TL;DR
This paper introduces a novel joint end-to-end filter pruning method for monocular depth estimation models, significantly reducing model size while maintaining accuracy, enabling deployment on low-end devices.
Contribution
It presents a new filter pruning approach that learns binary masks for filters, exploiting inter-filter relations to create lightweight models from large pre-trained networks.
Findings
Achieves around 5x compression with minimal accuracy loss on KITTI dataset.
Masking can improve baseline accuracy with fewer parameters.
Method enables deployment on resource-constrained devices.
Abstract
Convolutional neural networks (CNNs) have emerged as the state-of-the-art in multiple vision tasks including depth estimation. However, memory and computing power requirements remain as challenges to be tackled in these models. Monocular depth estimation has significant use in robotics and virtual reality that requires deployment on low-end devices. Training a small model from scratch results in a significant drop in accuracy and it does not benefit from pre-trained large models. Motivated by the literature of model pruning, we propose a lightweight monocular depth model obtained from a large trained model. This is achieved by removing the least important features with a novel joint end-to-end filter pruning. We propose to learn a binary mask for each filter to decide whether to drop the filter or not. These masks are trained jointly to exploit relations between filters at different…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3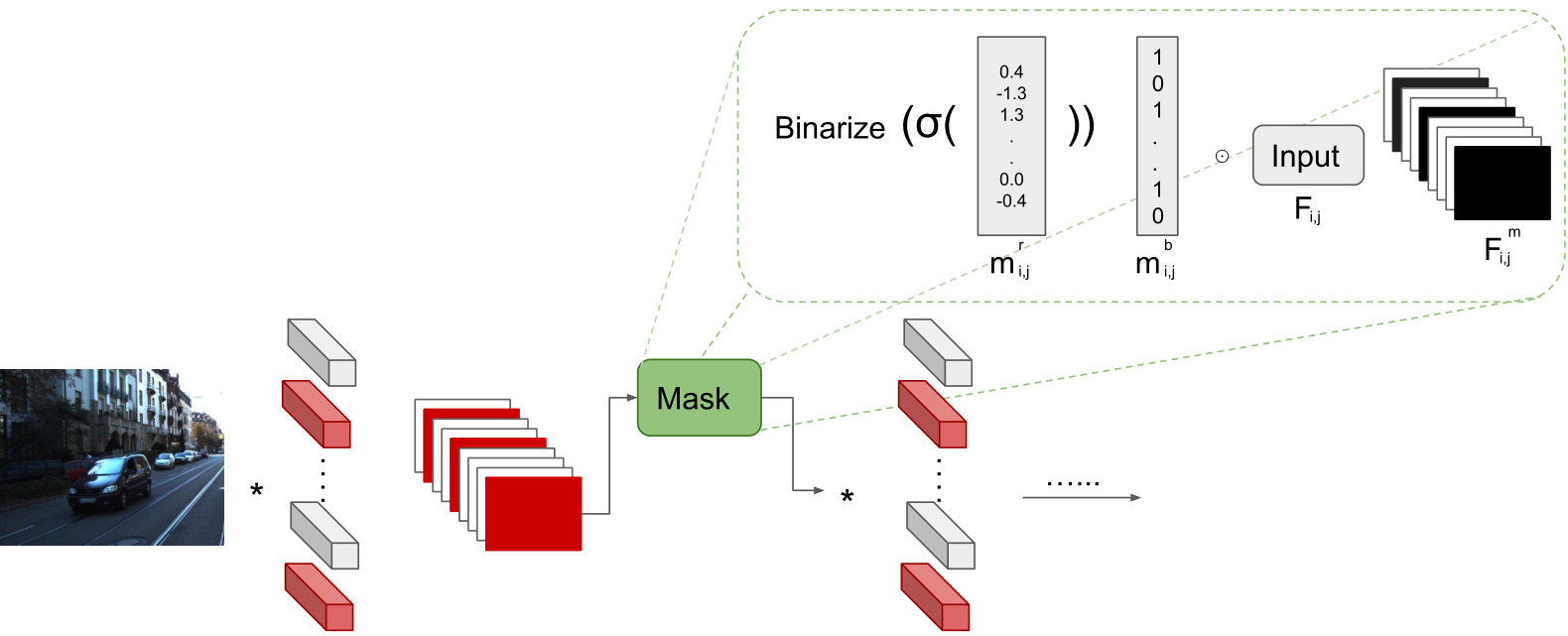 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14| Ours | Lower is better | ||
| Method | Dataset | D1 all | Params |
| LRC + Deep3D [1] | K | 59.64 | 31.6M |
| LRC + VGG [1] | K | 30.272 | 31.6M |
| VGG + | K | 32.183 1.9 | 7.5M 76.1% |
| LRC + Resnet50 [1] | K | 28.459 | 58.4M |
| PyD-Net [2] | K | 38.478 | 1.9M |
| LRC + VGG [1] | CS + K | 25.523 | 31.6M |
| VGG + | CS + K | 24.939 1.33 | 30.2M 4.2% |
| VGG + | CS + K | 26.861 1.3 | 4.3M 86.1% |
| LRC + VGG pp* [1] | CS + K | 25.077 | 31.6M 2x forward |
| LRC + Resnet50 [1] | CS + K | 24.504 | 58.4M |
| Ours | Lower is better | Higher is better | |||
| Method | Dataset | Abs Rel | RMS | Params | |
| Eigen et al. [10] | K | 0.203 | 6.307 | 0.702 | 54.2M |
| Liu et al. [22] | K | 0.201 | 6.471 | 0.680 | 40.0M |
| Zhou et al. [15] | K | 0.208 | 6.856 | 0.678 | 34.2M |
| LRC + VGG [1] | K | 0.148 | 5.927 | 0.803 | 31.6M |
| VGG + | K | 0.1356 | 5.891 | 0.827 | 5.7M 81.8% |
| PyD-Net | K | 0.163 | 6.253 | 0.759 | 1.9M |
| LRC + VGG [1] | CS+K | 0.124 | 5.311 | 0.847 | 31.6 |
| VGG + | CS+K | 0.124 | 5.280 0.03 | 0.848 | 30.8M 2% |
| VGG + | CS+K | 0.1452 | 5.835 0.524 | 0.815 | 5.9M 81.1% |
| LRC + ResNet50 pp* [1] | CS+K | 0.114 | 4.935 | 0.861 | 58.4M |
| PyD-Net [2] | CS+K | 0.148 | 5.929 | 0.800 | 1.9M |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
lightweight MONOCULAR DEPTH ESTIMATION model by JOINT END-TO-END FILTER PRUNING
Abstract
Convolutional neural networks (CNNs) have emerged as the state-of-the-art in multiple vision tasks including depth estimation. However, memory and computing power requirements remain as challenges to be tackled in these models. Monocular depth estimation has significant use in robotics and virtual reality that requires deployment on low-end devices. Training a small model from scratch results in a significant drop in accuracy and it does not benefit from pre-trained large models. Motivated by the literature of model pruning, we propose a lightweight monocular depth model obtained from a large trained model. This is achieved by removing the least important features with a novel joint end-to-end filter pruning. We propose to learn a binary mask for each filter to decide whether to drop the filter or not. These masks are trained jointly to exploit relations between filters at different layers as well as redundancy within the same layer. We show that we can achieve around 5x compression rate with small drop in accuracy on the KITTI driving dataset. We also show that masking can improve accuracy over the baseline with fewer parameters, even without enforcing compression loss.
**Index Terms— ** Monocular depth estimation, Filter pruning, Model compression
1 Introduction
Real-time monocular depth estimation is needed in many visual tasks such as in robot simultaneous localization and mapping (SLAM), collision avoidance, and augmented reality. Monocular cameras are attractive as they are already deployed on many every-day systems such as phones, dash-cameras, and surveillance cameras. Although depth estimation from a single view is ill-posed due to geometric ambiguity, convolutional neural networks (CNN) achieved impressive results by solving the task as a learning problem. These methods rely on large and deep models and thus require high-end GPUs to run in real-time. This hinders deployment on many applications that require low-power consumption as well as real time response. While these issues can be tackled by designing small models, not only this requires expert knowledge and multiple manual tuning, but also these small models do not benefit from the trained large ones. As shown in [3] and multiple work on distillation and pruning [4, 5], over-parameterization in training or guidance from large (teacher) models benefits the smaller model as a way of transfer learning. These methods achieve better accuracy compared to training the same small model from scratch. This gives rise to the idea of training large models and then applying pruning after training to get the smaller footprint, instead of training the small one from scratch.
In this paper, we propose to automatically generate thin models from trained larger ones in an end-to-end training to better scale up for large models as in depth estimation. We propose to train a binary mask for each convolutional filter that acts like a gate to drop the whole filter or not. In training, we encourage smaller models through inducing sparsity by minimizing the -norm of the masks. To take into account the task loss as well, the masks are trained with both loss and the depth estimation loss. Closest to our proposed pruning method is [4] in the masking aspect, however, we must emphasis that we learn the masks jointly on the whole network without prior knowledge on the compression rate per layer or computing layerwise sensitivity analysis as in [6]. In [4], the authors set the compression rate for each layer and adopt layer by layer pruning where each prune is followed by a finetune. Both of these points obstruct scalability for large datasets and models such as encoding-decoding architectures which are twice the size of classification models. All of these issues motivated us to train an end-to-end joint pruning method that can be adopted in large scale models and datasets suitable for depth estimation.
Our baseline deep models are trained based on LRC [1] casting the problem as image reconstruction from stereo input pairs in an unsupervised setup. Figure 1 shows an example output of our pruned model (5x size reduction), LRC and PyD-Net [2], a small-sized network. The pruned network produces smoother and more accurate depth prediction thanks to the pre-trained large model compared to similar small-sized models trained from scratch.
2 Related Work
In this section, we review literature on monocular depth estimation with supervised and unsupervised training.
Supervised monocular depth estimation. Methods in the supervised category directly estimate depth for each input pixel in the image given the ground-truth depth. Planar based approximation methods [8, 9] estimate local planes in the scene to predict 3D location and orientation for segmented patches. Eigen et al. [10] proposed a CNN model to directly infer the depth for each pixel in which lots of work followed this line of research [11, 12]. Ummenhofer et al. [12] proposed a deep model to infer both ego-motion from sequence of frames to leverage motion in the depth estimation. Finally, Fu et al. [13] proposed to discretize depth and cast the problem as a multi-class classification with ordinal regression loss. However, for all these methods, the supervised paradigm requires a large amount of labeled data available to successfully learn a robust depth estimation. Acquiring such data is expensive and even with LiDAR data available, careful manual filtering of wrong projections [14] and removing the twist effect due to orbital nature of the sensor is still required.
Unsupervised monocular depth estimation. To avoid the issue of labeled data availability, recent work were proposed by posing the problem as image reconstruction. The ground-truth labels were replaced by different cues and losses from sequence of images [15] or view synthesize [16, 17]. Godard et al. [1] samples the right image from learned disparity through differentiable bilinear module given stereo input. Zhou et al. [15] proposed to jointly predict the relative pose between unconstrained video sequences as well as computing the reconstruction loss between them. This has the advantage of removing the need of stereo pairs, but produces a less accurate final model due to moving objects. Finally closest to our focus, Poggi et al. [2] proposed PyD-Net, a small sized CNN trained in similar setup as [1] and allow for an affordable model on CPUs.
3 Method overview
In this section, we describe our end-to-end joint pruning method for monocular depth estimation. We base our solution on the unsupervised image reconstruction proposition by Godard et al. [1].
The pipeline contains two main losses: 1) Task loss, and 2) sparsity loss. Task loss includes all losses with image reconstruction, disparity smoothness, and lr-consistency. The sparsity loss is applied on the masks with -norm to encourage our model with fewer features.
Task loss. We train all the models with three weighted losses contributing to the final task loss as formulated in [1].
[TABLE]
Each loss term is calculated for both left and right images in the stereo input pair. The first term calculates the reconstruction loss between the original image and the warped image using SSIM [18] and difference. The second term encourages disparity discontinuities only at gradient of image . Finally, the left-right consistency term enforces coherence between predicted left disparity and predicted right disparity .
Mask sparsity loss. This loss term controls the model size. Before diving into the sparsity loss, we explain the masking formulation. First, we initialize real-valued mask for each layer with filters. A binary function is then applied on the real-valued masks to get based on a threshold (e.g outputs 1 and 0 otherwise). Finally, is applied on all the masks to form a sparsity loss term:
[TABLE]
where is the total number of layers in the network. Looking carefully at (2), as vectors are binary, the loss term is calculating the ratio between the total number of filters in the new model and the original large model. Minimizing this loss is equivalent to maximizing the compression rate. Our total loss is then given by
[TABLE]
Forward pass. Let be the th feature map of the th layer, the new feature map and binary mask are thus given by:
[TABLE]
We apply a sigmoid function on our real-valued masks to transfer the input into [0,1] range before passing though binarization. This simplifies the selection of threshold as a sensible choice would be 0.5. Finally, is passed as the new ()th layer’s input which corresponds to either or 0. Zeroing out a feature map simulates dropping the corresponding filter . Figure 2 shows the masking block embedded within the network summarizing the forward pass.
Backward pass. In the backward pass, we update the convolutional kernels and for each layer. As is a conditional non-differentiable function, we backpropagate the gradients to utilizing the straight-through-estimator (STE) proposed in [7]. They showed that we can approximate the gradient of a real valued weight with the gradient of its discretization. Even though gradients calculated through such a function (e.g ) are noisy, they serve as regularizers and are acceptable approximation of the true gradients to the real-valued masks. Using STE and from 4, we have the gradients as:
[TABLE]
The double sum stems from the fact that is shared among all spatial locations in .
4 Experiments and analysis
4.1 Experiments setup
We train all networks with 50 epochs, batch size 8, and Adam optimizer [19] with the default parameters 0.9 and 0.999. We set a learning rate scheduler that is initially set with and is halved each 10 epochs after the first 30 epochs. Binary masks are initialized with 1 to keep all the filters. Finally, we perform data augmentation on the fly by randomly flipping the input images horizontally and applying image transformation on the color spectrum as in [1].
We evaluate our pipeline with state-of-the-art large deep models and small proposed models for monocular depth estimation. The evaluations are done on KITTI dataset [14] on both Eigen and KITTI splits. We also make use of Cityscapes dataset [20] which is a large collected dataset containing 22,973 training stereo pairs. However, the provided depth images are generated using SGM [21], so not suitable for evaluation. We use it for pre-training and then fine-tuning on KITTI as previous work.
4.2 Evaluation
Results are compared using depth metrics from [10] but some are discarded due to limited space.
KITTI split. Table 1 shows the comparison on KITTI split with different deep models. As shown, our end-to-end pruning method achieved around 5x reduction in the number of parameters with small drop in accuracy. As the compression rate is optimized within the network, obtaining exact number of parameters for fair comparison with same sized models is hard. Although PyD-Net has fewer parameters, our method was able to generate an on par small sized model without manually engineering the model footprint. Interestingly, training the network with masks without enforcing compressing by optimizing only as described in Eq.1 provided a form of regularization to the network and improved the accuracy of the original trained network. This is similar to dropout [23] as dropping features in the training breaks co-adaptation between the features. VGG + outperforms VGG LRC with post-processing which requires double the time for two forward passes and achieves similar accuracy to Resnet50 LRC with 2x less parameters.
Eigen split. Table 2 shows evaluation on Eigen split with the other methods reporting on Eigen for completeness even with the noisy quality of the LiDAR ground truth. Our smaller models achieve better accuracy than the supervised methods [10, 22] and unsupervised method [15]. Interestingly, the gap in accuracy (e.g 5th column) between our pruned model and PyD-Net differs based on the training data. As small models require large amount of data (e.g CS+K) to achieve good results, our method on the other hand benefits from the pre-trained large model even when trained with KITTI dataset only. This shows the benefit from pruning rather than training from scratch specially with limited training data.
Qualitative results Figure 3 shows some qualitative comparison to LRC [1] and PyDNet [2]. Although our pruned model is 5x smaller than LRC, they still produce similar good quality smooth output. Our model benefits from the pre-trained VGG model to produce smooth output and not as noisy as the case with similar small sized model PyDNet. It is worth noting that small models (ours and PyDNet) better regularize scenes with fewer data in the training unlike LRC as shown in third column. However, the pruned model shows accuracy drop with small objects (e.g poles).
4.3 Conclusion
We proposed a lightweight model for monocular depth estimation motivated by pruning literature. Our joint end-to-end pruning is scalable for deep models adopted in depth estimation. We learn binary masks within the network to drop filters jointly without predefining layerwise compression rates. We showed how pruning benefits small model training compared to training from scratch specially with limited data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Clément Godard, Oisin Mac Aodha, and Gabriel J Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in CVPR , 2017, vol. 2, p. 7.
- 2[2] Matteo Poggi, Filippo Aleotti, Fabio Tosi, and Stefano Mattoccia, “Towards real-time unsupervised monocular depth estimation on cpu,” ar Xiv preprint ar Xiv:1806.11430 , 2018.
- 3[3] Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” ar Xiv preprint ar Xiv:1207.0580 , 2012.
- 4[4] Yihui He, Xiangyu Zhang, and Jian Sun, “Channel pruning for accelerating very deep neural networks,” in International Conference on Computer Vision (ICCV) , 2017, vol. 2.
- 5[5] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean, “Distilling the knowledge in a neural network,” ar Xiv preprint ar Xiv:1503.02531 , 2015.
- 6[6] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf, “Pruning filters for efficient convnets,” ar Xiv preprint ar Xiv:1608.08710 , 2016.
- 7[7] Yoshua Bengio, Nicholas Léonard, and Aaron Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” ar Xiv preprint ar Xiv:1308.3432 , 2013.
- 8[8] Ashutosh Saxena, Min Sun, and Andrew Y Ng, “Make 3d: Learning 3d scene structure from a single still image,” IEEE transactions on pattern analysis and machine intelligence , vol. 31, no. 5, pp. 824–840, 2009.
