Stochastic Inverse Reinforcement Learning
Ce Ju

TL;DR
This paper introduces stochastic inverse reinforcement learning (SIRL), a well-posed approach that estimates the probability distribution over reward functions from expert demonstrations, improving robustness and providing multiple solutions.
Contribution
It generalizes IRL to a probabilistic framework using MCEM, offering a succinct, robust, and transferable solution that captures the intrinsic properties of IRL.
Findings
Achieves good performance on the objectworld benchmark.
Provides a global perspective on IRL's intrinsic properties.
Generates multiple alternative solutions to IRL.
Abstract
The goal of the inverse reinforcement learning (IRL) problem is to recover the reward functions from expert demonstrations. However, the IRL problem like any ill-posed inverse problem suffers the congenital defect that the policy may be optimal for many reward functions, and expert demonstrations may be optimal for many policies. In this work, we generalize the IRL problem to a well-posed expectation optimization problem stochastic inverse reinforcement learning (SIRL) to recover the probability distribution over reward functions. We adopt the Monte Carlo expectation-maximization (MCEM) method to estimate the parameter of the probability distribution as the first solution to the SIRL problem. The solution is succinct, robust, and transferable for a learning task and can generate alternative solutions to the IRL problem. Through our formulation, it is possible to observe the intrinsic…
Click any figure to enlarge with its caption.
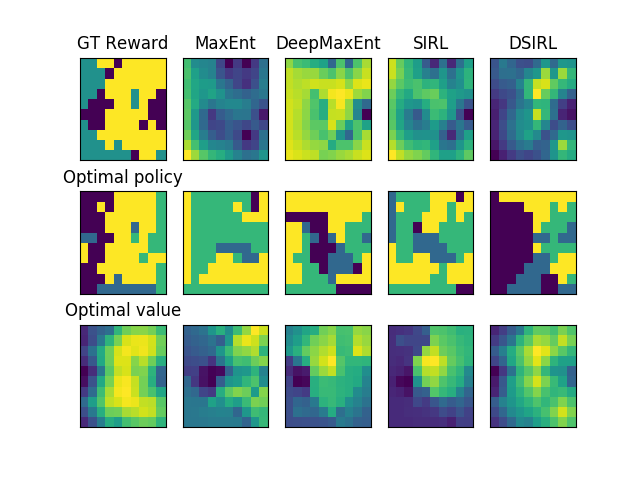 Figure 1
Figure 1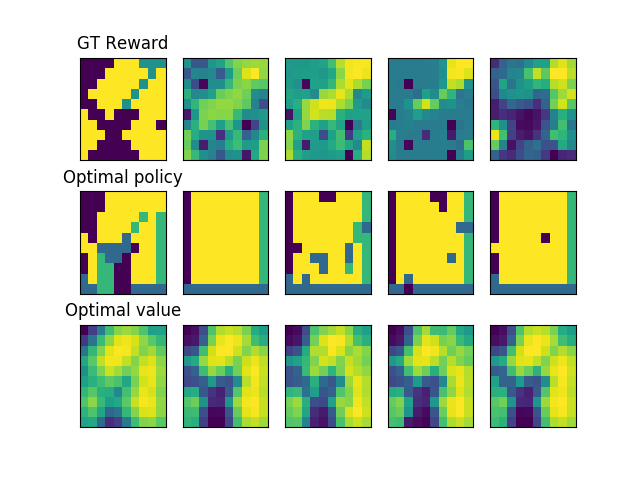 Figure 2
Figure 2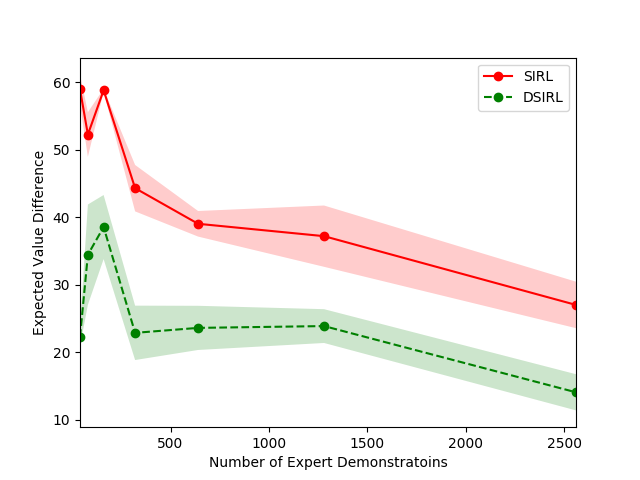 Figure 3
Figure 3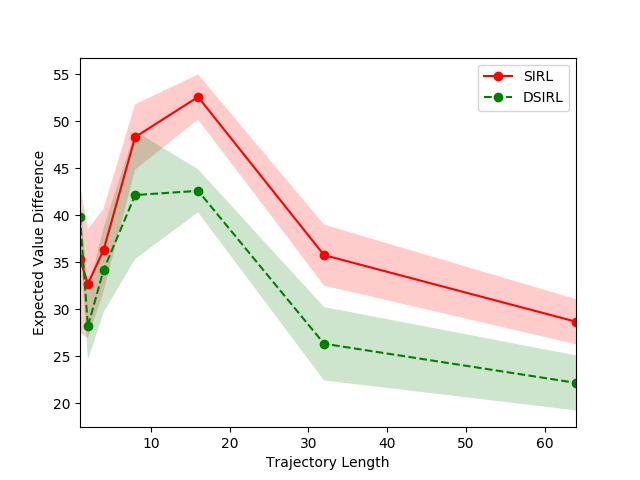 Figure 4
Figure 4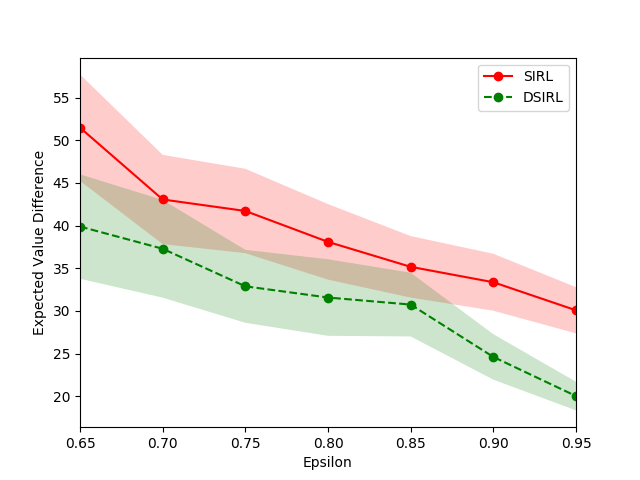 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsReinforcement Learning in Robotics · Advanced Multi-Objective Optimization Algorithms · Supply Chain and Inventory Management
Stochastic Inverse Reinforcement Learning
Ce Ju
Nanyang Technological University
Abstract
The inverse reinforcement learning (IRL) problem aims to recover the reward functions from expert demonstrations. However, like any ill-posed inverse problem, the IRL problem suffers the congenital disability that the policy may be optimal for many reward functions, and expert demonstrations may be optimal for many procedures. In this work, we generalize the IRL problem to a well-posed expectation optimization problem stochastic inverse reinforcement learning (SIRL) to recover the probability distribution over reward functions. We adopt the Monte Carlo expectation-maximization (MCEM) method to estimate the probability distribution parameter as the first solution to the SIRL problem. The solution is succinct, robust, and transferable for a learning task and can generate alternative solutions to the IRL problem. Through our formulation, it is possible to observe the intrinsic property of the IRL problem from a global viewpoint, and our approach achieves a considerable performance on the objectworld.
1 Introduction
The IRL problem addresses an inverse problem: a set of expert demonstrations determines a reward function over a Markov decision process (MDP) if the model dynamics are known Russell (1998); Ng et al. (2000). The recovered reward function provides a succinct, robust, and transferable definition of the learning task and ultimately determines the optimal policy. However, the IRL problem is ill-posed that the policy may be optimal for many reward functions, and expert demonstrations may be optimal for many policies. For example, all procedures are optimal for a constant reward function. Experts always act sub-optimally or inconsistently in a real-world scenario, which is another challenge.
To overcome these limitations, two classes of probabilistic approaches for the IRL problem are proposed, i.e., Bayesian inverse reinforcement learning (BIRL) Ramachandran & Amir (2007) based on Bayesians’ maximum a posteriori (MAP) estimation and maximum entropy IRL (MaxEnt) Ziebart et al. (2008); Ziebart (2010) based on frequentists’ maximum likelihood (MLE) estimation. BIRL solves for the distribution of reward functions without an assumption that experts behave optimally and encodes the external a priori information in a choice of a prior distribution. However, BIRL also suffers from the practical limitation that many algorithmic iterations are required for the Markov chain Monte Carlo (MCMC) procedure in a sampling of posterior over reward functions. Advanced techniques, for example, Kernel technique Michini & How (2012) and gradient method Choi & Kim (2011), are proposed to improve the efficiency and tractability of this situation.
MaxEnt employs the principle of maximum entropy to resolve the ambiguity in choosing demonstrations over a policy. This class of methods, inheriting the merits from previous non-probabilistic IRL approaches including Ng et al. (2000); Abbeel & Ng (2004); Ratliff et al. (2006); Abbeel et al. (2008); Syed & Schapire (2008); Ho et al. (2016), imposes regular structures of reward functions in a combination of hand-selected features. Formally, the reward function is a linear or nonlinear combination of the feature basis functions, which consists of a set of real-valued parts hand-selected by experts. This approach aims to find the best-fitting weights of feature basis functions through the MLE approach. Wulfmeier et al. (2015) and Levine et al. (2011) use deep neural networks and Gaussian processes to fit the parameters based on demonstrations respectively but still suffer from the problem that the changing environment dynamics shape the true reward.
Influenced by the work of Finn et al. (2016a; b), Fu et al. (2017) propose a framework called adversarial IRL (AIRL) to recover robust reward functions in changing dynamics based on adversarial learning and achieves superior results. Compared with AIRL, another adversarial method called generative adversarial imitation learning (GAIL) Ho & Ermon (2016) seeks to recover the expert’s policy rather than reward functions directly. Many follow-up methods enhance and extend GAIL for multipurpose in various application scenarios Li et al. (2017); Hausman et al. (2017); Wang et al. (2017). However, GAIL lacks an explanation of the expert’s behavior and a portable representation for the knowledge transfer, which are the merits of the class of the MaxEnt approach because the MaxEnt approach is equipped with the "transferable" regular structures over reward functions.
In this paper, under the framework of the MaxEnt approach, we propose a generalized perspective of studying the IRL problem called stochastic inverse reinforcement learning (SIRL). It is formulated as an expectation optimization problem aiming to recover a probability distribution over the reward function from expert demonstrations. The solution of SIRL is succinct and robust for the learning task in that it can generate more than one weight over feature basis functions that compose alternative solutions to the IRL problem. Benefits of the class of the MaxEnt method, the solution to our generalized problem SIRL is also transferable. Since the intractable integration in our formulation, we employ the Monte Carlo expectation-maximization (MCEM) approach Wei & Tanner (1990) to give the first solution to the SIRL problem in a model-based environment. In general, the solutions to the IRL problem are not always best-fitting in the previous approaches because a highly nonlinear inverse problem with limited information is very likely to get trapped in a secondary maximum in the recovery. Taking advantage of the Monte Carlo mechanism of a global exhaustive search, our MCEM approach avoids the secondary maximum and theoretically convergent demonstrated by pieces of literature Caffo et al. (2005); Chan & Ledolter (1995). Our approach is also quickly convergent because of the preset simple geometric configuration over weight space in which we approximate it with a Gaussian Mixture Model (GMM). Hence, our approach works well in a real-world scenario with a small and varied set of expert demonstrations.
In particular, the contributions of this paper are threefold:
We generalize the IRL problem to a well-posed expectation optimization problem, SIRL. 2. 2.
We provide the first theoretically existing solution to SIRL by the MCEM approach. 3. 3.
We show the effectiveness of our approach by comparing the performance of the proposed method to those of the previous algorithms on the objectworld.
2 Preliminary
An MDP is a tuple , where is the set of states, is the set of actions, and the transition function (a.k.a. model dynamics) \mathcal{T}:=\mathbb{P}(s_{t+1}=s^{\prime}\big{|}s_{t}=s,a_{t}=a) for and is the probability of being current state , taking action and yielding next state . Reward function is a real-valued function and is the discount factor. A policy is deterministic or stochastic, where the deterministic one is written as , and the stochastic one is as a conditional distribution . Sequential decisions are recorded in episodes consisting of states , actions , and rewards . The goal of reinforcement learning aims to get optimal policy for maximizing the expected total reward, i.e.
[TABLE]
Given an MDP without a reward function , i.e., MDPR=, and expert demonstrations . Each expert demonstration is sequential of state-action pairs. The goal of the IRL problem is to estimate the unknown reward function from expert demonstrations , and the reward functions compose a complete MDP. The estimated complete MDP yields an optimal policy that acts as closely as the expert demonstrations.
2.1 Regular Structure of Reward Functions
This section provides a formal definition of the regular (linear/nonlinear) structure of reward functions. The linear structure Ng et al. (2000); Ziebart et al. (2008); Syed & Schapire (2008); Ho et al. (2016) is an linear combination of feature basis functions, written as,
[TABLE]
where are a -dimensional feature functions hand-selected by experts.
The nonlinear structure Wulfmeier et al. (2015) is of the form as follows,
[TABLE]
where is neural networks of hand-crafted reward feature basis functions .
In the following section, we propose an optimization problem whose solution is a probability distribution over weights of basis functions .
2.2 Problem Statement
Given an MDP with a known transition function \mathcal{T}:=\mathbb{P}(s_{t+1}=s^{\prime}\big{|}s_{t}=s,a_{t}=a) for and and a hand-crafted reward feature basis function . A stochastic regular structure on the reward function assumes weights of the reward feature functions , which are random variables with a reward conditional probability distribution conditional on expert demonstrations . Parametrizing with parameter , our aim is to estimate the best-fitting parameter from the expert demonstrations , such that more likely generates weights to compose reward functions as the ones derived from expert demonstrations, which is called stochastic inverse reinforcement learning problem.
Suppose a representative trajectory class satisfies that each trajectory element set is a subset of expert demonstrations with the cardinality at least , where is a preset threshold and is the number of expert demonstrations, written as,
[TABLE]
Integrate out unobserved weights , and the SIRL problem is formulated to estimate parameter on an expectation optimization problem over the representative trajectory class as follows:
[TABLE]
Where trajectory element set assumed to be uniformly distributed for the sake of simplicity in this study, and is the conditional joint probability density function of trajectory element and weights for reward feature functions conditional on the parameter .
2.2.1 Note:
- •
Problem 1 is well-posed and typically not intractable analytically.
- •
Trajectory element set is usually known from the rough estimation of the statistics in expert demonstrations in practice.
- •
We introduce representative trajectory class to overcome the limitation of the sub-optimality of expert demonstrations Ramachandran & Amir (2007), which is also called a lack of sampling representativeness in statistics Kruskal & Mosteller (1979), e.g., driver’s demonstrations encode his preferences in driving style but may not reflect the true rewards of an environment. With the technique of representative trajectory class, each subset of driver’s demonstrations (i.e., trajectory element set ) constitutes a subproblem in Problem 1.
3 Methodology
In this section, we propose a novel approach to estimate the best-fitting parameter in Problem 1, which is called the two-stage hierarchical method, a variant of MCEM method.
3.1 Two-stage Hierarchical Method
The two-stage hierarchical method requires us to write parameter in a profile form . The conditional joint density in Equation 1 can be written as the product of two conditional densities and as follows:
[TABLE]
Take the log of both sides in Equation 2, and we have
[TABLE]
We maximize the right side of Equation 3 over the profile parameter in the expectation-maximization (EM) update steps at the -th iteration independently as follows,
[TABLE]
3.1.1 Initialization
We randomly initialize profile parameter and sample a collection of rewards weights . The reward weights compose reward in each learning task for .
3.1.2 First Stage
In the first stage, we aim to update parameter in the intractable expectation of Equation 4. Specifically, we take a Monte Carlo method to estimate model parameters in an empirical expectation at the -th iteration,
[TABLE]
where reward weights at the -th iteration are randomly drawn from the reward conditional probability distribution and compose a set of learning tasks with a trajectory element set uniformly drawn from representative trajectory class , for .
The parameter in Equation 6 has coordinates written as \Theta_{1}^{t+1}:=\Big{(}(\Theta_{1}^{t+1})_{1},\cdots,(\Theta_{1}^{t+1})_{N_{t}}\Big{)}. For each learning task , the -th coordinate is derived from maximization of a posteriori,
[TABLE]
which is a convex formulation maximized by a gradient ascent method.
In practice, we move steps uphill to the optimum in each learning task . The update formula of -step reward weights is written as
[TABLE]
The learning rate at the -th iteration is preset. Hence, the parameter is represented as \Theta_{1}^{t+1}:=\Big{(}{\mathcal{W}^{m}}^{\Theta^{t}}_{1},\cdots,{\mathcal{W}^{m}}^{\Theta^{t}}_{N_{t}}\Big{)}.
3.1.3 Second Stage
In the second stage, we aim to update parameter in the intractable expectation of Equation 5. Specifically, we consider the empirical expectation at the -th iteration as follows,
[TABLE]
where is implicit but fitting a set of -step reward weights in a generative model yields a large empirical expectation value. The reward conditional probability distribution is a generative model formulated as a Gaussian Mixture Model (GMM), i.e.
[TABLE]
where and , and parameter set .
We estimate parameter in GMM by the EM approach and initialize GMM with the -th iteration parameter with the procedure as follows:
For , we have
- •
Expectation Step: Compute responsibility for -step reward weight ,
[TABLE]
- •
Maximization Step: Compute weighted mean and variance by,
[TABLE]
After EM converges, and profile parameter .
Finally, when the two-stage hierarchical method converges, parameter of profile parameter is our desired best-fitting parameter for .
3.2 Termination Criteria
In this section, we discuss the termination criteria in our algorithm. EM usually terminates when the parameters do not substantively change after enough iterations. For example, one classic termination criterion in EM concludes at the -th iteration, satisfying as follows,
[TABLE]
for user-specified and , where is the model parameter in EM.
However, the same termination criterion for MCEM has a risk of early terminating because of the Monte Carlo error in the update step. Hence, we adopt a practical method in which the following stopping criterion holds three consecutive times,
[TABLE]
for user-specified and Booth & Hobert (1999). Other stopping criteria for MCEM refers to Caffo et al. (2005); Chan & Ledolter (1995).
3.3 Convergence Issue
The convergence issue of MCEM is more complicated than EM. In light of model-based interactive MDPR, we can always increase the sample size during each iteration of MCEM. In practice, we require the Monte Carlo sample size to satisfy the following inequality,
[TABLE]
A compact assumption over that parameter space is an additional requirement for the convergence property. A comprehensive proof refers to Chan & Ledolter (1995); Fort et al. (2003).
The pseudocode is given in Appendix.
4 Experiments
We evaluate our approach on a classic environment objectworld introduced by Levine et al. (2011), which is a particularly challenging environment with many irrelevant features and the high nonlinearity of the reward functions. Note that since almost only objectworld provides a tool that allows analysis and displays the evolution procedure of the SIRL problem in a 2D heat map, we skip the typical invisible physics-based control tasks for the evaluation of our approach, i.e., cartpole Barto et al. (1983), mountain car Moore (1990), MuJoCo Todorov et al. (2012), etc.
We employ the expected value difference (EVD) proposed by Levine et al. (2011) to be the metric of optimality as follows:
[TABLE]
which is a measure of the difference between the expected reward earned under the optimal policy , given by the valid reward, and the policy derived from the rewards sampling from our reward conditional probability distribution , where is the best estimation parameter in our approach.
4.1 Objectworld
The objectworld is a learning environment for the IRL problem. It is an grid board with colored objects placed in randomly selected cells. Each colored object is assigned one inner color, and one outer color from preselected colors. Each cell on the grid board is a state, and stepping to four neighbor cells (up, down, left, right) or staying in place (stay) are five actions with a 30% chance of moving in a random direction.
The ground truth of the reward function is defined in the following way. Suppose two primary colors of preselected colors are red and blue. The reward of a state is one of the states is within three steps of an outer red object and two steps of an outer blue object, -1 if the state is within three steps of an outer red object, and 0 otherwise. The other pairs of inner and outer colors are distractors. Continuous and discrete versions of feature basis functions are provided. For the continuous version, is a -dimensional real-valued feature vector. Each dimension records the Euclidean distance from the state to objects. For example, the first and second coordinates are the distances to the nearest inner and outer red object, respectively, through all colors. For the discrete version, is a -dimensional binary feature vector. Each -dimensional vector records a binary representation of the distance to the nearest inner or outer color object with the -th coordinate one if the corresponding continuous distance is less than .
4.2 Evaluation Procedure and Analysis
In this section, we design three tasks to evaluate the effectiveness of our generative model reward conditional probability distribution . For each task, the environment setting is as follows. The instance of a objectworld has 25 random objects with two colors and a 0.9 discount factor. Twenty expert demonstrations are generated according to the given optimal policy for recovery. The length of each expert demonstration is a 5-grid size trajectory length. Four algorithms for the evaluation include MaxEnt, DeepMaxEnt, SIRL, and DSIRL, where SIRL and DSIRL are implemented as Algorithm 2 in Appendix. The weights are drawn from reward conditional probability distribution as the coefficients of feature basis functions .
In our evaluation, SIRL and DSIRL start from 10 samples and double the sample size per iteration until it converges for the convergence issue, refer to Section 3.2. In the first stage, the epochs of algorithm iteration are set to 20, and the learning rates are 0.01. The parameter in representative trajectory set is preset as 0.95. In the second stage, 3-component GMM for SIRL and DSIRL is set with at most 1000 iterations before convergence. Additionally, the architecture of neural networks in DeepMaxEnt and DSIRL are implemented as a 3-layer fully connected with the sigmoid function.
4.2.1 Evaluation Platform
All the methods are implemented in Python 3.5 and Theano 1.0.0 with a machine learning distributed framework Ray Moritz et al. (2018). The experiments are conducted on a machine with Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz and Nvidia GeForce GTX 1070 GPU.
4.2.2 Recovery Experiment
In the recovery experiment, we compare the true reward function, the optimal policy, and the optimal value with ones derived from expert demonstrations under the four methods. Since our approach is an average of all the outcomes prone to imitate the actual optimal value from expert demonstrations, we use the mean of reward conditional probability distribution for SIRL and DSIRL as a comparison.
In Figure 2, the EVD of the optimal values in the last row are 48.9, 31.1, 33.7, and 11.3 for four methods, respectively, and the covariances of the GMM model for SIRL and DSIRL are limited up to 5.53 and 1.36 on each coordinate respectively. It yields that in a highly nonlinear inverse problem, the recovery abilities of SIRL and DISRL are better than MaxEnt’s and DeepMaxEnt’s, respectively. The reason is mainly that the Monte Carlo mechanism in our approach alleviates the problem of getting stuck in local minima by allowing random exits.
4.2.3 Robustness Experiment
In the robustness experiment, we evaluate the robustness of our approach that solutions generated by are adequate for the IRL problem. We design the following generative algorithm to capture the robust solutions with the pseudocode in Algorithm 1.
In the right generative algorithm, we use the Frobenius norm to measure the distance between weights drawn from as follows,
[TABLE]
We also constrain that each drawn weight in the solution set satisfies as follows,
[TABLE]
where represents any member in the solution set . are the preset thresholds in the generative algorithm.
In Figure 2, the right column figures are generated from weights in the solution set whose EVD values are around 10.2. Note that the recovered reward function in the first row has a similar but different pattern appearance. The optimal value derived from these recovered reward functions has a very small EVD value with a valid reward. It yields the effectiveness of our robust generative model, which can generate more than one solution to the IRL problem.
4.2.4 Hyperparameter Experiment
In the hyperparameter experiment, we evaluate the effectiveness of our approach under the influence of different preset quantities and qualities of expert demonstrations. The amount of information carried in expert demonstrations composes a specific learning environment, impacting our generative model’s effectiveness. We verify three hyperparameters, including the number of expert demonstrations in Figure 5, the trajectory length of expert demonstrations in Figure 5, and the portion size in representative trajectory class in Figure 5 on the objectworld. The shadow of the line in the figures represents the standard error for each experimental trial. Notice that the EVDs for SIRL and DSIRL decrease as the number, trajectory length of expert demonstrations, and portion size in the representative trajectory class increase. A notable point in Figure 5 is that very few expert demonstrations (less than 200) for our approach also yield small EVDs, which manifests the merit of the Monte Carlo mechanism.
5 Conclusion
In this paper, we propose a generalized problem SIRL for the IRL problem to get the distribution of reward functions. The new problem is well-posed, and we employ the method of MCEM to give the first succinct, robust, and transferable solution. In the experiment, we evaluate our approach on the objectworld, and the experimental results confirm the effectiveness of our approach.
Appendix A Appendix
The pseudocode of SIRL in Section 3 is as follows.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abbeel & Ng (2004) Pieter Abbeel and Andrew Y Ng. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the twenty-first international conference on Machine learning , pp. 1. ACM, 2004.
- 2Abbeel et al. (2008) Pieter Abbeel, Dmitri Dolgov, Andrew Y Ng, and Sebastian Thrun. Apprenticeship learning for motion planning with application to parking lot navigation. In 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems , pp. 1083–1090. IEEE, 2008.
- 3Barto et al. (1983) Andrew G Barto, Richard S Sutton, and Charles W Anderson. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE transactions on systems, man, and cybernetics , (5):834–846, 1983.
- 4Booth & Hobert (1999) James G Booth and James P Hobert. Maximizing generalized linear mixed model likelihoods with an automated monte carlo em algorithm. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 61(1):265–285, 1999.
- 5Caffo et al. (2005) Brian S Caffo, Wolfgang Jank, and Galin L Jones. Ascent-based monte carlo expectation–maximization. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 67(2):235–251, 2005.
- 6Chan & Ledolter (1995) KS Chan and Johannes Ledolter. Monte carlo em estimation for time series models involving counts. Journal of the American Statistical Association , 90(429):242–252, 1995.
- 7Choi & Kim (2011) Jaedeug Choi and Kee-Eung Kim. Map inference for bayesian inverse reinforcement learning. In Advances in Neural Information Processing Systems , pp. 1989–1997, 2011.
- 8Finn et al. (2016 a) Chelsea Finn, Paul Christiano, Pieter Abbeel, and Sergey Levine. A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models. ar Xiv preprint ar Xiv:1611.03852 , 2016 a.