Graph-Based Decoding Model for Functional Alignment of Unaligned fMRI Data
Weida Li, Mingxia Liu, Fang Chen, Daoqiang Zhang

TL;DR
This paper introduces a graph-based decoding model for functional alignment of unaligned fMRI data, enabling better aggregation and analysis across subjects with diverse and non-temporally aligned datasets.
Contribution
It proposes a flexible, kernel-based framework utilizing a cross-subject graph and low-dimensional feature assumptions to handle various types of unaligned fMRI data.
Findings
Outperforms state-of-the-art methods on temporally-aligned fMRI datasets.
Effectively handles temporally-unaligned fMRI data.
Demonstrates robustness across five different datasets.
Abstract
Aggregating multi-subject functional magnetic resonance imaging (fMRI) data is indispensable for generating valid and general inferences from patterns distributed across human brains. The disparities in anatomical structures and functional topographies of human brains warrant aligning fMRI data across subjects. However, the existing functional alignment methods cannot handle well various kinds of fMRI datasets today, especially when they are not temporally-aligned, i.e., some of the subjects probably lack the responses to some stimuli, or different subjects might follow different sequences of stimuli. In this paper, a cross-subject graph that depicts the (dis)similarities between samples across subjects is used as a priori for developing a more flexible framework that suits an assortment of fMRI datasets. However, the high dimension of fMRI data and the use of multiple subjects makes…
Click any figure to enlarge with its caption.
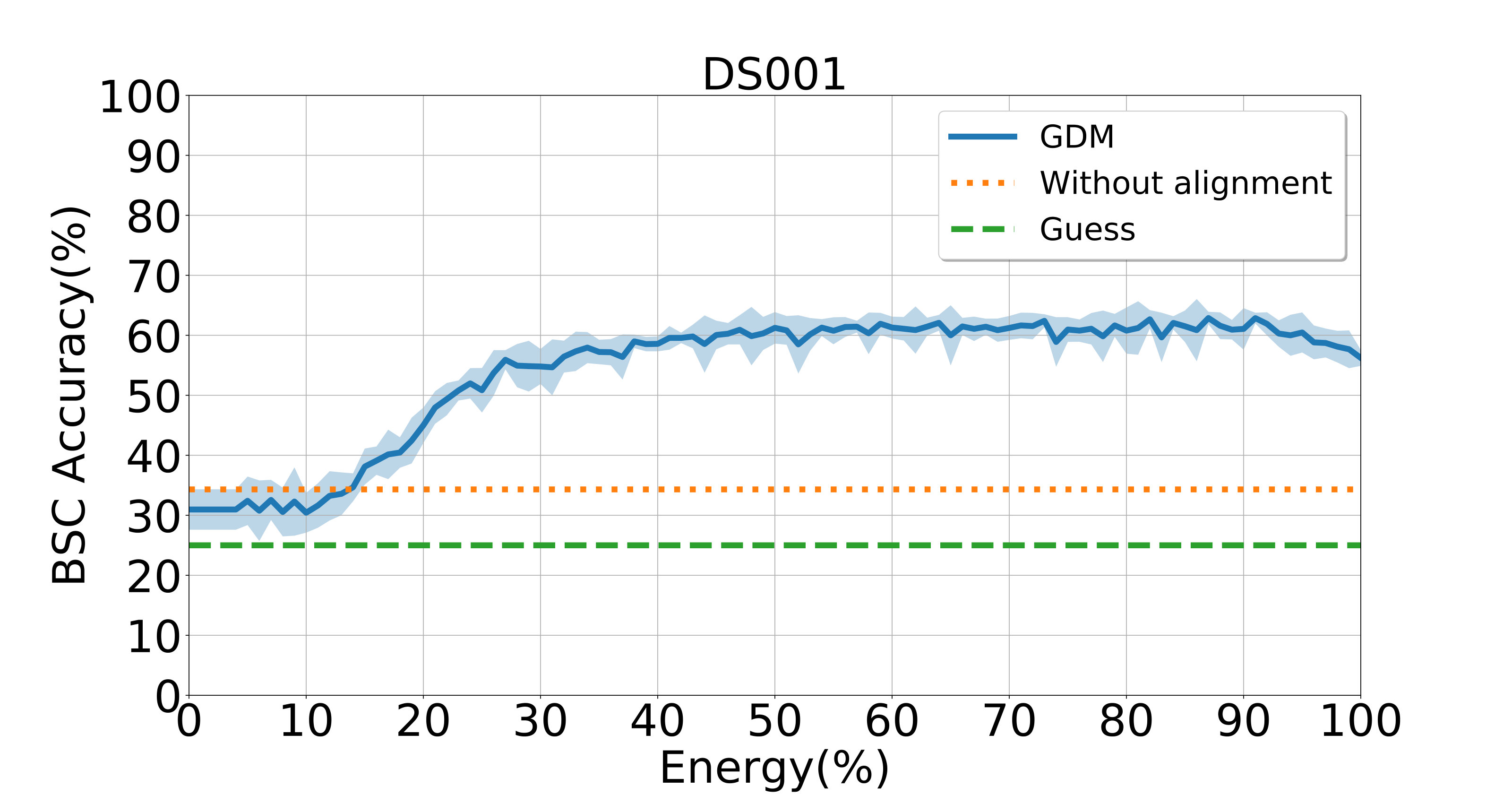 Figure 1
Figure 1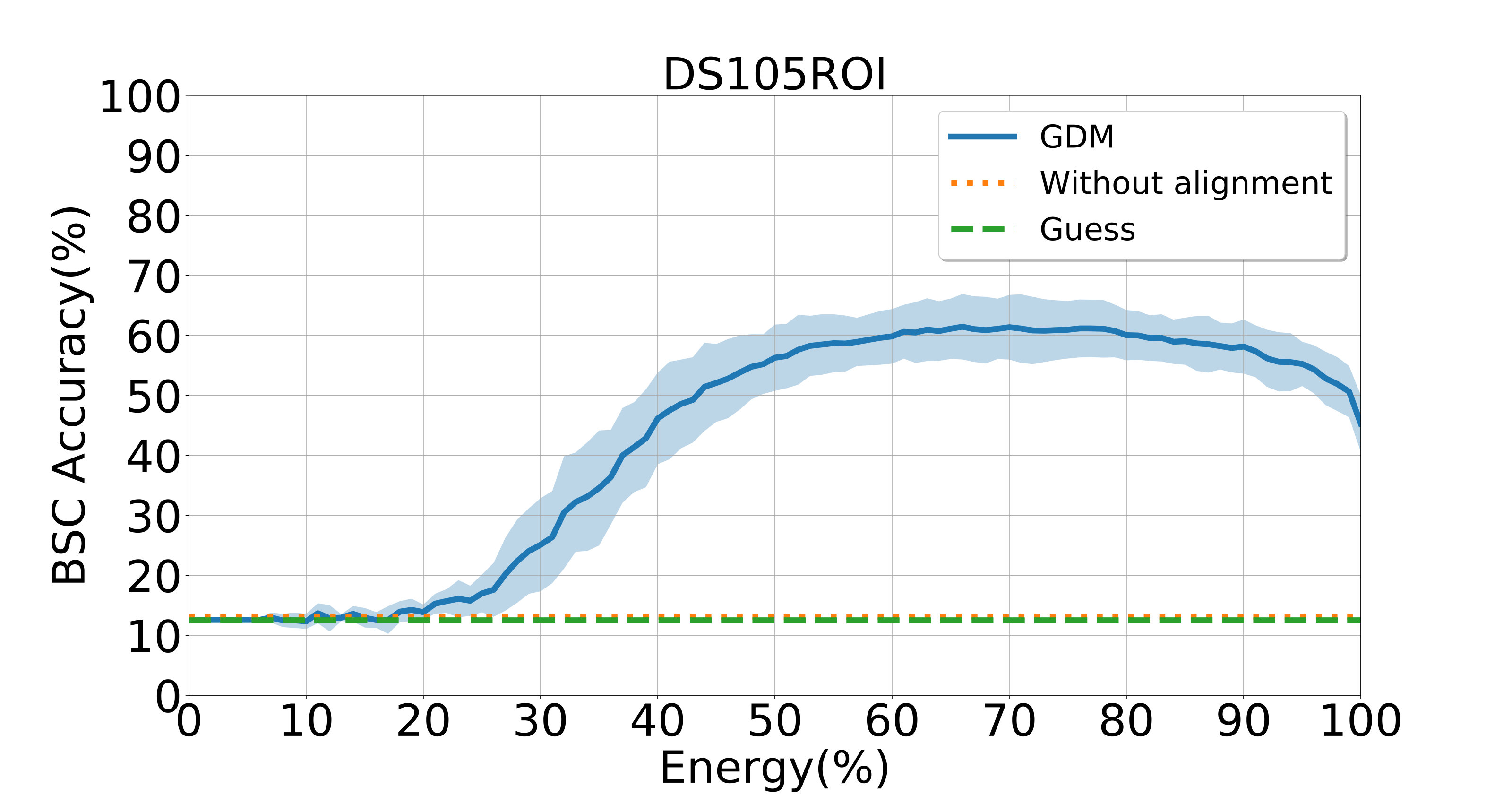 Figure 2
Figure 2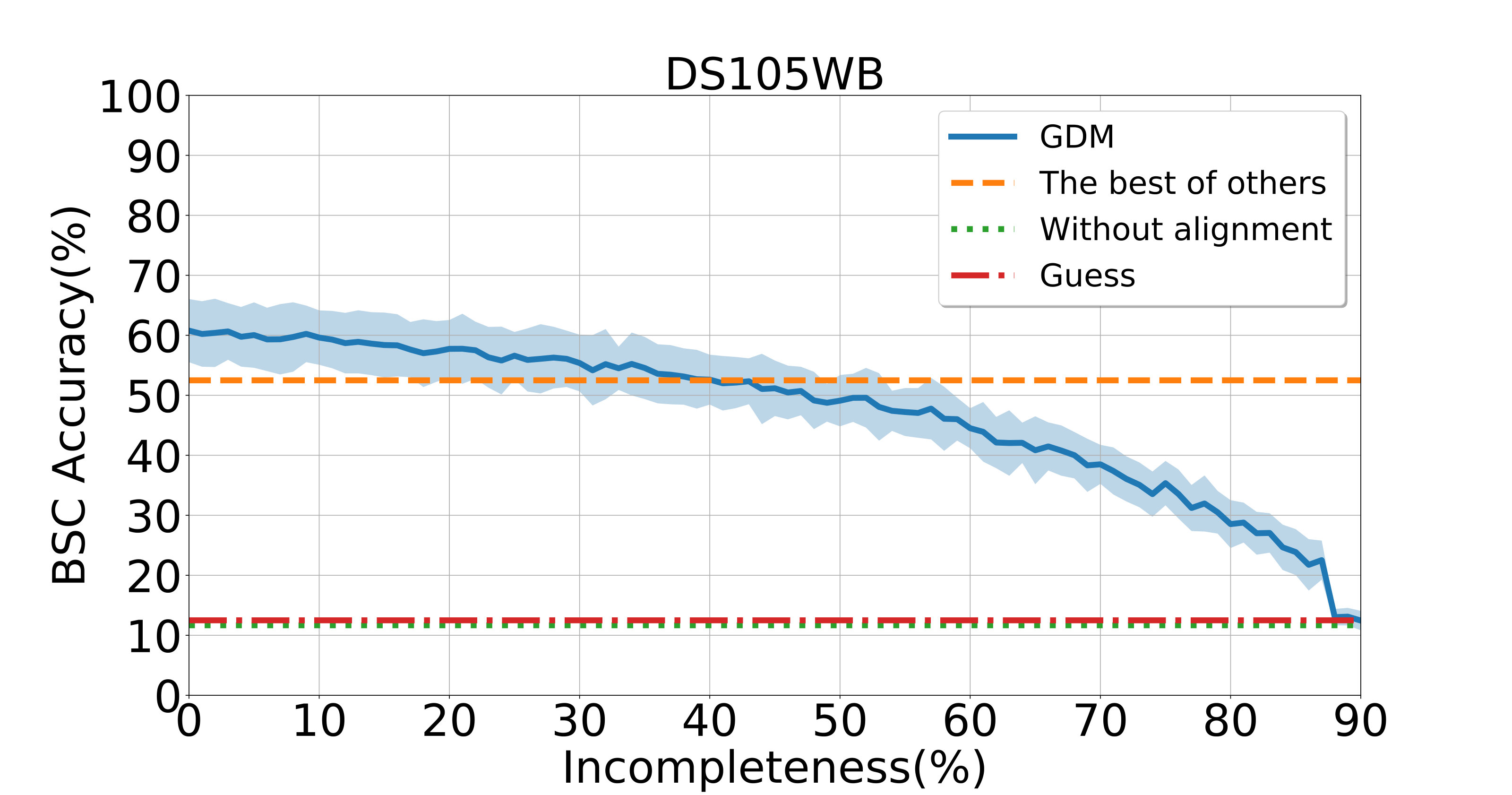 Figure 3
Figure 3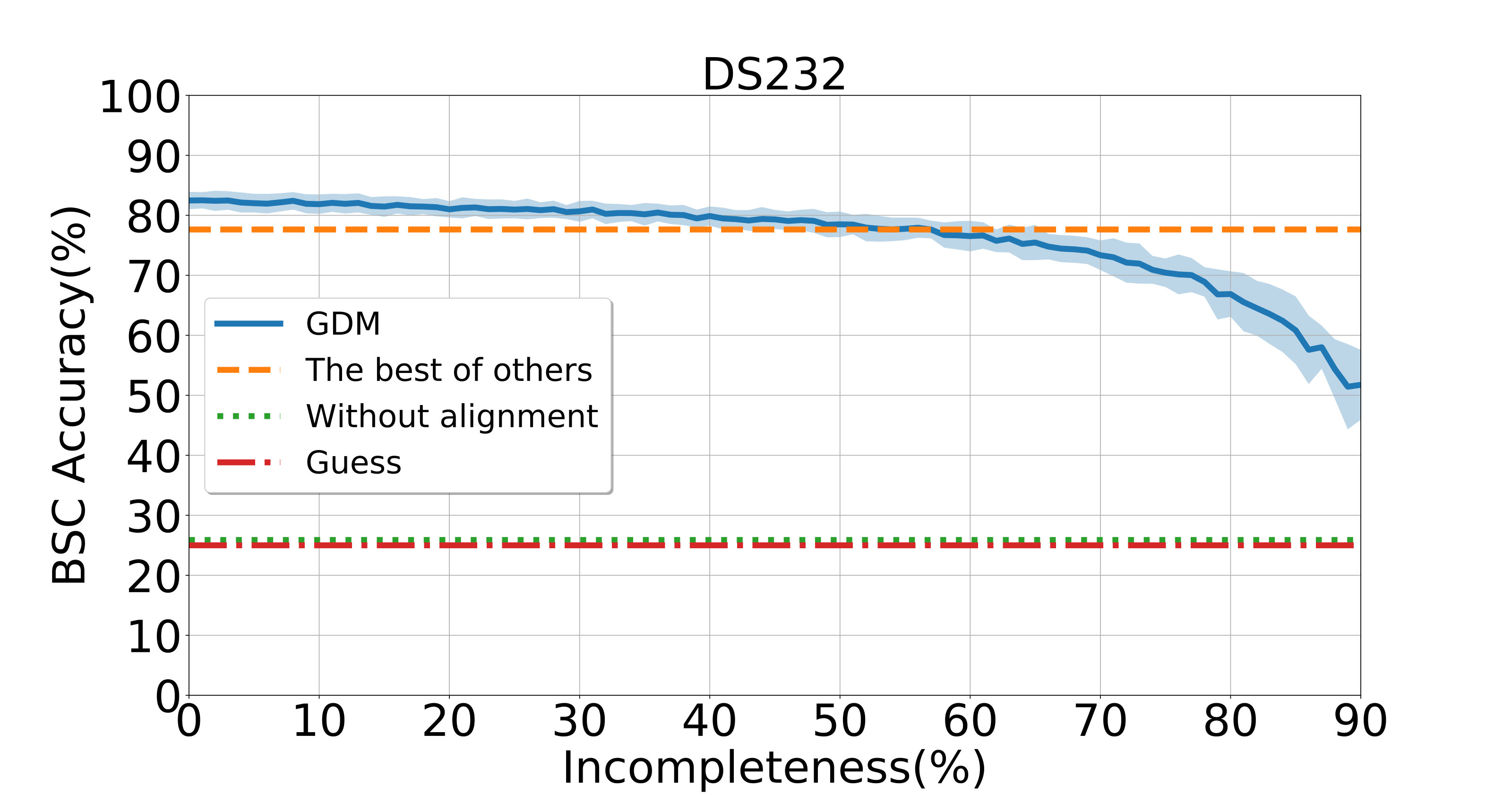 Figure 4
Figure 4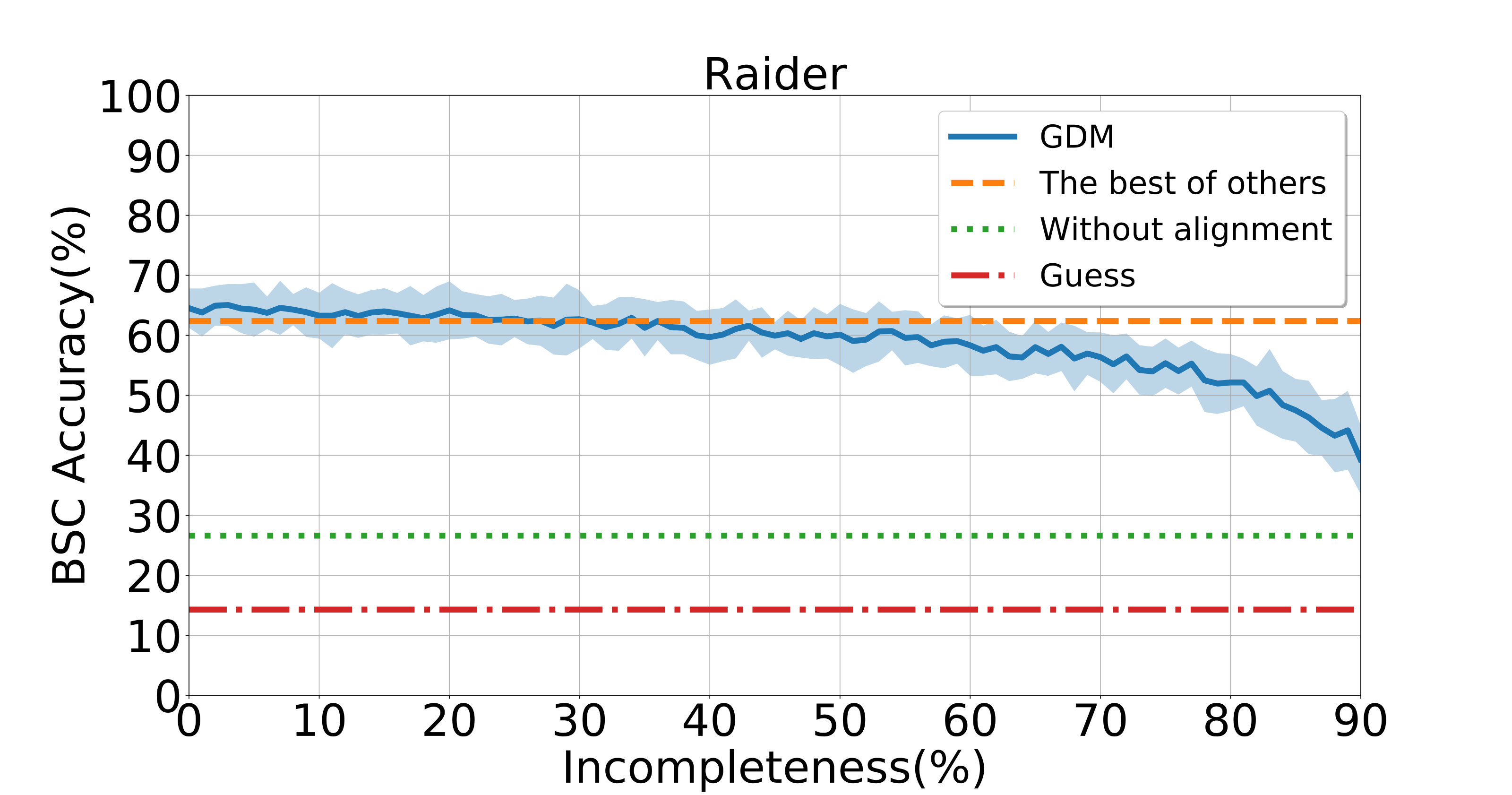 Figure 5
Figure 5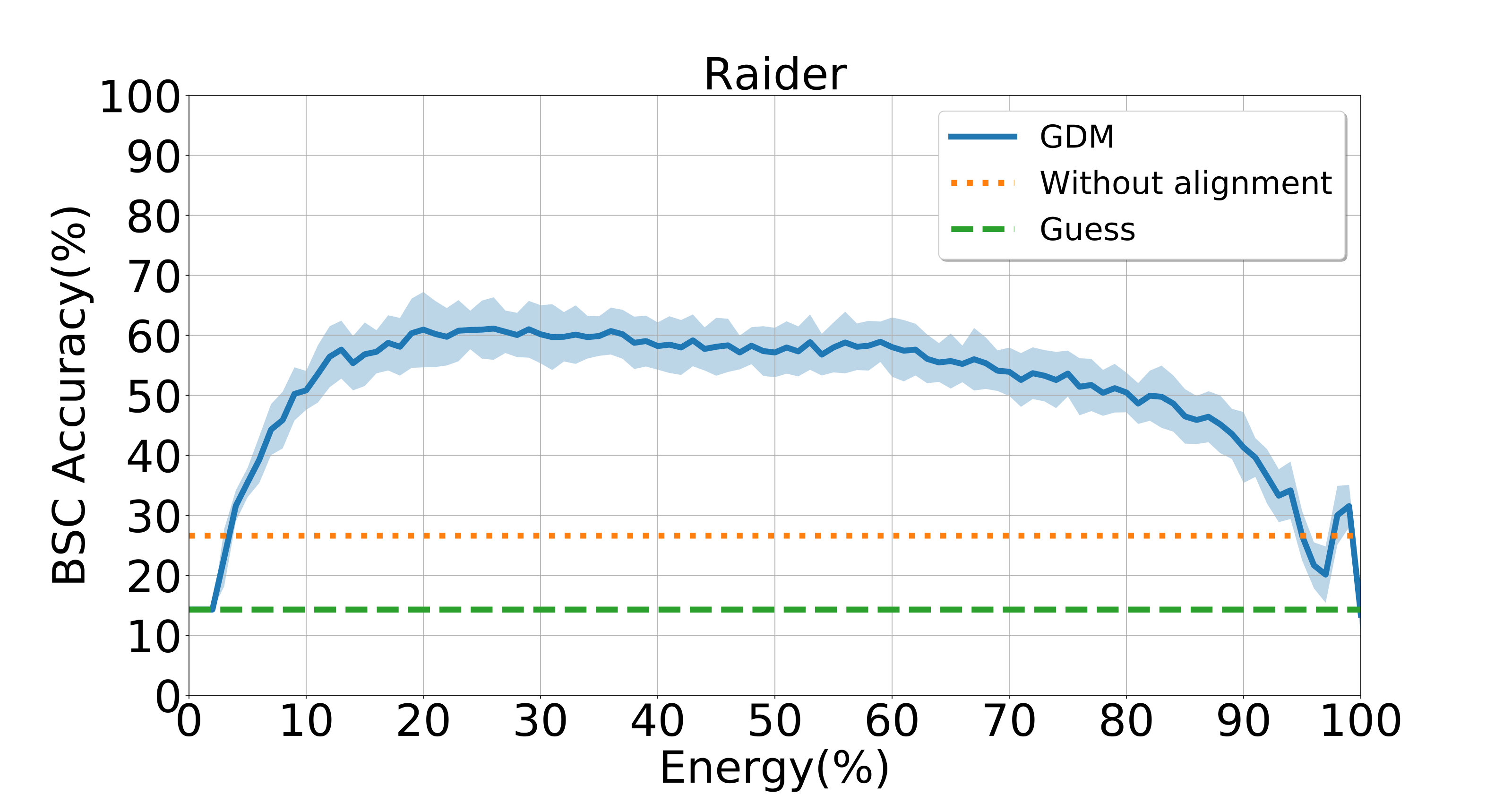 Figure 6
Figure 6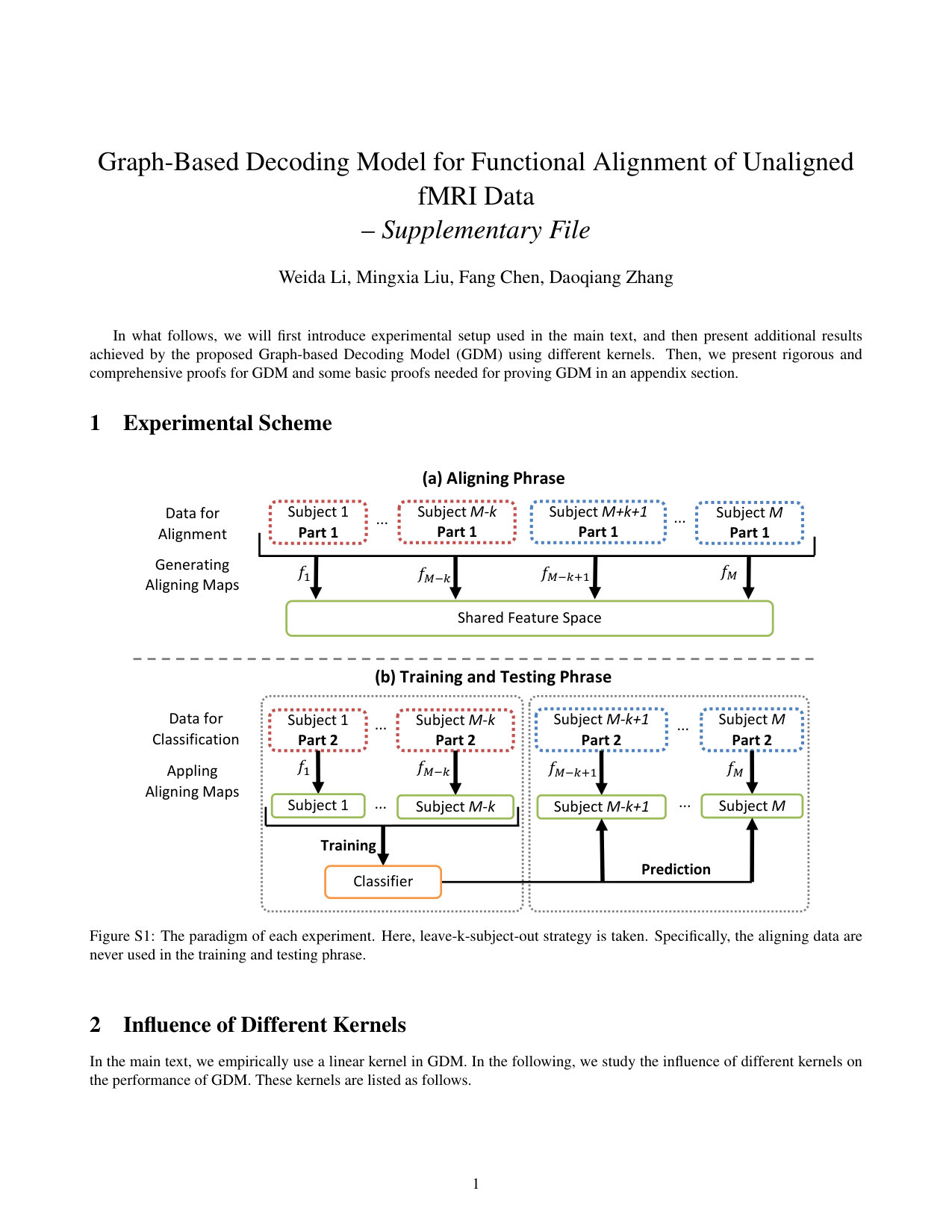 Figure 7
Figure 7| Dataset | #subject | #sample/subject | #feature | #category | energy() | #subject left out | ||
|---|---|---|---|---|---|---|---|---|
| DS105WB | 6 | 994 | 19174 | 8 | 10 | 82 | 0.8 | 1 |
| DS105ROI | 6 | 994 | 2294 | 8 | 10 | 82 | 0.8 | 1 |
| DS011 | 14 | 271 | 19174 | 2 | 10 | 82 | 0.3 | 2 |
| DS001 | 16 | 485 | 19174 | 4 | 10 | 82 | 0.5 | 4 |
| DS232 | 10 | 1691 | 9947 | 4 | 10 | 82 | 0.8 | 2 |
| Raider.Movie | 10 | 2203 | 1000 | — | 20 | 35 | — | — |
| Raider.Image | 10 | 56 | 1000 | 7 | — | — | 0.5 | 2 |
| Dataset(#class) | -SVM | HA | KHA | SVDHA | SRM | RSRM | RHA | GDM (Ours) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DS105WB(8) |
|
|
|
|
|
|
|
|
||||||||
| DS105ROI(8) |
|
|
|
|
|
|
|
|
||||||||
| DS011(2) |
|
|
|
|
|
|
|
|
||||||||
| DS232(4) |
|
|
|
|
|
|
|
|
||||||||
| DS001(4) |
|
|
|
|
|
|
|
|
||||||||
| Raider(7) |
|
|
|
|
|
|
|
|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFunctional Brain Connectivity Studies · Face Recognition and Perception · Neural dynamics and brain function
Graph-Based Decoding Model for Functional Alignment of Unaligned fMRI Data
Weida Li,1 Mingxia Liu,1,2* Fang Chen,1 Daoqiang Zhang1*
1College of Computer Science and Technology & MIIT Key Laboratory of Pattern Analysis and Machine Intelligence,
Nanjing University of Aeronautics and Astronautics, Nanjing, China
2School of Information Science and Technology, Taishan University, Taian, China
*Corresponding Authors: {mingxialiu, dqzhang}@nuaa.edu.cn
Abstract
Aggregating multi-subject functional magnetic resonance imaging (fMRI) data is indispensable for generating valid and general inferences from patterns distributed across human brains. The disparities in anatomical structures and functional topographies of human brains warrant aligning fMRI data across subjects. However, the existing functional alignment methods cannot handle well various kinds of fMRI datasets today, especially when they are not temporally-aligned, i.e., some of the subjects probably lack the responses to some stimuli, or different subjects might follow different sequences of stimuli. In this paper, a cross-subject graph that depicts the (dis)similarities between samples across subjects is used as a priori for developing a more flexible framework that suits an assortment of fMRI datasets. However, the high dimension of fMRI data and the use of multiple subjects makes the crude framework time-consuming or unpractical. To address this issue, we further regularize the framework, so that a novel feasible kernel-based optimization, which permits non-linear feature extraction, could be theoretically developed. Specifically, a low-dimension assumption is imposed on each new feature space to avoid overfitting caused by the high-spatial-low-temporal resolution of fMRI data. Experimental results on five datasets suggest that the proposed method is not only superior to several state-of-the-art methods on temporally-aligned fMRI data, but also suitable for dealing with temporally-unaligned fMRI data.
Introduction
Functional Magnetic Resonance Imaging (fMRI) is an imaging technology used to measure neural activity by using the blood-oxygen-level-dependent (BOLD) contrast as an indicator for cognitive states (?). The informative patterns encoded in fMRI enable investigators to study how the human brain works (?). Specifically, the use of multi-subject fMRI data is indispensable for accessing the validity and generality of the findings across subjects (?; ?). From another angle, aggregating multi-subject fMRI data is also critical due to the high-spatial-low-temporal (HSLT) resolution of fMRI, i.e., the number of samples (time points or volumes) is generally much smaller than the number of features (voxels) per subject. However, such aggregation is facing a challenge that both anatomical structure and functional topography vary across subjects (?). Hence, inter-subject alignment is an indispensable step in fMRI analysis.
Existing studies for inter-subject alignment include anatomical alignment and functional alignment, which can work in unison. In fact, anatomical alignment is usually used as a preprocessing step for fMRI analysis, by aligning anatomical features based on structural MRI images across subjects. Typical examples include Talairach alignment (?), cortical surface alignment (?) and so on. However, anatomical alignment generated limited accuracy since the size, shape and anatomical location of functional loci differ across subjects (?; ?). In contrast, functional alignment tries to directly align functional responses across subjects (?; ?). As more radical approaches of functional alignment, Hyperalignment (?) and Shared Response Model (SRM) (?) learn implicitly shared patterns across subjects, which are closely related to multi-view Canonical Correlation Analysis (CCA). Though both of them have been extensively studied and extended to an assortment, the existing related studies assume that the given fMRI datasets should be temporally-aligned across subjects (?; ?; ?). In other words, the sequential fMRI time points of each subject have to correspond to the same sequence of stimuli, like all subjects watching a movie together. Such a demand makes them not flexible enough as fMRI datasets today could be not temporally-aligned. For example, some subjects probably lack the responses to some stimuli, or different subjects may respond to different sequences of stimuli. Even though this problem could be somewhat solved by reordering and truncating (or down-sampling) the dataset to generate an aligned version (?), these processes may lead to an inevitable loss of information. A recent study tries to extend SRM into a semi-supervised one by exploiting labeled samples, the unlabeled samples are, however, required to be temporally-aligned (?).
In this paper, we aim to develop an adaptable functional alignment framework by using a cross-subject graph that depicts the (dis)similarities between all samples as a priori. Such a graph can be generated according to samples’ category labels or through inference (?). From this perspective, we can then focus on the (dis)similarity, which is encoded in a graph, between any two samples rather than merely caring about if the given fMRI dataset is temporally-aligned. However, the crude framework is unpractical as the related matrices are too large to be used, which is caused by the high dimension of fMRI data and the use of multiple subjects. To address this problem, the unrefined framework is regularized so that a novel feasible kernel-based optimization, which allows for non-linear feature extraction, could be theoretically set up. With such a regularization, the optimal solution is, sometimes, unique. Nevertheless, the high-spatial-low-temporal (HSLT) resolution of fMRI data causes that the generated optimal solution could indicate overfitting, i.e., it aligns all aligning samples perfectly. In a specific case, the culprit is that the dimension of the subspace spanned by the aligning samples equals to the number of them. Therefore, a low-dimension assumption, which agrees with that the number of informative features is generally less than the number of voxels, is imposed on each new feature space to avoid overfitting. The refined framework, together with the proposed optimization method, is referred to as Graph-based Decoding Model (GDM) in this paper. Notably, the objective function of Hyperalignment is the same as that of our GDM (with an evident graph). The main contributions of this paper are summarized as follows:
- i)
Unlike previous studies that rely on temporally-aligned data, GDM does not require temporal alignment for fMRI data. Once the prior information of the (dis)similarities among samples is available or can be inferred, one can employ our GDM to solve fMRI-based problems at hand. 2. ii)
Different from the conventional naive kernel implementation, the computational time of our proposed kernel-based optimization (naturally accompanied by a low-dimension assumption) is faster on the number of samples, making it suitable for processing large-scale dataset. 3. iii)
The feasible kernel-based optimization method with the low-dimension assumption is equipped with some theoretical guarantees.
In the following, we first briefly review related works, and concisely mention the notation and problem statement. Then, the proposed method GDM will be introduced in detail. We further introduce the materials used in this work, experimental setup, competing methods, and experimental results achieved by different methods on both aligned and unaligned datasets, which is followed by a Conclusion section. Related proofs and additional experimental results are given in the Supplementary File.
Related Works
The initial Hyperalignment (HA) method aims to seek implicitly shared features across subjects (?), which is based on the orthogonal Procrustes problem. It is the first that links functional alignment and multi-view CCA. The performance of Hyperalignment on fMRI analysis is dramatically increased compared with any other anatomical alignment methods. To tackle the singularity caused by the HSLT resolution of fMRI, Regularized Hyperalignment (RHA) was developed by Xu et al. (?).
However, neither of HA nor RHA can handle full-brain data. To address this issue, there have been several works: Chen et al. developed a Singular Vector Decomposition Hyperalignment (SVDHA), which firstly carries out a joint-SVD by grouping all subjects’ fMRI data for dimension reduction across subjects (?). Later, Chen et al. introduced a Shared Response Model (SRM) which can be modeled from probabilistic perspective by assuming that each sample from the latent common space has undergone a Gaussian noise disturbance (?). Solely linear feature extraction was considered until that Kernel Hyperalignment (KHA) was formulated by Lorbert and Ramadge (?). Since fMRI dataset may partially contain labels, a semi-supervised scheme based on SRM was studied by Turek et al. (?).
On the other hand, a Searchlight approach, which takes functional alignment method as a module, was established to enhance functional alignment further by assuming that any voxel is only in connection with voxels in its anatomical vicinity (?). Recently, a Robust SRM that accounts for individual variations was developed by Turek et al. (?).
Notation and Problem Statements
Notation
In this paper, the bold letters are reserved for matrices (upper) or vectors (lower), whereas the plain are for scalars. Given any sequence of matrices , let be the corresponding block diagonal matrix whose diagonal matrices are from the top left to the bottom right. Plus, for any matrix , refers to its -th column vector, is its -th entry, denotes the subspace spanned by the columns of and is the null space of , i.e., . Moreover, any vector is treated as a column vector and the subscript of indicates its shape.
Let be an fMRI dataset where and are the number of samples (time points or volumes) and features (voxels) of the -th subject, respectively, and is the total number of subjects. Due to the HSLT resolution of fMRI, . To develop a kernel-based method, we introduce a column-wised non-linear map that maps each sample, e.g., each column of , of the -th subject into a new feature space , which is a Hilbert space. Unlike Kernel Hyperalignment (?), subject-specific kernels are allowed. Here, different kernels could be thought to account for different structures of human brain. For simplicity, denote by setting for , and let be . Plus, let denote the number of the shared features across subjects.
Assumption for Theoretical Development
Generally, the dimension of could be infinite. For example, the reproducing kernel Hilbert space of Gaussian kernel is isomorphic to a subspace of (?). For clarity in the development of the optimization, we assume that is a finite dimensional real Hilbert space throughout the paper. The general lengthy proofs are left in the Supplementary File. Thus, and where is the dimension of .
The goal is to learn aligning maps for each subject such that they map populations of subjects’ fMRI responses into a shared space in which the disparities between subjects’ brains are eliminated. Here, we aim to learn linear aligning maps with good generalization. Therefore, and for where .
Proposed Method
Formulation
Cross-Subject Graph
A graph about the (dis)similarities among all samples are mostly available. For example, the part of temporally-aligned samples, the category of each sample, or the distances between samples tell which samples are closely related or distinctive. To describe such (dis)similarities, let be a cross-subject graph matrix where and indicates the (dis)similarity of the -th and -th samples, and thus . Here, or could refer to any sample from any subject.
Objective Function
Let be and be . Since contains all samples, the objective function can be expressed as
[TABLE]
where is the Laplacian matrix of the graph matrix (?) and is a diagonal matrix with . This objective function tries to separate the transformed samples and when but attempts to make them close when .
Constraint
Given a stimulus, suppose are subjects’ corresponding fMRI responses and the authentic aligning maps are already there. Since each subject’s fMRI responses to the same stimulus behave like a random variable, are expected to be from the same shared random variable. In other words, we do not require that for any . Therefore, the statistical constraint can be applied directly even if some samples are expected to be from the same latent response. The constraint means that each extracted shared feature is on the same scale and they are restricted be as uncorrelated as possible. The crude framework is
[TABLE]
Relationship between GDM and Hyperalignment
The Hyperalignment (HA) method is based on temporally-aligned dataset, assuming that for . Define a graph by setting when the -th and -th samples are aligned and otherwise. Then, , which is the objective function of HA, is equal to since
[TABLE]
where the optimal is .
Computational Cost
Problem (2) is a generalized eigenvalue problem, which has been studied extensively. However, with linear kernel, the size of or , which is , is too tremendous to be used. For example, the dataset DS001 used in our experiment includes subjects with features per subject, and then it requires at least GB to store or of shape , which is not affordable. Thus, an efficient feasible optimization is needed. The Proposition below is helpful for solving such an issue.
Proposition 1
If is one solution for problem (2), then there must be another solution that belongs to , and has the same objective value as .
Proof. can be decomposed uniquely as where and . Since
[TABLE]
Plugging into problem (2) leads to that satisfies the constraint and shares the same objective value with .
Regularized Framework
In Proposition 1, the trivial part exists due to the HSLT resolution of fMRI, i.e., . Such a trifling part indicates that it does not help produce a better solution, and thus there are many optimal solutions. If the trivial part is excluded by constraint, the optimal solution, sometimes, become unique, and a feasible optimization will be there. More details about the uniqueness are included in the Supplementary File. In a nutshell, the regularized framework is expressed as
[TABLE]
Optimization
Naive Kernel-Based Optimization
A simple way to solve GDM in Eq. (3) is to let be , where is a new variable. Then, becomes , where is constructed like . The optimal solution of GDM can be achieved by solving a generalized eigenvalue problem. However, with any kernel, the complexity in terms of will be at least where , meaning that it heavily depends on the number of samples. In the following, we propose a more efficient kernel-based optimization algorithm.
Proposed Kernel-Based Optimization
Here are some tricks to solve problem (3). For each , by spectral decomposition, where zero eigenvalues of are excluded. With , it leads to a Singular Vector Decomposition (SVD) of as
[TABLE]
As shown in the Supplementary File, can be decomposed similarly when the dimension of is infinite. Thus, the development below is without loss of generality. With Eq. (4), and then problem (3) is equivalent to
[TABLE]
To see this, denote the shape of by . Let be and be . Denote a map by setting . Since each column of belongs to , , which in turn leads to that is a bijection between and . Plugging into problem (3) leads to problem (5).
Proposition 2
Using spectral decomposition, where all eigenvalues of along the diagonal of from the top left to the bottom right are in ascending order. Denote the shape of by . If , the first columns of is optimal for problem (5).
Proof. Firstly, problem (5) is equivalent to
[TABLE]
where . As infers and for each , there is
[TABLE]
Let denote . Since , is optimal. Therefore, an optimal solution for problem (5) is indeed the first columns of .
An Optimal Solution for Regularized Framework and Its Uniqueness
Let denote the first columns of and take Eq. (4) into consideration, then an optimal solution for problem (3) is
[TABLE]
Since each is separable from , an optimal solution for subject is
[TABLE]
where are block matrices of , which is cut along the first dimension according to the dimensions of block matrices in .
By the equivalences above, if , there is no solution satisfying the constraint in problem (3) or (6) as there is no satisfying . If , or with , the optimal solution of problem (3) is unique except being rotated. In other words, if and are two optimal solutions, there is an orthogonal matrix such that . By the definition of , it implies that the shared feature space is unique except being rotated. More details are given in the Supplementary File.
Low-Dimension Assumption
Potential Overfitting of GDM
Suppose the dataset is temporally-aligned, which means that for any . Construct a graph matrix by setting if the -th and -th samples are temporally-aligned, and otherwise. With this graph matrix, the objective function of problem (3) with linear kernel becomes
[TABLE]
Assume that each is full-column rank. Let () be any matrix such that and take Eq. (4) into consideration where is replaced by . With and , satisfies the constraints in problem (3). However, for each , which implies that the generated optimal solution (8) aligns each aligning sample perfectly. The culprit is the full-column rank assumption of each , which is almost the case due to the HSLT resolution of fMRI, i.e., . Therefore, we impose a low-dimension assumption over each new feature space , which conforms with that the number of informative features is usually much less than the number of voxels. Suppose the low-dimension in is , then we try to fit the data in by an dimensional affine subspace111An dimensional affine subspace in is where is an dimensional subspace and ., i.e.,
[TABLE]
An optimal solution is and be the first columns of in Eq. (4) where for . The general proof for any Hilbert space is left in the Supplementary File.
Centralizing over Gram Matrices
To generate and apply , it is necessary to centralize all data by the mean of the aligning data, i.e., . Suppose is extra fMRI data for the -th subject. Denote all-one matrices by . For subject , the centralizing can be applied on the Gram matrices directly since
[TABLE]
From now on, suppose all Gram matrices have been centralized. As is provided in Eq. (4), , which is an SVD. Denote the number of the (non-zero) singular values in by . Assume the singular values in are in descending order and the first singular values approximately contains () energy , i.e., . By this way, the low dimension is controlled by . Therefore, the corresponding low-dimensional representation of would be where is the first columns of . Generally, with only Gram matrices, there is
[TABLE]
Nevertheless, the equality holds with the help of that is defined by the first columns of
Proposition 3
[TABLE]
Proof. Since where is the upper left submatrix of , there is .
Therefore, the proposed kernel-based optimization can easily incorporate the low-dimension assumption over each new feature space. It will be shown in our experiments that this is essential for getting useful results. The overall optimization procedure of GDM is summarized in Algorithm 1.
Complexity Analysis
The shape of is where and is the low-dimension of the -th subject. Suppose the Gram matrices are given, and for each , i.e., the number of the shared features is smaller than the sample size, the complexity of GDM is where . If each low-dimension is fixed, the complexity thus becomes . Notably, it could be reduced into by using parallel programming. By contrast, the naive kernel scheme cannot be parallelized, and the complexity of employing it is . Therefore, our proposed kernel method is more efficient compared to the naive kernel scheme. Besides, different from methods based on iterative optimization algorithms, one can obtain the optimal solution of GDM directly.
Experiments
Materials
We utilize five datasets shared by openfmri.org and Chen et al. (?). The relevant information about each dataset is outlined in Table 1. Raw datasets are preprocessed by using FSL (https://fsl.fmrib.ox.ac.uk/), following a standard process (i.e., slice timing, anatomical alignment, normalization, and smoothing). The default parameters in FSL were taken when the dataset does not provide. The description of each dataset is as follows:
- (1) DS105:
The fMRI data were measured while six subjects viewed gray-scale images of faces, houses, cats, bottles, scissors, shoes, chairs, and nonsense images (?). Hence, there are totally 8 categories in this dataset. Here, DS105WB contains the whole-brain fMRI data while the data in DS105ROI are based on a region of interest. 2. (2) DS011:
Fourteen subjects participated in a single task (weather prediction). In the first phase, they learned to predict weather outcomes (rain or sun) for two different cities. After learning, they predicted weather (?). Thus, there are two cognitive states. 3. (3) DS001:
Sixteen subjects were instructed to inflate a control balloon or a reward balloon on a screen. For a control balloon, subjects had merely one choice whereas they could choose to pump or cash out for another case. After opting to pump, the balloon may explode or expand (?). Hence, there are four different cognitive states. 4. (4) DS232:
Ten subjects were instructed to respond to images of faces, scenes, objects and phrase-scrambled versions of the scene images (?). 5. (5) Raider:
As a commonly-used one, it collected data from 10 subjects participating in two experiments. Firstly, 10 subjects watched a movie Raiders of the Lost Ark (2203 TRs). The data of movie dataset does not contain any label. In the next experiment, the same 10 subjects were shown 7 classes of images (female face, male face, monkey face, dog face, house, chair and shoes) (?).
It’s worth noting that, except for Raider, all four other datasets are not temporally-aligned. To compare GDM with other temporal-alignment-based methods, following the previous study in (?), these datasets (i.e., DS105, DS011, DS001, and DS232) are reordered and truncated, or downsampled, to be aligned according to their categories.
Experimental Setup
We follow the experiment setup with a cross-validation strategy in previous studies (?; ?), as illustrated by Fig. S1 and Fig. S2 in the Supplementary File. Specifically, except for the Raider, each subject’s data is equally divided into two parts with each category being equally split, one is for alignment whereas the other is for training or testing a classifier. Switching the roles of the two parts and leave--subject-out strategy are adopted for cross-validation. For instance, if there are subjects, leave--subject-out leads to folds for cross-validation. For Raider dataset, the movie data is taken for alignment while the image data is for classification. Here, the first time points of movie data are used for alignment. Then it is equally divided into threes parts with each part having 734 samples for cross-validation. Since a leave--subject-out is used in this dataset, there are a total of folds when using Raider. As shown in Fig. S1 in the Supplementary File, the experiment on each dataset contains two stages: 1) aligning phase, and 2) classification phase. At the first phase, one part of all subjects’ data are fed into a functional alignment method to yield the corresponding aligning maps . At the classification phase, the remaining part of data are first mapped to the shared feature space via the learned aligning maps and then used for classification model construction. Note that those data used at the aligning phase will not be used at the classification phase in our experiments.
Since each dataset (or part of it) used in this paper includes labels, the performance of alignment is assessed by testing how well a trained classifier can generalize to new subjects, i.e., between-subject classification (BSC) accuracy (?). Like previous studies, -SVM is used for classification (?).
Competing Methods
The proposed GDM method is compared with six state-of-the-art methods in the experiments, including (1) Hyperalignment (HA) (?), (2) Regularized Hyperalignment (RHA) (?), (3) Kernel Hyperalignment (KHA) (?), (4) SVD-Hyperalignment (SVDHA) (?), (5) Shared Response Model (SRM) (?), and (6) Robust SRM (RSRM) (?). All methods are implemented by ourselves in Python.
The parameter settings for each dataset are briefly listed in Table 1. For a fair comparison, the parameter in -SVM (with a linear kernel) is fixed for all methods on each dataset. For six competing methods, we choose the optimal hyperparameters according to their original papers. For our GDM model, a linear kernel is fixed, while the influence of different kernels are shown in Figs. S3-S8 in the Supplementary File. For the Raider dataset, we set if the -th and -th samples are temporally aligned; and , otherwise. For the other datasets, we set if the -th and -th samples are in the same category; and , otherwise.
Results on Aligned Datasets
On the temporally-aligned datasets, we report the BSC accuracy values achieved by eight different methods in Table 2. As can be seen from Table 2, for each aligned dataset, the proposed GDM method consistently outperforms the competing methods in terms of BSC accuracy. For example, GDM achieves the improvement of compared to the second best result (i.e., of RHA) on the DIS105WB dataset.
Results on Unaligned Datasets
To assess the performance of GDM when dealing with unaligned data, we randomly remove some data from each aligned dataset. Here, the term incompleteness means that percent of aligning data are randomly removed per subject. The corresponding results are shown in Fig. 1. Notably, six competing methods (i.e., HA, RHA, KHA, SVDHA, SRM, and RSRM) cannot be applied to such incomplete datasets since they are designed for aligned data. More results can be found in Figs. S3-S5 in the Supplementary File. From Fig. 1, one can observe that our GDM is able to preserve a dominant BSC accuracy with incompleteness up to at least . For the DS232 dataset, the performance of GDM still beats others with incompleteness. These results further validate the superiority of GDM in handling unaligned data.
Necessity of Low-Dimension Assumption
To evaluate the influence of low-dimension assumption on GDM, we perform another group of experiments to study the BSC values achieved by GDM with different energy ratios kept on three datasets, with results reported in Figure 2. This figure suggests that the best results are not achieved by GDM with energy on each dataset, thus verifying the importance of the low-dimension assumption. Besides, on the Raider dataset, GDM still achieves a good result with around energy kept. We conjecture that it results from the fact that the movie data contain much richer information than the visual data generated from simple objects. More results can be found in Figs. S6-S8 in the Supplementary File.
Conclusion
As an essential step in fMRI analysis, functional alignment removes the differences between subjects’ brains so that multi-subject fMRI data can be aggregated to make valid and general inferences. However, the existing methods cannot well handle unaligned fMRI datasets. In this paper, a flexible framework is developed on a cross-subject graph that depicts the (dis)similarities among all samples. To reduce the computational cost, the framework is regularized so that a novel feasible kernel-based optimization is analytically developed. To avoid overfitting caused by the HSLT resolution of fMRI, a low-dimension assumption is made over each new feature space, and we also propose a way to incorporate such an assumption into our proposed optimization. Experimental results attest to the superiority of GDM. In the future, we plan to study how to construct an informative graph matrix in different situations.
Acknowledgments
This work was in part supported by the National Natural Science Foundation of China (Nos. 61876082, 61732006, 61861130366, 61703301), the National Key R&D Program of China (Nos. 2018YFC2001600, 2018YFC2001602), the Taishan Scholar Program of Shandong Province in China, and the Shandong Natural Science Foundation for Distinguished Young Scholar in China (No. ZR2019YQ27).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Carlin and Kriegeskorte 2017] Carlin, J. D., and Kriegeskorte, N. 2017. Adjudicating between face-coding models with individual-face f MRI responses. P Lo S Computational Biology 13(7):e 1005604.
- 2[Chang and Lin 2011] Chang, C.-C., and Lin, C.-J. 2011. Libsvm: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology 2(3):27.
- 3[Chen et al . 2014] Chen, P.-H.; Guntupalli, J. S.; Haxby, J. V.; and Ramadge, P. J. 2014. Joint svd-hyperalignment for multi-subject f MRI data alignment. In 2014 IEEE International Workshop on Machine Learning for Signal Processing (MLSP) , 1–6. IEEE.
- 4[Chen et al . 2015] Chen, P.-H. C.; Chen, J.; Yeshurun, Y.; Hasson, U.; Haxby, J.; and Ramadge, P. J. 2015. A reduced-dimension f MRI shared response model. In Advances in Neural Information Processing Systems (NIPS) , 460–468.
- 5[Chung and Graham 1997] Chung, F. R., and Graham, F. C. 1997. Spectral graph theory . Number 92. American Mathematical Soc.
- 6[Conroy et al . 2009] Conroy, B.; Singer, B.; Haxby, J.; and Ramadge, P. J. 2009. f MRI-based inter-subject cortical alignment using functional connectivity. In Advances in Neural Information Processing Systems (NIPS) , 378–386.
- 7[De Sa et al . 2010] De Sa, V. R.; Gallagher, P. W.; Lewis, J. M.; and Malave, V. L. 2010. Multi-view kernel construction. Machine Learning 79(1-2):47–71.
- 8[Fischl et al . 1999] Fischl, B.; Sereno, M. I.; Tootell, R. B.; and Dale, A. M. 1999. High-resolution intersubject averaging and a coordinate system for the cortical surface. Human Brain Mapping 8(4):272–284.