TL;DR
This paper introduces a deep learning framework for vehicle re-identification that produces compact, discriminative features by combining variational feature learning with LSTM-based viewpoint relationship modeling, outperforming existing methods.
Contribution
It proposes a novel variational representation learning approach combined with LSTM to efficiently encode multi-view vehicle images into low-dimensional, highly discriminative features.
Findings
Feature dimension reduced to 256 without loss of accuracy
Achieved higher Top-1 and Top-5 retrieval accuracies than state-of-the-art methods
Effective multi-view relationship modeling with LSTM enhances re-identification performance
Abstract
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as 256, experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays…
Click any figure to enlarge with its caption.
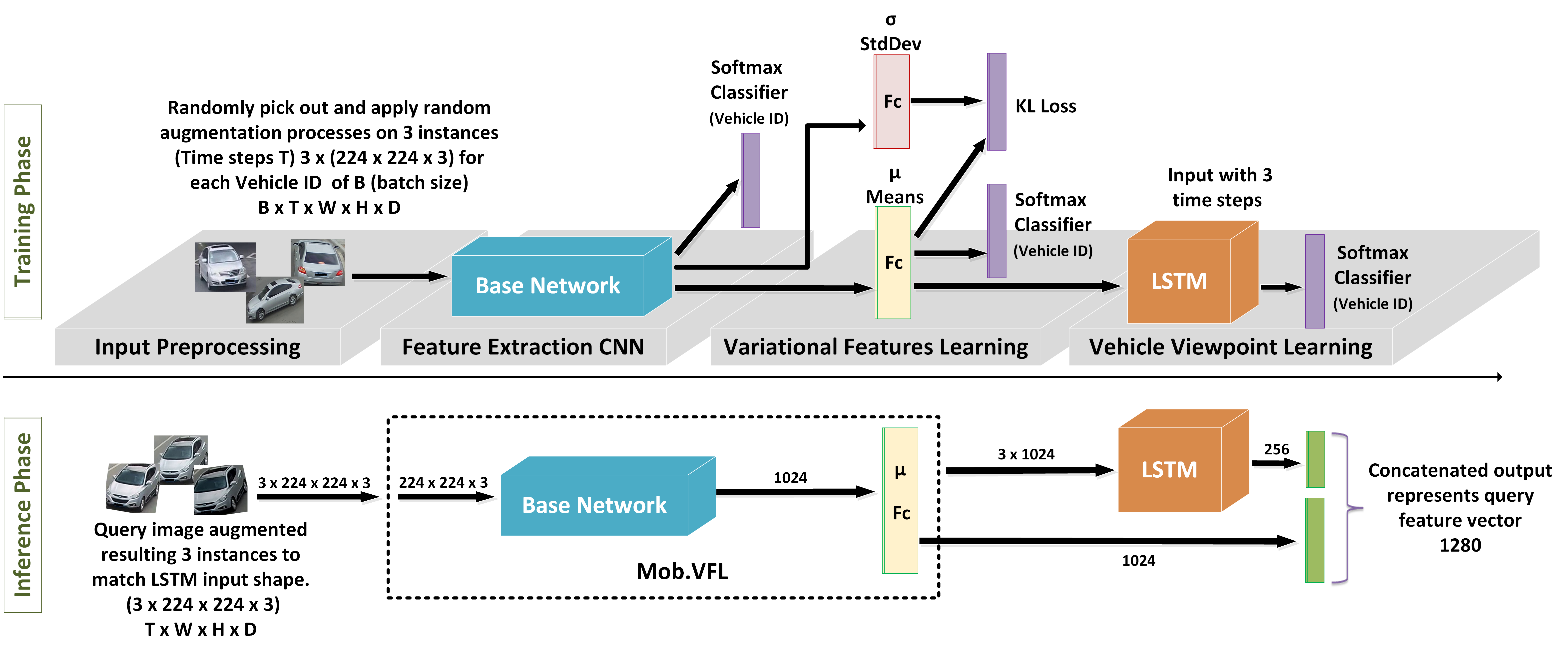 Figure 1
Figure 1| Component | Output Length | Top-1 | Top-5 |
|---|---|---|---|
| Mob.LSTM | 64 | 75.20 | 88.25 |
| 128 | 81.64 | 90.28 | |
| 256 | 83.37 | 92.37 | |
| 512 | 83.61 | 90.94 | |
| 1024 | 83.19 | 91.06 | |
| Mob.VFL | 256 | 85.28 | 92.49 |
| 1024 | 85.63 | 92.66 |
| Model | mAP % | Top-1 | Top-5 |
|---|---|---|---|
| Siamese-Visual [10] | 29.48 | 41.12 | 60.31 |
| FACT [22] | 18.49 | 50.95 | 73.48 |
| XVGAN [18] | 24.65 | 60.20 | 77.03 |
| OIF [14] | 48.00 | 65.92 | 87.66 |
| Siamese-CNN [10] | 54.21 | 79.32 | 88.92 |
| VAMI [12] | 50.13 | 77.03 | 90.82 |
| Path-LSTM [10] | 54.49 | 82.89 | 89.81 |
| VR-PROUD [17] | 40.5 | 83.19 | 91.12 |
| D-DLF [21] | 53.26 | 84.92 | 93.03 |
| Mob.VFL-LSTM(Ours) | 58.08 | 87.18 | 94.63 |
| SCCN-Ft+CLBL-8-Ft [19] | 25.12 | 60.83 | 78.55 |
| FACT+Plate-SNN+ STR [9] | 27.77 | 61.44 | 78.78 |
| OIF + ST [14] | 51.42 | 68.30 | 89.70 |
| Siamese-CNN+Path-LSTM[10] | 58.27 | 83.49 | 90.04 |
| VAMI [12] + STR [9] | 61.32 | 85.92 | 91.84 |
| QD-DLF [21] | 61.83 | 88.50 | 94.46 |
| Mob.VFL-LSTM + Mob.VFL⋆ (Ours) | 59.18 | 88.08 | 94.63 |
| Model | Test size 800 | Test size 1600 | Test size 2400 | |||||
|---|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | |||
| VGG-Triplet Loss[3] | 40.40 | 61.70 | 35.40 | 54.60 | 31.90 | 50.30 | ||
| VGG-CLL[3] | 43.60 | 64.20 | 37.00 | 57.11 | 32.90 | 53.30 | ||
| GoogLeNet [1] | 47.88 | 67.18 | 43.40 | 63.86 | 38.27 | 59.39 | ||
| FACT [22] | 49.53 | 68.07 | 44.59 | 64.57 | 39.92 | 60.32 | ||
| Mixed Diff-CLL[3] | 49.00 | 73.50 | 42.80 | 66.80 | 38.20 | 61.60 | ||
| XVGAN [18] | 52.87 | 80.83 | 49.55 | 71.39 | 44.89 | 66.65 | ||
| C2F-Rank [20] | 61.10 | 81.70 | 56.20 | 76.20 | 51.40 | 72.20 | ||
| VAMI [12] | 63.12 | 83.25 | 52.87 | 75.12 | 47.34 | 70.29 | ||
| Mob.VFL⋆ (Ours) | 73.37 | 85.52 | 69.52 | 81.00 | 67.41 | 78.48 | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSigmoid Activation · Tanh Activation · Long Short-Term Memory
Variational Representation Learning for Vehicle Re-Identification
Abstract
Vehicle Re-identification is attracting more and more attention in recent years. One of the most challenging problems is to learn an efficient representation for a vehicle from its multi-viewpoint images. Existing methods tend to derive features of dimensions ranging from thousands to tens of thousands. In this work we proposed a deep learning based framework that can lead to an efficient representation of vehicles. While the dimension of the learned features can be as low as , experiments on different datasets show that the Top-1 and Top-5 retrieval accuracies exceed multiple state-of-the-art methods. The key to our framework is two-fold. Firstly, variational feature learning is employed to generate variational features which are more discriminating. Secondly, long short-term memory (LSTM) is used to learn the relationship among different viewpoints of a vehicle. The LSTM also plays as an encoder to downsize the features.
**Index Terms— ** Deep Learning, LSTM, Variational Features, Vehicle Re-Identification
1 Introduction
Recently, vehicle image analysis has widely attracted researchers attention due to the increasing demand raised from intelligent public security and public transportation systems. The research mainly focused on vehicle classification [1, 2, 3, 4], vehicle detection and tracking [5, 6, 7], vehicle license plate verification [8] and vehicle retrieval or re-identification [3, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]. This paper works on the vehicle re-identification problem.
The current trend is to turn to deep learning techniques that are believed to be able to automatically derive proper features from various samples. To facilitate the emerging use of deep learning technique, several well annotated large-scale vehicle datasets [1, 3, 9, 22] have been published. Two main approaches have been utilized to improve the performance of vehicle re-identification. The first approach explores the best feature learning strategies for re-identification. Various deep learning models have been used, such as the combination of generative model with attentive LSTM network in [12], and the multimodal in [8]. Some studies such as [15, 12, 21] try to improve the output features by increasing their size, while others try to combine several feature vectors from different parallel/stacked sub-models, such as in [8, 10, 12]. There is also work that combines low level features with high context representation by mixing hand crafted features with CNN features [8].
The second approach focuses on the metric learning strategy used for calculating the similarity or distance between vehicle images. Representative works include [8, 12, 13] that have investigated pairwise distance metric learning , [3] that has proposed to learn the set distance metric between positive and negative image sets and [16] that has utilized triple loss [23]. The major problem of existing methods is that most of them can not be implemented in real-time applications due to the non-negligible large time and space requirement. What’s more, the discriminating ability of most existing representations are far from perfect. The performance of vehicle re-identification can be absolutely further improved by devising more efficient and accurate representations.
2 Proposed Model
Challenges in vehicle re-identification include how to match the query image with the gallery images that are of different viewpoints and, how to distinguish between various vehicle instances of the same color, type or model with the minimum apparence differences. Our framework tried to tackle these problems by combining four stages with three simple neural networks, which is depicted in Figure 1 and explained in detail as follows.
2.1 Input Preprocessing and Augmentation
The proposed framework has incorporated an LSTM component. Therefore the inputs in training phase are prepared with the dimension , while inputs dimension in inference phase are prepared with , where is for mini-batch size, is for time step, and are for width and height and is for depth of the image sequence, respectively. By default, we have adopted the time step of 3. In the training phase, the time step represents the three different augmented instances randomly picked out from the images of a single vehicle identity . This process helps the training network to learn identical representation for each vehicle regardless of its viewpoint. However, in the inference phase, since there may be only one query image for the vehicle, we have to generate another two instances by augmentation so as to match the time step of 3, as it illustrated in the first stage of Figure 1.
In order to increase the variability of each vehicle instance images we have applied various image augmentation techniques, including cropping, rotation and brightness adjustment. Based on our experiments, these operations help to increase the performance of vehicle re-identification, while other operations such as mirroring and color jittering have been excluded due to their negative effect on the training process.
2.2 CNN Feature Extraction
A deep convolutional neural network is used in this stage as a baseline network to extract high context features per input instance. Specifically, we have employed the MobileNet v1 [24] that not only helps to reduce overfitting but also runs faster than regular CNN with much fewer parameters. The output of this stage is a feature vector of size for each time step.
2.3 Variational Feature Learning
Inspired by the variational autoencoder learning [25], we trained the model with KL (Kullback-Leibler) divergence. Two fully connected layers are used to predict the means and the standard deviation of a Gaussian distribution . The outputs of this stage ensure the representation to diverse sufficiently. Besides, the outputs is well normalized. The KL divergence between the distribution and the prior is considered as a regularization which helps to overcome the overfitting problem. Along with KL divergence, Softmax classifier on top of the means layer is used to learn this network as it illustrated in third stage of Figure 1.
2.4 Viewpoint Learning and Encoding
While LSTM is normally used to learn the temporal relationship between a sequence of samples, we utilize it in this stage to achieve two goals: vehicle viewpoint understanding and feature encoding. To this end, we feed the LSTM with different instances, possibly of different viewpoints, of the same vehicle identity. It is expected that similar feature representation for the same vehicle regardless of the viewpoints can be learned. Another role of this layer is that we can further reduce the size of output features by controlling how many units are used in the LSTM. We have tested with different numbers of units and the results were quite promising that the performance did not drop significantly with the feature size reducing to as low as . Finally, on LSTM layer is trained using Softmax classifier on top of it with vehicle ID labels. Note that in the inference phase, the final vehicle feature vector is the output sequence of LSTM rather than the label vector.
3 Training and Inference
The models described in section 2 can be trained in different ways, either jointly or separately, depending on the characteristics of the datasets. In this work, for the VeRi dataset, we empirically found that the best practice is to train the three components separately, i.e., we freeze the previous components when training the current component. For the VehicleID dataset, since the third component of LSTM is not required due to the limited number of viewpoints, we have trained the CNN and the VFL components jointly. We fine-tuned pretrained MobileNet [24] on ImageNet [26] for both datasets. The first and the last components are trained with the Softmax classifier for 70 epochs using Adam optimizer [27] , with the initial learning rate set to 0.0001 and multiplied by 0.1 every 30 epochs. The equation (1) defines the Softmax classifier where denotes the output vector, denotes the target vector, and denotes the input to the neuron .
[TABLE]
For the second component, i.e., the VFL network, we used two weighted loss functions, as is shown in equation (2).
[TABLE]
The second term represents the KL loss and is defined by equation (3). The weight of KL loss is empirically set to in this work. and denote the predicted means and standard deviation of the Gaussian distribution while denotes the vector size. This component is trained for 50 epochs using Adam optimizer , with the initial learning rate set to 0.0001 and multiplied by 0.1 every 20 epochs.
[TABLE]
In the inference phrase, as illustrated in Figure 1, we only keep the Means layer for the VFL component. The overall inference pipeline involves the CNN feature extractor, the Mean layer and the LSTM layer. Note that we concatenate the outputs from both the last and the second components as the final feature vector.
4 Experimental Results
We have evaluated our method on two large-scale public datasets VehicleID [3] and VeRi [22]. The VeRi dataset contains images of vehicles for training and images of vehicles for testing. The pictures of this dataset are taken from various viewpoints with several surveillance cameras for each vehicle.
We have first done extensive experiments to investigate the effect of individual components as well as the impact of different feature sizes. As is shown in Table 1, for the combination of base CNN network with LSTM (denoted as Mob.LSTM), the Top-1 and Top-5 accuracies differ with the output sequence lengths. The best results are achieved when the length is 256. It is worth noting that the results have not dropped dramatically when the length is reduced to as low as 64, demonstrating the effectiveness of using LSTM in the model. On the other hand, the outputs of variational feature learning network (denoted as Mob.VFL) are slightly better than that of Mob.LSTM, with the highest accuracies being achieved when the output feature size is 1024.
To further verify the advantage of our work, we have compared our methods with several most recent related works, including Siamese-Visual [10], FACT [22], XVGAN [18], OIF [14], Siamese-CNN [10], VAMI [12], Path-LSTM [10], VR-PROUD [17], and D-DLF [21]. As is shown on the upper part of Table 2, our method provides the best Top-1 and Top-5 performance compared with the state-of-the-art methods.
It is generally believed that combining multiple networks may possibly boost the performance. For example, in [10] the authors have combined Siamese-CNN with Path-LSTM and observed a boost on the performance. In [21], the authors combined CNN network instances with different directional pooling layers to improve the performance. We therefore have used the default configuration of our method involving all three components as the base network and used the combination of CNN and the VFL components (jointly trained and denoted as Mob.VFL*⋆* ) as the second network. We then concatenate the outputs of these two networks and compare the results with other similar practices from the literature, as listed in the lower part of Table 2. It is shown that the combination of different configurations of our models has achieved the best performance in terms of Top-5.
VehicleID contains images of vehicles for training and images of vehicles for testing. This dataset contains only two viewpoints front and rear for each vehicle, which forces us to train without the LSTM layer but only with the baseline network and VFL jointly. We followed the evaluation protocol proposed in [3] and worked on three testing sets of size , and respectively. Table 3 shows the comparison between our method and several latest leading methods in the literature. Among these methods, VAMI of [12], which is a complex model using attention mechanism with generative adversarial network (GAN), shows the best performance in terms of the Top-1 and Top-5 retrieval accuracy. However, our method (denoted as Mob.VFL*⋆*) has achieved even better results than VAMI on all three test sets. Particularly, in the biggest testing set of 2400, our method has significantly increased the Top-1 accuracy from of VAMI to .
5 Conclusion
In this work, we have devised an efficient deep-learning-based framework that can derive highly discriminating representations for vehicle images, which helps to improve the performance of vehicle re-identificaton. Our framework is characterized by the combination of three components dedicated to different purposes. The base CNN network extracts the high context features based on which, the following variational feature learning component learns Gaussian distribution of the same vehicle instances. The last component which involves an LSTM layer plays two roles: extracting intra-class features from different viewpoints and reducing the size of the output feature vectors.
The effectiveness of our framework has been demonstrated by extensive experiments. It is also believed that the idea of using variational feature learning with KL divergence can not only boost the performance of vehicle re-identificaton, but also be extended to other similar scenarios such as content-based image retrieval and fine-grained classification to improve the quality of object representation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. Yang, P. Luo, C. C. Loy, and X. Tang, “A large-scale car dataset for fine-grained categorization and verification,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2015.
- 2[2] J. Sochor, A. Herout, and J. Havel, “Boxcars: 3d boxes as cnn input for improved fine-grained vehicle recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- 3[3] H. Liu, Y. Tian, Y. Wang, L. Pang, and T. Huang, “Deep relative distance learning: Tell the difference between similar vehicles,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- 4[4] J. T. Lee and Y. Chung, “Deep learning-based vehicle classification using an ensemble of local expert and global networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , 2017.
- 5[5] S. Ram and J. J. Rodriguez, “Vehicle detection in aerial images using multiscale structure enhancement and symmetry,” in 2016 IEEE International Conference on Image Processing (ICIP) , 2016.
- 6[6] J.-N. Xin, X. Du, and J. Zhang, “Deep learning for robust outdoor vehicle visual tracking,” in 2017 IEEE International Conference on Multimedia and Expo (ICME) , 2017.
- 7[7] M. Y. Yang, W. Liao, X. Li, and B. Rosenhahn, “Deep learning for vehicle detection in aerial images,” in 2018 25th IEEE International Conference on Image Processing (ICIP) , 2018.
- 8[8] X. Liu, W. Liu, T. Mei, and H. Ma, “Provid: Progressive and multimodal vehicle reidentification for large-scale urban surveillance,” IEEE Transactions on Multimedia , vol. 20, no. 3, pp. 645–658, 2018.
