When parallel speedups hit the memory wall
Alex F. A. Furtunato, Kyriakos Georgiou, Kerstin Eder, Samuel, Xavier-de-Souza

TL;DR
This paper introduces new analytical models for parallel speedup that incorporate the impact of the memory wall, accounting for data-access delay variations due to hardware configurations, validated through experiments.
Contribution
The work develops analytical speedup models that explicitly include data-access delay variations caused by the memory wall, outperforming machine-learning approaches in accuracy and measurement efficiency.
Findings
Models accurately capture memory wall effects on speedup.
Experimental validation confirms model effectiveness.
Proposed models require fewer measurements than machine learning.
Abstract
After Amdahl's trailblazing work, many other authors proposed analytical speedup models but none have considered the limiting effect of the memory wall. These models exploited aspects such as problem-size variation, memory size, communication overhead, and synchronization overhead, but data-access delays are assumed to be constant. Nevertheless, such delays can vary, for example, according to the number of cores used and the ratio between processor and memory frequencies. Given the large number of possible configurations of operating frequency and number of cores that current architectures can offer, suitable speedup models to describe such variations among these configurations are quite desirable for off-line or on-line scheduling decisions. This work proposes new parallel speedup models that account for variations of the average data-access delay to describe the limiting effect of the…
Click any figure to enlarge with its caption.
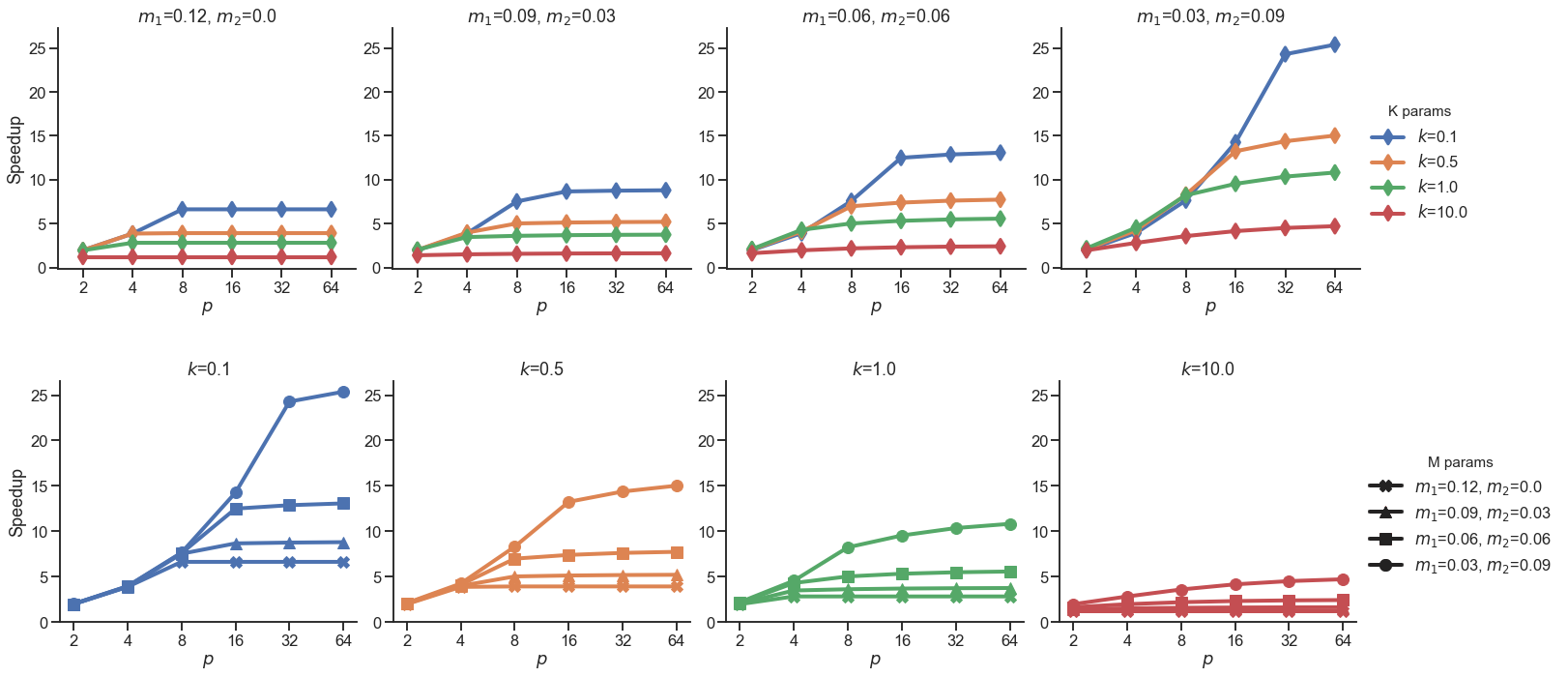 Figure 1
Figure 1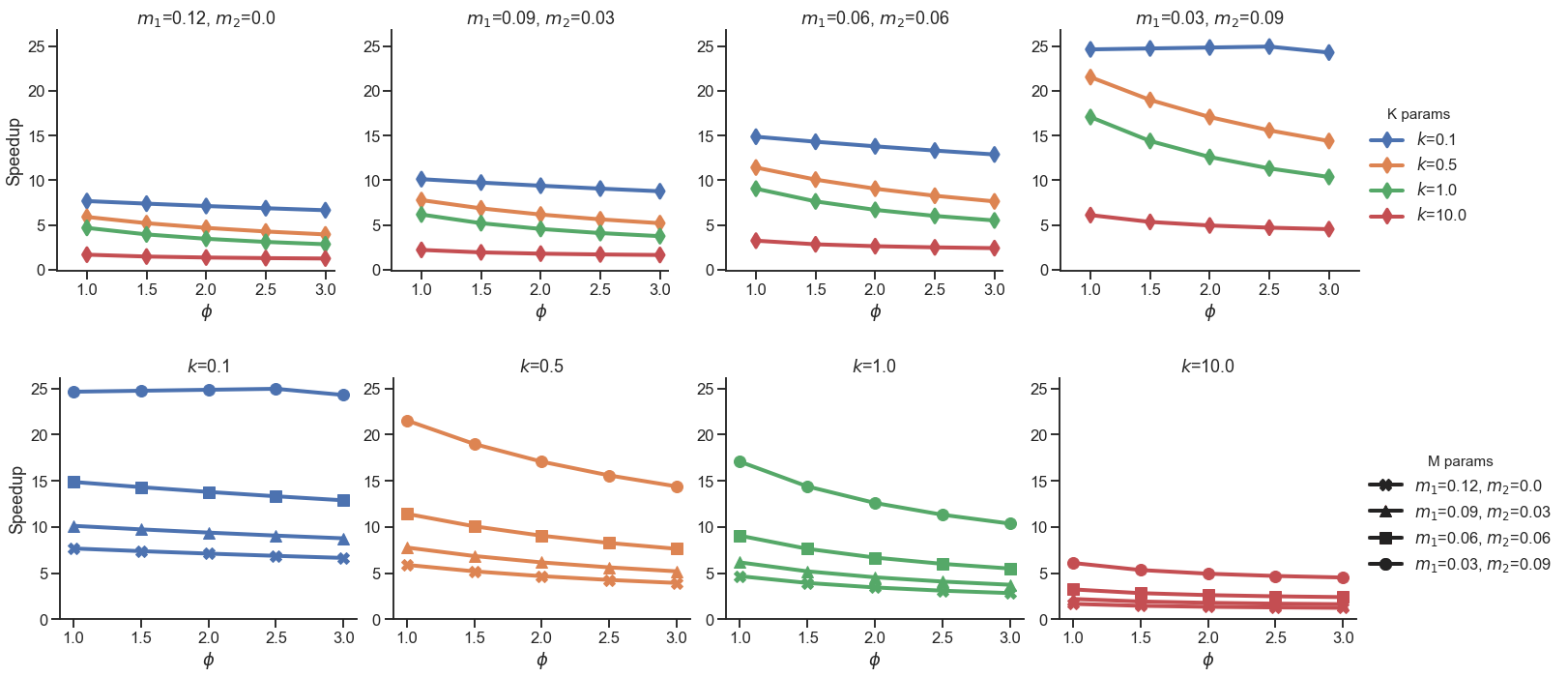 Figure 2
Figure 2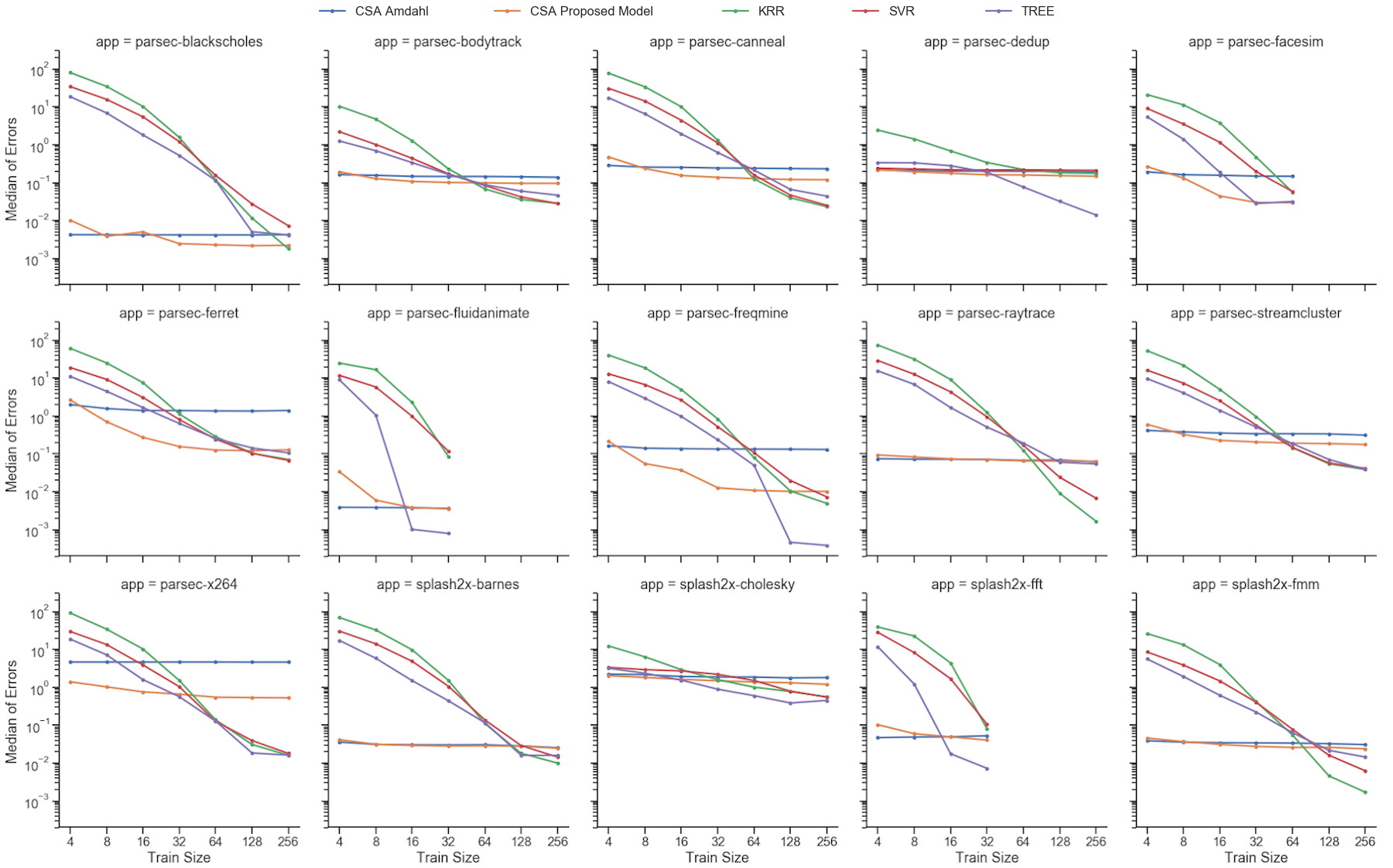 Figure 3
Figure 3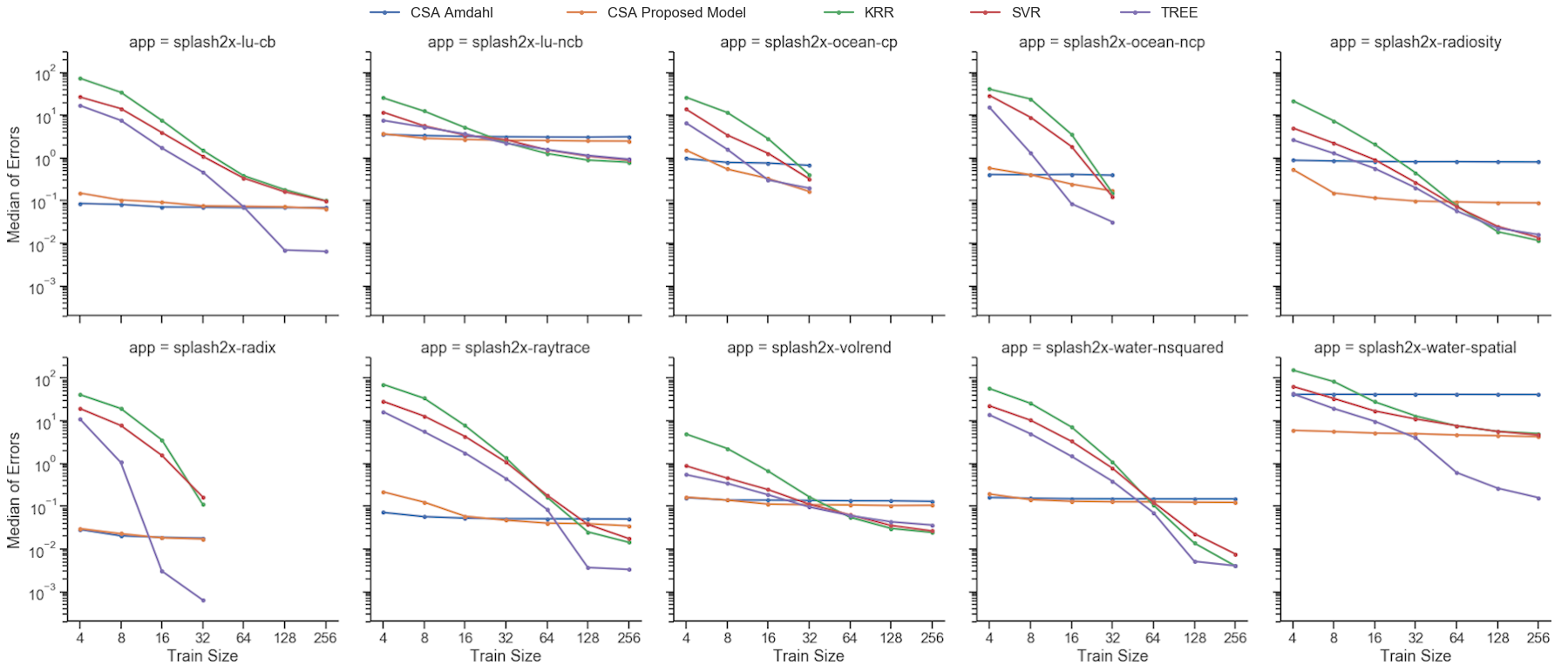 Figure 4
Figure 4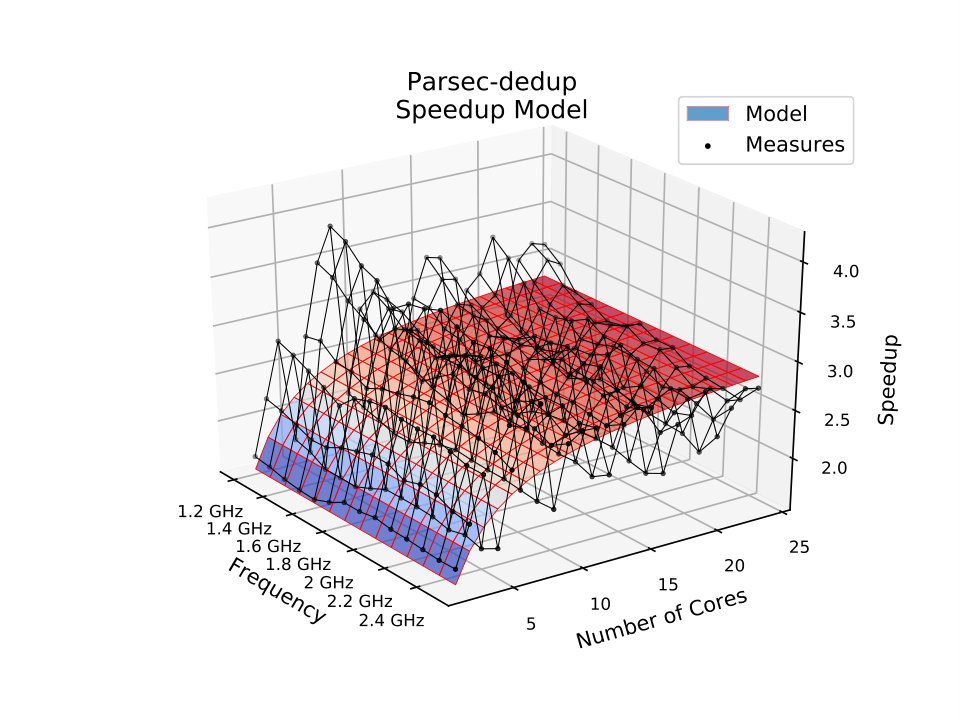 Figure 5
Figure 5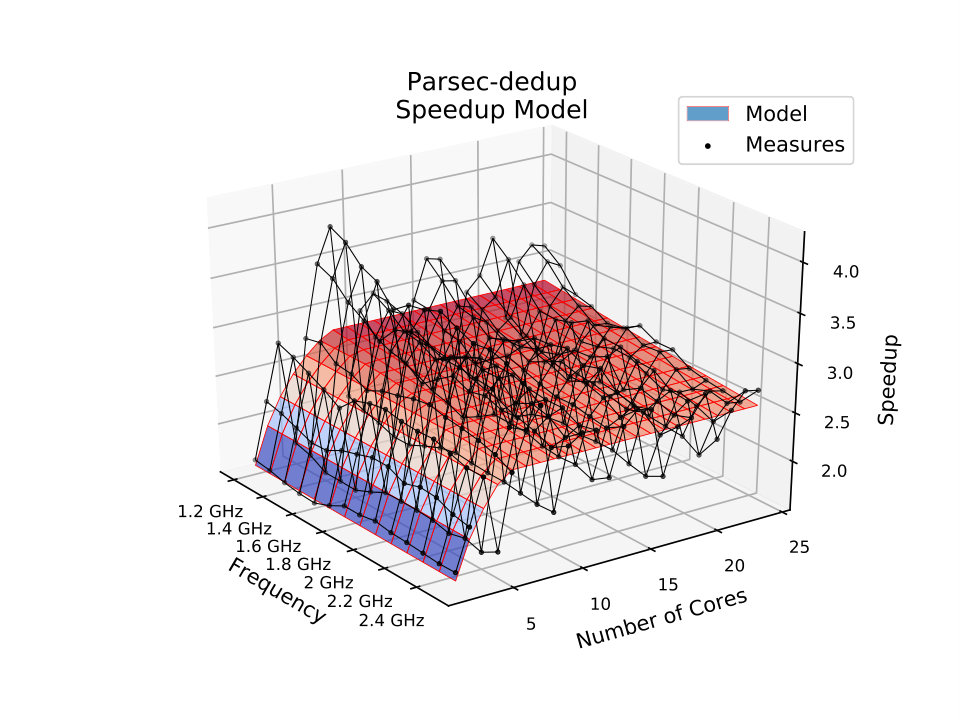 Figure 6
Figure 6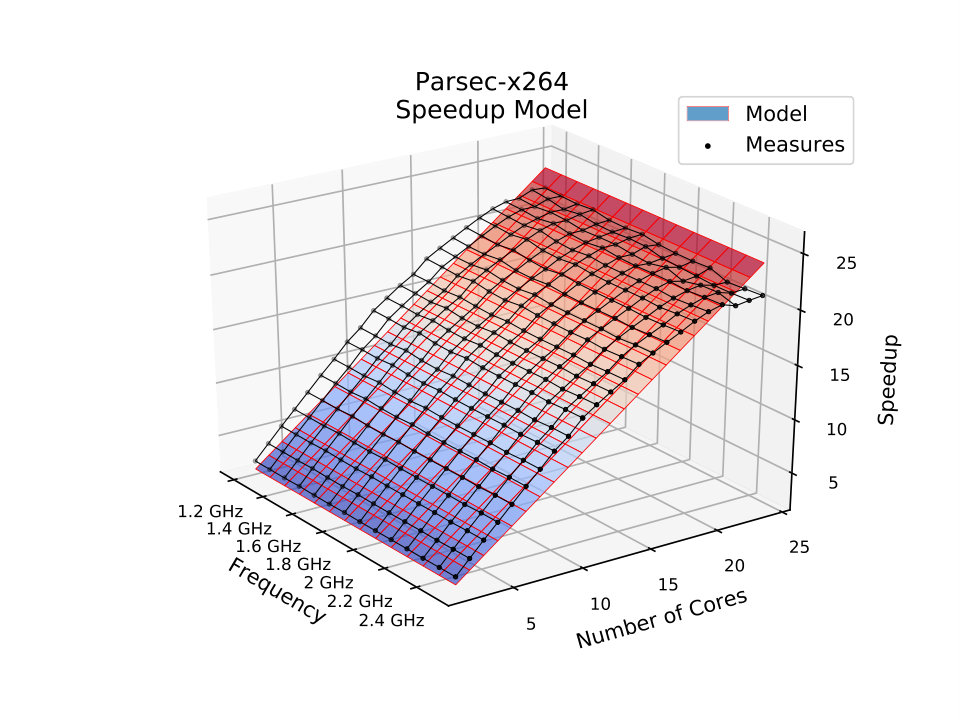 Figure 7
Figure 7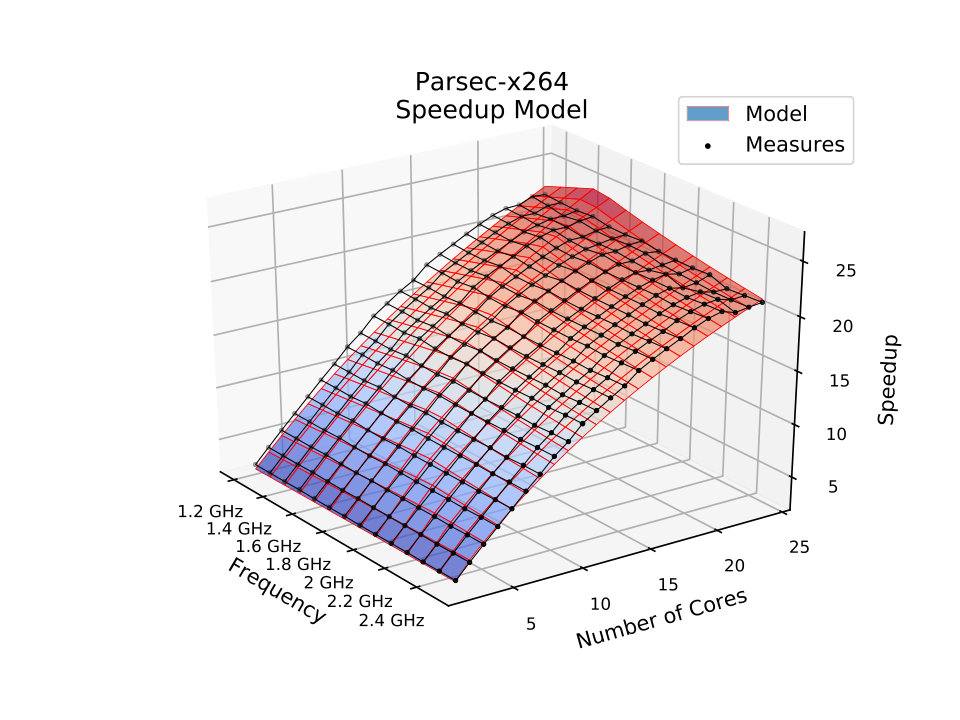 Figure 8
Figure 8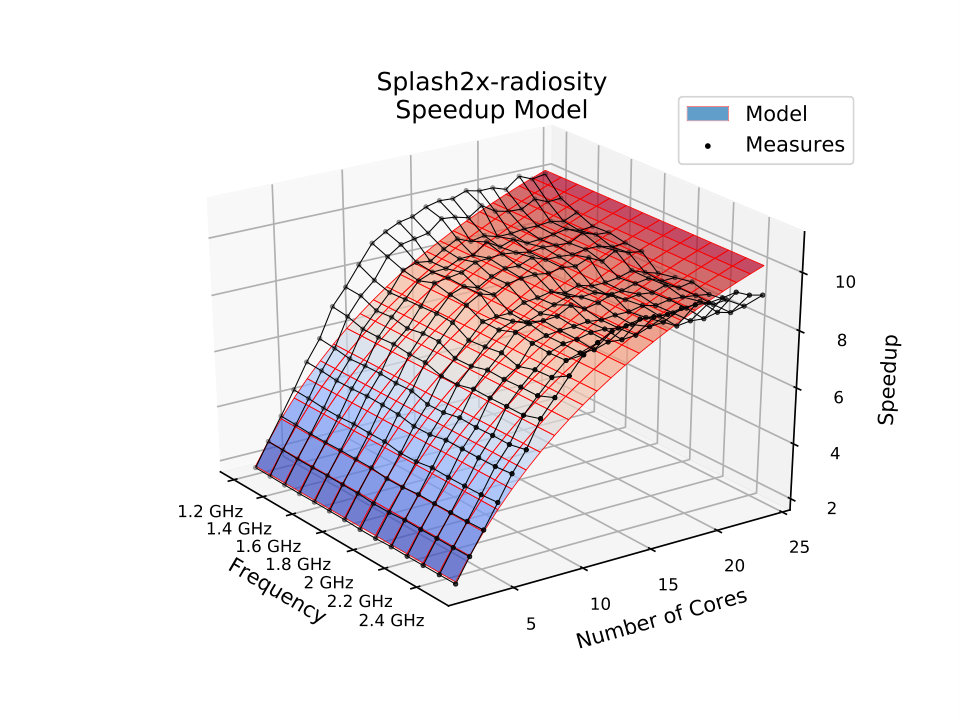 Figure 9
Figure 9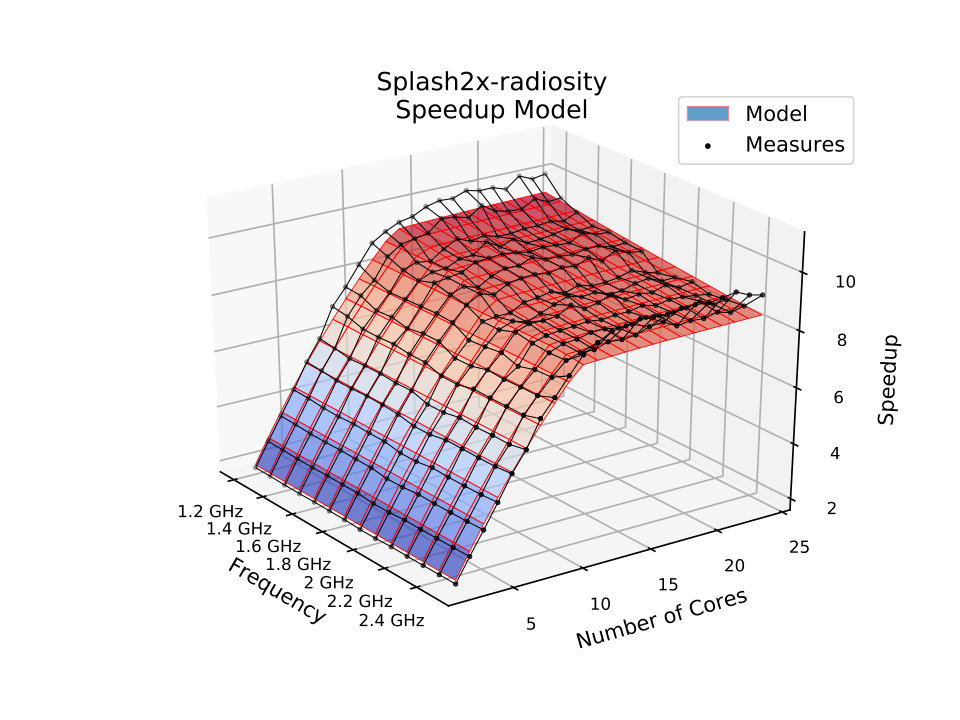 Figure 10
Figure 10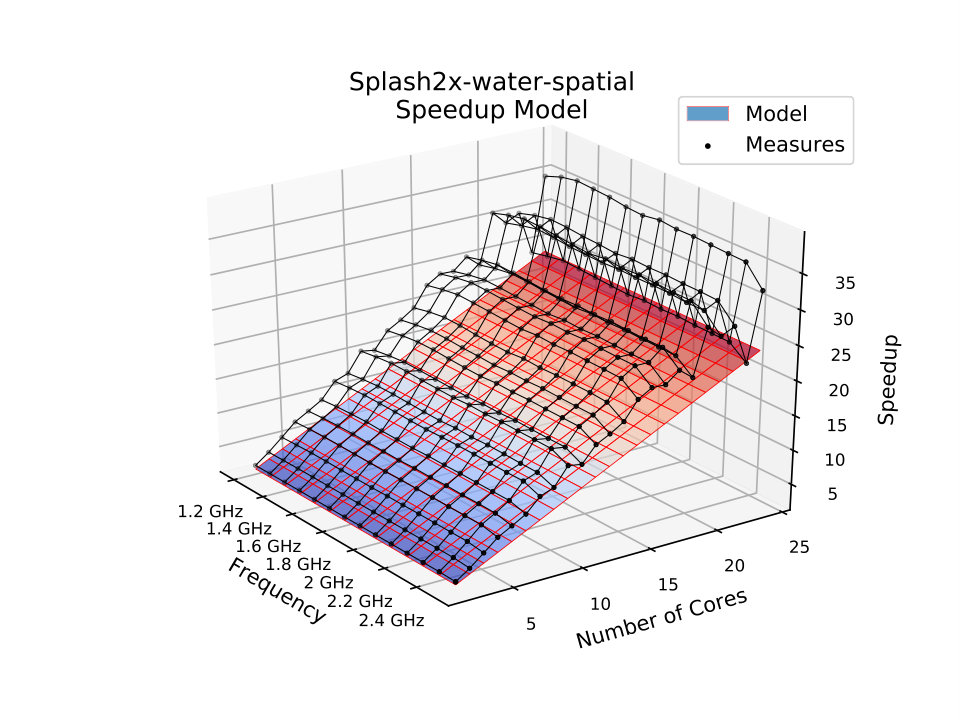 Figure 11
Figure 11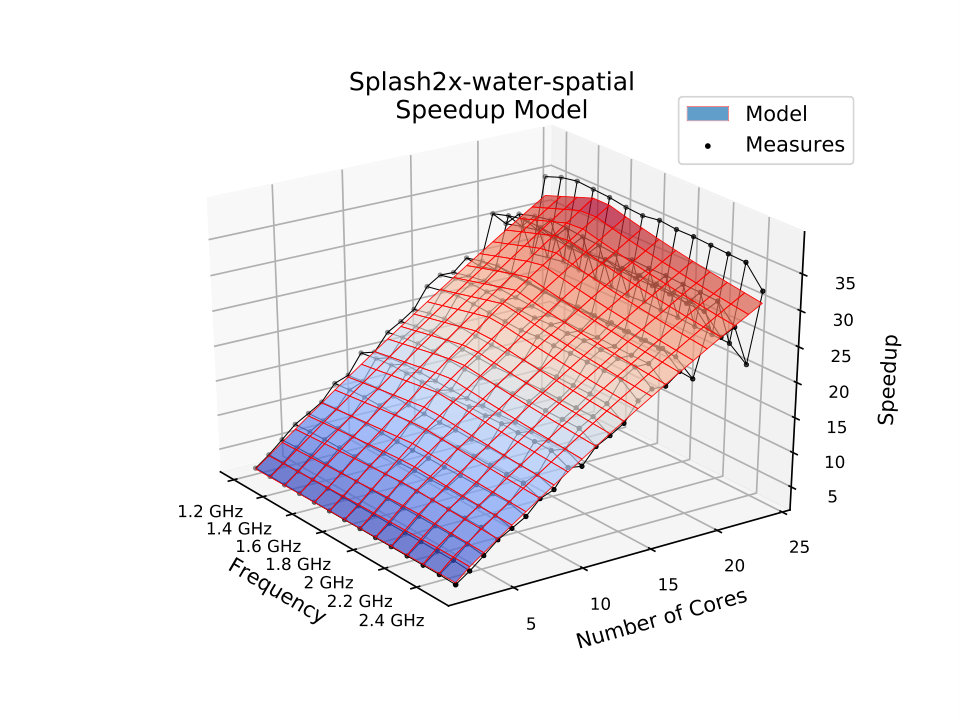 Figure 12
Figure 12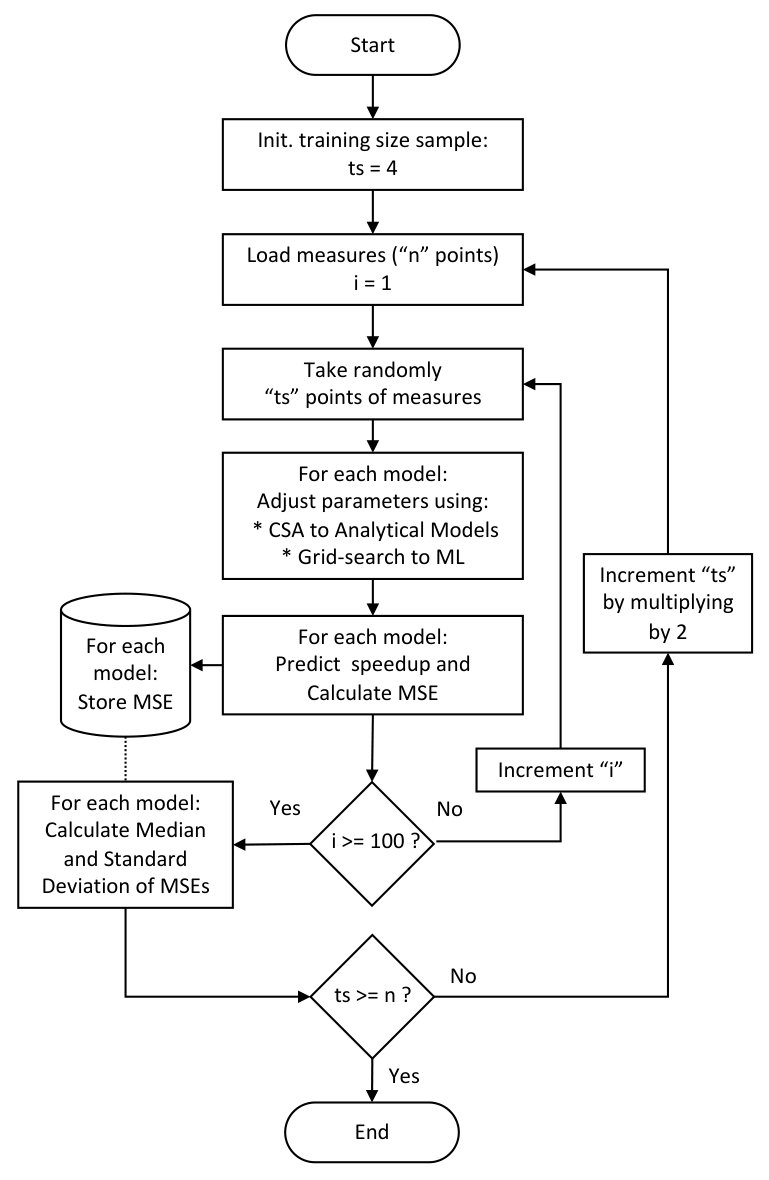 Figure 13
Figure 13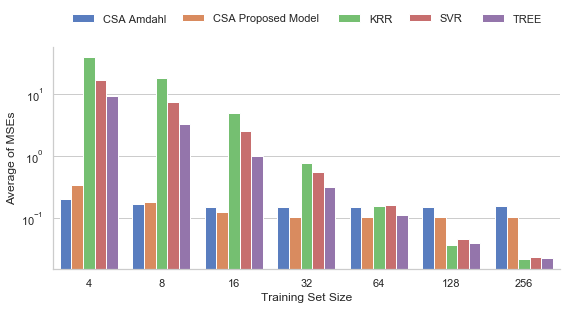 Figure 14
Figure 14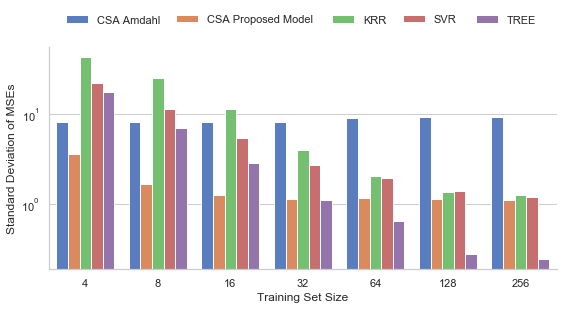 Figure 15
Figure 15| Number of | Amdahl’s Model (5) | Proposed model (15) | Accuracy | ||||||
| Benchmark Program | Measurements | MSE | MSE | Gain | |||||
| parsec-blackscholes | 322 | 1.0000 | 0.0042 | 0.7642 | 9.9264 | 0.0003 | 0.8761 | 0.0021 | 49.42 % |
| parsec-bodytrack | 322 | 0.8934 | 0.1417 | 0.8984 | 9.7185 | 0.0090 | 0.0000 | 0.0931 | 34.29 % |
| parsec-canneal | 322 | 0.9985 | 0.2325 | 0.9946 | 0.4341 | 0.0057 | 0.8562 | 0.1124 | 51.66 % |
| parsec-dedup | 322 | 0.6745 | 0.1969 | 0.7387 | 0.1545 | 0.3210 | 0.0000 | 0.1481 | 24.82 % |
| parsec-facesim | 84 | 0.9731 | 0.1443 | 0.9745 | 0.0950 | 0.0507 | 0.5482 | 0.0217 | 84.98 % |
| parsec-ferret | 322 | 0.9912 | 1.3371 | 0.9952 | 0.2348 | 0.0368 | 0.1610 | 0.1104 | 91.74 % |
| parsec-fluidanimate | 56 | 0.9834 | 0.0036 | 0.9954 | 0.0064 | 0.0174 | 0.9712 | 0.0029 | 19.49 % |
| parsec-freqmine | 322 | 0.9791 | 0.1316 | 0.9907 | 0.0050 | 0.0294 | 0.8209 | 0.0096 | 92.69 % |
| parsec-raytrace | 322 | 0.9959 | 0.0675 | 0.9155 | 9.9798 | 0.0039 | 0.7814 | 0.0623 | 7.70 % |
| parsec-streamcluster | 322 | 0.9860 | 0.3274 | 0.9864 | 4.7217 | 0.0061 | 0.0024 | 0.1766 | 46.06 % |
| parsec-x264 | 322 | 1.0000 | 4.6452 | 0.9771 | 1.6662 | 0.0087 | 0.2638 | 0.6169 | 86.72 % |
| splash2x-barnes | 322 | 0.9969 | 0.0290 | 0.8320 | 4.6578 | 0.0029 | 1.0000 | 0.0268 | 7.74 % |
| splash2x-cholesky | 322 | 0.8978 | 1.8236 | 0.9273 | 0.1274 | 0.1301 | 0.0000 | 1.2997 | 28.73 % |
| splash2x-fft | 56 | 0.9999 | 0.0436 | 0.9755 | 9.9984 | 0.0013 | 0.7153 | 0.0377 | 13.61 % |
| splash2x-fmm | 322 | 0.9629 | 0.0326 | 0.8785 | 9.9976 | 0.0261 | 0.6269 | 0.0253 | 22.38 % |
| splash2x-lu-cb | 322 | 0.9950 | 0.0668 | 0.7302 | 9.9672 | 0.0049 | 0.9257 | 0.0664 | 0.53 % |
| splash2x-lu-ncb | 322 | 0.9538 | 3.0182 | 0.9657 | 3.3786 | 0.0154 | 0.0001 | 2.1160 | 29.89 % |
| splash2x-ocean-cp | 56 | 0.9769 | 0.6297 | 0.9256 | 9.9994 | 0.0093 | 0.2050 | 0.3457 | 45.10 % |
| splash2x-ocean-ncp | 56 | 1.0000 | 0.3854 | 0.9244 | 9.1902 | 0.0027 | 0.3123 | 0.1793 | 53.48 % |
| splash2x-radiosity | 322 | 0.9408 | 0.8001 | 0.9674 | 0.1199 | 0.0940 | 0.0429 | 0.0844 | 89.45 % |
| splash2x-radix | 56 | 0.9961 | 0.0172 | 0.9965 | 0.0321 | 0.0591 | 0.0609 | 0.0152 | 11.71 % |
| splash2x-raytrace | 322 | 0.9973 | 0.0493 | 0.9520 | 1.1918 | 0.0040 | 0.9179 | 0.0356 | 27.81 % |
| splash2x-volrend | 322 | 0.8037 | 0.1327 | 0.7901 | 8.8634 | 0.1827 | 1.0000 | 0.1028 | 22.51 % |
| splash2x-water-nsquared | 322 | 0.9892 | 0.1468 | 0.8800 | 3.9348 | 0.0103 | 1.0000 | 0.1243 | 15.33 % |
| splash2x-water-spatial | 322 | 1.0000 | 41.7510 | 0.9947 | 1.7165 | 0.0022 | 0.2811 | 4.0755 | 90.24 % |
| Proposed | Decision Tree | |||
| Benchmark Program | points | time (s) | points | % |
| parsec-blackscholes | 8 | 1.8e+03 | 256 | 524.21% |
| parsec-bodytrack | 8 | 1.97e+03 | 64 | 239.79% |
| parsec-canneal | 8 | 1.96e+03 | 64 | 192.90% |
| parsec-dedup | 8 | 360 | 64 | 317.75% |
| parsec-facesim | 8 | 6.95e+03 | 64 | 251.87% |
| parsec-ferret | 8 | 3.76e+03 | 128 | 309.25% |
| parsec-fluidanimate | 32 | 1.26e+04 | 16 | -33.69% |
| parsec-freqmine | 8 | 5.67e+03 | 128 | 327.66% |
| parsec-raytrace | 32 | 5.02e+03 | 128 | 77.97% |
| parsec-streamcluster | 8 | 8.58e+03 | 64 | 198.05% |
| parsec-x264 | 4 | 826 | 32 | 283.11% |
| splash2x-barnes | 16 | 3e+03 | 128 | 154.25% |
| splash2x-cholesky | 4 | 0.719 | 16 | 196.13% |
| splash2x-fft | 16 | 1.1e+03 | 16 | 0.00% |
| splash2x-fmm | 16 | 2.33e+03 | 128 | 174.86% |
| splash2x-lu-cb | 256 | 1.1e+10 | 128 | -34.52% |
| splash2x-lu-ncb | 16 | 3.03e+09 | 32 | 47.32% |
| splash2x-ocean-cp | 8 | 2.41e+03 | 16 | 63.76% |
| splash2x-ocean-ncp | 16 | 6.52e+03 | 16 | 0.00% |
| splash2x-radiosity | 4 | 746 | 128 | 748.20% |
| splash2x-radix | 16 | 1.24e+03 | 16 | 0.00% |
| splash2x-raytrace | 32 | 6.51e+03 | 128 | 75.29% |
| splash2x-volrend | 8 | 1.65e+03 | 64 | 281.42% |
| splash2x-water-nsquared | 8 | 6.04e+03 | 64 | 198.94% |
| splash2x-water-spatial | 4 | 1.45e+03 | 32 | 303.15% |
| Mean | 22.08 | 76.80 | 195.91% | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\reserveinserts
28
11institutetext: Universidade Federal do Rio Grande do Norte, Brazil 22institutetext: University of Bristol, UK
When parallel speedups hit the memory wall
Alex F. A. Furtunato 11
Kyriakos Georgiou 22
Kerstin Eder 22
Samuel Xavier-de-Souza 11
Abstract
After Amdahl’s trailblazing work, many other authors proposed analytical speedup models but none have considered the limiting effect of the memory wall. These models exploited aspects such as problem-size variation, memory size, communication overhead, and synchronization overhead, but data-access delays are assumed to be constant. Nevertheless, such delays can vary, for example, according to the number of cores used and the ratio between processor and memory frequencies. Given the large number of possible configurations of operating frequency and number of cores that current architectures can offer, suitable speedup models to describe such variations among these configurations are quite desirable for off-line or on-line scheduling decisions. This work proposes a new parallel speedup model that accounts for the variations on the average data-access delay to describe the limiting effect of the memory wall on parallel speedups in homogeneous shared-memory architectures. Analytical results indicate that the proposed modeling can capture the desired behavior while experimental hardware results validate the former. Additionally, we show that when accounting for parameters that reflect the intrinsic characteristics of the applications, such as the degree of parallelism and susceptibility to the memory wall, our proposal has significant advantages over machine-learning-based modeling. Moreover, our experiments show that conventional machine-learning modeling, besides being black-boxed, needs about one order of magnitude more measurements to reach the same level of accuracy achieved by the proposed model.
1 Introduction
Amdahl’s Law [Amd67] has driven the chase for single-processor performance improvements for decades, but the end of frequency-upscaling and the stagnation of instruction level parallelism altogether led to the dawn of a new computational era: the multi-core and many-core era.
In this new era, parallel computing has become the conventional approach to achieve ever-increasing computational performance. Although parallelism is not new in computational systems, its real potential has been obfuscated for many decades by two main factors: Amdahl’s skepticism on the ability of parallel systems to scale performance, and the exponential speed growth of single processor systems. It is now a consensus that Amdahl had a limited view on parallelism, and thus numerous works have been emerging towards expressing and exploiting the advantages that parallel computing can offer [Gus88, SN93, Shi96, HM08, SC10]. Continuing to broaden and explore different views on parallelism remains of vital importance in maximizing the potentials that parallel computing can offer.
This paper widens the views on parallelism by exploring the effects of the number of cores and their operating frequency on the data-access delay for parallel applications that make extensive use of the main memory. Memory-bound programs are hard to model because their behavior is volatile across runs with different inputs and system configurations due to the variability of how such applications exploit the memory hierarchy. We dedicate the following paragraphs to describe the existing views on parallelism, which we argue do not consider these aspects.
Amdahl showed that even a tiny not parallelized code fraction of an application could compromise the applicability of multiple processors to scale the application’s performance [Amd67]. Long after Amdahl’s work on the inability of using multiple processors to scale performance, Gustafson’s “fixed-time speedup” approach to parallelism has shown that larger programs can benefit from more processors [Gus88]. Amdahl’s “fixed-size speedup” had a limited view on the potential of parallelism. Gustafson’s scaling model, known as Gustafson’s Law, opened the path to the multi-core and many-core era. In [Shi96], the author unifies Amdahl and Gustafson’s works and concludes that using the execution times instead of the serial and parallel fractions of the code could have avoided decades of unconstructive criticism against the advantages of using parallel processing. Sun and Ni [SN93] coined another prevalent model shortly after Gustafson’s seminal work. The authors present a memory-bounded speedup model, known as Sun and Ni’s Law. Their modeling demonstrates that the memory size is a limiting factor for parallel scalability.
More recently, other models extend these analyses to multi-core architectures, showing that they scale better for asymmetric and dynamic multi-core chips [HM08]. In [SC10], the authors summarize the contributions of three main speedup models (fixed-size, fixed-time, and memory-bounded speedups models) to the multi-core era, presenting a very optimistic view. However, their view assumes that the data-access delay is fixed and independent of the number of cores and problem sizes. This assumption is often unrealistic because of the memory wall [WM95], caused by the increasing data-access delay as the number of cores increases. In the following, we discuss three of the significant factors that can affect the data-access delay of an application running in a homogeneous shared-memory architecture: the application’s problem/input size, the number of cores utilized, and the ratio of the processor’s and memory’s frequencies.
While the scaling of the problem size may affect the data-access delay, whether this effect is negative or positive for performance depends on the application’s nature and on how the application is utilizing the targeted architecture. In general, increasing the input size can trigger a higher activity in the memory hierarchy, causing more cache misses, which subsequently generates more main memory accesses per cycle. Often, cache-blocking techniques can be applied to avoid or reduce this effect. The modeling presented in this paper does not consider variations in the problem/input size.
Increasing the number of cores can have an even more significant effect on the data-access delay depending on the architecture’s characteristics. For instance, even with the problem size kept constant, using more processing cores can cause an increasing data-access delay because the rate of access-requests per cycle can increase due to more cores making simultaneous requests to the same memory. When the demand for accesses reaches the memory’s nominal rate of attended requests per cycle, the average data-access delay starts to increase, stagnating the performance scaling in the number of cores, even for codes that are entirely parallel or that have a tiny serial fraction. Hence, for these cases, increasing the number of cores can indeed increase the data-access delay, which will undesirably generate an adverse effect on speedup in a form that resembles an increase in the serial fraction of the application. On the other hand, in the case of private-caches, increasing the number of cores can lead to more available caches, and thus, to fewer memory accesses that, up to a degree, will have a positive effect on the data-access delay and thus will possibly allow further performance gains through parallelization.
A third factor to consider is the ratio of the processor’s and memory’s frequencies. If the processor is running significantly faster than the memory, the data-access delay relative to the processor speed may also increase. Considering all these factors and their interactions is crucial both for developing parallel programs that do not become bounded by the memory and for finding the optimal configuration of the number of cores and the processor’s frequency that achieves maximum speedup for an application. Currently, there is no analytical model to capture these effects altogether. Some authors have used hardware performance counters to build models [WT16, AHSR*+*17, ZRJG15]. However, since those are processor-specific and not standardised, their use limits the portability of the models.
In this paper, we present a new analytical speedup-model for multi-core architectures that captures the adverse and the favorable effects on performance due to variations in the data-access delay caused by increasing the number of cores (see Section 2). The proposed model does not use performance counters and therefore is arguably more portable and less complex than those that do.
The proposed model has many practical uses, including finding suitable configurations [BSVXdS15, XdSBJS15, XdSBS*+*13] that, coupled to a power model, could achieve better energy efficiency while meeting the application’s performance constraint. It could also be used by operating systems to estimate relative performance of multiple applications and to implement resource-optimal scheduling. Estimating wall time for high performance computing jobs in unseen configurations is another possible practical use for the proposed model.
We initially investigate the potential abilities of the proposed model to capture the above effects analytically (Section 3). The analytical results indicated that the speedup is dependent on the ratio between the frequencies of the processor and the main memory, both for memory-bound applications and for processor-bound applications that became memory-bounded after an increase in the number of cores. The analysis indicated that the larger this ratio, the higher its limiting effect can be on the speedup and that this limitation grows with the degree of parallelism of the code.
The proposed modeling was then fitted with actual hardware measurements to validate our analytical findings (Section 4). Furthermore, we demonstrate that our approach has higher accuracy and lower variance than Amdahl’s model (Section 4.2). Comparisons to other analytical speedup models would not be more relevant since the other models differ from Amdahl’s model by aspects that were not considered in our experiments, such as the problem size and architectural features like memory hierarchy and the amount of memory available. Section 5 presents more details. Therefore, to the best of our knowledge, the features modeled by other models are orthogonal to the memory-wall effect modeled in this work. Thus, those models, and their features, are complementary to the proposed model.
We compare the proposed model to non-linear machine learning approaches (Section 4.3), which are considered more flexible than any analytical model. In this comparison, the proposed model is demonstrated to exhibit a higher accuracy while using fewer hardware measurements.
Finally, based on the presented modeling and experimental results, we then discuss the implications that the contributions of this paper can have in application-specific multi-core design and towards more energy-efficient parallel software.
The paper is organized as follows. In Section 2 we present our modeling for speedup as a function of the ratio between processor and memory frequencies. In Section 3 we analyze the model behavior. In Section 4, we detail the methodology used to validate the proposed models and provide results of experiments in real hardware. In Section 5 we put our contributions in perspective with the existing literature and, finally, in Section 6, we draw conclusions and suggest future work.
2 Variable-delay speedup model
In this section, we devise a new parallel speedup model that accounts for the effect of the variation in the number of cores on the data-access delay. Furthermore, the model allows us to describe the effect that variations of the ratio between processor and memory frequencies have on the speedup.
Let us first restate the equation for the speedup of an application running in parallel with cores as follows:
[TABLE]
where is the sequential time, measured when running the application on a single core processor, and is the time for running the same application in parallel with cores.
We now make some simplifying assumptions, desirable and necessary to achieve a good trade-off between accuracy and complexity of the proposed model. These are later proved to be satisfactorily sustained by the model validation presented in Section 4:
Assumption 1: The computations of a given application can be divided into two types of instructions: memory instructions and processor instructions. The former representing the loads and stores that generate accesses to the main memory and the latter representing those instructions that are carried out without data transfer and those loads and stores that are captured by the cache hierarchy. This is an abstraction similar to Amdahl’s assumption that the parallel and sequential parts of the code never overlap, which is often and generally not the case, but allows for model simplification. The total number of instructions is then given by
[TABLE]
where is the number of processor instructions, and is the number of memory instructions.
Assumption 2: The main memory can only attend requests at a given maximum rate. And, for a given parallel application, the access time is approximated by an average access time.
Assumption 3: For a specific processor frequency, the execution time of processor instructions can be approximated by an average value , which is inversely proportional to the processor operating frequency.
Assumption 4: For a specific processor frequency and memory frequency, the time necessary to execute a memory instruction, as defined in Assumption 1, can be approximated by an average value .
Then, the sequential execution time for the computation of all instructions can be given by
[TABLE]
Accordingly, the formulation of an equation for the parallel execution time for the computation of the same instructions depends on how these instructions are distributed and carried out by multiple processing elements. We use a simplistic model first coined by Amdahl in [Amd67] to model parallel software. The computation is modeled by a parallel fraction , representing the instructions that have no dependencies among them and that could be executed in parallel with no performance penalty, and its complement , which correspond to the serial fraction or the fraction of code that cannot be parallelized. The parallel execution time for processing cores would then be given by
[TABLE]
Amdahl’s model arises from combining (1) and (4), such that
[TABLE]
However, with Assumption 2, we must consider that the memory system can only attend requests at a given maximum rate. Therefore, the term that is divided by in (4) cannot decrease indefinitely. In fact, the execution time of the whole parallel computation cannot be accelerated beyond by increasing , which leads us to the following equation for the parallel execution time of the instructions with processing cores.
[TABLE]
Next, we devise a model that accounts for the variation in the number of memory accesses, dependent on the number of cores used, and the variation in the average duration of a memory instruction, dependent on the processor and memory frequencies ratio.
By combining (1), (3) and (6), we derive the first form of our speedup model:
[TABLE]
In terms of the ratio between the time to complete a memory instruction and the time to complete a processor instruction, by dividing everything by , we can rewrite (7) as
[TABLE]
where denotes the ratio between and .
The average duration of a memory instruction should depend on the processor instruction execution time and memory access frequency according to Assumption 4, which we model as follows.
[TABLE]
where is an application model parameter that models how the computation of memory instructions is affected by the frequency of the main memory. The effect of is stronger for memory-bound applications and weaker for those that are CPU-bound.
So, considering (9) and Assumption 3, the ratio can be expressed as
[TABLE]
where is the ratio between processor and memory frequencies,
[TABLE]
with and denoting the processor and memory frequencies, respectively.
Finally, to remove the absolute values of and from (8), we can rewrite it in terms of the fraction of memory instructions over the total number of instructions, , as follows.
[TABLE]
where
[TABLE]
Consequently,
[TABLE]
is the fraction of processor instructions over the total number of instructions involved in the computation. The ratio , however, is not fixed due to Assumption 1. When we vary the number of cores, the value of may also change due to the addition of more private caches, as discussed in Section 1. To account for variations in the number of memory instructions caused by variations in the number of cores, we rewrite (12) to express the final form of our proposed variable-delay speedup model as follows.
[TABLE]
for being the fraction of memory instructions observed when using cores, defined by
[TABLE]
with and denoting application model parameters and representing the serial case of , with . The minimum function limits the upper value of to 1, which represents an application that is 100% dependent on memory instructions. The term accounts for the portion of accesses that are not affected by changes in the number of cores. The term accounts for the portion of accesses that vary with changes in the number of cores, which for example would vary due to the addition of more private caches. With more caches, the main memory receives fewer accesses, and should decrease.
3 Model Analysis
In this section, we perform two parametric analyses with the model proposed in (15) to investigate the model’s behavior. What we intend is to present the model’s ability to capture the performance-limiting behavior caused by a change in the data-access delay. Then, in Section 4, this ability is validated by fitting the model in (15) to hardware measurements.
Firstly, we investigate the dependency between the number of cores and the data-access delay which causes the memory performance to decrease with an increase in the number of active cores. Secondly, we investigate the performance predictions for variations on the ratio between processor frequency and memory frequency.
Because exhaustive analyzes with seven parameters (, , , , , , and ) would be impractical, we propose a set of parameter-value combinations whose variations can better expose the behavior expected to be modeled.
3.1 Number of cores versus data-access delay
We analyzed the behavior of the proposed speedup model for systems with 2, 4, 8, 16, 32 and 64 processing cores. We assumed a parallel fraction , representing a highly parallel code, and a processor and memory frequencies ratio , which would denote, e.g. the memory functioning at 1.0 Ghz and the processor at 3.0 GHz. Fig. 1 presents the speedup plots of these configurations for different values of , , and .
As Fig. 1 shows, the model indicates that the ratio , affected by , has a significant effect on the speedups. The higher the , the higher the limiting effect on speedups as the number of cores increases, which resembles the effect of a reduction of the parallel fraction of the code. So, the parameter controls the memory access behavior of applications that depend on the variations of CPU and memory frequency ratio. For lower values of and , the speedups saturate faster with the increase in the number of cores, indicating that the application transitions from a processor-bound mode to a memory-bound one.
Fig. 1 also indicates the positive effects on the speedups caused by varying the number of cores with private caches. For larger values of , which drives the number of memory instructions down with the use of more cores, the speedups are considerably larger. Higher values of allow the transition to a memory-bound mode behavior to happen at a larger number of cores with higher speedups whereas lower values force this to happen at smaller numbers of cores with lower speedups.
Considering that the frequencies of processor and memory are constant, larger values of the parameter may represent applications with larger average memory-access time. So, in this case, a larger number of cores trend to saturate the speedup more quickly. On the other hand, the and parameters model the percentage of memory instructions of a particular application. The larger compared to , the more susceptible the application behavior is to larger memory delay caused by an increase in the number of cores.
3.2 Frequency ratio versus data-access delay
The analytical results of the previous subsection indicate that memory-bounded applications lose the apparent advantages of using more cores to achieve more considerable speedups at some point. The capacity of the memory to hold down the average data-access delay limits the speedup. Nonetheless, the effects of varying the ratio between the processor and memory frequencies remain to be analyzed.
With the following analysis, we intend to show that, according to the proposed model, a memory-bounded application can become processor bounded with a suitable adjustment of the ratio in order to make the processor work more symbiotically with the memory and, thus, could avoid processor idling, increase efficiency and decrease energy consumption.
We analyzed the behavior of our speedup model for computational tasks with parallel fractions running with 32 processing cores. Processor and memory frequency ratios varied according to , for which the plots are depicted in Fig. 2.
As expected, the proposed model reproduces the effect caused by varying the ratio of memory and processor frequencies. When the parameter increases—caused by an increase in the processor frequency, for example—the speedup decreases. However, this effect is more or less intense depending on the parameters that model the application. Thus, for the same number of cores, an increase in makes this negative effect more evident. On the other hand, the parameters and are related to the number of memory instructions and, therefore, an increase in these also increases the sensitivity of the application to variations in the processor frequency.
Note, in Fig. 2, that larger speedups can be achieved by reducing the ratio in almost all analyzed configurations. This shows that the decay in memory performance could be avoided by a suitable reduction of the processor’s operating frequency.
4 Model validation
In this section, we present the results of several modeling experiments in order to validate the proposed model with real applications running on multi-core processors in a shared-memory architecture.
4.1 Experimental Setup
We have measured the execution times for a set of applications varying the number of cores and their operating frequency in order to calculate their speedups for each frequency value. We validate the proposed model using the PARSEC [Bie11] and SPLASH-2 [WOT*+*95] parallel benchmark suites. They comprise a large and diverse set of applications, covering several different application domains, such as computational finance, computer vision, real-time animation or media processing. In total there were 25 programs, 11 from the PARSEC suite and another 14 from the SPLASH-2 suite. We used the number of threads to control the number of cores active during the execution of each benchmark application. This way, besides effectively controlling the number of cores available, we also isolate from the measurements the effect on speedup arising from using multiple threads per core, which is not the target of our validation.
The measured execution times were used to fit the proposed model and Amdahl’s model for each application. All model variables were fitted using the Coupled Simulated Annealing (CSA) [dSSVB10] global optimization method to minimize the Mean Squared Error (MSE) between the measured application speedups and their models. The CSA method used was the CSA modified (CSA-M).
The ratio between memory and processor instructions is modeled by the and parameters that make up the instruction ratio. These parameters are fitted, using the CSA optimizer, based on the execution time measurements of the whole application.
To vary the ratio between processor frequency and memory frequency, we changed the processor’s frequency for each execution round using the ’user-mode’ governor from the “Advanced Configuration and Power Interface” (ACPI) driver. In contrast, the frequency of the memory system was fixed and known.
The measurements were taken on a dual-socket shared memory platform with Intel(R) Xeon(R) CPU E5-2680 v3, 12 cores at 2.50 GHz, and 30 MB shared L3 cache. The L1 and L2 private caches have 64 KB and 256 KB, respectively. The operating processor core frequencies ranged from 1.2 GHz to 2.5 GHz, with steps of 100 Mhz. The number of cores ranged from 1 to 24, with unity steps, except for some applications that have the number of cores limited to a power of two. Hardware multi-threading was disabled to simplify modeling and to emphasize the effect of the memory wall. This way, cores were always running a single thread.
A Python version 3 library was developed111https://gitlab.com/lappsufrn/parsecpy.git to implement the CSA algorithm and the utility methods to fit the models, to store the collected data, and to plot the graphs of the experiments performed in this paper. The repository also contains text files with information on measurements, execution metadata, the model parameters and the respective modeling errors for all experiments.
In Section 4.2, we will assess Amdahl’s and the proposed model’s accuracy by fitting them to each application using all measurements available to compute the MSE values.
In Section 4.3, we will investigate how the accuracy of these models and the accuracy of an unstructured machine learning model vary according to the amount of information used to construct them.
4.2 Model accuracy
The accuracy for Amdahl’s model and the proposed model is summarized in Table 1 for all applications in terms of MSE. The table also shows the number of measurement points available for each application. Each measurement point represents a configuration of frequency and number of cores. These points are relative to the median of 10 runs of an application.
The MSE columns in Table 1 show that the results of the proposed model are considerably better than Amdahl’s model, with the proposed model scoring always better or the same. The application with the most similar MSE value is ”splash2x-lu-cb”, whose accuracy was only 0.53% better than with Amdahl’s model. On the other hand, ”splash2x-water-spatial” was the application whose difference in MSE value was 90.24% better for the proposed model. On average, the proposed model was 41.92% more accurate than Amdahl’s model considering all modeled applications.
To better present the ability of the proposed model to describe the speedup features of parallel applications correctly, we have selected a few applications for a more detailed analysis. For example, the PARSEC Dedup, a workload that uses ”deduplication” to compress a data stream [BKSL08], presents small differences in the MSE values of the two models. This application is hard to model because of abrupt speedup variation due to workload imbalance among threads [SR16]. Nevertheless, the proposed model improves Amdahl’s accuracy and accomplishes its task of modeling access-delay limitations by tilting speedups down for more substantial amounts of cores and larger ratios, as shown in Fig. 3b. The model manages to capture the angle of the speedups along the frequency axis which represents the ratio. The proposed model also presents a better fit for a smaller number of cores with a steeper slope enabled by the variable number of memory instructions in (16) that allows the modeling of the effect of overcoming cache size limitations.
For the PARSEC x264 application, an H.264/AVC video encoder, the proposed model reduces the MSE error by one order of magnitude. Fig. 4b shows how the proposed model surface is very close to the scatter plot of the measurements. It captures the super-linear speedup that occurs with this application because of the term in (16) that allows the number of memory instructions to decay with increase of the number of cores.
Fig. 5 presents the models for the SPLASH-2 Radiosity application. It computes the equilibrium distribution of light in a scene [WOT*+*95]. One of the computational characteristics of this algorithm is a large number of memory instructions and, therefore, it is an appropriate case study to prove the proposed model’s ability to capture the memory-wall effect on speedups. As in the previous applications, the proposed model presents a much better fit than the fit of Amdahl’s model. Fig. 5b shows how the proposed model captures the speedup’s slope that increases as processor frequency decreases. The model also captures the abrupt saturation that occurs when speedups hit the memory wall.
For SPLASH-2 Water Spatial application, which computes the forces that occur over time on a system with water molecules, Amdahl’s model failed to capture the super-linear speedup behavior, achieving the worst MSE errors among the other applications, as Fig. 6 illustrates. The proposed model presents a better fit, despite it underestimating speedups at lower frequencies. Nevertheless, its accuracy is more than 90% better.
4.3 Accuracy versus the number of measurements
The results of the previous section were obtained using all available measurements for all configurations of processor frequency and the number of cores. In most cases, each application was executed on 336 different configurations—14 different frequencies and 24 different numbers of cores. For practical scenarios, using as few measurements as possible is desirable to reduce the modeling overhead in terms of the use of computational resources and energy consumption.
In this section we study how the use of fewer sampling points affects model accuracy. With that we intend to support two claims:
- •
the proposed model can achieve reasonable accuracy even for a small number of measurements; and
- •
the number of measurements required for reasonable accuracy is much smaller than that required for unstructured models, such as those based on machine learning.
To support the former claim, we observed the accuracy of the models when fitted using various different numbers of measurements, starting from only 4 measurements and then doubling this number several times until reaching the closest power of two below the total number of available measurements for each application. To support the latter claim, we used machine learning techniques to model the applications using the same inputs as were used to fit the analytical models. The machine learning algorithms used for these experiments were: Kernel Ridge Regression (KRR), Decision Tree Regression (TREE) and Support Vector Machine Regression (SVR). Full details of the experiments can be found in the open-source repository mentioned earlier. In the following, we describe the methodology used to evaluate accuracy and variance for the models under analysis: Amdahl’s model (1) fitted with CSA; the proposed variable-delay model as given in (15) fitted with CSA; and the Machine Learning (ML) models. For Amdahl’s model we fitted the parallel fraction and for the proposed model we fitted as well as the other new parameters , , and .
For each number of samples, all measurement data were divided into a training or fitting set and a test set. The test set was always the remaining set of samples after removing the samples used to train or fit the models. The training or fitting for a given number of samples was repeated 100 times using each time a different set of random samples. All reported Mean Square Errors (MSEs) are the average of the MSE values of all 100 repetitions calculated using only the corresponding test sets. Fig. 7 illustrates the procedure used to compute the median of the MSE values for each set of 100 repetitions. The CSA method used 10 annealers limited to 30.000 iterations to fit the analytical models. The minimum and maximum limits of the model parameters were set to be between 0.0 and 1.0, for , and , and between 0.0 and 10.0 for . For the KRR and SVR models we used the implementation of the Scikit-learn Python module [PVG*+*11]. The hyper-parameters of the Radial Base Function (RBF) kernel used in the KRR and SVR were tuned using a 3-fold cross-validation with a grid search that was repeated for each new set of random measurements. The search range for the error penalty parameters: (SVR) and (KRR), and the kernel coefficient (SVR and KRR) were , and .
Fig. 8 and Fig. 9 resumes all MSE results for each application using different numbers of measurements. The horizontal axis is in logarithmic scale and holds the number of sample measurements used to fit or to train the models: 4, 8, 16, 32, 64, 128, and 256 samples. Some applications restrict the number of cores that can be used, and thus, have fewer data points in the plots. For example, PARSEC Fluidanimate is limited to run only with numbers of cores that are a power of two. The last data point in the plot is always the power-of-two number immediately below the total number of measurements available for each application.
The main behavior observed in Fig. 8 and Fig. 9 is that the analytical models obtain lower mean squared errors as they use more measurements for modeling until they reach a plateau. Another important observation is that the analytical models have higher accuracy for smaller training sizes than the Machine Learning models. Although the Decision Tree model is generally more accurate for sets of measurements with more than 128 samples, the proposed model was overall more accurate for the smaller number of measurements, except for size 4 and 8, for which Amdahl’s models scored best in many cases. The reason for Amdahl’s model scoring better than the proposed model for very small number of measurements is the same for the proposed model scoring better than Machine Learning models for midsize number of measurements: the more flexible the model is, i.e. the more parameters it has, the more information it requires to fit these parameters to the measured data while being sufficiently general.
The overall mean of the median MSE and standard deviation values of the five models across all applications according to the size of the sample set used in the modeling is depicted in Fig. 10 and Fig. 11.
Table 2 shows the time spent to model the speedups of each application using the proposed and using the Decision Tree model, which achieved the best results among the machine learning models analysed. The values reported for the proposed model refer to the number of points at which the accuracy of the proposed model surpasses the accuracy of Amdahl’s model. For example, for the Blackscholes application, the proposed model shows better results when the training set size was at least 8 points. On the other hand, the values reported for the Decision Tree model refer to the number of points at which this Machine Learning model achieves higher accuracy than the proposed model. In this case, for Blackscholes, Decision Tree performs better only when 256 points or more are used for training. The table shows that the difference in time and, proportionally, in energy consumption between both models can often be around one order of magnitude. On average, considering all applications, the Decision Tree needed about three times longer to obtain more accurate results than the proposed model.
In contrast to the machine learning model, the architecturally-inspired models require only a few executions of the application to provide sufficient good predictions of their speedups in configurations that were not previously assessed. This demonstrates an important advantage of these models, which allow an estimation of application performance for unseen configurations of a given architecture with reduced overheads of time and energy. On the other hand, if more sampling points are available, machine learning models provide better accuracy at the cost of a higher overhead.
The results demonstrate that there is space for the use of analytical models as opposed to the use of traditional Machine Learning-based models. Machine learning models do achieve higher accuracy when using a more representative data set for training. However, they fail to explain the behavior and features of the applications and their relation to hardware characteristics. In turn, analytical models require fewer data points to achieve accuracy similar to what Machine Learning can only achieve when using far more data points for training. Moreover, analytical models facilitate the understanding of the interplay between the hardware properties and the applications behavior, which makes their use important for software and hardware development.
5 Related Work
Inspired by earlier analytical models, such as [Amd67, Gus88, SN93], many more recent models attempt to capture better the behavior of application and architecture features that describe parallel speedups more precisely. None of them, however, consider the effect of the memory wall [WM95] on parallel speedups as considered in this work.
Analytical speedup models for multi-core processors were devised to describe communication [HZQ*+*13] and synchronization [EE10] overhead separately. Communication and synchronization overheads were modeled together in [YMG14] providing a more general description of both behaviors. Apart from not considering the effect of the memory wall on the modeled speedups, no hardware or simulation validation was presented to confirm their results.
Other analytical models for multi-core architectures consider the variations in parallel speedups caused by variations in the problem or input size, including the modeling of the parallel overhead [OFS*+*18] or not [NSS15]. The parallel overhead was also modeled together with the parallel speedup for distributed parallelism in [HH17]. Similar to our work, these studies also validated the models using execution time measurements, but no feature was associated with the effect of the memory wall.
The work of Liu and Sun [LS17] combines the limitations related to the finite size of the memory [SN93] with memory access concurrency [SW14] to provide a speedup model that can be used for multi-core design space exploration. Although this model contains elements that relate to our data-access delay speedup model, the authors focus on chip design and perhaps, for this reason, do not explore the effects of frequency variations on speedups.
The roofline model [WWP09] introduced a simple model for visualization of actual and attainable performance in the compute- and memory-bounded regions. The model uses the number of operations per byte of DRAM traffic as a metric. It considers only the bandwidth between main memory and Last Level Cache (LLC). More recently, the cache-aware roofline model [IPS14] extended the roofline model to include byte traffic between the cores, the various cache levels, and the main memory, which in fact is a generalization of the original roofline model. Both models are very useful to help finding architectural bottlenecks and which code optimizations should be applied to achieve better performance on specific hardware architecture. However, these models did not analyze the relationships between the operating frequency and the speedup of applications.
Therefore, to the best of our knowledge, this work is the first to explore the effect of operating frequency on the the speedup of parallel applications running on shared memory platforms. For this reason, the only model mentioned in this section that we used for comparison was the original Amdahl’s model, as many of the other works did. Moreover, since those models differ from Amdahl’s by aspects that were kept fixed in our experiments, such as the problem size and architectural features like memory hierarchy and the amount of available memory, other comparisons would not be relevant to this study.
6 Conclusions
We have presented a new modeling approach for estimating speedups of parallel applications that are subject to the limitations of the memory wall. The proposed modeling considers variations in the data-access delay of the main memory when the number of cores increases and when the processor’s or memory’s operating frequency change; capturing the effect of changing the ratio between the processor’s and the memory’s frequencies. To the best of our knowledge, this behavior was not described by previous analytical speedup models.
Several hardware experiments presented in this paper validate the ability of the proposed models to describe the memory wall behavior for many different applications.
Our analysis shows that reducing processor frequency reduces the adverse effect of the memory wall on parallel speedups, suggesting that there could be an optimal processor frequency for each number of cores used to run a given application. Therefore, we argue that this work is not a pessimistic view of multi-core scalability. Instead, it shows that the race toward single-core performance under the influence of Amdahl’s Law has perhaps obfuscated a more efficient way to match processor and memory frequencies for parallel applications. That is undoubtedly true if the focus is energy efficiency; as such models could be applied, for example, to devise better Dynamic Voltage and Frequency Scaling (DVFS) schemes for the Internet of Things [GXdSE17], data centers [PPZ*+*16], and high-performance computing [SFG*+*18].
Ideally, these new DVFS schemes may also consider the number of cores used by the application, such as in [DSDMD18, LCB16]. To be practical for this, the speedup models need to be able to predict performance at non-visited configurations with the smallest possible number of measurements. In this sense, we showed that, based on only about a dozen measurements, the proposed model can produce predictions that are as accurate as those obtained from three Machine Learning regression algorithms after training with at least a hundred measurements. On average, our model achieved higher accuracy than Amdahl’s model when using more than eight random measurements and also achieved higher accuracy than Decision Tree regression when using 64 random measurements or less. The standard deviation of our modeling was lower than Amdahl’s model for all measurements, and was lower than Decision Tree regression for 32 random measurements or less.
In contrast with Machine Learning speedup models, the proposed model holds an inherent mapping of the application features, such as rate of memory versus processor instructions and the value of the parallel and serial fractions of the code, which is often relevant to software and hardware development. In its turn, machine learning schemes, such as Decision Tree Regression, work as black boxes with relations between model parameters and applications behavior that are hard to infer. Additionally, evaluating analytical models is also faster, which makes it suitable for use in on-line performance and/or energy optimization schemes.
Despite the many different existing models for parallel speedups, the practical use of these models requires both better generalization and a lower fitting overhead. In this work, we have made contributions to both aspects, but there is still room for further improvements. For example, to make the model more general, the modeling of problem size could be included. For reducing fitting overhead, devising a heuristic to choose the initial measurements might work better than random sampling, as it has been observed in [Sen16]. For on-line fitting, increasing the complexity of the models as the number of measurements increases might also reduce fitting overhead. Extending this approach to speedup models for heterogeneous systems [BSVXdS15] is also promising, as the use of these systems has grown substantially in recent years.
Acknowledgment
This work was supported by High-Performance Computing Center at UFRN (NPAD/UFRN) and financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001, and in part by the Royal Society-Newton Advanced Fellowship award no. NA160108. It is also supported by the European-Union’s Horizon 2020 Research and Innovation Programme under grant agreement No. 779882, TeamPlay (Time, Energy and security Analysis for Multi/Many-core heterogeneous platforms). We also thank the Center for Information Services and High Performance Computing (ZIH) at TU Dresden for generous allocations of computer time.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[AHSR + 17] Mohammed A.N. Al-Hayanni, Rishad Shafik, Ashur Rafiev, Fei Xia, and Alex Yakovlev. Speedup and parallelization models for energy-efficient many-core systems using performance counters. Proceedings - 2017 International Conference on High Performance Computing and Simulation, HPCS 2017 , pages 410–417, 2017. doi:10.1109/HPCS.2017.68 . · doi ↗
- 2[Amd 67] G. M. Amdahl. Validity of the single processor approach to achieving large scale computing capabilities. Proc. AFIPS 1967 Spring Joint Computer Conf. 30 (April), Atlantic City, N.J. , pages 483–485, 1967.
- 3[Bie 11] Christian Bienia. Benchmarking Modern Multiprocessors . Philosophy doctor thesis, Princeton University, 2011.
- 4[BKSL 08] Christian Bienia, Sanjeev Kumar, Jaswinder Pal Singh, and Kai Li. The parsec benchmark suite: Characterization and architectural implications. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques , PACT ’08, pages 72–81, New York, NY, USA, 2008. ACM. URL: http://doi.acm.org/10.1145/1454115.1454128 , doi:10.1145/1454115.1454128 . · doi ↗
- 5[BSV Xd S 15] C.A. Barros, L.F.Q. Silveira, C.A. Valderrama, and S. Xavier-de Souza. Optimal processor dynamic-energy reduction for parallel workloads on heterogeneous multi-core architectures. Microprocessors and Microsystems , 39(6):418–425, aug 2015. URL: http://www.sciencedirect.com/science/article/pii/S 0141933115000617 , doi:10.1016/j.micpro.2015.05.009 . · doi ↗
- 6[DSDMD 18] Daniele De Sensi, Tiziano De Matteis, and Marco Danelutto. Simplifying self-adaptive and power-aware computing with nornir. Future Generation Computer Systems , pages –, 2018. URL: https://www.sciencedirect.com/science/article/pii/S 0167739 X 17326699 , doi:https://doi.org/10.1016/j.future.2018.05.012 . · doi ↗
- 7[d SSVB 10] Samuel Xavier de Souza, Johan A. K. Suykens, Joos Vandewalle, and Desiré Bollé. Coupled Simulated Annealing. IEEE Transactions on Systems, Man and Cybernetics. Part B, Cybernetics , 40(2):320–335, 2010. doi:10.1109/TSMCB.2009.2020435 . · doi ↗
- 8[EE 10] Stijn Eyerman and Lieven Eeckhout. Modeling critical sections in amdahl’s law and its implications for multicore design. SIGARCH Comput. Archit. News , 38(3):362–370, June 2010. URL: http://doi.acm.org/10.1145/1816038.1816011 , doi:10.1145/1816038.1816011 . · doi ↗