Domain Adaptation for Vehicle Detection from Bird's Eye View LiDAR Point Cloud Data
Khaled Saleh, Ahmed Abobakr, Mohammed Attia, Julie Iskander, Darius, Nahavandi, Mohammed Hossny

TL;DR
This paper introduces a domain adaptation framework using CycleGAN to improve vehicle detection accuracy in real LiDAR point cloud data by reducing the domain gap with synthetic data.
Contribution
It proposes a novel CycleGAN-based domain adaptation method specifically designed for vehicle detection in bird's eye view LiDAR point clouds.
Findings
Over 7% improvement in average precision on real BEV point cloud data
Effective bridging of synthetic and real LiDAR data domains
Enhanced vehicle detection performance in safety-critical applications
Abstract
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5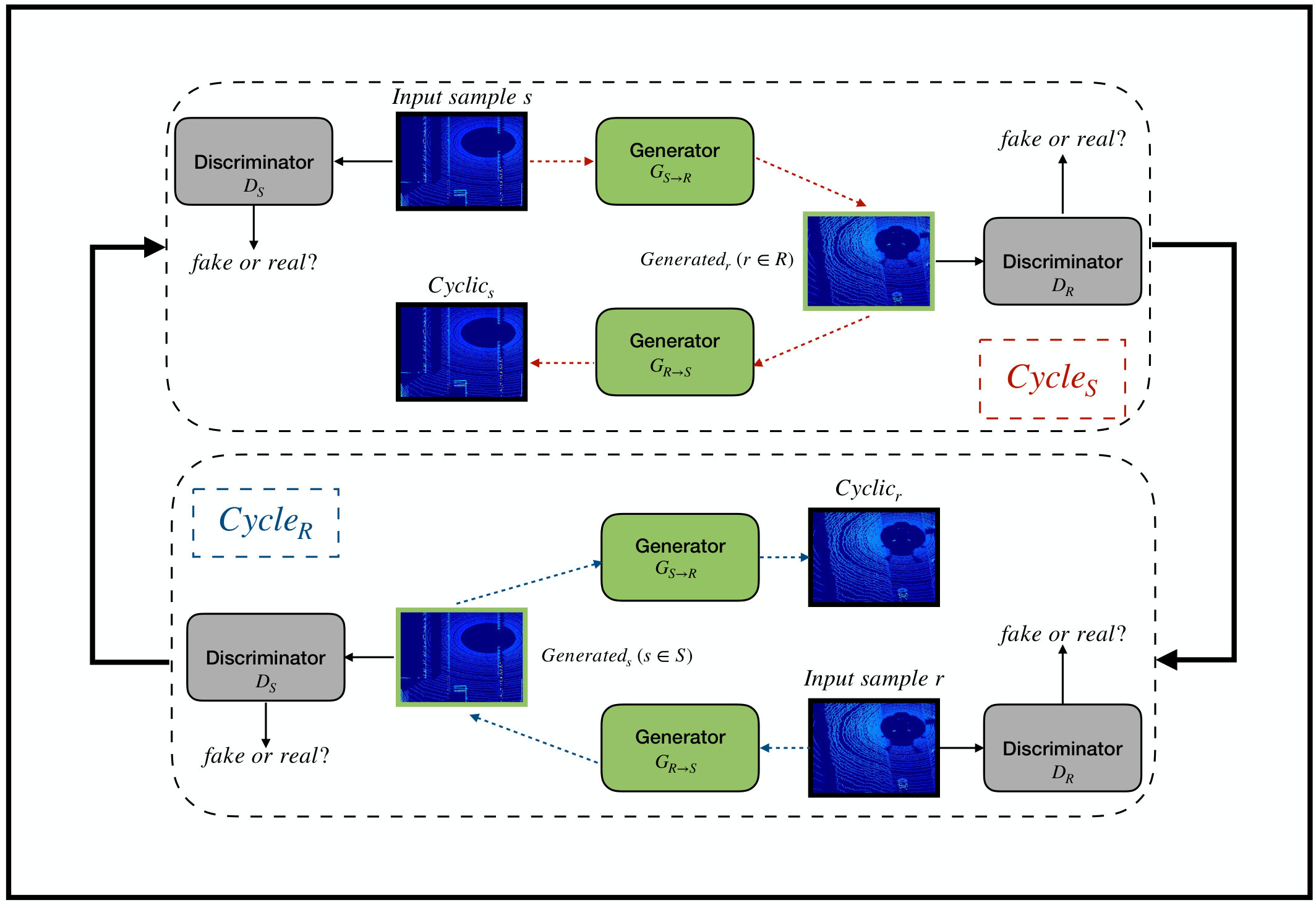 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8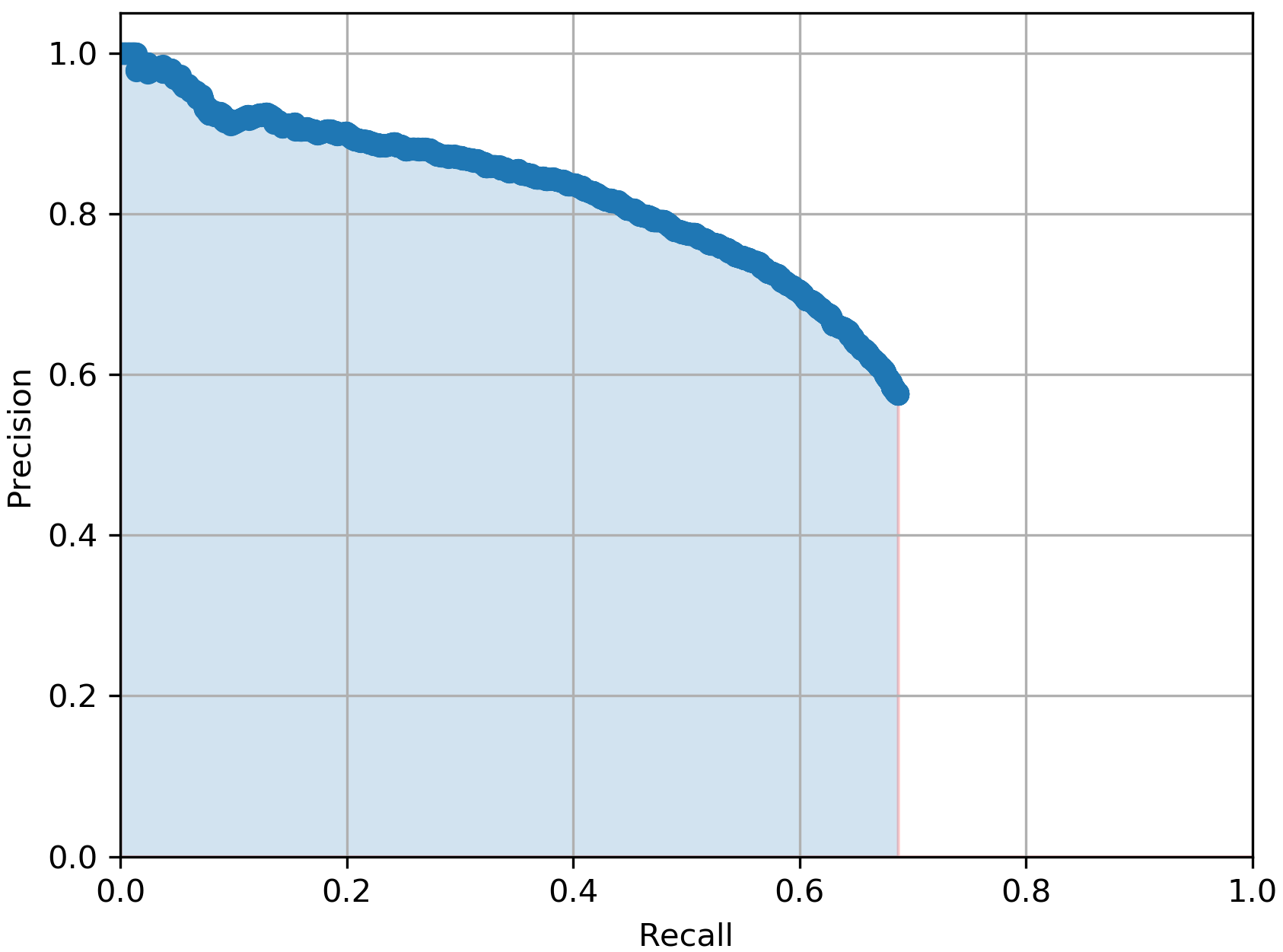 Figure 9
Figure 9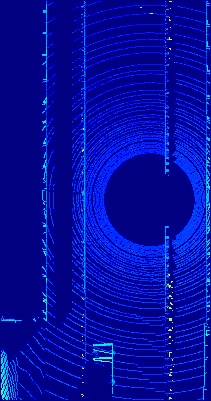 Figure 10
Figure 10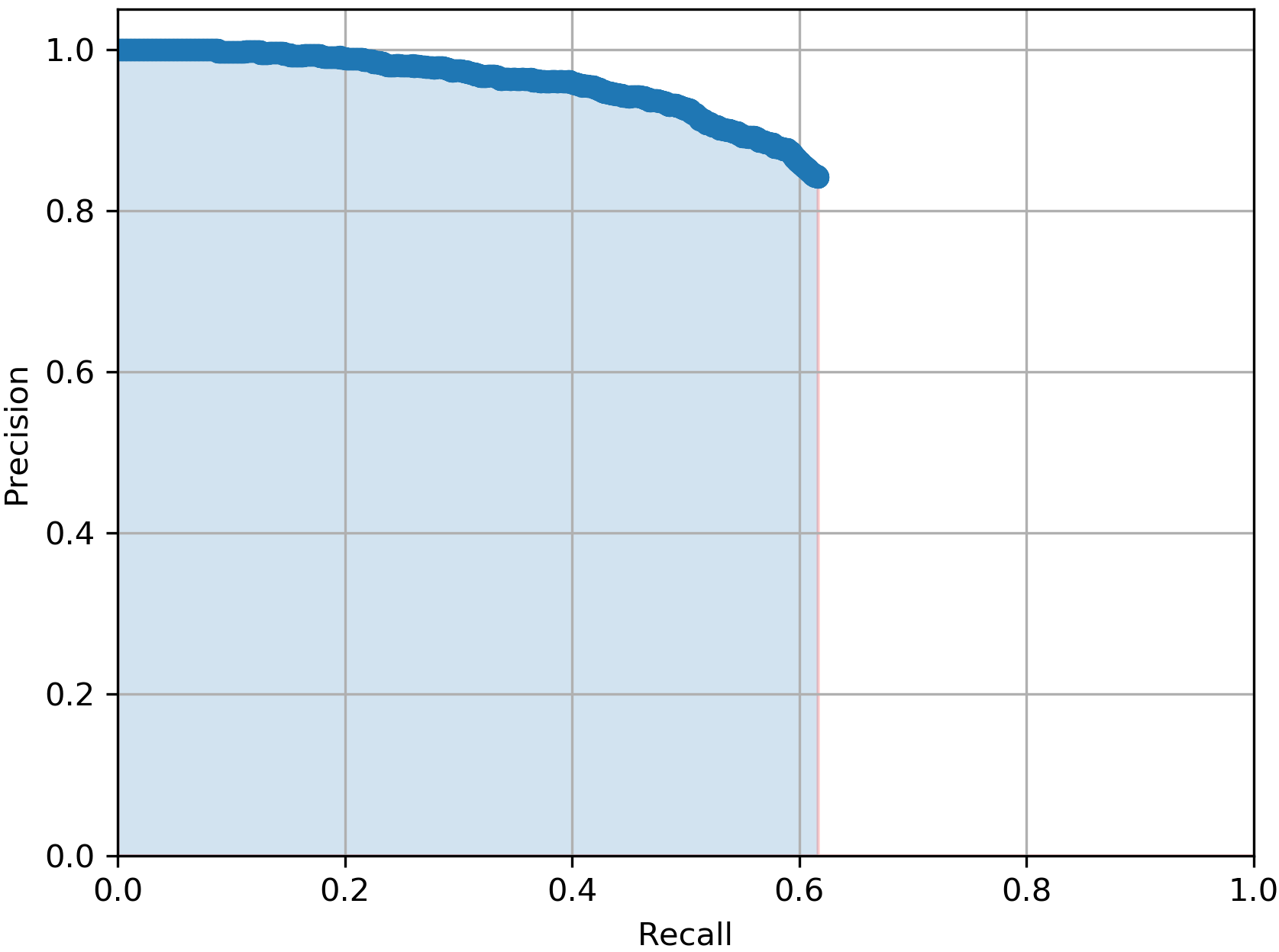 Figure 11
Figure 11 Figure 12
Figure 12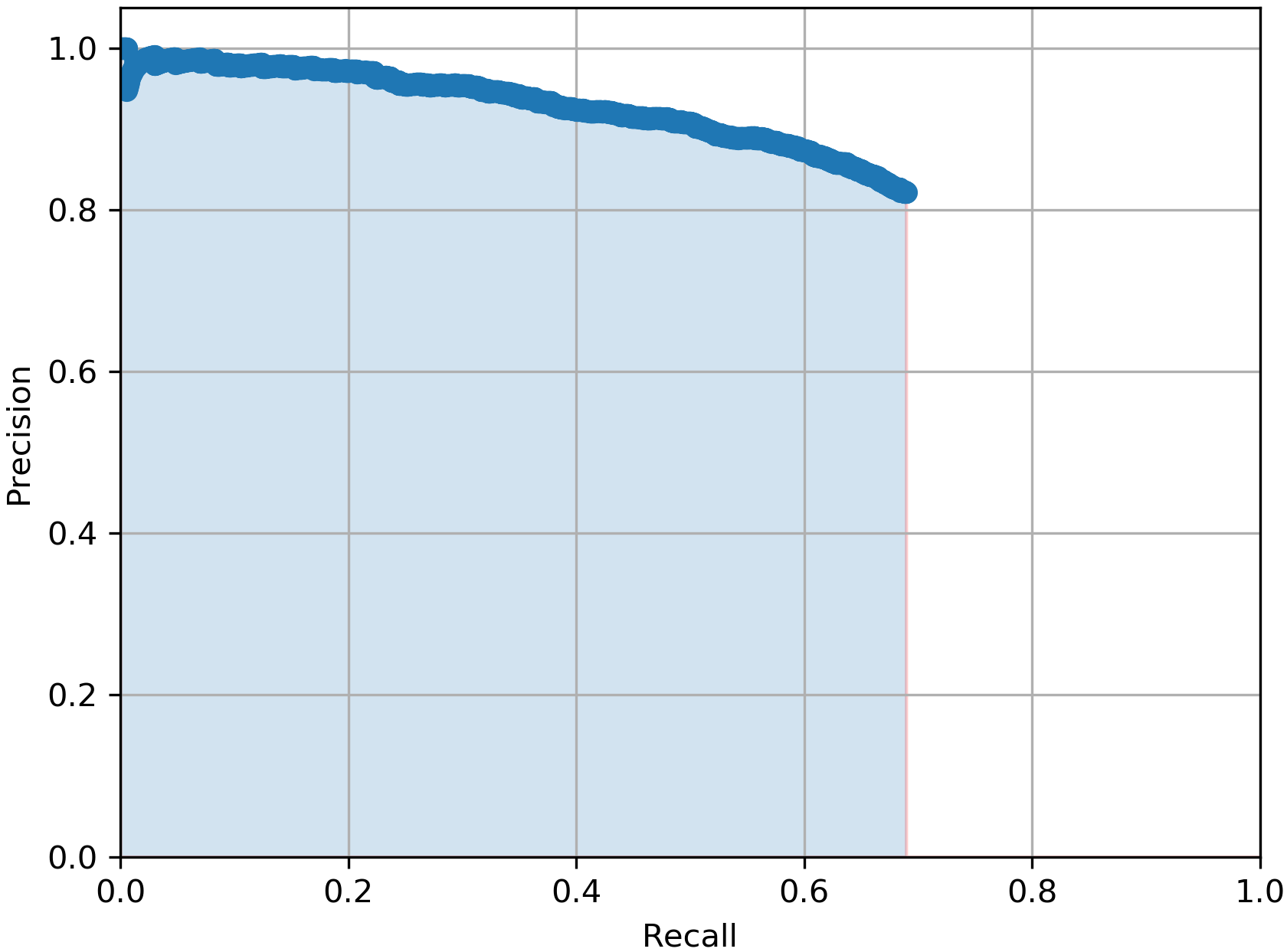 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18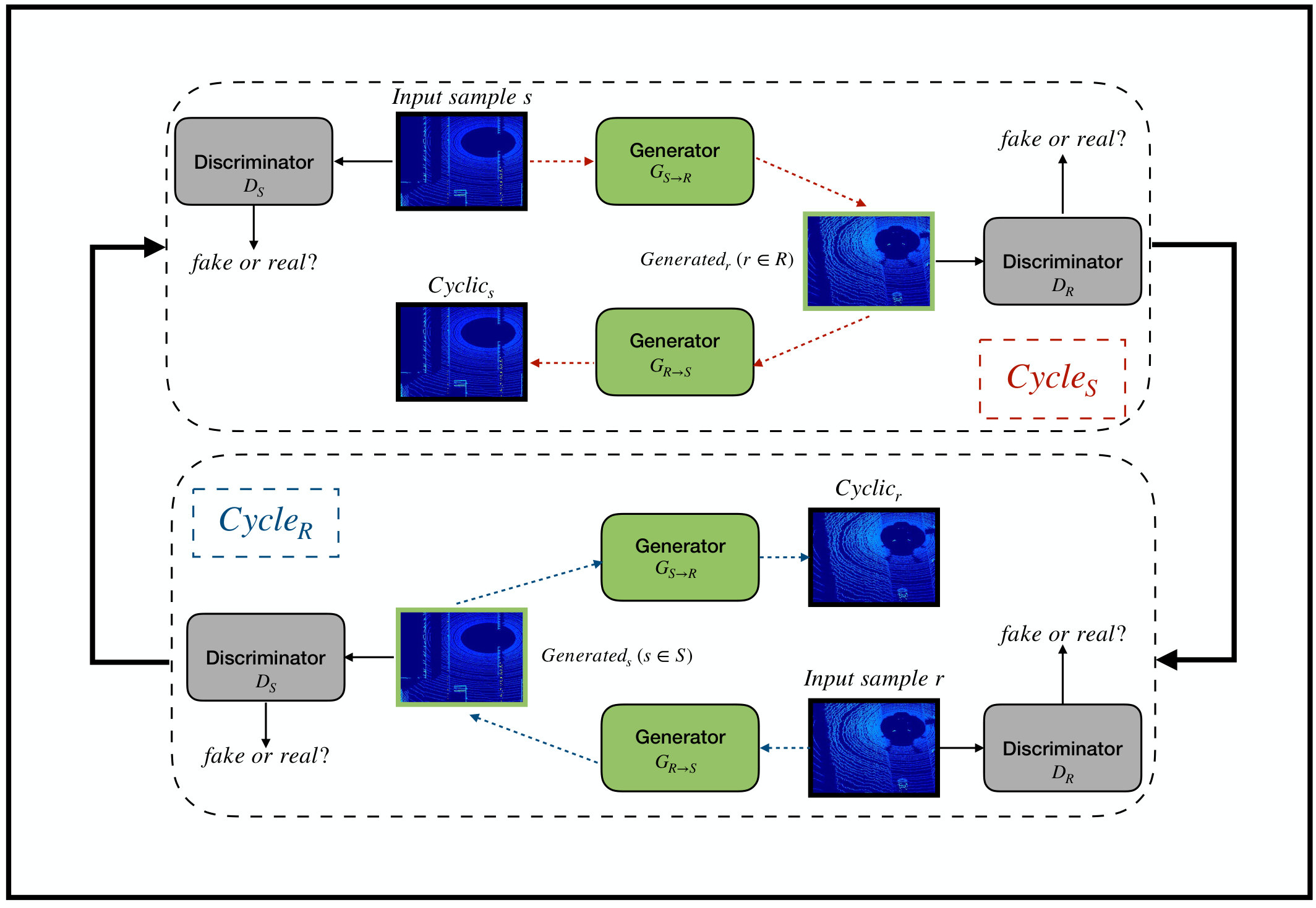 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21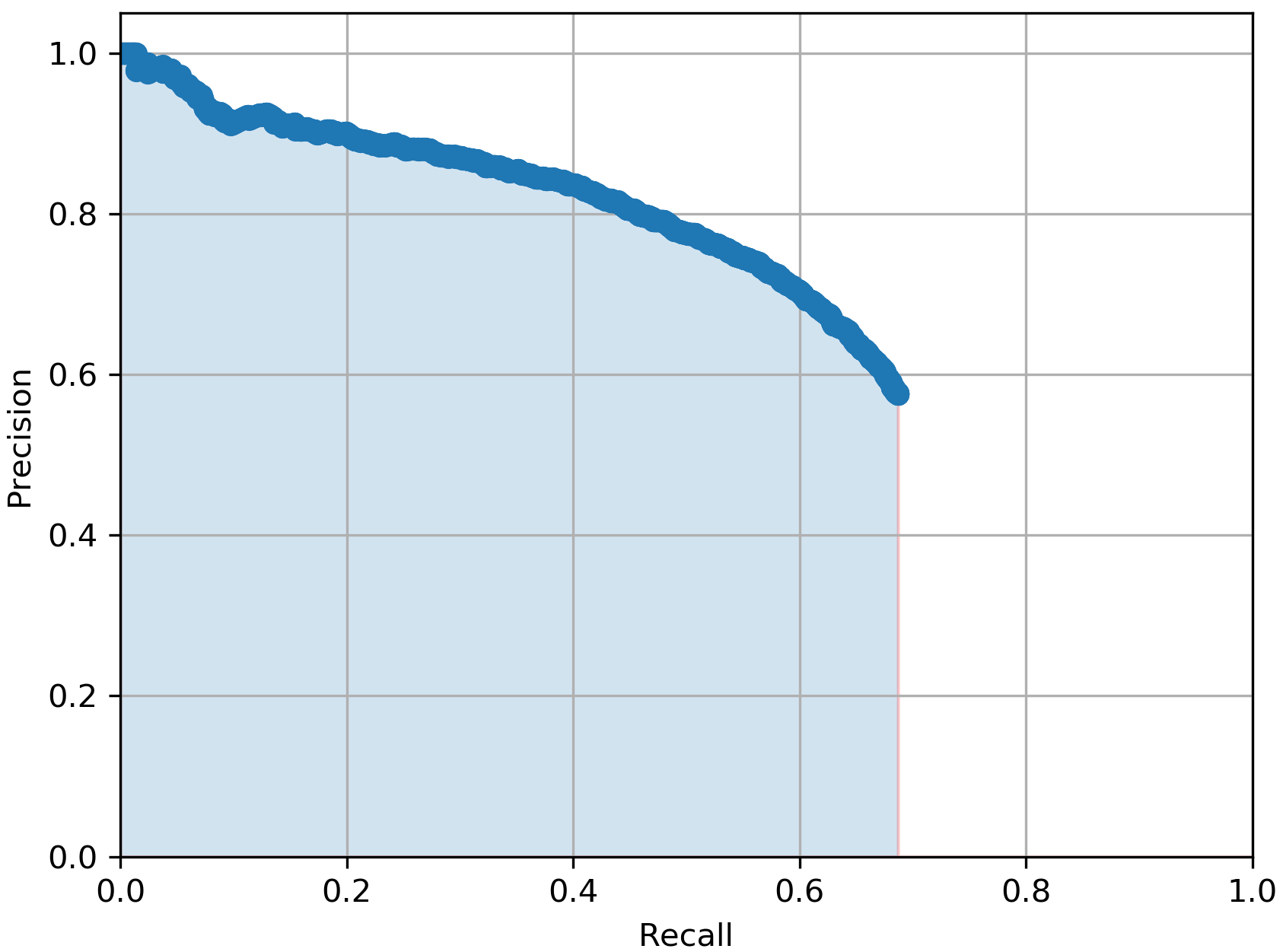 Figure 22
Figure 22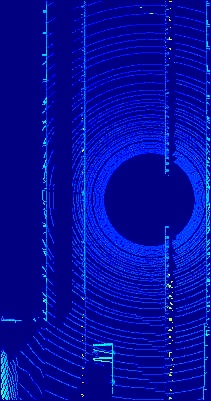 Figure 23
Figure 23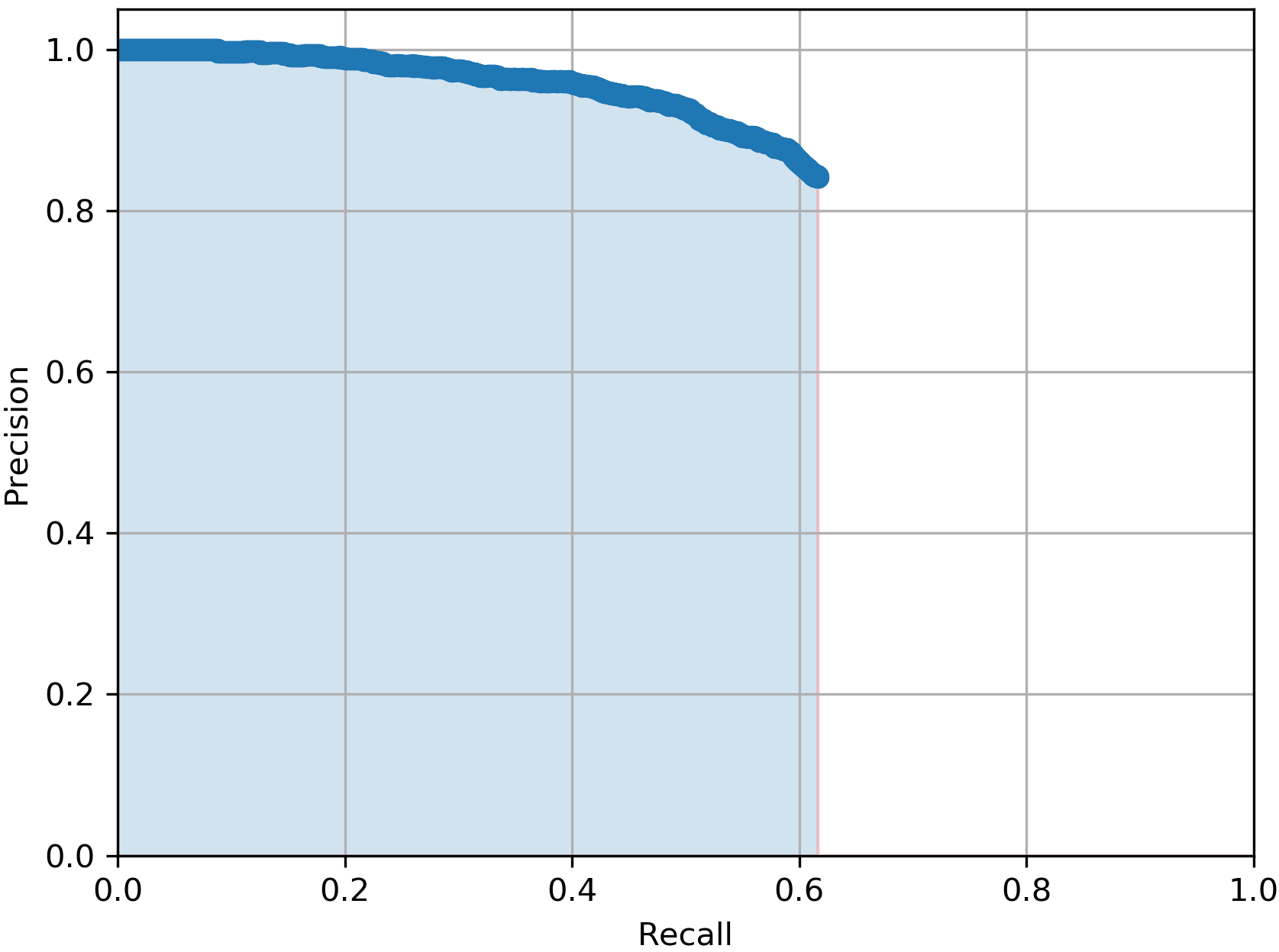 Figure 24
Figure 24 Figure 25
Figure 25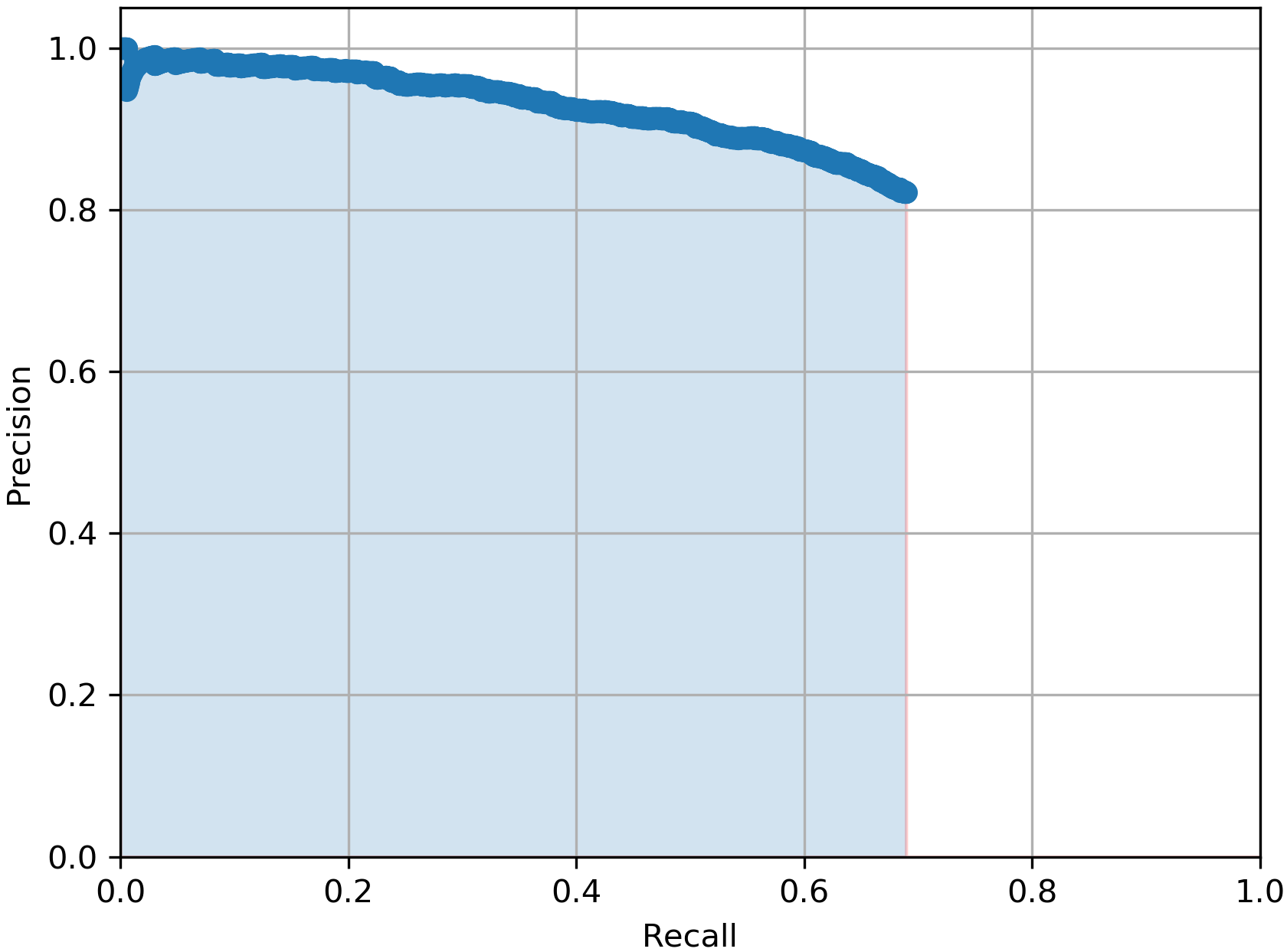 Figure 26
Figure 26| Model | Training Data | Average Precision (AP)% |
|---|---|---|
| SYN (only) | 29.93 | |
| DA (only) | 34.78 | |
| KITTI (only) | 57.26 | |
| KITTI+SYN | 59.16 | |
| KITTI+DA | 64.29 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Domain Adaptation for Vehicle Detection from Bird’s Eye View LiDAR Point Cloud Data
Khaled Saleh, Ahmed Abobakr, Mohammed Attia, Julie Iskander, Darius Nahavandi and Mohammed Hossny
Institute for Intelligent Systems Research and Innovation (IISRI)
Deakin University
Abstract
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation framework for bridging this gap between synthetic and real point cloud data. Our proposed framework is based on the deep cycle-consistent generative adversarial networks (CycleGAN) architecture. We have evaluated the performance of our proposed framework on the task of vehicle detection from a bird’s eye view (BEV) point cloud images coming from real 3D LiDAR sensors. The framework has shown competitive results with an improvement of more than 7% in average precision score over other baseline approaches when tested on real BEV point cloud images.
I Introduction
Recently, deep learning-based techniques such as convolution neural networks (ConvNets) have been achieving state-of-the-art results in many computer vision tasks such: object identification [1], scene understanding [2, 3], and human action recognition [4, 5, 6]. However, these techniques require a handful amount of labelled data for training them which is both time-consuming and cumbersome to get for many tasks. Thus, the utilisation of synthetic data for training such techniques got some momentum over the past few years [7, 8]. With synthetic data, the process for obtaining ground-truth labels becomes much easier and automated most of the time. However, still, the utilisation of synthetic data is not entirely reliable because of its limitations when it comes to the generalisation to real data.
In safety-critical applications such as a self-driving vehicle, one of the main sensors that are currently crucial for its development is the 3D LiDAR (Light Detection And Ranging) sensor. 3D LiDAR sensors can reliably provide 360 point cloud in traffic environment with coverage distance up to 200 meters ahead across different weather and lighting conditions. Thus, a number of deep-learning based techniques have recently been utilising its point cloud for many perception tasks for self-driving vehicles [9, 10]. The reason that the number of deep-learning techniques that rely on point-cloud data is not as much as the ones rely on visual data is the scarcity of labelled point cloud data. The labelling procedure for point cloud data is more complicated than visual data especially for tasks such as 3D object detection and per-point semantic segmentation. Thus, the usage of synthetic data has been explored, similar to the visual data modality data [7, 9]. However, the generalisation to real-point cloud data was rather limited due to the perfectness of the synthetic point cloud data (shown in Fig. 1, right) which is missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors (shown in Fig. 1, left). These artefacts are such as the variability of the LiDAR beams intensities or the motion distortion as a result of the motion of the 3D LiDAR.
Domain adaptation (DA) is one of the machine learning (ML) techniques that have been recently explored to bridge the aforementioned gaps between synthetic and real data domains [12]. In DA, the goal is to learn from one data distribution (referred to as the source domain) a perfect model on a different data distribution (referred to as the target domain). In traffic environments, DA has recently shown promising results for image translation between different domain pairs such as night/day, synthetic/real images and RGB/thermal images [13]. Since most of the previous DA techniques are based on 2D deep ConvNet architectures, thus their application on 3D point cloud data from 3D LiDAR sensors is not a straight forward task.
On the other hand, the recent deep-learning based techniques that have been applied on perception tasks using 3D point cloud data, they managed to find a way to adopt the same 2D ConvNet architectures to work on the 3D point cloud data. One of the most common techniques was to project a top-down bird’s eye view (BEV) of the point cloud data on a 2D plane (ie. ground). The representation of the 3D LiDAR point cloud data as a BEV was shown to be effective in many perception tasks for self-driving vehicles such as 3D object detection [14], road detection [15] and per-point semantic segmentation [16].
To this end, in this work, we will be proposing a DA approach for vehicle detection in real point cloud data from 3D LiDAR sensors represented as BEV images. The proposed DA approach will be a deep learning-based approach based on deep generative adversarial networks (GANs) [13]. For the vehicle detection task, it will be based on state-of-the-art deep object detection architecture YOLOv3 [1]. The rest of the paper is organised as follows. In Section II, a brief introduction to the different DA approaches with emphasis on deep learning based approaches will be reviewed in addition to a quick review on GANs. Section III, the methodology we followed for our proposed DA approach will be discussed thoroughly. Experiments and results are discussed in Section IV. Finally, Section V concludes.
II Related Work
Commonly, there are two ways to achieve DA either by directly translating one domain to the other or by obtaining a common-ground intermediate pseudo-domain between the two domains. In the following, firstly a quick review of the work related to the DA approaches will be provided specifically the approaches based on the direct translation between domains. Then, a brief summary of the DA work between simulated and real domains done in the context of traffic environments will be discussed.
II-A Adversarial Domain Adaptation
Historically, most of the work done on DA has been relying on the transformation between source and target domains based on linear representations [17, 18]. Until the emergence of the recent set of techniques based on non-linear transformation representations via neural networks [19, 20], which have achieved state-of-the-art results in a number of DA benchmarks [21, 22]. One of the most commonly non-linear-based representations DA approaches is the adversarial domain adaptation (ADA) approach [19]. ADA was inspired by the work done by Goodfellow et al. [23] on generative adversarial networks (GANs). In GANs, there are two deep neural networks trained simultaneously, namely a “generator” network and a “discriminator” network. The generator network, as the name implies, it generates new data instances using a uniform distribution, on the other hand, the discriminator network tries to decide whether or not this newly generated data instance has the same distribution as the training dataset distribution. Similarly, in ADA, it has the same two networks, where the generator network, generates instances from the source domain distribution to transform it into the target domain distribution. Whereas, the discriminator network tries to differentiate between the instances outputted from the actual target domain distribution and the ones generated from the generator network. Thus, this architecture is often referred to in the literature as the “conditional GAN”. One of the most recently successful ADA architectures is the Cycle-Consistent GAN (CycleGAN) [13] architecture. In CycleGAN, it is essentially comprised of two conditional GAN networks. The first network works on the transformation from the source domain () to the target domain (), , while the other one works on the transformation in the opposite direction, . The additional contribution for CycleGAN architecture was the introduction of a new loss function they call it the cycle-consistency loss function. This new loss function assures that if the two conditional GANs networks are connected, they will produce the following identity mapping: .
II-B DA Between Synthetic and Real for Perception Tasks
In the context of traffic environments, a number of perceptions tasks has been utilising the DA approach to bridge the gap between real domains from physical sensors and synthetic domains from simulated sensors [13, 24, 25]. It is worth noting that all of these works were only exploring one type of sensors which was cameras either RGB (monocular/stereo) or thermal. For example, in [13], a number of DA between different domains were introduced based on the CycleGAN architecture. For instance, they addressed the semantic segmentation task between the day and night domains on unpaired visual images from multiple road-based datasets. Similarly, in [24], Atapour et al. trained a ConvNet model on synthetic depth and RGB images from the famous game GTA in order to estimate a synthetic monocular depth image. In the testing/inference phase, they took an input real RGB image from the KITTI dataset [26] and with the help of a CycleGAN architecture, they transformed the real RGB image into a synthetic GTA game like RGB image. Then, they passed the synthetic RGB image to their initial trained model to estimate a synthetic depth image. Eventually, they used the same CycleGAN network again to adopt the estimated depth image from the synthetic image domain to a real RGB image domain.
On the other hand, in [25] Zhang et al. proposed deep-learning based approach for thermal infra-red object tracking. To overcome the scarcity of thermal images dataset, they utilised DA based on the CycleGAN architecture to transform images from visual domain to the thermal infra-red domain.
III Proposed Methodology
The main focus of this work is to provide a framework for bridging the gap between real and synthetic point cloud data represented as BEV images for the vehicle detection task. That being said, the same framework can still be used for other perceptions tasks on point cloud data such as semantic segmentation or object tracking. In this section, we will first provide our formulation for the problem at hand. Then subsequently, we will break-down the building blocks of the proposed framework.
III-A Problem Formulation
ConvNet-based architectures for object detection from BEV point cloud data has been achieving state-of-the-art results in many benchmarks [14]. However, with the available insufficient numbers of annotated BEV point cloud data for training such architectures, the trained models are still performing poorly especially in challenging scenarios. The utilisation of annotated synthetic BEV point cloud data from simulated traffic environments could be the key to increase the performance of such models. However, due to the domain shift between real and synthetic BEV point cloud data, the trained model on synthetic data is not necessarily guaranteed to generalise on the real data [10].
Thus, in our formulation for the vehicle detection task from real BEV point cloud data, we are proposing a framework for DA between synthetic BEV point cloud data and real BEV point cloud data. In the first stage of our framework, we train a CycleGAN model between unpaired synthetic BEV point cloud data and real BEV point cloud data. The trained model, in returns, learns a transformation from synthetic BEV point cloud data to real BEV point cloud data and vice versa. As a result, given any annotated synthetic BEV point cloud dataset with vehicles, the trained CycleGAN model will transform that dataset to an annotated real-like BEV point cloud data. Finally, using the transformed dataset, we could train another ConvNet-based model for the vehicle detection task in real BEV point cloud data.
III-B Deep Unsupervised DA via Cycle-Consistent GANs
As we earlier mentioned in Section II-B, the CycleGAN architecture has recently shown promising results in a number of DA tasks between real and synthetic visual domains. Thus, in this work, we will be exploring the CycleGAN architecture for the task of DA between real BEV point cloud domain and synthetic BEV point cloud domain. One of the advantages of the CycleGAN architecture in the context of DA is it can learn transformation between source and target domains without any supervised one-to-one mapping between the two domains. This is beneficial for our task because it is almost impossible for us to have the same traffic scenario and environment captured in both real BEV point cloud data and synthetic BEV point cloud data. However, we can have a handful amount of BEV point cloud data from each domain separately that represent the distribution of that domain.
More formally, given our two domains of the synthetic and the real BEV point cloud data domains. Then, the objective of our adopted CycleGAN-based DA approach (shown in Fig. 4) is to map between the distributions and from the synthetic and the real BEV point cloud domains respectively. The proposed CycleGAN-based DA approach achieve this mapping via the two generators, and and the two discriminators and . The generator will try to map the input source synthetic BEV point cloud image to some target real BEV point cloud image. While the generator is trying to map the generated BEV point cloud image from the real target domain back to its original source domain. The discriminator , on the other hand, is trying to differentiate between a BEV point cloud image and a generated BEV point cloud image from . Conversely, the discriminator will be trying to distinguish between a BEV point cloud image and a generated BEV point cloud image from . The two generators networks are deep ConvNet models.
The main building blocks of them are three blocks, namely the encoder, the transformer and the decoder respectively. The encoder’s job is to extract features on multiple levels progressively by down-sampling them from the input BEV point cloud image from both domains. The transformer, on the other hand, takes the extracted features vector encoder in the source domain and transform it into another feature vector in the opposite target domain. The decoder finally up-sample the transformed features vector back to the original shape and dimensionality as it was before going through the encoder. The architecture we used for that combination of encoder, transformer and decoder of our generator networks is based on the architecture proposed in [27]. The encoder in this architecture consists of two convolution layers, while the transformer consists of nine ResNet blocks and the decoder consists of two de-convolution/transposed convolution layers. The two discriminators architecture is a deep ConvNet model as well. They are based on the PatchGAN architecture from [28], which consists of three consecutive convolution layers for feature extraction in patches and a final 1D-convolution layer for the decision whether its input BEV point cloud image is fake or not.
In order to train the proposed CycleGAN-based DA approach for our task, we will be utilising the adversarial loss for the two generators that we have discussed above along with their corresponding discriminators. The first loss for the transformation from domain to domain is as follows:
[TABLE]
where is the synthetic BEV point cloud data domain and is its data distribution.
Similarly, the second loss for the transformation from domain to domain is as follows:
[TABLE]
Additionally, in order to penalise the generators of the trained model to generate more realistic BEV point cloud data from each domain and , the following third loss is added.
[TABLE]
where is the cycle-consistency loss which ensures the identity mapping of the each transformed sample BEV point cloud image back to its original source.
Given the three losses from Eq. 1, 2, 3, the objective loss function for the proposed CycleGAN-based DA approach is as follows:
[TABLE]
where is equal to 10 which was chosen empirically.
Finally, since the objective of training any deep ConvNet model is to minimise a certain loss function, which in our case is the joint loss function in Eq. 4. Thus, we will be using the Adam optimiser for minimising our objective joint loss function using a learning rate of 0.001.
III-C Vehicle Detection in BEV Point Cloud Data via YOLOv3
For the vehicle detection task, we will be the adopting state-of-the-art single stage deep ConvNet architecture for object detection, You Only Look Once (YOLOv3) architecture. Internally, YOLOv3 relies on k-means clustering to have prior bounding boxes “anchors” of a potential region of interests (ROIs) in the input image which goes through a total of 53 convolution layers to extract features from them on 3 different scales. YOLOv3 in returns predicts the four coordinates for the bounding box, an objectness score for each bounding box, and class score for the object that the bounding box may contain. The four coordinates are predicted using a sigmoid function. The objectness score is predicted using a logistic regression which is set to 1 if the bounding box of one of the anchors overlaps with a ground truth bounding box. The class score of a bounding box is predicted via multinomial logistic classifiers which is better than the traditional soft-max classifier when it comes to multi-label classification task such as object detection.
More specifically, in our vehicle detection task from BEV point cloud images, we relied on the YOLOv3-416 derivative architecture, which as the name implies works on input images with a resolution of .
IV Experiments
In this section, we will firstly discuss the datasets we have used for training and validating our trained models. Secondly, the performance of our models will be quantitatively and qualitatively evaluated.
IV-A Datasets
For the task of the DA between synthetic and real BEV point cloud images, we relied on two datasets. The first dataset is the recently released Motion-Distorted LiDAR Simulation (MDLS) dataset introduced in [9]. This dataset represents the synthetic domain of our CycleGAN-based DA approach discussed in Section III-B. The MLDS dataset was generated from high fidelity simulated urban traffic environments from the CARLA simulator [29] using a simulated Velodyne HDL-64E sensor. The dataset is originally meant for studying the effect of the motion distortion resulted from a moving vehicle-based 3D LIDAR sensor on the generated point cloud data. The dataset consists of two sequences of point cloud data from urban traffic environment involving between 60 to 90 moving vehicle, each one with an average duration of five minutes which results in total 6K point cloud scans. The dataset was annotated with the position of the vehicles in the scene. For our DA task, we first preprocessed the point cloud scans in order to get a BEV image of each scan according to the method introduced in [14]. As a result, we get a total of 6K BEV point cloud images similar to the right image shown in Fig. 1. The second dataset we utilised for the real domain of our CycleGAN-based DA approach is the BEV benchmark data from the KITTI dataset [11]. The BEV benchmark data consists of 7481 training images and point cloud scans and 7518 test images and point cloud scans. The point cloud data was captured using a real 3D LiDAR sensor the Velodyne HDL-64E sensor. The dataset contains annotations for multiple objects in the traffic scene such as vehicles, pedestrians and cyclists. Similar to the pre-processing step we have done for the MLDS dataset we did it as well for the KITTI dataset in order to get BEV point cloud images like the one shown on the left in Fig. 1. In our experiments for training our CycleGAN-based DA approach, we used a total 6K BEV point cloud images from the MLDS dataset and the 7481 BEV point cloud images of the training split from the KITTI dataset.
Similarly, for the task of the vehicle detection from BEV point cloud images we used the same aforementioned two datasets (MLDS and KITTI) in addition to the domain adapted BEV images from synthetic to real for training our YOLOv3 model. Since our ultimate goal in the vehicle detection task is to identify vehicles in real BEV point cloud images. Thus, we further split the total 7481 real BEV images from the KITTI dataset into 4K for training our YOLOv3 model and 3481 for testing the model.
IV-B Results and Discussion
Firstly, in order to evaluate the effectiveness of our proposed CycleGAN based DA approach for the vehicle detection task from real BEV point cloud images. In fig. 3, we show qualitative results of the trained CycleGAN-based DA approach between synthetic and real BEV point cloud images. In the first row of the figure is the input synthetic BEV point cloud image to our model. The second row represents the output from the generator of our trained CycleGAN model. The third row shows one sample of a real BEV point cloud image from the KITTI dataset. As it can be noticed, the generated BEV point cloud from our CycleGAN model is mimicking and trying to be consistent with the same structure exist in the real BEV point cloud image from KITTI. More specifically, the generated image captures pretty well the structure of the vehicles and the distortion/noise artefacts from resulting from the real Velodyne 3D LiDAR sensor.
For having more quantitative evaluation of our proposed CycleGAN based DA approach for the vehicle detection task, we trained two YOLOv3 models, the first one is trained using the 6K synthetic BEV point cloud images, while the other one is trained using the same 6K BEV point cloud images but the DA versions of them after feeding them to our trained CycleGAN model and getting its predicted DA real BEV point cloud images. Furthermore, we trained three additional YOLOv3 models with the only difference in the type of training data. The first model which as the name implies is trained on the 4K training split BEV point cloud images from the KITTI dataset. The second model is trained using on the 4K images from the KITTI dataset with an additional 6K synthetic BEV point cloud image from the MLDS dataset. The third and final model is trained using the same amount of data to the model, however instead of the MLDS synthetic BEV images we used the DA version predicted from our CycleGAN model.
In Table I, we report the performance of the total 5 YOLOv3 models we mentioned earlier when all are tested on the same 3481 testing real BEV point cloud images from the KITTI dataset. The evaluation metric we used is the average precision score (AP) which summarises the precision-recall curve that commonly used for evaluating object detectors. As it can be noticed from the table, the model outperformed the with more than 4% in AP score which proves our claim that our CycleGAN-based DA approach for the BEV point cloud images are more efficient than pure synthetic ones for the vehicle detection task. Additionally, the best performing model with 64.29% in AP score is the , which again proves the benefits of using domain adapted BEV point cloud images over the purse synthetic ones. This prevalent from Table I by the low AP scores from the and the models which achieved only AP score of 57.26% and 59.16% respectively.
For a qualitative measuring of the performance of the trained YOLOv3 models, in Fig. 4, we show a) input sample BEV point cloud image, b), c) and d) the detected bounding boxes (in green colour) from models , and respectively. The ground truth annotations are highlighted in the light blue colour, while the false or miss-detected objects are highlighted in red colour. As it can be shown, our model gives an accurate detection with the lowest false-positive rate.
V Conclusion
In this work, we have introduced a framework for domain adaptation between synthetic and real BEV point cloud images for the vehicle detection task. The proposed framework utilises deep generative adversarial networks, CycleGAN for the domain adaptation task. Then, given the domain adapted BEV point cloud images we trained a series of object detection models based on state-of-the-art deep ConvNet-based model, YOLOv3. The trained models have shown the effectiveness of the proposed DA approach for the vehicle detection task from real BEV point cloud images. Furthermore, we have evaluated the performance of the trained models on the testing split from real BEV point cloud images from the KITTI dataset. The best performing model was the one utilising our domain-adapted BEV point cloud images which achieved the highest average precision score of 64.29% with an improvement of more than 7% over the compared baseline approaches.
Acknowledgement
This research was fully supported by the Institute for Intelligent Systems Research and Innovation (IISRI) at Deakin University.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Redmon and A. Farhadi, “Yolov 3: An incremental improvement,” ar Xiv , 2018.
- 2[2] K. Saleh, R. A. Zeineldin, M. Hossny, S. Nahavandi, and N. El-Fishawy, “End-to-end indoor navigation assistance for the visually impaired using monocular camera,” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC) . IEEE, 2018, pp. 3504–3510.
- 3[3] K. Saleh, M. Attia, M. Hossny, S. Hanoun, S. Salaken, and S. Nahavandi, “Local motion planning for ground mobile robots via deep imitation learning,” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC) . IEEE, 2018, pp. 4077–4082.
- 4[4] K. Saleh, M. Hossny, and S. Nahavandi, “Cyclist trajectory prediction using bidirectional recurrent neural networks,” in Australasian Joint Conference on Artificial Intelligence . Springer, 2018, pp. 284–295.
- 5[5] A. Abobakr, M. Hossny, H. Abdelkader, and S. Nahavandi, “Rgb-d fall detection via deep residual convolutional lstm networks,” in 2018 Digital Image Computing: Techniques and Applications (DICTA) , Dec 2018, pp. 1–7.
- 6[6] K. Saleh, M. Hossny, and S. Nahavandi, “Long-term recurrent predictive model for intent prediction of pedestrians via inverse reinforcement learning,” in 2018 Digital Image Computing: Techniques and Applications (DICTA) . IEEE, 2018, pp. 1–8.
- 7[7] K. Saleh, M. Hossny, A. Hossny, and S. Nahavandi, “Cyclist detection in lidar scans using faster r-cnn and synthetic depth images,” in 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC) . IEEE, 2017, pp. 1–6.
- 8[8] K. Saleh, M. Hossny, and S. Nahavandi, “Effective vehicle-based kangaroo detection for collision warning systems using region-based convolutional networks,” Sensors , vol. 18, no. 6, p. 1913, 2018.