Mesh-based Camera Pairs Selection and Occlusion-Aware Masking for Mesh Refinement
Andrea Romanoni, Matteo Matteucci

TL;DR
This paper introduces a mesh refinement method that uses a novel camera pair selection strategy based on five metrics and an occlusion-aware approach to improve 3D scene reconstruction quality.
Contribution
It proposes a new camera pair selection method leveraging the initial 3D model and introduces an occlusion-aware refinement technique for better mesh accuracy.
Findings
Improved mesh refinement quality over state-of-the-art methods.
Effective camera pair selection based on scene coverage, overlap, resolution, parallax, and symmetry.
Robustness to occlusions enhances reconstruction accuracy.
Abstract
Many Multi-View-Stereo algorithms extract a 3D mesh model of a scene, after fusing depth maps into a volumetric representation of the space. Due to the limited scalability of such representations, the estimated model does not capture fine details of the scene. Therefore a mesh refinement algorithm is usually applied; it improves the mesh resolution and accuracy by minimizing the photometric error induced by the 3D model into pairs of cameras. The choice of these pairs significantly affects the quality of the refinement and usually relies on sparse 3D points belonging to the surface. Instead, in this paper, to increase the quality of pairs selection, we exploit the 3D model (before the refinement) to compute five metrics: scene coverage, mutual image overlap, image resolution, camera parallax, and a new symmetry term. To improve the refinement robustness, we also propose an explicit…
Click any figure to enlarge with its caption.
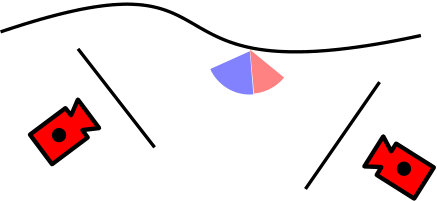 Figure 1
Figure 1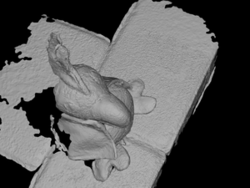 Figure 3
Figure 3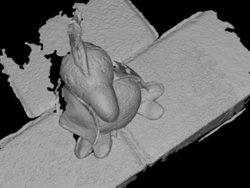 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14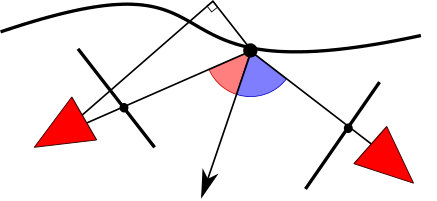 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21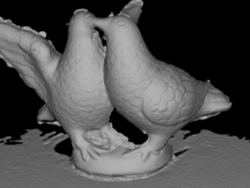 Figure 22
Figure 22 Figure 23
Figure 23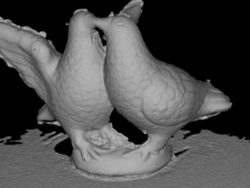 Figure 24
Figure 24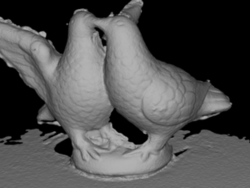 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| [44] | [45] | [12] | [4] | Proposed | |||
|---|---|---|---|---|---|---|---|
| 4 | Acc. | Mean | 0.7265 | 0.7947 | 0.3202 | 0.3254 | 0.3171 |
| Median | 0.4014 | 0.3016 | 0.1888 | 0.2028 | 0.1972 | ||
| Compl. | Mean | 0.6054 | 0.6014 | 0.7791 | 0.7988 | 0.7936 | |
| Median | 0.4257 | 0.3644 | 0.3245 | 0.3463 | 0.3370 | ||
| 6 | Acc. | Mean | 1.0727 | 0.6660 | 0.3681 | 0.3666 | 0.3433 |
| Median | 0.4568 | 0.2628 | 0.1993 | 0.2095 | 0.1990 | ||
| Compl. | Mean | 0.4281 | 0.4739 | 0.5208 | 0.5221 | 0.5095 | |
| Median | 0.3454 | 0.3568 | 0.3335 | 0.3427 | 0.3273 | ||
| 15 | Acc. | Mean | 0.9829 | 0.8544 | 0.4771 | 0.4614 | 0.4436 |
| Median | 0.5588 | 0.4379 | 0.2866 | 0.2754 | 0.2689 | ||
| Compl. | Mean | 0.3243 | 0.5028 | 0.6906 | 0.6709 | 0.6737 | |
| Median | 0.2606 | 0.3876 | 0.4203 | 0.3973 | 0.3981 | ||
| 18 | Acc. | Mean | 1.3916 | 0.9665 | 0.5125 | 0.4918 | 0.4696 |
| Median | 0.6793 | 0.4247 | 0.2603 | 0.2592 | 0.2547 | ||
| Compl. | Mean | 0.3640 | 0.4922 | 0.8996 | 0.8763 | 0.8742 | |
| Median | 0.2899 | 0.3715 | 0.3937 | 0.3740 | 0.3720 | ||
| 24 | Acc. | Mean | 3.4509 | 0.7518 | 0.3941 | 0.3871 | 0.3802 |
| Median | 0.5255 | 0.3141 | 0.2659 | 0.2651 | 0.2632 | ||
| Compl. | Mean | 0.4010 | 0.4827 | 0.8512 | 0.8293 | 0.8300 | |
| Median | 0.2954 | 0.3691 | 0.4339 | 0.4119 | 0.4124 | ||
| 36 | Acc. | Mean | 0.5972 | 0.6270 | 0.3125 | 0.2859 | 0.2801 |
| Median | 0.2317 | 0.2778 | 0.2007 | 0.1831 | 0.1831 | ||
| Compl. | Mean | 0.4622 | 0.6101 | 1.0331 | 1.0093 | 1.0070 | |
| Median | 0.2317 | 0.2930 | 0.2856 | 0.2527 | 0.2533 | ||
| 63 | Acc. | Mean | 2.4241 | 2.3992 | 0.9082 | 0.8461 | 0.7836 |
| Median | 0.2782 | 1.1192 | 0.2711 | 0.2495 | 0.2303 | ||
| Compl. | Mean | 0.4730 | 0.6401 | 0.7189 | 0.7159 | 0.7158 | |
| Median | 0.2782 | 0.3849 | 0.2985 | 0.2916 | 0.2924 | ||
| 106 | Acc. | Mean | 0.5918 | 0.7881 | 0.3028 | 0.2844 | 0.2765 |
| Median | 0.2793 | 0.3028 | 0.1902 | 0.1846 | 0.1821 | ||
| Compl. | Mean | 0.6902 | 0.7004 | 0.9950 | 0.9936 | 0.9935 | |
| Median | 0.2793 | 0.3244 | 0.3256 | 0.3220 | 0.3226 | ||
| 110 | Acc. | Mean | 3.4509 | 1.0922 | 0.7378 | 0.6867 | 0.6674 |
| Median | 0.5255 | 0.3802 | 0.2314 | 0.2237 | 0.2222 | ||
| Compl. | Mean | 0.4010 | 0.5547 | 0.5675 | 0.5872 | 0.5892 | |
| Median | 0.2954 | 0.4041 | 0.4134 | 0.4238 | 0.4272 | ||
| 114 | Acc. | Mean | 0.6104 | 0.5789 | 0.2734 | 0.2696 | 0.2714 |
| Median | 0.29700 | 0.2616 | 0.1835 | 0.1789 | 0.1802 | ||
| Compl. | Mean | 0.3544 | 0.4001 | 0.3895 | 0.3872 | 0.3878 | |
| Median | 0.2948 | 0.3191 | 0.2999 | 0.2964 | 0.2970 | ||
| 118 | Acc. | Mean | 5.5335 | 0.65.25 | 0.3093 | 0.2982 | 0.2911 |
| Median | 4.0794 | 0.2922 | 0.1946 | 0.1913 | 0.1897 | ||
| Compl. | Mean | 0.3682 | 0.5489 | 0.7389 | 0.7416 | 0.7399 | |
| Median | 0.2856 | 0.3296 | 0.3301 | 0.3302 | 0.3290 | ||
| 122 | Acc. | Mean | 0.6367 | 0.6621 | 0.3049 | 0.2920 | 0.2884 |
| Median | 0.3276 | 0.2967 | 0.1978 | 0.1920 | 0.1912 | ||
| Compl. | Mean | 0.3682 | 0.4576 | 0.6435 | 0.6441 | 0.6400 | |
| Median | 0.2856 | 0.3281 | 0.3278 | 0.3256 | 0.3226 |
| PC | SC | OC | SPC | OPC | OSC | OSP | OSPC | Proposed | |
|---|---|---|---|---|---|---|---|---|---|
| Average Position | 6.2 | 5.2 | 4.9 | 4.9 | 6.1 | 4.8 | 5.8 | 3.3 | 3.3 |
| Average Error Value | 0.4295 | 0.4258 | 0.4285 | 0.4276 | 0.4258 | 0.4281 | 0.4280 | 0.4223 | 0.4212 |
| Initial Mesh | [4] | Proposed | |
|---|---|---|---|
| MAE | 0.001513 | 0.001360 | 0.001199 |
| RMSE | 0.03890 | 0.03688 | 0.03462 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Mesh-based Camera Pairs Selection
and Occlusion-Aware Masking for Mesh Refinement
Andrea Romanoni
Matteo Matteucci
Politecnico di Milano, Italy
Abstract
Many Multi-View-Stereo algorithms extract a 3D mesh model of a scene, after fusing depth maps into a volumetric representation of the space. Due to the limited scalability of such representations, the estimated model does not capture fine details of the scene. Therefore a mesh refinement algorithm is usually applied; it improves the mesh resolution and accuracy by minimizing the photometric error induced by the 3D model into pairs of cameras. The choice of these pairs significantly affects the quality of the refinement and usually relies on sparse 3D points belonging to the surface. Instead, in this paper, to increase the quality of pairs selection, we exploit the 3D model (before the refinement) to compute five metrics: scene coverage, mutual image overlap, image resolution, camera parallax, and a new symmetry term. To improve the refinement robustness, we also propose an explicit method to manage occlusions, which may negatively affect the computation of the photometric error. The proposed method takes into account the depth of the model while computing the similarity measure and its gradient. We quantitatively and qualitatively validated our approach on publicly available datasets against state of the art reconstruction methods.
keywords:
MSC:
41A05, 41A10, 65D05, 65D17 \KWDKeyword1, Keyword2, Keyword3
††journal: Pattern Recognition Letters
\newwatermark
[allpages,color=gray!30,angle=45,scale=3,xpos=0,ypos=0]PRE-PRINT
1 Introduction
Multi-View Stereo (MVS) algorithms recover the 3D model of a scene captured by a set of images. Boosted by the benchmarks proposed in [1, 2, 3] and the enhancements in hardware capabilities, several works proposed several accurate and efficient MVS methods.
A well established MVS pipeline, first proposed by Vu et al. [4], estimates the camera positions with Structure-from Motion (SfM) [5, 6]; then it applies plane sweeping [7] or depth map fusion [8] to recover a dense point cloud representation of the scene. This pipeline builds a volumetric partitioning of the space in which the camera to point visibility rays are exploited to estimate free and occupied space (or an implicit representation of the model, such as Truncated Signed Distance Function); the free-occupied space boundary (or the zero crossing surface) is the model of the observed scene, usually represented by means of a mesh. To obtain a very accurate reconstruction, the last step of the pipeline is a refinement algorithm; it minimizes the photometric error induced by such mesh in pairs of cameras.
A fundamental aspect of a mesh refinement algorithm, and in general a Multi-View Stereo method, is the choice of the camera pairs used to compute and minimize the photometric error. It is well known that too narrow cameras imply noisy reconstruction results. On the other hand, images captured by cameras too far from each other could have limited overlap, i.e., the region of the scene perceived by both cameras is small. The right choice of these pairs leads to a coherent computation of the photometric error and, as a consequence, an effective gradient descent minimization. The most widespread Multi-View Stereo methods select for each camera a pairing view among the others by relying on several factors. Li et al. [9] and Ebner et al. [10] evaluate the baseline and the angle of the principal viewing direction between the cameras; instead, other methods [11, 12, 13, 14] consider the SfM 3D points and take into account the average angle between the camera-to-point viewing rays, the baseline among views and the scale. Vogiatzis et al. [15] leverage on similar metrics to filter out unreliable photometric measures, adopted to estimate the 3D model.
While pixel-wise camera pair selection has been addressed to estimate accurate point clouds in [16, 17, 18], mesh refinement literature has always limited the choice to the pairs of cameras sharing the visibility of the highest number of 3D points with sufficient parallax.
A second issue which affects mesh refinement and we address in this paper is related to model occlusions. For instance, in Fig. 1 image projects in through ; the patch in the green circle contains a discontinuity. In this case, while computing the projection error in the green patch corresponding to a pixel in the red region, state-of-the-art methods consider both the information from the blue and red (non-adjacent) parts of . This issue has been considered only when dealing with generative methods [19] or with a simple heuristic avoiding to evolve the mesh just in correspondence of edge segments joining visible and non-visible facets ([20]).
For these reasons, in this paper we propose three contributions:
A pairwise camera selection method exploiting the knowledge of an approximate model of the scene. It minimizes an energy function defined over the surface instead of just relying on camera poses or 3D points viewing angles (Section 3).
- 2.
An energy term to favor symmetric pairs and better compensate image noise while computing the gradient flow (Section 3).
- 3.
An occlusion-aware mask term to explicitly identify, for each pixel, which part of the neighborhood has to be considered, during mesh refinement, to compute the similarity measure and its gradient (Section 4).
2 Related works
Mesh refinement is a case of surface evolution. Surface evolution methods are framed into the variational framework formalized by Hermosillo et al. [21]. Early works represent the model by level set, i.e., as the zero crossing of a function [22, 23, 24, 25, 26, 27, 28]. Faugeras and Keriven et al. [22] define the level set by means of a partial differential equation of such that a point on the surface moves proportionally to the photo-consistency of its neighborhood. Jin et al. [23] and Yoon et al. [27] extend this approach to cope with specular reflection. While these methods integrate the photometric measure in the 3D domain, Yezzi and Soatto [24] show that integrating this measure on the image domain yields to more accurate results. Solem et al. [26] and Pons et al. [29, 28] replace the partial differential equation with a gradient leading to more robust mesh evolution. Finally, Fuhrmann et al. [25] adapts the considered neighborhood around surface points according to their scale. Even if level set methods achieve accurate results, the evolution process is not always easy to track and understand.
Differently from level set methods, mesh refinement algorithms directly represent the surface as a 2D mesh embedded into a 3D space [8, 30, 19, 31, 32, 33]: given an initial rough mesh of the scene, they move the position of its vertices to obtain a more faithful model. Vu et al. [8] discretized the continuous level set formulation of [28] to work directly with with meshes. Delaunoy et al. [32] extended this method to take into account occlusions and in [34] they jointly optimize the surface and the camera in a bundle adjustment fashion. Li et al. [35] proposed an improved smoothness term of the energy function to output very smooth surfaces keeping the details of the scene. Recently, Li et al. [20] simplify the mesh, decreasing the resolution where few vertices are sufficient to capture the structure of the scene, without affecting the accuracy significantly. In [36], photometric refinement is coupled with a moving object detection method to avoid using their image areas to refine the static model of the scene. Finally, two mesh refinement approaches [37, 38] exploit the semantic 2D segmentation of the images to improve the robustness of the refinement process, especially where two objects of different classes are adjacent.
Mesh Refinement
Mesh refinement takes as input an initial mesh which is a rough model of the scene and a set of images capturing the scene. The most popular approach, proposed in [4], minimizes an energy function :
[TABLE]
where represents the photo-consistency error of the model with respect to the images, and enforces the smoothness of the surface.
To minimize the term , the mesh refinement procedure applies gradient descent. Let’s consider two images and , and a point belonging to the surface (Fig. 2); we define the error function that decreases if the similarity between the patch around the projection of in and increases, e.g., in our case, the negative ZNCC of the pixels neighborhood. The energy in Equation (1) is defined as:
[TABLE]
where represents the reprojection of the image from the -th camera onto image through the surface , and is the image region where the reprojection is defined. Now, let be a vertex of the surface mesh , and be the barycentric coordinates of a surface point in the triangle with vertex . The discrete gradient of computed for a vertex is:
[TABLE]
By changing the variable of integration form to it is possible to integrate the energy over the image instead of over the surface . Let define as the normal at pointing outward the surface , the projection of x into the image, as the vector from camera to , as the depth of in camera (see Fig. 2); with the change of variable [28] we obtain:
[TABLE]
To define which pairs are adopted to compute the gradients, the most widespread methods [12, 4, 39] leverage on 3D points correspondences estimated by the Structure from Motion method adopted to calibrate the cameras. For each camera it chooses the camera with the highest number of common 3D points with a reasonable parallax (e.g., in [12] between and ).
Finally, the evolution process is complemented by the umbrella operator [40], which moves each vertex in the mean position of its neighbors; this approximates the Laplace-Beltrami operator, and it minimizes the energy term .
3 Model-based Camera Pairs Selection
One of the most relevant aspect to effectively minimize is the choice of the camera pairs . Instead of basing this choice on just 3D sparse points estimated by Structure from Motion, we propose to exploit the knowledge of the initial 3D mesh to find the camera pairs having a good trade-off between reasonable parallax and image overlap.
We first define a term to represent the quality of the parallax between camera and . Given the initial surface , the camera centers, and , and a point , let’s define the parallax as the angle . We compute the average parallax as:
[TABLE]
where represents the area of an image region, in this case the region . To define the reference parallax, we recall that small angles induce good overlap between patches, while larger angles induce more stability in the refinement process. Tola et al. [12] choose a small parallax between and to avoid erroneous image warping caused by occlusions. In our case, however, we know the geometry, and we explicitly handle occlusions, therefore we prefer a larger reference angle. In [41] the parallax ranges around to ; in [42] and in [43] the convergent angle, which is strictly related to the parallax, is chosen respectively as and . Among these values, we experimentally choose the reference parallax to be . Therefore, we define:
[TABLE]
where we put the variance .
To favor camera pairs with a similar resolutions and thus inducing coherent refinement, we introduce the resolution term . Let and be the distances of point from the two cameras respectively, normalized with respect to the corresponding focal length and . We define:
[TABLE]
as the normalized discrepancy of the resolutions of the two images with respect to the length of ray. We compute the average of these values as:
[TABLE]
To favor similar resolutions we define:
[TABLE]
where we put the variance , which represents a resolution discrepancy of .
Finally, to take into account overlap, we define as:
[TABLE]
Symmetry Term
In most cases, these two terms provide a fair evaluation of the camera pair quality with respect to the mesh refinement problem. However, in some cases, they are not sufficient to discriminate among different camera pairs. For instance, in Fig. 3, the surface is perceived by a reference camera and by two other cameras and . The surface is entirely visible by the three cameras, i.e., the overlap is 100%, and the baselines and have very similar values; by relying on just and , both pairs and are considered equally good (or equally bad).
To overcome this issue, we evaluate a third term that favors camera pairs with points of view symmetric with respect to the scene. Intuitively, since the surface evolves along its normal and assuming the images affected by Gaussian noise on the image plane, if we compute the gradient between captured by and captured by , similar noise in and in (inducing an uncertainty angle ) translate into significantly different gradient noises along . Instead, if we consider and the same noise affects similarly the gradients along . Statistically, in the former case, the noise accumulates as the gradients are computed, while, in the latter, they likely compensate each other.
In addition to parallax and overlap we then evaluate a symmetry term with respect to the surface normal. To do so we define the oriented angle difference (OAD): where is the normal of the surface at and, if the and belong to the same half-space defined by the plane parallel to through , then , otherwise . The OAD average on the surface is computed as:
[TABLE]
and, the novel energy term is computed as: where we put experimentally the variance . This term is combined with and to define the energy function for a pair of cameras and :
[TABLE]
where , and are three coefficient weighting the contribution of the three energy term (in our case , , and ).
Model Coverage
A second relevant aspect when choosing a camera pair is model coverage. While the overlap term is related to the overlap among the images in the pair, in principle no terms discussed previously avoids all the camera pairs perceive, and therefore refine just a small portion of the mesh. For this reason, we enforce camera pair configurations providing good coverage.
We first initialize the camera pairs as follows. Let be the set of cameras and the set of camera pairs adopted for the refinement. Our algorithm initializes the initial set of best camera pairs computed leveraging on the previous energy as , i.e., with the best pair for each camera.
To enforce model coverage, the idea is to perturb this initial set of pairs . In the first step we define the model coverage as the average number of camera pairs in which all the facets are visible. Let be the set of facets and let define a visibility function of facet with respect to cameras and , i.e. if is visible from both cameras, otherwise. Then, the global visibility of is and the coverage of the whole mesh is represented by .
The second step aims at replacing camera pair with a reasonable pair that, even at the cost of a small decrease of energy it improves the model coverage.
To do so, given the initial set , we compute and For each camera we compare the current camera pair with the second best camera pair among the pairs . If increases the mean coverage and decreases we try to switch and so to obtain a new set . If the sum of the energies then the pair change is successful, i.e., , otherwise We iterate this process until no further change happens (Algorithm 1).
Let notice that in the previous process we considered ony one camera for each reference camera . This does not represent a limitation of the algorithm but a choice to have a fair comparison with the baselines of Tola et al. [12] and our implementation of Vu et al. [4] that compare one camera for each reference too. We refer to the experimental section for a more detailed discussion.
4 Occlusion Aware Masking
For each pixel , the mesh refinement presented in Section 2 aggregates the gradients of the similarity measure from the neighboring pixels in a squared patch (in our case with size xpx) (Fig. 4(a)).
In most cases, all the pixels in contain information useful to refine the position of the 3D point corresponding to by gradient descent. However, in the case of occlusions, the squared patch contains information from regions of the scene not related to , which translates into errors in the gradient computation. To tackle this issue, we rely on the depth map of the current 3D model of the scene. The idea is to find which pixels of have a depth similar and coherent to the pixel , and to use only them during the similarity gradient computation. In the following these pixels are named valid pixels.
For each pixel , we compute the depth values as the camera to model distance (4(b)) and its difference with respect to the depth of pixel as (4(c)).
Since abrupt depth discontinuities would induce very high variances on the whole patch , in principle, the standard deviation of the values are not enough informative to classify the valid pixels.
For this reason we propose the following procedure- First, we cluster the pixels between those with a depth closer and those with a depth are farther to the depth of . In other words, we cluster all the values in two sets and , which contain respectively the values closest to [math] and closest to .
Then, we approximate a robust estimator of the standard deviation of the depths of the valid pixels. Assuming the pixels in to be likely valid, and the highest depth variances usually corresponding to the outer part of the patch, we compute as the value of the (spatially) farthest pixel w.r.t. the patch center . A pixel is valid when
In Fig. 5 we illustrate the first iteration of mesh refinement for DTU sequence 63: the intensity of red represents the number of pixels considered in the gradient computation. It is possible to notice that the number of pixels considered decreases approaching to the mesh discontinuities.
5 Experiments
We tested our refinement method against 12 sequences of the DTU dataset [46], the fountain-P11 [1] and the Southbuilding [47] sequences. In Table 1 we reported the quantitative results on the DTU dataset against state of the are MVS methods. As mentioned in the Section 3 to have a fair comparison against Tola et al. and Vu et al. we choose one image for each reference camera. Indeed, both in Tola et al. and in our implementation of Vu et al. for each reference camera the second camera is chosen by relying on the knowledge of the visibility of the Structure from Motion 3D points. For the implementation of Vu et al. we choose the camera with the highest number of common points with a parallax between 20 and 60, while Tola et al. with a parallax between 10 and 30 and at least 0.8 scale difference between the corresponding DAISY descriptors. In Figure 8 we tested our method comparing 1, 2, 4 or 8 cameras with respect to the reference image and the improvement obtained is almost negligible.
According to the procedure described in [46] we compared the distance (in mm) from refined 3D mesh to the ground truth point cloud to compute the accuracy of the model and vice-versa to evaluate its completeness. In the table we list the mean and median values of such distances. In these experiments we used as initial mesh those extracted by the method of Tola et al. + Poisson Reconstruction. Our method improves accuracy and completeness with respect to the baseline refinement [4]. In Table 2 we show the ablation study on the DTU dataset and in Fig. 9 we reported some examples of the outcome of our mesh refinement. From the actual proposal (last column of Table 2) we tested the refinement by using just subsets of the energy terms (P = Parallax, S = Symmetry, O = Overlap), with or without the coverage algorithm (represented by C) and with or without the masked refinement (represented by M). We do not mention the resolution prior since, in our scenario, it does not affect the result. This outcome is expected and coherent because the cameras have approximately the same distant from the model and the same image resolution. To have a better understanding of the performance of each version, we reported the average rank and the average error value. To compute the former, we ranked the algorithms for each row, i.e., for each error measure and each sequence, and we reported the average of these rankings. The latter was also used in [48] and it averages all the accuracy and completeness mean and median values for each column. In both cases, it is possible to notice that all the terms contribute to achieving a better outcome which is a good trade-off between accuracy and completeness. Fig. 6 shows how the masking refinement produces smoother results, by limiting the effect of occlusions.
Table 3 shows a further quantitative comparison evaluating the accuracy for the fountain-P11 dataset. We computed the Mean Absolute Error (MAE) and the Root Mean Squared Error (RMSE) as proposed in [1], i.e., by comparing the depth maps rendered from the reconstructed model and the GT mesh. Our refinement method improves the accuracy of the classical refinement method in [4].
The Southbuilding dataset does not provide a reference ground truth. However from Fig. 9 and Fig. 7 (and the images reported in the supplementary material with higher resolution) it is possible to notice that our refinement method produces an output with more details than[4], thanks to the effective choice of camera pairs, together with the masked refinement. In particular, Fig. 7 shows that the coverage procedure avoids refinement to focus only on one part of the model producing unbalanced mesh evolution (Fig. 7(a)).
It is worth noticing that the method we use to define the pairs of cameras and to mask the occlusions during the photometric refinement can be easily applied to any mesh refinement method without any relevant modification in the code.
6 Conclusions and future works
In this paper, we addressed two relevant issues of mesh refinement: the choice of camera pairs used to compute similarity gradients and the occlusion management. We defined a model-based energy function to evaluate the overlap, the parallax the resolution and the symmetry among the camera pairs and we proposed a procedure to choose the set of pairs which provides a good trade-off between the defined energy and the model coverage. We also proposed a novel strategy to mask the region of the patch adopted to compute the similarity measures and the gradients such that the influences of model occlusions ad discontinuities are neglected or, at least, limited. As future work, we plan to propose a parallel version of the presented refinement method that splits the mesh into several parts that can be processed independently. This allows exploring the level of parallelism depending on both the required mesh resolution and the computing platform. Moreover, we can optimize the energy-performance trade-off by leveraging the dynamic reconfiguration support offered in multi-core architectures [49, 50]. We also intend to improve the camera selection exploiting the information recovered by the dense Multi-View Stereo method such as [17], which jointly estimate image depths and pixel-wise camera pairs.
Acknowledgements
This work was partially founded by EIT digital
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Strecha, W. von Hansen, L. Van Gool, P. Fua, U. Thoennessen, On benchmarking camera calibration and multi-view stereo for high resolution imagery, in: Computer Vision and Pattern Recognition, IEEE, 2008, pp. 1–8.
- 2[2] S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, R. Szeliski, A comparison and evaluation of multi-view stereo reconstruction algorithms, in: Computer vision and pattern recognition, Vol. 1, IEEE, 2006, pp. 519–528.
- 3[3] H. Aanæs, R. R. Jensen, G. Vogiatzis, E. Tola, A. B. Dahl, Large-scale data for multiple-view stereopsis, International Journal of Computer Vision (2016) 1–16.
- 4[4] H. H. Vu, P. Labatut, J.-P. Pons, R. Keriven, High accuracy and visibility-consistent dense multiview stereo, IEEE Transactions on Pattern Analysis and Machine Intelligence 34 (5) (2012) 889–901.
- 5[5] P. Moulon, P. Monasse, R. Marlet, Others, Openmvg. an open multiple view geometry library., https://github.com/open MVG/open MVG .
- 6[6] C. Wu, S. Agarwal, B. Curless, S. M. Seitz, Multicore bundle adjustment, in: Computer Vision and Pattern Recognition, IEEE, 2011, pp. 3057–3064.
- 7[7] R. T. Collins, A space-sweep approach to true multi-image matching, in: Computer Vision and Pattern Recognition, IEEE, 1996, pp. 358–363.
- 8[8] H. H. Vu, R. Keriven, P. Labatut, J.-P. Pons, Towards high-resolution large-scale multi-view stereo, in: Computer Vision and Pattern Recognition, IEEE, 2009, pp. 1430–1437.