Robustification of deep net classifiers by key based diversified aggregation with pre-filtering
Olga Taran, Shideh Rezaeifar, Taras Holotyak, Slava Voloshynovskiy

TL;DR
This paper introduces a Key based Diversified Aggregation (KDA) mechanism that enhances deep neural network robustness against adversarial attacks through secret key-based randomization and multi-channel aggregation, preventing gradient-based bypasses.
Contribution
The paper proposes a novel KDA defense strategy that uses secret key-based randomization and multi-channel aggregation to improve neural network robustness against various adversarial attacks.
Findings
KDA significantly increases robustness against gradient-based attacks.
KDA effectively defends against non-gradient sparse perturbations.
Experimental results show high universality of the proposed method.
Abstract
In this paper, we address a problem of machine learning system vulnerability to adversarial attacks. We propose and investigate a Key based Diversified Aggregation (KDA) mechanism as a defense strategy. The KDA assumes that the attacker (i) knows the architecture of classifier and the used defense strategy, (ii) has an access to the training data set but (iii) does not know the secret key. The robustness of the system is achieved by a specially designed key based randomization. The proposed randomization prevents the gradients' back propagation or the creating of a "bypass" system. The randomization is performed simultaneously in several channels and a multi-channel aggregation stabilizes the results of randomization by aggregating soft outputs from each classifier in multi-channel system. The performed experimental evaluation demonstrates a high robustness and universality of the KDA…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6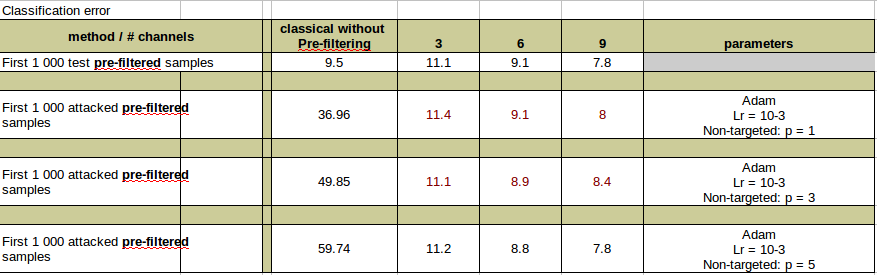 Figure 7
Figure 7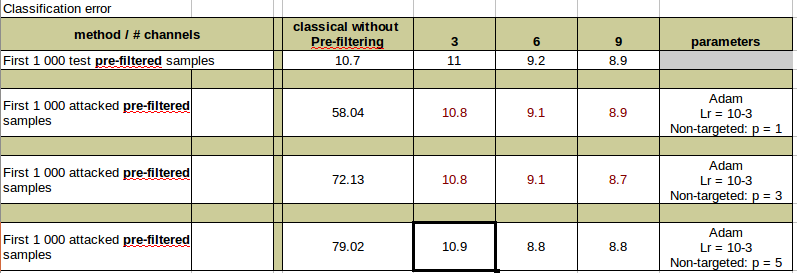 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10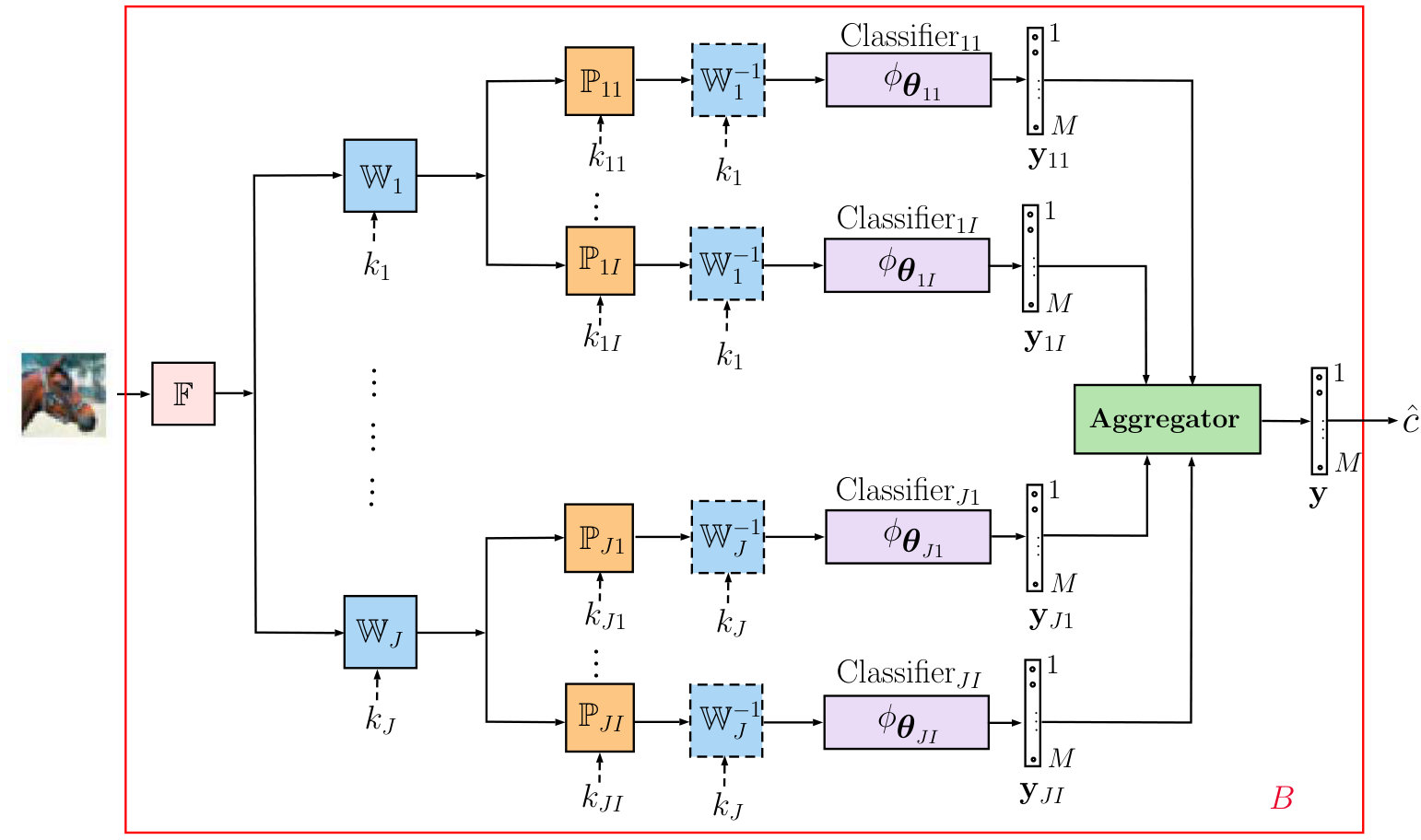 Figure 11
Figure 11 Figure 12
Figure 12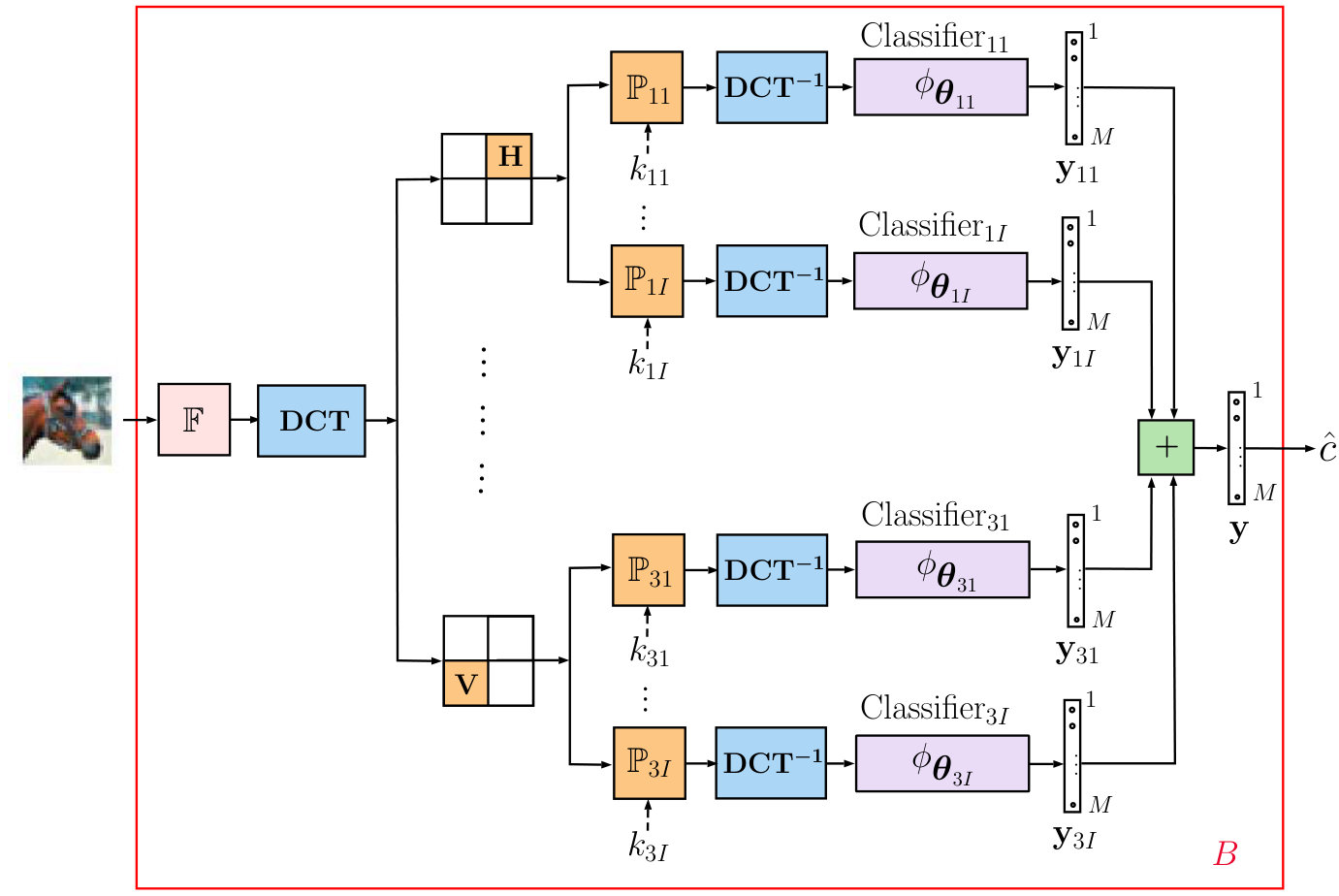 Figure 13
Figure 13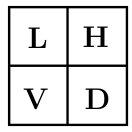 Figure 14
Figure 14 Figure 15
Figure 15| Attack type | Vanilla | |||
|---|---|---|---|---|
| 3 | 6 | 9 | ||
| Original | 21 | 21.2 | 19.6 | 19.4 |
| C&W | 100 | 22.42 | 21.3 | 21.04 |
| C&W | 100 | 24.58 | 23.52 | 23.03 |
| C&W | 100 | 22.8 | 21.39 | 21.21 |
| Attack type | Vanilla | |||
| 3 | 6 | 9 | ||
| VGG16 | ||||
| Original | 10.7 | 11 | 9.2 | 8.9 |
| OnePixel | 58.04 | 11 | 9.5 | 8.7 |
| OnePixel | 72.13 | 10.9 | 8.9 | 8.3 |
| OnePixel | 79.02 | 12.1 | 9.3 | 9.1 |
| ResNet18 | ||||
| Original | 9.5 | 11.1 | 9.1 | 7.8 |
| OnePixel | 36.96 | 11.5 | 9 | 7.7 |
| OnePixel | 49.85 | 11.5 | 9.1 | 7.8 |
| OnePixel | 59.74 | 11.7 | 9.2 | 7.8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Robustification of deep net classifiers by key based diversified aggregation with pre-filtering
Abstract
In this paper, we address a problem of machine learning system vulnerability to adversarial attacks. We propose and investigate a Key based Diversified Aggregation (KDA) mechanism as a defense strategy. The KDA assumes that the attacker (i) knows the architecture of classifier and the used defense strategy, (ii) has an access to the training data set but (iii) does not know the secret key. The robustness of the system is achieved by a specially designed key based randomization. The proposed randomization prevents the gradients’ back propagation or the creating of a ”bypass” system. The randomization is performed simultaneously in several channels and a multi-channel aggregation stabilizes the results of randomization by aggregating soft outputs from each classifier in multi-channel system. The performed experimental evaluation demonstrates a high robustness and universality of the KDA against the most efficient gradient based attacks like those proposed by N. Carlini and D. Wagner [1] and the non-gradient based sparse adversarial perturbations like OnePixel attacks [2].
**Index Terms— ** Adversarial attacks, black / gray-box, non-gradient / gradient based attacks, defense, machine learning.
1 Introduction
Deep Neural Networks (DNN) are used to solve a wide range of problems including the classification tasks. Despite the outstanding performance and remarkable achievements, the DNN systems have recently been shown to be vulnerable to adversarial attacks [3]. The adversarial attacks aim at tricking a decision of DNN classifiers by introducing carefully designed perturbations to a chosen target image. These perturbations, being usually quite small in magnitude and imperceptible, can drastically change the output of the classifier. This weakness seriously questions the usage of the DNN based systems in many security- and trust-sensitive applications.
In the recent years, the number of authors reported various adversarial attacks against the DNN classifiers. The diversity of discovered attacks is quite broad but without loss of generality one can cluster all attacks into three groups [4, 5]: (1) white-box attacks, (2) gray-box attacks and (3) black-box attacks. The white-box attacks assume that the attacker has a full access to the trained model and training data. Despite a big popularity of this group of attacks, their applicability to the real-life systems is questionable. The gray and black-box scenarios are more suited to the real-life applications. The gray-box attacks assume that the attacker has certain knowledge about the trained model but there exist some secret elements or an access to the intermediate results is limited. The back-box attacks allow the attacker only to observe the output of classifier to each input without any knowledge about used architecture or possibility to observe the internal states.
The existing defense mechanisms are also quite diverse [6, 5]. However, the growing number of defenses leads to a natural invention of new and even more universal attacks. In the overwhelming majority of cases, the main interest in the adversarial attack investigation is focused on the gradient based attacks and defenses. While the non-gradient attacks and suitable defenses receive less attention but are not less dangerous and important for practice. In this respect, the goal of our paper is to investigate a new family of defense strategies that can be applied for both gradient and non-gradient based adversarial attacks in gray and black-box scenarios. We name it a Key based Diversified Aggregation (KDA) with pre-filtering. The generalized diagram of the proposed system is illustrated in Figure 1. The main idea behind the KDA is to use cryptographic principles and to create an information advantage for the defender over the attacker. A secret is shared between the training and classification stages. The secret is implemented in a form of secret key used for the randomization. The system has two levels of randomization, each of which uses its own secret keys. The classification process is diversified in several channels with own randomization targeting specific randomly selected features. To reduce the negative effect of randomization, the soft outputs of multi-channels classifiers are aggregated.
The main contribution of this paper is twofold:
- •
A multi-channel classification architecture with the KDA mechanism as an universal defense strategy against the gradient and non-gradient based gray and black-box attacks.
- •
An investigation of the efficiency of the proposed approach on the well-known gradient and non-gradient based adversarial attacks.
The rest of paper is organized as follows. Section 2 introduces a new multi-channel classification architecture with the KDA. The efficient key-based data independent transformation is proposed in Section 3. Section 4 presents the empirical results obtained for the proposed algorithm. Finally, Section 5 concludes the paper.
2 Classification algorithm with Key based Diversified Aggregation
The generalized diagram of the proposed algorithm is shown in Figure 1 and it consists of five main blocks:
-
Pre-filtering that has an optional character. The goal of this block is to remove high magnitude outliers in the input images introduced by the attacker, if any. One can choose a broad range of pre-filtering algorithms from a simple local mean filter to more complex algorithms as, for example, BM3D [7] or based on DNN systems [8].
-
The input signal mapping into a transform domain via , . In general, the transform can be any linear mapper like a random projection or belong to the family of orthonormal transformations () like DFT (discrete Fourier transform), DCT (discrete cosines transform), DWT (discrete wavelet transform), etc. Moreover, can also be a learnable transform or even a deep encoder. However, to avoid any key-leakage from the trained transforms, we use the data independent transform in this paper. Thus, the transform is generated from a secret key . Along this line, one can also envision, for example, the DCT transform with the key defined sampling in the transform domain. We will detail below the properties of this transform.
-
Data independent processing , serves as a defense against gradient back propagation to the direct domain. As simple examples of such kind of processing one can mention a lossy sampling of the input signal of length as considered in [9] or a lossless permutation similar to [6]. The sub-block sign flipping presents an additional option. It should be pointed out that to make the data independent processing irreversible for the attacker, it is preferable to use the block based on a secret key .
-
Classification block can be represented by any family of classifiers. We consider a DNN based family.
-
Aggregation block can be any operation ranging from a simple summation to learnable operators or special aggregation networks adapted to the data or to a particular adversarial attack. We focus on additive aggregation to demonstrate the power of a simple strategy leaving the investigation of more complex aggregations to our future work.
As shown in Figure 1, in the proposed architecture the principal blocks are organized in a parallel multi-channel structure that can be followed by one or several aggregation blocks. The final decision is made based on the aggregated result. The rejection option can naturally be also envisioned.
It should be pointed out that the access to the intermediate results inside the considered system provides the attacker a possibility to use the full system as a white-box. The attacker can discover the secret keys and/or , make the the system end-to-end differentiable using the Backward Pass Differentiable Approximation technique [10] or via replacing the key based blocks by the bypass mappers. Therefore, it is important to restrict the access of the attacker to the intermediate results within the block (see Figure 1). That satisfies our assumption about gray and black-box attacks. Additionally, it is in the accordance with the Kerckhoffs’s cryptographic principle when we assume that the algorithm and architecture are known to the attacker besides the used secret key.
The training of the described classification architecture can be performed as follows:
[TABLE]
with:
[TABLE]
where is a classification loss, is a vectorized class label of the sample , corresponds to the aggregation operator with parameters , is the th classifier of the th channel, denotes the parameters of the classifier, equals to the number of training samples, is the total number of channels and equals to the number of classifiers per channel that we will keep fixed and equals to for all channels.
3 Randomization using key based sign flipping in the DCT domain
The core element of the defense in the proposed multi-channel architecture shown in Figure 1 is a data independent processing in a transform domain .
In our implementation, we use the DCT as a and the local sign flipping based on the individual secret key for each classifier. The term local means that the processing is done only in some sub-band or block of the input signal. In general, the signal can be split into overlapping or non-overlapping sub-bands of different sizes and different positions that are kept in secret. In our experiments for the simplicity and interpretability, we split the signal in the DCT domain into four non-overlapping fixed sub-bands of the same size denoted as: (L) top left that represents the low frequencies of the image, (V) vertical, (H) horizontal and (D) diagonal sub-bands as illustrated in Figure 2a. The key based sign flipping is applied independently in V, H and D sub-bands keeping all other sub-bands unchanged. The effects of such processing after the inverse DCT transform are perceptually almost unnoticeable and exemplified in Figure 2c - 2e.
The corresponding multi-channel architecture is illustrated in Figure 3. For simplicity, as an aggregation operator we use a simple summation. For the pre-filtering we use a filter based on a difference of the point of interest in the center of the window with the median value in the window of size around this point. If the magnitude of difference exceeds a specified threshold, the pixel is considered to be corrupted by the adversary and its value is replaced by a mean value computed in the window or otherwise, it is kept intact. Finally, each classifier is trained independently as:
[TABLE]
to ensure the best recognition in each channel under the introduced perturbation.
4 Experimental results
4.1 Setup
The efficiency of the proposed multi-channel architecture diversified and randomized by the key based sign flipping in the DCT domain against the adversarial attacks was tested for two scenarios:
-
Gray-box gradient based attack. As a gradient based attack we use the attack proposed in [1]. This attack is among the most efficient attacks against many proposed defense strategies. Further it will be referred to as C&W. In our experiment we use the C&W attacks based on , and norms.
-
Black-box non-gradient based attack. As a non-gradient based attack we use the OnePixel attack proposed in [2] that uses a Differential Evolution (DE) optimisation algorithm [11] for the attack generation. The DE algorithm doesn’t require the objective function to be differentiable or known but instead it observes the output of the classifier used as a black box. The OnePixel attack aims at perturbing limited number of pixels in the input image. In our experiments, we use this attack to perturb 1, 3 and 5 pixels.
For the fair comparison, the gradient based attacks were tested on the classifier with the architecture identical to those tested in [1]. The non-gradient based attacks were tested for the classifiers based on the VGG16 [12] an ResNet18 [13] architectures used in [11].
All experiments have been done on the CIFAR-10 dataset [14] that presents a particular interest as a data set with the images close to natural ones. The CIFAR-10 consists of 60000 colour images of size (50000 train and 10000 test) with 10 classes. Due to the fact that the attack generation process is sufficiently slow for all considered attacks the experimental results were obtained on the first 1000 test samples.
4.2 Empirical results and analysis
The results obtained for the gradient based attacks in the gray-box scenario are given in Table 1. The results obtained for the non-gradient based attacks in the black-box scenario are shown in Table 2. In both cases the column ”vanilla” corresponds to the accuracy of the original classifier without any defense. The row ”original” corresponds to the use of non-attacked original data.
The analysis of the obtained results for the gray-box gradient based attacks and the original non-attacked data demonstrates that the use of the proposed multi-channel architecture allows to improve the classification accuracy of vanilla classifier. This is quite remarkable by itself since it shows that the multi-channel processing with the aggregation does not degrade the performance due to the introduced randomization in contrast to many defense strategies based on gradient obfuscation or detection and rejection of attacked data mechanisms. In the case of attacked data, the C&W attacks achieves the 100% classification error on the vanilla undefended classifier thus showing a complete vulnerability of this deep classifier. At the same time, the use of the multi-channel architecture based on the same type of classifier with the proposed defense strategy improves the classification accuracy to the similar level of the vanilla classifier on the original non-attacked data. In the worst case of C&W attack, the classification error is only about 2% higher than on the original data.
In the case of black-box non-gradient based attacks, the use of the KDA improves the classification accuracy of the vanilla classifier similar to the previous case. In contrast to the gray-box scenario, the black-box attacks are not so harmful against the vanilla classifier. In the case of VGG16, the classification error of the vanilla classifier is about 60-80%. In the case of ResNet18, it is about 35-60%. For both classifiers the increase of the number of perturbed pixels () leads to the increase of classification error. The use of the proposed defense mechanism based on the KDA architecture allows to decrease the classification error to the level of classification on the original data or in other words it diminished the effect of these attacks.
In summary, one can conclude that the obtained results indicate that the KDA architecture with the proposed defense strategy demonstrates the high robustness to the gradient and non-gradient based attacks in the gray and black-box scenarios. Moreover, it allows to improve the classification accuracy of the vanilla classifiers. Finally, it should be pointed out that in all cases the increase of the number of classification channels and data independent processing leads to improving the classification accuracy. However, a trade-off between the further decrease of the classification error and the increase of the complexity of the algorithm should be carefully addressed that goes beyond the scope of this paper.
5 Conclusions
In this paper, we considered the defense mechanism against the gradient and non-gradient based gray and black-box attacks. The proposed mechanism is based on the multi-channel architecture with the randomization and the aggregation of classification scores. It is remarkable that the architecture of the defense is not tailored for each class of attacks and is uniformly used for both attacks. It is also interesting to note that the diversified classification with the aggregation of the outputs of classifiers allows not only to withstand the attacks but it also improves the accuracy of vanilla classifier. It is also important to remark that the proposed approach is compliant with the cryptographic principles when the defender has an information advantage over the attacker. In our future research, we plan to extend the aggregation mechanism to more complex learnable strategies instead of used summation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Nicholas Carlini and David Wagner, “Towards evaluating the robustness of neural networks,” in 2017 IEEE Symposium on Security and Privacy (SP) . IEEE, 2017, pp. 39–57.
- 2[2] Jiawei Su, Danilo Vasconcellos Vargas, and Kouichi Sakurai, “One pixel attack for fooling deep neural networks,” IEEE Transactions on Evolutionary Computation , 2019.
- 3[3] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy, “Explaining and harnessing adversarial examples,” in International Conference on Learning Representations (ICLR) , 2015.
- 4[4] Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Siwei Li, Li Chen, Michael E Kounavis, and Duen Horng Chau, “Shield: Fast, practical defense and vaccination for deep learning using jpeg compression,” ar Xiv preprint ar Xiv:1802.06816 , 2018.
- 5[5] Naveed Akhtar and Ajmal Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,” ar Xiv preprint ar Xiv:1801.00553 , 2018.
- 6[6] Olga Taran, Shideh Rezaeifar, and Slava Voloshynovskiy, “Bridging machine learning and cryptography in defence against adversarial attacks,” in Workshop on Objectionable Content and Misinformation (WOCM), ECCV 2018 , Munich, Germany, September 2018.
- 7[7] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Transactions on image processing , vol. 16, no. 8, pp. 2080–2095, 2007.
- 8[8] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol, “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,” Journal of machine learning research , vol. 11, no. Dec, pp. 3371–3408, 2010.