be serious uncertainties in the estimated parameters for that galaxy; degeneracies between model parameters may produce a good fit with substantial uncertainty in a parameter of interest. Furthermore, apart from redshifts, for which a true estimate (in the form of spectroscopic redshift) could be made for a subsample of objects and used to estimate the uncertainty for the whole population, measuring a “true” value for other physical parameters is difficult and the results often do not directly correspond to the predicted value. Moreover, the results would be affected by the photometric uncertainties, absence of a full photometric coverage and degeneracies between different parameters (Hildebrandt et al., 2010; Abdalla et al., 2011; Sánchez et al., 2014). (While this also applies to all methods, including our neural network method described here, the nonlinearity of a neural network changes the dependence on these effects, so depending on the exact degeneracies and uncertainties present, a neural network may have different performance.) Recent studies, such as Guidi et al. (2016) and Laigle et al. (2019), have used mock catalogues generated from galaxy simulations to provide a test data set with known values for many galaxy properties, an approach we adapt here.
Recently, Machine Learning (ML) techniques have emerged as independent alternatives for measuring the physical parameters of galaxies (Sadeh et al., 2016; Ball et al., 2008; Hogan et al., 2015; Masters et al., 2015). Using a training sample with known physical parameters, they generate statistical models to predict the distribution of those parameters in a target data set. The ML techniques are only applicable within the limits of the training data. Any extrapolation of them to a different redshift or mass regime would lead to errors in the final estimate. However, a distinct advantage of ML is that one could incorporate extra information (i.e. morphology, galaxy light profile) within the algorithm. The ML techniques are divided into two categories: supervised and unsupervised. In supervised ML, the input attributes (magnitudes and colors) are provided along with the output (redshift) and directly used for training in the learning process (Lima et al., 2008; Freeman et al., 2009; Gerdes et al., 2010). Here, the learning process is supervised by the input parameters. The unsupervised techniques do not use the desired output values (e.g. spectroscopic redshifts) for training purposes, and are less frequently used.
The use of ML methods to study galaxies in survey data has so far been focused on measuring photometric redshifts of galaxiesm with a few studies addressing other properties. This is because the ML algorithms can be more easily trained using the spectroscopic redshifts whereas for other parameters such “true” and unambiguous estimates are not possible to obtain without making serious assumptions. Detailed comparisons have been performed between different methods and algorithms measuring photometric redshifts (Carrasco Kind & Brunner, 2013; Dahlen et al., 2013; Beck et al., 2017) and masses (Mobasher et al., 2015) of galaxies. However, except in a few cases where ML techniques are used (MCC and neural net) these were mostly based on different variants of template fitting using observed or model SEDs. ML methods have also been used to study a diverse portfolio of galaxy properties besides redshift, including morphology (e.g. Abraham et al., 2018; Dai & Tong, 2018; Barchi et al., 2019; Caldeira et al., 2019; Khan et al., 2019; Walmsley et al., 2020), star formation rate (e.g. Stensbo-Smidt et al., 2017; Bonjean et al., 2019; Delli Veneri et al., 2019), and stellar masses (Bonjean et al., 2019; Dobbels et al., 2019, e.g.) as well as to detect unusual objects (e.g. Sharma et al., 2019). Alternate data vectors have also been used, such as in Pasquet et al. (2019) who use the per-filter pixel counts in multicolor postage stamps as their numerical data rather than measurements of total flux. Several approaches use unsupervised ML techniques to first compress the high-dimensional color-space information (through projection or selection) and then use functions of the compressed data vector to predict one or more physical properties (Beck et al., 2017; Stensbo-Smidt et al., 2017; Hemmati et al., 2019; Davidzon et al., 2019; Wright et al., 2019). ML methods can also be used to improve estimates from other techniques. For example, Carrasco Kind & Brunner (2014) used a Bayesian combination of photometric redshift Probability Density Functions (PDFs) using different ML methods to improve estimates of photometric redshifts. ML techniques are also attractive because they are computationally more efficient: once a method has been trained, it can be deployed cheaply on many galaxies (with computations typically being linear or polynomial), resulting in a much shorter computation time per galaxy than SED-fitting.
In this paper we use a machine learning technique, a neural network, to measure the stellar mass and star formation rates of galaxies with available photometric data and photometric redshifts using a training set of semianalytic galaxies from (Lu et al., 2014). The test sample in this study is from the Hubble Space Telescope (HST) Cosmic Assembly Near-infrared Deep Legacy Survey (CANDELS) GOODS-South field. This has imaging data in optical (ACS) and near-infrared (WFC3) wavelengths as well as Spitzer Space Telescope mid-infrared (IRAC) bands. We describe the CANDELS data and semianalytic galaxies in section 2, give an overview of the neural network ML algorithm we use in section 3, test our neural networks with a semianalytic test set in section 4, compare neural networks and template fitting on a mock data set in section 5, and finally apply our networks to CANDELS data in section 6, with summary and conclusions in section 7. Throughout the paper, we assume the cosmology of the simulation used to generate the mock catalog and semianalytic galaxies: , , , , , and .
2 Data
2.1 CANDELS galaxies
The Cosmic Assembly Near-IR Deep Extragalactic Legacy Survey (CANDELS; Grogin et al., 2011; Koekemoer et al., 2011) is a arcmin2 survey performed using the Wide Field Camera 3 (WFC3) and Advanced Camera for Surveys (ACS) on the Hubble Space Telescope. The survey consists of five fields (GOODS-S, GOODS-N, COSMOS, EGS, and UDS). Multi-waveband photometric imaging observations were performed spanning the wavelength range from UV to mid-infrared. In two of these fields (GOODS-S and GOODS-N) deeper photometric observations over smaller areas were performed.
In this study, we use data from the GOODS-S deep field (Guo et al., 2013) covering an area of 170 arcmin2. The combination of CANDELS pointings with supplementary data sets (Giavalisco et al., 2004; Riess et al., 2007; Bouwens et al., 2010; Windhorst et al., 2011) results in a multi-waveband catalog consisting of three WFC3 filters (F105W, F125W and F160W) and five ACS filters (F435W, F606W, F775W, F814W and F850LP). Any galaxy that was not detected in any of the above filters or which was not covered by imaging in any of the filters was excluded from the catalog. The final data set consists of 20,512 objects out of an initial 34,930.
We use the spectral energy distribution (SED) fitting code LePhare (Arnouts et al., 1999; Ilbert et al., 2006), combined with the Bruzual & Charlot (2003) stellar population synthesis models, to derive the physical properties for each galaxy (stellar mass and star formation rate). We assume an exponentially declining star formation history with nine different e-folding times in the range of . The dust properties are modeled with varying between 0 and 1.1 assuming the Calzetti et al. (2000) dust attentuation curve. We also take into account nebular emission line contribution as described in Ilbert et al. (2009) and assume a Chabrier initial mass function (Chabrier, 2003a), with lower and upper mass limits 0.01 Msun and 100 Msun respectively. We consider three different metallicity values: , , and .
LePhare produces a marginalized likelihood of stellar masses, and we use the median value of this likelihood as our stellar mass estimate (Chartab et al., 2020). To measure the star formation rate (SFR), we use the rest-frame UV luminosity which traces timescales of Myr which is associated with continuum from massive, short-lived and type stars. We adopt the Salim et al. (2007) SFR(UV) calibration:
[TABLE]
where MUV,AB is the dust-corrected monochromatic absolute UV magnitude in AB system. We measure the observed UV magnitude () by using the 1600Å flux density from the best-fit SED. The UV spectral slope () is measured by fitting a power law of the form between to the best-fit SED, with being the wavelength-dependent flux density. We dust correct the observed MUV by assuming the Meurer et al. (1999) calibration:
[TABLE]
where MUV is the dust-corrected UV magnitude. We use the Meurer et al. 1999 calibration to find the dust-corrected UV since it only requires a UV measurement, rather than the Calzetti et al. (2000) attenuation curve which needs E(B-V) measurements and is limited by the resolution of E(B-V) parameter being searched in SED fitting.
2.2 Semianalytic galaxies
We use mock catalogs generated from semianalytic models to mimic CANDELS observations, as presented in Lu et al. (2014). In short, a semianalytic model takes a cosmological dark-matter-only simulation and adds baryonic components with recipes for their evolution through cosmic time depending on the evolving properties of the dark matter host halo. This baryonic component can consist of stars, cold gas, and hot gas with various physical processes transferring mass from one component into another (e.g., stars can form from cold gas).
The mock catalog we use was presented in Lu et al. (2014) as the “Lu” model. It assumes heating of the gas by reionization which, in turn, limits the fraction of the baryons that collapse into the halos (Gnedin, 2000; Kravtsov et al., 2004). Radiative cooling is estimated assuming the Croton et al. (2006) model that collapses a fraction of the hot gas onto central (but not satellite) galaxies depending on the cooling timescale of the halo. As in other semianalytic models, the cold gas is assumed to be distributed in an exponential disk where stars are formed. A particular feature of model we use here is that the star formation rate depends on the circular velocity of the host halo in addition to the more typical dependences on star-forming gas mass and disk dynamical time scale. Supernova feedback reheats the cold gas and ejects both cold and hot gas. No explicit model for black hole accretion or AGN feedback is assumed, but a halo quenching model is implemented that switches off radiative cooling above a halo mass around . Galaxy mergers are handled by following subhalo information in the merger tree and assuming that even an unresolved subhalo will remain intact for some fraction of the dynamical friction time.
A fraction of the mass in new stars is assumed to convert into metals and is instantly recycled back into the disk (and from there into the cold and hot gas surrounding the disk, according to the above prescriptions), parameterized using a Chabrier initial mass function for stellar mass in the range of and (Chabrier, 2003b). The model therefore explicitly predicts the star formation history and the metallicity enrichment history of a model galaxy. These histories are converted into the intrinsic spectrum energy distribution (SED) for each mock galaxy by adopting the CB07 stellar population synthesis model Bruzual (2007), which is an updated version of the BC03 model (Bruzual & Charlot, 2003). The observed magnitudes are computed by integrating the SED that is redshifted according the redshift of the galaxy and weighted by the transmission functions of observational filters. We also adopt the Charlot & Fall (2000) model to account for dust attenuation and predict dust attenuated colors.
The merger trees for our mock catalogs used were drawn from the Bolshoi -body cosmological simulation (Klypin et al., 2011), with a volume of (250 Mpc/)3, using 8 billion particles with a mass resolution of , and 180 stored time steps. Halo finding was performed with the Rockstar code (Behroozi et al., 2013a) and merger trees were constructed using the Consistent Trees algorithm (Behroozi et al., 2013b). Lightcone halo mock catalogs are extracted from the simulation box. These lightcone catalogs mimic the five CANDELS fields, and have redshift range from to . Eight realizations are generated for each of the fields. Each dark matter halo in a lightcone catalog has a unique ID. The corresponding dark matter halo merger tree branch is found from the simulation box and rooted on the halo.
The model parameters used in Lu et al. (2014) are tuned to match calibration data. The main calibration set is the stellar mass function of local galaxies from Moustakas et al. (2013). Parameters were tuned using Markov Chain Monte Carlo chains with the differential evolution algorithm (Braak, 2006) and a likelihood based on a weighted , with a parameterization to account for incompleteness in the data at low mass.
The best fit model is adopted to apply onto each merger tree of the lightcone mocks to predict the star formation history of each galaxy hosted by every halo in the mock. The semianalytic models contain simulated magnitudes for the eight CANDELS bands described above.
We only use galaxies from the mock catalog within the redshift range . We also impose a cut such that mag, to avoid a small population of faint high-mass galaxies that are separated in parameter space from the rest of the models, and are significantly fainter than them.
In the real world, the data contains observational uncertainties. To examine how much observational error degrades the best-case performance of our neural networks, we will also analyze the simulations with pseudo-“observational error” applied. We incorporate errors in the mock catalogs using the observational errors associated with CANDELS galaxies. We measure the median multiplicative flux error in bins of magnitude with width 0.5. These were then linearly interpolated to obtain a typical multiplicative uncertainty for a given magnitude in the data. We then draw a random Gaussian-distributed number with a scale length given by this multiplicative uncertainty, and add the term to simulate observational errors. The simulation data perturbed in this way has distributions of magnitudes and colors similar to the CANDELS data. This pseudo-observational error is added when the catalogs are read into our neural network software, before any colors are computed or any splitting into training and validation data sets is performed. We also explore a case where we mimic the noise properties of only well-resolved galaxies, defined as galaxies with flux signal-to-noise ratios in each observed band. In both cases, after we have perturbed the magnitudes, we apply a cut to remove galaxies that have scattered below the minimum observed magnitude in each band.
2.3 Comparison of semianalytic models with CANDELS observations
The semianalytic models have been tuned to match observations (Lu et al., 2014). Here, we compare the galaxy magnitudes in both the noise-free and noisy case, to demonstrate the feasibility of using the semianalytic galaxies to train a neural network that is then applied to the CANDELS data.
In Fig. 2, we show color-color plots, with heatmaps showing the location of both the semianalytic galaxies (with and without simulated noise) and the observed CANDELS galaxies. We chose this projection of the higher-dimensional color space as good representatives of the general trend: the semianalytic galaxies without noise lie on thin manifolds, with the CANDELS galaxies being consistent with their overall trend but significantly broadened by observational noise, and the semianalytic galaxies with added noise looking similar to the CANDELS galaxies, but with some galaxies smeared outside the boundaries of the semianalytic and CANDELS galaxies by the noise. In the first panel, the vertical manifold at in the semianalytic galaxies does not show up strongly in the data. However, this is expected, as the galaxies on that part of the manifold are at higher redshift and fainter, below the CANDELS completeness limit.
We do not expect our machine learning method to be affected by the presence of objects in our semianalytic sample that do not appear in the CANDELS data, given that such objects are less frequent in number than representative objects. It is more important that all CANDELS galaxies have good representation in the semianalytic data set. Having semianalytic objects outside the bounds of the CANDELS galaxies merely means that we have trained a machine learning method for data it will never see. The only exception would be if the faint semianalytic galaxies introduced a degeneracy in the color-space manifold that is not there for brighter galaxies. However, we do not see signs of this in our data set (the quality of the fit to brighter galaxies does not improve when excluding fainter galaxies). have
3 Machine learning procedure
Machine learning techniques have recently been adapted to problems in astronomy including photometric redshifts (e.g. Sánchez et al., 2014; Bilicki et al., 2017; Tanaka et al., 2018), large-scale structure (Aragon-Calvo, 2018), galaxy morphologies (Domínguez Sánchez et al., 2018), and calibration factors for weak lensing data measurement algorithms (Tewes et al., 2018). In this work, we use the technique known as a neural network.
The idea of a neural network is simple. The underlying motivation is that we have a data vector (say galaxy colors), as well as a desired output (stellar mass, for example) that is a nonlinear function of that data vector, and we want to learn how to estimate the output given a new data vector. We don’t know the optimal form of the function, however, and even if we did, it is likely that the complicated form would make determining the parameter values analytically difficult. Neural networks computationally determine the important combinations of the data points, and the appropriate coefficients for those combinations, by breaking the prediction process down into a series of linear combinations of the data points, combined with nonlinear transformations of those sums to reproduce nonlinear behavior.
As illustrated in Fig. 3 for a single data point, in the usual neural network setup, a set of vectors is fed to a layer of computational units called nodes. Each node computes a weighted sum of the coordinates of each vector, and optionally applies a simple nonlinear function to the sum (which might clip negative values, for example). The output of the layer–one value for each node for each input datapoint–can then act as a new set of vectors, which is fed to a new layer of nodes. The final layer has only one node, and the value it computes for each data point is the prediction, , that corresponds to the true value of for the data points. The free parameters of the model produced by the network are the weights used to compute the weighted sum in each node. To compute the optimal values of these parameters—a process called training the network—iterative adjustments are made based on a comparison of the predictions to the known true values for the input data points . The iterations proceed until either the desired accuracy is reached or the network stops improving its accuracy. A more detailed overview of this technique with additional complications can be found in Goodfellow et al. (2016). Error estimation can be performed by training multiple networks (e.g. Bilicki et al., 2017) but here we use a simple point estimate from a single network. In its simplest form, a neural network consists of a series of matrix multiplications with a simple function applied to the outputs: for an input data point with features fed to a layer of nodes, the output of the th layer is simply
[TABLE]
where is a scalar or vector of offsets and is a matrix. The function is chosen to fit the problem at hand, while the values of the matrices are numerically trained to fit the training sample as described above. By convention, this function is called a “response function” in machine learning terminology. Again, the response function is usually nonlinear: if it is linear, then the whole network produces a simple linear combination of the input data. The computational difficulty of neural networks comes from the complexity of training the many values of the matrices, and particularly the difficulty of training more than one or two layers (Goodfellow et al., 2016; Lanusse et al., 2018, and references therein). The initial values of are typically set near 1 with small random offsets in each element (Abadi et al., 2015), meaning that (unless the random number generator is seeded in the exact same way) the same neural network architecture will produce slightly different predictions for the same training set.
The necessary choices to set up a neural network include:
- •
The number of layers
- •
The number of nodes in each layer
- •
The response functions
- •
The method used to train the network (i.e., to alter the weight matrices after each iteration)
- •
The function that computes a metric distance between the predicted points and the true values (the loss function)
We use the Google package TensorFlow111https://www.tensorflow.org/ (Abadi et al., 2015) to implement our neural network. TensorFlow is a highly-optimized framework designed to enable fast implementation of neural networks and other machine-learning problems. The package runs mostly compiled code to increase speed of execution, but the user interface is in Python. For this work, we use the high-level “Estimator” API for TensorFlow, which automates most of the bookkeeping necessary to setup and train a neural network. We began with a set of 2 10-node layers, as used before for photometric redshifts in e.g. Collister & Lahav (2004), and added nodes and layers until our performance (measured by the value of the loss function) stopped improving. We found optimal performance with a set of 3 20-node layers; we found this architecture to be complex enough to reproduce high-dimensional nonlinear manifolds in color space, while still being simple enough that the neural network training algorithm could converge on a good solution. The response functions in our network are the “relu”, or rectified linear unit, function (Glorot et al., 2011):
[TABLE]
This satisfies the requirement that is nonlinear in to reproduce nonlinear behavior, while still being computationally efficient.
Our loss function is a simple squared distance between the labels from our catalog and the predictions from a given training step of our neural network, summed over input training points :
[TABLE]
This is related to the that is more commonly used. In this case, we do not normalize by the expected values or expected uncertainty; we found that doing so has the effect of focusing the training first on small values of , in practice making it more difficult to find a manifold that works well for the entire parameter range.
3.1 Training the network
To train the network, we split the data into two sets: a set to use to train the coefficients of the network, and a set to evaluate how well our network is reproducing the data. The two sets must be different in order to avoid overfitting, the problem where the network reproduces not only the average trends in the data, but the specific noise fluctuations of the data set used for training (Goodfellow et al., 2016). We use a 70-30 split, with 70% of the data used to train the coefficients (called the “training set”) and 30% to check its performance at intervals (called the “validation set”). The galaxy color manifold is well-sampled in this simulated data set, such that this simple random split produces nearby neighbors from the training set for all data points in the validation set (relative to the distribution in the full data set), even in relatively sparse regions of color space.
We use stochastic gradient descent to train the network, in which we iteratively compute the predictions of the network on a random subset of our training data (Goodfellow et al., 2016). In our case, we find that using points per step works well, with a check against the validation set every steps ( total training data points passed through the network). We use the Adam optimizer (Kingma & Ba, 2014) to update the coefficients after every step. Briefly, the Adam algorithm involves an adaptive learning rate computed from moments of derivatives of the loss function, Eq. (5) so that the coefficients change more quickly when the gradient of the loss function is high, and then change only slowly as the loss function approaches a (local) minimum. We use the default parameter settings for the Adam optimizer implementation within TensorFlow. We explored changing the learning rate , which controls how fast or slow the coefficients change for a given value of the loss function, but accuracy and precision decreased as we moved away from the default value.
4 Application to semianalytic galaxies
In our semianalytic catalog, each mock galaxy is associated with four physical parameters: stellar mass , redshift , stellar metallicity , and average star formation rate .222Other quantities in the catalog, for example the dark matter halo mass, will correlate with galaxy light properties because they correlate with, for example, the stellar mass; for this work, we consider only the direct correlations, not such indirect correlations, which pick up both additional parameters like the stellar-halo mass connection and additional noise. There has been good progress in using machine learning techniques to measure photometric redshifts (Salvato et al., 2018). Therefore, we concentrate on measuring other parameters here.
We train networks using 5 possible sets of input data columns. We will use the bold letters in parentheses as shorthand in tables throughout the paper.
- •
Galaxy magnitudes (m)
- •
Galaxy pairwise colors (, , etc) (c)
- •
Galaxy magnitudes and pairwise colors (mc)
- •
All galaxy colors ( in addition to and , etc) (C)
- •
Galaxy magnitudes and all galaxy colors (mC)
Machine learning algorithms generally respond to information in different ways than the deterministic model-fitting methods more commonly used in astronomy. If the output is sensitive to a particular combination of data points (such as a color formed from two non-adjacent filters), then it is often more numerically efficient to give the algorithm this combination, even though the network could eventually learn that the given combination is important. The ML training algorithm may converge on an answer more quickly if relevant data combinations are given as inputs, since it does not have to learn that, for example, is an important combination of filters, before it learns exactly how relates to the physical parameter of interest. To some extent this is also dependent upon the training we are doing: we are, in some sense, optimizing the inputs for the architecture of our network, in addition to optimizing the network that uses those inputs. A different set of layer and node parameters, or a different learning rate, for example, might respond differently to the choice of input values.
To quantify how well a networks performs, in addition to the loss function, we will report the mean bias, uncertainty, and 3 outlier rate, computed for the parameter
[TABLE]
where, as above, is the true value of the galaxy property for data point , and is the predicted value for the galaxy property computed using the vector . We report , , and the fraction of data points with . We select the set of inputs with the minimum loss function as our optimal set, as this value is sensitive to both the bias and the uncertainty.
In this section, we will train neural networks for each of the main galaxy properties, with these 5 different input column choices, and with and without simulated photometric noise. We then analyze the bias and uncertainties in the results.
4.1 Basic predictions
4.1.1 Stellar mass
Table 1 shows that we achieve the best performance when our input data includes galaxy magnitudes as well as the set of all colors (not just pairwise colors). Again, while these combinations are possible for a neural network architecture to uncover, for our neural network architecture, we found that it was more efficient to provide all combinations at the beginning and let the network learn how best to include them, rather than letting those combinations be created by the network itself.
In Fig. 4, we show the loss function plotted against the number of training steps for different sets of input columns. The numerical noise of the algorithm is obvious from the non-monotonic behavior and sharp jumps in some of the lines. The magnitude-only or color-only networks, which did not perform as well for stellar mass, asymptote to relatively high values of the loss relatively early on; 100 steps in, however, the magnitude plus color networks are still improving.
In the absence of noise, our performance in is reasonable for individual galaxies, with overall biases a few percent or less and uncertainty of the order of 10%, as shown in Table 1. Visual inspection confirms that the overall distribution is well reproduced, although the K-S test indicates that the distributions are statistically different. The error as a function of galaxy parameter in Fig. 5 demonstrates that we can train the networks well where there is a high density of points, with increased errors towards the tails of the distribution.
We now compare our results to stellar mass measurements of mock catalogs. Mobasher et al. (2015) performed a comprehensive study to estimate uncertainties and sources of bias in measuring physical parameters in galaxies. A number of different tests were performed, based on different initial parameters and codes. Here we adopt their TEST-2A as our benchmark comparison. This is based on semianalytic models with a diversity of star formation histories and other parameters, and as with our semianalytic models, used measurements in CANDELS filter bands as their data set. We note that TEST-2A used more CANDELS bands than our measurement here: 13 instead of 8, including U-band, K-band, and Spitzer infrared data in addition to the Hubble optical and near-infrared bands we use, and excluding the F184W (ACS) filter that we use. Comparing to the distribution of biases and uncertainties returned by the individual methods in Mobasher et al. 2015, we find that we easily improve on the bias and have competitive uncertainty in our measurements. However, we expect to have lower bias: different assumptions of initial mass functions, star formation rates, etc were found by Mobasher et al. 2015 to be a source of systematic offsets between different codes, adding a constant bias to every galaxy, whereas we are implicitly assuming the same initial mass function and star formation rate since our samples are drawn from the same mock catalog. Our templates also have varying amounts of dust and varying metallicities, the lack of which has also been found to bias stellar mass estimates (Mitchell et al., 2013).
We repeat the analysis with pseudo observational error, either matched to the full uncertainty distribution or matched to the uncertainty distribution of galaxies which have at least a -detected flux measurement in each band. We show only the best-performing input column set from the noise-free case, after checking that this column choice still performs best when error is added. This additional simulated observational noise causes an increase in bias and a large increase in uncertainty, visible in the right-hand plots of Fig. 5. However, the average bias of dex is still smaller by an order of magnitude than any of the biases from Mobasher et al. (2015) (with the same caveat about correct implicit assumptions), and the uncertainty only a little worse than the maximum uncertainty from that comparison, 0.203 dex instead of 0.183 dex. Because the simulation with full pseudo observational uncertainty is the closest to the real data and will be reused throughout the paper, we will call it the ”GOODS-S mock with uncertainties”, to distinguish it from the base mocks that do not include observational error or include a lesser amount of uncertainty.
4.1.2 Metallicity
As with stellar mass, we find good performance from our metallicity-predicting neural networks, with small biases and order 10% uncertainty, as shown in Table 2 and Fig. 6. The overall predicted distribution is somewhat more skewed from the original distribution than in the stellar mass case, though again we perform well where the density of training points is high. As with the stellar mass, we perform worse when we use the GOODS-S mock with uncertainties, but not by a significant amount: an increase of bias by a factor of 2 and uncertainty by a factor of 3. This uncertainty, of 0.2 dex in the full-noise case, is larger than the convolutional neural network machinery of Wu & Boada (2018), who obtained 0.08 dex uncertainty, albeit using substantially more data (3-color 128x128 pixel cutouts, not eight measured magnitudes) and brighter and lower-redshift galaxies (brighter than 25th magnitude). We obtain a similar result to theirs in that low-metallicity galaxies have systematically high metallicity predictions in the presence of noise.
This good performance on metallicity requires some discussion. Metallicity is typically the hardest of the physical properties of galaxies measured by traditional methods. The dominant component of our performance is driven by the relationship between metallicity and stellar mass. There is a strong relationship between these quantities in data and in simulation (Lu et al., 2014, and references therein), and in practice the fact that we can fit stellar mass well means that most of our prediction of metallicity comes from the ability of the network to learn the connection and to predict from the photometry, as can be seen by the similar shape of the bias-parameter curves in the noisy right-hand columns of in Fig. 5 and Fig. 6. That cannot be the full picture–metallicity performs best when we use colors alone, while stellar mass performs best when we use both magnitudes and colors–but it is a significant contributor to our good results. To illustrate this, we fit a simple quadratic equation to the relationship in the simulations to predict a metallicity for each galaxy assuming no noise, and then we check how much improvement we get from the noise-free neural network when compared to this simple -based prediction. Fig. 7 shows a 2-D histogram of this improvement, with points above 0 being an improvement on the polynomial fit, and points below 0 having an increased bias. The bulk of our neural network predictions do improve on the simple model, by 1-2, but given that our data span more than 2 orders of magnitude, an improvement of 0.1-0.2 dex indicates that the simple stellar mass-metallicity relationship can explain a good fraction of our predicted metallicities. The additional improvement is also suggested by the fact that the metallicity network performs better without magnitudes, while the stellar mass network performs better with them, meaning that the metallicity network must be learning different information than stellar mass alone. Still, this effect suggests that, for any method, if metallicity is not well-constrained by the data, using a stellar mass-based prior with appropriate uncertainty may produce satisfactory results.
4.1.3 Star formation rate
For the star formation rate, we have slightly higher bias and uncertainty. The bias of dex corresponds to a 12 percent error in linear space, visible in the histogram of Fig. 8 as the blue prediction histogram peaking slightly higher than the true distribution in red. Much of the uncertainty is contributed by points with very low star formation rates. Fig. 8 shows the performance as a function of predicted star formation rate as well as a histogram of true and predicted values.
This increased bias relative to other physical parameters is consistent with results from the literature: Laigle et al. (2019), performing a similar comparison to ours using SED fitting and the Horizon-AGN hydrodynamic simulations (Kaviraj et al., 2017), find star formation rate biases of order 0.2 dex and uncertainties of order 0.2-0.6 dex, very consistent with our full-noise bias of dex and uncertainty of dex. We expect to do better than Laigle et al. 2019, however, since one of the limitations of the SED fitting approach is that a (usually simplistic) star formation history must be assumed, while our training sample is instead drawn from a simulation which allows for more variation in star formation history.
4.2 Redshift effects
None of these networks used redshift as an input, but template-fitting methods generally require it (Mobasher et al., 2015). Do our results improve if we add redshift as an input to the networks trained on the other galaxy properties? We take the best-performing input column set for stellar mass, metallicity, and star formation rate, and add redshift as an input. The results are summarized in Table 4. For stellar mass and star formation rate, the mean bias and the uncertainty both improve. However, the improvement in the uncertainty is generally small, and the change in bias is less than the uncertainty for all three galaxy properties. This is an encouraging result, as it means we can achieve good accuracy without needing to supplement our data with spectroscopic redshifts.
5 Comparison of SED-fitting and neural networks on mock data
We would like to use our trained neural networks on real data. However, real data lacks perfect information on the quantities we are measuring. For our comparison data set, then, we will measure our physical parameters of interest through template fitting.
Here we quantify the difference expected in the analysis due to the difference between the true values and the template-fitting results. Different underlying parameterizations or parameter choices in the mock catalog simulations and the SED templates (e.g., star formation histories and dust attenuation laws) may lead not just to an increase in RMS uncertainty or a global offset but to biases in different regions of the parameter space. To explore this effect, we perform the same SED template fitting procedure directly on the mock catalog for the GOODS-S region, doped with observational uncertainty as described previously, which we continue to call ”the GOODS-S mock with uncertainties”. We show the results for stellar mass and star formation rate in Fig. 9, with the result summarized in table form in Table 5. We find a clear offset at low stellar mass and a global offset in the star formation rate. The size is about as expected above , and somewhat larger for the less-frequent small stellar mass galaxies. The offset in star formation rate is also as expected, dex. Some of the large scatter is caused by the large number of faint galaxies in the semianalytic sample, where SED fitting does not perform as well; while the neural network performs better for these faint galaxies, on a more strongly magnitude-selected sample like we see in the CANDELS data, the performance of the two methods is similar. The scatter shown here, then, with the full complement of faint galaxies, will tend to underestimate the discrepancy between our neural network results and our SED-fitting results.
6 Performance on CANDELS data
Now, We turn to exploring if networks trained on semianalytic models can be applied to observed galaxy data. We use the CANDELS data from the GOODS-S field described in Section 2.1, with the physical parameters measured through template fitting as described in Section 5). From Mobasher et al. (2015), we know that different template-fitting methods can result in differences in the stellar masses of 0.2 dex. From Laigle et al. (2019), we expect that our star formation rate biases will also be of order dex with greater uncertainty. We may be able to improve on star formation rate in particular, since using a simulation has allowed us to use more complicated star formation histories than a typical SED fitting approach, and the simplicity of star formation histories is a major source of bias and uncertainty in SED-derived star formation rates. However, we are limited in the dust attenuation laws used in our simulation. Since this is also a major source of uncertainty in star formation rates (Laigle et al., 2019), our ability to improve on star formation rate performance may be similarly limited. Both of these give an estimate of the accuracy we should aim for in our estimates of the stellar mass and star formation rate by our neural network technique.
We show the performance on CANDELS data of the network trained on the GOODS-S mock with uncertainties in Table 6 and Fig. 10. The neural networks trained on semianalytic data without observational noise, or with limited observational noise, do not reproduce the data well. This is not surprising, however: the power of neural networks is that they reproduce high-dimensional nonlinear structures, so perturbing the data by some error has nonlinear effects on the prediction. As we add noise, the performance on the data improves, even though the performance on the mock catalogs degrades, since the training mock data becomes more similar to the observational data.
The difference between the neural network predictions and the template-fitting predictions for the stellar mass are within our expectation of 0.2 dex for differences between template-fitting methods with different assumptions. We note that the difference is of the opposite sign as would be expected from Fig. 9, where we expect the predicted stellar mass to be larger than the (underestimated) SED-fit stellar mass at low masses; exact comparisons cannot be made since we plot as a function of predicted stellar mass, meaning the curves from Fig. 9 are actually shifted by some amount in the -direction. Still, even including this effect, our median stellar masses are within the expectation. However, the star formation rate numbers are significantly more discrepant. Here, the difference is in the expected direction from Fig. 9, although larger; a rough estimate is that about half the observed bias is the bias from the SED fitting, meaning that we are likely within expectations for , but still above that bias value for smaller star formation rates. The large uncertainty in stellar mass likely derives from the uncertainty in the SED fits, which is large, up to dex, similar to the uncertainty in this comparison. Again, the star formation rate values have greater scatter than expected from either the SED fitting or from the neural network training, indicating that the trouble likely lies in a difference in the mock catalog relative to the data.
Interestingly, we sometimes obtain lower average bias or uncertainty when the method is applied to CANDELS data than we did on the simulations. This is because the neural networks, like most methods, perform better on brighter galaxies than fainter galaxies since brighter galaxies have lower relative uncertainty than fainter galaxies. Therefore, when we compare our results on simulations to our results on CANDELS data, we are conflating two effects: one, the fact that we are not as accurate or precise for a given individual galaxy in the CANDELS data as we are for a given galaxy of the same magnitude in the mock data, and two, the fact that we are measuring an average performance across a population and the CANDELS galaxies are on average “easier” since they are brighter. Using a population of brighter galaxies like the CANDELS data, in other words, will produce an apparently better result for the exact same method than using a population of fainter galaxies like the simulations. In our case, the size of the difference between the average apparent magnitude of the two populations—simulations and CANDELS data—is 0.2-0.35 magnitudes depending on the filter. This difference in average population improves our performance so much, just by being an easier problem to solve, that our average performance improves, even if our performance on similar galaxies worsens.
The performance in is promising, but the performance of star formation rate is less satisfactory. We consider here what could be causing this difference. The first possibility is differences between the physics of the simulation, the physics of the SED-fitting procedure, and the physics of the universe. Because both the simulation and the SED-fitting procedure have certain complexities the other method lacks, such as variation in star formation histories in the simulation and emission lines in the SED-fitting, and because we do not have truth values for the universe, distinguishing subtle differences would require more detailed investigation than we undertake here. However, we can investigate systematic differences between the SED fitting or the underlying CANDELS data and our training sample or training procedure. We can first rule out most causes that fault the SED fitting rather than the neural network: we know the approximate size of this uncertainty from our tests above.
The largest difference between the mock catalog and the observational data is that the mock catalog contains no noise. We dope the mock catalog with noise and improve our performance, but we are working with a pre-existing mock catalog that had already applied selection cuts to match the CANDELS data. Since the process of applying noise and applying cuts do not commute, we may have induced a kind of Eddington bias, where we are preferentially missing the type of faint galaxies (and therefore preferentially low mass and low star formation rate galaxies) that scattered up into our observational sample. The templates, being a parametric set intended to work as a kind of basis function space, do not suffer from this bias, and therefore would be more accurate if Eddington bias is considered. It is also possible that, while we correctly reproduce color-space density in one and two dimensions, we have incorrectly reproduced some higher-dimensional manifold when generating the noisy mock catalog, and therefore that more of our data points lie off the manifold than might be expected. As mentioned above, the major strength but also the major weakness of neural network solutions is that they can reproduce highly nonlinear manifolds. When the data are a highly nonlinear manifold, this is good; however, even a small movement off the expected manifold can cause an extremely poor extrapolation. The templates, being constrained, would not suffer this effect. We made some measurements of average distance to the nearest training sample point for both the test set and the observational data, and did not see any signs of increased distance, but distance measures can be hard to interpret in high-dimensional space so this is still a possibility. In the future, if an approach like this–ML algorithms trained on simulated data–is used to measure galaxy properties, a mock catalogue tuned not only to the physical parameters of interest but to the noise properties of the observational catalog will be needed to ensure accuracy. This is consistent with the findings of Davidzon et al. (2019), who spend significant effort reproducing the noise properties of their observational data.
7 Summary and Discussion
We train neural networks on semianalytic models to predict from photometric data three galaxy properties of scientific interest: stellar mass, stellar metallicity, and average star formation rate. In the absence of noise–the best-case scenario–we achieve excellent accuracy and precision on all properties, indicating that the mapping from galaxy photometry to galaxy physical properties has low enough noise and few degeneracies. Injecting artificial photometric noise degrades the performance on a reserved sample of semianalytic galaxies, but allows the algorithm to perform better on real data from CANDELS, which contains noise.
Our accuracy and precision show that semianalytic galaxies can be used to train neural networks that can produce photometric stellar masses, metallicities, and star formation rates, and that these galaxy properties are accessible targets for machine learning. However, our performance on noisy simulated data is not yet fully competitive with mature template-fitting and machine-learning methods from the literature. There are several likely reasons for this discrepancy. Because our model includes many more free parameters, we may be trading off precision (a narrower set of outputs generated by a template) with accuracy: our mean bias is lower for stellar mass, but our uncertainty is higher. Also, as mentioned in Section 4.1.2, we have used a wide range of fluxes and redshifts, a calibration set that may be more ambitious than some of the data sets we are comparing to. Still, as a first-step implementation of neural networks on these data, we have achieved good accuracy in predicting all galaxy properties.
If the offset and scatter between neural networks and SED-fitting on simulation data is similar in real CANDELS data, then the performance on real CANDELS data is not as accurate or precise as comparison data sets from the literature (Mobasher et al., 2015). Some of that is driven by our decreased accuracy in the presence of noise even for the semianalytic galaxies, although the fact that the galaxies in CANDELS are brighter, on average, than our semianalytic galaxies means that in some cases we do better on the average CANDELS galaxy than we do on the average semianalytic galaxy. Also, we note that the photometry in the semianalytic catalog was designed to match the CANDELS observed distributions, but since the CANDELS data are noisy and the semianalytic galaxies are not, we expect some mismatch between the locations of the underlying noise-free manifolds. Additionally, we do not expect perfect agreement, since the template-fitting results rely on other parameters (such as redshift and metallicity) that may differ from the values in our semianalytic catalogue; these differences in assumptions explain some of our observed discrepancies. Of course, some further underlying differences between the simulation and reality may make our comparison between the two methods less accurate. Assuming the measured relationship holds in CANDELS, then, and accounting for the measured bias and uncertainty between mock catalog values and the results from performing our SED fitting procedure on the mock catalogs, we have nearly competitive accuracy (in the sense of low bias) and precision (low scatter) in stellar mass, and competitive precision but larger-than-expected inaccuracy for star formation rate. For future research, we recommend that a study of this nature should use a mock catalog created for the purpose with photometric noise already included when generating the catalog, as this is the most likely cause of differences between our mock data and the CANDELS data.
Interestingly, our results show that adding redshift information to our training sample results in either minor improvement or in degradation of accuracy and precision, indicating that the networks are capable of learning the relevant mapping between color, redshift, and other galaxy properties without explicit redshift information. This indicates that competitive accuracy and precision can be achieved even for galaxies that lack spectroscopic redshifts, greatly increasing the available sample sizes for future studies.
We have been able to obtain good accuracy and precision for stellar metallicities, which is the most difficult to measure of the galaxy properties. This result is driven by a strong relationship between metallicity and stellar mass. We improve on the accuracy obtained by simply relying on a stellar mass–metallicity relation, but the improvement is order 0.1 dex, compared to the more than two orders of magnitude range in the parameter space, indicating that the predictive accuracy is dominated by the stellar mass–metallicity relation. This suggests the use of a strong stellar mass-metallicity prior when trying to obtain stellar metallicities from low-resolution data.
Future work will be needed to develop the machine learning architecture to a higher level of complexity and precision in order to be competitive in accuracy with currently-existing methods. However, our work shows that simple machine learning methods that do not know about the physics of galaxy formation and evolution can in principle reproduce galaxy property measurements with high accuracy, as long as the training set and the data of interest are consistent with one another and the machine learning is carefully trained to handle degeneracies and noise inherent in the data. This allows for not only the use of semianalytic models as a training set for galaxy property measurement, but also an increase of computational speed of template-fitting efforts–for example, if template-fitted stellar masses are available for a representative spectroscopic subset of a large photometric survey, then machine learning is a computationally efficient way to extend those template-fitting results to the larger photometric data set. As we have shown here, machine learning methods can be trained on complicated relationships between galaxy properties and photometry measurements drawn from a small number of filters, indicating that scientifically interesting galaxy properties can be measured with reasonable computational time on future datasets from large-scale photometric surveys.
Support for this work was provided by the University of California Riverside Office of Research and Economic Development through the FIELDS NASA-MIRO program. A portion of this research was carried out at the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration. We would like to acknowledge Dritan Kodra for the updated CANDELS photometric redshift catalog.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abadi et al. (2015) Abadi M., et al., 2015, Tensor Flow: Large-Scale Machine Learning on Heterogeneous Systems, https://www.tensorflow.org/
- 2Abdalla et al. (2011) Abdalla F. B., Banerji M., Lahav O., Rashkov V., 2011, MNRAS , 417, 1891 · doi ↗
- 3Abraham et al. (2018) Abraham S., Aniyan A. K., Kembhavi A. K., Philip N. S., Vaghmare K., 2018, MNRAS , 477, 894 · doi ↗
- 4Aragon-Calvo (2018) Aragon-Calvo M. A., 2018, preprint, ( ar Xiv:1804.00816 )
- 5Arnouts et al. (1999) Arnouts S., Cristiani S., Moscardini L., Matarrese S., Lucchin F., Fontana A., Giallongo E., 1999, MNRAS , 310, 540 · doi ↗
- 6Ball et al. (2008) Ball N. M., Brunner R. J., Myers A. D., Strand N. E., Alberts S. L., Tcheng D., 2008, Ap J , 683, 12 · doi ↗
- 7Barchi et al. (2019) Barchi P. H., et al., 2019, ar Xiv e-prints, p. ar Xiv:1901.07047
- 8Beck et al. (2017) Beck R., Lin C. A., Ishida E. E. O., Gieseke F., de Souza R. S., Costa-Duarte M. V., Hattab M. W., Krone-Martins A., 2017, MNRAS , 468, 4323 · doi ↗