PDH : Probabilistic deep hashing based on MAP estimation of Hamming distance
Yosuke Kaga, Masakazu Fujio, Kenta Takahashi, Tetsushi Ohki, Masakatsu, Nishigaki

TL;DR
This paper introduces PDH, a probabilistic deep hashing method that derives a hyperparameter-free loss function from image probability distributions, achieving high accuracy in image retrieval tasks.
Contribution
The paper presents a novel loss function for deep hashing derived from probability distributions, eliminating the need for hyperparameter tuning and improving retrieval accuracy.
Findings
Outperforms state-of-the-art hashing methods on MNIST, CIFAR-10, SVHN datasets.
Provides a theoretically grounded, hyperparameter-free loss function.
Achieves probabilistic optimality in image retrieval.
Abstract
With the growth of image on the web, research on hashing which enables high-speed image retrieval has been actively studied. In recent years, various hashing methods based on deep neural networks have been proposed and achieved higher precision than the other hashing methods. In these methods, multiple losses for hash codes and the parameters of neural networks are defined. They generate hash codes that minimize the weighted sum of the losses. Therefore, an expert has to tune the weights for the losses heuristically, and the probabilistic optimality of the loss function cannot be explained. In order to generate explainable hash codes without weight tuning, we theoretically derive a single loss function with no hyperparameters for the hash code from the probability distribution of the images. By generating hash codes that minimize this loss function, highly accurate image retrieval with…
Click any figure to enlarge with its caption.
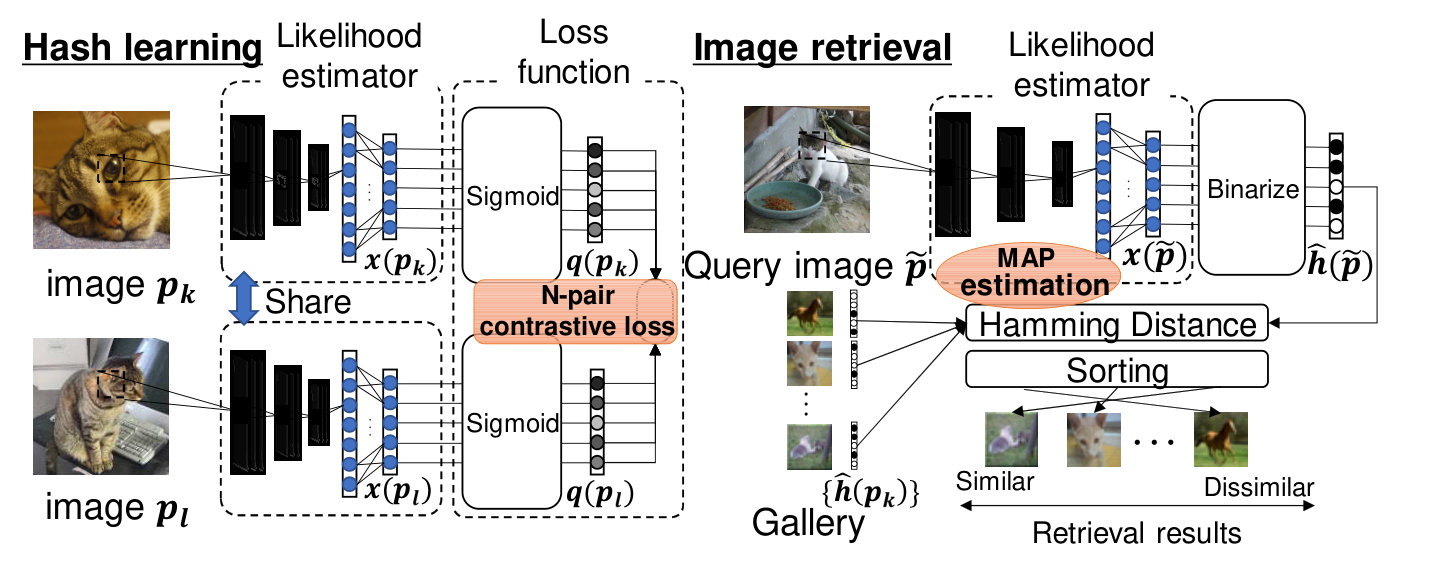 Figure 1
Figure 1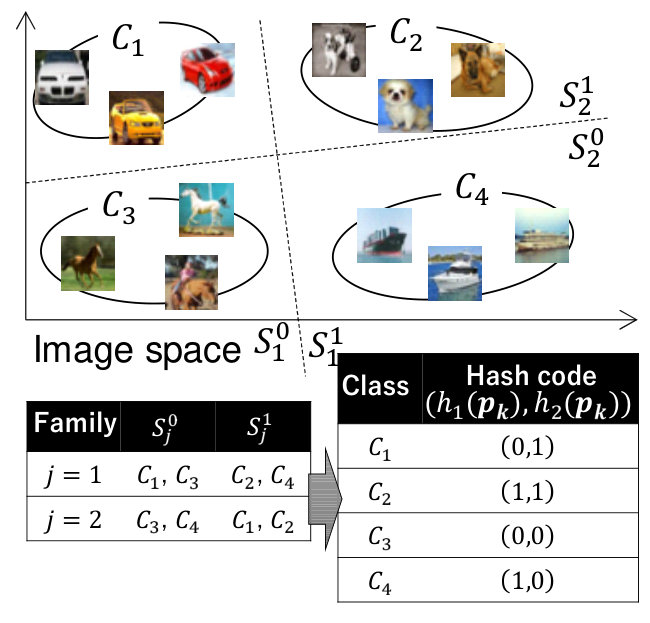 Figure 2
Figure 2| Method | MNIST | CIFAR-10 | SVHN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Length (bit) | 12 | 24 | 32 | 48 | 12 | 24 | 32 | 48 | 12 | 24 | 32 | 48 |
| KSH [7] | 24.30 | 36.63 | 31.10 | 33.25 | 17.65 | 14.80 | 15.50 | 16.63 | 24.18 | 24.36 | 24.72 | 21.87 |
| ITQ [5] | 37.63 | 53.87 | 51.76 | 54.11 | 12.93 | 14.06 | 13.40 | 15.11 | 16.22 | 16.85 | 19.67 | 19.89 |
| BRE [6] | 47.03 | 53.17 | 54.76 | 57.11 | 22.90 | 24.16 | 23.98 | 19.31 | 19.27 | 19.95 | 21.60 | 22.09 |
| DSH [10] | 96.05 | 97.35 | 98.10 | 98.13 | 38.17 | 38.70 | 40.19 | 37.29 | 73.16 | 70.33 | 82.16 | 77.33 |
| CNNH+ [9] | 97.57 | 97.89 | 98.04 | 98.33 | 40.00 | 42.00 | 44.89 | 44.55 | 78.32 | 81.46 | 81.81 | 84.00 |
| SSDH [11] | 98.83 | 98.97 | 98.96 | 99.15 | 82.31 | 84.07 | 83.78 | 84.28 | 93.19 | 93.98 | 93.95 | 94.46 |
| SFHC [12] | 90.09 | 90.93 | 93.04 | 96.18 | 58.07 | 58.74 | 61.39 | 53.19 | 83.56 | 78.23 | 76.16 | 79.83 |
| DCAH [13] | 99.50 | 99.44 | 99.53 | 99.54 | 85.85 | 87.38 | 87.00 | 86.33 | 95.48 | 96.28 | 95.95 | 96.45 |
| PDH | 99.73 | 99.74 | 99.78 | 99.77 | 95.26 | 95.81 | 96.04 | 95.58 | 96.90 | 96.90 | 97.04 | 97.06 |
| Datasets | ||||||
|---|---|---|---|---|---|---|
| 100 | 200 | 400 | 600 | 800 | 1000 | |
| MNIST | 99.70 | 99.70 | 99.71 | 99.70 | 99.70 | 99.71 |
| CIFAR-10 | 95.03 | 95.07 | 95.12 | 95.14 | 95.15 | 95.15 |
| SVHN | 96.85 | 96.90 | 96.94 | 96.95 | 96.96 | 96.96 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Image and Video Retrieval Techniques · Video Surveillance and Tracking Methods · Image Retrieval and Classification Techniques
IEEE Copyright Notice
© 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Accepted by the 26th IEEE International Conference on Image Processing(ICIP2019)
PDH : Probabilistic deep hashing
based on MAP estimation of Hamming distance
Abstract
With the growth of image on the web, research on hashing which enables high-speed image retrieval has been actively studied. In recent years, various hashing methods based on deep neural networks have been proposed and achieved higher precision than the other hashing methods. In these methods, multiple losses for hash codes and the parameters of neural networks are defined. They generate hash codes that minimize the weighted sum of the losses. Therefore, an expert has to tune the weights for the losses heuristically, and the probabilistic optimality of the loss function cannot be explained. In order to generate explainable hash codes without weight tuning, we theoretically derive a single loss function with no hyperparameters for the hash code from the probability distribution of the images. By generating hash codes that minimize this loss function, highly accurate image retrieval with probabilistic optimality is performed. We evaluate the performance of hashing using MNIST, CIFAR-10, SVHN and show that the proposed method outperforms the state-of-the-art hashing methods.
**Index Terms— ** hashing, image retrieval, deep learning, binary representation
1 Introduction
In recent years, an enormous amount of images has been managed on the web. In order to search images from such big data, search algorithms for content-based image retrieval (CBIR) have been studied. The problem of finding the data closest to the query on a certain distance measure is called the nearest neighbor (NN) search. In order to perform this NN search as it is, a huge amount of calculation time is required, so fast methods for obtaining an approximate nearest neighbor (ANN) has been studied.
Hashing is a method which is actively studied for ANN search [1]. In the hashing, images are mapped to binary hash codes while preserving semantic similarities between images. By using the hash codes, the retrieval for a huge amount of images can be performed with small computational time. Many hashing methods have been proposed [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]. Especially the supervised hashing methods learn hash functions by using supervised information such as image classes, thus high accuracy can be achieved for specific datasets [7, 8]. Furthermore, deep learning is applied to the supervised hashing, and higher accuracy is achieved than other types of hashing methods[9, 10, 11, 12, 13]. In these methods, multiple losses for hash codes and neural network parameters are defined. They generate hash codes that minimize the weighted sum of the losses. Therefore, an expert has to tune the weights for the losses heuristically, and the probabilistic optimality of the loss function cannot be explained.
In this paper, we theoretically derive a single loss function with no hyperparameters for the hash codes from the probability distribution of the images. We obtain convolutional neural networks that minimize the loss function. By binarizing the output of that networks, hash codes for image retrieval are calculated. We show that the Hamming distance between binarized hash codes is equivalent to the MAP estimation of the ideal hash distance. Based on this probabilistically optimal hash codes, we can perform highly accurate image retrieval. Our contributions in this paper are as follows: (1) We introduce new loss function with no hyperparameters for hash codes and show that the Hamming distance between hash codes has probabilistic optimality. (2) We show the experimental results that our hashing method outperforms the other state-of-the-art hashing methods in image retrieval.
2 Problem definition
We define the problem for generating hash codes that enable image retrieval with high precision. In this paper, we derive an ideal hash function from image probabilistic distributions. Let the retrieval target images be and its class set be , where is the number of the retrieval target images, is the dimension of an image and is the number of the class, respectively. Fig.2 shows an example of image classes on the image space. We assume that every image belongs to a single image class. Let the event that an image belongs to class denote .
Next, let families of image class set be , where is the number of families. The families satisfy and . Therefore, divides image classes into two subsets. The examples of these families are shown in Fig.2.
By using the image class set and the families of image classes , we define ideal hash functions ,
as follows:
[TABLE]
When image belongs to class , the value of hash function depends on the families , that include class .
Based on these hash functions, we define the mapping from images to hash codes; . In the image retrieval based on hashing, the Hamming distances between the hash codes are used as image dissimilarities. When and , the Hamming distance between hash codes is calculated as follows:
[TABLE]
In order to minimize the probability of hash collision for images in different classes, the families of image class set need to satisfy the following properties: (1) Each image class are randomly assigned to or independently. (2) . Based on this assumption, the expected value of Hamming distance is calculated as follows:
[TABLE]
This is the requirement for ideal hash distance under our assumption. This ideal hash distance is small when input images belong to the same class and large when the images belong to a different class. According to this property, image retrieval based on the hash function would achieve high precision. The purpose of this paper is to find hash functions that Hamming distances between the hash codes meet the above requirement.
3 Probabilistic deep Hashing
In accordance with the requirement for ideal hash functions in section 2, we propose probabilistic deep hashing (PDH) which can perform image retrieval with probabilistic optimality.
3.1 The concept of the PDH
First, we show the concept of the proposed method. Our PDH has two characteristics as follows:
We derive the property that the ideal hash codes should satisfy from the probability distribution of the image. We perform pairwise learning to bring the expected value of the Hamming distance between the hash codes closer to the ideal hash distance as described in Sec.3.3. This allows us to learn the hash functions that have close property to ideal hash functions. 2. 2.
We approximate the hash functions with convolutional neural networks (CNN). By assuming the output of the CNN as posterior probabilities of the hash function outputs, we show that the Hamming distance between the obtained hash codes is equal to the MAP estimation of the ideal hash distance as described in Sec.3.4. As a result, image retrieval with probabilistic optimality can be realized with high-speed bit operation.
By utilizing these characteristics, the PDH can perform image retrieval with high precision.
3.2 PDH Architecture
We show the architecture of the proposed method in Fig.2. The method consists of two parts: hash learning and image retrieval. In the hash learning part, we learn a likelihood estimator based on new loss function, and the detail of the hash learning is described in Sec.3.3. In the image retrieval part, hash codes of images are obtained by the likelihood estimator, and ANN search is performed based on Hamming distance between hash codes. The detail of the image retrieval is described in Sec.3.4.
3.3 Hash learning
First, we define the prior probability of image class and the likelihood for image when belongs to image class as follows:
[TABLE]
Here we derive the posterior probability of when is observed based on the bayes’ theorem.
[TABLE]
Here, is calculated as follows:
[TABLE]
where is the number of image classes that . Also, let a flag value for image class be when and otherwise. Finally, is calculated as follows:
[TABLE]
Here, is obtained as the output of the sigmoid function, and is the log-likelihood ratio for and when image is observed. Then, the log-likelihood ratio takes a large negative value when the probability that is high, and it takes a large positive value when the probability that is high. If the likelihood for images is known, can be calculated. However, it is difficult to obtain in advance, and we cannot calculate directly. In the proposed method, the log-likelihood ratio is approximated by convolutional neural networks as shown in Fig.2.
Next, we derive the Hamming distance between hash codes by using . With the posterior probabilities , the distance between hash codes can also be represented by a probability distribution. Assuming that the output of the hash functions is independent respectively, we calculate the expected value of the Hamming distance as follows:
[TABLE]
By using this expected value of Hamming distance, we define a loss function for the hash codes. The ideal values of the expected value of Hamming distance are shown in the Eq.(4). We define a loss function between and the ideal values. As a mini-batch of a training set for the loss function, where is sampled from . Then, the loss function is calculated as follows:
[TABLE]
This loss function is N-pair contrastive loss, which was obtained by modifying contrastive loss [14] by being inspired by N-pair loss [15]. We sample randomly mini-batch images from , input them to N-pair contrastive loss function Eq.(12), Eq.(11), and update the parameters of CNN so that the loss becomes small. By repeating this pairwise learning process, hash functions that meet the requirements for ideal hash functions can be obtained.
3.4 Image retrieval
ANN search is performed using the hash function for query image as shown in Fig.2. The outputs of CNN and are continuous values, thus they have to be binarize for generating hash codes. For discretizing and , we calculate MAP estimation of the distance function .
[TABLE]
where is defined as follows:
[TABLE]
Here, the condition for is expressed as follows:
[TABLE]
where is calculated as follows:
[TABLE]
Based on Eq.(13), Eq.(14), Eq.(15), Eq.(16), is calculated as follows:
[TABLE]
Therefore, the MAP estimation of the ideal hash distance is obtained as the Hamming distance between thresholded by 0.5. We use for image retrieval.
In this way, the distance function in the PDH is theoretically derived from the probability distribution on the image space. The Hamming distance between the hash codes obtained by the PDH is equivalent to the MAP estimation of the ideal hash distance and realizes a probabilistically explainable method including binarization of the CNN outputs.
4 Experiment
In order to confirm the effectiveness of the proposed method, we conduct evaluation experiments using three datasets.
4.1 Experimental setting
We use three image datasets: MNIST [16], CIFAR-10 [17], SVHN [18] for evaluation. We divide these datasets into training sets and test sets, and perform hash learning using training sets. For image retrieval, training sets and test sets are used as gallery and query, respectively. MNIST contains handwritten images of numbers (0-9) and consists of 60,000 training set (6,000 per class) and 10,000 test set (1,000 per class). CIFAR-10 contains 10 class natural images such as airplane and cat. In CIFAR-10, we randomly selected 50,000 images (5,000 per class) from 60,000 images as a training set and the remaining 10,000 as a test set (1,000 per class). SVHN contains house numbers in Google Street View images and consists of 73,257 training set and 26,032 test set. As a likelihood estimator, we use AlexNet[19] for MNIST and ResNet-50[20] for CIFAR-10, SVHN, respectively. We modify only the final layers of these networks to specific dimensional fully connected layers. These network weights are initialized by ImageNet [21] pre-trained models. We use the Stochastic Gradient Descent [22] as an optimizer for hash learning. We apply data augmentation including rotation, shift, flip and random erasing [23] to images in the training sets.
4.2 Evaluation protocols
As performance indicators, mean average precision (mAP) and precision@ are used. The mAP is the mean of average precision for the images of the same class in the gallery, see [24] for detailed calculation method. Precision@ is the percentage of true neighbors among the top data retrieved from the gallery by ANN search. See [24] for detailed calculation method. In order to confirm the effectiveness of the proposed method, we compare the accuracies with the conventional methods of KSH [7], ITQ [5], BRE [6], DSH [10], CNNH+[9], SSDH [11], SFHC [12], DCAH[13]. We refer to [13] on the accuracy of these conventional methods.
4.3 Experimental Results
The results of hashing methods are shown in the Table 1, 2. As shown in Table 1, our PDH outperforms the other state-of-the-art methods on mAP. Even when using a much short hash code of bits, high precision is maintained, and it is possible to search with high precision. Furthermore, as shown in Table 2, the precision@ of our PDH is almost unchanged for the value of . Therefore, even in the case of obtaining a small-scale similar image or obtaining a large-scale similar image, the proposed method works effectively.
5 Conclusion
In this paper, we propose probabilistic deep hashing (PDH) which generates probabilistically explainable hash codes. In our PDH, single loss function with no hyperparameter is derived from image probability distributions. By using this loss function, we can learn CNN-based hash functions. Furthermore, we show the probabilistic optimality of Hamming distance between hash codes. Based on this property, image retrieval with high precision is achieved. We evaluate the performance of hashing methods and show that our PDH outperforms the conventional state-of-the-art hashing methods.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Wang, T. Zhang, j. song, N. Sebe, and H. T. Shen, “A survey on learning to hash,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 40, no. 4, pp. 769–790, April 2018.
- 2[2] Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni, “Locality-sensitive hashing scheme based on p-stable distributions,” in Proceedings of the Twentieth Annual Symposium on Computational Geometry , New York, NY, USA, 2004, SCG ’04, pp. 253–262, ACM.
- 3[3] B. Kulis and K. Grauman, “Kernelized locality-sensitive hashing for scalable image search,” in 2009 IEEE 12th International Conference on Computer Vision , Sep. 2009, pp. 2130–2137.
- 4[4] Yair Weiss, Antonio Torralba, and Rob Fergus, “Spectral hashing,” in Advances in Neural Information Processing Systems 21 , D. Koller, D. Schuurmans, Y. Bengio, and L. Bottou, Eds., pp. 1753–1760. Curran Associates, Inc., 2009.
- 5[5] Y. Gong, S. Lazebnik, A. Gordo, and F. Perronnin, “Iterative quantization: A procrustean approach to learning binary codes for large-scale image retrieval,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 35, no. 12, pp. 2916–2929, Dec 2013.
- 6[6] Brian Kulis and Trevor Darrell, “Learning to hash with binary reconstructive embeddings,” in Advances in Neural Information Processing Systems 22 , Y. Bengio, D. Schuurmans, J. D. Lafferty, C. K. I. Williams, and A. Culotta, Eds., pp. 1042–1050. Curran Associates, Inc., 2009.
- 7[7] W. Liu, J. Wang, R. Ji, Y. Jiang, and S. Chang, “Supervised hashing with kernels,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition , June 2012, pp. 2074–2081.
- 8[8] F. Shen, C. Shen, W. Liu, and H. T. Shen, “Supervised discrete hashing,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2015, pp. 37–45.