Disparity-Augmented Trajectories for Human Activity Recognition
Pejman Habashi, Boubakeur Boufama, Imran Shafiq Ahmad

TL;DR
This paper introduces disparity-augmented trajectories for human activity recognition, improving accuracy by integrating disparity information with 2D trajectories without 3D reconstruction, and demonstrates superior performance on benchmark datasets.
Contribution
It proposes a novel fusion method of disparity data with 2D trajectories, enhancing activity recognition accuracy without complex 3D reconstruction.
Findings
Achieved a 2.76% accuracy improvement with disparity-augmented trajectories.
Validated the method on Hollywood 3D dataset with competitive results.
Faster processing speed compared to existing methods.
Abstract
Numerous methods for human activity recognition have been proposed in the past two decades. Many of these methods are based on sparse representation, which describes the whole video content by a set of local features. Trajectories, being mid-level sparse features, are capable of describing the motion of an interest-point in 2D space. 2D trajectories might be affected by viewpoint changes, potentially decreasing their accuracy. In this paper, we initially propose and compare different 2D trajectory-based algorithms for human activity recognition. Moreover, we propose a new way of fusing disparity information with 2D trajectory information, without the calculation of 3D reconstruction. The obtained results show a 2.76\% improvement when using disparity-augmented trajectories, compared to using the classical 2D trajectory information only. Furthermore, we have also tested our method on the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16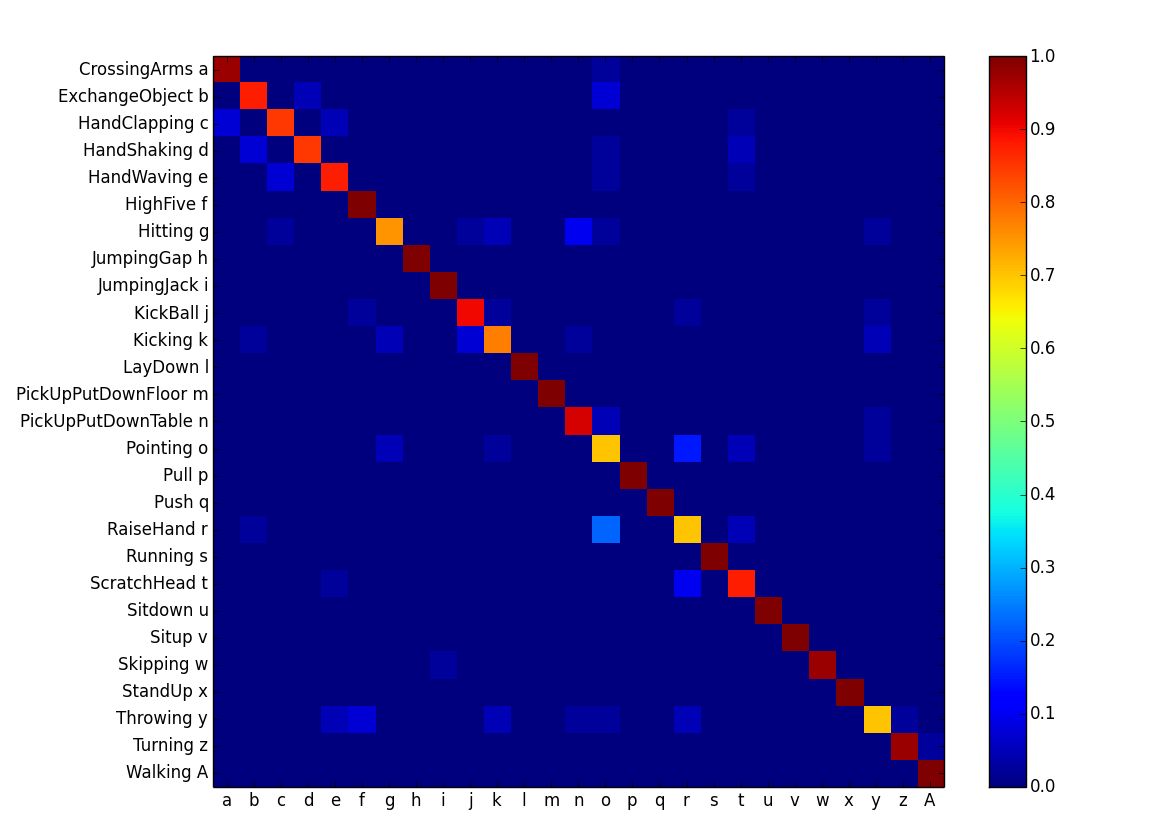 Figure 17
Figure 17| Crossing Arms | Exchange Object | Hand Clapping |
| Hand Shaking | Hand Waving | High Five |
| Hitting | Jumping Over Gap | Jumping Jack |
| Kick the Ball | Kicking | Lay Down |
| Pickup(Floor) | Pull | Pointing |
| Pickup(Table) | Push | RaiseHand |
| Running | Scratch Head | Sit down |
| Sit-up | Skipping | Standup |
| Throwing | Turning | Walking |
| Left Camera | Right Camera | Both Cameras | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Length | IP | LK | FB | IP | LK | FB | IP | LK | FB |
| 9 | 77.73 | 83.87 | 82.81 | 74.75 | 81.09 | 82.92 | 80.20 | 82.89 | 82.97 |
| 11 | 76.55 | 84.29 | 84.50 | 74.45 | 84.62 | 83.38 | 80.81 | 82.49 | 85.98 |
| 13 | 79.12 | 84.71 | 85.72 | 73.54 | 82.44 | 85.80 | 79.54 | 83.96 | 85.04 |
| 15 | 77.68 | 86.06 | 84.37 | 72.72 | 85.04 | 84.58 | 79.80 | 84.97 | 86.78 |
| 17 | 78.93 | 84.54 | 84.54 | 73.54 | 86.54 | 85.31 | 78.09 | 86.07 | 86.08 |
| 19 | 77.33 | 85.13 | 85.46 | 73.77 | 87.12 | 86.25 | 79.78 | 85.90 | 87.05 |
| 21 | 77.22 | 86.74 | 85.88 | 75.67 | 85.66 | 87.90 | 79.45 | 86.82 | 88.19 |
| 23 | 77.42 | 86.81 | 87.90 | 73.34 | 87.29 | 87.64 | 78.70 | 85.52 | 87.43 |
| 25 | 78.94 | 86.22 | 87.65 | 71.33 | 84.94 | 85.37 | 79.74 | 85.64 | 87.04 |
| 27 | 75.32 | 86.69 | 85.84 | 70.37 | 86.52 | 87.70 | 77.85 | 85.18 | 87.35 |
| Trajectory Shape Descriptor | |||||||
| Length | |||||||
| 11 | 84.50 | 85.80 | 85.30 | 84.84 | 84.08 | 84.79 | 82.10 |
| 13 | 85.72 | 87.46 | 87.95 | 88.42 | 85.68 | 86.18 | 83.15 |
| 15 | 84.37 | 86.48 | 87.07 | 88.55 | 88.21 | 86.44 | 84.96 |
| 17 | 84.54 | 86.94 | 89.09 | 88.42 | 87.11 | 86.20 | 85.43 |
| Trajectory Shape Descriptor | |||||
| Length | |||||
| 9 | 88.98% | 89.72% | 88.89% | 88.70% | 88.43% |
| 11 | 90.09% | 90.83% | 89.26% | 89.54% | 87.41% |
| 13 | 89.44% | 88.80% | 86.85% | 87.87% | 87.31% |
| 15 | 90.37% | 90.65% | 89.91% | 89.72% | 89.26% |
| 17 | 89.91% | 91.48% | 90.56% | 88.89% | 89.35% |
| 19 | 90.67% | 91.39% | 91.85% | 91.11% | 90.00% |
| 21 | 89.23% | 91.85% | 90.41% | 90.19% | 90.83% |
| 23 | 90.57% | 90.93% | 89.54% | 91.39% | 91.02% |
| Method | S1 | S2 | S3 | S4 | S5 | sum |
|---|---|---|---|---|---|---|
| DAT(our method) | 19.67s | 32.13s | 7.33s | 42.70s | 13.09s | 114.92s |
| Trajectory Aligned | 46.89s | 51.95s | 33.68s | 66.17s | 41.31s | 240.00s |
| Speed up | 238% | 161% | 459% | 155% | 311% | 209% |
| Method | Accuracy | |
| Trajectory based | Sparse Trajectories | 87.80% |
| Dense Trajectory | 88.74% | |
| DAT (Ours) | 91.85% | |
| Trajectory aligned | HOG | 89.54% |
| HOF | 92.72% | |
| MBH | 92.22% |
| Method | Accuracy |
|---|---|
| 2D TSD | 78% |
| 3D TSD | 74% |
| 2D TSD+3D TSD | 85% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Disparity-Augmented Trajectories
for Human Activity Recognition
Pejman Habashi111Correspoing Author
Boubakeur Boufama
Imran Shafiq Ahmad
School Of Comupter Science, University of Windsor, 401 Sunset Ave, Windsor, ON, CANADA N9B 3P4
Abstract
Numerous methods for human activity recognition have been proposed in the past two decades. Many of these methods are based on sparse representation, which describes the whole video content by a set of local features. Trajectories, being mid-level sparse features, are capable of describing the motion of an interest-point in 2D space. 2D trajectories might be affected by viewpoint changes, potentially decreasing their accuracy. In this paper, we initially propose and compare different 2D trajectory-based algorithms for human activity recognition. Moreover, we propose a new way of fusing disparity information with 2D trajectory information, without the calculation of 3D reconstruction. The obtained results show a 2.76% improvement when using disparity-augmented trajectories, compared to using the classical 2D trajectory information only. Furthermore, we have also tested our method on the challenging Hollywood 3D dataset, and we have obtained competitive results, at a faster speed.
keywords:
Human Activity Recognition , Disparity-Augmented Trajectory , Video Rectification , Video Content Analysis
1 Introduction
Automatic human activity recognition (HAR) is the process of automatically labeling the videos containing human movements with the corresponding action names. Johansson et al. [1] carried out an interesting experiment where, they attached markers to human joints before recording the movement of these markers in a video. In almost all cases, human subjects could say that the tags were attached to a human body. Furthermore, they were able to correctly guess the type of activity the actor was doing. Although this experiment clearly proves that the task of HAR is rather trivial for humans, it does not tell us whether the human brain uses 2D trajectories of these markers or creates a 3D trajectory model, before the actual recognition process.
Numerous approaches have been proposed for solving the problem of human activity recognition. The use of sparse representation, where each video is represented by a set of independent features, has gained a lot of popularity. Most of the features proposed in the literature focused on low-level features [2, 3, 4, 5, 6, 7, 8], that are directly extracted from the pixel information. Other works have used higher level features, such as main joint locations [9, 10, 11, 12], with the assumption that high-level features would yield better results, if they were accurately known. Unfortunately, extracting high-level features from cluttered scenes is a non-trivial task. It might require the use of specialized equipments, like color markers on human joints [13] for example, or Microsoft Kinect sensor or other active sensors, to create a depth map and to extract human skeleton from it [14, 15]. On the other hand, it is relatively easy to build a trajectory by tracking a set of 2D interest points across video frames. When compared to other sparse representation methods, trajectories are mid-level features that can yield competitive results. Recently, [16] proposed and compared different 2D trajectory-based HAR algorithms. In a separate work, [17] proposed a better trajectory shape descriptor to be used for HAR.
We have used disparity as another new feature to boost the performance of trajectory-based methods. To calculate disparities, two slightly different views of the subject are required. First, 2D trajectories are extracted from the left and right videos. Then, by matching these trajectories and mapping them to the rectified image planes, a disparity-augmented trajectory is created.
This paper demonstrates that adding the disparity information to the 2D trajectories, can be beneficial for human activity recognition. In particular, disparity-augmented trajectories have improved classification rates by 2.76% in our tests.
Both 2D and disparity-augmented trajectories are made of pixel locations across frames. To be used for classification, a descriptor, that can discriminate between different trajectories, should be defined based on the shape of trajectories. The descriptors used in this work were inspired by the ones used in [17].
We have also improved the performance of our proposed method by limiting the processing to the regions of interest, instead of the whole images. Our regions of interest consist of the parts in the video frames that contain movement. In particular, the graph connected component analysis algorithm was used to select the active areas in frames.
It is also worth noting that the use of trajectories proposed in this paper, is independent from the HAR task, and it can be applied to any other video categorization problem. However, to show the effectiveness of our proposed algorithms and compare them with the state of the art methods, we have applied and tested them on human activity recognition application.
In summary, this paper has the following contributions:
A new method to extract disparity-augmented trajectories from stereo videos
- 2.
Extension of the trajectory shape descriptor to higher dimensions
- 3.
A method to rectify stereo videos
- 4.
A new dataset of stereo videos
- 5.
Comparison of 2D trajectories versus disparity-augmented trajectories in the HAR domain
The remainder of this paper is organized as follows. Section 2 reviews related research works and Section 3 describes the method used for detecting human activity areas in video frames. Section 4 provides details for three different algorithms we have used to extract 2D trajectories and describes how the disparity information is added to the 2D trajectories. Section 5 describes the proposed trajectory shape encoding algorithm. Details of the learning method used can be found in section 6. Section 7 and Section 8 present the experimental results and the conclusion, respectively.
2 Background works
Trajectories have proven to be useful for aligning consecutive frames before extracting low-level features [18]. Even the extraction of deep learning feature vectors benefited from trajectory alignment [19]. Trajectory shapes can also be used directly for human activity recognition.
Wang et al. [20, 21, 18] exploited trajectories in separate contributions. In their works, a grid was used to dense sample video frames. Eigenvalues of the autocorrelation matrix was utilized to filter out the samples that were not easy to track. Dense optical flow field, proposed by Farnback [22], was applied to track these sample points in time. This flow was then employed to align the interest points neighborhoods before calculating the HOG and HOF features. They also proposed another trajectory shape descriptor, that did not outperform the other two.
Mademlis et al. [23] used disparity information to calculate HOG, HOF and MBH in different disparity zones before encoding them for activity recognition. Although their method improves the performance, but their use of disparity is limited to few disparity zones. Arguably the disparity can be used more efficiently for encoding task.
Hadfield et al. [24] used 3D Hollywood movies to create a challenging stereo dataset for human activity recognition. The authors estimated the calibration information using RANSAC method and repeating the process 100 times, before selecting the best estimation. Then, the extracted 3D information extracted was used to calculate 3.5D interest points. They have defined a 3D motion descriptors for each of these feature points and, they have normalized it to remove the effect of different camera rotations.
Matikainen et al. [25] used the technique of Kanade Lucas Tomasi (KLT) [26] to track a number of points and, created a trajectory for each of these points. Then, they used K-Means method to cluster the obtained trajectories in different clusters (words). They have also proposed to augment these trajectories by adding some affine transformation information, which represents the motion of various parts of the body. Finally, they have used a standard bag of words (BOW) method and SVM for clustering.
In another similar work, Messing et al. [27] used KLT to track keypoints of a video and created a generative model on the velocity history of these keypoints.
Sun et al. [28] proposed to track Scale Invariant Feature Transform (SIFT) points. They have used SIFT descriptors to match each keypoints across the frames. They have extracted features at different levels and used multichannel nonlinear SVM for human activity recognition.
More recently, [16, 17] demonstrated that good sparse trajectories could produce competitive results to low-level features, but with less computations. Besides, trajectories are a better choice for HAR as they encode the motion of a body, while low-level features usually encode the texture or movement within small neighborhoods in spatiotemporal space. This makes low-level features more dataset dependent.
3 Preprocessing
In order to reduce the overall processing time, we have developed a simple, yet effective, method for detecting the regions of interest (moving parts in the videos). The steps below describe how we detect and remove static (stable) regions from videos.
Estimate background with a mixture of Gaussian 2. 2.
Subtract estimated background from current frame 3. 3.
Highlight the moving parts of video by erosion and dilation operations 4. 4.
Extract the contours of motion 5. 5.
Find rectangular regions of interest as follows:
- (a)
Find a bounding box for each contour 2. (b)
Create a graph, where each node represents a bounding box and, if two boxes overlap or are close enough, have an edge between them 3. (c)
Use connected component labeling algorithm similar to [29] to find the connected components of this graph 4. (d)
Combine the boxes of each connected components. Each combined box represents a separate region of interest
The above algorithm allows the extraction of all non-static (motion) areas.
4 Trajectories for Human Activity Recognition
Trajectories are defined as the trail of 2D or 3D spatial feature points in time. The disparity-augmented trajectories are similar to 3D trajectories except that they have the disparity in addition to 2D information. Formally, a trajectory is defined as an ordered list of locations, sampled over time steps, where is the length of the trajectory. In a single video, the frame rate determines the distance between sampling times, so a trajectory in dimension can be defined as:
[TABLE]
Note that throughout this paper we assume that , but in practice and in our tests, .
To create a disparity-augmented trajectory, the corresponding 2D trajectories from two views of a subject are extracted and combined. Section 4.1 provides details of how these 2D trajectories are extracted. Then, section 4.2 explains how disparity is added to our 2D trajectories.
4.1 2D Trajectory Extraction
A 2D trajectory is an ordered list of 2D spatial coordinates in consecutive frames, formally defined as:
[TABLE]
Authors in [16] compared three different trajectory extraction algorithms and showed that a combination of FAST corner detector and Farnback optical flow for trajectory extraction outperformed other trajectory extraction algorithms. More details are given below for each of the three methods.
4.1.1 Interest Point Tracking
We refer to this method as “Interest Point Tracking” (IP). Starting from the first frame, interest points are extracted then tracked across frames to make trajectories. When a trajectory reaches a length of , it is considered a complete trajectory.
and are two sets to keep trajectories and matched feature points, respectively. For each frame , the set of feature points and the set of next frame feature points are extracted.
For each member of , a feature descriptor is calculated based on the appearance of the interest point neighborhood. Again, the algorithm could consider any feature descriptor.
We define a mapping , where
[TABLE]
is the frame number, is the feature descriptor vector for point and is the dimension of the descriptor (e.g., for standard SIFT descriptor ).
The neighborhood of a point is given by
[TABLE]
where is a distance measure and determines the radius of neighborhood. In our implementation, we have used the Manhattan distance.
The best match for is found within the neighborhood , based on the appearance of descriptors. To do so, for each , a mapping is defined as follow:
[TABLE]
where is a distance measure in descriptors space.
In our case, we used the Euclidean distance, where the closest match is considered the best match.
[TABLE]
An example of the obtained trajectories is displayed on Figure 1 left (best seen in color).
4.1.2 Lucas-Kanade Feature Point Tracking
We refer to this method as “Lucas-Kanade Trajectory” (LK), as it is based on Lucas-Kanade optical flow algorithm [30]. First, the feature points of each frame of the video are extracted. Then, Lucas-Kanade optical flow algorithm is used to find the location of each of these feature points in the next frames, hence creating the trajectories.
An example of the obtained LK trajectories are displayed on Figure 1 (middle).
4.1.3 Farnback Feature Point Tracking
This algorithm is similar to the Farnback optical flow algorithm [22], we refer to as “Farnback Trajectory” (FB). Farnback optical flow algorithm is newer than Lucas-Kanade algorithm and has shown a better performance [18, 22]. Farnback optical flow algorithm is also able to provide the dense optical flow field, while Lucas-Kanade optical flow was designed to track sparse feature points. This gives FB an advantage, especially when the selected points are not good feature points. However, our tests revealed that FB yields competitive results to LK, and both performed much better than IP.
First, the Farnback optical flow field is calculated before the feature points of each frame are extracted. Starting from the first frame, the location of each point in the next frame is predicted, using the pre-calculated optical flow field. These points are then connected as a trajectory.
The interest points of each frame are extracted using OpenCV implementation of FAST algorithm [31]. The dense optical flow field is obtained using Farnback motion estimation method [22]. The trajectories created by this algorithm are shown on Figure 1 (right).
4.2 Disparity-Augmented Trajectory
After the extraction of the 2D trajectories from the left and right videos, matching these trajectories is achieved based on local descriptors (section 4.2.1). The matched trajectories are then mapped to their corresponding rectified planes (section 4.2.2). Finally, their disparity is fused with the 2D spatial information (section 4.2.3).
4.2.1 Finding Matching Trajectories
Each trajectory starting point, in the left and right videos, are encoded with a SIFT descriptor and the best match of this descriptor is found by using the method in [32]. Starting from the first frame of the video, for each descriptor in the left frame, its best match is found in the right frame. To make the matching robust, we repeat the process between the right to the left frames and, only keep the reciprocal matches.
4.2.2 Video Rectification
The rectification is the process of mapping an image to a plane, where the y disparity becomes zero and only the x disparity remains. If and represent two matching points, between the left and right images, the fundamental matrix is the matrix that satisfies:
[TABLE]
The eight-point algorithm is used to estimate [33] and the FAST algorithm is used to find the feature points. The same algorithm, as explained in Section 4.2.1, is used to match the feature points between the left and right video frames.
The calculations of and rectification matrices and [34] depend on the quality of matched points. To address these issues, we propose the following technique to find the best estimation of , and . First, random frames of the stereo video are selected. For each pair of these stereo frames, , and are calculated. If and represent a matching point, then and represents the mapping of these corresponding points on the rectified plane, where ideally . Considering the matched trajectories from section 4.2.1, the best estimate of is the one that maximizes the number of trajectories that will be rectified with an acceptable y disparity. Figure 2 shows samples of two matching trajectories, one before rectification and the other one after rectification. In addition, because the calculation of is susceptible to outliers, we have also used the random sample consensus (RANSAC) method to make its calculation robust.
4.2.3 Calculating Disparity-Augmented Trajectories
Having the rectification matrices and , it is now easier to calculate the rectified left and right trajectories, and , as
[TABLE]
where and are the homogeneous representation of the left and right trajectories, respectively.
Each column of or represents a rectified trajectory image plane point. Consider two corresponding points and on left and right trajectories, respectively. The corresponding disparity augmented point will be given by:
[TABLE]
5 Trajectory Shape Descriptor
The method we used to create a descriptor for trajectories is an extension of [17], where the locations of interest points in 2D or 3D (2D plus disparity) spaces are encoded into trajectories. The latter are considered as discrete functions, that map time values to coordinates. The first and second derivatives of such mapping function, with respect to time, represent respectively the velocity and the acceleration of the interest point. Higher order derivatives encode higher order motion information. The final descriptor is obtained by concatenating these derivatives. In our experiments, we have used derivatives up to the 7th order, for single views and up to 5th order for multiple views.
Formally, each trajectory, defined in Equation 1, can be interpreted as a function of time that map time values to locations in space.
[TABLE]
where is the time between two consecutive frames and is the starting time of trajectory .
The first derivative of this function is given by:
[TABLE]
Because a video typically has a fixed frame rate, the smallest value of is the time distance between two consecutive frames (). Changing the unit of measurement from seconds to frames makes . Hence, the velocity equation 16 can be rewritten as:
[TABLE]
Similarly, the acceleration is given by
[TABLE]
Higher order functions can be defined as follows:
[TABLE]
The actual descriptor is created by the concatenation of these derivatives. For example, descriptor is given by the velocity (), descriptor is given by the concatenation of and and, descriptor is given by the concatenation of , and .
6 Learning phase
Our proposed trajectory shape representation, like other sparse representation methods, represents a video by a set of independent features. Formally, a video can be represented by a set of feature descriptors as:
[TABLE]
where is the dimension of the local descriptors.
Existing machine learning methods in general and SVM in particular, expect data as a vector of predetermined size. As a result, each set of these features should be represented by a vector. Different methods have been proposed in the literature. One of the conventional methods to convert sparse sets to a vector is based on the bag of words (BOW) [35][36]. Another favorite technique, known as Fisher Vector Encoding (FVE) [37, 38], combines the generative and discriminative methods [39]. Unlike BOW that uses only the first order statistics, FVE uses first and second order statistics for encoding [21]. Instead of using K-Means for clustering, Expectation Maximization (EM) is used to cluster data into K Gaussian Mixtures. Then, the created Gaussian mixture model (GMM) is used to estimate the means, variances and prior probabilities of the mixtures.
7 Results and discussion
This section first provides details on the used datasets and on our experimental setup.
7.1 Dataset
To the best of our knowledge, the only existing stereo dataset is the Hollywood 3D dataset, which has 13 different activity classes and a special ”No Action” class. This dataset is a very challenging one for trajectory-based methods, as the lengths of some videos are too short, making it impossible to create meaningful trajectories. In addition, sporadic camera motions create unwanted trajectories, which degrades the accuracy. There are also several videos that are labeled as single activities, while other activities are going on in the background. This usually confuses methods that assume a single activity in the field of view.
We have also created our own stereo dataset with 27 different activity classes, using static cameras.
Note that despite the amount of work that has been done on human action recognition, there is no universally accepted definition of a human action. This is especially visible in the different datasets that have been created so far. Some actions, like walking, running and jumping, are widely accepted [40, 41]. A single person usually performs these activities, with some of them containing human and objects/environment interactions, like riding a bike or shooting a basketball [42], playing cello and mopping the floor [43]. Some researchers went beyond this and created datasets for cooking different recipes [44].
In our own dataset, we considered actions to be sole movements of the human body, regardless of the background, environment or tools they might be using. Besides, we studied activities that contain the whole human body movement as actions. We considered 27 different actions for this dataset. The activities were selected based on the frequency of their appearance in other human datasets. Besides, we added activities that can be performed in an office setting. We did not use tools a lot. For example, for recording throwing, the actor does not throw anything, he/she simply acts like throwing. The only exception was for pushing/pulling objects, where a chair have been used. Our actions were performed by eleven different volunteers in an everyday office setting. Some activities were performed in different scenarios. For example, walking was performed four times by each actor: walking from left to right, walking from right to left, walking toward the camera and walking away from the camera. We used off-the-shelf cameras to record these activities. Our stereo system consisted of two cameras that were roughly at 30cm from each other. Five hours of activities were recorded by each camera, allowing us to obtain 4076 stereo video clips, from which 1188 were selected to represents 27 different activities. Each activity was performed four times by each of the eleven actors. Table 1 presents information about the recorded activities and some samples of these activities are shown on Figure 3.
7.2 Experimental Setup
Our tests were carried out on a Ubuntu machine, with eight 3.8 GHz cores and 8Gb of RAM. The video processing part, including trajectory extraction, was implemented in C++, using OpenCV library. The trajectory aligning algorithm was implemented in Python.
After obtaining a set of trajectory descriptors for each video, and since [21] has shown the ‘effectiveness’ of Fisher Vectors over other methods, we have used Fisher Vectors to prepare data before passing it to a standard support vector machine (libSVM [45]).
The data used for training and testing was split as follows. For each action, all videos of one actor are used for testing, while the remaining videos from other actors are used for training. A confusion matrix is calculated for each action. The blending of these matrices represents the overall confusion matrix. The accuracy, reported in the tables, is the ratio of correctly classified instances to the total number of samples, directly calculated from the overall confusion matrix.
7.3 2D Trajectories
Table 2 summarizes the obtained results of our HAR tests using 2D trajectories. Each column represents one of the algorithms proposed in this paper, with “both cameras” column refers to the simple stacking of left and right descriptors, without any further processing. The descriptors of the trajectories were calculated using the algorithm proposed in [20]. As it can be seen, FB outperforms the other two in most cases. LK closely follows FB and beats it in some cases. The reason why FB and LK are yielding similar results is because the selected feature points are the corners, which are easy to follow for both algorithms. Both FB and LK track pixels at subpixel accuracy, yielding smoother trajectories. On the other hand, IP algorithm uses pixel accuracy that degrades its results, as it can be seen on Figure 4.
The optimum trajectory length was 21 or 23 for LK and FB. Figure 5 compares the best results obtained from left, right and both cameras. As it can be seen, there is no significant difference between them. In other words, adding up trajectories seen by the left and right cameras did not improve the results.
7.4 Effect of Shape Descriptor
The proposed trajectory shape descriptor in this paper has improved the classification results. Table 3 shows the effect of the new algorithm on the accuracy. In the absence of noise, higher order derivatives might provide new information. So, higher order descriptors should produce better results in general. However, in practice the effect of noise and outliers is amplified by the derivatives. Besides, human activities do not have very complex motions. As a consequence, the accuracy has a local maximum bound. Table 3 and Figure 6 illustrate this effect. As it can be seen, and produced the best accuracy for trajectories, with length 17 and 15, respectively. As expected, higher order derivatives did not improve the performance.
7.5 Disparity-Augmented Trajectories
Table 4 summarizes the obtained results for disparity-augmented trajectories. Each row represents a trajectory length while each column represents an encoding algorithm. We have tested trajectory lengths that range between 9 and 27, and encoding up to the fifth degree. As it can be seen, the added disparity information increased the accuracy by around 2% in all cases. The best obtained result was for trajectory length 19 and encoding degree three. The general trend is that increasing the length of trajectory increases the accuracy of the classification. This trend is more obvious on Figure 7. The best results (91.85%) were obtained with and encoding, at trajectory lengths of 21 and 19, respectively.
Figure 8 illustrates the confusion matrix of a sample test. Each row represents an actual class and each column represents a predicted class. The number of correct classifications is normalized between zero and one. It is also worth noting that the classes in our dataset are balanced, i.e., the number of samples for each activity classes is the same for all classes. The misclassified instances from the matrix give interesting information about the behavior of trajectories for HAR. For example, the most confused classes in this figure are “pointing” and “raise hand”. The fact that for pointing to something, one should raise his/her hand shows that trajectories are capable of finding this similarity, but they are unable to distinguish between them in some cases. Another example is the classes “kicking a fixed object” and “kicking the ball”. These classes have very similar motions and hence, they are expected to be confused by any motion-based HAR method.
From another viewpoint, it can be assumed that human activities have no precise definitions. In particular, many human activities do have some overlaps. For example, raising hand to point to something or waving. So, it is evident that there is a conceptual overlap over the definition of these classes and it is not easy to separate them conceptually.
7.6 Time measurements
Our comparisons have shown that our disparity-augmented trajectory (DAT) method is faster than trajectory aligned methods (see Table 5). To test the time performance, five different random samples from the dataset were selected. Each reported time is the average of ten different runs. As it can be seen, the speed up gains vary between 1.5 to 4.5 times faster, depending on the selected activity samples. Overall, our proposed method is more than twice faster than the methods based on dense trajectories, as we are using sparse features.
7.7 Comparison
Table 6 shows the performance of our proposed method compared to the state of the art. The closest works to DAT are 2D dense trajectories [21] and 3D trajectories [46]. We applied the algorithm proposed in [18] on sparse feature points and the result reported as sparse trajectories in Table 6. As it can be seen, our proposed method was able to outperform both dense and sparse trajectory methods, with a good margin. Moreover, the proposed method produced better result compared to HOG, and competitive results to HOF and MBH. It should be noted that HOG, HOF and MBH need more computation time in comparison with our disparity-augmented trajectories.
Koperski et al.[46] used depth information to create 3D trajectories. They ran their tests on MSR DailyActivity 3D dataset, which has similar setting as our dataset, but recorded with an RGB-Depth camera. Because we are using disparity and not depth, it is not possible to run their algorithm on our dataset, and we cannot run our method on their dataset as well. Just for comparison, we reported their results in Table 7. As it can be seen, they could not improve the performance of 2D trajectories by using 3D data only. They only improved the performance by combining 2D and 3D data. This confirms again the effectiveness of our proposed trajectory shape descriptor.
We have also tested our method on Hollywood 3D dataset, but have used their disparities only. Table 8 shows our obtained results and their comparisons with the other relevant methods. Note that our proposed method was not designed to cope specifically with random camera motions and/or rotations, as they can degrade the trajectory extraction drastically. As it can be seen, our method still yields superior results compared to the trajectory aligned descriptors proposed in [20] and reported in [24]. Our method also outperforms the method proposed by [24] in terms of accuracy.
8 Conclusion
We have presented and compared three popular trajectory-based human action recognition methods. We have also enhanced the conventional trajectory encoding algorithms by considering higher order derivatives of individual trajectories. Furthermore, we have proposed a new method based on disparity-augmented trajectories for video content analysis. Because disparities carry the scene’s three-dimensional clues, we anticipated an improvement in the HAR performance. In particular, we have fused the disparity information with motion-based features. We have obtained improved results on HAR, when compared to traditional trajectory-based methods, at a lower computational cost.
Furthermore, we have demonstrated that trajectories are useful for video content analysis in general, and for human activity recognition in particular. The proposed shape encoding algorithm has improved the accuracy of activity recognition by about 1.5%. The disparity information added to trajectories has also enhanced the results by another 2.5%.
We have also discussed some limitations associated with trajectory-based activity recognition. Activities that are similar, from the movement point of view, might be confused. We believe that some actions are conceptually overlapping and are hard to be distinguished, when using the human movement information only.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. Johansson, Visual perception of biological motion and a model for its analysis, Perception & psychophysics 14 (2) (1973) 201–211.
- 2[2] I. Laptev, T. Lindeberg, Interest point detection and scale selection in space-time, in: Scale Space Methods in Computer Vision, Springer, 2003, pp. 372–387.
- 3[3] I. Laptev, On space-time interest points, International Journal of Computer Vision 64 (2-3) (2005) 107–123.
- 4[4] P. Dollár, V. Rabaud, G. Cottrell, S. Belongie, Behavior recognition via sparse spatio-temporal features, in: Visual Surveillance and Performance Evaluation of Tracking and Surveillance, 2005. 2nd Joint IEEE International Workshop on, IEEE, 2005, pp. 65–72.
- 5[5] I. Laptev, M. Marszalek, C. Schmid, B. Rozenfeld, Learning realistic human actions from movies, in: Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, IEEE, 2008, pp. 1–8.
- 6[6] M. Bregonzio, S. Gong, T. Xiang, Recognising action as clouds of space-time interest points, in: Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, IEEE, 2009, pp. 1948–1955.
- 7[7] H. Wang, M. M. Ullah, A. Klaser, I. Laptev, C. Schmid, et al., Evaluation of local spatio-temporal features for action recognition, in: BMVC 2009-British Machine Vision Conference, 2009.
- 8[8] J. Perš, V. Sulić, M. Kristan, M. Perše, K. Polanec, S. Kovačič, Histograms of optical flow for efficient representation of body motion, Pattern Recognition Letters 31 (11) (2010) 1369–1376.