Show, Price and Negotiate: A Negotiator with Online Value Look-Ahead
Amin Parvaneh, Ehsan Abbasnejad, Qi Wu, Javen Qinfeng Shi, Anton van, den Hengel

TL;DR
This paper introduces the Price Negotiator, a neural network model that enhances online negotiation by incorporating item images, external value prediction, and dynamic pricing, leading to improved negotiation outcomes.
Contribution
The study presents a novel neural network model that integrates visual information and external data for more effective online negotiation strategies.
Findings
Significantly improves agreement prices
Enhances price consistency and dialogue quality
Effective in supervised and reinforcement learning settings
Abstract
Negotiation, as an essential and complicated aspect of online shopping, is still challenging for an intelligent agent. To that end, we propose the Price Negotiator, a modular deep neural network that addresses the unsolved problems in recent studies by (1) considering images of the items as a crucial, though neglected, source of information in a negotiation, (2) heuristically finding the most similar items from an external online source to predict the potential value and an acceptable agreement price, (3) predicting a general price-based action at each turn which is fed into the language generator to output the supporting natural language, and (4) adjusting the prices based on the predicted actions. Empirically, we show that our model, that is trained in both supervised and reinforcement learning setting, significantly improves negotiation on the CraigslistBargain dataset, in terms of…
Click any figure to enlarge with its caption.
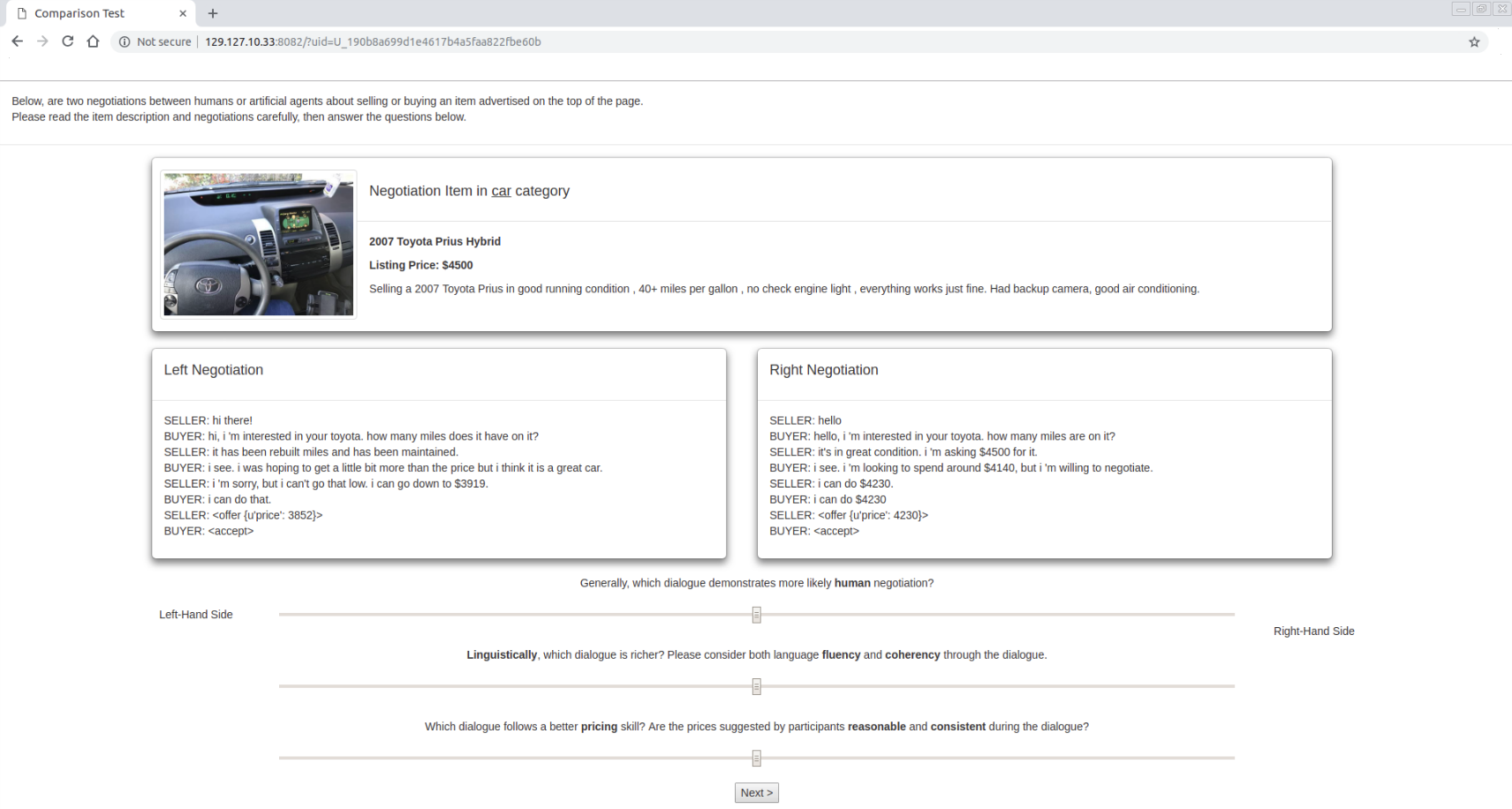 Figure 1
Figure 1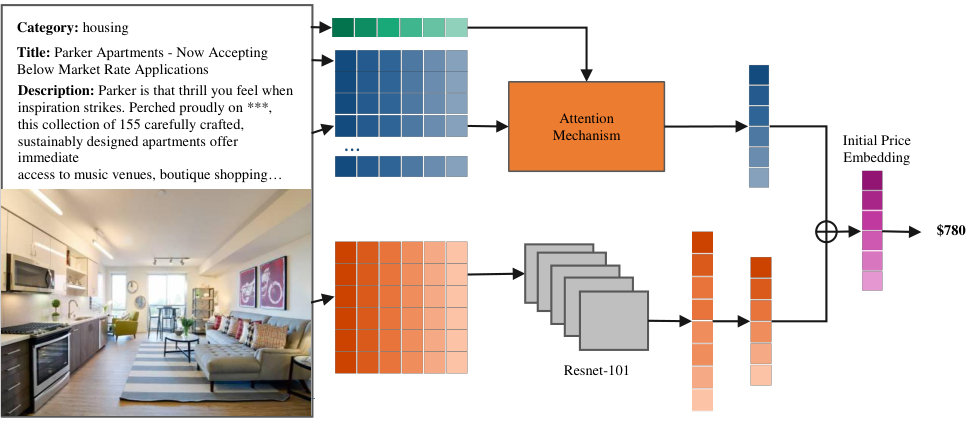 Figure 2
Figure 2 Figure 3
Figure 3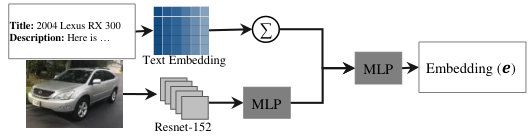 Figure 4
Figure 4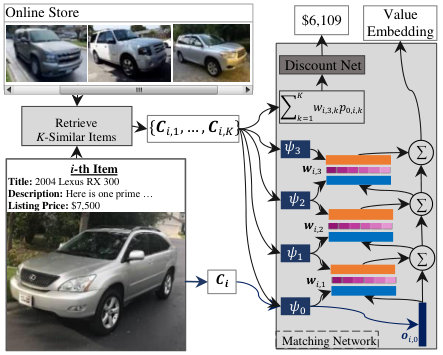 Figure 5
Figure 5 Figure 6
Figure 6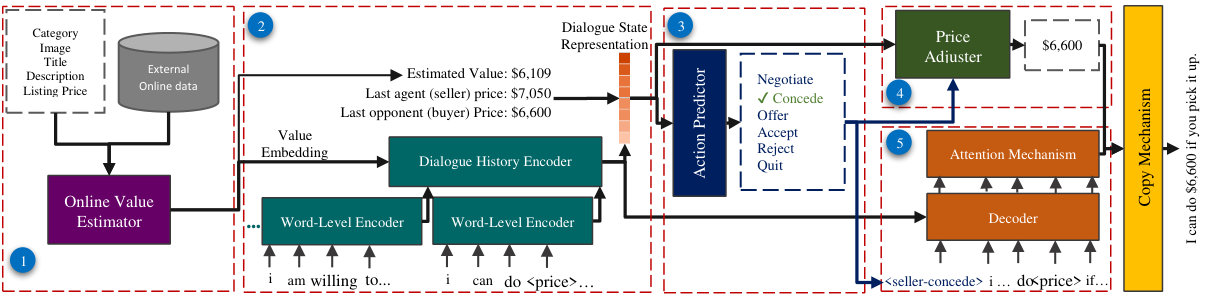 Figure 7
Figure 7 Figure 8
Figure 8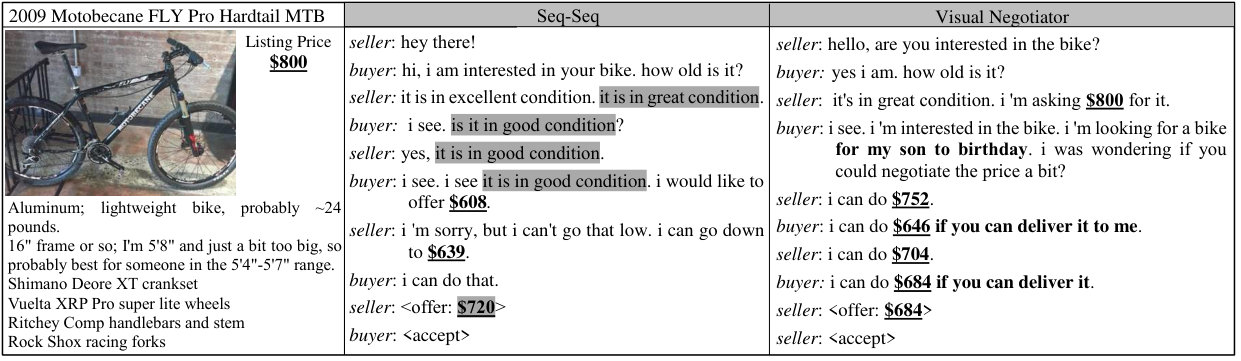 Figure 9
Figure 9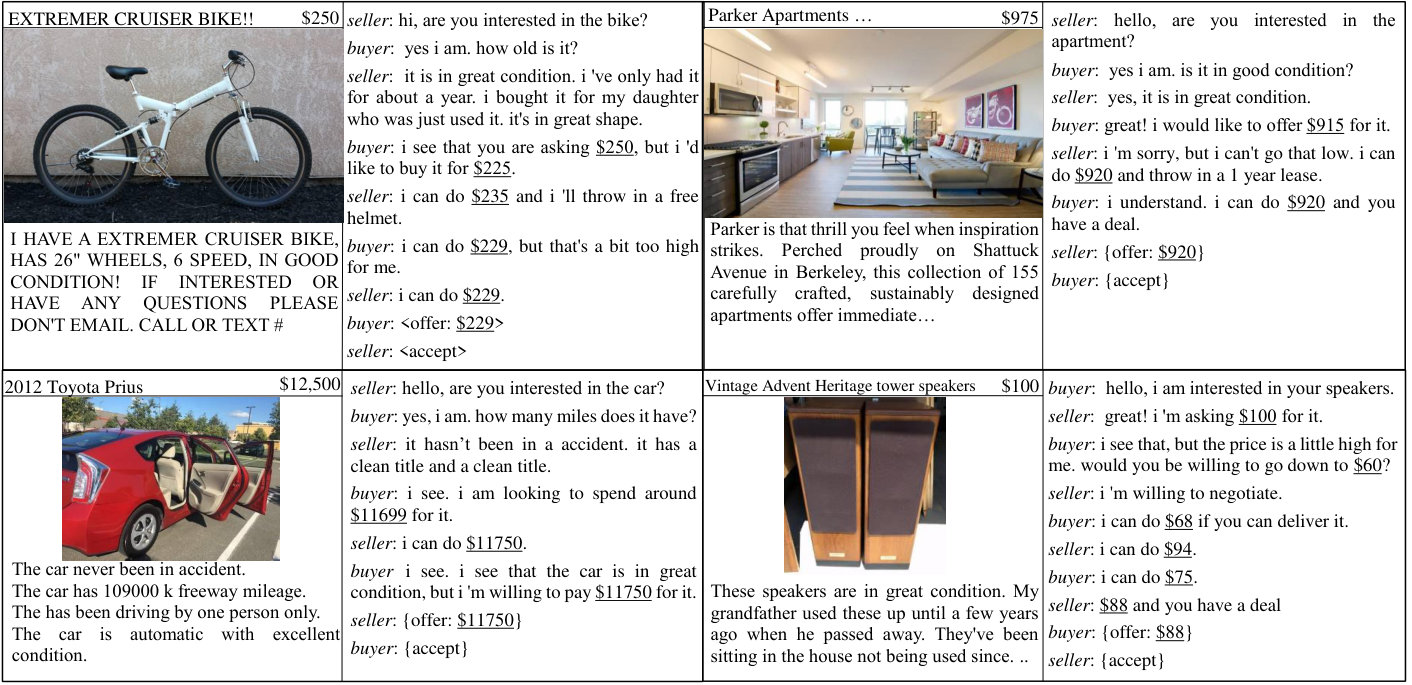 Figure 10
Figure 10| Category | Averaging | AVE | O-KNN | OVE |
|---|---|---|---|---|
| Bike | $475 | $422 | $55 | $27 |
| Car | $3,452 | $3,887 | $547 | $495 |
| Electronics | $114 | $69 | $14 | $6 |
| Furniture | $191 | $167 | $26 | $20 |
| Housing | $433 | $458 | $205 | $129 |
| Phone | $112 | $125 | $21 | $20 |
| Overall | $993 | $898 | $155 | $123 |
| Language Metrics | Pricing Metrics | |||||||
| Model | IBLEU | BLEU | Sentence Diversity | Vocabulary Diversity | Dialogue Length | Inconsistency in Pricing | Inconsistency in Offering | Human Divergence |
| SL(act)+rule[2] | 20.21 | 2.59 | 0.498 | 0.0467 | 18 | 1% | 9% | $383 |
| SL(word)[2] | 35.76 | 3.74 | 0.310 | 0.0385 | 7 | 6% | 6% | $375 |
| HRED[38] | 36.50 | 4.56 | 0.316 | 0.0336 | 10 | 6% | 17% | $325 |
| OVE+HRNE+LD | 37.32 | 4.24 | 0.353 | 0.0357 | 9 | 9% | 27% | $293 |
| OVE+HRNE+AP+LD | 39.12 | 4.74 | 0.375 | 0.0358 | 11 | 0% | 0% | $152 |
| OVE+HRNE+AP+PA+LD* | 41.68 | 4.85 | 0.442 | 0.0430 | 9 | 0% | 0% | $132 |
| OVE+HRNE+AP+PA+LD+RL** | 42.90 | 4.65 | 0.463 | 0.0432 | 9 | 0% | 0% | $125 |
| Model | Turing Test | Comparison Test | Interactive Test | ||||
|---|---|---|---|---|---|---|---|
| Human-likeness | Language | Pricing | Human-likeness | Language | Pricing | ||
| SL(word) | 35% | 37% | 34% | 31% | 2.2 | 3.2 | 2.6 |
| Price Negotiator+RL | 49% | 63% | 66% | 69% | 3.8 | 4.0 | 4.3 |
| Category | Price Negotiator | Price Negotiator+RL |
|---|---|---|
| Bike | $43 | $40 |
| Car | $712 | $607 |
| Electronics | $8 | $7 |
| Furniture | $23 | $22 |
| Housing | $135 | $117 |
| Phone | $20 | $19 |
| Overall | $151 | $131 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Show, Price and Negotiate: A Negotiator with Online Value Look-Ahead
Amin Parvaneh, Ehsan Abbasnejad, Qi Wu, Javen Qinfeng Shi and Anton van den Hengel
Australian Institute for Machine Learning, The University of Adelaide
{amin.parvaneh, ehsan.abbasnejad, qi.wu01, javen.shi, anton.vandenhengel}@adelaide.edu.au
Abstract
Negotiation, as an essential and complicated aspect of online shopping, is still challenging for an intelligent agent. To that end, we propose the Price Negotiator, a modular deep neural network that addresses the unsolved problems in recent studies by (1) considering images of the items as a crucial, though neglected, source of information in a negotiation, (2) heuristically finding the most similar items from an external online source to predict the potential value and an acceptable agreement price, (3) predicting a general price-based “action" at each turn which is fed into the language generator to output the supporting natural language, and (4) adjusting the prices based on the predicted actions. Empirically, we show that our model, that is trained in both supervised and reinforcement learning setting, significantly improves negotiation on the CraigslistBargain dataset, in terms of the agreement price, price consistency, and dialogue quality.
1 Introduction
Negotiation is an integral part of human interactions. It is a complex task that requires reasoning about the attitudes of the counterpart, mutual interests, and uttering convincing arguments and potentially appealing to sympathy. The prevalence of online shopping provides a test-bed for negotiation ability of artificial agents as human’s advocate for the best deals. This artificial agent has to assess the photos of the advertised item, understand the textual content, estimate its true value compared to the others in the market, and conduct a dialogue with its counterpart to reach an agreement.
Recently, Lewis et al. [1] pioneered negotiation as a specific form of dialogue systems in a DealOrNoDeal game where two artificial agents negotiate splitting of three items. Subsequently, He et al. [2] used real human dialogues on Craigslist advertisements to learn a dialogue model of negotiations. In both cases, in par with other dialogue systems, various sequence-to-sequence (Seq-Seq) encoder-decoders are utilised to model negotiations. Seq-Seq models (or more complex alternatives [3, 4] for that matter) are effective tools for learning the correlation between words (e.g. co-occurrences) and potentially the goal. However, negotiation presents a unique set of challenges beyond word correlation that distinguishes it to that of the conventional dialogue systems. Subsequently, these methods struggle to attain some indispensable aspects of a negotiation including: (1) extracting and utilising information from multiple sources (e.g. photos, texts, and numerals), (2) predicting a suitable price for the products to reach the best possible agreement, (3) expressing the intention conditioned on the price in natural language, and (4) offering consistent prices.
In this paper, we propose a price negotiator to address the aforementioned problems. Our negotiator, inspired by the modular needs of a negotiating agent, comprised of five main units particularly tailored for shopping: (1) online value estimator (OVE), (2) hierarchical recurrent negotiation encoder (HRNE), (3) action predictor controller, (4) price adjuster and (5) language decoder (see Figure 2 for details). For OVE, motivated by human behaviour, before starting negotiation we find similar items in online stores–simulating market evaluation. This is done by learning an embedding for the textual (title and description) and visual content of the listings and using a matching network to choose the most similar ones to the current item in the negotiation. Hence, an estimate of how much the item valued is prognosticated that allows the agent to uncover how demanding an item is and whether it’s worth the listing price.
Subsequently, in HRNE the counterpart’s dialogue is encoded conditioned on the content of the advertisement and the agent’s belief of its value. This is a significant and distinguishing aspect of our approach since OVE and HRNE effectively disentangle the value of an item from the language model. The output of this step is a dialogue state representation (encoding a combination of dialogue history representation, last prices proposed by the agents, textual and visual inputs and the estimated value) from which action predictor decides on the next step for the negotiation. In a nutshell, action predictor decides on continuing with the intention of convincing the counterpart, conceding, offering a price, accepting their terms or quitting. If the decision is to change the offer, then our price adjuster proposes a new price. From the state representation and the predicted action, our language decoder generates the appropriate language to convey the intentions of the agent. In any case, we use copy mechanism [5] to combine the new offered price to that of the appropriate negotiating words to utter.
We evaluate our proposed model on CraigslistBargain [2] which provides human-generated negotiations in various scenarios using Craigslist advertisements. Our experiments show that not only the language quality of the generated utterances from our approach outperforms the baselines, the prices are consistent and the agreed price is more similar to that of humans. Moreover, we show reinforcement learning [6]–that has become increasingly popular with dialogue systems–also improves our model’s performance. We also run several human studies to evaluate our negotiator.
In summary, our main contributions are as follows:
We propose a novel AI agent that performs negotiation for the best price for either a seller or a buyer. It utilises both visual and textual content for decision making, follows a consistent and human-like pricing strategy and, as our experiments show, outperforms the baselines on both language quality and agreement price. 2. 2.
Our negotiator, unlike its counterparts, is able to find the relevant online items to accurately predict its potential agreement price. This enables scalable and commercially viable applications and reduces human bias and inconsistency.
2 Related Work
2.1 Goal-Oriented Dialogue
Goal-oriented dialogue systems have a long history in natural language processing (NLP). Recently, researchers suggested to define a goal in open-domain dialogues to improve the consistency and engagement of the agent [7]. Additionally, multi-modal dialogue systems have gained strong interests in speech recognition [8] and computer vision communities[9, 10]. Specifically, visual goal-oriented dialogue systems have got the popularity by introducing miscellaneous tasks including \sayGuessWhat?![11, 12], \sayImage Guessing [13], \sayMNIST Counting Dialogue [14], \sayVisual Dialogue [15] and \sayCLEVR-Dialogue [16]. However, since the machine can play just one role (either questioner or answerer) in most applications, they are Visual Question Answering problems by nature rather than two-way, interactive dialogue systems [17, 15, 16]. In this paper, we focus on Visual Negotiation where the model is evaluated interactively in negotiations either with humans or with another model.
Generally, dialogue systems can be categorised into collaborative and competitive systems. In a collaborative dialogue environment, agents can help each other to reach a common goal. Applications include trip and accommodation reservation [18, 19], information seeking [20, 21, 22], mutual friend searching [23], navigation [24, 25], fashion product recommendation [9], disease diagnosis [26], addressee detection [27], emotion detection [28], and even donation persuasion [29]. In contrast, in a competitive dialogue environment, agents must negotiate to achieve an agreement based on their individual goals. Their goals are often opposite to each other. \saySettlers of Catan [30] and DealOrNoDeal [1] are two frontier tasks defined as competitive dialogues. Very recently, a new negotiation dataset is introduced by crawling tangible negotiation scenarios from the Craigslist website and collecting seller-buyer dialogues for each scenario [2]. Although our work is built on top of the same dataset, there are significant differences: (1) we propose to use the photos of the item as an important source of knowledge which was neglected in [2]; (2) before the negotiation, we prognosticate an ideal agreement price by analysing other similar items on online stores; (3) *we aim to estimate and refine the price in a consistent manner, and produce human-like dialogues. *
2.2 Dialogue Systems Design
Goal-oriented dialogue systems can be designed in a component-based fashion or end-to-end. In a component-based fashion, it typically has three separate modules: (1) natural language understanding (NLU) unit that maps an utterance into semantic slots to be understood and processed by the machine, (2) dialogue manager (DM) which selects the best action according to the output of NLU, and (3) natural language generator (NLG) which produces a meaningful response based on the action chosen by DM, either by looking at a set of possible responses for that action or by using a statistical machine learning language model [31, 32].
To overcome the complexity and bypass the reliance on human-crafted information retrieval rules in component-based approaches, end-to-end systems have been proposed in recent years [33, 34, 35, 36, 37, 38, 39, 24]. These systems often use an Seq-Seq architecture consisting of an encoder which receives the previous utterance(s) and encode them into a latent representation based on which the decoder can predict and generate the next utterance. In the end-to-end model proposed by He et al. [2] for the negotiation, prices are embedded similar to other words in the utterance. Since the range of the prices are broad and there is not any pre-trained embedding for them, their embedding is learned through the model training. In addition, the generated prices are inconsistent since they were produced based on the correlation with other words rather than the true underlying value of the item. Furthermore, this way of embedding the prices adds more complexity to the model and leads to weaker language model. In this research, we show that eliminating the prices from the dictionary of the model, can help the language model to generate better dialogues. We propose an end-to-end modular approach in which we predict the price and the supportive language separately from different heads of the network.
3 Price Negotiator
3.1 Problem Definition
The problem we consider is that of having two agents, namely a seller and a buyer, negotiating on the price of an item which is identified by an image, textual title and description. The items are classified into various categories as is the common practice in the online shopping websites. The seller advertises an item with a listing price and most likely agrees to offers closest to this value. The buyer on the other hand has a target price which is lower than the seller’s listing. While the buyers know the listing price, their target price is not revealed to the seller. It should be noted that a negotiation may end without an agreement.
Each negotiation scenario consists of an advertised item by providing its context information , where represents its visual cue/feature (i.e. photo), is the category in which the item has been advertised, is the title of the advertisement, is the description provided for the item, and is the listing price suggested by the seller. Additionally, at each dialogue turn , a sequence of utterances in previous turns is available as the dialogue history . It is noticeable that each utterance is a sequence of words (tokens) , where represents the maximum length of each utterance, and each word is represented as a -dimensional vector.
At -th round of negotiation, the agent generates the -th token conditioned on the context information , the dialogue history , and the previously generated tokens . The objective is to as closely as possible mimic the behaviour of a human in negotiation. Consequently, the prices agreed upon by an agent has to be as similar as possible to that of the human using convincing arguments.
3.2 Online Value Estimator
One of the essential skills in negotiation is to have a good estimation of the real value of the item. Humans usually search through different shopping websites to find similar items and compare their attributes and listing prices with those of the given item. Motivated by this, we designed the online value estimator (OVE), a deep neural network that can make a precise value prediction (Figure 3).
Given the context information of the item , the OVE component predicts a scalar value for the agreement price. This estimation is based on both visual features of the item, extracted from its photo ; its textual features extracted from its category , title and description ; and its listing price . Generally, the OVE component aims at minimising the difference between the predicted price and the ground-truth real agreed price . The ground-truth real price is calculated as the average of all agreed prices in human-human negotiations over the given item in the dataset. To predict a price we learn a deep neural network parameterised by through the minimisation of the following loss:
[TABLE]
where represents the number of items in the training set.
The price is predicted in a three-stage process. First, the extracted features of the items are used to find the -similar items from an online source of advertised items. The similarity between two items is defined as a combination of cosine similarities between their visual and textual features and the normalised abstract similarity between their listing prices.
Second, the matching network, a deep neural network with a structure akin to memory networks [40], takes these items and measures their importance in valuing the item. It worth mentioning that in contrast to [40], where they only embed text inputs, we propose multimodal embedding (Figure 4) that embeds the visual and textual features of the given item into a -dimensional representation . Specifically, our proposed matching network consists of 3 attention layers and 4 multimodal embeddings. At each layer the the correlation between the previous representation of the given item and multimodal embeddings of related similar items , which are extracted from -th multimodal embedding , is calculated as follows:
[TABLE]
Afterwards, the output of the layer (the item representation ), is calculated based on the following equation:
[TABLE]
Please note that the initial item representation also comes from the first multimodal embedding.
Finally, the correlation weights from the last layer of the network are multiplied by the listing prices of the corresponding similar items to achieve an estimated value for the given item. It worth to mention that since this value is calculated from the listing prices and the target is the agreement price, we pass the output through another fully connected layer, which we name it discount net, to estimate the final value for the item.
3.3 Hierarchical Recurrent Negotiation Encoder
One of the problems in conventional negotiation models is that they include price values (real numbers) in the vocabulary and treat them like ordinary words in the dialogue. This deters the intelligent agent from understanding the numerical meaning of the prices, and entangles the strategies for generating words and prices together. As a result, the prices generated in the dialogue, especially at final offering turn, are inconsistent in most cases.
In our price negotiator we devise a novel hierarchical recurrent encoder in which the prices in the utterances are replaced with a fix token (<price>) to be later replaced with the generated ones. In a hierarchical structure [38, 39, 24], our model encodes utterances in two levels: a word-level encoder that is an RNN network () mapping the word embedding of -th utterance (a sequence of maximum words) into a -dimensional vector () as the word-level representation of the utterance; and a dialogue history encoder that is another RNN network () which at each turn receives word-level representation of the previous utterances as the input and maps them to a -dimensional vector (). Since this representation should be conditioned on the value estimation resulted from OVE, we feed the output of the last layer of the matching network into this RNN as the initial hidden state.
Apart from the dialogue history representation, the last prices suggested by the agent and the opponent and the estimated price are embedded into a vector which represents the dialogue state (more details in section 4.2). This vector will then be used by other components to decide about action and prices that should be considered.
3.4 Action Predictor
The action predictor module is a multi-layer perceptron (MLP) that predicts the next action should be taken by the agent according to the dialogue state at round of the negotiation. In contrast to [2] who tried to predict coarse intents based on intent encoding, we suggested to predict extremely simpler actions, which are based on the price. Actions defined in our framework are:
- •
Negotiate tells the agent that it should continue the negotiation without changing the price.
- •
Concede determines that the agent should make a concession on its previously proposed price. In other words, the buyer should increase its suggested price and the seller needs to decrease its asking price when this action is predicted.
- •
Offer suggests that the agent should propose a final offer and wait for the response from its counterpart.
- •
Accept means that the agent should accept the official offer suggested by the opponent and terminate the negotiation successfully.
- •
Reject clarifies that the agent should reject the proposed offer.
- •
Quit means the agent should abandon the negotiation.
In the supervised training setting, this neural network learns parameters that better imitate human-like actions by minimising this loss function:
[TABLE]
where and represent the number of training dialogues and the number of agent’s turns in each dialogue respectively.
3.5 Price Adjuster
Proposing a reasonable price at each stage of the dialogue is fundamental for a negotiation agent. Our price adjuster module can make consistent price suggestions that lead the agent to reach the best possible agreement. This module is invoked only if the action predictor decides to concede or make an offer. In either case, the price adjuster, an MLP with parameters , predicts the ratio from which the agent should concede. This prediction is based on the current state of the dialogue and the action predicted by the action predictor . We discretise the price change ratio into six categories (more details in section 4.4) and optimise the network using this loss function:
[TABLE]
3.6 Language Decoder
Language decoder is an RNN that generates a sequence of words as the next utterance based on current dialogue state and the predicted action . To that end, we initialise its hidden state with the last hidden state from the dialogue history encoder. Additionally, we condition the starting token on the selected action, by defining different tokens for different actions. We then train an agent able to play both seller and buyer roles by defining different start tokens for the buyer and the seller.
In order to encourage the output to pay more attention to the most important parts of various available information sources, a global attention mechanism [4, 42] is applied to the outputs of the language decoder. This helps the system to ask or answer questions for different sources including the title, description and the outputs of word-level encoder for previous utterance.
To map the outputs of the model to a probability vector of our vocabulary size, a linear function (generative layer) and a LogSoftmax is applied to the output of the model. With language decoder we find the parameters of the RNN to maximise the likelihood of each word,
[TABLE]
3.7 Copy Mechanism
We disentangle prices from other words during the encoding and decoding by replacing prices in utterances with a fix token (<price>). While we encode the current proposed prices separately, the decoder only predicts the price location in the generated utterance. Similar to copy mechanism utilised in machine translation and question answering [5, 42], we replace the price point predicted by the language decoder module with the value calculated by the price predictor module to create the final output.
3.8 Overall Objective
The final objective function for the price negotiator model is to minimise the combination of losses introduced for each component.
[TABLE]
3.9 Reinforcement Learning
We use reinforcement learning to encourage our Price Negotiator agent to improve by employing self-play (i.e. two instances of our model play buyer and seller roles and negotiate with each other). Specifically, once supervised training of the network is done, the action predictor and the price adjuster are fine-tuned using REINFORCE algorithm. We assign a role to an agent (say seller) and let it negotiate against another (e.g. buyer) for a given scenario (i.e. image, title, description, listing price). At the end of negotiation, we evaluate the performance by providing a reward signal. Our reward signal measures how successful the agent was according to the distance between the agreed price and the estimated price predicted by the OVE. The motivation for the reward signal is to intrigue the agent to mimic human’s strategy and achieve the same agreement price. Thus, the action predictor network is updated by back propagating the following signal:
[TABLE]
where represents the total reward for negotiation . The same update is applied on price adjuster component, which is eliminated for the brevity.
4 Implementation Details
4.1 Dataset
All the experiments are performed on the CraigslistBargain dataset [2]. It contains 4,219 training dialogues, 471 evaluation dialogues and 500 test dialogues which are created based on , , and different items respectively.
To make the training process of OVE simple and fast, we simulated an online external data source. To that end, we scraped items advertised on Craigslist website and made a local source accessible by our online value estimator. It is notable that we set the number of selected items from the online source to 32 in all experiments.
4.2 Embeddings
In all the experiments, we use 300-dimensional vectors as the embedding for each word from pre-trained GloVe embedding [43]. In order to extract the features from the images, we utilised Resnet-152 [41] pre-trained on ImageNet dataset, which has shown exceptional performance in various object detection problems. We simply replaced its last fully-connected layer with another one to produce a -dimensional vector representing the image features.
The hierarchical recurrent negotiation encoder maps prices (either the agent price, the opponent price, or OVE estimated price) into a 7-dimensional one-hot vector which will be concatenated with the last hidden state of its dialogue history encoder to represent the dialogue state. To that end, similar to [2], prices are first normalised separately for each agent so that 1 is the agent’s target price and 0 is their bottom-line price. Defined in the negotiation scenario, the bottom-line price for the seller is the lowest price he/she is supposed to sell the item while for the buyer it is the highest value they should pay for the item. It worth mentioning that these bottom-line prices are not strict and agents can propose and agree on values outside of this range. After the normalisation, price range between 0 and 1 is segmented equally to 5 parts representing 5 classes and other two classes belong to values lower than 0 and higher than 1. Please note that prices lower than the seller’s bottom-line price or higher than buyer’s bottom-line price are represented as negative values for them.
4.3 Training Settings
All RNNs used as encoder or decoder are 2-layer LSTMs with -dimensional hidden states. Action predictor and price decoder networks have the same network architecture, a 4-layer fully-connected network with ReLU activation functions. We also applied a dropout with a rate of 0.3 to all parts of our architecture.
Parameters of the models are optimised using Adam with the learning rate set to 1e-3 in first 20 epochs and then decayed to 1e-4 for another 320 epochs. The batch size is set to 128 in all experiments.
It worth to mention that since the number samples for each class in both action prediction and price decoding tasks are imbalanced, we used weighted Cross-Entropy loss function where are calculated for each class and are used as the weights after normalisation.
Except for hierarchical dialogue encoder and the language decoder which are trained together, we trained other modules separately during the supervised learning process. Afterwards, for RL, we only optimised the action predictor and price decoder parameters for 5000 episodes using a learning rate of 1e-4.
4.4 Price Adjustment
In the experiments, the price adjuster branch of the negotiation model makes a multi-class decision about the ratio with which the agent should retreat. Specifically, the agent always begins from the listing price if it acts as the seller and , , or of the listing price (depending on the scenario) if it acts as the buyer. Then, at each turn, the price decoder decides how much the current price should be changed. Price changes are categorised into 6 classes representing the change ratio which is , , , , , or of either the listing price minus the target for the buyer or listing minus the of list for the seller. If the price decoder decides on altering the price, and the generated utterance contains a price token, it decreases (if being a seller) or increases (if being a buyer) the current price by the predicted ratio.
4.5 Evaluation Metrics
In this task, a negotiation is successful if the agents reach an agreement (by accepting a final offer from the opponent). However, the successful rate is not a suitable evaluation metric in this case because the ‘deal’ might be a bad one even it was accepted. Instead, we defined various dialogue evaluation metrics which can be categorised into three groups: (1) metrics that evaluate the language quality (human-likeness) of the generated dialogue, (2) metrics that evaluate the pricing strategy of the model, such as the difference between the machine agreed price and the ground truth price, and (3) human studies.
Language Metrics. In addition to BLEU score that measures how similar are the sequence of words generated in a machine-machine negotiation with those from human dialogues, we introduce Intent-BLEU (IBLEU), a new metric to measure the similarity of the intents taken by a machine with those taken by humans. More specifically, we extract the intents of each dialogue turn in a machine generated dialogue using the information retrieval approach introduced by [2]. For instance, the intent of saying \sayhello. is intro and the intent of saying \sayI can’t go that low. I can go down to n$-gram precision (for a maximum order of 4) of the generated sequence. The higher values of this metric shows the higher level of similarity with human.
Apart from IBLEU, we applied various word-level and sentence-level metrics to show the richness of the generated dialogues. We calculate the number of distinct sentences produced by the model and scale them by the total number of sentences as another new metric to show the language quality of the dialogue model. We also calculate the same metric at word-level to show the diversity of the lexical used by the model. And shorter dialogue length normally means the agent can make the deal in a shorter time.
Pricing Metrics. Two important metrics that measure the mistake ratio of the pricing are price inconsistency and offer inconsistency. When the seller proposes a price that is higher than the price previously suggested by themselves or is lower than the price offered by the seller, we consider it as an inconsistent pricing (see Figure 5). We also calculate the average distance between the agreed prices from the human’s agreed prices as another important measure to evaluate the pricing strategy of the model.
Human Studies. Apart from automatic evaluation, we measured the performance of our price negotiator model using human evaluations. We designed three experiments to evaluate the human-likeness, language richness, and pricing quality of the negotiation models based on both third-party and interactive human evaluation.
- •
Turing test: In this study, given a random dialogue generated from a negotiation model, the participant is asked to clarify whether or not the dialogue is generated by humans.
- •
Comparative test: During this test, two dialogues generated based on the same scenario, one from our price negotiator and another from the baseline model, are shown to the contributor. The participants are tasked with choosing the best negotiation according to the language and pricing qualities.
- •
Interactive test: Similar to [2], we put our price negotiator model along with the baseline model online and asked human volunteers to have a negotiation with a randomly chosen agent. At the end, they are asked to assess the quality of the agent in terms of human-likeness, language fluency and coherency, and pricing competency.
In our experiments, we gathered 400 Turing test, 400 comparative, and 20 interactive chat evaluations from 20 participants. It is worth noting that the scenarios and generated chats are randomly selected from the test set.
5 Results
5.1 Value Estimation Experiments
To have a better understanding about the value estimation ability of our model, we calculate the average normalised divergence of the value estimations from humans’ agreed prices in the test set, for each product category. Table 1 shows the results and several baseline models that are implemented for comparison. The simplest method is to use the average value of each category as the estimated value. We call this approach averaging. We also train an attention neural network named attention value estimator (AVE) that takes the visual and textual features of the item and outputs the predicted value. The third baseline is the average price of the -similar items found from external online source and we name it online k-nearest neighbours (O-KNN). Since O-KNN approach is using listing prices and to have a fair comparison with our model which enjoys a discount network, we applied the average discount ratio from the discount network (around ) over the estimated values of this approach.
From the Table 1, we can see the model proposed for online value estimation (OVE) can prognosticate an accurate agreement price for an item and beats all other baselines significantly. Using external sources and comparing item features with other items is useful, as the divergence of the predicted prices with the real agreement ones drop significantly in O-KNN approach. More importantly, the divergences drop extremely when similar items are matched with the given item using OVE model.
5.2 Negotiation Dialogue Evaluation
In order to compare our negotiator with other baseline models, we train three state-of-the-art methods that treat the prices as words. The first two models are trained to match the method proposed in [2] on CraigslistBargain. The first one is a simple sequence-to-sequence model, SL(word), and the second one is a modular approach (SL(act)+rule) which has applied various human-crafted rules to repeat utterances produced by humans. Additionally, a Hierarchical Recurrent Encoder-Decoder (HRED), as a widely-used end-to-end approach for dialogue systems, has been trained as another baseline model. Moreover, we have done several ablation studies to show the importance of each module in our proposed model.
Language Evaluation Results. Table 2 demonstrates the fact that price elimination from the language vocabulary improves the language quality. Especially, compared with SL(word) and HRED which are not based on human-crafted rules, dialogues generated from both price negotiator models enjoy remarkably more language diversity both in word level and sentence level, as the ratio of repetitive sentences, which has been encountered as a common problem in dialogue generation, has increased significantly in both variations of the proposed framework. Additionally, the dialogue and utterance length of the dialogues generated from these models is large enough to show the richness of the generated dialogues. Although it can be inferred from the results that SL(act)+rule is generating linguistically better dialogues as the sentence and vocabulary diversity of this model is larger than the proposed model, it should be mentioned that this diversity is due to heuristic rules that select templates from the dataset that are different from the previously selected ones.
Furthermore, a brief look at the IBELU scores demonstrates the superior performance of price negotiator model in comparison to all other ones. It means that this model acts most similarly to humans in different situations. Interestingly, a noticeable improvement in IBLEU score by applying reinforcement learning illuminates that RL pushes the agent to take more human-like decisions in different situations to persuade the opponent and receive the best reward.
Last but not least, the language assessment metrics in Table 3–including the Turing test and both human-likeness and language rates for both comparison and interactive tests–indicate that our proposed model has been accepted as a considerably more fluent and human-like negotiator by human participants.
Pricing Evaluation Results. Table 2 demonstrates results of calculating the pricing metrics. It is noticeable that both versions of the price negotiator models learn to propose consistent prices while maintaining the language quality. Besides, these models never make a mistake in offering prices which are in conflict with the prices discussed and agreed upon during the dialogue.
More importantly, the proposed price negotiator model understands the suitable agreement price for an item precisely. Table 2 shows remarkable decrease in agreed price divergence (the difference between the prices agreed by the model with those agreed by humans) resulted from price negotiator in comparison to those from other models. In other words, the proposed model can learn the value of items by an online value estimation and reach agreement on prices very close to those agreed by humans by taking human-like actions both in generating utterances and in proposing prices.
Finally, human pricing assessment results in Table 3 show our proposed price negotiator model consistently performs well in comparison to its counterpart.
Results from RL. In Table 2 and 4 we observe that using RL generally improves the performance. In particular, in Table 4 when RL is used, our approach learns to insist on the prior value estimated by OVE more effectively and utilise the language better to achieve its goal (i.e. buying/selling with minimal compromise to that estimated by OVE).
Ablation Study Results. Table 2 summarises the effect of each module independently. Simply adding online value estimator to the HRED model (OVE+HRNE+LD) results in a slight improvement in both IBLEU and human divergence metrics implying the agent’s ability to better imitate human behaviour. Once the action predictor (AP) is added we observe significant improvement in negotiation, both linguistically and in agreement prices. It is worth noting that action predictor controls the decisions of the agent and leads to reaching agreements that are remarkably closer to those by humans. Furthermore, having price adjuster (PA) and putting all of the modules together, not only the language quality is enhanced, but crucially the gap between machine and human agreed prices decreased considerably. This is due to the agent’s capability to use a specialised module that handles the prices. Finally, applying reinforcement learning (RL) helps the agent to make considerably better performance linguistically and price-wise. It should be stated that since the language decoder (LD) is an obligatory component and has the same architecture as other baselines, the ablation study over this component is not been considered.
6 Conclusion and Future Works
In this paper, we proposed a visual goal-oriented dialogue model for the seller-buyer negotiation. Our model, Price Negotiator is a modular framework for negotiation that utilises insights from human’s behaviour for disentangling various parts. In particular, we are the first model to incorporate a matching network for evaluating the underlying value of an item by consulting online stores in negotiation. Experiments on CraigslistBargain dataset show the superior performance of the proposed model both linguistically and in reaching a human-like agreement price in various scenarios.
For future we consider improving the current approach by: (a) adding external knowledge about the cost and the availability of side-offers, like free delivery; and (b) applying pre-trained language models, such as BERT [3], that may improve the understanding and generation performance.
7 Supplementary Materials
7.1 Estimated Value Usage
To have a better understanding about the importance of the estimated value (from OVE) in the negotiation, we assess the agent’s performance according to the changes in the estimated value. To that end, during the test time of the Visual Negotiator+RL agent, we make the negotiation more challenging by either increasing the estimated value for the seller (by 20%) or decreasing it for the buyer (again by 20%).
Interestingly, this modification results in a considerable increase in the distance between the agreed prices and the estimated value of the item (from 145). Additionally, we observe a 2% decrease in the agreement ratio of negotiations. These results reveal the impact of the value estimation on the agent and show that the agent competes with its counterpart to reach the most beneficial deal according to this estimated value, even if this competition ends up with a disagreement.
7.2 Human Evaluation Web Interface
Snapshots of the web interfaces of different human evaluations are shown in Figure 7 (Comparative Test), Figure 8 (Turing Test), and Figure 9 (Interactive Test). Additionally, a sample video of a live chat between our Price Negotiator and a human is provided through this link: https://drive.google.com/file/d/1tiKCo2ven0clScLtUsNWOwiDahYy4iXf/view?usp=sharing
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Mike Lewis, Denis Yarats, Yann Dauphin, Devi Parikh, and Dhruv Batra. Deal or no deal? end-to-end learning of negotiation dialogues. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 2443–2453, 2017.
- 2[2] He He, Derek Chen, Anusha Balakrishnan, and Percy Liang. Decoupling strategy and generation in negotiation dialogues. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 2333–2343, 2018.
- 3[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. ar Xiv:1810.04805 v 1 , 2018.
- 4[4] Thang Luong, Hieu Pham, and Christopher D. Manning. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages 1412–1421, 2015.
- 5[5] Thang Luong, Ilya Sutskever, Quoc Le, Oriol Vinyals, and Wojciech Zaremba. Addressing the rare word problem in neural machine translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 11–19, Beijing, China, July 2015. Association for Computational Linguistics.
- 6[6] Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning , 8:229–256, 1992.
- 7[7] Jianheng Tang, Tiancheng Zhao, Chenyan Xiong, Xiaodan Liang, Eric Xing, and Zhiting Hu. Target-guided open-domain conversation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 5624–5634, Florence, Italy, July 2019. Association for Computational Linguistics.
- 8[8] A. Potamianos, E. Fosler-Lussier, E. Ammicht, and M. Perakakis. Information seeking spoken dialogue systems— part ii: Multimodal dialogue. IEEE Transactions on Multimedia , 9(3):550–566, 2007.