PARI: A Probabilistic Approach to AS Relationships Inference
Guoyao Feng, Srinivasan Seshan, Peter Steenkiste

TL;DR
This paper introduces PARI, a probabilistic algorithm for inferring AS relationships that explicitly models uncertainty and interdependence, improving understanding of inference reliability.
Contribution
It presents a new paradigm for uncertainty modeling in AS relationship inference and implements it in the PARI algorithm, addressing gaps in prior deterministic methods.
Findings
PARI effectively captures uncertainty in AS relationship inference.
The approach improves the reliability of inferred relationships.
Interdependence modeling enhances inference accuracy.
Abstract
Over the last two decades, several algorithms have been proposed to infer the type of relationship between Autonomous Systems (ASes). While the recent works have achieved increasingly higher accuracy, there has not been a systematic study on the uncertainty of AS relationship inference. In this paper, we analyze the factors contributing to this uncertainty and introduce a new paradigm to explicitly model the uncertainty and reflect it in the inference result. We also present PARI, an exemplary algorithm implementing this paradigm, that leverages a novel technique to capture the interdependence of relationship inference across AS links.
Click any figure to enlarge with its caption.
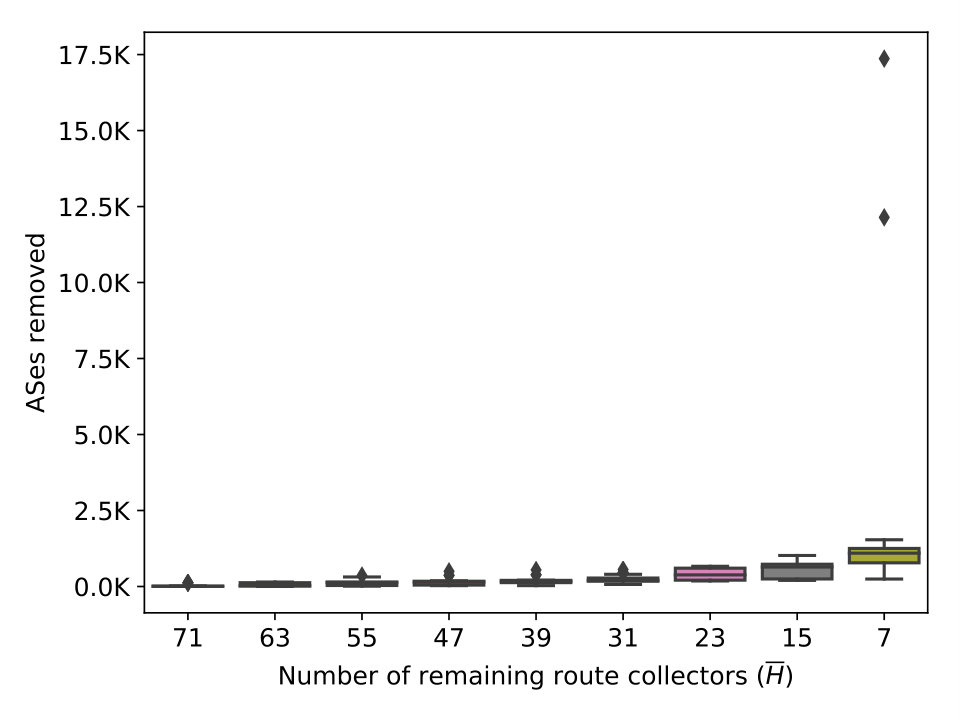 Figure 1
Figure 1 Figure 2
Figure 2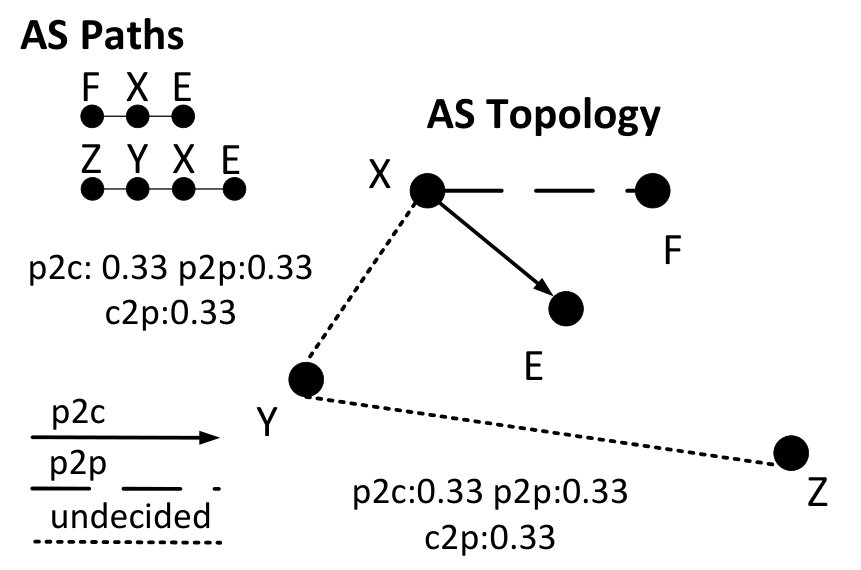 Figure 3
Figure 3 Figure 4
Figure 4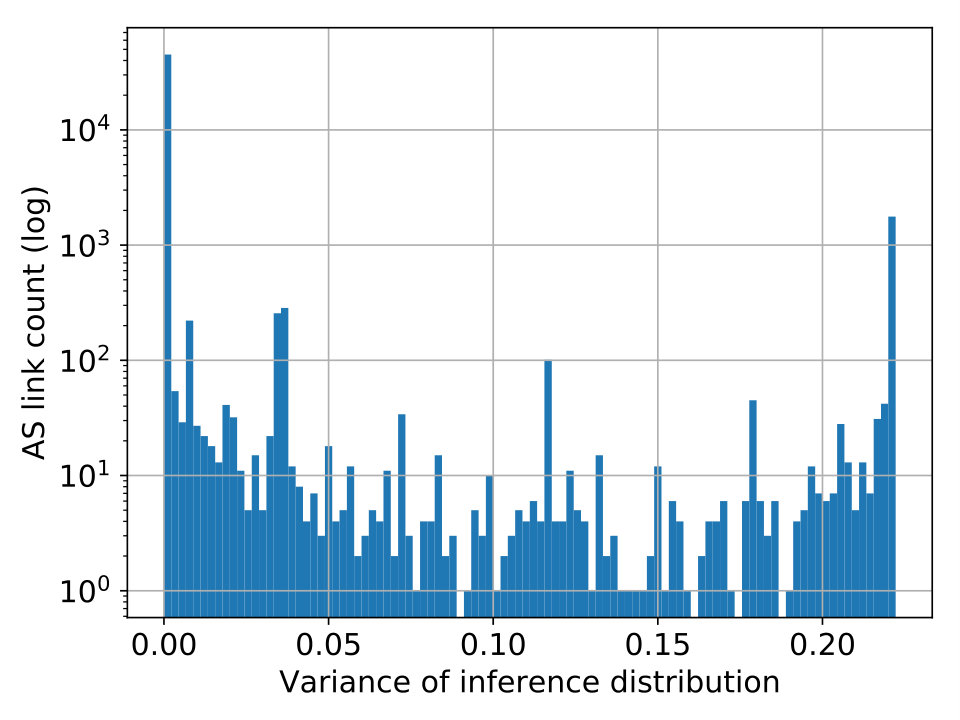 Figure 5
Figure 5 Figure 6
Figure 6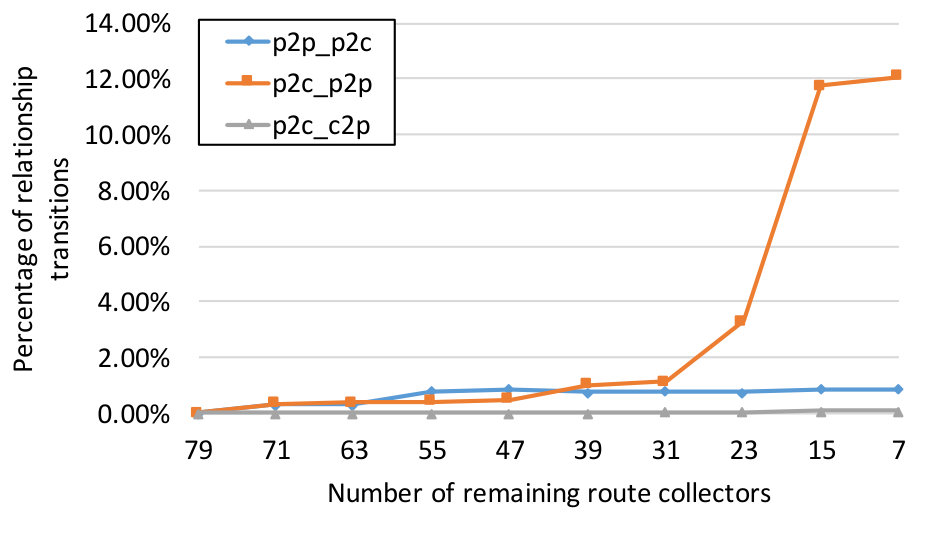 Figure 7
Figure 7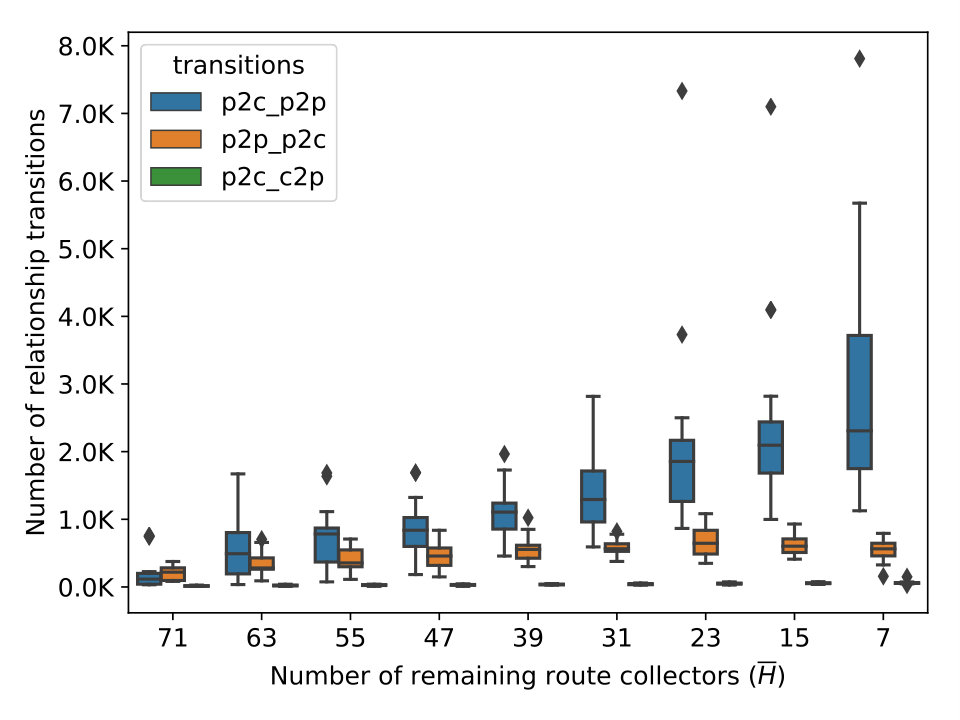 Figure 8
Figure 8 Figure 9
Figure 9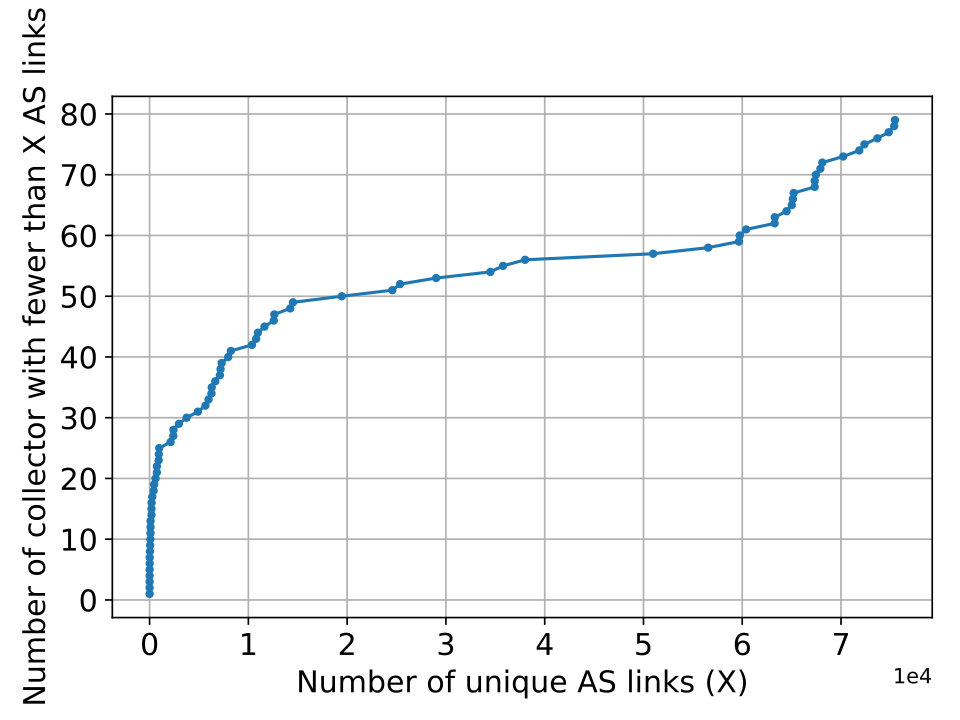 Figure 10
Figure 10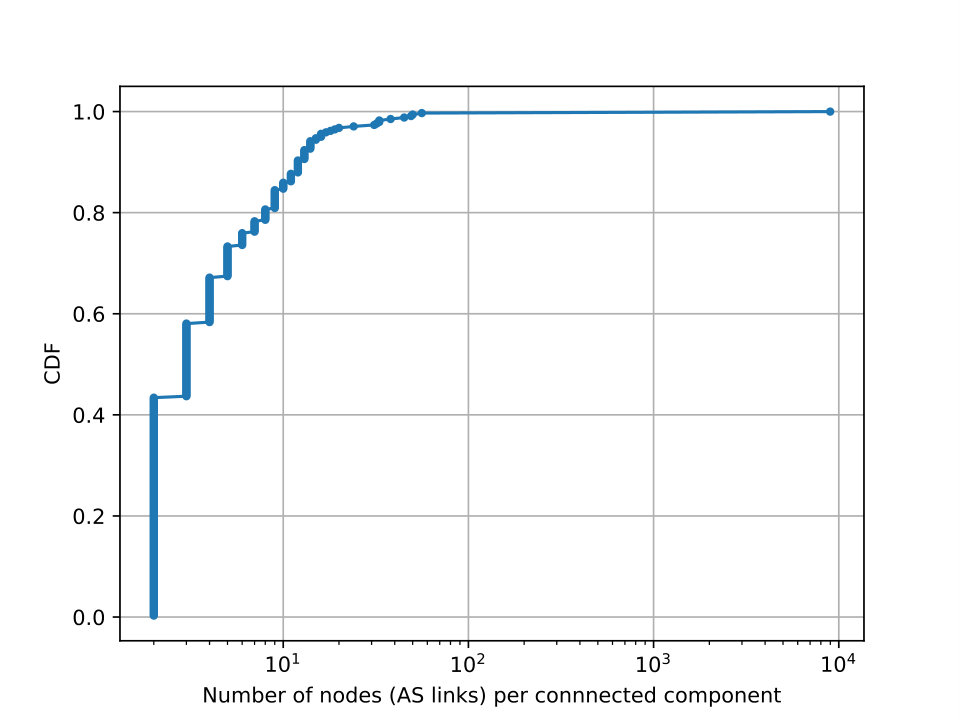 Figure 11
Figure 11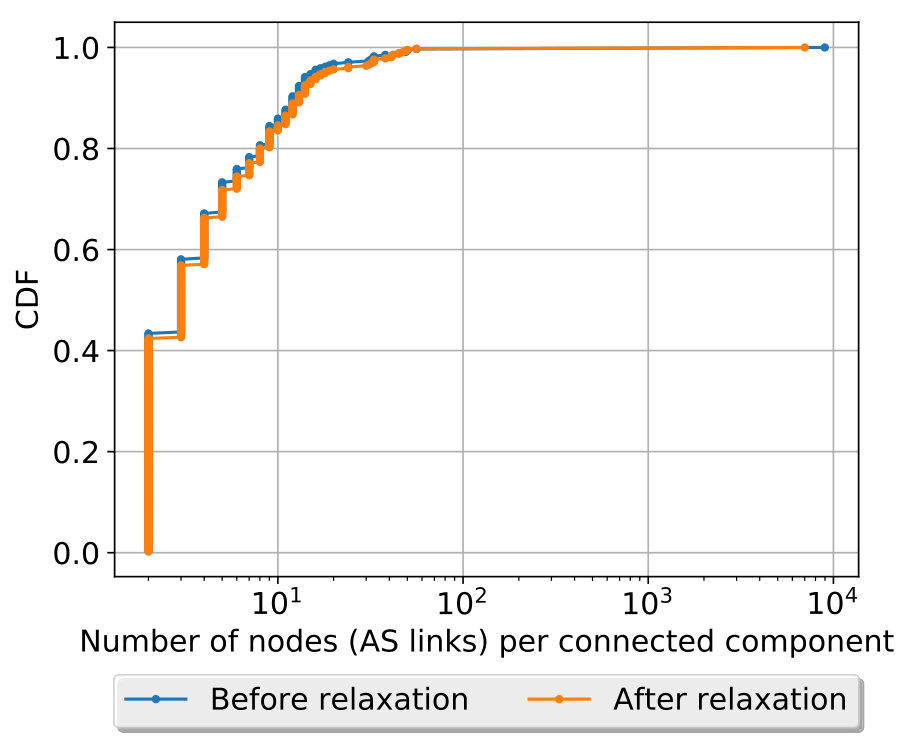 Figure 12
Figure 12 Figure 13
Figure 13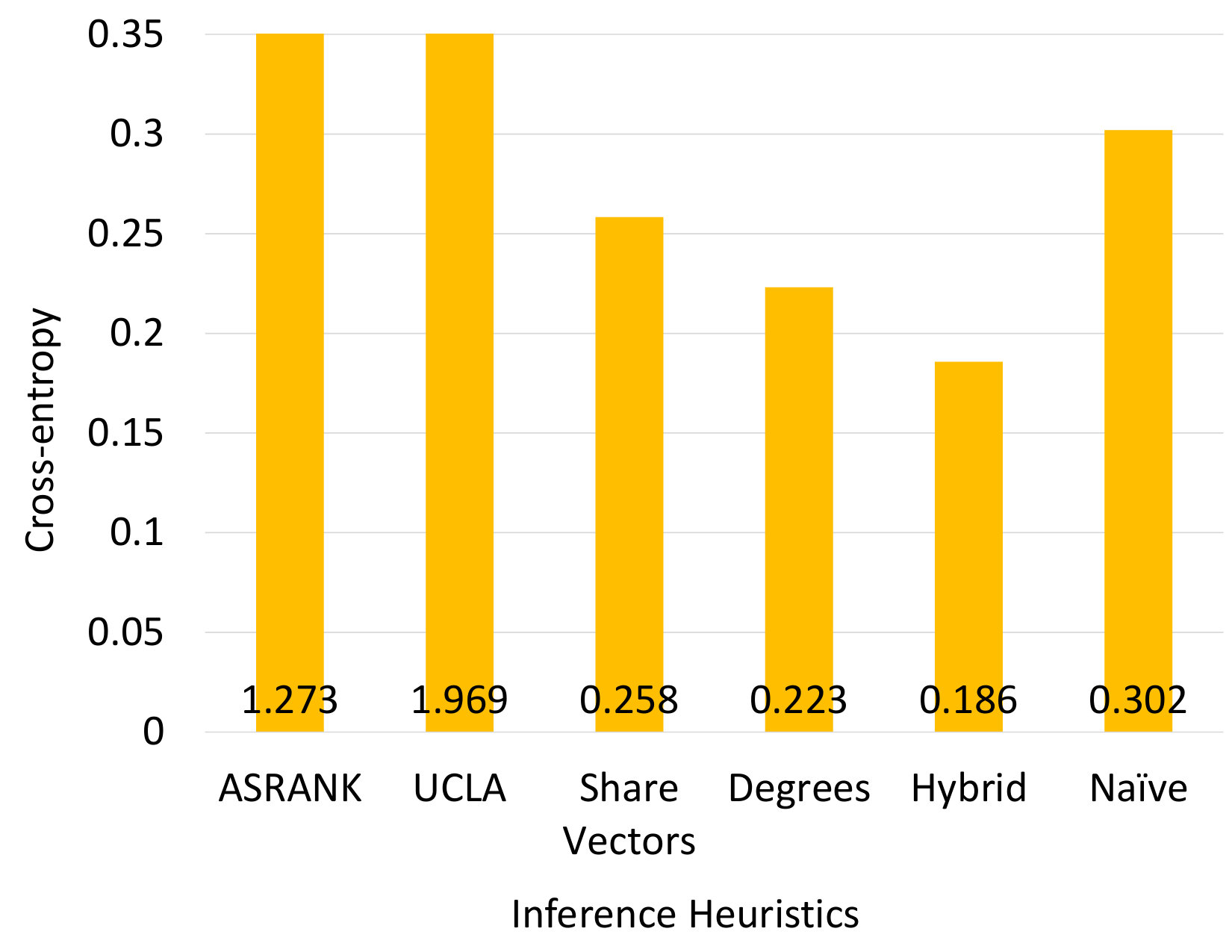 Figure 14
Figure 14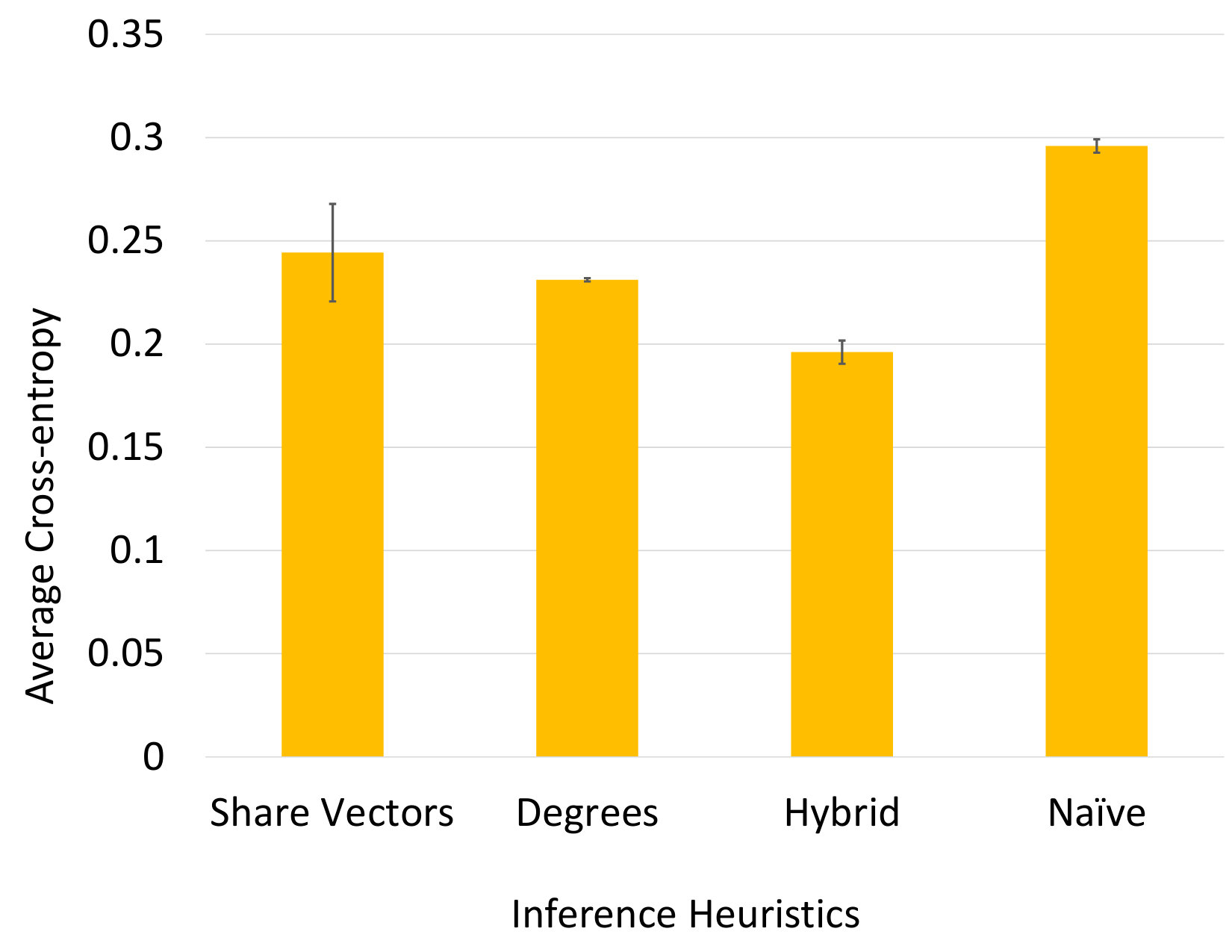 Figure 15
Figure 15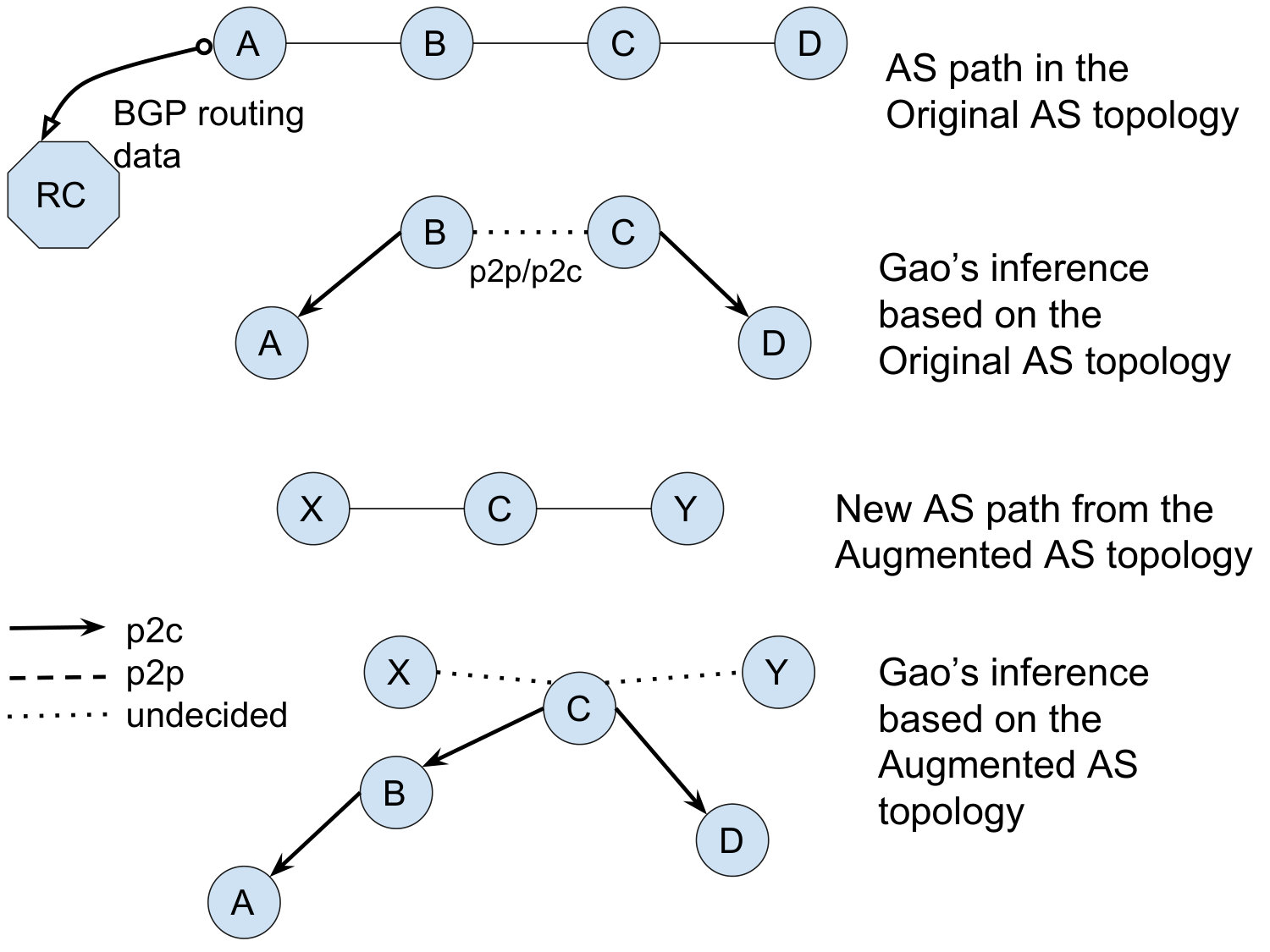 Figure 16
Figure 16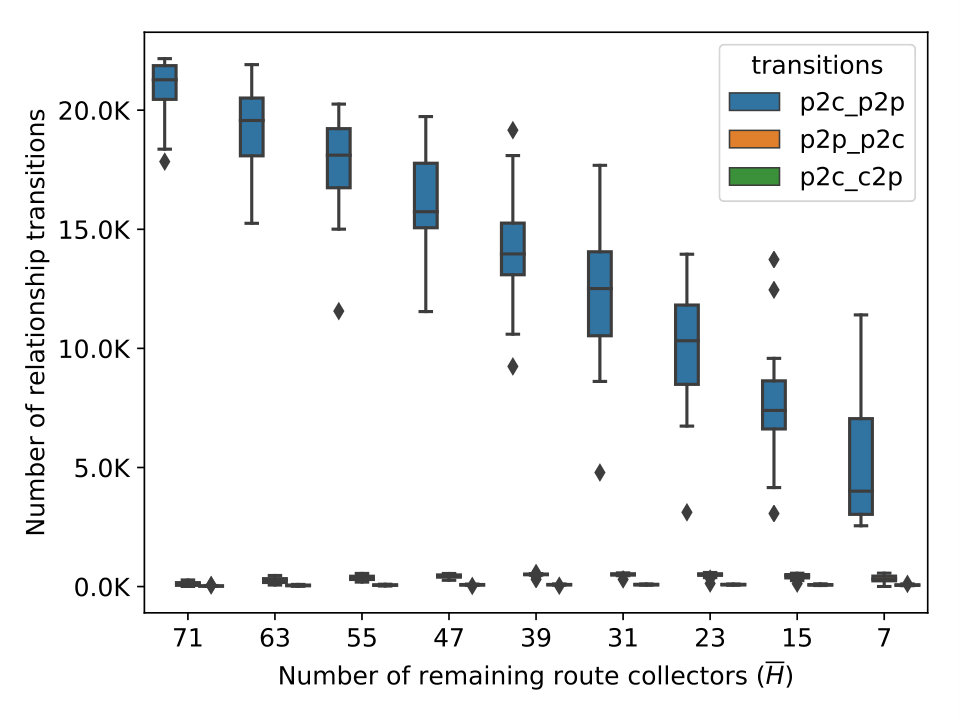 Figure 17
Figure 17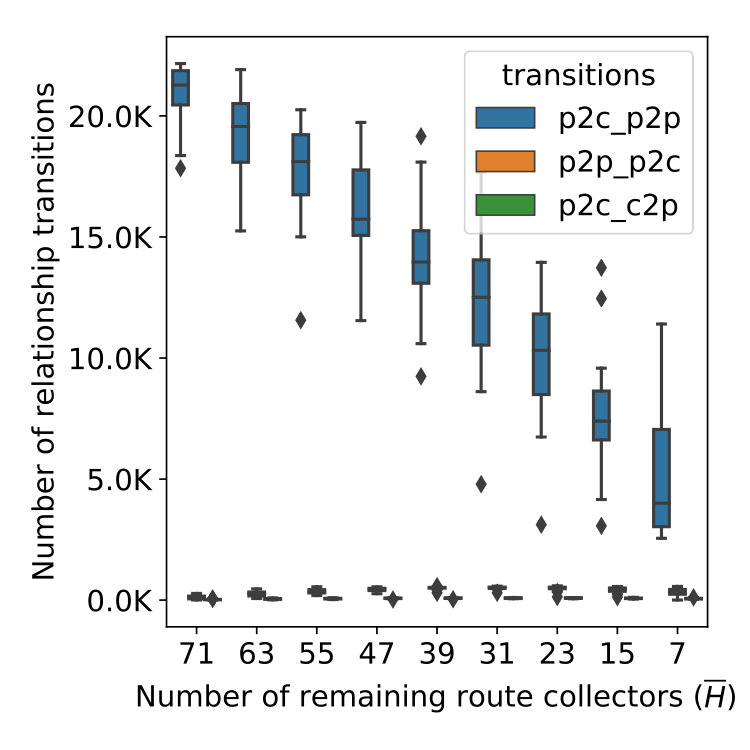 Figure 18
Figure 18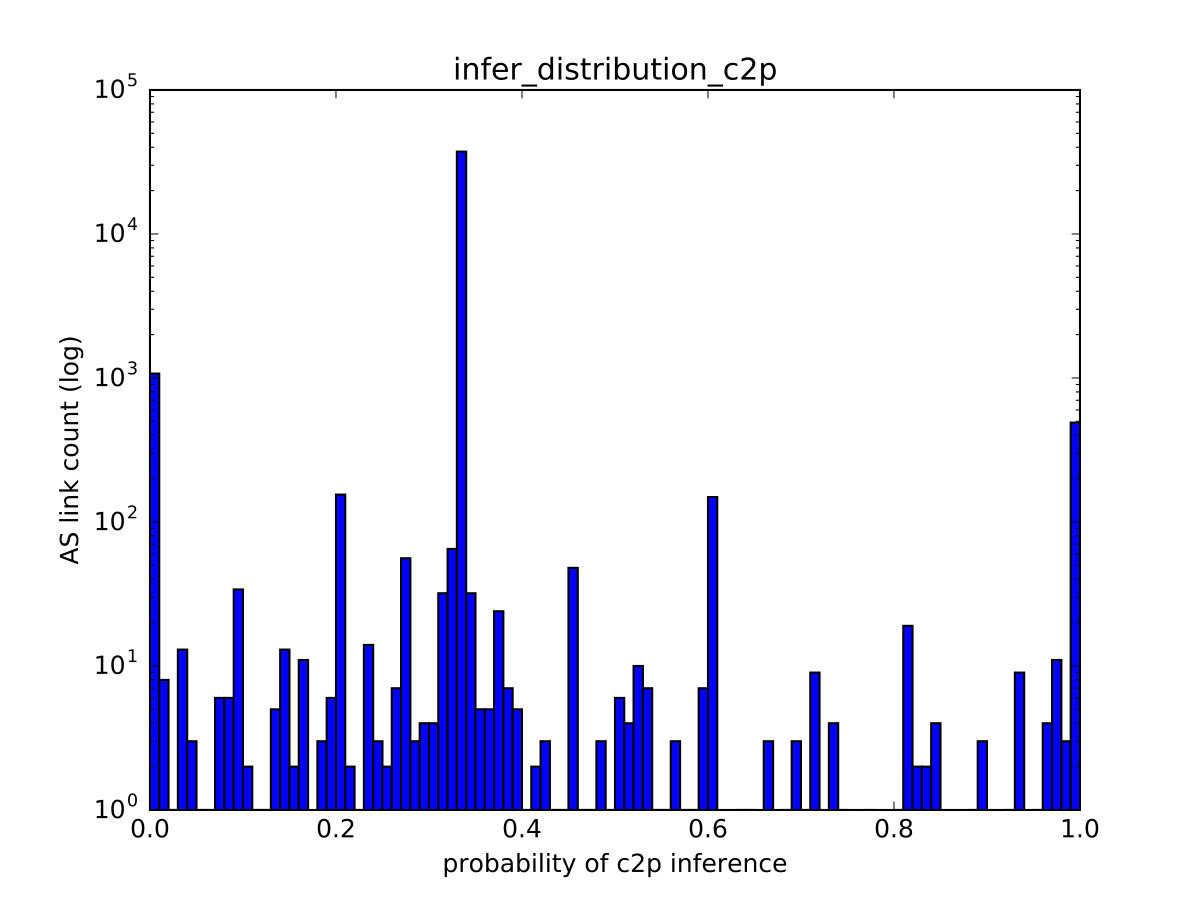 Figure 19
Figure 19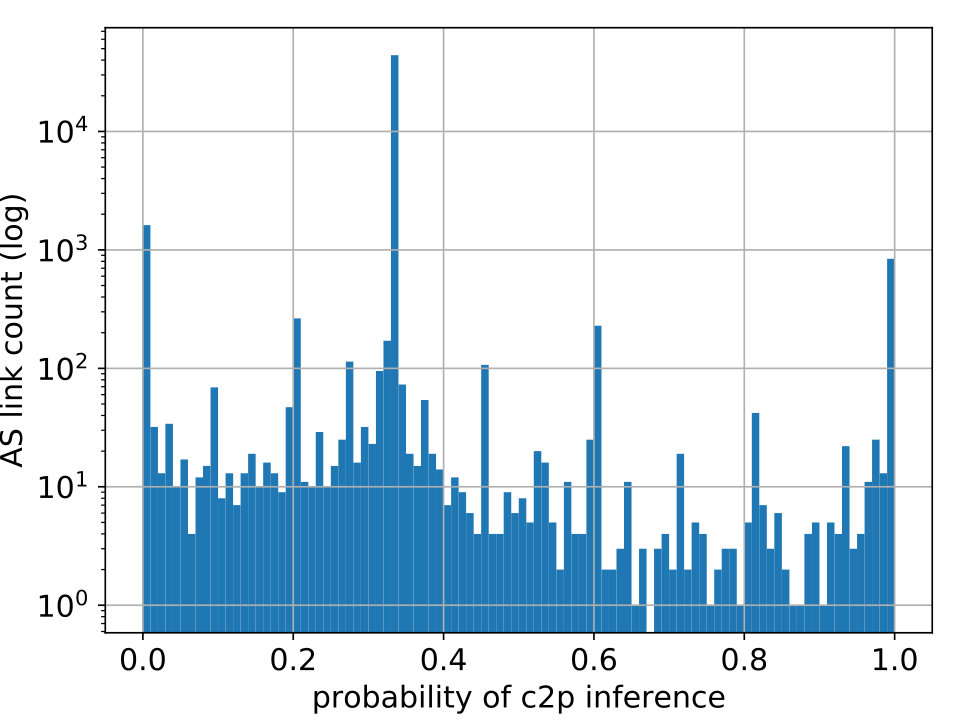 Figure 20
Figure 20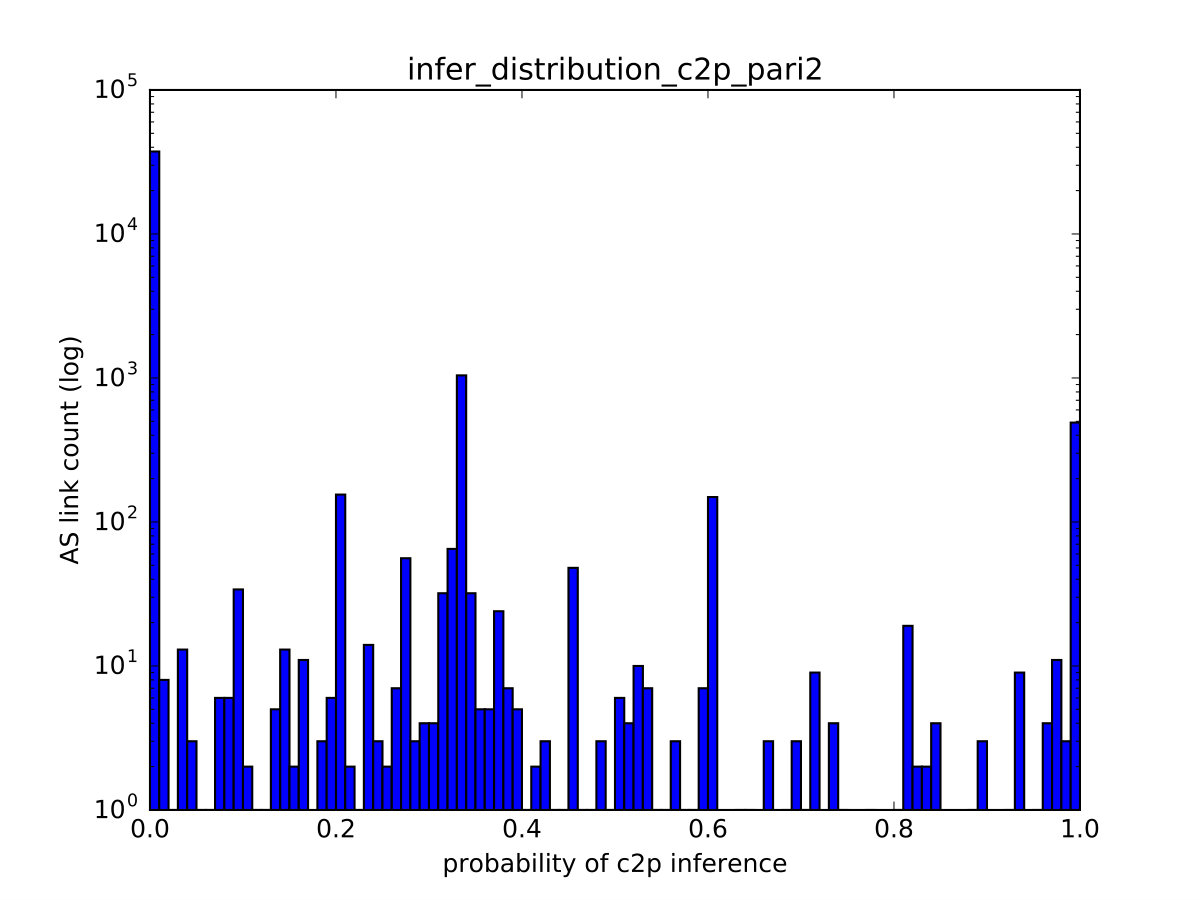 Figure 21
Figure 21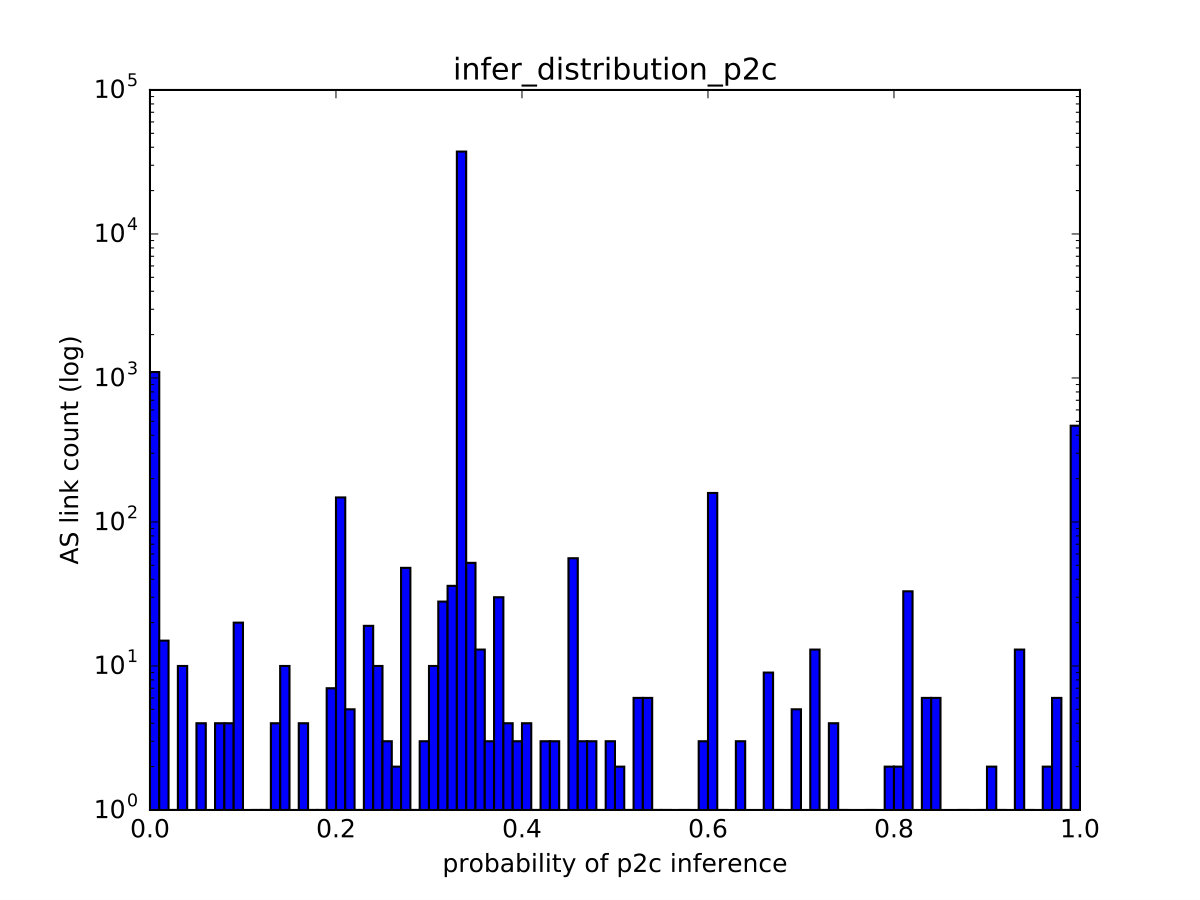 Figure 22
Figure 22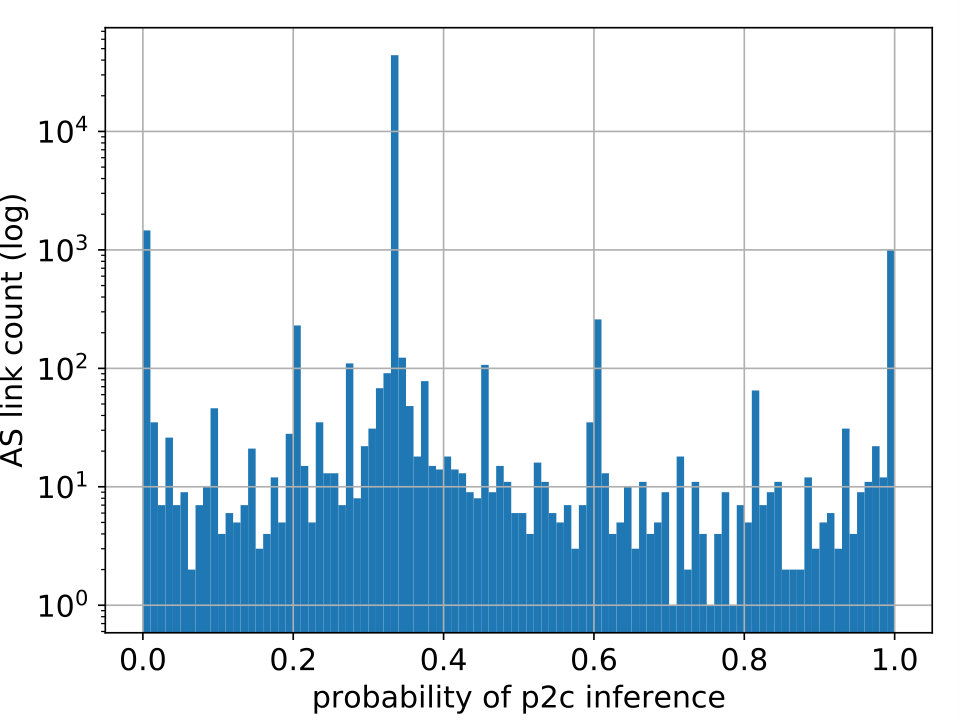 Figure 23
Figure 23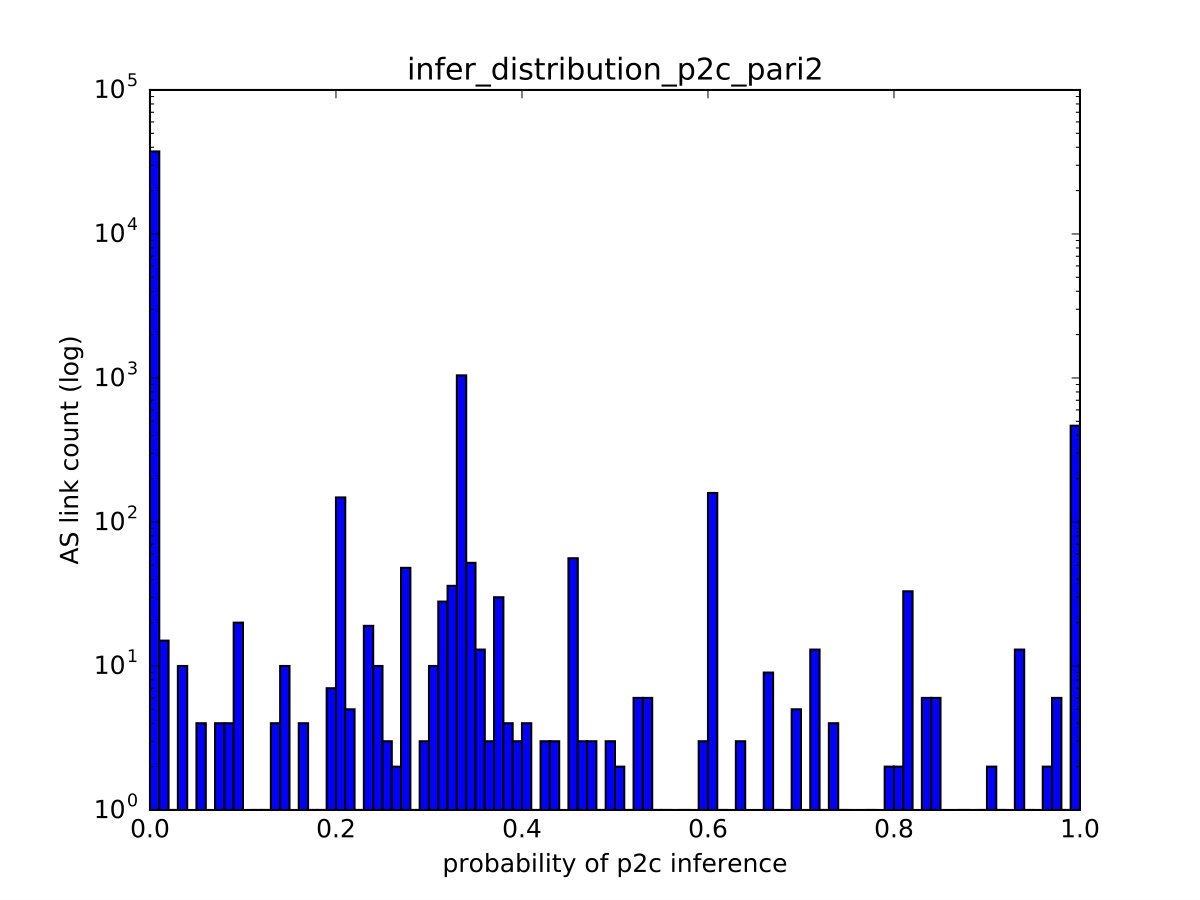 Figure 24
Figure 24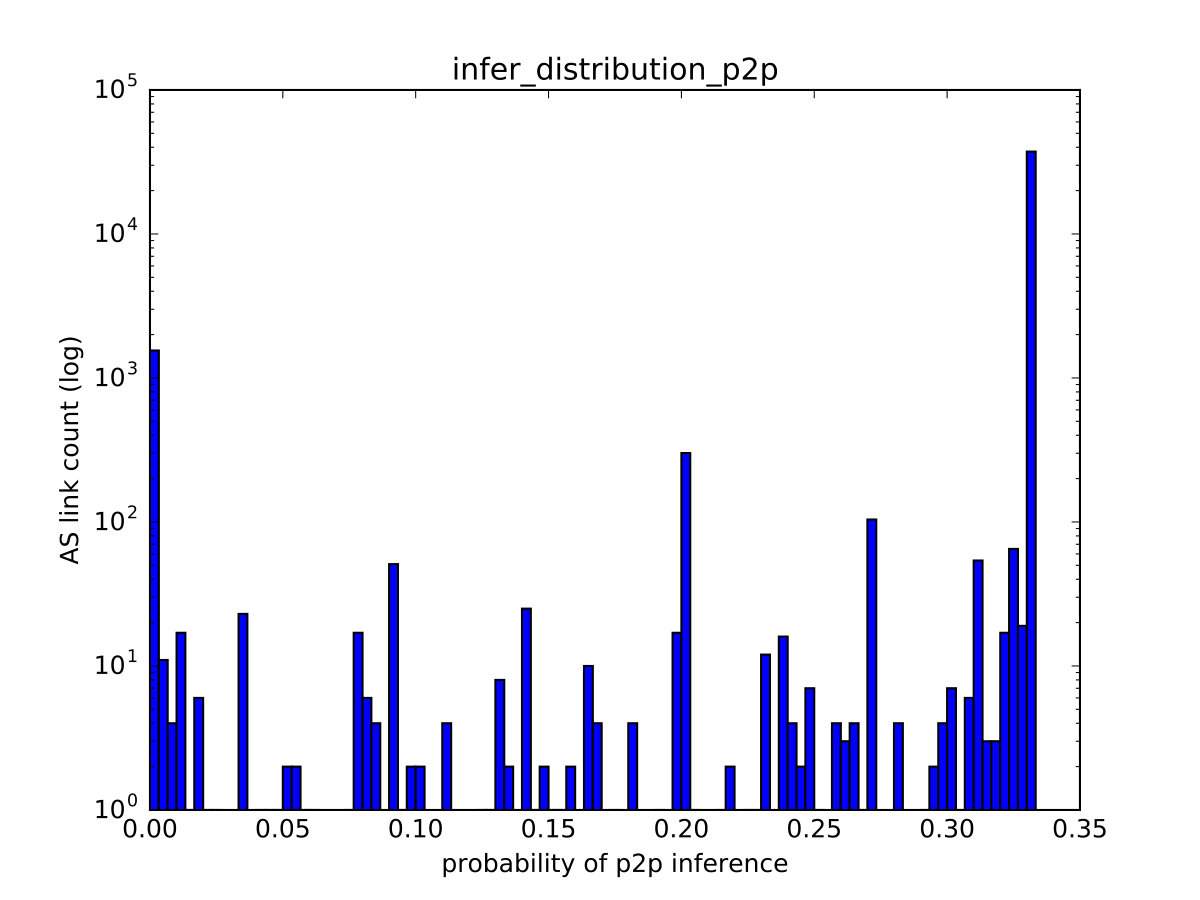 Figure 25
Figure 25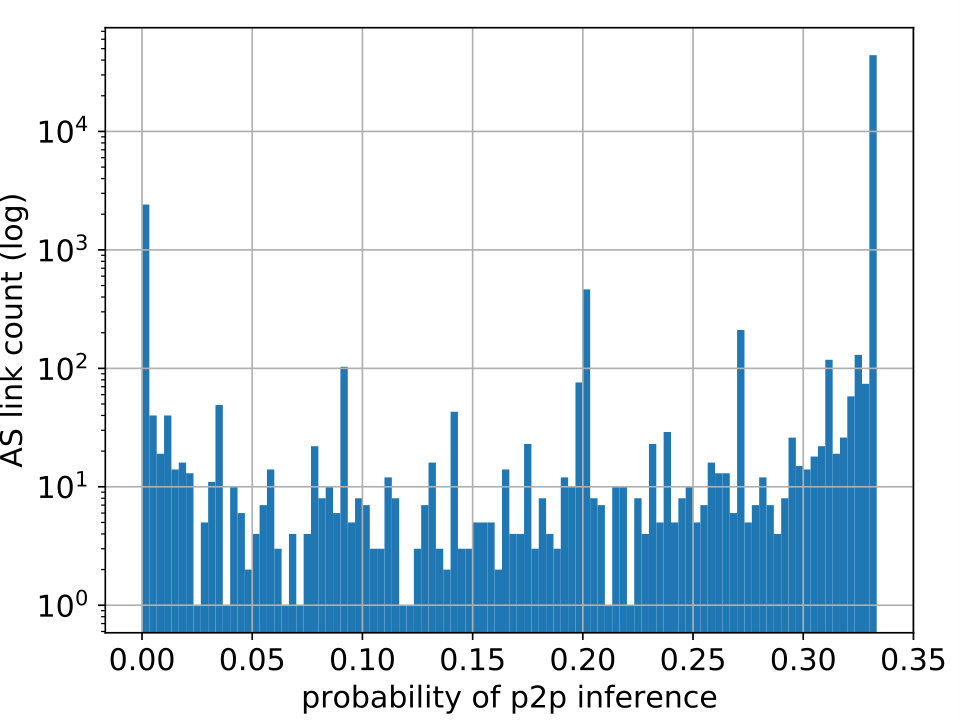 Figure 26
Figure 26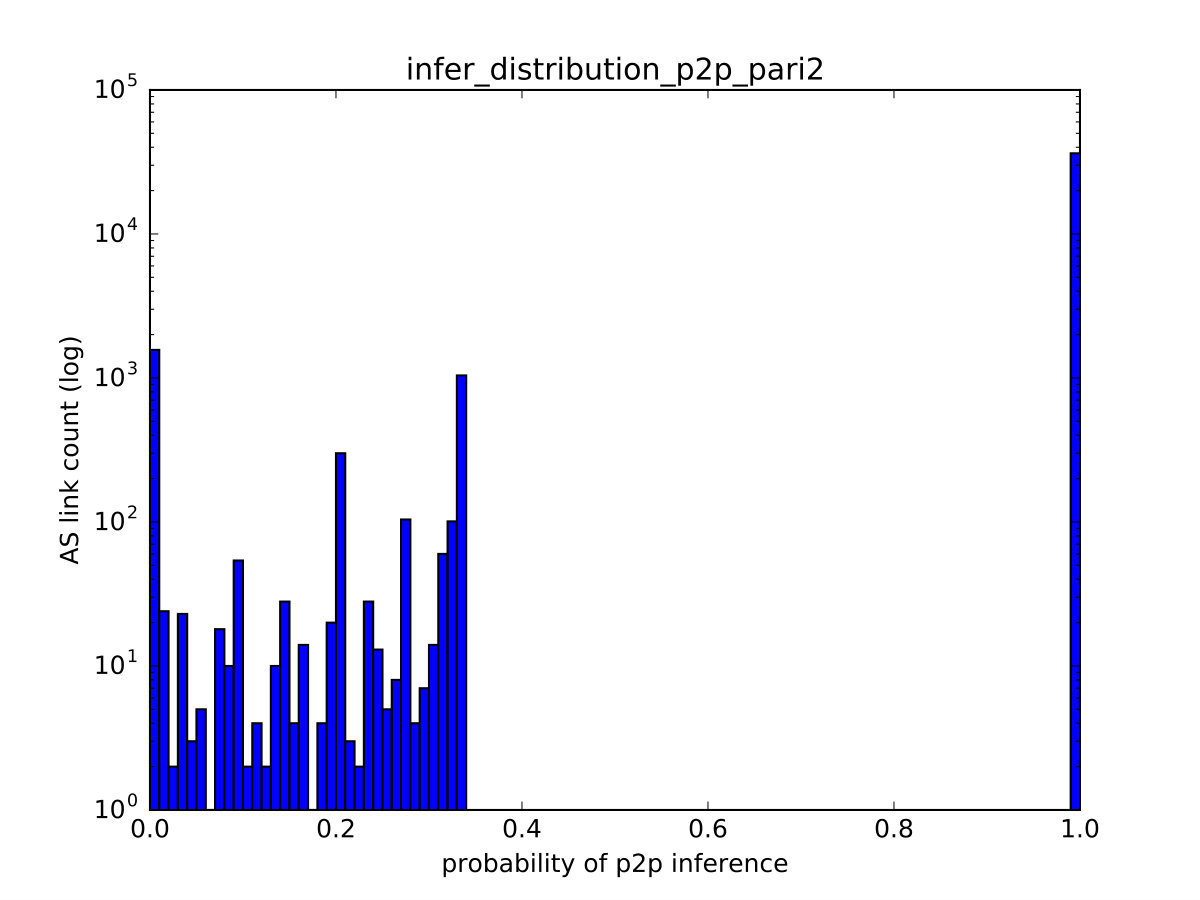 Figure 27
Figure 27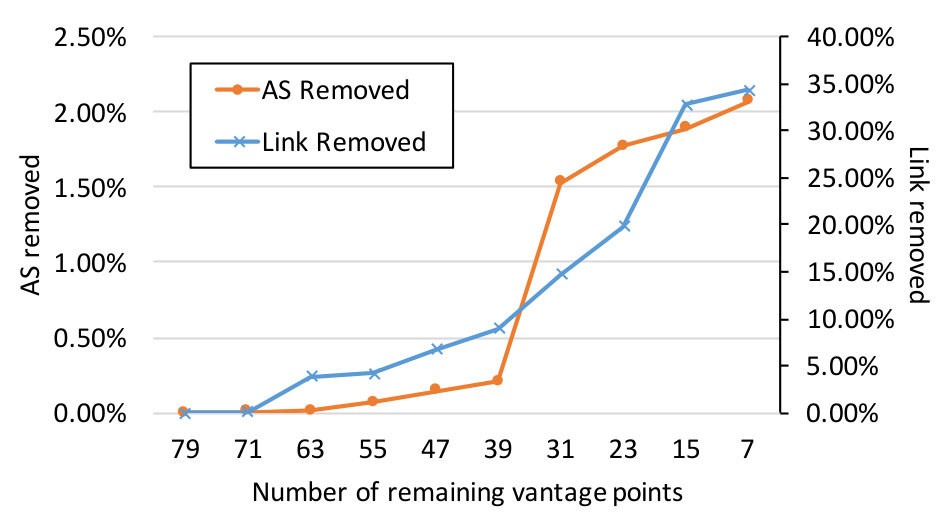 Figure 28
Figure 28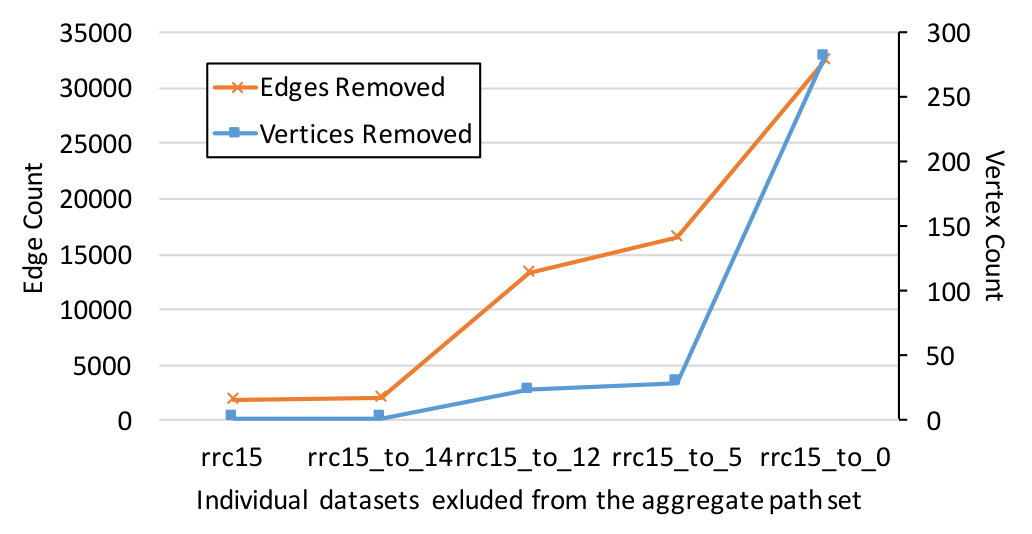 Figure 29
Figure 29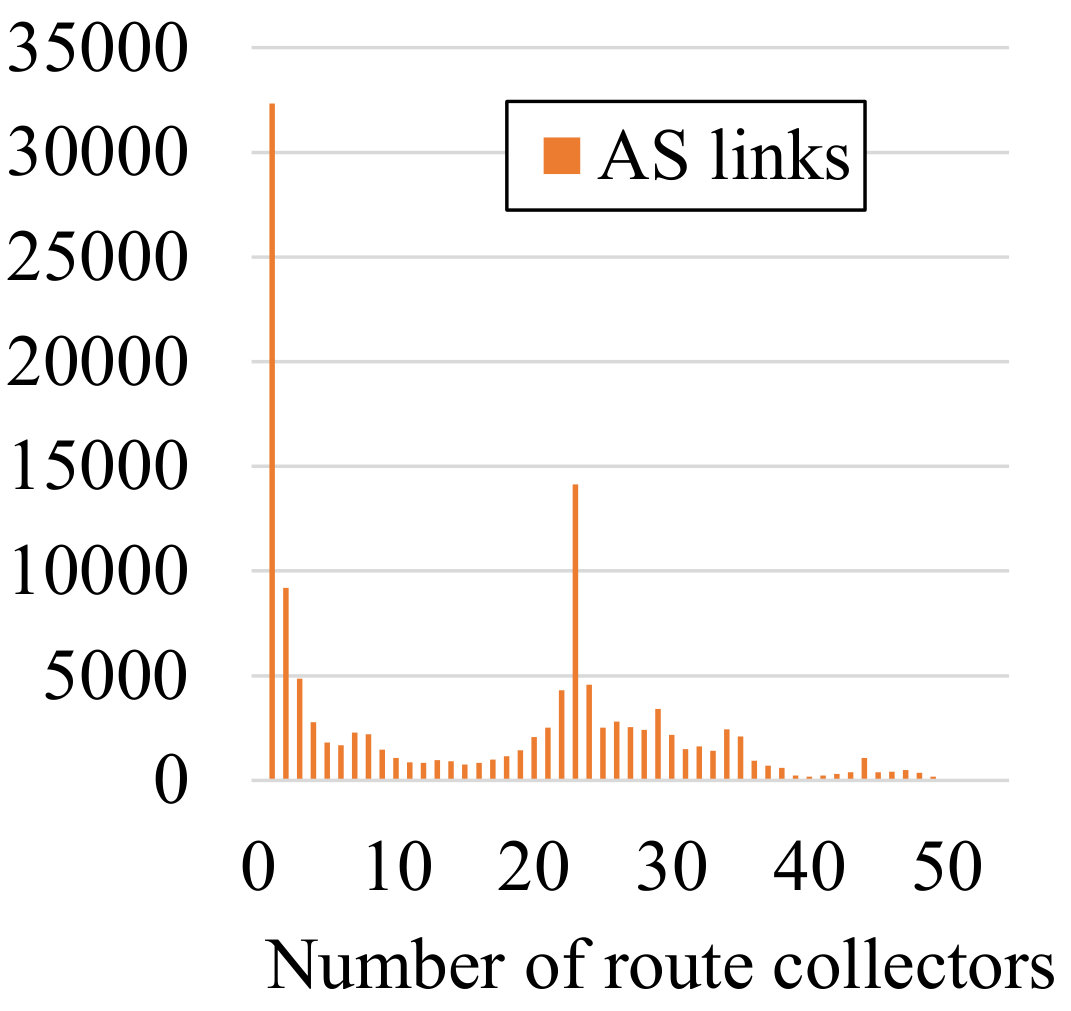 Figure 30
Figure 30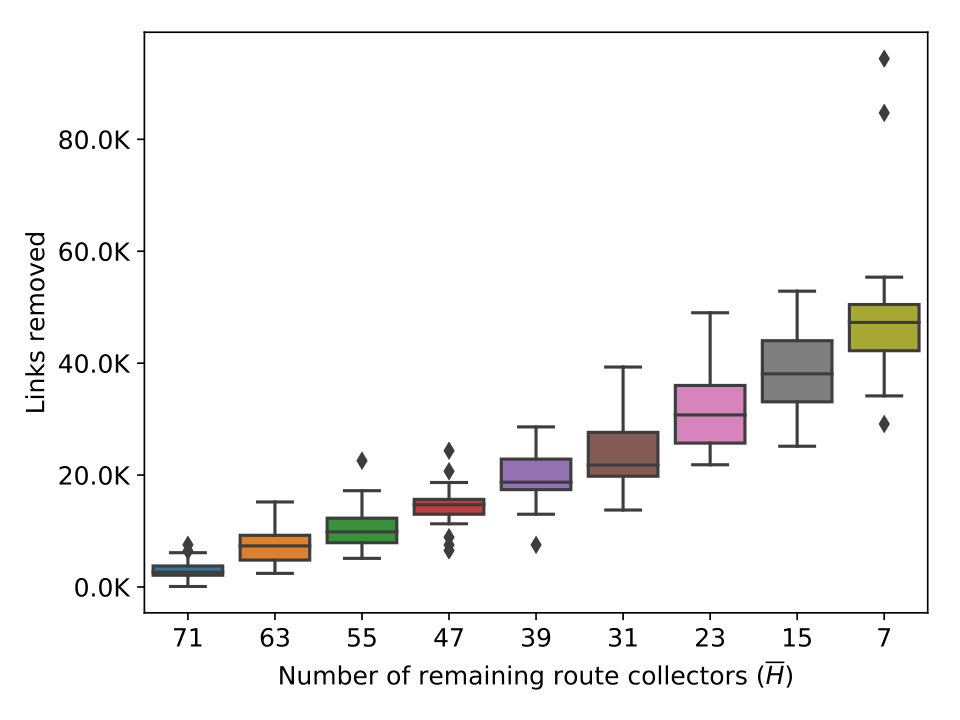 Figure 31
Figure 31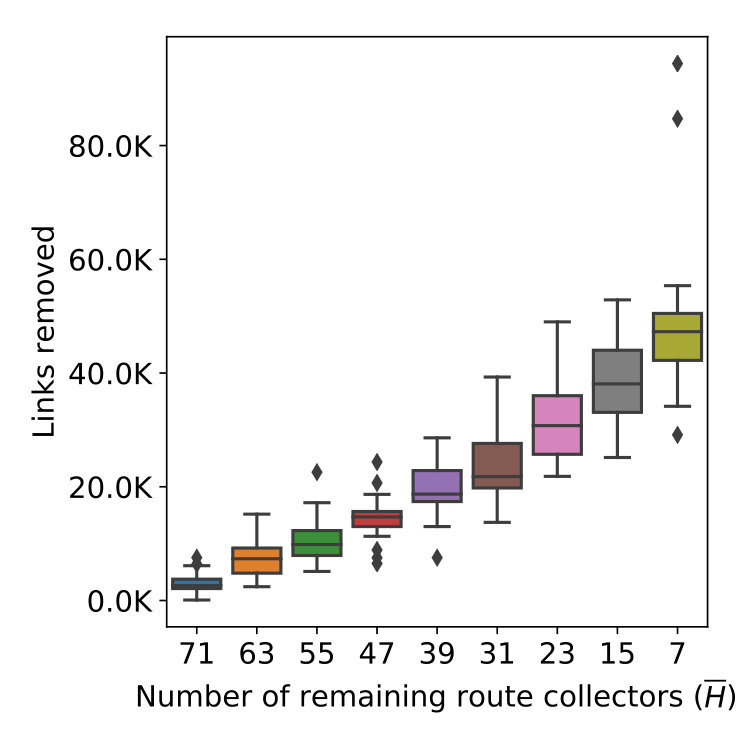 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34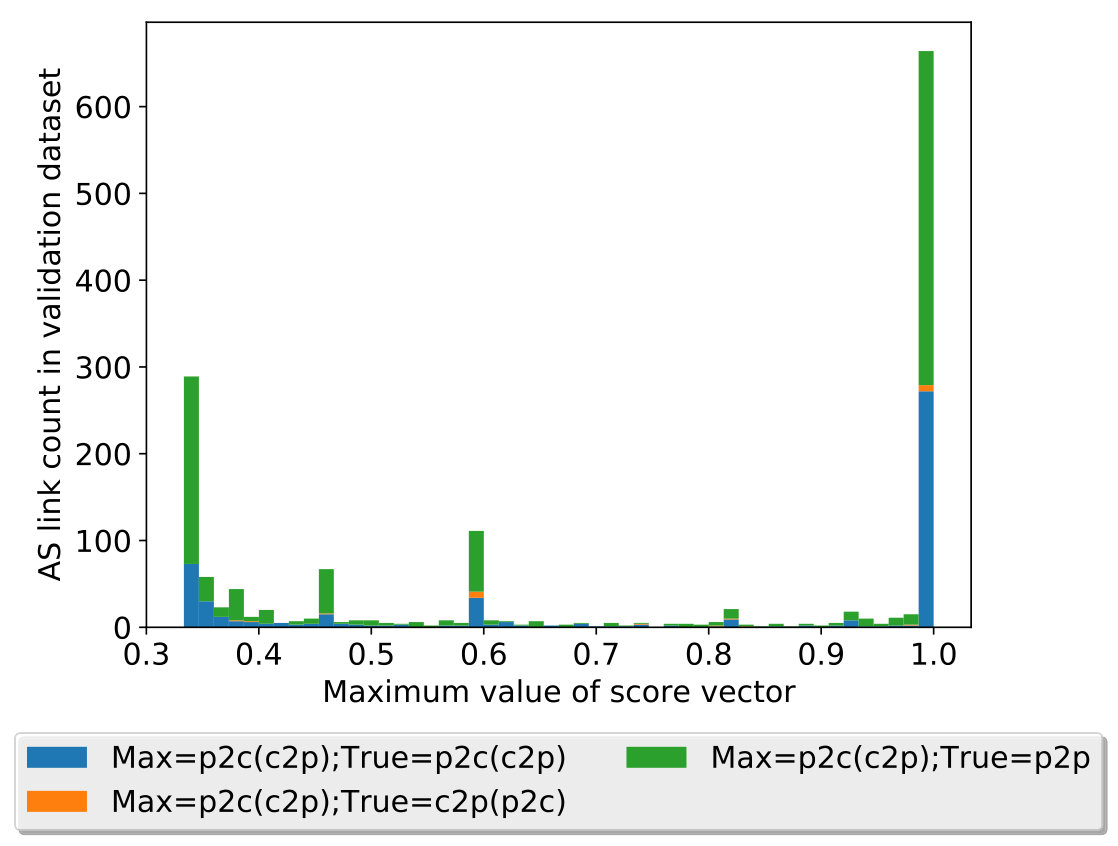 Figure 35
Figure 35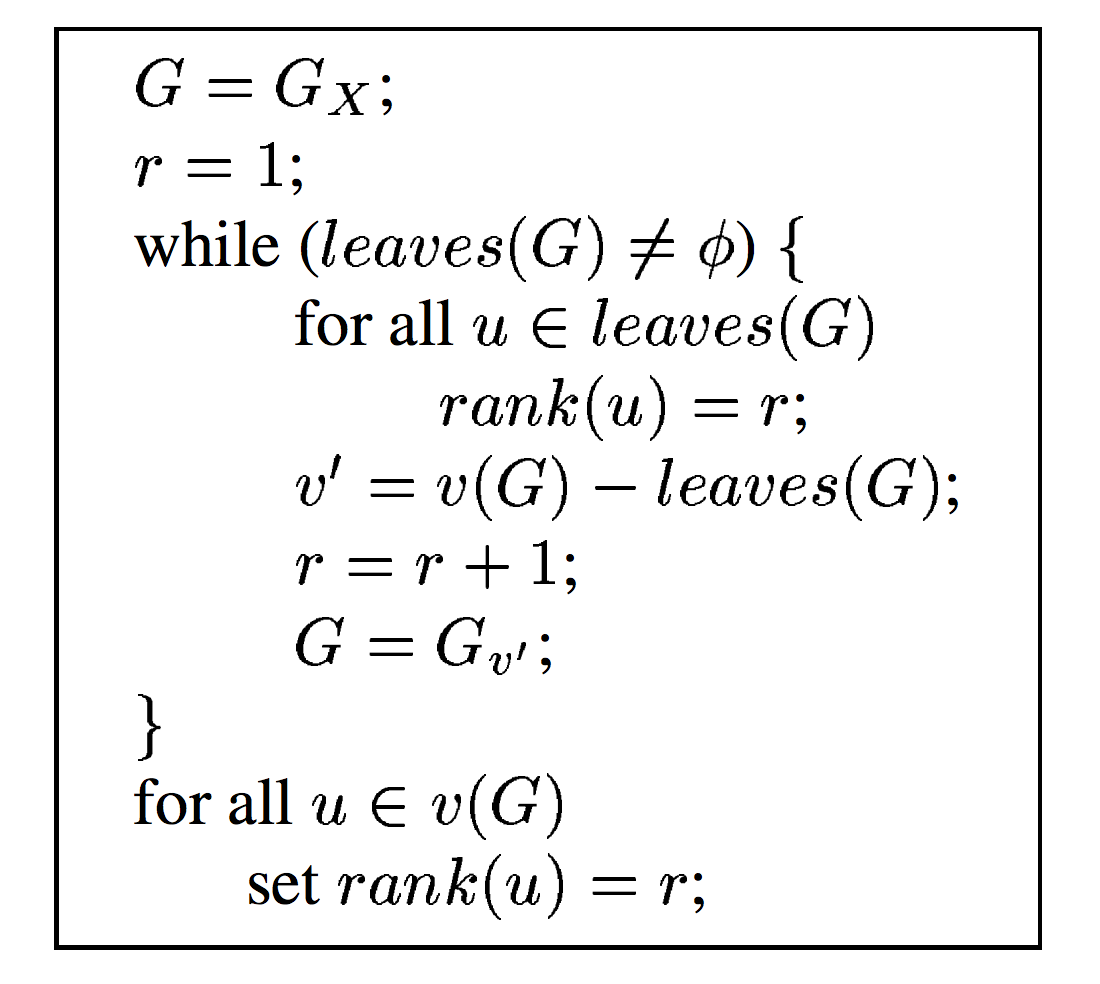 Figure 36
Figure 36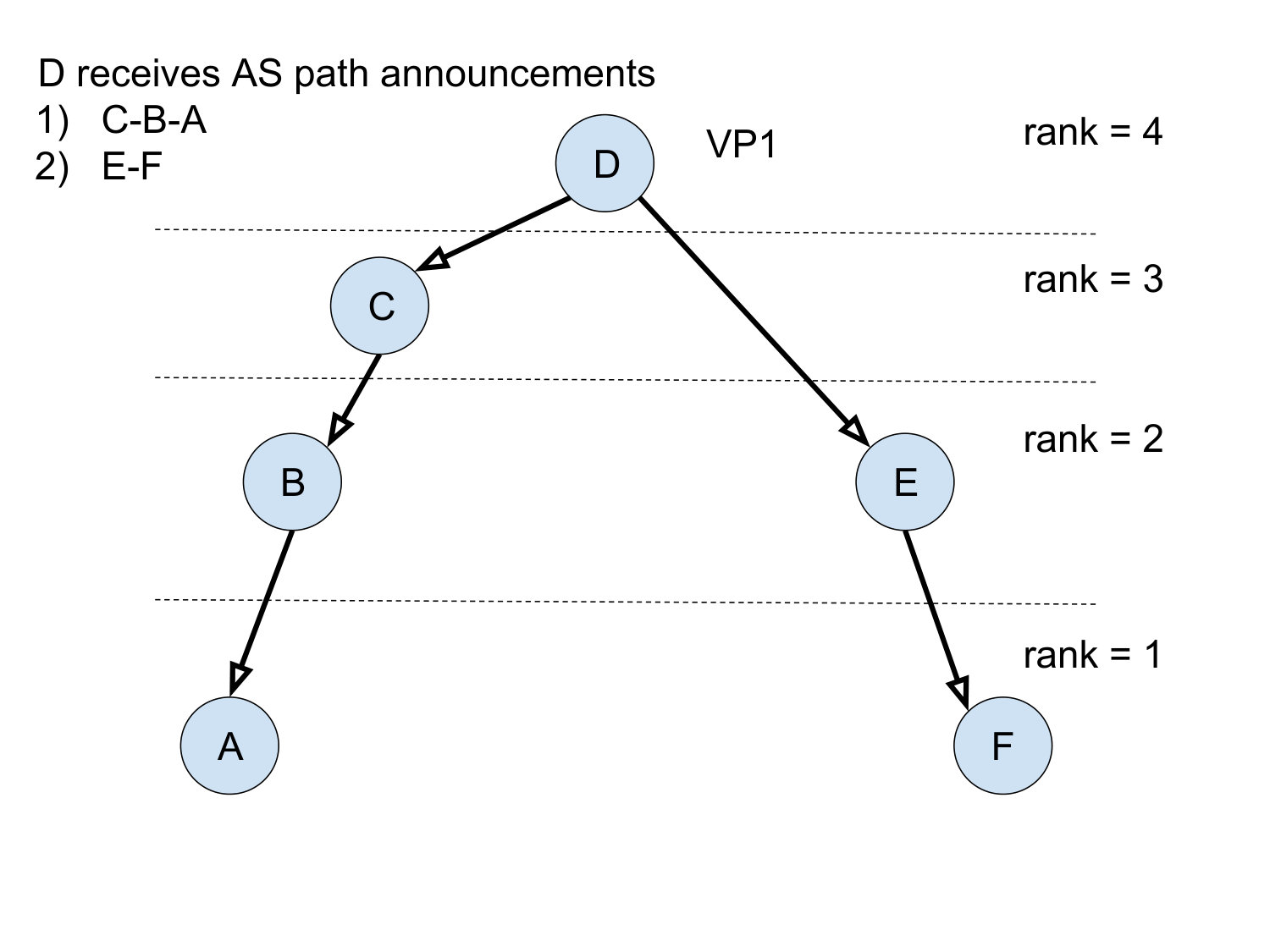 Figure 37
Figure 37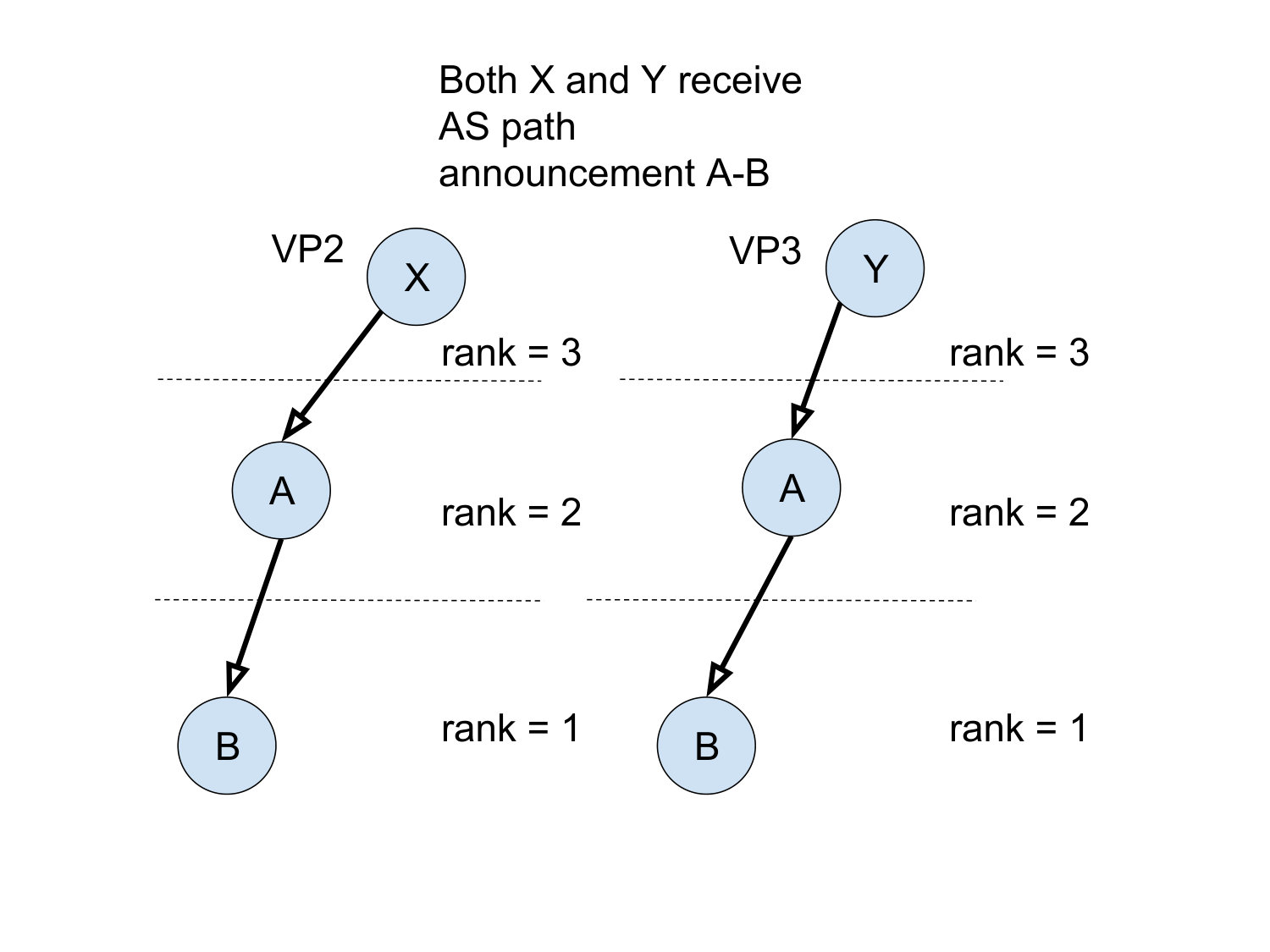 Figure 38
Figure 38 Figure 39
Figure 39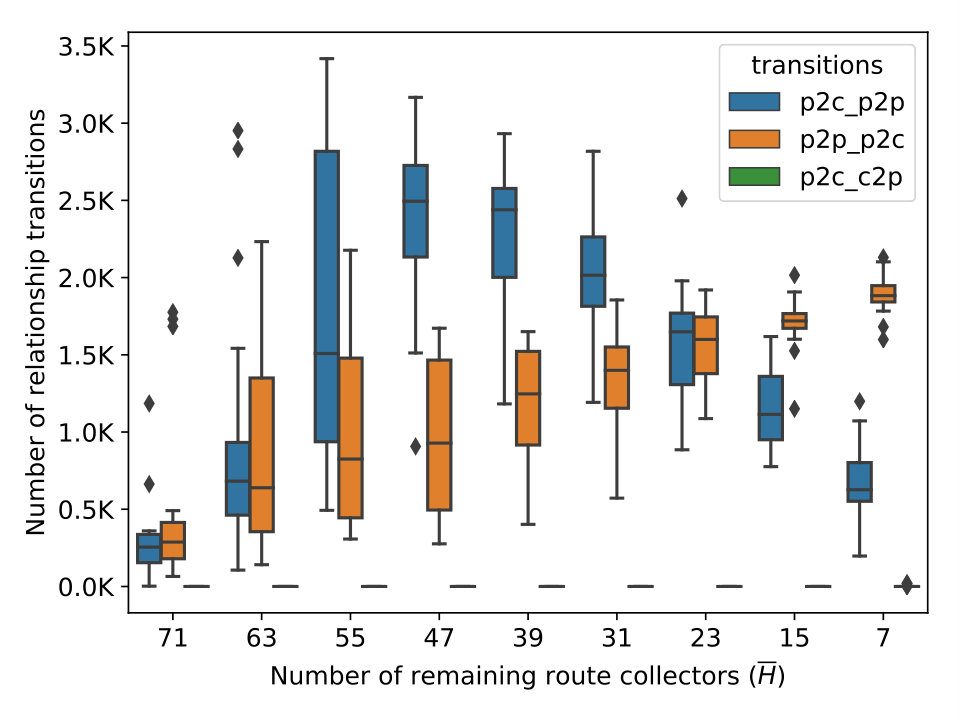 Figure 40
Figure 40| p2c | p2c | p2c | p2c/p2p/c2p |
| p2p | p2c | p2c | p2c/p2p/c2p |
| c2p | p2c | p2c | p2c/p2p/c2p |
| c2p | p2p | p2c | p2c/p2p/c2p |
| c2p | c2p | p2p | p2c |
| c2p | c2p | c2p | p2c |
| Inferred relationship | ||||
|---|---|---|---|---|
| True relationship | p2c | c2p | conflict | Total |
| p2c | 26339 | 26 | 64 | 26429 |
| p2p | 110 | 93 | 5 | 208 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Quality and Management · Anomaly Detection Techniques and Applications · Service-Oriented Architecture and Web Services
PARI: A Probabilistic Approach to AS Relationships Inference
Guoyao Feng
Carnegie Mellon University
,
Srinivasan Seshan
Carnegie Mellon University
and
Peter Steenkiste
Carnegie Mellon University
Abstract.
Over the last two decades, several algorithms have been proposed to infer the type of relationship between Autonomous Systems (ASes). While the recent works have achieved increasingly higher accuracy, there has not been a systematic study on the uncertainty of AS relationship inference. In this paper, we analyze the factors contributing to this uncertainty and introduce a new paradigm to explicitly model the uncertainty and reflect it in the inference result. We also present PARI, an exemplary algorithm implementing this paradigm, that leverages a novel technique to capture the interdependence of relationship inference across AS links.
1. Introduction
The Internet inter-domain routing topology consists of thousands of independent interconnected autonomous systems (AS). To route traffic in the Internet, these ASes connect to each other through the Border Gateway Protocol (BGP) and establish routing relationships, which are based on their private business agreements. Knowing these business relationships is essential to understanding how packets are routed on the network today and, therefore, critical to evaluating new protocol designs or network configurations. Unfortunately, these business agreements are typically kept private, which has motivated numerous past efforts (Gao, 2001; Xia and Gao, 2004; Subramanian et al., 2002; Di Battista et al., 2003; Dimitropoulos et al., 2007; Oliveira et al., 2010; Luckie et al., 2013) to infer the relationships based on observations of network routing. Past efforts typically classify the relationship between two ASes into one of the three major types: customer-to-provider (c2p) 111Inferring an AS link as c2p is equivalent to inferring the link as p2c., peer-to-peer (p2p), and sibling-to-sibling (s2s). While the accuracy of these inference algorithms has improved over time, we argue that inference algorithms inherently incorporate some form of uncertainty and error. In this paper, we argue that, unlike past work, explicitly incorporating uncertainty into reasoning about the AS relationships provides valuable benefits.
One source of the uncertainty in reasoning about AS relationships is that the fundamental guiding assumption adopted by the prior algorithms—the valley-free principle (Gao, 2001)—is by itself inadequate to deterministically infer the relationship for every link in the AS-level topology (Dimitropoulos et al., 2007). For instance, the principle can never infer a link as p2p and eliminate the possibility of it being p2c. As a result, past work must resort to additional assumptions and heuristics to classify links. Past efforts do consider the reliability of these heuristics “implicitly” by simply rank ordering them. This concept of relative uncertainty is never conveyed in the final output or used to holistically reason about the decision. In addition, the inference results depend on the coverage of AS paths received by the route collectors. For example, some algorithms (Luckie et al., 2013) rely on ASes’ transit/node degrees as a hint to determine the provider in a p2c relationship. However, newly deployed collectors may uncover more AS paths, causing ASes’ transit/node degrees and inferred relationships to change.
Motivated by the challenges above, we propose a novel framework that allows the algorithmic implementation to explicitly express and model uncertainty. Our framework features two key steps: principle-based and probabilistic inference. The principle-based inference step applies only dependable rules (principles) to make deterministic relationship inferences and ensures the inference results remain stable under varying coverage of AS paths. It takes a conservative strategy to trading off coverage in the number of links inferred for high accuracy. Then, for each undecided link, the probabilistic inference step outputs a vector of scores rather than a single relationship. This score represents our confidence in inferring the link as one of the possible relationships. Thus, our paradigm embraces uncertainty and makes it explicit when there is no strong evidence in favor of a particular type of relationship.
We have designed a concrete algorithm, PARI, that illustrates the value of this framework. PARI uses two principles for the principle-based step. The first principle leverages the observation that there exists a clique of well-known Tier-1 ASes interconnected by p2p links (Oliveira et al., 2010) and the second one is the valley-free principle. For probabilistic inference, we develop a novel technique to capture the interdependence between undecided links. For each link, it computes share, a metric that measures the number of valley-free inferences over the entire topology, under the condition that the link is inferred as one of the possible relationships. Then PARI uses the links’ shares as the features of a machine learning algorithm (logistic regression) to compute probability estimates as the score output of inference. It leverages a ground-truth data set to learn the model parameters.
Our evaluation results show that PARI’s principle-based inference achieves higher accuracy and is more stable than prior algorithms. Moreover, PARI’s probabilistic inference outperforms a naïve approach to expressing uncertainty. We also evaluate the efficacy of the share metric by comparing it against other metrics such as transit and node degrees as features for learning. We show that the share metric is not only effective by itself but also complementary to the transit and node degrees.
The contributions of our work are summarized as follows:
- (1)
We identify 4 sources of uncertainty in AS relationship and analyze their impact on the inference results. 2. (2)
We propose a novel framework to model inference uncertainty explicitly and reflect it in the results. 3. (3)
We propose PARI, an exemplary algorithm that implements this framework and leverages a novel technique to capture the interdependence between undecided links. Our evaluation indicates it achieves higher accuracy and stability compared to prior algorithms for deterministic inference and outperforms a naïve strategy to express uncertainty.
The paper is organized as follows. §2 describes the related works on AS relationship inference. In §3 we provide insights into the causes of uncertainty in relationship inference. §4 describes the new paradigm to explicitly reflect uncertainty in the inference output, followed by §5 that presents the PARI algorithm as an exemplary implementation of the paradigm. We evaluate the performance of PARI in §6. §7 concludes our work.
2. Related Work and Background
Inference Algorithms. The topic of AS relationship inference was started by Gao’s pioneering work (Gao, 2001) that classified an AS link into one of the three relationship types: p2c, p2p, and s2s. In a c2p relationship, the customer AS pays the provider AS for the traffic transmitted between them to obtain global reachability. In a p2p relationship, the two parties transmit traffic between their own networks and their customers networks with no payment involved. In the case of s2s relationship, the two ASes are owned by the same organization, and they transmit traffic between their providers/peers/siblings for free.
New inference algorithms (Subramanian et al., 2002; Di Battista et al., 2003; Dimitropoulos et al., 2007; Oliveira et al., 2010; Luckie et al., 2013) have been proposed in the follow-up works to achieve increasingly high accuracy. But uncertainty arises in relationship inference when they face problems such as the incomplete coverage of AS-level topology and the use of potentially unreliable heuristics. Unfortunately, none of the prior algorithms explicitly address it. Our work thus seeks to identify these contributing factors and develop a new paradigm that explicitly models the uncertainty and reflects it in the inference result.
We give a brief description of prior algorithms to provide the necessary context for the following sections. Gao’s algorithm assumes the valley-free property in AS paths to guide its inference. The valley-free property requires that an AS path starts with an uphill segment consisting of zero or more c2p or s2s links, followed by zero or one p2p links, and a downhill segment formed by zero or more p2c or s2s links. It also assumes a provider is usually larger than its customers and peers are of similar size in terms of node degree.
(Subramanian et al., 2002) formally defines the Type of Relationship (ToR) problem and presents a heuristic-based algorithm (MVP) that exploits partial views of the AS graph available from different vantage points. The ToR problem models relationship inference as an edge labeling problem on a graph derived from the AS paths, and asks for a labeling that maximizes the number of valley-free AS paths. (Di Battista et al., 2003) proves the speculation (Subramanian et al., 2002) that the ToR problem is indeed NP-complete in general. Their approach (DPP) involves mapping a simplified variant of the ToR problem to a 2SAT (Garey and Johnson, 1979) problem and is shown to be tractable if all AS paths follow the valley-free constraint.
The algorithm proposed in (Dimitropoulos et al., 2007) starts by inferring s2s relationships based on information from the IRR databases. Then it casts the task of c2p inference into a MAX2SAT problem that attempts to simultaneously maximize the number of valley-free paths and minimize the number of degree inversions (i.e., customer having a higher node degree than the provider). The last step infers p2p links using a heuristic based on (Di Battista et al., 2003) and (Gao, 2001).
The UCLA algorithm in (Oliveira et al., 2010) is designed based on the completeness of the AS-level topology observed by the public view. It obtains a clique of all Tier-1 ASes from external sources and infer as p2c the links following these ASes along the AS paths. The remaining links are inferred as p2p.
The ASRANK algorithm in (Luckie et al., 2013) does not strictly follow the valley-free constraint as the constraint’s underlying assumption about routing decision is not always valid (Roughan et al., 2011). Instead, it is replaced by the following assumptions: (1) there exists a peering clique of large transit providers at the top of the hierarchy; (2) a provider will announce customers’ routes to its providers; and (3) cycles of p2c links are not allowed. Their ground truth dataset covers 34.6% of the inferred relationships and shows ASRANK correctly infers 99.6% of known c2p relationships and 98.7% of known p2p relationships. Our goal is not to dramatically improve upon this measure of accuracy. Instead, it is to quantify the confidence that such systems have in their output decisions.
Data. We downloaded BGP data from three archives: PCH (House, 2017), RIS (Center, 2017), and Routeviews (of Oregon, 2017). PCH (Packet Clearing House) manages route collectors deployed on more than 100 IXPs around the world. It makes publicly available the daily routing table snapshots from these collectors. RIS (Routing Information Service), developed by RIPE NCC, also collects and stores Internet routing data from several locations around the globe. Routeviews started as a tool to obtain real-time information about the global routing system from the perspectives of several different backbones and locations around the Internet. It maintains a data archive of BGP RIBs and updates. Each collector manages multiple vantage points and receives their BGP data feeds.
The BGP dataset used by our experiments contained the AS paths from the daily routing table snapshots between April 1, 2012 and April 5, 2012. We chose this time range to match the timestamp of the ground truth dataset for evaluation, as we describe below. We combine AS paths from all collectors into the single aggregate path set, , which is then used as the input to the inference algorithms. We use to denote the set of all collectors. captures 79 route collectors with at least one valid AS route, over 128k AS links and more than 41k ASes.
We use the partial ground truth dataset released by (Luckie et al., 2013). It is derived from community attributes (Chandra et al., 1996) and RPSL (Alaettinoglu et al., 1999) from April 2012. It covers 16,248 p2p links and 31,886 p2c/c2p links.
We use the datasets above for the rest of the paper.
3. Uncertainty in AS Relationship Inference
In this section, we present 4 factors (§3.1-3.4) that make it impossible to deterministically infer a single relationship for certain links and describe how these factors can influence an algorithm’s output. We also provide some insights into possible strategies to mitigate their impact, paving the way for an uncertainty-aware solution. At the end we discuss the potential benefits of exposing inference uncertainty.
3.1. Dependence on Route Collectors’ Coverage
The ability to deploy route collectors can place limits on our visibility of the AS-level Internet topology. The incompleteness of the observable AS-level Internet topology has been studied by past research efforts. For example, (Oliveira et al., 2008, 2010) showed that single-period snapshots of public BGP datasets only reveal a small portion of the links connecting Tier-2 ASes; combining long period snapshots and historical data of BGP updates leads to significant improvement. Moreover, the public BGP data misses many peer links at Tier-2 and below, as a result of the valley-free property and the poor coverage of monitors at stub ASes. In this section, we analyze how these coverage limitations influence the results of inference algorithms. Specifically, §3.1.1 illustrates the effect through concrete examples drawn from prior algorithms: Gao’s, ASRANK, and MVP. §3.1.2 presents an empirical study using public BGP datasets.
Let us define the key terms used in the rest of the paper. The vantage points of a collector are identified by the set of first-hop ASes along the AS paths it receives. In Figure 1, vantage point is feeding BGP routing data (i.e., path ) to its route collector .
We quantify a route collector’s coverage as the number of links and vantage points it is able to observe222We choose not to measure by the number of unique paths because paths traversing the top of the hierarchy tend to share the same segments and contribute little new information in terms of coverage. For example, the same path announcement received by two vantage points constitute two unique paths even though the only difference is the ASN prepended by the vantage points.. We refer to the undirected graph formed by the set of AS paths from a set of vantage points as the Original AS topology whereas the one with additional vantage points as the Augmented AS topology. Given an AS link shared by both, an inference algorithm is deemed unstable if it infers different relationships under the two topologies, which implies inference uncertainty due to route collectors’ limited coverage.
3.1.1. Instability Causes
Algorithms can be unstable when paths from new vantage points becomes available as input, if they infer relationships based on measures that involve aggregates such as the total number of adjacent ASes.
We use Gao’s algorithm as an example to illustrate the problem. Gao’s algorithm starts by computing the node degree of each AS in the topology. Next, for each AS path, one of the ASes with the highest node degree is selected as the peak of the valley-free path. It then increments the c2p score of links preceding the peak and the p2c score of links following the peak. The third step infers links as p2c/c2p if their scores exceed a user-defined threshold. Finally, the algorithm revisits each AS path, filters out links that are impossible to have peering relationships, and assigns p2p relationship to links whose end points have similar node degrees.
To see how incomplete coverage affects the output of Gao’s algorithm, consider the AS path in the Original topology in Figure 1. Both and have a node degree of 2. Gao’s algorithm chooses one of the ASes with the highest node degree as the peak of the valley-free path; ASes on both sides of the peak are classified as either peers or customers. Without loss of generality we assume it selects as the peak of the AS path and is classified as either p2c or p2p. Now consider a new path in the Augmented topology, , which leads to ’s node degree to increase from 2 to 4. is now chosen as the peak in the first AS path and the link changes from p2c/p2p to c2p.
Note that the addition of vantage points also impacts other algorithms in similar ways. For example, transit degree, used by the ASRANK algorithm, and vantage-point rank, used by the MVP algorithm, are both affected by the number of vantage points.
3.1.2. Empirical Study of Stability
We present an empirical study to evaluate the stability of Gao’s, MVP, UCLA and ASRANK algorithms.
Route Collector Coverage. We start by profiling the coverage of the AS topology by route collectors. The histogram in Figure 2(a) groups the AS links by the number of collectors that are able to observe these links. We note that a significant portion of the links are seen by no more than 2 collectors. They are likely connected to stub ASes near the edge of the AS topology. The spike at 23 can be attributed to the high variance in the number of AS links observed by individual collectors. In particular, 53 collectors observe fewer than 30,000 links while 22 collectors observe over 50,000 links. A similar distribution is found in Figure 2(b) which captures the collectors’ coverage of vantage points and a minor spike takes place at 21.
The variation in route collectors’ coverage has a key implication. While individual collectors might cover some links or vantage points in common, each of them still contributes complementary information to form a more complete view of the AS topology. Moreover, topological information is lost if a route collector is not deployed or becomes unavailable because the majority of links and vantage points are only seen by a single collector.
Varying Topology Coverage. We evaluate the stability of relationship inference by progressively excluding route collectors from the set of all collectors, . This approach allows us to study the behavior of inference algorithms when existing collectors become unavailable or new collectors are introduced. Suppose denotes a set of indices of excluded collectors, the remaining collectors is therefore . For example, if , includes all collectors but “rrc15”. We refer to this step as shrinking. We bootstrap by generating a small random sample from the set of all collectors and gradually grows its by adding more random samples from the remaining collectors. In total, we randomly produce 20 series of for the results below.
A collector never returns to once it is moved to . We measure the stability of inference algorithms as the number of relationship transitions, or the number of links whose inference result changes due to shrinking.
Stability Results. Figure 3(a) and 3(b) show the increasing trend in the number of links and ASes removed as we progressively shrink . As declines from 79 to 7 through multiple steps, the average loss of ASes rises from 0 to 2301 (5.6%). However, the number of links experiences a dramatic drop, losing coverage of more than 38% (on average) of the links observed by . It is also important to realize that the number of links removed is not proportional to the number of excluded datasets because link coverage by different route collectors may overlap, especially at the top of the network hierarchy.
Figure 3(c) to 3(f) show the number of relationship transitions by the four algorithms as a result of shrinking . At each step of shrinking , we measure the number of links whose inferred relationship is different under and . For instance, the curves labeled ‘p2p_p2c’ represent links whose inferred relationship changes from p2p to p2c with respect to . In the case of UCLA (3(e)), the curves of ‘p2c_p2p’ is trending upwards as more collectors are excluded and eventually reaches a mean of 7.8k transitions. In contrast, the curves of ’p2c_c2p’ and ’p2p_p2c’ stay mostly flat. Judging from the rightmost column, one is tempted to think that an average of 8k total transitions do not seem substantial with respect to the 128k links in . But we note that it only requires the loss of coverage over 38% of the links and the transitions affect 10% of the remaining links, as shown in Figure 3(a). We observe a similar surge in the ‘p2c_p2p’ curve of ASRANK (3(f)), with a smaller magnitude. Its ‘p2p_p2c’ curve experiences a gradual increase as shrinks from 79 to 23 and witnesses a minor drop as the collector count decreases from 23 to 15. We also notice a small number of transitions from p2c to c2p. In contrast, the ’p2c_p2p’ curve of Gao’s (3(c)) follows the shrinking size of and trends downward. What is surprising, however, is the large number of transitions at , caused by a minor drop in the number of route collectors. MVP (3(d)) seems more stable than the rest as measured by the number of transitions. The results support our speculation that these algorithms are unstable.
The observations illustrate the level of stability for different algorithms. While experimental results (Luckie et al., 2013) show the best-performing algorithms such as ASRANK and UCLA achieve high precision and recall () in inference, they are sensitive to the number of route collectors available. In addition, the level of sensitivity may vary depending on the algorithm.
3.2. Uncertainty in p2p Relationship Inference
It is hard to unambiguously infer p2p relationships because commonly used techniques, such as the valley-free constraint, are incapable of determining that a link must be p2p and completely eliminate the possibility of it being p2c (Di Battista et al., 2003; Dimitropoulos et al., 2007). Consider a valid path with at least one AS link. If all links are c2p/p2c, there must exist a top provider adjacent to one or two customers under the valley-free constraint. The path remains valid if we classify a p2c link incident to the top provider as p2p. Conversely, given a valid path with a p2p link, replacing the p2p relationship with p2c or c2p will still leave the path valid. In general, this makes it more difficult to infer p2p than p2c relationships and the inference algorithms tend to leave the inference of p2p relationships as the last step after all p2c inferences are made.
Figure 4 is an example illustrating the challenge of inferring p2p relationship with certainty. Consider a path . In the first scenario, suppose that UCLA, or any algorithm that prioritizes p2c/c2p inference over p2p (Gao, 2001; Dimitropoulos et al., 2007; Luckie et al., 2013), is able to infer as p2c and as c2p. Algorithms typically infer the undecided link as p2p. But it could in fact be inferred as any one of the three relationships without violating the valley-free constraint. However, algorithms pick a single relationship, despite the uncertainty inherent to the scenario. Now consider another pathological scenario where the algorithm is only able to infer as p2c, leaving two consecutive links undecided. Inferring both and as p2p violates the valley-free constraint. Traditional algorithms aim to maintain the valley-free property and assign a single relationship, so they must speculate whether there exists a p2p link on this path and if yes, which of and should be inferred as p2p.
Prior algorithms have developed techniques to achieve high accuracy in p2p inference, but they are not as effective in handling such scenarios. For example, a common approach is to accurately infer as many p2c/c2p relationships as possible and the remaining links are then inferred as p2p333We focus our discussion on c2p/p2p/p2c because s2s relationships are uncommon.. The accuracy of p2p inference now hinges on the performance of p2c/c2p inference. However, the lack of evidence to support p2c/c2p inference is not a guarantee that a link is p2p, as the above example shows. As another example, UCLA assumes that a provider wants to announce paths from its customers to its providers and the monitors at Tier-1 ASes should be able to reveal all the downstream p2c relationships over time (Oliveira et al., 2010). A link hidden from all the Tier-1 ASes is less likely to be p2c, and thus should be inferred as p2p. Again, this rule only reduces rather than eliminates the possibility of incorrect p2p inference. The growing number of region-specific p2c relationships observable only below the provider AS (Luckie et al., 2013) makes the technique even less reliable. We conclude that we need a new strategy to express this inherent uncertainty in the inference results.
3.3. Algorithmic Paradigms
Broadly speaking, prior algorithms follow one of the two design paradigms: greedy (Gao, 2001; Xia and Gao, 2004; Subramanian et al., 2002; Oliveira et al., 2010; Luckie et al., 2013) and optimization-based (Di Battista et al., 2003; Dimitropoulos et al., 2007). An algorithm’s design paradigm is a deciding factor in its ability to identify the most probable relationship inference from multiple valid candidates. Using a collection of rules and heuristics, a greedy algorithm typically computes relationship inference over AS links in a sequential order. For a given link, its inference result might depend on another link’s result computed in a previous step. For instance, suppose there is an AS path and the greedy algorithm infers as p2c in a previous step. It can apply the valley-free constraint to infer as p2c next.
A greedy approach to AS relationship inference has a critical limitation: it does not support backtracking and branching. When making inference on an AS link, the algorithm must commit to one of the feasible relationships as governed by the rules and heuristics. If a mistake is made, a greedy algorithm cannot recover from it and the error can impact the inference results for the remaining links. Returning to the example above, we suppose that the algorithm has already inferred as p2c and as p2p, before it encounters the path . Clearly the path now violates the valley-free constraint. When the p2p inference was made on , however, it was possible that both p2p and p2c were feasible according to the valley-free constraint. Then a heuristic was used to break the tie and gave precedence to p2p over p2c. The violation could have been avoided if the algorithm had chosen p2c instead. Unfortunately, greedy algorithms lacks the capability to maintain the uncertainty of relationship inference across steps.
In contrast to the greedy approach, an optimization-based algorithm explores all feasible inferences simultaneously for all links. It usually encodes the heuristics and rules as constraints and optimize for a certain objective. For example, DPP (Di Battista et al., 2003) uses boolean variables to represent the orientation of links (i.e., p2c v.s. c2p) and a collection of 2-literal disjunctive clauses to express the valley-free constraint. The objective is set to minimize the number of unsatisfiable clauses, or equivalently, the number of invalid paths. But (Dimitropoulos et al., 2007) identifies the discrepancy that maximizing the number of valley-free paths does not necessarily translate to higher inference accuracy. In general, the objective of optimization-based algorithms is not fully aligned with the ideal objective to maximize the accuracy because the true relationships are not known and it is difficult to quantify the difference between the two objectives. It is this discrepancy in the two objectives that affects our level of confidence in the inference output and leads to uncertainty.
The main takeaway is that a new paradigm should be able to overcome the limitations of greedy and optimization-based algorithms.
3.4. Unreliable Assumptions and Rules
In addition to the valley-free constraint, inference algorithms must rely on additional assumptions to derive rules and heuristics. These assumptions vary in terms of reliability but prior algorithms fail to differentiate between them in terms of confidence level when making inferences.
For example, (Oliveira et al., 2010) and (Luckie et al., 2013) assume there exists a clique of Tier-1 providers interconnected through p2p links. It is easy to obtain a list of Tier-1 providers and the rule derived from the assumption achieves near-perfect inference accuracy when validated using a partial ground truth dataset (Luckie et al., 2013). However, these algorithms also use assumptions that depend on a predefined parameter or “magic constant”. For example, Gao’s algorithm compares the ratio of node degrees against a constant to determine the provider and customer roles for adjacent ASes. Links that are categorized using this parameter are not marked any differently than those using near-perfect rules. As another example, (Luckie et al., 2013) assumes that vantage points reporting routes to less than 2.5% of ASes are not announcing provider routes to the route collector. It is unclear why the % threshold is appropriate and how a different value can affect the accuracy. We believe unreliable assumptions can introduce uncertainty into the inference process and the labels generated by the corresponding rules should convey the uncertainty of the results.
3.5. Potential Benefits of Exposing Inference Uncertainty
The results of AS relationship inference have supported numerous research works (Huang et al., 2007; Shah and Zaman, 2011; Mahajan et al., 2002; Calder et al., 2013; Luckie et al., 2014). Exposing the uncertainty in inference opens up the opportunity to improve the robustness of their findings. We use two prior works to illustrate the potential benefits. (Huang et al., 2007) used AS relationships to evaluate the impact of peer-assisted video-on-demand (VoD) on ISPs. The authors showed that ISP-friendly peer-assisted VoD achieved 50% savings compared to solutions with no P2P. They also stated that the inference by CAIDA had been conservative because ISPs were unwilling to share their sibling and peering relationships. It is possible that quantifying the uncertainty in inference helps develop a bound rather than a single value on the estimated savings. As another example, (Mahajan et al., 2002) relied on AS relationships to understand BGP misconfigurations. The export policies, derived from the relationships, enabled the authors to identify export misconfigurations. The authors acknowledged that incorrect inference could lead to failure in identifying misconfigurations or mistake legitimate configurations as erroneous. Based on the uncertainty in inference, it might be possible to estimate the uncertainty in identifying misconfigurations.
4. Towards Probabilistic AS Relationship Inference
As we demonstrate in Section §3, uncertainty is inherent in AS relationship inference but largely ignored by prior algorithms. To bridge this gap, we propose a new framework that explicitly reflects uncertainty in the inference results. An exemplary algorithm is presented in §5.
We start by deriving the design requirements based on the insights from §3. First, when it comes to single-label (deterministic) inference, it should not rely on heuristics whose output may vary depending on the amount of information available, such as heuristics based on node or transit degrees ((§3.1)). This allows us to minimize the uncertainty caused by an incomplete view of the AS topology. Second, it should expose uncertainty by associating more than one type of relationship with an AS link if necessary 444The Gao’s algorithm may infer multiple relationships on one link but it seems to be an artifact of not enforcing mutual exclusion in the algorithm design. In fact, the total number of inferences exceed the number of links in the topology in the evaluation results (Gao, 2001). (§3.2). Third, it must differentiate unreliable assumptions and heuristics from the more trustworthy rules, such as the valley-free constraint (§3.4). Fourth, it should mitigate the limitations of greedy and optimization-based paradigms (§3.3).
Our framework consists of two major steps. After extracting a set of AS paths from the dataset, we identify potentially erroneous AS paths and remove or sanitize them. The remaining AS paths, collectively forming the AS topology, are then passed to the principle-based inference step where we attempt to apply principles, such as the valley-free constraint and other reliable rules, to deterministically infer one of the three possible relationships for each link in the topology (Step ①). If the principles manage to eliminate all but one relationship, the inference is complete for this link; otherwise, we leave it to the next step. Note that Step ① is intentionally conservative and incorporates rules such that it commits to an inferred relationship only if the confidence level is very high. Based on potentially less reliable assumptions and heuristics, the final step (Step ②) performs probabilistic inference and computes a tag, that represents our confidence in the inference, for each remaining link. The tag can be numerical or categorical. The separation of principle-based and probabilistic inference allows us to expose the level of uncertainty associated with each link. One might argue that our framework also suffers from drawbacks of the greedy algorithms since misclassifications made in Step ① can impact the tags calculated in Step ②. But the conservative selection of rules in Step ① prioritizes accuracy over coverage and thus minimize such mistakes. We defer describing how our framework also addresses limitations of the optimization-based approach to the concrete implementation in §5 where we exploit a partial ground truth dataset and formulate the objective to maximize inference accuracy directly.
4.1. A Flexible Framework
The proposed framework does not prescribe the specific rules to be used in Step ① and ②. We demonstrate the framework’s flexibility by illustrating the very diverse choices that can be made in the two steps.
Principle selection for Step ①. To attain high certainty, Step ① could for example rely on the valley-free constraint. It can also incorporate external knowledge such as the set of all Tier-1 ASes.
Heuristic selection for Step ②. Step ② is the major enabler of probabilistic inference, allowing not only a wide variety of heuristics but also different tag formats to express the confidence in the inference output.
First, the output of Step ② can be a categorical tag indicating “high” or “low” confidence. For example, building on prior work, recall that in Figure 4, and can be inferred as any one of the three relationships without violating the valley-free constraint. Now suppose we further observe that link is not seen in any AS path announced to or ’s providers. It is an indication that is more likely to be p2p. However, the heuristic exploits a “negative observation”; it is grounded in the lack of paths that the vantage points expect to observe and we have seen impact of incomplete coverage in §3.1. Thus, labeled links can receive a “high” or “low” confidence tag depending on whether they were classified based on the valley free constraint or based on negative observation heuristic. Optionally, we can also document the reason for the low confidence tag, would be labeled as (p2p, “low”, “negative observation”). We note that (Oliveira et al., 2010; Luckie et al., 2013) explore similar “negative observations”.
As another example, the tag could be numeric, e.g., a scalar. Recall from §3.4 that Gao’s algorithm compares the ratio of node degrees against a constant to determine the provider and customer roles for adjacent ASes. The intuition is that the extent to which the ratio deviates from 1 is an indication of how likely that one of the ASes is transiting traffic for the other. Thus, we may simply use this ratio as the numerical tag along with the c2p/p2c label. As for links inferred as p2p, we may set the tag value to be inversely proportional to the difference in transit/node degree of the end points.
We can also introduce richer tags and new heuristics. Consider a heuristic that outputs as a tag a vector of scores, where each score represents our confidence in inferring the link as one of the three relationships. For example, it may assign equal score values to all feasible relationships according to the valley-free constraint. We provide an example in Figure 5 where the AS topology is formed by two paths. Suppose that and are inferred as p2p and p2c respectively in Step ①. At this point, the other 2 links have two or more feasible relationships under the chosen principles. In this example, we use the aforementioned heuristic that assigns equal score values to all feasible relationships. Observe that if we infer as any one of c2p/p2p/p2c, there always exists an inference of such that all paths are valley-free. Thus, the heuristic assigns to all elements in the score vector of .
5. Probabilistic AS Relationship Inference Algorithm
In this section, we describe the Probabilistic AS Relationship Inference (PARI) algorithm that leverages our framework from §4. §5.1 to §5.3 describe in detail the implementation of Step ① and ② of the framework.
5.1. Preprocessing AS Paths
Similar to the filtering and sanitizing step described in (Luckie et al., 2013), PARI starts by preprocessing the set of AS paths. It first removes AS paths with loops and paths where two Tier-1 ASes are separated by one or more non-Tier-1 ASes. Both of these path types are signs of path poisoning usage. It also removes paths with unassigned ASes. For each path, if it identifies an AS used to operate IXP route servers, PARI removes it and establishes a link between its preceding and following neighbors.
5.2. Principle-based Inference
PARI’s principle-based inference adopts as principles two rules commonly used by the recent inference algorithms (Oliveira et al., 2010; Luckie et al., 2013). For the first principle, PARI leverages the observations that there exists a clique of Tier-1 ASes interconnected with p2p links at the top of the hierarchy and that the AS members of the clique are known. We can either identify the clique through preprocessing (Luckie et al., 2013) or obtain the list of top-tiers from public sources (Oliveira et al., 2010). The second principle imposes the constraint that the relationships assigned to links along an AS path must be valley-free.
After extracting a collection of valid AS paths from the dataset, PARI infers the links connecting a pair of Tier-1 ASes as p2p based on the first principle. Then, PARI infers a set of p2c links, with high confidence, following the second principle. The inference of p2c links has two phases. Phase @slowromancapi@ exploits the knowledge of Tier-1 ASes. Given an AS path , PARI searches for the last Tier-1 AS starting from . Suppose is the last Tier-1 AS along the path, we can deduce that is of type p2p or p2c because a Tier-1 AS has no provider. Moreover, the type of every link on the path segment must be p2c by the valley-free principle. PARI applies this procedure on each path and ends up with a set of p2c inferences. An idea similar to Phase @slowromancapi@ of p2c inference was proposed in (Oliveira et al., 2010). However, PARI takes it one step further and introduces a Phase @slowromancapii@ of p2c inference. It takes advantage of the outputs from Phase @slowromancapi@ and infers as many p2c links as possible by repeatedly iterating through the list of paths. Within each iteration, it applies the valley-free principle based on links that have been inferred in the previous iterations and makes p2c inference on undecided links accordingly. For example, consider another AS path where none of the nodes is Tier-1 AS. While Phase @slowromancapi@ cannot infer p2c links on directly, one of its links, , is inferred as p2c after is processed. The first iteration of Phase @slowromancapii@ is able to apply the valley-free principle and infer as p2c. The succeeding iterations can now leverage the inference result on . Phase @slowromancapii@ terminates when no new p2c links are produced in the last iteration.
Conflicts might arise from the procedure above. Specifically, a link might be inferred as p2c in one path but c2p in another path. The problem can be attributed to the observation of s2s links, where both end points can export their own routes and the routes of their customers, providers or peers (Gao, 2001). A study (Dimitropoulos et al., 2007) has shown that 31 out of 3724 verified relationships are s2s according to its survey data. PARI labels these links as “conflict” and leaves final classification of the link as either p2c or c2p to the probabilistic inference step.
The principle-based inference step is summarized in Algorithm 1.
5.3. Probabilistic Inference
In the last step, PARI performs probabilistic inference over the remaining undecided links. It starts with a procedure to compute a share vector, denoted by , for every undecided link. The vector measures the number of valley-free inferences over the entire topology, under the condition that the link is inferred as one of the relationships. Then we refine the procedure with a relaxation step to handle the case where no valley-free inference can be found. Finally, PARI outputs the score as the conditional probability that the type of relationship of a link is given its share vector . We choose Multinomial Logistic Regression (MLR)and leverage a partial ground truth dataset for learning the probabilistic model.
5.3.1. Computing Shares
By the valley-free principle, the inferred types of relationship of undecided links found within the same AS path are interdependent. For example, Figure 6 shows an AS topology with links and inferred as p2c by principle-based inference while the other links are undecided. In Path @slowromancapi@, if we infer any one of the undecided links as p2p, the other two links must be inferred as p2c or c2p; otherwise, it violates the valley-free principle.
To capture the interdependence imposed by valley-free principle, we introduce a graph called interdependence graph (). Each undecided AS link corresponds to a node in . For each pair of nodes in the topology, we connect them with an arc iff there exists at least one AS path that contains both AS links. For example, the two paths in Figure 6 leads to four nodes , , , and . An arc is created for a pair of nodes if they appear in the same path. Note that the interdependence relationship can span across different AS paths if they share the same undecided links. In the example, is the common link shared by Path @slowromancapi@&@slowromancapii@.
Now we associate each node in with three Boolean variables , , and and use them to denote c2p, p2p, and p2c relationships respectively. The valley-free principle can be expressed as a Boolean formula over these variables. Returning to the example in Figure 6, we can use to express the following constraint: if node is inferred as p2p, node must be p2c. By solving for a satisfying assignment of the formula, we can identify a valid valley-free inference over the undecided links. Moreover, the valley-free principle is typically insufficient to produce a unique satisfying assignment. For instance, if we assume that Path @slowromancapi@&@slowromancapii@ in Figure 6 are the only paths containing the four undecided links, then these nodes form a single connected component in and their inference are independent from other nodes in . Each satisfying assignment matches one of the valley-free inferences in Table 1.
We use to label the connected components in the and to denote the number of unique valley-free inferences over given that the predicate evaluates to true. The subscript is dropped when no predicate is specified. Returning to Figure 6, the number of valley-free inferences is and the number of valley-free inferences given that is inferred as c2p is . We express the share associated with and relationship as a normalized count
[TABLE]
where and is the connected component in which resides. In the running example, the share associated with and c2p is . The computation of can be reduced to a propositional model counting problem (Biere et al., 2009), or #SAT.
The definition above makes two assumptions. First, it enforces that the correct inference for the connected component is valley-free. It is justified because valley-free violation is uncommon (Giotsas and Zhou, 2012) and the valley-free principle is fundamental. We will describe how PARI handles the case where no valley-free inference can be found in §5.3.2. Second, it gives all possible valley-free inferences the same weight. We believe it is a reasonable assumption as it simplifies the computation of shares and leave part of the complexity of deciding the weights to the final step—computing probability estimates.
5.3.2. Relaxation for Unsatisfiable Connected Components
Some connected components might have no valley-free inference due to two reasons. First, (Giotsas and Zhou, 2012) identified valley paths using BGP Community data. If contains nodes representing AS links from these paths, the algorithm is unable to find valley-free inference. Second, incorrect inferences are made during the principle-based inference step and propagate to the probabilistic inference step.
Inspired by the idea of maximizing the number of satisfiable clauses (Dimitropoulos et al., 2007; Di Battista et al., 2003), we propose a relaxation method to mitigate these problems. As mentioned in §5.3, the valley-free constraint imposed over can be expressed as a Boolean formula. Our approach first leverages a MAX-SAT solver to determine an assignment maximizing the number of clauses that can be made true. For each clause that expresses an interdependence between AS links but is unsatisfied by the assignment, we remove the corresponding arc from . At the end of this process, is broken into one or more connected components. The same process is applied to each resulting component recursively if it remains unsatisfiable. Instead of ignoring the unsatisfied clauses, as in (Dimitropoulos et al., 2007; Di Battista et al., 2003), our method removes the interdependence that leads to these clauses.
Once an arc is removed from a component, the interdependence between two AS links, which must have appeared in the same AS path, is lost. The goal is to preserve as many interdependence relationships as possible. It is challenging to incorporate the existence of valley paths in PARI as the valley-free principle is fundamental in our approach to deriving the shares.
Algorithm 2 summarizes the procedure of computing share vectors in §5.3.1 and §5.3.2. It begins by identifying a set of connected components, , from the interdependence graph. Then for each component it calculates the number of valley-free inferences . If the value is 0, meaning the associated Boolean formula is unsatisfiable, it dismantles it into a set of smaller, satisfiable connected components, and merge them back to the group. Now that all connected components in the set are satisfiable, the nested for loop (line 7) proceeds to calculate the share vectors for each link in every connected component, which is parallelizable because no dependency spans across multiple components. Our evaluation on real datasets show that the while loop (line 2) terminates within two iterations and only a small percentage of links are removed due to splitting the connected components.
5.3.3. Computing Probability Estimates
Finally, we apply MLR to model the conditional probability using the elements of share vector as features. We decide to use MLR because it outputs not only the predicted type of relationship, but also the probability estimates. The ground truth dataset is partitioned into the training and test sets. MLR assumes that for some function parameterized by . Intuitively, it aims to estimate , the value of that is most consistent with the true relationship from the training set. The test set will be used to evaluate the model’s performance. Now consider an unlabeled link beyond the partial ground truth dataset. Based on its score vector , the trained model outputs to estimate the probability that its type of relationship is .
Importantly, MLR assumes that the relationship of undecided links are independent; but this is not true because the valley-free constraint induces interdependence across them. Markov Logic Network (Richardson and Domingos, 2006) (MLN) allows us to explicitly express the valley-free constraint using first-order logic. But our experience with an MLN inference engine (i.e., Tuffy (Niu et al., 2011)), indicates that it faces scalability issues when applied to the AS-level Internet topology. Therefore, we consider the share vectors as a reasonable compromise and leaves the search of a more scalable MLN-based solution as future work.
6. PARI Evaluation
In this section, we evaluate the performance of PARI. First, we show the results of the preprocessing step and introduce the set of tools used for the implementation. Then, we present the evaluation results for Step ① and ②. The details of the BGP data and the partial ground truth data are described in §2.
We rely on public BGP datasets in this evaluation. PARI’s preprocessing step extracts 7,153,208 out of 13,482,724 unique AS paths from these datasets. The result is a topology of 41,127 ASes and 130,076 links 555The topology after preprocessing has more links than the topology formed by all route collectors from in §2 because PARI introduces new links between the peering participants at the IXPs when the ASes that are serving as route servers are removed from AS paths..
In PARI’s probabilistic inference, we use sharpSAT (THURLEY, 2006) for counting the number of valid assignments over each connected component and Open-WBO (Martins et al., 2014) to determine the maximum number of satisfiable clauses for unsatisfiable components.
6.1. Principle-based Inference Results
We evaluate the principle-based inference step in terms of accuracy and stability. First, we show that PARI achieves higher accuracy than prior algorithms when it infers a single relationship on an AS link. We then turn to stability evaluation and analyze how the principle-based inference step helps address the issue in §3.1.
6.1.1. Accuracy
A set of 22 Tier-1 ASes is retrieved from (tier-one, 2017)666For consistency, we verify that they match the Tier-1 ASes identified in (Luckie et al., 2013), the source of the ground truth dataset.. PARI infers 151 p2p links across them, among which 131 are labeled as p2p in the ground truth dataset. One Tier-1 p2p link is not present in any of the paths in the input, so it cannot be inferred by PARI. Therefore, PARI correctly infers all validated p2p links in the clique of Tier-1 ASes.
The principle-based inference step infers 78,689 c2p/p2c links and 383 s2s links, among which 26,637 links are found in the ground truth dataset. Its confusion matrix is shown in Table 2. Observe that PARI correctly infers 26,339 out of 26,389 validated p2c links but it misclassifies 26 p2c links as c2p. 64 p2c links are inferred as both p2c and c2p. As described in §5.2, they represent a very small group of links experiencing conflicting inference results; each of them appears in multiple AS paths and applying the principles does not lead to the same relationship across all paths. The principle-based inference step does not infer p2p links, but it misclassifies a total of 208 p2p links as p2c, c2p, or conflict.
The accuracy of the principle-based inference step is 98.9%. Over the same set of validated links, ASRANK and UCLA achieve accuracies of 96.9% and 96.3%, respectively. Note that they are consistent with the overall performance of ASRANK and UCLA when applied to all validated links in the topology (97% and 95.5%). It means the subset of links are not deliberately chosen to favor PARI. To conclude, the principle-based step prioritizes reliability over coverage, achieving higher accuracy than ASRANK and UCLA on a subset of links.
6.1.2. Stability
The principle-based inference step not only attains higher accuracy than UCLA and ASRANK, but also features greater stability when faced with dwindling visibility over the AS topology. The upper plot of Figure 7 compares the number of p2c inferences made by UCLA, ASRANK and PARI when (the set of active route collectors) is . PARI infers more p2c (c2p) links than UCLA but fewer links than ASRANK. As mentioned in §5.2, the principle-based inference step starts by inferring p2c links that follow the p2p links connecting two Tier-1 ASes. Once it gathers a set of p2c links, it repeatedly scans the AS paths to expand the link set based on inferences made in the prior iterations. It is this iterative process that allows PARI to infer more p2c links than UCLA, without compromising accuracy. We believe ASRANK infers more p2c links than PARI because it incorporates a larger pool of rules, some of which are less reliable than the ones chosen by PARI.
The lower plot of Figure 7 depicts the number of p2c_c2p transitions as drops from 79 to 7, following the procedure presented in Figure 3. We focus on p2c_c2p transitions because the principle-based inference step only infers p2p relationship for links connecting Tier-1 ASes. Observe that PARI experiences many few transitions in comparison to UCLA and ASRANK, exhibiting stronger stability. We also evaluate PARI *, a variant of PARI that omits the iterative p2c inference process. Surprisingly, the transitions can be further reduced to 0 at the expense of a minor drop in the number of p2c inferences. PARI’s advantage can be attributed to the decision to always categorize links with conflicting inferences as anomalies (i.e., links inferred as different types of relationship on multiple AS paths) instead of committing to one of them.
6.2. Probabilistic Inference Results
Experiments in this section only involve links that remain unclassified after PARI’s principle-based inference step. We identify the subset of these links that are labeled by the ground truth dataset and further divide this subset into training (70%) and test (30%) sets. For training, we use the MLR implementation (LogisticRegressionCV) from scikit-learn (Pedregosa et al., 2011), with cross-validation and L2 regularization to lessen the amount of overfitting. We report the performance of probabilistic inference by evaluating the probability estimates computed by the trained model over the test set. Unless stated otherwise, the training and test error rates, measured by cross-entropy loss, are within 5% difference.
In order to compare the outputs of probabilistic inference and the deterministic algorithms, we convert every probability distribution into a single-relationship assignment. Specifically, we designate the type of relationship with the maximum probability as the single-relationship output of probabilistic inference. For example, consider the distribution where the elements are interpreted as the probability that the relationship is c2p, p2c, and p2p. The single-relationship output is p2p. It follows that conventional metrics such as accuracy becomes applicable. To evaluate an algorithm’s performance, we measure the cross-entropy between the true and inferred probability distributions. The true distribution is obtained by applying 1-of- encoding (Bishop, 2006) to the single-relationship assignment. For example, if a link is assigned p2p, we can associate it with the distribution .
Below, we examine PARI’s probabilistic inference in terms of its accuracy of single-relationship inference, how well its final output probabilities reflect confidence and whether its share vectors are better than other heuristics for estimation of probabilities.
6.2.1. Single-relationship Inference Accuracy
For single-relationship inference, PARI’s probabilistic inference is comparable to the state-of-the-art algorithms. PARI achieves an accuracy of 93% which is slightly lower than UCLA (94%) and ASRANK (96%) but much higher than Gao’s (65%). Note that we present the accuracy of single-relationship inference for completeness. The two key metrics to evaluate probabilistic inference are presented next.
6.2.2. Probability Estimate Accuracy
One of PARI’s advantages over prior algorithms is its ability to effectively express a varying level of confidence in the inference output that is consistent with the ground-truth data. We illustrate it through the correlation between the relationship with the maximum probability estimate () and the true relationship (), of links in the test set. For links with (shown in Figure 8(a)), we observe that the number of matches tend to dominate that of mismatches, indicating low uncertainty when the probability of p2p is high. In particular, in the rightmost bar (at 1.0), the number of matches at that point (hatched bar) is nearly two orders of magnitude higher than that of mismatches (red bar). In addition, For links with or , we recognize a similar trend in Figure 8(b) but the dominance of matches is less substantial.
6.2.3. Efficacy of Share Vectors
The share vectors are not the only heuristic that can be used to compute probability estimates; however, we believe that share vectors are effective compared to the alternatives. PARI’s key strength is that it opens the exploration of such algorithm designs. To illustrate the efficacy of share vectors, we consider three alternative for comparison: Naïve, Degrees and Hybrid. For any given link, the Naïve heuristic always outputs the relative frequency distribution of the true labels. For example, the probability of p2p is set to 0.92 if 92% of the links from the input have p2p as the true label. The Degrees heuristic is a variant of PARI’s probabilistic inference step that replaces the link’s share vector with the node/transit degrees of its endpoints as the link’s feature. The last heuristic, Hybrid, includes both share vectors and node/transit degrees as features.
Figure 9 measures the average cross-entropy between the true and inferred probability distributions for the above four heuristics, over 5 random splits of training and test sets. We examine the Naïve heuristic as a baseline for comparison. We note that all variants of PARI achieve lower average cross-entropy than Naïve. Degrees outperforms PARI with share vectors, showing that node/transit degrees is a useful feature. Hybrid combines share vectors and node/transit degrees, two complementary features, and it outperforms both PARI with share vectors and Degrees. We believe Hybrid’s advantage can be attributed to share vectors’ ability to encapsulate the interdependence across neighbor links as imposed by the valley-free constraint, which cannot be easily captured by the local properties such as node/transit degrees.
7. Conclusion
In this paper, we identify several causes of uncertainty in AS relationship inference and demonstrate why the problem deserves more attention by the research community. We propose a novel framework to inferring AS relationships that explicitly models the uncertainty and reflect it in inference output. We propose an exemplary algorithm (PARI) that implements this design paradigm and leverages a novel technique to capture the interdependence between undecided links. Our evaluation indicates it achieves higher accuracy and stability compared to prior algorithms for deterministic inference and outperforms a naïve strategy to express uncertainty.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Alaettinoglu et al . (1999) Cengiz Alaettinoglu, Curtis Villamizar, Elise Gerich, David Kessens, David Meyer, Tony Bates, Daniel Karrenberg, and Marten Terpstra. 1999. Routing policy specification language (RPSL) . Technical Report.
- 3Biere et al . (2009) Armin Biere, Marijn Heule, and Hans van Maaren. 2009. Handbook of satisfiability . Vol. 185. IOS press.
- 4Bishop (2006) Christopher M. Bishop. 2006. Pattern Recognition and Machine Learning (Information Science and Statistics) . Springer-Verlag, Berlin, Heidelberg.
- 5Calder et al . (2013) Matt Calder, Xun Fan, Zi Hu, Ethan Katz-Bassett, John Heidemann, and Ramesh Govindan. 2013. Mapping the expansion of Google’s serving infrastructure. In Proceedings of the 2013 conference on Internet measurement conference . ACM, 313–326.
- 6Center (2017) RIPE Network Coordination Center. 2017. Routing Information Service Raw Data. https://www.ripe.net/analyse/internet-measurements/routing-information-service-ris/ris-raw-data . [Online; accessed 12-October-2017].
- 7Chandra et al . (1996) R Chandra, P Traina, and T Li. 1996. BGP communities attribute . Technical Report.
- 8Di Battista et al . (2003) Giuseppe Di Battista, Maurizio Patrignani, and Maurizio Pizzonia. 2003. Computing the types of the relationships between autonomous systems. In INFOCOM 2003. Twenty-Second Annual Joint Conference of the IEEE Computer and Communications. IEEE Societies , Vol. 1. IEEE, 156–165.