A Memory-Efficient Sketch Method for Estimating High Similarities in Streaming Sets
Pinghui Wang, Yiyan Qi, Yuanming Zhang, Qiaozhu Zhai, Chenxu Wang,, John C.S. Lui, Xiaohong Guan

TL;DR
This paper introduces MaxLogHash, a memory-efficient sketching method for accurately estimating high set similarities in streaming data, outperforming existing techniques in memory usage while maintaining accuracy.
Contribution
We propose MaxLogHash, a novel sketch method that significantly reduces memory requirements for estimating high similarities in streaming sets, addressing limitations of prior compressed MinHash variants.
Findings
MaxLogHash is about 5 times more memory efficient than MinHash.
It achieves comparable accuracy with smaller register sizes.
Experimental results confirm its effectiveness on various datasets.
Abstract
Estimating set similarity and detecting highly similar sets are fundamental problems in areas such as databases, machine learning, and information retrieval. MinHash is a well-known technique for approximating Jaccard similarity of sets and has been successfully used for many applications such as similarity search and large scale learning. Its two compressed versions, b-bit MinHash and Odd Sketch, can significantly reduce the memory usage of the original MinHash method, especially for estimating high similarities (i.e., similarities around 1). Although MinHash can be applied to static sets as well as streaming sets, of which elements are given in a streaming fashion and cardinality is unknown or even infinite, unfortunately, b-bit MinHash and Odd Sketch fail to deal with streaming data. To solve this problem, we design a memory efficient sketch method, MaxLogHash, to accurately estimate…
Click any figure to enlarge with its caption.
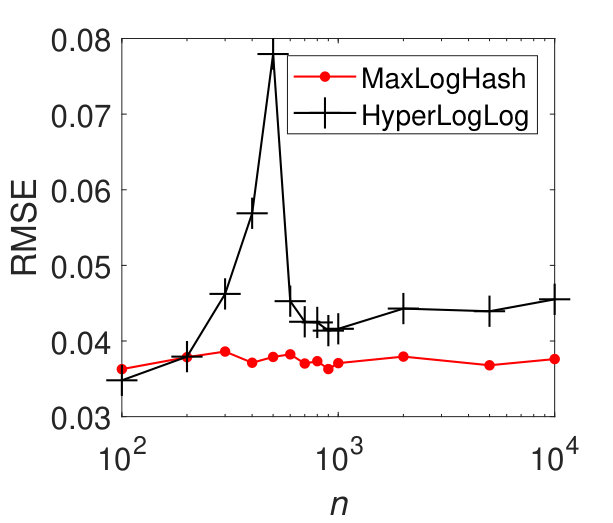 Figure 1
Figure 1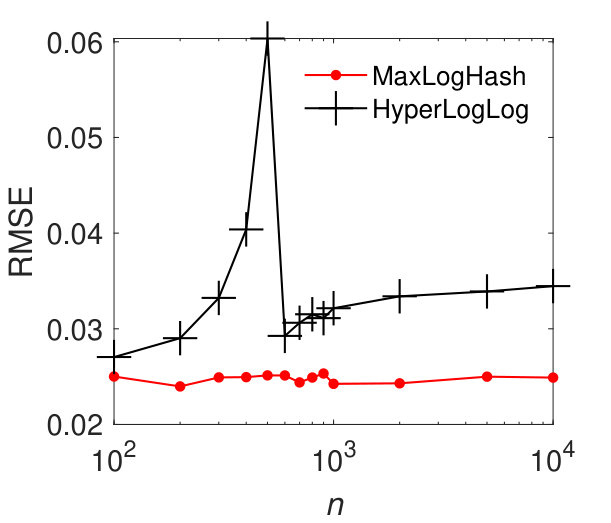 Figure 2
Figure 2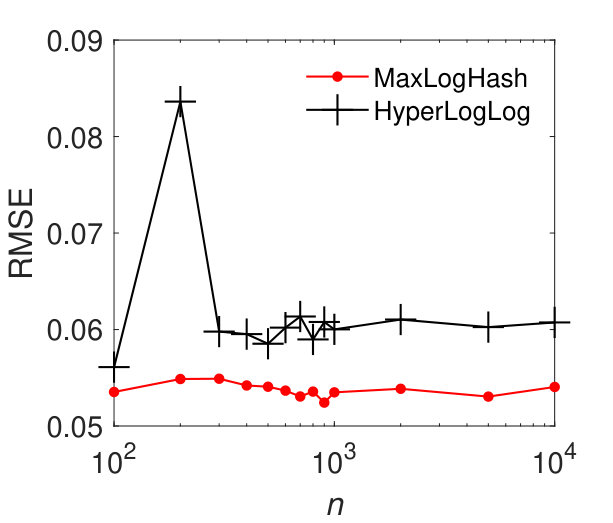 Figure 3
Figure 3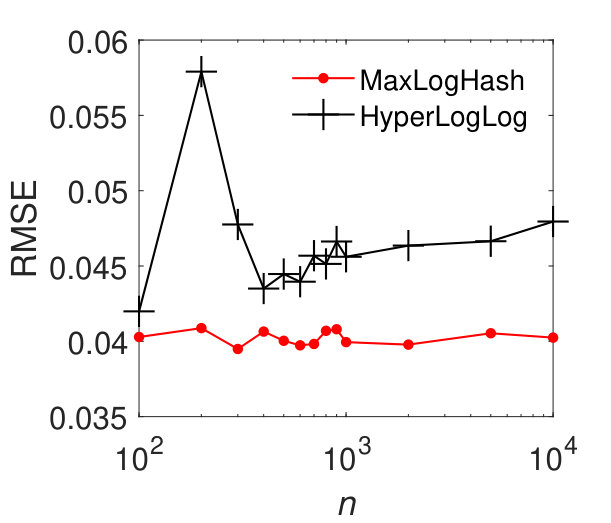 Figure 4
Figure 4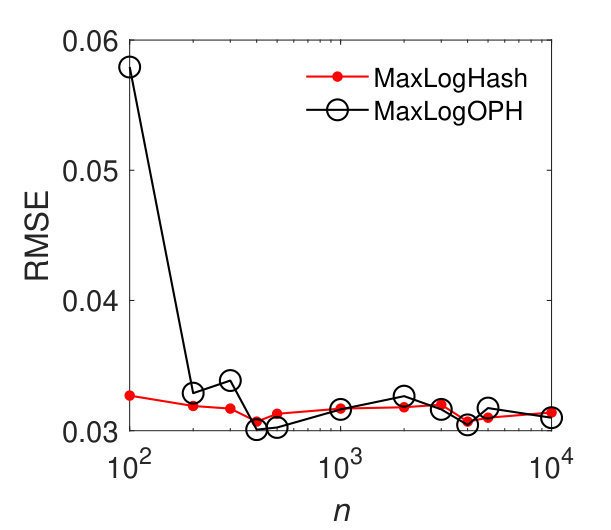 Figure 5
Figure 5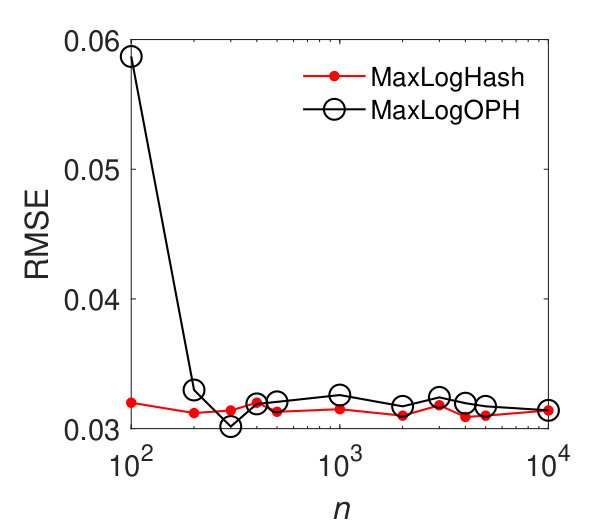 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8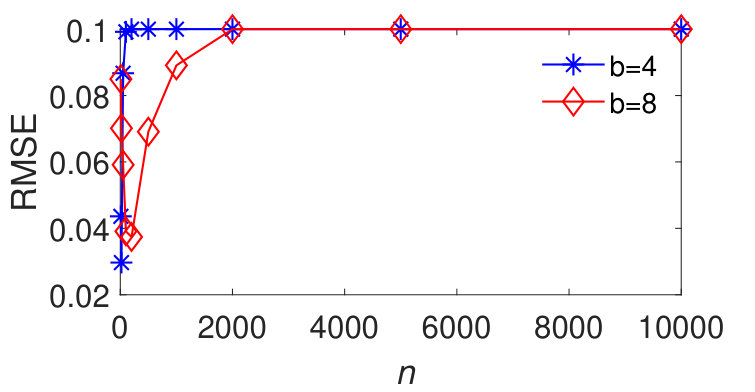 Figure 9
Figure 9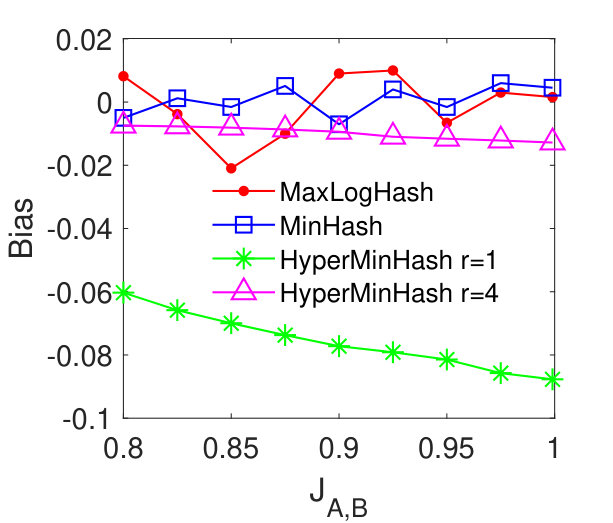 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12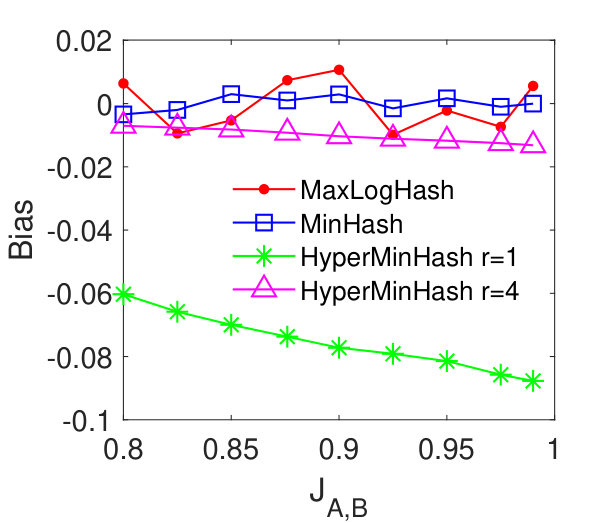 Figure 13
Figure 13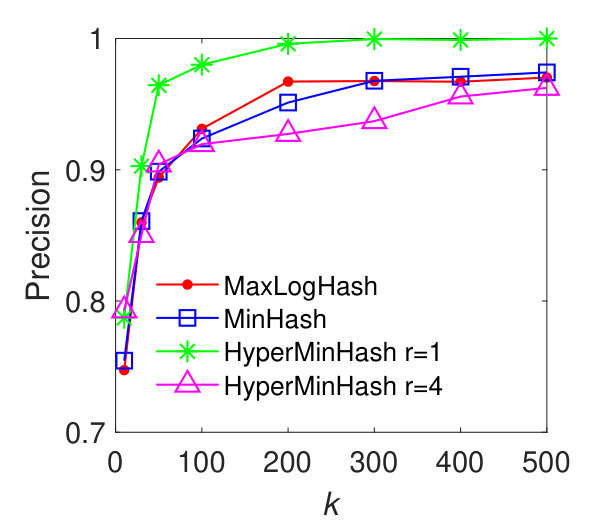 Figure 14
Figure 14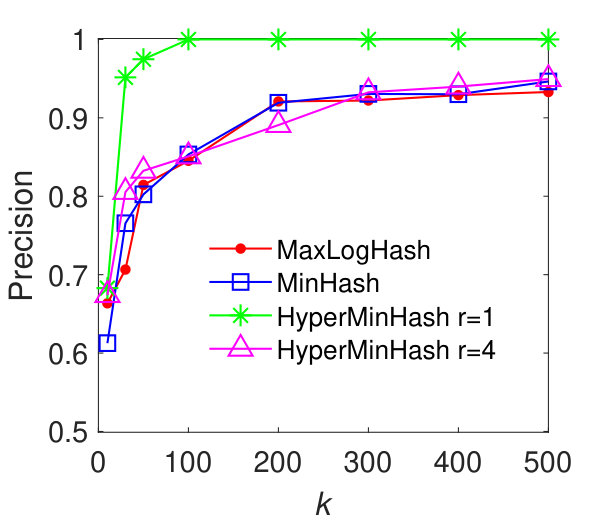 Figure 15
Figure 15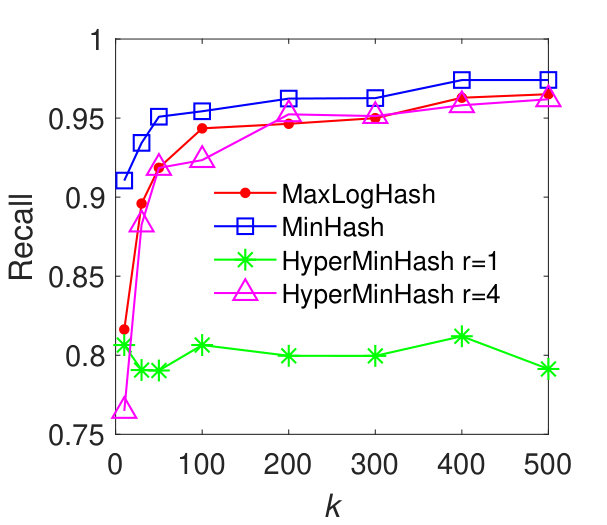 Figure 16
Figure 16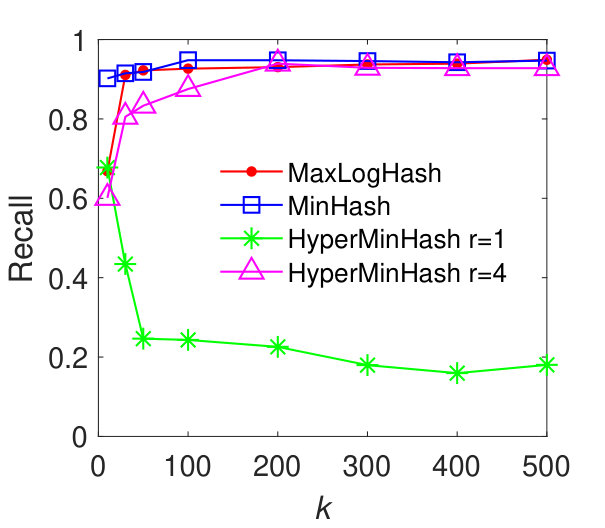 Figure 17
Figure 17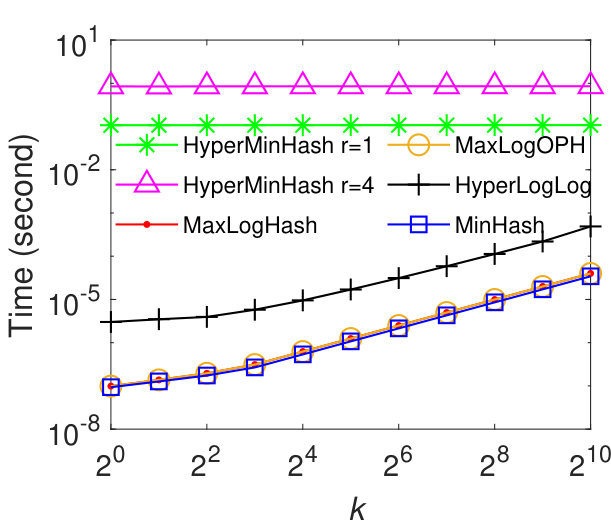 Figure 18
Figure 18 Figure 19
Figure 19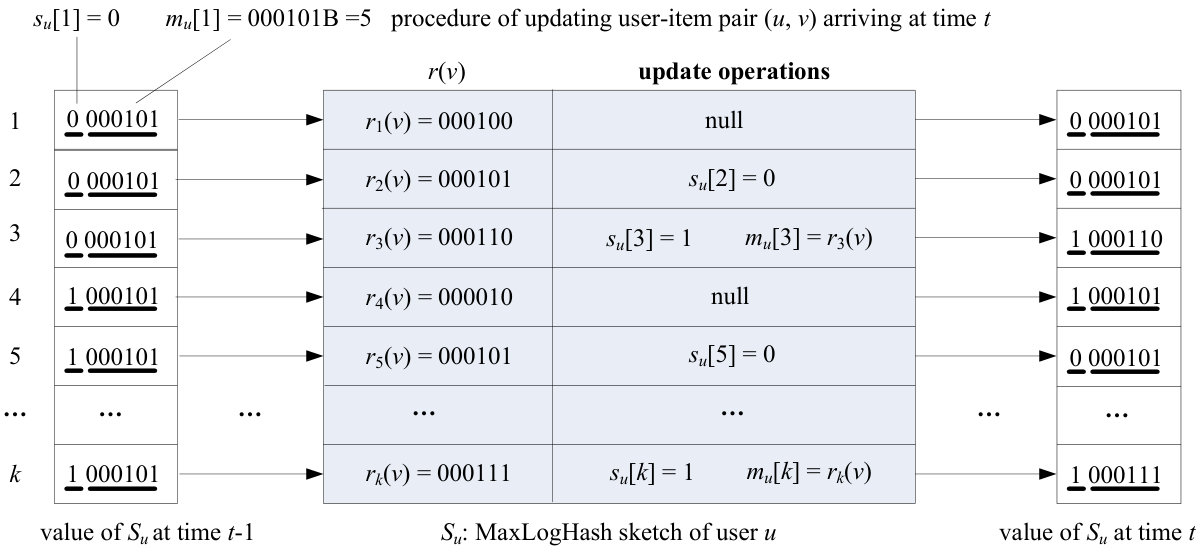 Figure 20
Figure 20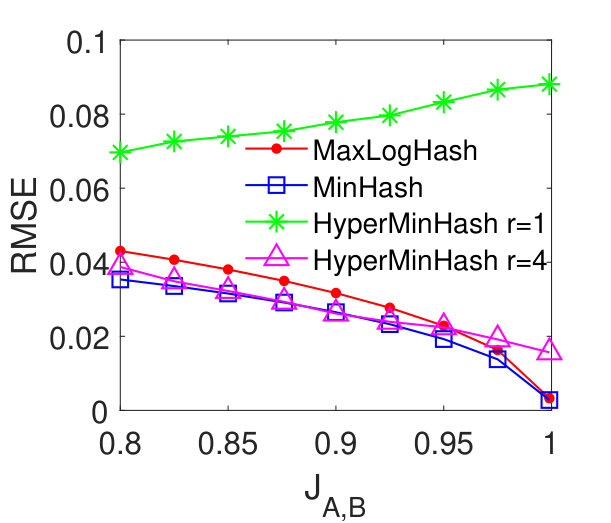 Figure 21
Figure 21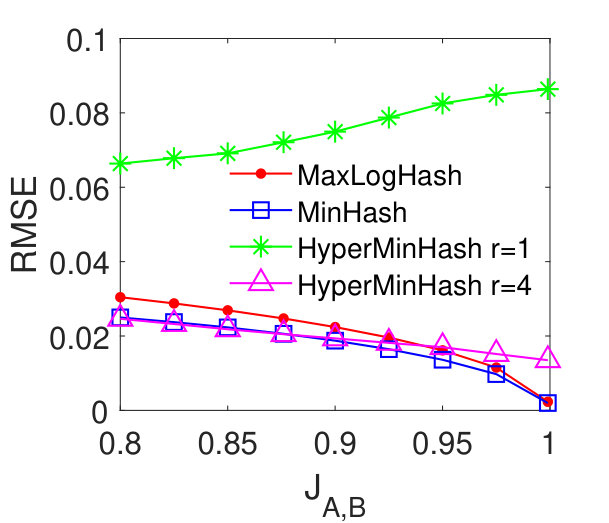 Figure 22
Figure 22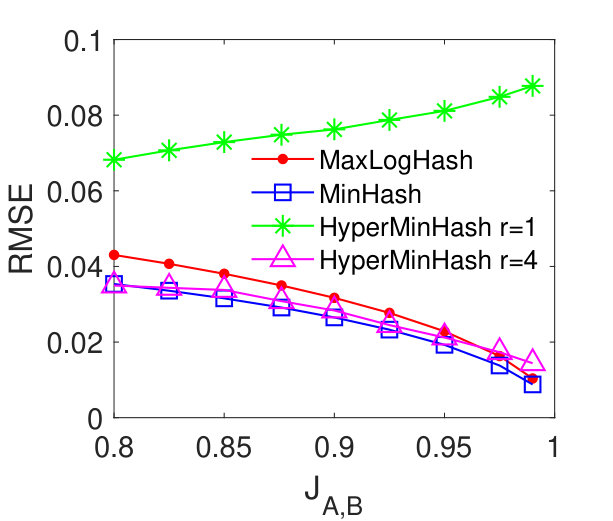 Figure 23
Figure 23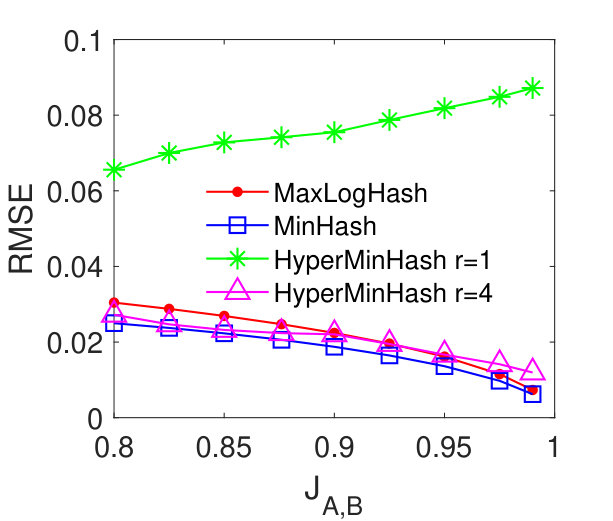 Figure 24
Figure 24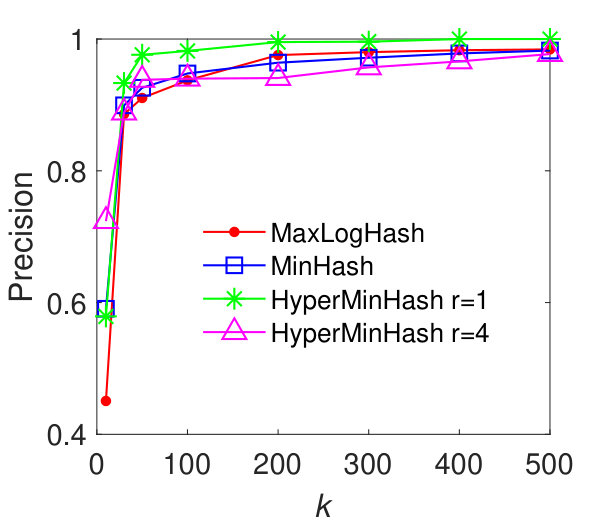 Figure 25
Figure 25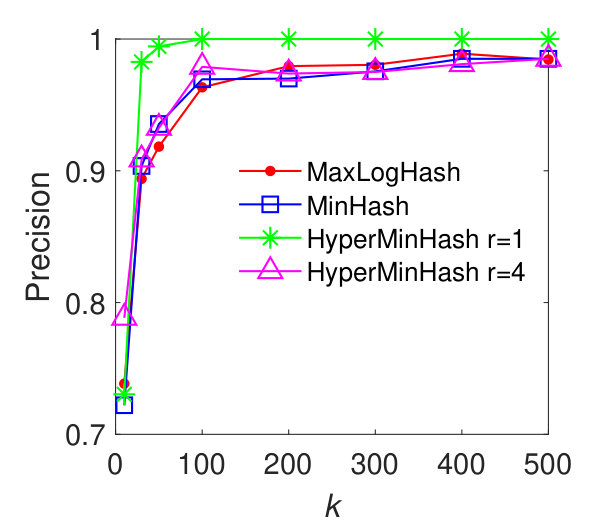 Figure 26
Figure 26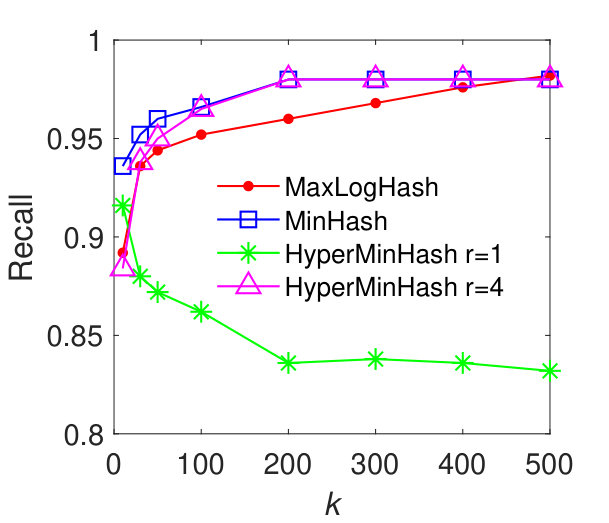 Figure 27
Figure 27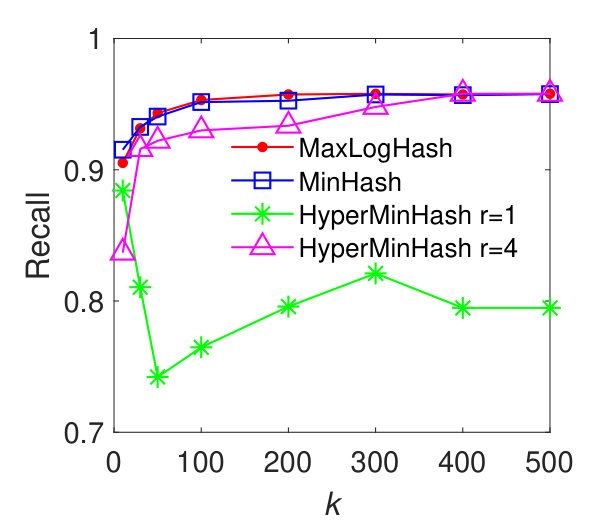 Figure 28
Figure 28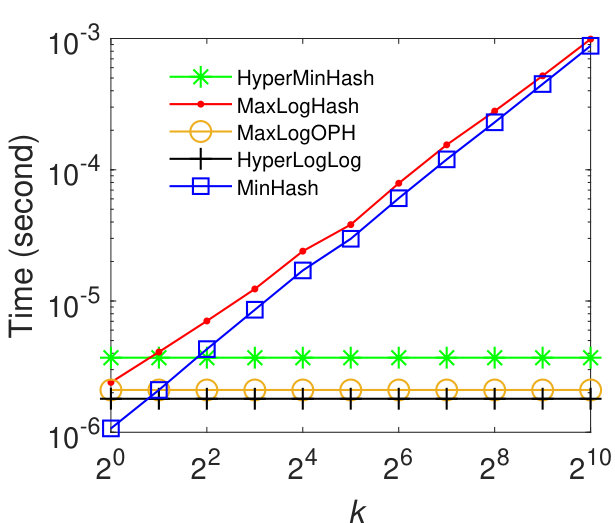 Figure 29
Figure 29Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Memory-Efficient Sketch Method for Estimating
High Similarities in Streaming Sets
Pinghui Wang1,2,⋆, Yiyan Qi1,⋆, Yuanming Zhang1, Qiaozhu Zhai1, Chenxu Wang2,∗
and
John C.S. Lui3, Xiaohong Guan2,1,4,∗
1NSKEYLAB, Xi’an Jiaotong University, Xi’an, China2Shenzhen Research Institute of Xi’an Jiaotong University, Shenzhen, China3The Chinese University of Hong Kong, Hong Kong4Department of Automation and NLIST Lab, Tsinghua University, Beijing, China
phwang,qzzhai,cxwang,[email protected], qiyiyan,[email protected],
(2019)
Abstract.
Estimating set similarity and detecting highly similar sets are fundamental problems in areas such as databases, machine learning, and information retrieval. MinHash is a well-known technique for approximating Jaccard similarity of sets and has been successfully used for many applications such as similarity search and large scale learning. Its two compressed versions, -bit MinHash and Odd Sketch, can significantly reduce the memory usage of the original MinHash method, especially for estimating high similarities (i.e., similarities around 1). Although MinHash can be applied to static sets as well as streaming sets, of which elements are given in a streaming fashion and cardinality is unknown or even infinite, unfortunately, -bit MinHash and Odd Sketch fail to deal with streaming data. To solve this problem, we design a memory efficient sketch method, MaxLogHash, to accurately estimate Jaccard similarities in streaming sets. Compared to MinHash, our method uses smaller sized registers (each register consists of less than 7 bits) to build a compact sketch for each set. We also provide a simple yet accurate estimator for inferring Jaccard similarity from MaxLogHash sketches. In addition, we derive formulas for bounding the estimation error and determine the smallest necessary memory usage (i.e., the number of registers used for a MaxLogHash sketch) for the desired accuracy. We conduct experiments on a variety of datasets, and experimental results show that our method MaxLogHash is about 5 times more memory efficient than MinHash with the same accuracy and computational cost for estimating high similarities.
Streaming algorithms;Sketch;Jaccard coefficient similarity
⋆Pinghui Wang and Yiyan Qi contributed equally to this work.
∗Corresponding Author.
††copyright: acmcopyright††journalyear: 2019††copyright: acmcopyright††conference: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining; August 4–8, 2019; Anchorage, AK, USA††booktitle: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’19), August 4–8, 2019, Anchorage, AK, USA††price: 15.00††doi: 10.1145/3292500.3330825††isbn: 978-1-4503-6201-6/19/08††ccs: Mathematics of computing Probabilistic algorithms††ccs: Information systems Similarity measures††ccs: Theory of computation Sketching and sampling
1. Introduction
Data streams are ubiquitous in nature. Examples range from financial transactions to Internet of things (IoT) data, network traffic, call logs, trajectory logs, etc. Due to the nature of these applications which involve massive volume of data, it is prohibitive to collect the entire data streams, especially when computational and storage resources are limited (Li2018Approximate, ). Therefore, it is important to develop memory efficient methods such as sampling and sketching techniques for mining large streaming data.
Many datasets can be viewed as collections of sets and computing set similarities is fundamental for a variety of applications in areas such as databases, machine learning, and information retrieval. For example, one can view each mobile device’s trajectory as a set and each element in the set corresponds to a tuple of time and the physical location of the device at time . Then, mining devices with similar trajectories is useful for identifying friends or devices belonging to the same person. Other examples are datasets encountered in computer networks, mobile phone networks, and online social networks (OSNs), where learning user similarities in the sets of users’ visited websites on the Internet, connected phone numbers, and friends on OSNs is fundamental for applications such as link prediction and friendship recommendation.
One of the most popular set similarity measures is the Jaccard similarity coefficient, which is defined as for two sets and . To handle large sets, MinHash (or, minwise hashing) (Broder2000, ) is a powerful set similarity estimation technique, which uses an array of registers to build a sketch for each set. Its accuracy only depends on the value of and the Jaccard similarity of two sets of interest, and it is independent from the size of two sets. MinHash has been successfully used for a variety of applications, such as similarity search (BroderSEQUENCES1997, ), compressing social networks (ChierichettiKDD2009, ), advertising diversification (GollapudiWWW2009, ), large scale learning (LiNIPS2011, ), and web spam detection (UrvoyTOW2008, ). Many of these applications focus on estimating similarity values close to 1. Take similar document search in a sufficiently large corpus as an example. For a corpus, there may be thousands of documents which are similar to the query document, therefore our goal is not just to find similar documents, but also to provide a short list (e.g., top-10) and ranking of the most similar documents. For such an application, we need effective methods that are very accurate and memory-efficient for estimating high similarities. To achieve this goal, there are two compressed MinHash methods, -bit MinHash (PingWWW2010, ) and Odd Sketch (MitzenmacherWWW14, ), which were proposed in the past few years to further reduce the memory usage of the original MinHash by dozens of times, while to provide comparable estimation accuracy especially for large similarity values. However, we observe that these two methods fail to handle data streams (the details will be given in Section 3).
To solve the above challenge, recently, Yu and Weber (YuArxiv2017, ) develop a method, HyperMinHash. HyperMinHash consists of registers, whereas each register has two parts, an FM (Flajolet-Martin) sketch (Flajolet1985, ) and a -bit string. The -bit string is computed based on the fingerprints (i.e., hash values) of set elements that are mapped to the register. Based on HyperMinHash sketches of two sets and , HyperMinhash first estimates and then infers the Jaccard similarity of and from the number of collisions of -bit strings given . Later in our experiments, we demonstrate that HyperMinHash not only exhibits a large bias for high similarities, but it is also computationally expensive for estimating similarities, which results in a large estimation error and a big delay in querying highly similar sets. More importantly, it is difficult to analytically analyze the estimation bias and variance of HyperMinHash, which are of great value in practice–the bias and variance can be used to bound an estimate’ error and determine the smallest necessary sampling budget (i.e., ) for a desired accuracy. In this paper, we develop a novel memory efficient method, MaxLogHash, to estimate Jaccard similarities in streaming sets. Similar to MinHash, MaxLogHash uses a list of registers to build a compact sketch for each set. Unlike MinHash which uses a 64-bit (resp. 32-bit) register for storing the minimum hash value of 64-bit (resp. 32-bit) set elements, our method MaxLogHash uses only 7-bit register (resp. 6-bit register) to approximately record the logarithm value of the minimum hash value, and this results in 9 times (resp. 5 times) reduction in memory usage. Another attractive property is that our MaxLogHash sketch can be computed incrementally, therefore, MaxLogHash is able to handle streaming-sets. Given any two sets’ MaxLogHash sketches, we provide a simple yet accurate estimator for their Jaccard similarity, and derive exact formulas for bounding the estimation error. We conduct experiments on a variety of publicly available datasets, and experimental results show that our method MaxLogHash reduces the amount of memory required for MinHash by 5 folds to achieve the same desired accuracy and computational cost.
The rest of this paper is organized as follows. The problem formulation is presented in Section 2. Section 3 introduces preliminaries used in this paper. Section 4 presents our method MaxLogHash. The performance evaluation and testing results are presented in Section 5. Section 6 summarizes related work. Concluding remarks then follow.
2. Problem Formulation
For ease of reading and comprehension, we say that each set belongs to a user, elements in the set are items (e.g., products) that the user connects to. Let denote the set of users and denote the set of all items. Let denote the user-item stream of interest, where is the element of occurred at discrete time , and are the element’s user and item, which represents a connection from user to item . We assume that has no duplicate user-item pairs111Duplicated user-item pairs can be easily checked and filtered using fast and memory-efficient techniques such as Bloom filter (BloomACMCommun1970, )., that is, when . Let be the item set of user , which consists of items that user connects to before and including time . Let denote the union of two sets and , that is, Similarly, we define the intersection of two sets and as Then, the Jaccard similarity of sets and is defined as
[TABLE]
which reflects the similarity between users and . In this paper, we aim to develop a fast and accurate method to estimate for any two users and over time, and to detect pairs of high similar users. When no confusion arises, we omit the superscript to ease exposition.
3. Preliminaries
In this section, we first introduce MinHash (Broder2000, ). Then, we elaborate two state-of-the-art memory-efficient methods -bit MinHash (PingWWW2010, ) and Odd Sketch (MitzenmacherWWW14, ) that can decrease the memory usage of the original MinHash method. At last, we demonstrate that both -bit MinHash and Odd Sketch fail to handle streaming sets.
3.1. MinHash
Given a random permutation (or hash function222MinHash assumes no hash collisions.) from elements in to elements in , i.e., a hash function maps integers in to distinct integers in at random. Broder et al. (Broder2000, ) observed that the Jaccard similarity of two sets equals
[TABLE]
where . Therefore, MinHash uses a sequence of independent permutations and estimates as
[TABLE]
where is an indicator function that equals 1 when the predicate is true and 0 otherwise. Note that is an unbiased estimator for , i.e., , and its variance is
[TABLE]
Therefore, instead of storing a set in memory, one can compute and store its MinHash sketch , i.e.,
[TABLE]
which reduces the memory usage when . The Jaccard similarity of any two sets can be accurately and efficiently estimated based on their MinHash sketches.
3.2. b-bit MinHash
Li and König (PingWWW2010, ) proposed a method, -bit MinHash, to further reduce the memory usage. -bit MinHash reduces the memory required for storing a MinHash sketch from or bits333A 32- or 64-bit register is used to store each , . to bits. The basic idea behind -bit MinHash is that the same hash values give the same lowest bits while two different hash values give the same lowest bits with a small probability . Formally, let denote the lowest bits of the value of for a permutation . Define the -bit MinHash sketch of set as
[TABLE]
To mine set similarities, Li and König (PingWWW2010, ) first compute for each set , and then store its -bit MinHash sketch . At last, the Jaccard similarity is estimated as
[TABLE]
is also an unbiased estimator for , and its variance is
[TABLE]
3.3. Odd Sketch
Mitzenmacher et al. (MitzenmacherWWW14, ) developed a method Odd Sketch, which is more memory efficient than -bit MinHash when mining sets of high similarity. Odd Sketch uses a hash function that maps each tuple , , to an integer in at random. For a set , its odd sketch consists of bits. Function maps tuples into bits of at random. , , is the parity of the number of tuples that are mapped to the bit of . Formally, is computed as
[TABLE]
The Jaccard similarity is then estimated as
[TABLE]
Mitzenmacher et al. demonstrate that is more accurate than under the same memory usage (refer to (MitzenmacherWWW14, ) for details of the error analysis of ).
3.4. Discussion
MinHash can be directly applied to stream data. We can easily find that MinHash sketch can be computed incrementally. That is, one can compute the MinHash sketch of set from the MinHash sketch of set as
[TABLE]
Variants -bit MinHash and Odd Sketch cannot be used to handle streaming sets. Let denote the lowest bits of . Then, one can easily show that
[TABLE]
It shows that computing requires the hash value of each . In addition, we observe that cannot be approximated as , which can be computed incrementally, because equals 0 with a high probability when . Similarly, we cannot compute the odd sketch of a set incrementally. Therefore, both -bit MinHash and Odd Sketch fail to deal with streaming sets.
4. Our Method
4.1. Basic Idea
Let be a function that maps any element in to a random number in range . i.e., . Define the log-rank of with respect to hash function as We compute and store
[TABLE]
Let us now develop a simple yet accurate method to estimate Jaccard similarity of streaming sets based on the following properties of function .
Observation 1. can be represented by an integer of no more than bits with a high probability. For each , we have , and thus supported on the set , that is,
[TABLE]
Then, one can easily find that
[TABLE]
For example, when and , we only require 6 bits to store with probability at least 0.999.
Observation 2. can be computed incrementally. This is because
[TABLE]
Observation 3. can be easily estimated from and with a little additional information. We find that
[TABLE]
Due to the limited space, we omit the details of how is derived. Similar to MinHash, we have . Therefore, we have . Although can be estimated similar to MinHash using hash functions , that is,
[TABLE]
unfortunately, it is difficult to compute from . To solve this problem, we observe
[TABLE]
where indicates that there exists one and only one element in of which log-rank equals .
Based on the above three observations, we propose to incrementally and accurately estimate the value of using hash functions . Then, we easily infer the value of .
4.2. Data Structure
The MaxLogHash sketch of a user , i.e., , consists of bit-strings, where each bit-string , has two components, and , i.e., At any time , records the maximum hash value of items in with respect to hash function , i.e., , where refers to the set of items that user connected to before and including time ; consists of 1 bit and its value indicates whether there exists one and only one item such that . As we mentioned, we can use bits to record the value of with a high probability (very close to 1). When , we use a hash table to record tuples for all users.
4.3. Update Procedure
For each user , when it first connects with an item in stream , we initialize the MaxLogHash sketch of user as where . That is, we set indicator and register . For any other item that user connects to after the first item , i.e., an user-item pair occurring on stream after the user-item pair , we update it as follows: We first compute the log-rank of item , i.e., , . When is smaller than , we perform no further operations for updating the user-item . When , it indicates that at least two items in has a log-rank value . Therefore, we simply set . When , we set .
4.4. Jaccard Similarity Estimation
Define variables
[TABLE]
[TABLE]
Let . Note that indicates that there exists one and only one element in set of which log-rank equals with respect to function . Then, we have the following theorem.
Theorem 1.
For non-empty sets and , we have , , when . Otherwise, we have
[TABLE]
where
Proof.* * Let be the maximum log-rank of all items in . When two items and in or has the log-rank value , we easily find that . When only one item in and only one item in have the log-rank value , we easily find that . Let
[TABLE]
Then, we find that event happens (i.e., ) only when one item in has a log-rank value larger than all items in . For any item , we have and so , supported on the set . Based on the above observations, when , we have
[TABLE]
Therefore, we have
[TABLE]
where the last equation holds because .
Define variable From Theorem 1, the expectation of is computed as
[TABLE]
Therefore, we have
[TABLE]
Note that the cardinality of set (i.e. ) is unknown. To solve this challenge, we find that
[TABLE]
Figure 1 shows that the value of , We easily find that when . Therefore, we estimate as
[TABLE]
4.5. Error Analysis
The error of our method MaxLogHash is shown in the following theorem.
Theorem 2.
For any users , we have
[TABLE]
where . The variance of is computed as
[TABLE]
When , we have , and so and .
Proof.* * From equation (1), we easily have
[TABLE]
To derive , we first compute
[TABLE]
Then, we have
[TABLE]
From the definition of , we have
[TABLE]
Then, we easily obtain a closed-form formals of from equation (4.5).
4.6. Reduce Processing Complexity
Inspired by OPH (one permutation hashing) (Linips2012, ), which significantly reduces the time complexity of MinHash for processing each element in the set, we can use a hash function which splits items in into registers at random, and each register , , records as well as the value of indicator , which is similar to the regular MaxLogHash method. We name this extension as MaxLogOPH. MaxLogOPH reduces the time complexity of processing each item from to . When , our experiments demonstrate that MaxLogOPH is comparable to MaxLogHash in terms of accuracy.
5. Evaluation
The algorithms are implemented in Python, and run on a computer with a Quad-Core Intel(R) Xeon(R) CPU E3-1226 v3 CPU 3.30GHz processor. To demonstrate the reproducibility of the experimental results, we make our source code publicly available444http://nskeylab.xjtu.edu.cn/dataset/phwang/code/MaxLog.zip.
5.1. Datasets
For simplicity, we assume that elements in sets are 32-bit numbers, i.e., . We evaluate the performance of our method MaxLogHash a variety of datasets.
- Synthetic datasets. Our synthetic datasets consist of set-pairs and with various cardinalities and Jaccard similarities. We conduct our experiments on the following two different settings:
Balanced set-pairs (i.e., ). We set and vary in . Specially, we generate set by randomly selecting different numbers from and generate set by randomly selecting different numbers from set and different numbers from set . In our experiments, we set by default.
Unbalanced set-pairs (i.e., ). We set and , where we vary . Specially, we generate set by randomly selecting different numbers from and generate set by selecting different elements from .
- Real-world datasets. Similar to (MitzenmacherWWW14, ), we evaluate the performance of our method on the detection of item-pairs (e.g., pairs of products) that always appear together in the same records (e.g., transactions). We conduct experiments on two real-world datasets555http://fimi.ua.ac.be/data/: MUSHROOM and CONNECT, which are also used in (MitzenmacherWWW14, ). We generate a stream of item-record pairs for each dataset, where a record can be viewed as a transaction and items in the same record can be viewed as products bought together. For each record in the dataset of interest and every item in , we append an element to the stream of item-record pairs. In summary, MUSHROOM and CONNECT have and records, and distinct items, and and item-record pairs, respectively.
5.2. Baselines
Our methods use -bit registers to build a sketch for each set. We compare our methods with the following state-of-the-art methods: MinHash (Broder2000, ). MinHash builds a sketch for each set. A MinHash sketch consists of 32-bit registers.
HyperLogLog (FlajoletAOFA07, ). A HyperLogLog sketch consists of 5-bit registers, and is originally designed for estimating a set’s cardinality. One can easily obtain a HyperLogLog sketch of by merging the HyperLogLog sketches of sets and and then use the sketch to estimate . Therefore, HyperLogLog can also be used to estimate by approximating .
HyperMinHash (YuArxiv2017, ). A HyperMinHash sketch consists of -bit registers and -bit registers. The first -bit registers can be viewed as a HyperLogLog sketch. To guarantee the performance for large sets (including up to elements), we set .
5.3. Metrics
We evaluate both efficiency and effectiveness of our methods in comparison with the above baseline methods. For efficiency, we evaluate the running time of all methods. Specially, we study the time for updating each set element and estimating set similarities, respectively. The update time determines the maximum throughput that a method can handle, and the estimation time determines the delay in querying the similarity of set-pairs. For effectiveness, we evaluate the error of estimation with respect to its true value using metrics: bias and root mean square error (RMSE), i.e., and . Our experimental results are empirically computed from independent runs by default. We further evaluate our method on the detection of association rules, and use precision and recall to evaluate the performance.
5.4. Accuracy of Similarity Estimation
MaxLogHash vs MinHash and HyperMinHash. From Figures 2 (a)-(d), we see that our method MaxLogHash gives comparable results to MinHash and HyperMinHash with . Specially, the RMSEs of these three methods differ within and continually decrease as the similarity increases. The RMSE of HyperMinHash with significantly increases as increases. We observe that the large estimation error occurs because HyperMinHash exhibits a large estimation bias. Figures 2 (e)-(h) show the bias of our method MaxLogHash in comparison with MinHash and HyperMinHash. We see that the empirical biases of MaxLogHash and MinHash are both very small and no systematic biases can be observed. However, HyperMinHash with shows a significant bias and its bias increases as the similarity value increases. To be more specific, its bias raises from to when the similarity increases from to . One can increase to reduce the bias of HyperMinHash. However, HyperMinHash with large desires more memory space. For example, HyperMinHash with has comparable accuracy but requires times more memory space compared to our method MaxLogHash. Compared with MinHash, MaxLogHash gives a times reduction in memory usage while achieves a similar estimation accuracy. Later in Section 5.6, we show that our method MaxLogHash has a computational cost similar to Minhash, but is several orders of magnitude faster than HyperMinHash when estimating set similarities.
MaxLogHash vs HyperLogLog. To make a fair comparison, we allocate the same amount of memory space, bits, to each of MaxLogHash and HyperLogLog. As discussed in Section 4, the attractive property of our method MaxLogHash is its estimation error is almost independent from the cardinality of sets and , which does not hold for HyperLogLog. Figure 3 shows the RMSEs of MaxLogHash and HyperLogLog on sets of different sizes. We see that the RMSE of our method MaxLogHash is almost a constant. Figures 3 (a) and (b) show the performance of HyperLogLog suddenly degrades when and the cardinalities of and are around , because HyperLogLog uses two different estimators for cardinalities within two different ranges respectively (FlajoletAOFA07, ). As a result, our method MaxLogHash decreases the RMSE of HyperLogLog by up to . As shown in Figures 3 (c) and (d), similarly, the RMSE of our method MaxLogHash is about 2.5 times smaller than HyperLogLog when and the cardinalities of and are around .
MaxLogHash vs MaxLogOPH. As discussed in Section 4.6, the estimation error of MaxLogOPH is comparable to MaxLogHash when is far smaller than the cardinalities of two sets of interest. We compare MaxLogOPH with MaxLogHash on sets with increasing cardinalities to provide some insights. As shown in Figure 4, MaxLogOPH exhibits relatively large estimation errors for small cardinalities. When and the cardinality increases to (about ), we see that MaxLogOPH achieves similar accuracy to MaxLogHash. Later in Section 5.6, MaxLogOPH significantly accelerates the speed of updating elements compared with MaxLogHash.
5.5. Accuracy of Association Rule Learning
In this experiment, we evaluate the performance of our method MaxLogHash, MinHash, and HyperMinHash on the detection of items (e.g., products) that almost always appear together in the same records (e.g., transactions). We conduct the experiments on real-world datasets: MUSHROOM and CONNECT. We first estimate all pairwise similarities among items’ record-sets, and retrieve every pair of record-sets with similarity . As discussed previously (results in Figure 3), HyperLogLog is not robust, because it exhibits large estimation errors for sets of particular sizes. Therefore, in what follows we compare our method MaxLogHash only with MinHash and HyperMinHash. As shown in Figure 5, MaxLogHash gives comparable precision and recall to MinHash and HyperMinHash with . We note that MaxLogHash gives up to and times reduction in memory usage in comparison with MinHash and HyperMinHash respectively.
5.6. Efficiency
We further evaluate the efficiency of our method MaxLogHash and its extension MaxLogOPH in comparison with MinHash and HyperLogLog. Specially, we present the time for updating each coming element and computing Jaccard similarity, respectively. We conduct experiments on synthetic balanced datasets. We omit the similar results for real-world datasets and synthetic unbalanced datasets. Figure 6 (a) shows that the update time of MaxLogOPH and HyperLogLog is almost a constant and our method outperforms other baselines. The update time of HyperMinHash is almost irrelevant to its parameter and thus we only plot the curve for . Specially, MaxLogOPH is about and times faster than HyperMinHash and MinHash. Figure 6 (b) shows that our methods MaxLogHash and MaxLogOPH have estimation time similar to MinHash, while they are about times faster than HyperLogLog and 4 to 5 orders of magnitude faster than HyperMinHash.
6. Related Work
Jaccard similarity estimation for static sets. Broder et al. (Broder2000, ) proposed the first sketch method MinHash to compute the Jaccard similarity of sets, which builds a sketch consisting of registers for each set. To reduce the amount of memory space required for MinHash, (PingWWW2010, ; MitzenmacherWWW14, ) developed methods -bit MinHash and Odd Sketch, which are dozens of times more memory efficient than the original MinHash. The basic idea behind -bit MinHash and Odd Sketch is to use probabilistic methods such as sampling and bitmap sketching to build a compact digest for each set’s MinHash sketch. Recently, several methods (Linips2012, ; ShrivastavaUAI2014, ; ShrivastavaICML2014, ; ShrivastavaICML2017, ) were proposed to reduce the time complexity of processing each element in a set from to .
Weighted similarity estimation for static vectors. SimHash (or, sign normal random projections) (CharikarSTOC2002, ) was developed for approximating angle similarity (i.e., cosine similarity) of weighted vectors. CWS (Manasse2010, ; HaeuplerMT2014, ), ICWS (IoffeICDM2010, ), 0-bit CWS (LiKDD2015, ), CCWS (WuICDM2016, ), Weighted MinHash (ShrivastavaNIPS2016, ), PCWS (WuWWW2017, ), and BagMinHash (Ertl2018, ) were developed for approximating generalized Jaccard similarity of weighted vectors666The Jaccard similarity between two positive real value vectors and is defined as ., and Datar et al. (DatarSOCG2004, ) developed an LSH method using -stable distribution for estimating distance for weighted vectors, where . Campagna and Pagh (CampagnaKAIS2012, ) developed a biased sampling method for estimating a variety of set similarity measures beyond Jaccard similarity.
Similarity estimation for data streams. The above weighted similarity estimation methods fail to deal with streaming weighted vectors, whereas elements in vectors come in a stream fashion. To solve this problem, Kutzkov et al. (KutzkovCIKM2015, ) extended AMS sketch (AlonSTOC1996, ) for the estimation of cosine similarity and Pearson correlation in streaming weighted vectors. Yang et al. (YangICDM2017, ) developed a streaming method HistoSketch for approximating Jaccard similarity with concept drift. Set intersection cardinality (i.e., the number of common elements in two sets) is also a popular metric for evaluating the similarity in sets. A variety of sketch methods such as LPC (Whang1990, ), FM (Flajolet1985, ), LogLog (Durand2003, ), HyperLogLog (FlajoletAOFA07, ), HLL-TailCut+ (XiaoZC17, ), and MinCount (GiroireDAMNew2009, ) were proposed to estimate the stream cardinality (i.e., the number of distinct elements in the stream), and can be easily extended to estimate by merging the sketches of sets and . Then, one can approximate because . To further improve the estimation accuracy, Cohen et al. (CohenKDD2017, ) developed a method combining MinHash and HyperLogLog to estimate set intersection cardinalities. Our experiments reveal that these sketch methods have large errors when first estimating and , and then approximating the Jaccard similarity . As mentioned in Section 3, MinHash can be easily extended to handle streaming sets, but its two compressed versions, -bit MinHash and Odd Sketch fail to handle data streams. To solve this problem, Yu and Weber (YuArxiv2017, ) developed a method, HyperMinHash, which can be viewed as a joint of HyperLogLog and -bit MinHash. HyperMinHash consists of registers, whereas each register has two parts, an FM sketch and a -bit string. The -bit string is computed based on the fingerprints (i.e., hash values) of set elements that map to the register. HyperMinhash first estimates and then infers the Jaccard similarity of sets and from the number of collisions of -bit strings given . Our experiments demonstrates that HyperMinHash exhibits a large bias for high similarities and it is several orders of magnitude slower than our methods when estimating the similarity.
7. Conclusions and Future Work
We develop a memory efficient sketch method MaxLogHash to estimate the similarity of two sets given in a streaming fashion. We provide a simple yet accurate estimator for Jaccard similarity, and derive exact formulas for the estimator’s bias and variance. Experimental results demonstrate that MaxLogHash can reduce around 5 times the amount of memory required for MinHash with the same desired accuracy and computational cost. Compared with our method MaxLogHash, the state-of-the-art method HyperMinHash exhibits a larger estimation bias and its estimation time is 4 to 5 orders of magnitude larger. Although HyperLogLog can be extended to estimate Jaccard similarity, its estimation error (resp. estimation time) is about 2.5 times (resp. 10 times) larger than our methods. In the future, we plan to extend MaxLogHash to weighted streaming vectors and fully dynamic streaming sets that include both set element insertions and deletions.
Acknowledgment
The research presented in this paper is supported in part by National Key R&D Program of China (2018YFC0830500), National Natural Science Foundation of China (U1736205, 61603290), Shenzhen Basic Research Grant (JCYJ20170816100819428), Natural Science Basic Research Plan in Shaanxi Province of China (2019JM-159). The work of John C.S. Lui is supported in part by the GRF R4032-18.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Kaiyu Li and Guoliang Li. Approximate query processing: What is new and where to go? Data Science and Engineering , 2018.
- 2[2] Andrei Z Broder, Moses Charikar, Alan M Frieze, and Michael Mitzenmacher. Min-wise independent permutations. J. Comput. Syst. Sci. , 60(3):630–659, June 2000.
- 3[3] A. Broder. On the resemblance and containment of documents. In SEQUENCES , 1997.
- 4[4] Flavio Chierichetti, Ravi Kumar, Silvio Lattanzi, Michael Mitzenmacher, Alessandro Panconesi, and Prabhakar Raghavan. On compressing social networks. In KDD , pages 219–228, 2009.
- 5[5] Sreenivas Gollapudi and Aneesh Sharma. An axiomatic approach for result diversification. In WWW , pages 381–390.
- 6[6] Ping Li, Anshumali Shrivastava, Joshua L. Moore, and Arnd Christian König. Hashing algorithms for large-scale learning. In NIPS. , pages 2672–2680, 2011.
- 7[7] Tanguy Urvoy, Emmanuel Chauveau, Pascal Filoche, and Thomas Lavergne. Tracking web spam with html style similarities. ACM Trans. Web , 2(1), March 2008.
- 8[8] Ping Li and Arnd Christian König. b-bit minwise hashing. In WWW , pages 671–680, 2010.