Can NetGAN be improved on short random walks?
Amir Jalilifard, Vinicius Carid\'a, Alex Mansano, Rogers Cristo

TL;DR
This paper proposes a new method for initializing random walks in NetGAN, which improves graph generation accuracy and consistency, especially for short walks, by estimating node importance based on local influence.
Contribution
It introduces a novel node importance estimation method for initializing random walks in NetGAN, enhancing performance and stability over traditional random start approaches.
Findings
Significantly improved accuracy in graph generation.
Reduced variance and outliers in results.
Better performance with short random walks.
Abstract
Graphs are useful structures that can model several important real-world problems. Recently, learning graphs have drawn considerable attention, leading to the proposal of new methods for learning these data structures. One of these studies produced NetGAN, a new approach for generating graphs via random walks. Although NetGAN has shown promising results in terms of accuracy in the tasks of generating graphs and link prediction, the choice of vertices from which it starts random walks can lead to inconsistent and highly variable results, especially when the length of walks is short. As an alternative to random starting, this study aims to establish a new method for initializing random walks from a set of dense vertices. We purpose estimating the importance of a node based on the inverse of its influence over the whole vertices of its neighborhood through random walks of different sizes.…
Click any figure to enlarge with its caption.
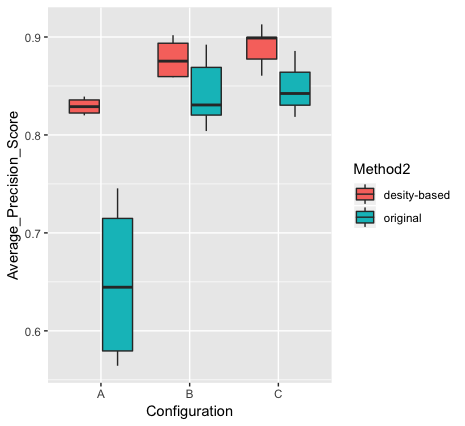 Figure 1
Figure 1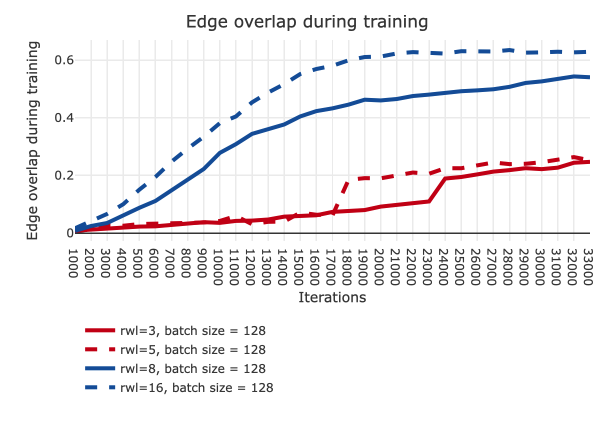 Figure 2
Figure 2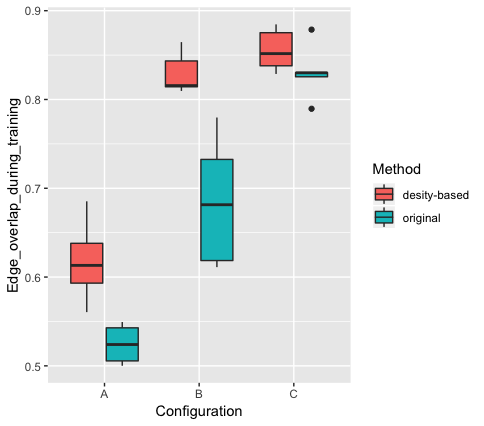 Figure 3
Figure 3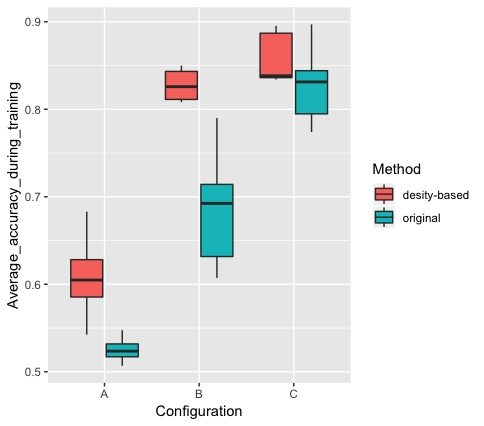 Figure 4
Figure 4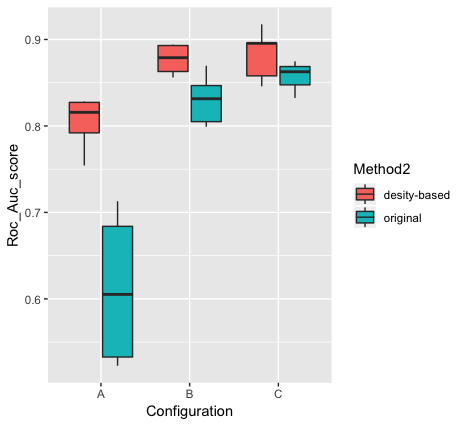 Figure 5
Figure 5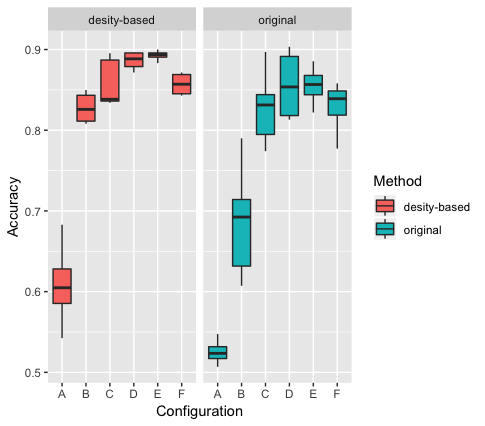 Figure 6
Figure 6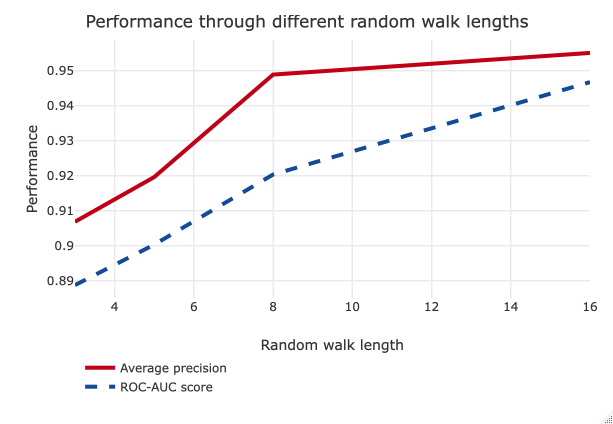 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Graph Neural Networks · Complex Network Analysis Techniques · Machine Learning and Data Classification
Can NetGAN be improved on short random walks?
Jalilifard A.; Caridá V.F.; Mansano A.F.; Cristo R.S. @itau-unibanco.com.br
Data Science Team - Digital Customer Service
*Itaú Unibanco, São Paulo, Brazil
*amir.jalilifard; vinicius.carida; alex.mansano; rogers.cristo
Abstract
Graphs are useful structures that can model several important real-world problems. Recently, learning graphs has drawn considerable attention, leading to the proposal of new methods for learning these data structures. One of these studies produced NetGAN, a new approach for generating graphs via random walks. Although NetGAN has shown promising results in terms of accuracy in the tasks of generating graphs and link prediction, the choice of vertices from which it starts random walks can lead to inconsistent and highly variable results, specially when the length of walks is short. As an alternative to a random starting, this study aims to establish a new method for initializing random walks from a set of dense vertices. We purpose estimating the importance of a node based on the inverse of its influence over the whole vertices of its neighborhood through random walks of different sizes. The proposed method manages to achieve a significantly better accuracy, less variance and lesser outliers.
Index Terms:
graph learning, density based random walks, NetGAN
I Introduction
One of the main obstacles in artificial intelligence applications is to discover valuable hierarchical models that represent probability distributions over the types of data encountered [1]. The most remarkable results in deep learning have involved discriminative models, often used to map data into high-dimensional, rich sensory input to a class label [2, 3].
Recently, there has been renewed interest in evaluating graphs with machine learning due to a collection of practical applications in which they can be employed. Nonetheless, it is quite challenging to obtain a model that captures all the essential properties of real graphs. As a particular non-Euclidean data structure for machine learning, graph analysis generally concentrates on node classification, link prediction, and clustering [4].
Graphs can be utilized to describe numerous processes across diverse fields, such as social sciences (social networks) [5, 6], natural sciences (physical systems [7, 8] and protein-protein interaction networks [9]), knowledge graphs [10] as well as other researching areas [11].
Regarding graph learning, Graph Neural Networks (GNN) [12, 13] are deep learning methods which have been widely applied due to its convincing performance and high interpretability.
As a result of the complications on approximating many intractable probabilistic computations that arise in maximum likelihood evaluation and related strategies, and also due of the difficulty of leveraging the benefits of piece-wise linear units in the generative context, Goodfellow [14] has proposed Generative Adversarial Networks (GAN) as a new generative model estimation procedure.
GANs promoted significant advancements in the state-of-the-art over the classic prescribed approaches like Gaussian mixtures [15]. The method also achieved great results in other scenarios such as image generation and 3D objects synthesis [16, 17, 18].
Associating the concepts of both GNN and GAN, NetGAN [19] was proposed as one of the first methods to produce neural graph generative models. The essential idea behind it is to convert the problem of graph generation into walk generation, employing random walks from a specific graph as data input, and training a generative model using the GAN architecture. The generated graph tends to preserve important topological features of the original graph, including the initial amount of nodes [4].
NetGAN approach offers strong generalization features, as indicated by its competitive link prediction performance on several data-sets. It can further be used for generating graphs well-suited to capture the complex nature of real-world networks [19]. On the other hand, in spite of the above-mentioned aspects, the method scalability is related as one of its drawbacks. NetGAN takes numerous generated random walks to generate representative transition counts for large graphs. Accordingly, instead of determining an arbitrary amount of random walks, a probable enhancement of NetGAN would be the adoption of a conditional generator capable of, given a starting node, provide a more even graph walking coverage and better scalability.
In this work we introduce a method to learn graphs through short random walks originated from dense vertices. We specifically emphasis on using short random walks because as the size of random walks is increased, the proportion of number of separate observations to the number of predictors tends to decrease, resulting in over-fitting problem. This is more evident when the training graph has small size. In order to be able to use short random short walks, it is necessary to start them from the vertices which provide more information for the learning algorithm. Thus, we propose a new procedure to compute the importance of a node based on the inverse of its influence over all vertices in its neighborhood, through random walks of varied sizes. Ultimately, the most important nodes are used as the starting points.
II Problem statement
NetGAN initializes its random walks from a set of randomly chosen nodes. Although this approach is appropriate for sampling from different regions of the graph, it also leads to having different results with high variance after each training session. This becomes more noticeable for random walks of short length, producing less generalized trained models. We propose a method for determining the best nodes for initializing random walks instead of choosing them randomly. By limiting the possible start points and adopting better random walk initializers, our method reduces the variability of results and enhances the learning accuracy.
A graph is denoted as , where is the set of vertices, represents the edges between the vertices and is the weight of edges. The problem of finding adequate start points for initializing random walks is to find a set of vertices that decrease the entropy of walks which itself results in a higher information gain. A desired set of vertices should achieve a better graph generation accuracy and a training model which is less dependent on the random choice of initializers.
In the problem of finding best random walk initializers, there exist two main issues: (1) measuring the influence of a vertex on a set of neighbors through random walks, and (2) converting this influence to a metric which determines the adequacy of a vertex for initializing a random walk. In the next session, we will explain our proposed method for tackling each of these issues.
III Method
Good initializing points are important for learning the structure of a graph through random walks. In a scenario when the beginning vertex has limited access to its neighborhood through different paths, the amount of information gained while visiting the nodes through distinct random walks is not significant. Instead of selecting the starting point randomly, we follow the motivation of [20] for initializing the random walks from graph centroids from density point of view. We assume that if a vertex has several access to a group of graph vertices through of random walks, this vertex is located in a dense region of graph, providing better information for an algorithm like NetGAN. On the other hand, if a vertex is in a sparse region, it has access to less number of regions and as a result supplies less information.
We follow the definition of neighborhood distance proposed in [21], although, instead of using this distance for finding the closeness of two nodes, we take advantage of the probabilistic characteristic of this distance so as to find the dense regions of the graph. First, the transition probability matrix is calculated as following:
[TABLE]
where is the weight of the edge between and and is the number of neighbors of . Here, we assume that all the weights are equal to 1, although the proposed method is applicable for weighted graphs.
Having the transition probability, the distance between two nodes is defined as
[TABLE]
where is the length of random walk path from to , is the probability of returning to the initial state and is the probability of reaching from to .
Then the neighborhood random walk distance matrix on a structure graph is
[TABLE]
Theorem 1**.**
Given a graph and a set of vertices , if vertex is located in a denser region than , initiating a random walk from the first results in a lower entropy than the later, carrying more information.
Proof.
The entropy of an event is defined as
[TABLE]
For a sub-graph the density of is defined to be
[TABLE]
If vertex is located in a denser sub-graph than another vertex, say , has higher degree than . Based on the equations 1 and the definition of density function in [21], denser nodes have access to more other vertices through distinct random walks, meaning that the sum of all degrees in a dense region is higher than the sparse one. Therefore, if and are number of neighbors of and respectively, therefore
[TABLE]
From equation (2) we defined the distance between two nodes as sum of the transition probabilities of a random walk through all the middle edges. Thereby, considering (6)
[TABLE]
The influence of vertex on another vertex is defined as
[TABLE]
where .
The density function is calculated as following
[TABLE]
Based on equation (8), the influence metric is proportional to the random walk distance between two nodes. Then the lesser the sum of all the random walk distances of the denser it is. Since we defined the distance as the probability of successive walks, the entropy of a random walk is calculated as
[TABLE]
Consequently, the denser a vertex, the lower the distance and entropy and as result the more information gain. ∎
Notice that by accessibility we mean the probability of walking on different paths through a random walk. If a node is located on a sparse region, the probability of walking on the same randomly chosen path is more than a denser region. Also, we defined the density in terms of accessibility through random walks of length . Without this constraint, the theory would be wrong (consider a dense node in a small component that is disconnected from a large component or perhaps connected to a large component via a single link and consider a sparse node in the large component which is connected to a node in a dense region).
IV Results and discussion
In this section, we evaluate the quality of generated graphs via random walks started from dense nodes in terms of link prediction precision and ROC curve. We compare all the results with those of NetGAN. For all the experiments, we followed all the preprocessing steps of the original paper. The CORA-ML [22] was used in all the conducted experiments. As in [19], we treat the graph as undirected. We randomly used one of the connected components of CORA-ML with 303 vertices and tested our algorithm against the performance of original NetGAN when applied on the same graph.
In order to find the best nodes to start a random walk, we first sampled 100 random walks from each vertex in order to find the graph paths. After forming the transition and the distance matrix, the densities were calculated and then the vertices were ordered in ascending fashion. Since NetGAN’s authors did not inform the motivation of the choice of the configurations they used for analyzing the results, we first tested the original NetGAN with diverse configurations. We found out that the choice of batch size, length of random walks and the initial vertices of random walk can significantly change the results. The more the batch size and the higher the length of the random walk, the higher the precision.
Although there is a high correlation between the performance of NetGAN with batch size and random walk length separately, we could not find any meaningful correlation between batch size and random walk directly. This comes from the fact that based on our tests setting a high random walk length can compensate the small size of batch and vice-versa. Furthermore, when the batch size is chosen to be small, the choice of initial random walk points becomes more crucial. On the other hand, if both random walk length and batch size are set to be big, this may cause over-fitting. Thereby, we chose the configurations that are proportional to the tests carried out by authors of NetGAN (see Figures 1 and 2).
In order to evaluate the proposed method, we calculated the vertex density for random walks of length equal to 2 to 4 and batch size of 13, 19, 25, respectively. As it was mentioned before, these configurations are proportional to the original configuration used by authors in [19].
Unlike the random approach proposed in [19], our approach limits the choice of vertices to those with a higher chance of representing new information through each random walk. As seen in Figure 3, for all the configurations, the proposed method yields a higher accuracy and lesser variance for the most part. As illustrated, the original method has a poor performance for short random walks, although as the length of walks is increased, the accuracy of original method becomes closer to our method.
As shown in Figure 4, our method also results in a better edge overlap during the training and a less average variance through a variety of configurations.
We finally investigate the performance of our method in terms of ROC-AUC score and average precision score. Based on our results, the proposed method has better average link prediction precision and ROC-AUC scores (see Figure 5).
As shown by several different metrics, starting random walks from dense vertices lead having better performance in NetGAN. Also as illustrated in Table I, using dense vertices result in significantly better average accuracy during the training phase, average link prediction precision and average ROC-AUC scores. Using the current method, we managed to get link prediction precision up to 92.8% and an average score of 89%. Although the objective of the proposed method is to improve the performance of NetGAN for short random walks, we compared the performance of our method with the random initializer approach. Based on our results, when the size of random walks is increased (when the random walk length becomes bigger than 6), the performance of the random approach in terms of average ROC-AUC and average link prediction precision is slightly better compared to our method. Nevertheless, the performance of our method in terms of average accuracy during the training phase is always better independent of the size of the random walk.
Although this was not our intention in this research, there are two possible ways to improve the performance of the current method for random walks of even larger size than 6. As we mentioned earlier, we sampled the graph using 100 random walks of size 8 for each vertices in order to find the possible paths of the graph. This means that our sample is just an approximation of the real graph paths and finding all the paths of size between every two nodes may return a slightly better set of dense vertices and improve the performance of current method for longer random walks. The second possible way is to add a percentage of randomly chosen vertices to the set of dense vertices and also choosing the random walk paths based on the importance of each vertex in terms of its density (for now the probability of each vertex to be chosen is equal for all the vertices existing in the set of most dense vertices).
V Conclusion
NetGAN uses a random strategy to choose vertices that initialize the random walks. This approach raises the variance in accuracy and precision of link prediction and compels the use of more steps in the random walk to compensate the possible poor initializers, thus getting more information through larger walks.
In this paper we develop a new method dedicated to determine better starting points so that NetGAN can get less variant results and more precise predictions by learning graphs via short random walks. Applying the probabilistic distances, we demonstrated that if the random walks starts from denser regions they may have lower entropy, culminating in more information gain. All the vertices are ordered based on its calculated density value. Since denser vertices have an abundance of connections, starting a random walk from those nodes minimizes the chance of reiterating through the same path, and consequently provides more information for NetGAN.
We tested our hypothesis with various configurations and with multiple performance metrics including accuracy, ROC-AUC score, edge overlap during the training and average link prediction precision. Compared with NetGAN random approach, our method had better results in all experiments. More specifically, our results show that starting the random walk from dense vectors significantly increases the accuracy and link prediction precision. Using short random walks not only decreases the training time, but unlike the large random walks it makes the trained model less prone to over-fitting. Nonetheless, the performance of the random strategy becomes closer to our method as the length of random walks increases. One possible future work could concentrate on the investigation of combining some randomly determined vertices with the dense ones in order to have even better sampling strategy.
VI Conflict of interest
The current method was proposed and tested by a group of data scientists from Itaú Unibanco. Any opinions, findings, and conclusions expressed in this manuscript are those of the authors and do not necessarily reflect the views, official policy or position of Itaú Unibanco.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Y. Bengio et al. , “Learning deep architectures for ai,” Foundations and trends® in Machine Learning , vol. 2, no. 1, pp. 1–127, 2009.
- 2[2] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 82–97, Nov 2012.
- 3[3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems , 2012, pp. 1097–1105.
- 4[4] J. Zhou, G. Cui, Z. Zhang, C. Yang, Z. Liu, and M. Sun, “Graph neural networks: A review of methods and applications,” ar Xiv preprint ar Xiv:1812.08434 , 2018.
- 5[5] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Advances in Neural Information Processing Systems , 2017, pp. 1024–1034.
- 6[6] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” ar Xiv preprint ar Xiv:1609.02907 , 2016.
- 7[7] A. Sanchez-Gonzalez, N. Heess, J. T. Springenberg, J. Merel, M. Riedmiller, R. Hadsell, and P. Battaglia, “Graph networks as learnable physics engines for inference and control,” ar Xiv preprint ar Xiv:1806.01242 , 2018.
- 8[8] P. Battaglia, R. Pascanu, M. Lai, D. J. Rezende et al. , “Interaction networks for learning about objects, relations and physics,” in Advances in neural information processing systems , 2016, pp. 4502–4510.