TL;DR
This paper introduces a novel fractional order gradient method for training convolutional neural networks, improving convergence speed and accuracy while avoiding local minima by combining fractional and integer order gradients.
Contribution
A simplified fractional order gradient method based on Caputo's definition is proposed, enabling effective training of CNNs with improved convergence and accuracy.
Findings
Demonstrates fast convergence in experiments
Achieves high accuracy on various tasks
Shows ability to escape local optima
Abstract
This paper proposes a fractional order gradient method for the backward propagation of convolutional neural networks. To overcome the problem that fractional order gradient method cannot converge to real extreme point, a simplified fractional order gradient method is designed based on Caputo's definition. The parameters within layers are updated by the designed gradient method, but the propagations between layers still use integer order gradients, and thus the complicated derivatives of composite functions are avoided and the chain rule will be kept. By connecting every layers in series and adding loss functions, the proposed convolutional neural networks can be trained smoothly according to various tasks. Some practical experiments are carried out in order to demonstrate fast convergence, high accuracy and ability to escape local optimal point at last.
Click any figure to enlarge with its caption.
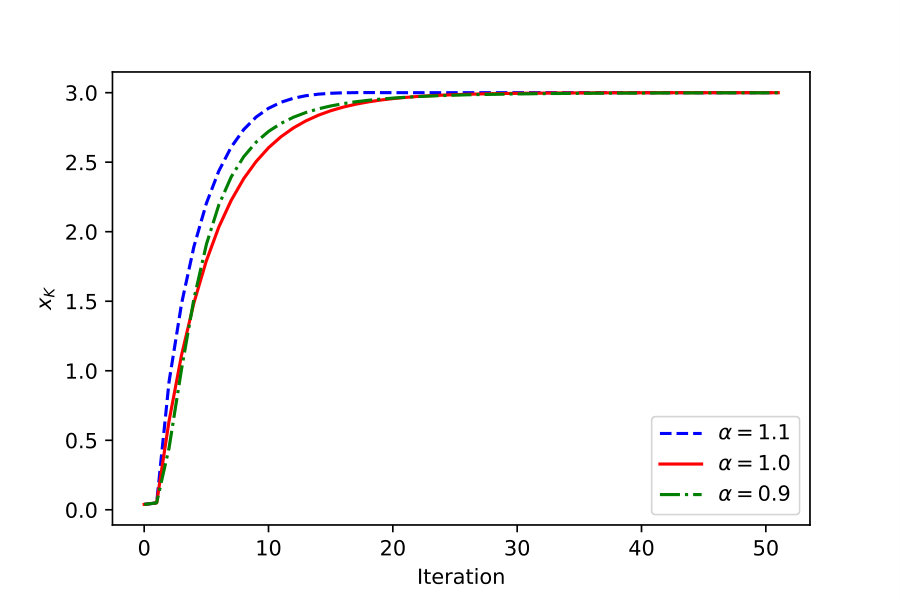 Figure 1
Figure 1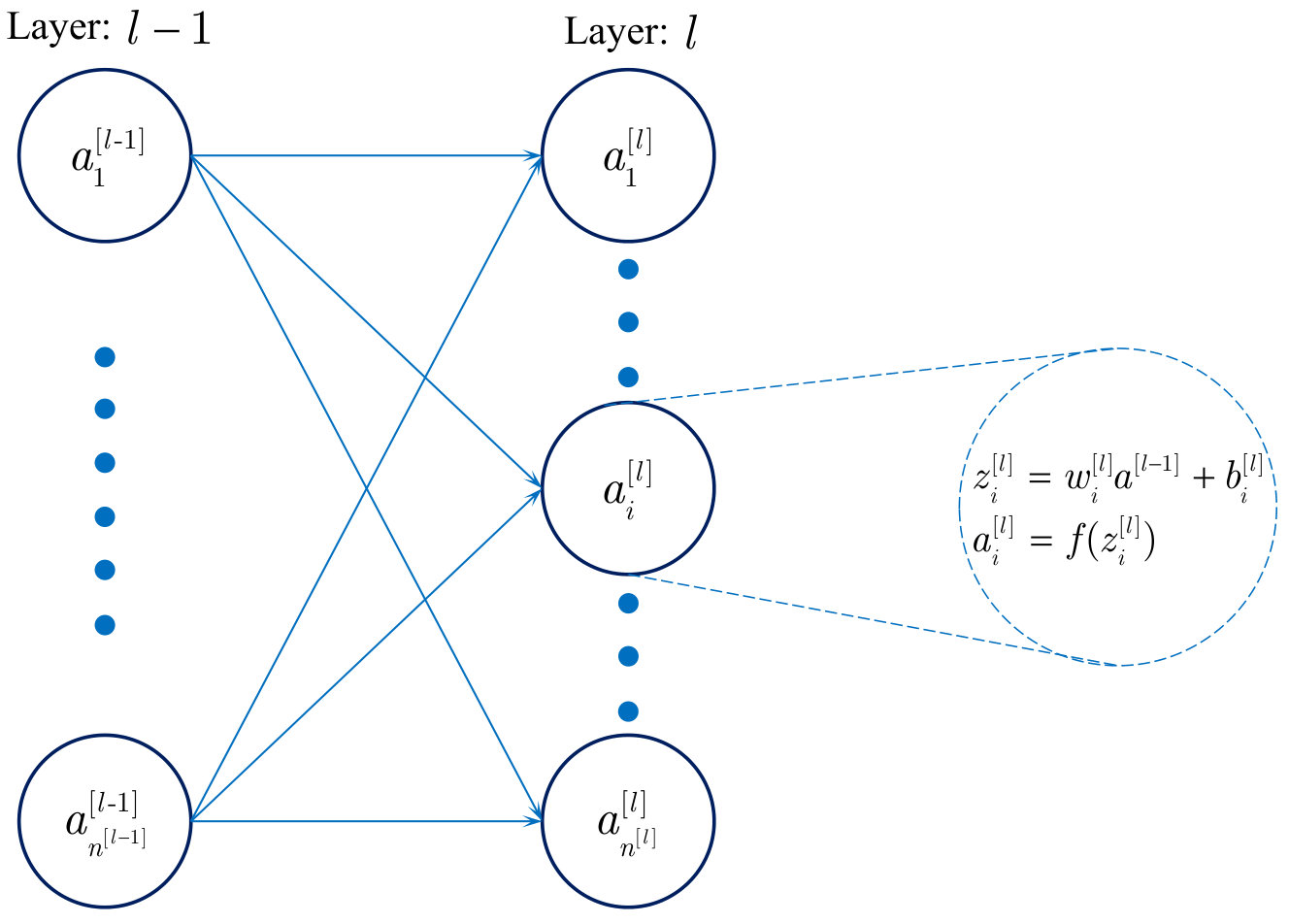 Figure 2
Figure 2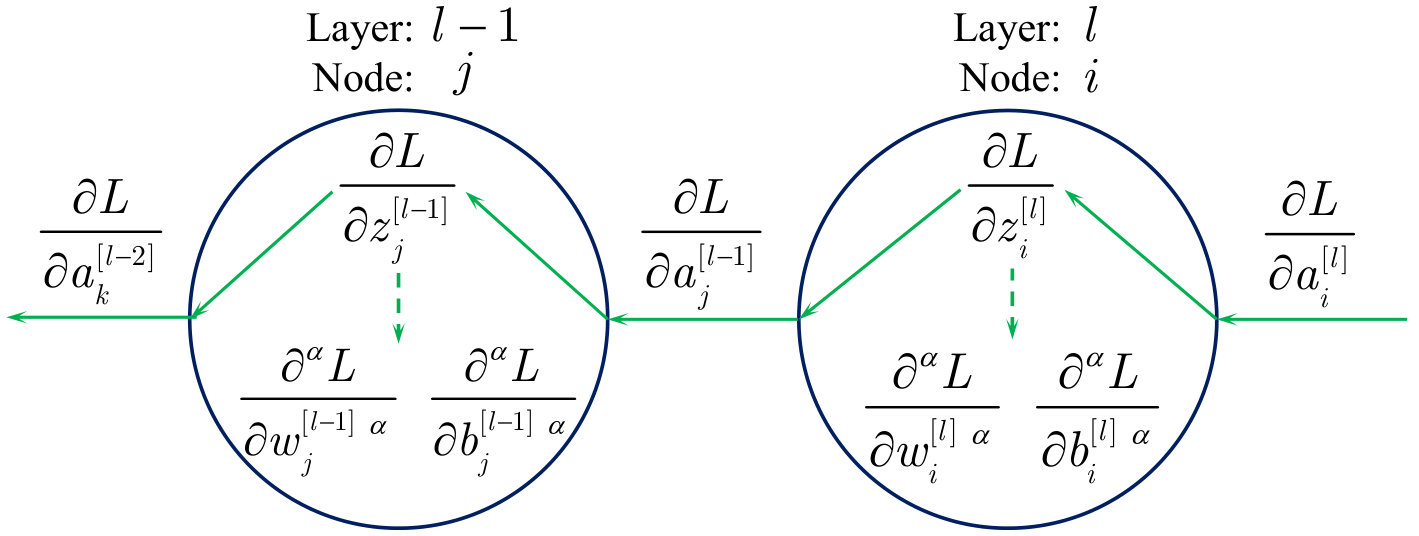 Figure 3
Figure 3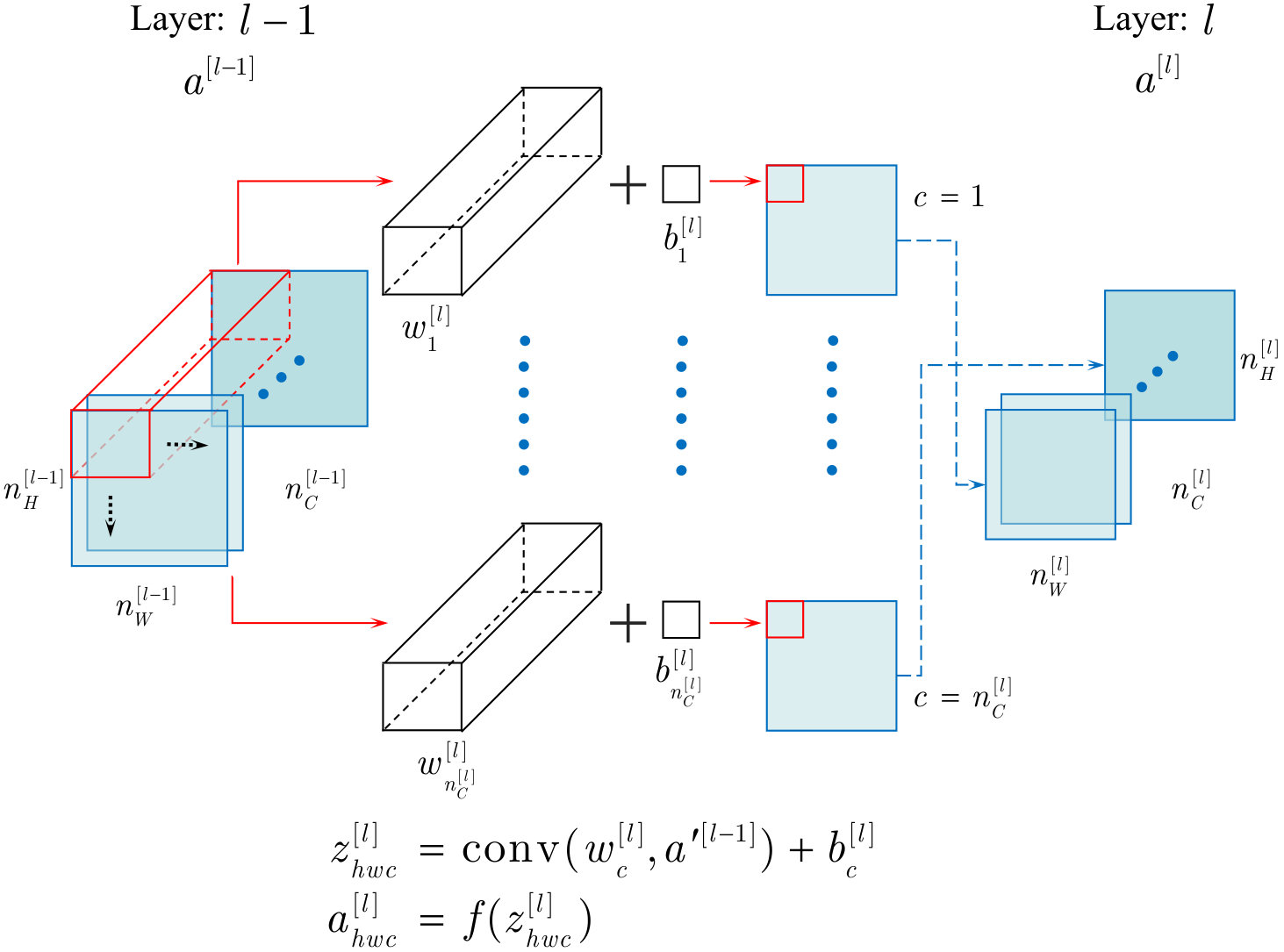 Figure 4
Figure 4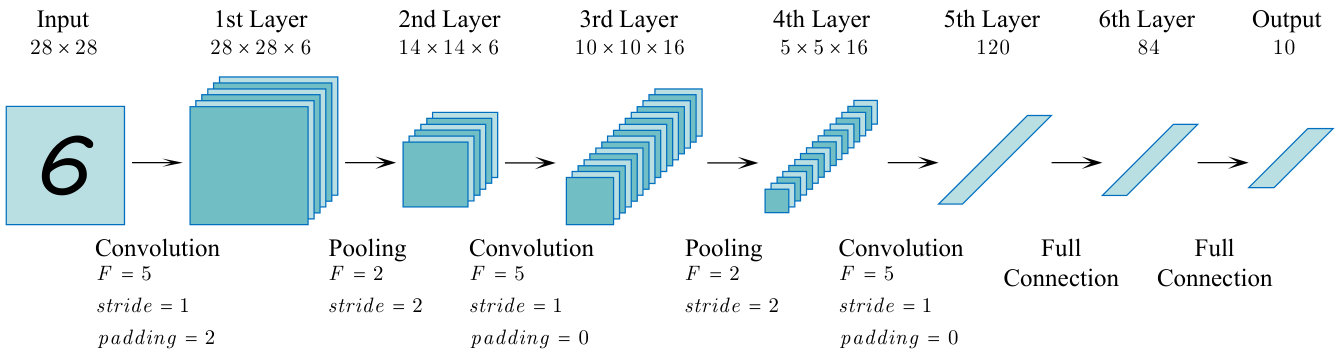 Figure 5
Figure 5 Figure 6
Figure 6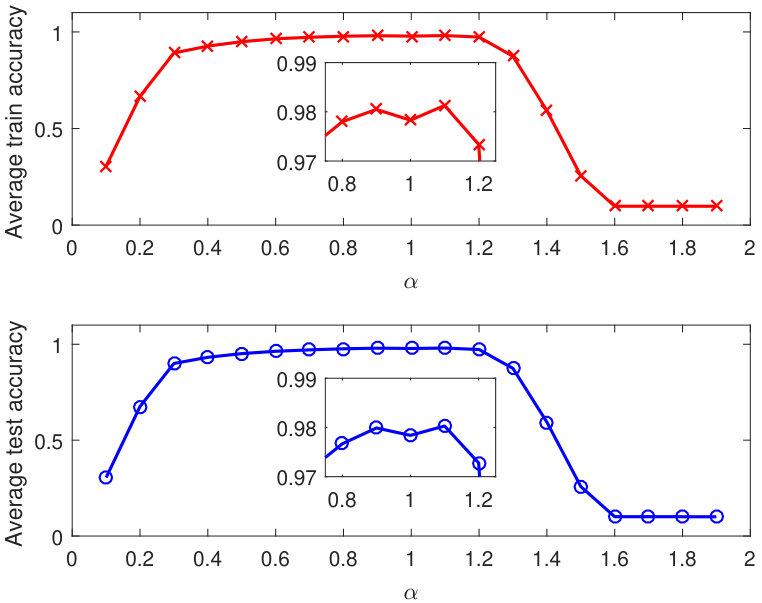 Figure 7
Figure 7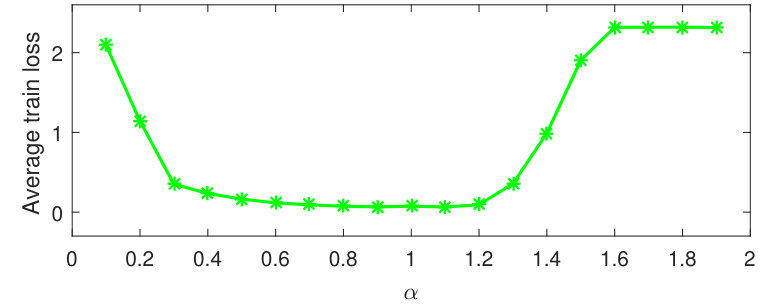 Figure 8
Figure 8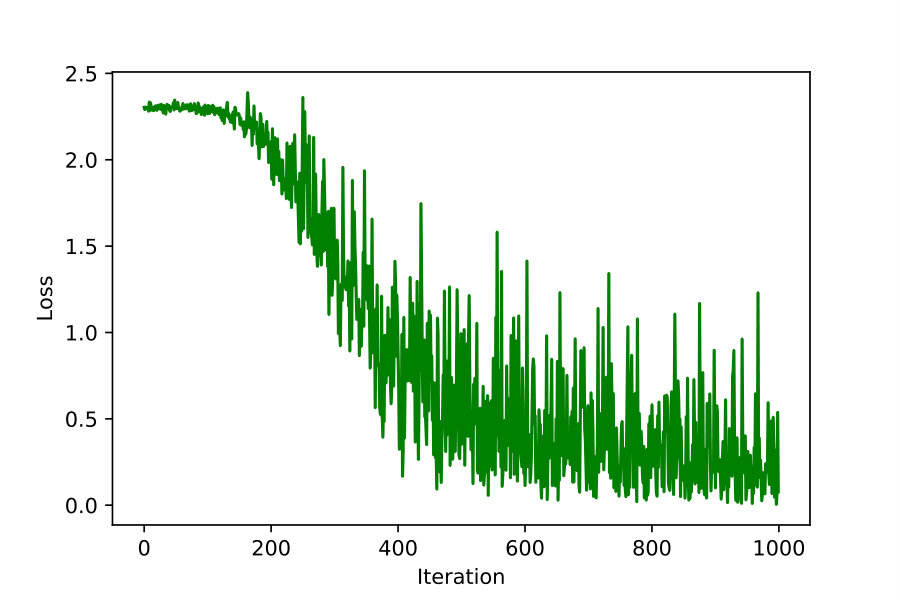 Figure 9
Figure 9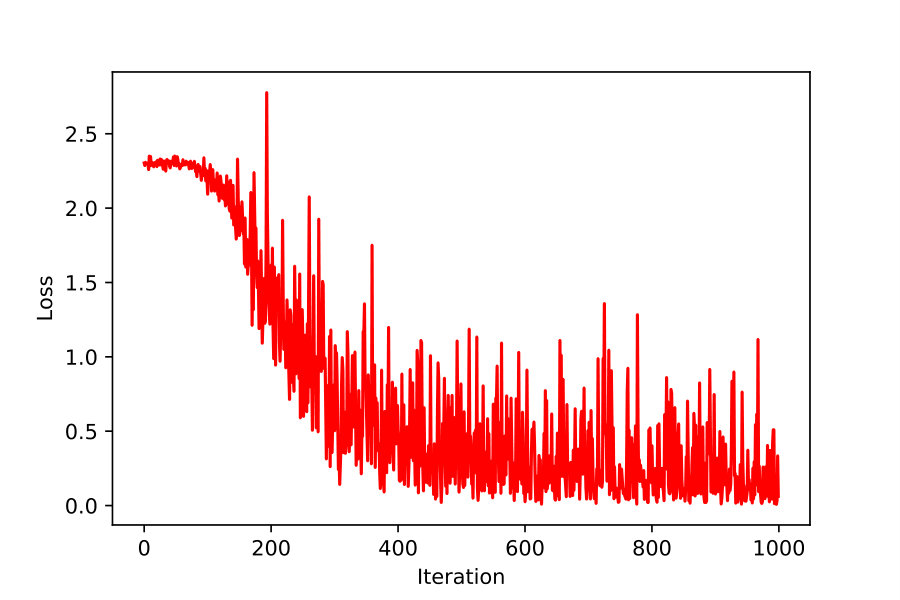 Figure 9
Figure 9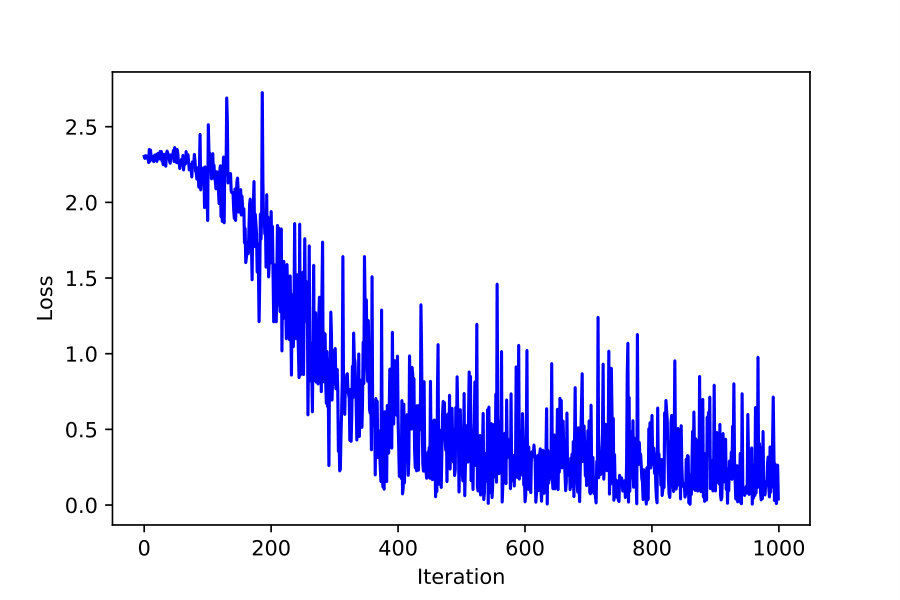 Figure 9
Figure 9| Loss function: | |
|---|---|
| Learning rate: | |
| Batch size: | |
| Initial weight: | |
| Initial bias: | |
| Number of iteration: | |
| Number of epoch: |
| order() | training accuracy | testing accuracy |
|---|---|---|
| 1.9 | 0.0980 | 0.1006 |
| 1.8 | 0.0978 | 0.1009 |
| 1.7 | 0.0978 | 0.1009 |
| 1.6 | 0.0978 | 0.1009 |
| 1.5 | 0.2556 | 0.2581 |
| 1.4 | 0.5924 | 0.5938 |
| 1.3 | 0.8739 | 0.8741 |
| 1.2 | 0.9734 | 0.9728 |
| 1.1 | 0.9813 | 0.9803 |
| 1.0 | 0.9783 | 0.9781 |
| 0.9 | 0.9805 | 0.9799 |
| 0.8 | 0.9780 | 0.9767 |
| 0.7 | 0.9724 | 0.9711 |
| 0.6 | 0.9646 | 0.9637 |
| 0.5 | 0.9498 | 0.9516 |
| 0.4 | 0.9267 | 0.9322 |
| 0.3 | 0.8913 | 0.9004 |
| 0.2 | 0.6671 | 0.6759 |
| 0.1 | 0.3052 | 0.3050 |
| order() | 0.9 | 1.0 | 1.1 |
|---|---|---|---|
| variance | 0.65370 | 0.56961 | 0.57697 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Convolutional neural networks with fractional order gradient method
Dian Sheng
Yiheng Wei
Yuquan Chen
Yong Wang
Department of Automation, University of Science and Technology of China, Hefei, 230026, China
Abstract
This paper proposes a fractional order gradient method for the backward propagation of convolutional neural networks. To overcome the problem that fractional order gradient method cannot converge to real extreme point, a simplified fractional order gradient method is designed based on Caputo’s definition. The parameters within layers are updated by the designed gradient method, but the propagations between layers still use integer order gradients, and thus the complicated derivatives of composite functions are avoided and the chain rule will be kept. By connecting every layers in series and adding loss functions, the proposed convolutional neural networks can be trained smoothly according to various tasks. Some practical experiments are carried out in order to demonstrate fast convergence, high accuracy and ability to escape local optimal point at last.
keywords:
Fractional order calculus; Gradient method; Neural networks; Backward propagation
††journal: Neurocomputing
1 Introduction
Machine learning technology powers many aspects of modern society: from web searches to content filtering on social networks to recommendations on e-commerce websites, and it is increasingly presented in consumer products such as cameras and smart phones [1]. During the development of machine learning, a variety of artificial neural networks have been created and gradually playing a more and more important role. Although it is still far from perfection, artificial neural networks are proven to be excellent enough, especially for convolutional neural networks (CNN). Research on CNN can be traced back to . Based on visual cortex, Fukushima designed the neural networks named ’neocognitron’ which is regarded as the origin of CNN [2]. As a breakthrough has been made for the back propagation neural networks (BPNN) [3], the first CNN was invented by applying the backward propagation in training model [4]. After the emergence of two-dimensional CNN, scholars proposed a series of networks such as LeNet [5, 6], AlexNet [7], VGG [8], GoogLeNet[9] and ResNet [10]. However, no matter how deep or large a neural network is, the key of algorithm is gradient method in backward propagation.
As fractional order calculus is successfully applied in LMS filtering [11, 12, 13], systems identification [14, 15], control theories [16, 17, 18, 19] and so on, there arises a new trend that introduces fractional order calculus into gradient method. Professor Pu is the first one who pays attention to fractional order gradient method. He adopts fractional order derivatives to replace the integer order derivatives in traditional gradient method directly [20]. According to the definitions of fractional order derivatives [21], not only current information but also historical one are taken into consideration, thus it is potential for fractional order gradient to escape local optimal point. Nevertheless, such gradient method cannot ensure the convergence to real extreme point, even if the objective function is a simple quadratic function. To remedy this congenital defect, Chen uses truncation and short memory principle to modify the fractional order gradient method [22, 23] which turns out: it is convergent to real extreme point just as integer order method do, but with faster convergent speed than integer order method.
During the research of fractional order gradient method, some scholars have found its application to artificial neural networks at the same time. Considering that fractional order derivatives of composite functions are complicated, professor Wang only uses fractional order gradients for updating parameters so that the chain rule will be kept to calculate integer order gradients along backward propagation [24]. Similar method is followed but the different structure of networks is applied in [25]. Their experiments demonstrate that fractional order gradients improve the networks performance on accuracy, and the cost of time has changed little because of relatively simpler calculation by adopting Caputo’s definition. However, their fractional order gradient method is based on the strict definition of fractional order derivatives, which leads to the same problem as [20].
Even if great efforts have been made to neural networks with fractional order gradient method, it is still a novel research and far away from perfection at present. There remain some aspects to be improved.
The convergence to real extreme point is necessary for gradient method.
- 2.
The available range of fractional order can be extended to .
- 3.
Neural networks of more complicated structure are worth researching in depth.
- 4.
How to use the chain rule in fractional order neural networks is still a problem.
- 5.
Loss function may be chosen as not only quadratic function but cross-entropy function.
Therefore, this paper provides conventional CNN with a novel fractional order gradient method. To the best of our knowledge, no scholar has ever investigated the CNN by fractional order gradient method. The proposed method is creative for neural networks as well as gradient method. First, based on the Caputo’s definition of fractional order derivatives, a fractional order gradient method is designed and proved to converge to real extreme point. Second, the gradients in backward propagation of neural networks are divided into two categories, namely the gradients transferred between layers and the gradients for updating parameters within layers. Third, the updating gradients are replaced by fractional order one, but transferring gradients are integer order so that the chain rule could be kept using. With connecting all layers end-to-end and adding loss functions, the CNN with fractional order gradient method is achieved. What’s more, the proposed neural networks validate that fractional order gradients perform outstanding acts of fast convergence, good accuracy and ability to escape local optimal point.
The remainder of this article is organized as follows. Section 2 introduces a fractional order gradient method and provides some basic knowledge for subsequent use. Fractional order gradient method is recommended for the fully connected layers and convolution layers in Section 3, respectively. In Section 4, some experiments are provided to illustrate the validity of the proposed approach. Conclusions are given in Section 5.
2 Preliminaries
A general CNN is composed of convolution layers, pooling layers and fully connected layers. Fractional order gradient method is applicable for all layers except pooling layers, since there is no need of updating parameters in pooling layers. In the fully connected layers, each node is connected to all nodes of last layer, whereas the convolution layers use many convolution kernels to scan the input. In spite of different structures, their backward propagations are almost the same, which make the study on gradient method much easier. Before the introduction of fractional order gradients within backward propagations, some preliminary knowledge needs emphasizing here.
There are some widely accepted definitions of fractional order derivative , such as Riemann-Liouville, Caputo and Grunwald-Letnikov, but the Caputo’s one is chosen for subsequent use, since its derivative of constant equals zero. The Caputo’s definition is
[TABLE]
where , is the Gamma function, is the initial value. Alternatively, (1) can be rewritten as the following form
[TABLE]
Suppose to be a smooth convex function with a unique extreme point . It is well known that each iterative step of the conventional gradient method is formulated as
[TABLE]
where is the iterative step size or learning rate, is iterative times. Similarly, the fractional order gradient method is written as
[TABLE]
If fractional order derivatives are directly applied in (4), the above fractional order gradient method cannot converge to the real extreme point , but to an extreme point under definition of fractional order derivatives, such extreme point is associated with initial value and order, generally not equal to [20].
To guarantee the convergence to real extreme point, an alternative fractional order gradient method [22] is considered via following iterative step
[TABLE]
with and
[TABLE]
When only the first item is reserved and its absolute value is introduced, the fractional order gradient method with is simplified as
[TABLE]
Theorem 1**.**
If fractional order gradient method (7) is convergent, it will converge to the real extreme point .
Proof.
It is a proof by contradiction. Assume that converges to a different point , namely . Therefore, it can be concluded that for any sufficient small positive scalar , there exists a sufficient large number such that for any . Then must hold.
According to (7), the following inequality is obtained
[TABLE]
with .
Considering that one can always find a such that , then the following inequality will hold
[TABLE]
The above inequality could be rewritten as . When this inequality is introduced into (11), the result is
[TABLE]
which implies that is not convergent. It contradicts to the assumption that is convergent to , thus the proof is completed. ∎
Remark 1**.**
When a small positive value is introduced, the following fractional order gradient method will avoid singularity caused by .
[TABLE]
Compared with gradient method based on strict definition of fractional order derivatives [20], the modified fractional order gradient methods (7) and other similar methods [22] are proven to be convergent to the real extreme point. To demonstrate faster convergence of proposed gradient method, a common type of objective function, namely quadratic function, is selected to show optimizing process.
The objective function is where the step size is set to and two initial points are randomly chosen in . Other initializations are completely available only if the distance between two points is restricted to a small range. As is shown by Fig. 1, the optimizing process is obviously promoted with the application of fractional order gradient method.
In view of theory and practice above, compared with existing integer order or fractional order gradient method, the proposed fractional order gradient method not only is convergent to real extreme point but also converges with faster speed.
3 CNN with fractional order gradients
Although the key procedure of mathematical calculation is quite similar in convolution layers and fully connected layers, the different structures lead to different ways to research. First of all, fully connected layers with fractional order gradient are introduced.
3.1 Fully connected layers
The training procedure of neural networks contains two steps, one of them is forward propagation. Such propagation between two layers is illustrated as Fig. 2, where superscript is the number of layer, subscript is the number of node in certain layer, is the output of -th node in -th layer.
The output is from
[TABLE]
where is weight, is bias, is the output of last layer and function is activation function.
Another step of training procedure is backward propagation, in which fractional order gradient method takes the place of traditional method. Due to imperfect use of chain rule in fractional order derivatives, the gradients of backward propagation are a blend of fractional order and integer order. As is shown in Fig 3, there are two types of gradients that pass through layers. One is the transferring gradient (solid line) which links nodes between two layers, the other is updating gradient (dotted line) which is used for parameters within layers. is the loss function, is the fractional order, and are defined as fractional order gradients of and , respectively.
In order to use the chain rule continuously, the transferring gradient is provided with integer order
[TABLE]
but the updating gradient is replaced by fractional order
[TABLE]
with and . When the fractional order gradient (7) is adopted, the gradient of the -th iteration becomes
[TABLE]
where and are parameters and at the -th iteration, is output at the ()-th iteration. Consequently, the fractional order updating gradient is achieved by introducing (26) to (23)
[TABLE]
where and are and at the -th iteration, respectively.
Actually, samples are not input one by one in most case. When a batch of samples are input each time, (31) turns into
[TABLE]
where is batch size, the subscript means -th sample of a batch. After vectorization, above equations are simplified as
[TABLE]
where
[TABLE]
[TABLE]
[TABLE]
[TABLE]
[TABLE]
signs like and are the element-wise calculation, is the Hadamard product, is the sum of a matrix along horizontal axis. Then the updating parameters of fully connected layers can be summarized as
[TABLE]
Theorem 2**.**
The fully connected layers updated by fractional order gradient method (44, 47) are convergent to real extreme point.
Proof.
When integer order gradients are adopted in backward propagation, the gradients of and can be written as
[TABLE]
Thus fractional order gradients (44) turn into
[TABLE]
Then the updating parameters (47) becomes
[TABLE]
For a certain element in or , the or can be updated by
[TABLE]
It is similar to the proof of Theorem 1. Assume that converges to a point that is different from real extreme point , namely . Therefore, it can be concluded that for any sufficient small positive scalar , there exists a sufficient large number such that for any . Then must hold.
According to (63), the following inequality is obtained
[TABLE]
with .
Considering that one can always find a such that , then the following inequality will hold
[TABLE]
The above inequality could be rewritten as . When this inequality is introduced into (68), the result is
[TABLE]
which implies that is not convergent. Similarly, the same result will be easily obtained for . It contradicts to the assumption mentioned before, thus the proof is completed ∎
Compared with integer order backward propagation [26], the same transferring gradient is kept, but the difference exists in updating gradient where the order is changed as and . Even so, based on the Theorem 2, and updated by fractional order gradients will converge to the same real extreme points as integer order gradients do.
Remark 2**.**
Because of integer order transferring gradient, the chain rule is still available for the proposed gradient method (44, 47), which avoids complicated calculation caused by fractional order derivatives, especially derivatives of activation function. As modified fractional order gradient (7) is applied smoothly, the speed of convergence is improved and real extreme point can be reached now.
3.2 Convolution Layers
Although the key calculation of convolution layers is similar to fully connected layers, the complicated structure makes its iterative algorithm different. It is hard to understand the algorithm without help of figures or auxiliary descriptions.
For subsequent research, the forward propagation of convolution layers is drawn briefly in Fig. 4 where is the output of the -th layer, and are weight and bias for channel , is the size of convolution kernel, is a slice of by selecting rows and columns over all channels (red cube), , and are height, width and channels of output , respectively.
Similarly, the gradients of backward propagation are divided into two types. The transferring gradient of convolution layers is also kept the same as integer order gradient. Considering that the input is a batch of samples, the updating gradient is
[TABLE]
where is the weight that contains all , is the over all samples.
When the fractional order gradient method (7) is introduced, the updating gradient at the -th iteration is changed to
[TABLE]
where is of the -th sample. It could be simply regarded as with
[TABLE]
[TABLE]
and is moving length of convolution kernel each time. After vectorization, (83) is further simplified as
[TABLE]
In order to show the algorithm clearly, the calculation of (88) is transformed to following process.
Then the updating parameters of convolution layers is as follows
[TABLE]
Theorem 3**.**
The convolution layers updated by fractional order gradient method (88, 91) are convergent to real extreme point.
The proof resembles Theorem 2. By introducing integer order gradients, the gradients in (88) are changed into the form like (53). Then it is a proof by contradiction that could be done for each element of and in (91).
Remark 3**.**
Based on backward propagation of convolution layers, when padding is introduced into the -th layers, the transferring gradient will be influenced. The gradient calculated by Algorithm 1 is the gradient of padded output. The padded part of needs deleting. However, there is no change happened for the updating gradient of fractional order.
Remark 4**.**
During the training procedure, a tiny value could be added to (44, 88) so that the singularity caused by or is avoided easily. Hence the gradients modified by (14) are listed below
[TABLE]
[TABLE]
When convolution layers, pooling layers and fully connected layers are connected end-to-end, it will fulfill some tasks like classification. Many types of functions, such as quadratic function and cross-entropy function , are available to loss function of proposed method. And the gradient on output of the last layer is still integer order. The backward propagation between layers of different types is simple. Reshaping is needed only when the gradients correspond to different shapes. Finally, a type of complete convolutional neural networks will combine with fractional order gradient to fulfill a task and demonstrate the effectiveness of proposed method. For example, the LeNet [6] is a simple CNN which will be adopted for subsequent experiment.
4 Experiments
The task of experiments is to identify handwriting number by fractional order convolutional neural networks. The experiments are carried out by the MNIST dataset which consists of 60,000 handwritten digit images for the training and another 10,000 samples for testing. Consequently, the whole structure of LeNet is presented in Fig. 5.
The corresponding parameters are listed below. is the output of networks for the -th smaple and is label with one-hot form.
The experiments are carried out by 10 times. All parameters, such as weights, bias and the inputting order of samples, are randomly initialized each time. Consequently, the training accuracy and testing accuracy with different fractional order are shown in Table 1.
It could be observed that the accuracy of fractional order gradient methods with and is higher than the integer order gradient method in most cases. What’s more, when average accuracy of 10 experiments is taken into consideration, the integer order one shows a little less accuracy. In Fig. 7, the average accuracy of training and testing results is drawn over .
Although fractional order gradient method works well in CNN, it is not effective enough all the time when or . The reason of such low accuracy is caused by the the Gamma function in fractional order calculus (1). The Gamma function in fractional order gradient method (44, 88) is a very large number for or . As a result, the gradients are too small to reduce the loss function and sink into a local extreme point quickly. Since it is often a point close to the initial point, the loss does not decrease or only decreases a little bit. This phenomenon is also demonstrated by Fig. 8.
To analyze fractional order gradients further, the Fig. 9 is drawn here to show the average loss function of first 1000 iterations. Even if all loss functions are decreasing during training, the loss iterated by fractional order gradients seems to prefer jumping farther. Compared with integer order gradient method in Fig. 9(b), the points are more dispersed for fractional order cases, especially for in Fig. 9(a). In addition, each variance of different loss function is listed below.
The larger variance often indicates looser distribution, which implies that fractional order gradient method helps optimizing process jump frequently and far. Therefore, it is provided with more possibility to escape the local optimal point.
In view of seemingly complicated calculation, it seems that fractional order gradient method needs more time than integer order one. However, the training speed of fractional order CNN is almost as fast as integer order CNN. Taking all experiments into consideration, the average training time spent by integer order CNN is only 0.53% less than fractional order CNN with . Similar speed also exists in other cases for . There are two reasons that result in such fast speed of fractional order gradient method for CNN. One reason is that only updating gradients are replaced by fractional order. The other reason is that the fractional order updating gradients are obtained according to integer order gradients and the additional calculation in fractional order updating gradients are quite simple.
5 Conclusions
The backward propagation of neural networks is investigated by fractional order gradient method in this paper. After modification of fractional order gradient, the proposed gradient method can ensure the convergence to real extreme point, and has been successfully applied in CNN for updating parameters. It is the first time for CNN to cooperate with fractional order calculus. The chain rule in backward propagation is completely preserved since integer order gradients are still used for transferring between layers. Both the range of fractional order and the type of loss function are enlarged. Moreover, the proposed fractional order gradient method verifies its fast convergence, high accuracy and ability to escape local optimal point in neural networks when compared with integer order case. It is believed that this paper provides a new way to study gradient method and its application.
Acknowledgements
The work described in this paper was fully supported by the National Natural Science Foundation of China (No. 61573332, No. 61601431), the Fundamental Research Funds for the Central Universities (No. WK2100100028), the Anhui Provincial Natural Science Foundation (No. 1708085QF141) and the General Financial Grant from the China Postdoctoral Science Foundation (No. 2016M602032).
References
- LeCun et al. [2015]
LeCun, Y., Bengio, Y., Hinton, G..
Deep learning.
Nature 2015;521(7553):436.
- Fukushima [1980]
Fukushima, K..
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.
Biological Cybernetics 1980;36(4):193–202.
- Rumelhart et al. [1988]
Rumelhart, D.E., McClelland, J.L., Group, P.R., et al.
Parallel distributed processing.
Boston: MIT press Cambridge; 1988.
- Alexander et al. [1990]
Alexander, W., Hanazawa, T., Hinton, G., Kiyohiro, S., Lang, K..
Phoneme recognition using time-delay neural networks.
Readings in Speech Recognition 1990;1(2):393–404.
- LeCun et al. [1989]
LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., et al.
Backpropagation applied to handwritten zip code recognition.
Neural Computation 1989;1(4):541–551.
- LeCun et al. [1998]
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P., et al.
Gradient-based learning applied to document recognition.
Proceedings of the IEEE 1998;86(11):2278–2324.
- Krizhevsky et al. [2012]
Krizhevsky, A., Sutskever, I., Hinton, G.E..
Imagenet classification with deep convolutional neural networks.
In: 2012 Neural Information Processing Systems (NIPS). Lake Tahoe, USA; 2012, p. 1097–1105.
- Simonyan and Zisserman [2015]
Simonyan, K., Zisserman, A..
Very deep convolutional networks for large-scale image recognition.
In: 2015 International Conference on Learning Representations (ICLR). San Diego, USA; 2015, p. 1–14.
- Szegedy et al. [2015]
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al.
Going deeper with convolutions.
In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA; 2015, p. 1–9.
- He et al. [2016]
He, K.M., Zhang, X.Y., Ren, S.Q., Sun, J..
Deep residual learning for image recognition.
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA; 2016, p. 770–778.
- Raja and Chaudhary [2015]
Raja, M.A.Z., Chaudhary, N.I..
Two-stage fractional least mean square identification algorithm for parameter estimation of carma systems.
Signal Processing 2015;107:327–339.
- Cheng et al. [2017]
Cheng, S.S., Wei, Y.H., Chen, Y.Q., Li, Y., Wang, Y..
An innovative fractional order lms based on variable initial value and gradient order.
Signal Processing 2017;133:260–269.
- Yin et al. [2019]
Yin, W.D., Wei, Y.H., Liu, T.Y., Wang, Y..
A novel orthogonalized fractional order filtered-x normalized least mean squares algorithm for feedforward vibration rejection.
Mechanical Systems and Signal Processing 2019;119:138–154.
- Cheng et al. [2018]
Cheng, S.S., Wei, Y.H., Sheng, D., Chen, Y., Wang, Y..
Identification for hammerstein nonlinear armax systems based on multi-innovation fractional order stochastic gradient.
Signal Processing 2018;142:1–10.
- Cui et al. [2018]
Cui, R.Z., Wei, Y.H., Cheng, S.S., Wang, Y..
An innovative parameter estimation for fractional order systems with impulse noise.
ISA Transactions 2018;82:120–129.
- Li et al. [2009]
Li, Y., Chen, Y.Q., Podlubny, I..
Mittag-Leffler stability of fractional order nonlinear dynamic systems.
Automatica 2009;45(8):1965–1969.
- Lu and Chen [2010]
Lu, J.G., Chen, Y.Q..
Robust stability and stabilization of fractional-order interval systems with the fractional order : the case.
IEEE Transactions on Automatic Control 2010;55(1):152–158.
- Yin et al. [2014]
Yin, C., Chen, Y.Q., Zhong, S.M..
Fractional-order sliding mode based extremum seeking control of a class of nonlinear systems.
Automatica 2014;50(12):3173–3181.
- Wei et al. [2017]
Wei, Y.H., Du, B., Cheng, S.S., Wang, Y..
Fractional order systems time-optimal control and its application.
Journal of Optimization Theory and Applications 2017;174(1):122–138.
- Pu et al. [2015]
Pu, Y.F., Zhou, J.L., Zhang, Y., Zhang, N., Huang, G., Siarry, P..
Fractional extreme value adaptive training method: fractional steepest descent approach.
IEEE Transactions on Neural Networks and Learning Systems 2015;26(4):653–662.
- Monje et al. [2010]
Monje, C.A., Chen, Y.Q., Vinagre, B.M., Xue, D.Y., Feliu, V..
Fractional-Order Systems and Controls: Fundamentals and Applications.
London: Springer; 2010.
- Chen et al. [2017]
Chen, Y.Q., Gao, Q., Wei, Y.H., Wang, Y..
Study on fractional order gradient methods.
Applied Mathematics & Computation 2017;314:310–321.
- Chen et al. [2018]
Chen, Y.Q., Wei, Y.H., Wang, Y., Chen, Y.Q..
Fractional order gradient methods for a general class of convex functions.
In: 2018 Annual American Control Conference (ACC). Milwaukee, USA; 2018, p. 3763–3767.
- Wang et al. [2017]
Wang, J., Wen, Y.Q., Gou, Y.D., Ye, Z.Y., Chen, H..
Fractional-order gradient descent learning of bp neural networks with caputo derivative.
Neural Networks 2017;89:19–30.
- Bao et al. [2018]
Bao, C.H., Pu, Y.F., Yi, Z..
Fractional-order deep backpropagation neural network.
Computational Intelligence & Neuroscience 2018;2018:1–10.
- Rumelhart et al. [1986]
Rumelhart, D.E., Hinton, G.E., Williams, R.J., et al.
Learning representations by back-propagating errors.
Nature 1986;323:533–536.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Le Cun et al. [2015] Le Cun, Y., Bengio, Y., Hinton, G.. Deep learning. Nature 2015;521(7553):436.
- 2Fukushima [1980] Fukushima, K.. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics 1980;36(4):193–202.
- 3Rumelhart et al. [1988] Rumelhart, D.E., Mc Clelland, J.L., Group, P.R., et al. Parallel distributed processing. Boston: MIT press Cambridge; 1988.
- 4Alexander et al. [1990] Alexander, W., Hanazawa, T., Hinton, G., Kiyohiro, S., Lang, K.. Phoneme recognition using time-delay neural networks. Readings in Speech Recognition 1990;1(2):393–404.
- 5Le Cun et al. [1989] Le Cun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W., et al. Backpropagation applied to handwritten zip code recognition. Neural Computation 1989;1(4):541–551.
- 6Le Cun et al. [1998] Le Cun, Y., Bottou, L., Bengio, Y., Haffner, P., et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE 1998;86(11):2278–2324.
- 7Krizhevsky et al. [2012] Krizhevsky, A., Sutskever, I., Hinton, G.E.. Imagenet classification with deep convolutional neural networks. In: 2012 Neural Information Processing Systems (NIPS). Lake Tahoe, USA; 2012, p. 1097–1105.
- 8Simonyan and Zisserman [2015] Simonyan, K., Zisserman, A.. Very deep convolutional networks for large-scale image recognition. In: 2015 International Conference on Learning Representations (ICLR). San Diego, USA; 2015, p. 1–14.
