Finding our Way in the Dark: Approximate MCMC for Approximate Bayesian Methods
Evgeny Levi, Radu V. Craiu

TL;DR
This paper introduces perturbed MCMC algorithms that recycle past samples to accelerate approximate Bayesian methods like ABC and BSL, making complex Bayesian analyses more computationally feasible.
Contribution
It presents a novel MCMC approach that enhances efficiency of ABC and BSL by leveraging sample recycling, supported by theoretical analysis and empirical validation.
Findings
Significant reduction in the number of simulations needed.
Maintains accuracy while improving computational speed.
Effective in complex Bayesian models.
Abstract
With larger data at their disposal, scientists are emboldened to tackle complex questions that require sophisticated statistical models. It is not unusual for the latter to have likelihood functions that elude analytical formulations. Even under such adversity, when one can simulate from the sampling distribution, Bayesian analysis can be conducted using approximate methods such as Approximate Bayesian Computation (ABC) or Bayesian Synthetic Likelihood (BSL). A significant drawback of these methods is that the number of required simulations can be prohibitively large, thus severely limiting their scope. In this paper we design perturbed MCMC samplers that can be used within the ABC and BSL paradigms to significantly accelerate computation while maintaining control on computational efficiency. The proposed strategy relies on recycling samples from the chain's past. The algorithmic design…
Click any figure to enlarge with its caption.
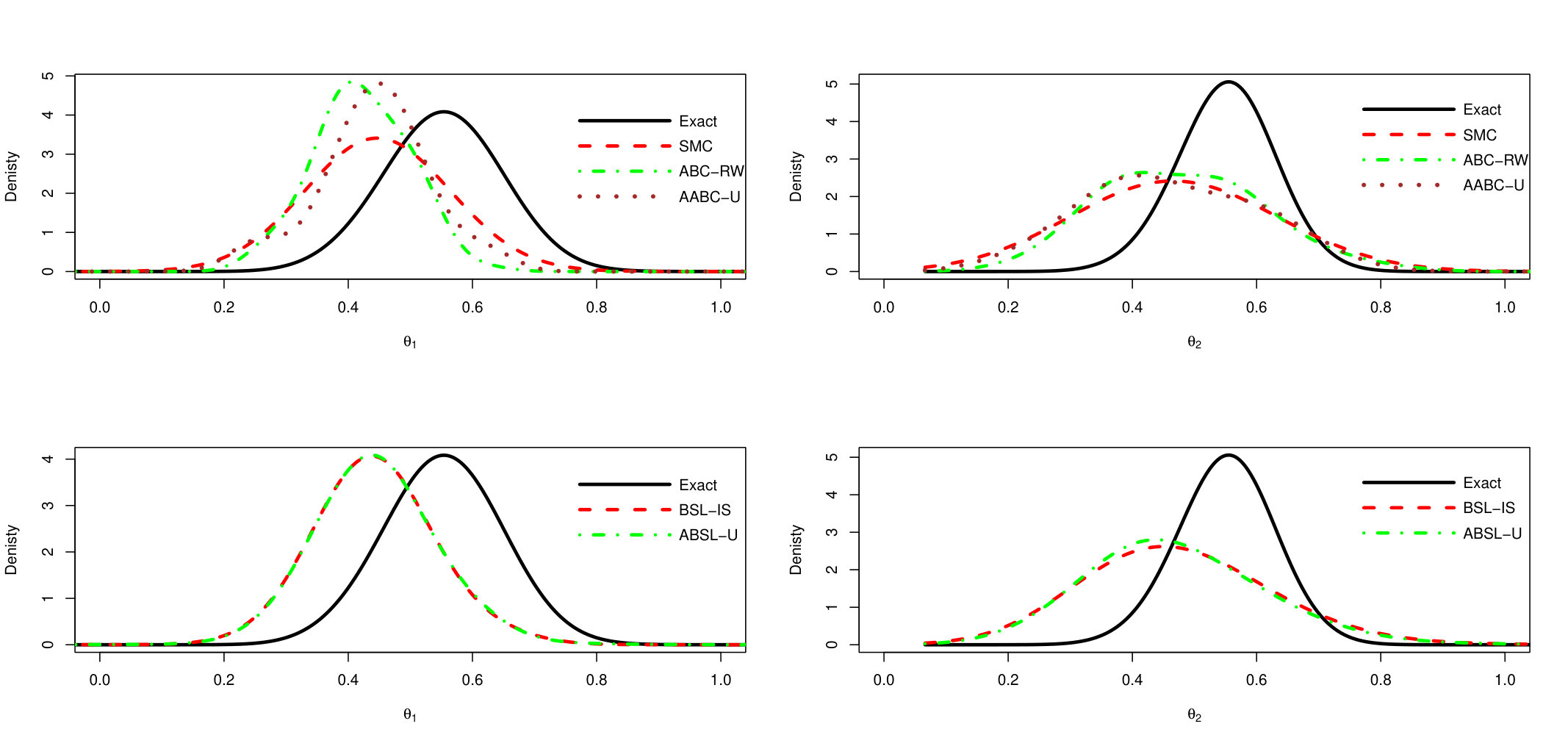 Figure 1
Figure 1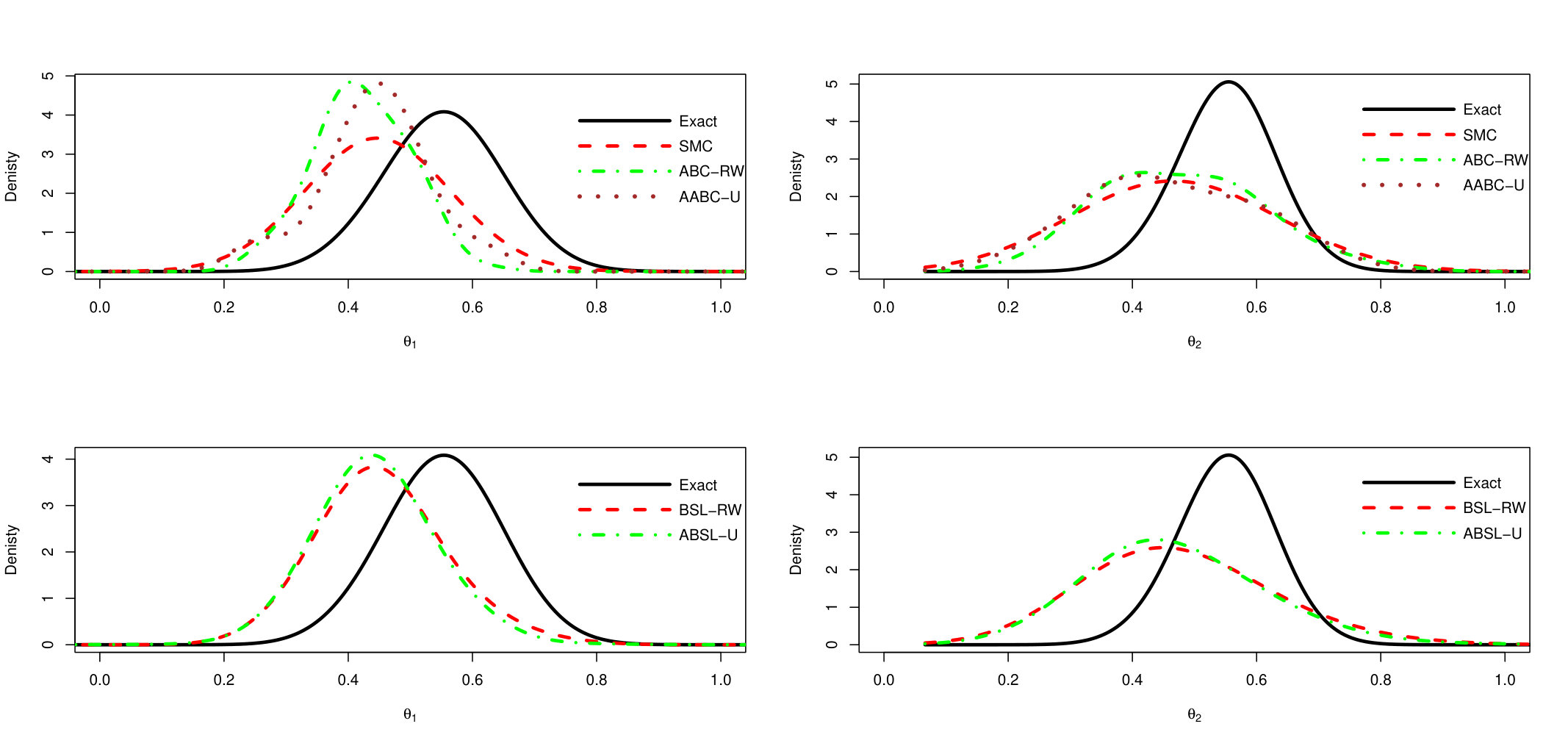 Figure 2
Figure 2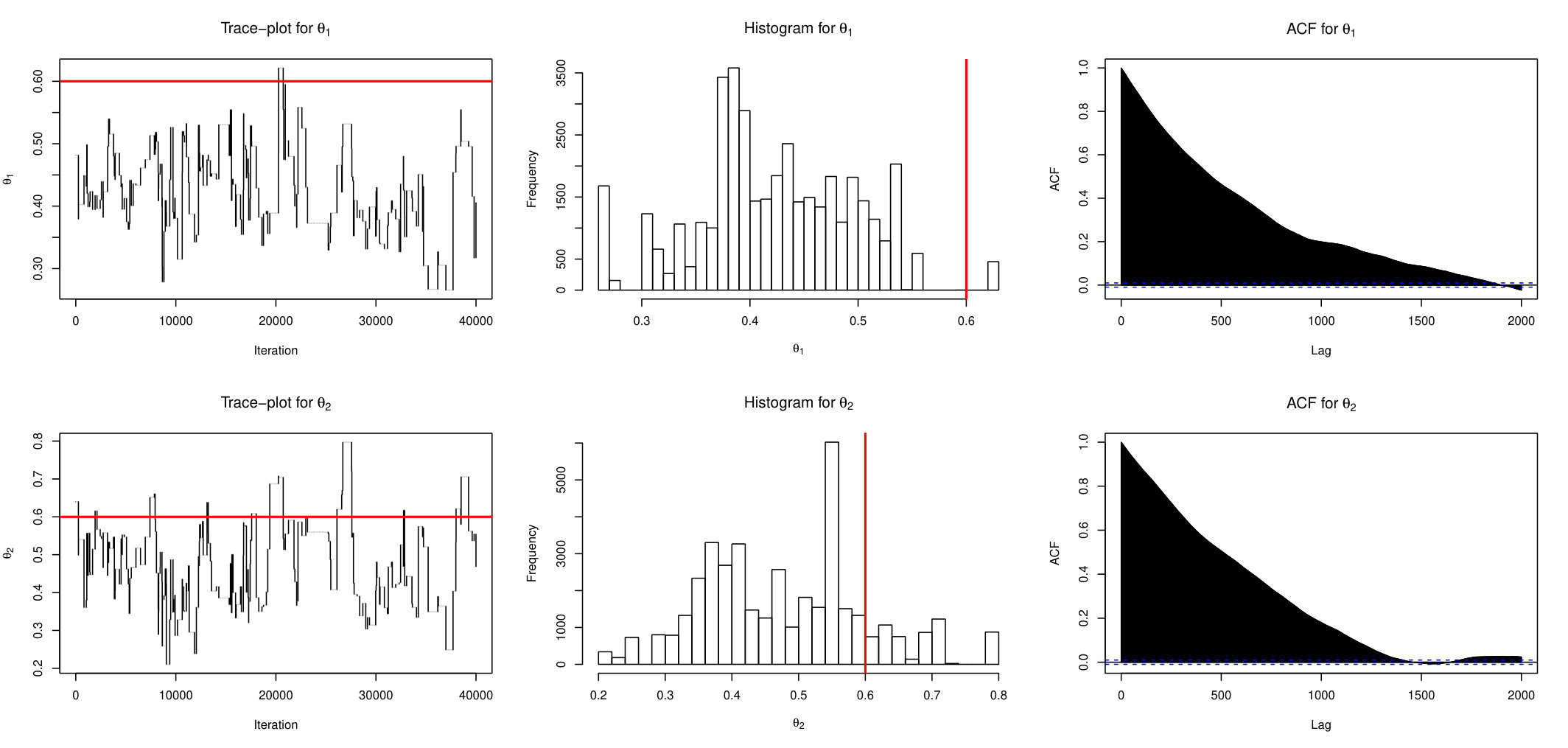 Figure 3
Figure 3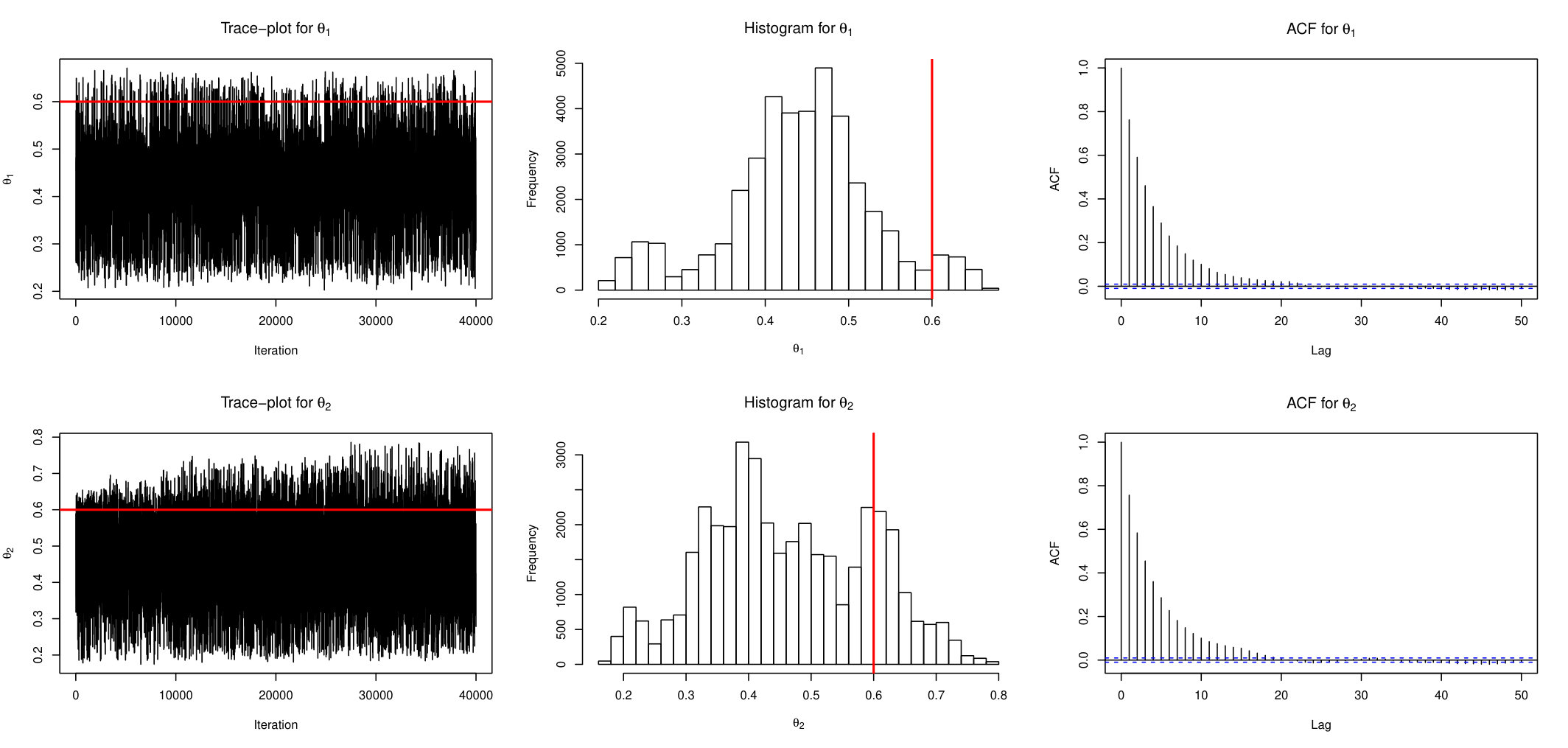 Figure 4
Figure 4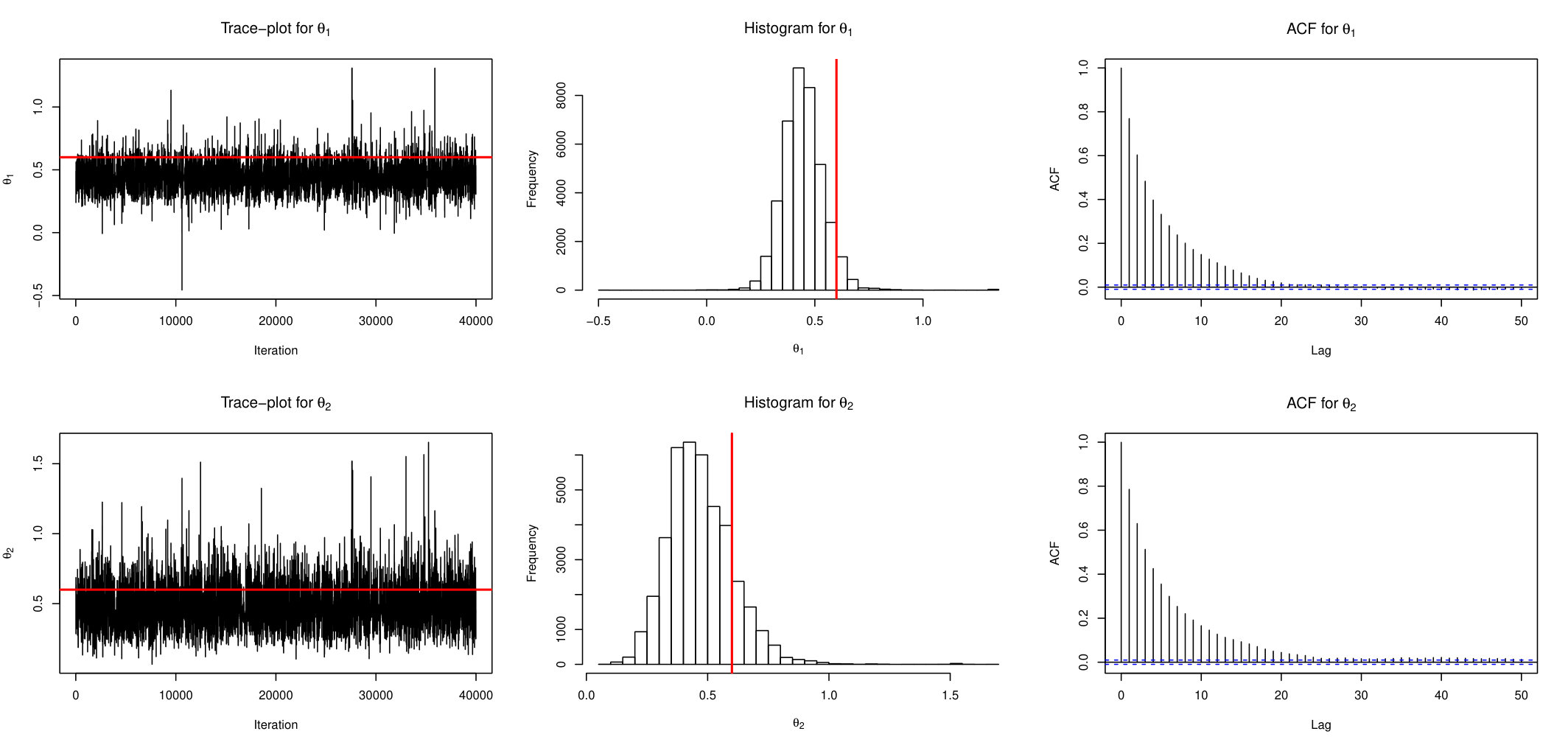 Figure 5
Figure 5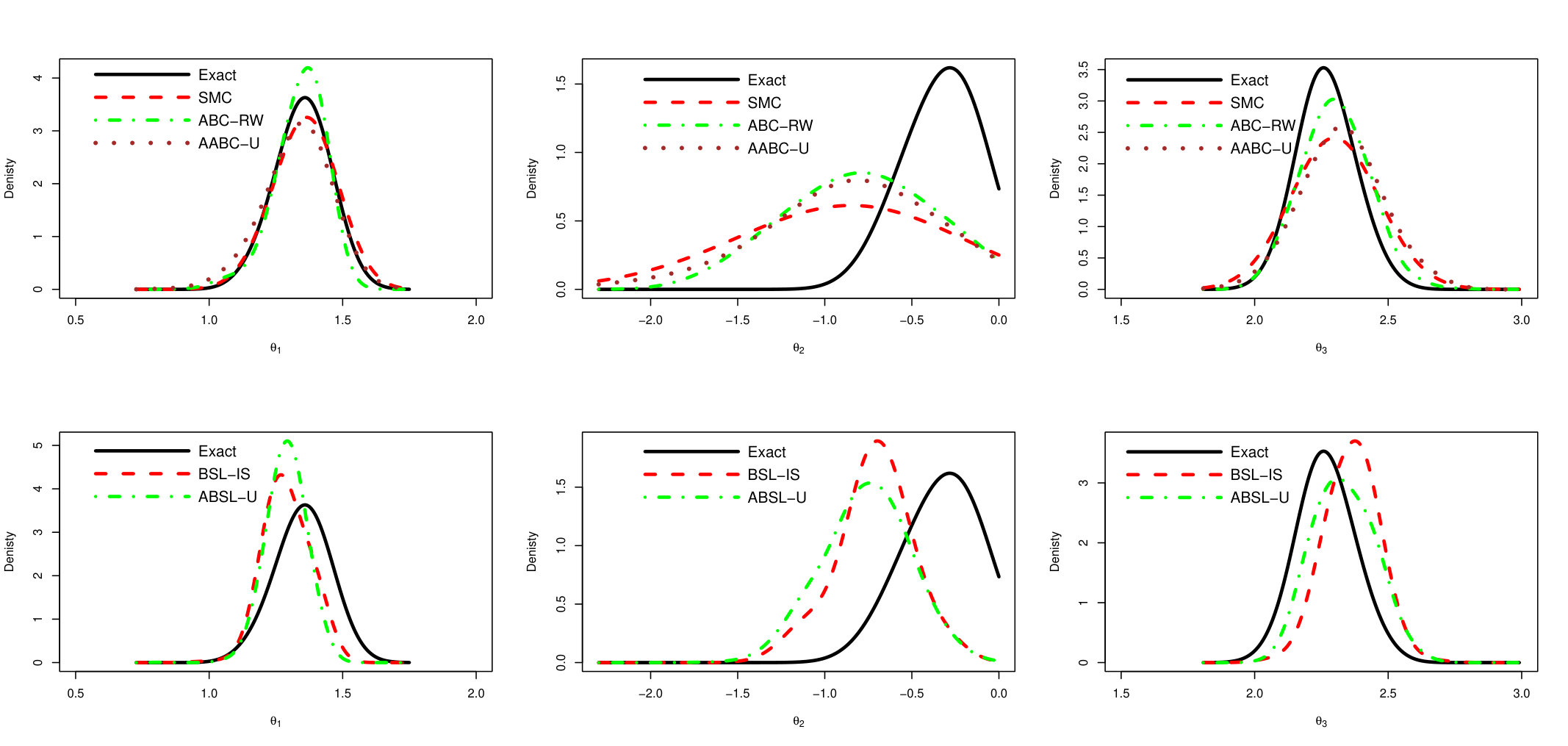 Figure 6
Figure 6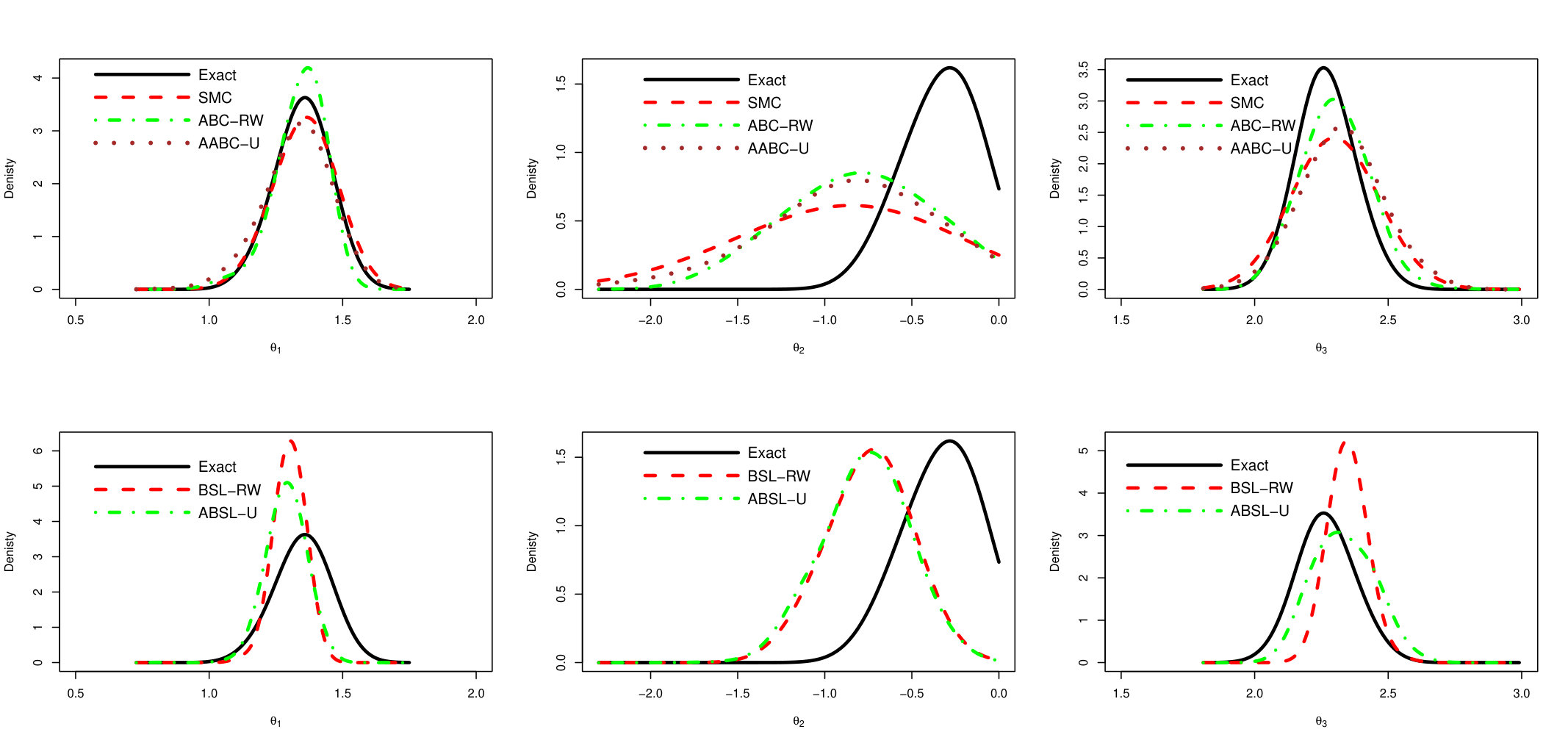 Figure 7
Figure 7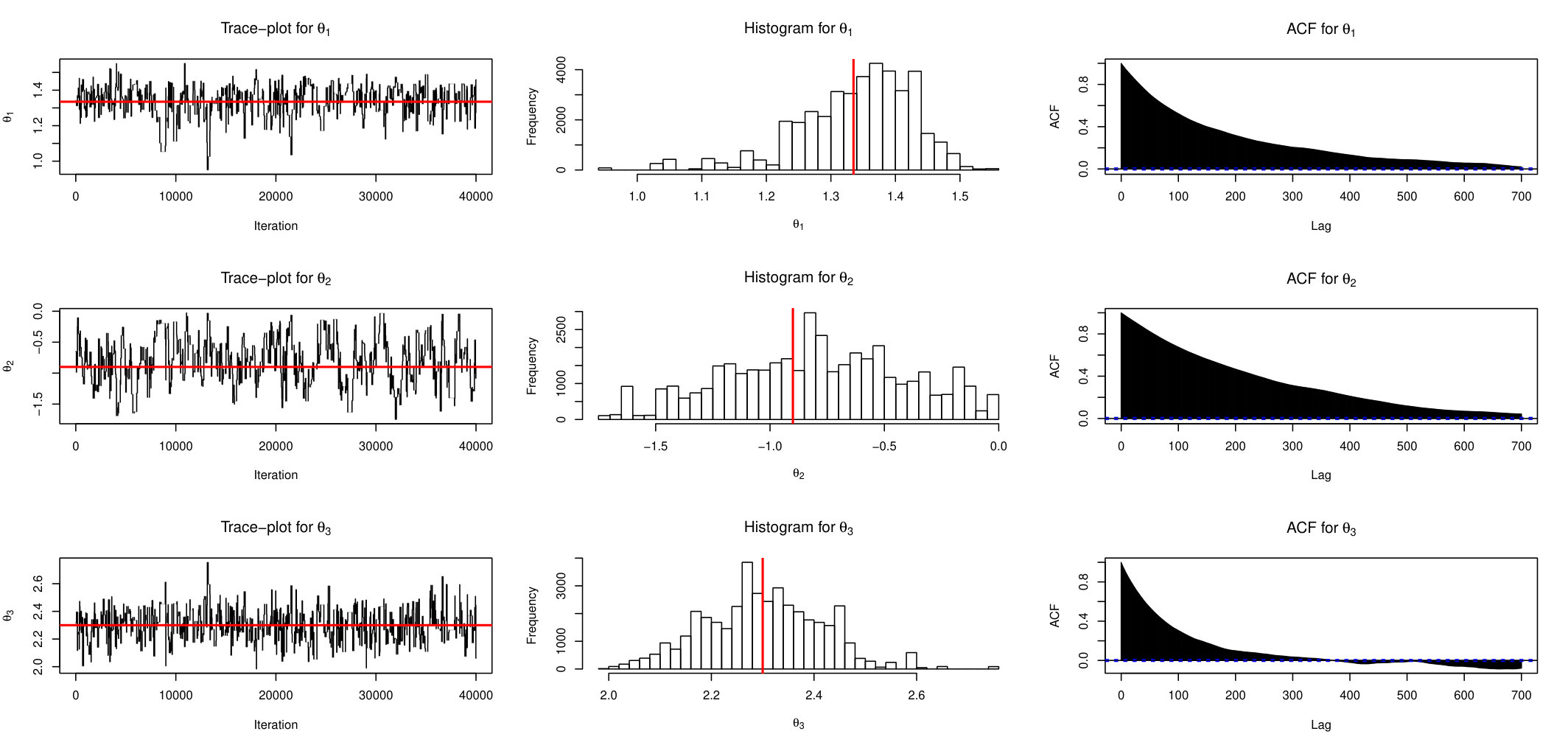 Figure 8
Figure 8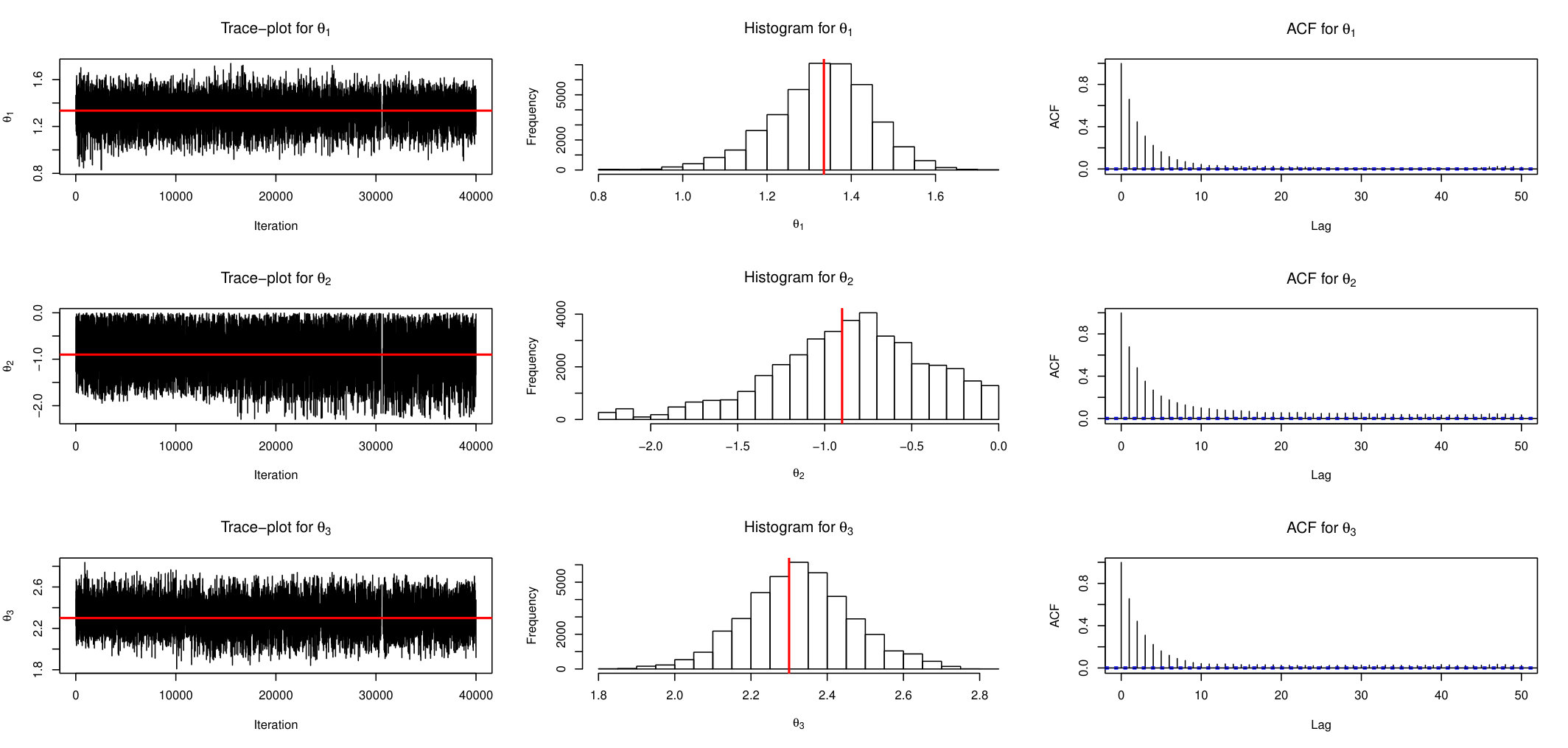 Figure 9
Figure 9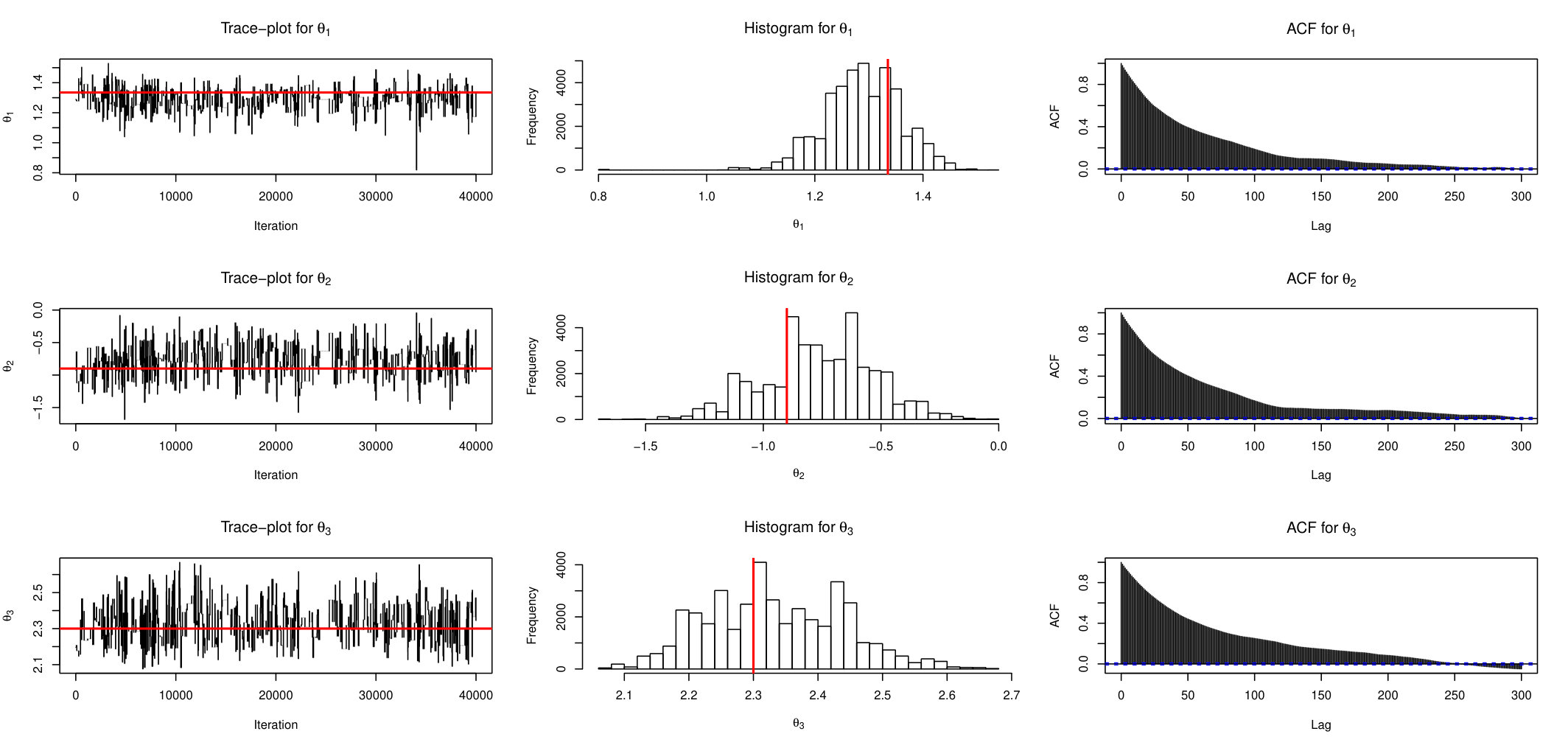 Figure 10
Figure 10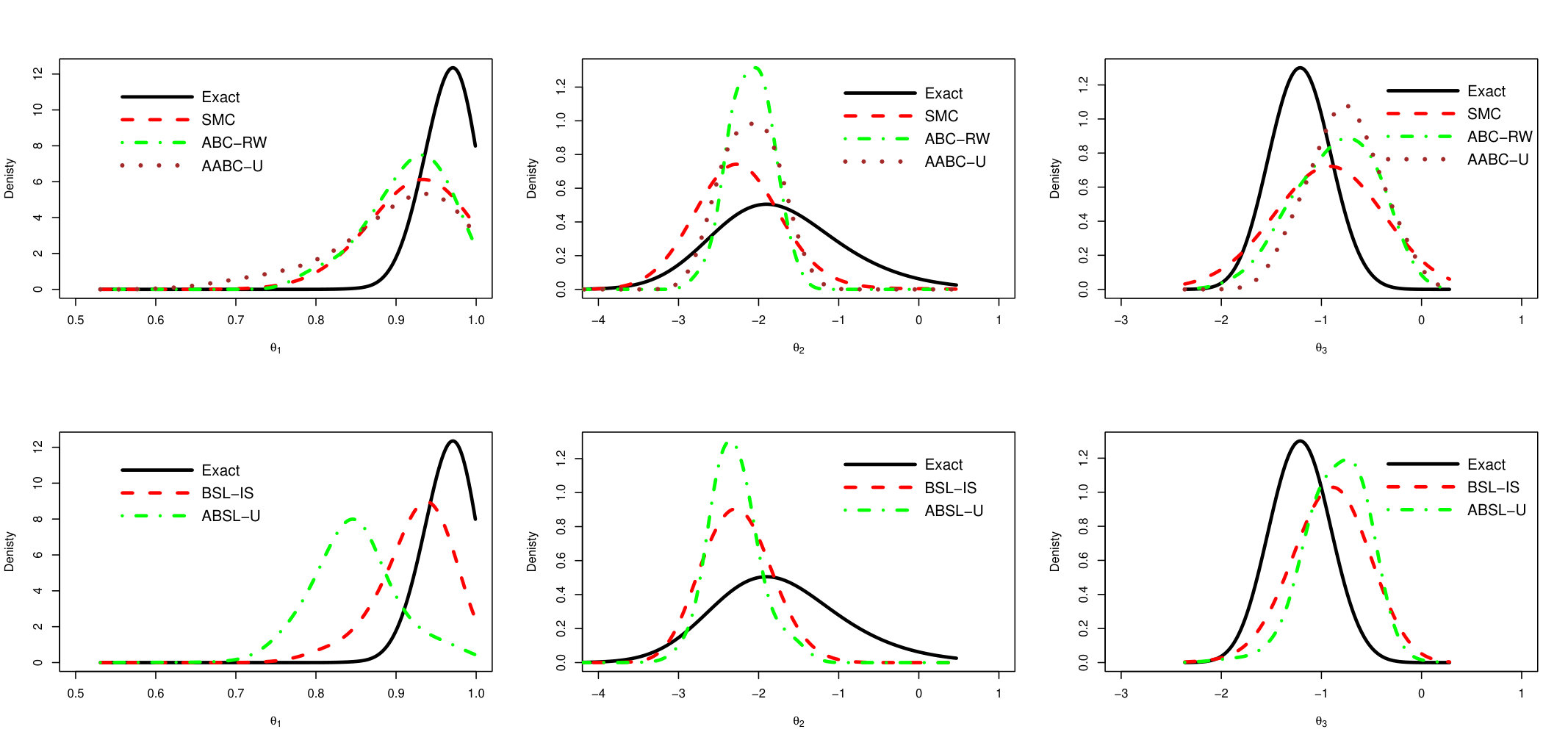 Figure 11
Figure 11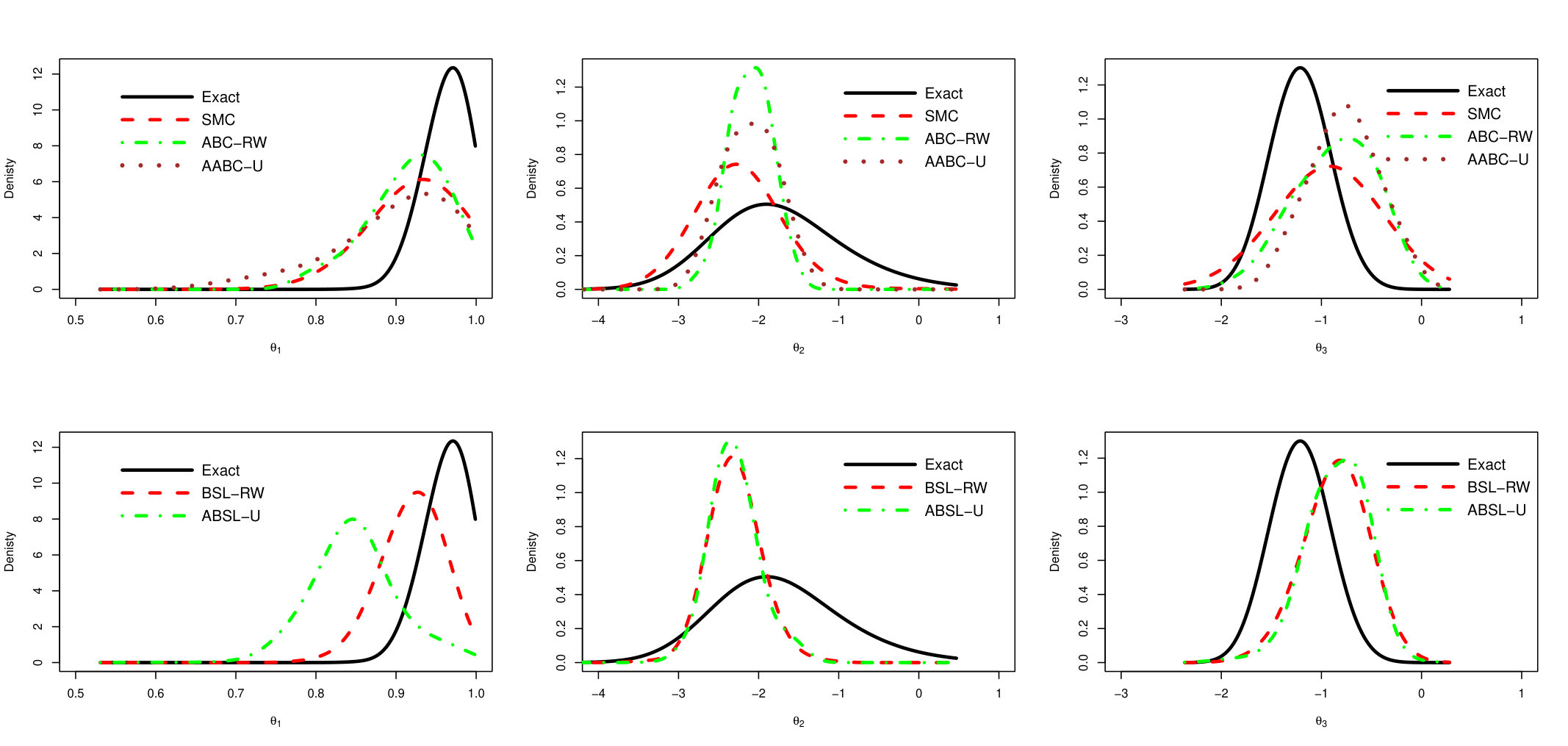 Figure 12
Figure 12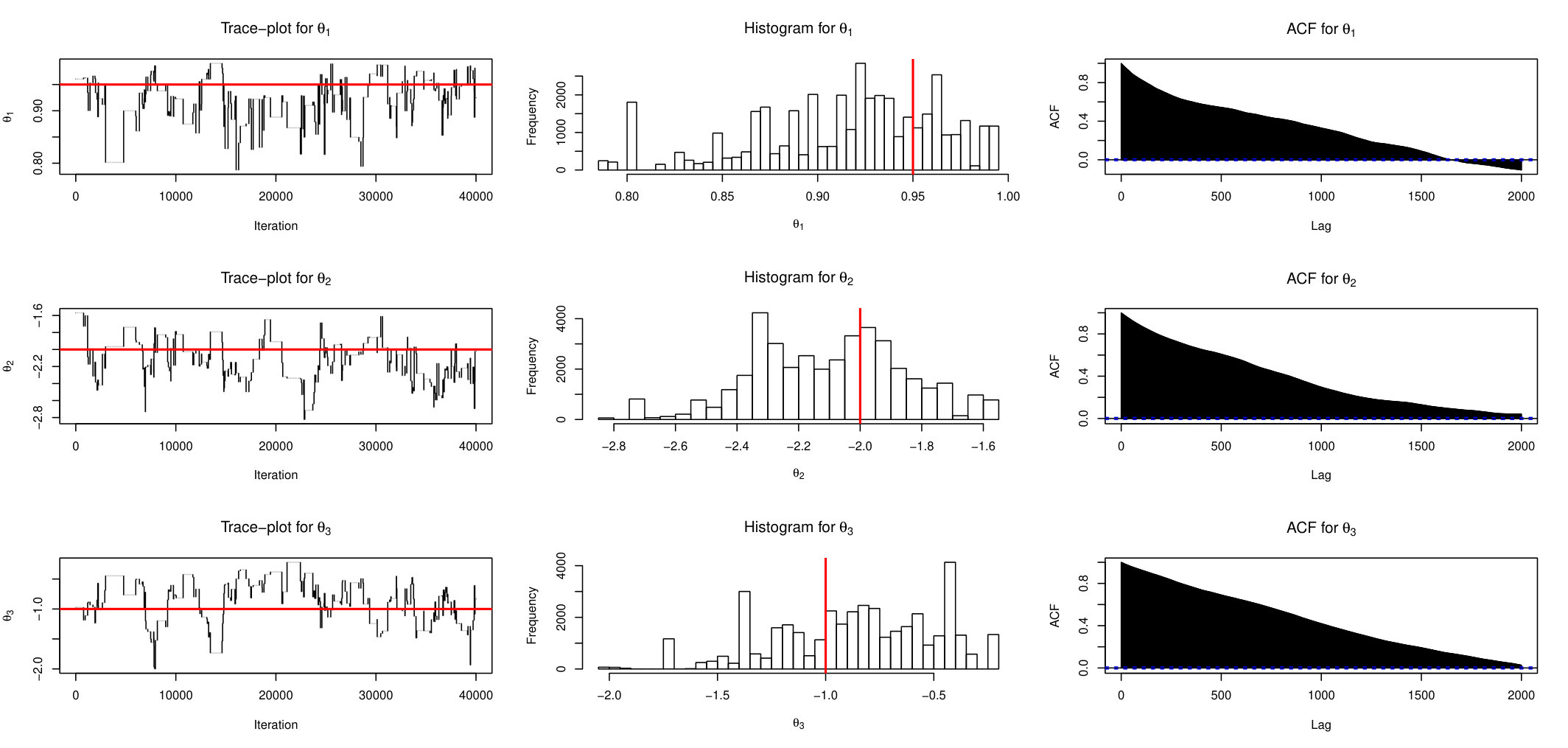 Figure 13
Figure 13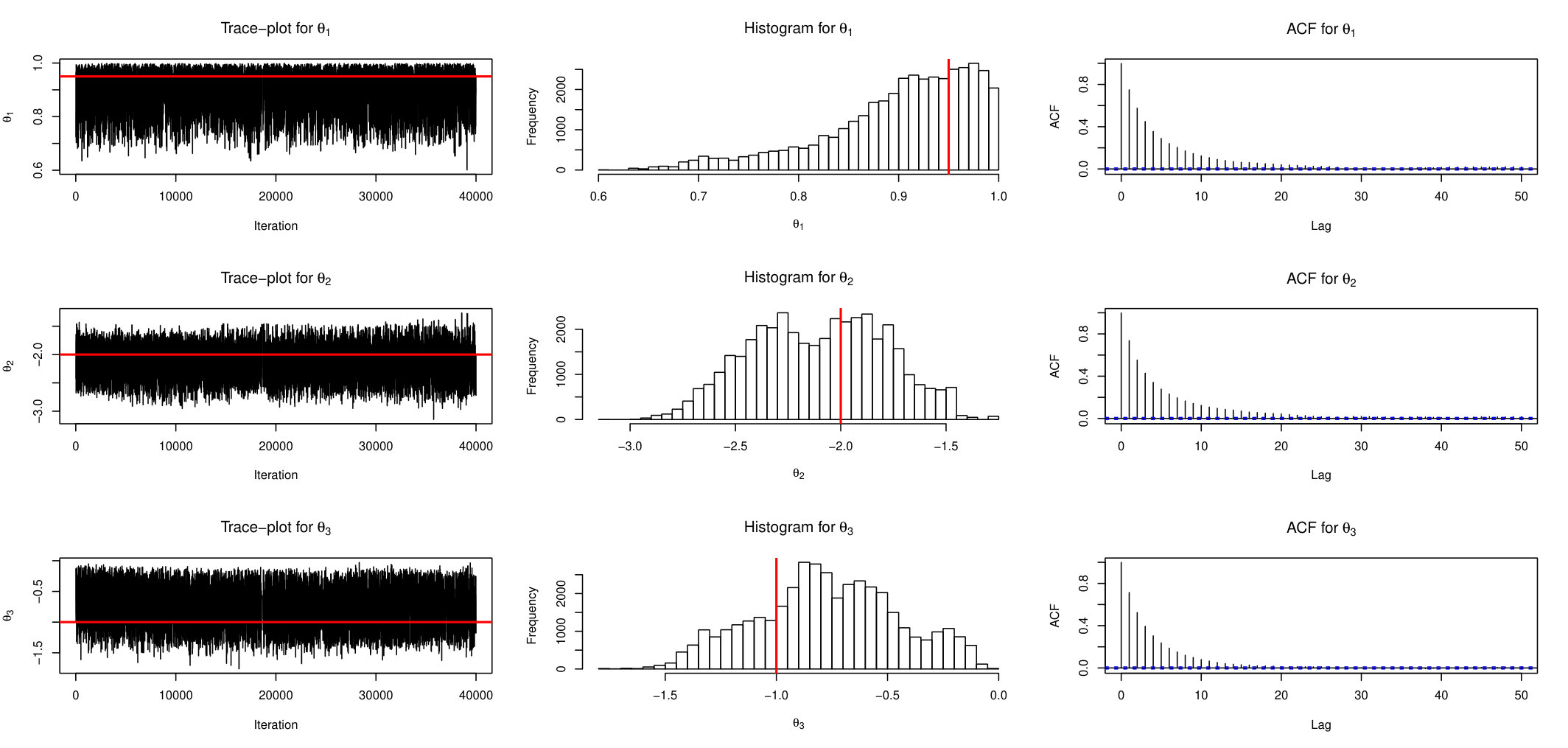 Figure 14
Figure 14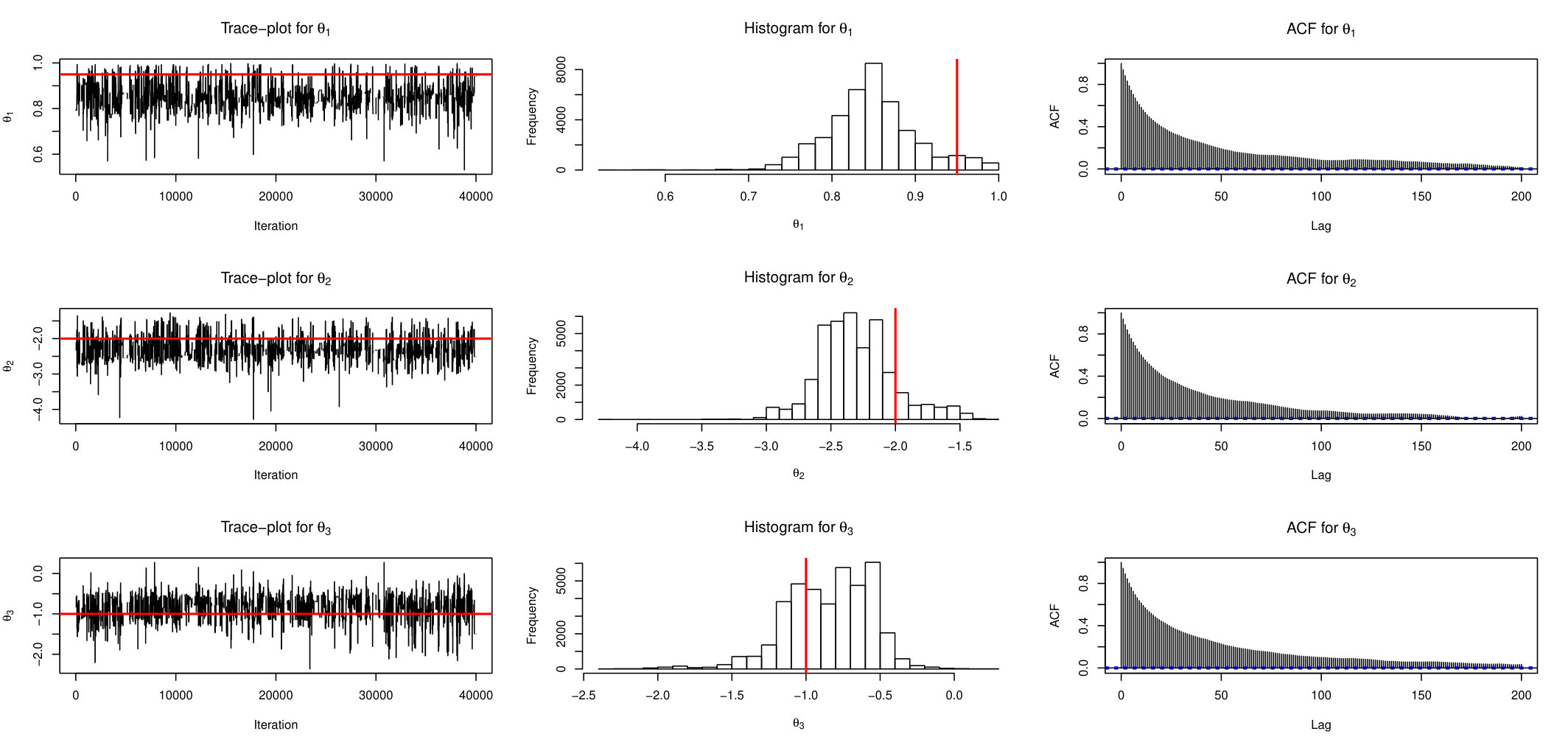 Figure 15
Figure 15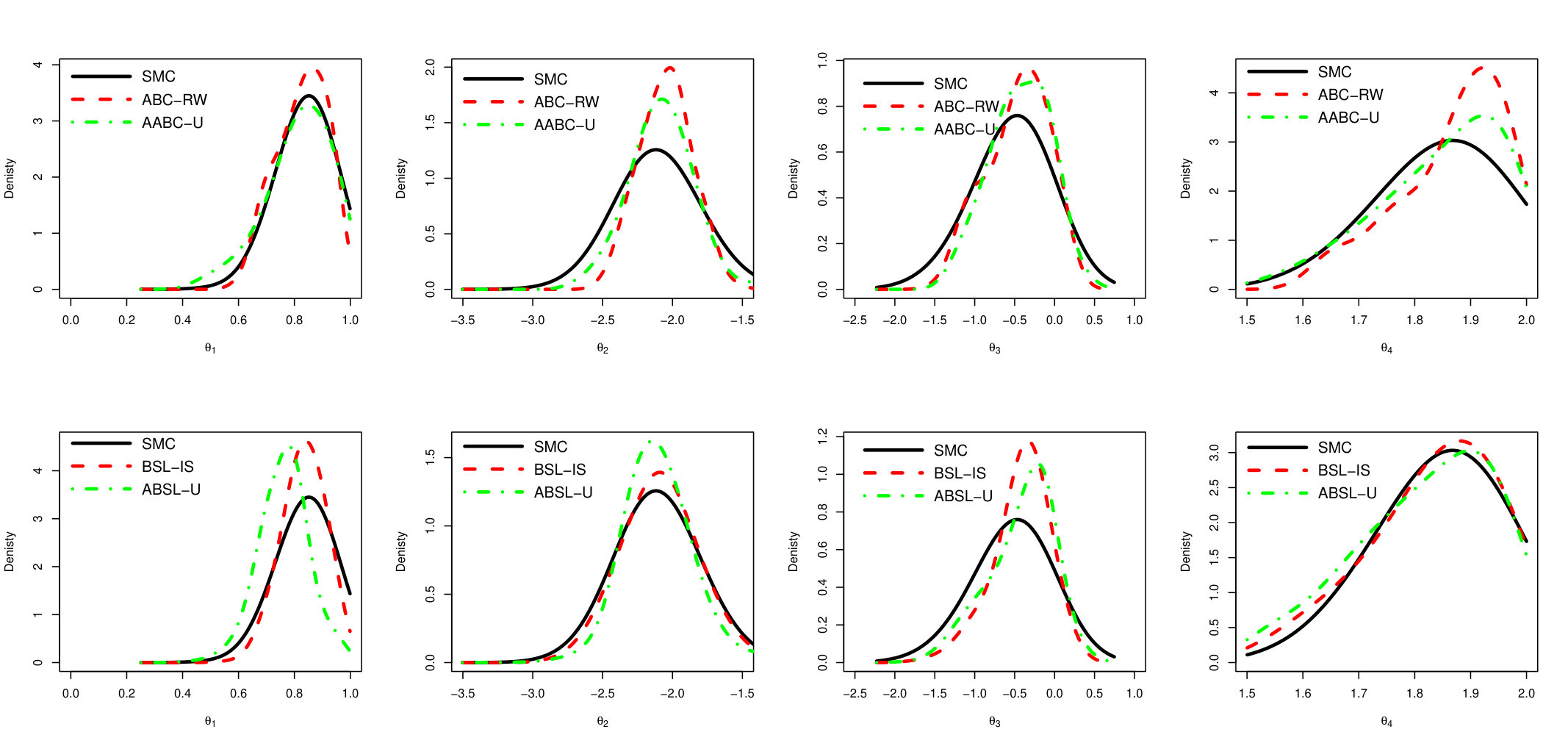 Figure 16
Figure 16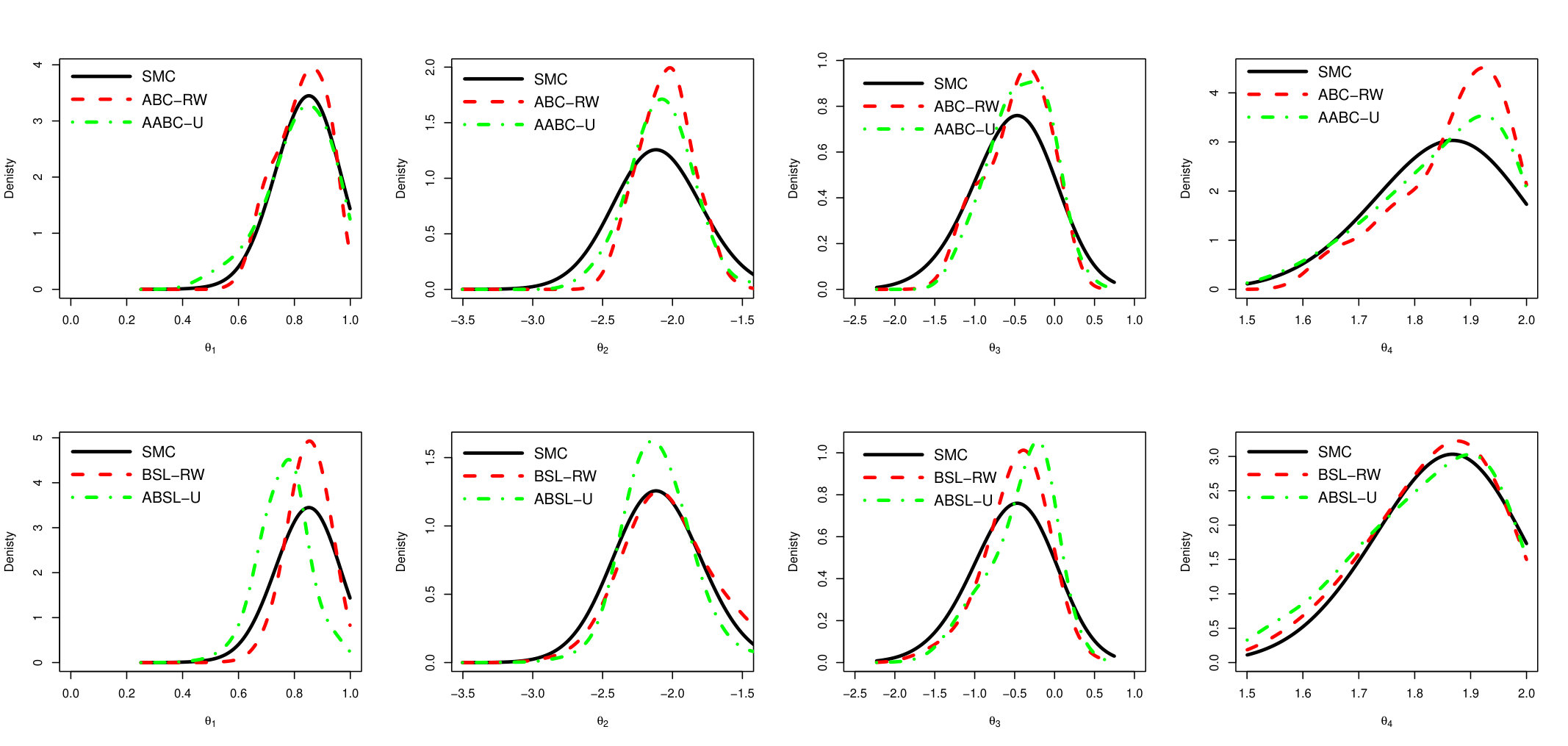 Figure 17
Figure 17 Figure 18
Figure 18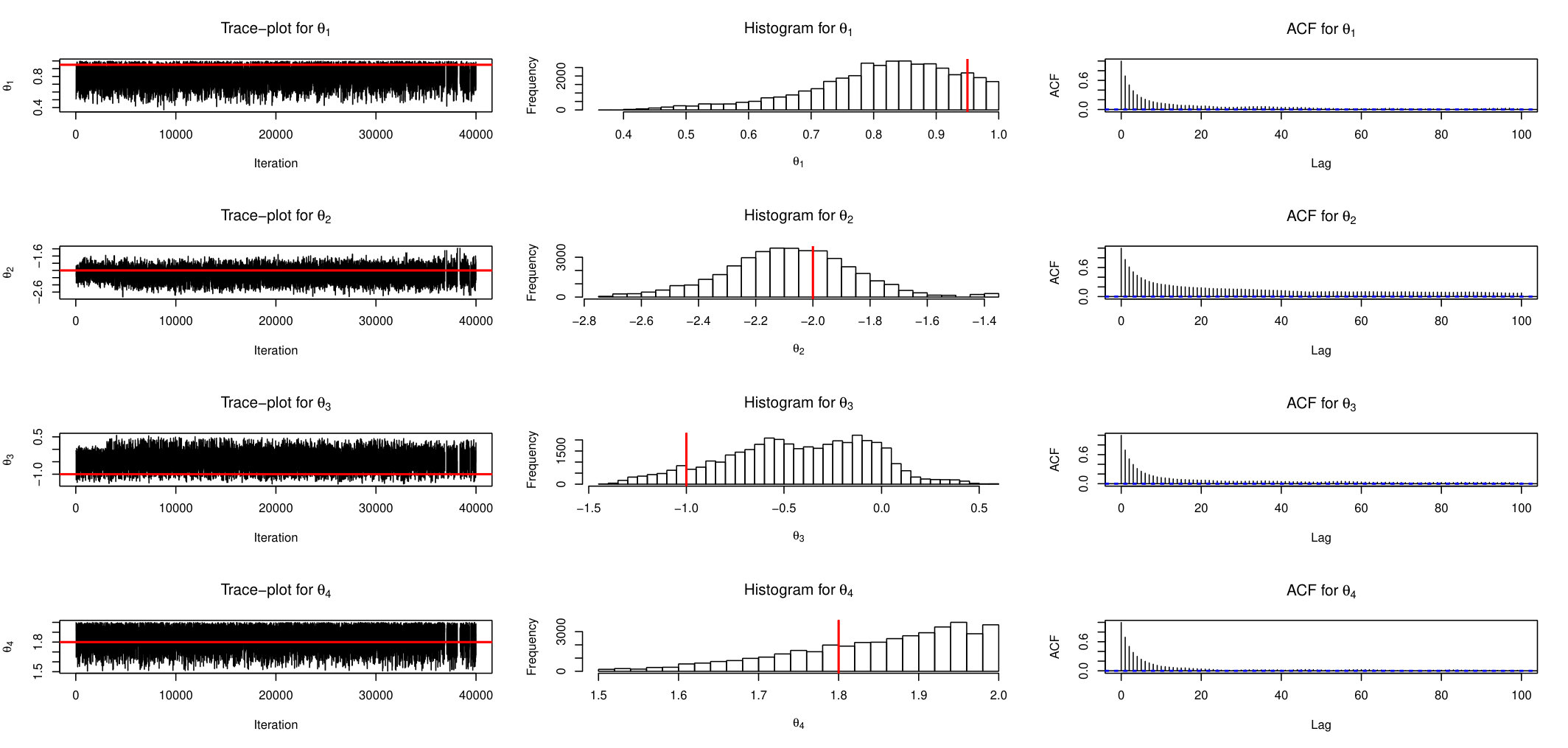 Figure 19
Figure 19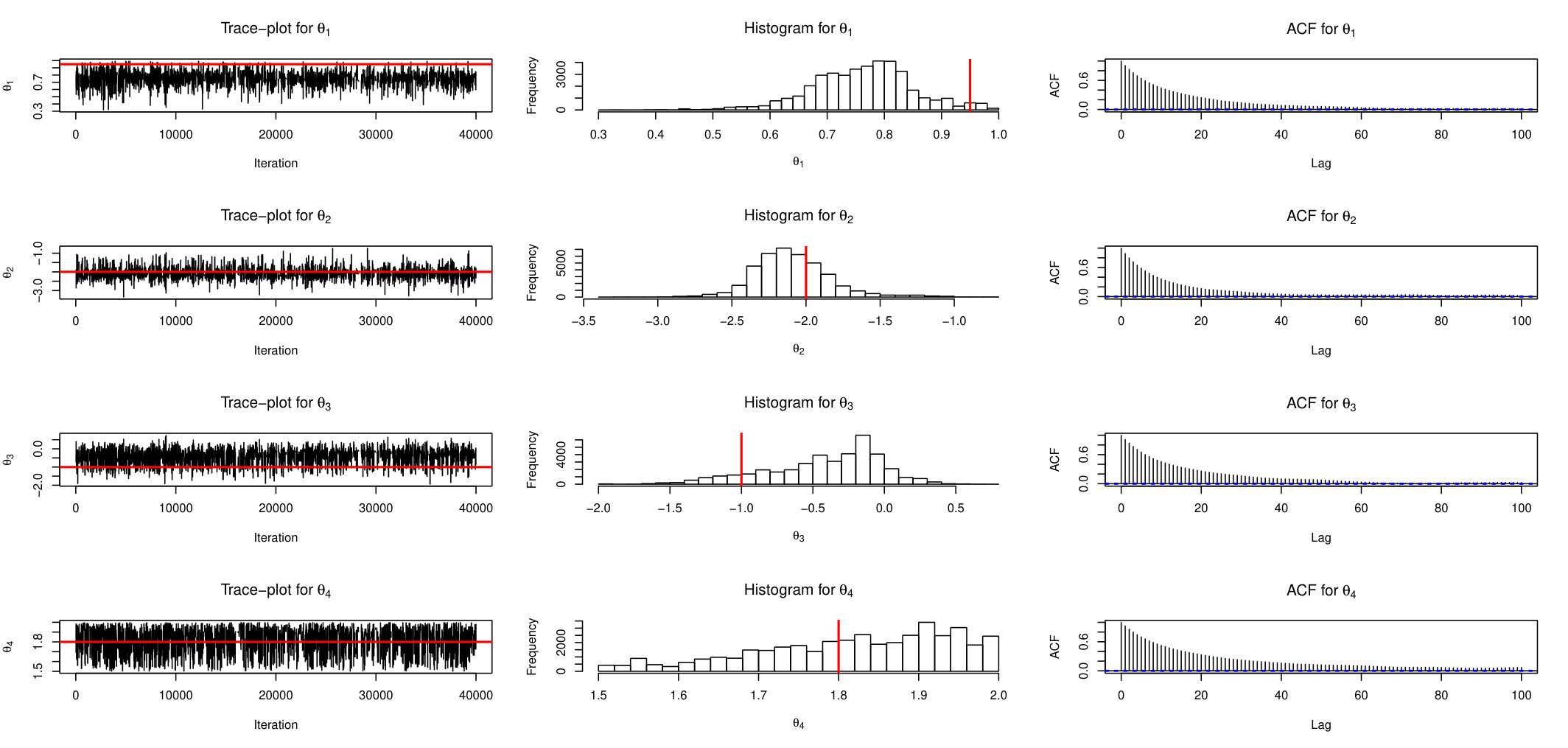 Figure 20
Figure 20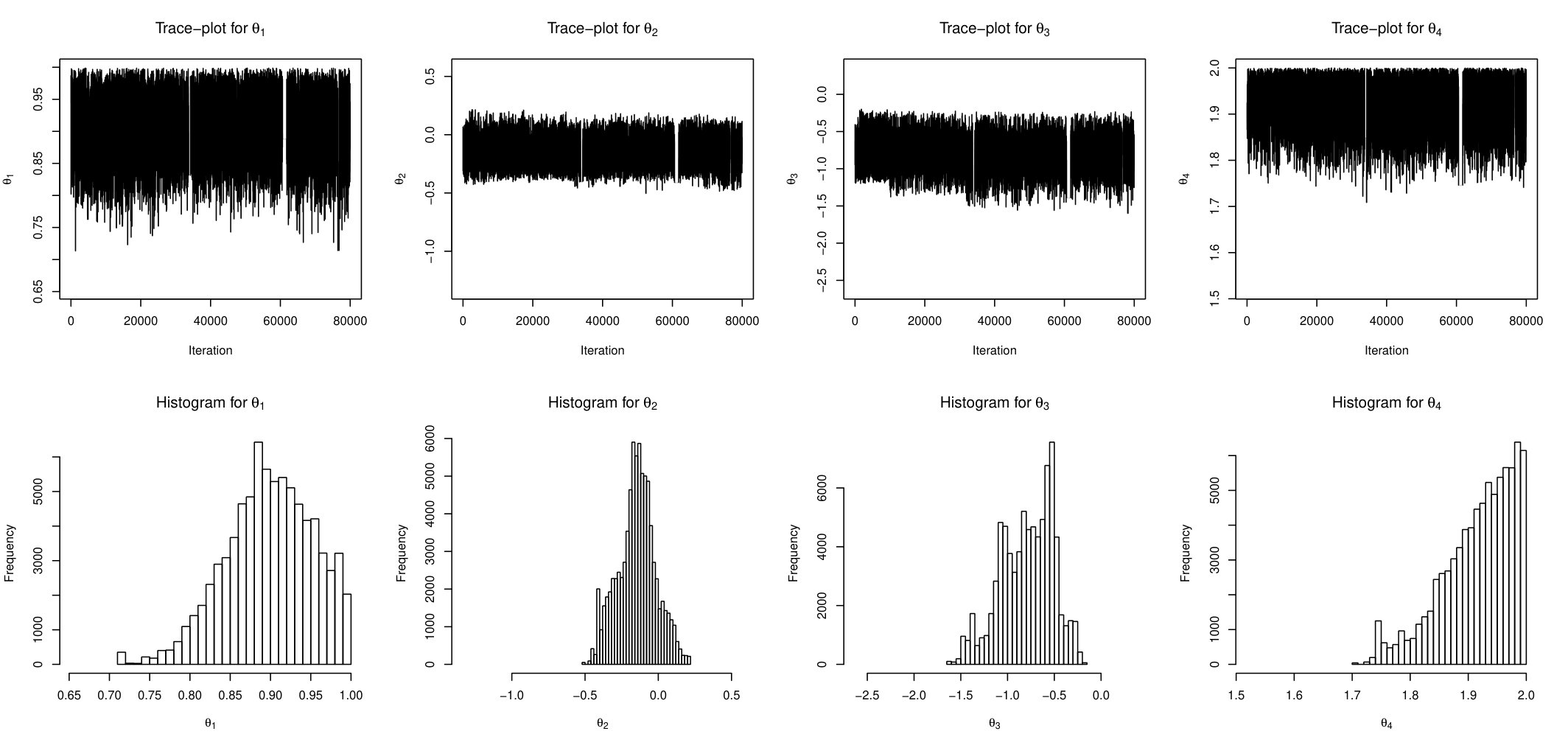 Figure 21
Figure 21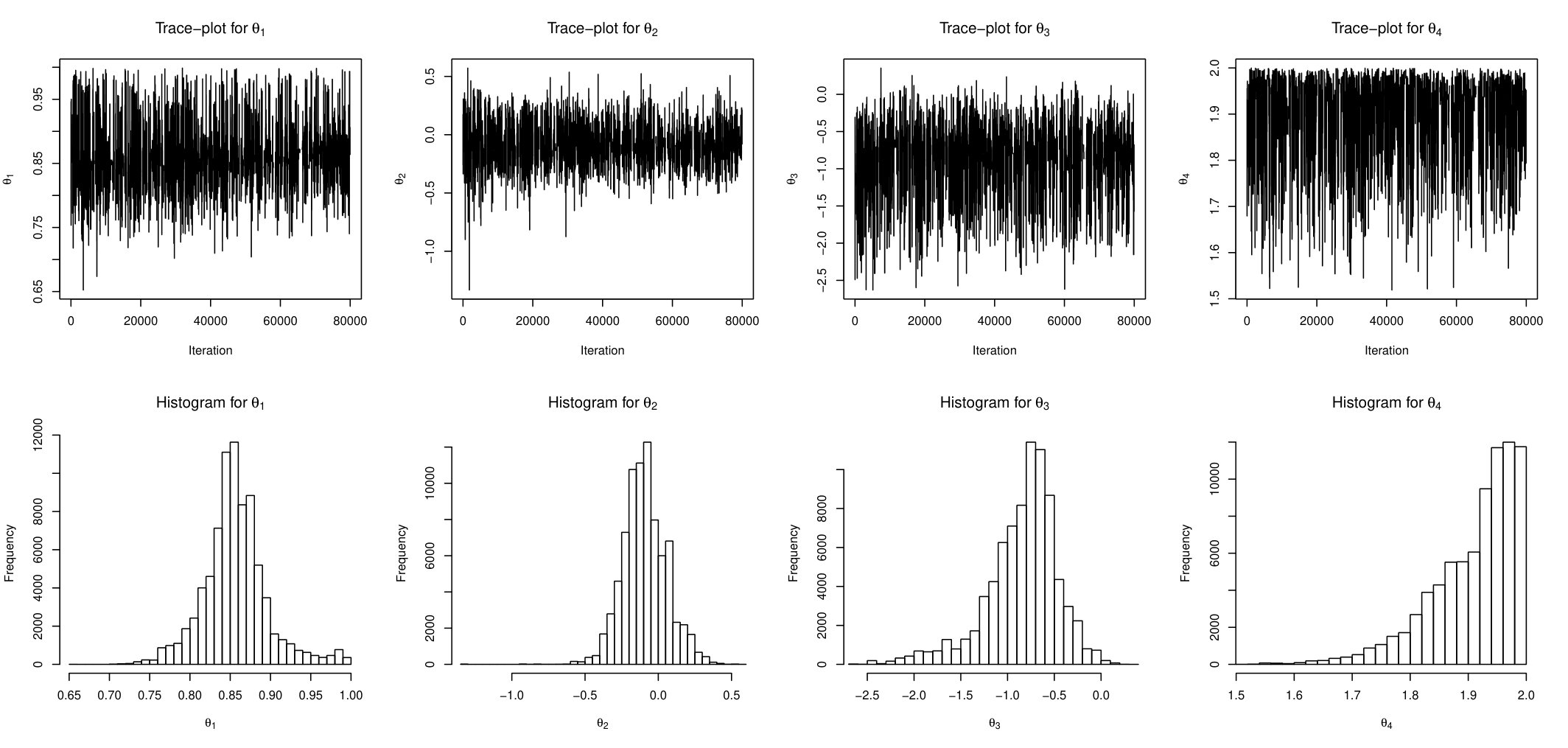 Figure 22
Figure 22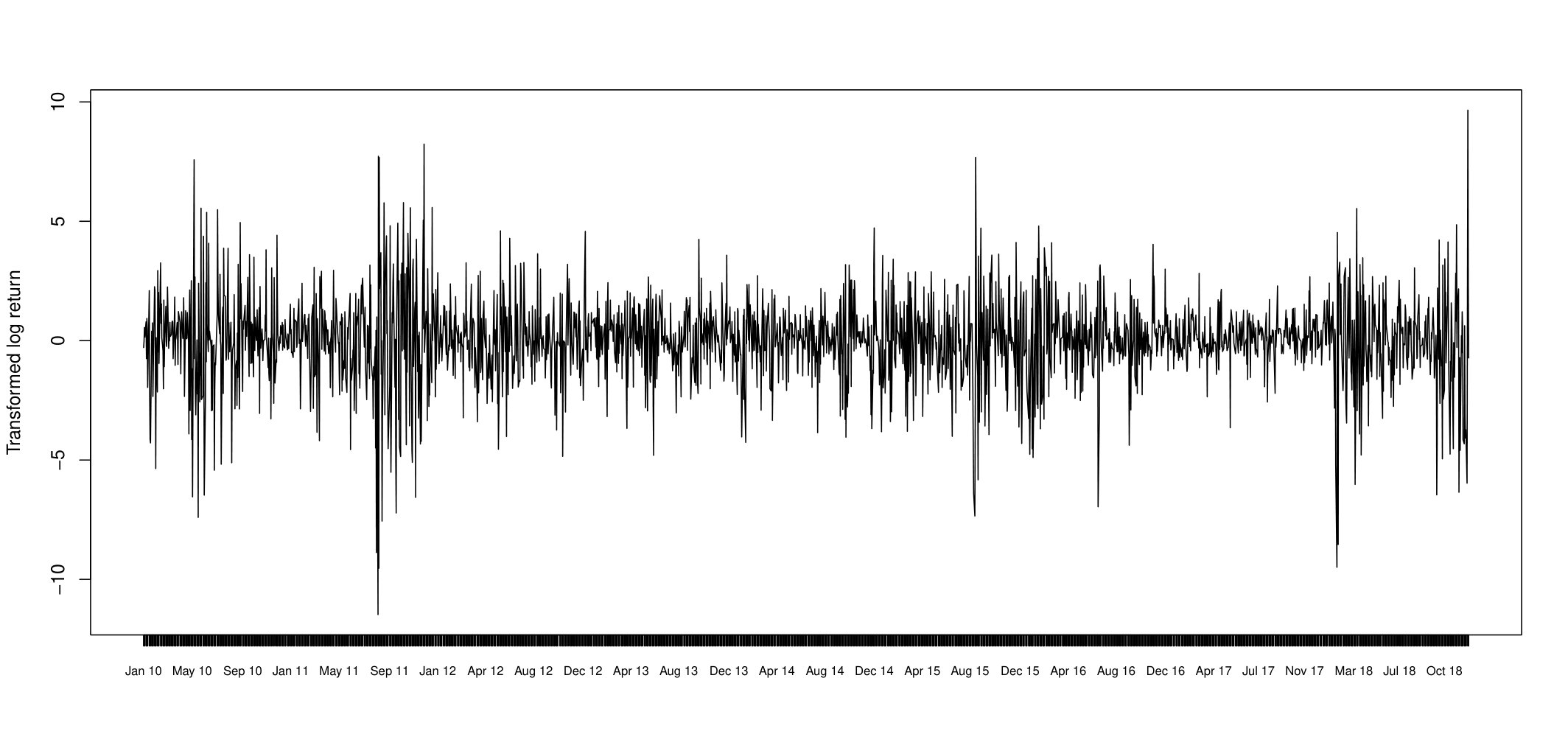 Figure 23
Figure 23| Diff with exact | Diff with true parmater | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | DIM | DIC | TV | ESS | ESS/CPU | |||
| SMC | 0.082 | 0.0045 | 0.418 | 0.014 | 0.115 | 0.116 | 471 | 0.505 |
| ABC-RW | 0.088 | 0.0063 | 0.466 | 0.016 | 0.123 | 0.124 | 23 | 0.231 |
| ABC-IS | 0.084 | 0.0067 | 0.455 | 0.016 | 0.115 | 0.116 | 44 | 0.389 |
| AABC-U | 0.083 | 0.0071 | 0.444 | 0.018 | 0.116 | 0.117 | 3446 | 6.215 |
| AABC-L | 0.080 | 0.0067 | 0.438 | 0.017 | 0.112 | 0.113 | 2820 | 5.107 |
| BSL-RW | 0.082 | 0.0070 | 0.438 | 0.015 | 0.114 | 0.115 | 252 | 0.282 |
| BSL-IS | 0.081 | 0.0070 | 0.436 | 0.015 | 0.114 | 0.115 | 841 | 0.923 |
| ABSL-U | 0.081 | 0.0095 | 0.443 | 0.017 | 0.114 | 0.115 | 3950 | 5.584 |
| ABSL-L | 0.082 | 0.0078 | 0.441 | 0.015 | 0.114 | 0.115 | 4165 | 6.030 |
| Diff with exact | Diff with true parmater | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | DIM | DIC | TV | ESS | ESS/CPU | |||
| SMC | 0.152 | 0.0177 | 0.378 | 0.086 | 0.201 | 0.219 | 472 | 0.521 |
| ABC-RW | 0.135 | 0.0201 | 0.389 | 0.059 | 0.180 | 0.189 | 87 | 0.199 |
| ABC-IS | 0.139 | 0.0215 | 0.485 | 0.063 | 0.195 | 0.205 | 47 | 0.099 |
| AABC-U | 0.147 | 0.0279 | 0.402 | 0.076 | 0.190 | 0.204 | 3563 | 4.390 |
| AABC-L | 0.141 | 0.0258 | 0.392 | 0.070 | 0.189 | 0.201 | 4206 | 5.193 |
| BSL-RW | 0.129 | 0.0080 | 0.382 | 0.038 | 0.206 | 0.209 | 131 | 0.030 |
| BSL-IS | 0.122 | 0.0082 | 0.455 | 0.022 | 0.197 | 0.198 | 33 | 0.007 |
| ABSL-U | 0.103 | 0.0054 | 0.377 | 0.023 | 0.170 | 0.171 | 284 | 0.180 |
| ABSL-L | 0.106 | 0.0051 | 0.382 | 0.012 | 0.173 | 0.173 | 207 | 0.135 |
| Diff with exact | Diff with true parmater | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | DIM | DIC | TV | ESS | ESS/CPU | |||
| SMC | 0.232 | 0.0428 | 0.417 | 0.187 | 0.255 | 0.316 | 471 | 0.336 |
| ABC-RW | 0.210 | 0.0396 | 0.459 | 0.228 | 0.255 | 0.342 | 31 | 0.097 |
| ABC-IS | 0.179 | 0.0439 | 0.460 | 0.196 | 0.219 | 0.294 | 30 | 0.090 |
| AABC-U | 0.194 | 0.0447 | 0.424 | 0.212 | 0.217 | 0.304 | 1793 | 2.445 |
| AABC-L | 0.189 | 0.0441 | 0.420 | 0.211 | 0.235 | 0.316 | 1659 | 2.253 |
| BSL-RW | 0.200 | 0.0360 | 0.411 | 0.175 | 0.227 | 0.287 | 131 | 0.043 |
| BSL-IS | 0.195 | 0.0362 | 0.404 | 0.175 | 0.225 | 0.285 | 346 | 0.113 |
| ABSL-U | 0.229 | 0.0422 | 0.551 | 0.184 | 0.241 | 0.303 | 871 | 0.822 |
| ABSL-L | 0.231 | 0.0410 | 0.548 | 0.197 | 0.240 | 0.311 | 843 | 0.817 |
| Diff with SMC | Diff with true parmater | Efficiency | ||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | DIM | DIC | TV | ESS | ESS/CPU | |||
| SMC | 0.000 | 0.0000 | 0.000 | 0.221 | 0.201 | 0.299 | 468 | 0.267 |
| ABC-RW | 0.078 | 0.0126 | 0.205 | 0.248 | 0.198 | 0.317 | 24 | 0.069 |
| ABC-IS | 0.082 | 0.0151 | 0.306 | 0.232 | 0.221 | 0.320 | 26 | 0.071 |
| AABC-U | 0.069 | 0.0124 | 0.170 | 0.250 | 0.183 | 0.310 | 1303 | 1.617 |
| AABC-L | 0.069 | 0.0132 | 0.161 | 0.246 | 0.181 | 0.305 | 1256 | 1.546 |
| BSL-RW | 0.044 | 0.0116 | 0.122 | 0.225 | 0.181 | 0.289 | 123 | 0.037 |
| BSL-IS | 0.045 | 0.0103 | 0.125 | 0.226 | 0.177 | 0.287 | 285 | 0.084 |
| ABSL-U | 0.063 | 0.0133 | 0.228 | 0.225 | 0.181 | 0.289 | 832 | 0.735 |
| ABSL-L | 0.061 | 0.0140 | 0.230 | 0.236 | 0.183 | 0.299 | 757 | 0.671 |
| AABC-U | ABSL-U | |||||
|---|---|---|---|---|---|---|
| Parameter | 2.5% Quantile | Average | 97.5% Quantile | 2.5% Quantile | Average | 97.5% Quantile |
| 0.787 | 0.899 | 0.990 | 0.775 | 0.856 | 0.959 | |
| -0.411 | -0.147 | 0.112 | -0.369 | -0.092 | 0.222 | |
| -1.405 | -0.790 | -0.304 | -1.858 | -0.841 | -0.206 | |
| 1.758 | 1.916 | 1.997 | 1.721 | 1.909 | 1.996 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Finding our Way in the Dark: Approximate MCMC for Approximate Bayesian Methods
Evgeny Levi
Radu V. Craiu Email: [email protected]
(Department of Statistical Sciences, University of Toronto)
Abstract
With larger amounts of data at their disposal, scientists are emboldened to tackle complex questions that require sophisticated statistical models. It is not unusual for the latter to have likelihood functions that elude analytical formulations. Even under such adversity, when one can simulate from the sampling distribution, Bayesian analysis can be conducted using approximate methods such as Approximate Bayesian Computation (ABC) or Bayesian Synthetic Likelihood (BSL). A significant drawback of these methods is that the number of required simulations can be prohibitively large, thus severely limiting their scope. In this paper we design perturbed MCMC samplers that can be used within the ABC and BSL paradigms to significantly accelerate computation while maintaining control on computational efficiency. The proposed strategy relies on recycling samples from the chain’s past. The algorithmic design is supported by a theoretical analysis while practical performance is examined via a series of simulation examples and data analyses.
Keywords: Approximate Bayesian Computation, Synthetic Likelihood, Perturbed MCMC, k-Nearest-Neighbor.
1 Introduction
Since the early 1990s Bayesian statisticians have been able to operate largely due to the rapid development of Markov chain Monte Carlo (MCMC) sampling methods (see, for example Craiu and Rosenthal, 2014, for a recent review). Given observed data with sampling density indexed by parameter , Bayesian inference for functions of rely on the characteristics of the posterior distribution
[TABLE]
where denotes the prior distribution. When the posterior distribution in (1) cannot be studied analytically, we rely on MCMC algorithms to generate samples from . While traditional MCMC samplers such as Metropolis-Hastings or Hamiltonian MCMC (see Brooks et al., 2011, and references therein) can sample distributions with unknown normalizing constants, they rely on the closed form of the unnormalized posterior, .
The advent of large data has altered in multiple ways the framework we just described. For example, larger data tend to yield likelihood functions that are much more expensive to compute, thus exposing the liability inherent in the iterative nature of MCMC samplers. In response to this challenge, new computational methods based on divide and conquer (Scott et al., 2016; Wang and Dunson, 2013; Entezari et al., 2018), subsampling (Bardenet et al., 2014; Quiroz et al., 2015), or sequential Balakrishnan et al. (2006); Maclaurin and Adams (2015) strategies have emerged. Second, it is understood that larger data should yield answers to more complex problems. This implies the use of increasingly complex models, in as much as the sampling distribution is no longer available in closed form.
In the absence of a tractable likelihood function, statisticians have developed approximate methods to perform Bayesian inference when, for any parameter value , data can be sampled from the model. Here we consider two alternative approaches that have been proposed and gained considerable momentum in recent years: the Approximate Bayesian Computation (ABC) (Marin et al., 2012; Baragatti and Pudlo, 2014; Sisson et al., 2018a; Drovandi, 2018) and the Bayesian Synthetic Likelihood (BSL)(Wood, 2010; Drovandi et al., 2018; Price et al., 2018). Both algorithms are effective when they are combined with Markov chain Monte Carlo sampling schemes to produce samples from an approximation of and both share the need for generating many pseudo-data sets . This comes with serious challenges when the data is large and generating a pseudo-data set is computationally expensive. In this paper we tackle the reduction of computational burden by recycling draws from the chain’s history. While this reduces drastically the computation time, it alters the transition kernel of the original MCMC chain. We demonstrate that we can control the approximating error introduced when perturbing the original kernel using some of the error analysis for perturbed Markov chains developed recently by Mitrophanov (2005), Johndrow et al. (2015b) and Johndrow and Mattingly (2017).
The paper is structured as follows. Section 2 briefly reviews the ABC method and Section 3 introduces the proposed MCMC algorithms for ABC. Section 4 reviews BSL sampling and extends the proposed methods to this class of approximations. The practical impact of these algorithms is evaluated via simulations in Section 5 and data analyses in Section 6. The theoretical analysis showing control of perturbation errors in total variation norm is in Section 7. The paper closes with conclusions and ideas for future work.
2 Approximate Bayesian Computation
In order to illustrate the ABC sampler, let us consider the following Hidden Markov Model (HMM)
[TABLE]
Unless Gaussian distributions are used to specify the transition and emission laws given in (2) and (3), respectively, the marginal distribution cannot be calculated in closed form. It is possible to treat the hidden random variables as auxiliary and sample them using Particle MCMC (PMCMC) (Andrieu et al., 2010) or ensemble MCMC (Shestopaloff and Neal, 2013). However, computations become increasingly difficult as increases. Moreover, for some financial time series models such as Stochastic Volatility for log return, the -Stable distribution may be useful to model transition and/or emission probabilities (Nolan, 2003). The challenge is that the stable distributions do not have closed form densities, thus rendering the particle and ensemble MCMC impossible to use. Other widely used examples where the likelihood functions cannot be expressed analytically include various networks models (e.g., Kolaczyk and Csárdi, 2014) and Markov random fields (Rue and Held, 2005). For such models with intractable or computationally expensive likelihood evaluations, simulation based algorithms such as ABC are frequently used for inference. In its simplest form, the ABC is an accept/reject sampler. Given a user-defined summary statistic , the Accept/Reject ABC is described in Algorithm 1.
We emphasize that a closed form equation for the likelihood is not needed, only the ability to generate from for any . If is a sufficient statistics and then the algorithm yields posterior samples from the true posterior . Alas, the level of complexity for models where ABC is needed, makes it unlikely for these two conditions to hold. In order to implement ABC under more realistic assumptions, a (small) constant is chosen and is accepted whenever , where is a user-defined distance function. The introduction of and the use of non-sufficient statistics remove layers of exactness from the target distribution. The approximating distribution is denoted and we have
[TABLE]
In light of (4) one would like to have , but if the sample size of is large, then the curse of dimensionality leads to . Thus, obtaining even a moderate number of samples using ABC can be an unattainable goal in this case. In almost all cases of interest, is not a sufficient statistics, implying that some information about is lost. Not surprisingly, much attention has been focused on finding appropriate low-dimensional summary statistics for inference (see, for example Robert et al., 2011; Fearnhead and Prangle, 2012; Marin et al., 2014; Prangle, 2015). In this paper we assume that the summary statistic is given.
In the absence of information about the model parameters, the prior and posterior distributions may be misaligned, having non-overlapping regions of mass concentration. Hence, parameter values that are drawn from the prior will be rarely retained making the algorithm very inefficient.
Algorithm 2 presents the ABC-MCMC algorithm of Marjoram et al. (2003) which avoids sampling from the prior and instead relies on building a chain with a Metropolis-Hastings (MH) transition kernel, with state space , proposal distribution and target distribution
[TABLE]
where . Note that the goal is the marginal distribution for which is:
[TABLE]
There are a few alternatives to Algorithm 2. For instance, Lee et al. (2012) approximates via one of its unbiased estimators, where and each is simulated from . The use of unbiased estimators for when computing the MH acceptance ratio can be validated using the theory of pseudo-marginal MCMC samplers (Andrieu and Roberts, 2009). Clearly, when the probability is very small, this method would require simulating a large number of s (or equivalently s) in order to move to a new state. Other MCMC designs suitable for ABC can be found in Bornn et al. (2014).
Sequential Monte Carlo (SMC) samplers have also been successfully used for ABC (henceforth denoted ABC-SMC) (Sisson et al., 2007; Lee, 2012; Filippi et al., 2013). ABC-SMC requires a specified decreasing sequence . Lee’s method Lee (2012) uses the Particle MCMC design (Andrieu et al., 2010) in which samples are updated as the target distribution evolves with . More specifically, it starts by sampling from using Accept-Reject ABC. Subsequently, at time all samples are sequentially updated so their distribution is (see Lee, 2012, for a complete description). The advantage of this method is not only that it starts from large , but also that it generates independent draws. A comprehensive coverage of computational techniques for ABC can be found in Sisson et al. (2018b) and references therein. We also note a general lack of guidelines concerning the selection of , which is unfortunate as the performance of ABC sampling depends heavily on its value. To make a fair comparison between different methods, we revise ABC-MCMC algorithm by introducing a decreasing sequence ( is number of ”steps”) similar to ABC-SMC and ”learning” transition kernel during burn-in as in Algorithm 3.
Since the choice of proposal distribution can considerably influence the performance of ABC-MCMC, we consider finite adaptation during the burn-in period of length . In addition, during burn-in the also varies, starting with a higher value (which makes it easier to find the initial value) and gradually decreasing in accordance to a pre-determined scheme. In our implementations we use independent MH sampling or RWM. In the former case, the proposal is Gaussian with . The RWM proposal is with (Roberts et al., 1997, 2001).
All the algorithms discussed so far rely on numerous generations of pseudo-data. Since the latter can be computationally costly, proposals for reducing the simulation cost are made in Wilkinson (2014) and Järvenpää et al. (2018). The approaches are based on learning the dependence between and and, from it, establishing directly whether a proposal should be accepted or not. Flexible regression models are used to model these unknown functional relationships. The overall performance depends on the signal to noise ratio and on the model’s performance in capturing patterns that can be highly complex.
To accelerate ABC-MCMC we consider a different approach and propose to store and utilize past simulations (with appropriate weights) in order to speed up the calculation while keeping under control the resulting approximating errors. The objective is to approximate for any at every MCMC iteration using past simulated proposals, making the whole procedure computationally faster. The changes proposed perturb the chain’s transition kernel and we rely on the theory developed by Mitrophanov (2005) and Johndrow et al. (2015a) to assess the approximating error for the posterior. The k-Nearest-Neighbor (kNN) method is used to integrate past observations into the transition kernel. The main advantage of kNN is that it is uniformly strongly consistent which guarantees that for a large enough chain history, we can control the error between the intended stationary distribution and that of the proposed accelerated MCMC as shown in Section 7.
3 Approximated ABC-MCMC (AABC-MCMC)
In this section we describe an ABC-MCMC algorithm that utilizes past simulations to significantly improve computational efficiency. As noted previously, the ABC-MCMC with threshold targets the density
[TABLE]
where with and . Denote and note that if were known for every then we could run an MH-MCMC chain with invariant target density proportional to . Alas, is almost always unknown and unbiased estimates can be computationally expensive or statistically inefficient. We build an alternative approach that relies on consistent estimates of that rely on the chain’s past history, are much cheaper to compute, and require a new theoretical treatment.
To fix ideas, suppose that at time we generate the proposal and suppose that at iteration , all the proposals , regardless whether they were accepted or rejected, along with corresponding distances are available for . This past history is stored in the set . Given a new proposal , we generate and compute . Set , , and estimate using
[TABLE]
where are weights and is a decreasing function. We discuss a couple of choices for the function below.
Remark 1: Note that if some of the past proposals have been accepted, then the Markovian property of the chain is violated since the acceptance probability does not depend solely on the current state, but also on the past ones. We defer the theoretical considerations for dealing with adaptation in the context of perturbed Markov chains to a future communication. Below, we modify slightly the construction above while respecting the core idea.
In order to separate the samples used as proposals from those used to estimate in (8), we will generate at each time two independent samples and from . Then, the history collects the samples while the proposal used to update the chain is the sample. With this notation (8) becomes
[TABLE]
where and .
Remark 2: Even if is greater than (which would trigger automatically rejection for ABC-MCMC), suppose there is a close neighbour of whose corresponding is less than . Then the estimated will not be zero and there is a chance of moving to a different state. Intuitively, this is expected to reduce the variance of the accepting probability estimate.
Remark 3: When comparing the unbiased estimator
[TABLE]
with the consistent estimator
[TABLE]
we hope to outperform both the small and large cases in (10). For the small , we expect to reduce the variability in our acceptance probabilities, while for larger we expect to reduce the computational costs without sacrificing much in terms of precision.
Since the proposed weighted estimate is no longer an unbiased estimator of , a new theoretical evaluation is needed to study the effect of perturbing the transition kernel on the statistical analysis. Central to the algorithm’s utility is the ability to control the total variation distance between the desired distribution of interest given in (7) and the modified chain’s target. As will be shown in Section 7, we rely on three assumptions to ensure that the chain would approximately sample from (7): 1) compactness of ; 2) uniform ergodicity of the chain using the true and 3) uniform convergence in probability of to as .
The k-Nearest-Neighbor (kNN) regression approach (Fix and Hodges, 1951; Biau and Devroye, 2015) has a property of uniform consistency (Cheng, 1984). Define (in our numerical experiments we have used ). Without loss of generality we relabel the elements of according to distance so that and corresponds to the smallest and largest among all distances , respectively. The kNN method sets to zero for all . For , we focus on the following two weighting schemes:
- (U)
The uniform kNN with for all ; 2. (L)
The linear kNN with for so that the weight decreases from to [math] as increases from to .
The kNN’s theoretical properties that are used to validate our sampler rely on independence between the pairs . Therefore, throughout the paper, we use an independent proposal in the MH sampler, i.e. and is Gaussian. The entire procedure is outlined in Algorithm 4.
To conclude, at the end of a simulation of size the MCMC samples are and the history used for updating the chain is . The two sequences are independent of one another, i.e. for any , the elements in are independent of the chain’s history up to time .
Note also that is required in order to determine the acceptance probability at step . In this case the -value may be updated if is small enough.
In the next section we extend the approximate MCMC construction to Bayesian Synthetic Likelihood. In Sections 5 and 6 we use numerical experiments to show that the proposed procedure generally improves the mixing of a chain.
4 BSL and Approximated BSL (ABSL)
An alternative approach to bypass the intractability of the sampling distribution is proposed by Wood (2010). His approach is based on the assumption that the conditional distribution for a user-defined statistic given is Gaussian with mean and covariance matrix . The Synthetic Likelihood (SL) procedure assigns to each the likelihood , where and denotes the density of a normal with mean and covariance . SL can be used for maximum likelihood estimation as in Wood (2010) or within the Bayesian paradigm as proposed by Drovandi et al. (2018) and Price et al. (2018). The latter work proposes to sample the approximate posterior generated by the Bayesian Synthetic Likelihood (BSL) approach, , using a MH sampler. Direct calculation of the acceptance probability is not possible because the conditional mean and covariance are unknown for any . However, both can be estimated based on statistics sampled from their conditional distribution given . More precisely, after simulating and setting , , one can estimate
[TABLE]
so that the synthetic likelihood is
[TABLE]
The pseudo-code in Algorithm 5 shows the steps involved in the BSL-MCMC sampler. Since each MH step requires calculating the likelihood ratios between two SLs calculated at different parameter values, one can anticipate the heavy computational load involved in running the chain for thousands of iterations, especially if sampling data is expensive. Note that even though these estimates for the conditional mean and covariance are unbiased, the estimated value of the Gaussian likelihood is biased and therefore pseudo marginal MCMC theory is not applicable. Price et al. (2018) presented an unbiased Gaussian likelihood estimator and have empirically showed that using biased and unbiased estimates generally perform similarly. They have also remarked that this procedure is very robust to the number of simulations , and demonstrate empirically that using to produce similar results.
The normality assumption for summary statistics is certainly a strong assumption which may not hold in practice. Following up on this, An et al. (2018) relaxed the jointly Gaussian assumption to Gaussian copula with non-parametric marginal distribution estimates (NONPAR-BSL), which includes joint Gaussian as a special case, but is much more flexible. The estimation is based, as in the BSL framework, on pseudo-data samples simulated for each .
Clearly, BSL is computationally costly and requires many pseudo-data simulations to obtain Monte Carlo samples of even moderate sizes. To accelerate BSL-MCMC we propose to store and utilize past simulations of to approximate for any , making the whole procedure computationally faster. As in the previous section, we separate the simulation used to update the chain from the simulation used to enrich the history of the chain. The approach can trivially be extended for NONPAR-BSL but we do not pursue it further here. K-Nearest-Neighbor (kNN) method is used as a non-parametric estimation tool for different quantities described above. As will be shown in Section 7 with the proposed method we can control the error between the intended stationary distribution and that of the proposed accelerated MCMC.
Approximated Bayesian Synthetic Likelihood (ABSL)
Setting and assuming conditional normally for this statistic the objective is to sample from
[TABLE]
During the MCMC run, the proposal is generated from and the history is enriched using , and . Then for any , the conditional mean and covariance of statistics vector is estimated using past samples as weighted averages:
[TABLE]
Again the weights are functions of distance between proposed value and parameters’ values from the past , where is the Euclidean norm. To get appropriate convergence properties we use the kNN approach to calculate weights , where only the closest values to are used in the calculation of conditional means and covariances. As in the previous section, uniform (U) and linear (L) weights are used. Once again we expect that the use of the chain’s cumulated history can significantly speed up the whole procedure since it relieves the pressure to simulate many data sets at every step. The use of the independent Metropolis kernel ensures that contains independent draws which is required for theoretical validation in Section 7. We will also show that under mild assumptions and if is compact, the proposed algorithm exhibits good error control properties. In order to get a rough idea about the proposal, we propose to perform finite adaptation with adaptation points during the burn-in period. Algorithm 6 outlines the proposed Approximated BSL (ABSL) method. For the simulations we report on in the next section, we have used and to be consistent with AABC-MCMC, ABC-MCMC-M and ABC-SMC procedures.
5 Simulations
We analyze the following statistical models:
- (MA2)
Simple Moving Average model of lag 2; 2. (R)
Ricker’s model; 3. (SVG)
Stochastic volatility with Gaussian emission noise; 4. (SVS)
Stochastic volatility with -Stable errors.
For all these models, the simulation of pseudo data for any parameter is simple and computationally fast, but the use of standard estimation methods can be quite challenging, especially for (R), (SVG) and (SVS). For ABC samplers before running a MCMC chain we estimate initial and final thresholds and (15 equal steps in log scale were used for all models) and the matrix which is used to calculate the discrepancy .
To estimate , we use the following steps:
- •
Set
- •
Repeat steps I and II below for times (=3 in our implementations)
I
Generate 500 pairs from and calculate discrepancies with
II
Let with smallest discrepancy. Finally generate 100 pseudo-data from , compute corresponding summary statistics and set to be the inverse of covariance matrix of .
We set to be the 5% quantile of the observed discrepancies. The final is obtained by implementing a Random Walk version of Algorithm 3 and decreasing gradually by setting as the 1% quantile of discrepancies corresponding to accepted samples generated between adaption points and , for .
The number of simulations was set to 500 and 100 just for computational convenience and is not driven by any theoretical arguments.
We compare the following algorithms:
- (SMC)
Standard Sequential Monte Carlo for ABC; 2. (ABC-RW)
The modified ABC-MCMC algorithm which updates and the random walk Metropolis transition kernel during burn-in; 3. (ABC-IS)
The modified ABC-MCMC algorithm which updates and the Independent Metropolis transition kernel during burn-in; 4. (BSL-RW)
Modified BSL where it adapts the random walk Metropolis transition kernel during burn-in; 5. (BSL-IS)
Modified BSL where it adapts the independent Metropolis transition kernel during burn-in; 6. (AABC-U)
Approximated ABC-MCMC with independent proposals and uniform (U) weights; 7. (AABC-L)
Approximated ABC-MCMC with independent proposals and linear (L) weights; 8. (ABSL-U)
Approximated BSL-MCMC with independent proposals and uniform (U) weights; 9. (AABC-L)
Approximated BSL-MCMC with independent proposals and linear (L) weights. 10. (Exact)
Likelihood is computable and posterior samples are generated using an MCMC algorithm that is example-specific.
For SMC 500 particles were used, total number of iterations for ABC-RW, ABC-IS, AABC-U, AABC-L, ABSL-U and ABSL-L is 50000 with 10000 for burn-in. Since BSL-RW and BSL-IS are much more computationally expensive, total number of iterations were fixed at 10000 with 2000 burn-in and 50 pseudo-data simulations for every proposed parameter value (i.e. ). The Exact chain was run for 5000 iterations and 2000 for burn-in. It must be pointed out that all approximate samplers are based on the same summary statistics, same discrepancy function and the same sequence, so that they all start with the same initial conditions.
For more reliable results we compare these sampling algorithms under data set replications. In this study we set the number of replicates , so that for each model 100 data sets were generated and each one was analyzed with the described above sampling methods. Various statistics and measures of efficiency were calculated for every model and data set, letting represent posterior samples from replicate , iteration and parameter component and similarly posterior from an exact chain (all draws are after burn-in period). We let denote the true parameter that generated the data. Moreover let , be estimated density function at replicate and components for approximate and exact chains respectively. Then the following quantities are defined:
[TABLE]
where is defined as average of over index and in similar manner and representing variance and covariance respectively. The first three measures are useful in determining how close posterior draws from different samplers are to the draws generated by the exact chain (when it is available). On the other hand the last three are standard quantities that measure how close in mean square posterior means are to the true parameters that generated the data. To study efficiency of proposed algorithms we need to take into account CPU time that it takes to run a chain as well as auto-correlation properties. Define auto-correlation time (ACT) for every parameter’s component and replicate of samples as:
[TABLE]
where is auto-correlation coefficient at lag . In practice we sum all the lags up to the first negative correlation. Letting to be number of chain iterations (after burn-in) and correspond to total CPU time to run the whole chain during replicate , we use Effective Sample Size (ESS) and Effective Sample Size per CPU (ESS/CPU) as:
[TABLE]
Note that these indicators are averaged over parameter components and replicates. ESS intuitively can be thought as approximate number of ”independent” samples out of , the higher is ESS the more efficient is the sampling algorithm, when ESS is combined with CPU (ESS/CPU) it provides a powerful indicator for MCMC’s efficiency. Generally a sampler with highest ESS/CPU is preferred as it produces larger number of ”independent” draws per unit time.
5.1 Moving Average Model
A popular toy example to check performances of ABC and BSL techniques is MA2 model:
[TABLE]
The data are represented by the sequence . It is well known that follow a stationary distribution for any , but there are conditions required for identifiability. Hence, we impose uniform prior on the following set:
[TABLE]
It is very easy to see that the joint distribution of is multivariate Gaussian with mean 0, diagonal variances , covariance at lags 1 and 2, and respectively and zero at other lags. In this case, (Exact) sampling is feasible. For simulations we set , and define summary statistics as sample variance and covariances at lags 1 and 2. First we show results based on one replicate. Figure 1 shows the trace plots, histograms and auto-correlation functions estimated from posterior draws for parameters and for the AABC-U sampler. Note that only post burn-in samples are shown.
Similarly, Figure 2 and Figure 3 display the behaviour of ABSL-U sampler and standard ABC-RW, respectively. From these plots it is apparent that the proposed AABC-U and ABSL-U have much better mixing than ABC-RW. In the interest of keeping the paper length within reasonable limits, we briefly mention that additional simulations suggest that AABC-L is similar to AABC-U and ABSL-L to ABSL-U, while ABC-IS is outperformed by ABC-RW.
In order to summarize and compare the information in the MCMC draws produced by the approximated samplers and the exact chain, we plot the estimated densities in Figure 4. The left and right side plots refer to and , respectively. The two upper plots compare the estimated density of the exact MCMC sampler with ABC-based ones (SMC, ABC-RW and AABC-U), while the two lower plots compare the exact sampler with Synthetic Likelihood based methods (BSL-IS and ABSL-U).
The posterior distributions evaluated from AABC-U is very similar to those produced by SMC and ABC-RW, but all are distinct from the Exact one. This latter difference may be due to the loss of information incurred when the posterior is conditional on a non-sufficient statistic. Similarly, the distribution produced by ABSL-U draws is very close to that of BSL-IS. These observations hold for both components, and .
To study accuracy, precision and efficiency of proposed samplers we perform a simulation study where 100 data sets are generated and all samplers are run for every data set. The results are summarized in Table 1.
Examining this table we immediately note that ESS/CPU measure is much larger for proposed algorithms than for standard methods. The improvement is very substantial, for example ESS/CPU for AABC-U is 12 times larger than for the best standard ABC procedures like SMC. Similar results are shown for Bayesian Synthetic Likelihood. We also examine DIM, DIC, TV and MSE quantities that provide information about the proximity of approximate samples to the exact MCMC ones. For all these quantities the smaller the value the better is the sampler. We see that all these measures for AABC-U and AABC-L are very similar to SMC, ABC-RW and ABC-IS and frequently outperforms them. Similarly for BSL approach. Another observation is that the approximated algorithm with uniform and linear weights generally perform very similarly.
5.2 Ricker’s Model
Ricker’s model is analyzed very frequently to test Synthetic Likelihood procedures Wood (2010); Price et al. (2018). It is a particular instance of hidden Markov model:
[TABLE]
where is Poisson distribution with mean parameter and . Only sequence is observed, because the first 50 values are ignored. Note that all parameters are unrestricted, the prior is given as (each prior parameter is independent):
[TABLE]
We restrict the range of as all algorithms become unstable for outside this interval. Note that the marginal distribution of is not available in closed form, but transition distribution of hidden variables and emission probabilities are known and hence we can run Particle MCMC (PMCMC) Andrieu et al. (2010) or Ensemble MCMC Shestopaloff and Neal (2013) to sample from the posterior distribution . Here we are utilizing the Particle MCMC with 100 particles. As suggested in Wood (2010) we set and define summary statistics as the 14-dimensional vector whose components are:
- (C1)
#, 2. (C2)
Average of , , 3. (C3:C7)
Sample auto-correlations at lags 1 through 5, 4. (C8:C11)
Coefficients of cubic regression
, , 5. (C12-C14)
Coefficients of quadratic regression
, .
Figures 5, 6 and 7 show trace-plots, histograms and ACF function for AABC-U, ABSL-U and ABC-RW samplers for each component (red lines correspond to the true parameter).
We show here ABC-RW instead of ABC-IS because the latter exhibits a poorer performance. The main observation is that mixing of AABC-U is much better than in ABC-RW with smaller auto-correlation values. ABSL-U has higher auto-correlations than AABC-U but still performs quite well. To see how close the draws from simulation-based algorithms to the draws from the Exact chain, we plot the estimated approximate posterior marginal densities in Figure 8. The two upper plots (left and right are associated to parameter’s component) compares estimated density of exact PMCMC sampler (with 100 particles) with ABC-based ones (SMC, ABC-RW and AABC-U), two lower plots compare the Exact sampler with Synthetic Likelihood based methods (BSL-RW and ABSL-U).
Note that ABC-based samplers (SMC, ABC-RW and AABC-U) have very similar estimated densities. The densities of Synthetic Likelihood methods are also similar. For the second component there is a large difference between exact and approximate posteriors which may be caused by the loss of information induced by the choice of summary statistics.
A more general study, where results are averaged over 100 independent replicates, is shown in Table 2.
Again, the proposed strategies clearly outperform in terms of overall efficiency (ESS/CPU). For instance, AABC-U is about 10 times more efficient than standard SMC and ABSL-U is 6 times more efficient than BSL-RW. At the same time DIM, DIC, TV and MSE are generally smaller for approximate methods than for standard ones.
5.3 Stochastic Volatility with Gaussian emissions
When analyzing stationary time series, it is frequently observed that there are periods of high and periods of low volatility. Such phenomenon is called volatility clustering, see for example (Lux and Marchesi, 2000). One way to model such a behaviour is through a Stochastic Volatility (SV) model, where variances of the observed time series depend on hidden states that themselves form a stationary time series. Consider the following model which depends on three parameters :
[TABLE]
Only is observed while are hidden states. The parameter controls the auto-correlation of hidden states, while and are unrestricted and relate to the hidden states influence on the variability of the observed series. Given a hidden state, the distribution of the observed variable is normal which may not be appropriate in some examples. We introduce the following priors, independently for each parameter:
[TABLE]
We set the true parameters to and length of the time series . We use Particle MCMC (PMCMC) as the Exact sampling scheme. Since pseudo-data sets can be easily generated for every parameter value, the SV is a good example to demonstrate the performances of the generative algorithms considered here. For summary statistics we use a 7-dimensional vector whose components are:
- (C1)
#, 2. (C2)
Average of , 3. (C3)
Standard deviation of , 4. (C4)
Sum of the first 5 auto-correlations of , 5. (C5)
Sum of the first 5 auto-correlations of , 6. (C6)
Sum of the first 5 auto-correlations of , 7. (C7)
Sum of the first 5 auto-correlations of .
Here is defined as -quantile of the sequence . As was shown in Schmitt et al. (2015) and Dette et al. (2015) the auto-correlation of indicators (under different quantiles) can be very useful in characterizing a time series and that is why we have added (C5),(C6) and (C7) to the summary statistic. We focus here on and its auto-correlations since model parameters only affect variability of (auto-correlation of is zero for any lag). Figures 9, 10 and 11 show trace-plots, histograms and ACF function for AABC-U, ABSL-U and ABC-RW samplers respectively for each component (red lines correspond to the true parameter).
The major observation is that AABC-U and ABSL-U are less sluggish than ABC-RW, exhibiting smaller auto-correlation values.
In Figure 12 we compare the sample-based kernel smoothing posterior marginal density estimates for Exact, SMC, ABC-RW and AABC-U (top row) as well as Exact, BSL-IS and ABSL-U (bottom row).
We note that all samples obtained from the approximate algorithms are exact posterior (produced using PMCMC with 100 particles). Generally all ABC-based samplers perform similarly, on the other hand ABSL-U performs worse than generic BSL-IS in this run as it is shifted away from the exact posterior for and .
To get more general conclusions we show average results in Table 3 over 100 data replicates.
Again we note that the proposed algorithms outperform the benchmark samplers by 8 times in ESS/CPU. Moreover AABC-U and AABC-L have very similar or smaller values for DIM, TV and MSE, which demonstrates that these samplers are much more efficient than standard methods and at the same produce as accurate (or more accurate) parameter estimates as generic algorithms.
ABSL-U and ABSL-L on the other hand did not perform well for this model, TV and MSE for these samplers are larger by 10% than generic ones.
5.4 Stochastic Volatility with -Stable errors
As was pointed out in the previous sub-section, standard SV model assumes that the conditional distribution of the observed variables is Gaussian. Frequently, in financial time series, a large sudden drop occurs, thus raising serious doubts about the latter assumption. Often, it is suggested to use heavy tailed distributions (instead of Gaussian) to model financial data. We consider a family of distributions named -Stable, denoted , with two parameters (stability parameter) and (skew parameter). Two special cases are and which correspond to Cauchy and Gaussian distribution respectively, note that for the distribution has undefined variance. We define the following SV model with -Stable errors with parameter :
[TABLE]
This model is very similar to the simple SV with only difference that emission errors follow -Stable distribution with unknown stable parameter and fixed skew of . We generally prefer negative skew emission probability to model large negative financial returns. As in the previous simulation example and are unrestricted. The prior distribution for this model is (independently for each parameter):
[TABLE]
We set the true parameters to and length of the time series . The major challenge with this model is that there are no closed-form densities for -Stable distributions. Hence, most MCMC samplers, including PMCMC and ensemble MCMC, cannot be used to sample from the posterior. However sampling from this family of distributions is feasible which makes it particularly amenable for simulation based methods like ABC and BSL. For summary statistics we use a 7-dimensional vector whose components are:
- (C1)
#, 2. (C2)
Average of , 3. (C3)
Standard deviation of , 4. (C4)
Sum of the first 5 auto-correlations of , 5. (C5)
Sum of the first 5 auto-correlations of , 6. (C6)
Sum of the first 5 auto-correlations of , 7. (C7)
Sum of the first 5 auto-correlations of .
Figures 13,14 and 15 show trace-plots, histograms and ACF function for AABC-U, ABSL-U and ABC-RW samplers respectively for each component (red lines correspond to the true parameters).
As in previous examples the mixing of AABC-U and ABSL-U is much better than of ABC-RW. Since exact sampling is not feasible in this example we compare samplers to SMC (instead of exact samples), the plotted estimated densities are in Figure 16, here we have chosen BSL-IS over BSL-RW because it has better general performance in this model.
Generally all simulation-based samplers have similar densities in this example.
For more general conclusions we show average results in Table 4 over 100 data replicates. Here to calculate DIM, DIC and TV, samplers are compared to SMC since exact draws cannot be obtained.
As in previous examples ESS/CPUs for AABC-U, AABC-L, ABSL-U and ABSL-L are roughly 8 times larger than benchmark algorithms. For this example looking at DIM, DIC and TV maybe misleading since approximated samplers are compared to another approximate sampler. Much more informative is MSE measure, it is very similar across ABC-based and BSL-based algorithms. Therefore we can conclude that proposed samplers perform very well in this example.
6 Data Analysis
For real world example we consider Dow-Jones index daily log returns from January 1, 2010 until December 31, 2018. The data were downloaded from Yahoo Finance111https://ca.finance.yahoo.com/ website. Given a time series of prices , , log returns are calculated in the following way:
[TABLE]
The resulting time series is of length 2262. To make log returns more suitable for analysis, we standardize by subtracting its mean and then multiply each return by 200, so that absolute values were not too small, Figure 17 shows transformed returns.
This time series () has mean zero by construction, and its auto-correlations and partial auto-correlations are insignificant for any lag. However, it is obvious that variances are correlated and there are alternating periods of low and high variability. This prompts us to use Stochastic Volatility model with -Stable errors as described in the previous section. Since the likelihood does not exist for this class of models, the simulation-based methods are probably the only available tools for the inference. The evolution of time series is described by equation (23) and the parameter’s prior is set as in equation (24). The skewed parameter of Stable distribution is fixed at value of . To estimate the posterior distribution we run AABC-U and ABLS-U samplers. The summary statistic for both methods is the same 7-dimensional vector defined in section 5.4. Each chain was run for 100 thousand iterations with last 80 thousands used for inference. Figures 18 and 19 show trace-plots and histograms for AABC-U and ABSL-U samplers respectively for each parameter.
The conclusions are in agreement with the ones suggested by the simulation study. The mixing of AABC-U is generally better than of ABSL-U. However, posterior draws of ABSL-U for the first 3 components are uni-modal, symmetric and bell-shaped, which is not surprising since the use of Gaussian priors within the BSL method yields Gaussian posteriors due to conjugacy. Table 5 reports posterior mean and 95% credible intervals for every parameter and for both samplers.
AABC-U and ABSL-U produce similar results. We see that the estimated correlation between adjacent variables in the hidden layer is about and the estimate of -Stable emission noise is . This model can produce more extreme values than those predicted by one with standard Gaussian noise.
7 Theoretical Justifications
In this section we show that the novel approximated ABC MCMC and BSL samplers with independent proposals exhibit ergodic properties in a long run. In other words, we want to show that as number of MCMC iterations increases marginal distribution of converges to appropriate posterior distribution in total variation and sample averages converge to the true expectations.
We start by reviewing our notation. Let represent the prior and proposal distributions for respectively. For AABC we define a function as where and . Then given a proposed the acceptance probability is:
[TABLE]
This MH procedure defines an exact transition kernel which we call . Since is not available in closed form we will estimate it using k-nearest-neighbor approach.
Let represent independent samples from for AABC. Actually contains past generated samples that were saved before th iteration. Given and we apply kNN to approximate and by calculating local weighted averages of for that are close to or . We denote such estimate , and the probability of proposal acceptance for this perturbed algorithm (more on perturbed MCMC can be found in Roberts et al. (1998); Pillai and Smith (2014); Johndrow and Mattingly (2017)) is:
[TABLE]
The approximate kernel transition is , the goal is to show that as the distance between this transition and the exact one converges to zero, where distance is defined as:
[TABLE]
where the last distance is ”total variation” distance between two measures. First we show that under strong consistency assumption of , perturbed kernel converges to the exact one.
Theorem 7.1**.**
Suppose is compact, with probability 1 and for all . Then for any there exists such that for all , .
Next let be a collection of perturbed kernels each distance from the exact kernel. For illustration consider an example when auxiliary set grows with number of iterations, in this case at each iteration a new kernel is used in the chain. We want to show that this procedure will results in ergodic chain with appropriate convergence results. For most of the presented results below we refer to the work of Johndrow et al. (2015b) on convergence properties of perturbed kernels.
To obtain useful convergence results we need to make additional Doeblin Condition assumption about the exact kernel :
Definition 7.1** (Doeblin Condition).**
Given a kernel , there exists such that
[TABLE]
We also choose so that and which by Remark 2.1 in Johndrow et al. (2015b) guarantees that every member of satisfies Doeblin Condition with and has a unique invariant measure. Thus we define the following 3 assumptions:
- (A1)
Exact transition kernel satisfies satisfies the Doeblin Condition, 2. (A2)
For any , , 3. (A3)
.
Now, let be invariant measure of the exact kernel , and the perturbed chain is a Markov chain with . Also define marginal distribution of denoted by , and equal to with each , and being identity transition (for convenience). First we need to examine the total variation distance between and average measure , in other words:
[TABLE]
Then we have the following important convergence result:
Theorem 7.2**.**
Suppose that (A1), (A2) and (A3) are satisfied. Let be any probability measure on , then
[TABLE]
which implies that this difference can be arbitrary small for sufficiently large and small enough .
Next we focus on the following mean squared error (MSE):
[TABLE]
where is bounded function and . The main objective here is to find the upper bound for this MSE when perturbed MCMC is used and how it depends on the sample size . To obtain the main result we introduce the following lemma:
Lemma 7.3**.**
Suppose: (A2) and (A3) are satisfied; , where is a probability distribution; is the marginal distribution of , . Let and be bounded functions with and . Then
[TABLE]
The next important convergence results follows (similar to Theorem 2.5 of Johndrow et al. (2015b)):
Theorem 7.4** (Approximation of MSE).**
Suppose that (A1), (A2) and (A3) are satisfied. Let denote the invariant measure of , be a bounded function and , where is a probability distribution . Then
[TABLE]
In other words this expectation can be made arbitrary small for sufficiently large and small enough .
Based on these theorems we obtain convergence results for AABC and ABSL algorithms. To that end, we consider the following assumptions:
- (B1)
is a compact set.
- (B2)
continuous density of independent proposal distribution.
- (B3)
continuous density of prior distribution.
- (B4)
continuous function of .
- (B5)
In kNN estimation assume that with uniform or linear weights.
- (B6)
and are continuous functions of for every with representing th component of summary statistic .
- (B7)
and are bounded functions.
- (B8)
where for every .
Theorem 7.5** (Ergodicity of AABC).**
Consider the proposed AABC sampler with threshold and let: denote the prior measure on , denote simulated pairs with . Assume (B1)-(B5)* hold. Then for sufficiently large (number of past simulations) and (number of chain iterations), assumptions (A1)-(A3) are satisfied and the results established in Theorems 7.2 and 7.4 follow.*
Corollary 7.5.1** (Ergodicity of ABSL).**
Assume that (B1)-(B8)* hold. Let be the prior distribution on , , the set of simulated pairs . Then for sufficiently large (number of past simulations) and (number of chain iterations), assumptions (A1)-(A3) are satisfied and the results established in Theorems 7.2 and 7.4 follow.*
To prove the results above we will utilize the following two theorems, one is about the strong uniform consistency of kNN estimators the later one is about uniform ergodicity of Hastings algorithm with independent proposal.
Theorem 7.6** (Uniform Consistency of kNN - Cheng (1984)).**
Given independent , let be support of distribution of , and (kNN estimator) (here are permuted indices that order distances between and from smallest to largest). Suppose weights satisfy
- (i)
,
- (ii)
* for , and with and ,*
- (iii)
.
If
- (i)
* is compact,*
- (ii)
* is continuous function,*
- (iii)
* is bounded random variable,*
- (iv)
* satisfies ,*
then with probability 1.
Note that the uniform and linear weights satisfy assumptions above.
Theorem 7.7** (Independent Metropolis sampler - Mengersen et al. (1996)).**
*Suppose is a MH Markov Chain with invariant distribution , independent proposal and acceptance probabilities .
If there exists such that for all , then the algorithm is uniformly ergodic so that (here is conditional distribution of given ).*
7.1 Proofs of theorems
Proof of Theorem 7.1.
Note that w.p.1 implies that for all and in :
[TABLE]
[TABLE]
therefore by Slutsky’s theorem we obtain
[TABLE]
for all in . therefore
[TABLE]
Since is a continuous function, Continuous Mapping Theorem implies that
[TABLE]
Note that this not just a point-wise convergence, but uniform convergence in probability so that one will work for all . That is, for any , and there exists such that for all , .
Another important observation is that (fixing , and letting and for convenience)
[TABLE]
Because and applying definition of convergence in probability. The above inequality shows that we can make this expected value arbitrary small by taking large enough , moreover this result is uniform so one will work for all and .
Next we focus on the distance between two transition kernels, this discussion is similar to the proof of Corollary 2.3 in Alquier et al. (2016). Observe that (using independent proposals):
[TABLE]
where and . Fix , and noting that total variation between two probability distributions that have densities is also equal to:
[TABLE]
Therefore
[TABLE]
and it follows that
[TABLE]
for any and and large enough by (31). Since this result is true for any we finally get the main result:
[TABLE]
∎
Proof of Theorem 7.2.
We generally follow the proof of Theorem 2.4 in Johndrow et al. (2015b). First observe that:
[TABLE]
By Assumptions 2 and 3, we get:
[TABLE]
and
[TABLE]
Using these results, the triangular inequality and formula for sum of finite geometric series we establish that:
[TABLE]
Finally we get the main result using that fact that is invariant for (again using sum of finite geometric series)
[TABLE]
∎
Proof of Lemma 7.3.
Without loss of generality we assume that , next define:
[TABLE]
[TABLE]
so that . Then we get the following
[TABLE]
where is point mass at and using our notation corresponds to conditional distribution of given fixed value of .
Using the general observation that for any two measures and and any bounded function the following inequality holds
[TABLE]
we find that:
[TABLE]
note that this result is for any . Returning to (37) we get that:
[TABLE]
Finally by triangular inequality for any and similarly for . The desired result follows immediately. ∎
Proof of Theorem 7.4.
Using our standard notation , Theorem 7.2, Lemma 7.3 and simple results for double sum of geometric series we get
[TABLE]
Obtaining the desired result. ∎
Proof of Theorem 7.5.
First by (B1) - (B4), Theorem 7.7 guarantees uniform ergodicity of the exact chain with where is the normalizing constant of the posterior. Note that since is compact, ratio is continuous and never zero. Therefore also satisfies Doeblin Condition. Next from (B1), (B4) and (B5), Theorem 7.6 implies that with probability 1. Hence by Theorem 7.1 perturbed kernel can be made arbitrary close to the exact kernel for sufficiently large . Note that total variation distance between and decreases to zero as increases. Finally assumptions of Theorems 7.2 and 7.4 follow trivially. ∎
Proof of Corollary 7.5.1.
First by (B1), (B2), (B3), (B4) and (B8), Theorem 7.7 guarantees uniform ergodicity of the exact chain with where is the normalizing constant of the posterior. Note that since is compact, ratio is continuous and never zero. Therefore satisfies Doeblin Condition. Next from (B1), (B5), (B6) and (B7), Theorem 7.6 implies that with probability 1. Hence by Theorem 7.1 perturbed kernel can be made arbitrary close to the exact kernel for sufficiently large . Note that total variation distance between and decreases to zero as increases. Finally assumptions of Theorems 7.2 and 7.4 follow trivially. ∎
8 Conclusion
In this paper we proposed to speed up generic ABC-MCMC and BSL algorithms by storing past simulations. This approach significantly accelerates the process and can be very useful for models where simulation of a pseudo data set is computationally expensive or when large number of MCMC iterations is required. We presented theoretical arguments and necessary assumptions for convergence properties of the perturbed chain. The performance of these strategies were examined via a series of simulations under different models. All simulations summaries show that proposed methods significantly improve mixing and efficiency of the chain and at the same time produce as accurate and precise parameter estimates as generic samplers.
Acknowledgments
We thank Jeffrey Rosenthal and Stanislav Volgushev for constructive comments. RVC is grateful to the organizers of the BIRS workshop “Validating and Expanding Approximate Bayesian Computation Methods” for creating a stimulating environment that generated ideas for this work. Finally, we acknowledge funding support from NSERC of Canada.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Alquier et al. (2016) Alquier, P. , Friel, N. , Everitt, R. and Boland, A. (2016). Noisy Monte Carlo: Convergence of Markov chains with approximate transition kernels. Statistics and Computing 26 29–47.
- 2An et al. (2018) An, Z. , Nott, D. J. and Drovandi, C. (2018). Robust Bayesian synthetic likelihood via a semi-parametric approach. ar Xiv preprint ar Xiv:1809.05800 .
- 3Andrieu et al. (2010) Andrieu, C. , Doucet, A. and Holenstein, R. (2010). Particle Markov chain Monte Carlo methods. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 72 269–342.
- 4Andrieu and Roberts (2009) Andrieu, C. and Roberts, G. O. (2009). The pseudo-marginal approach for efficient Monte Carlo computations. The Annals of Statistics 37 697–725.
- 5Balakrishnan et al. (2006) Balakrishnan, S. , Madigan, D. et al. (2006). A one-pass sequential Monte Carlo method for Bayesian analysis of massive datasets. Bayesian Analysis 1 345–361.
- 6Baragatti and Pudlo (2014) Baragatti, M. and Pudlo, P. (2014). An overview on approximate Bayesian computation. In ESAIM: Proceedings , vol. 44. EDP Sciences.
- 7Bardenet et al. (2014) Bardenet, R. , Doucet, A. and Holmes, C. (2014). Towards scaling up Markov chain Monte Carlo: an adaptive subsampling approach. In International Conference on Machine Learning (ICML) .
- 8Biau and Devroye (2015) Biau, G. and Devroye, L. (2015). Lectures on the nearest neighbor method . Springer.