Consistent Fixed-Effects Selection in Ultra-high dimensional Linear Mixed Models with Error-Covariate Endogeneity
Abhik Ghosh, Magne Thoresen

TL;DR
This paper addresses the challenge of variable selection in ultra-high dimensional linear mixed models with endogeneity, proposing a new method that remains consistent despite correlation between errors and covariates.
Contribution
It introduces the PFGMM approach for fixed effects selection in the presence of error-covariate endogeneity, proving its oracle consistency and demonstrating its effectiveness.
Findings
PFGMM achieves oracle consistency in fixed effects selection.
The method performs well under various types of endogeneity.
Empirical results validate the proposed approach's utility.
Abstract
Recently, applied sciences, including longitudinal and clustered studies in biomedicine require the analysis of ultra-high dimensional linear mixed effects models where we need to select important fixed effect variables from a vast pool of available candidates. However, all existing literature assume that all the available covariates and random effect components are independent of the model error which is often violated (endogeneity) in practice. In this paper, we first investigate this important issue in ultra-high dimensional linear mixed effects models with particular focus on the fixed effects selection. We study the effects of different types of endogeneity on existing regularization methods and prove their inconsistencies. Then, we propose a new profiled focused generalized method of moments (PFGMM) approach to consistently select fixed effects under 'error-covariate' endogeneity,…
Click any figure to enlarge with its caption.
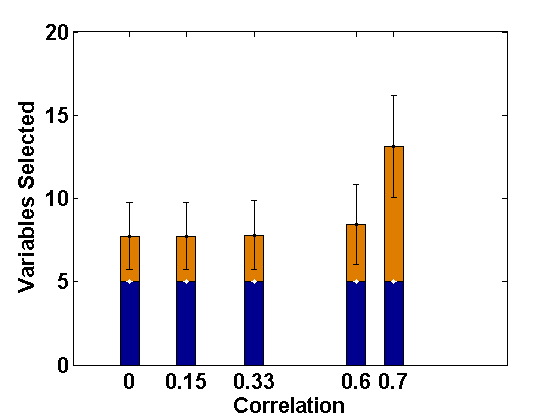 Figure 1
Figure 1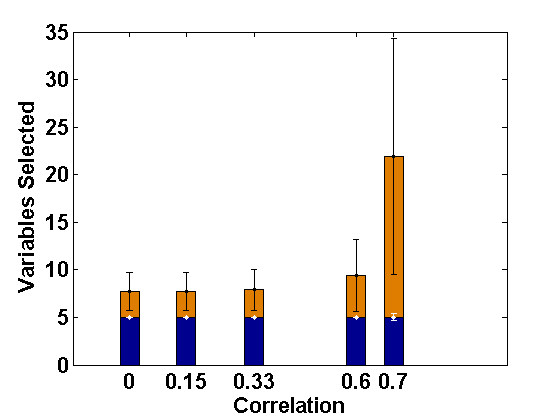 Figure 2
Figure 2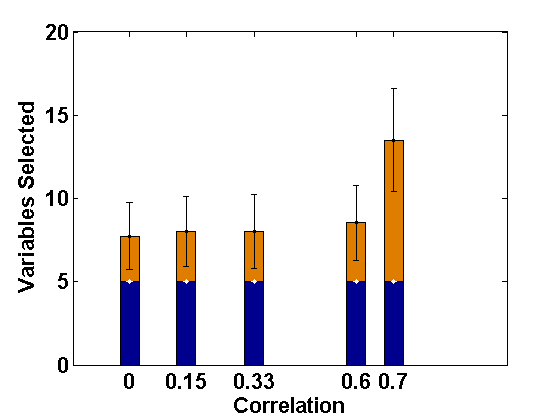 Figure 3
Figure 3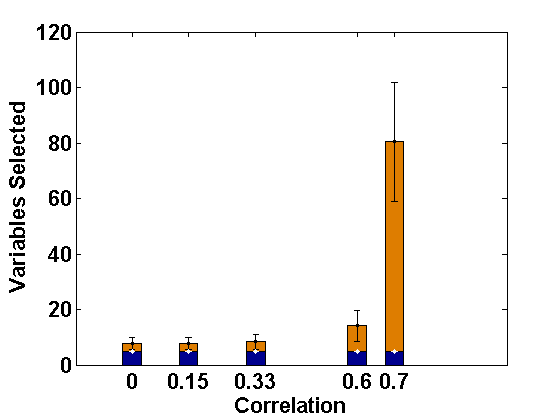 Figure 4
Figure 4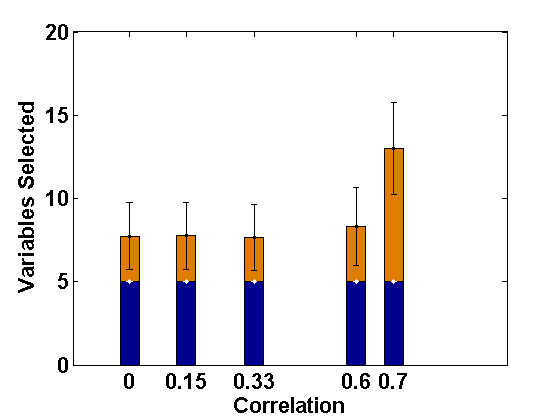 Figure 5
Figure 5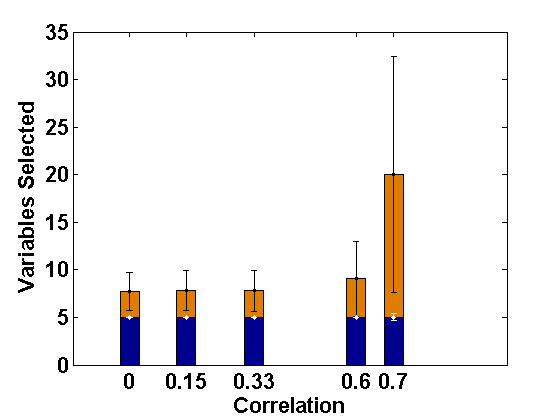 Figure 6
Figure 6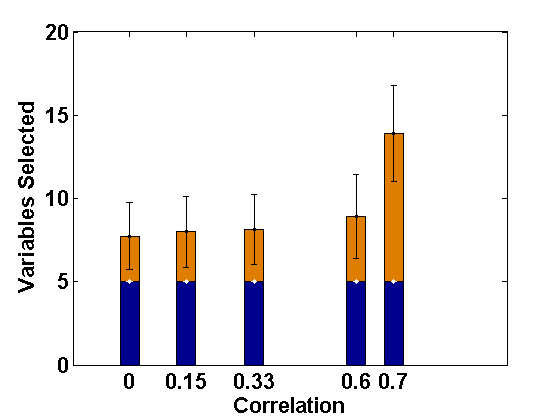 Figure 7
Figure 7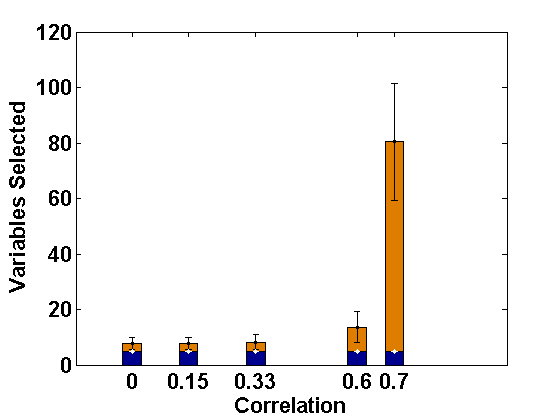 Figure 8
Figure 8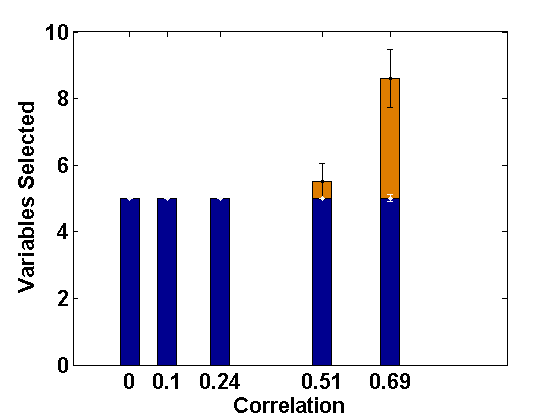 Figure 9
Figure 9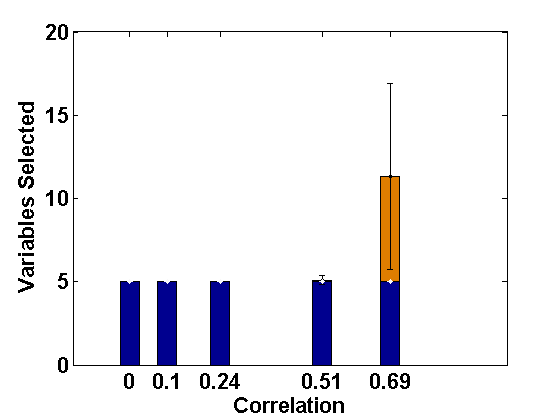 Figure 10
Figure 10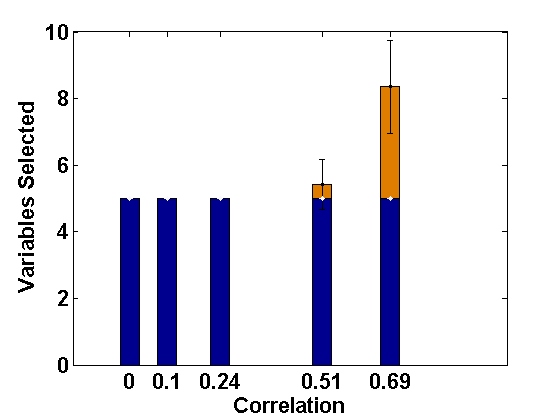 Figure 11
Figure 11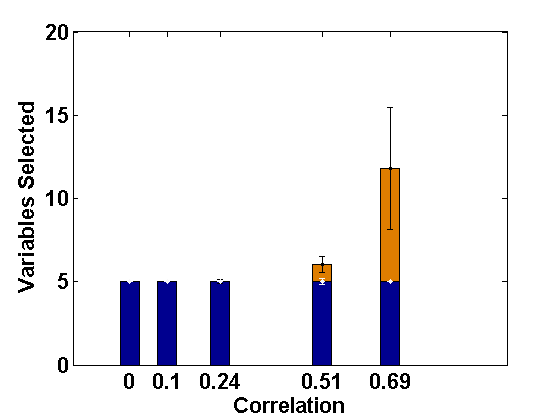 Figure 12
Figure 12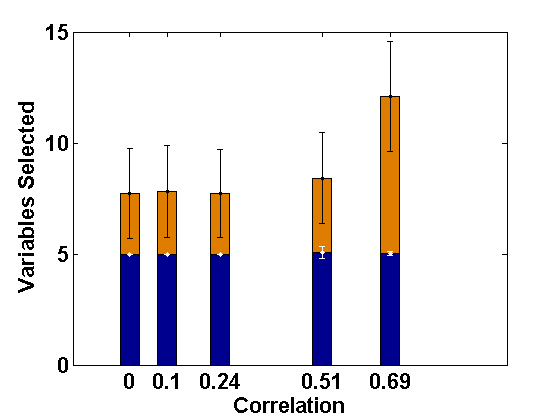 Figure 13
Figure 13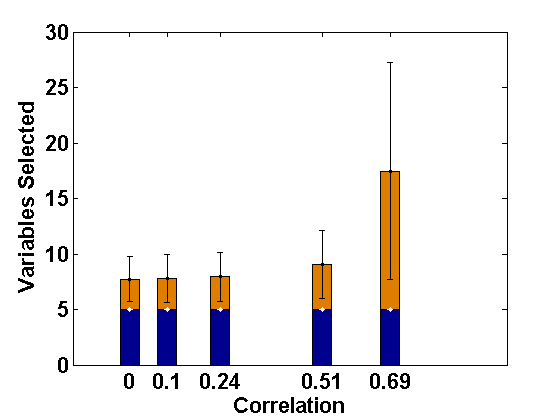 Figure 14
Figure 14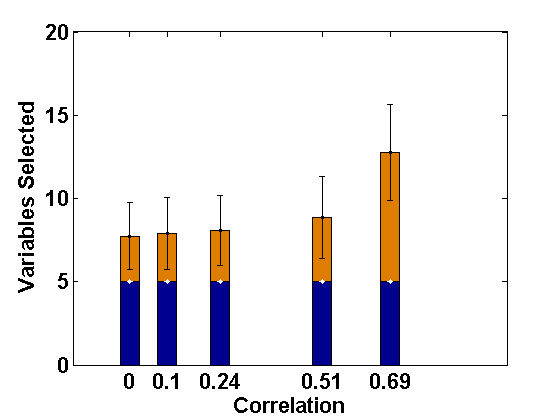 Figure 15
Figure 15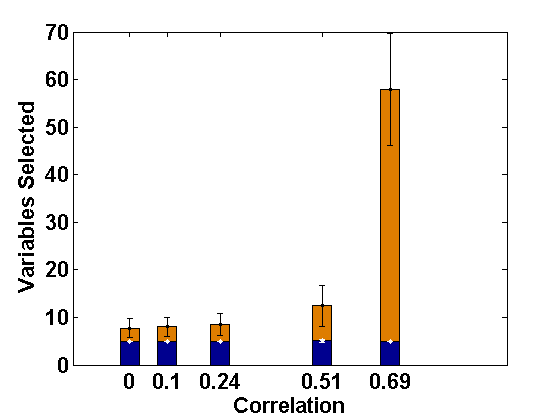 Figure 16
Figure 16| Endogenous | covariates | TP | PE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No Endogeneity | |||||||||||||
| None | Mean | 6.96 | 5.00 | 0.17 | 1.01 | 2.05 | 4.00 | 3.00 | 2.99 | 0.00 | 0.23 | 0.36 | 0.43 |
| SD | 2.91 | 0.00 | 0.03 | 0.37 | 0.40 | 0.06 | 0.07 | 0.06 | 0.00 | 0.04 | 0.31 | 0.35 | |
| MSE | – | – | – | 0.1335 | 0.1604 | 0.0032 | 0.0047 | 0.0035 | 0.0000 | 0.0018 | 0.1375 | 0.1406 | |
| Correlated with error (Level-1 endogeneity) | |||||||||||||
| Set 1 | Mean | 10.41 | 5.00 | 0.03 | 0.87 | 1.99 | 4.00 | 3.00 | 2.98 | 0.00 | 0.05 | 0.44 | 0.35 |
| SD | 1.64 | 0.00 | 0.01 | 0.40 | 0.37 | 0.03 | 0.04 | 0.03 | 0.00 | 0.01 | 0.31 | 0.27 | |
| MSE | – | – | – | 0.1718 | 0.1329 | 0.0011 | 0.0013 | 0.0012 | 0.0000 | 0.0406 | 0.1123 | 0.1144 | |
| Set 2 | Mean | 10.13 | 5.00 | 0.03 | 0.90 | 2.02 | 4.00 | 2.98 | 3.03 | 0.00 | 0.05 | 0.35 | 0.39 |
| SD | 1.95 | 0.00 | 0.01 | 0.34 | 0.38 | 0.03 | 0.03 | 0.01 | 0.00 | 0.01 | 0.28 | 0.30 | |
| MSE | – | – | – | 0.1222 | 0.1409 | 0.0010 | 0.0013 | 0.0008 | 0.0000 | 0.0420 | 0.1183 | 0.1187 | |
| Set 3 | Mean | 8.45 | 5.00 | 0.03 | 0.86 | 2.06 | 3.98 | 3.00 | 2.99 | 0.00 | 0.05 | 0.46 | 0.40 |
| SD | 1.50 | 0.00 | 0.01 | 0.32 | 0.34 | 0.03 | 0.03 | 0.03 | 0.00 | 0.01 | 0.32 | 0.28 | |
| MSE | – | – | – | 0.1250 | 0.1201 | 0.0010 | 0.0009 | 0.0009 | 0.0000 | 0.0414 | 0.1138 | 0.1063 | |
| Set 4 | Mean | 23.45 | 5.00 | 0.01 | 0.86 | 2.00 | 3.99 | 3.00 | 2.99 | 0.00 | 0.01 | 0.49 | 0.39 |
| SD | 4.64 | 0.00 | 0.00 | 0.38 | 0.34 | 0.01 | 0.02 | 0.02 | 0.00 | 0.00 | 0.35 | 0.28 | |
| MSE | – | – | – | 0.1607 | 0.1123 | 0.0003 | 0.0003 | 0.0003 | 0.0000 | 0.0586 | 0.1281 | 0.1100 | |
| Correlated with random intercept (Level-2 endogeneity) | |||||||||||||
| Set 1 | Mean | 7.28 | 4.96 | 0.55 | 1.00 | 2.00 | 3.96 | 2.96 | 2.98 | 0.00 | 0.67 | 0.45 | 0.67 |
| SD | 2.93 | 0.40 | 3.84 | 0.39 | 0.42 | 0.40 | 0.30 | 0.31 | 0.00 | 4.46 | 0.40 | 2.07 | |
| MSE | – | – | – | 0.1487 | 0.1781 | 0.1636 | 0.0937 | 0.0929 | 0.0000 | 19.8562 | 0.1677 | 4.2397 | |
| Set 2 | Mean | 7.21 | 5.00 | 0.17 | 0.99 | 2.01 | 4.00 | 3.00 | 3.00 | 0.00 | 0.23 | 0.43 | 0.44 |
| SD | 2.54 | 0.00 | 0.03 | 0.33 | 0.32 | 0.06 | 0.06 | 0.01 | 0.00 | 0.04 | 0.37 | 0.39 | |
| MSE | – | – | – | 0.1075 | 0.1011 | 0.0039 | 0.0033 | 0.0001 | 0.0000 | 0.0018 | 0.1491 | 0.1672 | |
| Set 3 | Mean | 5.24 | 4.64 | 5.97 | 0.98 | 2.08 | 3.52 | 2.64 | 2.64 | 0.00 | 6.64 | 0.51 | 0.42 |
| SD | 1.63 | 0.98 | 15.98 | 0.63 | 0.36 | 1.31 | 0.98 | 0.98 | 0.00 | 17.61 | 0.84 | 0.34 | |
| MSE | – | – | – | 0.3983 | 0.1311 | 1.9233 | 1.0834 | 1.0829 | 0.0000 | 347.9638 | 0.6949 | 0.1325 | |
| Set 4 | Mean | 12.47 | 4.28 | 7.66 | 0.98 | 1.62 | 3.29 | 2.46 | 2.43 | 0.00 | 8.80 | 0.43 | 4.69 |
| SD | 6.78 | 1.54 | 16.27 | 0.36 | 0.82 | 1.55 | 1.16 | 1.15 | 0.00 | 18.63 | 0.71 | 9.74 | |
| MSE | – | – | – | 1.2489 | 3.2745 | 13.1795 | 6.9913 | 7.2183 | 0.1296 | 416.7764 | 0.5136 | 110.9365 | |
| Correlated with random slope (Level-2 endogeneity) | |||||||||||||
| Set 1 | Mean | 7.70 | 5.00 | 0.17 | 1.02 | 1.95 | 4.00 | 3.01 | 2.98 | 0.00 | 0.24 | 0.39 | 0.42 |
| SD | 3.58 | 0.00 | 0.03 | 0.32 | 0.38 | 0.08 | 0.07 | 0.06 | 0.00 | 0.04 | 0.31 | 0.34 | |
| MSE | – | – | – | 1.1992 | 3.9375 | 15.9995 | 8.6771 | 8.9100 | 0.1296 | 0.0019 | 0.1245 | 0.1353 | |
| Set 2 | Mean | 7.51 | 5.00 | 0.16 | 0.98 | 1.96 | 4.00 | 2.99 | 3.00 | 0.00 | 0.22 | 0.43 | 0.34 |
| SD | 2.63 | 0.00 | 0.03 | 0.40 | 0.35 | 0.07 | 0.06 | 0.01 | 0.00 | 0.04 | 0.32 | 0.24 | |
| MSE | – | – | – | 1.2623 | 3.9604 | 16.0081 | 8.5702 | 8.9975 | 0.1296 | 0.0020 | 0.1208 | 0.1060 | |
| Set 3 | Mean | 5.28 | 4.72 | 4.75 | 0.85 | 1.94 | 3.64 | 2.73 | 2.74 | 0.00 | 5.31 | 0.51 | 0.41 |
| SD | 1.54 | 0.90 | 14.70 | 0.63 | 0.42 | 1.15 | 0.86 | 0.87 | 0.00 | 16.29 | 0.70 | 0.34 | |
| MSE | – | – | – | 0.4140 | 0.1764 | 1.4431 | 0.8130 | 0.8138 | 0.0000 | 288.3149 | 0.4839 | 0.1350 | |
| Set 4 | Mean | 12.64 | 4.20 | 8.69 | 1.02 | 1.59 | 3.20 | 2.39 | 2.37 | 0.00 | 10.01 | 0.55 | 5.62 |
| SD | 7.24 | 1.61 | 17.43 | 0.58 | 0.85 | 1.61 | 1.20 | 1.19 | 0.00 | 19.98 | 0.73 | 11.63 | |
| MSE | – | – | – | 1.4746 | 3.2622 | 12.7758 | 6.9904 | 7.0482 | 0.1296 | 490.5430 | 0.5336 | 159.4848 | |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PLS | Mean | 0.988 | 1.984 | 4.030 | 3.002 | 2.985 | 0.000 | 0.544 | 0.550 | 0.230 |
| SD | 0.162 | 0.155 | 0.076 | 0.062 | 0.052 | 0.003 | 0.163 | 0.170 | 0.034 | |
| MSE | 0.026 | 0.024 | 0.007 | 0.004 | 0.003 | 0.000 | 0.026 | 0.029 | 0.002 | |
| PFGMM | Mean | 0.987 | 1.997 | 4.003 | 2.995 | 2.996 | 0.010 | 0.544 | 0.550 | 0.230 |
| SD | 0.168 | 0.153 | 0.071 | 0.060 | 0.048 | 0.000 | 0.163 | 0.170 | 0.034 | |
| MSE | 0.028 | 0.023 | 0.005 | 0.004 | 0.002 | 0.000 | 0.026 | 0.029 | 0.002 | |
| 2MLE | Mean | 0.990 | 1.994 | 4.003 | 2.995 | 2.996 | 0.000 | 0.540 | 0.549 | 0.241 |
| SD | 0.161 | 0.153 | 0.070 | 0.059 | 0.049 | 0.000 | 0.163 | 0.173 | 0.035 | |
| MSE | 0.026 | 0.023 | 0.005 | 0.004 | 0.002 | 0.000 | 0.027 | 0.030 | 0.001 | |
| 2REML | Mean | 0.990 | 1.994 | 4.003 | 2.995 | 2.996 | 0.000 | 0.565 | 0.575 | 0.248 |
| SD | 0.161 | 0.153 | 0.070 | 0.059 | 0.049 | 0.000 | 0.170 | 0.180 | 0.036 | |
| MSE | 0.026 | 0.023 | 0.005 | 0.004 | 0.002 | 0.000 | 0.028 | 0.032 | 0.001 |
| Method | ||||||||||
| Endogeneity Variable: Set 1 | ||||||||||
| PLS | Mean | 0.877 | 1.982 | 4.020 | 3.015 | 2.971 | 0.000 | 0.545 | 0.539 | 0.052 |
| SD | 0.162 | 0.152 | 0.034 | 0.028 | 0.033 | 0.002 | 0.163 | 0.151 | 0.011 | |
| MSE | 0.041 | 0.023 | 0.002 | 0.001 | 0.002 | 0.000 | 0.027 | 0.023 | 0.039 | |
| PFGMM | Mean | 0.965 | 1.974 | 4.004 | 2.996 | 2.994 | 0.010 | 0.545 | 0.539 | 0.052 |
| SD | 0.212 | 0.254 | 0.069 | 0.060 | 0.050 | 0.000 | 0.163 | 0.151 | 0.011 | |
| MSE | 0.046 | 0.065 | 0.005 | 0.004 | 0.003 | 0.000 | 0.027 | 0.023 | 0.039 | |
| 2MLE | Mean | 0.992 | 1.992 | 4.003 | 2.996 | 2.994 | 0.000 | 0.535 | 0.548 | 0.240 |
| SD | 0.164 | 0.155 | 0.070 | 0.059 | 0.050 | 0.000 | 0.163 | 0.173 | 0.038 | |
| MSE | 0.027 | 0.024 | 0.005 | 0.003 | 0.003 | 0.000 | 0.027 | 0.030 | 0.001 | |
| 2REML | Mean | 0.992 | 1.992 | 4.003 | 2.996 | 2.994 | 0.000 | 0.560 | 0.573 | 0.247 |
| SD | 0.164 | 0.155 | 0.070 | 0.059 | 0.050 | 0.000 | 0.170 | 0.180 | 0.039 | |
| MSE | 0.027 | 0.024 | 0.005 | 0.003 | 0.003 | 0.000 | 0.028 | 0.032 | 0.001 | |
| Endogeneity Variable: Set 2 | ||||||||||
| PLS | Mean | 0.873 | 1.979 | 4.034 | 2.990 | 3.032 | 0.000 | 0.546 | 0.540 | 0.047 |
| SD | 0.154 | 0.150 | 0.048 | 0.033 | 0.014 | 0.004 | 0.159 | 0.152 | 0.011 | |
| MSE | 0.040 | 0.023 | 0.003 | 0.001 | 0.001 | 0.000 | 0.025 | 0.023 | 0.041 | |
| PFGMM | Mean | 0.858 | 1.983 | 3.996 | 2.959 | 3.083 | 0.010 | 0.546 | 0.540 | 0.047 |
| SD | 0.235 | 0.246 | 0.048 | 0.044 | 0.010 | 0.000 | 0.159 | 0.152 | 0.011 | |
| MSE | 0.075 | 0.060 | 0.002 | 0.004 | 0.007 | 0.000 | 0.025 | 0.023 | 0.041 | |
| 2MLE | Mean | 0.915 | 1.998 | 3.996 | 2.959 | 3.083 | 0.000 | 0.544 | 0.549 | 0.125 |
| SD | 0.156 | 0.151 | 0.047 | 0.043 | 0.010 | 0.000 | 0.159 | 0.159 | 0.033 | |
| MSE | 0.031 | 0.022 | 0.002 | 0.004 | 0.007 | 0.000 | 0.025 | 0.025 | 0.017 | |
| 2REML | Mean | 0.915 | 1.998 | 3.996 | 2.958 | 3.083 | 0.000 | 0.568 | 0.573 | 0.129 |
| SD | 0.156 | 0.151 | 0.047 | 0.043 | 0.010 | 0.000 | 0.166 | 0.166 | 0.033 | |
| MSE | 0.031 | 0.022 | 0.002 | 0.004 | 0.007 | 0.000 | 0.027 | 0.027 | 0.016 | |
| Endogeneity Variable: Set 3 | ||||||||||
| PLS | Mean | 0.868 | 2.046 | 4.014 | 3.014 | 2.979 | 0.000 | 0.549 | 0.570 | 0.041 |
| SD | 0.159 | 0.014 | 0.029 | 0.028 | 0.029 | 0.002 | 0.164 | 0.150 | 0.010 | |
| MSE | 0.042 | 0.002 | 0.001 | 0.001 | 0.001 | 0.000 | 0.027 | 0.022 | 0.044 | |
| PFGMM | Mean | 0.894 | 2.094 | 3.998 | 3.007 | 2.997 | 0.010 | 0.549 | 0.570 | 0.041 |
| SD | 0.184 | 0.009 | 0.045 | 0.043 | 0.036 | 0.000 | 0.164 | 0.150 | 0.010 | |
| MSE | 0.045 | 0.009 | 0.002 | 0.002 | 0.001 | 0.000 | 0.027 | 0.022 | 0.044 | |
| 2MLE | Mean | 0.905 | 2.094 | 3.998 | 3.007 | 2.996 | 0.000 | 0.548 | 0.594 | 0.105 |
| SD | 0.158 | 0.009 | 0.045 | 0.042 | 0.036 | 0.000 | 0.164 | 0.165 | 0.026 | |
| MSE | 0.034 | 0.009 | 0.002 | 0.002 | 0.001 | 0.000 | 0.027 | 0.028 | 0.022 | |
| 2REML | Mean | 0.905 | 2.094 | 3.998 | 3.007 | 2.996 | 0.000 | 0.572 | 0.595 | 0.109 |
| SD | 0.158 | 0.009 | 0.045 | 0.042 | 0.036 | 0.000 | 0.170 | 0.165 | 0.027 | |
| MSE | 0.034 | 0.009 | 0.002 | 0.002 | 0.001 | 0.000 | 0.029 | 0.028 | 0.021 | |
| Endogeneity Variable: Set 4 | ||||||||||
| PLS | Mean | 0.842 | 1.979 | 4.034 | 3.018 | 2.983 | 0.001 | 0.538 | 0.518 | 0.005 |
| SD | 0.156 | 0.148 | 0.019 | 0.019 | 0.017 | 0.002 | 0.158 | 0.138 | 0.002 | |
| MSE | 0.049 | 0.022 | 0.002 | 0.001 | 0.001 | 0.000 | 0.025 | 0.021 | 0.060 | |
| PFGMM | Mean | 0.942 | 1.995 | 4.004 | 2.996 | 2.995 | 0.010 | 0.538 | 0.518 | 0.005 |
| SD | 0.265 | 0.155 | 0.070 | 0.060 | 0.050 | 0.000 | 0.158 | 0.138 | 0.002 | |
| MSE | 0.073 | 0.024 | 0.005 | 0.004 | 0.002 | 0.000 | 0.025 | 0.021 | 0.060 | |
| 2MLE | Mean | 0.997 | 1.993 | 4.004 | 2.996 | 2.994 | 0.000 | 0.537 | 0.546 | 0.241 |
| SD | 0.160 | 0.155 | 0.070 | 0.060 | 0.050 | 0.000 | 0.163 | 0.172 | 0.035 | |
| MSE | 0.025 | 0.024 | 0.005 | 0.004 | 0.003 | 0.000 | 0.027 | 0.030 | 0.001 | |
| 2REML | Mean | 0.997 | 1.993 | 4.004 | 2.996 | 2.994 | 0.000 | 0.562 | 0.572 | 0.248 |
| SD | 0.160 | 0.155 | 0.070 | 0.060 | 0.050 | 0.000 | 0.170 | 0.180 | 0.036 | |
| MSE | 0.025 | 0.024 | 0.005 | 0.004 | 0.003 | 0.000 | 0.028 | 0.032 | 0.001 | |
| Method | |||||||
|---|---|---|---|---|---|---|---|
| 5 | PLS | 39 | 0.050 | 0.057 | 0.028 | 0.045 | 4.42E-07 |
| PFGMM+2REML | 5 | 0.146 | 0.126 | 0.053 | 0.073 | 9.66E-08 | |
| 2 | PLS | 113 | 0.030 | 0.048 | 0.022 | 0.039 | 7.33E-09 |
| PFGMM+2REML | 11 | 0.146 | 0.098 | 0.031 | 0.063 | 2.13E-07 | |
| 1.5 | PLS | 136 | 0.026 | 0.046 | 0.020 | 0.033 | 2.77E-09 |
| PFGMM+2REML | 30 | 0.046 | 0.059 | 0.053 | 0.047 | 1.50E-07 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Consistent Fixed-Effects Selection in Ultra-high dimensional Linear Mixed Models with Error-Covariate Endogeneity
Abhik Ghosh1 and Magne Thoresen2
1 Indian Statistical Institute, India
2 Department of Biostatsitics, University of Oslo, Norway
Abstract
Recently, applied sciences, including longitudinal and clustered studies in biomedicine require the analysis of ultra-high dimensional linear mixed effects models where we need to select important fixed effect variables from a vast pool of available candidates. However, all existing literature assume that all the available covariates and random effect components are independent of the model error which is often violated (endogeneity) in practice. In this paper, we first investigate this important issue in ultra-high dimensional linear mixed effects models with particular focus on the fixed effects selection. We study the effects of different types of endogeneity on existing regularization methods and prove their inconsistencies. Then, we propose a new profiled focused generalized method of moments (PFGMM) approach to consistently select fixed effects under ‘error-covariate’ endogeneity, i.e., in the presence of correlation between the model error and covariates. Our proposal is proved to be oracle consistent with probability tending to one and works well under most other type of endogeneity too. Additionally, we also propose and illustrate a few consistent parameter estimators, including those of the variance components, along with variable selection through PFGMM. Empirical simulations and an interesting real data example further support the claimed utility of our proposal.
Keywords: Ultra-high dimensional Mixed Effects Models; Profiled Focused Generalized Method of Moments; Oracle variable selection; Endogeneity.
1 Introduction
Linear mixed effects models are widely used for analysis of clustered data in econometrics, biomedicine and other applied sciences. It consists of additional random-effect components, along with the usual fixed-effects regression modeling, to account for variability among clusters. In biomedical applications, typical examples are longitudinal studies with repeated measurements within individuals and multi-center studies with patients clustered within centers. Due to recent technological advances, we often have access to sets of extremely high-dimensional explanatory variables, typically so-called omics data, in such studies. Hence, the potential fixed effects variables are often in the order of millions even in studies with relatively few patients. Thus, we have to select the important fixed-effects variables from the vast pool of available variables under an ultra-high dimensional set-up. Note that, in most such studies the relevant random effect variables are typically few, and their selection is not necessary.
Mathematically, given groups (e.g., centers) indexed by , we observe responses in the -th group, denoted by the -dimensional vector . The associated fixed and random effect covariate values are, respectively denoted by the matrix and the matrix ; often is a subset of . Let denote the total number of observations. Then, the linear mixed model (LMM) is defined as (Pinheiro and Bates, 2000)
[TABLE]
where is the fixed effects (regression) coefficient vector, s are the random effects and s are random error components in the model. We assume that and , for each , and they are independent of each other and also of the s. Here denotes the identity matrix of order and is a model variance matrix defined in terms of a -dimensional (unknown) parameter vector ; e.g., with , or with , etc. Then, given (and ), , independently for each , where . Stacking the variables in larger matrices, we can rewrite the LMM (1) as
[TABLE]
where , , , and . Now given , with . We wish to perform inference about the unknown regression parameter and the variance parameter vector . As described in the beginning, in this paper, we assume that , but , and prefixed. In particular, we assume the ultra-high dimensional set-up with for some , which is often the case with omics data analysis. Then the total number of parameters is and we need to impose a sparsity condition for estimating . This entitles a selection of important fixed-effect variables; we assume that the number of such variables is . Then, the selection of these important fixed-effect variables and the parameter estimation are done by maximizing a suitably penalized log-likelihood function (Schelldorfer, Buhlmann and Van de Geer, 2011; Ghosh and Thoresen, 2018; Fan and Li, 2012); the resulting estimator of is known as the maximum penalized likelihood estimator (MPLE); see Section 2.
Under our ultra-high dimensional regime, an important desired property of the MPLE is the oracle variable selection consistency which ensures that all the true important variables and only those are selected with probability tending to one, asymptotically. All the existing literature study this property of the MPLE under the crucial assumption of independence of the covariates with the model error and the random effects ; these independence assumptions are referred to as the ‘exogeneity’ of the model. However, they may not always hold in practice, and the corresponding situation is referred to as ‘endogeneity’ which is formally defined below.
Definition 1.1
Consider the LMM (1) and let the -th covariate be denoted as .
- •
We have “unit level endogeneity” or “level-1 endogeneity” when is correlated with the model error term , i.e., . We also refer to this as ‘error-covariate endogeniety’.
- •
We have “cluster level endogeneity” or “level-2 endogeneity” when is correlated with some random effect , i.e., .
- •
A variable is said to be ‘endogenous’ when it is correlated with the model error term or some random effect .
The problem of endogeneity has already been extensively studied for the classical low-dimensional settings and appropriate remedies are developed using some suitable instrumental variables (IVs); see, among many others, Ebbes et al. (2004, 2015), Kim and Frees (2007), Wooldridge (2010,2012), Bates et al. (2014). In our ultra-high dimensional set-up, it is practically too demanding to always expect all exogeneity assumptions to hold; in particular, the assumption regarding independence between the error and all the covarites is quite vulnerable and not verifiable for extremely large . We will see, in Section 2, that the usual MPLE of the LMM parameters gets seriously affected under endogeneity; it also significantly increases the number of false positives in fixed effects selection. To our knowledge, there is no literature on studying the effects of such endogeneity and developing appropriate remedies under high-dimensional mixed models. This paper aims to tackle this important problem with particular focus on level-1 endogeneity and to propose a new consistent selection procedure of fixed-effect variables, along with estimation of all parameters, under such endogenity.
The endogeneity issue in high or ultra-high dimensional models was first considered in Fan and Liao (2014) under the usual regression set-up where the authors proposed a focused generalized method-of-moments (FGMM) estimator to consistently select and estimate the non-zero regression coefficients. In this paper, we will extend their FGMM approach to consistently select the important fixed effect variables under our ultra-high dimensional LMM set-up and then to estimate the variance parameters in a second stage. The proposed method is shown to satisfy the oracle variable selection consistency for the fixed effects even under error-covariate endogeneity. The overall procedure is implemented by an efficient algorithm and verified with suitable numerical illustrations.
The main contributions of the paper can be summarized as follows.
- •
We investigate the effect of endogeneity on the selection of fixed-effects and parameter estimation in ultra-high dimensional linear mixed-effects models (LMMs). This is indeed the first such attempt for mixed models with exponentially increasing number of fixed-effects and we prove the inconsistency of the corresponding penalized likelihood procedures under endogeneity.
- •
We propose a new procedure for selecting important fixed-effects variables in presence of level-1 endogeneity for the ultra-high dimensional LMM. Our method is based on the profiled focused generalized method of moments (PFGMM). It handles the endogeneity issue through the use of appropriate IVs and uses general non-concave penalties like SCAD to carry out sparse variable selection. The problem of unknown variance components is solved by the use of an appropriate proxy matrix. Our proposal is seen to produce significantly less false positives, both in simulations and in a real data application, compared to the usual penalized likelihood method of Fan and Li (2012) in the presence of endogeneity in data.
- •
We rigorously prove the consistency of the estimates of fixed-effects coefficients and their oracle variable selection property under appropriate verifiable conditions. Our assumptions on the penalty are completely general and cover most common non-concave penalties like either SCAD or MCP. The proof also allows the important selected variables to be endogenous, by allowing the IVs to be completely external to the regression model.
- •
We also prove, under appropriate conditions, an asymptotic normality result for the estimates of the fixed-effects coefficients obtained by our PFGMM. This will further help us to develop testing procedures in endogenous high-dimensional LMM in the future.
- •
An efficient computational algorithm is also discussed along with the practical issue of selecting the proxy matrix and the regularization parameter. Along with extensive numerical illustrations, good-to-go suggestions for their choices are also provided which are expected to work for most practical data with strong signal-to-noise ratio. The (unoptimized) MATLAB code is available from the authors upon request.
- •
Once the important fixed-effects variables are selected consistently, we also discuss and illustrate a few second stage estimation procedures to estimate the variance parameters along with refinements of the fixed-effects coefficients .
- •
Although our primary focus is on level-1 endogeneity, finally we also briefly illustrate the effects of level-2 endogeneity on our proposed PFGMM approach of variable selection. Interestingly, our proposal is seen to work consistently in most such scenarios; a finding we would like to investigate theoretically in our subsequent works.
The rest of the paper is organized as follows. We start with the description of the usual maximum penalized likelihood approach and its inconsistency in the presence of endogeneity in Section 2. In Section 3, we discuss the proposed PFGMM approach with its motivation, oracle consistency of variable selection property, asymptotic normality result and computational aspects with numerical illustrations. Estimation of the variance parameters in the second stage refinement are discussed and illustrated in Section 4. The effect of level-2 endogeneity on the proposed PFGMM is examined numerically in Section 5 and a real data application is presented in Section 6. Finally the paper ends with brief concluding remarks in Section 7.
2 The MPLE under Endogeneity
Let us start with a brief description of the MPLE under the ultra-high dimensional LMM considering the notation of Section 1. Using the normality of the stacked response in our LMM (2), the corresponding log-likelihood function of the parameters turns out to be
[TABLE]
Adding an appropriate penalty to each component of through a penalty function , the MPLE is defined as the minimizer of the penalized objective function given by
[TABLE]
With suitable regularization parameter , the MPLE obtained by the minimization of with respect to simultaneously selects the important (non-zero) components of along with estimating consistently. However, the computation is a little tricky for different penalty functions and several extensions have been proposed. In particular, Schelldorfer, Buhlmann and Van de Geer (2011) have considered the penalty in (4) under high-dimensionality, whereas Ghosh and Thoresen (2018) have extended the theory for general non-concave penalties under both low and high-dimensional set-ups. An alternative two-stage approach has been proposed in Fan and Li (2012) which uses a proxy matrix in place of the unknown and then maximize the resulting profile likelihood of only, with suitable penalizations, to select the important fixed effect variables; the estimation and selection of random effect variables are considered in a second step. Under certain assumptions, including exogeneity (no endogeneity), all these existing approaches to obtain the MPLE are shown to satisfy the oracle variable selection consistency, i.e., they estimate exactly the true active set (set of non-zero regression coefficients) with probability tending to one.
We now study the effect of different types of endogeneity on the MPLE through a numerical illustration. Here, we use the algorithm proposed by Ghosh and Thoresen (2018) with the famous SCAD penalty (Antoniadis and Fan, 2001; Fan and Li, 2001); other existing algorithms also indicate the same behavior of the MPLE under endogeneity and are skipped for brevity. More illustrations are provided in later sections.
Example 2.1. We simulate random samples from the LMM (1) with , for each (so that ), , , and the random effects coefficients having distribution , where . The design matrix has the first column as yielding the intercept, and the next columns are chosen from a multivariate normal distribution with mean and a covariance matrix having -th element as for all ; the first two columns of correspond to the two random effect covariates and are kept non-penalized. The true values of the parameters , and are , and for , whereas (correlated covariates) is considered. The SCAD penalty is used with tuning parameter and the regularization parameter is chosen by minimizing the BIC in each replication. We replicate this process 100 times, without endogeneity, to compute the summary measures about the performance of the MPLE as reported in Table 1.
Next, to study the effects of endogenity, some covariates are made endogenous with either the model error () or the -th random effect , respectively, through the transformations
[TABLE]
These produce correlations of and , respectively, for the model error or -th random-effect coefficients with the endogenous covariates. The summary performance measures of the resulting MPLE under such endogeneity are reported in Table 1 for (strong correlations of 0.688 and 0.698, respectively) and four particular sets of endogenous covariates: (i) Set 1: , i.e, 10 unimportant covariates are endogenous, (ii) Set 2: , i.e, 10 unimportant covariates and one important fixed effect covariate are endogenous, (iii) Set 3: , i.e, one important covariate that have both fixed effect component and random effect slope is endogenous along with 10 unimportant covariates, and (iv) Set 4: , i.e, all unimportant covariates are endogenous.
The major observations from Table 1 and other similar simulations, not reported here for brevity, can be summarized as follows.
- •
Under endogeneity, we have a significant increase in false positives compared to the ideal exogenous case. The number of such wrongly selected fixed effect variables further increases with the strength of endogeneity and/or number of endogenous variables. Such an effect is more serious for level-1 endogeneity compared to level-2 endogeneity.
- •
Under level-1 endogeneity, we are not expected to loose any truly significant fixed-effect variables. But, in some cases of level-2 endogeneity, we may loose true positives as well.
- •
The model prediction error is reduced in presence of level-1 endogeneity, since more variables are selected in the final model. However, for level-2 endogeneity, the model prediction error can increase significantly when we loose the few true positives.
- •
The intercept is estimated with increased bias and MSE for level-1 endogeneity, whereas the estimates of the other fixed-effects are affected more by level-2 endogeneity.
- •
The error variance also becomes severely underestimated in presence of level-1 endogeneity. Level-2 endogeneity has a mixed effect in this case, producing significantly overestimated values of for some cases with higher degrees of endogeneity.
- •
As known, the random effect variances are generally underestimated even under the ideal exogenous conditions. The effect of endogeneity on them is not very clear but always moderate except for level-2 endogeneity with the full set of unimportant variables (Set 4).
As our motivation is to select the important fixed-effect variables from a large pool of available candidates, in summary, the effect of level-1 endogeneity is more serious and needs proper treatment to decrease the false positives; on the other hand, level-2 endogeneity needs to be controlled to ensure no loss in true positives.
Having an idea of the effect of different types of endogeneity on the MPLE, we can now investigate this from a theoretical point of view. In Theorem 2.1, we first present a set of necessary conditions for the MPLE to be consistent, both for estimation and fixed-effects selection, in the LMM (1). We will then show that at least one of these conditions do not hold under endogeneity; hence, the MPLE is inconsistent under endogeneity.
Theorem 2.1** (Necessary conditions for consistency of any sparse estimator in the LMM)**
Consider the LMM (1) where the estimation is to be performed by minimizing a general loss function , need not to be the likelihood loss, along with a general penalty . Assuming sparsity of the true fixed effect coefficient , let be the (true) active set, , and which may or may not depend on the sample size . Further, assume the following results hold.
- (C1)
* is twice differentiable with respect to its arguments and the maximum of its second derivatives at the true parameter value is .* 2. (C2)
There is a local minimizer of the penalized objective function which satisfies , and , as , where and are the elements of corresponding to the indices in and , respectively, and denotes the non-zero elements of with indices in . 3. (C3)
The penalty function is non-negative with , is nonincreasing on for some , and .
Then, for any , we have
[TABLE]
The proof of this theorem has been given in the Online Supplementary material. Here, it is important to note that Theorem 2.1 is established without any reference to the exogeneity or endogeneity conditions. It presents a necessary condition (5) for the parameter estimates to be consistent, as in (C2), for a general class of loss functions satisfying (C1) and the penalties satisfying (C3). Since it is a necessity result, the rate of consistency in (C2) is not important. Further, Condition 3 about the penalty function is indeed the same as the one used in Theorem 2.1 of Fan and Liao (2014) and is quite general; it is satisfied by most common penalties including , SCAD or MCP by appropriately choosing the sequence of regularization parameter . Thus, as in Fan and Liao (2014), our result in Theorem 2.1 rather provides a necessary condition (5) on the loss function for a large class of useful penalty functions. Since (C1) always holds for the likelihood loss, if (5) is not satisfied then all the consistency results in (C2) cannot hold for the resulting MPLE. It is known that (C2) and hence (5) must hold for the MPLE under exogeneity. In the following theorem, we will show that (5) fails to hold under any sort of endogeneity indicating the inconsistency of the MPLE, in at least one aspect; the proof is given in the Online Supplementary material.
Theorem 2.2** (Inconsistency of the MPLE in Endogenous LMM)**
Consider the LMM (1) with the likelihood loss given by (3), in negative, and the satisfying Condition (C3) of Theorem 2.1. Suppose that at least one in at least one group is endogenous (level-1 or level-2) and that the and the model error both have finite 4th order moments. If denotes a (local) MPLE such that , then either
[TABLE]
where , , and are as defined in Theorem 2.1 for the MPLE.
3 Focused Selection of Fixed Effect Variables under Level-1 Endogeneity
Consider the LMM set-up as described in Section 1. We now propose a new extension of the MPLE of Fan and Li (2012), that will lead to consistent oracle selection of important fixed effect variables, using the FGMM approach with non-concave penalization. The FGMM loss function, as initially proposed by Fan and Liao (2014) in the context of high-dimensional linear regression, simultaneously performs sparse selection and applies the IV method against endogeneity. The IV method basically assumes the availability of a vector of observable instrumental variables which is correlated with the covariates but uncorrelated with the model error, i.e., The choice of a proper IV (s) helps us to tackle different statistical problems; they are often chosen as a function of the covariates or even a subset of and hence the above condition can be easily verified through some simple moment conditions. As noted earlier, the IV technique is seen to be extremely useful to address the endogeneity issues in classical low-dimensional LMM; see Hall and Horowitz (2005), Wooldridge (2010), Lin et al. (2015), Chesher and Rosen (2017) for some recent IV methods.
3.1 The Profiled Focused GMM (PFGMM) with non-concave penalization
Under the LMM set-up considered in this paper, keeping consistent with the many real-life applications, we have assumed that the number of random effects are small enough so that their individual analysis is possible in the classical sense. Hence, we assume that the matrix is positive definite (pd). Let us first assume, for the time being, that the variance parameter is known. Then, based on (3), the likelihood of the only parameter becomes
[TABLE]
Note that, this is also the profiled likelihood of obtained by substituting the MLE of the random effect vector , given , in the joint likelihood of and given covariates; see Fan and Li (2012) for details. A penalized version of this profile likelihood (in logarithm) can be maximized for sparse selection of the fixed effects and estimation of the corresponding coefficients; Fan and Li (2012) have suggested to use a suitable proxy matrix for the unknown .
Now, in the presence of endogeneity, we need to additionally apply the IV method to achieve consistency. Let us again assume, for the time being, that and hence is known. Let us define the transformed variables
[TABLE]
Then we have and hence . Therefore, the profile likelihood of , given in (6), under the LMM (1) is also the ordinary likelihood of under the following linear regression model in the transformed space:
[TABLE]
Under level-1 endogeneity in the LMM (1), we also have endogeneity in the transformed regression (7) with . Noting that (7) is exactly the same model as considered by Fan and Liao (2014), our idea is to apply their FGMM approach to this transformed model in the transformed space and then go back to the original space of the data to achieve our goal of fixed effects selection in the LMM (1) with endogeneity. This would have been straightforward if the original data were independent and identically distributed (iid) and was known, but none of these conditions hold in practice. Hence, we need appropriate non-trivial extensions to handle the implementation and theoretical derivations. Let us start with defining our proposed loss function.
Note that the components of are iid and those of are independent with the same variance but different means. Let us denote the corresponding random variables in the transformed space by and , respectively. Then, obtaining a consistent solution under endogeneity is based on the availability of an appropriate set of observable instrumental variables in the transformed space such that
[TABLE]
Fan and Liao (2014) achieved variable selection consistency under endogeneity through over-identification via the use of two sets of sieve functions (Chen, 2007), say, and where and are scalar functions. Letting denote the index set of true non-zero coefficients, the above condition of IV implies that, for , we have the following set of over-identified equations:
[TABLE]
Under these conditions, Fan and Liao (2014) have proposed to consider the FGMM loss function
[TABLE]
where for all and is a diagonal weight matrix with non-zero weights corresponding only to the non-zero components of . In particular, the non-zero weights of components can be chosen as the inverse of the estimated variances of and , respectively. Then, a consistent solution of the transformed problem can be obtained by minimizing the penalized FGMM loss function; see Fan and Liao (2014) for details.
Now, let us look back at our original problem under the LMM (1) and map the FGMM loss function (10) back into our data space to get a clear idea for this case. Note that, through an inverse transformation, we can assume for some IV in the data space. Hence the FGMM loss function for our mixed model set-up turns out to have the form
[TABLE]
Note that, in practice with mixed models, we can not directly minimize this FGMM loss function or its penalized version because it depends on the unknown variance parameters through . To avoid this problem, we follow the approach of Fan and Li (2012) and propose to use in place of , where is some suitable proxy matrix for the unknown variance component matrix . Therefore, we finally minimize, with respect to , the penalized objective function
[TABLE]
We will refer to as the profiled Focused GMM (PFGMM) loss function based on its link to the profile likelihood. If we would have used for known variance parameters, the asymptotic consistency results for the resulting estimator would have followed directly from the results of Fan and Liao (2014). However, we will here prove that, even using the proxy matrix , we can still achieve variable selection consistency under the linear mixed model provided the proxy matrix is not very far away from the truth; we will present the rigorous proof along with necessary assumptions in the next subsection.
3.2 Oracle Variable Selection Consistency
Consider the set-up of the previous subsection and assume that the true parameter value is the unique solution of the set of over-identified IV equations in (8), where the non-zero component vector . Further, we need the following sets of assumptions.
**Assumptions on the penalty (P):
**The general penalty function satisfies
- (P1)
is concave and non-decreasing on , with ,
- (P2)
has continuous derivative on , with ,
where denotes the strength of the signal,
- (P3)
There exists a constant such that , where
[TABLE]
It is worthwhile to note that Conditions (P1)–(P3) are quite standard in high-dimensional analysis and used by several authors including Fan and Liao (2014). These are satisfied by a large class of folded-concave penalties including with , hard-thresholding, SCAD and MCP for appropriately chosen tuning parameters. Also for any , by the concavity of the penalty functions. Condition (P2) is related to the signal strength, on which we need the following additional assumptions depending on the dimension of the problem; these are needed to ensure variable selection consistency and are satisfied also by properly chosen SCAD and MCP penalties for strong signal and small .
Assumptions on the dimension and signal strength (A):
- (A1)
, , .
- (A2)
and
Next we assume the following conditions on the instrumental variables and with the notation and for . These are motivated from Fan and Liao (2014) and similar justifications hold for their selection; see Remark 4.1 there. We use the notations and to denote the smallest and the largest eigenvalues, respectively.
Assumptions on the Instruments (I):
- (I1)
There exists such that
[TABLE]
- (I2)
Var and Var are bounded away from both zero and infinity uniformly in and .
- (I3)
and are bounded away from zero.
- (I4)
There exist constants such that and , where
[TABLE]
- (I5)
There exists a constant such that , where
[TABLE]
Note that, Assumptions (I4) and (I5) additionally depend on the choice of proxy matrix , which appear in . This is the key to handle the presence of random effects in the loss function by substituting the unknown . However, we do not need to be consistent for in our derivations; it is sufficient that the proxy matrix is close to in the sense of the following assumption.
Assumptions on the Proxy Matrix (M):
- (M1)
and , for some .
- (M2)
, where denotes the -th column of the matrix defined in Assumption (I4).
Then we have the following main theorem. For simplicity in presentation, we have deferred its proof to the Online Supplementary material.
Theorem 3.1
Consider the set-up of LMM (1) with the true parameter value being Assuming sparsity of , let be the (true) active set with size and . Suppose and Assumptions (P), (A), (I) and (M) hold. Then, there exists a local minimizer of the PFGMM objective function in (12) that satisfies the following properties.
- a)
, where corresponds to the elements of with indices in . 2. b)
If denotes the estimated active set, then . 3. c)
For any unit vector , where corresponds to the elements of with indices in , denotes the non-zero elements of with indices in , and . 4. d)
In addition, the local minimizer is strict with probability arbitrarily close to one for all sufficiently large .
Remark 3.1
Although we have three types of unknown parameters in the LMM (1), the PFGMM loss function depends only on the fixed-effects coefficient parameter . Thus, the minimization of the PFGMM objective function in (12) only produce an estimate of which, in turn, also selects the important fixed-effects associated with the non-zero coefficients in due to the use of a sparse non-concave penalty function. Once is obtained, the estimation of the other variance parameters needs to be done in a second stage, which is described later in Section 4.
Remark 3.2
It is worthwhile to note that, although we have proposed the PFGMM approach considering level-1 endogeneity in the LMM (1), its oracle consistency results in Theorem 3.1 is not hampered by the presence of level-2 endogeneity. This is because the transformed model (7) and hence the PFGMM loss function in (13) do not involve the random effects if the proxy matrix is chosen appropriately. However, the required assumptions might become stricter if endogeneity is present also in the associated random effect covariates . Therefore, we expect the proposed PFGMM approach to work well in selecting important fixed-effect variables even under level-2 endogeneity in well-specified LMM; we will further illustrate this aspect empirically through simulations in Section 5.
3.3 Computational Aspects
For implementing the proposed PFGMM algorithm, one can follow the same algorithm as used by Fan and Liao (2014) on the transformed variables and . But, these transformed variables leading to the loss function in (11) are not known, so we need to use the proxy matrix and the approximated loss given in (13). So, given a proxy matrix , we first compute the matrix and its square root . For computation of the matrix square root we use the Blocked Schur algorithm as developed by Deadman et al. (2013); its implementation can be found in standard statistical softwares like MATLAB or R (function named ‘sqrtm’ in both). Then, the approximation of the transformed variables are computed as and . Following this, the FGMM loss function based on and is nothing but the proposed loss in (13) and hence we can next device an algorithm following the Fan and Liao (2014) approach. The minimization of the resulting penalized PFGMM objective function is done through the iterative coordinate algorithm applied to a smoothed version of the non-smooth PFGMM minimization problem. More details and justifications can be found in Fan and Liao (2014); for brevity, we only present the crucial considerations regarding the choice of proxy matrix and the choice of regularization parameter in our context.
**On the Choice of Proxy matrix:
**The choice of proxy matrix is not straightforward from the assumed conditions but some light can be shed following the discussions in Fan and Li (2012, Section 2.3). In particular, assuming standard non-singularity conditions involving the random effects covariates , one possible choice of which can be obtained for large is times the identity matrix. We have used this particular proxy matrix for all our empirical illustrations in the present paper.
**On the Choice of :
**Although for the regression modeling considered in Fan and Liao (2014), the regularization parameter can be chosen by cross-validation and hence can also be used in connection with any loss function other than likelihood-loss (like the FGMM loss), it is not ideal to apply the cross-validation technique in case of mixed models. In likelihood based estimation and variable selection in high or ultra-high dimensional LMMs, the usual proposal is to choose corresponding to the minimum value of the BIC given by (Schelldorfer et al., 2011; Delattre et al., 2014; Ghosh and Thoresen, 2018)
[TABLE]
When we are using the proposed PFGMM loss function to estimate in the ultra-high dimensional mixed model, one can define a natural extension of BIC as
[TABLE]
where is the estimate of obtained through the proposed PFGMM approach with regularization parameter . But, in this context, it may be questionable if the above formulations provide the correct penalty and this clearly needs further detailed investigation. However, it has been observed that the simple choice of , as suggested in Fan and Liao (2014), works sufficiently well for all our numerical studies.
3.4 Empirical illustrations
We consider the same simulation set-up as in Example 2.1 with level-1 endogeneity and different values of the underlying parameters and apply the proposed PFGMM algorithm to select the relevant fixed-effects variables. In particular, we consider the true values of as representing strong signal, and the values of other parameters as and as in Example 2.1. Further, we consider two values of ; 0 and , indicating uncorrelated and correlated covariates, respectively, and different values of to represent varying strength of endogeneity (correlations being 0, 0.1, 0.24, 0.51, 0.69, respectively); note that gives the ideal case with no endogeneity. We have also studied negative values of with the same magnitudes leading to negative correlations, but their effects are the same as the positive cases (only depends on the magnitudes) and hence the results are not reported in the paper for brevity. The values of the regularization parameter is taken as , following the suggestion of Fan and Liao (2014). For comparison, we also apply the profile likelihood proposal (referred to here as the PLS) of Fan and Li (2012). The average sizes of the estimated active sets obtained by both methods are presented in Figures 1 and 2, respectively, for the correlated and the independent covariate cases.
These empirical illustrations clearly show the significantly improved performance of the proposed PFGMM method under level-1 endogeneity. In particular, for correlated covariates, even a small amount of endogeneity (small ) increases the estimated active set sizes in the PLS method, which becomes further damaging for larger extent of endogeneity, either through more endogenous variables or higher values of . On the other hand, the proposed PFGMM method produces an active set of size almost equal to the original active set size (5) under any extent of endogeneity and the variation over different replications is also negligible compared to the PLS method. The results for the independent variables are also similar although the harmful effect of endogeneity on the PLS method is not significant for smaller values of . The proposed PFGMM method still performs better than the PLS method overall, producing the same sets of active variables in the cases where the PLS also performs well.
The next section describes the performance of estimated regression coefficients obtained through PFGMM, PLS and further refinements along with the estimation of the variance components.
4 Estimation of the Variance Parameters
Once we have selected the important fixed effect variables consistently through the proposed PFGMM algorithm, our problem reduces to a low dimensional one. Let denote the set of indices of estimated non-zero coefficients, which is asymptotically the same as the true active set with probability tending to one from Theorem 3.1. So, we now have the reduced model
[TABLE]
Also, we have an estimate of , which is consistent and asymptotically normal from Theorem 3.1. Then, the most straightforward and intuitive estimates of can be obtained by applying the maximum likelihood method to the resulting residual (random effect) model
[TABLE]
We will refer to the resulting estimator, say as the PFGMM estimator of in the line of the associated PFGMM estimator of . It is important to note that the PFGMME of will also be consistent and asymptotically normal by standard results on likelihood based inference for the low-dimensional residual model (16). Once has been computed as described in Section 3, the PFGMME of can be computed routinely by using the available software packages for low-dimensional LMM (e.g., package ‘lme4’ in R, function ‘fitlme’ in MATLAB).
Alternatively, if we just want to use the proposed PFGMM for selection of important fixed effects, in the second stage we can also fine-tune the estimates of along with estimation of to achieve better finite sample efficiency. For this purpose, we consider the reduced low-dimensional linear mixed effect model given in (15), containing only the fixed-effect variables from selected by the PFGMM algorithm, and apply the standard maximum likelihood (ML) or the restricted maximum likelihood (REML) approach to get the new estimates of and of . Let us refer to the resulting estimators of obtained by the second stage ML or REML, respectively, as the 2MLE or 2REMLE. Their performances in comparison to the PFGMM estimator of are illustrated below through a simulation.
Example 4.1. Let us repeat the simulation exercise from Section 3.4, but now we estimate the parameters by the proposed PFGMM, 2MLE and 2REMLE. The resulting mean values of the estimators, along with their standard deviation (SD) and mean squared error (MSE), for the cases of exogeneity () and extreme endogeneity with are reported in Tables 2 and 3, respectively. For comparison, we have also reported the estimates obtained by the PLS method, where the variance parameters are estimated by maximizing the likelihood of the corresponding residual model.
One can clearly observe from Table 2 that, under exogeneity, the parameter estimates obtained from either of the methods are quite similar although the estimates of error variance are slightly better through the 2MLE or 2REML approach. On the other hand, under endogeneity (Table 3), the PLS approach produces biased estimates of fixed-effect intercepts, with larger variance and it significantly underestimates the error variance . The estimates obtained by the PFGMM method correct the bias of the intercept significantly but still have somewhat larger variance of this estimate and also an underestimated value of . However, the second stage proposal of 2MLE or 2REMLE produces highly efficient estimators of both the fixed-effect coefficients and variance parameters, which are similar to those obtained in the case of an exogenous model, even in the presence of extreme endogeneity of correlation for Sets 1, 2 and 4. Only for Set 3, where a random slope is correlated with the error vector, our proposed methods still have some significant (negative) bias in estimating the fixed intercept and error variance , although other parameters are estimated with excellent accuracy through 2MLE or 2REMLE. One should notice that, for the two stage proposals, we are now again in a situation with endogeneity. See further comments related to this under Remark 4.1.
The other values of give similar results, except for Set 3, and hence they are omitted for brevity. In the case of endogenous random slope variables (Set 3) with moderate values of (and hence correlations) our method is surprisingly underestimating the fixed-effect intercept term to a larger magnitude and needs further investigation; see Remark 4.1 below.
In summary, the proposed PFGMM method selects the true positive fixed-effect variables with extremely small amount of false positives under any extent of level-1 endogeneity, but the resulting estimates of fixed-effect coefficients are somewhat biased and the resulting residual model also underestimates the variance parameters, specially . However, the second stage estimators 2MLE or 2REML again correct them to yield accurate estimators of all the parameters under most level-1 endogeneity except when the random slop is endogenous.
Remark 4.1** (When endogeneous covariate also has random effect)**
As we have already noted, although providing extremely good results in terms of our main target of fixed-effect selection, the proposed FGMM as well as its second stage refinement cannot fully address the parameter estimation problem (just like PLS) in cases where the covariates having random effects are endogenous with the error terms. However, since the proposed FGMM can select the true active sets quite accurately, we can concentrate on the reduced low-dimensional model (with only the selected fixed-effect covariates) to get a corrected parameter estimate in the second stage by using a suitably modified approach instead of 2MLE and 2REML. Since there are already enough literature on the endogeneity issue of mixed-effects models, a proper (low-dimensional) IV method, e.g., 2-stage or 3-stage least squares, can be chosen for the above purpose for a second stage refinement to PFGMM. To keep the focus of the present paper clear on the fixed-effects selection in the high-dimensional context, we have not discussed these low-dimensional modifications for parameter estimation in the reduced model here, as they can be easily covered by existing literature.
Another important phenomenon has been observed in our simulations with Set 3 endogenous covariates and for different values of . Surprisingly, the bias of the fixed effect intercept and random effect variances decreases with increasing extent of endogeneity, contrary to all other cases and our standard intuition. This contradictory behavior of all the methods, PLS, PFGMM, 2MLE and 2REML, indicates the need for further investigation and we hope to study this aspect in our future work.
5 What happens in the Presence of Additional Level-2 endogeneity?
Although we have developed our proposed method for consistent selection of fixed effect variables in the LMM with level-1 endogeneity, it is also of interest to examine how our proposed PFGMM and its second stage refinements perform in presence of level-2 endogeneity.
For comparative consistency, let us again reconsider the simulation set-up of Example 2.1, but now with different extents of level-2 endogeneity in both random intercept and slope components separately for ; this leads to correlations of 0, 0.15, 0.33, 0.6, 0.7, respectively, in both cases. Since the effect of level-2 endogeneity has already been observed to be significant in case of correlated covariates, we only present the corresponding results regarding selection of fixed effect variables (active set sizes) through the usual PLS method (Fan and Li, 2012) and the PFGMM method, and for four sets of endogenous covariates as in Example 2.1. These are shown in Figures 3 and 4, respectively, for the cases of endogenous random intercept and slopes. From these Figures, as well as additional simulations not reported here, it has been observed that our proposed PFGMM method performs extremely well in selecting exactly the truly significant variables compared to the PLS method even in these cases of level-2 endogeneity. Except for very high level of endogeneity, the PFGMM method selects exactly the true active set in most cases as under level-1 endogeneity (or exogeneity).
Thus, if the main objective is the selection of important fixed effect variables, the proposed PFGMM serves the purpose in presence of any sort of endogeneity in the data, provided the signal is reasonably strong. The requirement of a strong signal is related to the choice of regularization parameter and is also expected from our Assumption (A) required to prove the oracle variable selection consistency of PFGMM. As noted in Remark 3.2, the theoretical derivations are also justified and linked through our numerical illustrations on this aspect.
We have also studied the effect of level-2 endogeneity on parameter estimation in different proposals and the results are seen to be quite promising except for Set 3, as in the case of level-1 endogeneity. Our focus being variable selection in the present paper, for brevity, we will not discuss estimation results here.
6 A Real Data Application
We are analyzing data from a randomized controlled cross-over trial in 47 subjects (Hansson et al., 2019). The subjects were exposed to four different meals with similar fat contents, and the response was serum concentration of triglycerids (TG) measured before the meal and 2, 4, and 6 hours after. It is well known that an elevated level of TG is associated with an increased risk of cardiovascular disease, and it is of interest to understand individual variation in TG response and to characterize individuals with an unfavorable response. In this study we will focus on lipid subclasses. In addition to the primary expousure (meal), we have measurements of lipid subclasses in blood, taken before each meal. Our primary interest is if the triglyceride response to the meal (say ), as measured over six hours, depends on the level of some of the lipid subclasses (covariates s). We will analyze this by a mixed model
[TABLE]
where , , denote the dummy variables representing time 2, 4 and 6 hours, respectively, and is the number of different available lipid subclasses. Here we have four random effect coefficients , , corresponding to random intercept and three time dummy variables. Additionally, we have fixed effect coefficients s, s and s, which need to be estimated from the repeated (incomplete) observations from only 47 patients. However, we assume that only a few of the available lipid subclasses will influence the triglyceride response significantly, and our goal is to identify these subclasses.
Therefore, we are in a sparse high-dimensional regime, and we can apply the proposed PFGMM method as an alternative to the PLS method to select important lipid subclasses, assuming for , and . It is difficult to test for endogeneity in high-dimensional models in practice. However, due to the high dimensions one will almost expect endogeneity to arise incidentally. In the current example, important potential confounders are also omitted from the model, which would be expected to lead to endogeneity problems. From our simulation studies in Section 3.4 we observed that the PLS method has serious problems with over-selection in situations with endogenous covariates, and hence, we will consider a large reduction in the number of selected variables by our method as a sign of endogeneity.
We have applied both the methods with different values of the regularization parameter for the purpose above. We observe that, in each case, the PFGMM method selects way less significant variables compared to the existing PLS approach, giving us less false positives; see Table 4 for a few illustrative cases. This clearly indicates the presence of significant endogeneity in the data and the advantages of our proposed PFGMM approach becomes clear.
In the same Table 4, the variance estimates obtained by the second stage refinement 2REML are also reported; clearly the error variance reduces as we select more and more fixed effect variables by lower -values. The appropriate model can be chosen via proper justification along with biological significance of the resulting model estimates. For example, the model with selecting 11 fixed effects looks the best candidate for the present example, since it provides a very low model error and still a rather sparse model. Of particular interest is the selection of a total of seven interaction parameters, pointing to subclasses of particular interest when it comes to triglyceride response. Without going into detail about the lipid subclasses, two of the discoveries seem obvious, as they are related to subclasses rich in triglycerides. Furthermore, four parameters are pointing to subclasses related to Hdl cholesterol, a parameter known to be connected to triglycerides, while the significance of the last subclass being picked up is more unclear.
As an alternative to the model selection above, one can apply a proper extension of BIC to chose a data driven value of the regularization parameter . Some indications are provided in Section 3.3 since the usual BIC often gets affected by the presence of endogeneity in the data. However, more investigation is needed on appropriate BIC extensions under endogeneity which we hope to do in future work.
Finally, we should mention that we have used the unimportant covariates as a general vector of instrumental variables, which is seen to perform well in all our simulations studies; such instruments were also suggested by Fan and Liao (2014) while dealing with high-dimensional regression models with endogeneity. More detailed study on finding an optimal instrumental variable will surely be an interesting future research problem.
7 Conclusions
In this paper we have studied the problem of endogeneity in high-dimensional LMM with particular attention to the selection of important fixed-effect variables under error-covariate endogenity. We have proved the inconsistency of the usual penalized likelihood approach for such cases and proposed a new PFGMM approach of consistent selection of the fixed-effects combining the ideas of generalized method of moments, instrumental variables and proxy matrix for the unknown variance component matrix. The oracle variable selection property as well as the consistency and asymptotic normality of the estimated fixed effects coefficients are derived under appropriate assumptions.
This work opens up many different new research questions for future research. The immediate follow-up would be the detailed analysis of level-2 endogeneity and its effect on the usual likelihood method as well as our proposed PFGMM method. We should develop appropriate modifications in such cases, if needed, to establish variable selection consistency. The second stage estimators may be further investigated for theoretical optimality. Further, a suitable extension of BIC should be studied, both theoretically and empirically, to select the regularization parameter from endogenous data. Although we have indicated a possible solution, detailed analysis is due for future works.
**Acknowledgements.
**The majority of this work was done when the first author was visiting the University of Oslo, Norway, through the support of a grant from the Norwegian Cancer Society. The research of the first author is also partially supported by the INSPIRE Faculty Research Grant from Department of Science and Technology, Govt. of India.
Appendix A Online Supplementary Material
A.1 Proof of Theorem 1
Define . Then, by an application of the Karush-Kuhn-Tucker (KKT) condition on the local minimizers and , we get
[TABLE]
where if , and if . Therefore, by using the monotonicity and the limit of from Condition (C3), we get
[TABLE]
Next, by the first order Taylor series expansion of at around , we get a on the line segment joining and such that
[TABLE]
Therefore, in the event having probability tending to one [by Condition (C2)], we get
[TABLE]
where the last step follows by Cauchy-Swartz inequality; here is the dimension of . Now, by Conditions (C1) and (C2), we get
[TABLE]
Then the theorem follows using (18)
A.2 Proof of Theorem 2
First let us note that, for the likelihood loss , we have
[TABLE]
for any , where denotes the -th column of the matrix . Therefore, by an application of Strong law of Large Numbers, we have the following result in terms of the transformed regression model given in Equation (3.7) of the main paper:
[TABLE]
where and represent the random variables corresponding to the transformed error and the -th transformed covariate (column) in . Now, if is endogenous, then clearly and will be correlated and hence the limit in (19) will be non-zero. Then the proof follows directly from the results of Theorem 1.
A.3 Proof of Theorem 3
We will first show that our Assumptions (A), (I) and (M) together with (P) imply the following four results for the PFGMM loss function given in Eq. 3.11 of the main paper.
- (R1)
, where denotes the gradient with respect to the (non-zero) elements of in . Note that by our Assumptions. 2. (R2)
For any , there exists a positive constant such that, for all sufficiently large ,
[TABLE] 3. (R3)
For any , and any non-negative sequence , there exists a positive integer such that, for all ,
[TABLE]
where denotes the Frobenius norm of a matrix . 4. (R4)
For any , there exists a positive constant such that, for all sufficiently large ,
[TABLE]
Then, Parts (a) and (b) of our Theorem 3 follow from Theorems B.1 and B.2 of Fan and Liao (2014). Note that the assumptions required on the penalty functions there are exactly the same as our Assumption (P); see Fan and Liao (2014) for details.
In the following, we will use the notations and
[TABLE]
Note that . We will now prove results (R1)–(R4).
**Proof of (R1):
**By standard derivative calculations, we get where . Now, by Assumption (I4), we know that . Also, by Assumption (I2), the elements in are uniformly bounded in probability, and hence
[TABLE]
Next, we study the difference of the random variables and . By Assumption (M1), we get
[TABLE]
That is . By the Woodbury formula, since and are both positive definite, we get . Therefore,
[TABLE]
Further, by Assumption (M2), we have
[TABLE]
Then, , and as before we get . Therefore,
[TABLE]
Combining (22) and (23), along with our basic IV assumption (Eq. (3.8) of the main paper), we have . Therefore, from (21), we get
[TABLE]
But, by the choice of IV . So, using the Bonferroni inequality and the exponential-tail Bernstein inequality along with Assumption (I1) and the normality of , we get a positive constant such that, for any ,
[TABLE]
Thus,
[TABLE]
Similarly, we can show
[TABLE]
Combining with (24) we get , proving (R1).
**Proof of (R2):
**Note that, by standard derivative calculations, we have
Fix any . By Assumption (I2), there exists a constant such that for all sufficiently large . Also, by Assumption (I4), there exists a constant such that , where is as defined in Assumption (I4). Now, let us consider the events
[TABLE]
On the event , we have
[TABLE]
But, we already have . And, by the definition of matrix , we have for all sufficiently large . Hence which completes the proof of (R2).
**Proof of (R3):
**Fix any , and any non-negative sequence . For all satisfying , we have for all . Thus, . Also
[TABLE]
Combining we get
[TABLE]
which completes the proof of (R3).
**Proof of (R4):
**The proof follows in the same line of argument as in Appendix C.1.2 of Fan and Liao (2014) and hence left out for brevity.
**Proof of Parts (a)-(b) of Theorem 3:
**Under the results (R1)–(R4) along with Assumption (P), we can apply Theorem B.2 of Fan and Liao (2014) for our PFGMM loss to conclude Part (a) of Theorem 3, and we also get that . Further, from Theorem B.1 of Fan and Liao (2014), we have . Then,
[TABLE]
Therefore, , and hence .
**Proof of Part (c) of Theorem 3:
**We start with the KKT condition for which gives
[TABLE]
where sgn denote the sign function, denotes the element-wise product and
[TABLE]
By the Mean-Value Theorem, we can get lying on the segment joining and such that
[TABLE]
Therefore, denoting , we get
[TABLE]
Now, take any unit vector . Then, since by definition, using the consistency of we have from the above equation that
[TABLE]
To tackle the first term in (27), we recall that , where the random component is normally distributed with
[TABLE]
So, by the central limit theorem, for any unit vector ,
[TABLE]
Further, by definition . Hence, by Slutsky’s theorem, we have
[TABLE]
Next, for the second term in (27), we apply Lemma C.2 of Fan and Liao (2014) to get, under Assumption (P),
[TABLE]
Also, by Assumptions (I4)–(I5), we have . Hence, applying Assumptions (A1)–(A2), we get
[TABLE]
Further, by continuity of , one can easily show that
[TABLE]
Also, we have . Then, combining the above equations with Assumption (A1), we have . Hence, we get
[TABLE]
Therefore, using (28) and (29) in (27) with the help of Slutsky’s theorem, we get the desired asymptotic normality result completing the proof of the theorem.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Antoniadis A. and Fan, J. (2001) Regularization of Wavelets Approximations. Journal of the American Statistical Association , 96, 939–967.
- 2[2] Bates, M. D., Castellano, K. E., Rabe-Hesketh, S., and Skrondal, A. (2014). Handling correlations between covariates and random slopes in multilevel models. Journal of Educational and Behavioral Statistics, 39(6), 524-549.
- 3[3] Chen, X. (2007). Large sample sieve estimation of semi-nonparametric models. In Handbook of Econometrics VI . J. J. Heckman and E. E. Leamer, Eds. North-Holland, Amsterdam.
- 4[4] Chesher, A., and Rosen, A. M. (2017). Generalized instrumental variable models. Econometrica , 85(3), 959-989.
- 5[5] Deadman, E., Higham, N. J. and R. Ralha. (2013). Blocked Schur algorithms for computing the matrix square root . Lecture Notes in Comput. Sci., 7782, Springer-Verlag, pp. 171–182.
- 6[6] Delattre, M., Lavielle, M., and Poursat, M. A. (2014). A note on BIC in mixed-effects models. Electronic journal of statistics , 8(1), 456-475.
- 7[7] Ebbes, P., Böckenholt, U., and Wedel, M. (2004). Regressor and random‐effects dependencies in multilevel models. Statistica Neerlandica , 58(2), 161-178.
- 8[8] Ebbes, P., Wedel, M., Böckenholt, U., and Steerneman, T. (2005). Solving and testing for regressor-error (in) dependence when no instrumental variables are available: With new evidence for the effect of education on income. Quantitative Marketing and Economics , 3(4), 365-392.