Fundamental Law of Memory Recall
Michelangelo Naim, Mikhail Katkov, Sandro Romani, Misha Tsodyks

TL;DR
This paper introduces a universal law of memory recall based on an associative search model, predicting the average number of items recalled from memory, validated through large-scale experiments.
Contribution
It proposes a parameter-free, deterministic model of memory recall that accurately predicts recall capacity across individuals, revealing a common stereotyped search process.
Findings
Predicted recall capacity matches experimental data
Discovered a universal law of memory recall
Validated model with large-scale crowd-sourced experiments
Abstract
Free recall of random lists of words is a standard paradigm used to probe human memory. We proposed an associative search process that can be reduced to a deterministic walk on random graphs defined by the structure of memory representations. This model makes a parameter-free prediction for the average number of memory items recalled () out of items in memory: . This prediction was verified in a large-scale crowd-sourced free recall and recognition experiment. We uncovered a novel law of memory recall, indicating that recall operates according to a stereotyped search process common to all people.
Click any figure to enlarge with its caption.
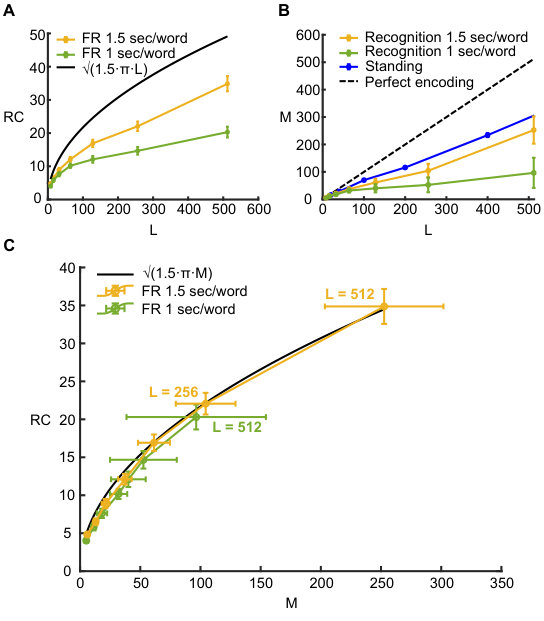 Figure 1
Figure 1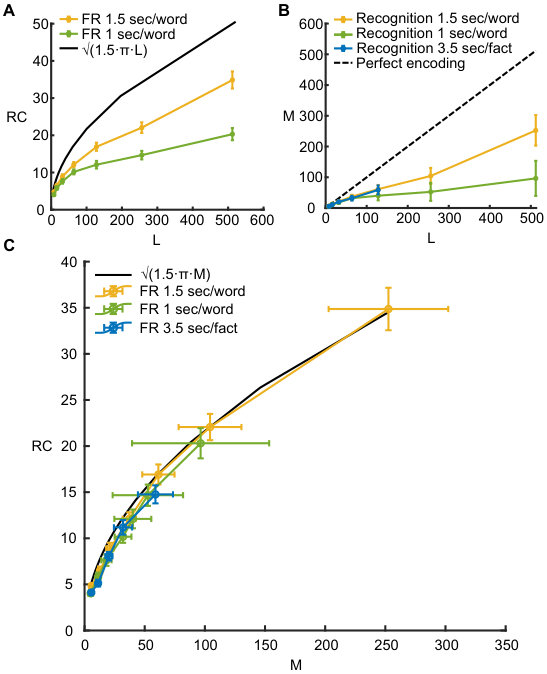 Figure 2
Figure 2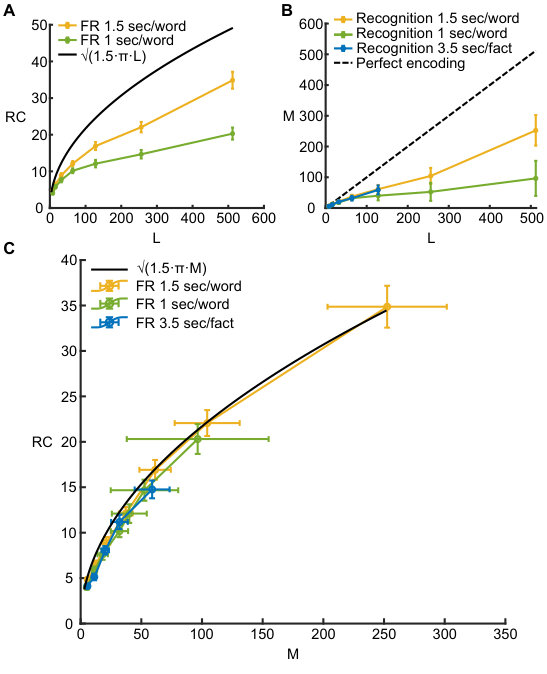 Figure 3
Figure 3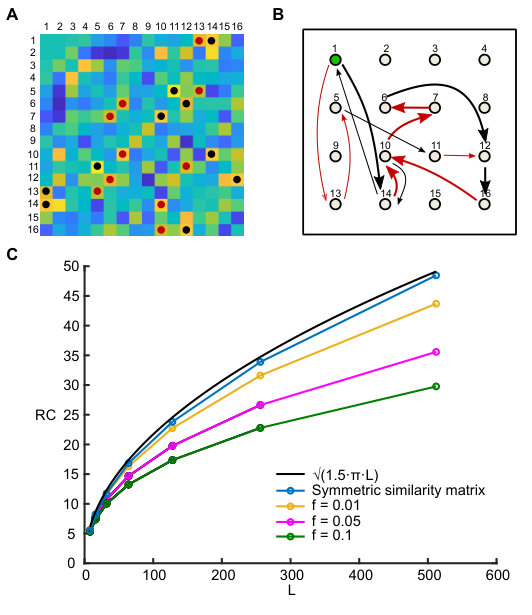 Figure 4
Figure 4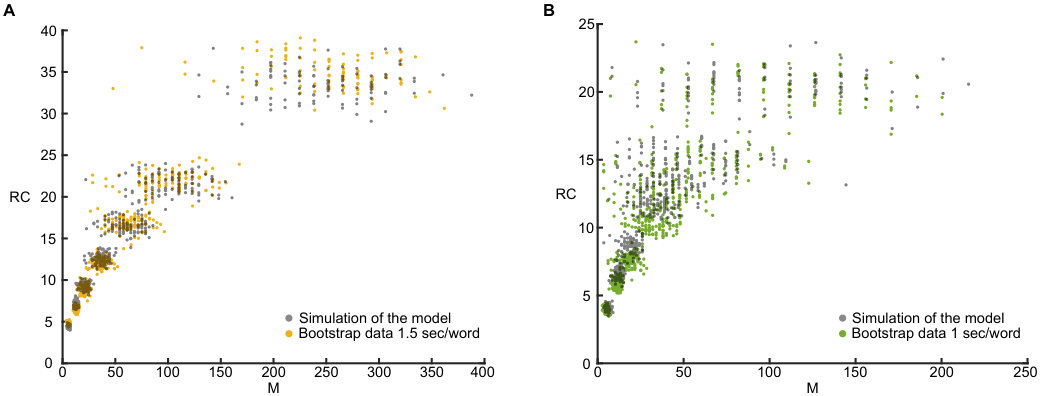 Figure 5
Figure 5 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
**Fundamental Law of Memory Recall **
Michelangelo Naim1+, Mikhail Katkov1+, Sandro Romani2, Misha Tsodyks1,3*
**1 Department of Neurobiology, Weizmann Institute of Science, Rehovot 76000, Israel
2 Janelia Research Campus, Howard Hughes Medical Institute, Ashburn, Virginia 20147
3 The Simons Center for Systems Biology, Institute for Advanced Study, Princeton, NJ 08540
- these authors contributed equally to this work
Abstract
Human memory appears to be fragile and unpredictable. Free recall of random lists of words is a standard paradigm used to probe episodic memory. We proposed an associative search process that can be reduced to a deterministic walk on random graphs defined by the structure of memory representations. The corresponding graph model can be solved analytically, resulting in a novel parameter-free prediction for the average number of memory items recalled () out of items in memory: . This prediction was verified with a specially designed experimental protocol combining large-scale crowd-sourced free recall and recognition experiments with randomly assembled lists of words or common facts. Our results show that human memory can be described by universal laws derived from first principles.
Keywords: Model, Neural Network, Free recall, Working Memory, Theory
Human cognition is typically considered to be too complex to be described by physics-style universal mathematical laws (see a notable exception in the form of a universal law of generalization proposed in Shepard 1987). Human memory in particular is a critically important mental capacity that includes multiple processes, most crucially acquisition, maintenance and recall (see e.g. Dudai 2004). While human memory capacity for information is practically infinite, all of the mentioned processes are not entirely reliable, for example recall is often a challenging task even when information being recalled is encoded in memory. An important advantage for studying recall is that it can be precisely quantified with a classical paradigm of ’free recall’ (see e.g. Kahana 2012). Typical experiments involve recalling randomly assembled lists of words in an arbitrary order after a brief exposure. When the presented list becomes longer, the average number of recalled words grows but in a sublinear way (Binet and Henri 1894; Standing 1973; Murray et al. 1976). The exact mathematical form of this relation is controversial and was found to depend on the details of experimental procedures, such as presentation rate (Waugh 1967). In some studies, recall performance was found to exhibit a power-law relation to the number of presented words (Murray et al. 1976), but parameters of this relation were extremely variable across different experimental conditions.
These observations seem to rule out any possibility that memory recall can be described by a universal mathematical law that would hold for all experimental conditions and all people. Yet in this study we demonstrate with new experiments that most of the variability in recall can be accounted for by measuring the acquisition and maintenance of information during the presentation phase of the experiment, and when that is controlled, recall itself is much more predictable. Moreover, relation between the number of items in memory and the average fraction of it that can be successfully recalled is described by a parameter-free analytical expression derived here from the deterministic model introduced in (Romani et al. 2013; Katkov et al. 2017). In other words, despite the overall unpredictability of human memory, some aspects of it obey simple universal laws.
††margin:
**Figure 1. Associative search model of free recall.
(A) SM (similarity matrix) for a list of items (schematic). For each recalled item, the maximal element in the corresponding row is marked with a black spot, while the second maximal element is marked with a red spot.
(B) A graph with nodes illustrates the items in the list. Recall trajectory begins with the first node, and proceeds to an item with the largest similarity to the current one (black arrow) or the second largest one (red arrow) if the item with the largest similarity is the one recalled just before the current one. When the process returns to the 10th item, a second sub-trajectory is opened up (shown with thinner arrows) and converges to a cycle after reaching the node for the second time.
(C) Comparison between simulations with random symmetric similarity matrix (blue line) and SM defined by random sparse ensembles with sparsity (yellow line), (magenta line), (green line) and number of neurons. Each point is the mean of simulations. Black line corresponds to theoretical .**
The proposed recall process is based on two principles:
- •
Memory items are represented in the brain by overlapping random sparse neuronal ensembles in dedicated memory networks;
- •
The next item to be recalled is the one with a largest overlap to the current one, excluding the item that was recalled on the previous step.
The first principle is a common element of most neural network models of memory (see e.g. Hopfield (1982); Tsodyks and Feigel’man (1988)), while the second one is inspired by “Search of Associative Memory” (SAM, elaborated later). More specifically, item representations are chosen as random binary {0,1} vectors where each element of the vector chosen to be 1 with small probability independently of other elements. Overlaps are defined as scalar products between these representations. The model is illustrated in Fig. 1 (more details in Supplemental Material), where the matrix of overlaps (‘similarity matrix’, or SM) between memory representations is shown in Fig. 1a. Fig. 1b is a graph that shows the transitions between memory items induced by the SM. When the first item is recalled (say the st one in the list), the corresponding row of the matrix, which includes the overlaps of this item with all the others, is searched for the maximal element ( element in this case), and hence the item is recalled next. This process continues according to the above rule (black arrows), unless it points to an item that was just recalled in the previous step, in which case the next largest overlap is searched (red arrows). After a certain number of transitions, this process begins to cycle over already visited items. This happens either the first time a previously recalled item is reached again, or the process could make some number of transitions over previously recalled items (items in Fig. 1b) to open up a new trajectory (items ) until finally converging to a cycle. After the cycle is reached, no new items can be recalled.
In our previous publication (Romani et al. 2013) we showed that the average number of recalled items (recall capacity, or ) scales as a power-law function of the number of items in the list, with exponent that depends on sparseness parameter . Here we focus on the sparse limit of this model, , when one can neglect the correlations between different elements of the SM and replace it by a random symmetric matrix (see e.g. Quian Quiroga and Kreiman (2010), for biological motivation for considering a very sparse encoding). We show below that while the corresponding graph model has a history-dependent transition rule and hence is more complex than the standard family of graphs resulting from random mappings (see e.g.Harris (1960)), it can still be solved analytically in terms of the average number of items visited before converging to a cycle.
It is instructive to first consider the simpler case of a fully random asymmetric SM with independent elements. In this case, transitions between any two items are equally likely, with probability . When an item is reached for the second time the process enters into a cycle. Therefore the probability that out of items will be retrieved is simply
[TABLE]
where we considered a limit of large number of items in the list () and assumed that , which is confirmed a posteriori below. The average number of recalled words can then be calculated as
[TABLE]
which is a well known result in random graphs literature (Harris (1960); Katz et al. (1996)).
When the SM is symmetric, as in our case, the statistics of transitions in the corresponding graph is more complicated (see Supplemental Material for more details about the derivation). In particular, the probability for a transition to one of the previously recalled items scales as rather than as in the case of asymmetric SMs, and hence the average length of trajectory until the first return converges to . Moreover, with probability the trajectory then turns towards previous items and opens up a new route until again hitting a previously recalled item, etc. Taken together, the chance that recall trajectory enters a cycle after each step asymptotically equals to , as opposed to for the fully random matrix, and hence the can be obtained by replacing by in Eq. (2):
[TABLE]
see Fig. 1c for the comparison of this analytical estimate with numerical simulations of the model. We emphasize that Eq. (3) does not have any free parameters that could be tuned to fit the experimental results. Hence, both the exponent and coefficient of this power law expression are a result of the assumed recall mechanism; in other words, this equation constitutes a true prediction regarding the asymptotic recall performance for long lists of items as opposed to earlier theoretical studies. Here we present the results of our experiments designed to test this prediction.
††margin:
**Figure 2. Human recall and recognition performance. **
(A) Average number of words recalled as a function of the number of words presented. Black line: Eq. (3). Yellow line: experimental results for presentation rate sec/word. Green line: experimental results for presentation rate sec/word. The error in is a standard error of the mean.
(B) Estimated average number of encoded words/sentences for lists of different lengths. Black dashed line corresponds to perfect encoding, green line corresponds to presentation rate sec/word and yellow line to presentation rate sec/word; blue line corresponds to lists of short sentences (see text for details). The error in is computed with bootstrap procedure (Efron and Tibshirani 1994).
(C) Average number of words/sentences recalled as a function of the average number of encoded words. Black line: theoretical prediction, Eq. (4). Green line: experimental results for presentation rate sec/word. Yellow line: experimental results for presentation rate sec/word. Blue line: experimental results for short sentences. The error in is a standard error of the mean, while the error in is computed with bootstrap procedure (see Supplemental Material for details).
The universality of the above analytical expression for seems to contradict our everyday observations that people differ in terms of their memory effectiveness depending, e.g. on their age and experience. Moreover, it is at odds with previous experimental studies showing that performance in free recall task strongly depends on the experimental protocol, for example presentation rate during the acquisition stage (see e.g. Murdock Jr 1960, 1962; Roberts 1972; Howard and Kahana 1999; Kahana et al. 2002; Zaromb et al. 2006; Ward et al. 2010; Miller et al. 2012; Grenfell-Essam et al. 2017) and the extent of practice (Klein et al. 2005; Romani et al. 2016). Since most of the published studies only considered a limited range of list lengths, we performed free recall experiments on the Amazon Mechanical Turk® platform for list lengths of and words, and two presentation rates: and seconds per word. To avoid practice effects, each participant performed a single free recall trial with a randomly assembled list of words of a given length. The results confirm previous observations that recall performance improves as the time allotted for acquisition of each word increases, approaching the theoretical prediction of Eq. (3) from below (see Fig. 2a).
We reasoned that some or all of the variability in the experimentally observed could result from the variability in the number of words that remain in memory as candidates for recall after the list is presented. In particular, some of the words could be missed at presentation, while others could be acquired but later erased or degraded. It seems reasonable that acquisition depends on various factors, such as attention, age of participants, acquisition speed, etc. One should then correct Eq. (3) for , replacing the number of presented words with the number of words in memory after the whole list is presented, :
[TABLE]
To test this conjecture, we designed a novel experimental protocol that involved performing both recall and recognition experiments on the same group of participants. Each participant performed one recognition and one recall trial with lists of the same number of words (but different words between recognition and recall) and under identical presentation conditions, including presentation rate, in order to independently evaluate the average number of words in memory, and the average number of words recalled. Following Standing (1973), at the end of presentation we showed each participant a pair of words, one from the list just presented (target) and one randomly chosen lure, requesting to report which word was from the list. The average number of words remaining in memory () was then estimated from the fraction of correctly recognized words () by assuming that if a target word was still encoded at the end of presentation, it will be chosen during recognition test, otherwise the participant will randomly guess which of the two words is a target: . Importantly, each participant performed a single recognition test, to avoid the well known effect of ‘output interference’ between subsequent recognition tests for a single list (see e.g. Criss et al. 2011).
Fig. 2b shows the estimated average as a function of list length (see Supplemental Material for details of analysis). Results confirm that acquisition improves with time allotted to presentation of each word. Standard error of the mean for the number of encoded words across participants, for each list length and each presentation speed, was estimated with a bootstrap procedure by randomly sampling a list of participants with replacement (Efron and Tibshirani 1994, see Supplemental Material).
In Fig. 2c experimentally obtained (yellow and green lines) is compared with the theoretical prediction of Eq. (4) (black line), where is the average number of encoded words, estimated in the recognition experiment. Remarkably, agreement between the data and theoretical prediction is very good for both presentation rates, even though the number of encoded and recalled words is very different in these two conditions for each value of list length. We also performed multiple simulations of our recall algorithm (Romani et al. 2013; Katkov et al. 2017) and found that it captures the statistics of the recall performances as accessed with bootstrap analysis of the results (see Fig. id1 in Supplemental Material).
Experiments presented above, as well as the vast majority of previous recall experiments, were performed with lists of words. To test the generality of our model prediction, we generated a set of short sentences expressing common knowledge facts, such as ‘Earth is round’ or ‘Italians eat pizza’, etc. We repeated our experiments with random lists of and such sentences, each presented for seconds (see Supplementary Material for more details of the analysis). As shown in Figs. 2b and 2c, performance with lists of sentences is very close to that of words with words per second presentation rate, albeit with some small deviations towards lower levels.
Discussion
The results presented in this study show that the relation between the number of words in memory and the number of recalled words conforms with remarkable precision to the analytical, parameter-free expression Eq. (4), derived from a deterministic associative search model of recall. The relation between these two independently measured quantities holds even though both of them strongly depend on the number of presented words and on the presentation rate. We further confirmed the generality of Eq. (4) by repeating the experiments with lists of short sentences expressing common knowledge facts. Hence it appears that memory recall is a more universal process than memory acquisition and maintenance. The crucial aspect of the model is the similarity matrix between the items that determines the recall transitions, but the precise nature of this matrix beyond its statistics across the presented lists and/or across participants does not have to be specified. It seems plausible that different people will have different similarity matrices, reflecting their unique language experience, which makes direct estimation of it rather challenging. However, our previous study (Recanatesi et al. (2015), see also Howard et al. (2007)) showed that recall transitions are sensitive to the measure of semantic similarity called Latent Semantic Analysis (LSA), which represents the number of times two words appear together in a representative corpora of natural text (Landauer and Dumais (1997)). This indicates that there is some degree of universality in inter-word similarities across all people.
Several influential computational models of recall were developed in cognitive psychology that incorporate interactive probabilistic search processes (see e.g. Raaijmakers and Shiffrin 1980; Gillund and Shiffrin 1984; Howard and Kahana 2002; Laming 2009; Polyn et al. 2009; Lehman and Malmberg 2013). These cognitive models have multiple free parameters that can be tuned to reproduce the experimental results on recall quite precisely, including not only the number of words recalled but also the temporal regularities of recall, such as primacy, recency and temporal contiguity effects (Murdock Jr 1962; Murdock and Okada 1970; Howard and Kahana 1999). However, most of the free parameters lack clear biological meaning and cannot be constrained before the data is collected, hence the models cannot be used to predict the recall performance but only explain it a posteriori. Our recall model can be viewed as a radically simplified version of the classical ‘Search of Associative Memory’ model (SAM), see Raaijmakers and Shiffrin 1980. In both models, recall is triggered by a matrix of associations between the items, which in SAM is built up during presentation according to a rather complex set of processes, while in our model is simply assumed to be a fixed, structure-less symmetric matrix (see Fig. 1). Subsequent recall in SAM proceeds as a series of attempted probabilistic sampling and retrievals of memory items, until a certain limiting number of failed attempts is reached after which recall terminates. In our model, this is replaced by a deterministic transition rule that selects the next item with the strongest association to the currently recalled one. As a result, recall of new items terminates automatically when the algorithm begins to cycle over already recalled items, without a need to any arbitrary stopping rule. Finally, SAM assumes that all the presented words are stored into long-term memory to different degrees, i.e. could in principle be recalled, while in the current study we assume that only a certain fraction of words remain in memory at the end of presentation to become candidates for recall. This assumption is confirmed a posteriori by the collapse of vs curves for different presentation rates (see Supplementary Material for more detailed argumentation). We also neglected the well-documented effects of short-term memory on free recall (see e.g. Glanzer and Cunitz (1966)), which are very small in our data (see Supplementary Material).
We consider it little short of a mystery that with these radical simplifications, the model predicts the recall performance with such a remarkable precision and without the need to tune a single parameter. This suggests that despite all the simplifications, the model faithfully captures a key first-order effect in the data. Future theoretical and experimental studies should be pursued to probe which aspects of the model are valid and which are crucial for the obtained results.
Acknowledgments
This research has received funding from the European Union’s Horizon 2020 Framework Programme for Research and Innovation under the Specific Grant Agreement No. 785907 (Human Brain Project SGA2); EU-M-GATE 765549 and Foundation Adelis. S.R. is supported by the Howard Hughes Medical Institute. We thank Drs. Mike Kahana and Eli Nelken for helpful comments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Binet and Henri (1894) Alfred Binet and Victor Henri. Mémoire des mots. L’Année psychologique , 1(1):1–23, 1894.
- 2Criss et al. (2011) Amy H Criss, Kenneth J Malmberg, and Richard M Shiffrin. Output interference in recognition memory. Journal of Memory and Language , 64(4):316–326, 2011.
- 3Dudai (2004) Yadin Dudai. The neurobiology of consolidation, or, how stable is the engram? Annual Review of Psychology , 55(4):51–86, 2004.
- 4Efron and Tibshirani (1994) Bradley Efron and Robert J Tibshirani. An introduction to the bootstrap . CRC press, 1994.
- 5Gillund and Shiffrin (1984) Gary Gillund and Richard M Shiffrin. A retrieval model for both recognition and recall. Psychological review , 91(1):1, 1984.
- 6Glanzer and Cunitz (1966) M Glanzer and A. R Cunitz. Two storage mechanisms in free recall. Journal of Verbal Learning & Verbal Behavior , 5(4):351–360, 1966.
- 7Grenfell-Essam et al. (2017) Rachel Grenfell-Essam, Geoff Ward, and Lydia Tan. Common modality effects in immediate free recall and immediate serial recall. Journal of Experimental Psychology: Learning, Memory, and Cognition , 43(12):1909, 2017.
- 8Harris (1960) Bernard Harris. Probability distributions related to random mappings. The Annals of Mathematical Statistics , pages 1045–1062, 1960.