Efficient Attack Correlation and Identification of Attack Scenarios based on Network-Motifs
Steffen Haas, Florian Wilkens, Mathias Fischer

TL;DR
This paper introduces a network-motif based method for correlating and identifying attack scenarios in intrusion detection data, achieving high accuracy and significant data reduction.
Contribution
It presents a novel motif-based graph approach for attack correlation that efficiently characterizes and identifies known and unknown attack scenarios.
Findings
Classifies up to 96% of attacks correctly
Reduces data size to 1% of original
Reliable detection of attack variations
Abstract
An Intrusion Detection System (IDS) to secure computer networks reports indicators for an attack as alerts. However, every attack can result in a multitude of IDS alerts that need to be correlated to see the full picture of the attack. In this paper, we present a correlation approach that transforms clusters of alerts into a graph structure on which we compute signatures of network motifs to characterize these clusters. A motif representation of attack characteristics is magnitudes smaller than the original alert data, but still allows to efficiently compare and correlate attacks with each other and with reference signatures. This allows not only to identify known attack scenarios, e.g., DDoS, scan, and worm attacks, but also to derive new reference signatures for unknown scenarios. Our results indicate a reliable identification of scenarios, even when attacks differ in size and at…
Click any figure to enlarge with its caption.
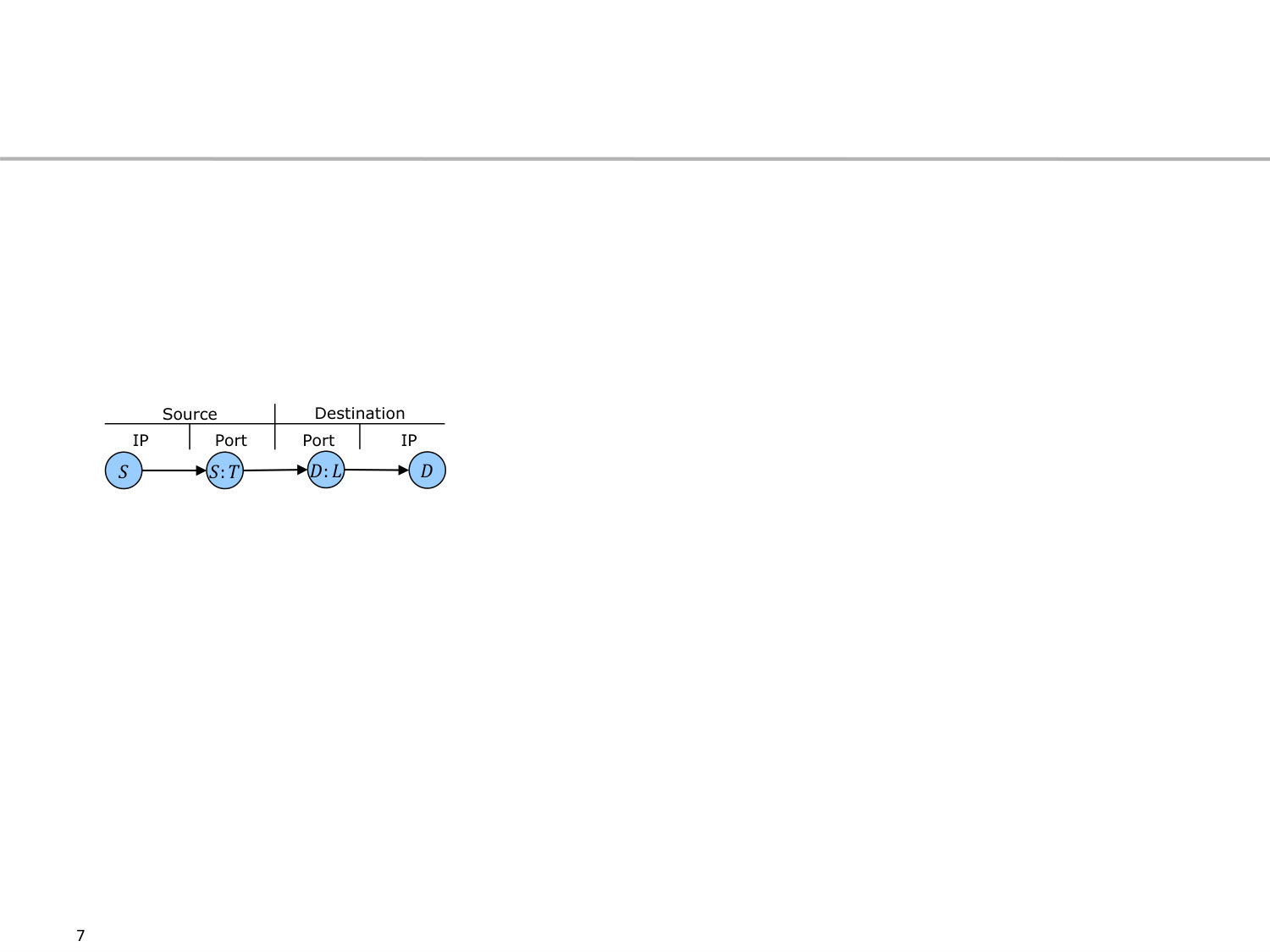 Figure 1
Figure 1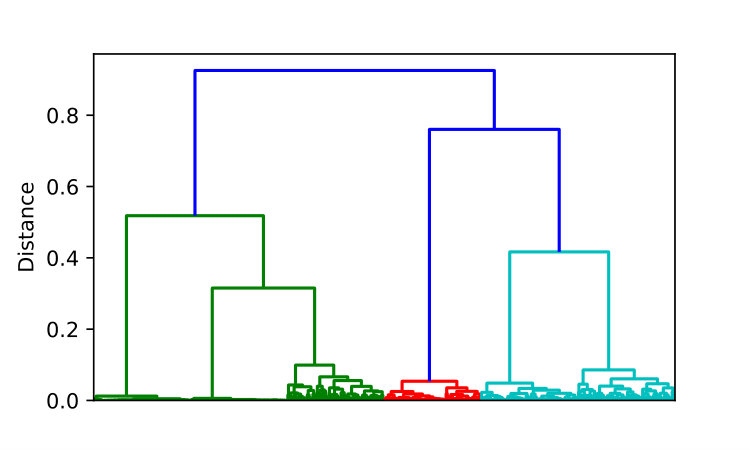 Figure 2
Figure 2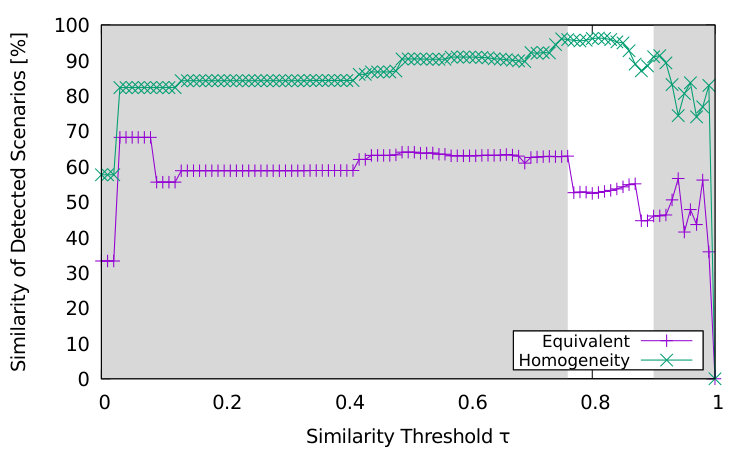 Figure 3
Figure 3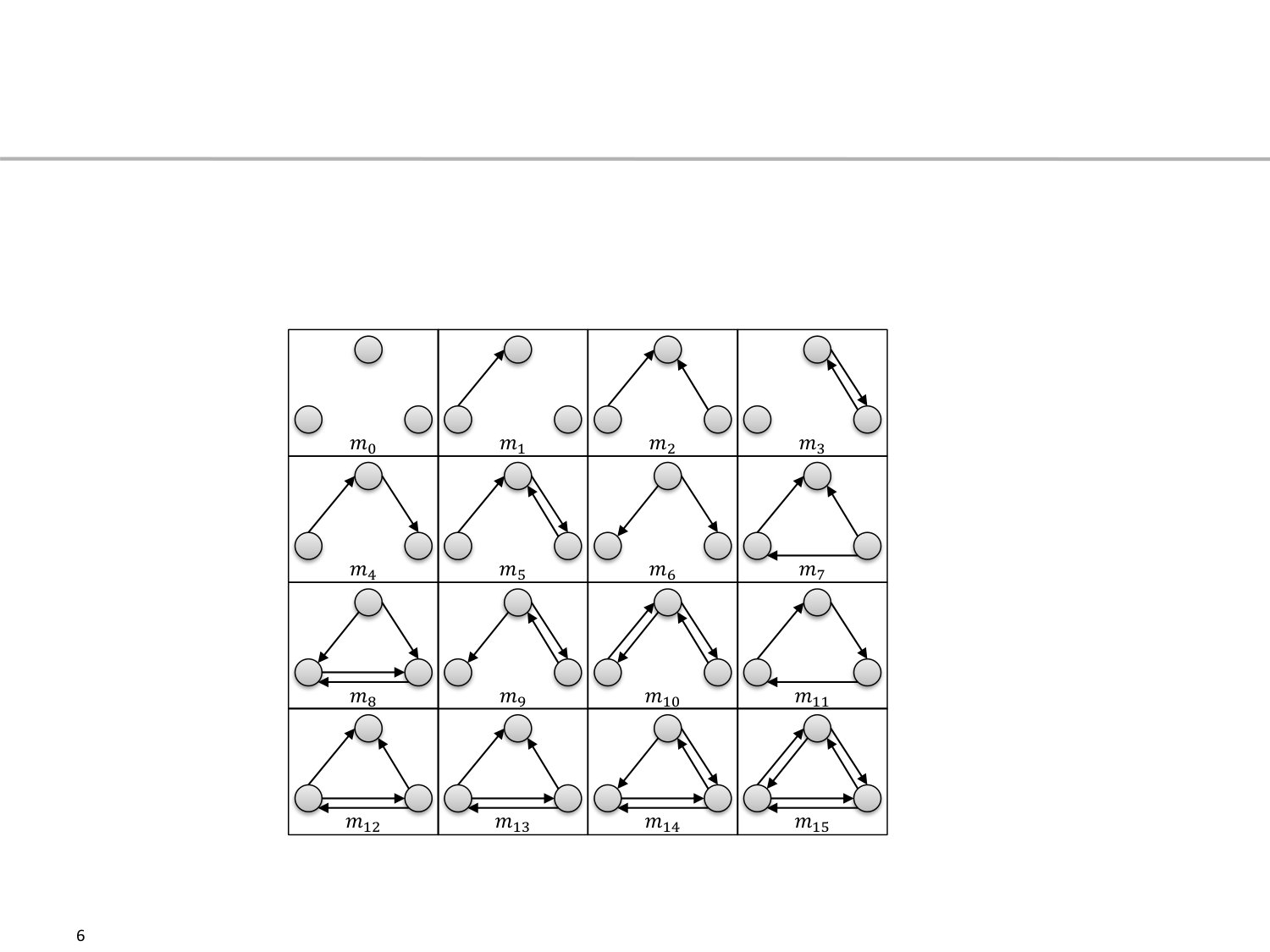 Figure 4
Figure 4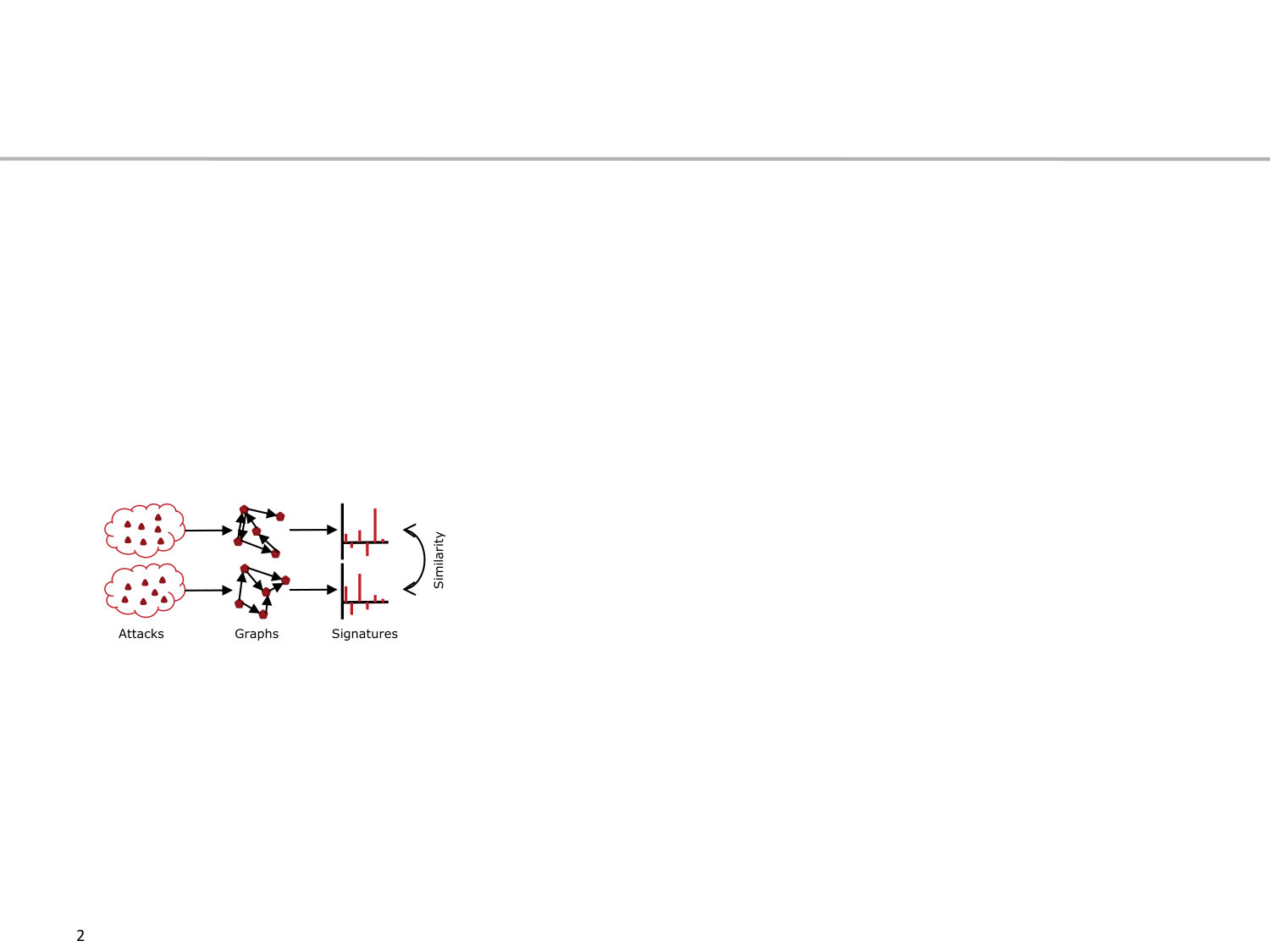 Figure 5
Figure 5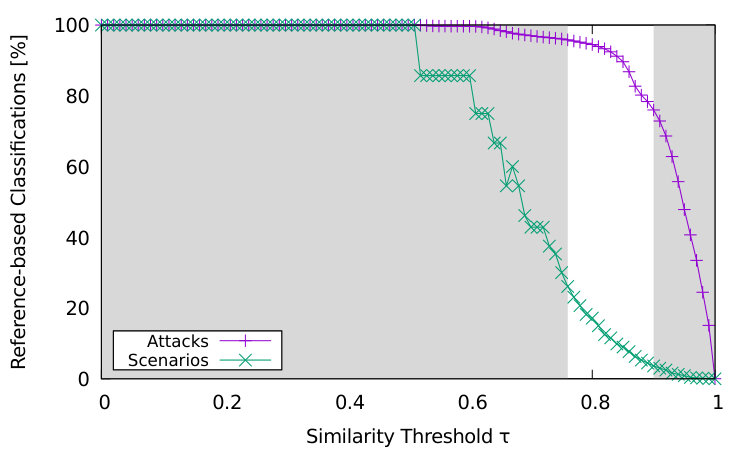 Figure 6
Figure 6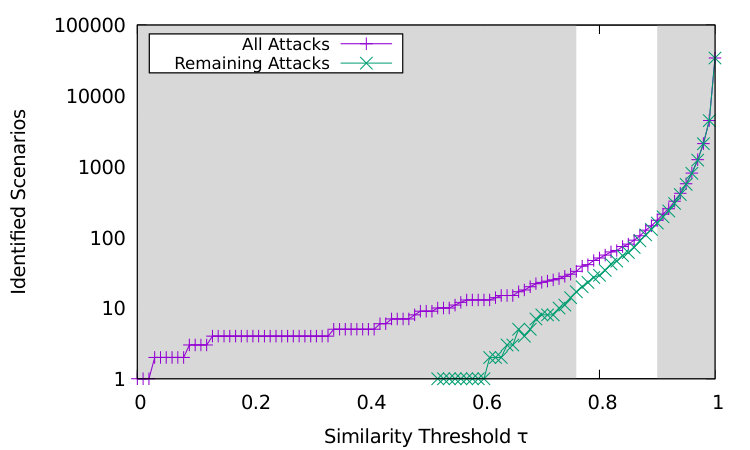 Figure 7
Figure 7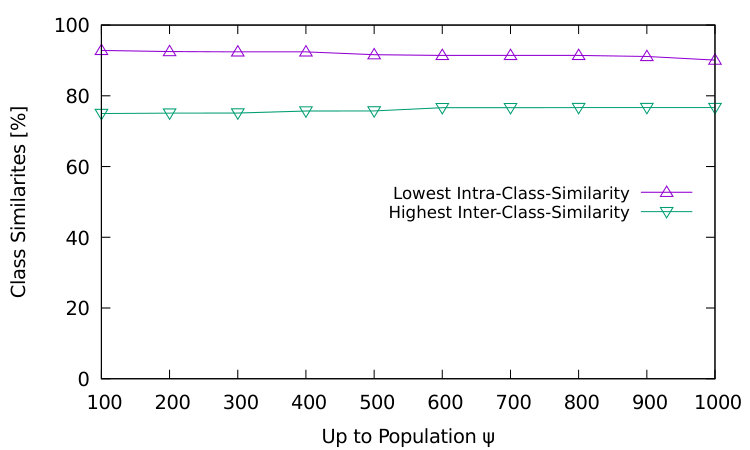 Figure 8
Figure 8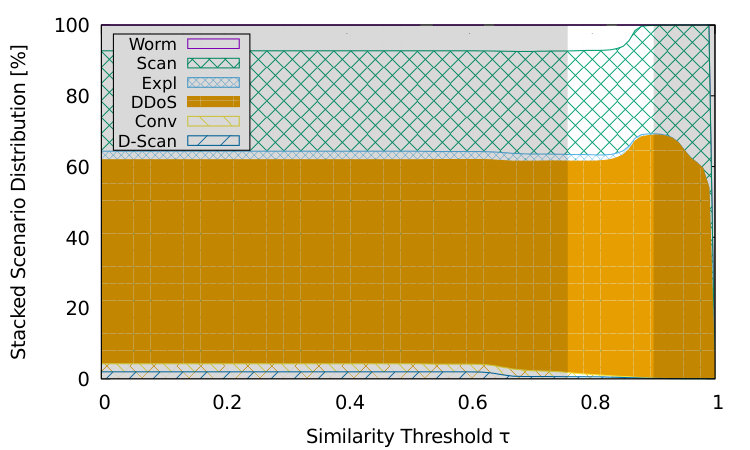 Figure 9
Figure 9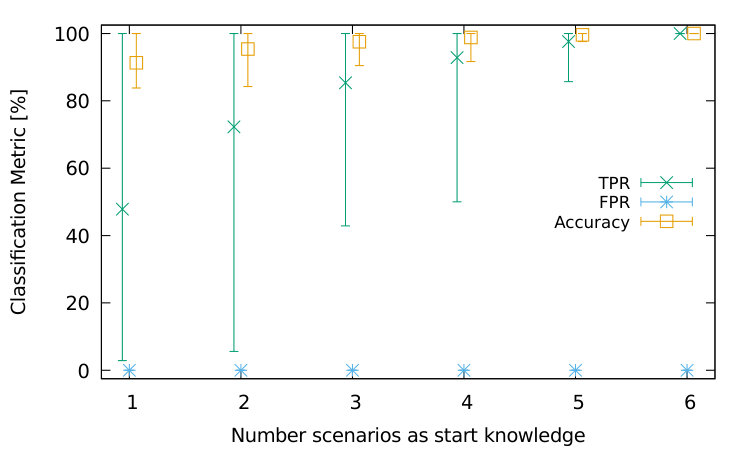 Figure 10
Figure 10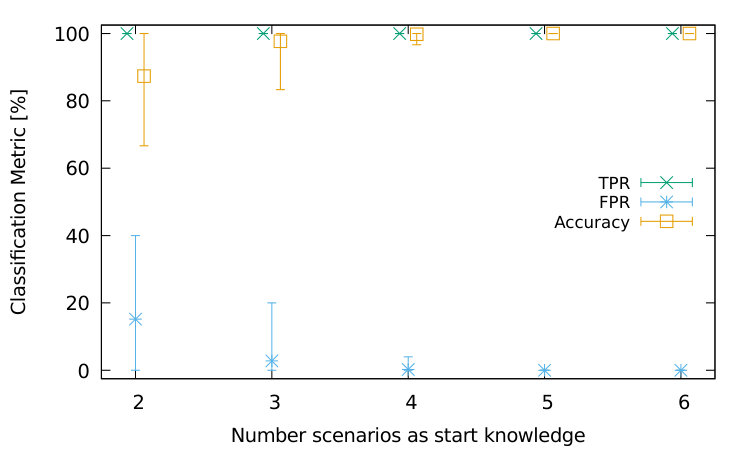 Figure 11
Figure 11| Lowest Intra-Class | Highest Inter-Class | ||
|---|---|---|---|
| Similarity [%] | Similarity [%] (with) | ||
| DDoS | 99.64 | 78.77 | (Worm) |
| Scan | 99.29 | 73.58 | (Worm) |
| D-Scan | 88.26 | 73.42 | (Conv) |
| Worm | 89.98 | 78.77 | (DDoS) |
| Expl | 92.65 | 73.00 | (D-Scan) |
| Conv | 91.52 | 73.42 | (D-Scan) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Efficient Attack Correlation and Identification of Attack Scenarios based on Network-Motifs
1st Steffen Haas
University Hamburg
2nd Florian Wilkens
University Hamburg
3rd Mathias Fischer
University Hamburg
Abstract
An Intrusion Detection System (IDS) to secure computer networks reports indicators for an attack as alerts. However, every attack can result in a multitude of IDS alerts that need to be correlated to see the full picture of the attack. In this paper, we present a correlation approach that transforms clusters of alerts into a graph structure on which we compute signatures of network motifs to characterize these clusters. A motif representation of attack characteristics is magnitudes smaller than the original alert data, but still allows to efficiently compare and correlate attacks with each other and with reference signatures. This allows not only to identify known attack scenarios, e.g., DDoS, scan, and worm attacks, but also to derive new reference signatures for unknown scenarios. Our results indicate a reliable identification of scenarios, even when attacks differ in size and at least slightly in their characteristics. Applied on real-world alert data, our approach can classify and assign attack scenarios of up to 96% of all attacks and can represent their characteristics using 1% of the size of the full alert data.
Index Terms:
intrusion detection, attacks, alert correlation, network motifs
††publicationid: pubid: 978-1-7281-1025-7/19$31.00 ̵̃© ̵̃2019 IEEE
I Introduction
In our interconnected society, attacks on IT systems can have significant impact. A common security practice is to deploy a network-based Intrusion Detection Systems (IDS) and/or a host monitoring and host IDS. Such IDS will output alerts when they detect security incidents. Subsequently, alert correlation can be leveraged to find relations among all alerts and to cluster them to attacks, e.g., based on alert similarity [1]. In recent years, the increasing network traffic challenges network-based intrusion detection with the data volume that needs to be analyzed. Because of that, scalable Collaborative IDSs (CIDS) [2] emerged. They deploy multiple IDS sensors in the network and collaboratively analyze traffic on the level of alert detection [3] or alert correlation [4, 5, 6]. For that, IDS sensors either communicate with a central alert correlation unit or directly with each other.
Despite the benefits of larger visibility and load distribution that come with CIDSs, they introduces new challenges to the alert correlation process as individual sensors now need to exchange high-volume data in the form of alerts. A pairwise comparison and correlation of all attacks and their alerts via a CIDS induces a high computation and communication overhead. For example, in a centralized CIDS, every sensor will share every single alert with the central alert correlation unit. To avoid this, an efficient and compact abstraction for attacks is required that can be precomputed by every sensor, shared efficiently, and that still allows for an efficient analysis of attacks and their interconnections. To achieve this, the attack abstraction needs to be significantly smaller than the original alert sets. Correlating attacks on the basis of their smaller abstractions, consumes significant less resources and therefore allows for faster and more efficient correlation algorithms. Thus, a CIDS benefits from a small abstraction through less data that needs to be exchanged between individual sensors or in between sensors and a central alert correlation unit. However, such a reduction in size should preserve characteristic information on the attack. Hence, these abstractions of alert sets should represent some kind of fingerprints that can be compared with each other, e.g., for similarity. Most algorithms correlate attacks with respect to common attackers, i.e., on the basis of common IP addresses [7, 8, 6]. However, a more generic approach is required that subsumes specific correlation algorithms and can be applied to a decentralized CIDS setting. For that, correlating according to the same attack scenario might be equally important. An attack scenario is a class of attacks that all show a characteristic communication pattern among the involved hosts. The communication structure of a DDoS attack is different from a worm spreading and both differ from the lateral movement of an attacker in a network.
The main contribution of this paper is a novel attack correlation algorithm that uses abstractions of attacks based on network motifs to identify attack scenarios. For that, we transform all alerts belonging to an attack into a graph representation from which we derive motif signatures. Motifs are characteristic subgraphs and a motif signature summarizes the occurrence of different types of motifs in a graph. It thus can serve as a fingerprint for the respective attack and does neither include IP addresses nor ports. This allows not only for a more compact attack representation, it is also more privacy-preserving as attack patterns can be shared without revealing identities of involved systems and services. That can help to reduce the load in a CIDS, as IDS sensors exchange motif signatures first and only when signatures match, i.e., they experience similar attacks, they would exchange more detailed information, e.g., complete alert clusters. Our results indicate that we can correlate attacks from the same attack scenario with high accuracy and that our approach can also operate in a completely unsupervised setting to detect unknown attack scenarios. We apply our approach on real-world data and can represent the motif characteristics of attacks at 1 % of the size of the full data and can classify and assign attack scenarios to up to 96 % of all attacks.
The remainder of this paper is structured as follows. In Section II we present related work. Section III describes our approach that incorporates motifs into an attack correlation algorithm for the identification of known attack scenarios and for learning new attack scenarios. The performance is evaluated in Section IV and Section V concludes our work.
II Related Work
We present related work with respect to three areas. First, we look at alert correlation algorithms that cluster alerts to attacks and then classify these attacks based on predefined scenarios. Second, we look at approaches to data sharing in Collaborative Intrusion Detection Systems (CIDS). Last, we look at how network motifs have been previously used in the context of network security.
Attack Scenarios
There are many alert correlation algorithms that extract the predominant information from a set of alerts, where each alert consists of attributes such as source and destination IP and port. The intention is to find groups of alerts within the larger set of alerts that share a common pattern and thus are likely to belong to the same underlying attack. These patterns usually consists of multiple pairs of attributes and their corresponding values which are equal for all alerts in the same cluster. Zhou et al. [7] describe how to reduce a large alert set to attribute patterns by using a lattice structure. Furthermore, they identified eight special types of patterns and assign them a so-called attack type. For example, a pattern with fixed source IP and port and fixed destination port is a distributed reflector DoS. Instead of finding attribute patterns among the alerts, Haas et al. [6] propose community clustering on an alert graph. The authors then assign each resulting attack cluster one of four scenarios that are differentiated by the number of attackers and victims respectively. Zhu et al. [9] automatically construct attack scenarios from alert data by modeling causal relationship of two alerts in neural networks. Jero et al. [10] present a more specific approach to scenario detection. They leverage a state machine model of TCP congestion control to automatically generate abstract attack strategies.
Data Sharing in CIDS
In CIDS, sensors are distributed in the network [2]. They perform intrusion detection locally [11] but exchange (parts of) their detection results. A low volume data exchange is usually desired for efficiency. Cai et al. [5] propose a DHT-based overlay that is used by the sensors for detecting worms. For that, sensors generate signatures about suspicious packets locally and share them amongst each other. A worm is detected if the signature is observed by a sufficient amount of sensors in the CIDS. Domino [4] is an overlay system with multiple layers that was designed for the monitoring of Internet outbreaks. The so-called axis nodes are organized in a DHT-based overlay and form the backbone of the system. Satellite nodes form communities and report their alert data to axis nodes to share their aggregation in the axis overlay. These summaries describe attack data and are based on ports, sources, or alert clusters. Julisch [12] presents an alert correlation approach based on attribute-oriented induction that aggregates attributes in an alert set to report attribute patterns similar to Zhou et al. [7]. The resulting pattern with their corresponding values is an compression of the alert set itself. Locasto et al. [8] propose a privacy-preserving compression of alert data for sharing suspicious IP addresses. They are inserted into a bloom filter, a bitmap that basically allows insertion and lookup operations of hashed input. This prevents anyone from retrieving the raw IP addresses but allows for lookups of a specific IP address. A compression in size is also achieved because multiple IPs can be inserted into the bloom filter that is of fixed size.
Network Motifs for Network Security
A directed graph with its vertices and edges can be characterized by network motifs [13]. They express how the vertices are connected among each other in . For that, we look at individual sub-graphs that consist of a fixed number of vertices, i.e., nodes from and out of edges .
The idea of motifs is based on the finite number of edges that can at most exist among any nodes, which is limited by in case of a directed graph. This further means that different graphs can be generated with nodes. Motifs in fact describe isomorphic classes for these possible graphs. Thus, a motif expresses a specific pattern how nodes could be interconnected. For example, for subgraphs of size , distinct motif patterns exists, which are identified by their motif index with . Figure 1 shows all possible motifs for , where represents nodes without any edges and all directed edges exist for . Thus, we can map any subgraph to a motif index . When we do this for all subgraphs in our graph and count the occurences of every , the result is called a motif-signature. Such a signature describes how often a specific motive is present in graph . With respect to network security, Allan et al. [14] are identifying application types in network traffic. With the help of motifs, they analyze the communication graph to predict the application. Juszczyszyn et al. [15] show that motifs can be used to detect statistical anomalies in the communication graph during an attack in the network. Similarly, Harshaw et al. [16] characterize the role of individual systems in the communication graph to detect the presence of an attack.
However, to the best of our knowledge, there is no related work that uses motifs in intrusion detection to identify attack scenarios. GAC [6] can only identify four pre-defined cluster classes (oto, otm, mto, mtm). Our Motif-approach can characterize attacks generically, predefined, dynamically, and way more fine-grained. Compared to [15, 16], our data basis is on alert data and we use a novel graph model for representing communication relationships (preserving different usage behaviour of ports). The authors of [15, 16] have shown that attacks change the NetFlow graphs significantly. In contrast, we (1) design a system that allows to compare attack characteristics, (2) evaluate the ability to differentiate between different attacks, and (3) create attack signatures that can be shared to identify similar attacks.
III Characteristics of Attack Scenarios
With the increasing amount of attacks on computer networks and IT systems, there is a need to efficiently categorize, filter and correlate alerts to understand the root cause of an attack and to be able to choose appropriate countermeasures for its mitigation. We present an approach based on network motifs [13] that provides abstractions of attacks, i.e., of their alert data. Our motif abstraction is a fixed size characteristic fingerprint of an attack. Thus, it can be magnitudes smaller than the corresponding alert data and allows for a faster comparison of attacks. With the help of this motif abstraction, our approach identifies attack scenarios and is even able to learn previously unknown scenarios. It can be deployed in a centralized or decentralized manner.
The goal is to inspect attacks in a way that differs from most algorithms that search for common attributes among the alerts from different attacks. These approaches can reveal if two victims are targeted by the same attacker but they cannot tell if the attacker performs the same kind of attack in both cases. That is why our approach identifies and compares attacks regarding their attack scenario, which basically describes how attackers and victims interact. If an attack is not only involving a single attacker and a single victim, the questions arises who of the involved hosts attacks whom. The answer can be simple for a Distributed Denial of Service (DDoS), where all attackers target one victim. But how to differentiate between a worm spreading and a coordinated scan, where each of the attackers scans a subset of victims?
In the next Section III-A, we describe the principles behind the classification of attack scenarios by calculating the similarities between motif signatures on the alert data of attacks. Afterwards in Section III-B, we describe how to utilize the comparison of motif signatures to classify known and unknown attack scenarios.
III-A Comparing Characteristics of Attacks
The basic idea of our correlation algorithm is to transform a set of alerts into a much smaller representation that conserves structural characteristics of attacks. We found network motifs, specifically the so-called motif signatures (cf. Section II), to be a perfect candidate to summarize the communication structure of the hosts involved in an attack. This allows for an easy comparison of the structural characteristics of attacks, even without prior knowledge of these characteristics and mostly independent from the attack size.
Please note that we present a correlation on attack level, which requires the alert data to be clustered in the preferred way of choice, e.g. [6, 12], to extract clusters of alerts. This is also the first step according to the schematic overview of the approach in Figure 2. In the following we describe the next steps in detail, which is the transformation of attack data into graphs, the calculation of motifs signatures, and their comparison.
III-A1 Transformation to Graph
We assume attack characteristics to be based on the communication structure among hosts. This structure is derived from all alerts , where an alert has several attributes. For our purpose, we define an alert with source IP and source port and with destination IP and destination port . Based on these four attributes of alerts, we generate a Communication Structure Graph for all alerts of an attack . In , nodes represent either a host by its IP address or the port on a specific host. The edges reflect who attacked whom and whether a single port is relevant in the attack.
To build the graph for a specific attack , all alerts are added to it consecutively. For that, the set of nodes is extended by nodes representing the hosts, i.e., , and nodes representing their ports, i.e., . This notation ensures that ports are always bound to hosts. To reflect who attacked whom, the edges are added to in . Intuitively, this describes what is visualized in Figure 3, the port and IP used to attack another IP on a respective port.
III-A2 Calculation of Signature
The last step to get from an alert set via the graph to its small abstraction is to calculate the motif signature of the graph (cf. Section II). For that, we enumerate all subgraphs of size and assign them to a specific motif pattern with . Counting the number of occurrences for all motifs results in a motif signature , which is a vector containing the absolute number of occurrences of every . As is directly dependent on the graph size , it does not allow to compare the structure of two graphs that are of different sizes.
To enable this comparison, the authors in [13] present the so-called Z-Score. It uses the signature of graph to calculate for every how much it is over- or underrepresented compared to a random graph of the same size and with the same number of edges as . The Z-Score of a specific motif in a graph is calculated by with being the absolute number of motif in , being the average absolute count of motif in respective random graphs, and its standard deviation . This is done for every absolute number of motifs in . We denote the resulting motif signature with the Z-Score values as . Any motif signature can simply be represented as an array of fixed length, e.g., 16 for 3-motifs.
III-A3 Comparison of Signatures
When comparing two motif signatures and , we want to calculate how similar they are. Their similarity should be 1, i.e., , if the signatures are equal. However, finding a metric to calculate the similarity in a meaningful manner is not intuitive. The reason is because even the values in the Z-Score signature are not limited to a fixed range. As the graph size, i.e. attack size, still has an impact on the Z-Score values, we cannot directly compare the values of every motif in two signatures and . Doing so would not achieve high similarity for attacks with similar characteristics but of different size. We have to design the comparison between two motif signatures in such a way that similar attack characteristics are identified even if the attacks are of different sizes. For that, a motif that is statistically over- or underrepresented in should also be statistically over- or underrepresented in . Furthermore, we make the comparison to consider how much a specific motif is over- or underrepresented compared to the other motifs in the signature. The idea is to not have a pairwise comparison of the motif values in and . Instead, the similarity between and reflects how similar the relations among the motif values in are to the relations among the motif values in .
For such a comparison, the Z-Score signatures and are interpreted as vectors , always of fixed length. This means, we can think of a signature as a vector in a multi-dimensional space with the number of dimensions equal to the length of the vectors. The higher the values in a signature, the larger is the vector in the multi-dimensional space. To be independent from the vector length, we calculate the angle between two vectors in the multi-dimensional space. For that, we use the inner product and the Euclidean norms and for the calculation of the angle (Equation 1). This finally leads to the similarity (Equation 2).
[TABLE]
[TABLE]
When we compare the Z-Score signatures to classify attack scenarios, we define a threshold for their minimum similarity. Above this threshold, two signatures belong to the same attack scenario. Next, Section III-B makes use of this threshold when testing if an attack matches a given attack scenario or when clustering attacks for unknown attack scenarios.
III-B Classification of Attacks
Once the alerts of every attack are transformed into motif signatures , the motif signatures of the different attacks, i.e., alert sets, are compared. The goal is to find attacks with the same characteristics. Such a comparison can be calculated extremely fast as a motif signature is of a fixed and far smaller size than the respective alert sets. For the attack correlation algorithm, predefined characteristics of attacks can be used to identify specific attack scenarios and to label them accordingly. Alternatively, the attack correlation operates without a knowledge database and learns attack scenarios on its own. It labels attacks according to dynamically derived characteristics of alert sets. Both approaches are described in the following.
III-B1 Signature-based Classification
To identify scenarios in alert sets, we first need definitions for the characteristics of already known attack scenarios that we name reference scenarios . Thus, a reference scenarios reflects the characteristics of a specific attack scenario and therefore is representative for all attacks of this attack scenario and their alert sets, respectively. In fact, is just the motif signature of a typical attack in the attack scenario that should be identified. It is modeled by transforming a representative alert set into a Communication Structure Graph and by computing its motif signature . Hence, set consists of small motif signatures. The size of this set equals the number of predefined attack scenarios that should be identified.
When classifying an attack , its motif signature is compared to all reference signatures using the similarity function described in Section III-A3. In general, the highest similarity determines the attack scenario that is assigned to attack . However, the minimum similarity threshold needs to be respected, because there could be attacks from unknown scenarios that are not included in . Hence, they should not be labeled with a known attack scenario. When assigning all attacks to the reference scenarios, it results in attack clusters , at most one per reference scenario. The requirement for attacks of the same scenario to have a minimum similarity to the respective reference scenario is formalized in Equation 3. The requirement of closest match among all reference scenarios is formalized in Equation 4.
[TABLE]
[TABLE]
III-B2 Unsupervised Clustering
Apart from using motif signatures to identify predefined attack scenarios, we explain how motifs can be used to cluster similar attacks and to dynamically derive reference scenarios for them. In the following, we describe the process of learning new attack scenarios via a hierarchical clustering in two steps. This only highlights the capabilities of motifs for applications in intrusion detection. The fundamentals presented here should be easily adaptable to more sophisticated detection algorithms, e.g. for anomaly detection or collaborative intrusion detection.
Hierarchical Clustering
To learn attack scenarios, we first cluster attacks in a way such that all attacks from the same attack scenario belong to one group. For that, we cluster attacks based on the similarity of their motif signatures . We designed the comparison of motif signatures to aim for high similarities among signatures for attacks of the same scenario and low similarities of signatures for attacks from different scenarios. The intention is that clustering the motif signatures of attacks results in attack clusters, one for each detected attack scenario. We find hierarchical clustering best to cluster attacks into attack scenarios for two reasons. First, we can use the similarity threshold (c.f. Section III-A3) as clustering parameter to intuitively control the clustering and its outcome. And second, the visualization as dendrogram allows an human inspection of the potential clusters depending on .
We use as clustering parameter in hierarchical clustering to control the minimum similarity, i.e., maximum distance, for two attacks, so that they are still part of the same attack scenario. Thus, must be chosen in a way such that (1) it is low enough to allow attacks of the same scenario to result in one cluster and (2) it is high enough that two attacks of different scenarios do not result in the same cluster. An example for hierarchical clustering of attacks is visualized as dendrogram in Figure 4. The x-axis of the figure represents the individual attacks and the y-axis represents as maximum distance for two attacks or scenarios to be merged into the same scenario. Hence, at distance [math], only equal attacks will be merged and at distance , all attacks are merged into a single scenario. When stepping from [math] to , similar attacks or scenarios are merged once the value on the y-axis reaches their respective distance. The idea in hierarchical clustering is to define a cut-off distance, which determines the final clusters. The outcome are the clusters, i.e. scenarios, that all the attacks have been merged into at the specific cut-off distance in the dendrogram.
We use the cut-off distance to form clusters of attacks with the desired maximum heterogeneity within a cluster. The hierarchical clustering of for the set of attacks merges clusters with respect to the maximum distance within the resulting cluster, which is known as the complete method [17]. This means that attack scenarios are defined by the maximum distance between contained attacks, which can be formally stated as in Equation 5.
[TABLE]
Deriving Reference Scenarios
The attacks in a cluster formed by hierarchical clustering are supposed to belong to the same attack scenario because of their similar characteristics. To actually extract the characteristics for each attack cluster, a motif signature is derived per cluster as reference scenario to represent the new attack scenario. Instead of constructing a signature ourselves, we pick the signature of the attack that is most typical for the cluster. We define the most typical attack of a cluster to have the highest similarity with every other attack on average. This is formalized in Equation 6.
[TABLE]
After these two steps, a set of attacks, i.e., a set of alert sets, is represented by a number of reference scenarios that is controlled by the similarity threshold .
IV Evaluation
For evaluating our correlation algorithm (cf. Section III), we implemented it in Python. The implementation encompasses the graph generation, motif calculation and comparison as well as the identification of known attack scenarios (cf. Section III-B1) and the detection of unknown scenarios (cf. Section III-B2). Prior to the description of the experiments and their results, we introduce the alert datasets used for the experiments in Section IV-A.
The experiments are divided into two parts. First, Section IV-B evaluates the applicability of motif signatures to identify and compare different attack scenarios. By simulating attacks, we show that our correlation algorithm can correctly classify attack scenarios, mostly independent from the attack sizes. The second part in Section IV-C then evaluates our correlation algorithm on real-world data.
IV-A Attack Data
Although our correlation algorithm operates on alerts, it is important to notice that the algorithm works with abstractions of attacks. Hence, the input to our correlation algorithm are alerts of specific attacks, i.e., clusters of alerts that each represents an individual attack. For clustering alerts to attacks, we refer to other algorithms, e.g., [18, 6, 12, 9, 19]. In the experiments we use two different types of alert data:
- •
Synthetic alerts of attacks with ground-truth and control over to carefully evaluating the classification accuracy of our approach. We further use this method of alert generation for the construction of reference scenarios (cf. Section III-B1).
- •
Real-world alerts from DShield111https://secure.dshield.org.
Next, we explain how to generate instances of attack scenarios with the help of synthetic alerts. Afterwards, we introduce the DShield data set as a source for real-world alerts.
IV-A1 Instances of Attack Scenarios
To create synthetic attack data, we generate alerts for a specific attack scenario. In our experiments we use six different scenarios, each of them defining a pattern for the data generation. An instance of an attack is determined by its attack pattern and its attack size. The values for IP and ports are randomly chosen from the full IP and port range, respectively.
Attack Patterns
For our experiments, we describe the alert patterns for six attack scenarios. We use these patterns for two purposes: 1) For generating synthetic alerts of attacks for the evaluation of scenario classification and 2) for the definition of reference scenarios used during classification. The names and characteristics of the six attack scenarios are as follows:
A Distributed Denial of Service (DDoS) attack is characterized by alerts that all share the same destination IP and port. Thus, multiple attackers target a specific host and service. We can parameterize this attack by alerts that are generated on average per attacker. Attackers use random source ports, which are reused in subsequent alerts with a probability . A Scan attack is characterized by alerts that share the same attacker IP. Random source ports are used to scan for the same destination port on multiple target machines. On average alerts are generated per target and the attacker reuse a source port with a probability . A Distributed Scan (D-Scan) is similar to a Scan attack but with both multiple attackers and targets, e.g., when a Scan is coordinated by a botnet [20]. Then, tasks for scanning all targets are split among the attackers. Characteristic for this scenario is the ratio of attackers to targets, which we denote as . Additionally, targets might be scanned multiple times, i.e., from multiple attackers. In this case, alerts are generated per target. A Worm attack is characterized by alerts that all share the same destination port. Additionally, all hosts are attackers and target randomly of other hosts via random source ports. An Exploration (Expl) attack is characterized by a single attacker that targets hosts. Each compromised host serves as source for attacks on further hosts. Each compromised host targets new hosts and all source and target ports are random. The pattern of an Convergence (Conv) attacker is the opposite of an Exploration attack. The actual target is attacked by hosts that themselves are attacked by hosts and so on.
For our experiments, we parameterize these six attack patterns as follows. Per source or target, alerts are generated. Ports are reused with a probability where appropriate. In case of lateral movement in a network, it is done with a spread factor of , which means that in each step a new compromised host targets 5 new hosts. If a scenario is characterized by multiple attackers and targets, their ratio is , which means the same amount of attackers and targets. In the case of the worm scenario, each host attacks of the other hosts.
Attack Variations
In reality not all attacks of the same attack scenario are equal with respect to their alerts. Of course they differ in the actual IPs and ports, which, however, are not visible anymore in the motif signature of the attack. More interesting is the variation in the attack size. Also, clustered alerts of an attack can contain false positives which causes variations in the alerts of an attack. Attack variations of the six scenarios are input to the experiments in Section IV-B.
We cause attack variations by generating attacks of different size, i.e., the population , which is the number of hosts involved in the attack. The attack patterns define how many of the individual hosts are attackers, targets, or both. For example, in a DDoS attack of size 100, there would be one target and 99 attackers.
IV-A2 DShield Data Set
We are also using real-world data from the Internet Storm Center222SANS Technology Institute, Internet Storm Center, https://isc.sans.edu that operates DShield, which is a platform for sharing data from security devices, e.g., from firewalls. The DShield logs consist of alerts from multiple sensors around the globe. For our real-world experiments, we are using all alerts collected on August, 22th in 2016. These are 4,517,497 alerts in total and are a result of several attacks.
As our approach for scenario classification works on attacks, i.e., on alerts of the same attack, we first have to group the DShield alerts into clusters. For that, we are using the GAC clustering approach [6] that clusters alerts based on attribute similarity. In contrast to other clustering approaches, e.g., [7, 12], GAC does not enforce clusters with static attribute patterns. Instead, it identifies cliques of alerts that form a community, which allows a high diversity in the alert clusters and therefore in the attack scenarios. If we would use clustering algorithms with static attribute patterns, alert clustering would not be able to produce alert clusters for certain attack scenarios. Applying GAC clustering with a minimum similarity of in between alerts and a clique size of on the DShield data results in 34,204 clusters. They are the actual input to the real-world evaluation in Section IV-C.
IV-B Classification of Attack Scenarios
The most important question is if our motif-based classification can fulfill the requirements to our classification problem (cf. Section I). We require the abstraction of attacks to be small and the fingerprinting of attacks to be characteristic for their scenarios. The fulfillment of the first requirement is given, because the data volume, i.e., size of all alert data can be magnitudes larger than the size of motif signatures. Thus, we investigate if a single motif signature is representative for all variants of an attack scenario. For that, motif signatures have to be very similar for attacks of the same attack scenario. We denote this as intra-class-similarity, which describes the similarities among attacks from the same attack scenario. In addition, we also have to look at the inter-class-similarity, which is the similarity between attacks from different attack scenarios.
IV-B1 Similarities of Scenario Classes
In this experiment, we investigate the intra-class similarities and inter-class similarities for attacks of the same size , i.e., number of hosts. For that, we created 1000 attacks for each of the six scenarios defined in Section IV-A1 and measured their similarities. Please note that the attack patterns themselves inherent some randomness, so that two attacks of the same scenario differ in their alert data even if they are of equal size. Apart from different IPs and ports, the relation for who of the attackers target whom of the victims is chosen differently every time an attack instance is generated. More randomness is introduced, because of the generation parameter multiple alerts are generated for some attackers, which also differs every time.
Table I tells us how different attacks from an individual scenario might be, i.e., the lowest intra-class similarity. The highest variation is measured among the D-Scan attacks (lowest similarity of 88.26%) and the most similar attacks from the same scenario are the DDoS and Scan attacks, each with a similarity of more than 99%. We also measured the inter-class-similarities and report the highest similarities per scenario in Table I. There are some attack scenarios that share characteristics. The worm is similar to DDoS and Scan with 78.77% and 73.58%, respectively. The D-Scan is similar to Expl and Conv with 73.00% and 73.42%, respectively.
As the lowest intra-class similarity is always higher than the highest inter-class similarity, motifs are an appropriate abstraction for alert data to preserve the characteristics of attack scenarios. For attacks of the same size, the results indicate that our approach can correctly classify attack scenarios, both in sense of identifying the correct reference scenarios and detecting scenarios in unsupervised clustering.
IV-B2 Scaling with Attack Size
Apart from the question if the intra-class-similarity is always higher than the inter-class-similarity, the influence of the size of an attack is of interest. This is important because attacks can greatly differ in their sizes, i.e., number of hosts . Our motif-based classification is required to detect the attack scenario for an attack with 100 hosts but also for an attack with 1000 hosts. For that, we generate attacks for the six attack scenarios described in Section IV-A1 with different attack sizes. For the generated attacks, we calculate the intra-class similarity or the pairwise inter-class similarity, respectively, depending on if two attacks are from the same scenario or not. We calculate the similarities for different sets of attacks. In the set of attacks, we control the difference between the size of smallest and largest attack, i.e., how different the attacks are with respect to their size. The smallest attacks always encompass 100 host and the largest attacks are of size up to 1000.
In Figure 5, we evaluate the similarities depending on the attack sizes, i.e., when increasing the range of attack sizes in steps of 100. On the x-axis is the upper bound of the population size , meaning a value on the y-axis depending on a specific plots the similarities among attacks of sizes in steps of 100. On the y-axis, we plot the lowest intra-class-similarity and highest inter-class-similarity among all attack scenarios. As long as the first curve is above the second one, it is possible to correctly classify the attacks in our data set. The gap between both curves indicates the potential range for the classification parameter to achieve correct classifications. The results indicate that our motif-based approach can preserve the attack characteristics mostly independent from the attack size. For attacks of size 100 only, the width of the range for is . When clustering data sets that contain attacks of sizes between 100 and 1000, the width slowly decreases to . With respect to attack sizes between 100 and 1000 and with respect to our six attack scenarios in this experiment, the average value of should be about .
IV-B3 Learning new Scenario Classes
Another question, especially regarding how to choose , is how the accuracy of learning new scenarios depends on general knowledge of attack scenarios. While the unsupervised algorithm (cf. Section III-B2) can detect and characterize new scenarios, it is a matter of operating the attack clustering with an appropriate value for , not of specific previously defined reference signatures. For different choices of setting , we show how deriving unknown scenarios performs. In this paper, we define only six attack scenarios but our approach is not limited to them. As our attack abstraction enables the identification and comparison of structural characteristics of attacks, our approach can potentially learn any new scenarios as long as they sufficiently differ in their communication structure. Another potential goal is to divide known scenarios into more fine-grained ones, i.e., differentiate a reflection DDoS from a DDoS performed by a botnet. However, for simplicity we only define the six general scenarios here and leave more (fine-grained) scenarios to future work. To still investigate the learning of new scenarios in this experiment, we assume a knowledge of only a subset of the six scenarios.
According to the results illustrated in Figure 5, the more is towards the upper bound of the possible range, the definition of attack scenarios becomes more strict. This results in a higher probability for false negatives in classifications in case the attacks of a new scenario have a higher variation than the previously known ones. However, a high also ensures precise classifications by reducing false positives in classifications in case the attacks of a new scenario share characteristics with a previously known one. If is set towards the lower bound of the range, there is a higher chance that attacks will be correctly classified although they look different than expected by the attack scenario. In turn, this increases the likelihood of false positives.
For this experiment, we use the same data set as in Section IV-B2, containing attacks from the six scenarios with 100 to 1000 hosts. We then simulate limited knowledge by only considering the attacks from a subset of scenarios. For each combination of 1 to 6 scenarios, we measure the lowest intra-class and highest inter-class similarities as in Table I and then determine the highest and lowest possible for the attack scenarios as in Figure 5. As there are multiple possible combinations of scenarios per number of scenarios, Figure 6 plots the minimum, maximum, and average value for the true-positive-rate (TPR), false-positive-rate (FPR), and accuracy of classification. As is based on the lowest known intra-class similarity in Figure 6(a), attacks from all remaining scenarios will definitively go to another class, i.e., we accept a lower TPR but therefore minimize the FPR for learning new scenarios. In contrast, Figure 6(b) is based on the highest known inter-class similarity, which maximizes the TPR but accepts a higher FPR in return. Thus, choosing from the higher or lower boundary of possible range balances the ratio between expected TPR and FPR.
The results here for unsupervised clustering describe the worst-case performance of attack classification. For signature-based classification (cf. Section III-B1), attacks are only required to be more similar to the reference signature of their respective scenario than to the reference signature of a different scenario.
IV-C Real-World Results
After analyzing our scenario classification on artificial data for which we have the ground truth, we also apply it on the DShield real-world data (cf. Section IV-A2) and report the performance of our motif-based correlation algorithm for the detection of attack scenarios. As reference scenarios, we use one attack with 100 host for each of the six attack scenarios in Section IV-A1. As the results of Section IV-B indicate that the similarity threshold should be , we mark the respective range for on the x-axis in all following figures. Choosing from this range is a prerequisite to distinguish attacks from the six reference scenarios.
For this real-world evaluation, we look both at classifying attacks with the help of reference scenarios and detecting scenarios with unsupervised clustering to compare them.
IV-C1 Efficiency of Motif Signatures
An efficient data structure for the abstraction of attacks is necessary when sharing attack information and process them in a distributed manner [8, 4]. To evaluate the compression rate of our motif signatures during the real-world experiments, we measured the total size required at different stages, i.e., in representation structures, for the 34,204 attacks in the DShield data set:
[TABLE]
Hence, the size was reduced to 1.12% of the full alert data and 1.43% of the alerts with relevant attributes only.
IV-C2 Signature-based Classification
We first utilize reference-based clustering to identify attacks that we found in the DShield data set that can be classified using reference scenarios. If identified, we assign the attack to one of the six reference scenarios based on the similarity threshold . For the attacks that could not be classified, we apply unsupervised clustering, which results in additional classes, i.e., unknown attack scenarios.
Figure 7 shows the performance of the reference-based classification depending on . Figure 7(a) in particular illustrates how many attacks or scenarios have been classified or detected with the help of reference scenarios. For that, the curve labeled attacks plots the portion of the 34,204 attacks that have been assigned to one of the six reference scenarios. For a similarity threshold , all attacks are assigned a reference scenario. For larger , the attacks have to match the reference scenarios more closely. It is likely that the attacks obtained from the DShield data set come with false-positive alerts. Therefore, these attacks cannot be assigned a reference scenario when close matches with the reference scenarios are required. Furthermore, the data set can contain attacks that are not covered by our six reference scenarios and will therefore not match any of them. In the marked range of , however, we were able to classify at least 76% and up to 96% of the attacks in the DShield data set. In Figure 7(a) we investigate the relation between the number of scenarios detected through reference-based clustering and the number of scenarios detected through unsupervised clustering of the remaining attacks. We also plot the portion of the total detected scenarios which are identified with the help of a reference scenario. In the marked range of , they are between 4% and 26%.
Figure 7(b) shows the distribution of reference scenarios among the identified attacks. The portions of the scenarios are stacked, so the aggregation of all six scenarios is 100%. As expected from a real-world data set, the most predominant attack scenarios are DDoS with in between 60% and 69% as well as Scan with in between 29% and 31%. Although for each of the six reference scenarios there is at least one attack identified in the marked range of , we have to note that not all reference scenarios can technically show up in the DShield data set. This is because the destination IP addresses are hashed and therefore it is not possible to observe attacks in which an individual host is both, an attacker and a victim. This excludes the scenarios worm, expl, and conv. Considering this technical restriction, we conclude that in practice a large similarity threshold should be chosen to avoid an unacceptable amount of false positive detections.
IV-C3 Unsupervised Clustering
We now evaluate the unsupervised clustering of the complete DShield real-world data set. For that, we apply hierarchical clustering (cf. Section III-B2) on the DShield attacks and report the analysis of resulting classes in Figure 8 depending on the similarity threshold .
Figure 8(a) shows the number of detected scenarios for unsupervised clustering on a log-scale. Within the marked range of , we see between 33 and 174 clusters. Defining scenarios by higher similarities, i.e., , larger than 0.9, rapidly increases the number of scenarios and should only be used for fine-grained scenarios. We also count the number of detected scenarios resulting from an unsupervised clustering of attacks that could not be assigned a reference scenario. We call these detected scenarios remaining in Figure 8(a). The number of detected scenarios indicate that only searching for our six reference scenarios is not enough. Instead, it is important to also apply unsupervised clustering at least on attacks for which no reference scenario can be assigned.
We also compare the results of reference-based and unsupervised clustering. Our motivation is to find out for which value of the clustering parameter we get consistent results. As we have no ground-truth, we define two metrics to measure the similarity between the reference clusters for respective reference signatures and the unsupervised clusters .
The metric Equivalent indicates how close candidates among the unsupervised clusters match our reference clusters . For that, we find the best candidate cluster for every reference cluster based on the Jaccard index, i.e., intersection over union, which is calculated by . An unsupervised cluster can be matched to at most one reference cluster . The metric represents the average Jaccard metric for the best matches among all reference clusters .
The metric Homogeneity indicates the average accuracy for clusters that include at least one attack identified by the reference-based classification. In each of these clusters , among all contained attacks, we measure the fraction of attacks from the scenario that is present in the cluster most frequently. The metric represents the average homogeneity among all these clusters weighted by their sizes.
The comparison between signature-based clustering and unsupervised clustering according to the metrics Equivalent and Homogeneity is shown in Figure 8(b), depending on the similarity threshold . For the marked range of , the Homogeneity is between 87% and 97% and the Equivalent is between 56% and 72%. According to the experiment results of Section IV-C2, a similarity threshold close to 0.9 seems to be reasonable. Although the highest Homogeneity is achieved for , which is in the lower half of the possible values for , the Homogeneity at is still at 91%. However, we note that between the metric Homogeneity drops to 87%. This drop correlates with the changes of the proportions among the different attack scenarios in Figure 7(b). From that perspective, would be recommended to find attacks for our six scenario classes.
The two metrics Homogeneity and Equivalent for comparing signature-based clustering and unsupervised clustering indicate the following. Clustering attacks from unknown scenarios is done with high uncertainty. While unsupervised clustering is able to differentiate between attacks from different scenarios, it will not be able to perfectly classify a high variability of attacks without any previous knowledge. Hence, it is a good approach to provide as much reference scenarios as possible and to use unsupervised clustering to learn new attack scenarios and to create reference scenarios in a semi-supervised fashion.
V Conclusion
With our motif-based approach, we are able to calculate characteristic signatures of attacks. To achieve that, we process large amounts of attacks from alerts reported by Intrusion Detection Systems. Clustered alerts are converted into motif signatures that are an abstraction over the original attack. These signatures are of small sizes and thus can be compared very fast. With the help of this abstraction, we can identify known attack scenarios, detect similar attacks, and can even learn about new attack scenarios. Our attack correlation is not limited to central grouping of similar attacks or to label them with their respective attack scenario. It is also suitable for collaborative intrusion detection, where individual sensors could exchange only the small motif signatures instead of large amounts of alerts.
Our experiments indicate that the motif-based abstraction is a suitable representation of attacks to preserve the scenario characteristics, especially for attacks of different sizes. Using six representative attack scenarios, up to 96% of attacks recorded in a real-world alert set were successfully classified. Based on both artificial and real-world experiments, we found the best performance could be achieved when clustering attacks with a similarity of at least 90%. Furthermore, we highlighted how we can learn and detect new attack scenarios when operating our approach adaptively.
For future work we plan to investigate more fine-grained attack scenarios. Also, we plan to use motif-based signatures for the detection of specific attack scenarios in large unclustered alert sets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. V. Zhou, C. Leckie, and S. Karunasekera, “A survey of coordinated attacks and collaborative intrusion detection,” Computers & Security , 2010.
- 2[2] E. Vasilomanolakis, S. Karuppayah, M. Mühlhäuser, and M. Fischer, “Taxonomy and Survey of Collaborative Intrusion Detection,” ACM Computing Surveys (CSUR) , no. 4, 2015.
- 3[3] C. G. Cordero, S. Hauke, M. Mühlhäuser, and M. Fischer, “Analyzing flow-based anomaly intrusion detection using Replicator Neural Networks,” in Annual Conference on Privacy, Security and Trust (PST) , 2016.
- 4[4] V. Yegneswaran, P. Barford, and S. Jha, “Global Intrusion Detection in the DOMINO Overlay System,” in Network and Distributed System Security Symposium (NDSS) , 2004.
- 5[5] M. Cai, K. Hwang, Y.-K. Kwok, S. Song, and Y. Chen, “Collaborative Internet Worm Containment,” IEEE Security & Privacy , vol. 3, 2005.
- 6[6] S. Haas and M. Fischer, “GAC: Graph-Based Alert Correlation for the Detection of Distributed Multi-Step Attacks,” in ACM/SIGAPP Symposium On Applied Computing (SAC) , 2018.
- 7[7] C. V. Zhou, C. Leckie, and S. Karunasekera, “Decentralized multi-dimensional alert correlation for collaborative intrusion detection,” Journal of Network and Computer Applications , no. 5, 2009.
- 8[8] M. E. Locasto, J. J. Parekh, A. D. Keromytis, and S. J. Stolfo, “Towards Collaborative Security and P 2P Intrusion Detection,” in IEEE Workshop on Information Assurance and Security , 2005.