Capturing Evolution Genes for Time Series Data
Wenjie Hu, Jianping Huang, Liang Wu, Yang Yang, Zongtao Liu, Zhanlin, Sun, Bingshen Yao, Ke Chen

TL;DR
This paper introduces a novel framework for modeling time series data by capturing latent user behavior patterns, called evolution genes, which improve prediction accuracy and provide interpretability.
Contribution
It proposes a unified approach to identify evolution genes in time series using classification and adversarial generation, enhancing both prediction and explanation capabilities.
Findings
Achieved an average +10.56% F1 score improvement
Effectively captures latent user behaviors
Provides interpretable insights into time series evolution
Abstract
The modeling of time series is becoming increasingly critical in a wide variety of applications. Overall, data evolves by following different patterns, which are generally caused by different user behaviors. Given a time series, we define the evolution gene to capture the latent user behaviors and to describe how the behaviors lead to the generation of time series. In particular, we propose a uniform framework that recognizes different evolution genes of segments by learning a classifier, and adopt an adversarial generator to implement the evolution gene by estimating the segments' distribution. Experimental results based on a synthetic dataset and five real-world datasets show that our approach can not only achieve a good prediction results (e.g., averagely +10.56% in terms of F1), but is also able to provide explanations of the results.
Click any figure to enlarge with its caption.
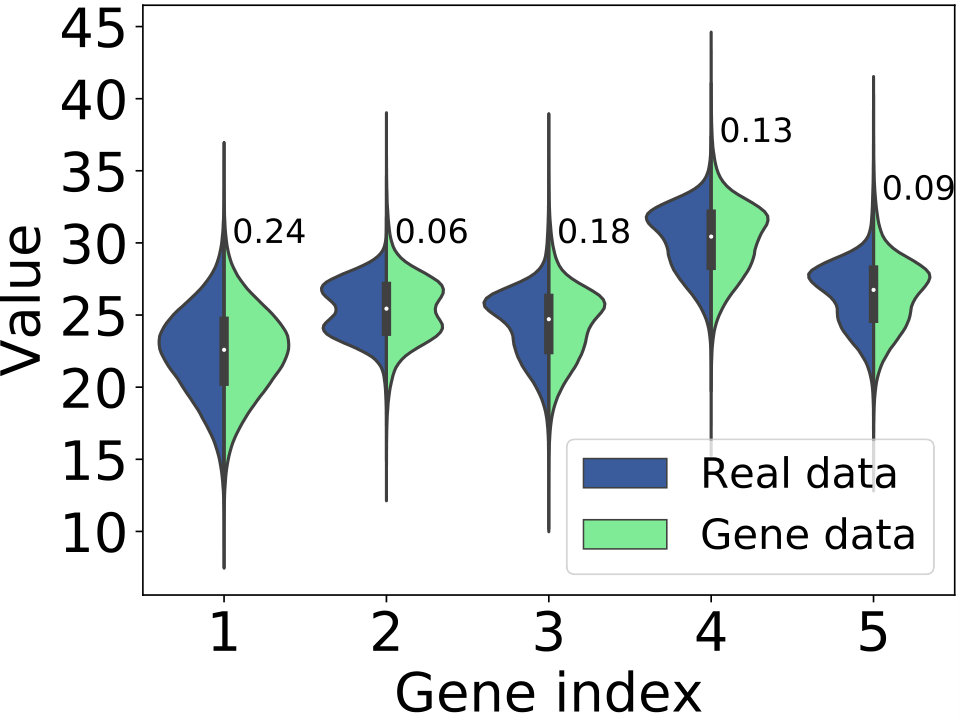 Figure 1
Figure 1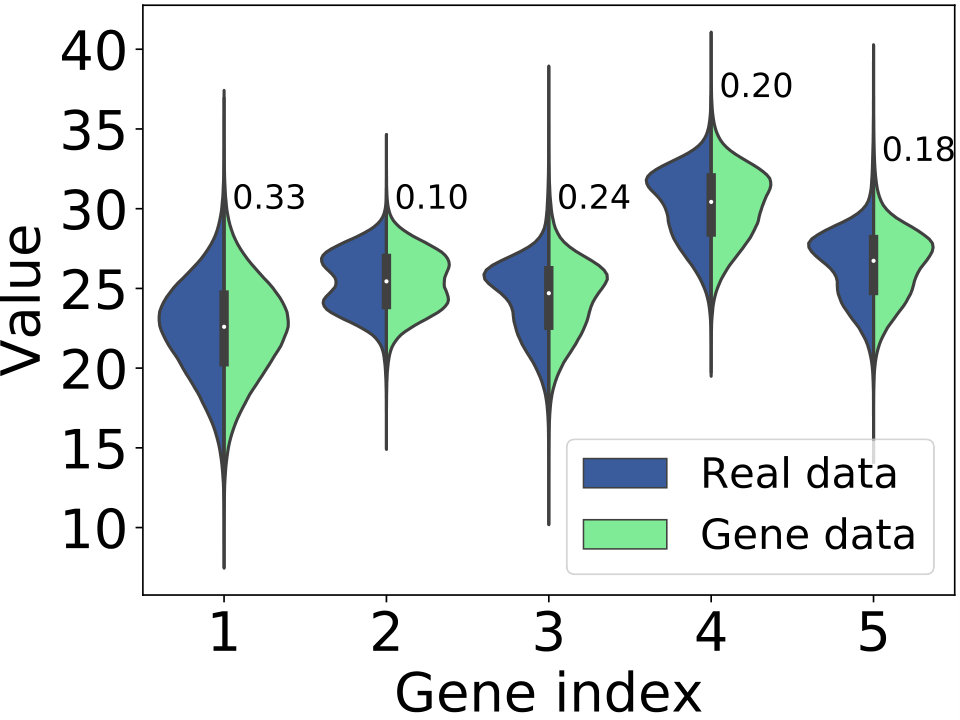 Figure 2
Figure 2 Figure 3
Figure 3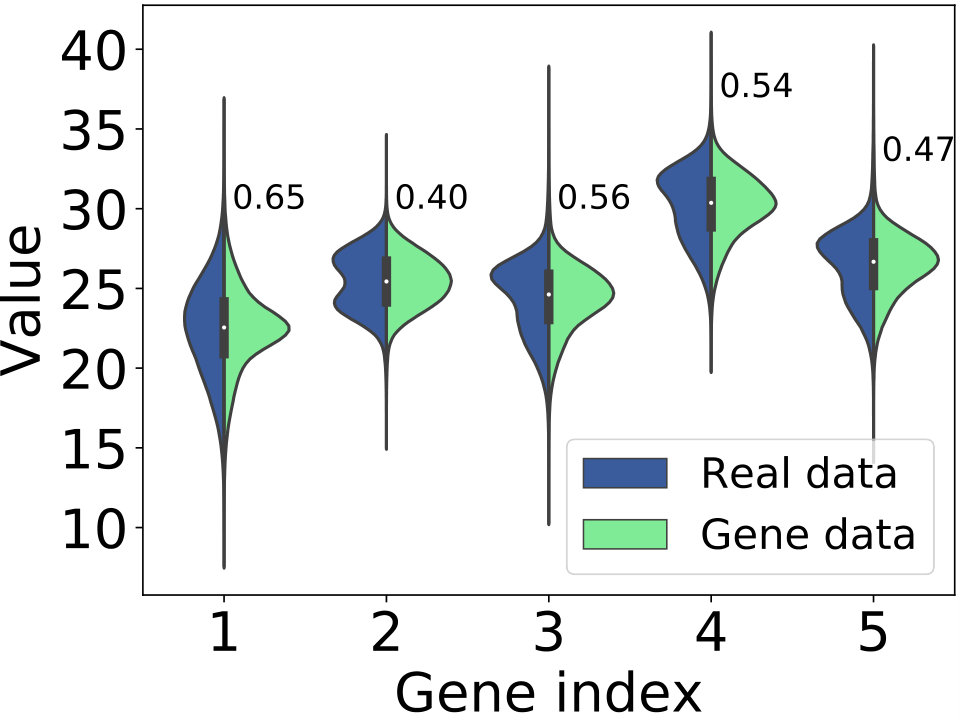 Figure 4
Figure 4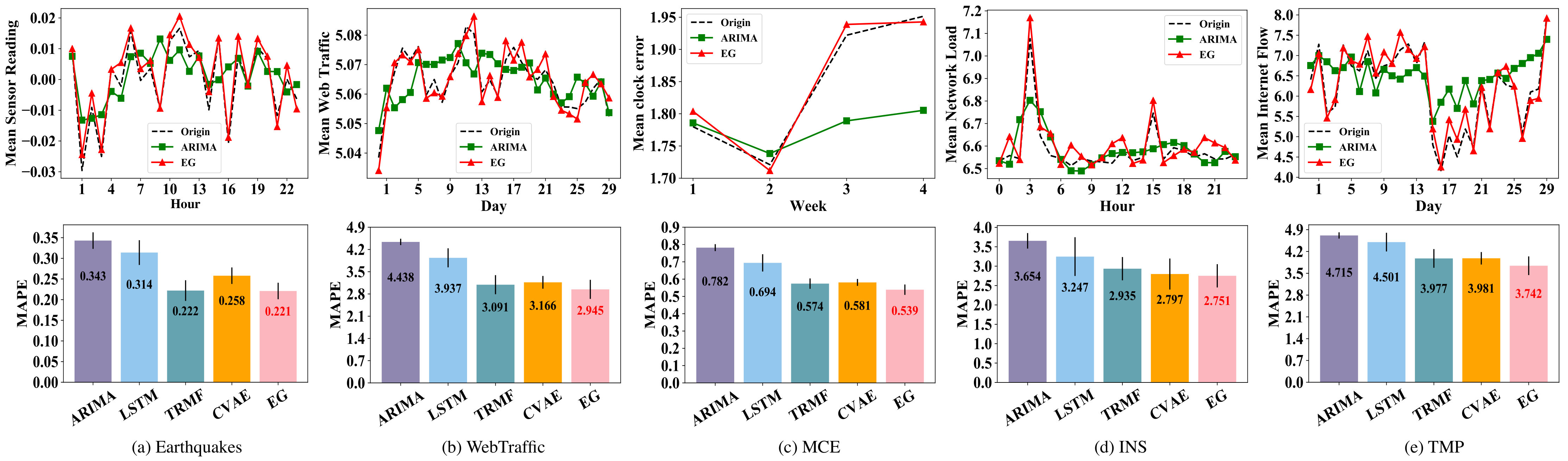 Figure 5
Figure 5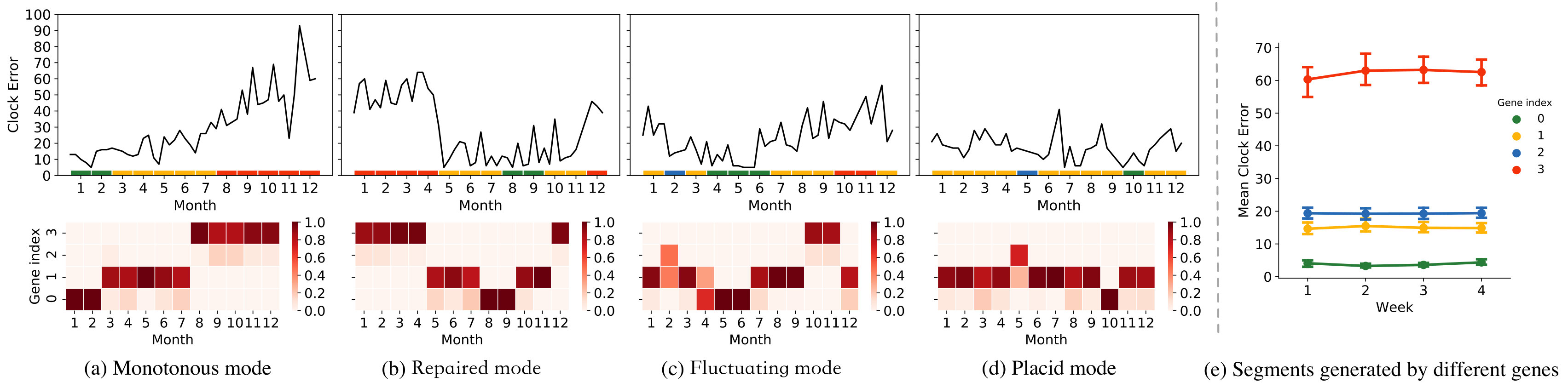 Figure 6
Figure 6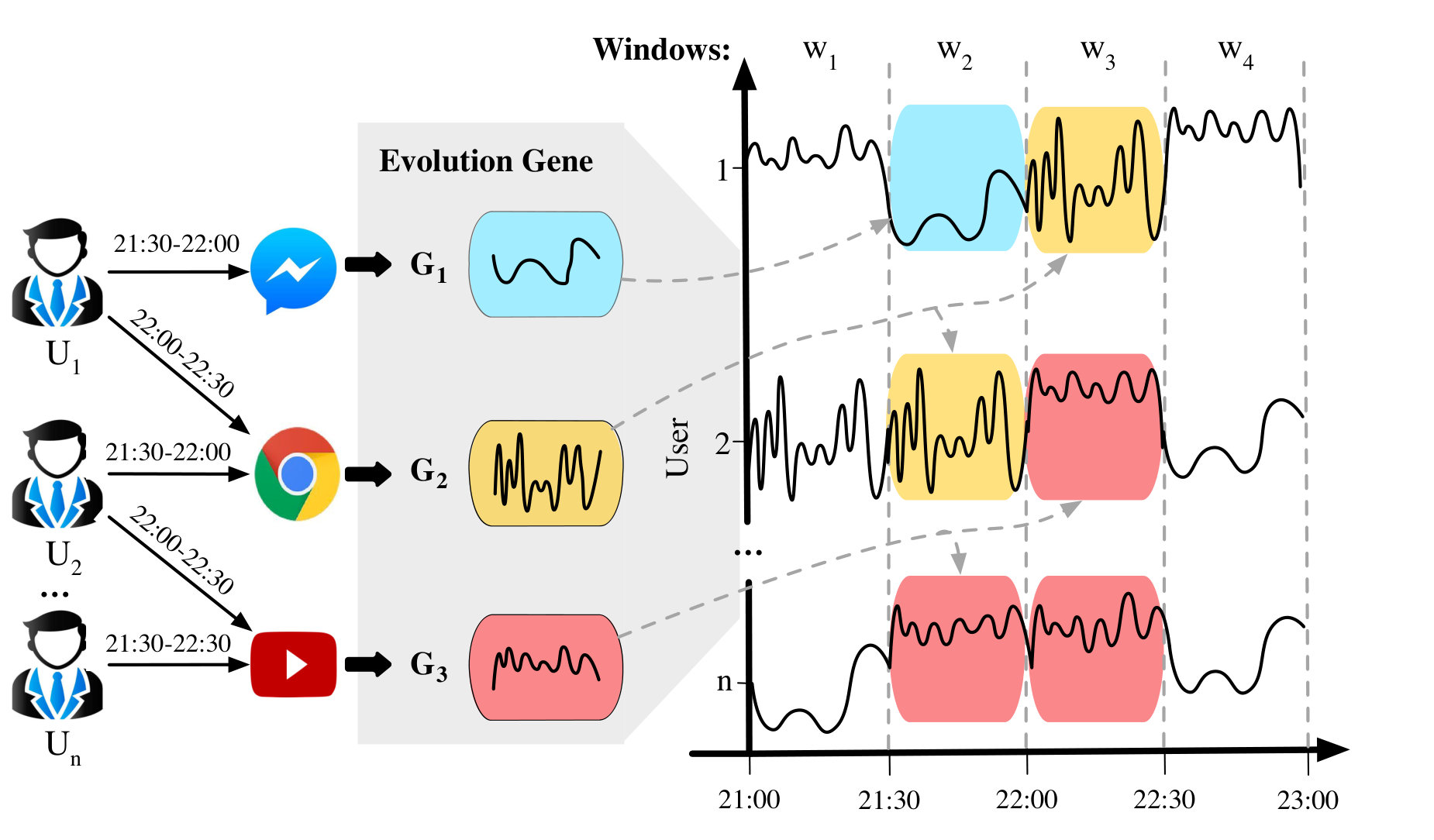 Figure 7
Figure 7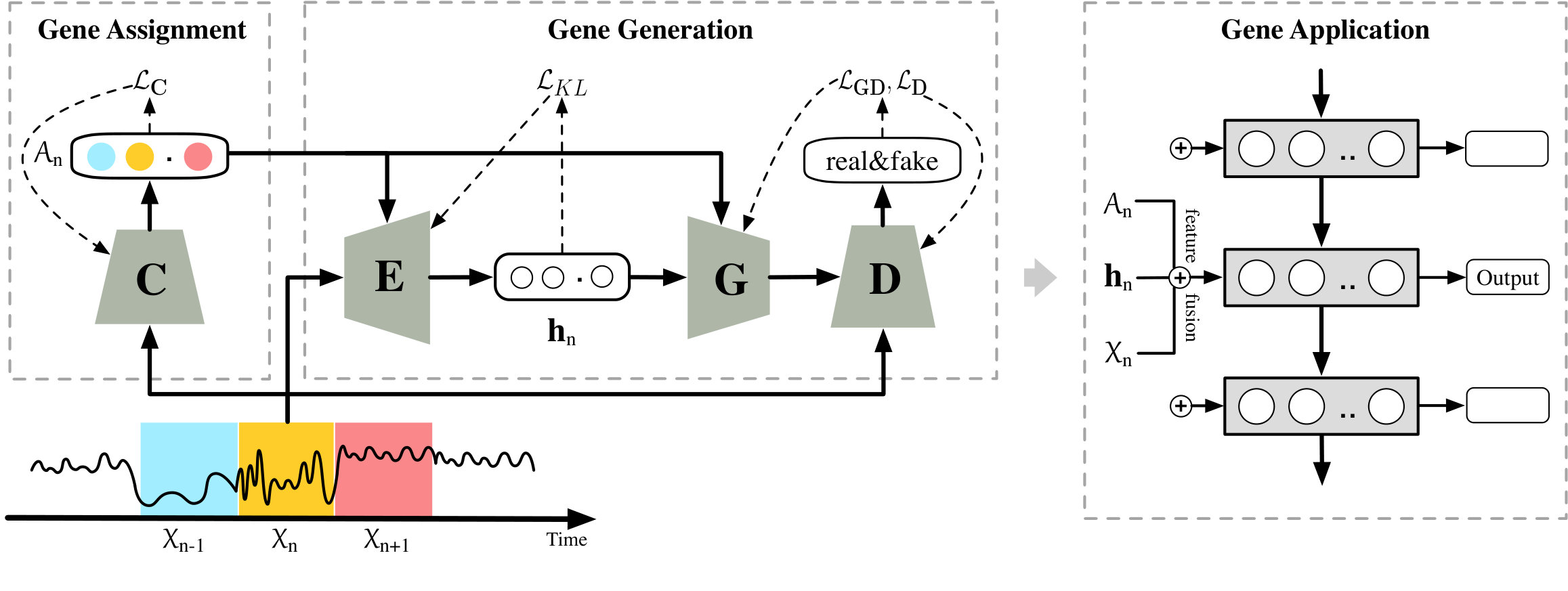 Figure 8
Figure 8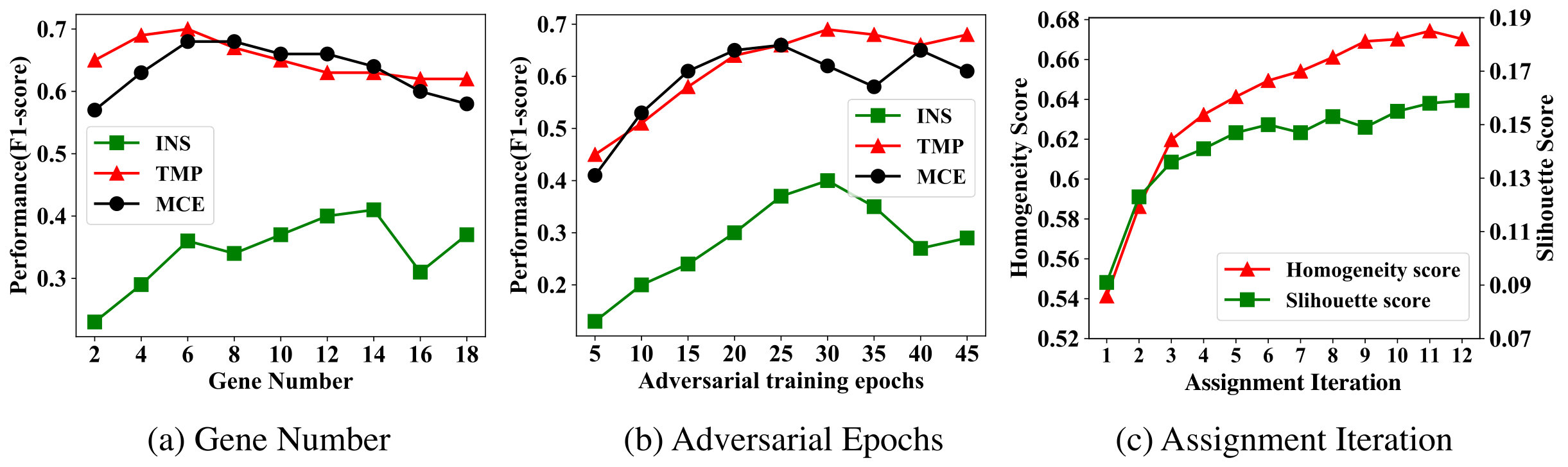 Figure 9
Figure 9| NN-ED | NN-DTW | NN-CID | FS | TSF | SAX-VSM | MC-DCNN | LSTM | CVAE | GeNE | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| WebTraffic | Precision | ||||||||||
| Recall | |||||||||||
| ClockErr | Precision | 59.90 | 60.17 | 57.12 | 54.34 | 76.80 | 65.12 | 78.94 | 79.69 | 77.92 | 80.33 |
| Recall | 34.82 | 41.41 | 40.86 | 43.54 | 52.61 | 59.96 | 49.27 | 53.56 | 54.12 | 58.17 | |
| 44.01 | 49.04 | 47.55 | 48.34 | 62.50 | 62.44 | 60.70 | 64.10 | 64.32 | 67.45 | ||
| NetFlow | Precision | 28.51 | 27.14 | 52.65 | 31.66 | 48.11 | 62.71 | 53.77 | 60.25 | 63.27 | 71.50 |
| Recall | 19.33 | 21.73 | 10.25 | 16.73 | 21.04 | 28.41 | 5.79 | 28.01 | 26.78 | 33.15 | |
| 23.01 | 24.13 | 17.05 | 21.84 | 29.13 | 40.11 | 10.38 | 38.23 | 37.57 | 45.34 | ||
| MonthPlan | Precision | 54.43 | 51.95 | 56.12 | 65.17 | 54.20 | 72.22 | 76.79 | 56.21 | 74.86 | 80.23 |
| Recall | 47.88 | 52.43 | 49.26 | 58.82 | 60.94 | 59.05 | 66.13 | 53.15 | 59.22 | 64.57 | |
| 50.95 | 52.14 | 52.44 | 61.85 | 57.42 | 64.94 | 71.06 | 54.63 | 66.14 | 71.55 | ||
| Metric | K-means | Agglo | Birch | HMM | GMM | GeNE |
|---|---|---|---|---|---|---|
| Homogeneity | 0.546 | 0.533 | 0.537 | 0.612 | 0.637 | 0.674 |
| Silhouette score | 0.091 | 0.089 | 0.092 | 0.101 | 0.112 | 0.158 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTime Series Analysis and Forecasting · Anomaly Detection Techniques and Applications · Stock Market Forecasting Methods
Capturing Evolution Genes for Time Series Data
Wenjie Hu*†, Jianping Huang∗, Liang Wu∗, Yang Yang†, Zongtao Liu†, Zhanlin Sun†, Bingshen Yao§, Ke Chen∗*
†College of Computer Science and Technology, Zhejiang University, Hangzhou, China∗State Grid Zhejiang Electric Power Supply Co. Ltd., China§Rensselaer Polytechnic Institute, Troy, New York, USA†{aston2une, yangya, tomstream, zhanlinsun15}@zju.edu.cn, ∗{huang_jianping, wuliang1127, chenke}@zj.sgcc.com.cn, *§*[email protected]
(2019)
Abstract.
The modeling of time series data is becoming increasingly critical in a wide variety of applications. Overall, data evolves by following different patterns, which are generally caused by different user behaviors. Given a time series, we define the evolution gene to capture the latent user behaviors and to describe how the behaviors lead to the generation of time series. In particular, we propose a uniform framework that recognizes different evolution genes of segments by learning a classifier, and adopt an adversarial generator to implement the evolution gene by estimating the segments’ distribution. Experimental results based on a synthetic dataset and five real-world datasets show that our approach can not only achieve a good prediction results (e.g., averagely + in terms of F1), but is also able to provide explanations of the results.
Time series, evolution gene, generative model
††copyright: acmlicensed††conference: ; ; ††journalyear: 2019††price: 15.00††doi: 10.1145/1122445.1122456††isbn: 978-1-4503-9999-9/18/06
1. Introduction
The modeling of time series data has attracted significant attention from the research community in recent years, due to its broad applications in different domains such as financial marketing and bioinformation(Janakiraman et al., 2017; Du et al., 2016; Barbosa et al., 2016; Chapfuwa et al., 2018). For example, a communication company might formulate a user’s network flow as a time-sensitive segments , where each element denotes how the user uses flow at the -th time window. The systems then work to understand the user’s behavior behind each segment, and predict his or her flow cost in future. Appropriate phone plans are then recommended to the user on the basis of this model. More specifically, users’ flow-costs evolve over time by following different patterns. As Figure 1 illustrates, when watching movies, a user begins to use a certain volume of flow in a certain time period, but uses a low flow during the chat. Meanwhile, another user has unstable flow loads when surfing the Internet, that flow will be higher when clicking pages and lower when reading pages.
Different evolution patterns of time series reflect different user behaviors, which exist a certain regularity. For example, users usually browse the Internet for some information after chatting, or spend a long time watching a movie, and occasionally cut out because of chatting. Thus, if a method is able to extract user behaviors behind given segments, learn how each behavior leads the generation of segment, and capture the transition of user behaviors, it can be more predictive in time series. However, to the best of our knowledge, most existing works, such as deep neural network-based models (e.g., LSTM and VAE) (Du et al., 2016; Kingma and Welling, 2014) do not distinguish different patterns and use only one single model for generating all data. Meanwhile, traditional mixture models (e.g. GMM and HMM) (Bouttefroy et al., 2010; Yang and Jiang, 2014) ignore the transition of user behaviors over time which turns out to have good performances in recent research.
**Evolution gene. ** In this paper, we propose the concept of evolution gene (or gene for short) to quantitatively describe how each kind of user behavior generates the corresponding time series. More specifically, we define the gene as a generative model that captures the distribution patterns and learns to generate the segments. As shown in Figure 1, there are three different genes, each corresponding to a particular user behavior. For instance, generates the flow segments of chatting online, while generates the flow segments of watching movies. For a given sequence of time series segments , we aim to learn and extract the gene of each segment , based on which we further predict the future value and the event that will happen at the time window .
This problem is nontrivial. A straightforward baseline is to first cluster these segments, assign each cluster a gene, and then learn the generator for each cluster independently. However, other than considering the distance of samples like most clustering algorithms do, our goal is to determine which segments share similar distribution and sequential patterns. Therefore, the above baseline does not work well, as will be demonstrated in our experiments (see Table 2). The question of how to design an appropriate algorithm to recognize genes is the major challenge in this work.
Once aware of time series genes, we then aim to estimate what event will happen in future. Traditional works mainly predict events according to the data value of a snapshot, such as dynamic time warping (Lines and Bagnall, 2015), complexity-invariant distance(Batista et al., 2014) and elastic ensemble(Lines and Bagnall, 2015). They concentrate on different distance measurements and find the nearest sample. However, the behaviors’ evolution are more important for the prediction task. For example, an watt-hour meter experiencing a sudden drop in electricity consumption implies an abnormal event, which may be either caused by early damage to the meter or power-stealing behavior. Building the connection between the behavior evolution and the future event is another challenge.
Here, we propose a novel model: Generative Mixture Nonparam-etric Encoder (GeNE), which distinguishes the distribution patterns of time series by learning generating the corresponding segments. This model has three major components: gene recognition, aims at learning the corresponding genes of segments; gene generation, aims at learning generating segments from each gene; gene application, aims at modeling the behavior evolution and applying the learned genes to future value and event prediction.
We evaluate the proposed model on a synthetic dataset and four real-world datasets. The experimental results demonstrate our advantage over several state-of-the-art algorithms on three different tasks (e.g., averagely + in terms of F1). Moreover, we demonstrate some meaningful interpretation of our method by visualizing the behavior evolution. We apply our method to predict clock error fluctuation of watt-hour meter in the State Grid of China111The state-owned electric utility of China, and the largest utility company in the world. and help to reduce electrical equipment maintenance workloads by 50%, which cost around $300 million per year222http://www.sgcc.com.cn/ywlm/index.shtml.
Accordingly, our contributions are as follows:
- •
We define the concept of evolution gene to formally describe how latent behaviors generate time series;
- •
We propose a novel and uniform framework that distinguishes the latent behaviors and model their evolution on time series.
- •
We construct sufficient experiments, based on both synthetic and real-world datasets, to validate whether our method is capable of modeling time series. Experimental results exhibit our method’s advantage over eleven state-of-the-art algorithms in different prediction tasks.
- •
We have deployed our model to the real scenario for identifying abnormal watt-hour meters, under the corporation with State Grid of China. Through the application, we find that the genes learned by our model can provide some explanations for the anomalies in practice.
2. Generative Mixture Nonparametric Encoder
2.1. Preliminaries
The task considered in this paper is to capture the behavior evolution behind time series, and then to utilize these patterns to predict the value and event that will happen in the future.
Formally, let be an observation-sequence with time windows in a time series data. Each is a segment in the time window whose length is . has a physical meaning, such as one day has 24 hours or one month has 30 days. Each is a single- or multi-variate observation with variables, denoted as . represents the future event occurring under observation-sequence , where is the set of markers and is the specific event marker. We define as the recognition probability of for behaviors, where and . We aim to infer the future values and event probability . Here, we propose a novel generative method to model the time series that focuses on distinguishing the distribution patterns of segments and their overall behavior evolution on the time series.
2.2. General Description
We propose a novel model, Generative Mixture Nonparametric Encoder (GeNE), which distinguishes different behaviors behind the time series by learning the corresponding genes, and captures distribution patterns of each segment to make prediction. We put these two objectives into a uniform framework. As Figure 2 shows, given the number of genes , the proposed model consists of three components: gene recognition, aims at recognizing the corresponding genes of segments. gene generation, aims at generating segments of each gene; gene application, aims at applying the learned genes to the downstream tasks, such as prediction or classification of time series.
**Gene recognition. ** This component is to recognize the corresponding genes of each segment , which can be implemented in several different ways like clustering algorithms. In this work, for distinguishing the distribution and sequential patterns of segments simultaneously, we propose a sequence-friendly classification network (implemented by RNN or LSTM) to improve the recognition from the clustering algorithms. We practically compare this method with other potential implementations and find that it has the best performance (see details in Table 2 of Section 3).
**Gene generation. ** This component is to learn genes for generating segments, which aims at capturing segments’ distribution patterns. In this work, gene generation is implemented by an adversarial generator , which structure is like CVAE-GAN (Bao et al., 2017), but the loss is more concise. It captures the superior distribution patterns which outperform other implementations (see details in Section 3).
**Gene application. ** Genes recognize the behaviors behind the segments, which is represented by the different distribution patterns. They can be combined sequentially on the time series , just like the biological genetic code. Hence, we propose a recurrent structure to combine these genes on the time series and apply them to the downstream tasks, which leads to a superior predictive and interpretive model as Section 3 and Section 4 show.
Overall, gene recognition provides the supervised information to guide the gene generation, which improves the ability of capturing segments’ distribution patterns. They are irrelevant to the downstream tasks and thus can be off-line trained. Gene application is based on the “end-to-end” learning, which adjusts gene recognition and generation for the real-time response. We will introduce each component in detail in the following chapters.
2.3. Gene Recognition
As described in Section 1, time series data evolves by different distributions, which are generally caused by different behaviors. Hence, we can find these behaviors behind the time series via capturing the distributions. However, the traditional clustering algorithms focus on the distance between different samples. They treat each variable as an independent individual without considering the sequential similarity, and thus is not suit for the gene recognition. We explore a novel method to overcome these difficulties mentioned above.
Generally, given the number of genes , we first initialize a recognition via traditional distance-based clustering algorithms , such as K-means, input of which is the mean and variance of each segment’s variables. The formulation is:
[TABLE]
The motivation here is that, if the mean and variance are close in distance, the segments are more likely to have a similar distribution (Bagnall et al., 2017), thus they should be recognized into the same gene.
However, there may be two segments with different sequential patterns but similar distribution, such as the trend, mutations, or zero numbers etc. Therefore, we need a method to distinguish these sequential patterns for recognizing genes. Following this idea, we design a sequence-friendly classification network , where is the model parameters, to capture the sequential patterns in segments and improve the quality of the current gene recognition. Specifically, the network takes raw segments as input and outputs a -dimensional vector, and then turns into probabilities using a softmax function. The output of each entry represents the probability . In the training stage, the deep neural network tries to minimize the cross-entropy loss as follow:
[TABLE]
where is the real empirical joint distribution of segments, which can be estimated by sampling. We take the network ’s recognition as the newly recognition and repeat the steps until the error rate converged, where and are the old and new gene recognition at each iteration. For the implementation of the classification network , we use RNN or a modern variant like LSTM, which is good at capturing the sequential patterns in the time series.
2.4. Gene Generation
The segments corresponding to the same gene have the similar distributions, that the non-parametric generative model is a natural and effective way to estimate them. As Figure 2 shows, we input segments with the gene recognition into a CVAE-GAN structure, which encode the segments into the hidden space under the condition of gene recognition, and discriminate the fake samples generated from the variational approach.
More specifically, for each segment and its gene recognition , each gene represents its distribution patterns by an encoder network , which obtains a mapping from the real segment to the hidden vector . We use a multivariate Gaussian distribution with a diagonal covariance structure to present the variational approximate posterior:
[TABLE]
Based on the variational approach, for each segment, when the encoder network outputs the mean and covariance of the hidden vector, genes can sample the hidden vector , where is a random vector and represents the element-wise multiplication. We use the KL loss to reduce the gap between the prior and the proposal distributions, i.e:
[TABLE]
After obtaining the mapping from to , each gene can then map the generated segments by an generator network, which formulates as . The discriminator network estimates the probability that a segment comes from the real samples rather than , which tries to minimize the loss function:
[TABLE]
where is the real empirical joint distribution and is a simple distribution, e.g., isotropic Gaussian or uniform. The training procedure for is to maximize the probability of making a mistake, while tries to minimize:
[TABLE]
In practice, the distributions of “real” and “fake” samples may not overlap with each other, especially at the early stage of the training process. Hence, the discriminator network can separate them perfectly, that is, we always have and . Therefore, when updating genes , the gradient . Consequently, the training process of will be unstable. Recent works (Gulrajani et al., 2017) also theoretically show that training GAN often involves dealing with the unstable gradient of .
To solve this problem, we use a mean feature matching objective for the gene. The objective requires the center features of the generated samples to match the center features of the real samples. Let denote features on an intermediate layer of the discriminator network. Then tries to minimize the loss function:
[TABLE]
In order to maintain simple in our experiment, we choose the input of the last fully connected layer of network as the feature . Both the and are trained by a stochastic gradient descent (SGD) optimization algorithm.
We present the procedure of Generative Mixture Nonparametric Encoder in Algorithm 1.
2.5. Gene Application and Learning
Genes recognize the behaviors behind the segments, which is represented by the different distribution patterns. They can be combined sequentially on the time series. The sequence of genes reveals the behavior evolution of this time series, which leads to a superior predictive and interpretive model (Section 4 will present it in detail). In this work, we propose a recurrent structure to combine these genes on the time series and apply them to the downstream tasks, which mainly focus on the prediction and classification of time series.
Formally, given observation-sequence , we first get all the gene recognition by network , and the distribution patterns of the most likely genes. We fuse these features using a hybrid RNN structure, as shown in Figure 2, which the latent vector is donated as .
**Feature Fusion. ** We update the latent vector after receiving the memory from the past, segment , gene recognition , and genes’ patterns . The formulation is:
[TABLE]
where , and are the learnable weight or bias vectors, and is the matrix product.
**Output ** The last application layer apply an “end-to-end" mechanism to the downstream tasks (predicting the future value and the event ). denotes the neural networks, which takes the last latent vector as input. For the value prediction, outputs a vector, and then turns into predicted value using a Relu function. In the experiment, we use DCNN (Zeiler and Fergus, 2013) as and back propagate mean-square loss to train the network, which the loss can be formulated as:
[TABLE]
For the event prediction, it can be turned into a classification problem. outputs a -dimensional vector, and then turns into probabilities using a softmax function. In the training stage, model tries to minimize the cross-entropy loss as follow:
[TABLE]
Above all, we can enhance the performance of prediction by genes.
**End-to-end learning. ** We next introduce the end-to-end learning of GeNE. The complete loss of GeNE network is as follows:
[TABLE]
where are tuning parameters, which control the trade-off between the gene recognition and gene generation relative to the gene application objective. In our experiments, we set .
Intuitively, classifier is trained to fit the current recognition of segments. Meanwhile, the elements () of genes are trained via an adversarial process on the real/fake samples under the condition of ’s output. More specifically, in each iteration, we first train to output the current recognition, and then train to capture the segments’ distribution. The recognition of distinguishes the segments and gives them specific gene index , so that unsupervised adversarial training is transferred to supervised adversarial training. It improves the ability of the gene to capture distribution patterns. Then, we compare the new and old recognition and determine whether to end the iteration. For the application layer, recursive hidden vector fuses these patterns transferred from gene recognition and generation, and applies them into the prediction tasks. We back propagate the loss to learn the gene application and use lower learning rate to adjust gene recognition () and gene generation (). We present the complete procedure in Algorithm 2.
3. Experiment
3.1. Datasets
We employ five datasets to construct our experiments, including a synthetic dataset and four real-world datasets. A synthetic dataset is used to validate the recognition and generation of genes, and real-world datasets are used to validate the effectiveness of GeNE by application. One real-world dataset comes from Kaggle333https://www.kaggle.com. The State Grid of China, the largest utility company in the world, and China Telecom, the major mobile service provider in China, provide the other three datasets.
**Synthetic. ** We generate five clusters of synthetic samples in . Each sample is a multivariate series with 10 sequential windows; each segment has 20 time points, and each point contains 3 variables. Each cluster has 10K samples. In particular, for the -th cluster, each dimension of a sample is generated using a mixed Gaussian distribution with mean and standard deviation : . The mean and standard deviation are acquired randomly,
**Web Traffic Time Series Forecasting (WebTraffic). ** This dataset comes from Kaggle, which is taken from Jul 1st 2015 up until Dec 31st 2016 and each data point is the number of daily views of the Wikipedia article. We set a classification task of predicting whether there will be rapid growth (the curve slope greater than 1) in next months (30 days) based on the most recent readings in the past year (12 months). In total, we extract 105k negative cases and 38k positive cases from 145k daily readings.
**Information Networks Supervision (NetFlow). ** This dataset is provided by China Telecom. It consists of around 242K network flow series, each of which describes hourly in- and out-flow of different servers, spanning from Apr 1st 2017 to May 10th 2017. When an abnormal flow goes through server ports, the alarm states will be recorded. Our goal is to use the daily network flow data within 15 days to predict if there will be an abnormal flow in the next day. In total, we identify 2K abnormal flow series and 240K normal ones.
**Telecom Monthly Plan (MonthPlan). ** This dataset is also provided by China Telecom. It includes daily mobile traffic usage for 120K users from Aug. 1st 2017 to Nov. 30th 2017. For a user in each day, we obtain 12 kinds of traffic usage records (e.g., total usage, local usage, etc.). In this case, we predict whether a user will switch to a new monthly plan, which is associated with high limitation of mobile traffic, according to her recent three-month traffic usage. Considering only 0.05% of all users adopt the new plan, we use an under-sampling method and obtain a balanced data subset with 16K instances for cross-validation.
**Watt-hour Meter Clock Error (ClockErr). ** This dataset is provided by the State Grid of China. It consists of around 4 million clock error series, each of which describes the deviation time, compared with the standard time, and the communication delay of different watt-hour meters per week, The duration is from Feb. 2016 to Feb. 2018. When the deviation time exceeds 120s, the meter will be marked as abnormal. Our goal is to predict the potential abnormal watt-hour meters in the next month by utilizing clock data from the past 12 months. In total, we identify 0.5 million abnormal clock error series and 3.5 million normal ones. We will give a more concrete description of the background of this dataset in Section 4.
3.2. Validation on Synthetic Data
**Performance on gene recognition. ** In the synthetic data, we set supervised (homogeneity) and unsupervised (silhouette coefficient) evaluation metrics. The homogeneity score indicates whether all of its subsets contain only data points which are members of a single gene, and the silhouette score indicates how well each object lies within its gene. We compare GeNE’s result with those obtained by several different clustering algorithms, including K-means clustering, Agglomerative, Birch clustering, Hidden Markov Model (HMM) (Yang and Jiang, 2014) and Gaussian Mixture Model (GMM) (Bouttefroy et al., 2010) . As Table 2 shows, K-means performs relatively better than Agglomerative, Birch clustering, which illustrates the distance is a significant indicator for the high-dimensional time series. The performance of HMM and GMM presents that distribution is critical for modeling time series. GeNEachieves the highest score in both homogeneity and silhouette score, which suggests that classification network captures the sequential patterns in segments and outperforms in distinguishing genes.
**Performance on gene generation. ** Figure 3 presents the generative distribution of each gene learned by different methods on synthetic data. According to the result of CVAE (Figure 3(b)), each generated sample shows a similar mean but different variance. CGAN’s generated samples are similar to real ones (Figure 3(c)), and can even fit bimodal distribution as the second gene. We can see that GeNE obtains better results than CGAN and CVAE, as is more similar to the distributions of original samples. This proves that GeNE performs better at capturing the distribution patterns of segments.
3.3. Predicting Future Event
We then evaluate our proposed model in terms of its accuracy in predicting future events, which then turns into a classification problem of given . We compare our proposed model against the following night baseline models, which have proven to be competitive across a wide variety of prediction tasks:
- •
NN-ED, NN-DTW and NN-CID: Given a sample, these methods calculate their nearest neighbor in the training data and use the nearest neighbor’s label to classify the given sample. To quantify the distance between samples, they consider different metrics, which are, respectively, Euclidean Distance, Dynamic Time Warping (Berndt and Clifford, 1994) and Complexity Invariant Distance (Batista et al., 2011).
- •
Fast Shapelets (FS): This is a fast shapelets algorithm that uses shapelets as features for classification (Rakthanmanon and Keogh, 2013).
- •
Time Series Forest (TSF): This is a tree-ensemble method that derives features from the intervals of each series (Deng et al., 2013).
- •
SAX-VSM: This is a dictionary method that derives features from the intervals of each series (Senin and Malinchik, 2013).
- •
MC-DCNN and LSTM: These are two deep neural network-based methods proposed in (Zheng et al., 2014) and (Hochreiter and Schmidhuber, 1997) respectively.
Besides the above methods, we further consider the following generative models as baselines:
- •
CVAE: This method uses CVAE (Sohn et al., 2015) as gene without discriminator and uses the same feature fusion method for prediction.
- •
GeNE: This is the proposed method. We use as to train GeNEnetworks.
**Comparison results. ** Table 1 compares the results of event prediction. We use precision, recall and F-measures () as metrics. Here, we prefer to use as metric because precision is more important than recall in this scene. We observe that all quantifying-distance methods based on nearest neighbors perform similarly but are unstable, which may be attributed to peculiarities in the data, since the NN-DTW method does not outperform on the INS and TMP datasets. Moreover, feature-extracted methods have relatively better recall on MCE and TMP datasets, such as the dictionary-method SAX-VSM, but precisions do not outperform simultaneously, which may not adapt to the unbalanced sample. The neural network approaches (MC-DCNN, LSTM) perform poorly on small-scale data (Earthquakes), for they might be more suitable for processing large-scale data due to their model complexity. The generative method utilizes the genes’ distribution patterns and models the behavior evolution, which leads to a better performance on the five real-world datasets. CVAE outperforms near-neighbor methods on all datasets, which attributes to modeling behavior evolution behind the time series. As we expected, due to the ability to fitting distribution better, GeNEperforms better than CVAE and outperforms these baselines.
3.4. Parameter Analysis
Finally, we study the sensitivity of the model parameters: iterations of recognition (), adversarial epochs () and the number of genes (). We present the results on synthetic dataset and three real-world datasets. we use the performance of F1 score, which is based on the future event prediction, as metric, and compare the different hyper-parameters, Figure 4(a) shows that the gene number influences the model performance differently on the three real-world datasets. The F1 score is not bound to improve as the gene number increases and the peaks of gene number in TMP and MCE datasets are around 6 and 8 but the peak in INS dataset is around 14. We conclude that this is an empirically determined parameter that may vary across different datasets. Figure 4(b) presents that the performance of GeNEon future event prediction is positively related to the training epoch at first, after which there are fluctuations that may be caused by the instability of adversarial training. As shown in Figure 4(b), the best parameter of adversarial training epochs in the three real-world datasets are around 25 to 30. Finally, Figure 4(c) shows how influences the performance of gene recognition. We compare the homogeneity score and silhouette score in different iterations. We can see the fully trained classifier is the prerequisite for learning patterns of the gene. The growth curve approximates the log function, which grows fast in the early stage and tends to stabilize in the later stage.
4. Application
We have deployed GeNE to State Grid Wenzhou Power Supply Co. Ltd. to detect abnormal status of watt-hour meters. More specifically, GeNE will detect high-risk meters at the beginning of every month, identify the factor that causes the abnormality by analyzing the behavior evolution of meters (Here, the behaviors of watt-meters are the different levels of indications), and suggest engineers to adopt corresponding strategies in advance. It turns out that GeNE is able to reduce the maintenance workloads of watt-hour meters by 50%, which costs around $300 million per year previously. In this section, we will introduce the background of this application and present a case study to demonstrate that GeNE not only achieves around 80% precision of anomaly prediction, but precisely captures the different evolution modes of watt-hour meters. For simplicity, we use four genes to present this application.
**Background. ** In a watt-hour meters, the clock is one of the basic and the most important components, whose accuracy is directly related to whether the meter can accurately measure the data in different time periods. However, due to several factors, such as inaccurate clock synchronization signals, the crystal oscillator of device, communication delay, and device response delay, the time recorded by the watt-hour meter may deviate from the standard time inevitably. Furthermore, different factors on the watt-hour meter will lead the clock error to evolve by following different modes. For example, the crystal oscillator will cause the clock error to fluctuate in one direction, while unstable communication environment will lead to the swinging clock error. Therefore, discovering these different evolution modes of clock errors has great significance for diagnosing and maintaining watt-hour meters. Our method is expected to not only predict the error state of the given watt-hour meter, but also reveals different evolution modes of clock errors. In particular, we manually find four most representative evolution modes as follows:
- •
Monotonous mode: The clock error fluctuates in one direction over time (12 months), which may be caused by the crystal oscillator of device.
- •
Repaired mode: The clock error will recover at a certain time, which may caused by receiving the clock synchronization signals from the superior terminal.
- •
Fluctuating mode: The clock error fluctuates violently, which may be caused by the poor communication environment.
- •
Placid mode: The clock error fluctuates gently, which is the ideal status of healthy watt-hour meters.
The above four patterns have covered over 93% samples. Therefore we mainly study these representative patterns and ignore others (e.g., sudden drop or rise of clock error) in this section.
**Recognizing evolution modes. ** Is the proposed model able to disclose and model these four evolution modes? Before we answer this question, we present the different watt-meters’ behaviors by the average value of clock error that generated by different genes in Figure 5(e). We see that average clock error of gene #3 is significant larger than that of other genes, which suggests that gene #3 denotes an “abnormal behavior” corresponding to abnormal watt-hour meters.
Figure 5(a)-(d) visualizes four watt-hour meters with observed clock errors that follow different evolution modes (in plots) and how GeNErecognizes genes to each segment (in heat map, where the y-axis indicates the probability of each gene being recognized to the segments at different time). For example, the clock error that evolves by following the monotonous mode keeps small value at first, and will keep growing over time (Figure 5(a)). Correspondingly, we see that our model captures this process and tends to recognize “normal behavior” to the sample first, while eventually determines it has the “abnormal behavior” (i.e., gene #3). Therefore, we see that the way our model learn genes is identical to the monotonous mode. Similar results can be observed in other three modes. In particular, our model recognizes “normal behaviors” and “abnormal behaviors” alternately to the watt-hour meter with repaired mode and fluctuating mode (Figure 5(b)-(c)), while tends to keep recognizing “normal behaviors” to the samples with placid mode (Figure 5(d)).
5. Related Work
**Time series modeling. ** Time series modeling have been used in many domains, such as anomaly detection (e.g., abnormal mutation (Chapfuwa et al., 2018) and gradual decline (Janakiraman et al., 2017; Du et al., 2016)); human behavior recognition (e.g., circadian rhythms and cyclic variation (Althoff et al., 2017; Pierson et al., 2018)); and biology applications (e.g., the hormonal cycles (Chiazze et al., 1968)). The majority have concentrated on different distance measurements to model evolutionary data, such as dynamic time warping (Lines and Bagnall, 2015; Chiazze et al., 1968), move–split–merge (Stefan et al., 2013), complexity-invariant distance (Batista et al., 2014) and elastic ensemble (Lines and Bagnall, 2015; Chapfuwa et al., 2018). Some methods focus on sequence-clustering by distance (Zhou et al., 2017; Althoff et al., 2017), which aims to find a better distance to model series and enhance the clustering performance. However, this is different from our task. Some feature-based classifiers have also been explored (Baydogan and Runger, 2016; Kurashima et al., 2018), which are distinguished by the frequency of segment repetition rather than by its distribution. They form frequency counts of the recurring patterns, then build classifiers based on the resulting histograms (Lin et al., 2012; Xu et al., 2018).
Model-based algorithms fit a generative model to each series, then measure the similarity between the series using the similarity of the model’s parameters. The parametric approaches used include fitting auto-regressive models(Shokoohi-Yekta et al., 2015), hidden Markov models(Yang and Jiang, 2014; Wu and Gleich, 2017) and kernel models(Kurashima et al., 2018), which rely on the artificial knowledges. Recently, many models using neural networks have been proposed (Wang et al., 2018b, a; Binkowski et al., 2018). Deep learning methods for series data have mostly been studied in high-level patterns representation. The main idea behind these approaches is that of modeling the fusion of multiple factors like time or space, etc. .
**Deep generative models. ** Generative models have recently attracted significant attention, and the nonparametric learning ability over large (unlabeled) data endows them with more potential and vitality. There have been many recent developments of deep generative models (Karras et al., 2018; Chapfuwa et al., 2018; Xu et al., 2018; Arjovsky and Bottou, 2017). Since deep hierarchical architectures allow them to capture complex structures in the data, all these methods show promising results in generating natural sample that are far more realistic than conventional generative models. Among them are two main themes: Variational Auto-encoder (VAE) (Kingma and Welling, 2014) and Generative Adversarial Network (GAN) (Goodfellow et al., 2014). Variational Auto-encoder (VAE) pairs a differentiable encoder network with a decoder/generative network. The encoder network intended to represent a data instance in a latent hidden space, which the inference is done via variational methods. A disadvantage of VAE is that, because of the injected noise and imperfect element-wise measures such as the squared error, the generated samples are often blurry (Bao et al., 2017). Generative Adversarial Network (GAN) is another popular generative model. It simultaneously trains two models: a generative model to synthesize samples, and a discriminative model to differentiate between natural and synthesized samples. However, the GAN model is hard to converge in the training stage and the samples generated from GAN are often far from natural. Class conditional synthesis can significantly improve the quality of the generated samples(Sohn et al., 2015; Odena et al., 2016). As a result, a lot of recent research has focused on finding better training algorithms (Karras et al., 2018) for GANs as well as gaining better theoretically understanding of their training dynamics (Arjovsky and Bottou, 2017; Mescheder et al., 2018)
Our model differs from all these models. We use a classifier to learn the genes corresponding to segments, then use a CVAE-GAN structure (Bao et al., 2017) to estimate the distribution patterns. We predict the future events and values based on the distribution evolution.
6. Conclusions
In this paper, we study the problem of capturing the behavior evolution behind the time series and predicting future events. Based on that, we define the “gene”, to model the generation of time series from different behaviors. We take advantage of CVAE-GAN structure to learn the genes and estimate segments’ distribution patterns. Additionally, a classifier is learned to select gene for each segment. We propose Generative Mixture Nonparametric Encoder (GeNE) that places these two tasks into a uniform framework, which consists of a classifier to learn “gene” to different segments, and learning distribution patterns by the adversarial generator. We apply these patterns into modeling behavior evolution by a recursive structure. To validate the effectiveness of the proposed model, we conduct sufficient experiments based on both synthetic and real-world datasets. Experimental results show that our model outperforms several state-of-the-art baseline methods. Meanwhile, we demonstrate the interpretability of our model by applying it to the real maintenance of watt-hour meters in the State Grid Corporation of China.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Althoff et al . (2017) Tim Althoff, Eric Horvitz, Ryen W White, and Jamie M Zeitzer. 2017. Harnessing the Web for Population-Scale Physiological Sensing: A Case Study of Sleep and Performance. WWW (2017), 113–122.
- 3Arjovsky and Bottou (2017) Martin Arjovsky and Leon Bottou. 2017. Towards Principled Methods for Training Generative Adversarial Networks. ICLR (2017).
- 4Bagnall et al . (2017) Anthony J Bagnall, Jason Lines, Aaron Bostrom, James Large, and Eamonn J Keogh. 2017. The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. DMKD (2017), 606–660.
- 5Bao et al . (2017) Jianmin Bao, Dong Chen, Fang Wen, Houqiang Li, and Gang Hua. 2017. CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training. ICCV (2017), 2764–2773.
- 6Barbosa et al . (2016) Samuel Barbosa, Cosley Dan, and Amit Sharma. 2016. Averaging Gone Wrong: Using Time-Aware Analyses to Better Understand Behavior. WWW (2016), 829–841.
- 7Batista et al . (2014) Gustavo E. Batista, Eamonn J. Keogh, Oben Moses Tataw, and Vinícius M. Souza. 2014. CID: An efficient complexity-invariant distance for time series. DMKD 28, 3 (2014), 634–669.
- 8Batista et al . (2011) Gustavo EAPA Batista, Xiaoyue Wang, and Eamonn J Keogh. 2011. A complexity-invariant distance measure for time series. SDM (2011), 699–710.