Wilkinson's bus: Weak condition numbers, with an application to singular polynomial eigenproblems
Martin Lotz, Vanni Noferini

TL;DR
This paper introduces a new weak condition number framework that better predicts the accuracy of solutions in problems where classical and stochastic theories fail, with applications to singular polynomial eigenproblems.
Contribution
It develops a novel weak condition number theory that improves prediction of computational accuracy in challenging problems and demonstrates practical estimation methods.
Findings
Weak condition numbers outperform classical ones in predicting accuracy.
Application to singular polynomial eigenproblems shows improved insights.
Practical estimation methods for weak condition numbers are provided.
Abstract
We propose a new approach to the theory of conditioning for numerical analysis problems for which both classical and stochastic perturbation theory fail to predict the observed accuracy of computed solutions. To motivate our ideas, we present examples of problems that are discontinuous at a given input and have infinite classical and stochastic condition number, but where the solution is still computed to machine precision without relying on structured algorithms. Stimulated by the failure of classical and stochastic perturbation theory in capturing such phenomena, we define and analyse a weak worst-case and a weak stochastic condition number. This new theory is a more powerful predictor of the accuracy of computations than existing tools, especially when the worst-case and the expected sensitivity of a problem to perturbations of the input is not finite. We apply our analysis to the…
Click any figure to enlarge with its caption.
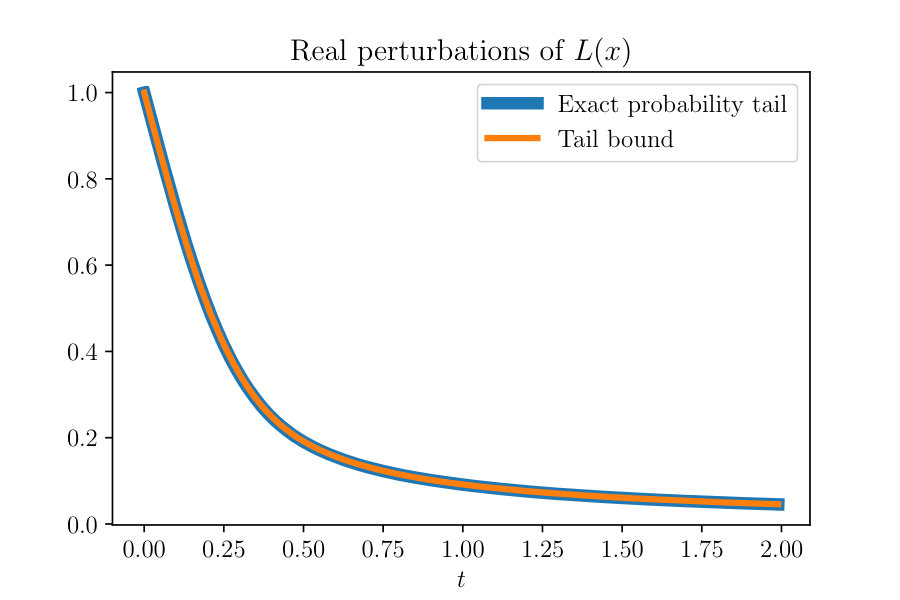 Figure 1
Figure 1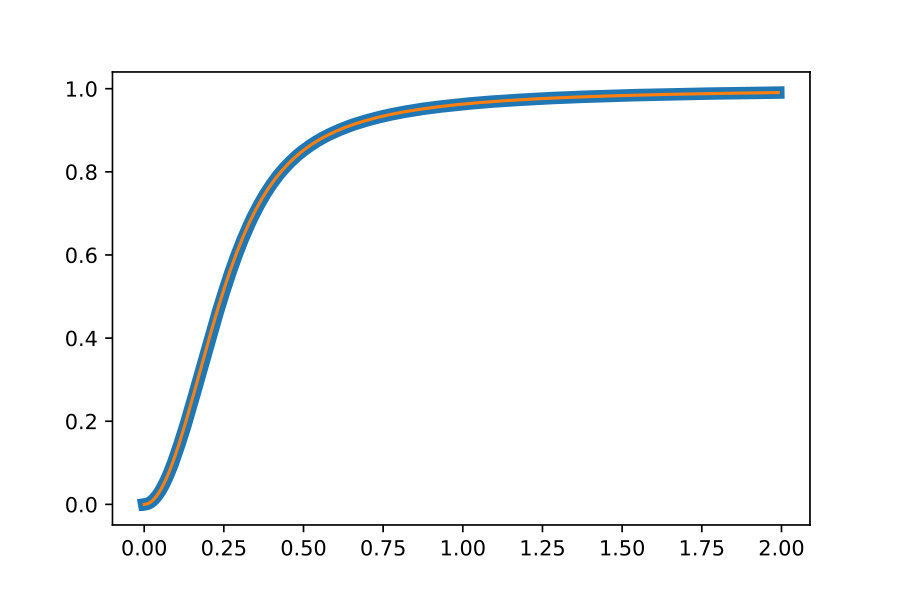 Figure 2
Figure 2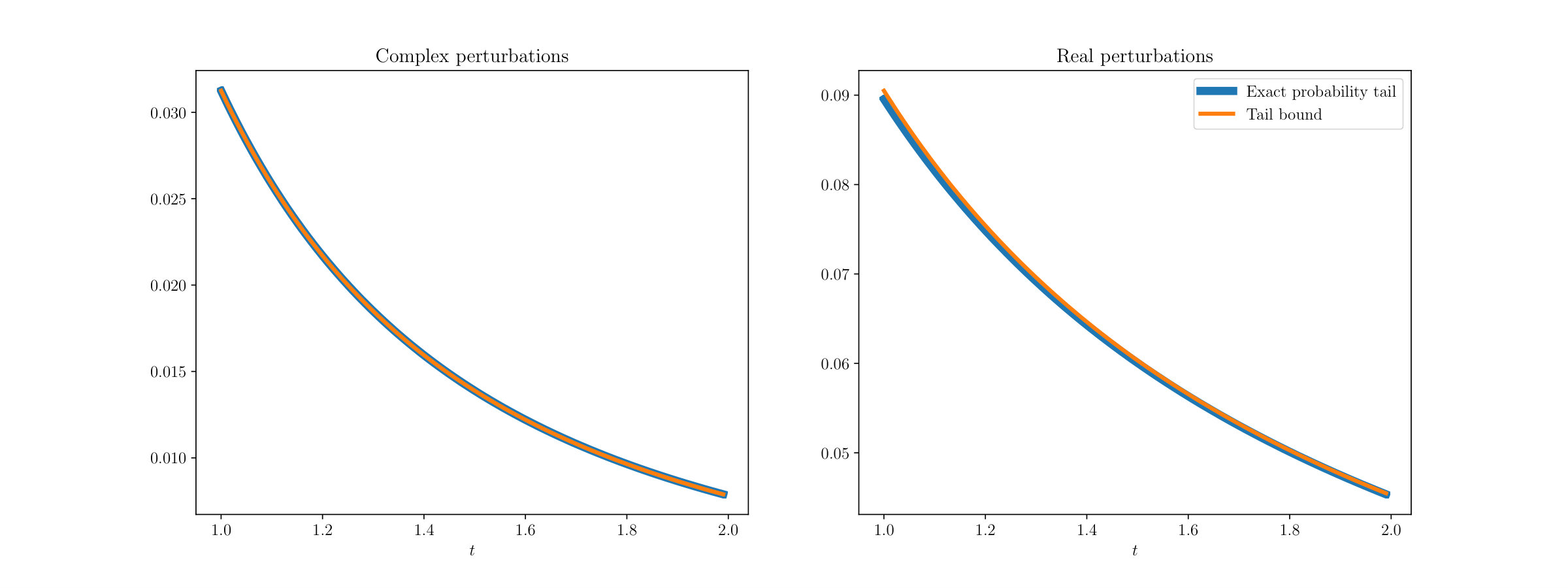 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
∎
11institutetext: M. Lotz 22institutetext: Mathematics Institute, The University of Warwick. 22email: [email protected] 33institutetext: V. Noferini 44institutetext: Department of Mathematics and Systems Analysis, Aalto University. 44email: [email protected]
Wilkinson’s bus: Weak condition numbers,
with an application to singular polynomial eigenproblems
Martin Lotz
Vanni Noferini
(Received: date / Accepted: date)
Abstract
We propose a new approach to the theory of conditioning for numerical analysis problems for which both classical and stochastic perturbation theory fail to predict the observed accuracy of computed solutions. To motivate our ideas, we present examples of problems that are discontinuous at a given input and even have infinite stochastic condition number, but where the solution is still computed to machine precision without relying on structured algorithms. Stimulated by the failure of classical and stochastic perturbation theory in capturing such phenomena, we define and analyse a weak worst-case and a weak stochastic condition number. This new theory is a more powerful predictor of the accuracy of computations than existing tools, especially when the worst-case and the expected sensitivity of a problem to perturbations of the input is not finite. We apply our analysis to the computation of simple eigenvalues of matrix polynomials, including the more difficult case of singular matrix polynomials. In addition, we show how the weak condition numbers can be estimated in practice.
Keywords:
condition number stochastic perturbation theory weak condition number polynomial eigenvalue problem singular matrix polynomial
MSC:
15A15 15A18 15B52 60H99 65F15 65F35
1 Introduction
The condition number of a computational problem measures the sensitivity of an output with respect to perturbations in the input. If the input-output relationship can be described by a differentiable function near the input, then the condition number is the norm of the derivative of . In the case of solving systems of linear equations, the idea of conditioning dates back at least to the work of von Neumann and Goldstine Neumann1947 and Turing Turing1948 , who coined the term. For an algorithm computing in finite precision arithmetic, the importance of the condition number stems from the “rule of thumb” popularized by N. J. Higham (Higham1996, , §1.6),
[TABLE]
The backward error is small if the algorithm computes the exact value of at a nearby input, and a small condition number would certify that this is enough to get a small overall error. Higham’s rule of thumb comes from a first order expansion, and in practice it often holds as an approximate equality and is valuable for practitioners who wish to predict the accuracy of numerical computations. Suppose that a solution is computed with, say, a backward error equal to . If then one would trust the computed value to have (at least) meaningful decimal digits.
The condition number can formally still be defined when is not differentiable, though it may not be finite. If is not locally Lipschitz continuous at an input, then the condition number is ; a situation clearly beyond the applicability of Higham’s rule. Inputs at which the function is not continuous are usually referred to as ill-posed. Based on the worst-case sensitivity one would usually only expect a handful of correct digits when evaluating a function at such an input, and quite possibly none.111The number of accurate digits that can be expected when the problem is continuous but not locally Lipschitz continuous requires a careful discussion. It depends on the unit roundoff , on the exact nature of the pathology of , and on . For example, computing the eigenvalues of a matrix similar to an Jordan block for is Hölder continuous with exponent but not Lipschitz continuous. Usually this translates into expecting only about accuracy, up to constants, when working in finite precision arithmetic. For a more complete discussion, see GW1976 , where pathological examples of derogatory matrices are constructed, whose eigenvalues are not sensitive to finite precision computations (for fixed ), or also (konstantinov2003perturbation, , §3.3). For discontinuous , however, these subtleties alone cannot justify any accurately computed decimal digits. On the other hand, a small condition number is not a necessary condition for a small forward-backward error ratio: it is not inconceivable that certain ill-conditioned or even ill-posed problems can be solved accurately. Consider, for example, the problem of computing an eigenvalue of the matrix pencil (linear matrix polynomial)
[TABLE]
this is a singular matrix pencil (the determinant is identically zero) whose only finite eigenvalue is simple and equal to (see Section 3 for the definition of an eigenvalue of a singular matrix polynomial and other relevant terminology). The input is and the solution is . If the QZ algorithm QZ , which is the standard eigensolver for pencils, is called via MATLAB’s command eig 222MATLAB R2016a on Ubuntu 16.04, the output is:
eig(L0,-L1)
ans =
-138.1824366539536
-0.674131242894470
1.000000000000000
0.444114486065683
All but the third computed eigenvalues are complete rubbish. This is not surprising: singular pencils form a proper Zariski closed set in the space of matrix pencils of a fixed format, and it is unreasonable to expect that an unstructured algorithm would detect that the input is singular and return only one eigenvalue. Instead, being backward stable, QZ computes the eigenvalues of some nearby matrix pencil, and almost all nearby pencils have eigenvalues. On the other hand, the accuracy of the approximation of the genuine eigenvalue is quite remarkable. Indeed, the condition number of the problem that maps to the exact eigenvalue is infinite because the map from matrix pencils to their eigenvalues is discontinuous at any matrix pencil whose determinant is identically zero. To make matters worse, there exist plenty of matrix pencils arbitrarily close to and whose eigenvalues are all nowhere near . For example, for any ,
[TABLE]
where
[TABLE]
has characteristic polynomial and therefore, by an arbitrary choice of the parameters , can have eigenvalues literally anywhere. Yet, unaware of this worrying caveat, the QZ algorithm computes an excellent approximation of the exact eigenvalue: correct digits! This example has not been carefully cherry-picked: readers are encouraged to experiment with any singular input in order to convince themselves that QZ often computes333Of course, if the exact solution is not known a priori, one faces the practical issue of deciding which of the computed eigenvalues are reliable. There are various ways in which this can be done in practice, such as artificially perturbing the problem; the focus of our work is on explaining why the correct solution has been shortlisted in the first place; see hmp18 for a more practical perspective. accurately the (simple) eigenvalues of singular pencils, or singular matrix polynomials, in spite of being a discontinuous problem. See also hmp18 for more examples and a discussion of applications. Although the worst-case sensitivity to perturbations is indeed infinite, the raison d’être of the condition number, which is to predict the accuracy of computations on a computer, is not fulfilled.
Why does the QZ algorithm accurately compute the eigenvalue, when the map describing this computational problem is not even continuous? Two natural attempts at explaining this phenomenon would be to look at structured condition numbers and/or average-case (stochastic) perturbation theory.
An algorithm is structured if it computes the exact solution to a perturbed input, where the perturbations respect some special features of the input: for example singular, of rank , triangular, or with precisely one eigenvalue. The vanilla implementation of QZ used here is unstructured in the sense that it does not preserve any of the structures that would explain the strange case of the algorithm that computes an apparently uncomputable eigenvalue.444There exist algorithms able to detect and exploit the fact that a matrix pencil is singular, such as the staircase algorithm VanDooren1979 . It does, however, preserve the real structure. In other words, if the input is real, QZ computes the eigenvalues of a nearby real pencil. Yet, by taking real in the example above, it is clear that there are real pencils arbitrary close to whose eigenvalues are all arbitrarily far away from . 2. 2.
The classical condition number is based on the worst-case perturbation of an input; as discussed in (Higham1996, , §2.8), this approach tends to be overly pessimistic in practice. Numerical analysis pioneer James Wilkinson, in order to illustrate that Gaussian elimination is unstable in theory but in practice its instability is only observed by mathematicians looking for it, is reported to have said trefethen2012smart
[TABLE]
In other words: in Wilkinson’s experience, the likelihood of seeing the admittedly terrifying worst case appeared to be very small, and therefore Wilkinson believed that being afraid of the potential catastrophic instability of Gaussian elimination is an irrational attitude. Based on this experience, Weiss et al. weiss1986average and Stewart stewart1990stochastic proposed to study the effect of perturbations on average, as opposed to worst-case; see (Higham1996, , §2.8) for more references on work addressing the stochastic analysis of roundoff errors. This idea was later formalized and developed further by by Armentano armentano2010stochastic . This approach gives some hope to explain the example above, because it is known that the set of perturbations responsible for the discontinuity of has measure zero dd09 . However, this does not imply that on average perturbations are not harmful. In fact, as we will see, the stochastic condition number for the example above (or for similar problems) is still infinite! Average-case perturbation analysis, at least in the form in which it has been used so far, is still unable to solve the puzzle.
While neither structured nor average-case perturbation theory can explain the phenomenon observed above, Wilkinson’s colourful quote does contain a hint on how to proceed: shift attention from average-case analysis of perturbations to bounding rare events. We will get back to the matrix pencil (1) in Example 5.3, where we show that our new theory does explain why this problem is solved to high accuracy using standard backward stable algorithms.
In summary, the main contributions of this paper are
a new species of ‘weak’ condition numbers, which we call the weak worst-case condition number and the weak stochastic condition number, that give a more accurate description of the perturbation behaviour of a computational map (Section 2); 2. 2.
a precise probabilistic analysis of the sensitivity of the problem of computing simple eigenvalues of singular matrix polynomials (Sections 4 and 5); 3. 3.
an illustration of the advantages of the new concept by demonstrating that, unlike both classical and stochastic condition numbers, the weak condition numbers are able to explain why the apparently uncomputable eigenvalues of singular matrix polynomials, such as the eigenvalue in the example above, can be computed with remarkable accuracy (Example 5.3); 4. 4.
a concrete method for bounding the weak condition numbers for the eigenvalues of singular matrix polynomials (Section 6).
1.1 Related work
Rounding errors, and hence the perturbations considered, are not random (Higham1996, , 1.17). Nevertheless, the observation that the computed bounds on rounding errors are overly pessimistic has led to the study of statistical and probabilistic models for rounding errors. An early example of such a statistical analysis is Goldstine and von Neumann goldstine1951numerical , see (Higham1996, , 2.8) and the references therein for more background. Recently, Higham and Mary higham2018new obtained probabilistic rounding error bounds for a wide variety of algorithms in linear algebra. In particular, they give a rigorous foundation to Wilkinson’s rule of thumb, which states that constants in rounding error bounds can be safely replaced by their square roots.
The idea of using an average, rather than a supremum, in the definition of conditioning was introduced by Weiss et.al. weiss1986average in the context of the (matrix) condition number of solving systems of linear equations, and a more comprehensive stochastic perturbation theory was developed by G. W. Stewart stewart1990stochastic . In armentano2010stochastic , Armentano introduced the concept of a smooth condition number, and showed that it can be related to the worst case condition. His work uses a geometric theory of conditioning and does not extend to singular problems.
The line of work on random perturbations is not to be confused with the probabilistic analysis of condition numbers, where a condition number is a given function, and the distribution of this function is studied over the space of inputs (see BC2013 and the references therein). Nevertheless, our work is inspired by the idea of weak average-case analysis amelunxen2017average that was developed in this framework. Weak average-case analysis is based on the observation, which has origins in the work of Smale smale1981fundamental and Kostlan kostlan1988complexity , that discarding a small set from the input space can dramatically improve the expected value of a condition number, shifting the focus away from the average case and towards bounding the probability of rare events. Our contribution is to apply this line of thought to study random perturbations instead of random inputs. However, we stress that we do not seek to model the distribution of perturbations. The aim is to formally quantify statements such as “the set of bad perturbations is small compared to the set of good perturbations”. In other words, the (non-random) accumulation of rounding errors in a procedure would need a very good reason to give rise to a badly perturbed problem.
The conditioning of regular polynomial eigenvalue problems has been studied in detail by Tisseur tisseur2000backward and by Dedieu and Tisseur in a homogeneous setting dedieu2003perturbation . A probabilistic analysis of condition numbers (for random inputs) for such problems was given by Armentano and Beltrán armentano2017polynomial over the complex numbers and by Beltrán and Kozhasov beltran2018real over the real numbers. Their work studies the distribution of the condition number on the whole space of inputs, and such an analysis only considers the condition number of regular matrix polynomials. A perturbation theory for singular polynomial eigenvalue problems was developed by de Terán and Dopico dd10 , and our work makes extensive use of their results. A method to solve singular generalized eigenvalue problems with plain QZ, based on applying a certain perturbation to them, is proposed in hmp18 (see also the references therein); note that our work goes beyond this, by showing how to estimate the weak condition number that could guarantee, often with overwhelming probability, that QZ will do fine even without any preliminary perturbation step.
1.2 Organization of the paper
The paper is organized as follows. In Section 2 we review the rigorous definitions of the worst-case (von Neumann-Turing) condition number and the stochastic framework (Weiss et.al., Stewart, Armentano), and comment on their advantages and limitations. We then define the weak condition numbers as quantiles and argue that, even when Wilkinson’s metaphorical bus hits von Neumann-Turing’s and Armentano-Stewart’s theories of conditioning, ours comes well endowed with powerful dodging skills. In Section 3 we introduce the perturbation theory of singular matrix polynomials, along with the definitions of simple eigenvalues and eigenvectors. We define the input-output map underlying our case study and introduce the directional sensitivity of such problems. In Section 4, which forms the core of this paper, we carry out a detailed analysis of the probability distribution of the directional sensitivity of the problems introduced in Section 3. In Section 5, we translate the probabilistic results from Section 4 into the language of weak condition numbers and prove the main results, Theorem 5.1 and Theorem 5.2. In Section 6 we sketch how our new condition numbers can be estimated in practice. Along the way we derive a simple concentration bound on the directional sensitivity of regular polynomial eigenvalue problems. Finally, in Section 7, we give some concluding remarks and discuss potential further applications.
2 Theories of conditioning
For our purposes, a computational problem is a map between normed vector spaces 555One can, more generally, allow and to be anything with a notion of distance, such as general metric spaces or Riemannian manifolds. All the definitions of condition can be adapted accordingly; in this paper we focus on the case of normed vector spaces. We will also only need such a map to be defined locally near an input of interest.
[TABLE]
and we will denote the (possibly different) norms in each of these spaces by . Following the remark on (High:FM, , p. 56), for simplicity of exposition in this paper we focus on absolute, as opposed to relative, condition numbers. The condition numbers considered depend on the map and an input .
As we are only concerned with the condition of a fixed computational problem at a fixed input , in what follows we omit reference to and in the notation.
Definition 2.1 (Worst-case condition number)
The condition number of at is
[TABLE]
If is Fréchet differentiable at , then this definition is equivalent to the operator norm of the Fréchet derivative of . However, Definition 2.1 also applies (and can even be finite) when is not differentiable. In complexity theory BCSS1998 ; BC2013 , an elegant geometric definition of condition number is often used, which is essentially equivalent to Defintion 2.1 under certain assumptions (which include smoothness).
The following definition is loosely derived from the work of Stewart stewart1990stochastic and Armentano armentano2010stochastic , based on earlier work by Weiss et. al. weiss1986average . In what follows, we use the terminology for a random variable with distribution , and for the expectation with respect to this distribution.
Definition 2.2 (Stochastic condition number)
Let be a -valued random variable with distribution and assume that and . Assume that the function is measurable. Then the stochastic condition number is
[TABLE]
Remark 2.3
We note in passing that Definition 2.2 depends on the choice of a measure . This measure is a parameter that the interested mathematician should choose as convenient; this is of course not particularly different than the freedom one is given in picking a norm. In fact, it is often convenient to combine these two choices, using a distribution that is invariant with respect to a given norm. Typical choices that emphasize invariance are the uniform (on a sphere) or Gaussian distributions, and the Bombieri-Weyl inner product when dealing with homogeneous multivariate polynomials (BC2013, , 16.1). Technically speaking, the distribution is on the space of perturbations, rather than the space of inputs.
If is differentiable at and is finite dimensional, then it was observed by Armentano armentano2010stochastic that the stochastic condition number can be related to the worst-case one. We illustrate this relation in a simple but instructive special case. Consider the setting666Armentano’s results apply to differentiable maps between Riemannian manifolds, and cover the moments of the directional derivative as well: they are stronger and are derived with a more comprehensive approach. where () is differentiable at , so that is the operator norm of the differential. If denote the singular values of (with for ), then . If is the uniform distribution on the sphere, then
[TABLE]
where for (a) we used the fact that
[TABLE]
and for (b) we used the orthogonal invariance of the uniform distribution on the sphere. As we will see in the case of singular polynomial eigenvalue problems with complex perturbations, the bound (2) does not hold in general, as the condition number can be infinite while the stochastic condition number is bounded. However, sometimes it can happen that the stochastic condition number is also infinite, because the “directional sensitivity” (see Definition 2.4) is not an integrable function. For example, for the problem of computing the eigenvalue of the singular pencil in the introduction, in spite of the fact that real perturbations are analytic for all but a proper Zariski closed set of perturbations dd09 , when restricting to real perturbations, we get
[TABLE]
Despite this, QZ computes the eigenvalue with digits of accuracy.
To remedy the shortcomings of the stochastic condition number as defined in 2.2, we propose a change in focus from the expected value to tail bounds and quantiles, and the key concept for that purpose is the directional sensitivity. Just as the classical worst-case condition corresponds to the norm of the derivative, the directional sensitivity corresponds to a directional derivative. And, just as a function can have some, or all, directional derivatives while still not being continuous, a computational problem can have well-defined directional sensitivities but have infinite condition number.
Definition 2.4 (Directional sensitivity)
The directional sensitivity of the computational problem at the input with respect to the perturbation is
[TABLE]
The directional sensitivity takes values in . In numerical analytic language, the directional sensitivity is the limit, for a particular direction of the backward error, of the ratio of forward and backward errors of the computational problem ; this limit is taken letting the backward error tend to zero (again having fixed its direction), which could also be thought of as letting the unit round-off tend to zero. See, e.g., (Higham1996, , §1.5) for more details on this terminology.
The directional sensitivity is, if it is finite, times the norm of the Gâteaux derivative of at in direction . If is Fréchet differentiable, then the Gâteaux derivative agrees with the Fréchet derivative, and we get
[TABLE]
If is a -valued random variable satisfying the conditions of Definition 2.2 and if is Gâteaux differentiable in almost all directions, then by the Fatou-Lebesgue Theorem we get
[TABLE]
When integrating, null sets can be safely ignored; however, depending on the exact nature of the divergence (or lack thereof) of the integrand when approaching those null sets, the value of the integral need not be finite. To overcome this problem and still give probabilistically meaningful statements, we propose to use instead the concept of numerical null sets, i.e., sets of finite but small (in a sense that can be made precise depending on, for example, the unit roundoff of the number system of choice, the confidence level required by the user, etc.) measure. This is analogous to the idea that the “numerical zero” is the unit roundoff. We next define our main characters, two classes of weak condition numbers which generalize, respectively, the classical worst-case and stochastic condition numbers.
In the following, we fix a probability space and a random variable , where we consider endowed with the Borel -algebra. We further assume that
[TABLE]
The following definitions assume that is -measurable. This is the case, for example, if is measurable and the directional (Gâteaux) derivative exists -a.e.
Definition 2.5 (Weak worst-case and weak stochastic condition number)
Let and assume that is -measurable. The -weak worst-case condition number and the -weak stochastic condition number are defined as
[TABLE]
Remark 2.6
We note that one can give a definition of the weak worst-case and weak stochastic condition number that does not require to be a random variable, by setting
[TABLE]
where we used the notation for the measure of a set if there is no ambiguity. This form is reminiscent of the definition of weak average-case analysis in amelunxen2017average , and when is a random variable it can be shown to be equivalent to 2.5. Moreover, this slightly more general definition better illustrates the essence of the weak condition numbers: these are the (worst-case and average-case) condition numbers that ensue when one is allowed to discard a “numerically invisible” subset from the set of perturbations.
The directional sensitivity has an interpretation as (the limit of) a ratio of forward and backward errors, and hence the new approach provides a potentially useful general framework to give probabilistic bounds on the forward accuracy of outputs of numerically stable algorithms. Moreover, as we will discuss in Section 6, upper bounds on the weak condition numbers can be computed in practice for a natural distribution. One can therefore see as a parameter representing the confidence level that a user wants for the output, and any computable upper bound on becomes a practical reliability measure on the output, valid with probability . Although of course round-off errors are not really random variables, we hope that modelling them as such can become, with this “weak theory”, a useful tool for numerical analysis problems whose traditional condition number is infinite.
3 Eigenvalues of matrix polynomials and their directional sensitivity
Algebraically, the spectral theory of matrix polynomials is most naturally described over an algebraically closed field; however, the theory of condition is analytic in nature and it is sometimes of interest to restrict the coefficients, and their perturbations, to be real. In this section we give a unified treatment of both real and complex matrix polynomials. For conciseness we keep this overview very brief; interested readers can find further details in dd10 ; dd09 ; Dopico2018 ; GLR09 ; Noferini2012 and the references therein. A matrix polynomial is a matrix , where is a field. Alternatively, we can think of it as an expression
[TABLE]
with . If we require , then the integer in such an expression is called the degree of the matrix polynomial 777By convention, the zero matrix polynomial has degree .. We denote the vector space of matrix polynomials over of degree at most by . A matrix polynomial is called singular if and otherwise regular. An element is said to be a finite eigenvalue of if
[TABLE]
where is the field of fractions of , that is, the field of rational functions with coefficients in . We assume throughout rank (which implies ) and degree . The geometric multiplicity of the eigenvalue is the amount by which the rank decreases in the above definition,
[TABLE]
There exist matrices with , , that transform into its Smith canonical form,
[TABLE]
where the invariant factors are non-zero monic polynomials such that for . If one has the factorizations for some , with for and not dividing any of the , then the are called the partial multiplicities of the eigenvalue . The algebraic multiplicity is the sum of the partial multiplicities. Note that an immediate consequence of this definition is . If (i.e., all non-zero equal to ) then the eigenvalue is said to be semisimple, otherwise it is defective. If (i.e., for and zero otherwise), then we say that is simple, otherwise it is multiple.
A square matrix polynomial is regular if , i.e., if is not identically zero. A finite eigenvalue of a regular matrix polynomial is simply a root of the characteristic equation , and its algebraic multiplicity is equal to the multiplicity of the corresponding root. If a matrix polynomial is not regular it is said to be singular. More generally, a finite eigenvalue of a matrix polynomial (resp. its algebraic multiplicity) is a root (resp. the multiplicity as a root) of the equation , where is the monic greatest common divisor of all the minors of of order (note that ).
Remark 3.1
The concept of an eigenvalue, and the other definitions recalled here, are valid also in the more general setting of rectangular matrix polynomials. However, in that scenario a generic matrix polynomial has no eigenvalues dd09 ; as a consequence, a perturbation of a matrix polynomial with an eigenvalue would almost surely remove it. This is a fairly different setting than in the square case, and a deeper probabilistic analysis of the rectangular case beyond the scope of the present paper.
We mention in passing that there are possible ways to extend the analysis to the rectangular case, such as embedding them in a larger square matrix polynomial or (at least in the case of pencils, or linear matrix polynomials) consider structured perturbations that do preserve eigenvalues.
3.1 Eigenvectors
To define the eigenvectors, let and be minimal bases Dopico2018 ; Forney1975 ; Noferini2012 of and (as vector spaces over ), respectively. For , it is not hard to see Dopico2018 ; Noferini2012 that and are vector spaces over of dimension .
Note that and for , and that the difference in dimension is the geometric multiplicity, . A right eigenvector corresponding to an eigenvalue is defined (Dopico2018, , Sec. 2.3) to be a nonzero element of the quotient space . A left eigenvector is similarly defined as an element of . In terms of the Smith canonical form (4), the last columns of , evaluated at , represent a basis of , while the last columns of , evaluated at , represent a basis of .
In the analysis we will be concerned with a quantity of the form , where are representatives of eigenvectors. It is known (Dopico2018, , Lemma 2.9) that is equivalent to the existence of a polynomial vector such that and . Then,
[TABLE]
implies that for any representative of a left eigenvector we get . It follows that for an eigenvalue representative , depends only the component of orthogonal to , and an analogous argument also shows that this expression only depends on the component of orthogonal to . In practice, we will therefore choose representatives and for the left and right eigenvalues that are orthogonal to and , respectively, and have unit norm. If is a matrix polynomial with simple eigenvalue , then there is a unique (up to sign) way of choosing such representatives and .
3.2 Perturbations of singular matrix polynomials: the De Terán-Dopico formula
Assume that , where , is a matrix polynomial of rank , and let be a simple eigenvalue. Let be a matrix whose columns form a basis of , and such that the columns of form a basis of . Likewise, let be a matrix whose columns form a basis of , and such that the columns of form a basis of . In particular, and are representatives of, respectively, right and left eigenvectors of . The following explicit characterization of a simple eigenvalue is due to De Terán and Dopico (dd10, , Theorem 2 and Eqn. (20)). To avoid making a case distinction for the regular case , we agree that if and are empty.
Theorem 3.2
Let be matrix polynomial of rank with simple eigenvalue and as above. Let be such that is non-singular. Then for small enough , the perturbed matrix polynomial has exactly one eigenvalue of the form
[TABLE]
Note that in the special case we recover the expression for regular matrix polynomials from (tisseur2000backward, , Theorem 5) and (dd10, , Corollary 1),
[TABLE]
where are left and right eigenvectors corresponding to the eigenvalue .
3.3 The directional sensitivity of a singular polynomial eigenproblem
We can now describe the input-output map that underlies our analysis. By the local nature of our problem, we consider a fixed matrix polynomial of rank with simple eigenvalue , and define the input-output function
[TABLE]
that maps to , maps to for any and satisfying the conditions of Theorem 3.2, and maps any other matrix polynomial to an arbitrary number other than .
An immediate consequence of Theorem 3.2 and our definition of the input-output map is an explicit expression for the directional sensitivity of the problem. Here we write for the Euclidean norm of the vector of coefficients of as a vector in . From now on, when talking about the “directional sensitivity of an eigenvalue in direction ”, we implicitly refer to the input-output map defined above.
Corollary 3.3
Let be a simple eigenvalue of and let be a regular matrix polynomial. Then the directional sensitivity of the eigenvalue in direction is
[TABLE]
In the special case , we have
[TABLE]
For the goals in this paper, these results suffice. However, we note that it is possible to obtain equivalent formulae for the expansion that, unlike the one by De Terán and Dopico, do not involve the eigenvectors of singular polynomials.
Finally, we introduce a parameter that will enter all of our results, and coincides with the inverse of the worst-case condition number in the regular case . Choose representatives of the eigenvectors that satisfy and (if ) . For such a choice of eigenvectors, define
[TABLE]
We conclude with the following variation of (tisseur2000backward, , Theorem 5). For a proof of the following result, see (adhikari2011structured, , Lemma 2.1) or alam2019sensitivity for a discussion in a wider context.
Proposition 3.4
Let be a regular matrix polynomial and a simple eigenvalue. Then the worst-case condition number of the problem of computing is .
Remark 3.5
In practice, an algorithm such as QZ applied to will typically compute all the eigenvalues of a nearby matrix polynomial. Therefore, any conditioning results on the conditioning of our specific input-output map will explain why the correct eigenvalue is found among the computed eigenvalues, but not tell us how to choose the right one in practice. For selecting the right eigenvalue one could use heuristics, such as computing the eigenvalues of an artificially perturbed problem. For more details on these practical considerations, we refer to hmp18 .
4 Probabilistic analysis of the directional sensitivity
In this section we study the probability distribution of the directional sensitivity of a singular polynomial eigenvalue problem To deal with real and complex perturbations simultaneously as far as possible, we follow the convention from random matrix theory edelman2005random and parametrize our results with a parameter , where if and if . We consider perturbations , which we identify with the matrix (each ), and denote by the Euclidean norm of considered as a vector in , where (equivalently, the Frobenius norm of the matrix ). When we say that is uniformly distributed on the sphere, written with for real perturbations and and if is complex, we mean that the image of under an identification is uniformly distributed on the corresponding unit sphere . To avoid trivial special cases, we assume that and , so that, in particular, .
The following theorem characterizes the distribution of the directional sensitivity under uniform perturbations.
Theorem 4.1
Let be a matrix polynomial of rank and let be a simple eigenvalue of . If , where if and if , then the directional sensitivity of in direction satisfies
[TABLE]
where denotes a beta distributed random variable with parameters and , and and are independent.
The proof is given later in this section, after having introduced some preliminary concepts and results. If , then the directional sensitivity is distributed like the square root of a beta random variable, and in particular it is bounded. Using the density of the beta distribution, we can derive the moments and tail bounds for the distribution of the directional sensitivity explicitly.
Corollary 4.2
Let be a matrix polynomial of rank and let be a simple eigenvalue of . If , where if and if , then the expected directional sensitivity of in direction is
[TABLE]
If , then for we have the tail bounds
[TABLE]
If , then .
Proof
For the expectation, using Theorem 4.1 in the case , we have
[TABLE]
where denotes a distributed random variable. The claimed tail bounds and expected values for follow by applying Lemma A.1 with , , , and . If , the expected value follows along the lines, and the deterministic bound follows trivially from the boundedness of the beta distribution.
Remark 4.3
In the context of random inputs, it is common to study the logarithm of a condition number instead of the condition number itself BC2013 ; Edelman1988 . Thus, even when the expected condition is not finite, the expected logarithm may still be small. Using a standard argument (see, e.g., (BC2013, , Proposition 2.26)) we can deduce a bound on the expected logarithm of the directional sensitivity:
[TABLE]
The logarithm of the sensitivity is relevant as a measure for the loss of precision.
As the derivation of the bounds (10) using Lemma A.1 shows, the cumulative distribution functions in question can be expressed exactly in terms of integrals of hypergeometric functions. This way, the tail probabilities can be computed to high accuracy for any given , see also Remark 4.6. However, as the derivation of the tail bounds in Appendix A also shows, the bounds given in Corollary 4.2 are sharp for fixed and , as well as for fixed and . Figure 1 illustrates these bounds for a choice of small parameters (, , , ). Moreover, the bounds (10) have the added benefit of being easily interpretable. These tail bounds can be interpreted as saying that for large and/or , it is highly unlikely that the directional sensitivity will exceed (which by Proposition 3.4 is the worst-case condition bound in the smooth case ).
Example 4.4
Consider again the matrix pencil from (1). This pencil has rank , and the cokernel and kernel are spanned by the vectors and , respectively, given by
[TABLE]
The matrix polynomial has the simple eigenvalue , and the matrix has rank . The cokernel and the kernel are spanned by the columns of the matrices and , given by
[TABLE]
Let be the second column of and let be the second coumn of . The vectors and are orthogonal to and and have unit norm. We therefore have
[TABLE]
Hence, . Figure 2 shows the result of comparing the distribution of , found empirically, with the bounds obtained in Theorem 4.1. The relative error in the plot is of order .
The plan for the rest of this section is as follows. In Section 4.1 we recall some facts from probability theory and random matrix theory. In Section 4.2 we discuss the QR decomposition of a random matrix, and in Section 4.3 we use this decomposition to prove Theorem 4.1
4.1 Probabilistic preliminaries
We write for a normal distributed (Gaussian) random vector with mean and covariance matrix , and for a complex Gaussian vector; this is a -valued random vector with expected value , whose real and imaginary parts are independent real Gaussian random vectors with covariance matrix (a special case are real and complex scalar random variables, ). We denote the uniform distribution on a sphere by . Every Gaussian vector can be written as a product with and independent, where is -distributed with degrees of freedom, and .
4.1.1 Projections of random vectors
The squared projected lengths of Gaussian and uniform distributed random vectors can be described using the and the beta distribution, respectively. A vector is -distributed with degrees of freedom, , if the cumulative distribution function (cdf) is
[TABLE]
The special case is the exponential distribution with parameter , written . The beta distribution is defined for , and has cdf supported on ,
[TABLE]
where is the beta function. For a vector , denote by the projection onto the first coordiantes and by its squared length. The following facts are known:
- •
If , then ;
- •
If , then .
The first claim is a standard fact about the normal distribution and can be derived directly from it, see for example Boltzmann1881 . The statement for the uniform distribution can be derived from the Gaussian one, but also follows by a change of variables from expressions for the volume of tubular neighbourhoods of subspheres of a sphere, see for example (BC2013, , Section 20.2). Since all the distributions considered are orthogonally (in the real case) or unitarily (in the complex case) invariant, these observations hold for the projection of a random vector onto any -dimensional subspace, not just the first coordinates.
4.1.2 Random matrix ensembles
If is a singular matrix polynomial with a simple eigenvalue , then the set of perturbation directions for which the directional sensitivity is not finite is a proper Zariski closed subset, see Theorem 3.2. It is therefore natural and convenient to consider probability measures on the space of perturbations that have measure zero on proper Zariski closed subsets. This is the case, for example, if the measure is absolutely continuous with respect to the Lebesgue measure. In this paper we will work with real and complex Gaussian and uniform distributions. For a detailed discussion of the random matrix ensembles used here we refer to (forrester2010log, , Chapters 1-2).
For a random matrix we write if each entry of is an independent random variable, and call this a Gaussian random matrix. In the case this is called the Ginibre ensemble ginibre1965statistical . Centered () Gaussian random matrices are orthogonally (if ) or unitarily (if ) invariant ((mezzadri2007, , Lemma 1)) and the joint density of their entries is given by
[TABLE]
which takes into account the fact the real and imaginary parts of the entries of a complex Gaussian have variance . In addition, we consider the circular real ensemble for real orthogonal matrices in , and the circular unitary ensemble dyson1962threefold for unitary matrices in , where both distributions correspond to the unique Haar probability measure on the corresponding groups.
4.2 The probabilistic QR decomposition
Any nonsingular matrix has a unique QR-decomposition , where (if ) or (if ), and is upper triangular with (trefethen97, , Part II). The following proposition describes the distribution of the factors and in the QR-decomposition of a (real or complex) Gaussian random matrix.
Proposition 4.5
Let be a Gaussian random matrix, . Then can be factored uniquely as , where is upper triangular and
- •
* if and if ;*
- •
* for ;*
- •
* for .*
Moreover, all these random variables are independent.
An easy and conceptual derivation of the distribution of can be found in mezzadri2007 , while the distribution of can be deduced from the known expression for the Jacobian of the QR-decomposition (edelman2005random, , 3.3).
4.3 Proof of Theorem 4.1
In this section we present the proofs of Theorem 4.1 and the corollaries that follow from it. To simplify notation, we set . Recall from Corollary 3.3 the expression
[TABLE]
where the columns of are orthonormal bases of and , the columns of represent bases of and , respectively, and is defined in (9).
Proof of Theorem 4.1. We first assume . By the scale invariance of the directional sensitivity , we consider Gaussian perturbations (recall that we interpret as a vector in ), where . This scaling ensures that the entries of are independent random variables. Since the distribution of is orthogonally/unitarily invariant, the quotient has the same distribution as the quotient , where is the upper left submatrix of and the upper left matrix. For the distribution considered, is almost surely invertible, with inverse . By Cramer’s rule, . We are thus interested in the distribution
[TABLE]
where is the lower right corner of the inverse of an Gaussian matrix . To study the distribution of , we resort to the probabilistic QR-decomposition discussed in Section 4.2. If is the unique QR-decomposition of with positive diagonals in , then the inverse is given by , and a direct inspection reveals that the lower-right element of is .
From Section 4.2 it follows that or , and . Moreover, each column of is uniformly distributed on the sphere , so that (by Section 4.1.1), and are independent. We therefore get
[TABLE]
Setting (see (9)), we arrive at
[TABLE]
Let . Then we can rearrange the coefficients of to a matrix so that
[TABLE]
Moreover, if is an orthogonal/unitary matrix with as first column, then
[TABLE]
where . If we denote by the vector consisting of those entries of that are not in , then
[TABLE]
It follows that
[TABLE]
Therefore, the factor , itself a square of a (real or complex) Gaussian, is a summand in a sum of squares of Gaussians, and the quotient
[TABLE]
is equal to the squared length of the projection of a uniform random vector in onto the first coordinates. By Section 4.1.1, this is distributed. Denoting this random variable by and by , we obtain
[TABLE]
This establishes the claim in the case . If , we use the expression (see (6)),
[TABLE]
where and are eigenvectors. By orthogonal/unitary invariance, has the same distribution as the the squared norm of a Gaussian. By the same argument as above, we can bound in terms of , and the quotient with is then the squared projected length of the first coordinates of a uniform distributed vector in , which is distributed.
Remark 4.6
If is large, then for a (real or complex) Gaussian perturbation with entry-wise variance , by Gaussian concentration (see (boucheron2013concentration, , Theorem 5.6)), is close to with high probability:
[TABLE]
This means that the distribution of for a Gaussian perturbation will be close to that of for a uniform perturbation. Even for moderate sizes of and , the result can be numerically almost indistinguishable.
In fact, when is Gaussian, then the distribution can be expressed explicitly as
[TABLE]
where denotes the confluent hypergeometric function (this follows by mimicking the proof of Theorem 4.1, expressing the distribution in terms of a quotient of a and a beta random variable, and writing out the resulting integrals). Similarly, using the same computations as in the proof of Lemma A.1, we get the exact expression
[TABLE]
where is the hypergeometric function. The case distinction corresponds to different branches of the solution of the hypergeometric differential equation. See pearson2009computation ; pearson2017numerical for more on computing with hypergeometric functions.
5 Weak condition numbers of simple eigenvalues of singular matrix polynomials
The tail bounds on the directional sensitivity can easily be translated into statements about condition numbers and discuss some consequences and interpretations.
Theorem 5.1
Let be a matrix polynomial of rank , and let be a simple eigenvalue of . Then
- •
the worst-case condition number is
[TABLE]
- •
the stochastic condition number, with respect to uniformly distributed perturbations, is
[TABLE]
- •
if and , then the -weak worst-case condition number, with respect to uniformly distributed perturbations, is bounded by
[TABLE]
The expression for the stochastic condition number involves the quotient of gamma functions, which can be simplified using the well-known bounds
[TABLE]
which hold for wendel1948 . Using these bounds on the numerator and denominator of (13), we get the more interpretable
[TABLE]
The bound on the weak condition number (14) shows that , which is the median of the same random variable of which is the expected value, is bounded by , which is the expression of the worst-case condition number in the regular case .
The situation changes dramatically when considering real matrix polynomials with real perturbations, as in this case even the stochastic condition becomes infinite if the matrix polynomial is singular. In the statement we denote the resulting condition number with respect to real perturbations by using the superscript .
Theorem 5.2
Let be a real matrix polynomial of rank , and let be a simple eigenvalue of . Then
- •
the worst-case condition number is
[TABLE]
- •
the stochastic condition number, with respect to uniformly distributed real perturbations, is
[TABLE]
- •
if and , then the -weak worst-case condition, with respect to uniformly distributed real perturbations, is
[TABLE]
- •
if and , then the -weak stochastic condition number satisfies
[TABLE]
It is instructive to compare the weak condition numbers in the singular case to the worst-case and stochastic condition number in the regular case. In the regular case (), when replacing the worst-case with the stochastic condition we get an improvement by a factor of , which is consistent with previous work armentano2010stochastic (see also Section 2) relating the worst-case to the stochastic condition. We will see in Section 6.1 that the expected value in the case captures the typical perturbation behaviour of the problem more accurately than the worst-case bound. Among the many possible interpretations of the weak worst-case condition, we highlight the following:
- •
Since the bounds are monotonically decreasing as the rank increases, we can get bounds independent of . Specifically, we can replace the quotient with . This is useful since, in applications, the rank is not always known.
- •
While the stochastic condition number (18), which measures the expected sensitivity of the problem of computing a singular eigenvalue, is infinite, for the median sensitivity is bounded by
[TABLE]
The median is a more robust and arguably better summary parameter than the expectation.
- •
Choosing in (20), we get a weak stochastic condition bound of
[TABLE]
That is, the condition number improves from being unbounded to sublinear in , by just removing a set of inputs of exponentially small measure.
Example 5.3
Consider the matrix pencil from (1). This matrix pencil has rank , with only one simple eigenvalue . As we will see in Example 4.4, the constant appearing in the bounds is
[TABLE]
In this example, , and , so that , , and
[TABLE]
For small enough we get the (not optimized) bound .
It is easy to translate Corollary 4.2 into the main results, Theorem 5.1 and Theorem 5.2. For the weak stochastic condition, we need the following observation, which is a variation of (amelunxen2017average, , Lemma 2.2).
Lemma 5.4
Let be a random variable such that for . Then for any ,
[TABLE]
Proof of Theorem 5.1 and Theorem 5.2. The statements about the worst-case, (12) and (17), and about the stochastic condition number, (13) and (18), follow immediately from Theorem 4.1 and Corollary 4.2.
For the weak condition number in the complex case, if , then setting
[TABLE]
we get , and therefore, using the complex tail bound from Corollary 4.2,
[TABLE]
This yields . If , then we use the fact that the weak condition number is monotonically decreasing with (intuitively, the larger the set we are allowed to exclude, the smaller the condition number will be), to conclude that , where .
For the real case, if we use the bound
[TABLE]
which follows from (15). If , set
[TABLE]
Then
[TABLE]
where for the last inequality we used the fact that . We conclude that . If , then we use the monotonicity of the weak condition just as in the complex case. Finally, for the weak stochastic condition number in the real case, we use Lemma 5.4 with , and in the conditional expectation. We just saw that , so that
[TABLE]
where we used Lemma 5.4 in the second inequality.
6 Bounding the weak stochastic condition number
In this section we illustrate how the weak condition number of the problem of computing a simple eigenvalue of a singular matrix polynomial can be estimated in practice. More precisely, we show that the weak condition number of a singular problem can be estimated in terms of the stochastic condition number of nearby regular problems. Before deriving the relevant estimates, given in Theorem 6.3, we discuss the stochastic condition number of regular matrix polynomials.
6.1 Measure concentration for the directional sensitivity of regular matrix polynomials
For the directional sensitivity in the regular case, , the worst-case condition number is , as was shown in Proposition 3.4. In addition, the expression for the stochastic condition number involves a ratio of gamma functions (see Corollary 4.2 or the case in Theorem 5.1 and Theorem 5.2). From (15) we get the approximation , so that the stochastic condition number for regular polynomial eigenvalue problems satisfies
[TABLE]
This is compatible with previously known results about the stochastic condition number in the smooth setting (see the discussion in Section 2). A natural question is whether the directional sensitivity is likely to be closer to this expected value, or closer to the upper bound .
Theorem 4.1 describes the distribution of as that of the (scaled) square root of a beta random variable. Using the interpretation of beta random variables as squared lengths of projections of uniformly distributed vectors on the sphere (see Section 4.1.1), tail bounds for the distribution of therefore translate into the problem of bounding the relative volume of certain subsets of the unit sphere. A standard argument from the realm of measure concentration on spheres, Lemma 6.1, then implies that with high probability, will stay close to its mean.
Lemma 6.1
Let be a uniformly distributed vector on the (real or complex) unit sphere, where if and if . Then
[TABLE]
Proof
For complex perturbations, we get the straight-forward bound
[TABLE]
In the real case, a classic result (see (ball1997elementary, , Lemma 2.2) for a short and elegant proof) states that the probability in question is bounded by
[TABLE]
The claimed bound follows by replacing with for the sake of a uniform presentation.
The next corollary follows from the description of the distribution of in Theorem 4.1, and the characterization of beta random variables as squared projected lengths of uniform vectors from Section 4.1.1.
Corollary 6.2
Let be a regular matrix polynomial and let be a simple eigenvalue of . If , where if and if , then for we have
[TABLE]
6.2 The weak condition number in terms of nearby stochastic condition numbers
It is common wisdom that computing the condition number is as hard as solving the problem at hand, so at the very least we would like to avoid making the computation of the condition estimate more expensive than the computation of the eigenvalue itself. We will therefore aim to estimate the condition number of the problem in terms of the output of a backward stable algorithm for computing the eigenvalue and a pair of associated eigenvectors.
Let be a matrix polynomial of rank with a simple eigenvalue , and let be a regular perturbation. Denote by the eigenvalue of that converges to (see Theorem 3.2), and let and be the corresponding left and right eigenvectors of the perturbed problem. As shown in (dd10, , Theorem 4) (see Theorem 6.4 below), for all outside a proper Zariski closed set, the limits
[TABLE]
converge to representatives of left and right eigenvectors of associated to . Whenever these limits exist and represent eigenvectors of , define
[TABLE]
Note that these parameters depend implicitly on a perturbation direction , even though the notation does not reflect this. The parameters and are the limits of the worst-case and stochastic condition numbers, and , as . Since almost sure convergence implies convergence in probability, we get
[TABLE]
whenever the left-hand side of this expression is finite.
A backward stable algorithm, such as vanilla QZ, computes an eigenvalue and associated unit-norm eigenvectors and of a nearby problem . If is small, then , and , so that we can approximate the values (23) using the output of such an algorithm. Unfortunately, this does not yet give us a good estimate of , as the definition of makes use of very special representatives of eigenvectors (recall from Section 3.1 that for a singular matrix polynomials, eigenvectors are only defined as equivalence classes). The following theorem shows that we can still get bounds on the weak condition numbers in terms of .
Theorem 6.3
Let be a singular matrix polynomial of rank with simple eigenvalue . Then
[TABLE]
If , then for any we have the tail bounds
[TABLE]
For the proof of Theorem 6.3 we recall the setting of Section 3. Let and be matrices whose columns are orthonormal bases of and , respectively, and such that and are bases of and , respectively. If and in (23), then . In general, however, we only get a bound. To see this, recall from Section 3.1 that depends only on the component of that is orthogonal to , and the component of that is orthogonal to . In particular, has rank one, and we have (recall )
[TABLE]
The key to Proposition 6.3 lies in a result analogous to Theorem 3.2 for the eigenvectors by de Terán and Dopico (dd10, , Theorem 4).
Theorem 6.4
Let be matrix polynomial of rank with simple eigenvalue and as above. Let be such that is non-singular. Let be the eigenvalue of the non-singular matrix pencil
[TABLE]
and let and be the corresponding left and right eigenvectors. Then for small enough , the perturbed matrix polynomial has exactly one eigenvalue as described in Theorem 3.2, and the corresponding left and right eigenvectors satisfy
[TABLE]
Given a matrix polynomial and a perturbation direction , we can therefore assume that the eigenvectors of a sufficiently small perturbation in direction are approximated by and , where are the eigenvectors of the matrix pencil (26). We would next like to characterize these eigenvectors for random perturbations . As with the rest of this paper, the following result is parametrized by a parameter which specifies whether we work with real or complex perturbations.
Proposition 6.5
Let be a matrix polynomial of rank with simple eigenvalue , and let be a random perturbation. Let be left and right eigenvectors of the linear pencil (26), let and , and define as in (23). Then
[TABLE]
Proof
By scale invariance of (26), we may take to be Gaussian, with (so that ). Set , so that . Using (25), the eigenvectors associated to (26) are then characterized as solutions of
[TABLE]
It follows that and are proportional to , and hence
[TABLE]
Clearly, each of the vectors and individually is uniformly distributed. They are, however, not independent. To simplify notation, set . For the condition estimate we get, using (25),
[TABLE]
By orthogonal/unitary invariance of the Gaussian distribution, the random vector is uniformly distributed on . It follows that is distributed like the absolute value of the projection of a uniform vector onto the first coordinate. For the expected value, the bound follows by observing that the expected value of such a projection is bounded by . For the tail bound, using (21) (with replaced by ) we get
[TABLE]
This was to be shown.
Proof of Theorem 6.3. If and , then
[TABLE]
and we get the upper bound
[TABLE]
For the weak condition numbers, using Theorem 5.1 and Theorem 5.2, we get the bounds
[TABLE]
For the tails bounds in the complex case, note that in the complex case we have
[TABLE]
where we used Proposition 6.5 for the inequality. The real case follows in the same way.
7 Conclusions and outlook
The classical theory of conditioning in numerical analysis aims to quantify the susceptibility of a computational problem to perturbations in the input. While the theory serves its purpose well in distinguishing well-posed problems from problems that approach ill-posedness, it fails to explain why certain problems with high condition number can still be solved satisfactory to high precision by algorithms that are oblivious to the special structure of an input. By introducing the notions of weak and weak stochastic conditioning, we developed a tool to better quantify the perturbation behaviour of numerical computation problems for which the classical condition number fails to do so.
Our methods are based on an analysis of directional perturbations and probabilistic tools. The use of probability theory in our context is auxiliary: the purpose is to quantify the observation that the set of adversarial perturbations is small. In practice, any reasonable numerical algorithm will find the eigenvalues of a nearby regular matrix polynomial, and the perturbation will be deterministic and not random. However, as the algorithm knows nothing about the particular input matrix polynomial, it is reasonable to assume that if the set of adversarial perturbations is sufficiently small, then the actual perturbation will not be in there. Put more directly, to say that the probability that a perturbed problem has large directional sensitivity is very small is to say that a perturbation, although non-random, would need a good reason to cause damage.
The results presented continue the line of work of amelunxen2017average , where it is argued that, just as sufficiently small numbers are considered numerically indistinguishable from zero, sets of sufficiently small measure should be considered numerically indistinguishable from null-sets. One interesting direction in which the results presented can be strengthened is to use wider classes of probability distributions, including such that are discrete, and derive equivalent (possibly slightly weaker) results. One important side-effect of our analysis is a focus away from the expected value, and more towards robust measures such as the median888The use of the median instead of the expected value in the probabilistic analysis of quantities was suggested by F. Bornemann bornemann . and other quantiles.
Our results hence have a couple of important implications, or “take-home messages”, that we would like to highlight:
The results presented call for a critical re-evaluation of the notion of ill-posedness. It has become common practice to simply identify ill-posedness with having infinite condition, to the extent that condition numbers are often defined in terms of the inverse distance to a set of ill-posed inputs, an approach that has been popularized by J. Demmel Demmel1987 ; Demmel1988 .999For the complexity analysis of iterative algorithms, and in particular for problems related to convex optimization, the “distance to ill-posedness” approach may often be the most natural setting. For convex feasibility problems, for example, the ill-posed inputs form a wall separating primal from dual feasible problem instances, and closeness to this wall directly affects the speed of convergence of iterative algorithms; see BC2013 for more on this story. The question of whether the elements of such a set are actually badly behaved a practical sense is often left unquestioned. Our theory suggests that the set of inputs that are actually ill-behaved from a practical point of view can be smaller than previously thought. 2. 2.
Average-case analysis (and its refinement, smoothed analysis burgisser2010smoothed ) is, while well-intentioned, still susceptible to the caprices of specific probability distributions. More meaningful results are obtained when, instead of analysing the behaviour of perturbations on average, one shifts the focus towards showing that the set of adversarial perturbations is small; ideally so small, that hitting a misbehaving perturbation would suggest the existence of a specific explanation for this rather than just bad luck. In terms of summary parameters, our approach suggests using, in line with common practice in statistics, more robust parameters such as the median instead of the mean.
A natural question that arises from the first point is: if some problems that were previously thought of as ill-posed are not (in the sense that the set of discontinuous perturbation directions is negligible), then which problems are genuinely ill-posed? In the case of polynomial eigenvalue problems, we conjecture that problems with semisimple eigenvalues are not ill-conditioned in our framework; in fact, it appears that much of the analysis performed in this section can be extended to this setting. It is not completely obvious which problems should be considered ill-posed based on this new theory. That some inputs still should can be seen for example by considering Jordan blocks with zeros on the diagonal; the computed eigenvalues of perturbations of the order of machine precision will not recover the correct eigenvalue in this situation. Our analysis in the semisimple case is based on the fact that the directional derivative of the function to be computed exists in sufficiently many directions.
Another consequence is that much of the probabilistic analyses of condition numbers based on the distance to ill-posedness, while still correct, can possibly be refined when using a smaller set of ill-posed inputs. In particular, it is likely that condition bounds resulting from average-case and smoothed analysis can be refined. Finally, an interesting direction would be to examine problems with high or infinite condition number that are not ill-posed in a practical sense in different contexts, such as polynomial system solving or problems arising from the discretization of continuous inverse problems.
Acknowledgements
The spark that led to this paper was ignited at the workshop “Algebra meets numerics: condition and complexity” on November 6-7, 2017 in Berlin; we are grateful to the organisers Peter Bürgisser and Felipe Cucker for inviting us and for pointing out the work of Armentano and Stewart. In addition the authors would like to thank Carlos Beltrán and Daniel Kressner for valuable feedback, and the anonymous referees for useful comments. We are greatly indebted to Dennis Amelunxen, whose vision of weak-average case analysis inspired this work.
We would like to acknowledge financial support from the Manchester Institute for Mathematical Sciences (MIMS) during the early stages of this project, and the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme Approximation, Sampling and Compression in Data Science while this work was completed.
Appendix A Moments and tails for ratios of beta random variables
In this appendix we compute the expected value and tail bounds for moments of quotients of beta random variables.
Lemma A.1
Let and , random variables. Then for such that ,
[TABLE]
If , then . Moreover, the probability tails are bounded by
[TABLE]
Proof
We focus on the case of the quotient ; the statement for follows by simply setting in the calculations below. Set . For ,
[TABLE]
If , then the step from (A) to (B) breaks down, since the integral diverges. For the tail bound we proceed similarly. If , then
[TABLE]
where for the inequality (1) we used that when . If , then
[TABLE]
where for (2) we used that .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. Adhikari, R. Alam, and D. Kressner. Structured eigenvalue condition numbers and linearizations for matrix polynomials. Linear algebra and its applications , 435(9):2193–2221, 2011.
- 2[2] R. Alam and S. Safique Ahmad. Sensitivity analysis of nonlinear eigenproblems. SIAM Journal on Matrix Analysis and Applications , 40(2):672–695, 2019.
- 3[3] D. Amelunxen and M. Lotz. Average-case complexity without the black swans. Journal of Complexity , 41:82–101, 2017.
- 4[4] D. Armentano. Stochastic perturbations and smooth condition numbers. Journal of Complexity , 26(2):161–171, 2010.
- 5[5] D. Armentano and C. Beltrán. The polynomial eigenvalue problem is well conditioned for random inputs. SIAM Journal on Matrix Analysis and Applications , 40(1):175–193, 2019.
- 6[6] K. Ball. An elementary introduction to modern convex geometry. Flavors of geometry , 31:1–58, 1997.
- 7[7] K. Beltrán, C.and Kozhasov. The real polynomial eigenvalue problem is well conditioned on the average. Foundations of Computational Mathematics , May 2019.
- 8[8] L. Blum, F. Cucker, M. Schub, and S. Smale. Complexity and Real Computation . Springer-Verlag, New York, NY, USA, 1998.