Improving Small-Scale CMB Lensing Reconstruction
Boryana Hadzhiyska, Blake D. Sherwin, Mathew Madhavacheril, Simone, Ferraro

TL;DR
This paper introduces a new, more optimal method for small-scale CMB lensing reconstruction called Gradient-Inversion, which outperforms traditional quadratic estimators in simulations, promising enhanced cosmological insights.
Contribution
The paper develops and validates a novel Gradient-Inversion method for small-scale CMB lensing reconstruction, improving accuracy over quadratic estimators in idealized simulations.
Findings
Reduces errors on lensing auto-power spectrum by a factor of ~4 at L=5000-9000.
Achieves a factor of ~2.6 improvement in cross-correlation errors.
Demonstrates potential for more precise small-scale CMB lensing measurements.
Abstract
Over the past decade, the gravitational lensing of the Cosmic Microwave Background (CMB) has become a powerful tool for probing the matter distribution in the Universe. The standard technique used to reconstruct the CMB lensing signal employs the quadratic estimator (QE) method, which has recently been shown to be suboptimal for lensing measurements on very small scales in temperature and polarization data. We implement a simple, more optimal method for the small-scale regime, which involves taking the direct inverse of the background gradient. We derive new techniques to make continuous maps of lensing using this "Gradient-Inversion" (GI) method and validate our method with simulated data, finding good agreement with predictions. For idealized simulations of lensing cross- and autospectra that neglect foregrounds, we demonstrate that our method performs significantly better than…
Click any figure to enlarge with its caption.
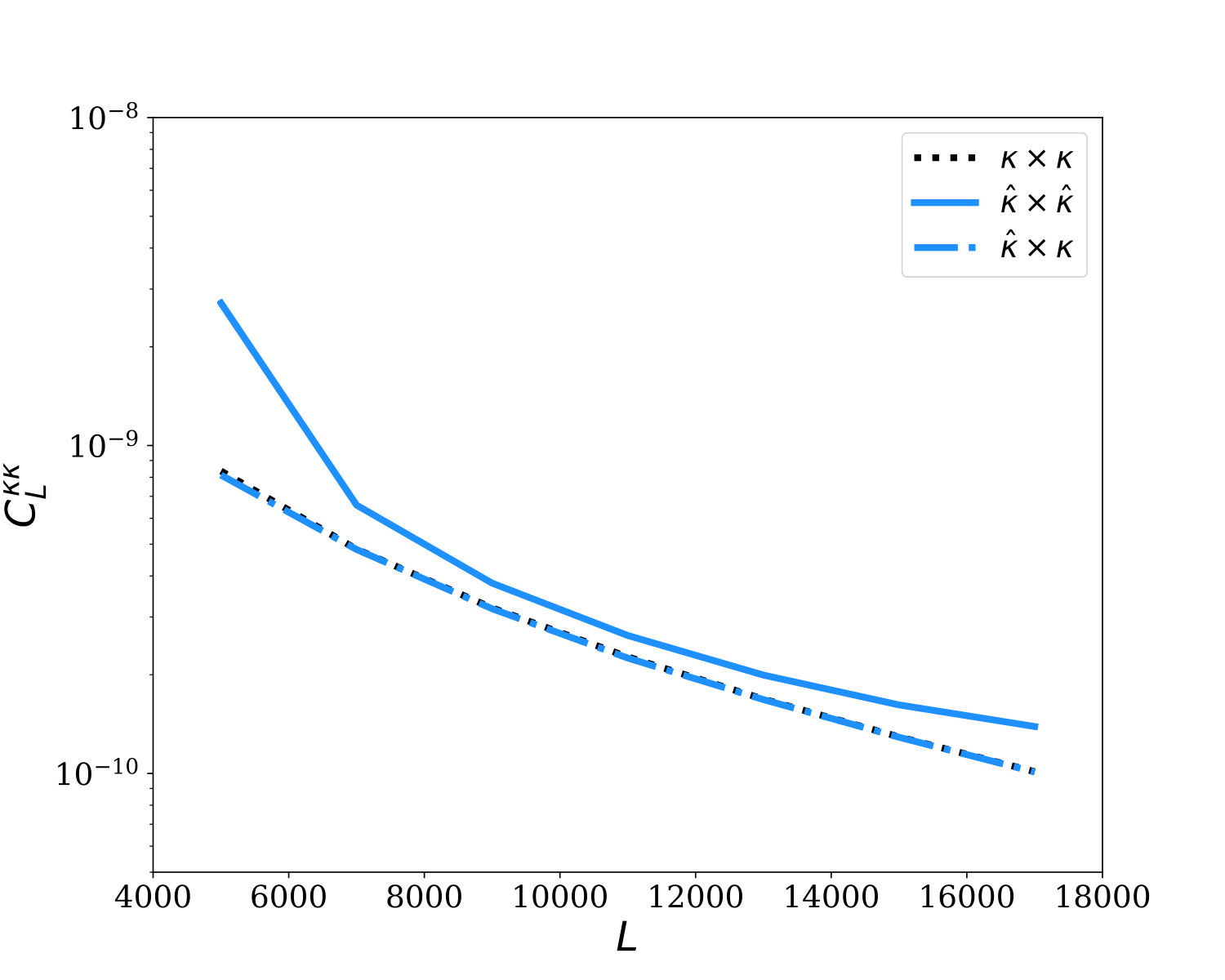 Figure 1
Figure 1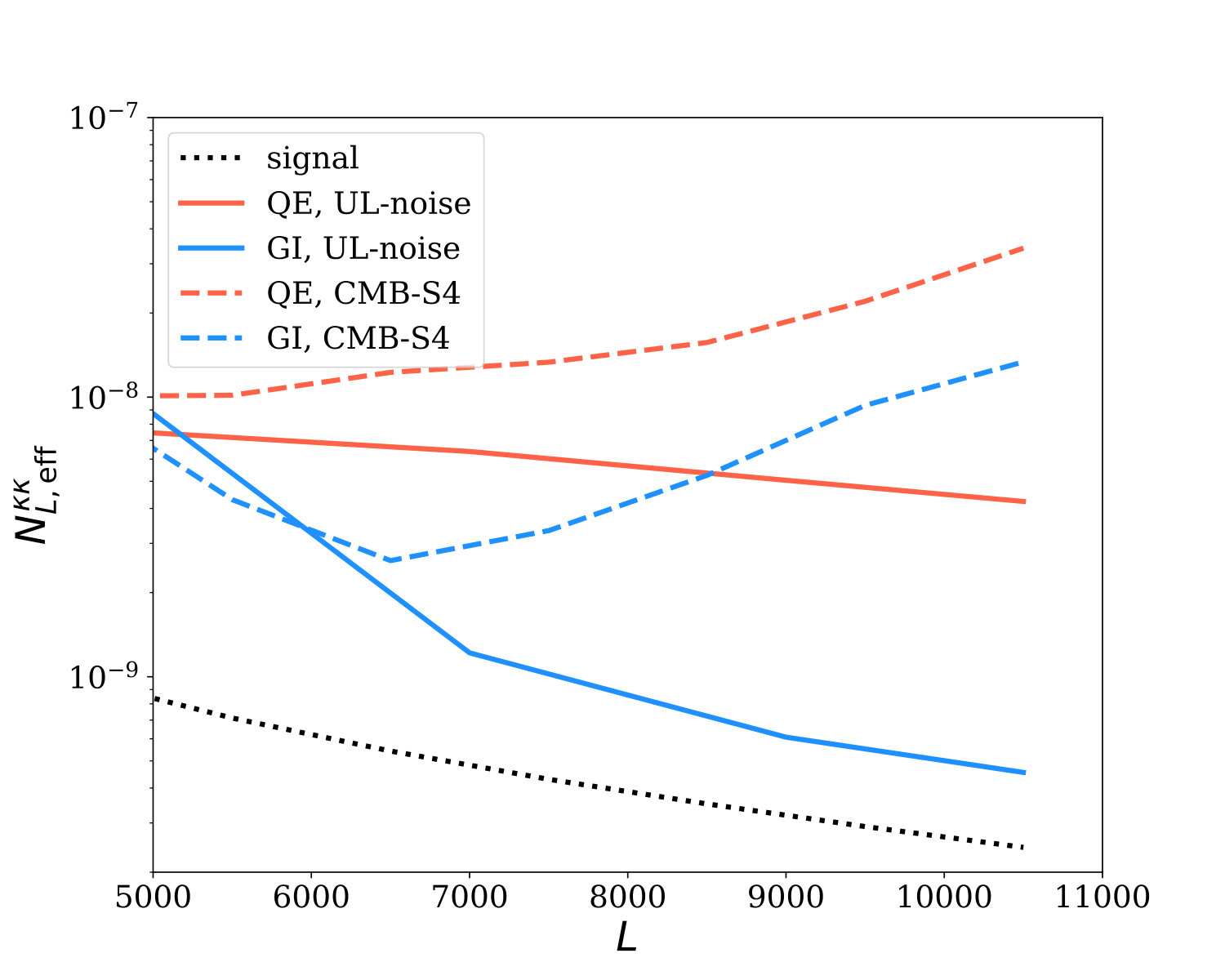 Figure 2
Figure 2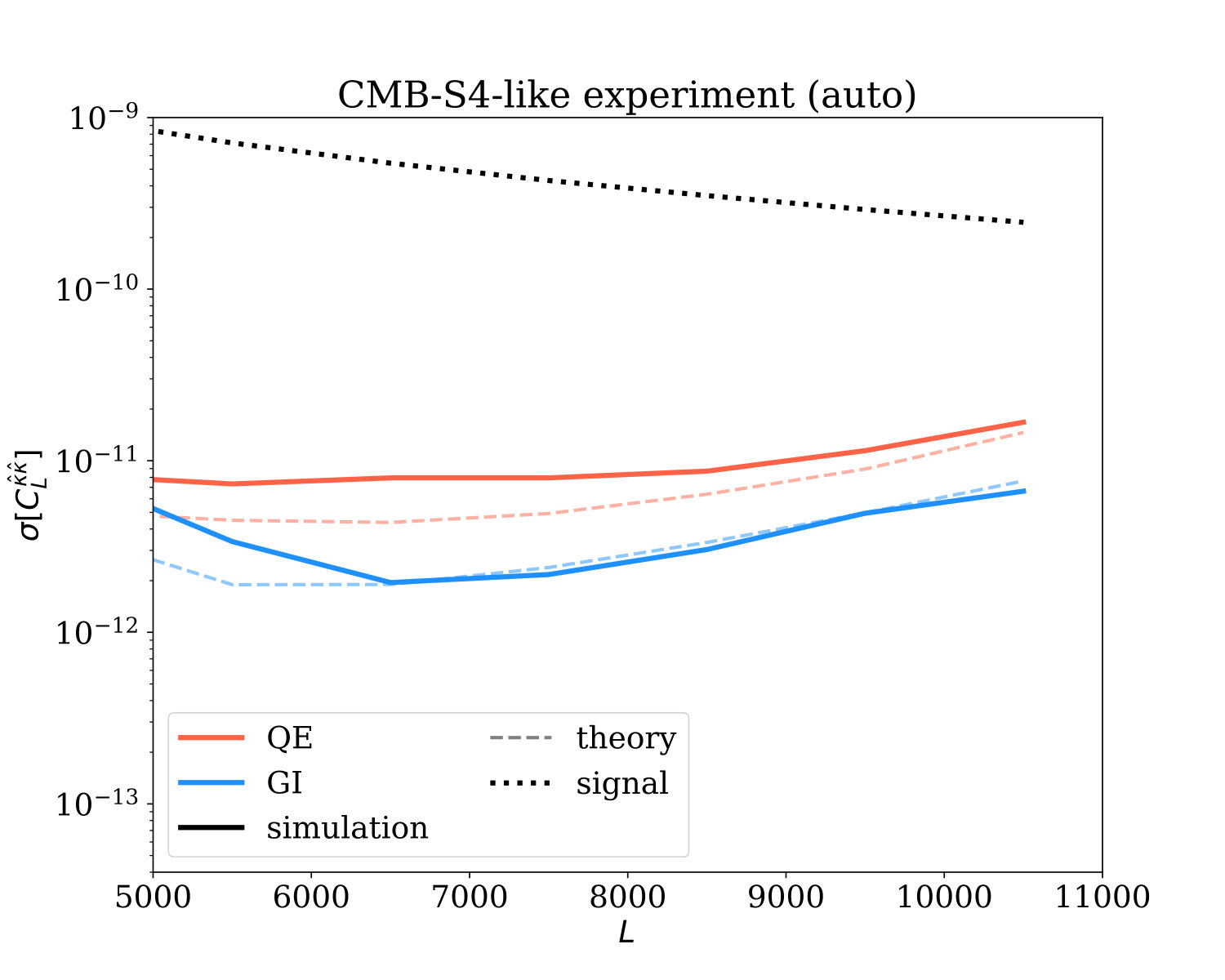 Figure 3
Figure 3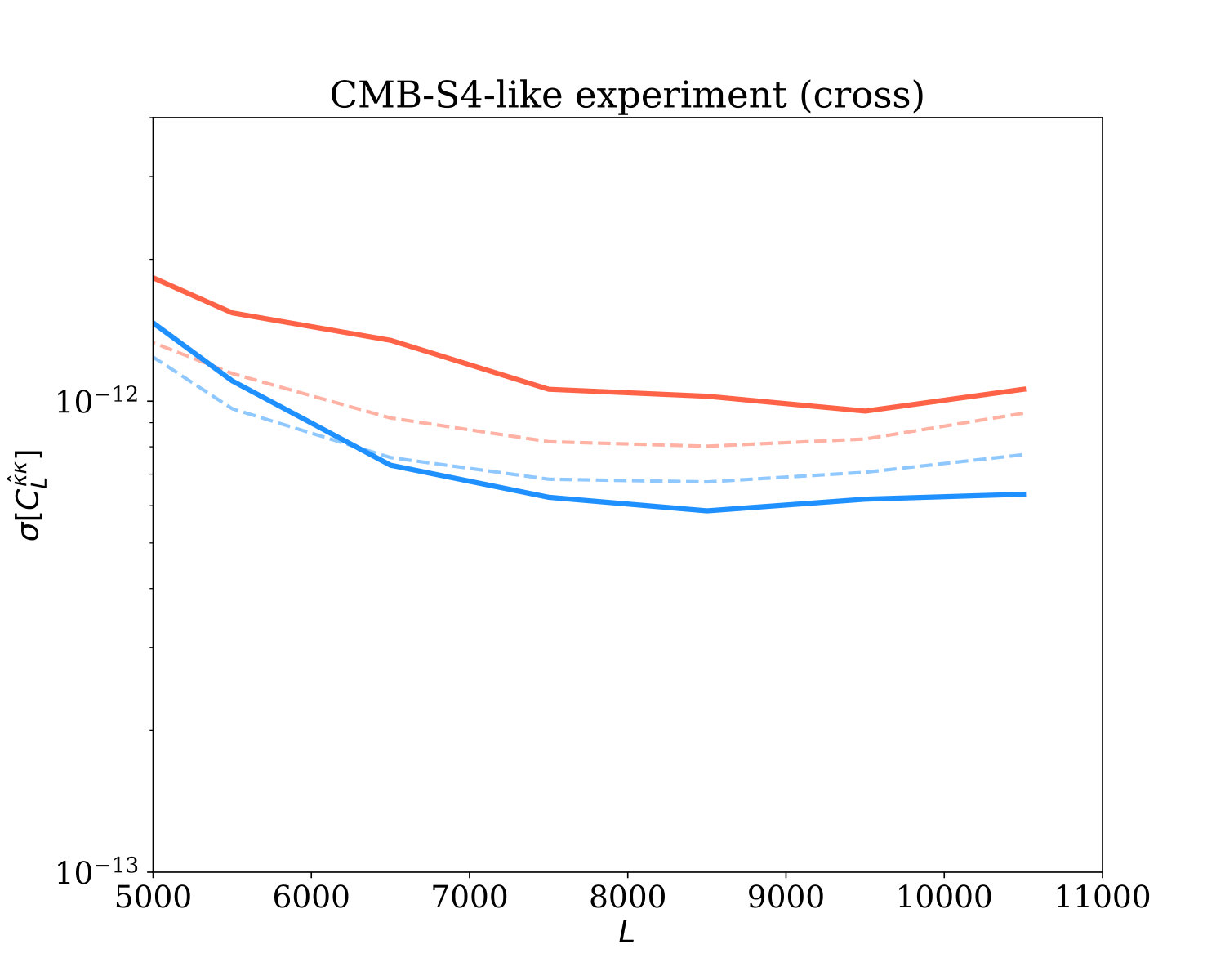 Figure 4
Figure 4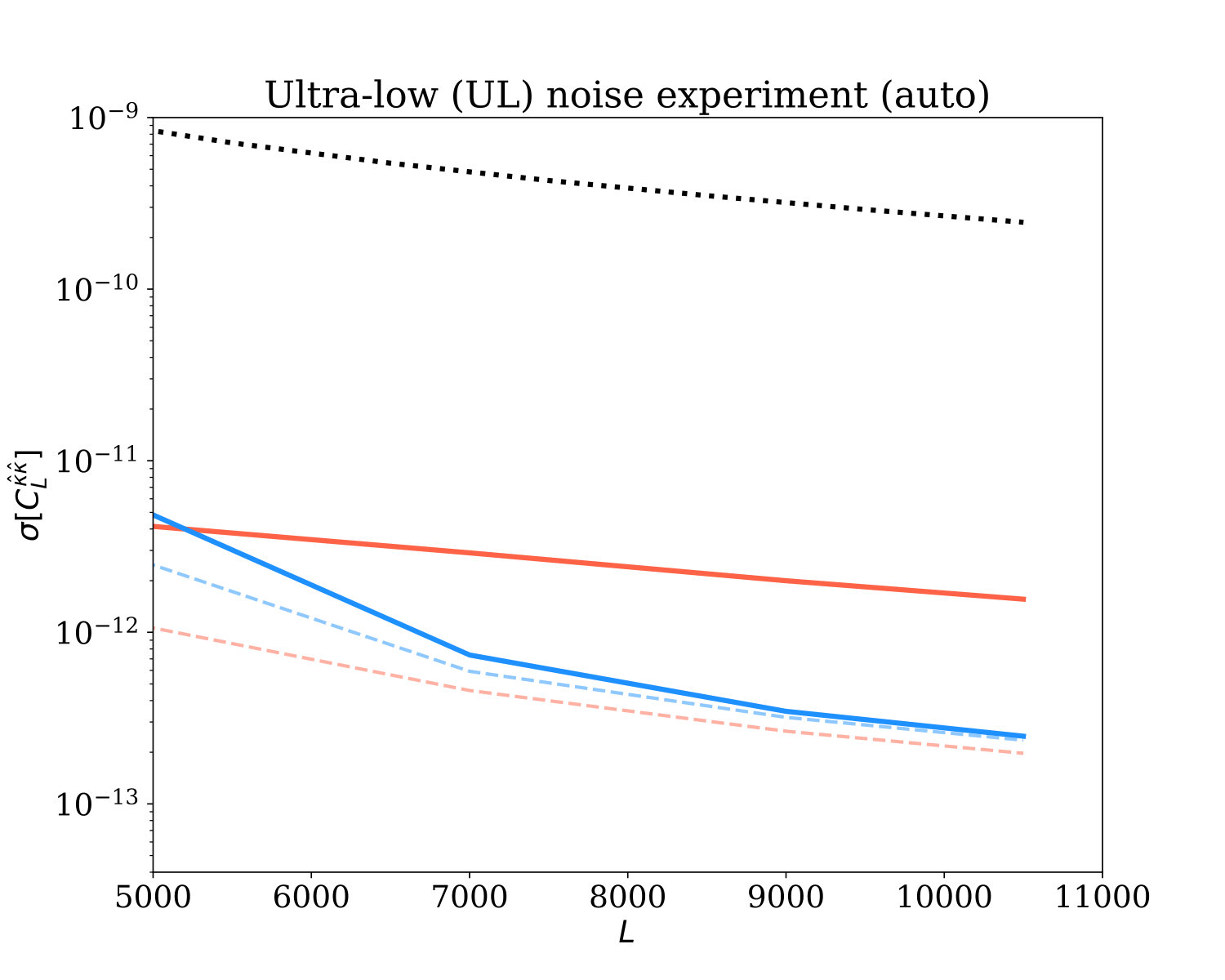 Figure 5
Figure 5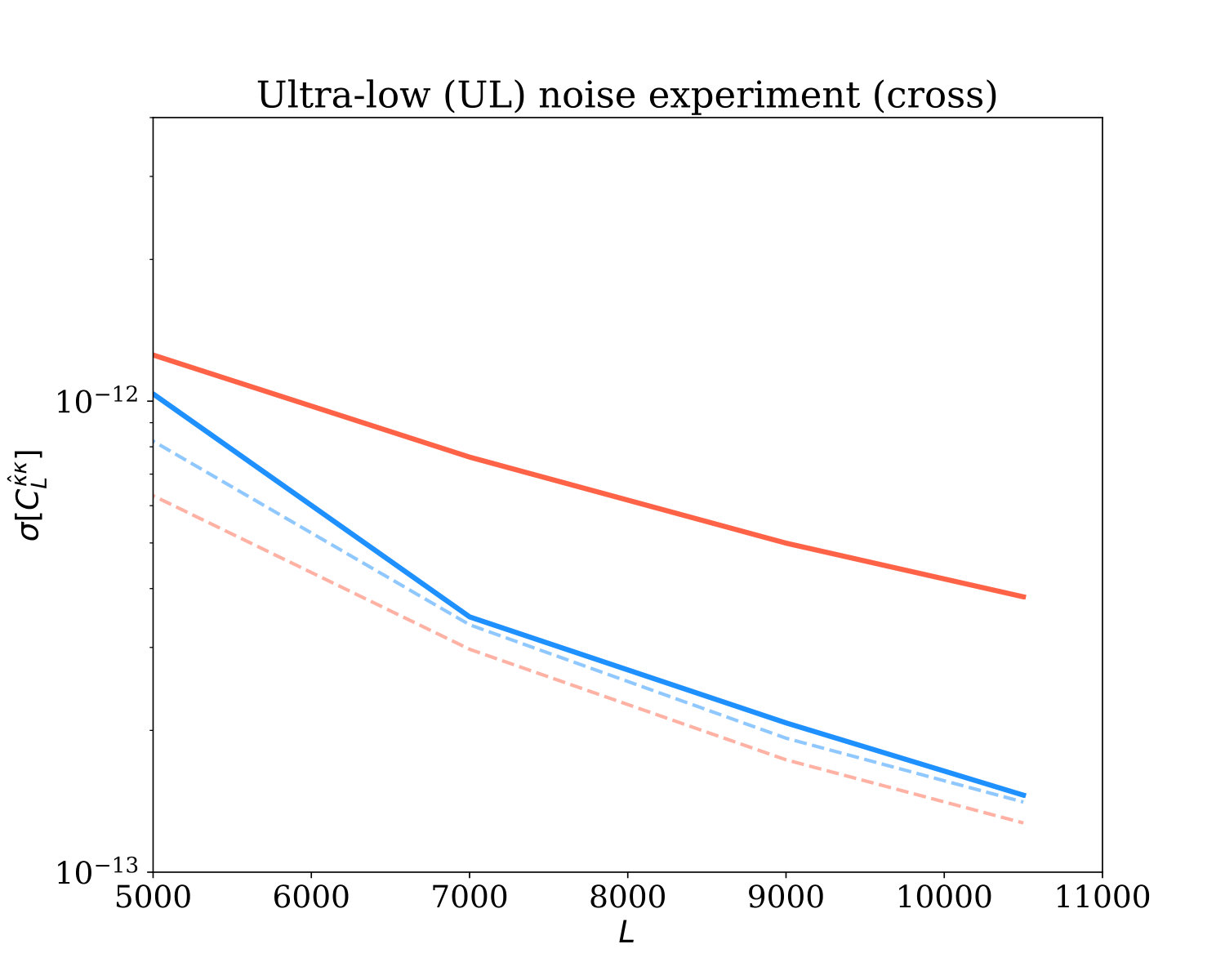 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9| SNR | UL | S4-like | SO-like |
|---|---|---|---|
| -range | 4000 18000 | 5000 11000 | 5000 9000 |
| Cross QE | 710 | 550 | 195 |
| Cross GI | 4100 | 1440 | 270 |
| Auto QE | 205 | 100 | 7 |
| Auto GI | 1515 | 360 | 30 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Improving Small-Scale CMB Lensing Reconstruction
Boryana Hadzhiyska
Harvard-Smithsonian Center for Astrophysics, 60 Garden St., Cambridge, MA 02138, USA
Department of Applied Mathematics and Theoretical Physics, University of Cambridge, Wilberforce Road, Cambridge CB1 2AD, United Kingdom
Blake D. Sherwin
Department of Applied Mathematics and Theoretical Physics, University of Cambridge, Wilberforce Road, Cambridge CB1 2AD, United Kingdom
Kavli Institute for Cosmology Cambridge, University of Cambridge, Wilberforce Road, Cambridge CB1 2AD, United Kingdom
Mathew Madhavacheril
Department of Astrophysical Sciences, Princeton University, Princeton, NJ 08544, USA
Simone Ferraro
Lawrence Berkeley National Laboratory, One Cyclotron Road, Berkeley, CA 94720, USA
Berkeley Center for Cosmological Physics, University of California, Berkeley, CA 94720, USA
Abstract
Over the past decade, the gravitational lensing of the Cosmic Microwave Background (CMB) has become a powerful tool for probing the matter distribution in the Universe. The standard technique used to reconstruct the CMB lensing signal employs the quadratic estimator (QE) method, which has recently been shown to be suboptimal for lensing measurements on very small scales in temperature and polarization data. We implement a simple, more optimal method for the small-scale regime, which involves taking the direct inverse of the background gradient. We derive new techniques to make continuous maps of lensing using this “Gradient-Inversion” (GI) method and validate our method with simulated data, finding good agreement with predictions. For idealized simulations of lensing cross- and autospectra that neglect foregrounds, we demonstrate that our method performs significantly better than previous quadratic estimator methods in temperature; at , it reduces errors on the lensing auto-power spectrum by a factor of for both idealized CMB-S4 and Simons Observatory-like experiments and by a factor of for cross-correlations of CMB-S4-like lensing reconstruction and the true lensing field. We caution that the level of the neglected small-scale foreground power, while low in polarization, is very high in temperature; though we briefly outline foreground mitigation methods, further work on this topic is required. Nevertheless, our results show the future potential for improved small-scale CMB lensing measurements, which could provide stronger constraints on cosmological parameters and astrophysics at high redshifts.
I Introduction
Building on progress in CMB experimentation and theory, the gravitational lensing of the cosmic microwave background (CMB) has recently emerged as a powerful cosmological probe. The CMB lensing signal arises from the deflection of CMB photons as they pass through the matter distribution between the surface of last scattering and us; this lensing deflection induces subtle, non-Gaussian correlations of the CMB anisotropies in both temperature and polarization. Reconstructing and analyzing a lensing map from CMB data can provide a wealth of information on the sum of the neutrino masses, the equation of state of dark energy, the properties of inflation and the early universe (via delensing), and astrophysics at high redshift (through cross-correlations) Smith et al. (2006); Planck Collaboration et al. (2018). Rapid progress in the extraction of the lensing signal has been made only recently with the first detections in cross- and auto-correlation in 2007 Smith et al. (2007) and 2011 respectively Das et al. (2011), followed by significantly improved measurements by the SPT, Planck, SPTpol and POLARBEAR collaborations van Engelen et al. (2012); Omori et al. (2017); Ade et al. (2016); Story et al. (2015); Ade et al. (2014). While the field has already advanced significantly, CMB lensing science still has great potential, with large increases in the lensing signal-to-noise ratio expected from ongoing and upcoming ground-based CMB experiments such as AdvancedACTPol, SPT-3G, POLARBEAR-II, Simons Observatory and CMB-S4.
Lensing is most commonly reconstructed using the quadratic estimator (QE) proposed by Hu and Okamoto Hu and Okamoto (2002). It was shown by Hirata and Seljak (2003); Horowitz et al. (2017); Carron and Lewis (2017) that in the low-noise regime in polarization, the QE is suboptimal, as it is only an approximation to the much more computationally expensive optimal (maximum likelihood) solution. While it was long thought that the QE was sufficient in temperature, we recently pointed out that this is not the case and that the QE is, in fact, suboptimal on small angular scales in temperature Horowitz et al. (2017). For small-scale reconstruction from temperature, the QE approach is hindered by the fact that the precision of the reconstruction is limited by cosmic variance of the background CMB gradient, whereas a true optimal solution, in principle, should not be. Furthermore, its errors become highly correlated on small-scales, so that measuring more modes does not offer significant improvements when one accounts for the covariance between them properly. More optimal methods suffer neither of these problems on small scales. We recently showed that on very small scales the so called “Gradient-Inversion” (GI) approach, the idea of which was first proposed by Seljak and Zaldarriaga (2000), can avoid the QE cosmic-variance limit and is close to optimal for reconstruction of these small-scale lenses Horowitz et al. (2017). However, in our previous work, we only discussed the relevant estimator assuming the approximation of a small, constant-gradient patch of sky, and only analyzed its impact on cluster lensing reconstruction.
In this work, we derive the most general GI lensing algorithm, allowing the reconstruction of a large-area, continuous small-scale lensing map from CMB data; we characterize this estimator’s performance for both lensing auto- and cross-spectra. Our paper is structured as follows. In section II we briefly review the QE and its limitations, contrasting it with the GI method proposed by Horowitz et al. Horowitz et al. (2017). In section III we present a new derivation of the continuous GI estimator for small-scale lensing reconstruction and describe the implementation of our algorithm. Finally, we focus on the signal-to-noise ratio improvement over the standard QE method and discuss systematic error challenges and potential applications of our methods.
II Motivation
The lensing of the CMB can be described by a remapping of the unlensed CMB tempearture field to give a lensed field :
[TABLE]
where we have expanded to first order in the lensing potential . Although this first-order approximation can be poor at the field level, it works quite well on small enough scales, where the primary temperature fluctuations are severely suppressed by diffusion damping. We can find which scales contribute to the gradient of the temperature by computing its variance up to some multipole
[TABLE]
where we are working in the flat sky approximation. As discussed in Hu et al. (2007a); Horowitz et al. (2017), the gradient variance saturates at . Therefore, if we restrict ourselves to small lenses where , the first-order approximation of Eq. 1 should be very good. This is the regime we will concentrate on in this work.
Neglecting the unlensed temperature in this small-scale regime due to Silk damping, the gradient inversion (GI) solution for the lensing potential in a small patch of sky with a single (constant) background gradient was proposed by Seljak and Zaldarriaga (2000) and extended by Horowitz et al. (2017):
[TABLE]
where is the constant gradient of the unlensed CMB temperature in the small patch of sky considered. If we recall that contains instrument noise as well as signal, i.e. that (where has noise power spectrum ), we can see that the noise level depends on the local gradient:
[TABLE]
We note that in the first expression for , and can in principle be measured with arbitrary accuracy assuming low enough noise, if we make the approximation that the effects of lensing on the large scale gradient are small, i.e. that can be measured as .
In the small-scale limit, the QE estimator has the following form:
[TABLE]
where the notation refers to an averaging over realizations of the unlensed CMB. In contrast to the GI estimator, the standard QE does something suboptimal in the low-noise limit: rather than “correctly” dividing out the gradient, it multiplies by the gradient and divides by the gradient RMS to preserve correct normalization. This implies that the QE is limited by an unnecessary cosmic variance error in the low-noise limit; in addition, the error is correlated across different modes which share a common gradient.
While, under the approximations outlined previously, the GI method is close to optimal in the small-scale limit, it has thus far only been defined for a constant gradient. In the next section we will discuss the extension to varying gradients.
III The continuous gradient inversion estimator
The standard gradient inversion estimator was derived in the limit of a very small map with a constant gradient. In this section, we will attempt to make our derivation of the estimator form more rigorous and more generally applicable, extending our lensing reconstruction algorithm to large, real maps. Our strategy will be to relate our final target – Fourier space quantities such as power spectra – to an intermediate quantity involving real space correlation functions, where we can more easily apply approximations that are naturally made in real space, such as assuming slowly varying local gradients.
III.1 Deriving the estimator
We will begin by deriving a large-map GI estimator in a simplified and suboptimal manner, neglecting instrumental noise and foregrounds and weighting all regions of the map equally. (A better weighting that maximizes signal-to-noise will be derived later.) Let us define the estimator:
[TABLE]
where is a weight function that only depends on via the slowly varying gradient field (which is assumed to be well-known). Initially, our goal will be to derive such that it gives an unbiased lensing reconstruction.
To begin, we may write
[TABLE]
where we have introduced “large-pixel” window functions , which are much larger than the lensing scales of interest, but are sufficiently small that we can assume the temperature gradient is constant within the large pixels. The pixel windows are zero outside the -th pixel and equal to one inside. Since the map is high-pass filtered, we can assume that so that
[TABLE]
We can similarly write the true field in terms of the large pixelization:
[TABLE]
To correctly reconstruct the field using an estimator , our requirement is that
[TABLE]
We can write this power spectrum in terms of the correlation function
[TABLE]
where indicates both i) an ensemble average over realizations of small-scale CMB, lensing and noise and ii) a spatial average over within a very large region with many independent gradients. However, throughout this analysis, we will assume the gradients to be fixed and, as stated previously, assume them to be well known. In some cases it will be helpful to average over small-scale fields, denoted , and , marked , in separate steps. (This implies .)
Now we may evaluate the real space correlation function, which will allow us to make a number of relevant approximations. Averaging only over small-scale fields in a first step, we obtain
[TABLE]
We may assume that, since we have high pass filtered to remove long wavelength modes in our estimator (and are, in any case, only considering lensing on small scales, which approximately corresponds to very small correlations), only correlations within the same pixel are significantly non-zero, and we will neglect all others. Therefore only the terms contribute to the sum. In addition, we may assume that within one pixel , the temperature gradient is not a varying field, but approximately takes on a constant value . This gives us:
[TABLE]
We now write the potential-potential gradient correlation function in Fourier space to give:
[TABLE]
We can now connect this expression to the definition of the power spectrum in terms of the correlation function. For this purpose, we average equation (14) over , i.e. add , to give
[TABLE]
and insert this two point correlation function into the power spectrum expression of Eq. (11), noting also that the mean value for over is simply , i.e. one over the number of pixels. We thus obtain
[TABLE]
Performing the integral, we obtain ; this allows us to perform the integral to give:
[TABLE]
In other words, our cross-correlation measurement is equal to the true cross-correlation in each large pixel, weighted by and averaged over all pixels. It can clearly be seen that if we set we obtain
[TABLE]
as required, with each large-pixel region contributing equally to the cross-spectrum.
We note that for the correct reconstruction of each mode of the lensing , we require a different, specific weight function . We similarly denote the estimator that uses this particular weight function as ; this estimator is correctly normalized to recover the mode ; i.e., if we Fourier Transform , then the mode is correctly reconstructed. Here we have the understanding that a superscripted L implies that a spatial weighting is being applied with the purpose of reconstructing at a fixed target wavenumber . This is to be distinguished from a subscript L, which is the true Fourier conjugate variable of the coordinate describing the real space map. The two variables will be equal if the correct spatial weighting has been applied in order to reconstruct each mode, as will be shown below to be the case in all realistic applications.
In the previously derived simple estimator, all pixels of the map make equal contributions to the final lensing power spectrum. However, a more optimal estimator should up-weight pixels with a large gradient, as these have a larger signal . We will now derive such a more optimally weighted estimator.
Our derivation proceeds similarly to that presented previously. The small-scale temperature is now assumed to be described by , where noise has a power spectrum . We again consider the estimator
[TABLE]
As before, we obtain for the cross-correlation of the reconstruction with the input:
[TABLE]
Similarly, we can obtain an expression for the reconstruction power spectrum
[TABLE]
Given these cross- and auto-spectra, we can find the weight function that minimizes the variance of our new estimator, which we define as:
[TABLE]
We must minimize the reconstruction variance subject to the normalization constraint that , which is equivalent to
[TABLE]
We can perform this minimization using a Lagrange multiplier
[TABLE]
where and are as in Eqs. 20 and 21 above.
Setting and then imposing the normalization condition to solve for , after some algebra we obtain our final weighting for our estimator
[TABLE]
Approximating this as a continuous function, we obtain
[TABLE]
Therefore, our final estimator for lensing (factoring out and cancelling several factors) is:
[TABLE]
To optimally recover a mode , we must simply take the Fourier transform (FT) of and select the mode with wavenumber ; i.e. we must evaluate . The Fourier transform of , of course, contains a full array of other pixels , but we discard these as our spatial weighting is not optimal or unbiased for these modes.
In addition, we note that while the estimator contains the unobservable true unlensed gradient, we approximate it by low-pass filtering the observed, lensed map (removing all power above ) and taking a real-space derivative operation. The tests described later in this work verify that this approximation does not introduce a bias. Here the second line represents the gradient-dependent normalization that corrects for the weighting of different regions.
Our estimator can be interpreted as an unbiased estimator multiplied by a weight function that increases the contribution from large-gradient, high signal-to-noise regions. Building on this intuition, our final estimator can be more compactly represented as
[TABLE]
where we have defined the optimal spatial weighting function as . However, we will justify in subsequent paragraphs why, to validate our methods using simulations, we use a slightly suboptimal weight . It can be seen that, as expected, is simply a spatial window function that upweights high signal-to-noise regions (where the gradient is large) and downweights low signal-to-noise ones.
We note that in the signal-dominated limit, Eq. (28) reduces to the naive gradient inversion estimator.
In the noisy limit, when reconstructing over a large area with many independent gradients, this appears at first glance very similar to the standard quadratic estimator. However, in fact, there is a significant difference to the quadratic estimator, namely how the estimator is normalized. For a single, constant gradient, we have argued previously that the quadratic estimator is suboptimally normalized, making an error of order . Naively, spatially averaging over would drive the GI normalization to the RMS value used in the quadratic estimator. However, the normalization error is reduced only by the square root of the number of independent gradients that are averaged over; since the error on all lensing observables averages down by the same amount, the relative impact of this mis-normalization compared to the lensing spectrum error bars is not reduced by spatial averaging. We hence expect the local mis-normalization, arising from the gradient cosmic variance error, to remain a key limiting factor for the quadratic estimator. The GI estimator does not suffer from this limitation.
The GI estimator we have derived and seek to implement, as shown in equation (28) makes use of a spatial weight (or mask) function ; in the optimal case, this should be given by , effectively a Wiener filter. However, we encountered significant difficulties in implementing this optimal weighting function for low noise levels. A likely source of our implementation problems was the fact that our estimator derivation is only valid for weights which are spatially slowly varying. For very low noise levels, however, the window function varies very rapidly: though is typically equal to , along directions where the gradient is perpendicular to the wavevector , very rapidly takes on a zero weight, leading to sharp edges in the window function. To regularize the weight, we modified our filtering to be a simple inverse noise filter:
[TABLE]
For noise-dominated modes, this is already (near-) optimal; for signal dominated modes, this leads to moderate loss in the area used, which typically only has a modest impact on signal-to-noise. As is visible from the form of the window function, the theoretical prediction for the noise on our estimator for a particular fixed, local gradient is given by
[TABLE]
The modification to this expression in the case of multiple gradients is discussed in more detail in Appendix A along with other subtleties regarding the noise of our estimator.
III.2 Applying the estimator: summary of the algorithm for lensing reconstruction
In this section we will briefly outline the estimation procedure, Eq. 28, used for reconstruction of the lensing potential field for a given simulated lensed image using the GI method.
For each target wavevector on a discrete FFT grid given by spacing , where and are the map dimensions (in this case, arcmin) and are integers ranging over the number of pixels, our procedure for obtaining the map and the power spectrum is described by the following steps:
- (i)
We obtain the gradient field of the temperature as follows. We first filter the observed lensed temperature map, i.e. we remove the small-scale information (), where the gradient saturates. We then apply a real-space numerical differentiation (using second order accurate central differences) to this filtered field in order to obtain the gradient. We denote this gradient of the map as and for the subsequent steps of the algorithm, substitute , appearing in the derivations in Section III, with it, as the true unlensed is not observable.
- (ii)
Construct the unweighted estimator as defined in Eq. 6. At a given position , the value of the estimator depends only on the local gradient and the value of the lensed temperature . (Note that zeros of the gradient are not problematic after the weighting in the next step is applied.)
- (iii)
Apply an inverse noise weighting to it, i.e. compute , where the window function is given in Eq. 29. The motivation behind choosing this form for the filtering function is that it upweights large-gradient, high signal regions; it also downweights the modes perpendicular to the gradient direction, as they have infinite variance. Thus, we obtain a real-space map of the lensing potential weighted for this specific wavevector.
- (iv)
Fourier transform the estimator and keep only the value of the transformed estimator at the target wavenumber , i.e. (). The reason for this step is that the weighting we apply to the reconstructed map in the previous step is by construction optimal for the target wavevector, , we chose initially (Eq. 18). To obtain the reconstructed map, normalize by , where averages are over real space (i.e., ). This step returns the normalized estimator derived in Eq. 28. For each target wavevector pixel, we repeat this procedure to build up the entire reconstructed map in Fourier space. This requires us to perform a full spatial weighting and Fourier transform of the map for each pixel, which becomes more computationally expensive as the size of the maps is increased (though the algorithm could potentially be sped up by applying the same weighting to blocks of similar ).
- (v)
Compute the 2-dimensional power spectrum. The the cross power spectrum (between the reconstructed and the true fields) is given by , while auto power spectrum (of the reconstructed field) can be obtained as , where for the normalization we have used the standard expressions for calculating pseudo- power spectra given a spatially dependent slowly varying window function Efstathiou (2004).
- (vi)
Finally, bin the power spectrum with appropriately chosen maximal multipole and number of bins . In the subsequent sections, we show the computed power spectra with and for an ultra-low noise experiment and and for a CMB-S4-like experiment (although much of the signal-to-noise will be at lower multipoles). The small-scale regime is where we expect our method to outperform the QE most significantly.
IV Results and Discussion
In order to test our method, we apply it to simulations mimicking data from CMB temperature measurements with different instrumental noise levels. We simulate the lensing deflection using the following algorithm, described in Nguyen et al. (2019). First, we generate a 2-dimensional Gaussian random field realization from a theoretical CMB unlensed temperature power spectrum with a pixel size of 0.05 arcmins on a pixel map. The CMB maps are remapped (using fifth order spline interpolation to more accurately apply the deflection) to produce a lensed temperature map from a Gaussian realization of the convergence field as predicted from the theoretical power spectrum. The lensed map is then convolved with a beam of appropriate size and instrumental white noise is added. It is then downsampled to pixel maps in Fourier space in order to avoid the need to use a pixel window function and to speed up the lensing reconstruction. We thus obtain lensed temperature map realizations with simulated instrumental noise of area deg2 and a pixel size of 0.1 arcmins.
In this section, we consider three measures of instrumental noise for future experiments:
- •
Ultra-low (UL) noise experiment: Futuristic experiment with a noise factor of K-arcmin and a beam size of arcmin.
- •
CMB-S4-like experiment: CMB-S4-like experiment with a noise factor of K-arcmin and a beam size of .
- •
SO-like experiment: Simons Observatory (SO)-like experiment with a noise level of K-arcmin and a beam size of .
The simulations are highly simplified and optimistic in that they contain no Sunyaev-Zel’dovich signal, Cosmic Infrared Background emission or any other extragalactic foreground; we revisit the topic of foreground contamination later. We note that these experiments are highly signal-dominated on large scales in temperature, which means that the local gradient can be measured with high accuracy.
Throughout this section, we will be comparing the GI method with the QE one to test whether one indeed observes an improvement on small scales, as we expect based on our discussion in Section III. The QE convergence field estimate is obtained from the standard TT estimator Hu et al. (2007b) calculated using the modes to . However, we have checked that the QE reconstruction maps give nearly identical results if is decreased below (even to [math]). The gradient leg is then low-pass filtered to remove the modes. For the autospectrum calculation, we, furthermore, apply a realization-dependent subtraction to the QE results (which reduces off-diagonal bandpower correlations) Namikawa et al. (2013); Sherwin et al. (2017); Nguyên et al. (2019). Note that our method is not expected to work on scales with below , so we apply a high-pass filter to the lensed temperature map before performing a GI reconstruction on the simulations. We further note that the statistical power of the QE is reduced in the small-scale regime compared to naive forecasts. This effect is a consequence of the fact that the errors on the different modes are highly correlated Horowitz et al. (2017) – a fact not accounted for in the theoretical model of its reconstruction noise.
IV.1 Reconstructed Maps
In Fig. 1, we show a comparison between the true (input) and the GI-reconstructed lensing convergence fields. We denote the convergence field by and it is related to the lensing potential by . To aid with visualization of the reconstruction, the input lensing convergence field has been modified with the addition of large, randomly scattered massive point sources on top of the CMB lensing convergence map. We expect that modes with variation nearly perpendicular to the gradient direction or patches where the magnitude of the gradient is small will be reconstructed with very large noise and will, thus, be downweighted by applying the inverse noise filtering function, , described in the previous section.
Indeed, in regions where the magnitude of the gradient is large, the values of the reconstructed maps appear to be larger as well. This is a consequence of the fact that the inverse noise filter applied on the reconstructed maps downweights patches with small gradients, and they end up with values close to zero in the reconstructed plots. In particular, it is easy to see that some of the artificial point sources have been recovered quite well by the GI method, while others are not at all discernible in the reconstruction map. By glancing at the magnitude of the gradient map, it becomes evident why that is the case – the point sources located in positions of the map where the gradient is large have been correctly identified by the GI estimator, while those in regions with small gradient are missing from the reconstruction. The same qualitative behavior can in fact be observed in the QE-reconstructed maps as well; however, the weighting of regions with different gradients is expected to be suboptimal for the QE (see end of Subsection III.1 for discussion).
IV.2 Estimator Validation and Power Spectra
In Fig. 2, we show the auto- and cross-power spectra (blue solid and dashed-dotted lines, respectively) obtained through the GI method from 360 simulations of a small CMB temperature patch as measured by a CMB-S4-like experiment and compare them with the auto power spectrum of the true lensing signal (black dashed curve). The cross power spectrum of the GI-reconstructed lensing matches the true input lensing power to high accuracy, demonstrating that the GI reconstruction algorithm is unbiased and works well for . No bias subtraction is required in this case, which makes this cross-correlation measurement a highly robust validation of our algorithm.
The auto-power spectrum of the raw reconstructed convergence field, which includes a reconstruction noise bias, is somewhat larger than the signal on large scales and on small scales , i.e., it becomes noise dominated. Even so, a measurement of the power spectrum is possible because of the large number of modes. We note that the reconstruction noise bias present here could be characterized by simulation and subtracted, estimated and removed using data-derived methods (see discussion later), or reduced by cross-correlating different splits of the data. We defer a detailed discussion of robust autospectrum bias subtraction to future work.
IV.3 Simulated Estimator Performance
In this subsection, our goal is to characterize the performance of the GI estimator and to compare it with that of the QE estimator, the current standard for reconstructing lensing from CMB temperature.
For this purpose, we will use simulations to compute the errors on measurements of auto- and cross-power spectra with the reconstructed lensing field. Using the 360 simulations of lensing reconstruction described in the previous section, we measure and bin the lensing power spectrum and the lensing cross-correlation with the input convergence field; from these simulated measurements, we determine the covariance matrices and standard deviations for cross- and auto-spectra, for both GI and QE. For the autospectra, we assume that reconstruction noise biases will be characterized by monte-carlo simulations; since subtracting a mean bias does not affect fluctuations, we do not subtract the reconstruction noise bias when determining covariances. We show our results in Fig. 3.
As seen in the top panels of Fig. 3, the standard deviation (error) of the measured auto-power spectrum for the ultra-low noise experiment (top right) using the GI estimator is significantly smaller than the result from the QE simulations across all -modes under consideration, reaching a full order of magnitude in difference around . For an experiment with CMB-S4-like noise (top left), the error in the GI auto-correlation measurements is smaller by about a factor of 5 at compared with the QE, and seems to decrease the smaller the scale probed, leveling off and remaining non-negligible.
The bottom two panels of Fig. 3 shows the standard deviation of the measured cross-power spectrum. In both the case of an ultra-low noise experiment and a CMB-S4-like experiment, the GI estimator appears to have smaller error bars than the QE on small scales (). In particular, for the UL-noise case (light-red and light-green curves), on scales around , our method outperforms the QE significantly, improving it by a factor of . The CMB-S4 case (bottom left panel) also sees improvement when the GI method is applied, but it is somewhat more modest, at about a factor of over all scales shown.
We can also compare our simulated results with approximate theoretical predications. In Section III, we presented the theoretical framework for forcasting the noise of the GI approach. In particular, we showed that the noise on our estimator (in terms of the lensing potential field) approximately takes the form given in Eq. 30 (see a more detailed discussion of the GI noise in Appendix A). We assume Gaussian covariance Knox (1995) to convert this reconstruction noise power to errors :
[TABLE]
where the power spectra can include cross-spectra and autospectra , which include the reconstruction noise power. Following our results in Fig. 2, we assume . We thus obtain theoretical predictions for the errors which are shown in Fig. 3 using thin lines.
We expect our theoretically derived expression for the GI noise to be accurate in the limit from Fig. 2, where the primary CMB is highly suppressed by diffusion damping. This is indeed what is observed in Fig. 3: for (), GI theory and simulation are in good agreement with each other for the case of CMB-S4-like experiment (dark-blue thin vs. thick curves). For the UL-noise experiment the agreement becomes more evident at . On larger scales, , the primordial temperature fluctuations are not negligible, and many assumptions made in deriving the GI estimator on small scales break down. Therefore, it is perhaps not surprising that the errors from the simulations do not match the approximate theoretical calculation on these scales. Regarding the match of simulated results to simple theoretical predictions for the QE, as shown in Nguyen et al. Nguyen et al. (2019) for bandpowers (and in Horowitz et al. Horowitz et al. (2017) for clusters) , we confirm that the QE indeed has a much larger error on small scales than expected by the “naive” prediction which neglects mode coupling. This is especially true of the UL-noise experiment, where the difference is of about an order of magnitude on all scales. This suggests that if one wants to forecast the QE noise more correctly, a more careful treatment of its reconstruction noise has to be applied. On larger scales (), we have verified that QE theory and simulation agree well, as expected. We emphasize that the large improvements of the GI estimator we have found are relative to the simulated QE, not the QE forecasts (which are overly optimistic).
To summarize the improvements expected from the GI estimator, we now calculate the cumulative signal-to-noise on lensing observables for different experiments. In Table 1, we show the signal-to-noise ratio,
[TABLE]
computed over a range of -modes for three noise levels, mimicking the fiducial ultra-low noise and Stage-IV-like experiments, with and indexing the bandpower bins and denoting the covariance of the measured power spectra, (cross) and (auto). Notice that here we loosen the assumption of Gaussian covariance to obtain more accurate estimates of the SNR, as indeed we observe non-negligible correlations between the small-scale modes of the QE-reconstructed power spectra. This is less true in the GI case, as expected. We have also added a forecast for an experiment similar to Simons Observatory (SO) , assuming instrumental noise with beam arcmin and noise factor K-arcmin, as it is the fastest approaching CMB observational project with potential to go to small enough scales in temperature. This calculation also includes the effect of off-diagonal bandpower covariances. We infer an improvement of the GI estimator over the QE on the order of times for the UL-noise case and about and for SO-like and CMB-S4, respectively, on small scales .
We note that applying a more optimal window function, such as the full Wiener filter in Eq. 28, could, to some extent, further increase the precision of the GI lensing measurements on small-scales.
In the small-scale regime, we caution that there are significant contributions from foreground contaminants which still need to be properly accounted for (see Subsection IV.5). Though there are several possibilities for mitigating these with multifrequency cleaning and estimator modification, we note that our forecasts are therefore likely optimistic. Nevertheless, especially at moderate , the GI estimator appears promising for improving lensing signal-to-noise from future experiments beyond what was thought possible using the QE estimator.
IV.4 Effective Reconstruction Noise
Another useful metric for comparing estimator performance is to calculate the reconstruction noise power spectrum, or, equivalently, the noise per lensing mode. However, due to inhomogeneous spatial weighting, the GI estimator can have a different effective area than the QE, so that a naive comparison is difficult. We proceed instead as follows. We define the effective reconstruction noise as the level of noise that would give the same power spectrum error bars given a simple forecast with uniform weighting across the map. We can therefore calculate it by inverting the Gaussian covariance formula defined above (Eq. 31) for the lensing autospectrum to yield
[TABLE]
where is the standard deviation of the auto power spectra measured from multiple simulations and is the theoretical power spectrum of the convergence field.
In Fig. 4, we show the QE and GI effective noise curves, where we use statistical results derived from simulations (360 GI reconstructions for UL noise; 300 GI reconstructions for SO-like and S4-like noise; 1000 QE reconstructions for each noise level). The graphs suggest that the GI noise of the estimator for an ultra-low noise experiment is on the order of 10 times smaller than that of the QE for . For an experiment with CMB-S4-like instrumental noise, the improvement is more modest, peaking at , where the ratio between the two curves is about 5. In both cases, the GI estimator results in a significantly more accurate measurement of the lensing field.
IV.5 Systematic Errors from Foregrounds
Though the methods we have described for improved small-scale lensing reconstruction appear promising, small-scale extragalactic foregrounds will likely be a significant limiting factor for such analyses.
This is especially true for temperature reconstruction, which is the focus of this paper and is expected to have higher signal-to-noise. Polarization reconstruction should have minimal small-scale foregrounds, and we will briefly discuss the extension of our methods to polarization in Appendix B, but we will defer a detailed treatment to future work.
In temperature, as previously mentioned, several extragalactic foregrounds are of primary concern on small angular scales: Cosmic Infrared Background (CIB) emission and the thermal and kinematic Sunyaev-Zel’dovich effects (tSZ and kSZ). Other contaminants such as radio source emission are likely subdominant. CIB and tSZ foregrounds have a distinctive frequency dependence; this, in principle, allows them to be separated from the blackbody CMB and lensing signals using multi-frequency measurements of the small-scale CMB from upcoming experiments.
The kSZ effect, on the other hand, cannot be separated using multifrequency data, as it has a blackbody frequency dependence. At first glance it therefore presents a more serious challenge, with the potential to significantly bias small-scale lensing measurements. However, the kSZ differs in an important way from lensing: the lensing signal is correlated with the background CMB gradient, whereas the kinetic SZ effect and other foregrounds are not. (This, of course, assumes that the gradient itself has a negligible kSZ contribution; we will briefly revisit this assumption below.) Building on this statistical difference, we can construct simple methods to avoid any kSZ bias to lensing measurements.
We will here briefly outline such a method to remove kSZ bias in autospectrum measurements using the GI lensing estimator. To calculate the bias from kSZ (in addition to that arising from instrument noise and other sources), we simply evaluate the GI estimator with the gradient coordinates offset by a small vector ,
[TABLE]
Here is chosen to be longer than the correlation lengths of the CMB fluctuations and the lensing, but small enough that the noise properties are unchanged. Since the kSZ, noise and other effects and foregrounds are not correlated with the large scale gradient Ferraro and Hill (2018); Smith and Ferraro (2017); Amblard et al. (2004), we can determine the non-lensing foreground and noise bias by simply calculating the power spectrum of . This can be subtracted off from the raw reconstruction power to calculate the lensing power spectrum, taking . The normalization function (which can be obtained via simulation or analytics) is required because also contains some lensing signal, though it is very sub-optimally weighted and thus significantly reduced in amplitude; re-normalization is needed to restore an unbiased measurement of the lensing power spectrum.
While this method should remove the leading source of kSZ bias, an additional, smaller non-Gaussian bias could arise because the measured CMB gradient also contains kSZ at a low level; this should be explored further in future work.
We also note that, even with reduced foreground biases, the kSZ contribution could still inflate errors and lower signal-to-noise in temperature, especially at very high . Possible ways to reduce kSZ foreground contributions to errors (aside from simply relying on polarization-based reconstructions) might include subtracting a reconstructed kSZ map derived from galaxy surveys or quadratic kSZ reconstructions. We will defer a detailed exploration of foreground issues to future work.
V Conclusions
The standard tool used for reconstruction of the gravitational lensing field is the quadratic estimator, but it has recently been shown to be suboptimal on small angular scales. The most rigorous way to overcome this limitation is to adopt an optimal approach (e.g., Hirata and Seljak (2003); Carron and Lewis (2017); Millea et al. (2017)), but this is not necessarily the most computationally efficient one, and in any case, algorithms that rapidly converge on small scales have not yet been presented. In this small-scale regime, a simple gradient-inversion estimator (GI) should approach the optimal solution.
In this paper, we have derived a more general GI algorithm, one that is now capable of reconstructing lensing over large fields. We have applied it to simulations of the lensed CMB temperature field to validate the method and characterize its performance. For idealized, foreground-free simulations, we have shown that the GI-reconstructed auto and cross correlation error bars are significantly smaller than those derived using the QE. In particular, we found that when using our method on small scales for the computation and analysis of the cross-correlations between these next-generation experiments, one obtains a much more precise result, with measurement errors which are approximately times smaller for CMB-S4 and for SO-like than the corresponding ones for QE at . The improvement of the auto-correlation power spectrum is even more substantial: a factor of for both CMB-S4 and SO-like in the highly optimistic scenario of removed foregrounds and measured small-scale anisotropies. We argue that the origin of these improvements lies in the fact that, unlike the GI, the QE is limited by gradient cosmic variance.
We expect that the small-scale lensing measurements could, to some extent, be even further improved by fully implementing the weighting derived in Eq.28 without any approximations.
Though we have presented simple ideas for mitigating or removing foreground biases to the estimator, we caution that the levels of extragalactic foregrounds are large, and that a full examination of the impact of foregrounds has been left to future work. However, as sketched out in Appendix B, an analogous version of the GI estimator can also easily be derived for the case of polarization; the polarization GI estimator has the advantage that it does not suffer from comparable foreground contamination.
Small-scale lensing reconstruction has many potential applications to cosmology such as constraining cosmological parameters, distinguishing between dark matter models (e.g. Nguyen et al. (2019),Sehgal et al. (2019)), validating galaxy weak lensing shear measurements, and constraining high-redshift astrophysics. If further work on polarization, foregrounds and systematics is successful, the improved small-scale lensing reconstruction algorithms presented here could allow new scientific possibilities in these areas.
Acknowledgements.
We thank Anthony Challinor, Ben Horowitz, Antony Lewis, Emmanuel Schaan and Uros Seljak for useful discussions. B.H. was supported by the Benefactors’ scholarship at St John’s College, Cambridge University. B.D.S. was supported by an STFC Ernest Rutherford Fellowship and an Isaac Newton Trust Early Career Grant. S.F. was in part supported by a Miller Fellowship at the University of California, Berkeley and by the Physics Division at Lawrence Berkeley National Laboratory.
Appendix A Noise Discussion
In this appendix, we discuss the theoretical prediction of the reconstruction noise in more detail. As discussed in Section III, the noise on our estimator for a local gradient is given by
[TABLE]
We average over space and over different gradients to obtain the noise power spectrum. If the gradient modes are uncorrelated, then the minimum variance weights are given by
[TABLE]
where is the total area over which we are averaging.
In our initial approximations we have assumed that the noise on the CMB temperature on small scales is merely the instrumental noise; in reality, it can be more accurately modeled by “noise” power coming from other first-order contributions to the lensed temperature power spectrum (see Eq. 4.16 in Ref. Lewis and Challinor (2006))
[TABLE]
The second and third terms here are an attempt to isolate the contributions to the lensed power spectrum that do not arise from a particular lensing mode. The instrumental noise is estimated using the conventional parametrization Knox (1995) to be
[TABLE]
where the noise factor, , is measured in K-rad and the beam full-width half maximum (FWHM), , in radians (given in arcmin in the paper for convenience).
Appendix B Polarization Estimator
Similarly to the temperature estimators considered earlier, we can straightforwardly extend the GI method to polarization. In this appendix, we outline the approach one would take, assuming a constant gradient within the patch under consideration. This approximation is in fact not completely unreasonable in the limit of small-scale lensing we are interested in. A proper treatment of combining different patches with different gradient magnitudes and directions would follow in an analogous manner to what was developed in Section III.
As shown in Lewis and Challinor (2006), we can write the lensed and fields on small scales as:
[TABLE]
[TABLE]
We then have two estimators for the deflection potential with two filter functions:
[TABLE]
[TABLE]
Multiplying Eq. 39 and Eq. 40 by and , we average over CMB realizations of the polarization map, requiring that the estimators are unbiased, to obtain:
[TABLE]
[TABLE]
It follows that:
[TABLE]
[TABLE]
We, thus, end up with the two estimators:
[TABLE]
[TABLE]
with noise power spectra:
[TABLE]
[TABLE]
We thus effectively get two new estimators for the lensing potential which weighted appropriately, can provide a better estimator for the lensing potential. Polarization measurements, in addition, have significantly lower foreground contamination compared to temperature measurements. The generalization for many CMB patches of different gradients follows the approach outlined in Section III and will be addressed in a subsequent paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Smith et al. (2006) K. M. Smith, W. Hu, and M. Kaplinghat, Phys. Rev. D 74 , 123002 (2006) , ar Xiv:astro-ph/0607315 [astro-ph] . · doi ↗
- 2Planck Collaboration et al. (2018) Planck Collaboration, N. Aghanim, Y. Akrami, M. Ashdown, J. Aumont, C. Baccigalupi, M. Ballardini, A. J. Banday, R. B. Barreiro, N. Bartolo, S. Basak, K. Benabed, J. P. Bernard, M. Bersanelli, P. Bielewicz, J. J. Bock, J. R. Bond, J. Borrill, F. R. Bouchet, F. Boulanger, M. Bucher, C. Burigana, E. Calabrese, J. F. Cardoso, J. Carron, A. Challinor, H. C. Chiang, L. P. L. Colombo, C. Combet, B. P. Crill, F. Cuttaia, P. de Bernardis, G. de Zotti, J. Delabrouil
- 3Smith et al. (2007) K. M. Smith, O. Zahn, and O. Dore, Phys. Rev. D 76 , 043510 (2007) , ar Xiv:0705.3980 [astro-ph] . · doi ↗
- 4Das et al. (2011) S. Das, B. D. Sherwin, P. Aguirre, J. W. Appel, J. R. Bond, C. S. Carvalho, M. J. Devlin, J. Dunkley, R. Dünner, T. Essinger-Hileman, J. W. Fowler, A. Hajian, M. Halpern, M. Hasselfield, A. D. Hincks, R. Hlozek, K. M. Huffenberger, J. P. Hughes, K. D. Irwin, J. Klein, A. Kosowsky, R. H. Lupton, T. A. Marriage, D. Marsden, F. Menanteau, K. Moodley, M. D. Niemack, M. R. Nolta, L. A. Page, L. Parker, E. D. Reese, B. L. Schmitt, N. Sehgal, J. Sievers, D. N. Spergel, S. T. Stagg · doi ↗
- 5van Engelen et al. (2012) A. van Engelen, R. Keisler, O. Zahn, K. A. Aird, B. A. Benson, L. E. Bleem, J. E. Carlstrom, C. L. Chang, H. M. Cho, T. M. Crawford, A. T. Crites, T. de Haan, M. A. Dobbs, J. Dudley, E. M. George, N. W. Halverson, G. P. Holder, W. L. Holzapfel, S. Hoover, Z. Hou, J. D. Hrubes, M. Joy, L. Knox, A. T. Lee, E. M. Leitch, M. Lueker, D. Luong-Van, J. J. Mc Mahon, J. Mehl, S. S. Meyer, M. Millea, J. J. Mohr, T. E. Montroy, T. Natoli, S. Padin, T. Plagge, C. Pryke, C. L. Re · doi ↗
- 6Omori et al. (2017) Y. Omori, R. Chown, G. Simard, K. T. Story, K. Aylor, E. J. Baxter, B. A. Benson, L. E. Bleem, J. E. Carlstrom, C. L. Chang, H. M. Cho, T. M. Crawford, A. T. Crites, T. de Haan, M. A. Dobbs, W. B. Everett, E. M. George, N. W. Halverson, N. L. Harrington, G. P. Holder, Z. Hou, W. L. Holzapfel, J. D. Hrubes, L. Knox, A. T. Lee, E. M. Leitch, D. Luong-Van, A. Manzotti, D. P. Marrone, J. J. Mc Mahon, S. S. Meyer, L. M. Mocanu, J. J. Mohr, T. Natoli, S. Padin, C. Pryke, C. L. R · doi ↗
- 7Ade et al. (2016) P. A. R. Ade et al. (Planck), Astron. Astrophys. 594 , A 15 (2016) , ar Xiv:1502.01591 [astro-ph.CO] . · doi ↗
- 8Story et al. (2015) K. T. Story, D. Hanson, P. A. R. Ade, K. A. Aird, J. E. Austermann, J. A. Beall, A. N. Bender, B. A. Benson, L. E. Bleem, J. E. Carlstrom, C. L. Chang, H. C. Chiang, H. M. Cho, R. Citron, T. M. Crawford, A. T. Crites, T. de Haan, M. A. Dobbs, W. Everett, J. Gallicchio, J. Gao, E. M. George, A. Gilbert, N. W. Halverson, N. Harrington, J. W. Henning, G. C. Hilton, G. P. Holder, W. L. Holzapfel, S. Hoover, Z. Hou, J. D. Hrubes, N. Huang, J. Hubmayr, K. D. Irwin, R. Keisler, · doi ↗