Identifying Present-Bias from the Timing of Choices
Paul Heidhues, Philipp Strack

TL;DR
This paper investigates whether time preferences, including present-bias, can be inferred solely from observed task completion timing, using a model with unobserved costs and benefits and known stopping probabilities.
Contribution
It establishes conditions under which present-bias and time consistency can be identified or ruled out from timing data without parametric assumptions.
Findings
The probability of task completion increases towards the deadline for present-biased agents.
Stationary payoff distributions can rationalize observed behavior under certain preference parameters.
Without parametric assumptions, time consistency cannot be ruled out even with known long-run discount factors.
Abstract
Timing decisions are common: when to file your taxes, finish a referee report, or complete a task at work. We ask whether time preferences can be inferred when \textsl{only} task completion is observed. To answer this question, we analyze the following model: each period a decision maker faces the choice whether to complete the task today or to postpone it to later. Cost and benefits of task completion cannot be directly observed by the analyst, but the analyst knows that net benefits are drawn independently between periods from a time-invariant distribution and that the agent has time-separable utility. Furthermore, we suppose the analyst can observe the agent's exact stopping probability. We establish that for any agent with quasi-hyperbolic -preferences and given level of partial naivete , the probability of completing the task conditional on not having…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1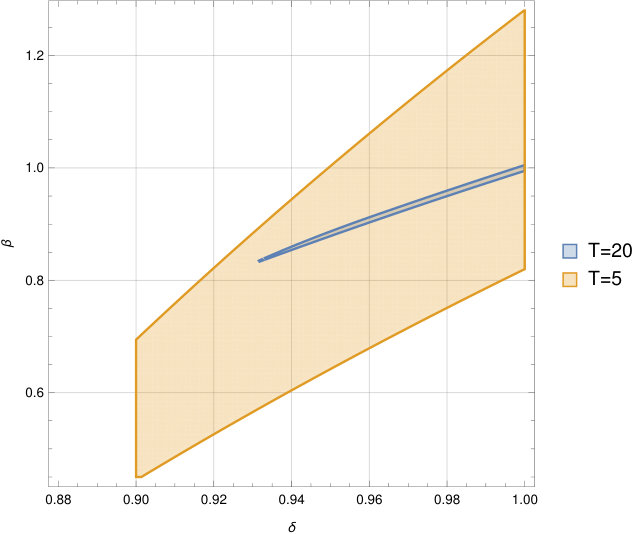 Figure 2
Figure 2| Parametric Family | Sq. Distance Minimzation | Likelihood Maximization | |||
|---|---|---|---|---|---|
| Distance | Log-Likelihood | ||||
| Normal Sophisticate | 0.819 | 0.0026777 | 0.818 | 1.59188 | |
| Normal Naive | 0.817 | 0.00231803 | 0.816 | 1.59187 | |
| Extreme Value Sophisticate | 0.57 | 0.0402888 | 0.5705 | 1.59638 | |
| Extreme Value Naive | 0.561 | 0.0396802 | 0.562 | 1.59627 | |
| Logistic Sophisticate | 0.7605 | 0.00331235 | 0.7595 | 1.59189 | |
| Logistic Naive | 0.7565 | 0.00267175 | 0.7555 | 1.59188 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Identifying Present-Bias from the Timing of Choices111We thank Ned Augenblick, Stefano DellaVigna, Ori Heffetz, Botond Kőszegi, Muriel Niederle, Charles Sprenger, Dmitry Taubinsky, and Florian Zimmermann for insightful and encouraging comments. Part of the work on this paper was carried out while the authors visited briq, whose hospitality is gratefully acknowledged.
Paul Heidhues
DICE
Philipp Strack
UC Berkeley
Abstract
Timing decisions are common: when to file your taxes, finish a referee report, or complete a task at work. We ask whether time preferences can be inferred when only task completion is observed. To answer this question, we analyze the following model: each period a decision maker faces the choice whether to complete the task today or to postpone it to later. Cost and benefits of task completion cannot be directly observed by the analyst, but the analyst knows that net benefits are drawn independently between periods from a time-invariant distribution and that the agent has time-separable utility. Furthermore, we suppose the analyst can observe the agent’s exact stopping probability. We establish that for any agent with quasi-hyperbolic -preferences and given level of partial naivete , the probability of completing the task conditional on not having done it earlier increases towards the deadline. And conversely, for any given preference parameters and (weakly increasing) profile of task completion probability, there exists a stationary payoff distribution that rationalizes her behavior as long as the agent is either sophisticated or fully naive. An immediate corollary being that, without parametric assumptions, it is impossible to rule out time-consistency even when imposing an a priori assumption on the permissible long-run discount factor. We also provide an exact partial identification result when the analyst can, in addition to the stopping probability, observe the agent’s continuation value.
Introduction
Intuition and evidence suggests that many individuals are time-inconsistent; at any particular point in time the (near) present gets an additional weight in intertemporal tradeoffs (e.g. Strotz, 1956; Frederick et al., 2002; Augenblick et al., 2015; Augenblick and Rabin, 2016). Especially when individuals fail to fully anticipate their predictable preference changes, such present-focused individuals tend to procrastinate (Akerlof, 1991; O’Donoghue and Rabin, 1999, 2001): they will often excessively delay the completion of tedious tasks such as filing taxes or paying parking-tickets. And when facing a gratifying task—such as taking a day off—, present-focused individuals often precrastinate. To model the resulting interpersonal-conflict of preference changes in a simple and tractable way, Laibson (1997) adopted intergenerational discounting models (Phelps and Pollak, 1968) to individual decision-making. His quasi-hyperbolic discounting model captures the present-focus of individuals by introducing an additional present-bias parameter that discounts all future utility into Samuelson (1937)’s time-separable exponential-discounting model. O’Donoghue and Rabin (1999, 2001) extend this framework by introducing (partial) naivete, and illustrating such individuals’ tendency to delay unpleasent tasks. Since excessive procrastination is a robust prediction of (naive) hyperbolic discounting models, it seems natural to use task-completion data to identify time-inconsistent preferences from the pattern of completion times. In line with this idea, previous research classifies individuals as time-inconsistent if they complete tasks at or close to the deadline (Brown and Previtero, 2018; Frakes and Wasserman, 2016) or estimates the degree of time-inconsistency from completion times under parametric assumptions (Martinez et al., 2017).222Brown and Previtero (2018) classify individuals that select their health care plan close to the deadline as procrastinators and look for correlated behavior in other financial domains. Frakes and Wasserman (2016) investigate the behavior of patent officers that have to complete a given quota of applications supposing that the cost of working on a patent are deterministic and identical across days. In their model, for conventional discount rates the empirically observed bunching close to the deadline is inconsistent with exponential discounting. While earlier papers do not address the concern of unobservable and random opportunity cost, Martinez et al. (2017) allow for random opportunity costs and use a parametric approach to identify time preferences.
In this paper, we ask whether time preferences can be inferred by an outside observer—referred to as the analyst—when only task completion is observed absent parametric assumptions on the (unobservable) cost and benefit of task completion. A key difficulty in doing so is to separate naivete or time-preference-based explanations of delay from those due to the option value of waiting (Wald, 1945; Weisbrod, 1964; Dixit and Pindyck, 1994): whenever the cost of doing a certain task is stochastic, a time-consistent individual may wait in the hope of getting a lower cost draw tomorrow.333Throughout, we abstract from another reason that tasks may not be completed: forgetting. Conceptually, one can think of the agent in our analysis as getting a non-intrusive reminder at the beginning of every period. This is not to say that limited memory and the strategic response to it are unimportant in determining task completion behavior in the field. See, for example, Heffetz et al. (2016) for how reminders determine when parking fines are payed, Altmann et al. (2019) for how deadlines and reminders determine the probability of making a check-up appointment at the dentist, and Ericson (2017) for how time-inconsistency and limited memory interact.
Section 2 introduces our task-completion model. We consider an analyst who, from observing task completion times of a partially-naive quasi-hyperbolic discounter, tries to learn about some or all of the following parameters: the long-run discount factor , the present-bias parameter , or the degree of sophistication . To facilitate learning by the analyst, we assume that the agent’s task-completion payoffs are drawn each period from the same underlying payoff distribution. Absent any such a priori restriction, it is straightforward to rationalize any observed stopping behavior independently of the agent’s taste for immediate gratification and degree of sophistication, leaving no hope for identification thereof.444For example, suppose in every period the cost of doing the task is either one or zero, allowing for time-varying probability that the cost are zero. Simply setting the probability that the cost are zero in each period equal to that period’s observed task completion probability rationalizes the data for any time-separable utility function. Furthermore, to make identification easier, we suppose that the analyst can observe the individual’s exact stopping probability in each period. Intuitively, one may think of the analyst as having access to an ideal data set with (infinitely) many observations of either the same individual in identical situations or a homogenous group of individuals. Again, this assumption strongly favors the analyst’s ability to learn about underlying parameters. Finally, we impose that individuals can be described as (partially) naive quasi-hyperbolic discounters. We are agnostic as to the nature of the task, so our analysis applies when task-completion leads to immediate benefits, immediate costs, or both.
In Section 3, we introduce two motivating examples. The first highlights that, even when the parametric form of the underlying unobservable payoff distribution are known, bunching at the deadline is insufficient to distinguish a time-consistent from a time-inconsistent agent. In the example, the cost of completing the task are drawn from a log-normal distribution and in every period the stopping behavior of time-consistent agent looks almost identical to that of an agent with a present-bias parameter , whose cost are drawn from a different log-normal distribution. The second example illustrates how the estimated present-bias can depend crucially on common parametric assumptions about the unobservable payoff distribution—even when the analyst knows (or guesses correctly) the long-run discount factor, as well as the mean and variance of the underlying stationary payoff distribution. While we suppose that in reality payoffs are drawn from a uniform distribution and the agent is time-consistent , when the analyst supposes costs are drawn either from a normal, log-normal, extreme value, or logistic distribution, her squared-distance-minimizing or likelihood-maximizing estimate of varies between , with the exact value depending on the parametric family (and the degree of sophistication) the analyst imposes. Furthermore, the squared error associated with some of these incorrect estimates is below %—suggesting that with finite noisy data it is difficult for the analyst to realize when she picks an incorrect functional form. Motivated by the importance of the parametric assumptions in the example, we turn to the main focus of the paper: what lessons about time-inconsistent preferences and naivete thereof can be learned non-parametrically?
As a useful preliminary step, Section 4 establishes that the agent’s perceived continuation value is characterized by a simple recursive equation. Section 5 establishes that for any quasi-hyperbolic discounter—independently of whether she is sophisticated or (partially) naive and of her degree of impatience—the subjective continuation value decreases the closer the agent gets to the deadline. To see the intuition behind the theorem, consider first the case in which the task always generates a net benefit. Then from the perspective of Self 1, all future selves are too impatient, and hence tend to perform the task to early. By extending the deadline, the formerly last period’s self now can decide and perform the task later. As from any earlier self’s perspective she is too eager to complete the task, the direct effect of additional delay on any earlier self is positive. Now consider the former penultimate self; her perceived continuation value of waiting increases because she strictly prefers future selves to wait whenever they choose to do so. This, in turn, induces her to act more patiently, benefiting all earlier selfs, and so forth. Hence, in the case of net benefits, a quasi-hyperbolic discounter does not want to impose an earlier deadline.
Consider next the case in which completing the task is always costly. When comparing a -period to -period deadline, Self 1 realizes that if she does not engage in the task in the period problem, Self 2 will face a -period problem. That subgame is identical to the one she faces in the period problem, and future selves who are periods away from the deadline will therefore behave identically in the two problems. Hence for , the task completion probability -periods before the deadline is identical, and due to discounting of future costs, Self 1 is strictly better off when selecting the -period problem and not doing the task. The formal proof extends these intuitions to the case in which the support of the net benefit distribution can contain positive and negative payoffs.
Because the agent in our model completes the task when the current benefit is greater than her subjective continuation value, Theorem 1 implies that a quasi-hyperbolic discounter becomes more and more likely to complete the task the closer she is to the deadline. This, therefore, provides another simple testable prediction, which also implies that the agent never wants to impose a shorter deadline.555Despite her tendency to procrastinate, hence, when the payoffs are independently drawn from a stationary distribution, a quasi-hyperbolic discounter’s willingness to pay for an earlier deadline is always non-positive. This is noteworthy as self-imposed deadlines by students has been used to identify sophisticated procrastinators (e.g. Ariely and Wertenbroch, 2002; Bisin and Hyndman, 2018); our result suggests that these students either do not have quasi-hyperbolic preferences or that they must foresee a non-stationary environment, which induces them to impose an earlier deadline. A self-imposed-deadline-based classification, hence, is conservative in identifying agents who are aware of their time-inconsistent preferences. Through a simple counterexample, however, we also highlight that this result relies on payoffs each period being drawn from the same underlying distribution.666Furthermore, in Section 8 we note that the prediction need not hold for a heterogenous population of time-consistent individuals that each faces a stationary payoff distribution.
Section 6 establishes our main result: if the agent is either sophisticated () or fully naive (), for any given long-run discount factor and present-bias parameter , any given penalty of not completing the task, and any weakly increasing profile of task completion, there exists a stationary payoff distribution that rationalizes the agent’s behavior (Theorems 2 and 3, respectively). This implies that for any data set the analyst may observe, absent parametric assumptions it is impossible for her to learn anything about the agent’s degree of time-inconsistency or level of sophistication. Importantly, this absence of even partial identification continues to hold even if the analyst imposes a priori restrictions on permissible long-run discount factors. A very rough intuition for this fact is as follows: whether a self prefers to do a task today or tomorrow depends on her time preferences and on the perceived option value of waiting. The option value of waiting, in turn, depends on the payoff distribution. Through changing the unobservable payoff distribution, we can hence undo a change in the present bias or long-run discount factor of the agent.
Technically, however, a local change in the payoff distribution changes continuation values in every period in a highly non-linear way, so to establish that we can construct an appropriate payoff distribution, we need a non-local argument. This is where we use the assumption that the agent is either sophisticated or fully naive. The fact that a sophisticated agent makes no forecast error enables us rewrite the recursive equations determining the perceived continuation values in a simple manner. Based on this rewrite, we transfer the search for an appropriate distribution to that of solving for a fixed point of a system of linear equations. This proof method, however, cannot be used if the agent is partially naive as the corresponding system becomes non-linear.
For a fully naive agent the problem becomes tractable for a different reason. Because a fully naive agent believes to be time-consistent, we can establish that a first-order stochastic increase in the stationary payoff distribution, increases the agent’s subjective continuation value in every period (Lemma 2). In addition, we establish that we can map subjective continuation values into a payoff distribution that gives rise to the desired completion times in such a way that greater subjective continuation values lead to a first-oder stochastic increase in the stationary payoff distribution. The combination of these two steps leads to a monotone operator on subjective continuation values to which we can apply Tarski’s Theorem, and thereby establish the existence of a payoff distribution that gives rise to the data’s stopping probabilities. We also, however, provide a simple example in which a first-order stochastic dominance increase in the stationary payoff distribution makes a sophisticated quasi-hyperbolic discounter worse off. In the example, the agent prefers to pay a fixed utility-tax immediately upon completing the task. This tax reduces his temptation to stop even after a low payoff realization, and the induced more virtuous behavior of future selves overcompensates the direct payoff loss due to the tax. The example highlights why our proof technique does not cover the more general case of a partially naive agent.
In our proofs of Theorems 2 and 3, we freely construct a stationary net-benefit distribution. One may hope to identify present-bias through economically meaningful restrictions on this distribution. Arguably, the most natural assumptions are those regarding the moments of the net-benefit distribution; for example, an analyst may have an idea regarding the possible expected net benefit of doing the task—that is regarding the mean of —or may be willing to impose that net benefits do not vary to much between periods (restricting the variance of ). Our example in Section 3, however, already highlights that even fixing these moments, common parametric assumptions can lead to widely varying estimates of the agent’s time preferences. To expand on this point, in Section 6.3 we establish that as long as the penalty is unobservable or the task is mandatory, we can find a net benefit distribution with any given mean and non-zero variance that rationalizes the observed stopping behavior for a time-consistent agent with . Any identification of present-bias parameter in this case, therefore, must follow from parametric restrictions on higher-order moments of the distribution, for which we see no convincing economic motivation in most contexts.
Section 7 asks whether non-parametric identification is feasible with richer data in which the analyst does not only observe the stopping probabilities but, in addition, observes the agent’s willingness to pay for continuing with the stopping problem in each period. In the case of tax-filing, for example, this amount to eliciting the willingness to pay for having someone else file one’s taxes immediately with zero hassle.777As we explain carefully in Section 7, our procedure does not explicitly or implicitly rely on the agent comparing monetary rewards at different points in time, so it is robust to standard critiques of eliciting time-preference via monetary rewards (Augenblick et al., 2015; Ericson and Laibson, 2019; Ramsey, 1928). For the case of a sophisticated agent who’s contemporaneous utility function is quasi-linear in money, Theorem 4 provides an analytical answer in closed form. Indeed, to check whether or not the data is consistent with a given pair of parameters , the analyst only needs to verify a simple set of inequalities. The key analytical insight is contained in Lemma 3, which establishes that it suffices to consider distributions that have mass points. Intuitively, the option value of waiting is determined by the probability with which the agent stops at given future point in time and the expected payoff conditional on doing so. Hence, moving the probability mass between any two continuation values to the expected payoff conditional on falling between these two values leaves the agent’s continuation values and stopping probabilities unaltered. Therefore, the analyst can restrict attention to such relatively simple distributions. Economically, observing the continuation values allows the analyst to distinguish between a taste for immediate gratification and option-value-of-waiting-based delays because a high option value requires the unobservable payoffs to differ significantly. As a consequence, as the deadline approaches and the agent foresees less future draws, the option value must decrease quickly. In contrast, a present-biased agent’s continuation value decreases at a slower rate. We also argue that at the cost of relying on numerical techniques commonly used in applied work, our set-identification result can be extended straightforwardly to cover partial naivete and non-linear utility in money.
Applying our Theorem 4 to the example introduced in Section 3, however, illustrates that the analyst may need to observe a large number of continuation values to be able to tightly identify the present-bias parameter. In the example, there is no meaningful identification with periods of data, but periods are enough to tightly identify when is known to the analyst. Given that we made a number of assumptions facilitating identification—such as that the exact stopping probabilities and continuation values are observable to the analyst—, we think that the overall message of our analysis suggests a substantial amount of additional data is needed to empirically identify a taste for immediate gratification or the degree of sophistication without relying on parametric assumptions. We point out that if the analyst observes a heterogenous population, much richer stopping patterns can be explained in Section 8, where we conclude by discussing some broader implications of our analysis.
Setup
Let time be discrete. We consider an agent with quasi-hyperbolic preferences who can choose when and whether to complete a single given task before some deadline . More precisely, we suppose that the agents’ utility is time-separable, and denote a level of instantaneous utility the agent receives in period by ; let
[TABLE]
denote the utility over sequence of of self . Following O’Donoghue and Rabin (1999), we allow the agent to have incorrect beliefs regarding future selves’ behavior. The agent believes that all future selfs maximize
[TABLE]
We allow for any vector of preference and belief parameters . In case , the agent has time-consistent preferences with an exponential discount factor . In case , she has a taste for immediate gratification. We say she is sophisticated—i.e. perfectly predicts her future behavior—when , she is fully naive—i.e. believes that her future selves behave according to her current preference—if , and otherwise say that she is partially naive. Our setup covers the case in which the agent overestimates her own future taste for immediate gratification as well as the case in which she underestimate it .
The agent can complete the task once during the periods , so that is the deadline before which the task needs to be completed. If the agent does not undertake the task in a given period , we normalize her instantaneous utility to zero. If she completes the task she gets an instantaneous utility of zero in period , while if she did not complete the task by the end of period , the agents gets a (utility) penalty of in period .888In other words, is self ’s continuation value when not completing the task. Expressing the penalty in this way simplifies the exposition below. Setting , this encompasses the case where the task is mandatory so that the agent is forced to complete the task by the end of period ; and setting , this encompasses the case in which the task is optional so the agent only completes the task if her active self decides to do so. Finally, we suppose that in every period the instantaneous utility of completing the task is drawn independently from a given payoff distribution , which is known to the agent.
We look for perception-perfect equilibria (O’Donoghue and Rabin, 1999, 2001) in which each self chooses an optimal strategy given its prediction of future selves’ behavior, and a self ’s prediction of future selves’ behavior are consistent with how a future self with preference parameter would optimally behave. More formally, let be the history of payoff realizations up to time . A pure strategy for Self is a mapping , with the interpretation that means Self completes the task. A perception-perfect equilibrium is a pair of strategies and such that for all , maximizes under the assumption that selves use strategy , and for all , the strategy maximizes under the assumption that selves use strategy . In addition, we restrict attention to perception-perfect equilibria in which all selves that are indifferent between completing the task and waiting choose to wait.999Without a given tie-breaking assumption, we could rationalize any behavior by simply assuming that the payoff of completing the task is [math] with certainty in all periods. In that case, any stopping probability in any period is trivially optimal, independently of the agent’s time preferences. All our results below extend to the case in which the agent completes the task with some given positive probability when indifferent. Furthermore, in case the agent’s benefit distribution admits a density, the tie-breaking assumption is obviously immaterial. And even otherwise, the case in which there is a mass-point at a payoff at which the agent is indifferent between completing the task and waiting is knife-edge.
Examples on the Influence of Parametric Assumptions
Example 1**.**
To illustrate the difficulty of identifying time-inconsistency from an agent’s stopping behavior, consider the following stylized example. A sophisticated agent receives a parking fine, which has to be paid within ten days of receiving it. In case she does not pay the fine, she incurs a known cost of \5\delta=1$.
Figure 1 compares the stopping behavior of a time consistent agent who draws the cost of completing the task from a log-normal distribution whose underlying normal distribution has mean and variance (red bar plot) to that of a sophisticated time-inconsistent one with a present-bias parameter who draws the cost from a log-normal distribution with parameters (blue bar plot).
An obvious first lesson from the example is that bunching at the deadline is no reliable guide to identifying time-inconsistency: both agents probability of completing the task in the final period is just above 50%. Indeed, both agents stopping behavior is remarkably similar throughout and the observed stopping probabilities differ by less than in any period, suggesting that even an analyst who wants to test only between these two possible types faces a difficult problem in practice.101010Independently of our work, Heffetz, O’Donoghue and Schneider observe that substantially different values of can explain the parking-ticket payment behavior in New York City, which they analyze in Heffetz et al. (2016). They illustrate this supposing that the cost for paying the parking ticket is drawn from the small parametric family of distributions that has a mass point at zero and admit a constant density on an interval above zero. Their real-world data nicely demonstrates the practical importance of the identification challenge we illustrate in Example 1 with synthetic data. We are very grateful to these authors for sharing their example with us during private communication.
In the above illustrative example, the analyst knows or correctly guesses the parametric class of distributions (log-normal) from which the payoffs are drawn. The example suggests that without knowing its exact parameters, nevertheless, it is hard to correctly identify the time-preference parameters. In reality, however, payoffs are drawn from an unobservable payoff distribution and for typical field data—such as parking tickets—an analyst does not know the parametric form of the payoff distribution. The following example highlights how crucial common functional form assumptions routinely imposed in applied papers can be in determining the analyst’s findings. For this example, we suppose that the analyst has precise prior knowledge about the mean and the variance of the unobservable payoff distributions but is unsure as to the exact parametric family from which these payoffs are drawn. Indeed, it strikes us as extremely unreasonable that an analyst has prior knowledge beyond some (typically vague) ideas about the first two moments of this distribution.
Example 2**.**
We suppose that the agent has periods to complete the task and the agent’s value of completing the task are drawn from a uniform distribution over ; in reality the agent is time-consistent with .111111Think of a parent that promised their kid to see a theatre play that shows for seven more days. The parent is self-employed and needs to complete tasks at work as they come in. When not being very busy, the parent enjoys the joint activity. When very busy, however, he is distracted during the play and needs to stay up late afterwards completing his work tasks. Not going to the play after having promised to do so, however, is not a possibility. The corresponding stopping probabilities are , which we suppose the analyst can observe exactly. In addition, we assume the analyst knows the true mean ([math]) and standard deviation () of the stationary payoff distribution but not its exact functional form. Furthermore, suppose the analyst correctly imposes that when analyzing the data. Let the analyst consider four standard parametric families of distributions: normal, log-normal, extreme value, and logistic. For each of these families, the analyst selects the parameter that best fits—in the sense of squared distance or log-likelihood—the observed stopping probabilities allowing the agent to be either naive or sophisticated. Table 1 reports the parameter estimates for and the squared distance/log-likelihood for the different parameterizations of the error distribution.121212The estimates are computed using grid search with a distance of between grid points.
The analyst’s estimates of range between even in this idealized situation in which she has infinite data, actually knows the mean and standard deviation of , and knows the long-run discount factor . And if the analyst engaged in model testing selecting the model on the basis of minimizing squared distance or maximizing log-likelihood, she would conclude that the agent is naive time-inconsistent with while in truth the agent is time-consistent and . Furthermore, for the normal distribution the squared difference in stopping probabilities in the sophisticated and naive case are remarkably small (less than ), so (in a finite data set analogue) nothing would indicate to the analyst that these are bad distributional choices to model the unobservable shocks.131313 If the analyst does not know the mean and standard deviation of the shock distribution and thus needs to estimate these parameters as well, she is able to fit the data even better, making it even harder to detect her misspecification.
Our general results below, which establish that non-parametrically the degree of time-inconsistency is never identified from task completion data, prove that the above examples are not artefacts of the numbers we have chosen. For every set of model parameters and any given dataset, there exists some unobserved stationary payoff distribution that perfectly fits the data. Thus, the analyst can rule out parameter values for only through ad-hoc assuming a specific parametric family of distributions. As a consequence, the analyst’s conclusions are—in line with Example 2—solely determined by her parametric choice for the unobservable payoff distribution.
Preliminary Analysis: Recursive Structure
We begin by establishing that the agent’s problem has a simple recursive structure. A strategy is a cutoff strategy with cutoffs if
[TABLE]
Self completes the task if and only if her realized payoff is strictly greater than . Furthermore, selves believe that Self will complete the task if and only if her realized payoff is strictly greater than . Hence both the perceived and actual strategy in the final period are cutoff strategies. Similarly, if all future selves are perceived to use cutoff strategies, Self can calculate the perceived continuation value of waiting, and will complete the task if and only if her current payoff is greater than this perceived continuation value. Hence, by induction, all selves use a cutoff strategy and perceive their future selves to use a cutoff strategy.
For a partially-naive quasi-hyperbolic discounter, the time and time selves have the same beliefs about the strategy future selves—i.e. selves active after time —use. Self thus believes that if she does not complete the task at time , the task will be completed at the (random) time
[TABLE]
where is the perceived cutoff that selves believe Self will use. Trivially, for all the stopping time equals conditional on not stopping before time ,
[TABLE]
Hence, Self believes that her perceived continuation utility if she does not complete the task at time is given by
[TABLE]
Since Self stops whenever the value of completing the task immediately is greater than her subjective continuation value, the time at which the task is completed conditional on not having been completed before time is given by
[TABLE]
We first show that the perceived continuation values satisfy a recursive equation.141414Throughout this paper, denotes the Riemann–Stieltjes integral.
Lemma 1** (Recursive Characterization).**
A pair of strategies constitute a perception-perfect equilibrium if and only if both are cut-off strategies with cutoffs that satisfy the equations
[TABLE]
and .
Proof.
We first show that the conditions are necessary for a perception-perfect equilibrium. We already argued that any equilibrium must be in cutoff strategies and that the cutoffs used by each self must equal their perceived continuation value . We can rewrite the perceived continuation utility by considering the event that the task is completed in period as well as the complementary event that it is completed later
[TABLE]
Since is distributed according to and conditional on not stopping in period , we can use the definition of a Riemann–Stieltjes integral to rewrite the above as
[TABLE]
Using the definition of to rewrite the last summand above, we therefore have that
[TABLE]
Here, is the cutoff that Self actually uses. Prior selves, however, believe that Self discounts with hyperbolic weight , so the perceived cutoff they think Self uses solves
[TABLE]
Using this equation to replace in (4) establishes that the continuation values satisfy the recursive equation
[TABLE]
That any such pair of cutoff strategies constitutes a perception-perfect equilibrium follows from checking the (perceived) optimality conditions inductively starting from the last period. ∎
To see the intuition behind Equation 3, suppose first that the agent is sophisticated () in which case (). Then the first term is the discounted benefit of stopping tomorrow, which the agent does whenever the benefit of stopping falls above the continuation value of tomorrow’s self. This payoff is discounted according to Self ’s short-term discount factor . The second term captures the fact that with probability tomorrow’s self continues because it prefers its perceived continuation value . As today’s self discounts payoffs that realize after period by a factor of more than tomorrow’s self, this term is discounted with . When predicting future behavior, a partially naive agent uses the perceived cutoffs determined by the continuation value a former time self believes Self has. If , current selves overestimate future selves’ patience and, hence, the cutoff they use. If , current selves underestimate future selves’ patience and, hence, their cutoffs.
Rate of Task Completion Increases Over Time
Building on this recursive formulation, this section establishes that a partially-naive quasi-hyperbolic agent is (weakly) more likely to stop and complete the task, the closer she is to the deadline . In other words, the longer away the deadline, the higher the perceived continuation value of the current self. Because the payoff distribution is stationary, comparing the perceived continuation value of period to that of period is equivalent to comparing the perceived continuation in the first period of task-completion with a deadline of to that with a deadline of . Interestingly, since the perceived continuation value increases in the distance to the deadline, therefore, a quasi-hyperbolic agent would never want to impose an earlier deadline to keep herself from procrastinating excessively. While obvious for an exponential discounter—adding an extra period simply increases her choice set and hence makes her better off—the question of whether to limit future selves delay possibility is much more subtle when the agent is a quasi-hyperbolic discounter. Indeed, when the distribution of net benefits is not stationary, it is easy to construct counterexamples in which Self 1 would want to impose an early deadline on future selves.
Example 3** (Self 1 wants to impose a deadline with a time-dependent payoff distribution).**
Consider a sophisticated agent with who has two periods to complete a mandatory task, and who has a deterministic cost of in the first and in the second period. Due to her present bias, the agent will complete the task in period 2 giving Self 1 a utility of -1/2. Now add the chance to complete the task in a third period at a cost of 1.5. Then Self 2 strictly prefers to procrastinate, and if Self 1 waits, her utility is -3/4. Thus, adding another period in which the task can be completed makes Self 1 worse off. As a result, Self 1 would be willing to impose a two-period deadline.
Intuitively, because preferences between today’s self and future selves are not aligned, if payoffs depend on time restricting future selves’ choices through imposing a deadline can be beneficial to today’s self. Bisin and Hyndman (2018) provide further examples in which a sophisticated quasi-hyperbolic agent benefits from imposing a deadline when costs of doing a mandatory task follow a Markov process in which higher costs today are associated with higher costs tomorrow.151515While in our simple example the state changes deterministically, continuity of payoffs implies that the example also hold if with a small probability the costs are redrawn from a uniform distribution over and otherwise move up deterministically towards the state as in our example. What is perhaps surprising is that if costs—or net benefit in our setup—are uncorrelated over time, a sophisticated quasi-hyperbolic agent never wants to impose a deadline.
Indeed, when the payoff distribution is the same across periods, we have:
Theorem 1** (Monotonicity of the Continuation Value).**
Let .
- i)
The subjective continuation values are non-increasing over time
[TABLE] 2. ii)
Every self prefers a later deadline.
Parts and are equivalent since when the payoff distribution is identical across periods, the subjective continuation value in a given period equals the value in the problem with a deadline of periods. To understand intuitively why a quasi-hyperbolic agent’s Self does not want to impose a deadline with a stationary payoff distribution, consider first the case in which doing the task is always costly—i.e., where the support of is a subset of . When comparing a -period to -period deadline, Self 1 realizes that if she does not engage in the task in the period problem, self 2 will face a -period problem. That subgame is identical to the one she faces in the period problem, and future selves who are periods away from the deadline will behave identically in the two problems. Hence for , the task completion probability -periods before the deadline is identical, and due to discounting of future costs, Self 1 is strictly better off selecting the -period problem and not doing the task in the first period.
Suppose now instead, that the agent is sophisticated with quasi-hyperbolic parameter and that the payoff of completing the task is always positive—i.e., the support of is a subset of . From the perspective of a Self , future selves are to impatient, and therefore to willing to cash in the positive benefit in every future period. Suppose now that Self 1 can extend the deadline from to periods. In this case, Self will wait for sufficiently low net benefits. Because the time self is more impatient than Self 1 would want it to be, whenever the impatient Self chooses to wait, Self 1’s expected payoff increases from waiting. Thus, conditional on reaching period , the longer deadline benefits Self 1. Now consider Self . With the longer deadline, Self ’s benefit from waiting increases because it always prefers its future self to not complete the task when the future self chooses to do so. Hence, Self will also act less impatiently, which again benefits Self 1 conditional on reaching period . By induction, hence, in expectation Self 1 benefits in every future period from the deadline extension.
Because a partially naive Self 1 thinks that she is sophisticated, and in either case a sophisticated agent’s Self 1 does not want to impose a deadline, a partially naive agent will not want to do so either. Hence, the perceived continuation value of a partially naive agents also increase in the distance to the deadline.
Our proof studies properties of solutions to the recursive equation (3) to extend the above intuitions to cases in which the support of the payoff distribution may contain positive and negative elements, and hence some future selves can be a priori to eager and others not eager enough to complete the task.
We now turn to an immediate implications of Theorem 1. Note that the probability that the agent stops in period conditional on not having stopped before is the probability that the value of completing the task is above the subjective continuation value ; i.e.
[TABLE]
As the subjective continuation value is non-increasing, we have that the objective probability that the agent stops in period is non-decreasing.
Corollary 1**.**
Let . For any given benefit distribution and in every perception-perfect equilibrium, the objective probability with which the agent completes the task conditional on not having completed it before is non-decreasing towards the deadline, i.e.
[TABLE]
Independently of the naivete and preference-parameters of a hyperbolic discounter, Corollary 1 provides a simple testable prediction about her task-completion behavior when payoffs are independently and identically distributed over time: the likelihood of completing the task is increasing over time. Section 8, however, emphasizes that researchers need individual not group data to test this prediction.161616Interestingly, this result holds independently of whether the agent over- or underestimates estimates , i.e. whether or .
Remark 1*.*
Corollary 1 establishes that the probabilities of stopping conditional on not having stopped previously increase over time. The unconditional stopping probability, however, may either increase or decrease. This difference is of practical relevance: for example, the conditional stopping probabilities increase over time in the tax-filing data of Martinez et al. (2017) while the unconditional stopping probabilities decrease.171717See Figure 1 and 2 in Martinez et al. (2017).
Time-Preferences are Unidentifiable from Task Completion
In this section, we identify a strong sense in which time-preferences are unidentifiable from task completion choices. Recall that we established that for any arbitrary preference profile and any belief , the profile of stopping probabilities is non-decreasing. In this section we establish the converse: absent (parametric) restrictions on the payoff distribution , we show that any non-decreasing profile of stopping probabilities is consistent with any arbitrary preference profile in case either the agent is either sophisticated () or fully naive (). Hence, it is impossible, for example, to distinguish a naive time-inconsistent agent from a time-consistent one based on their task-completion behavior. Importantly, this impossibility continues to hold even if a researcher is willing to exogenously impose that the “long-run discount factor” equals , as is plausible in many applications in which one observes task completion on a frequent (e.g. daily) basis. Similarly, even if the researcher is willing to impose a priori restrictions on plausible levels of —including the strong requirement that the agent is time-consistent—, absent exogenous restrictions on , no information on or can be inferred from the task-completion data.
Intuitively, whether a self prefers to do a task today or tomorrow depends on her time preferences (as well as beliefs about future selves’ time preferences) and on the perceived option value of waiting. The option value of waiting, in turn, depends on the payoff distribution. Through changing the unobservable payoff distribution, we can hence undo a change in the present-bias or long-run-discount factor of the agent. Technically, however, a local change in the payoff distribution affects continuation values in every period in a highly non-linear way, so to establish that we can construct an appropriate payoff distribution, we need a non-local argument. When the agent is either sophisticated or fully naive—for different technical reasons that we explain below—the analysis simplifies and allows us to establish that we can indeed rationalize the stopping behavior for any arbitrarily chosen .
For the case in which the penalty is unobservable, we furthermore illustrate that the data is rationalizable as the optimal behavior of a fully patient time-consistent agent facing an unobservable payoff distribution with any given expected value and (non-zero) variance of the distribution; any parametric identification of present bias in such a task-completion setting, therefore, must be based on a prior knowledge of higher-order moments of the benefit distribution.
6.1 Time-Preferences are Unidentifiable: Sophisticated Case
In this subsection, we establish that absent (parametric) restrictions on the payoff distribution , any non-decreasing profile of stopping probabilities is consistent with any arbitrary preference profile of a sophistcated quasi-hyperbolic discounter. In particular, we have:
Theorem 2** (Non-identifiability).**
Suppose the agent is sophisticated . For every non-decreasing sequence of stopping probabilities , every , and every penalty , there exists a distribution that rationalizes the agent’s stopping probabilities as the (unique) outcome of a perception perfect equilibrium.
Technically, to prove the theorem, we construct a distribution with mass points, where each of the non-extreme values equals the agent’s (correctly perceived) continuation value in a given period ; i.e. the second lowest mass point is set at the value , and so on. The probability on each mass point is chosen so that the agent—who waits if and only if —selects the exogenously given stopping probability. The constructions is feasible since when , the recursive representation (Lemma 3) takes a particular simple form, and together with the chosen construction of the distribution gives rise to a system of linear equations, which can be solved forward.
6.2 Time-Preferences are Unidentifiable: Naive Case
We now turn to the case in which the agent believes to be time-consistent and establish that for every chosen non-decreasing sequence of stopping probabilities and every chosen preference profile , there exists a payoff distribution that admits a piecewise constant density and induces the agent to choose the stopping behavior given by the data.
Theorem 3** (Non-identifiability).**
Suppose the agent believes to be time-consistent . For every non-decreasing sequence of stopping probabilities , every , and every penalty , there exists a distribution that rationalizes the agent’s stopping probabilities as the unique outcome of any perception perfect equilibrium.
Our formal proof in the appendix proceeds roughly as follows. Step (i). Fix the agent’s time preference as well as period ’s continuation value (which equals ). Step (ii). Take an arbitrary -element vector of non-increasing continuation values . Step (iii). Here, we generate a payoff distribution for these continuation values that gives the desired stopping probabilities. In particular, we put a probability mass that is equal to the difference in the exogenously given stopping probability between period and between the corresponding period’s perceived continuation values, for simplicity using a uniform density. This step, hence, amounts to mapping continuation values into distributions that lead to the correct stopping probabilities. Step (iv). Calculate the actual continuation values that the new payoff distribution from the third step gives rise to. This maps the set of distributions back into the vector of continuation values. By Theorem 1, these continuation values are again non-decreasing, and thus the combined function maps a non-increasing sequence of continuation values into a non-increasing sequence of continuation values. Step (v). We show that this function is bounded and maps sequences from an appropriately chosen interval into itself. Furthermore, the function is monotone as higher continuation values lead to a better distribution (in the sense of first-order stochastic dominance) and a better distribution increases the subjective continuation values for an agent who believes to be time-consistent (established in Lemma 2 below). Thus, the mapping from continuation values into continuation values is a monotone mapping from a complete lattice into a complete lattice, and by Tarski’s Theorem admits at least one fixed point. Any fixed point gives the desired distribution, since by Step (iii) the stopping probabilities are correct and by Step (iv) the continuation values are those consistent with the limit distribution. Furthermore, because by Lemma 2 below, the continuation values are strictly decreasing when and , the limit distribution that we construct is continuous, so that the agent’s stopping behavior is unique.
As explained in the above sketch, the proof of Theorem 3 relies on the following Lemma.
Lemma 2**.**
Suppose and the agent believes to be time-consistent .
- i)
For every distribution with and , the continuation values are strictly decreasing . 2. ii)
A first-order stochastic dominance increase in the payoff distribution increases the vector of subjective continuation values point-wise.
Part shows that whenever there is a positive probability that the utility from completing the task in the final period before the deadline is less than that from not completing the task, an agent who believes to be time-consistent (i.e. who has beliefs ) has a strictly positive willingness to pay for extending the deadline. Here, the assumption that and rules out that it is optimal for the agent to always complete the task immediately.181818As a trivial counterexample to the finding when the assumption is dropped, suppose the task yields a (net) positive deterministic payoff above . Then the agent would always complete the task immediately, and hence is unwilling to pay for extending the deadline. Thereby, it allows us to strengthen the finding of Theorem 1 for the case of .
The second part of the Lemma shows that any improvement in the payoff distribution weakly increases the subjective continuation values in all periods. Obviously, for a time-consistent agent an improvement in the payoff distribution raises the second to last period’s continuation payoff. Furthermore, from the third to last period’s perspective, the increase in the payoff distribution and the penultimate period’s continuation value, makes it more desirable to reach the second to last period, that is increases its continuation value; etc… . And because an agent with beliefs thinks she is time-consistent from tomorrow on, it similarly increases her continuation values.
While economically we do not believe that the restriction to fully naive or actually time-consistent agents (with ) is important for Theorem 3 to hold, our mathematical proof uses this assumption when arguing that subjective continuation values increase in a first-order-stochastic dominance shift in the payoff distribution, which in turn allows us to use Tarski’s Theorem. In general, due to a time-inconsistent agent’s the conflict of interest between her different selves, a first-oder-dominance improvement of her payoffs need not raise subjective continuation values as the following example highlights.
Example 4** (A sophisticated -agent can prefer a fixed uniformly payoff-reducing tax).**
Let and the agent be sophisticated (). To simplify the calculation, we set but the argument obviously extends to sufficiently close to . We compare the agent’s expected welfare and (subjective) continuation values in a three-period voluntary-task-completion problem across two scenarios.191919Because even the lowest payoff from completing the task is positive, the agent always completes the task voluntarily. Our results, thus, remain unchanged if task completion becomes mandatory. One without a tax, and one in which the agent has to pay a fixed utility tax of in the period in which she completes the task. Let the distribution of payoffs absent a tax be such that with probability the agent receives a payoff of , and with the remaining probability of the agent receives a payoff of . Straightforward calculations (see the Supplementary Appendix) establish that the agent strictly prefers the tax to the no tax situations and that the tax increases the first-period continuation value.
Note that the tax introduced in Example 4 is the same independent of when the agent completes the task and in that sense is not tailored to punish an agent for giving in to early temptations. Intuitively, nevertheless, the tax in the above example lowers the temptation to quit immediately in period 2 as it reduces the benefits from doing so. As a result, the agent obtains a commitment device to only stop when payoff are high in the second or first period. The benefits thereof overcompensate the direct payoff reduction through the tax, and thereby raise earlier periods’ continuation values.
Lemma 2 and Example 4 jointly imply that one can (sometimes) identify agents that believe to have self control problems : such an agent can have a strictly positive willingness to pay to make his payoff distribution strictly worse. In contrast, an agent who believes to be time-consistent () and hence does not foresee future self-control problems will never want to do so.
6.3 Known Expected Value and Variance
For our very general results, we have not restricted the class of permissible distribution functions. One may hope to rule out time-consistency and find evidence through restricting features of the distribution. Perhaps the most natural way of doing so would be two make restrictions regarding the moments of ; for example, an analyst may have an idea regarding the possible expected net benefit of doing the task—that is regarding the mean of —or may be willing to impose that net benefits do not vary to much between periods (restricting the variance of ).
We now briefly observe that if the penalty is unobservable, even with a priori knowledge of the mean and variance of it is impossible to rule-out time-consistent behavior. To see this, consider an agent for whom . Theorem 2 implies that there exists a net benefit distribution that rationalizes any increasing profile of stopping probabilities. Furthermore, in this case the recursive formulation of the problem in Lemma 3 simplifies to
[TABLE]
Hence, if the distribution together with the penalty rationalize the data, so does the distribution together with the penalty for any . In other words, we can always select a net benefit distribution with a given expected value. Furthermore for any , the stopping behavior remains optimal if we scale the net-benefits and by . This implies that we can not only select a distribution with a given mean but that we can at the same time select any desired variance and explain the observed stopping behavior.202020Indeed, since the construction of in the proof of Theorem 2 uses bounded support, we can rationalize the observed stopping behavior as resulting from a patient agent () whose net benefits vary arbitrarily little.
Corollary 2**.**
Suppose the agent is time-consistent and fully patient . For every non-decreasing sequence of stopping probabilities , and every and , there exists a distribution with mean and variance and a penalty that rationalizes the agent’s stopping probabilities as the (unique) outcome of a perception perfect equilibrium.
Non-Parametric Identification with Richer Data
Above, we established that stopping data by itself is insufficient to test for time preferences. A natural question is whether richer data allows the analyst to learn about the agent’s time-preferences. To do so, the analyst needs to disentangle whether the stopping behavior is driven by a desire to delay incurring costs or by the option value of drawing a better payoff in the future. Observe that in the latter case, a considerable option value requires payoff to differ significantly. Hence, as the deadline approaches and a waiting agent faces fewer future draws, the continuation value should drop considerably. In contrast, even with a (relatively) constant option value, an agent who is present biased is willing to delay a costly activity to the last minute. Thus, observing, in addition to task-completion times, continuation values directly should facilitate the non-parametric identification of . We, thus, analyze how much the analyst can learn when also observing the continuation values.
More formally, consider the case in which the analyst observes the agent’s stopping behavior (infinitely often) as well as his exact willingness to pay for continuing with the task. Conceptually, the analyst could elicit this information by selecting some stopping problems in which she offers the agent a mechanism at the end of period that truthfully elicits her willingness to pay for continuing with the task from onwards.212121If the analyst sees infinitely many identical agents, she can randomly select agents. Label these agents . At the end of period , the analyst then elicits agent ’s willingness to pay for facing the task-completion problem from period to . She can do so using a standard Becker-De Groot-Marschak mechanism (Becker et al., 1964). Denote the amount she is willing to pay at the end of period by . If the agent’s utility is quasi-linear in money, which is a good approximation in the standard hyperbolic discounting model whenever the involved stakes are relatively small—as in the case of parking tickets—, then observing is equivalent to observing the continuation value ; otherwise, for some monotonically increasing utility function . We provide an exact analytical result regarding partial identification for the case of linear utility in money and a sophisticated agent. But, we also highlight that—at the cost of having to use numerical methods common in empirical work to solve for the admissible parameter range—our results can be readily extended in multiple directions, including partial naivete and non-linear utility in money. Importantly, below we also point out that our procedure identifies the time-preferences over effort even if the agent discounts money—due to time-preferences or the ability to borrow or save—differently than effort, which implies that our time-preference identification is robust to standard criticisms of eliciting time preferences using monetary choices (Augenblick et al., 2015; Ericson and Laibson, 2019; Ramsey, 1928).
As a preliminary observation, recall that Theorem 1 and Corollary 1 imply that the elicited continuation values must be non-increasing and the observed stopping probabilities non-decreasing. We refer to data that has these properties as plausible.222222If is observable then in addition we require that . Any data that is not plausible cannot be justified by our quasi-hyperbolic setup. Imposing that the agent is sophisticated, we now show how to non-parametrically identify the set of that are consistent with the observed data. Using Lemma 1 and the fact that an agent stops whenever his payoff is strictly above the continuation value, for a sophisticate the continuation values and conditional stopping probabilities must satisfy
[TABLE]
Conversely, if a pair satisfies (5) for a given plausible data set, then Lemma 1 implies that it gives rise to a perception perfect equilibrium for a sophisticated agent.
Note that the right-hand-side of (5) is given by the data and hypothesized values of and . Thus, the data is consistent with a given pair if and only if there exists a distribution that solves (5). As a preliminary step, we show that whenever (5) admits a solution, it also admits a solution that is a distribution consisting of mass points.
Lemma 3**.**
Whenever (5) admits a solution for a plausible data set, there exists a solution that consists of exactly mass points located at that satisfy
[TABLE]
with associated probabilities given by
[TABLE]
Intuitively, two distributions give rise to the same stopping probability when the probability mass above the continuation values is the same. And the only things that matters for the option value of waiting is the probability with which the agent stops at given future point in time and the expected payoff conditional on doing so. By moving the probability mass between any two continuation values to the expected payoff conditional on falling between these two values, thus, the incentives to wait are unaltered. Furthermore, because the observed stopping probabilities determine the continuation mass between any two continuation values, the question of whether the analyst can non-parametrically match the observed data for a given boils down to the question of whether she can do so by choosing a distribution consisting of mass points in the appropriate intervals.
Conceptually, Lemma 3 hence allows the analyst to search over a finite dimensional rather than an infinite-dimensional space of possible distribution. Indeed, under the distributional restriction given by the lemma, (5) becomes a non-linear system with finitely many real-valued unknowns. Theorem 4, which we prove in the Appendix, shows that this system can be transformed into a simple set of transparent inequalities that identify the values of and that are consistent with the observed stopping behavior and elicited continuation values.
Theorem 4** (Non-Parametric Identification).**
Suppose for all and that .232323We require only to simplify the statement. Plausible data is consistent with and sophistication if and only if (i)
[TABLE]
and (ii) for all , where
[TABLE]
The theorem provides an exact characterization of what time-preference parameters are consistent with the observed rich data. To illustrate its implications, consider the example from Section 3 in which , the agent’s payoff of completing the task are uniformly distribiuted over , and the agent is time-consistent with (this is the setup of Example 2). We illustrate the set of parameters the analyst can identify non-parametrically for and in Figure 2. It is immediate that—in contrast to the case of unobservable continuation values—not all parameter combinations are consistent with the data.
Figure 2, however, also illustrates that even if the analyst correctly imposes that , she cannot make precise inference in the case where . Indeed, in the example any between and is consistent with the data. This changes drastically for in which case is tightly identified once is imposed. Without imposing , however, the inference about remains imprecise even in the case of , as it is impossible to reject . Overall, the example suggests that rich data—including a significant number of continuation values—are needed for tight parameter estimates.
What allows the analyst to separate the option-value-from-waiting based reason for delaying the task from time-preference-based ones with a rich enough data set? If the agent is patient, he will only delay completing the task with high probability in case he expects a better draw with high probability. This implies that there needs to be considerable variation in the underlying payoff distribution. But then as the deadline moves closer, the agent foresees getting less and less draws, which means the option values quickly drops. In contrast, if time preferences are the underlying reason for delaying, the continuation value will drop much more slowly as the deadline approaches. The additional data on continuation values, hence, allows for set identification of the preference parameters.
Since it is the change in option value that allows identification, one can also use other related data. For example, the willingness to pay for extending the deadline reflects the drop in continuation value, and therefore would also give rise to a rich data set that would allow non-parametric set identification. Again, however, our example suggests that many such observations are needed, suggesting that a tight estimation of agents’ time inconsistency requires “extremely rich” task-completion data.
Generalizations of this Methodolgy
We think of the Theorem 4 as a proof of concept, and analysts can adopt it to the data at hand and the assumption they are willing to make. For example, it is in principle straightforward to adopt the above analysis to allow for partial naivete. In that case, however, one needs to be careful to account not only for the probability mass and expectation of falling between two actual continuation values but also differentiate whether a given probability mass falls above or below the anticipated continuation values . An analog to Lemma 3 implies that this can be done with mass points. In this case, however, for intervals that are bounded by anticipated and not actual continuation values, the probability that falls into this interval is unknown. As a result, the analyst needs to choose both the mass point and the weight on it (with the appropriate constraints from the observed stopping behavior), giving rise to quadratic constraints. While this can be solved numerically using standard techniques, a simple transparent closed-form solution as in the case of Theorem 4 is unavailable. Similarly, because we only need to consider a finite number of mass points, one can allow for non-linear utility in money, which—imposing that utility is increasing in money—requires the analyst to choose increasing utility values in addition to the mass points.242424If the analyst wants to impose risk-aversion in money, this adds simple (linear) constraints that ensure that the slope of is non-increasing in . Again, this can be solved using standard numerical techniques.
Time-Preferences over Money
One important aspect of our procedure is that it does not (explicitly or implicitly) impose constraints on how the agent handles monetary payments at different points in time. It is sufficient for contemporaneous utility to be separable in money, and the marginal utility of receiving money to be the same across periods. This assumption is consistent with an intertemporal set-up in which the agent can borrow and lend at given interest rates—in which case the interest rate determines how she trades off monetary payments at different points in time (Ericson and Laibson, 2019; Ramsey, 1928). But it is also consistent with an agent narrow bracketing and consuming small monetary payments immediately—or reasoning as if she does so—so long as she trades of money and effort consistently over time. The procedure outlined in this section thus works for either specification of the agent’s time preferences over monetary payments.
Discussion
Our results establish a strong form of non-identifiability in that—absent data on continuation values—even with ideal stopping data in which the analyst observes the exact stopping probability for each individual separately, without parametric assumptions nothing can be learned regarding the agent’s discount factor, taste for immediate gratification, or degree of sophistication. In reality, an analyst is likely to observe a large group of agents and infer their average stopping probability; if the group is homogenous our analysis applies. If individuals, however, in addition differ in their unobservable payoff distribution or time preferences, the analyst’s problem becomes even more difficult. In that case, for example, it is easy to generate non-monotone stopping probabilities for the overall population. As a simple example, suppose there are two types of agents in the population that face a three-period mandatory task-completion problem. The first type stops in each period with probability 1, while the second type only stops in the final period. If is the fraction of the first type, then the aggregate stopping probability is in the first period, [math] in the second, and in the final period, which is clearly non-monotone.252525See Heffetz et al. (2016) for a more detailed discussion of heterogeneity as well as empirical evidence on its importance in determining when individuals pay their parking fines.
Importantly, we establish our formal result for the specific task-completion setting analyzed, and they should not be misconstrued as implying complete non-identifiability of the quasi-hyperbolic discounting model in other settings. In richer and different datasets, it is possible to identify more directly. For example, lotteries (or contracts) that payoff differently depending on the agent’s own future behavior can be used to reveal whether the agent missperceives her own future behavior and, hence, whether she is (partially) naive in the quasi-hyperbolic discounting model (see, for example, DellaVigna and Malmendier, 2006; Spiegler, 2011). Similarly, if the agent is willing to pay for reducing her choice set or for imposing a fine for certain future actions, she values commitment and—within the quasi-hyperbolic discounting framework—must be time-inconsistent (see, for example, Strotz, 1956). Such identification strategies, however, rely on data that is fundamentally different from the task-completion data for which we establish the impossibility of non-parametric identification.
Indeed, even in the closely related, but different, problem of task-timing (Carroll et al., 2009; Laibson, 2015) in which the benefit from doing the task start accumulating as soon as the agent finishes it, it is possible to construct examples in which an agent wants to commit to an earlier deadline, implying that at least partial identification of perceived present-bias () is theoretically feasible. While agents may theoretically benefit from imposing a deadline in such task-timing problems, however, the calibration of the example in Laibson (1997) suggests that their willingness to do so is small, suggesting that identifying time-inconsistency may nevertheless be challenging in real-world data.
The broader economic lesson from our analysis is that conclusions about time-preferences can quickly be driven by seemingly innocuous parametric assumptions. Our results on set-identification with richer data illustrate, however, that it is possible—and in our setting surprisingly easy—to avoid functional form assumptions. We, thus, think of these results as a proof of concept for the feasibility of non-parametric analysis within the quasi-hyperbolic discounting framework.
Finally, let us emphasize the obvious fact: even though present-bias is non-identifiable in our task-completion settings absent data on continuation values, present-bias may still be a major driver for the wide-spread observation that agents complete tasks last minute. Our results simply caution that the observed task-completion behavior in these settings on its own is not enough to conclude that present-bias is widespread.
Appendix
Define the function as
[TABLE]
As the following lemma formally establishes, has a number of convenient properties.
Lemma 4**.**
The function has the following properties:
- i)
For all , the perceived continuation values satisfy . 2. ii)
* is non-decreasing for , is right-continuous, and has only upward jumps.*
Let . Then has the following additional properties:
- iii)
* for all and there exists such that for all .* 2. iv)
Let . Then satisfies and . 3. v)
If , then
Proof of Lemma 4: follows immediately from Lemma 1. To see that holds, observe that we can rewrite as
[TABLE]
Note that both the first and the second summand are non-decreasing for , and that the first summand is continuous in while the second is right-continuous and has only upward jumps as is a CDF.
To see that holds, observe that the integral in the first summand of (7) is bounded from below by and, thus, for
[TABLE]
For establishing the second part, note that
[TABLE]
We next argue that this implies that there exist a such that for all , . Suppose otherwise, then there exists a sequence such that . Furthermore, for this sequence , a contradiction.
We now show . Observe that since has only upward jumps, has only upward jumps. Because by the set is non-empty, the fact that has only upward jumps implies that satisfies . Furthermore, it follows immediately from that the set contains only , and hence that .
To show , note that for Equation 7 together with implies that
[TABLE]
where the inequality follows from the facts that and . ∎
Proof of Theorem 1: That statements i) and ii) of the theorem are equivalent is argued in the main text. Here, we prove statement i).
We begin by establishing the result for . Trivially, Self ’s perceived continuation value is . Define , which is well defined by Lemma 4, and . By Lemma 4, and , we have that
[TABLE]
As and (by Lemma 4, )), we have that . We now proceed by induction to show that this implies that . We distinguish two cases: First,. In this case the monotonicity of , established in Lemma 4, , together with Equation 8 implies that and, thus, by induction . Second if , then by Lemma 4, , and hence it follows from Equation 8 that . We conclude that for all .
Hence, since , we have
[TABLE]
Finally, we establish the result for . First, note that the right-hand-side of (6) is continuous in and as by Lemma 4 , it follows that the continuation values are continuous in . Let be the continuation value in period as a function of . We already established that for all . By continuity, we have that . ∎
Proof of Theorem 2: Fix a non-decreasing sequence of stopping probabilities , , and a penalty . We will construct a distribution that implies the stopping probabilities for a sophisticate.
Pick any perceived first-period cutoff such that
[TABLE]
Using in Lemma 1, the perceived continuation values satisfy
[TABLE]
Let be the sum of Dirac measures
[TABLE]
at the mass points satisfying
[TABLE]
Let the probability of each mass point be given by
[TABLE]
Note that as . Since the mass points of are exactly at the continuation values, we get that for the recursive equation for the continuation values simplifies to a recursive equation for the mass points ; i.e.
[TABLE]
We furthermore restrict attention to distributions for which Equation (11) is also satisfied for , i.e. for which satisfies Equation (12) evaluated at . In that case, (12) implies that for ,
[TABLE]
As (13) can be solved forward and are known, we can use it to determine . Given the values , we can determine by solving (12) for
[TABLE]
Denote this solution by . If is strictly increasing then the distribution defined in (10) has mass points exactly at the continuation values and leads to the given stopping probabilities .
We are thus left left to show that the resulting solution is increasing. We will show that by induction for . by construction as . We next do the induction step and assume that . Since for one has , (13) implies that
[TABLE]
where and . Since for , we have , it follows that is non-decreasing in this case. We are left to show the result for and . This implies that
[TABLE]
The last inequality here follows from our choice of . We thus have shown that . It is left to show that . By chosing large enough, we can without loss of generality assume that . If and , we have that
[TABLE]
As , , and , this is a contradiction and completes the proof. ∎
Proof of Lemma 2: ** :** By Theorem 1, the subjective continuation vales are weakly decreasing. For the sake of a contradiction, suppose the subjective continuation value is constant across two periods. Denote by \underline{m}=\min\big{(}\text{supp}\,F\big{)} the left end-point of the support of . By assumption . By Lemma 4 , we have that for all , where, by Equation 7, g(x)=\delta\int_{-\infty}^{\infty}\max\Big{\{}z,x\Big{\}}\,dF(z). Note that is non-decreasing, strictly increasing for all , and that for . Suppose that for some . This implies that . Hence, and as is strictly increasing for , there can not exist a such that . Hence, for all . As , this implies that for all . By Lemma 4 , however, any fixed point of is non-negative, so that , contradicting the assumption that .
We now show : Let be the continuation values associated with and the continuation values associated with . We want to show that for every . We show the result by backward induction over . The start of the induction is that . In the induction step, we show that implies
[TABLE]
We are now ready to prove Theorem 3.
Proof of Theorem 3: Let be the uniform CDF on for and a Dirac measure for . Fix some . Consider a non-decreasing sequence of stopping probabilities and for every non-increasing sequence of continuation values with , define the function
[TABLE]
where
[TABLE]
and
[TABLE]
is a distribution: We begin by showing that is a cumulative distribution function. Note that and that for ,
[TABLE]
and . For every , the function is non-decreasing and non-negative as the CDF is non-decreasing and non-negative. It thus follows that is a well defined CDF with support .
Continuation values induced by : Consider now the continuation values induced by . By Lemma 1, they solve the equation
[TABLE]
with . Denote by the function mapping to using (17). By Theorem 1, is non-increasing. As is non-increasing and , it follows that for all . Furthermore, as
[TABLE]
Thus, if , we have that
[TABLE]
Consequently, maps into itself, where is the set of non-increasing sequences contained in , i.e.
[TABLE]
Any fixed-point of induces a solution: We next argue that if is a fixed point of then the distribution induces the stopping probabilities and thus solves our problem. By Lemma 2 , any fixed-point must be strictly decreasing . As is a fixed point of , the agent stops in period if and only if , which happens with probability
[TABLE]
Where we used (16) in the second to last equality. Thus, any distribution associated with a fixed point of induces the correct stopping probabilities.
has a fixed-point: It remains for us to argue that has a fixed point. We note that is a complete bounded lattice, as the point-wise maximum (minimum) over increasing sequences is increasing.262626To see this note, that is a minimal element and is a maximal element. Furthermore, the point-wise infimum and supremum over any subset of lie in . We next note that respects first order stochastic dominance (FOSD), ie. if then is greater than in FOSD.272727We use the notation for point-wise comparisons. By Lemma 2 , increasing the distribution of payoffs in FOSD will (weakly) increase the subjective continuation values. As a consequence is a monotone operator, i.e. if . By Tarski’s fixed point theorem, thus has a fixed point on the lattice .
Uniqueness: Finally, we note that as the subjective continuation values is strictly decreasing has no mass points. Consequently, the probability that the agent is ever indifferent between stopping and continuing equals zero. Thus, any perception perfect equilibrium leads to the same distribution . ∎
Proof of Lemma 3: Let the pair solve 5. From now one, fix . Let denote the expectation taken with respect to the cumulative distribution function , and the probability mass with respect to .
We now specify a distribution that has the properties specified in the Lemma. The mass points are located at
[TABLE]
and their probability mass is given by as specified in the Lemma. Observe that by construction, we have
[TABLE]
Since solves 5 and for all by construction, one has
[TABLE]
Furthermore,
[TABLE]
Thus, since solve 5 so do . ∎
Proof of Theorem 4: Lemma 3 implies for a plausible data set that (5) admits a solution if and only if there exists and a monotone function such that
[TABLE]
Equation 21 is equivalent to and for all
[TABLE]
and thus completely determines . From now on we thus consider as given.
Equation 20 for is equivalent to
[TABLE]
We note that there exists satisfying the above equation and (19) if and only if
[TABLE]
That this is necessary follows as (19) provides a lower bound on and . Since, , this is also sufficient as you can always chose arbitrarily large. Rearranging for and plugging in yields
[TABLE]
Next, we consider (20) for . Subtracting (20) evaluated at from (20) evaluated at yields
[TABLE]
which is equivalent to
[TABLE]
The above equation admits a solution satisfying (19) if and only if for all , . Rewriting using the definition of from the statement of the theorem, 20 admits a solution satisfying (19) if for all both and , and in addition
[TABLE]
This completes the proof.∎
Supplementary Appendix: Example 4.
This appendix establishes the claims made in Example 4.
As the immediate payoffs of task-completion in the support of are always positive, an active agent will complete the task in the final period. Furthermore, observe that the agent will complete the task in the penultimate period even for the low benefit draw since
[TABLE]
that is, the payoff of stopping immediately is greater than the discounted expected payoff of stopping in the final period. Hence, the subjective continuation value in period is the discounted expected value of always stopping in period 2, i.e.
[TABLE]
Given the continuation value , the agent will complete the task in the first period for both a high and a low payoff realization. Hence,—for simplicity282828Our payoff comparison between the case with and without a tax is unaffected by whether or not Self 0 applies to discount future payoffs. following the usual convention and presuming the long-run Self 0 does not use to discount future payoff—Self 0’s expected benefit from facing the stopping problem is .
Suppose now that the agent faces a tax of (1/8) that she must pay when completing the task. Hence, she faces a new (after tax) payoff distribution that with probability pays and with probability pays . Again, an active agent will complete the task in the final period as payoffs of doing so are always positive. Furthermore, when drawing the high payoff, an agent will always complete the task immediately.
In the penultimate period, the agent will not complete the task when drawing a low payoff of since
[TABLE]
that is the payoff of stopping immediately is lower than the discounted expected payoff of completing the task in the final period.
Taking the behavior in the penultimate period into account, the agent’s first-period continuation value is
[TABLE]
This already establishes that the first period continuation value is higher with a tax than without it. Furthermore, when facing the tax, the agent will not complete the task in the first period when facing a low payoff since
[TABLE]
Using this fact, Self 0’s expected payoff of facing the problem with a tax is
[TABLE]
We conclude that the sophisticated agent strictly prefers the tax.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Akerlof (1991) Akerlof, George A. , “Procrastination and Obedience,” American Economic Review , 1991, 81 (2), 1–19.
- 3Altmann et al. (2019) Altmann, Steffen, Christian Traxler, and Philipp Weinschenk , “Deadline and Cognitive Limitations,” November 2019. Working Paper.
- 4Ariely and Wertenbroch (2002) Ariely, Dan and Klaus Wertenbroch , “Procrastination, Deadlines, and Preformance: Self-Control by Precommitment,” Psychological Science , 2002, 13 (3), 219–224.
- 5Augenblick and Rabin (2016) Augenblick, Ned and Matthew Rabin , “An Experiment on Time Preference and Misprediction in Unpleasant Tasks,” 2016. Working Paper.
- 6Augenblick et al. (2015) , Muriel Niederle, and Charles Sprenger , “Working over Time: Dynamic Inconsistency in Real Effort Tasks,” The Quarterly Journal of Economics , 2015, 130 (3), 1067–1115.
- 7Becker et al. (1964) Becker, Gordon M., Morris H. De Groot, and Jacob Marschak , “Measuring Utility by a Single-Response Sequential Method,” Behavioral Science , 1964, 9 , 226–232.
- 8Bisin and Hyndman (2018) Bisin, Alberto and Kyle Hyndman , “Present-Bias, Procrastination and Deadlines in a Field Experiment,” June 2018. Working Paper.