A Reinforcement Learning Perspective on the Optimal Control of Mutation Probabilities for the (1+1) Evolutionary Algorithm: First Results on the OneMax Problem
Luca Mossina, Emmanuel Rachelson, Daniel Delahaye

TL;DR
This paper explores using Reinforcement Learning to dynamically control mutation probabilities in a (1+1) evolutionary algorithm on the OneMax problem, demonstrating how RL can optimize algorithm parameters without prior knowledge of transition probabilities.
Contribution
It introduces a novel RL-based approach for parameter control in evolutionary algorithms, combining model-based and model-free methods to improve optimization performance.
Findings
RL can effectively optimize mutation probabilities in evolutionary algorithms.
Q-Learning approach does not require explicit transition probabilities.
Method allows integration of expert knowledge into parameter control.
Abstract
We study how Reinforcement Learning can be employed to optimally control parameters in evolutionary algorithms. We control the mutation probability of a (1+1) evolutionary algorithm on the OneMax function. This problem is modeled as a Markov Decision Process and solved with Value Iteration via the known transition probabilities. It is then solved via Q-Learning, a Reinforcement Learning algorithm, where the exact transition probabilities are not needed. This approach also allows previous expert or empirical knowledge to be included into learning. It opens new perspectives, both formally and computationally, for the problem of parameter control in optimization.
Click any figure to enlarge with its caption.
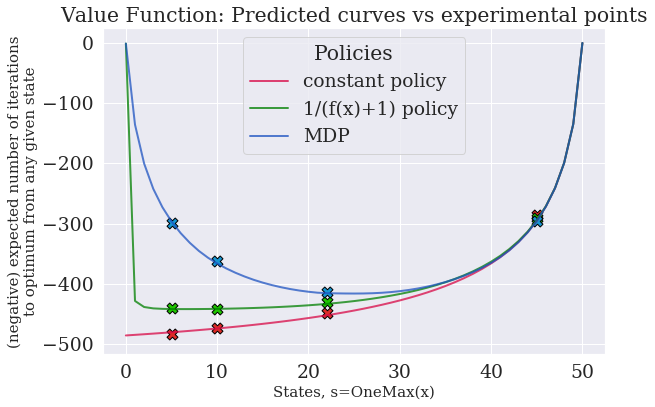 Figure 1
Figure 1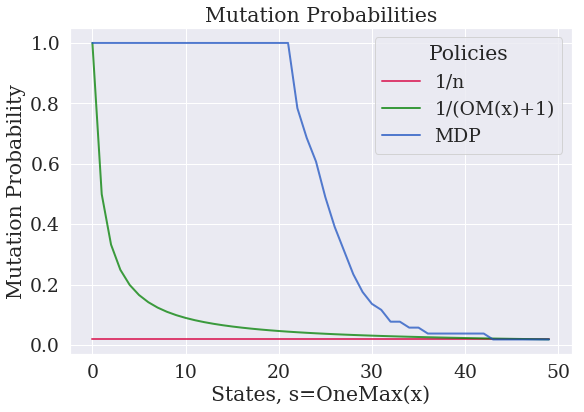 Figure 2
Figure 2| Policy | Constant | 1/(s+1) | MDP |
|---|---|---|---|
| Average | 442 | 430 | 412 |
| Standard Deviation | 163 | 165 | 164 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEvolutionary Algorithms and Applications · Reinforcement Learning in Robotics · Metaheuristic Optimization Algorithms Research
MethodsQ-Learning
A Reinforcement Learning Perspective on the Optimal Control of Mutation Probabilities for the (1+1) Evolutionary Algorithm: First Results on the OneMax Problem
Luca Mossina1
Emmanuel Rachelson1
Daniel Delahaye2
(1ISAE-SUPAERO, Université de Toulouse
2ENAC, Université de Toulouse
)
Abstract
We study how Reinforcement Learning can be employed to optimally control parameters in evolutionary algorithms. We control the mutation probability of a (1+1) evolutionary algorithm on the OneMax function. This problem is modeled as a Markov Decision Process and solved with Value Iteration via the known transition probabilities. It is then solved via -Learning, a Reinforcement Learning algorithm, where the exact transition probabilities are not needed. This approach also allows previous expert or empirical knowledge to be included into learning. It opens new perspectives, both formally and computationally, for the problem of parameter control in optimization.
1 Problem statement
We maximize the OneMax function: via the (1+1) Evolutionary Algorithm (EA) by which, given a random initialization of , at every iteration, each of the bits is flipped (mutated) with probability , yielding a solution candidate . If , is kept. We proceed until the terminal condition is met. We regard the evolution of as a stochastic process, conditioned at each step by . This yields a Markov Decision Process (MDP (Puterman,, 2014)), whose optimal control policy can be found via Dynamic Programming when the transition probabilities are known and Reinforcement Learning (RL) when only experience data is available111An online compendium with proofs and code to replicate our results is available at https://github.com/**********.
2 Related Work
Recent results (Karafotias et al.,, 2015) have proposed new mechanisms to dynamically control parameters in evolutionary algorithms, in opposition to just tuning and fixing them prior to optimization. Some theoretical results (Bottcher et al.,, 2010; Doerr and Wagner,, 2018; Doerr and Doerr,, 2015; Giessen and Witt,, 2015) have demonstrated the intuition (e.g. 1/5th rule) that adaptive parameters can perform substantially better than static tuning, producing also optimal behaviours in some cases. When exact analyses are not possible, we propose to use RL (Sutton et al.,, 1998) to estimate such optimal behaviours. Indeed, promising results (Karafotias et al.,, 2014; Buzdalova et al.,, 2014) have hinted the potential of the generic use of RL in EA.
3 Markov Decision Process
During the execution of the EA, we want to sequentially change to minimize the expected termination time. This problem can be formulated as an MDP, with states and actions (a discretization of the mutation probability ). At each step, a reward is obtained, where if the terminal state is reached, and otherwise. An optimal parameter control policy maximizes222For readers used to MDP notations: this total reward criterion (no discount factor ) is well defined for Stochastic Shortest Path problems such as the one considered here. for any initial state .
3.1 Transition Probabilities
The transition matrix , describes the probability of transitioning to a state from any given any action . At any iteration , has ones and zeros. Let 333binomial distribution of parameters . be the random variable (r.v.) describing the ones gained at the end of an iteration and be the r.v. for the ones lost. is the r.v. for the net gain after a mutation. Note that is the difference of independent binomial distributions. By convolution, it follows that the probability mass function of is:
[TABLE]
Under the (1+1)EA, if , the solution candidate is rejected as no negative values are admissible. The r.v. for the state of our EA process has thus values , where and .
4 Optimal Parameter Control
We briefly introduce the two main methods used to compute the optimal policy: one based on Dynamic Programming (Bellman,, 1957), the other relying on -Learning (Watkins,, 1989).
4.1 Dynamic Programming
The function (called ’s value function) maps state to (minus) their expected time-to-termination. The optimal policy’s value function is defined recursively by Equation 1. Value Iteration is the Dynamic Programming algorithm that repeatedly applies Equation 1 until convergence to .
[TABLE]
Figure 1 reports the computed value functions for the following three policies (plotted in Figure 2):
- •
the constant commonly used in (1+1)EA,
- •
the policy from (Bottcher et al.,, 2010) (originally designed for the LeadingOnes function),
- •
the optimal policy found via Value Iteration.
In Figure 1 the marks corresponds to the empirical average , for 2000 runs initialized respectively at . In Table 1 one can find the average for a random starting state.
4.2 -Learning
Although one can explicitly compute the transition probabilities for the parameter control problem based on the OneMax function, such probabilities are generally not available. Learning mechanisms such as -Learning, allow to obtain , using sampled transitions, without explicitly requiring .
[TABLE]
To that end, it learns the optimal state-action value function . -learning is a stochastic approximation process: it repeats the operation of Equation 2 in all states and actions until convergence to (which boils down to solving Equation 1). The optimal policy is then the greedy policy .
5 Discussion
The approach presented above generalizes straightforwardly to other problems and algorithms. Our goal in this contribution was to illustrate how a RL perspective on (optimal) Parameter Control can help bring new contributions to the Optimization field. Extending this contribution to a larger class of problems opens new challenges:
- •
Continuous actions (parameters) are a common limitation in RL, generally overcome using Policy Gradient methods.
- •
The state of an optimization process is problem and algorithm specific and might not always define a Markov process, thus leading to partial observability and/or approximations.
- •
The curse or dimensionality is a crucial issue in RL and introducing expert knowledge in the learning process can greatly help the convergence.
- •
Convergence to an optimal parameter control policy can take advantage of sampling the optimization process at will.
- •
Minimizing the expected termination time is not the only relevant criterion. For instance, a natural alternative would be to maximize the time-discounted value function improvements (an approach close to the idea of regret minimization).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bellman, (1957) Bellman, R. (1957). Dynamic Programming . Princeton University Press.
- 2Bottcher et al., (2010) Bottcher, S., Doerr, B., and Neumann, F. (2010). Optimal fixed and adaptive mutation rates for the leadingones problem. In Parallel Problem Solving from Nature, PPSN XI .
- 3Buzdalova et al., (2014) Buzdalova, A., Kononov, V., and Buzdalov, M. (2014). Selecting evolutionary operators using reinforcement learning: Initial explorations. In Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation .
- 4Doerr and Doerr, (2015) Doerr, B. and Doerr, C. (2015). Optimal parameter choices through self-adjustment: Applying the 1/5-th rule in discrete settings. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation .
- 5Doerr and Wagner, (2018) Doerr, C. and Wagner, M. (2018). On the effectiveness of simple success-based parameter selection mechanisms for two classical discrete black-box optimization benchmark problems. ar Xiv preprint ar Xiv:1803.01425 .
- 6Giessen and Witt, (2015) Giessen, C. and Witt, C. (2015). Population size vs. mutation strength for the (1+ λ 𝜆 \lambda ) ea on onemax. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation .
- 7Karafotias et al., (2014) Karafotias, G., Eiben, A. E., and Hoogendoorn, M. (2014). Generic parameter control with reinforcement learning. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation .
- 8Karafotias et al., (2015) Karafotias, G., Hoogendoorn, M., and Eiben, Á. E. (2015). Parameter control in evolutionary algorithms: Trends and challenges. IEEE Transactions on Evolutionary Computation , 19(2):167–187.