NGO-GM: Natural Gradient Optimization for Graphical Models
Eric Benhamou, Jamal Atif, Rida Laraki, David Saltiel

TL;DR
This paper introduces NGO-GM, a natural gradient optimization method for graphical models that improves parameter learning by directly optimizing the objective function, outperforming traditional methods like EM.
Contribution
It presents a novel natural gradient-based approach for parameter estimation in graphical models, offering a more direct and potentially more effective alternative to EM.
Findings
Better performance than traditional methods in trend detection
Less prone to overfitting in financial market analysis
Theoretically justified and empirically validated approach
Abstract
This paper deals with estimating model parameters in graphical models. We reformulate it as an information geometric optimization problem and introduce a natural gradient descent strategy that incorporates additional meta parameters. We show that our approach is a strong alternative to the celebrated EM approach for learning in graphical models. Actually, our natural gradient based strategy leads to learning optimal parameters for the final objective function without artificially trying to fit a distribution that may not correspond to the real one. We support our theoretical findings with the question of trend detection in financial markets and show that the learned model performs better than traditional practitioner methods and is less prone to overfitting.
Click any figure to enlarge with its caption.
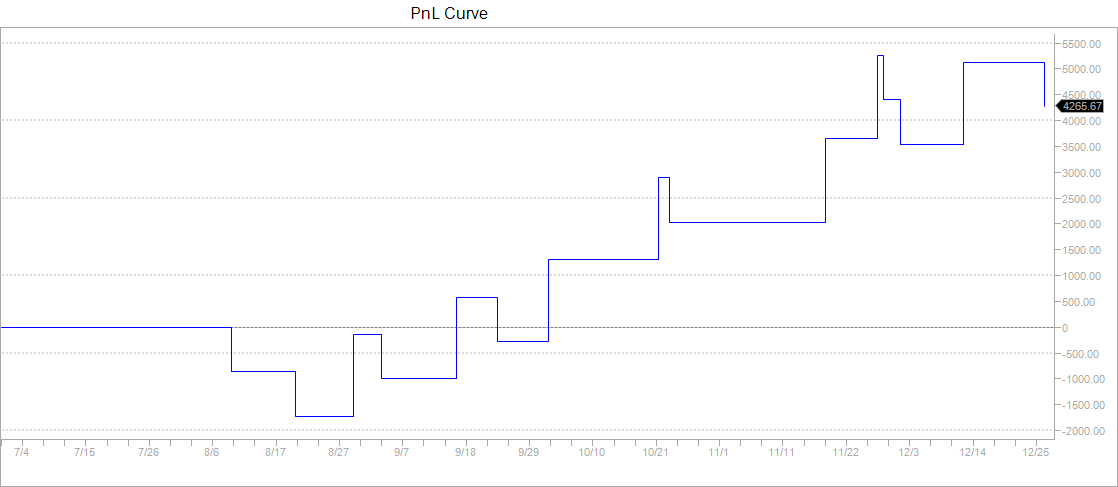 Figure 1
Figure 1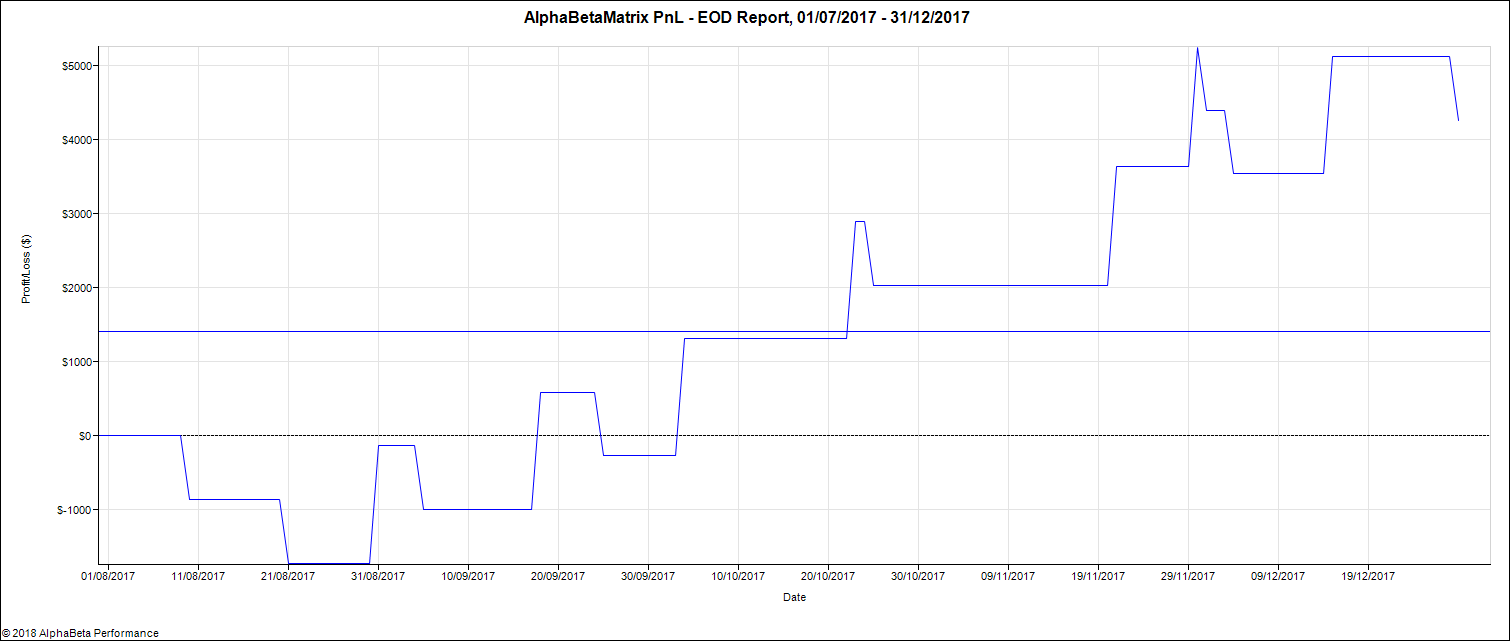 Figure 2
Figure 2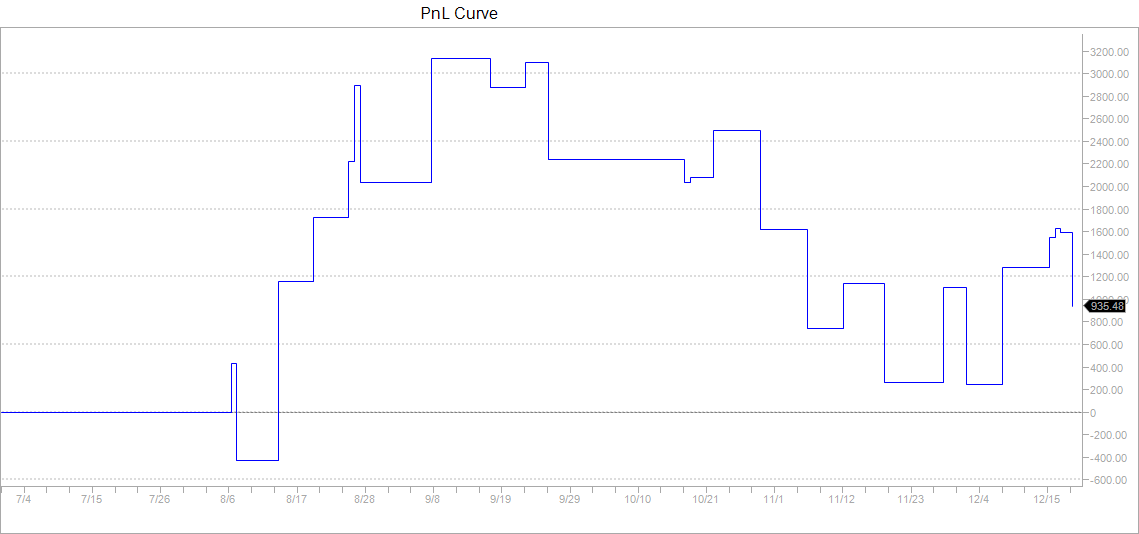 Figure 3
Figure 3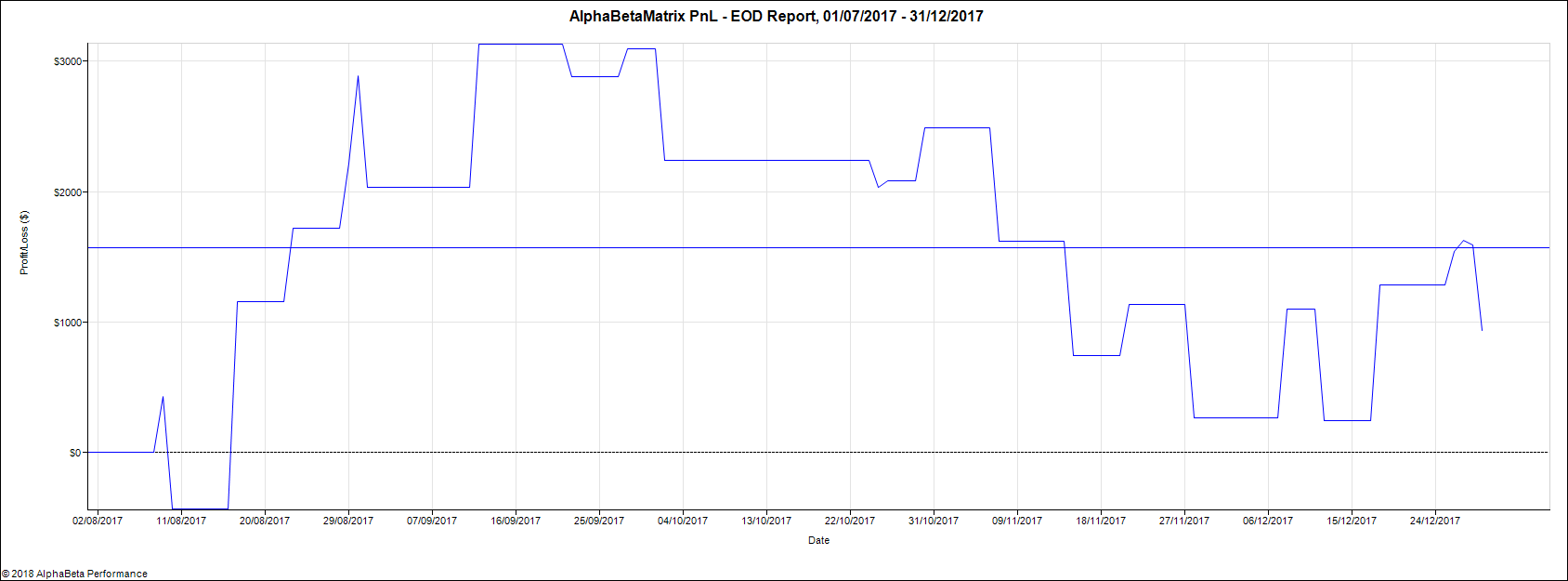 Figure 4
Figure 4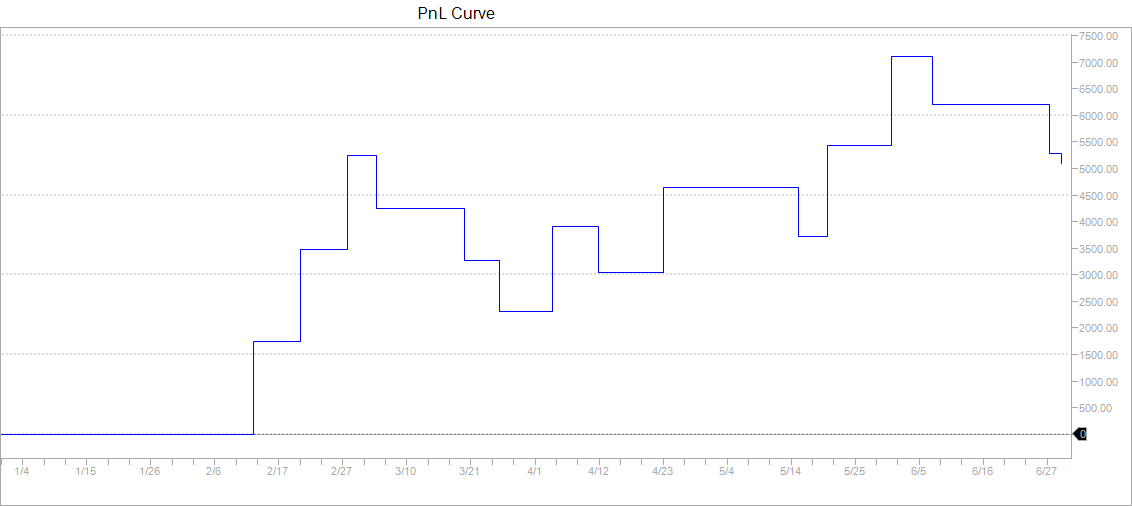 Figure 5
Figure 5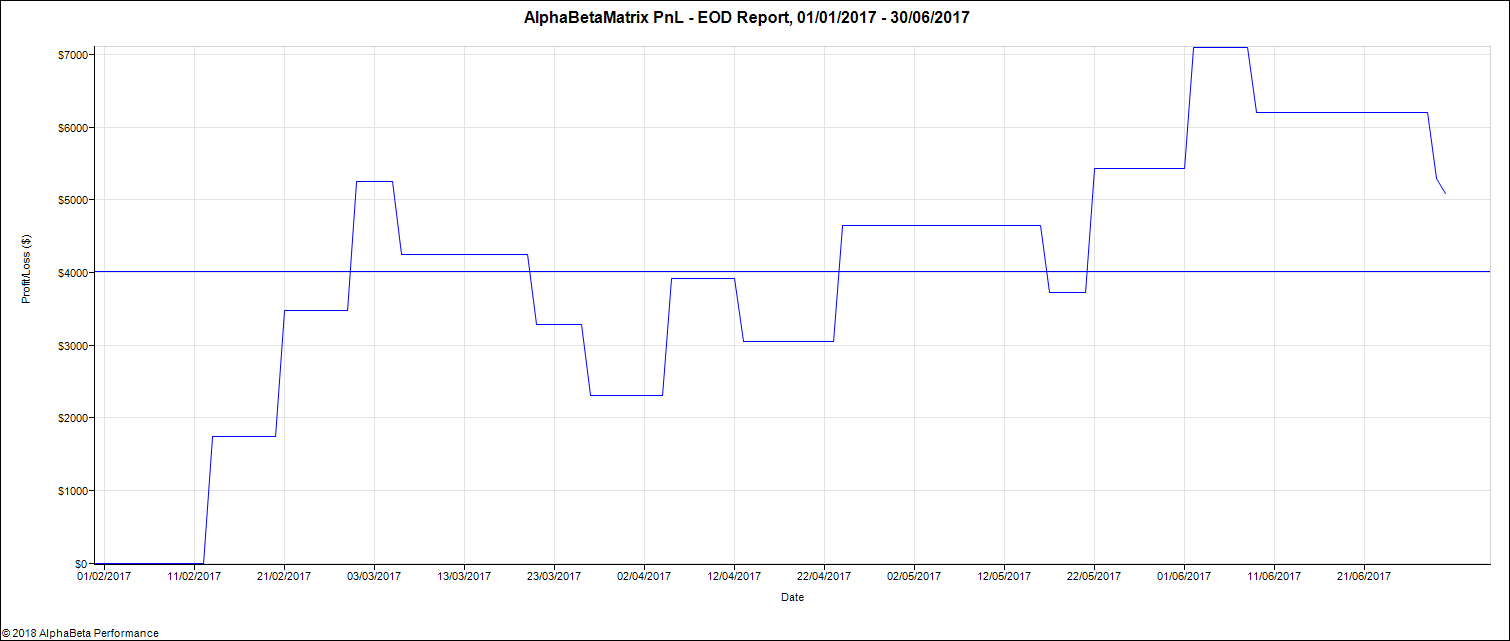 Figure 6
Figure 6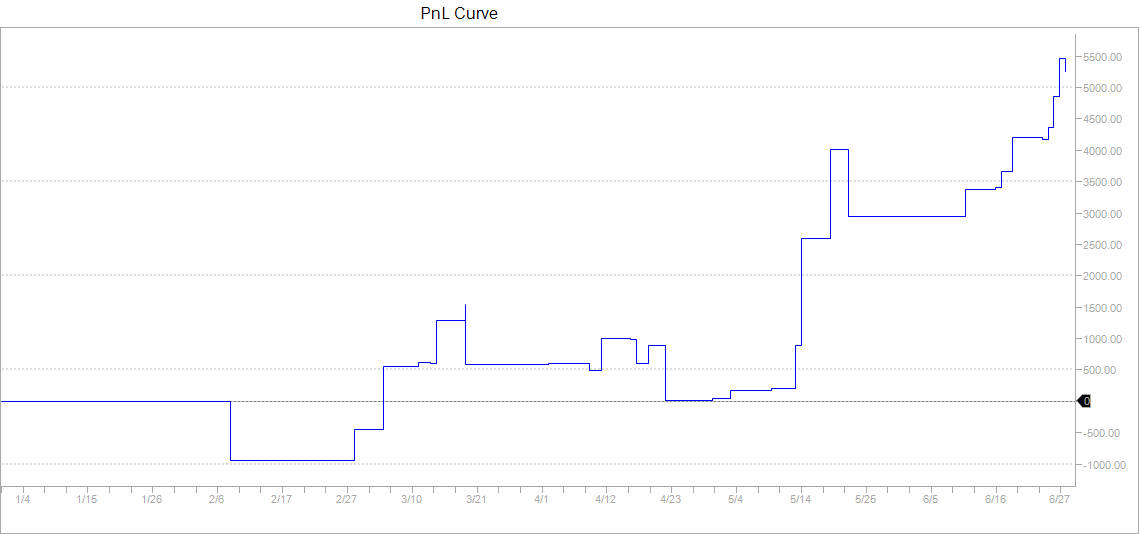 Figure 7
Figure 7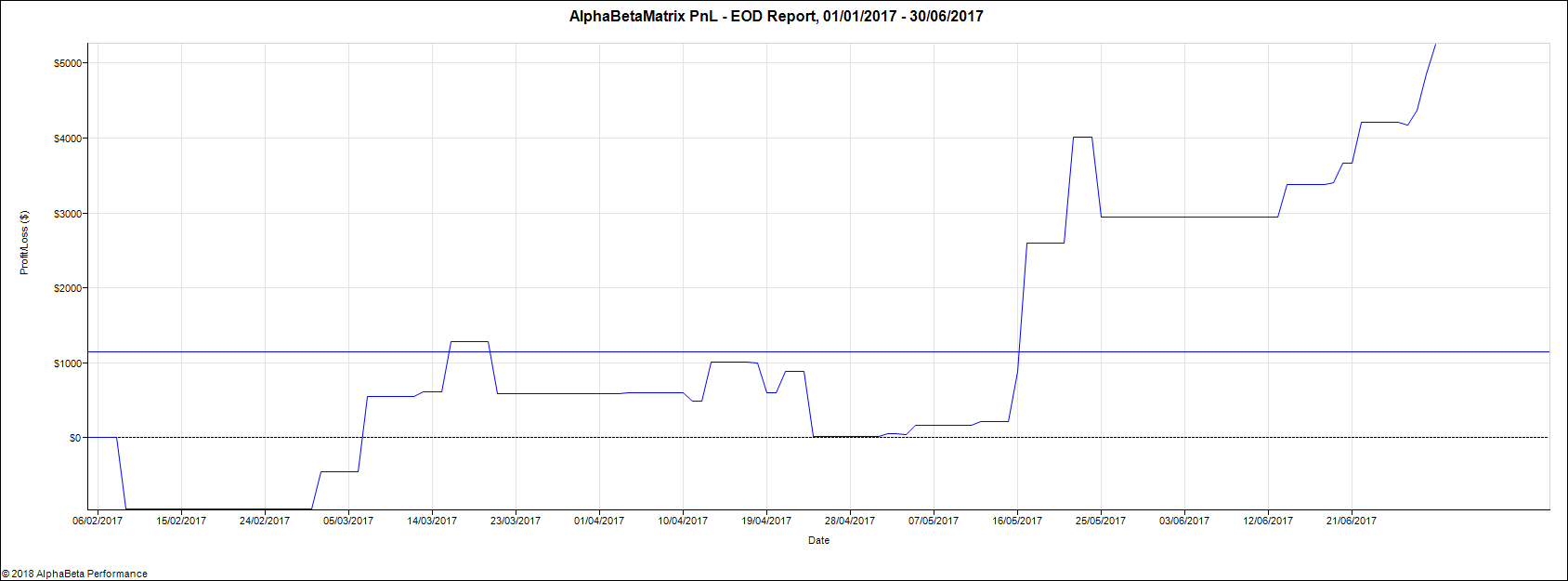 Figure 8
Figure 8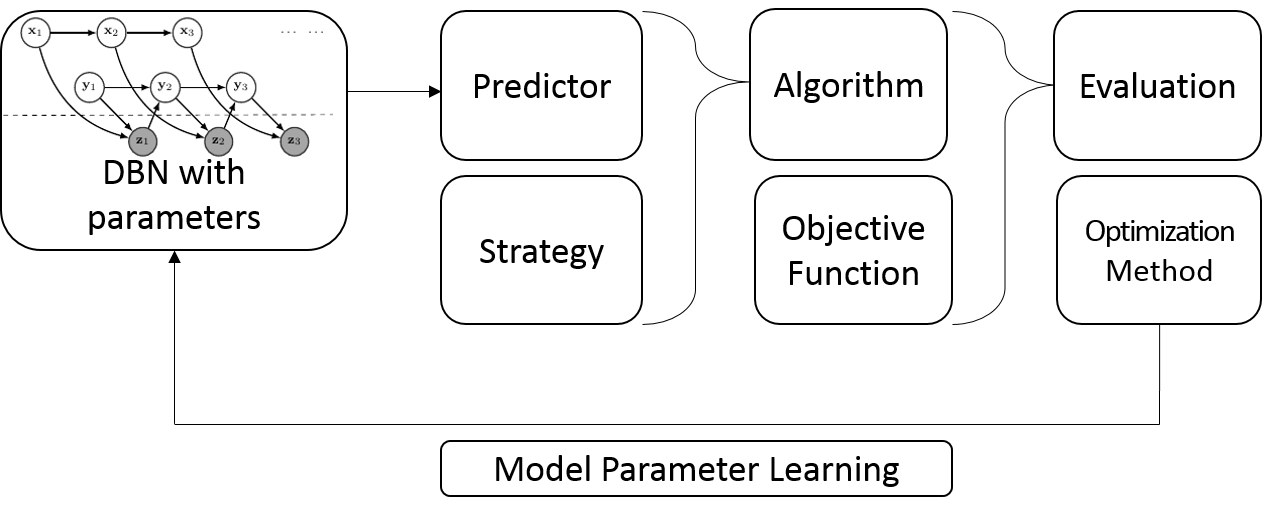 Figure 9
Figure 9| Parameters | threshold | stop | target | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Value | 24.8 | 11.8 | 46.2 | 77.5 | 67 | 99.9 | 99.9 | 5 | 80 | 150 |
| Performance | Net Profit | Avg. Trade | Tot. Net Profit (%) | Ann. Net Profit (%) |
| Train | 5,086 € | 339.05 € | 5.09% | 10.59% |
| Test | 4,266 € | 284.38 € | 4.27% | 8.69% |
| Performance | Vol | Sharpe Ratio | Max. Drawdown | Recovery Factor |
| Train | 6.54% | 1.62 | -2,941 € | 3.510 |
| Test | 6.20% | 1.40 | -1,721 € | 4.948 |
| Performance | Profit Factor | # of Trades | # of Contracts Avg. Winning Trade | Max. conseq. Winners |
| Train | 1.75 € | 15 | 1,692.09 € | 3 |
| Test | 1.62 € | 15 | 1,588.92 € | 2 |
| Algo | Train: Percent Profitable | Train: Total Net Profit | Test: Total Net Profit | Test: Recovery Factor |
| MA Cross over | 54 % | 5,260.00 € | 935 € | 0.32 |
| EM optimized model | 42 % | 5,165.72 € | 2,250 € | 0.56 |
| NGD Graphical model | 48 % | 5,085.79 € | 4,266 € | 2.48 |
| Algo | Test: Sharpe Ratio | Total # of Trades | Overall Profit Factor | Test: Max. Drawdown |
| MA Cross over | 0.41 | 26 | 1.13 | -€2,889 |
| EM optimized model | 0.85 | 28 | 1.25 | -€2,523 |
| NGD Graphical model | 1.40 | 30 | 1.62 | -€1,721 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
oddsidemargin has been altered.
textheight has been altered.
marginparsep has been altered.
textwidth has been altered.
marginparwidth has been altered.
marginparpush has been altered.
The page layout violates the UAI style. Please do not change the page layout, or include packages like geometry, savetrees, or fullpage, which change it for you. We’re not able to reliably undo arbitrary changes to the style. Please remove the offending package(s), or layout-changing commands and try again.
NGO-GM: Natural Gradient Optimization for Graphical Models
Eric Benhamou
A.I Square Connect, Lamsade
&Jamal Atifl
Lamsade*†*
&Rida Laraki
Lamsade*†*
&David Saltiel
A.I Square Connect*∗* A.I Square Connect, Neuilly sur Seine, France Lamsade, Université Paris Dauphine, PSL, France
Abstract
This paper deals with estimating model parameters in graphical models. We reformulate it as an information geometric optimization problem and introduce a natural gradient descent strategy that incorporates additional meta parameters. We show that our approach is a strong alternative to the celebrated EM approach for learning in graphical models. Actually, our natural gradient based strategy leads to learning optimal parameters for the final objective function without artificially trying to fit a distribution that may not correspond to the real one. We support our theoretical findings with the question of trend detection in financial markets and show that the learned model performs better than traditional practitioner methods and is less prone to overfitting.
1 Introduction
One of the most challenging question in social sciences and in particular financial markets, is to be able from past observations to make some meaningful predictions. Part of the challenge comes from multiple difficulties. First of all, there is no universally established physical law and our model will be at best a simplified version and at worst a complete non sense. Second, sequential information does not imply stationarity of the process: data may incur regime changes. Third, we should find the right balance between not enough and too much modeling.
To be able to represent connection between our variables, an efficient and meaningful framework is graphical models. As stated in [Jordan, 2012], graphical models are a marriage between probability theory and graph theory. They are powerful as they provide a condensed way to represent variables dependencies. The graphical representation allows not only compacting information, it also provides a powerful formalism for reasoning under uncertainty. It represents knowledge about the dynamics of the variables, their dependencies and their conditional distribution, hence sometimes called also Dynamic Bayesian Networks (DBN).
Graphical models exploit latent variables to make the model better in terms of explanation power. By defining a joint distribution over visible and latent variables, the corresponding distribution of the observed variables is obtained by marginalization. This has the nice property to express relatively complex distributions in terms of more tractable joint distributions over the expanded variable space. The canonical atomic example of hidden variable models is the mixture distribution in which the hidden variable is the discrete component label that provides the corresponding distribution for the observable variable. The static version leads to the Gaussian mixture model and in continuous space to the factor analysis model while the dynamic version leads respectively to HMM and the Kalman filter model, often referred to as the state space model and represented by figure 1. However, dynamic graphical models can be more complex as given by figure 2 with combination of the Kalman filter (KF) model and echo state networks (ESN) or by figure 3 with feedback from past observations to next step latent variables. We will exploit a combination of the latter in our numerical experiments.
To finalize our model, we need to solve the issue of learning the its parameters. The typical learning approach is the Expectation Maximization (EM) algorithm. It was initially developed for mixture models, in particular Gaussian mixtures and other natural laws such as Poisson, binomial, multinomial and exponential distributions, see [Hartley, 1958] and [Dempster et al., 1977]. It was only when the link between latent variables and Kalman filter models was made that it became clear that it could also be applied to Kalman and extended Kalman filters (see [Cappe et al., 2010] or [Einicke et al., 2010]). The EM method is so far the state of the art method for learning graphical model parameters as it provides an efficient way to find model parameters in a fraction of seconds (see for instance [Neal and Hinton, 1999], but also [Pfeifer and Protzel, 2018], [Li and McCormick, 2017], [Robin et al., 2017], [Levine, 2018]). Interestingly [Xu and Jordan, 1996] shows that the EM method can be viewed as a gradient descent where the decrement is computed as the projection of the gradient, making it a variable metric gradient ascent. Similarly, [Amari, 1995] proves that the E and M steps in EM can be interpreted as dual projected gradient flows under dual affine connections using information geometry. This advocates to find alternatives that are also gradient descent but in the natural space.
We argue that although EM enjoys several nice properties, it misses the point that graphical models are imprecise and simplified models for the reality especially when tackling complex problems such as time series forecasting. In particular, whenever we apply graphical models to economics and finance, we are forced to make some modeling assumptions about the state dynamics and the graph topology (the DBN structure). These assumptions may be incorrectly specified and add some bias compared to reality. Trying to use a best fit approach through maximum likelihood estimation and Kullback Leibler divergence optimization may miss this point and try to fit at all cost the model on data. It does not factor in the interdependence between our graphical model and the actions related to this graphical model. In the case of social sciences, if the graphical model is used to make a forecast which is then used to make a parametric action, the EM method does not take into account the interrelation between parameters of the graphical model denoted by and the ones of the action denoted by . To measure the efficiency of the full set of parameters , we rely on a cost function that can contain a regularizer to lead to smooth parameters. In finance, this cost function can be for instance a measure of the performance of our prediction taking into account the risk in our actions.
We present here a new approach that takes a radical point of view and focuses on the final efficiency of our model. Graphical model parameters are now estimated in terms of their efficiency for the cost function together with the action parameters rather than just their distributional fit to data. We rely on information geometric optimization to find a local optimum for our final cost function. Our key features are the following:
- •
it is possible to directly optimize the cost function with a stochastic optimization approach and in particular the CMA-ES method;
- •
this approach computes a natural gradient in the implicit Fisher information Riemannian manifold;
- •
it is a good alternative to the EM approach as it does not fit at any cost the distribution of our graphical model to reality but rather looks at model efficiency measured by a loss function related to the problem under study;
- •
the estimation of our model parameters is performed jointly with the action strategy parameters;
- •
numerical results show that the overfitting issue of this approach due to local minima is less than the EM approach as it takes into account that the model dynamics is incorrectly specified.
The rest of the paper is organized as follows. Section 2 presents the overall framework and the resulting optimization problem. Section 3 provides some theoretical arguments that favor stochastic optimization approaches based on Information Geometric Optimization (IGO). Section 4 discusses an example in finance. Our method outperforms traditional trend following methods by far. We finally conclude about some possible extensions and further experiments.
2 Settings
Suppose we have determined an architecture for our Dynamic Bayesian Network. This may be inspired by combinations of simple network architectures such as those in Figures 1, 2, 3. This model is used for some specific goal. In our case, it is used to forecast some times series. But this is not our final objective! We are interested in using this forecast to perform a specific action. In the case of a financial market algorithmic trading strategy, we will use the forecast to make an informed decision and decide whether we should buy, sell or do nothing with a financial asset. To keep things simple, we will assume that when we take our decision, we target a pre-determined movement amplitude, materialized by a profit target and a stop loss level. The signal for the action is given by the difference between the forecast generated by our graphical model and the last price. To avoid false signals, we add an additional threshold parameter for our action and consider that there is an uptrend signal (respectively a downtrend signal) if the forecast is above the last price plus a threshold (respectively below the last price minus a threshold). Using a fixed price target, a stop loss and a threshold is quite realistic and is done by many practitioners as presented in various papers, e.g. [Labadie and Lehalle, 2010], [Giuseppe Di Graziano, 2014], [Fung, 2017], or [Vezeris et al., 2018]. The profit target ensures that the strategy locks the profit in real money and is technically corresponding to a limit order while the stop loss, technically corresponding to a stop order, safeguards the overall risk by limiting losses whenever the market backfires and contradicts the presumed direction.
The price target, stop loss and threshold are three additional parameters that govern our action. These parameters are closely interconnected to our network parameters. If the network’s prediction is accurate enough, we should aim for a large price movement, hence a large price target and a small stop loss. If it is not accurate enough, on the contrary, we should reduce the price target and increase the stop loss. We hold the position until either the trade reaches the profit target and exits in a profit or it touches the stop loss level and exits with a loss. The objective function to measure the performance of the model is the eponymous Sharpe ratio (introduced in [Sharpe, 1966]) that corresponds to the ratio of the strategy net return over its standard deviation. We add an regularization term to ensure sparsity of the dynamic graphical model parameters. Although this approach may recall reinforcement learning theory, the dynamic nature of our graphical model makes the usage of standard reinforcement learning tools such as Q-learning inappropriate.
On this simple example, we clearly see that optimizing graphical model parameters in a standalone fashion is not optimal and that these parameters should be evaluated together with the action parameters at the light of our loss function as represented by figure 4. We want to maximize the Sharpe ratio of our trading strategy over time. This optimization problem is non convex with potentially many local optima. Moreover, the binary nature of our action, i.e. we sell or buy as soon as our forecast hits the past level plus or minus the threshold, leads to discontinuities.
The fundamental difference between EM method and ours is to jointly optimize the model and the action parameters, learning . Because model and action parameters are interconnected, this approach well fits our initial desiderata. It optimizes our final criteria, the loss function, and not the maximum likelihood of our graphical model. We will present in the next section some important results from information geometric optimization that allow us to tackle this complex optimization problem using a natural gradient descent.
3 Information Geometric Optimization
3.1 Natural gradient descent
Compared to the usual gradient descent method, the natural gradient takes into account the intrinsic geometric structure of the underlying Riemmanian space. Since the seminal work of [Amari, 1998], it has been widely adopted by the machine learning community [Pascanu and Bengio, 2014], [Bernacchia et al., 2018]. In gradient descent, the usual update step is where is the optimization parameter at iteration , the learning rate, and the cost function. The method of natural gradients replacement proposes to change the gradient descent with where is a matrix that defines the Riemannian metric in the space of the parameters. This is very powerful as it computes the fastest descent when looking at the Riemannian metric induced by the parameters. In distributions space, the Riemannian metric is associated with the Fisher information matrix [Rao, 1945, Jeffreys, 1946]. In general, it is difficult to apply the natural gradient descent because we need to invert the Fisher information matrix, which is computationally heavy, except in some particular cases where there exists a closed form like for instance for exponential family distributions. We will follow the seminal works of [Ollivier et al., 2017] and [Akimoto, 2012] and present a stochastic optimization method that performs numerically natural gradients efficiently.
We denote by a metric space and associate to a Borel -field and a measure on denoted by and respectively. Typically is and is the Lebesgue measure on . We are interested in minimizing a -measurable real value function . In order to make our optimization invariant with respect to various standard transformations of , instead of minimizing , it is better to find the minimum of a loss (also referred to as an invariant cost) function that is invariant to any strictly increasing transformation of . We define as the -measured volume of the unit ball in the functional space with radius , that is
[TABLE]
Said differently, is the measure of all the elements whose value is less or equal to . We are interested in finding the optimum of the loss function with respect to a family of probability distributions on , . Compared to standard optimization, we define a quasi-objective function, sometimes referred to as a utility function, , on the parameter space defined as the expected value of our loss function over the space of distributions to the power : , namely . The intuition behind the exponent is to ensure that the utility is in a sense dimensionless and homogeneous to the square of a Euclidean distance. This is because in dimension , a unit ball is homogeneous to a radius of dimension , where as the square of a Euclidean distance is of dimension . We will see in the practical example of a a quadratic function (see subsection 3.5) that this choice of exponent makes the explicit computation of the natural gradient easy.
In [Ollivier et al., 2017], this utility function is defined as the opposite of the weighted quantile, , where is non-increasing weight function. This choice is not easy to analyze as the quantile depends on the current parameter . At each iteration, the loss function changes making it hard to analyze. In [Akimoto, 2012], the utility (referred to as the quasi objective) function is defined as where represents any monotonically increasing set function on , i.e., for any , s.t. . Our function is somehow simpler as the loss function is just the expected volume of all the elements whose value is less or equal to for while the Utility function is similar but homogeneous to a Euclidean distanced squared.
We are interested in performing a natural gradient descent on a Riemannian manifold given by equipped with the Fisher information metric . We choose the Fisher metric because it is the unique metric that does not depend on the choice of parameterization as explained in [Amari and Nagaoka, 2007]. The natural gradient is easy to obtain and is just the gradient with respect to the Fisher information matrix metric. One can “easily” compute it and get that it is provided by the product of the inverse of the Fisher information matrix with the standard or vanilla gradient of the function to minimize. We can then apply a natural gradient descent as follows:
[TABLE]
where is the learning rate. Compared to the vanilla gradient, we have an additional term given by . We present below an algorithm that allows performing the natural gradient descent in a general case. To make things clearer, we will present the algorithm in the case where we can explicitly compute the inverse of the Fisher information matrix and the standard gradient . We will call this the Closed form Natural Gradient or (NGD). We will then present the Monte-Carlo NGD that allows performing the natural gradient descent in a general framework efficiently.
Historically, this approach of computing a natural gradient in the space of distributions was done empirically and without strong theoretical arguments in the Evolution Strategies community. The most prominent approach belonging to this work which is indeed a natural gradient method is the CMA-ES algorithm [Hansen and Ostermeier, 2001]. Although CMA-ES has been state of the art in this line of research as shown by the various benchmarks of the Comparing Continuous Optimisers (COCO) INRIA platform for ill-posed functions, it was only later, after the works of [Akimoto et al., 2010], [Glasmachers et al., 2010], [Akimoto et al., 2012], [Akimoto, 2012], and the deep theoretical study of [Ollivier et al., 2017]) that the community realizes that this algorithm performs a natural gradient descent. In the following we adapt these theoretical proofs to the setting of our graphical model learning problem. The CMA-ES algorithm has led to a large number of papers and articles and we refer the interesred reader to [Hansen and Ostermeier, 2001], [Auger et al., 2004], [Igel et al., 2007], [Auger and Hansen, 2009], [Hansen and Auger, 2011], [Auger and Hansen, 2012], [Hansen and Auger, 2014], [Akimoto et al., 2015], [Akimoto et al., 2016], [Ollivier et al., 2017] and [Varelas et al., 2018] to cite a few.
3.2 Closed Form (CF) NGD Algorithm
In order to study the key property of the CMA-ES, we focus on the case where and suppose the measure to be the Lebesgue measure on , denoted , while denotes the Borel -field on .
Concerning the sampling distribution, we will work with the Gaussian distribution as it has the maximum entropy among distributions with known first two moments. Our distribution space, denoted by is parameterized by the parameter . We adopt the traditional moment parameters, that is the mean vector , which is in and the covariance matrix , which is a symmetric and positive definite matrix of dimension , which leads that is indeed the normal written as .
The loss function is naturally associated to the Lebesgue measure and defined as In order to optimize our function, we look at the infimum of
[TABLE]
If there is only one optimum, this translates into finding the domain where the mean vector equals the global minimum of while the covariance matrix is null.
It is worth noticing that the choice of the moment parameterization of Gaussian distributions does affect the behavior of the natural gradient update (1) with finite learning rate . However, the steepest direction of on the statistical manifold is invariant under the choice of parameterization as explained in [Ollivier et al., 2017]. Using explicit computation for the normal, we get the natural gradient descent summarized by proposition 3.1 below.
Proposition 3.1**.**
If the loss function is squared integrable (), using two different learning rates for the mean vector and the covariance, the natural gradient descent (1) writes:
[TABLE]
[TABLE]
Proof.
Refer to A in the supplementary material for more details. ∎
Equations (2) defines the closed-form or deterministic natural gradient descent (NGD) method, which is an ideal case where we know the optimum solution. This ideal case is useful for deriving fruitful properties of our optimization method but is useless in practice.
3.3 Monte-Carlo (MC) NGD Algorithm
We now turn to the real algorithm that is efficient in real-world situations. It tackles the issue of unknown and untractable gradient for our quasi objective function: . The last resort solution is to estimate the gradient with Monte Carlo simulations. We approximate the natural gradient and simulate the natural gradient descent with the algorithm 1.
This algorithm is the Monte Carlo version of our NGD algorithm. In [Ollivier et al., 2017], this is referred as the stochastic NGD algorithm. Compared to the closed-form NGD algorithm, we evaluate thanks to a Monte Carlo simulation. This makes this algorithm stochastic in nature. In order to have the same behavior each time we run this algorithm, we freeze random seeds to ensure similar results for the normal random numbers. The core of the algorithm is to generate samples from a multivariate Gaussian distribution , evaluate their value, computes the loss functions afterwards. The estimates are obtained as follows. In order to get the intuition of the Monte Carlo approximation, recall that the loss function is given by:
[TABLE]
In our Monte-Carlo algorithm, a first step consists in computing the integral as the corresponding Riemann sum:
[TABLE]
For the multivariate Gaussian, the probability weights are given by p_{\theta^{t}}(x_{j})=1/\sqrt{(2\pi)^{d}\det(\Sigma)}\exp\bigl{(}-\lVert z_{j}\rVert^{2}/2\bigr{)} where the are standardized normal draws. It is worth noticing that these weights are not the traditional ones of the CMA-ES algorithm. CMA-ES relies rather on logarithmic weights [Hansen and Auger, 2014] and takes a fraction (denoted by , that means something different from our mean vector) out of candidates. In this setting, we use all the candidates to compute the new mean and covariance. From a theoretical point of view, the weights introduced in [Akimoto, 2012] are more meaningful and make the study of the property of this stochastic optimization algorithm simpler. The next step is to estimate the natural gradient according to equations (2) as follows:
[TABLE]
In the final natural gradient update, it is important to have both the mean and the covariance learning rates not too large. We will see in the next section the reason of the limitation of the learning rates when looking at the positivity of the covariance matrix at each step as well as when examining convergence properties.
3.4 Basic Properties
**Invariance. ** Invariance properties are fundamental for the efficiency of optimization algorithm. Our stochastic optimization has two major invariance properties: under monotonic transformations of the objective function and under affine transformations of the search space. Invariance under monotonic transformation means the algorithm performs equally well on the function and on , the composition of with any function strictly increasing. This explains why it performs well on ill-conditioned functions whereas conventional gradient methods like Newton method relies on convexity properties of the objective function and handles this non-convex problems less well. This invariance property is a direct consequence of the loss function. Invariance under affine transformations of the search space is the key idea behind the Newton’s method. The adapation of the covariance matrix at each step explains the performance of this algorithm on ill-conditioned objective functions.
**Positivity. ** The covariance matrix must be positive definite and symmetric at each iteration. Although [Krause et al., 2016] recently took the additional constraint to Cholesky decompose the covariance matrix, we can explicitly compute the condition on the learning rate to ensure that in our NGD algorithms the covariance matrix always remains positive definite symmetric. Proposition 3.2 shows that the learning rate has too be small enough. Should the learning rate be larger than the critical value, the covariance matrix would be be non positive.
Proposition 3.2**.**
Provided that the matrix and the various matrices are positive definite, the covariance matrix remains positive definite (and symmetric) for each in the closed form NGD algorithm. Should the matrix not be positive (with eigen values negative or null), would not be positive. In the Monte-Carlo NGD algorithm, the condition is modified into should be positive definite for any .
Proof.
Refer to B in the supplementary material for more details. ∎
Remark 3.1**.**
In case, the matrix for the Closed Form case and for the Monte-Carlo case has some positive eigen values, this result can be re-expressed trivially in terms of eigenvalues and state that the learning rate is bounded by for the Closed Form case and for the Monte Carlo case where denotes the largest eigenvalue of a matrix . This is quite intuitive. The greater the critical largest eigenvalue is, the bigger the gradient is. Hence the learning rate should not be too large to go too far. Reciprocally the smaller the critical largest eigenvalue is, the smaller the gradient is. Should the matrices previously mentioned have only negative values, there would be no bound on the learning rate. This result is already presented in [Akimoto, 2012] but without mentioning that the two matrices shall not be necessarily positive. We will see in the trivial case of the quadratic function in subsection 3.5, that the matrix in the Closed Form case can be explicitly computed and given by with given by proposition 3.4. Should not be positive, the matrix would not be neither.
**Convergence. ** Although the gradient estimator defined in (3) may not be necessarily unbiased, yet it converges to the true natural gradient as proved by proposition 3.3. This implies in particular that the Monte-Carlo NGD approximates well the closed-form NGD when we increase the sample size . Let us denote by the natural gradient operator, and by the Monte Carlo estimate of the natural gradient.
Proposition 3.3**.**
Let be independent and identically distributed (i.i.d) random vectors following . Let us denote the vectorization of matrix , that is the vector obtained by stacking matrix columns on top of one another. Let and be the loss function estimator given by (4) and the natural gradient estimator where in (3) the are replaced by .
If the loss function is squared integrable: , then the gradient estimator of our utility function converges almost surely: , where represents almost sure convergence.
Proof.
Refer to C in the supplementary material. This result was proved as early as 2011 by [Ollivier et al., 2017] although their final manuscript was published a few years latter. Our approach though is quite original as we use the fundamental property of almost sure convergence that implies also Cesaro convergence. As Monte Carlo estimates are in nature Cesaro sums, this remarkable property ensures convergence of the MC NGD algorithm. Intrinsically, it means our Monte Carlo estimate is consistent. This is the theoretical foundation for our algorithm. The square integrability condition is crucial to guarantee the convergence of the algorithm. ∎
3.5 Convergence Properties
Since the MC NGD algorithm is quite complex, we are forced to simplify the problem and look at convergence properties only for the CF NGD algorithm. We additionally restrict ourselves to the canonical convex-quadratic function , as introduced in [Auger et al., 2004], where is a positive definite symmetric matrix. We also make assumptions on our learning rates: there exist and such that
[TABLE]
A way to satisfy these inequalities is to set (respectively with (resp. ) being a learning rate constant for (resp. ) such that (resp. ).
With these assumptions, we can prove the global convergence of and with linear convergence speed as stated by the proposition 3.4 below. The optimum of our quadratic test function is zero. In the following, we denote by the Frobenius norm of , namely .
Proposition 3.4**.**
For the canonical quadratic optimization, the natural gradient descent is explicit and given by
[TABLE]
where
[TABLE]
with the regular Gamma function. Suppose (7) and (8) hold, then (resp. ) converges to zero with a rate of convergence defined as the of the ratio of two consecutive terms upper bounded by (respectively ).
Proof.
Refer to D in the supplementary material. The intuition of the result of the convergence appeared as early as in [Auger et al., 2004] and was progressively improved and more detailled in [Arnold and Hansen, 2010], [Akimoto, 2012], [Beyer, 2014] and lately [Hansen, 2016] among others. The novelty of our proof is the explicit computation of the natural gradient descent update equations with the true computation of the constant in the update equations (9). ∎
Remark 3.2**.**
Proposition 3.4 is remarkable because it indicates that the rate of convergence is linear, which is unexpectedly fast for this kind of algorithms and explains why the CMA-ES is currently the state of the art solution for several complex optimization settings.
4 Numerical Results
In order to test the efficiency of our optimization procedure that results in a CMA-ES optimization for Learning parameters of our graphical model and the price target and stop loss, we look at a trend following algorithm where we enter a long (respectively short) trade if the dynamic Bayesian network forecast is above (respectively below) the previous day closing price. For each comparison, we add an offset to avoid triggering false alarm signals. We set for each trade a pre-determined profit and stop loss target in ticks. The chosen architecture for our graphical model is a combination of model of Figure 2 and 3 and given in Figure 5.
The corresponding dynamic is composed of two latent variables representing short and long term effects, denote respectively: and . We assume that long term effect impacts the next long term latent variable while there is no influence of short term latent variable on the next long term effect latent variable. This results in the following equations:
[TABLE]
We assume that the observation noise follows a multivariate normal distribution with zero mean and covariance matrix given by : . In addition, the initial state, and noise vectors at each step are assumed to be all mutually independent. We also denote by the covariance matrix of . We assume the following parameters:
[TABLE]
The variable is computed as the ratio of the difference between the last price observation and the running minimum over the difference between the running maximum and minimum observed over 20 periods. The pseudo code is given in Algorithm 2.
Our resulting algorithm depends on the following parameters , the parameters of our dynamic graphical model, the profit target, the stop loss and the signal threshold . We could estimate the graphical model parameters with the EM procedure, then optimize the profit target, stop loss and signal threshold separately. However, if by bad luck, the dynamics of the graphical model is incorrect, the noise induced by wrong specification will be factored in these three parameters.
We opt rather for a combined optimization of all the parameters. We use one minute data for the S&P 500 index futures from 01Jan2017 to 01Jan2018 but take daily decisions. We train our model on the first 6 months representing about 170,000 data points and test it on the next six months. For a model given by equations (11) and (12) and parameters specified in (25), the optimization encompasses 18 parameters: , the profit target, the stop loss and the signal offset , making it non trivial. We use the CMA-ES algorithm to find the optimal solution. In our optimization, we add a penalty to enforce sparsity of our parameters. Obtained parameters are summarized in Table 1. Out of 18 parameters, only 10 are not null. Table 2 shows that statistics for train and test are very similar, which is a good sign for little overfitting. Figures 6 and 7 are very similar confirming our intuition of reduced overfitting.
We compare our algorithm with a classical EM and a traditional Moving Average (MA) crossover approach to test the efficiency of our graphical model for trend detection. The MA algorithm generates a buy (resp. sell) signal when the fast moving average crosses above (resp. below) the long moving average. Table 3 details the results of this comparison. We see that on the train dataset, the three algorithms share similar performances (similar first two columns) but they perform quite differently on the test set and only our graphical model manages to have a Sharpe ratio over 1 on the test period. Overall, the MA algorithm seems to suffer from overfitting as it performance in the test set is very different from the one on the train. This is confirmed by Figure 8 and 9, with sharp contrast between train and test.
5 Conclusion
In this paper, we presented a novel approach for learn-ing parameters in dynamic graphical models that tackles the targeted usage of our dynamic graphical model and incorporates them in the natural gradient optimization of the loss function. Compared to EM method, this method performs better in real scenarios and is less prone to overfitting.
Appendix A Proof of proposition 3.1
Proof.
The regularity condition that the expectation of our loss function is square integrable () implies that for any , we also have .
Hence we can interchange the order of integration and differentiation and compute the natural gradient update as
[TABLE]
where is the score function, defined as the gradient of the log-likelihood of the multivariate Gaussian distribution with respect to its moment parameters.
For a multi variate normal distribution, the score function is given by
[TABLE]
For a multi variate normal distribution, the Fisher matrix information has a closed form given by
[TABLE]
where denotes the Kronecker product operator. The natural gradient writes
[TABLE]
Combining (26), (27) and (28), and splitting the learning rate among the mean vector and the covariance matrix, with two different learning rates, we obtained
[TABLE]
with
[TABLE]
which concludes the proof. ∎
Appendix B Proof of proposition 3.2
Proof.
The symmetry is obvious. Let us prove that the matrix is positive definite for each by mathematical induction. The result is trivially true for as is positive definite. Suppose that at step the result is true and that the matrix is positive definite and symmetric. Notice that the update 2 writes
[TABLE]
for the closed form (C) NGD and
[TABLE]
for the Monte Carlo case. Using the result that if and are symmetric positive definite, then is also positive definite, we get that stays positive definite. This concludes the proof that the matrix is positive definite for each . Should the learning rate be too large so that the inner term in 30 for the closed form case, and for the Monte Carlo case are not definite positive, the next iteration would also be not definitive positive. Should the previous matrices be non positive, the next iteration would non positive, which concludes the proof. ∎
Appendix C Proof of proposition 3.3
We will decompose this proof into various elementary lemmas. Usually, when proving convergence for Monte Carlo, one relies on traditional statistical tools like the strong law of large numbers as well as some measure tools like Lebesgue’s dominated convergence, Cauchy Schwartz inequality, etc… However, we take an original approach and rather use connection between single term convergence and Cesaro convergence. A first lemma that is intuitive is that almost sure convergence implies almost sure (a.s.) Cesaro convergence. To make things more precise, let be a random variable of and a series of real valued functions.
Lemma C.1**.**
If converges almost surely to 0, then its Cesaro sum obtained for independent realizations of converges almost surely to 0. In other words,
[TABLE]
where are i.i.d. variables.
Proof.
For , we have
[TABLE]
By assumption, almost everywhere in as tends to infinity. This implies that almost everywhere in as tends to infinity. We can apply the Lebesgue’s dominated convergence theorem to prove that as . This implies that is finite for sufficiently large. The strong law of large numbers (LLN) applies and proves that the right hand side of (32) converges to when becomes large. The last expectation converges to [math] when grows to infinity. This concludes the proof. ∎
Remark C.1**.**
That convergence implies Cesaro convergence relies strongly on the almost sure convergence nature. Should the initial convergence only be in probability, the convergence of our series of functions would not imply Cesaro convergence. Take for instance a standard Gaussian variable and the series of function where is equal to 0 everywhere except when and takes the value where is the cumulative density function (c.d.f). Take n independent standard Gaussian variables, it is easy to see that the Cesaro sum does not converge to 0 as its mean is by construction equal to 1, while converges in probability to 0. This is because the function takes non zero value on a smaller and smaller interval measure: but with a value that explodes and is given by to compensate for the reduced interval on which the function is not null.
The second lemma concerns the almost sure consistency of our estimator of the loss function.
Lemma C.2**.**
* converges a.s. to *
Proof.
The estimator writes as
[TABLE]
hence, we have
[TABLE]
We know that which implies for any dimension . This implies in particular taht is finite almost everywhere. We can safely apply the strong law of large numbers to get
[TABLE]
almost surely and almost everywhere in , which concludes the proof. ∎
We are now ready to prove proposition 3.3.
Proof.
The assumption in proposition 3.3 is that is square integrable, that is , hence is also integrable, which leads trivially that the expectation of is finite
[TABLE]
The variance of being non negative, we have the trivial inequality between the first two moments:
[TABLE]
Moreover, Cauchy-Schwarz inequality gives us that
[TABLE]
Using the relationship between the variance of the score and the information Fisher, we can notice that . This implies also that the expectation of is finite
[TABLE]
Let us take the function series as the difference between our estimated loss function and the loss function:
[TABLE]
Let us decompose in three terms as follows:
[TABLE]
We want to prove that almost surely. We can examine successively the three terms.
Using (34) and the strong law of large numbers, the first term converges to almost surely as tends to infinity.
We now examine the second and third terms in (35). To conclude the proof, we need to prove that these two terms converge a.s. to zero.
Let us tackle the second term. By lemma C.2, we know that our estimated loss function is almost surely consistent, which implies that converges almost surely to [math]. By lemma C.2, this implies that we have the almost surely Cesaro convergence of
[TABLE]
The almost sure convergence (36) implies that the limit agrees with . We also have from (33) and from the strong law of large numbers that the Cesaro sum converges almost surely to the expectation . The latter is finite by assumption. Also, by the strong law of large numbers we have that the Cesaro sum also converges to [math] when tends to infinity. We can conclude that the second term of (35) converges to zero almost surely.
We are now left with the third term of (35). The proof of its almost sure convergence to zero is similar. A Cauchy-Schwarz inequality applied to the second term of (35) gives us a way to control the third term as follows:
[TABLE]
We can take of the two terms in this inequality successfully. The strong law of large numbers proved that the second term of the right hand side converges to the expectation , which can be expressed in terms of the trace of the inverse of the Fisher information matrix: which is finite. This means that the second term of the right hand side converges to a constant. We are left to prove that the first term on the right hand side converges to zero almost surely. By lemma C.2, we have that almost everywhere in as , which implies that almost everywhere in as . By lemma C.1, this implies the Cesaro convergence of to 0 almost everywhere in as which concludes the proof. ∎
Appendix D Proof of proposition 3.4
Like for proposition 3.3, we will first prove a few lemma and the result will become easy. Since our objective function is explicit and given by a parabola, which is a very simple function, we can explicitly compute the natural gradient ascent. This is the subject of the first lemma:
Lemma D.1**.**
The closed-form NGD algorithm on the benchmark quadratic function writes as
[TABLE]
with the constant given by
[TABLE]
where the Gamma function.
Proof.
The natural gradient is directly related to the inverse Fisher information matrix times the gradient of the loss function:
[TABLE]
To fully make explicit the above formula, we need to compute explicitly and prove that it is given by
[TABLE]
We can remark that is equivalent to the volume of the ellipsoid given , or equivalently, . The last set is the image of unit ball under the transformation given by or equivalently . The change of volume under this linear map is given by the determinant of the transform which is , hence,
[TABLE]
where is the volume of the unit ball in dimension . The utility or quasi objective function is defined as the expectation of the loss function to the power . Hence, we get
[TABLE]
Differentiating the both side of the above relation, we have
[TABLE]
We can use the fact that the volume of the unit ball is given by
[TABLE]
to get
[TABLE]
with
[TABLE]
For a multi variate Gaussian distribution, the inverse of the Fisher information matrix is given by
[TABLE]
where denotes the Kronecker product operator. Multiplying the gradient of our utility function (44) by the inverse of the Fisher information matrix (45), we get equation (43), which concludes the proof. ∎
The second lemma relates to the condition number of a diagonal matrix series that satisfies a particular recursive relationship given by
[TABLE]
We also take the convention that is the th largest value of the matrix . We recall that for a symmetric matrix , its condition number denoted by is defined by the ratio of its maximal to its minimal eigen value. For the specific case of a diagonal matrix, this is simply the ratio of its largest to its smallest value.
Lemma D.2**.**
Let a diagonal matrix series that satisfies (46), with the constraint on the learning rate at each step given by:
[TABLE]
Then, the series of condition number of the matrix satisfies for any the following inequalities:
[TABLE]
Proof.
We can remark that for any , . This is trivially obtained by the fact that as by definition, is the largest eigen value, we have for any , which combined with the constraint (46) implies .
Let suppose without loss of generality that we have sorted the diagonal matrix elements by their value so that the first element of the diagonal matrix value is the largest eigen values, the second element the second largest value, etc.. Let us now prove that the mapping between the matrix position and the eigen values ranking order stays the same between step and .
Let us prove the result by mathematical induction. The result is true for step . Suppose the result is true at step and . From (46) and the inequality , we have
[TABLE]
with equality holding if and only if . Therefore, if , then , which implies the result holds also at time .
As by convention there is mapping between diagonal element position and their eigen value rank, the condition number of matrix is computed at each step as the ratio of the first and last element of the diagonal matrix given by . According to our recursive equation (46) we have
[TABLE]
We can notice that the second term in the right hand side is bounded as follows:
[TABLE]
Because of the lower bound on the learning rate in (47), the right term in the above inequality is bounded by . This leads to the result:
[TABLE]
This concludes the proof. ∎
Remark D.1**.**
As the condition number defined as the ratio of the maximum with the minimum eigen value converges to 1, this implies that the diagonal matrix converges to the identity matrix in the sense of the Frobenius norm times its maximal eigen value (or equivalent its minimal eigen value as they get similar as tends to infinity). This is not by magic. The proportional convergence to the identity matrix is forced by the inequalities (47), satisfied by the learning rate at each step which forces all the matrix eigen values to progressively converge to a common number. We can also note that the largest eigen value converges to zero as tends to infinity and is decreasing. This means in particular that in order to satisfy the condition (47), the learning rate needs to be not too small and specifically not below . This implies that the learning rate makes a trade-off between a small value to ensure that it is below but above , with the latter becoming larger and larger as becomes smaller and smaller.
A third lemma concerns the relationship between largest singular values and matrix norm. We denote by the th largest singular value of a matrix , and its largest singular value.
Lemma D.3**.**
Let be a positive definite matrix and a positive definite symmetric matrix, then we have the following matrix norm inequality:
[TABLE]
Proof.
Using trace commutation property and relationship between the norm and the trace, we have
[TABLE]
Additionally, the J. von Neumann’s trace inequality [Mirsky, 1975] gives us
[TABLE]
where and are any matrices in . Combining (52) and (53), we get
[TABLE]
∎
Remark D.2**.**
Indeed, this lemma is quite obvious when looking at the variational definition of singular matrix, that is for a matrix , the first or largest singular value is written as the solution of the following maximization program
[TABLE]
Said differently, it also says that the maximum singular value is the operator norm of the matrix .
A powerful result that was initially proved in [Akimoto, 2012] is that the covariance matrix of the NGD algorithm converges proportionally to the inverse of the Hessian matrix of our quadratic problem which is given by . To prove this convergence, we shows that the condition number of converges to 1 with a linear speed. This is the subject of the following lemma:
Lemma D.4**.**
If the learning rate for the covariance matrix satisfies inequalities (8), then the condition number of converges to one with a linear rate of convergence given by
[TABLE]
Remarkably, we also have that the condition number is upper bounded by
[TABLE]
Finally, if the limit exists, in equation (54), can be replaced by
Proof.
We are interested in the condition number of the matrix . To make the form more symmetric, we can notice that it is better to look at the symmetrized term . This term does exist because is a positive definite and symmetric matrix, hence it admits a square root . As is a positive definite and symmetric matrix, we can decompose it in an orthogonal matrix and a diagonal matrix as follows: , where the diagonal elements of are the eigenvalues of and each column of is the eigenvector corresponding to each diagonal element of . The orthogonal and diagonal matrix decomposition may not be unique but we will first prove that if we find an initial orthogonal matrix that diagonalizes , it will also diagonalize the matrix for any .
Let us prove this result by mathematical induction The result is true for step as is a positive definite and symmetric matrix, hence it admits an orthogonal and diagonal matrix decomposition , such that the diagonal elements of are the eigenvalues of and each column of is the eigenvector corresponding to each diagonal element of . Let us assume that at the result holds at step , that is admits an orthogonal and diagonal matrix decomposition such that
[TABLE]
Using first lemma D.1, we can use the covariance matrix update (39). If we multiply both the right and the left side of the covariance matrix update (39) by , we get:
[TABLE]
Reformulating the above equation in terms of the orthogonal and diagonal matrix decomposition, we get:
[TABLE]
As is trivially a diagonal matrix, the above equation proves that the orthogonal also diagonalizes . This proves that the result holds for step . In addition, we get as a by product that the next step diagonal matrix is related to the previous step diagonal matrix as follows:
[TABLE]
which is very interesting and is almost the update equation of our lemma D.2. To get exactly the update equation, the trick is to introduce the diagonal matrix as the constant and remark that equation (56) is transformed into:
[TABLE]
which is exactly the update of the lemma D.2. At this stage, we can notice various interesting remarks:
- •
the condition number of matrix is also equal to the one of the matrix itself equal to the condition number of itself equal to the condition number of
- •
the diagonal matrix series satisfies the assumption of lemma D.2, hence we get
[TABLE]
or equivalently
[TABLE]
These remarks imply that the following upper bound for the condition number of
[TABLE]
which exactly the equation (55). Moreover a trivial usage of squeeze (also known as the pinching or sandwich) theorem proves that
[TABLE]
as the condition number of a matrix is always lower bounded by 1. Using our first remark about the equality of the condition number of the matrix with the one of matrix and equation (49), we also get
[TABLE]
This proves the equation (54). Moreover, if the limit exists, from (48), we see that one can replace by in (54). This concludes the proof. ∎
Remark D.3**.**
Lemma D.4 is remarkable as it proves that the covariance gradually adapts to the inverse of the Hessian of our optimization problem, performing something quite similar to a Newton decrement.
We can now prove the speed convergence part of proposition 3.4 as follows:
Proof.
Using lemma D.1 and lemma D.3, we can apply the matrix and vector norm inequality to (37) and (38), we get
[TABLE]
Likewise, the same applies for the update of the covariance matrix given by equations (39) and (40), leading to a similar inequality for the matrix norm of the covariance
[TABLE]
Let us look at the maximum singular value as follows:
[TABLE]
We can tackle these terms one by one. Using the lemma D.4, we have that
[TABLE]
while assumptions (7) states that
[TABLE]
leading to
[TABLE]
This implies linear convergence of with rate of convergence at most , that is
[TABLE]
Likewise, the reasoning is almost the same for the covariance matrix, and we also get
[TABLE]
which proves the linear convergence of with rate of convergence at most , that is
[TABLE]
which ends the proof. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Akimoto, 2012] Akimoto, Y. (2012). Analysis of a natural gradient algorithm on monotonic convex-quadratic-composite functions. In Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation , GECCO ’12, pages 1293–1300, New York, NY, USA. ACM.
- 2[Akimoto et al., 2012] Akimoto, Y., Auger, A., and Hansen, N. (2012). Convergence of the continuous time trajectories of isotropic evolution strategies on monotonic c 2 -composite functions. In Coello, C. A. C., Cutello, V., Deb, K., Forrest, S., Nicosia, G., and Pavone, M., editors, Volume 7491 of Lecture Notes in Computer Science , pages 2–51. Springer.
- 3[Akimoto et al., 2015] Akimoto, Y., Auger, A., and Hansen, N. (2015). Continuous optimization and CMA-ES. In Genetic and Evolutionary Computation Conference, GECCO 2015, Madrid, Spain, July 11-15, 2015, Companion Material Proceedings , pages 313–344.
- 4[Akimoto et al., 2016] Akimoto, Y., Auger, A., and Hansen, N. (2016). CMA-ES and advanced adaptation mechanisms. In Genetic and Evolutionary Computation Conference, GECCO 2016, Denver, CO, USA, July 20-24, 2016, Companion Material Proceedings , pages 533–562.
- 5[Akimoto et al., 2010] Akimoto, Y., Nagata, Y., Ono, I., and Kobayashi, S. (2010). Bidirectional relation between cma evolution strategies and natural evolution strategies. Lecture Notes in Computer Science - Proceedings of Parallel Problem Solving from Nature - PPSN XI , 6238:154–163.
- 6[Amari and Nagaoka, 2007] Amari, S. and Nagaoka, H. (2007). Methods of Information Geometry . American Mathematical Society.
- 7[Amari, 1995] Amari, S.-I. (1995). Information Geometry of the EM and em Algorithms for Neural Networks. Neural Netw. , 8(9):1379–1408.
- 8[Amari, 1998] Amari, S.-I. (1998). Natural gradient works efficiently in learning. Neural Comput. , 10(2):251–276.