TL;DR
The paper introduces the Machine Learning Bazaar, a comprehensive framework that unifies ML components, automates pipeline creation, and supports multi-task AutoML across diverse data types and problem domains.
Contribution
It presents a novel unified API for ML primitives, a pipeline composition approach, and a multi-task AutoML system capable of handling various data modalities and problem types.
Findings
Demonstrated 5 real-world use cases.
Evaluated over 456 ML tasks.
Searched through 2.5 million pipelines.
Abstract
As machine learning is applied more widely, data scientists often struggle to find or create end-to-end machine learning systems for specific tasks. The proliferation of libraries and frameworks and the complexity of the tasks have led to the emergence of "pipeline jungles" - brittle, ad hoc ML systems. To address these problems, we introduce the Machine Learning Bazaar, a new framework for developing machine learning and automated machine learning software systems. First, we introduce ML primitives, a unified API and specification for data processing and ML components from different software libraries. Next, we compose primitives into usable ML pipelines, abstracting away glue code, data flow, and data storage. We further pair these pipelines with a hierarchy of AutoML strategies - Bayesian optimization and bandit learning. We use these components to create a general-purpose,…
Click any figure to enlarge with its caption.
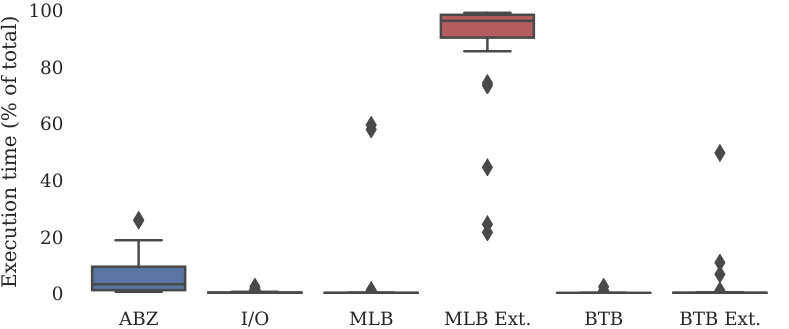 Figure 1
Figure 1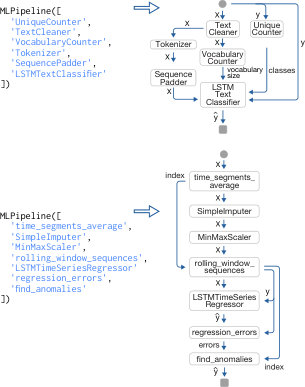 Figure 2
Figure 2 Figure 3
Figure 3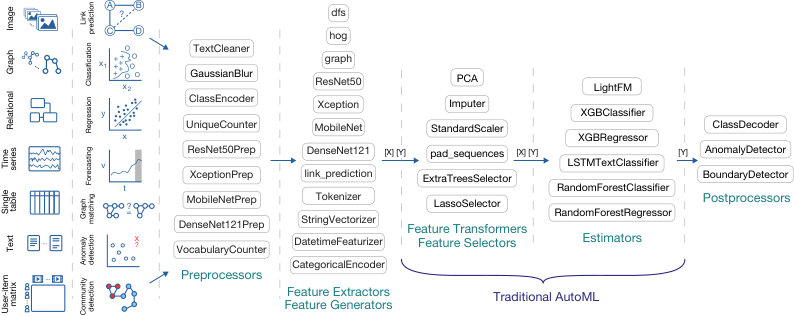 Figure 4
Figure 4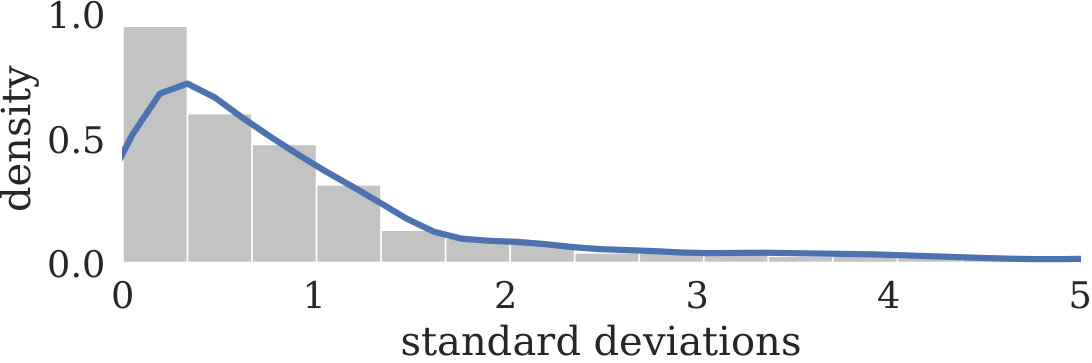 Figure 7
Figure 7| Source | Count | Source | Count |
|---|---|---|---|
| scikit-learn | 39 | XGBoost | 2 |
| MLPrimitives (custom) | 27 | LightFM | 1 |
| Keras | 25 | OpenCV | 1 |
| pandas | 16 | python-louvain | 1 |
| Featuretools | 4 | scikit-image | 1 |
| NumPy | 3 | statsmodels | 1 |
| NetworkX | 2 |
| System | Top pipeline | Beats Expert 1 | Beats Expert 2 | Rank |
|---|---|---|---|---|
| System 1 | 29 | 57 | 31 | 1 |
| ML Bazaar | 18 | 56 | 28 | 2 |
| System 3 | 15 | 47 | 22 | 3 |
| System 4 | 14 | 46 | 21 | 4 |
| System 5 | 10 | 42 | 14 | 5 |
| System 6 | 8 | 43 | 15 | 6 |
| System 7 | 8 | 33 | 12 | 7 |
| System 8 | 6 | 24 | 11 | 8 |
| System 9 | 4 | 25 | 13 | 9 |
| System 10 | 2 | 27 | 12 | 10 |
| min | p25 | p50 | p75 | max | |
| Number of examples | 7 | 202 | 599 | 3,634 | 6,095,521 |
| Number of | 2 | 2 | 3 | 6 | 115 |
| Columns of | 1 | 3 | 9 | 22 | 10,937 |
| Size (compressed) | 3KiB | 21KiB | 145KiB | 2MiB | 36GiB |
| Size (inflated) | 22KiB | 117KiB | 643KiB | 7MiB | 42GiB |
| Data Modality | Problem Type | Tasks | Pipeline Template |
| graph | community detection | 2 | |
| graph matching | 9 | ||
| link prediction | 1 | ||
| vertex nomination | 1 | ||
| image | classification | 5 | |
| regression | 1 | ||
| multi table | classification | 6 | |
| regression | 7 | ||
| single table | classification | 234 | |
| collaborative filtering | 4 | ||
| regression | 87 | ||
| timeseries forecasting | 35 | ||
| text | classification | 18 | |
| regression | 9 | ||
| timeseries | classification | 37 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
The Machine Learning Bazaar: Harnessing the ML Ecosystem for Effective System Development
Micah J. Smith
MIT
,
Carles Sala
MIT
,
James Max Kanter
Feature Labs
and
Kalyan Veeramachaneni
MIT
(2020)
Abstract.
As machine learning is applied more widely, data scientists often struggle to find or create end-to-end machine learning systems for specific tasks. The proliferation of libraries and frameworks and the complexity of the tasks have led to the emergence of “pipeline jungles” — brittle, ad hoc ML systems. To address these problems, we introduce the Machine Learning Bazaar, a new framework for developing machine learning and automated machine learning software systems. First, we introduce ML primitives, a unified API and specification for data processing and ML components from different software libraries. Next, we compose primitives into usable ML pipelines, abstracting away glue code, data flow, and data storage. We further pair these pipelines with a hierarchy of AutoML strategies — Bayesian optimization and bandit learning. We use these components to create a general-purpose, multi-task, end-to-end AutoML system that provides solutions to a variety of data modalities (image, text, graph, tabular, relational, etc.) and problem types (classification, regression, anomaly detection, graph matching, etc.). We demonstrate 5 real-world use cases and 2 case studies of our approach. Finally, we present an evaluation suite of 456 real-world ML tasks and describe the characteristics of 2.5 million pipelines searched over this task suite.
machine learning; AutoML; software development; ML pipelines; ML primitives
††journalyear: 2020††copyright: acmlicensed††conference: Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data; June 14–19, 2020; Portland, OR, USA††booktitle: Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD’20), June 14–19, 2020, Portland, OR, USA††price: 15.00††doi: 10.1145/3318464.3386146††isbn: 978-1-4503-6735-6/20/06††ccs: Computing methodologies Machine learning††ccs: Software and its engineering Abstraction, modeling and modularity††ccs: Software and its engineering Software development techniques
1. Introduction
Once limited to conventional commercial applications, machine learning (ML) is now being widely applied in physical and social sciences, in policy and government, and in a variety of industries. This diversification has led to difficulties in actually creating and deploying real-world systems, as key functionality becomes fragmented across ML-specific or domain-specific software libraries created by independent communities. In addition, the process of building problem-specific end-to-end systems continues to be marked by ML and data management challenges, such as formulating achievable learning problems (Kanter et al., 2016), managing and cleaning data and metadata (Miao et al., 2017; van der Weide et al., 2017; Bhardwaj et al., 2015), scaling tuning procedures (Falkner et al., 2018; Li et al., 2018), and deploying models and serving predictions (Baylor et al., 2017; Crankshaw et al., 2015). In practice, engineers and data scientists often spend significant effort developing ad hoc programs for new problems: writing “glue code” to connect components from different software libraries, processing different forms of raw input, and interfacing with external systems. These steps are tedious and error-prone and lead to the emergence of brittle “pipeline jungles” (Sculley et al., 2015).
These points raise the question, “How can we make building ML systems easier in practical settings?” A new approach is needed to designing and developing software systems that solve specific ML tasks. Such an approach should address a wide variety of input data modalities, such as images, text, audio, signals, tables, graphs, and learning problem types, such as regression, classification, clustering, anomaly detection, community detection, graph matching; it should cover the intermediate stages involved, such as data preprocessing, munging, featurization, modeling, and evaluation; and it should enable AutoML functionality to fine-tune solutions, such as hyperparameter tuning and algorithm selection. Moreover, it should offer coherent APIs, fast iteration on ideas, and easy integration of new ML innovations. In sum, this ambitious goal would allow almost all end-to-end learning problems to be solved or built using a single framework.
To address these challenges, we present the Machine Learning Bazaar,111Just as one open-source community was described as “a great babbling bazaar of different agendas and approaches” (Raymond, 1999), our framework is characterized by the availability of many compatible alternatives, a wide variety of libraries and custom solutions, a space for new contributions, and more. a framework for designing and developing ML and AutoML systems. We organize the ML ecosystem into composable software components, ranging from basic building blocks like individual classifiers to full AutoML systems. With our design, a user specifies a task, provides a raw dataset, and either composes an end-to-end pipeline out of pre-existing, annotated, ML primitives or requests a curated pipeline for their task (Figure 1). The resulting pipelines can be easily evaluated and deployed across a variety of software and hardware settings and tuned using a hierarchy of AutoML approaches. Using our own framework, we have created an AutoML system which we have entered in participation in DARPA’s Data-Driven Discovery of Models (D3M) program; ours is the first end-to-end, modular, publicly released system designed to meet the program’s goal.
To preview the potential of development using our framework, we highlight the Orion project within MIT for ML-based anomaly detection in satellite telemetry (Figure 2), as one of several successful real-world applications that uses ML Bazaar for effective ML system development (Section 4.1). The Orion pipeline processes a telemetry signal using several custom preprocessors, an LSTM predictor, and a dynamic thresholding postprocessor to identify anomalies. The entire pipeline can be represented in a short Python snippet, custom processing steps are easily implemented as modular components, two external libraries are integrated without glue code, and the pipeline can be tuned using composable AutoML functionality.
Our contributions in this paper include:
- A composable framework for representing and developing ML and AutoML systems: Our framework enables users to specify a pipeline for any ML task, ranging from image classification to graph matching, through a unified API (Sections 2 and 3).
- The first general-purpose automated machine learning system: Our system, AutoBazaar, is, to the best of our knowledge, the first open-source, publicly-available, system with the ability to reliably compose end-to-end, automatically-tuned, solutions for 15 data modalities and problem types (Section 3.3).
- Successful applications: We describe 5 successful application of our framework on real-world problems (Section 4).
- A comprehensive evaluation: We evaluated our AutoML system against a suite of 456 ML tasks/datasets covering 15 ML task types, analyzing 2.5 million scored pipelines (Section 5).
- Open-source libraries: Components of our framework have been released as the open-source libraries MLPrimitives,
MLBlocks, BTB, piex, and AutoBazaar.
2. The Machine Learning Bazaar
The ML Bazaar is a composable framework for developing ML and AutoML systems based on a hierarchical organization of and unified API for the ecosystem of ML software and algorithms. One can use curated or custom software components for every aspect of the practical ML process, from featurizers for relational datasets to signal processing transformers to neural networks to pre-trained embeddings. From these primitives, data scientists can easily and efficiently construct ML solutions for a variety of ML task types, and ultimately, automate much of the work of tuning these models.
2.1. ML Primitives
A primitive is a reusable, self-contained, software component for ML paired with the structured annotation of its metadata. It has a well-defined fit/produce interface wherein it receives input data in one of several formats or types, performs computations, and returns the data in another format or type. With this categorization and abstraction, widely varying functionality required to construct ML pipelines can be collected in a single location. Primitives can be re-used in chained computations while minimizing glue code written by callers. An example primitive annotation is shown in Figure 3.
Primitives encapsulate different types of functionality. Many have a learning component, such as a random forest classifier. Many primitives, categorized as transformers, may have no learning component and only have a produce method, but are very important nonetheless. For example, the Hilbert and Hadamard transforms from signal processing would be important primitives to include when building an ML system to solve a task in Internet-of-Things.
Some primitives do not change the values in the data, but simply prepare or reshape the data. These glue primitives are intended to reduce glue code required to connect primitives into a full system. An example of this type of primitive is pandas.DataFrame.unstack.
2.1.1. Annotations
Each primitive is annotated with machine-readable metadata that enables its usage and automatic integration within an execution engine. Annotations allow us to unify a variety of primitives from disparate libraries, reduce the need for glue code, and provide information about the tunable hyperparameters. This full annotation222The primitive annotation specification is described and documented in full in the associated MLPrimitives library. is provided in a single JSON file and has three major sections:
- •
Meta-information. This section has the name of the primitive, the fully-qualified name of the underlying implementation as a Python object, and other detailed metadata, such as the author, description, documentation URL, categorization, and the data modalities it is most used for. This information enables searching and indexing primitives.
- •
Information required for execution. This section has the names of the methods pertaining to fit/produce in the underlying implementation as well as the data types of the primitive’s inputs and outputs. When applicable, for each primitive, we annotate the ML data types of declared inputs and outputs, i.e., recurring objects in ML that have a well-defined semantic meaning, such as a feature matrix , a target vector , or a space of class labels classes. We provide a mapping between ML data types and synonyms used by specific libraries as necessary. This logical structure will help dramatically decrease the amount of glue code developers must write (Section 2.2.1).
- •
Information about hyperparameters. The third section details all the hyperparameters of the primitive — their names, descriptions, data types, ranges, and whether they are fixed or tunable. It also captures any conditional dependencies between the hyperparameters.
We have developed the open-source MLPrimitives 333https://github.com/HDI-Project/MLPrimitives library which contains a number of primitives adapted from different libraries (Table 1). For libraries that already provide a fit/produce interface or similar (e.g. scikit-learn), a primitive developer has to write the JSON specification and point to the underlying estimator class.
To support integration of primitives from libraries that need significant adaptation to the fit/produce interface,
MLPrimitives also provides a powerful set of adapter modules that assist in wrapping common patterns. These adapter modules then allow us to integrate many functionalities as primitives from the library without having to write a separate object for each — thus requiring us to write only an annotation file for each primitive. Keras is an example of such a library.
For developers, domain experts, and researchers, MLPrimitives enables easy contribution of new primitives in several ways by providing primitive templates, example annotations, and detailed tutorials and documentation. We also provide procedures to validate proposed primitives against the formal specification and a unit test suite. Finally, contributors can also write custom primitives.
Currently, MLPrimitives maintains a curated catalog of high-quality, useful primitives from 12 libraries,444As of MLPrimitives v0.2.4. as well as custom primitives that we have created (Table 1). Each primitive is identified by a fully-qualified name to differentiate primitives across catalogs. The JSON annotations can then be mined for additional insights.
2.1.2. Designing for contributions
We considered multiple alternatives to the primitives API, such as representing all of them as Python data structures or classes, regardless of their type (i.e. transformers or estimators). One disadvantage of these alternatives is that it makes it more difficult for domain experts to contribute primitives. We have found that domain experts, such as engineers and scientists in the satellite industry, prefer writing functions rather than other constructs such as classes, and many domain-specific processing methods are simply transformers without a learning component.
2.1.3. Lightweight integration
Another option we considered was to enforce that every primitive— whether brought over from a library with a compatible API or otherwise — be integrated via a Python class with wrapper methods. We opted against this approach as it led to excessive wrapper code and created redundancy, which made it more difficult to write primitives. Instead, for libraries that are compatible, our design requires that we only create the annotation file.
2.1.4. Language independence
In this work, we focus on the wealth of ML functionality that exists in the Python ecosystem. Through ML Bazaar’s careful design, we could also support other common languages in data science like R, MATLAB, and Julia and enable multi-language pipelines. Starting from our JSON primitive annotation format, a multi-language pipeline execution backend would be built that uses language-specific kernels or containers and relies on an interoperable data format such as Apache Arrow. A language-independent format like JSON provides several additional advantages. It is both machine- and human- readable and writeable. It is also a natural format for storage and querying in NoSQL document stores, allowing developers to easily query a knowledge base of primitives for the subset appropriate for a specific ML task type, for example.
2.2. Building ML pipelines
To solve practical learning problems, we must be able to instantiate and compose primitives into usable programs. These programs must be easy to specify with a natural interface, such that developers can easily compose primitives without sacrificing flexibility. We aim to support both end-users trying to build an ML solution for their specific problem who may not be savvy about software engineering, as well as system developers wrapping individual ML solutions in AutoML components. In addition, we provide an abstracted execution layer, such that learning, data flow, data storage, and deployment are handled automatically by various configurable and pluggable backends. As one realization of these ideas, we have implemented MLBlocks,555https://github.com/HDI-Project/MLBlocks a library for composing, training, and deploying end-to-end ML pipelines.
2.2.1. Steps and Pipelines
We introduce ML pipelines, which collect multiple primitives into a single computational graph. Each primitive in the graph is instantiated in a pipeline step, which loads and interprets the underlying primitive and provides a common interface to run a step in a larger program.
We define a pipeline as a directed acyclic multigraph
, where is a collection of pipeline steps, are the directed edges between steps representing data flow, and is a joint hyperparameter vector for the underlying primitives. A valid pipeline — and its generalizations (Section 3.1) — must also satisfy acceptability constraints that require the inputs to each step to be satisfied by the outputs of another step connected by a directed edge.
The term “pipeline” is used in the literature to refer to a ML-specific sequence of operations, and sometimes abused (as we do here) to refer to a more general computational graph or analysis. In our conception, we bring foundational data processing operations of raw inputs into this scope, like featurization of graphs, multi-table relational data, time series, text, and images, as well as simple data transforms, like encoding integer or string targets. This gives our pipelines a greatly expanded role, providing solutions to any ML task type and spanning the entire ML process beginning with the raw dataset.
2.2.2. Pipeline description interface
Large graph-structured workloads can be difficult to specify for end-users due to the complexity of the data structure and such workloads are an active area of research in data management. In ML Bazaar, we consider three aspects of pipeline representation: ease of composition, readability, and computational issues. First, we prioritize easily composing complex ML pipelines by providing a pipeline description interface (PDI) in which developers specify only the topological ordering of all pipeline steps in the pipeline without requiring any explicit dependency declarations. These steps can be passed to our libraries as Python data structures or loaded from JSON files. Full training-time (fit) and inference-time (produce) computational graphs can then be recovered (Algorithm 1). This is made possible by the meta-information provided in the primitive annotations, in particular, the ML data types of the primitive inputs and outputs. We leverage the observation that steps that modify the same ML data type can be grouped into the same subpath. In cases where this information does not uniquely identify a graph, the user can additionally provide an input-output map which serves to explicitly add edges to the graph, as well as other parameters to customize the pipeline.
Though it may be more difficult to read and understand these pipelines from the PDI alone as the edges are not shown nor labeled, it is easy to accompany them with the recovered graph representation (Figures 2 and 5).
The resulting graphs describe abstract computational workloads, but we must be able to actually execute them for purposes of learning and inference. From the recovered graphs, we could re-purpose many existing data engineering systems as backends for scheduling and executing the workloads (Rocklin, 2015; Zaharia et al., 2016; Shoumik et al., 2018). In our MLBlocks execution engine, a collection of objects and a metadata tracker in a key-value store are iteratively transformed through sequential processing of pipeline steps. The Orion pipeline would be executed using MLBlocks as shown in Figure 2(c).
2.3. Discussion
Why not scikit-learn?
Several alternatives exist to our new ML pipeline abstraction (Section 2.2), such as scikit-learn’s Pipeline (Buitinck et al., 2013). Ultimately, while our pipeline is inspired by these alternatives, it aims to provide more general data engineering and ML functionality. While the scikit-learn pipeline sequentially applies a list of transformers to and only before outputting a prediction, our pipeline supports general computational graphs, accepts multiple data modalities as input simultaneously, produces multiple outputs, manages evolving metadata, and can use software from outside the scikit-learn ecosystem/design paradigm. For example, we can use our pipeline to construct entity sets (Kanter, 2015) from multi-table relational data for input to other pipeline steps. We can also support pipelines in an unsupervised learning paradigm, such as in Orion, where we create the target “on-the-fly” (Figure 5).
Where’d the glue go?
To connect learning components from different libraries with incompatible APIs, data scientists end up writing “glue code”. Typically, this glue code is written within pipeline bodies. In ML Bazaar, we mitigate the need for this glue by pushing the need of API adaptation down to the level of primitive annotations, which are written once and reside in central locations, amortizing the adaptation cost. Moreover, the need for glue code arises in creating intermediate outputs and shaping of the data. We created a number of primitives that support these common programming patterns and miscellaneous needs in development of a ML pipeline. These are, for example, data reshaping primitives like pandas.DataFrame.unstack, data preparation primitives like pad_sequences required for Keras-based LSTMs, and utilities like UniqueCounter that count the number of unique classes.
Interactive development
Interactivity is an important aspect of data science development for beginners and experts alike, as they build understanding of the data and iterate on different modeling ideas. In ML Bazaar, the level of interactivity possible depends on the specific runtime library. For example, our MLBlocks library supports interactive development in a shell or notebook environment by allowing the inspection of intermediate pipeline outputs and by allowing pipelines to be iteratively expanded starting from a loaded pipeline description. Alternatively, ML primitives could be used as a backend pipeline representation for software that provides more advanced interactivity such as drag-and-drop. For interfaces that require low latency pipeline scoring to provide user feedback such as (Crotty et al., 2015), ML Bazaar’s performance depends mainly on the underlying primitive implementations (Section 5).
Supporting new task types
While ML Bazaar handles 15 ML task types (Table 4), there are many more task types for which we do not currently provide pipelines in our default catalog (Section 5.5). To extend our approach to support new task types, it is generally sufficient to write several new primitive annotations for pre-processing input and post-processing output — no changes are needed to the core ML Bazaar software libraries such as MLPrimitives and MLBlocks. For example, for the anomaly detection task type from the Orion project, several new simple primitives were implemented: rolling_window_sequences, regression_errors, and find_anomalies. Indeed, support for a certain task type is predicated on the availability of a pipeline for that task type rather than any characteristics of our software libraries.
Primitive versioning
The default catalog of primitives from the MLPrimitives library is versioned together, and library conflicts are resolved manually by maintainers through carefully specifying minimum and maximum dependencies. This strategy ensures that the default catalog can always be used, even if there are incompatible updates to the underlying libraries. Automated tools can be integrated to aid both end-users and maintainers in understanding potential conflicts and safely bumping library-wide versions.
3. AutoML System Design and Architecture
From the components of the ML Bazaar, data scientists can easily and effectively build ML pipelines with fixed hyperparameters for their specific problems. To improve the performance of these solutions, we introduce the more general pipeline templates and pipeline hypertemplates and then present the design and implementation of AutoML primitives which facilitate hyperparameter tuning and model selection, either using our own library for Bayesian optimization or external AutoML libraries. Finally, we describe AutoBazaar, one specific AutoML system we have built on top of these components.
3.1. Pipeline templates and hypertemplates
Frequently, pipelines require hyperparameters to be specified at several places. Unless these values are fixed at annotation-time, hyperparameters must be exposed in a machine-friendly interface. This motivates pipeline templates and pipeline hypertemplates, which generalize pipelines by allowing a hierarchical tunable hyperparameter configuration space and provide first-class tuning support.
We define a pipeline template as a directed acyclic multigraph , where is the joint hyperparameter configuration space for the underlying primitives. By providing values for the unset hyperparameters of a pipeline template, a specific pipeline is created.
In some cases, certain values of hyperparameters can affect the domains of other hyperparameters. For example, the type of kernel for a support vector machine results in different kernel hyperparameters, and preprocessors used to adjust for class imbalance can affect the training procedure of a downstream classifier. We call these conditional hyperparameters, and accommodate them with pipeline hypertemplates.
We define a pipeline hypertemplate as a directed acyclic multigraph , where is a collection of pipeline steps, are directed edges between steps, and is the hyperparameter configuration space for pipeline template . A number of pipeline templates can be derived from one pipeline hypertemplate by fixing the conditional hyperparameters.
3.2. AutoML Primitives
Just as primitives units components of ML computation, AutoML primitives represent components of an AutoML system. We separate AutoML primitives into tuners and selectors. In our extensible AutoML library for developing AutoML systems, BTB,666https://github.com/HDI-Project/BTB we provide various instances of these AutoML primitives.
3.2.1. Tuners
Given a pipeline template, an AutoML system must find a specific pipeline with fully-specified hyperparameter values to maximize some utility. Given pipeline template and a function that assigns a performance score to pipeline with hyperparameters , the tuning problem is defined as . We introduce tuners, AutoML primitives which provide a record/propose interface in which evaluation results are recorded to the tuner by the user or by an AutoML controller and new hyperparameters are proposed in return.
Hyperparameter tuning is widely studied and its effective use is instrumental to maximizing the performance of ML systems (Bergstra et al., 2011; Bergstra and Bengio, 2012; Feurer et al., 2015; Snoek et al., 2012). One widely used approach to hyperparameter tuning is Bayesian optimization (BO), a black-box optimization technique in which expensive evaluations of are kept to a minimum by forming and updating a meta-model for . At each iteration, the next hyperparameter configuration to try is chosen according to an acquisition function. We structure these meta-models and acquisition functions as separate BO-specific AutoML primitives that can be combined together to form a tuner. Researchers have argued for different formulations of meta-models and acquisition functions (Oh et al., 2018; Wang et al., 2017; Snoek et al., 2012). In our BTB library for AutoML, we implement the GP-EI tuner, which uses a Gaussian Process meta-model primitive and an Expected Improvement (EI) acquisition function primitive, among several other tuners. Many other tuning paradigms exist, such as those based on evolutionary strategies (Loshchilov and Hutter, 2016; Olson et al., 2016), adaptive execution (Jamieson and Talwalkar, 2016; Li et al., 2017), meta-learning (Gomes et al., 2012), or reinforcement learning (Drori et al., 2018). Though we have not provided implementations of these in BTB, one could do so using our common API.
3.2.2. Selectors
For many ML task types, there may be multiple pipeline templates or pipeline hypertemplates available, each with their own tunable hyperparameters. The aim is to balance the exploration-exploitation tradeoff while selecting promising pipeline templates to tune. For a set of pipeline templates , we define the selection problem as . We introduce selectors, AutoML primitives which provide a compute_rewards/select API.
Algorithm selection is often treated as a multi-armed bandit problem where the score returned from a selected template can be assumed to come from an unknown underlying probability distribution. In BTB, we implement the UCB1 selector, which uses the upper confidence bound method (Auer et al., 2002), among several other selectors. Users or AutoML controllers can use selectors and tuners together to perform joint algorithm selection and hyperparameter tuning.
3.3. Building an AutoML system
Using the ML Bazaar framework, we have built AutoBazaar,777https://github.com/HDI-Project/AutoBazaar an open-source, end-to-end, general-purpose, multi-task, automated machine learning system. It consists of several components: an AutoML controller; a pipeline execution engine; data stores for metadata and pipeline evaluation results; loaders and configuration for ML tasks, primitives, etc.; a Python language client; and a command-line interface. AutoBazaar is an open-source variant of the AutoML system we have developed for the DARPA D3M program.
We focus here on the core pipeline search and evaluation algorithms (Algorithm 2). The input to the search is a computational budget and an ML task, which consists of the raw data and task and dataset metadata — dataset resources, problem type, dataset partition specifications, and an evaluation procedure for scoring. Based on these inputs, AutoBazaar searches through its catalog of primitives and pipeline templates for the most suitable pipeline that it can build. First, the controller loads the train and test dataset partitions, and , following the metadata specifications. Next, it loads from its default catalog and the user’s custom catalog a collection of candidate pipeline templates suitable for the ML task type. Using the BTB library, it initializes a UCB1 selector and a collection of GP-EI tuners for joint algorithm selection and hyperparameter tuning. The search process begins and continues for as long as the computation budget has not been exhausted. In each iteration, the selector is queried to select a template, the corresponding tuner is queried to propose a hyperparameter configuration, a pipeline is generated and scored using cross validation over , and the score is reported back to the selector and tuner. The best overall pipeline found during the search, , is re-fit on and scored over . Its specification is returned to the user alongside the score obtained, .
4. Applications
In this paper, we claim that ML Bazaar makes it easier to develop ML systems. We provide evidence for this claim in this section by describing 5 real-world use cases in which ML Bazaar is currently used to create both ML and AutoML systems. Through these industrial applications we examine the following questions: Does ML Bazaar support the needs of ML system developers? If not, how easy was it to extend?
4.1. Use cases
Anomaly detection for satellite telemetry
ML Bazaar is used by a communications satellite operator which provides video and data connectivity globally. This company wanted to monitor more than 10,000 telemetry signals from their satellites and identify anomalies, which might indicate a looming failure severely affecting the satellite’s coverage. This time series/anomaly detection task was not initially supported by any of the pipelines in our curated catalog. Our collaborators were able to easily implement a recently developed end-to-end anomaly detection method (Hundman et al., 2018) using pre-existing transformation primitives in ML Bazaar and by adding several new primitives: a primitive for the specific LSTM architecture used in the paper and new time series anomaly detection postprocessing primitives, which take as input a time series and time series forecast, and produce as output a list of anomalies, identified by intervals . This design enabled rapid experimentation through substituting different time series forecasting primitives and comparing the results. In current work, they apply ML pipelines to 82 publicly available satellite telemetry signals from NASA and evaluate the anomaly detections against 105 known anomalies. The work has been released as the open-source Orion project888https://github.com/D3-AI/Orion and is currently under active development.
Predicting clinical outcomes from electronic health records
Cardea is an open-source, automated framework for predictive modeling in health care on electronic health records following the FHIR schema. Its developers formulated a number of prediction problems including predicting length of hospital stay, missed appointments, and hospital readmission. All tasks in Cardea are multitable regression or classification. From ML Bazaar, Cardea uses the featuretools.dfs primitive to automatically engineer features for this highly-relational data and multiple other primitives for classification and regression. The framework also presents examples on a publicly available patient no-show prediction problem. The framework has been released as an open-source project.999https://github.com/D3-AI/Cardea
Failure prediction in wind turbines
ML Bazaar is also used by a multinational energy utility to predict critical failures and stoppages in their wind turbines. Most prediction problems here pertain to the time series classification ML task type. ML Bazaar has several time series classification pipelines available in its catalog and they enable usage of time series from 140 turbines to develop multiple pipelines, tune them, and produce prediction results. Multiple outcomes are predicted, ranging from stoppage and pitch failure to less common issues, such as gearbox failure. This library is released as the open-source GreenGuard project.101010https://github.com/D3-AI/GreenGuard
Leaks and crack detection in water distribution systems
A global water technology provider uses ML Bazaar for a variety of ML needs, ranging from image classification for detecting leaks from images, to crack detection from time series data, to demand forecasting using water meter data. ML Bazaar provides a unified framework for these disparate needs. The team also builds custom primitives internally and uses them directly with the MLBlocks backend.
4.2. DARPA D3M program
DARPA’s Data-Driven Discovery of Models (D3M) program, of which we are participants, aims to spur development of automated systems for model discovery for use by non-experts. Among other goals, participants aim to design and implement AutoML systems that can produce solutions to arbitrary ML tasks without any human involvement. We used ML Bazaar to create an AutoML system to be evaluated against other teams from US academic institutions. Participants include ourselves (MIT), CMU, UC Berkeley, Brown, Stanford, TAMU, and others. Our system relies on AutoML primitives (Section 3) and other features of our framework, but does not use our primitive and pipeline implementations (neither MLPrimitives nor MLBlocks).
We present results comparing our system against other teams in the program. DARPA organizes an evaluation every 6 months (Winter and Summer). During evaluation, AutoML systems submitted by participants are run by DARPA on 95 tasks spanning several task types for three hours per task. At the end of the run, the best pipeline identified by the AutoML system is evaluated on held-out test data. Results are also compared against two independently-developed expert baselines (MIT Lincoln Laboratory and Exline).
Results from one such evaluation from Spring 2018 were presented by (Shang et al., 2019). We make comparisons from the Summer 2019 evaluation, the results of which were released in August 2019 — the most recent evaluation as of this writing. Table 2 compares our AutoML system against 9 other teams. Given the same tasks and same machine learning primitives, this comparison highlights the efficacy of the AutoML primitives (BTB) in ML Bazaar only — it does not provide any evaluation of our other libraries. In its implementation, our system uses a GP-MAX tuner and a UCB1 selector. Across all metrics, our system places 2nd out of the 10 teams.
4.3. Discussion
Through these applications using the components of the ML Bazaar, several advantages surfaced.
4.3.1. Composability
One important aspect of ML Bazaar is that it does not restrict the user to use a single monolithic system, rather users can pick and choose parts of the framework they want to use. For example, Orion uses only MLPrimitives/MLBlocks, Cardea uses MLPrimitives but integrates the hyperopt library for hyperparameter tuning, our D3M AutoML system submission mainly uses AutoML primitives and BTB, and AutoBazaar uses every component.
4.3.2. Focus on infrastructure
The ease of developing ML systems for the task at hand freed up time for teams to think through and design a comprehensive ML infrastructure. In the case of Orion and GreenGuard, this led to the development of a database that catalogues the metadata from every ML experiment run using ML Bazaar. This had several positive effects: it allowed for easy sharing between team members, and it allowed the company to transfer the knowledge of what worked from one system to another system. For example, the satellite company plans to use the pipelines that worked on a previous generation of the satellites on the newer ones from the beginning. With multiple entities finding uses for such a database, creation of such infrastructure could be templatized.
4.3.3. Multiple use cases
Our framework allowed the water technology company to solve many different ML task types using the same framework and API.
4.3.4. Fast experimentation
Once a baseline pipeline has been designed to solve a problem, we notice that users can quickly shift focus to developing and improving primitives that are responsible for learning.
4.3.5. Production ready
A fitted pipeline maintains all the learned parameters as well as all the data manipulations. A user is able to serialize the pipeline and load it into production. This reduces the development-to-production lifecycle.
5. Experimental evaluation
In this section, we experimentally evaluate ML Bazaar along several dimension. We also leverage our evaluation results to perform several case studies in which we show how a general-purpose evaluation setting can be used to assess the value of specific ML and AutoML primitives.
5.1. ML task suite
The ML Bazaar Task Suite is a comprehensive corpus of tasks and datasets to be used for evaluation, experimentation, and diagnostics. It consists of 456 ML tasks spanning 15 task types. Tasks, which encompass raw datasets and annotated task descriptions, are assembled from a variety of sources, including MIT Lincoln Laboratory, Kaggle, OpenML, Quandl, and Crowdflower. We created train/test splits and organized the folder structure. Other than this, we do not do any preprocessing (sampling, outlier detection, imputation, featurization, scaling, encoding, etc.), presenting data in its raw form as it would be ingested by end-to-end pipelines. Our publicly-available task suite can be browsed online111111https://mlbazaar.github.io or through piex,121212https://github.com/HDI-Project/piex our library for exploration and meta-analysis of ML tasks and pipelines. The covered task types are shown in Table 4 and a summary of the tasks is shown in Table 3.
We made every effort to curate a corpus that was evenly balanced across ML task types. Unfortunately, in practice, available datasets are heavily skewed to traditional ML problems of single-table classification and our task suite reflects this deficiency (though 49% are not single-table classification). Indeed, among other evaluation suites, the OpenML 100 and the AutoML Benchmark (Bischl et al., 2017; Gijsbers et al., 2019) are both exclusively comprised of single-table classification problems. Similarly, evaluation approaches for AutoML methods usually target the black-box optimization aspect in isolation (Golovin et al., 2017; Guyon et al., 2015; Dewancker et al., 2016) without considering the larger context of an end-to-end pipeline.
5.2. Pipeline search
We run the search process for all tasks in parallel on a heterogenous cluster of 400 AWS EC2 nodes. Each ML task is solved independently on a node of its own over a 2-hour time limit. Metadata and fine-grained details about every pipeline evaluated are stored in a MongoDB document store. The best pipelines for each task, after checkpoints at 10, 30, 60, and 120 minutes of search, are selected by considering the cross-validation score on the training set and are then re-scored on the held-out test set.131313Exact replication files and detailed instructions for the experiments in this section are included here: https://github.com/micahjsmith/ml-bazaar-2019 and can be further analyzed using our piex library.
5.3. Computational bottlenecks
We first evaluate the computational bottlenecks of the AutoBazaar system. To assess this, we instrument AutoBazaar and our framework libraries (MLBlocks, MLPrimitives, BTB) to determine what portion of overall execution time for pipeline search is due to our runtime libraries vs. other factors such as I/O and underlying component implementation. The results are shown in Figure 6. Overall, the vast majority of execution time is due to execution of the underlying primitives (p25=90.2%, p50=96.2%, p75=98.3%). A smaller portion is due to the AutoBazaar runtime (p50=3.1%) and a negligible (p50<0.1%) portion of execution time is due to our other framework libraries and I/O. Thus, performance of pipeline execution/search is largely limited by the performance of the underlying physical implementation from the external library.
5.4. AutoML performance
One important attribute of AutoBazaar is the ability to improve pipelines for different tasks through tuning and selection. We measure the improvement in the best pipeline per task, finding that the average task improves its best score by 1.06 standard deviations over the course of tuning, and that 31.7% of tasks improve by more than 1 standard deviation (Figure 7). This demonstrates the AutoBazaar pipeline search effectiveness that a user may expect to obtain. However, as we describe in Section 3, there are many possible AutoML primitives that can be implemented using our tuner/selector APIs; a comprehensive comparison is beyond the scope of our work.
5.5. Expressiveness of ML Bazaar
To further examine the expressiveness of ML Bazaar to solve a wide variety of tasks, we randomly selected 23 Kaggle competitions from 2018, comprising tasks ranging from image and time series classification to object detection and multi-table regression. For each task, we attempted to develop a solution using existing primitives and atalogs.
Overall, we were able to immediately solve 11 tasks. We did not currently support 4 task types: image matching (2 tasks), object detection within images (4 tasks), multi-label classification (1 task), and video classification (1 task). We could readily support these within our framework by developing new primitives and pipelines. In the remaining tasks, multiple data modalities were provided to participants (i.e. some combination of image, text, and tabular data). To support these tasks, we would need to develop a new “glue” primitive for concatenating separately-featurized data from each resources to create a single feature matrix. Though our evaluation suite contains many examples of tasks with multiple data resources of different modalities, we had written pipelines customized to operate on certain common subsets (i.e. tabular + graph). We can never expect to have already implemented pipelines for the innumerable diversity of ML task types, but we can still write new primitives and pipelines using our framework to solve these problems.
5.6. Case study: evaluating ML primitives
When new primitives are contributed by the ML community, they can be incorporated into pipeline templates and pipeline hypertemplates, either to replace similar pipeline steps or to form the basis of new topologies. By running the end-to-end system on our evaluation suite, we can assess the impact of the primitive on general-purpose ML workloads (rather than overfit baselines).
In this first case study, we compare two similar primitives: annotations for the XGBoost (XGB) and random forest (RF) classifiers. We ran two experiments, one in which RF is used in pipeline templates and one in which XGB is substituted instead.
We consider relevant pipelines to determine the best scores produced for 367 tasks. We find that the XGB pipelines substantially outperformed the RF pipelines, winning 64.9% of the comparisons. This confirms the experience of practitioners, who widely report that XGBoost is one of the most powerful ML methods for classification and regression.
5.7. Case study: evaluating AutoML primitives
The design of the ML Bazaar AutoML system and our extensive evaluation corpus allows us to easily swap in new AutoML primitives (Section 3.2) to see to what extent changes in components like tuners and selectors can improve performance in general settings.
In this case study, we revisit (Snoek et al., 2012), which was influential for bringing about widespread use of Bayesian optimization for tuning ML models in practice. Their contributions include: (C1) proposing the usage of the Matérn 5/2 kernel for tuner meta-model (see Section 3.2.1), (C2) describing an integrated acquisition function that integrates over uncertainty in the GP hyperparameters, (C3) incorporating a cost model into an EI per second acquisition function, and (C4) explicitly modeling pending parallel trials. How important was each of these contributions to a resulting tuner?
Using ML Bazaar, we show how a more thorough ablation study (Lipton and Steinhardt, 2018), not present in (Snoek et al., 2012), would be conducted to address these questions, by assessing the performance of our general-purpose AutoML system using different combinations of these four contributions. Here we focus on contribution C1. We run experiments using a baseline tuner with a squared exponential kernel (GP-SE-EI) and compare it with a tuner using the Matérn 5/2 kernel (GP-Matern52-EI). In both cases, kernel hyperparameters are set by optimizing the marginal likelihood. Thus we can isolate the contributions of the proposed kernel in the context of general-purpose ML workloads.
In total, pipelines were evaluated to find the best pipelines for a subset of 414 tasks. We find that there is no improvement from using the Matérn 5/2 kernel over the SE kernel — in fact, the GP-SE-EI tuner outperforms, winning 60.1% of the comparisons. One possible explanation for this negative result is that the Matérn kernel is sensitive to hyperparameters which are set more effectively by optimization of the integrated acquisition function. This is supported by the over-performance of the tuner using the integrated acquisition function in the original work; however, the integrated acquisition function is not tested with the baseline SE kernel, and more study is needed.
6. Related work
Researchers have developed numerous algorithmic and software innovations to make it possible to create ML and AutoML systems in the first place.
ML libraries
High-quality ML libraries have originated over a period of decades. For general ML applications, scikit-learn implements many different algorithms using a common API centered on the influential fit/predict paradigm (Buitinck et al., 2013). For specialized analysis, libraries have been developed in separate academic communities, often with different and incompatible APIs (Bradski, 2000; Hagberg et al., 2008; Kula, 2015; Kanter, 2015; Bird et al., 2009; Abadi et al., 2015). In ML Bazaar, we connect and link components of these libraries, only creating missing functionality ourselves.
ML systems
Prior work has provided several approaches for making it easier to develop ML systems. For example, caret (Kuhn, 2008) standardizes interfaces and provides utilities for the R ecosystem, but without enabling more complex pipelines. Recent systems have attempted to provide graphical interfaces, like (Gong et al., 2019) and Azure Machine Learning Studio. Development of ML systems is closely tied to the execution environments needed to train, deploy, and update the resulting models. In SystemML (Boehm et al., 2016) and Weld (Shoumik et al., 2018), implementations of specific ML algorithms are optimized for specific runtimes. Velox (Crankshaw et al., 2015) is an analytics stack component that efficiently serves predictions and manages model updates.
AutoML libraries
AutoML research has often been limited to solving sub-problems of an end-to-end ML workflow, such as data cleaning (Deng et al., 2017), feature engineering (Kanter, 2015; Khurana et al., 2016), hyperparameter tuning (Snoek et al., 2012; Gomes et al., 2012; Thornton et al., 2013; Feurer et al., 2015; Olson et al., 2016; Jamieson and Talwalkar, 2016; Li et al., 2017; Hirzel et al., 2019), or algorithm selection (van Rijn et al., 2015; Hirzel et al., 2019). Thus AutoML solutions are often not widely applicable or deployed in practice without human support. In contrast, ML Bazaar integrates many of these existing approaches and designs one coherent and configurable structure for joint tuning and selection of end-to-end pipelines.
AutoML systems
These AutoML libraries, if deployed, are typically one component within a larger system that aims to manage several practical aspects such as parallel and distributed training, tuning, and model storage, and even serving, deployment, and graphical interfaces for model building. These include ATM (Swearingen et al., 2017), Vizier (Golovin et al., 2017), and Rafiki (Wang et al., 2018), as well as commercial platforms like Google AutoML, DataRobot, and Azure Machine Learning Studio. While these systems provide many benefits, they have several limitations. First, they each focus on a specific subset of ML use cases, such as computer vision, NLP, forecasting, or hyperparameter tuning. Second, these systems are designed as proprietary applications and do not support community-driven integration of new innovations. ML Bazaar provides a new approach to developing such systems in the first place: it supports a wide variety of ML task types, and builds on top of a community-driven ecosystem of ML innovations. Indeed, it could serve as the backend for such ML services or platforms.
The DARPA D3M program (Lippmann et al., 2016), of which we are participants, aims to spur development of automated systems for model discovery for use by non-experts. Several differing approaches are being developed within this context. For example, Alpine Meadow (Shang et al., 2019) focuses on efficient search for producing interpretable ML pipelines with low latencies for interactive usage. It combines existing techniques from query optimization, Bayesian optimization, and multi-armed bandits to efficiently search for pipelines. AlphaD3M (Drori et al., 2018) formulates a pipeline synthesis problem and uses reinforcement learning to construct pipelines. In contrast, ML Bazaar is a framework to develop ML or AutoML systems in the first place. While we present our open-source AutoBazaar system, it is not the primary focus of our work and represents a single point in the design space of AutoML systems using our framework libraries. Indeed, one could use specific AutoML approaches like the ones described by Alpine Meadow or AlphaD3M for pipeline search within our own framework.
7. Conclusion
Throughout this paper, we have built up abstractions, interfaces, and software components for data scientists, data engineers, and other practitioners to effectively develop machine learning systems. Developers can use ML Bazaar to compose one-off pipelines, tunable pipeline templates, or full-fledged AutoML systems. Researchers can contribute individual ML or AutoML primitives and make them easily accessible to a broad base for inclusion in end-to-end solutions.
We have applied this approach to several real-world ML problems and entered our AutoML system in an automated modeling program. As we collect more and more scored pipelines, we expect opportunities will emerge for meta-learning and debugging on ML tasks and pipelines, as well as the ability to track progress and transfer knowledge within data science organizations. We will focus on several complementary extensions in future work. These include continuing to improve our AutoML system and making it more robust for everyday use by a diverse user base, and studying how to best support users of different backgrounds in using and interacting with ML and AutoML systems.
Acknowledgements.
The authors would like to thank Plamen Valentinov Kolev for contributions running experiments and testing datasets. The authors also acknowledge the contributions of the following people: Laura Gustafson, William Xue, Akshay Ravikumar, Ihssan Tinawi, Alexander Geiger, Sarah Alnegheimish, Saman Amarasinghe, Stefanie Jegelka, Zi Wang, Benjamin Schreck, Seth Rothschild, Manual Alvarez Campo, Sebastian Mir Peral, Peter Fontana, and Brian Sandberg. The authors are part of the DARPA Data-Driven Discovery of Models (D3M) program, and would like to thank the D3M community for the discussions around the design. This material is based on research sponsored by DARPA and Air Force Research Laboratory (AFRL) under agreement number FA8750-17-2-0126. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation thereon. The view and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies of endorsements, either expressed or implied, of DARPA and Air Force Research Laboratory (AFRL) or the U.S. Government. Authors MJS, CS, and KV acknowledge support and user feedback from Iberdrola S.A. and SES S.A.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Abadi et al . (2015) Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanh
- 3Auer et al . (2002) Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. 2002. Finite-time analysis of the multiarmed bandit problem. Machine learning 47, 2-3 (2002), 235–256.
- 4Baylor et al . (2017) Denis Baylor, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, Mustafa Ispir, Vihan Jain, Levent Koc, Chiu Yuen Koo, Lukasz Lew, Clemens Mewald, Akshay Naresh Modi, Neoklis Polyzotis, Sukriti Ramesh, Sudip Roy, Steven Euijong Whang, Martin Wicke, Jarek Wilkiewicz, Xin Zhang, and Martin Zinkevich. 2017. TFX: A Tensor Flow-Based Production-Scale Machine Learning Platform. In KDD .
- 5Bergstra and Bengio (2012) James Bergstra and Yoshua Bengio. 2012. Random Search for Hyper-Parameter Optimization. JMLR 13 (2012), 281–305.
- 6Bergstra et al . (2011) James S Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for hyper-parameter optimization. In NIPS . 2546–2554.
- 7Bhardwaj et al . (2015) Anant Bhardwaj, Souvik Bhattacherjee, Amit Chavan, Amol Deshpande, Aaron J Elmore, Samuel Madden, and Aditya Parameswaran. 2015. Data Hub: Collaborative Data Science & Dataset Version Management at Scale. In CIDR .
- 8Bird et al . (2009) Steven Bird, Ewan Klein, and Edward Loper. 2009. Natural language processing with Python: analyzing text with the natural language toolkit . O’Reilly Media, Inc.
