TL;DR
ElfStore is a novel distributed data storage service for edge and fog computing environments that ensures reliable, scalable, and resilient data management directly on edge devices, reducing dependence on cloud storage.
Contribution
It introduces ElfStore, the first federated edge-local storage system with reliable data replication, federated metadata indexing, and resilience features tailored for IoT deployments.
Findings
ElfStore achieves low overheads and scalability in IoT deployments.
The system maintains data reliability and balanced storage utilization.
Performance is primarily limited by network bandwidth.
Abstract
Edge and fog computing have grown popular as IoT deployments become wide-spread. While application composition and scheduling on such resources are being explored, there exists a gap in a distributed data storage service on the edge and fog layer, instead depending solely on the cloud for data persistence. Such a service should reliably store and manage data on fog and edge devices, even in the presence of failures, and offer transparent discovery and access to data for use by edge computing applications. Here, we present Elfstore, a first-of-its-kind edge-local federated store for streams of data blocks. It uses reliable fog devices as a super-peer overlay to monitor the edge resources, offers federated metadata indexing using Bloom filters, locates data within 2-hops, and maintains approximate global statistics about the reliability and storage capacity of edges. Edges host the actual…
Click any figure to enlarge with its caption.
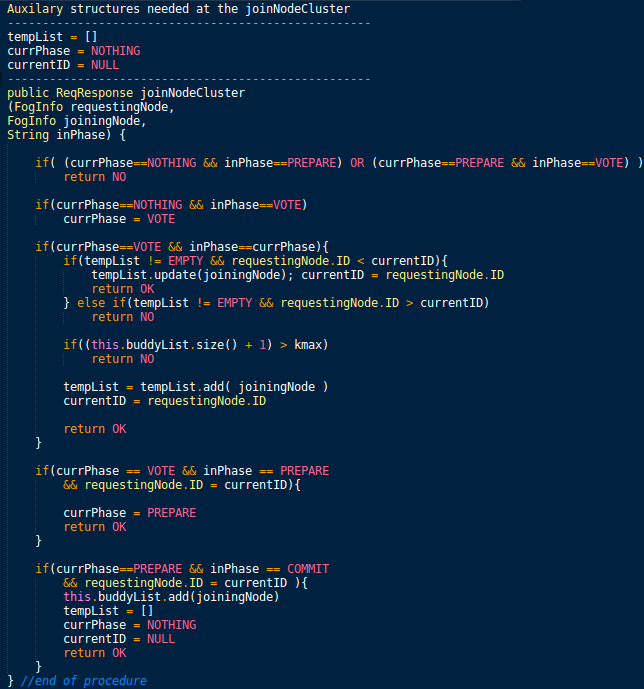 Figure 1
Figure 1 Figure 2
Figure 2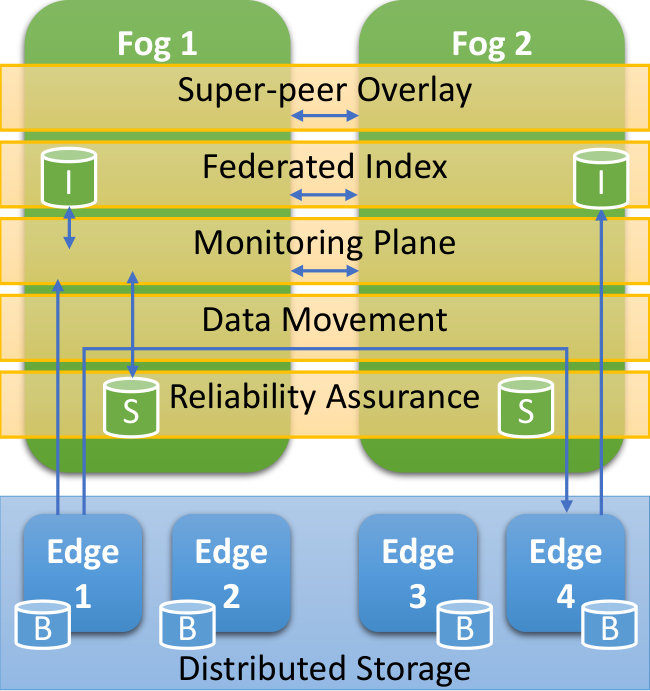 Figure 3
Figure 3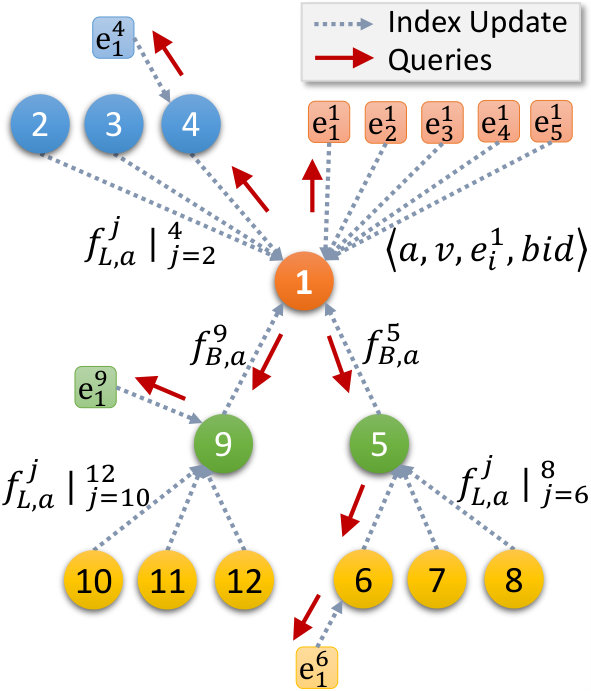 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6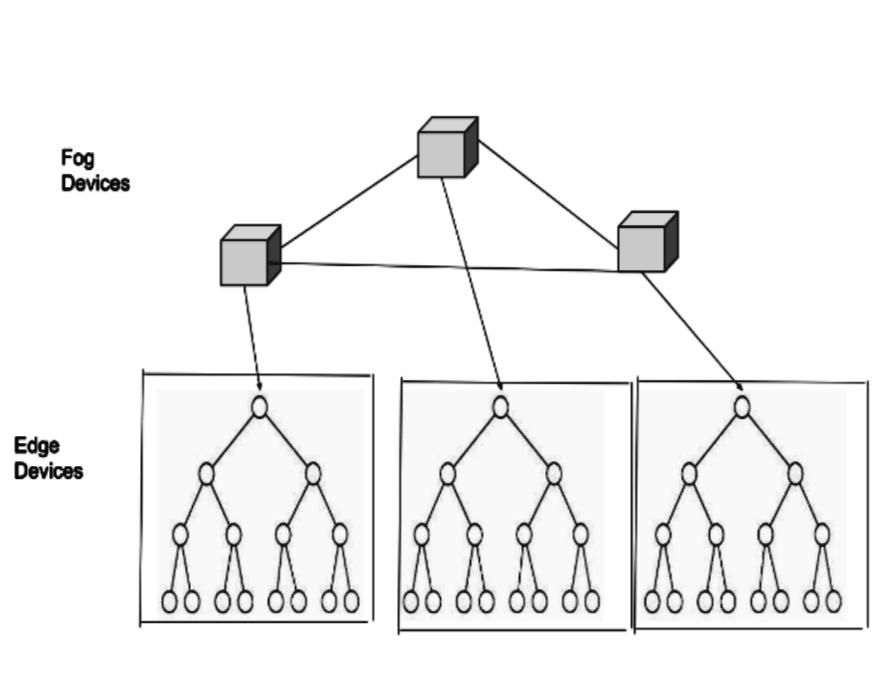 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12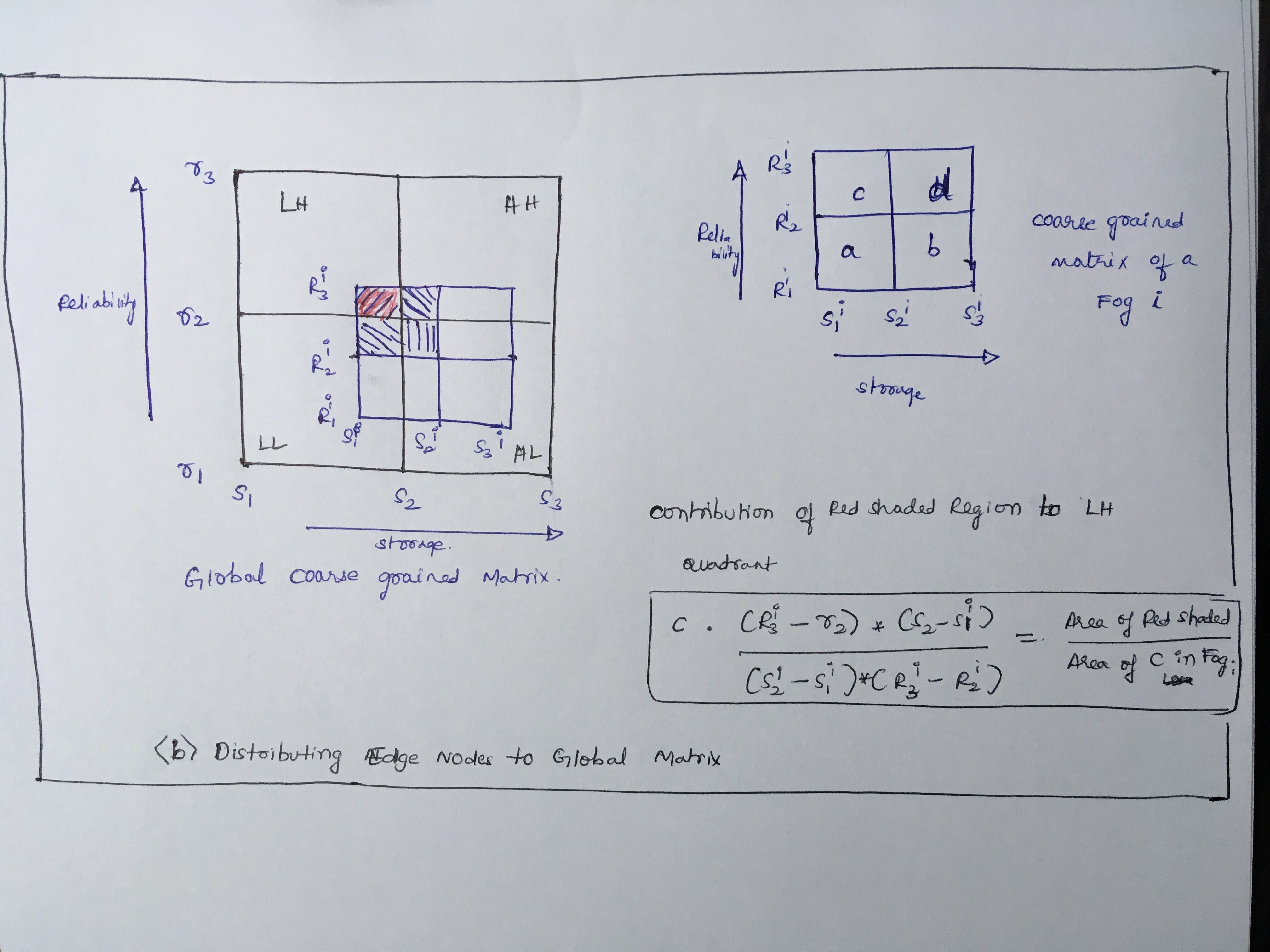 Figure 13
Figure 13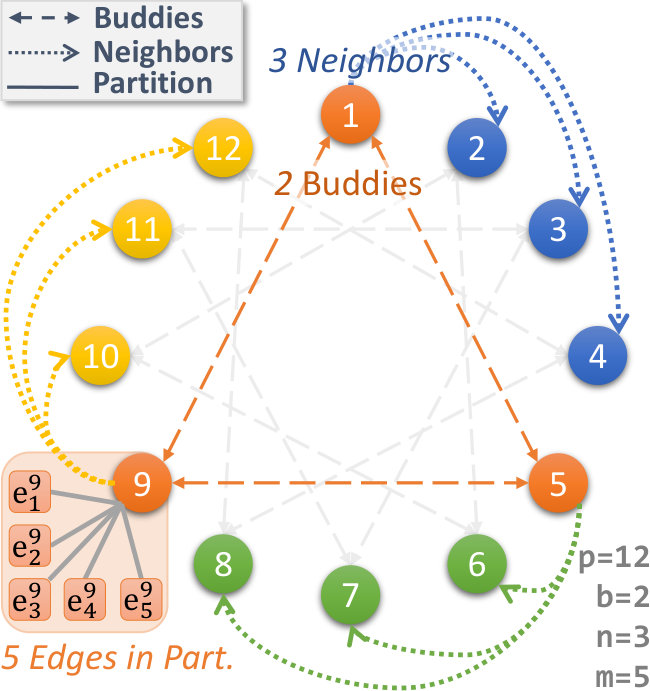 Figure 14
Figure 14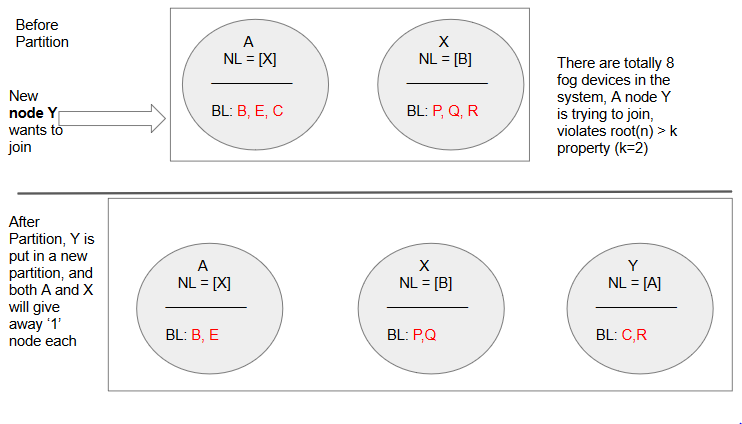 Figure 15
Figure 15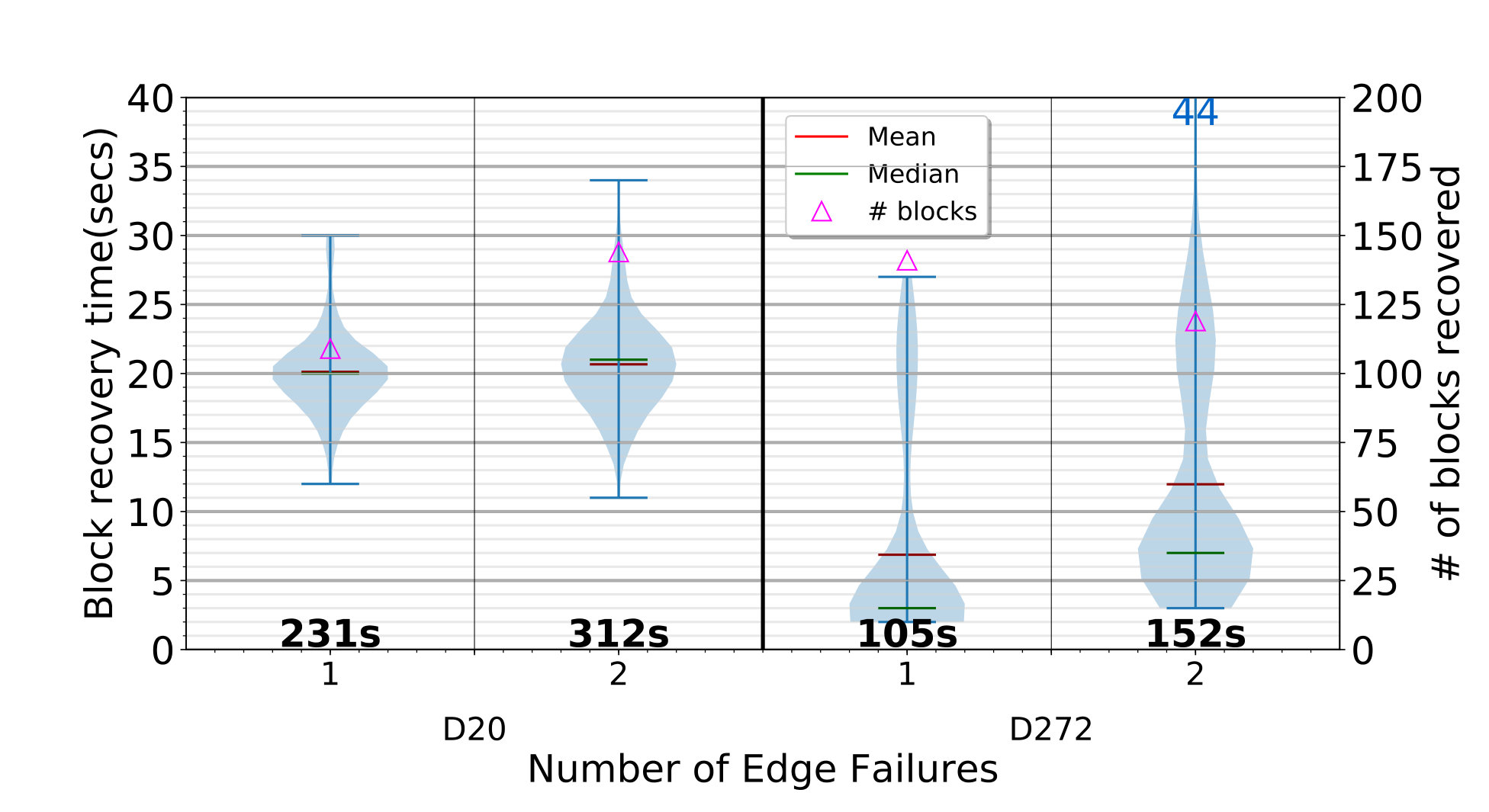 Figure 16
Figure 16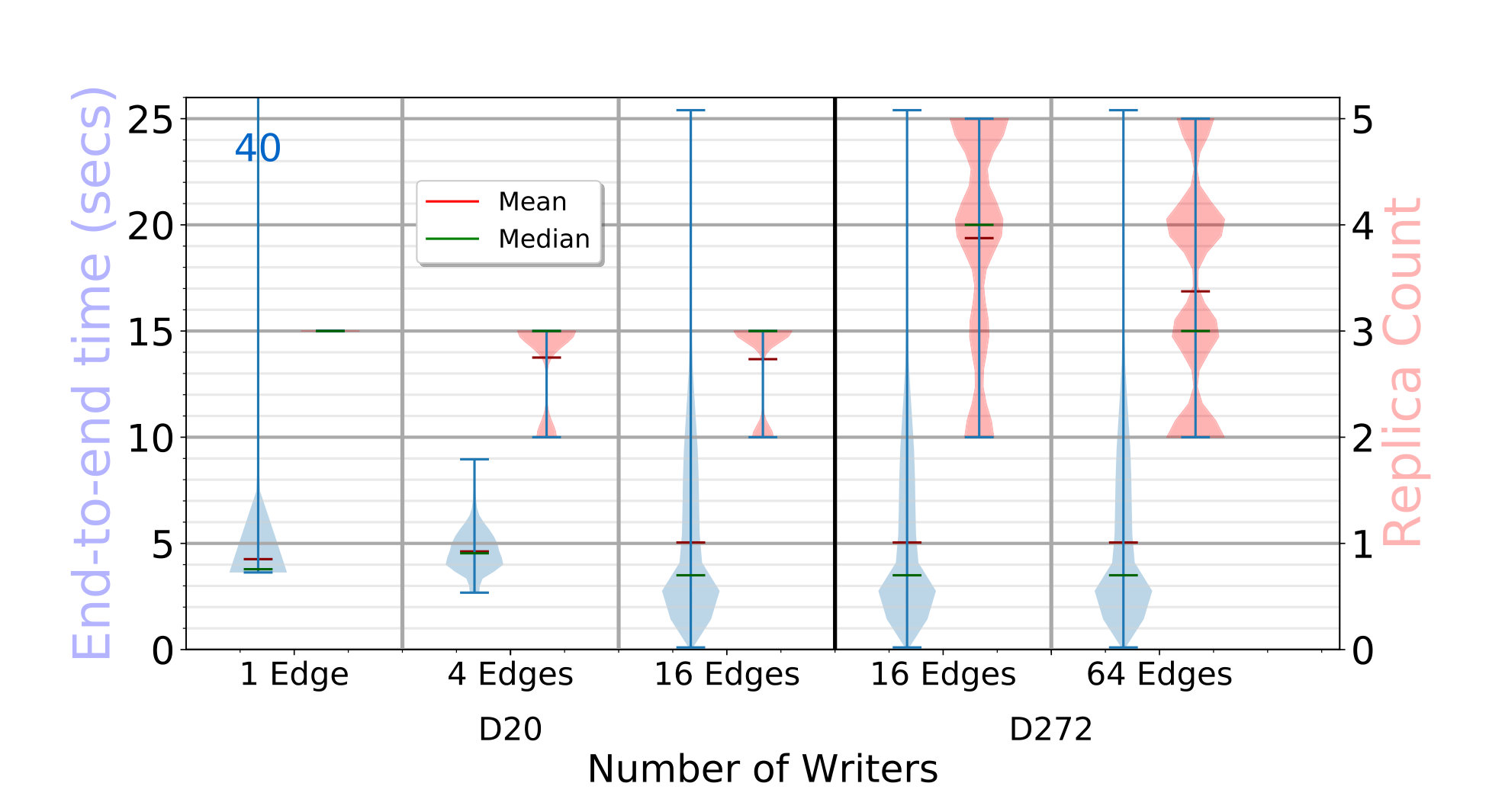 Figure 17
Figure 17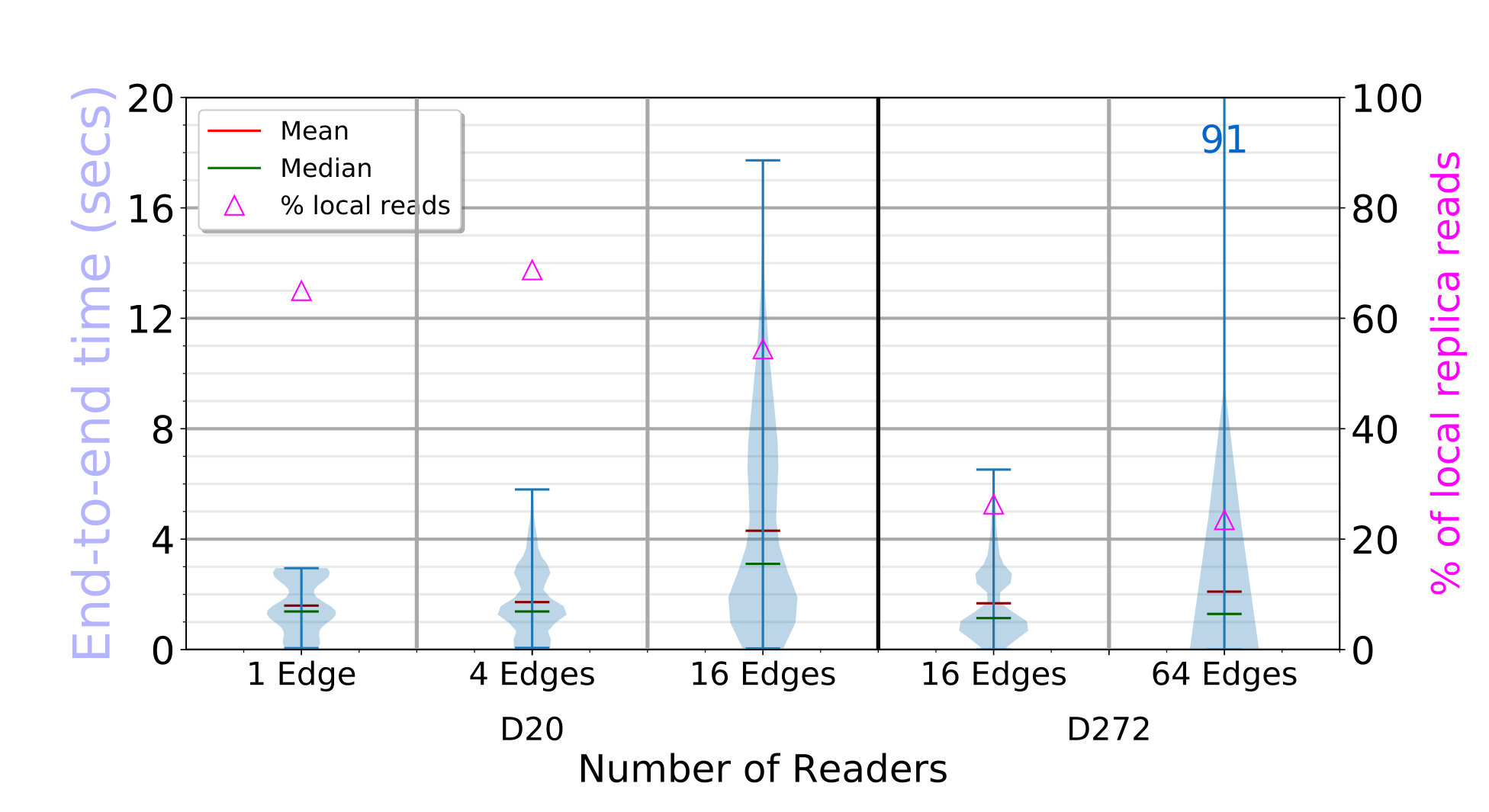 Figure 18
Figure 18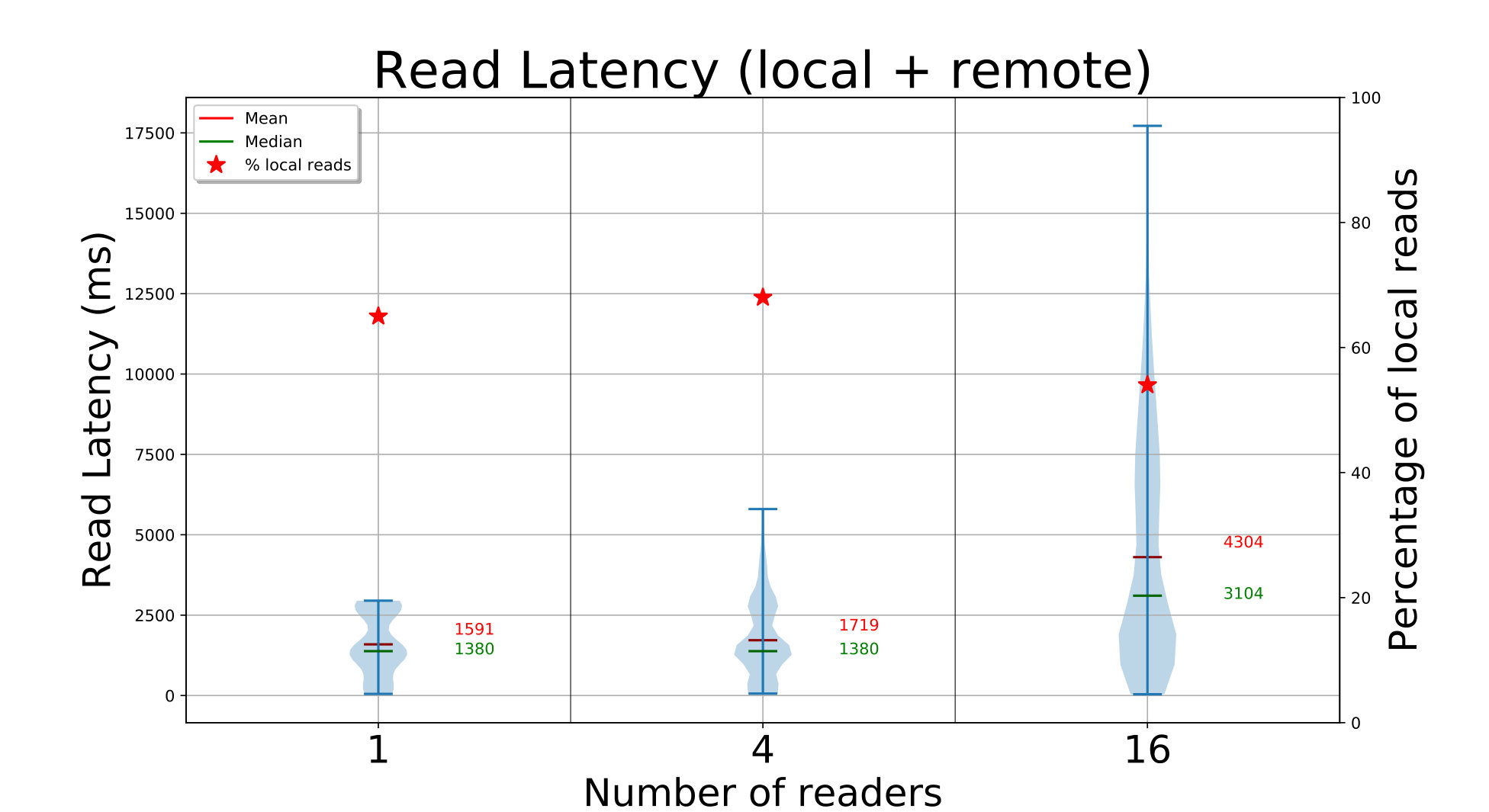 Figure 19
Figure 19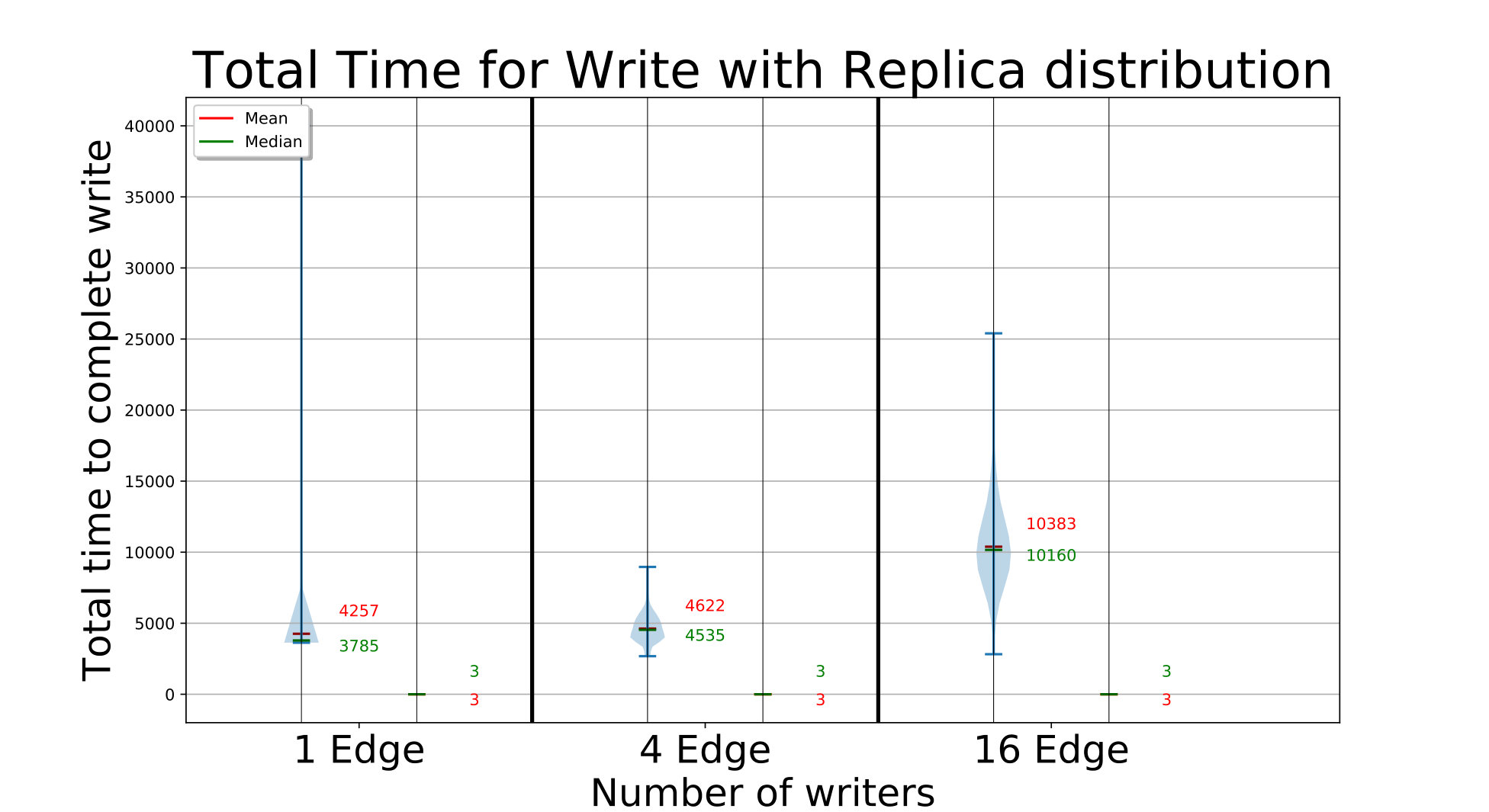 Figure 20
Figure 20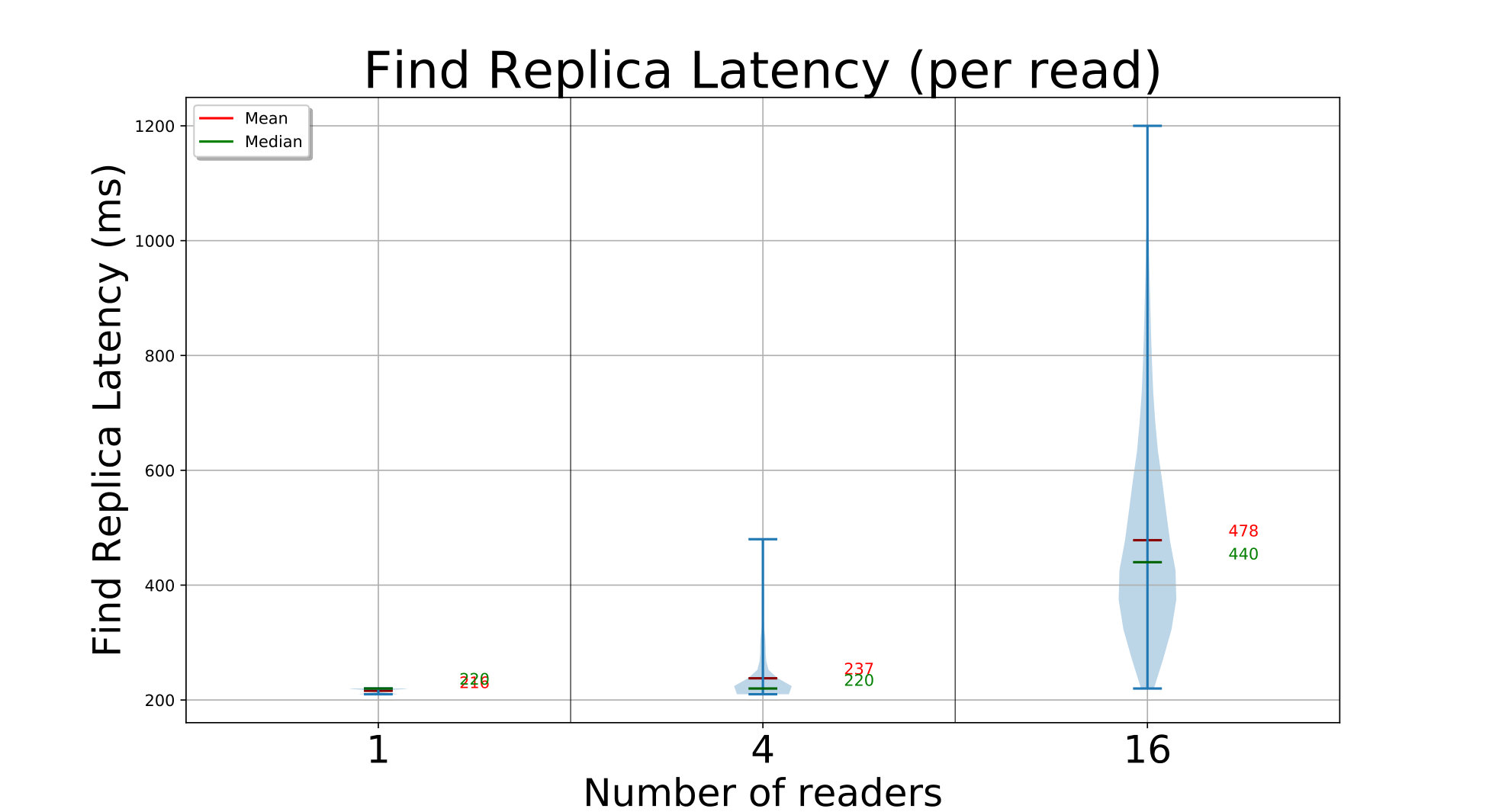 Figure 21
Figure 21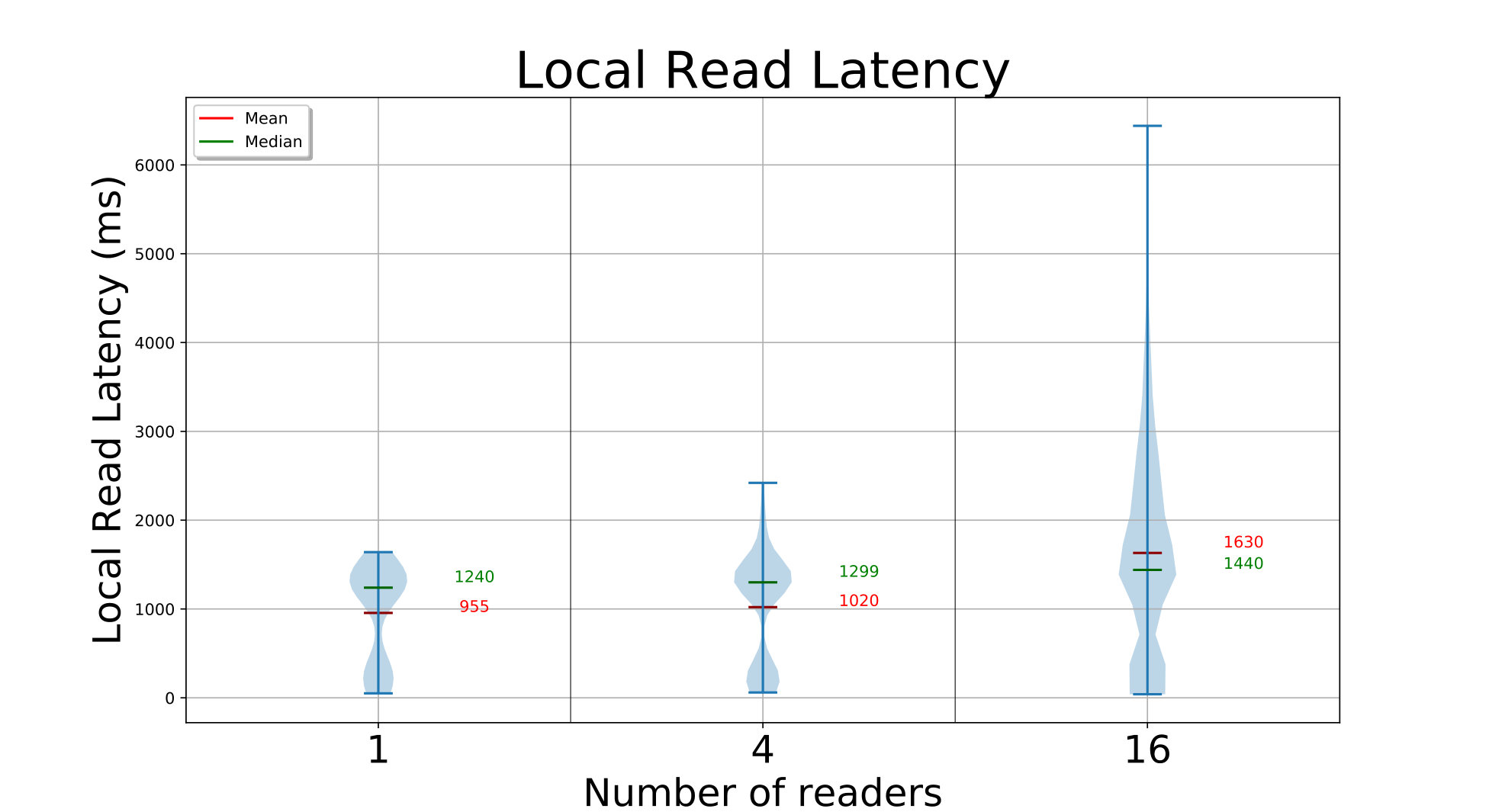 Figure 22
Figure 22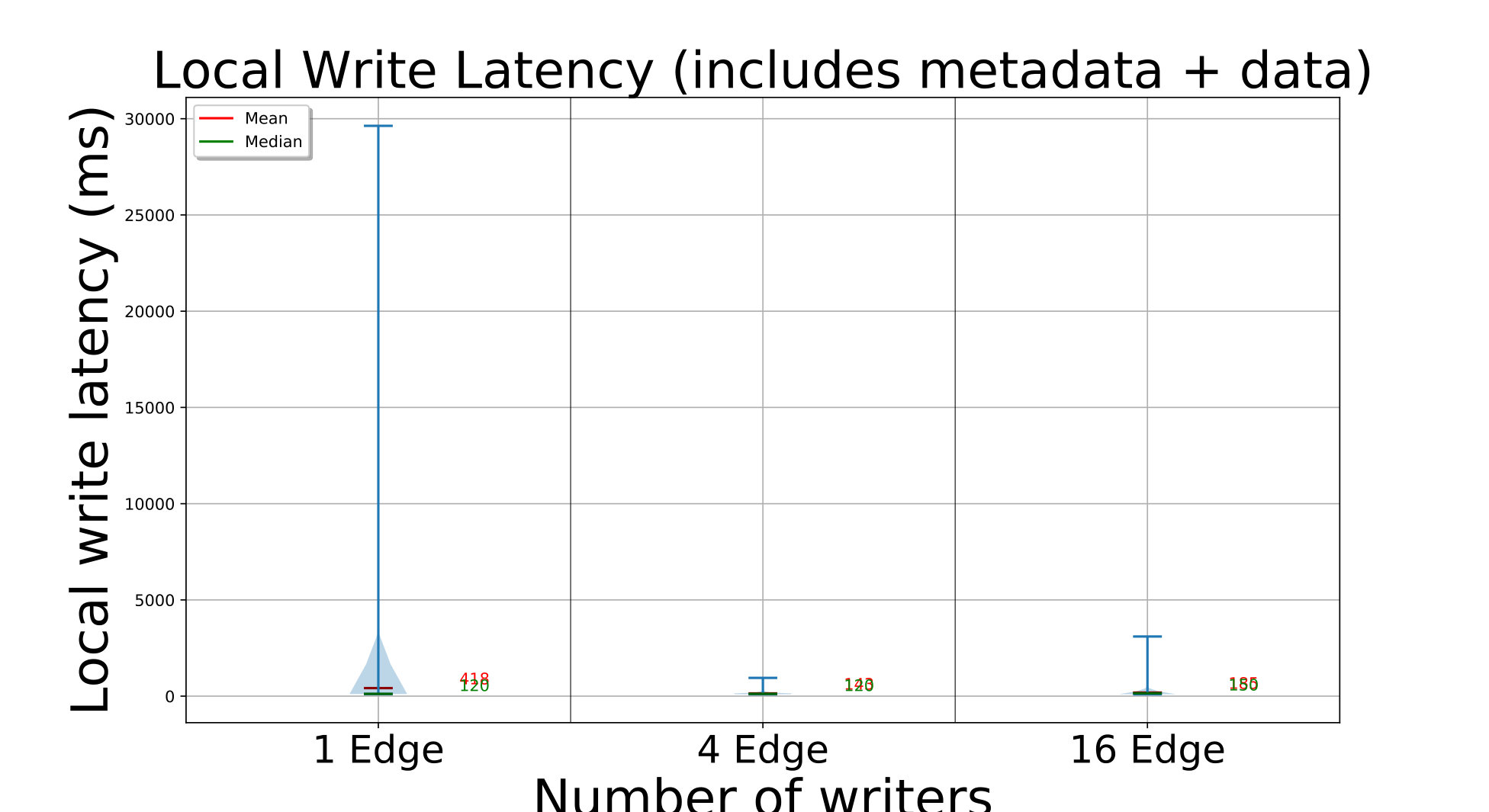 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25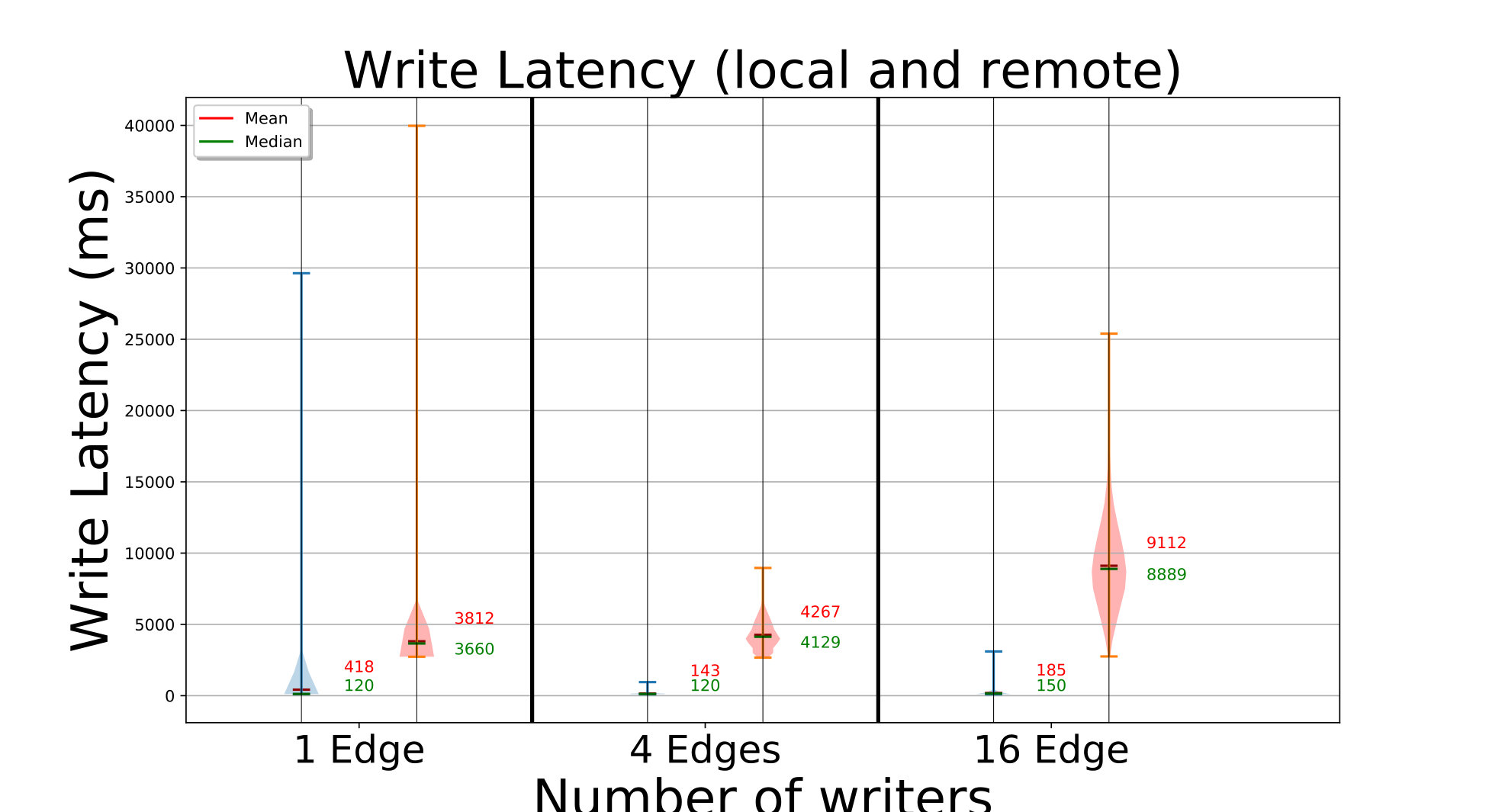 Figure 26
Figure 26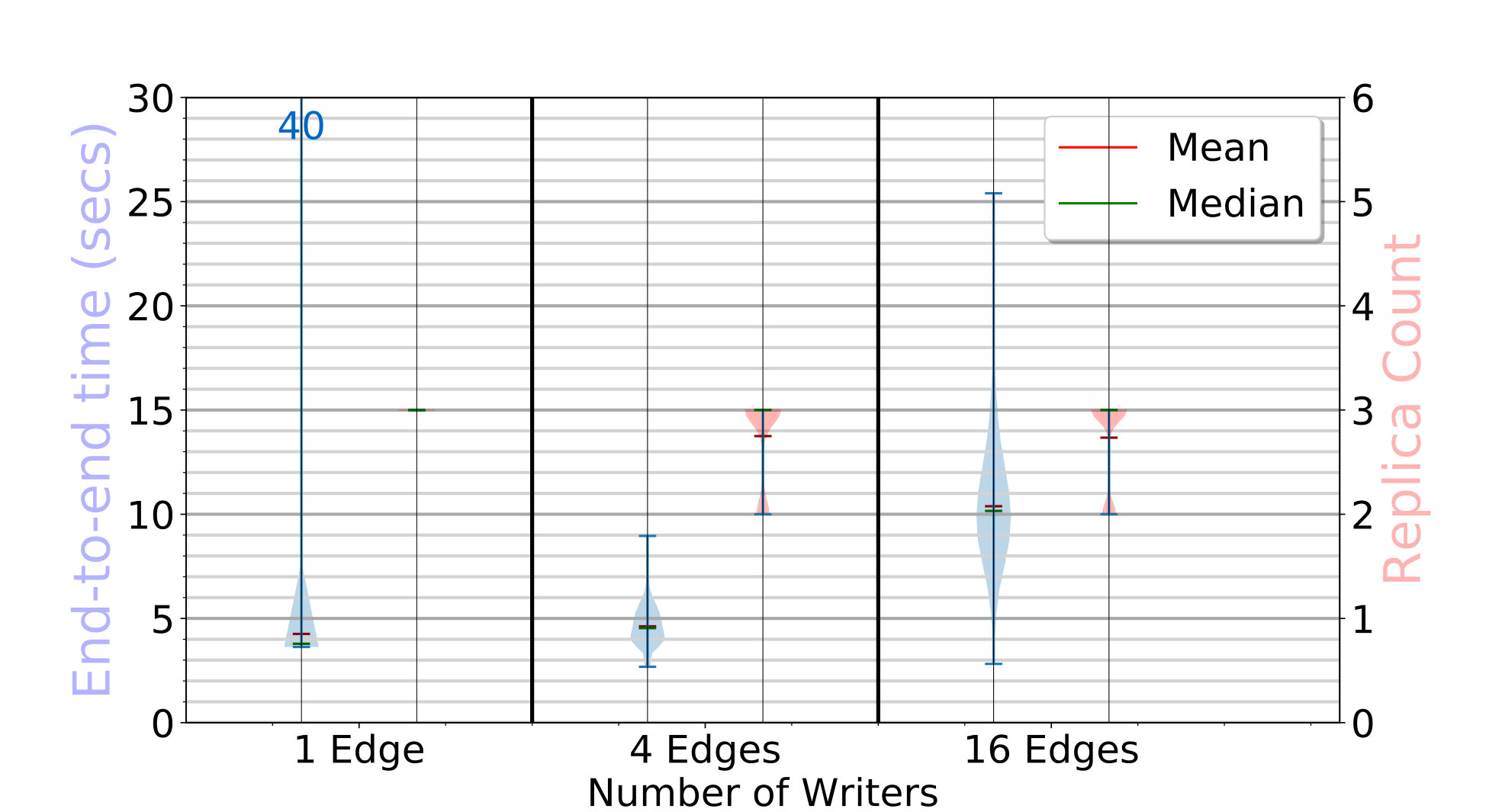 Figure 27
Figure 27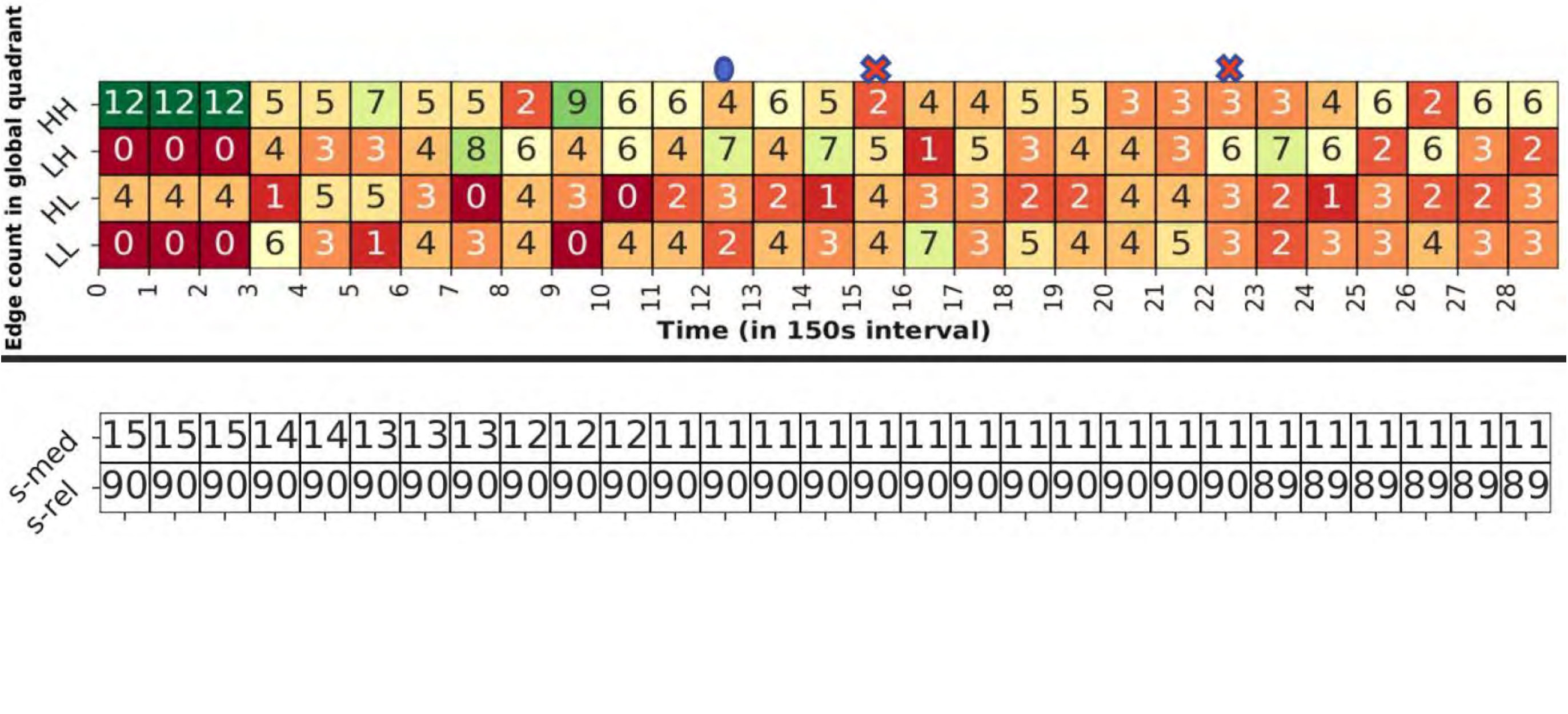 Figure 28
Figure 28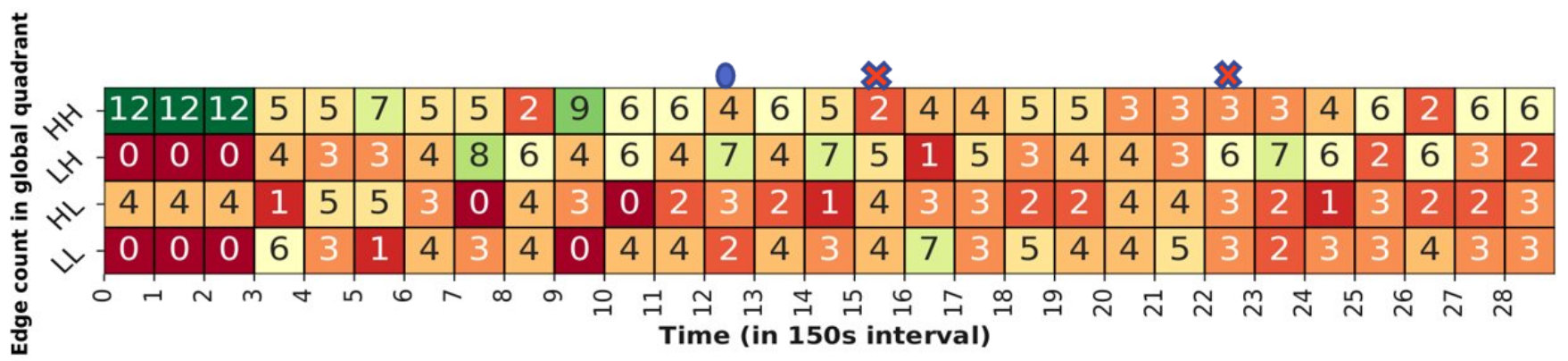 Figure 29
Figure 29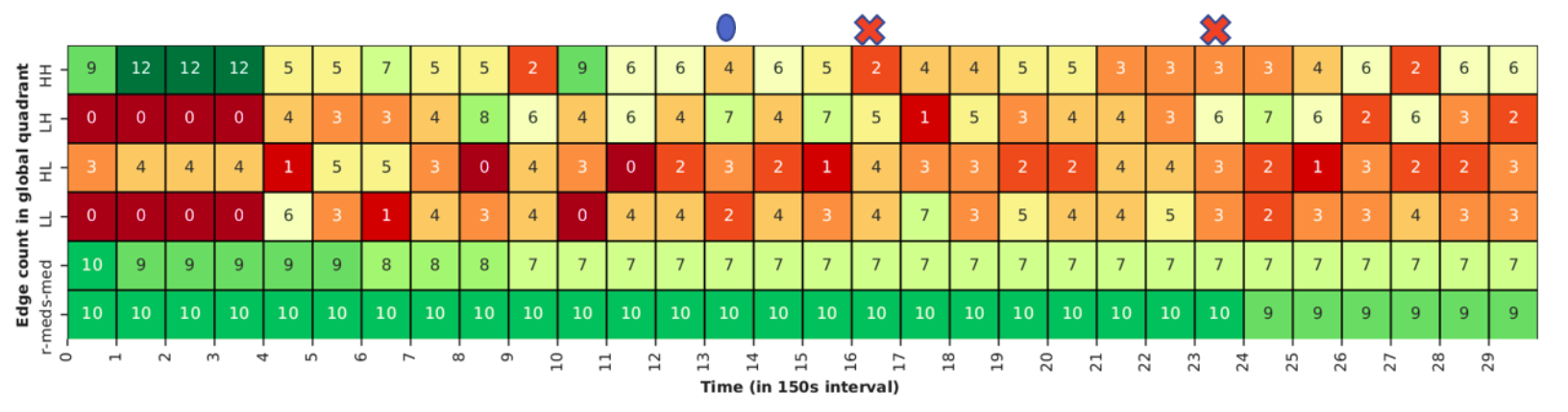 Figure 30
Figure 30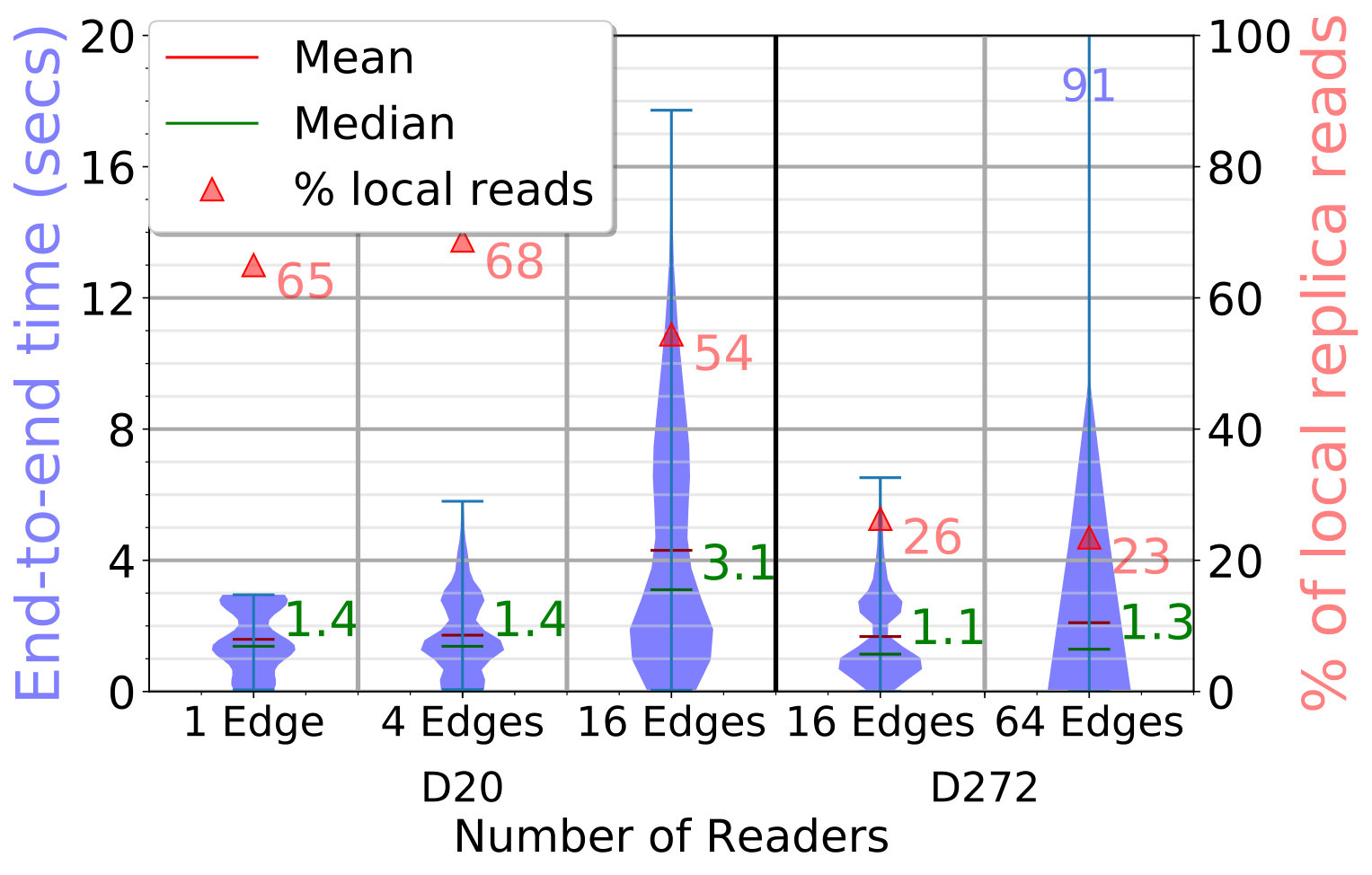 Figure 31
Figure 31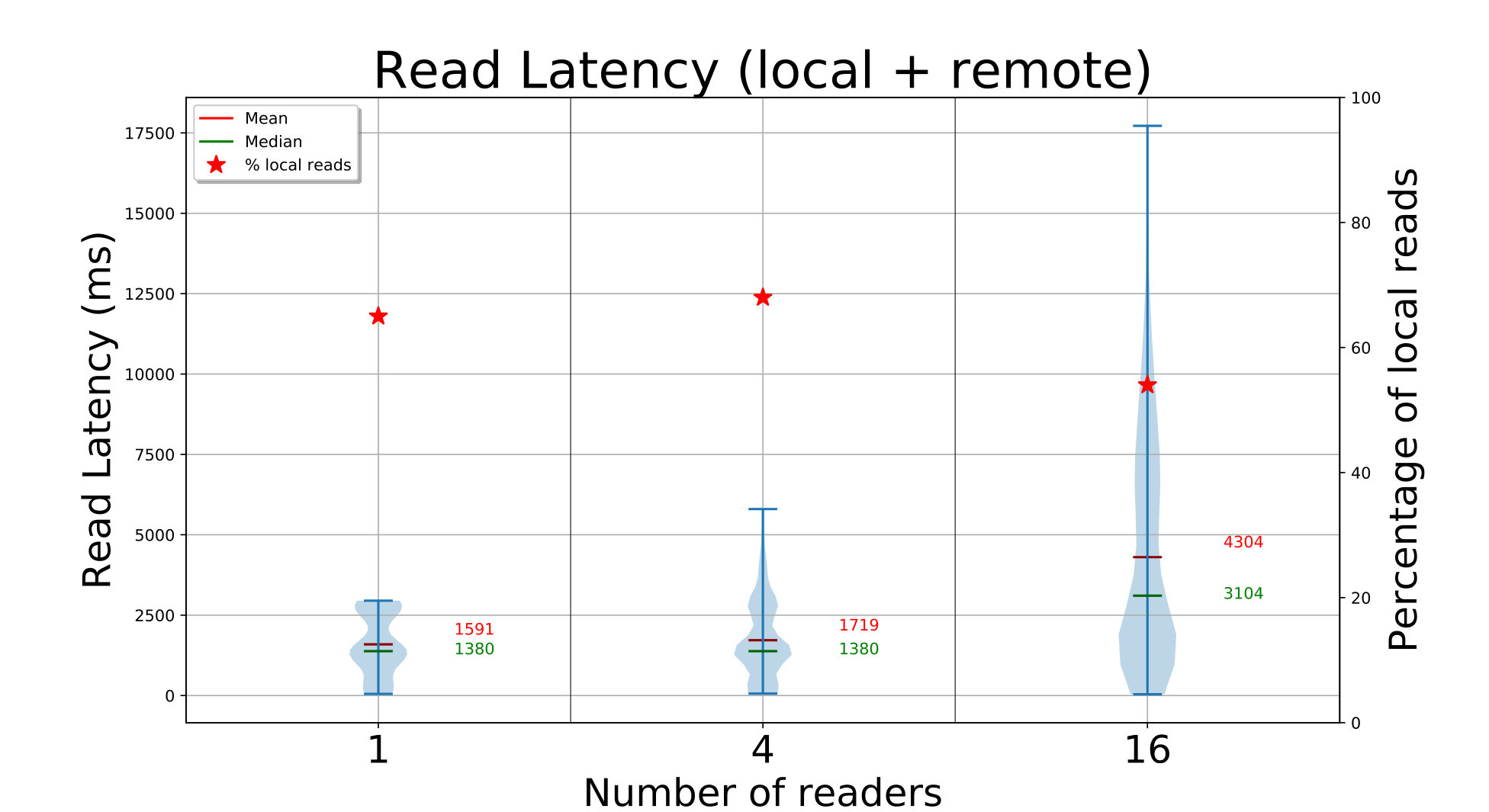 Figure 32
Figure 32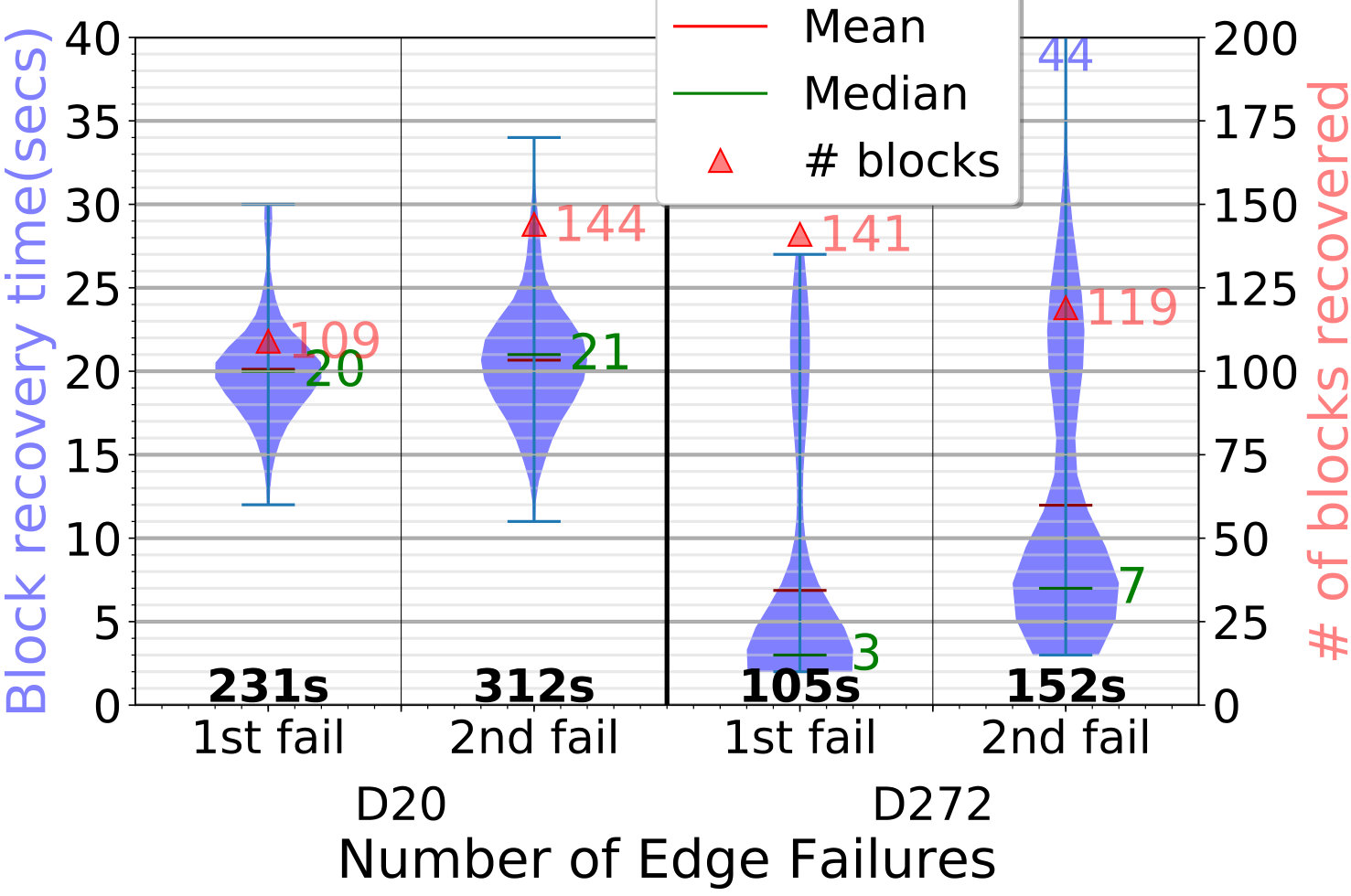 Figure 33
Figure 33 Figure 34
Figure 34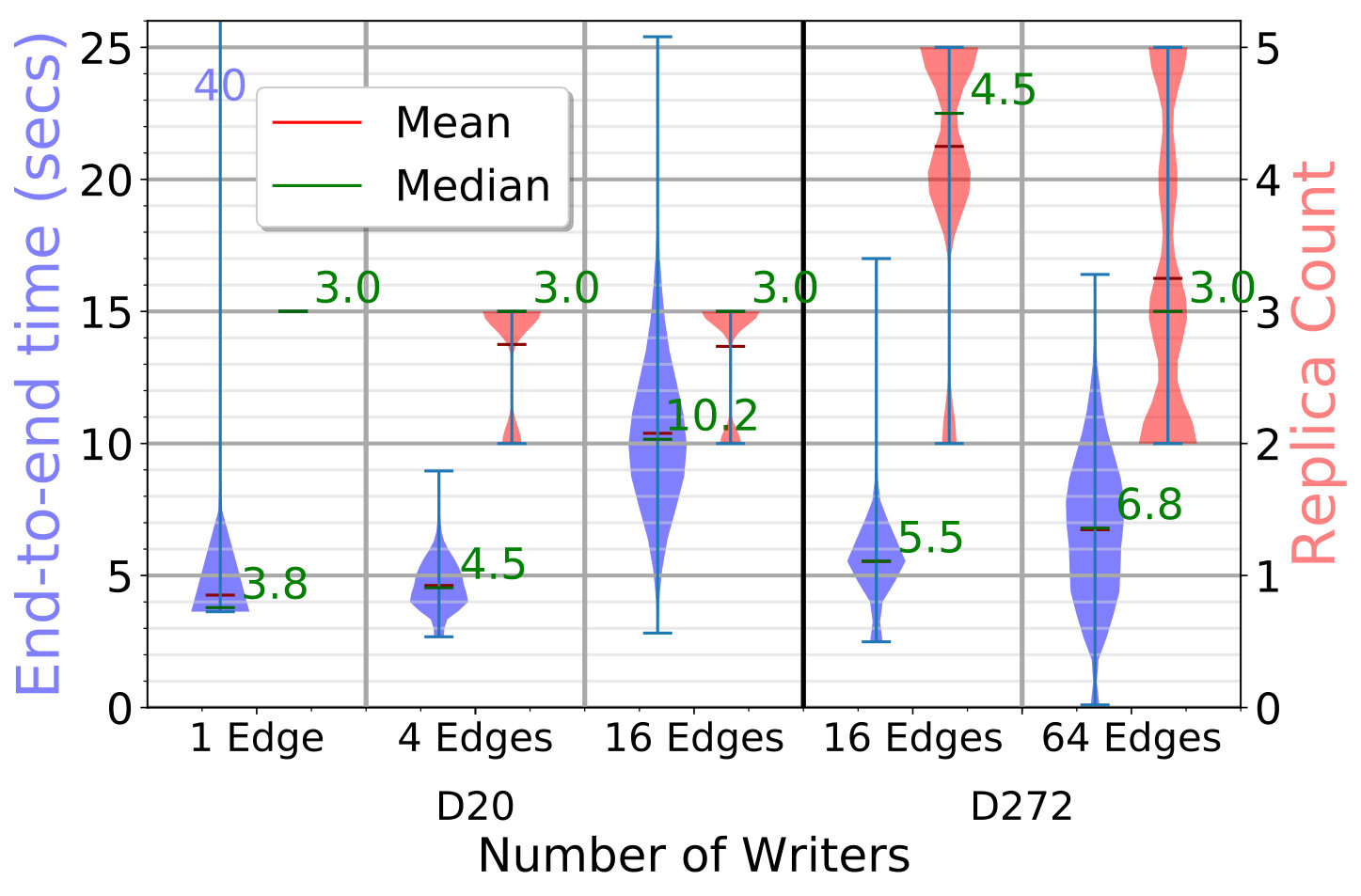 Figure 35
Figure 35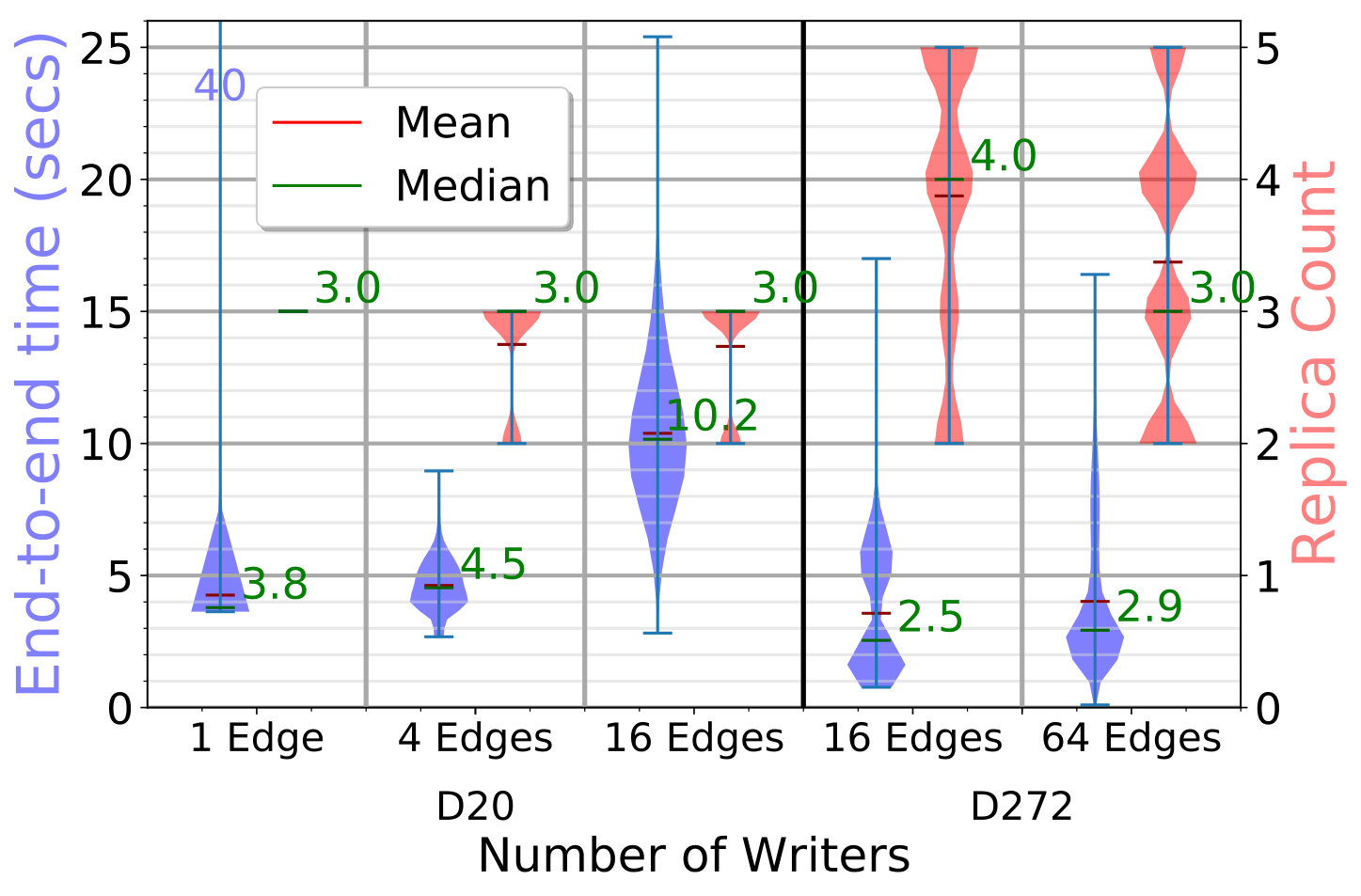 Figure 36
Figure 36 Figure 37
Figure 37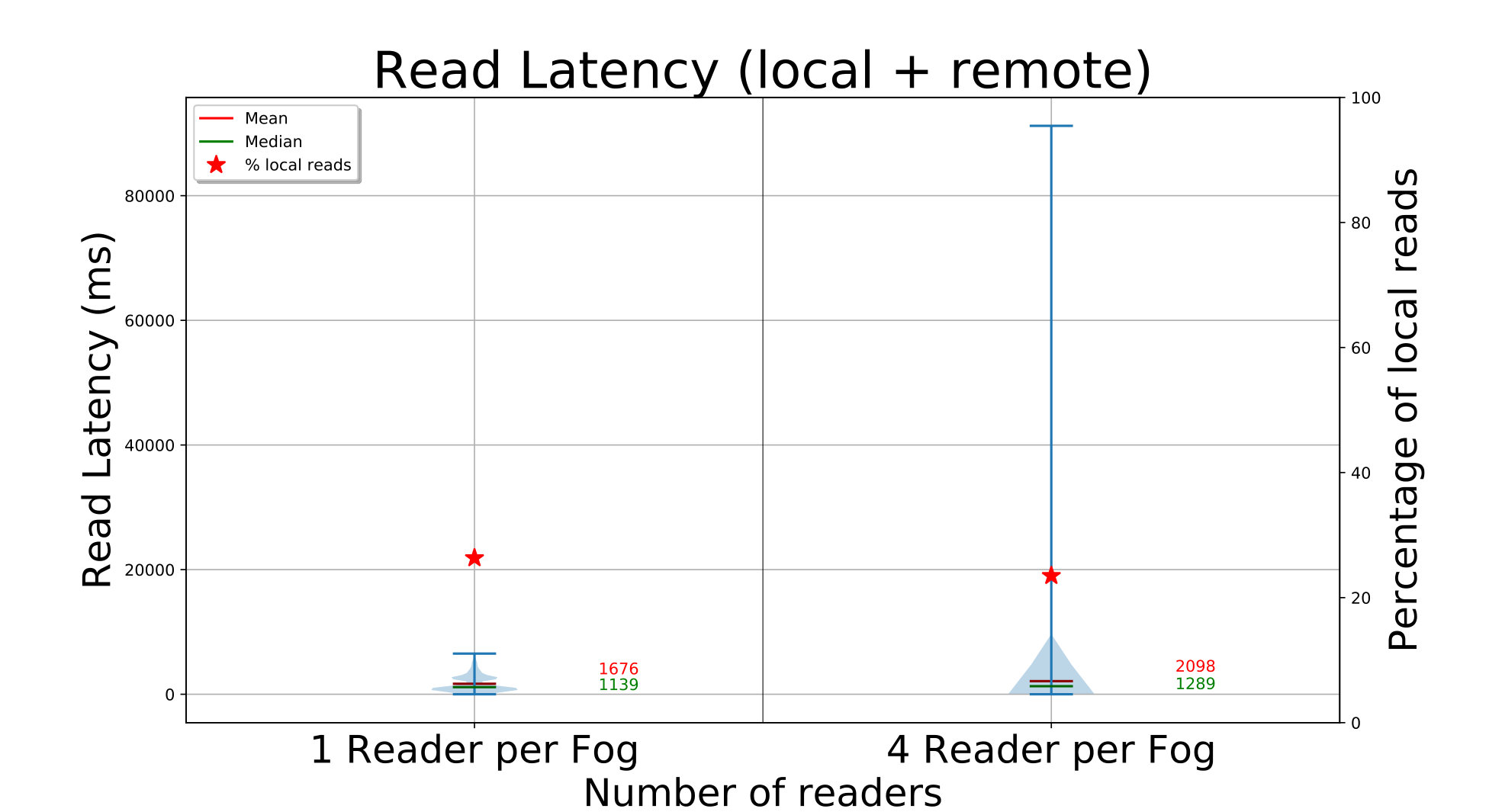 Figure 38
Figure 38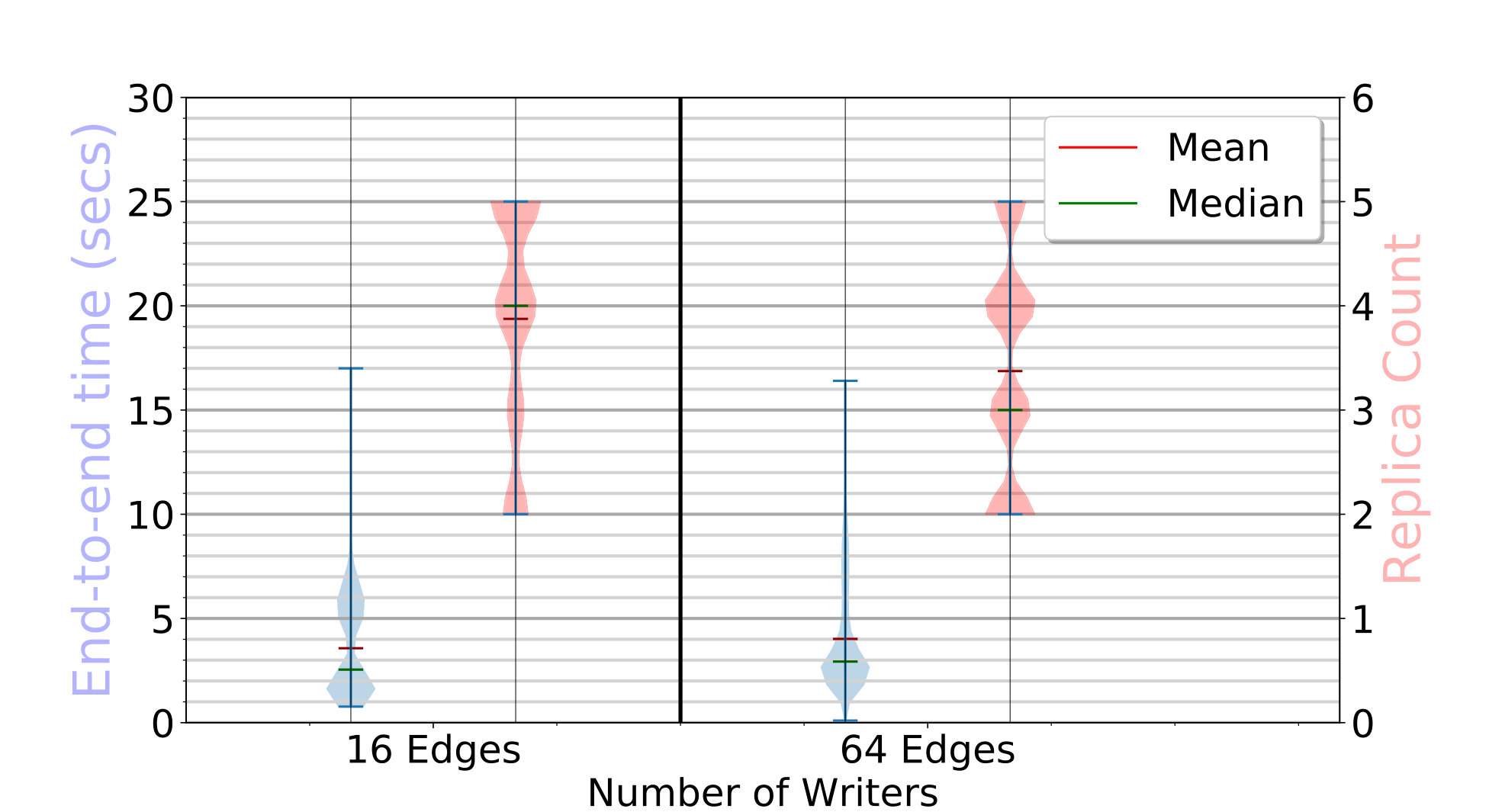 Figure 39
Figure 39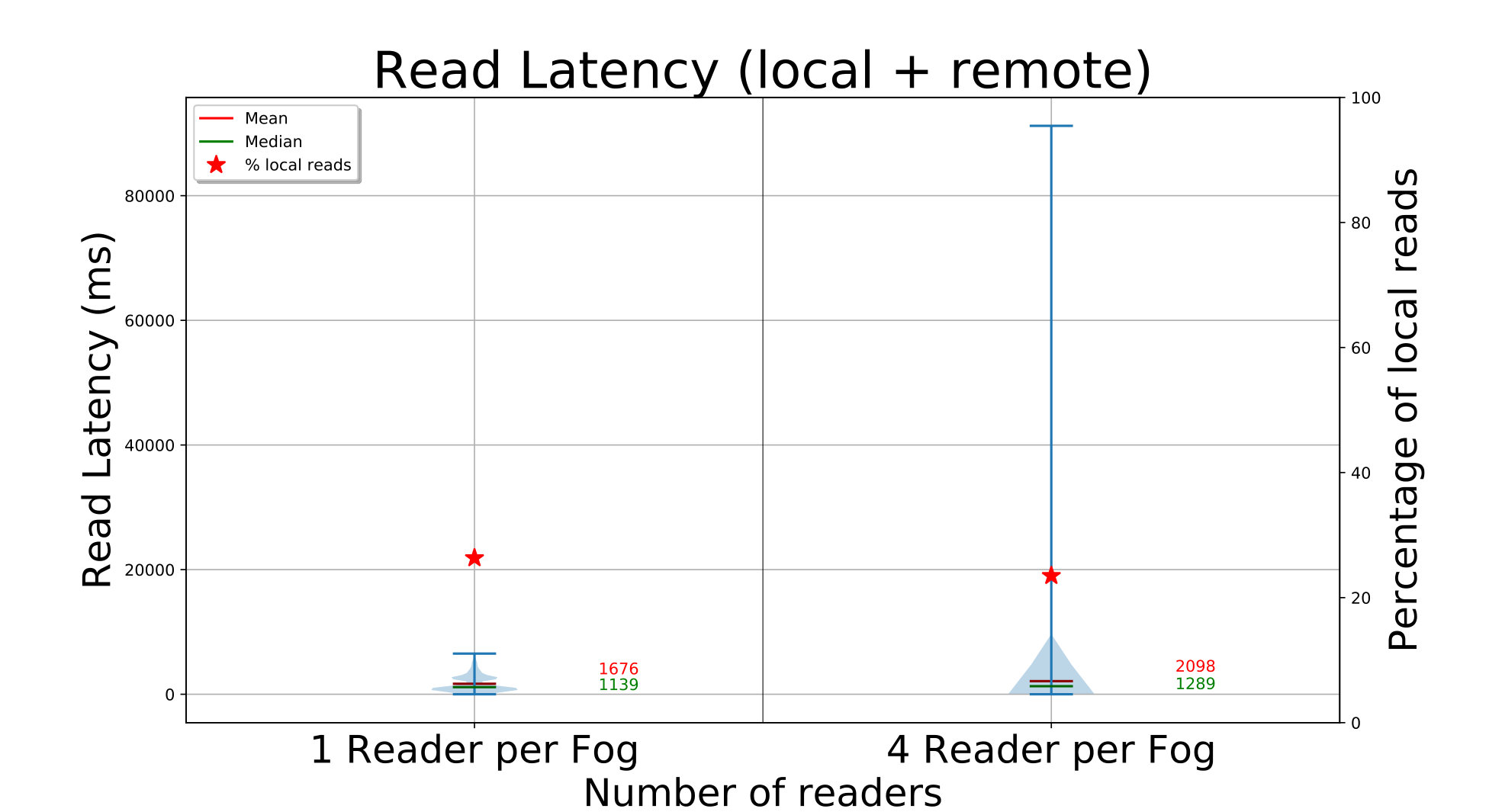 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
ElfStore: A Resilient Data Storage Service for Federated Edge and Fog Resources ***To appear in IEEE International Conference on Web Services (ICWS), Milan, Italy, 2019
Sumit Kumar Monga, Sheshadri K R and Yogesh Simmhan
Department of Computational and Data Sciences,
Indian Institute of Science (IISc), Bangalore 560012, India
Email: [email protected], [email protected], [email protected]
Abstract
Edge and fog computing have grown popular as IoT deployments become wide-spread. While application composition and scheduling on such resources are being explored, there exists a gap in a distributed data storage service on the edge and fog layer, instead depending solely on the cloud for data persistence. Such a service should reliably store and manage data on fog and edge devices, even in the presence of failures, and offer transparent discovery and access to data for use by edge computing applications. Here, we present ElfStore, a first-of-its-kind edge-local federated store for streams of data blocks. It uses reliable fog devices as a super-peer overlay to monitor the edge resources, offers federated metadata indexing using Bloom filters, locates data within 2-hops, and maintains approximate global statistics about the reliability and storage capacity of edges. Edges host the actual data blocks, and we use a unique differential replication scheme to select edges on which to replicate blocks, to guarantee a minimum reliability and to balance storage utilization. Our experiments on two IoT virtual deployments with and devices show that ElfStore has low overheads, is bound only by the network bandwidth, has scalable performance, and offers tunable resilience.
1 Introduction
The growing prevalence of Internet of Things (IoT) deployments as part of smart city and industrial infrastructure is leading to a rapid influx of data generated continuously from thousands of sensors [1]. These data sources include smart utility meters, air pollution monitors, security cameras, and equipment sensors. Analytics over these data, in real-time or periodically, helps make intelligent decisions for the efficient and reliable management of such complex systems [2].
At the same time, IoT is also leading to the availability of edge and fog computing devices on the field, as part of sensors and gateways [3]. Affordable edge devices like Raspberry Pi are often co-located with the sensors on private and wide-area networks to acquire data, perform local analytics, and transmit it to cloud data centers for persistence [4]. Fog devices like NVidia Jetson TX2 manage neighboring edge devices on the network, offer more advanced computing for further analytics or aggregation, and also forward data to the cloud. In large IoT deployments, the edge and fog devices are often organized in a 2-level hierarchy for ease of management and scalability [5], and complemented by cloud resources.
Edge computing is motivated by the access to such cheap or free edge and fog compute resources, the reduced network latency between the data source and the analytics that makes the decision (e.g., power grid management), and to mitigate network use by high-bandwidth applications (e.g., video analytics for urban safety) [6, 7]. There is active research on composing micro-services and scheduling dataflows for execution on edge and fog resources, in combination with or instead of cloud resources [8, 9]. These platform services allow applications to run continuously over incremental data.
However, two key gaps exist. One, there is a lack of transparent data access service at the edge or fog, from which such applications can consume their input. Typically, streaming application bind to specific device endpoints or topics on a central publish-subscribe broker, while file-based applications use ad hoc mechanisms. Ideally, applications should be able to use the logical features of the data they are interested in, such as its metadata, rather than its physical address, to access it. Two, data generated on the edge and fog are only transiently available on them, and eventually moved to the cloud for persistence, a key reason being that edge devices are usually less reliable. So, applications using such data are forced to run on the cloud, or move them back to the edge for computing.
These motivate the need for a distributed data storage and management service over fog and unreliable edge devices that offers content-based discovery, transparent access, and high availability of data, across a wide area network and in the presence of device failures. This ensures data locality for application micro-services on the edge, allows the cumulative storage capacity of the edge devices to be efficiently used, and avoids transferring data to the cloud for persistence. The storage service should also be optimized for data that is continuously generated, as is common for IoT sensor data, and yet allow access to different temporal or logical segments within the data stream.
We make the following specific contributions in this paper:
We propose ElfStore, an Edge-local federated Store, which is a first-of-its-kind stream-based, block-oriented distributed storage service over unreliable edge devices, with fog devices managing the operations using a super-peer overlay network. 2. 2.
We propose a federated indexing model using Bloom filters maintained by fogs for a scalable, probabilistic search for blocks based on their metadata properties. 3. 3.
We offer tunable resilience for blocks using a novel differential replication scheme across unreliable edges. This uses approximate global statistics at the fogs to decide on replica placement, which is sensitive to edge reliability, balances capacity usage, and ensures data durability.
The rest of the paper is organized as follows. We review related work to highlight the novelty of our contributions in Sec. 2, introduce the ElfStore service architecture and operations, federated indexing and tunable replication in Sec. 3, present detailed experiments to validate the design and scalability in Sec. 4, and offer our conclusions in Sec. 5.
2 Related Work
There has been limited work on distributed data storage on edge and fog resources, as reviewed and classified in Moyasiadis, et al. [10]. Rather than off-load to cloud or aggregate to reduce the size, we instead adopt a peer-to-peer (P2P) model which does not reduce data fidelity, and maintains locality on edge and fog resources, with reliability guarantees. Others [11] have evaluated existing distributed cloud object stores, Rados (Ceph), Cassandra and Inter Planetary File System (IPFS), for use on edge and fog resources, and proposed extensions. However, these store data only on the fog layer, with the fog assumed to be high-end Xeon servers with GB RAM. We instead design our storage service for practical and large-scale edge and fog resources that run on Pi- and Jetson-class devices with – ARM cores and – GB RAM, and use the edge devices as first-class entities for persistence.
IPFS [12] is used for storing web content on a wide-area network. It uses a Merkle tree to capture the directory structure, content-based addressing for files, and a P2P Distributed Hash Table (DHT) to map the file’s hash to its peer locations. BitTorrent is used for data movement, and the data is replicated when a client downloads it. Confais, et al. [13] have deployed IPFS on fog and cloud resources using Network Attached Storage (NAS). They extend IPFS to support searching at the local fog, besides the DHT, to speed up access to local content. However, storage is limited to the fog and not edge, and there is no active replication to ensure reliability upon failures.
FogStore [14] proposes a distributed key-value store on fog resources with replication and differential consistency. Our focus is on reliably storing a stream of blocks of a much larger size, where resilience and capacity constraints are met. Others [15] propose repositories hosted on stable fogs (referred to as “edges”) that are populated by data from transient edges (“mobile devices”), and act as a reverse-Content Distribution Network (CDN) to serve requests from the cloud too. Reliability is a non-goal in their design and no experiments are presented. vStore [16] supports context-aware placement of data on fog and cloud resources, with mobile devices generating and consuming these data. It uses a rules engine to place and locate data based on its context metadata, but ignores reliability as edge devices do not store data.
Chen, et al. [17] examine fault-tolerant and energy-efficient data storage and computation on a set of edge devices (“mobile clouds”), without any fog or cloud. They use k-of-n erasure coding, where files are fragmented and coded fragments placed on energy-efficient edge devices. Access to data is by creating n tasks that execute on the edge devices containing the fragments, and waiting for k of them to complete, so as to decode and process the original fragment. This tightly-couples processing with storage on the same devices, rather than offer an independent data service like us. Also, it is designed for –’s of edge devices since all-to-all information is required for decision making, while we use fog overlays that can scale to ’s of fogs and ’s of edges. They do not support searching by metadata like we do. Lastly, erasure codes while space-efficient compared to replication, are time-inefficient for recovery on unreliable systems, like the ones we consider [18].
RFS [19] is a distributed file system hosted on the cloud but optimized for mobile clients (edges) with transient network connectivity. While the cloud holds the encrypted master data, clients selectively pre-fetch, decrypt and cache parts of the file based on their access patterns. Clients have exclusive access to their encrypted home directory, and common access to shared directories. The master data in the cloud is reliable.
P2P systems like Chord, Pastry and BitTorrent have proposed distributed file, block and key-value storage on unreliable peers on wide-area networks [20]. We adopt several of these concepts such as super-peers [21], but simplify and enhance their performance for edge and fog deployments with less device flux, guarantee a minimum durability for stored blocks, and balance the storage capacity across peers. We also use an efficient federated indexing using Bloom filters [22].
Cloud storage services like HDFS and Ceph [23] have been vital to the success of Big Data platforms by separating the distributed storage layer from the computing layer, like Apache Spark or MapReduce, while allowing co-location during scheduling. We adopt a similar model for edge and fog, while being aware of the network topology, sensitive to variable failure rates of edges, and offering search capability.
In summary, none of the existing literature or systems provide a scalable distributed store for storing, searching and accessing streams of objects generated from IoT sensing devices on fog and unreliable edges, while guaranteeing reliability, balancing capacity, and leveraging the topology of fog and edge resources.
3 ElfStore Architecture
In this section, we describe the desiderata, the supported operations, our design choices, and the architecture for Edge-local federated Store (ElfStore).
Our system model has two types of resources, edge and fog. Edges like Raspberry Pi have constrained compute and memory (e.g., -core ARM32 CPU, GB RAM), and about GB of SD card storage. These commodity devices are cheap but unreliable, especially when operating in the field, and have an expected failure rate. Each edge connects to a single fog, through a wireless or wired private local area network (W/LAN), and the fog manages it. Fogs like Jetson TX2 have moderate resource capacity (e.g., -core ARM64 CPU, GB RAM, GB HDD), and serve as a gateway to the public Internet for their edges to connect to other fogs and their edges. Fog resources are reliable, and connect with each other through a wired Metropolitan or Wide Area Network (MAN/WAN). We plan to support city-scale deployments having –’s of fogs, each managing –’s of edges [7].
Given this, there are several design goals and assumptions for our data storage service. (1) Applications running on edge, fog or other devices on the Internet may put, search and get data and associated metadata from the service. However, we expect that the edges will be the predominant clients to the store, generating and writing data continuously from co-located sensors, and consuming data for edge micro-services. (2) The edges will serve as the primary storage hosts for the data to enhance locality (hence, “edge-local”), with the fogs used for management and discovery. We avoid cloud as a storage location, though it can have clients that access the data for processing or long-term archival. (3) Data that is stored must meet a minimum reliability level, even with edge failures, and have sufficient availability. The typical lifetime of the hosted data is in days or months (not years), as edge applications are likely to be interested in recent data. Adequate cumulative storage capacity should be available on the edges. (4) The store should scale as edges join and leave the system, often triggered by device failures and their stateless recovery, or occasional capacity expansion. Its performance should also weakly scale with the number of clients. (5) We assume a fully-trusted environment, where all edge and fog devices are secure, part of the same management domain, and there are no access restrictions to the contents.
The ElfStore architecture (Fig. 1) addresses these requirements, and offers a federated storage service for streams of blocks. It uses the local disks on unreliable edges in the LAN as the persistent layer, and fogs on the WAN connected using a super-peer overlay as the management layer. It guarantees reliability at the block-level using differential replication, and helps search for streams and blocks over their metadata using federated Bloom filter indexes. These are discussed next.
3.1 Data Model and Operations
IoT data is often streaming, and arrives continuously from sensors. While publish-subscribe brokers enable access for real-time processing, we handle data storage and application access in the short- and medium-term. Since this data accumulates over time, ElfStore adopts a hybrid data model consisting of a stream of blocks. Here, the storage namespace has a flat set of streams, identified by unique stream IDs, and a sequence of data blocks within a stream ID, each having a unique block ID. Streams have associated metadata properties as a set of name–value pairs, and is used in searching. Each block has a data payload as a byte-array, and also metadata properties.
Stream properties include the stream ID, start and end time range of its blocks, sequence IDs of the blocks, and user-defined properties like sensor type, spatial location, etc. Block properties are stream ID, block ID, sequence number, MD5 checksum, timestamp, and domain properties. Our store is optimized for append rather than update operations, with data and metadata often (but not always) immutable.
While this model resembles other block and object stores like HDFS, Ceph and Azure Blobs, we additionally allow users to search over the block and stream metadata to discover block IDs to access. This is useful when the IoT clients micro-batch sensor streams and create blocks with different temporal event ranges, and consumers wish to access blocks containing a particular time segment; or when different variables from the same sensor is placed in different blocks of a stream and users wish to access blocks holding specific variables. If need be, streams can be treated as directories and blocks as files within them to even offer a distributed file-system view.
Given this, ElfStore supports the following service API:
- •
CreateStream(sid, smeta[], r) This creates a logical stream with ID sid, with r as the stream’s reliability (i.e., reliability required for its blocks), and registers its metadata with the local (owner) fog, with an initial version number, and indexes it for searching. Metadata properties may be static or dynamic.
- •
Open|ReopenStream(sid) This is optionally used before Put to acquire an exclusive write lock to the stream for this client. Its response is the lease duration. Reopen renews the lease before it expires.
- •
PutBlock(sid, bid, bmeta[], data, lease) Put adds a single new block bid to the end of the stream sid, with the given data payload and the stream’s reliability, and registers its static block metadata for searching. If lease is passed from Open or Renew, it supports concurrent puts. Else, it behaves as an optimistic, lock-free protocol.
- •
UpdateBlock(sid, bid, data, lease) This updates the data contents for all replicas of an existing block, but is otherwise similar to put.
- •
UpdateStreamMeta(smeta[], v) This allows the dynamic metadata properties for a stream to be updated, where smeta has the updated properties and v the version number of the old metadata being updated.
- •
FindStream(squery) This searches for streams that match a given set of static stream properties provided in the squery, and returns their IDs.
- •
FindBlock(bquery) This searches for blocks that match a given set of static properties provided in the bquery, and returns their stream and block IDs.
- •
GetStreamMeta(sid, latest) This fetches the cached metadata for the stream sid and their version. The latest flag forces the most recent version of the metadata to be fetched.
- •
GetBlock(sid, bid) This downloads the data and metadata for the given stream and block ID.
Every fog runs a service that exposes these APIs, and clients can initiate an operation on any fog. These can be enhanced in future by APIs like InsertBlock, GetBlockRange, GetBlockMeta, DeleteBlock, DropStream, etc.
3.2 Device Management
3.2.1 Super-peer Overlay
ElfStore uses a P2P model for device management and search. Fogs act as super-peers and edges as peers within them [21]. Each edge peer attaches to a single fog super-peer, which serves as its parent and manages search and access to its data and storage. A fog and its edges form a fog partition. This reflects practical IoT deployments where such a 2-level hierarchy is common [5]. E.g., there may be a fog within a university campus, and all edges in the campus LAN are part of this fog partition.
Typical P2P networks scale exponentially, but require a logarithmic number of hops to locate information [20]. Each (super)peer maintains routing details to (super)peers, where is the number of items that can be stored in the network. These form an overlay network that takes up to hops to locate a peer containing an item ID. Since we expect the fogs to number within the thousands and without a lot of flux, we instead maintain the super-peer overlay as a recursive 2-level tree. Each fog maintains a list of buddy fogs at the first level (which form a buddy pool), and a list of neighbor fogs at the second level, where is the total number of fog devices. Buddy pools are mutually exclusive, as are the neighbors of buddies in each pool. This limits our searches to hops – first to a buddy and then to its neighbor †††This model can be easily extended to a classic super-peer overlay that scales to millions of fogs but with hops, or to support -level redundancy for fog failures by having edges use all buddies as parent fogs [21].. Edges know which parent fog to join, and since our fogs do not come and go often, existing P2P discovery mechanisms or even simpler techniques can be used for constructing this overlay network.
Fig. 2a shows fog super-peers in an overlay, each with buddies and the other fogs being partitioned across these buddies to give neighbors each. For brevity, neighbors for only one buddy pool and edges for only one fog partition are shown. E.g., fog 9 maintains details on its buddies 1 and 5, neighbors 10, 11 and 12, and edges, –.
3.2.2 Health Monitoring and Statistics
Light-weight heartbeat events that are a few bytes long and sent often (–) are used to monitor the devices. We also piggy-back tens of bytes of metadata and statistics in these heartbeats. This monitoring plane enables fail-fast detection of device failures, and federated statistics to be maintained (Fig. 1).
Each edge in a fog partition sends heartbeats to its parent fog when it is online, say every . The arrival or loss of an edge is detected using this. Multiple heartbeat misses indicate a loss, and will trigger re-replication of blocks on the missing edge, while an edge arrival will make its storage available. This obviates the need for a “graceful” entry or exit of edges. Fogs in a buddy pool send heartbeats to each other. Besides detecting the loss of a buddy and recovering its state (in future), this passes aggregate statistics from each buddy about its neighbors to others in the pool. Likewise, neighbors of a fog send it heartbeats and statistics periodically. Such heartbeats between buddies, and between neighbors and a fog, can help maintain the overlay network as fogs come and go.
3.3 Data Discovery using Federated Indexes
Typical P2P DHTs use consistent hashing over their IDs to locate the peer hosting the content. But we provide a unique feature to locate streams and blocks using their static metadata, and not just ID. We maintain a federated index, updated using the heartbeat events, to enable this (Fig. 1). First, each fog maintains a partition index of the metadata for blocks present in its edges and streams registered with it. This index is updated when a stream is created on the local fog that becomes its owner, or when a block replica is placed on it as part of an PutBlock call or a re-replication.
Each edge sends a tuple to its parent fog i, when a block with property name and value is put on it‡‡‡The block and stream IDs themselves are a property name. We use a similar approach for stream metadata, but omit its discussion for brevity.. The fog maintains the index , that locates edges and block IDs in its partition that match a name–value pair. This update tuple is shown in Fig. 2b for fog 1 from its edges, and allows the fog to answer 0-hop queries – FindBlock queries over these property name(s) can be answered locally to return the matching block IDs and edges.
We also maintain a hierarchical Bloom filter from neighbors, buddies and their neighbors to identify fog partitions that potentially host block(s) matching a given key–value pair, within 2 hops of the fog initiating the search request. Specifically, each fog i applies its edge metadata updates to a local Bloom filter for each property name, given as , where is a fixed bit-width multi-level hash function, are the set of distinct values for the property name a for blocks present in this partition, and the Bloom filter is formed by a bitwise OR over all the hashes [24]. We test if a value is probably present in the filter by checking if the bitwise OR of the filter with a hash of the value is non-zero, i.e., .
Bloom filters can have false positives, whose frequency is determined by the number of unique values inserted, the number of bits in the hash, and the quality of the hash [24]. But it has constant-time insertion and lookups, and compact storage. In our experiments, we use a SHA1 hash per property name.
Also, Bloom filters do not support deletions, and hence used to only index static properties and not dynamic ones. This can be relaxed in future using Cuckoo Filters [25].
When the local Bloom filter is updated, a fog sends it to other fogs it is a neighbor of, as part of the heartbeats. Each fog i maintains list of neighbor Bloom filters for a property name a, one per neighbor fog j, given as . This lets a fog check if any neighbor possibly contains blocks matching a given name–value query, and if so, forward the FindBlock query to the neighbor for an exact match using its local index . Fig. 2b shows neighbors fogs 2, 3, 4 sending their updates to fog 1, and responding to 1-hop queries.
Lastly, each fog encodes its local Bloom filters and its neighbor’s Bloom filters into a recursive Bloom filter [22], and sends it to its buddies. For a fog j with neighbors fog k, this buddy Bloom filter is constructed as . Each fog maintains buddy Bloom filters, , which allows it to test if its buddies or their neighbors possibly match a given query. E.g., in Fig. 2b, buddy fog 9 constructs a buddy Bloom filter from its neighbor Bloom filters, fogs 10, 11, 12, and its local Bloom filter, and passes it to fog 1. This uses it for 1-hop (forward request to buddy) or 2-hop (forward to buddy’s neighbors) queries.
Since client requests are routed through a fog, each fog maintains a cache of metadata retrieved from others as part of various operations. This allows fast responses to other clients from the local fog’s cache rather than the parent fog, but can return stale dynamic properties. Clients can pass a flag to force the latest metadata to be fetched. We do not cache data blocks to reduce the storage overhead, though it is a simple extension.
3.4 Reliable Data Management and Access
Each edge has a pre-defined device reliability , which can be part of the device specification or inferred from field experience. We also assume that blocks hosted on them are permanently lost when they disconnect from their parent fog.
ElfStore uses differential replication to ensure that a block of size that it stores meets its block reliability , by placing replicas on edges having available storage capacity and reliabilities , such that and . So the replication count depends on both the reliability required for the block, and the reliabilities of the edges used. When a fog receives a request to put a block with its stream’s reliability, it determines the replication factor and the exact edges to put these replicas on. E.g., a reliability of (i.e., ) can be achieved for a block by replicating it on edges with reliabilities, such that ,
or on edges having .
The key challenge is that with of edge devices, it is not possible for each fog to maintain the current capacity and reliability of every edge device to make this decision. Instead, just as we used federated indexes to locate blocks, we similarly propagate and maintain approximate statistics about the storage and reliability of edges in various fog partitions within the overlay network to help make this decision.
3.4.1 Approximate Statistics
Each edge reports its reliability and available storage capacity to its parent fog, periodically as part of its heartbeat. Each fog i then determines the minimum, maximum and median reliabilities and storage capacities for all its edges, and , along with the count of edges that fall within each quadrant of this 2D space, , as illustrated in Fig. 3(d). Here, we have edges with reliability between and capacity between ; edges with and ; and so on for the other 2 quadrants.
These edge counts correspond to the combinations of high/low capacity and high/low reliability, HH, HL, LL, HL. We will also have , and , depending on rounding errors.
These -tuple values are then sent to the fogs we are a neighbor of, as part of heartbeats. Similarly, buddies exchange their neighbors’ and their own tuples with other buddies. Using these -tuples acquired from all fogs, each fog independently and consistently constructs a global distribution matrix, as follows. We first find the global min and max storage range among all the fogs, and , and likewise the reliability range, and . We divide each range and into equiwidth buckets, and for each fog i, proportionally distribute its count among the storage buckets that overlap with , and its count among buckets that overlap with ; and similarly, distribute counts and proportionally to reliability buckets that overlap with the reliability sub-ranges for the fog. We sum these bucket values across all fogs, and calculate the global median storage and reliability, and . This gives us the bounds of the global quadrants.
For the -tuples for the fogs, A, B, C and D shown in Fig. 3(a), their contributions to the storage and reliability buckets are shown in (b) and (c), using buckets. These help decide the global bounds in (d).
E.g., fog B contributes it edges proportionally to the storage buckets that fall between , and edges to the storage buckets that between . From these plots, we find the new global medians, and .
Now, for each fog i, we consider the area overlap of each if its local quadrants with each of the global quadrants, and proportionally include the fog’s edge count from that local to the global quadrant. E.g., in Fig. 3(a), fog C contributes all its edge counts in quadrants and to the global which fully contains them, while the edges in its and local quadrants, which overlap with both the global quadrants and , are shared proportionally in a ratio of : between them. This gives the global count of edges in each of these four storage and reliability quadrants, HH, HL, LL, HL. Given this, a fog is mapped to the quadrant where its median-center falls. E.g., fog A falls in LL and C in HL.
3.4.2 Replica Placement for Put
We use this information maintained independently but consistently on each fog to handle the PutBlock operation, invoked by a client on any fog. The fog receiving a put request for a block of size queries the stream to get its reliability, . It then selects a series of fog partitions, and chooses an edge within each for placing a replica such that we (1) balance the use of fogs with both high and low reliability edges to ensure that a sustainable mix of edges remain, (2) give preference to fogs that have a higher available storage to ensure effective use of capacity, (3) select different fogs for each replica to enhance partition-tolerance and locality with diverse clients, (4) bound the replication factor to a minimum and maximum value set by the user, and (5) meet the block’s reliability requirement.
We select fog partitions from different quadrants in the global matrix in a particular sequence to meet the above goals. Specifically, we alternate between HH and HL quadrants to prioritize high-capacity fogs. Within the global quadrant, we pick a random fog and test if it has a non-zero edge count in a complementary reliability quadrant. E.g., for a fog that maps to the HH quadrant of the global matrix, we check for edges in its HL or LL local quadrants, and for a fog in the HL global quadrant, we test for edges in its HH or LH local quadrants. If the fogs have zero edges in these quadrants, we expand to the other two local quadrants as well.
The sequence order of global and local quadrants that are tested is given in Fig. 3(e), and a variant of a Z-order curve. Intuitively, this picks edges close to the median global reliability and with high capacity. The reliability is initially met by median edges. As their capacity is exhausted, the edges with more extreme (low or high) reliability move closer to the median and will be chosen. Later, this helps us find pairs of edges with low and high reliability that together give a reliability similar to the initial two median reliability edges. As an optimization, we always try and place the first replica locally, if the writing client is on an edge. We also pick edges in different fog partitions unless there is no available capacity.
A fog i that is chosen will provide a minimum reliability of if the edge is in the HL or LL local quadrant, or if in HH or LH. This is a conservative estimate since the actual edge selected within the fog may have a reliability as high as or , respectively. We pick as many fogs as needed to meet the block’s reliability or the minimum replication count.
The fogs chosen in this manner are sent to the client, which then directly contacts each fog concurrently to place a replica of the block. Each fog selects an edge with the least reliability in the specified local quadrant, and puts the block on it. In case the global matrix is stale and the fog cannot find a suitable edge, this fog can use its own global matrix to find an alternative fog with a similar non-empty global and local quadrant. Since the edge may be on a private network, the data moves from the client to the parent fog hosting a replica, and from it to the edge. If the client is an edge, it will also pass through its own parent fog first, but not otherwise, to avoid the extra hop. The fog also registers the block metadata with itself, propagates to the federated indexes as described before, and updates the stream metadata at the owner fog with the block ID, MD5 checksum, and block count.
3.4.3 Getting a Block
Getting a block involves finding the fogs containing the block replicas using its ID from the local fog. This first returns the local fog or the possible neighbor fogs that may contain it, based on a local index or Bloom filter lookup. The client contacts the local fog if present in the response, and this will have the replica. Else, the client contacts each neighbor fogs, which checks its local index, and if present, returns the block from the edge to the client.
If none of the local or neighbor fogs hold a copy, or in the rare case these were all false positives, we recheck with the local fog and force it to search its buddy Bloom filters. It forwards the find request to matching buddies to check their local index and neighbor Bloom filters, in – hops. This will return the global list of fogs that may contain the replica, and the client contacts each to get the first available replica.
3.4.4 Re-replication for Recovery
A parent fog detects an edge failure due to missing heartbeats. This triggers a recovery of all block replicas present on the edge to ensure each block’s reliability requirement is still met. For this, the fog uses the same edge selection approach as above, except that it tries to find a single fog that has an edge with a reliability similar to the edge that failed. The parent fog then gets an existing block replica from a surviving edge, and puts it on the newly selected fog and an edge within it. This selection of alternative devices and re-replication onto them is done concurrently for lost blocks on the failed edge. While we currently assume that the reliability for an edge does not change over time, in future, this same technique can be extended to expand or contract the number of replicas to adapt to dynamism in the reliability.
3.5 Consistent Concurrency and Updates
3.5.1 Concurrent Puts and Updates with Leasing
The default PutBlock operation is optimistic, and assumes that just one client is writing to the stream. With concurrent clients adding blocks, the order in which the blocks are appended to the stream depends on the order in which the stream metadata at the owner fog is updated with the new block IDs. Here, we will need a user-defined sequence number in the block metadata for partial ordering of blocks written by one client.
However, for global ordering of blocks with concurrent clients, we offer a soft-lease mechanism. Here, the client first calls OpenStream to try and acquire a lease for a certain duration. This request is forwarded to the owner fog for the stream, which logs and returns a successful lease for the requested (or a pre-defined) duration, if no other client holds an active lease on this stream. The response has the duration and a session key, which is a unique random nonce used for auditing. PutBlock then passes the client ID, lease duration and session key to the fogs where the replicas will be placed. These fogs sanity-check if the lease duration is valid, and log the client ID and session key for this operation, before writing the block replica to their edge. The client also adds the new block IDs to the stream metadata.
This soft-lease model is light-weight, but does not enforce locking of the stream. It is up to the clients to ensure that they have acquired a valid lease before they call puts in parallel to avoid inconsistent ordering. But, the logs maintained at the fogs allow us to later verify the validity of the operations.
The lease on a stream can be used by the client across multiple
Put|UpdateBlock operations. This lets it write a series of blocks to the stream with guaranteed contiguous order. If the lease is going to expire before an operation, the client Renews it with the fog, which returns an extended lease duration if it has not expired. If the lease has expired and no other client has acquired the lease since then, the fog goes ahead and extends the lease. This reduces leasing overhead dues to time-skews, without affecting consistency. If an OpenStream fails due to another client having the lease, the client can poll and retry acquisition. There is no explicit close stream operation, and the lease is released on expiry.
UpdateBlock is similar to PutBlock, but replaces the selection of replicas using the global matrix, with finding the fogs holding all the current replicas for the block, similar to GetBlock. Once located, the client sends the updated block data to each replica, and also updates the stream metadata with the new MD5 checksum for the block.
3.5.2 Stream Metadata Updates
When a stream is created, it is registered with an owner fog that holds it metadata. These properties may be static or dynamic. While static properties are indexed and searchable, the values of dynamic properties can be updated but not searched on.
Leasing is useful when multiple operations are done with a single lease to amortize its cost. But metadata updates are single operations. So we assign version numbers to dynamic metadata properties and employ a test and set pattern to allow consistent and concurrent updates to them. This version is returned by GetStreamMeta. Cached versions of the stream metadata also maintain and return the version in their cache.
When updating the metadata for a stream, the client first does a GetStreamMeta, updates the values of the returned dynamic properties, and sends the new property values and the earlier version number to the owner fog of the stream. The fog tests if the current version matches the passed version, and if so, sets the passed dynamic properties and increments the version. But, if the current version is greater than the one that is passed, then the client is trying to update a stale copy of the dynamic property. This may be due to using an older cached metadata on a different fog, or another client having updated the metadata with the owner fog since the last access by this client. Then the update call fails, and the client has to get the latest metadata and retry with the new version number.
There are also system-defined dynamic properties that are maintained as part of various APIs, such as the block count, list of block IDs, and their MD5 checksums, for a stream. These cannot be modified directly by the client, but the framework updates these internally using a similar pattern.
4 Experiments
ElfStore is implemented in Java using the Apache Thrift cross-platform micro-services library. The fog service has the bulk of the logic, while the edge services are light-weight.
We conduct experiments to validate the performance, resilience and scalability of ElfStore. We use the VIoLET container-based IoT virtual environment to define two deployments [26]. In the first, D20, we have fog containers on a public network, with edges connected to each fog in a private network. This gives a total of devices running on Azure D32 VMs (-core, GB RAM). The D272 configuration has fogs, with edge containers each, for a total of devices on public and private networks. They run on Azure D32 VMs. All devices in each fog partition run on the same VM. The edge containers have CPU and memory resources that match a Raspberry Pi 3B (-cores@ GHz, GB RAM, GB disk space), while the fog containers map to a Jetson TX1 (-cores@ GHz, GB RAM), as defined in VIoLET. Network links have a bandwidth of Mbps. We use a Normal distribution for the edges’ reliability, with for D20, and for D272.
4.1 Put Block Performance
4.1.1 Put performance without leasing
For the D20 setup, we run experiments with or edges concurrently calling the PutBlock API on their local fog parent with a blocks size of , in a loop for times. We set a reliability of for all these streams, and a min and max replication factor of and . For the D272 setup, we perform two experiments with and concurrent edge clients spread across the fogs. Each edge calls put for iterations. They put blocks of size or and use reliabilities of or , with uniform probability. This diversity reflects realistic scenarios. Leasing is not enabled, and edges put to distinct streams in their local fog; one replica will be placed in the local edge.
The end-to-end latency distribution in seconds for the put API calls is shown as blue violin plots on the left Y axis of Fig. 4a. For a single API call, this is the time to find the fogs to place block replicas on, copy all replicas to the target edges concurrently, and register the block metadata. Each violin distribution has data points.
For D20, with 1 edge writing, each put call takes a median of . Since each replica is in size, the link speed is , and we need hops – from client to parent fog, parent fog to target fog, and target fog to edge – about are spent just in data movement.
Zooming in, the time to find the replica placement is just as the parent fog takes a local decision, and the time to update the metadata index is also ; this is mostly the service call overhead.
These times do not vary much as we increase to concurrent edges writing from different fog partitions, with their median time at . But with edges putting blocks in parallel, all edges of every fog are active. Since they all route data through their parent fog to a remote fog, the data transfered out from the fog for edges in its partition is . Hence, its available bandwidth limits the performance, taking a median of .
So ElfStore’s overheads are minimal in all these cases, and we are only bandwidth bound.
For D272, each edge is randomly assigned to put blocks of either or in size, times. For 16 edges, there are edges each putting blocks of these two sizes, while for 64 edges, there are writing blocks and the rest writing blocks. Fig. 4a shows that the median latency with concurrent edges is about and it only marginally increases to for edges. The smaller time than D20 is due to the use of smaller block sizes and a smaller client load, compared to the total edge count.
If we limit our analysis to just the edges on D272 putting blocks (plots omitted for brevity), we report that the median time for the (of ) edges writing blocks is while for (of ) edges it is . These are higher than D20 primarily due to the higher replication factor, which has grown from being to as high as , as seen in the red violin on the right Y axis of Fig. 4a. This increases the data transfer time, both due to additional bandwidth and the compute cost of concurrent threads doing these operations.
The higher replication factor and its wider distribution for D272, spanning the full range of – copies allowed, are due to its lower and more variable edge reliability of . In contrast, D20’s reliability of results in a replication factor of –. This clearly shows the differential replication at work.
4.1.2 Put performance with leasing
We initialize the D20 setup with block writes without leasing. Then, we perform additional block puts per client to a random stream, from , and concurrent clients, with a lease acquired on the stream for , and renewed a median of times.
Different edges may select the same stream to write to. Besides the end-to-end latency for these leased-puts, which now includes the lease acquisition and renewal time (left Y axis in Fig. 4b), and the replica count (right Y axis), we also show the concurrent writers count for a stream (right Y axis).
With or edges doing puts, we see that the median latency is and . These are comparable to the previous experiments without leasing for the same number of writers. This is due to the lower median replication factor of in these runs (compared to earlier). This is due to a higher overall reliability of the edge devices in these runs, despite sampling from the same edge reliability distribution. No two edges have selected the same stream to write to in these runs. This indicates that the edge reliabilities, replication count and bandwidth usage have a bigger impact on the end-to-end latency than the leasing overheads.
With clients, the median latency is lower than without leasing at due to the smaller replication count. But the latency distribution is much wider, reaching . This is because multiple edges pick the same stream to write to, as seen in the right-most violin. We have streams selected by edges each to write to, and stream picked by edges. Hence, with concurrent writers and leasing, only one will write to the stream at a time while the others poll to acquire the lease. This lasts till all blocks are put by an existing edge with the lease.
The peak latency to write a block is for the stream with clients. The last edge to get the lease was waiting for blocks to be written by the previous two edges, that takes about . So the latency for this edge to put its first block is , while putting the rest of its blocks does not have additional leasing overheads.
4.2 Find and Get Block Performance
We do a similar set of concurrent FindBlock and GetBlock API calls from , and edges for the D20 setup, and from and edges for D272. ElfStore has been loaded with blocks (D20) or blocks (D272) using the previous put runs. Each edge finds random block IDs from the ones inserted, followed by a get of that block.
The time to find and get each block is shown in Fig. 4c (left Y axis), and a magenta triangle on the right Y axis indicates the percentage of times a replica from the local partition is read. The find API call is fast, taking about with and edges for D20, and about with edges. In the latter case, each fog is servicing concurrent edge requests and hence marginally slower.
Once the replicas for a block ID are identified, we get one of the replicas – preferring a replica in the local fog partition, if present. For D20, we see that the get latencies have a bimodal distribution. There are peaks at and for and edges, and at and for edges. This is due to the mix of local and remote replicas that an edge accesses. Edges are able to get a local replica copy – of the time, resulting in the lower latency peak. This range is within the we expect – since all edge clients put blocks uniformly, of all the blocks have their first replica locally; of the remaining of blocks, there is a chance on the non-local replicas to be on that fog. The second peak reflects the copying of a remote replica. Just like for the write, we are bandwidth bound as the concurrency increases, showing that ElfStore has low overheads.
The performance for D272 is equally fast, taking a median – with or edge readers. It benefits from – of blocks being only in size. However, this is despite only of blocks having a local replica out of the median 4 replicas per block. This too matches the expected local fraction of . In fact, the small number of local copies means that the latency distribution is tighter. So ElfStore weakly scales for gets too.
4.3 Metadata Update Performance
We conduct experiments on the D20 setup to measure the latency for stream metadata updates, using , and concurrent edges as clients. Each client randomly picks one of the existing streams, and performs GetStreamMeta and UpdateStreamMeta operations alternately on it. It is possible for two clients to select the same stream to perform an update. Since we use version checking rather than leasing for metadata updates, it is likely that the version of a stream metadata being updated may have been updated by a concurrent client and hence fail. We report the latency for get and update metadata (left Y axis) and the count of failed updates (right Y axis) in Fig. 5a; failed updates are not retried.
With just or clients, no two streams are randomly picked for update by the same client, and only local streams are chosen. So all updates are at the local fog, and complete successfully with a median latency of .
But with clients, streams are selected by a pair of clients to update concurrently. This causes of the total of updates to fail due to staleness, as seen in the right Y axis. The update time also increases to a median of . This is primarily due to a majority of the metadata updates happening on a remote fog partition, unlike the and edge cases, and this causes an extra network hop in the VIoLET environment.
4.4 Block Recovery Performance
Lastly, we measure the responsiveness of ElfStore in recovering from edge failures, and ensuring that the blocks maintain their reliability levels. We load and blocks into the D20 and D272 setups, like before, and then kill one of the edges with the least reliability. We track the time taken by its parent fog to detect the loss, and start re-replicating the lost blocks on other edges. Once recovery is complete, we kill another low reliability edge. Fig. 5b plots the time to re-replicate each block on the left Y axis violin, the number of blocks recovered on the right Y axis, and list the total recovery time at the bottom, shown after the first and the second failures.
In all cases, of lost blocks are re-replicated.
We see that the re-replication time per block is for D20, and – for D272. These are comparable to the sum of the get and put times seen before, since we get a surviving replica and put it on a new edge. Also, recovery of blocks is done in parallel on the fog using – threads. Hence, while – blocks are recovered depending on the failing edge, the total recovery time is only –. So the thread parallelism gives us a speedup.
We further examine how our global matrix changes as blocks are populated in ElfStore, and when failures happen. Fig. 5c shows a heatmap of the edge-counts in the global matrix quadrants (top rows) and the median storage and latency values (bottom rows), updated every along the X axis, for D20. At time steps [math]–, edges are concurrently writing blocks in a loop. Initially, the median available storage , and all edges fall in the high capacity quadrants, HH or HL. As replicas are written to fogs in these quadrants and their edge capacities get used on a priority, the count shifts from HH and HL, to LH and LL, e.g., from step to . Eventually, this disk usage causes the median capacity to change, say, from to after step . This causes borderline fogs, earlier classified as low capacity, to move to the high capacity, and become prioritized for selection. So we keep selecting fogs that are in and around the median value.
After step , there is an edge failure and the total edge count drops from to . The ensuing re-replication causes the missing blocks to be copied to an existing edge. While only one replica is created, this is done by concurrent threads. So the edge counts again shift from high to low capacities. When a second edge fails after step , it even causes the median reliability to drop from to .
5 Conclusions
In this paper, we have presented a novel distributed storage service for edge and fog resources that offers a transparent means for edge computing applications to access streams of data blocks persisted locally. This avoids the need to move IoT data to and from the cloud, other than for long-term archival. ElfStore leverages ideas from both P2P networks and Big Data storage like HDFS. It uses a federated index for -hop searching of blocks, with hierarchical Bloom filters over static metadata properties for fast probabilistic searches at scale. It maintains approximate global statistics on storage and reliability distributions of edges on different fogs, which helps it select fogs and edges for differential replication. This guarantees tunable reliability of each block. Our experiments demonstrate the low overhead of ElfStore, with block read and write performance bound only by the network speed. Consistent and concurrent updates of blocks and metadata are also validated. It also performs automated and rapid block re-replication on edge failures, to maintain the required reliability.
As future work, we plan to include support for overlay creation, as available in existing P2P literature, and use buddy pools to handle unreliable fogs as well. We can also enforce the leases as locks, and support access control, auditing and non-repudiation mechanisms. Larger scale and comparative experiments, and concurrent-failure tests are planned as well §§§Acknowledgment: We thank Shrey Baheti from the DREAM:Lab for help with the experiments. This work was supported by grants from VMWare, Microsoft Azure and the Indo-US Science and Technology Forum (IUSSTF)..
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Perera, A. Zaslavsky, P. Christen, and D. Georgakopoulos, “Sensing as a service model for smart cities supported by internet of things,” Transactions on Emerging Telecommunications Technologies , 2014.
- 2[2] Y. Simmhan, S. Aman, A. Kumbhare, R. Liu, S. Stevens, Q. Zhou, and V. Prasanna, “Cloud-based software platform for big data analytics in smart grids,” Computing in Science & Engineering (Ci SE) , 2013.
- 3[3] A. V. Dastjerdi and R. Buyya, “Fog computing: Helping the internet of things realize its potential,” IEEE Computer , 2016.
- 4[4] X. Xu, S. Huang, L. Feagan, Y. Chen, Y. Qiu, and Y. Wang, “Eaaas: Edge analytics as a service,” in IEEE ICWS , 2017.
- 5[5] J. He, J. Wei, K. Chen, Z. Tang, Y. Zhou, and Y. Zhang, “Multi-tier fog computing with large-scale iot data analytics for smart cities,” IEEE Internet of Things Journal , 2017.
- 6[6] P. Garcia Lopez, A. Montresor, D. Epema, A. Datta, T. Higashino, A. Iamnitchi, M. Barcellos, P. Felber, and E. Riviere, “Edge-centric computing: Vision and challenges,” ACM SIGCOMM Computer Communication Review , 2015.
- 7[7] M. Yannuzzi, F. van Lingen, A. Jain, O. L. Parellada, M. M. Flores, D. Carrera, J. L. Pérez, D. Montero, P. Chacin, A. Corsaro et al. , “A new era for cities with fog computing,” IEEE Internet Computing , 2017.
- 8[8] P. Ravindra, A. Khochare, S. P. Reddy, S. Sharma, P. Varshney, and Y. Simmhan, “Echo: An adaptive orchestration platform for hybrid dataflows across cloud and edge,” in ICSOC , 2017.
